Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
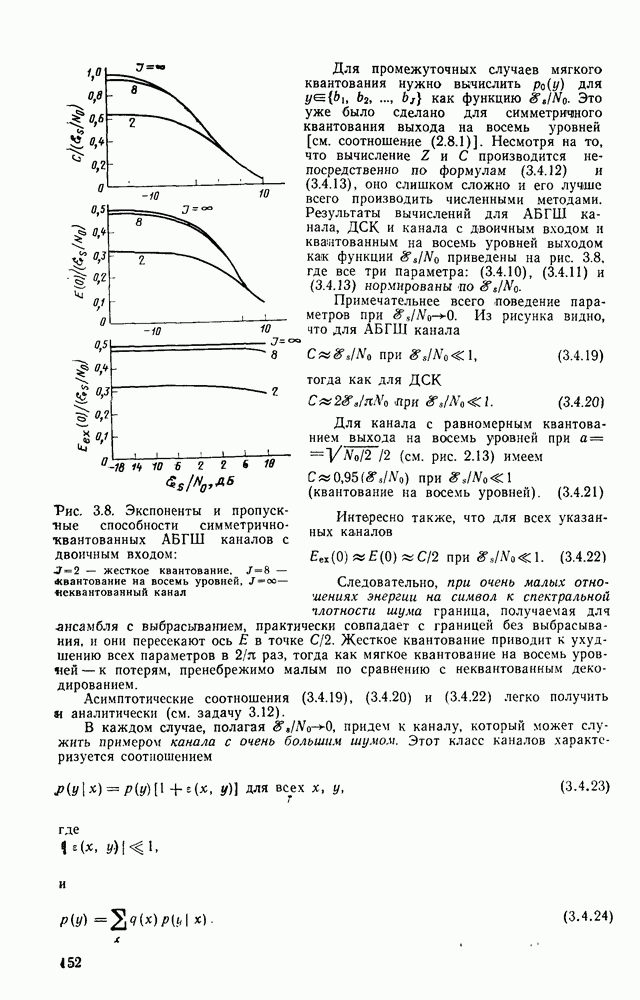
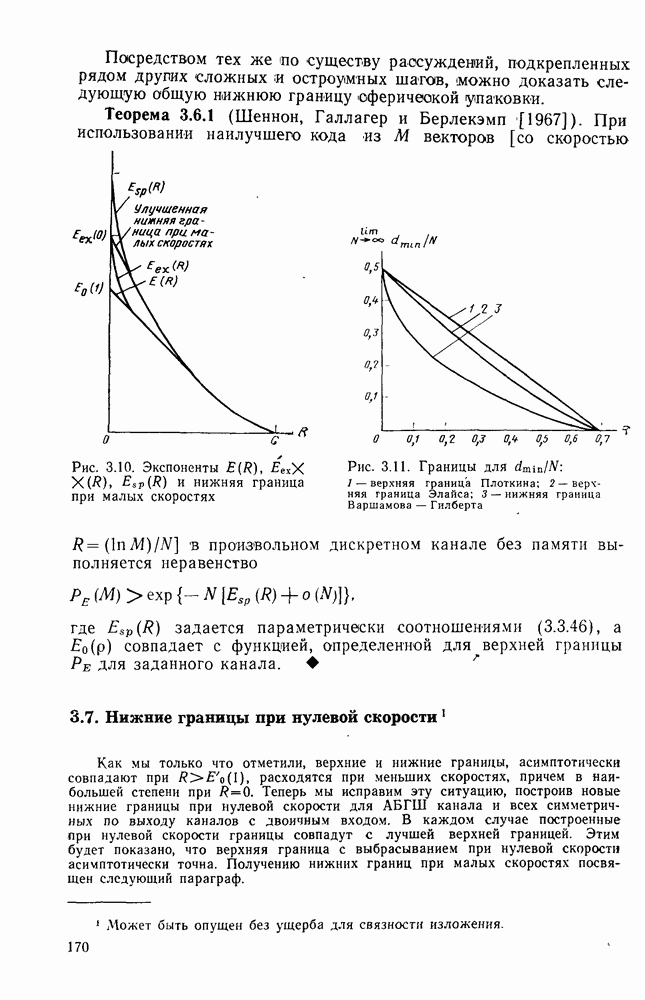
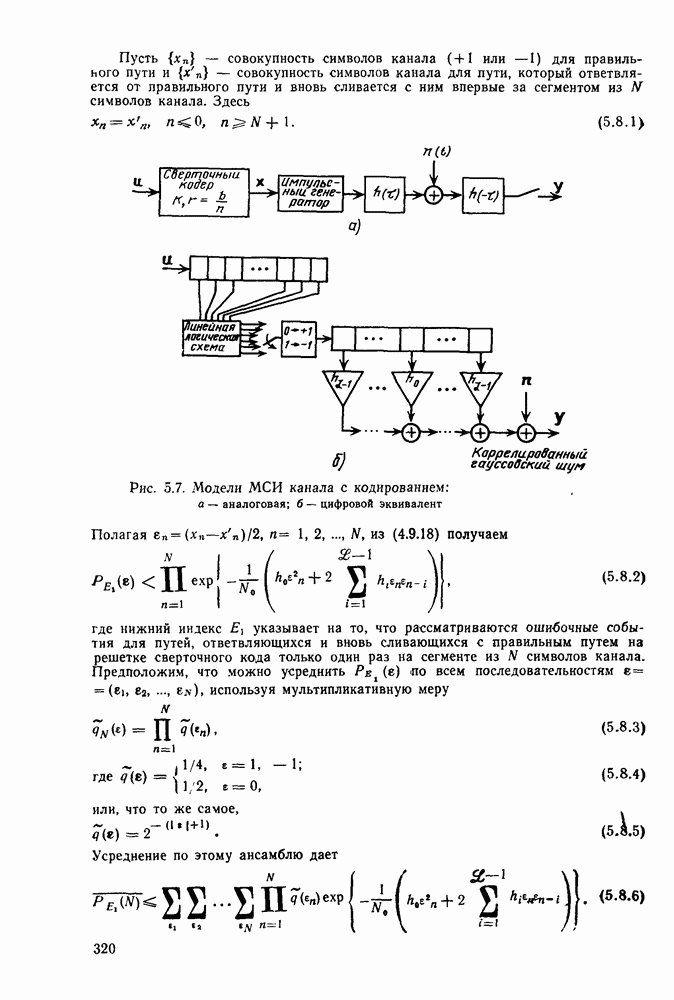
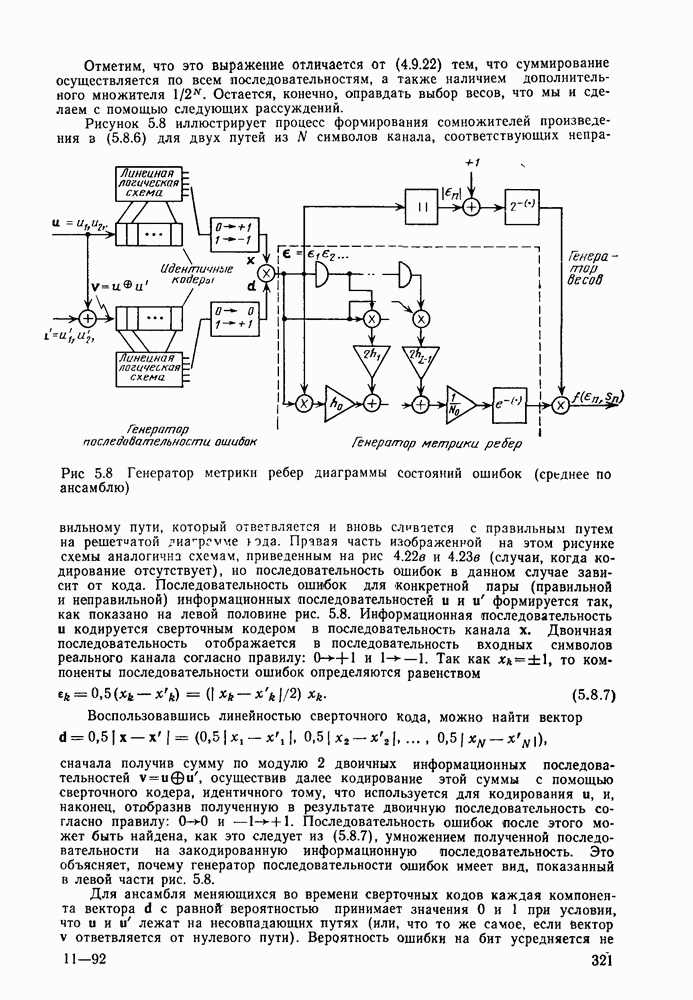
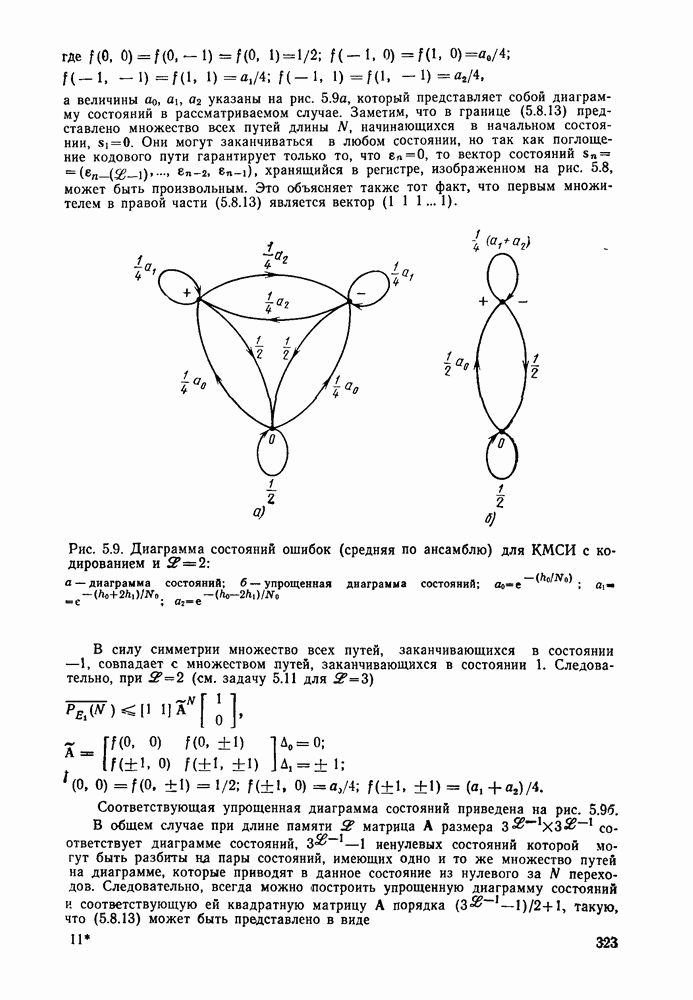
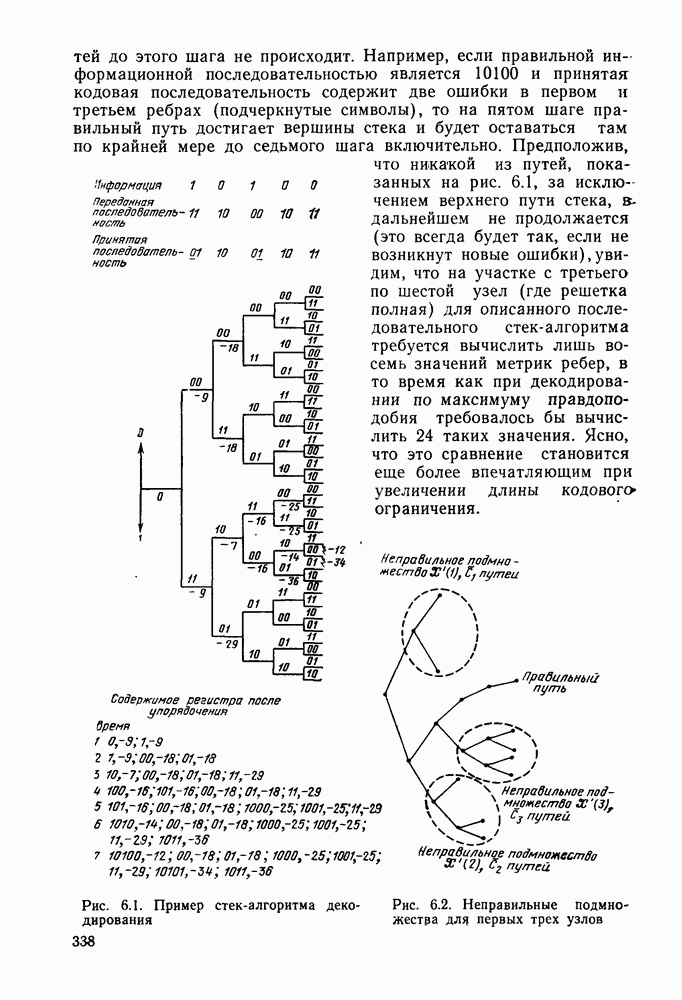
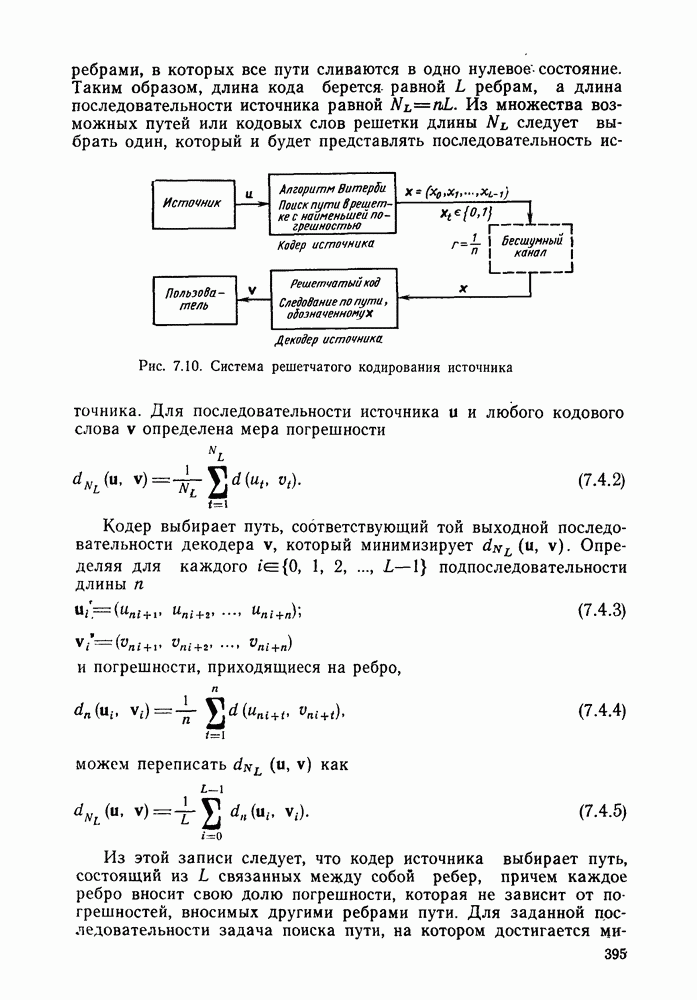
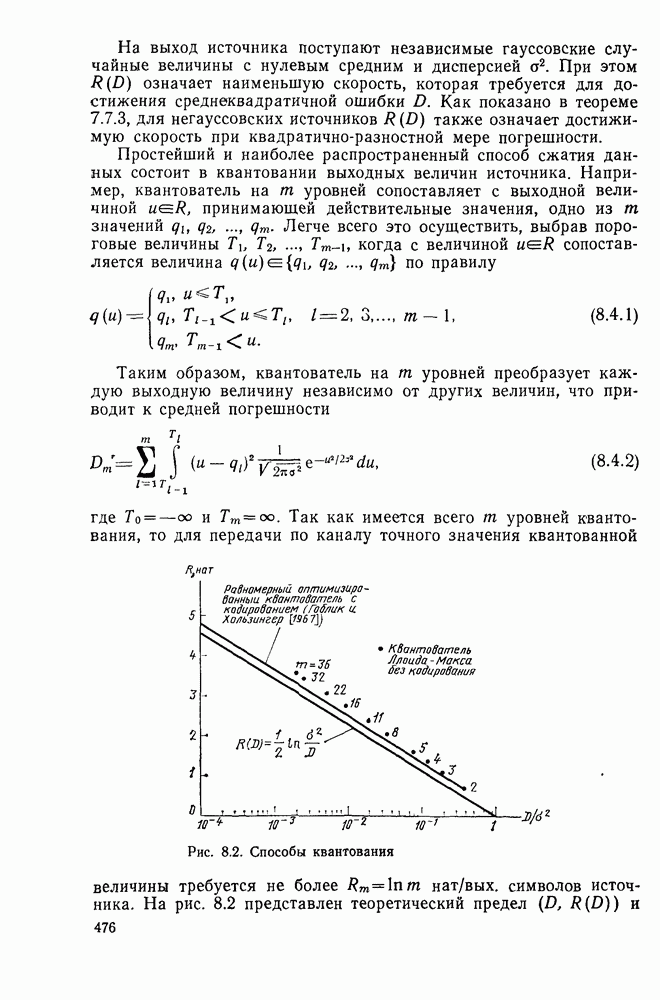
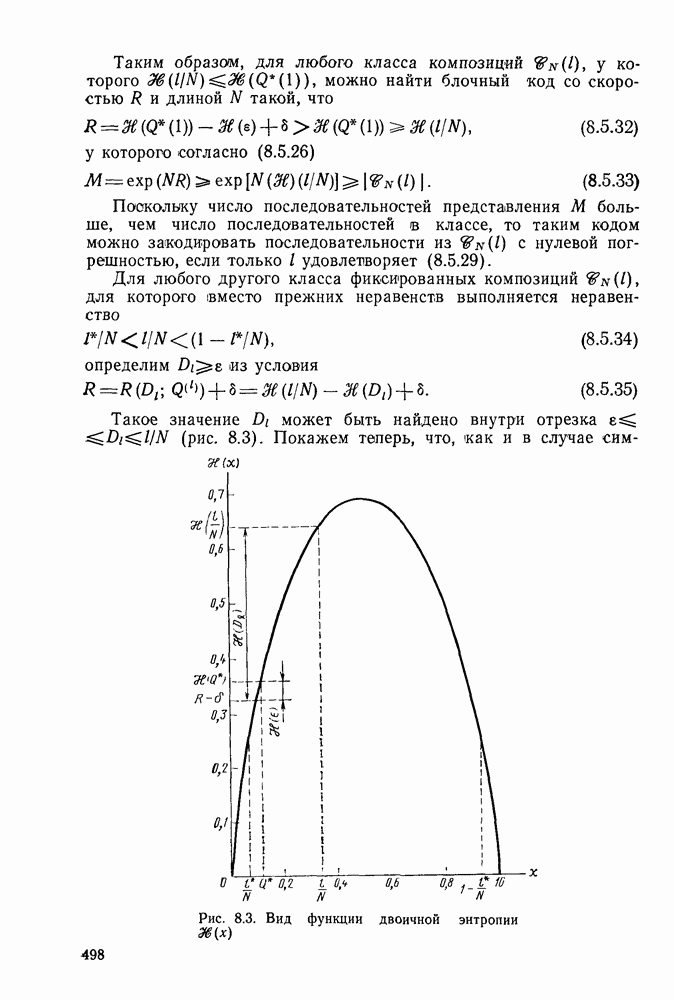
6.5. Алгоритм Фано и другие последовательные алгоритмы декодированияБазовый стек-алгоритм последовательного декодирования является результатом процесса изобретения, упрощения и отбора последовательно открытых алгоритмов, каждый из которых был проще предыдущего как с точки зрения описания, так и с точки зрения анализа. Первый последовательный алгоритм декодирования, предложенный и проанализированный Возенкрафтом [1957] использовал последовательность порогов (каждый из которых был «слабее» предыдущего), предназначенных для исключения всех путей неправильного подмножества узла Алгоритмы Зигангирова и Джелинека являются наиболее близкими к алгоритму, описанному выше. Они различаются, однако, некоторыми деталями, введенными, чтобы сделать их более удобными для практической реализации. Во-первых, оба алгоритма не учитывают слияний и, таким образом, не сравнивают метрику пути, вновь вводимого в стек, с метрикой пути той же длины, уже находящегося в стеке и оканчивающегося в том же состоянии. Однако это существенно не увеличивает вероятность ошибки, так как в § 6.3 слияний очень полезно, так как операция устранения слияний, выполняемая согласно блок-схеме, приведенной в табл. 6.1, потребовала бы существенного увеличения времени вычислений, необходимого для обработки каждого ребра. Значительно более серьезным недостатком базового стек-алгоритма является то, что приращение в узле Третьим и, по-видимому, наиболее неприятным недостатком базового стек-алгоритма является то, что стек должен быть упорядочен после введения в него каждого нового пути, а это требует, вообще говоря, выполнения в каждый момент времени очень большого числа сравнений. Алгоритм Джелинека частично обходит эту проблему, требуя лишь приближенной упорядоченности путей в стеке. А именно, все пути, значения метрики которых лежат в интервале
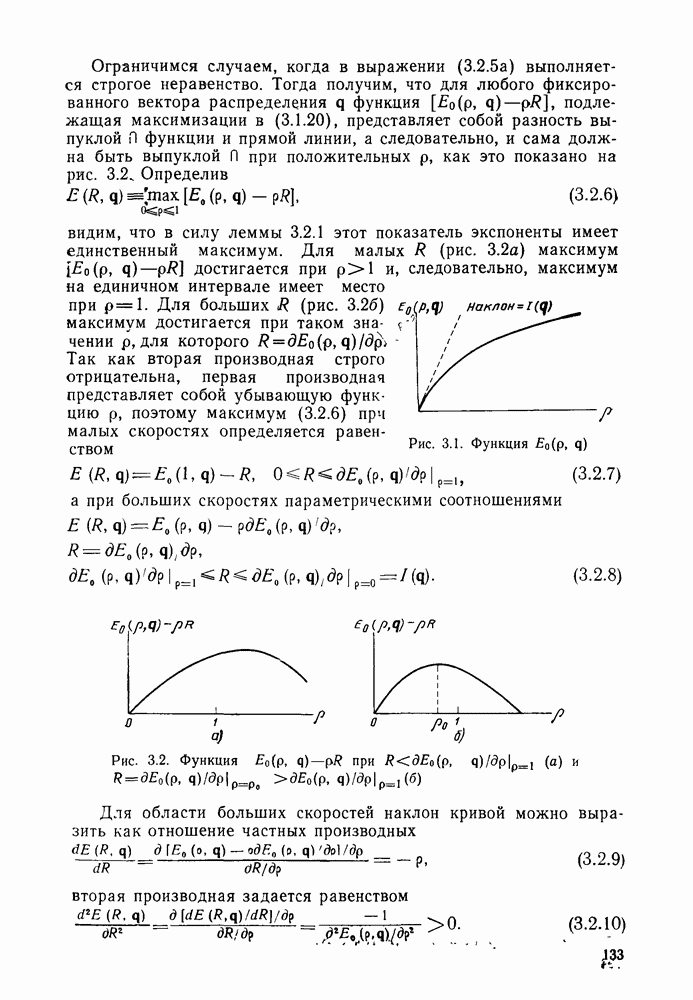
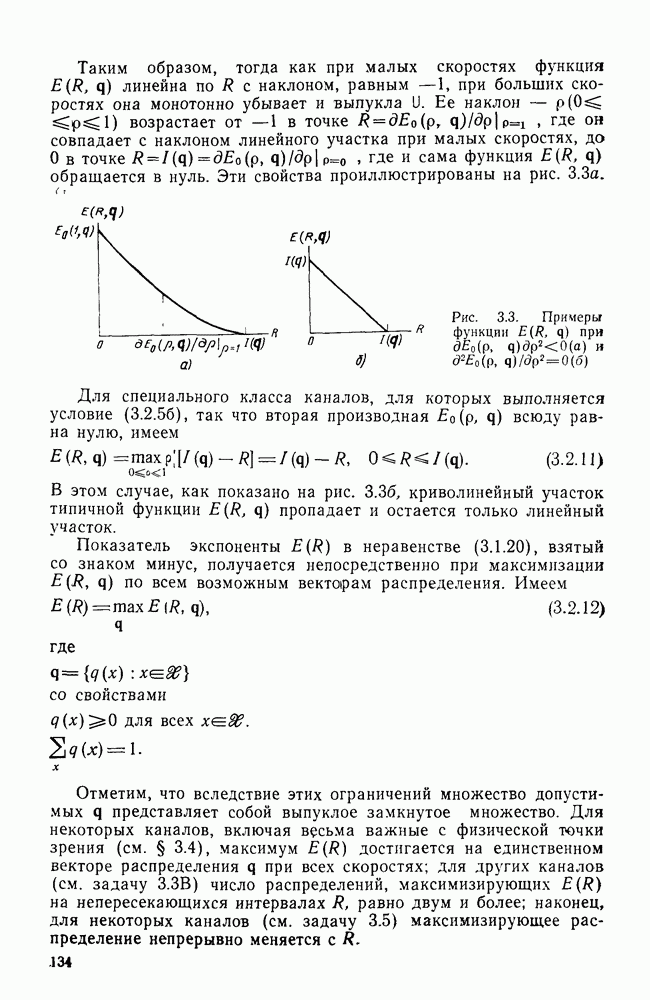
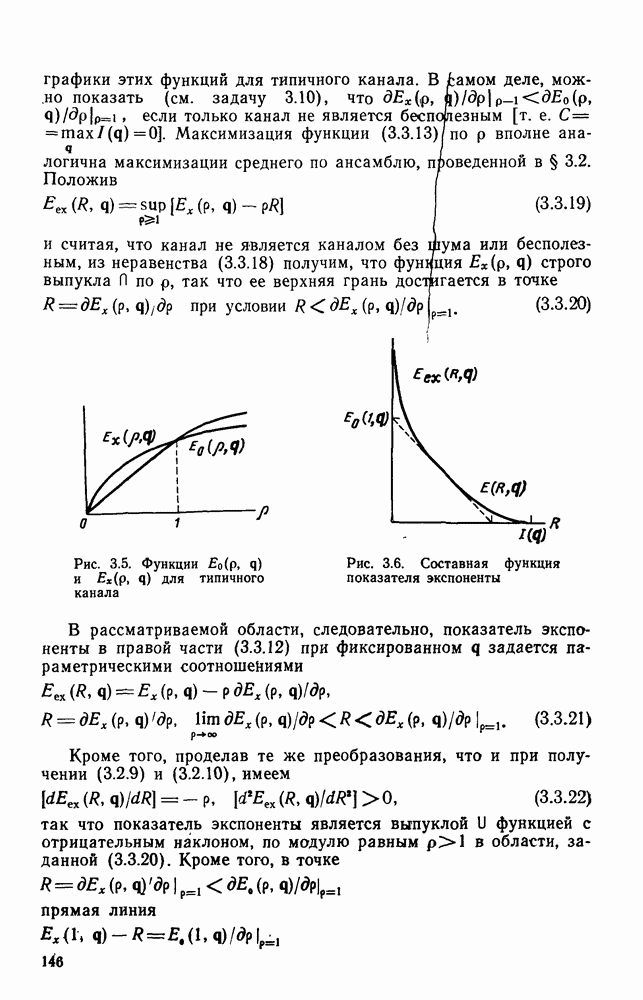
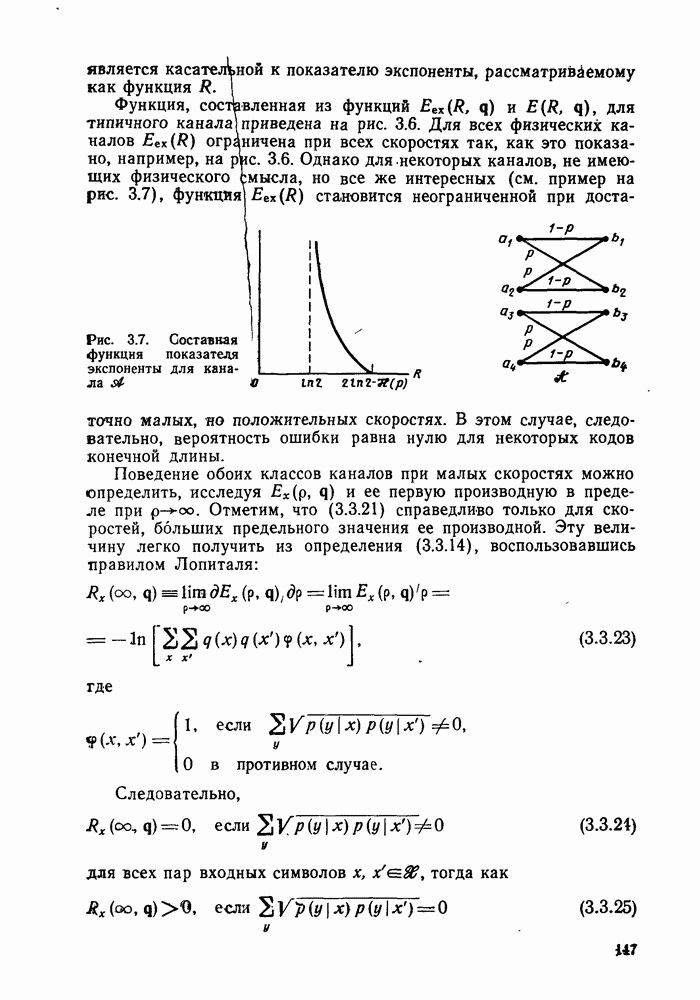
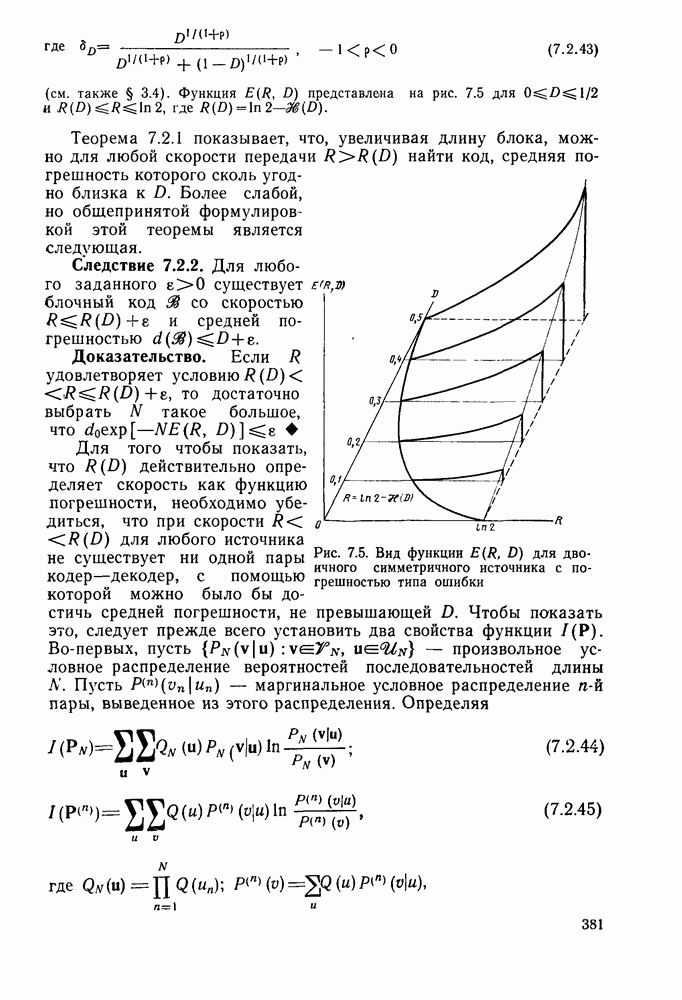
В остальном анализ распределения числа вычислений выполняется точно так же, как и в § 6.2; единственное отличие заключается в том, что появляется множитель Наконец, перейдем к алгоритму Фано, который считается наиболее удобным для практической реализации. Он также использует последовательность порогов для метрики, расположенных друг от друга на расстоянии А. Наиболее привлекательной чертой этого алгоритма является то, что в каждый момент времени этот алгоритм анализирует только один путь, что требует хранения одного пути и его метрики, а не всех путей. Как правило, 1 алгоритм продолжает движение вдоль заданного пути до тех пор, пока метрика пути растет. Если только метрика начинает уменьшаться, он возвращается назад и обследует другие пути, ответвляющиеся от узлов уже обследованного пути. Он осуществляет это изменением лорога сравнения на величину, кратную А. Порог увеличивается на А всякий раз, когда метрика при движении вперед значительно возрастает, и уменьшается на А при движении назад. Эта процедура выполняется таким образом, что ни один узел не обследуется при движении вперед дважды при одном и том же значении порога: при каждом последующем продвижении вперед через данный узел порог должен быть меньше, чем при предыдущем обследовании этого узла. Более детально с алгоритмом Фано можно ознакомиться, если рассмотреть его блок-схему, приведенную на рис. 6.6. Содержащееся в первом блоке указание «смотреть вперед в лучший узел» означает вычисление метрик для обоих ребер и пробное увеличение метрики текущего узла на наибольшую из метрик этих двух ребер. Если был только что обследован лучший узел и текущий порог
Рис. 6.6. Алгоритм последовательного декодирования Фано для двоичного дерева осуществляется через точку А, которая соответствует однократному выполнению операции обследования пути назад. В обоих случаях метрика узла, в который попадает декодер, сравнивается с порогом Если при выполнении операции первого блока — обследовании пути вперед — оказывается, что узел имеет метрику Исчерпывающее описание алгоритма Фано имеется у Возенкрафта и Джекобса [1965] и у Галлагера [1968]. Его характеристики, так же, как и сам анализ, по существу аналогичны характеристикам и анализу стек-алгоритма. Действительно, приращение порога Фано всегда выбирает на дереве тот же путь, что и стек-алгоритм. Единственное различие между ними заключается в том, что алгоритм Фано может обследовать узел пути несколько раз, в то время как при использовании стек-алгоритма этот узел требует лишь однократного обследования. Результатом этого является некоторое увеличение числа вычислений ребер, которое количественно выражается в появлении дополнительного множителя в границах, полученных в теореме 6.2.1. Этот недостаток обычно более чем окупается значительным уменьшением требуемого объема памяти.
|
 |
Оглавление
|






























































































































































































































































































































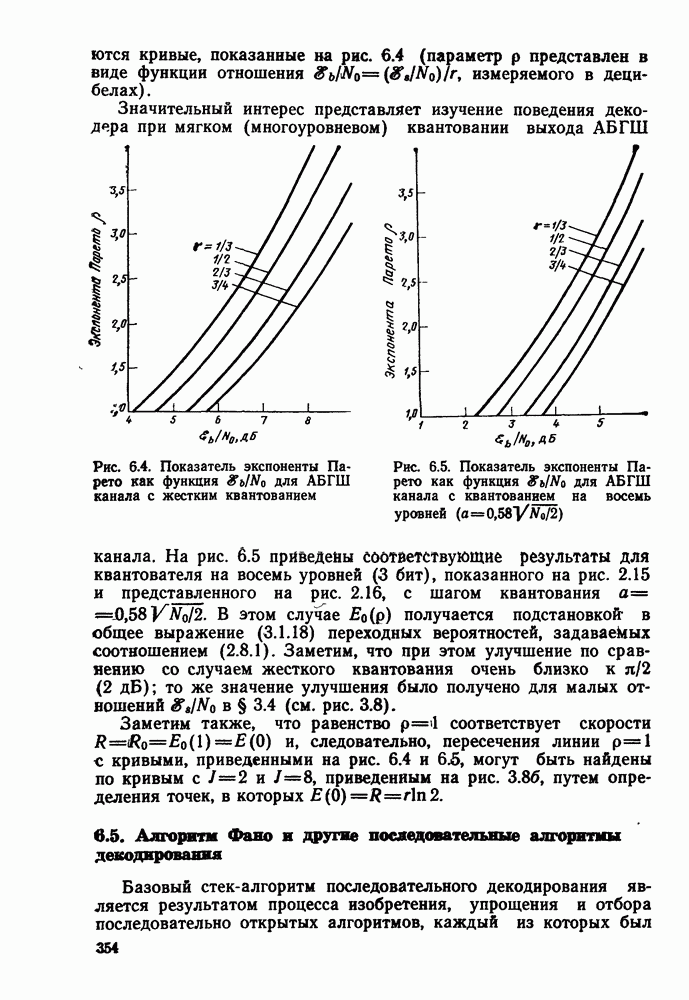


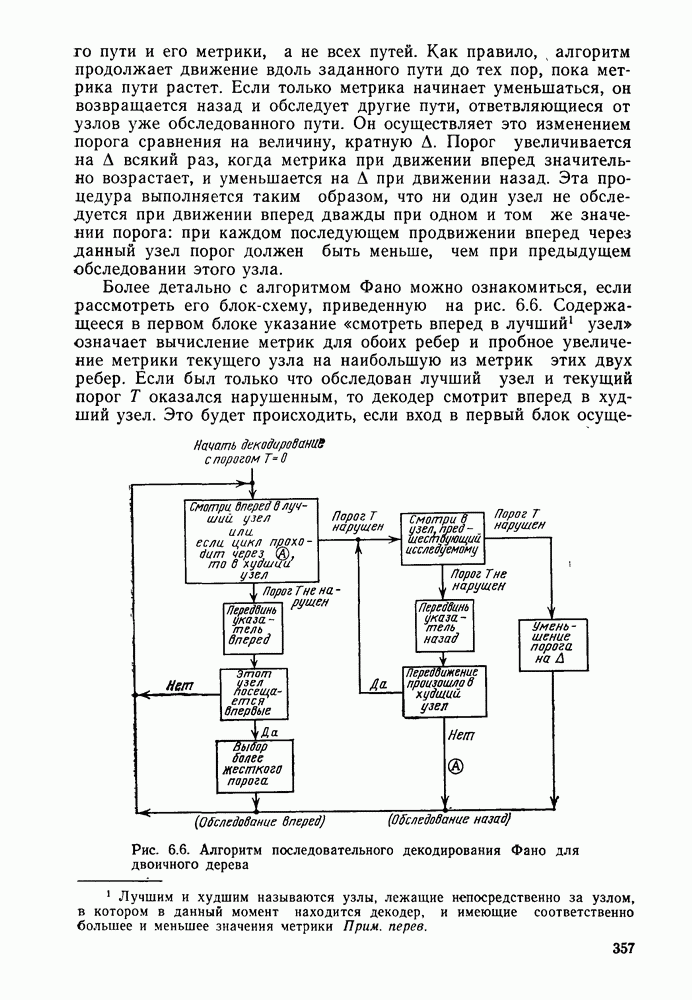



































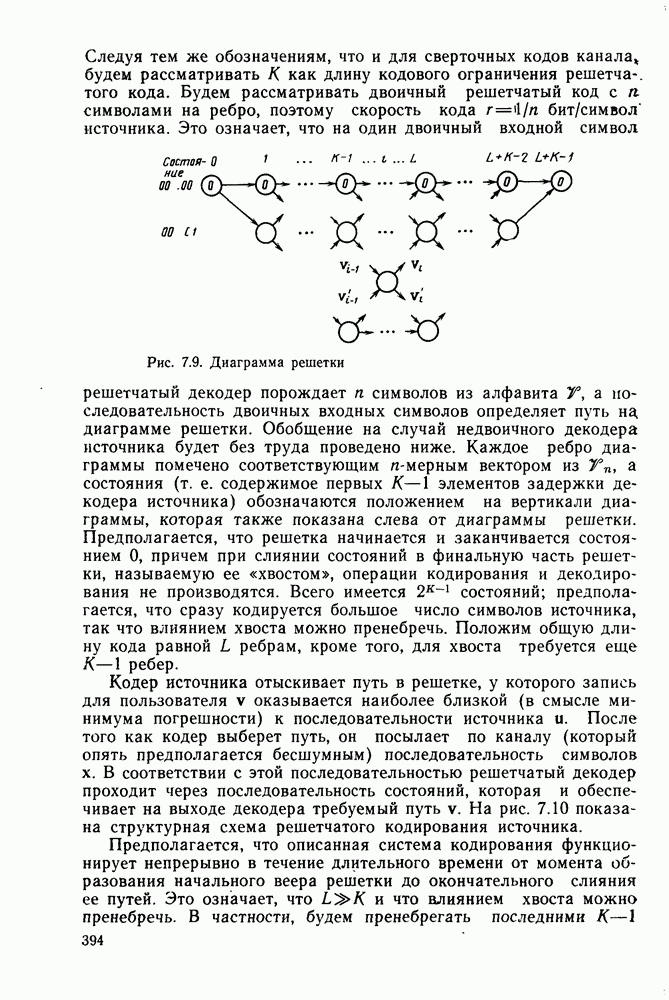



































































































































 до начала обследования путей, исходящих из узла
до начала обследования путей, исходящих из узла  Эта техника сейчас имеет главным образом историческое значение. Следующим важных шагом был алгоритм, описанный Фано [1963], полный анализ которого появился в работах Юдкина [1964], Возенкрафта и Джекобса [1965] и Галлагера [1968]. С практической точки зрения алгоритм Фано, по-видимому, все еще остается наиболее важным и будет рассмотрен ниже. Стек-алгоритм, который лежит в основе алгоритма, рассматривавшегося в § 6.1-6.4, был предложен и проанализирован независимо Зигангировым ([1966] и Джелинеком [1969а]. Определенную методическую ценность имеет также полупоследовательный алгоритм, предложенный Витерби [1967а] (см. задачу 6.4) и обобщенный Форни [1974].
Эта техника сейчас имеет главным образом историческое значение. Следующим важных шагом был алгоритм, описанный Фано [1963], полный анализ которого появился в работах Юдкина [1964], Возенкрафта и Джекобса [1965] и Галлагера [1968]. С практической точки зрения алгоритм Фано, по-видимому, все еще остается наиболее важным и будет рассмотрен ниже. Стек-алгоритм, который лежит в основе алгоритма, рассматривавшегося в § 6.1-6.4, был предложен и проанализирован независимо Зигангировым ([1966] и Джелинеком [1969а]. Определенную методическую ценность имеет также полупоследовательный алгоритм, предложенный Витерби [1967а] (см. задачу 6.4) и обобщенный Форни [1974].
 было ограничено сверху вероятностью того, что неправильный путь будет обследован до точки слияния. Это равносильно предположению о том, что ошибка появляется всегда, когда неправильный путь может слиться с правильным. Поэтому полученные ранее границы вероятности ошибки остаются справедливыми, даже если сравнение сливающихся путей не выполняется. Что касается распределения вычислений, то возможно, что отказ от исключения сливающихся путей будет приводить к возрастанию числа вычислений, так как стек в этом случае Может содержать ненужные дубликаты путей. Но, как только что было указано, вероятность этого события имеет тот же порядок, что и вероятность ошибки, которая убывает экспоненциально с длиной кодового ограничения К. Более того, верхняя граница распределения числа вычислений не зависит от К, а следовательно, К может быть сделано очень большим, например много большим, чем при декодировании по максимуму правдоподобия (этот вопрос еще будет обсуждаться в следующем параграфе). При этом изменение вероятности ошибки и дополнительные вычисления, связанные с игнорированием слияний, оказываются пренебрежимо малыми. С практической же точки зрения игнорирование
было ограничено сверху вероятностью того, что неправильный путь будет обследован до точки слияния. Это равносильно предположению о том, что ошибка появляется всегда, когда неправильный путь может слиться с правильным. Поэтому полученные ранее границы вероятности ошибки остаются справедливыми, даже если сравнение сливающихся путей не выполняется. Что касается распределения вычислений, то возможно, что отказ от исключения сливающихся путей будет приводить к возрастанию числа вычислений, так как стек в этом случае Может содержать ненужные дубликаты путей. Но, как только что было указано, вероятность этого события имеет тот же порядок, что и вероятность ошибки, которая убывает экспоненциально с длиной кодового ограничения К. Более того, верхняя граница распределения числа вычислений не зависит от К, а следовательно, К может быть сделано очень большим, например много большим, чем при декодировании по максимуму правдоподобия (этот вопрос еще будет обсуждаться в следующем параграфе). При этом изменение вероятности ошибки и дополнительные вычисления, связанные с игнорированием слияний, оказываются пренебрежимо малыми. С практической же точки зрения игнорирование
 размера стека (а следовательно, и объема необходимой памяти) пропорционально
размера стека (а следовательно, и объема необходимой памяти) пропорционально  числу вычислений в неправильном подмножестве, а поэтому оно также является случайной величиной с распределением Парето. В алгоритме Зигангирова этот недостаток частично устраняется исключением из стека тех путей, метрика которых меньше метрики пути, находящегося на вершине стека, более чем на некоторую фиксированную величину
числу вычислений в неправильном подмножестве, а поэтому оно также является случайной величиной с распределением Парето. В алгоритме Зигангирова этот недостаток частично устраняется исключением из стека тех путей, метрика которых меньше метрики пути, находящегося на вершине стека, более чем на некоторую фиксированную величину  Вероятность исключения правильного пути при этом убывает экспоненциально по
Вероятность исключения правильного пути при этом убывает экспоненциально по  так что влияние этой процедуры на характеристики алгоритма может быть сведено почти к нулю.
так что влияние этой процедуры на характеристики алгоритма может быть сведено почти к нулю.
 помещаются в
помещаются в  ячейку; все пути из ячейки на вершине стека подлежат дальнейшему обследованию в порядке их поступления в эту ячейку (стек имеет процедуру выдачи «последним поступил, первым выдан»). При этом требуется, чтобы метрика любого пути, не хранящегося в данной ячейке, сравнивалась лишь с одним значением метрики, общим для всех путей из этой ячейки. Влияние такого приближенного упорядочивания можно легко оценить количественно. Основное условие дальнейшего обследования неправильного пути (6.2.1) изменяется и переходит в следующее:
ячейку; все пути из ячейки на вершине стека подлежат дальнейшему обследованию в порядке их поступления в эту ячейку (стек имеет процедуру выдачи «последним поступил, первым выдан»). При этом требуется, чтобы метрика любого пути, не хранящегося в данной ячейке, сравнивалась лишь с одним значением метрики, общим для всех путей из этой ячейки. Влияние такого приближенного упорядочивания можно легко оценить количественно. Основное условие дальнейшего обследования неправильного пути (6.2.1) изменяется и переходит в следующее:

 Так как на последнем шаге выбираем
Так как на последнем шаге выбираем  то в конечном счете у множителя А в (6.2.20) появится лишь дополнительный сомножитель
то в конечном счете у множителя А в (6.2.20) появится лишь дополнительный сомножитель  которым, очевидно, в асимптотике можно пренебречь. По тем же соображениям тот же дополнительный множитель появится и в оценке Р6[см. (6.3.12)].
которым, очевидно, в асимптотике можно пренебречь. По тем же соображениям тот же дополнительный множитель появится и в оценке Р6[см. (6.3.12)].
 оказался нарушенным, то декодер смотрит вперед в худший узел. Это будет происходить, если вход в первый блок
оказался нарушенным, то декодер смотрит вперед в худший узел. Это будет происходить, если вход в первый блок

 и если последний не нарушается
и если последний не нарушается  то указатель поиска передвигается вперед в этот узел. Следующий шаг состоит в том, чтобы определить, первый или не первый раз попадает декодер в этот узел при последовательном декодировании (поиске). Можно показать (Галлагер [1968]), что если декодер попадает в узел первый раз, то метрика в предыдущем узле будет меньше порога
то указатель поиска передвигается вперед в этот узел. Следующий шаг состоит в том, чтобы определить, первый или не первый раз попадает декодер в этот узел при последовательном декодировании (поиске). Можно показать (Галлагер [1968]), что если декодер попадает в узел первый раз, то метрика в предыдущем узле будет меньше порога  В этом случае можно попытаться увеличить порог на величину, равную произведению А на наименьшее целое число так, что
В этом случае можно попытаться увеличить порог на величину, равную произведению А на наименьшее целое число так, что  и после этого продолжать обследование пути вперед. Если же узел уже обследовался ранее, то до начала обследования новых узлов порог не увеличивается, и это существенно, так как в противном случае можно было бы войти в замкнутый цикл и повторять одни и те же операции бесконечно долго.
и после этого продолжать обследование пути вперед. Если же узел уже обследовался ранее, то до начала обследования новых узлов порог не увеличивается, и это существенно, так как в противном случае можно было бы войти в замкнутый цикл и повторять одни и те же операции бесконечно долго.
 то декодер должен перейти в режим обследования пути назад. При этом осуществляется вычитание метрики последнего ребра из метрики текущего узла. Если полученная разность удовлетворяет порогу
то декодер должен перейти в режим обследования пути назад. При этом осуществляется вычитание метрики последнего ребра из метрики текущего узла. Если полученная разность удовлетворяет порогу  то указатель перемещается назад; если ребро, по которому был сделан шаг назад, было лучшим из двух ребер, исходящих из только что достигнутого узла, то должно быть обследовано худшее ребро. При этом декодер возвращается к операции обследования пути вперед через точку А. Если же ребро было худшим, то других ребер, которые можно обследовать вперед и» данного узла, больше нет. Следовательно, необходимо продолжить обследование пути назад. Если при обследовании пути назад текущий порог
то указатель перемещается назад; если ребро, по которому был сделан шаг назад, было лучшим из двух ребер, исходящих из только что достигнутого узла, то должно быть обследовано худшее ребро. При этом декодер возвращается к операции обследования пути вперед через точку А. Если же ребро было худшим, то других ребер, которые можно обследовать вперед и» данного узла, больше нет. Следовательно, необходимо продолжить обследование пути назад. Если при обследовании пути назад текущий порог  нарушается, двигаться назад уже нельзя. Когда это случается, становится ясно, что все пути, достижимые отсюда с действующим текущим порогом
нарушается, двигаться назад уже нельзя. Когда это случается, становится ясно, что все пути, достижимые отсюда с действующим текущим порогом  были обследованы и что все они в конце концов нарушили порог
были обследованы и что все они в конце концов нарушили порог  В этом случае порог уменьшается на А и предпринимается новая попытка обследования пути вперед. Заметим также, что если узел обследуется два или более раз, то при каждом повторном посещении он обследуется с меньшим текущим значением порога; это также исключает образование бесконечных циклов.
В этом случае порог уменьшается на А и предпринимается новая попытка обследования пути вперед. Заметим также, что если узел обследуется два или более раз, то при каждом повторном посещении он обследуется с меньшим текущим значением порога; это также исключает образование бесконечных циклов.
 для алгоритма Фано играет в точности ту же роль, что и размер «ячейки»
для алгоритма Фано играет в точности ту же роль, что и размер «ячейки»  в алгоритме Джелинека. Гейст [1973] показал при некоторых довольно слабых ограничениях, что алгоритм
в алгоритме Джелинека. Гейст [1973] показал при некоторых довольно слабых ограничениях, что алгоритм