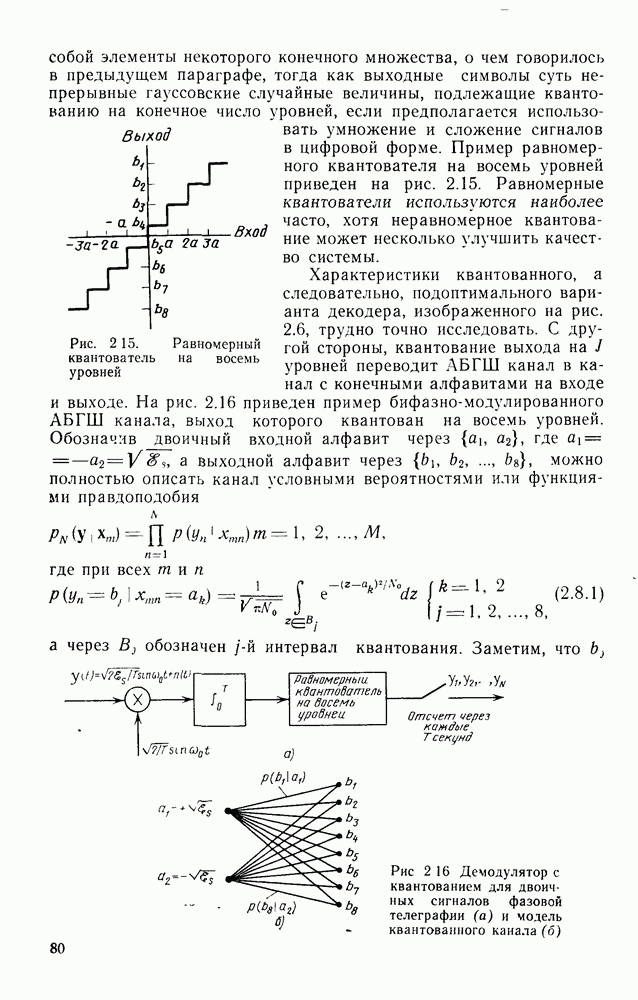
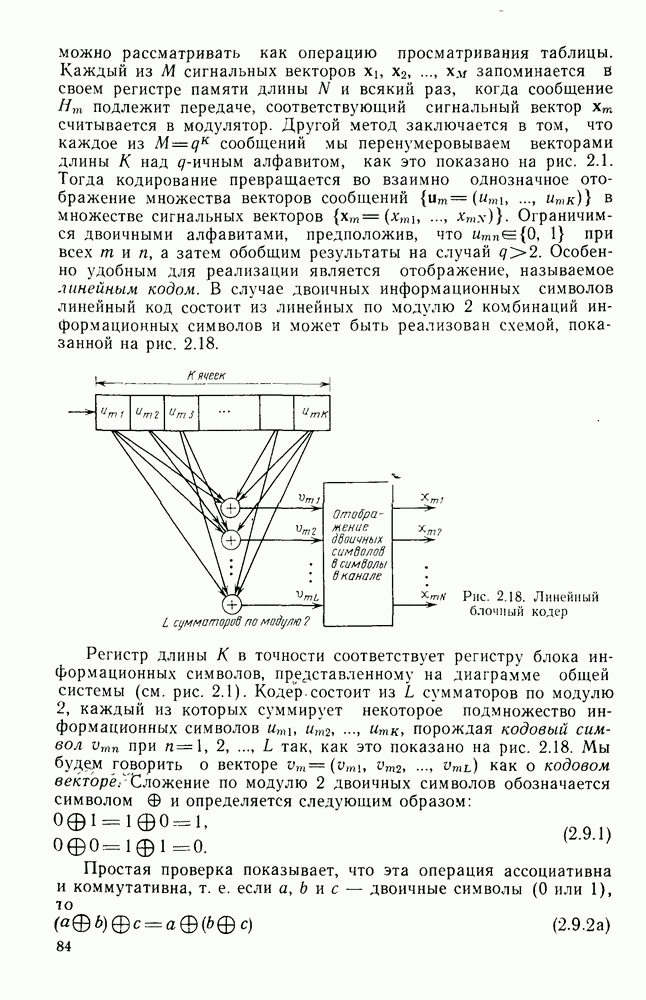
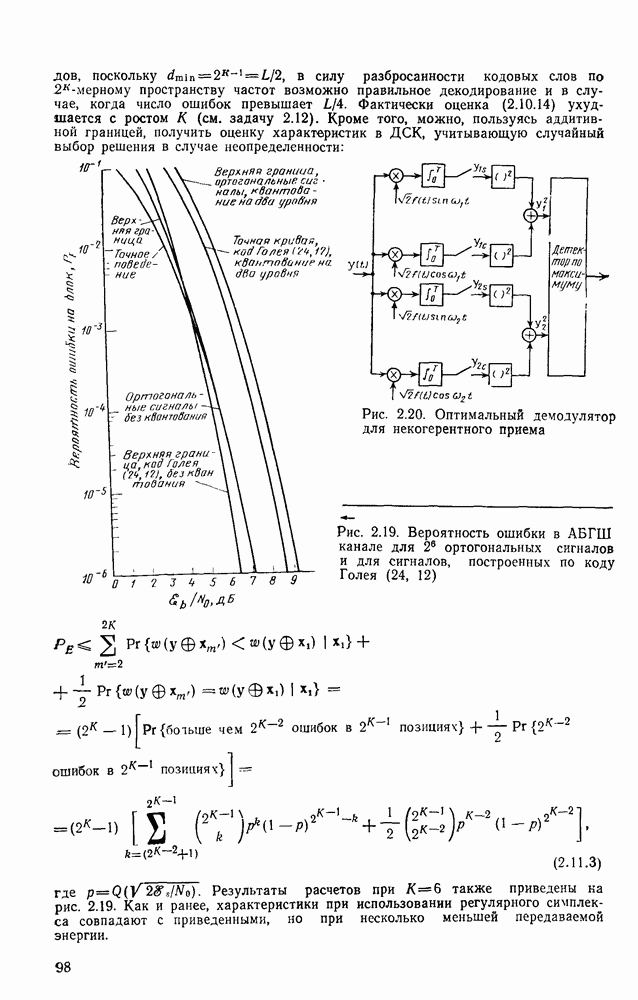
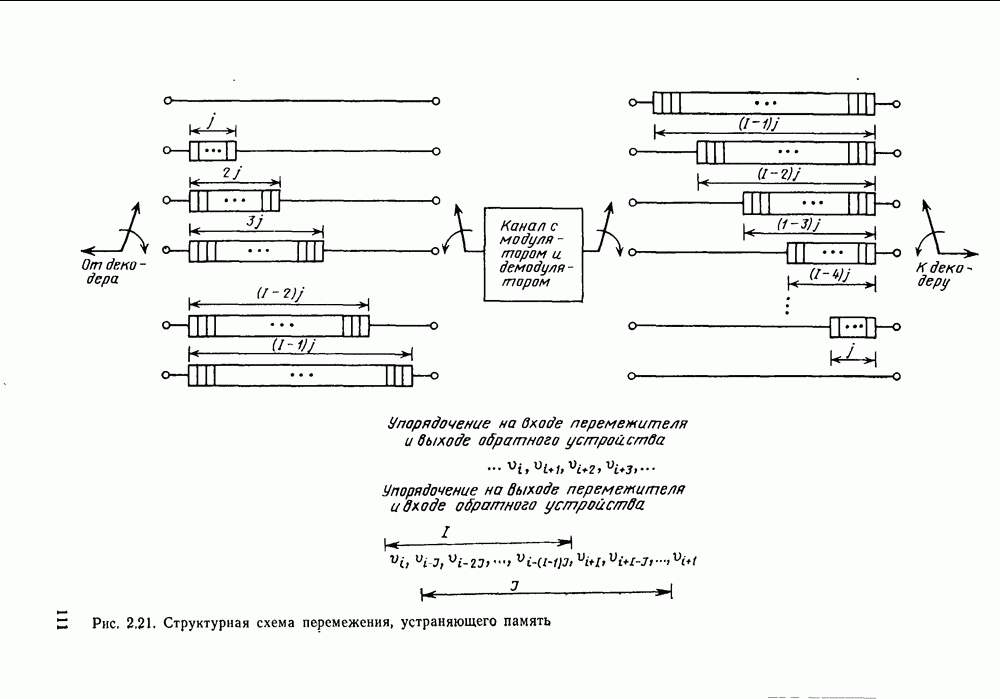
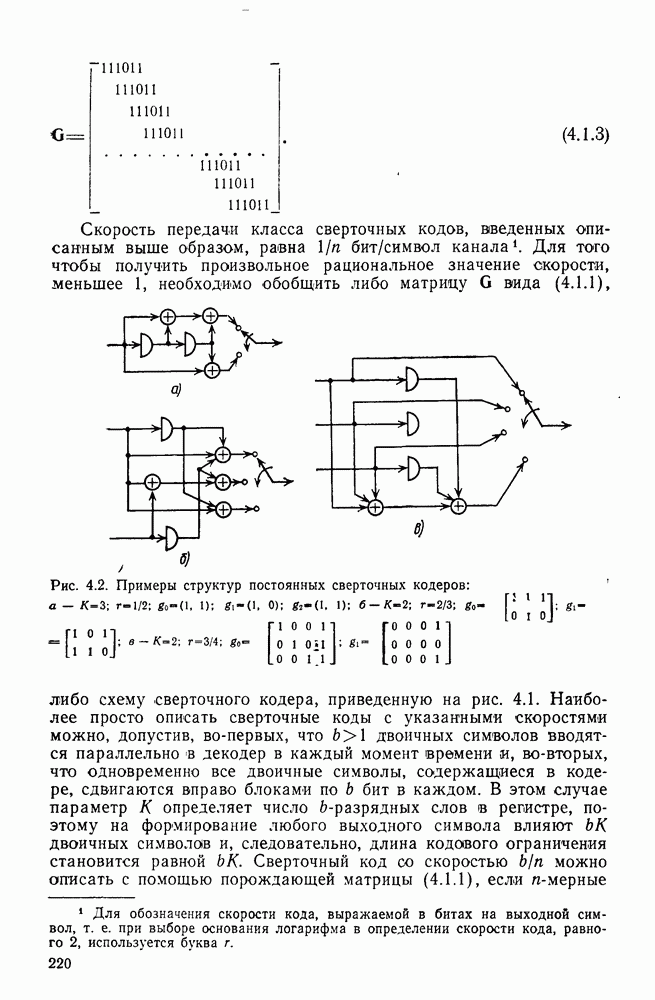
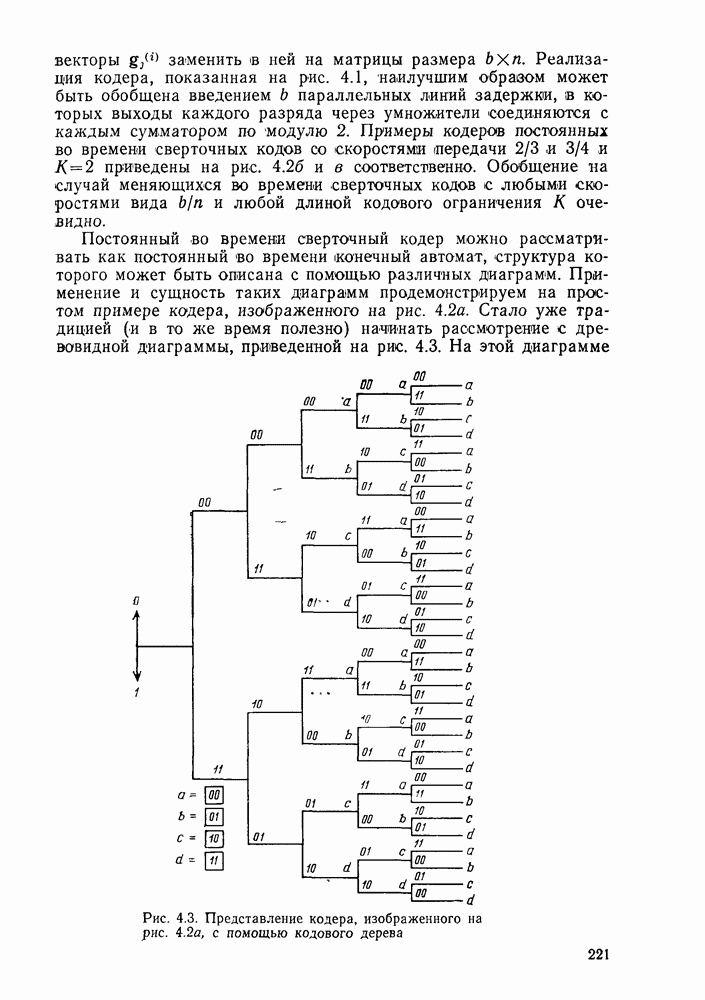
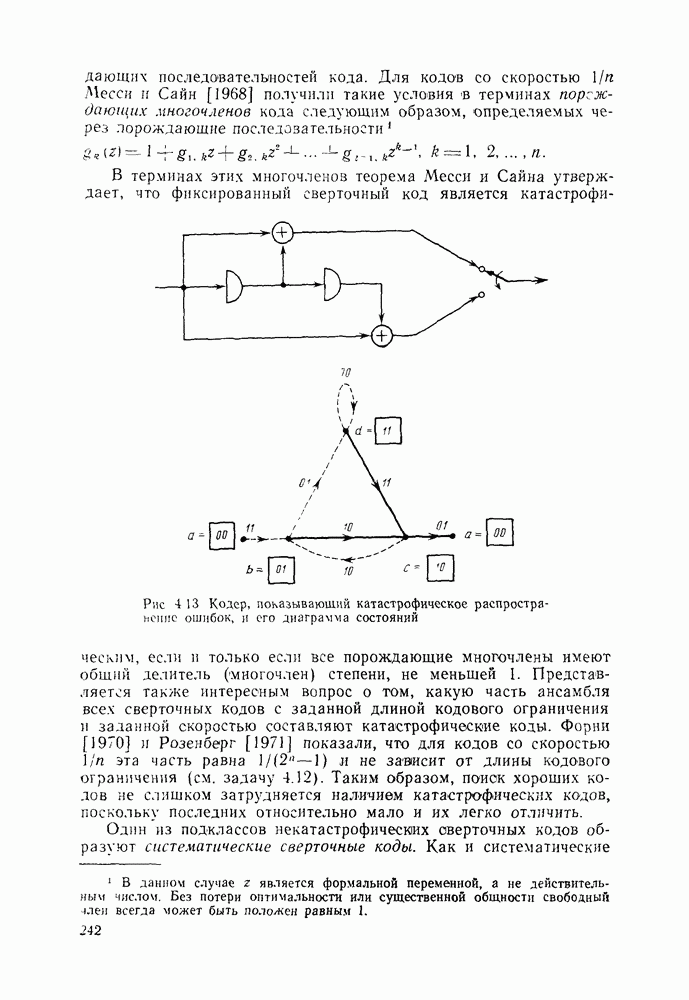
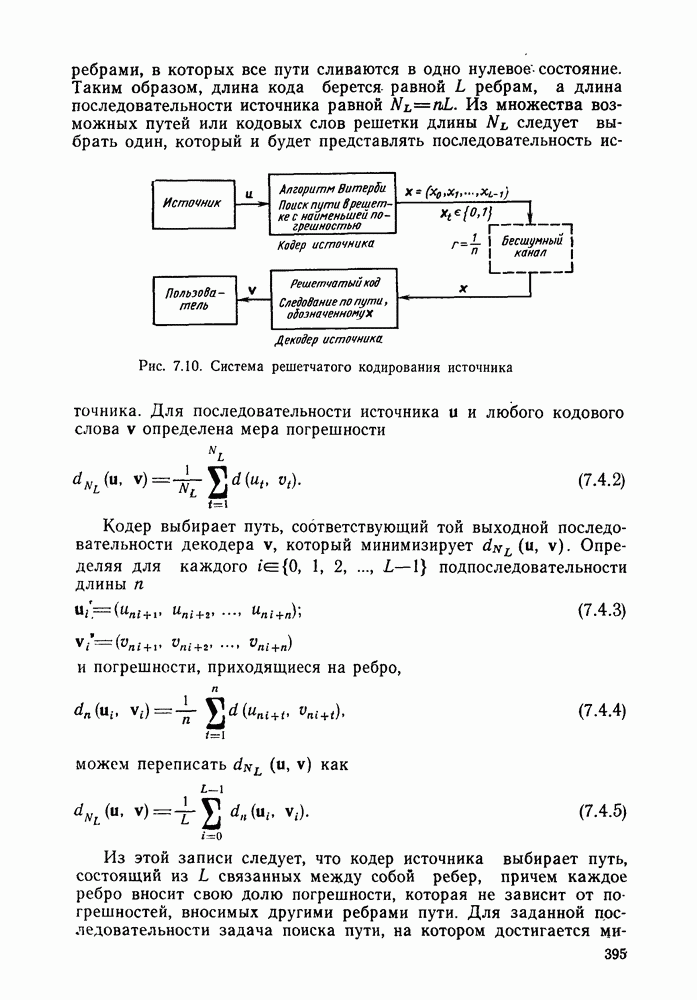
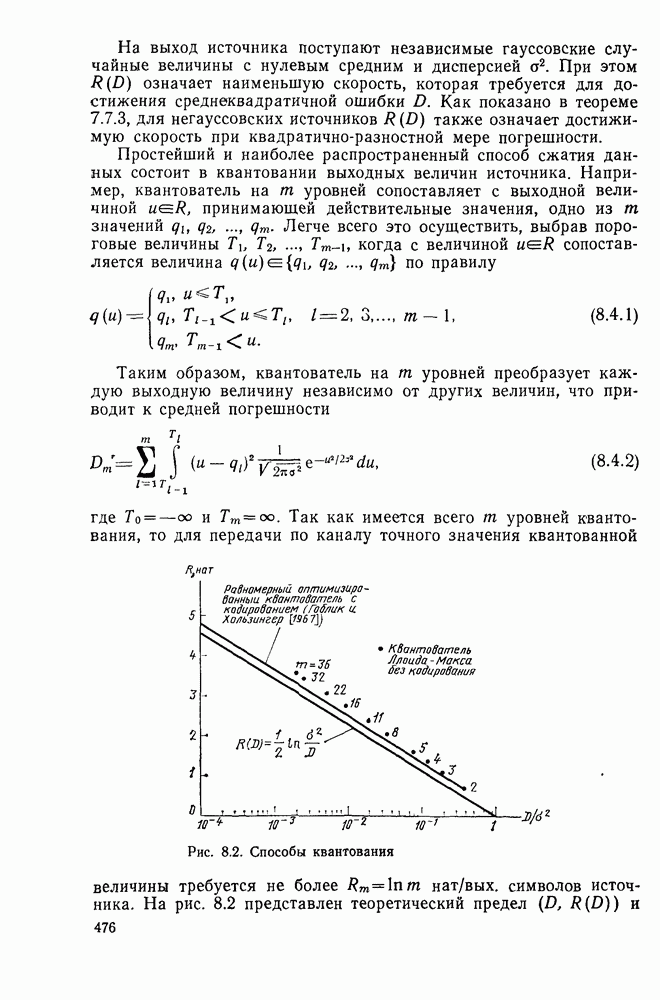
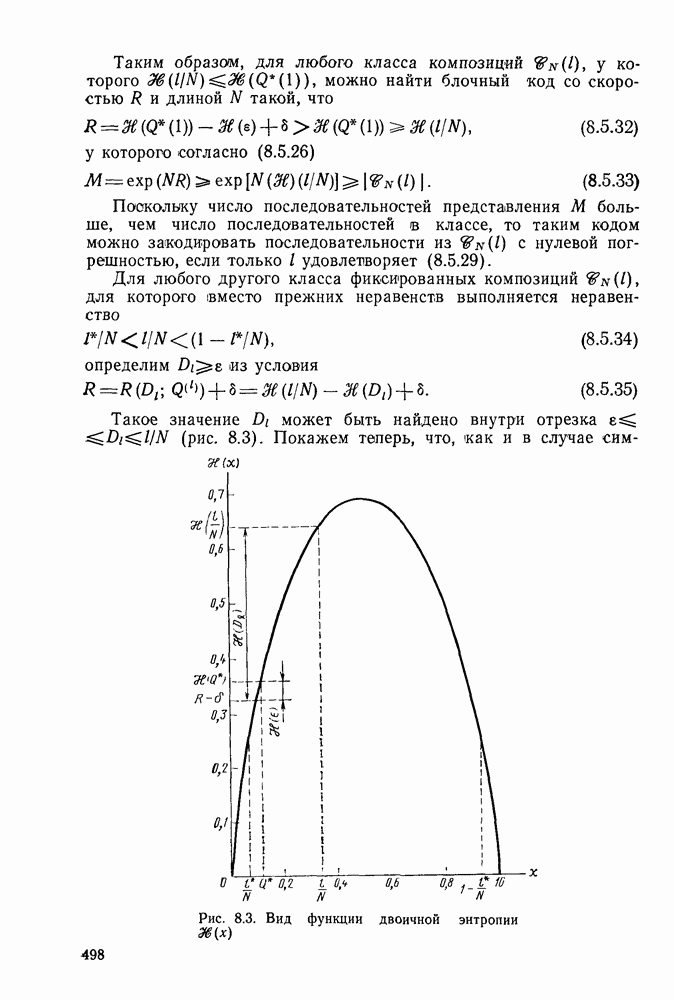
Макеты страниц
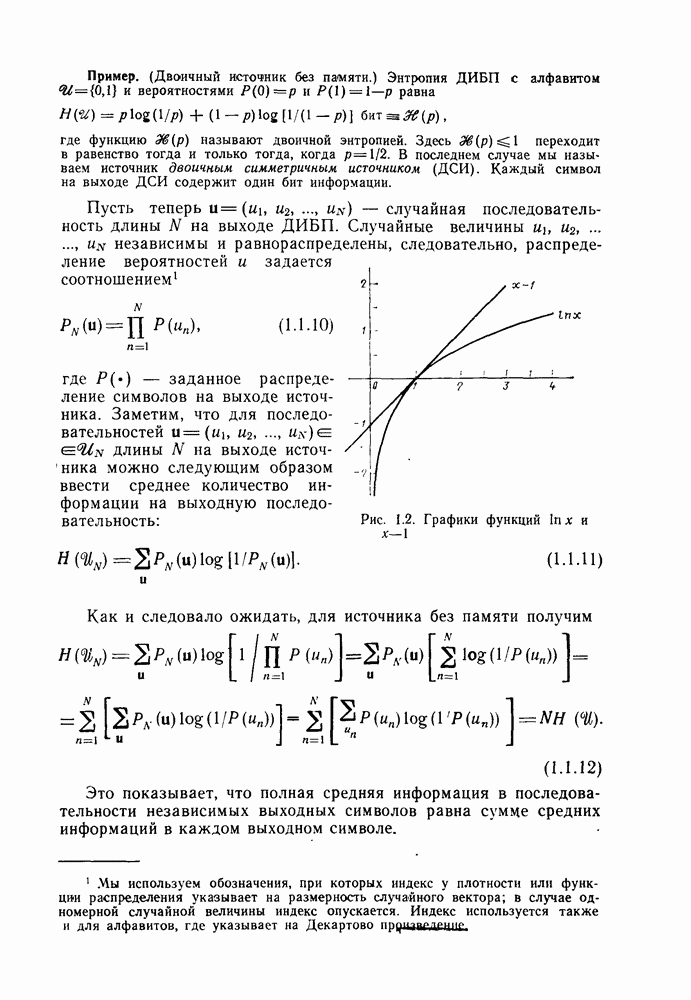
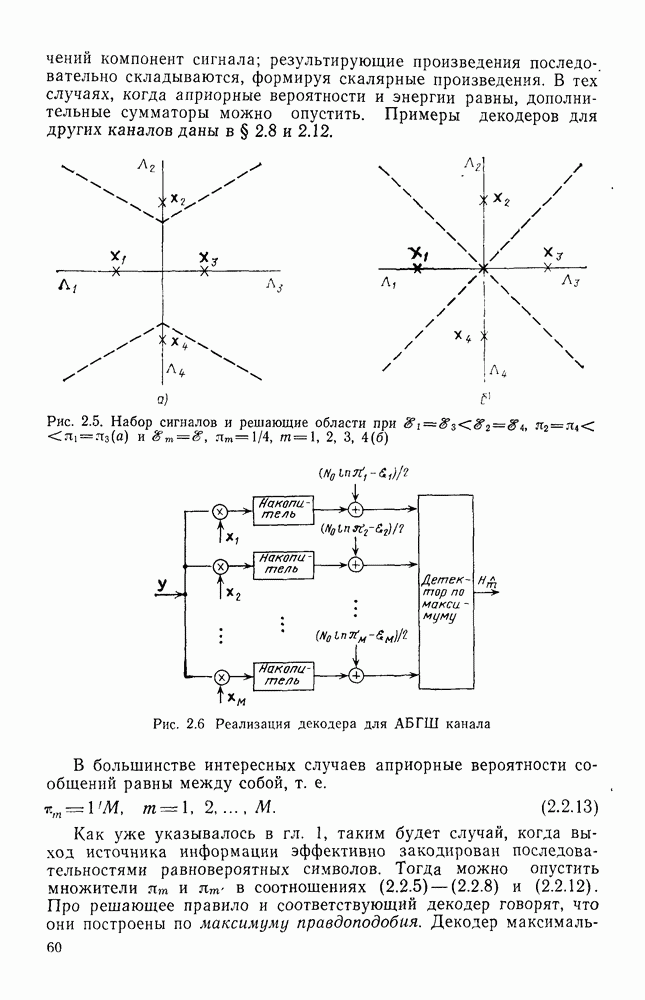
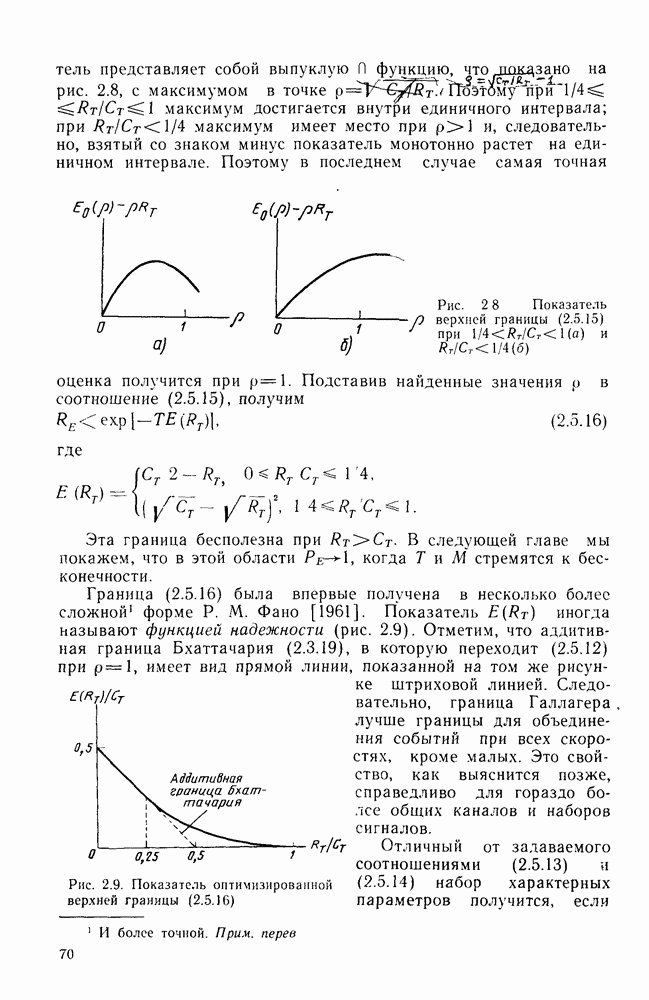
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
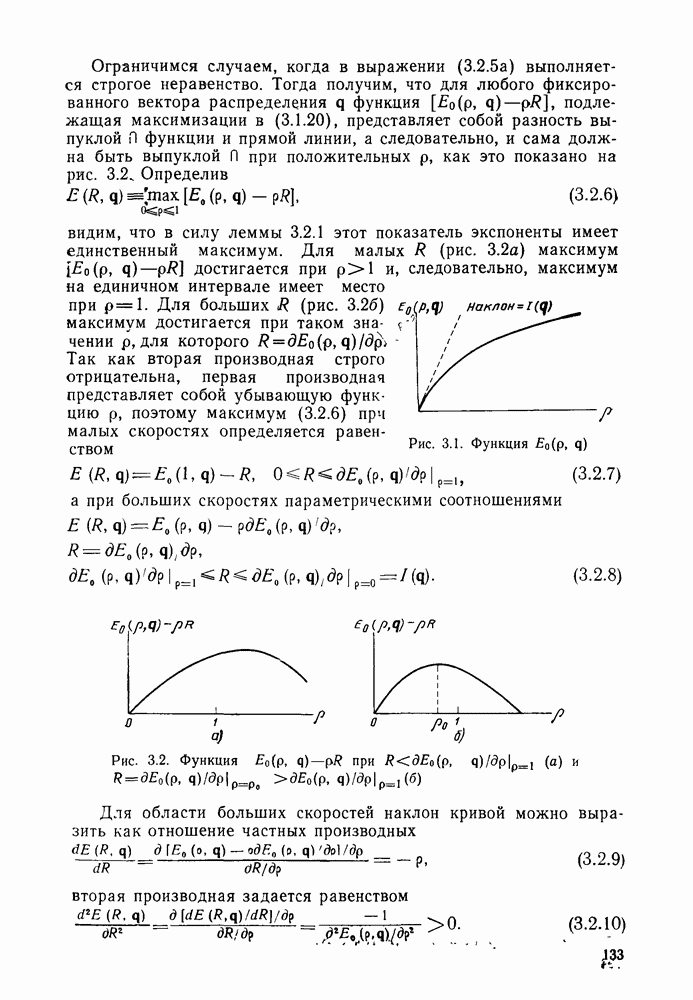
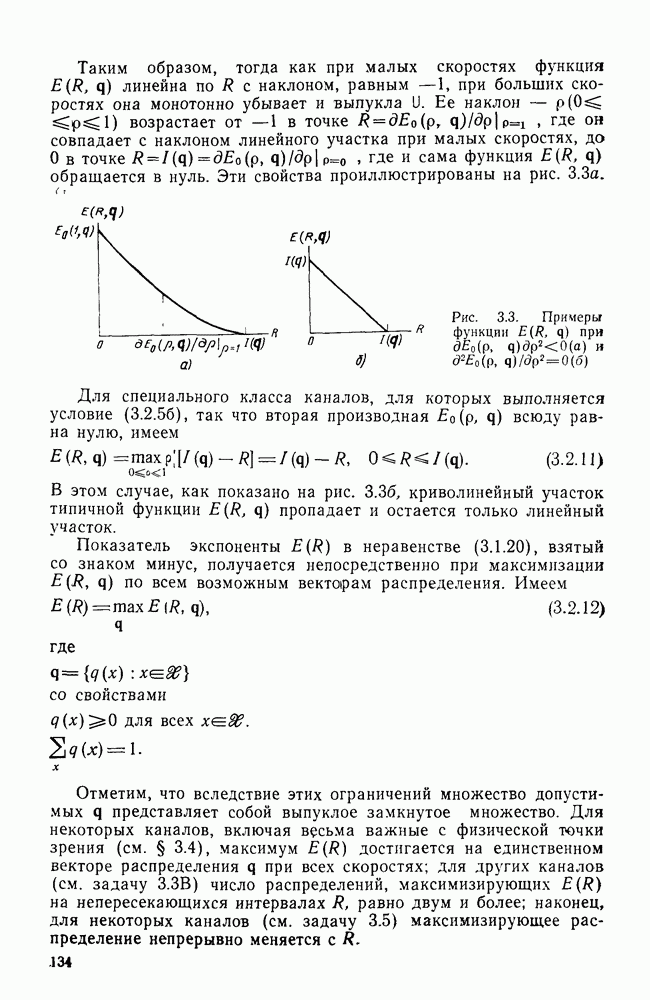
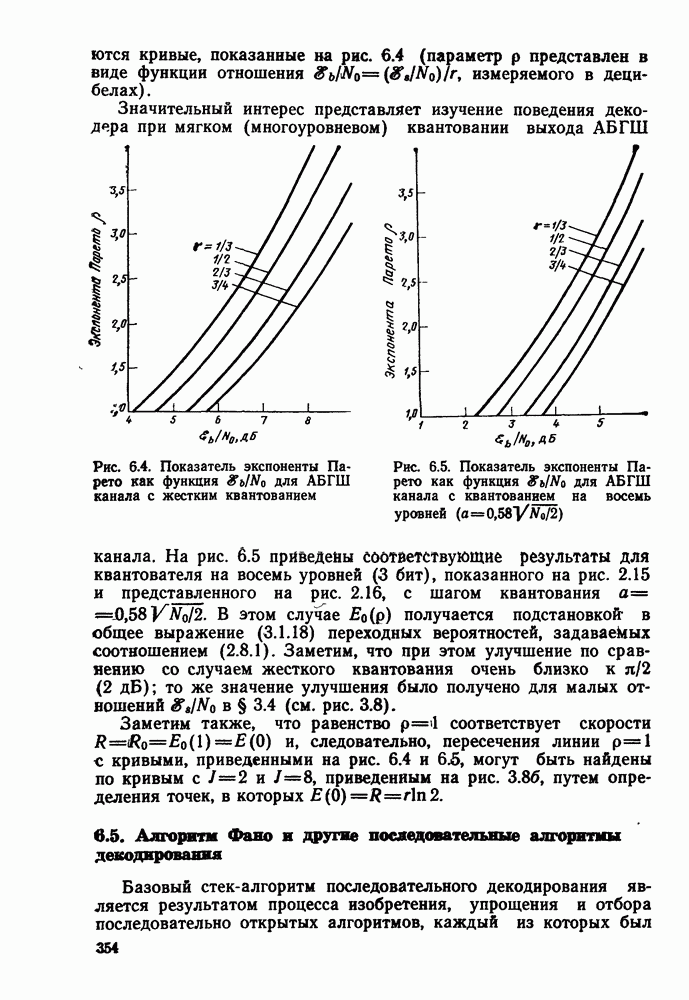
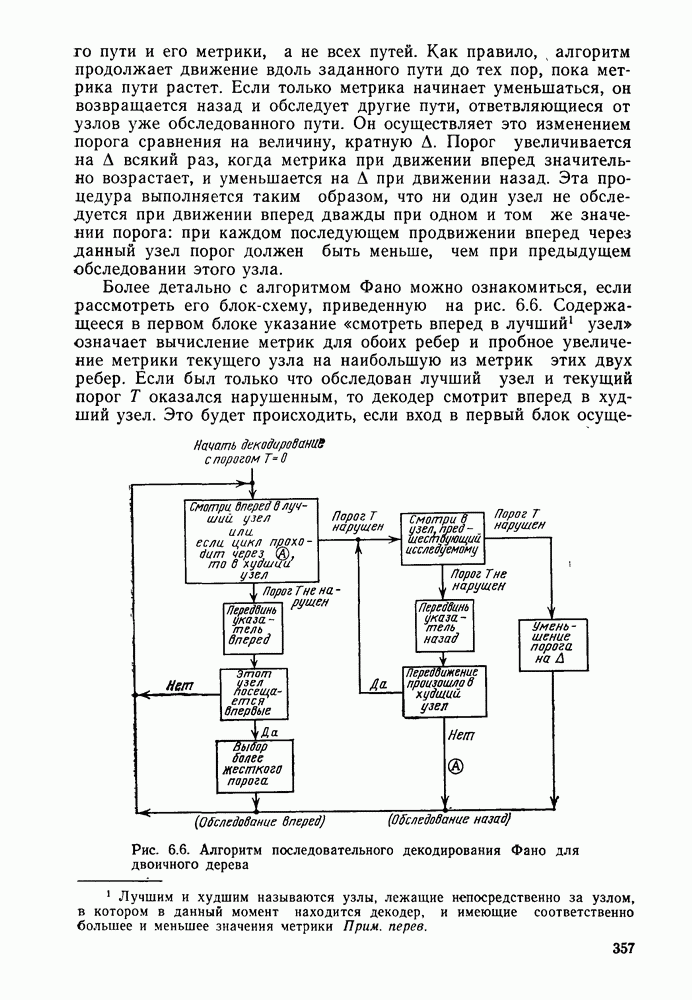
4.8. Декодирование с обратной связью
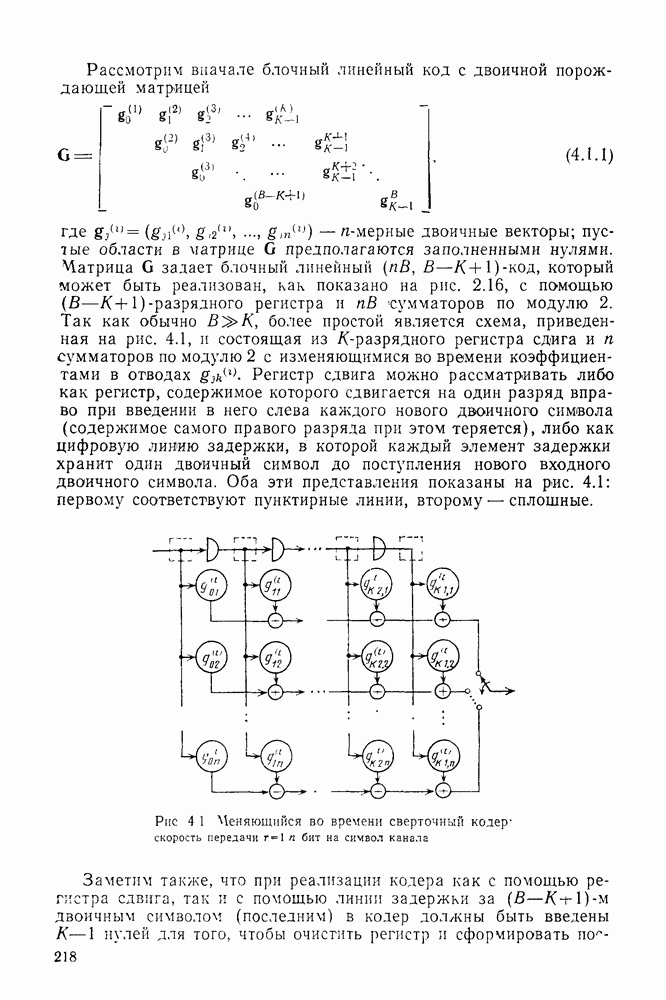
До сих пор рассматривалось только декодирование по максимуму правдоподобия сверточных кодов. При этом был построен и проанализирован алгоритм Витерби, приспособленный к
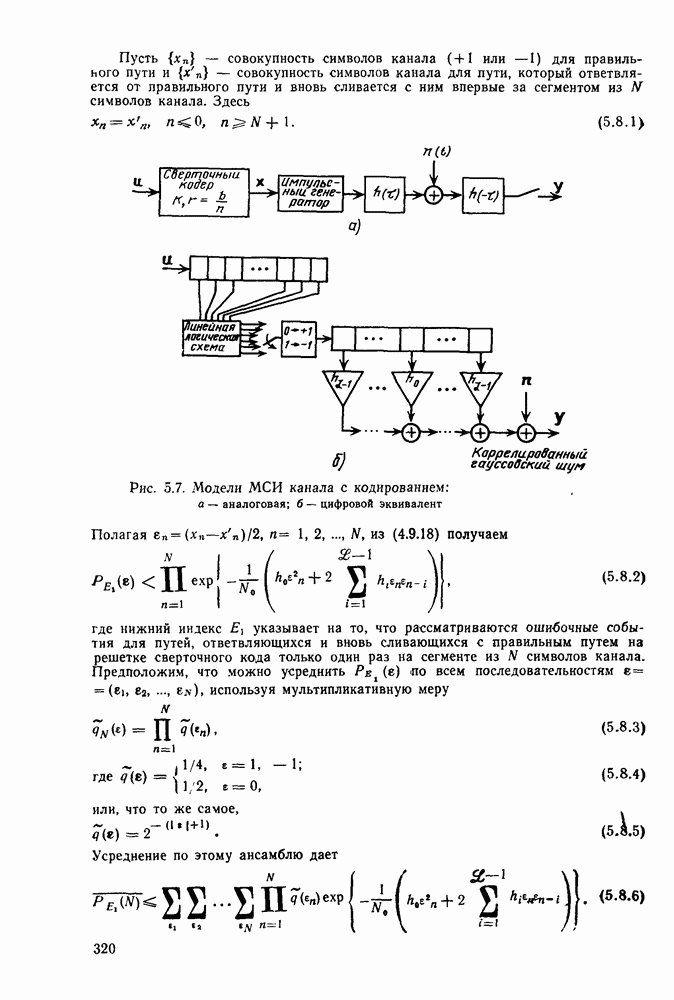
структуре кодов. Основным недостатком этого алгоритма, конечно, является то, что, хотя вероятность ошибки для него убывает экспоненциально с ростом длины кодового ограничения, число состояний кодера, а следовательно, и сложность декодера возрастают, и тоже экспоненциально. Отчасти для того, чтобы обойти этот недостаток, был построен, проанализирован и использован в системах со сверточными кодами >ряд других алгоритмов декодирования. Последовательное декодирование позволяет достичь асимптотически той же вероятности ошибки, что и декодирование по максимуму правдоподобия, но уже без проведения исчерпывающего поиска в множестве всех состояний. При последовательном декодировании число обследуемых состояний, по существу, не зависит от длины кодового ограничения, что позволяет использовать очень большие значения К, а следовательно, достичь очень малых вероятностей ошибок. Эта очень оптимистичная картина омрачается тем фактом, что число метрик состояний, с которыми оперирует декодер, является случайной величиной с неограниченными моментами высших порядков, что на практике оказывается причиной некоторого ухудшения характеристик. Для того чтобы дать соответствующие доказательства для таких сложных, с точки зрения анализа, алгоритмов декодирования, какими являются последовательные алгоритмы, необходимо вначале изучить более детально свойства ансамблей сверточных кодов. Это будет сделано в гл. 5, а в гл. 6 вновь вернемся к рассмотрению последовательного декодирования.
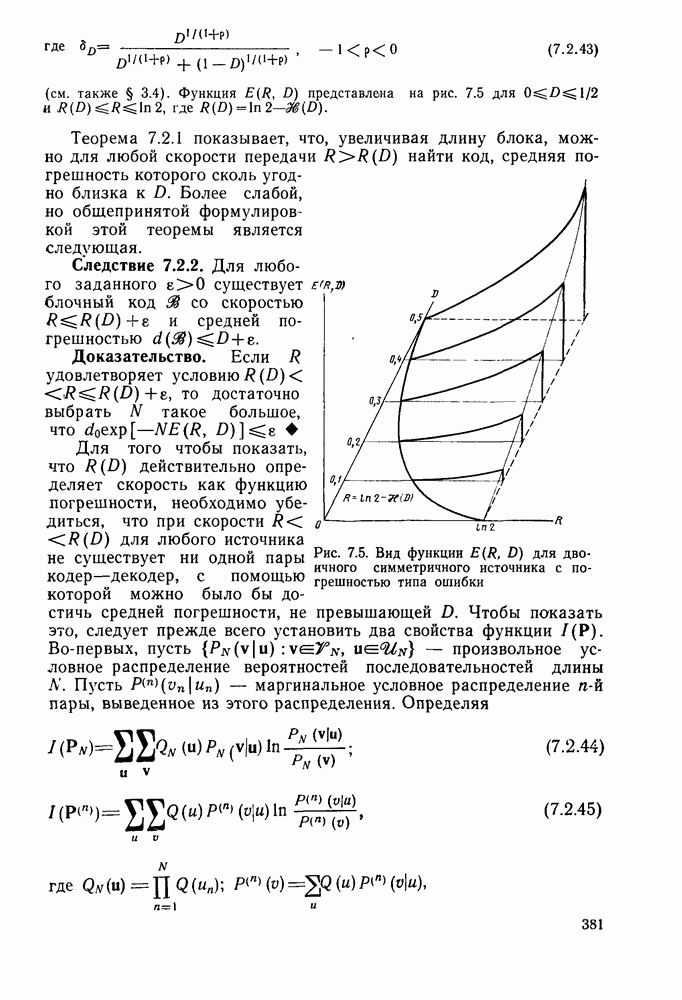
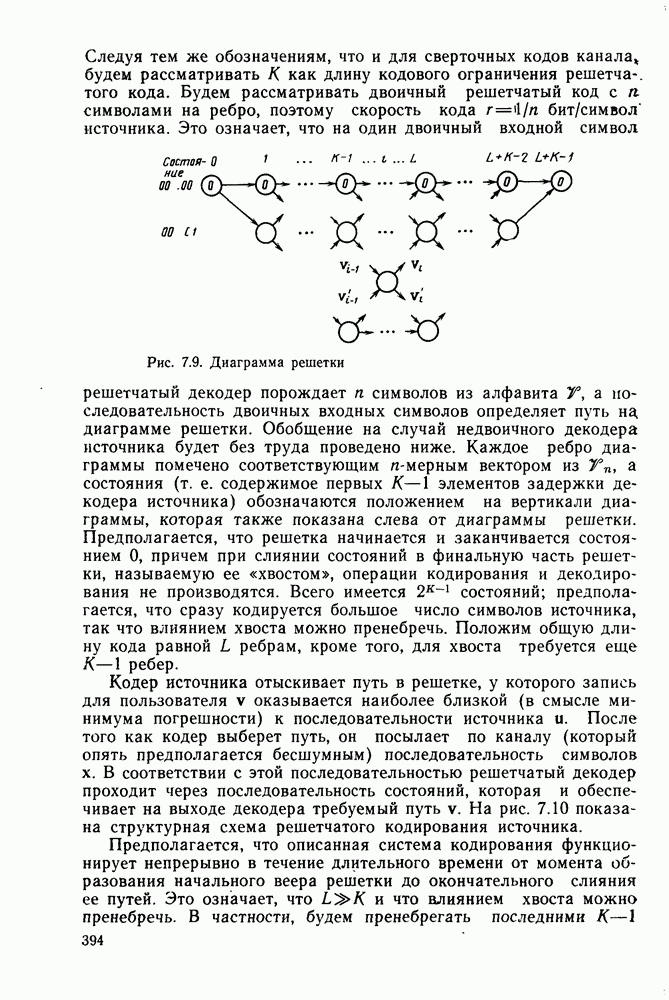
Другой класс алгоритмов декодирования, известный под общим названием декодирование с обратной связью, получил распространение благодаря простоте входящих в него алгоритмов и возможности их использования в оистемах передачи с разнесением данных. Принцип работы декодера с обратной связью, а точнее синдромного декодера с обратной связью, легче всего понять на конкретном примере. На рис. 4.17а приведены простейший кодер со скоростью передачи 1/2, его решетчатая и древовидная диаграммы соответственно. Очевидно, что свободное расстояние этого кода равно 3, так что если ДСК вносит лишь одну ошибку в последовательность из двух ребер (на длине кодового ограничения), то эта ошибка будет исправлена декодером максимального правдоподобия (по минимуму расстояния). Предположим, что вместо декодера максимального правдоподобия, как это было ранее, используется декодер с ограниченной памятью, который принимает решения о данном символе или ребре по максимуму правдоподобия на основании только конечного числа полученных ребер. Например, предположим, что решение принимается о первом двоичном символе на основании двух ребер, показанных на кодовом дереве в пунктирном прямоугольнике А. Если
значение метрики одного из узлов а или  является наибольшим, то принимается решение о том, что первым символом был 0; если же наибольшее значение метрики имеет один из узлов с или является наибольшим, то принимается решение о том, что первым символом был 0; если же наибольшее значение метрики имеет один из узлов с или  то принимается решение в пользу 1. В частности, если по ДСК принята последовательность то принимается решение в пользу 1. В частности, если по ДСК принята последовательность  то метрика (расстояние Хэмминга со знаком минус) равна —1 в узле с и имеет меньшие значения во всех остальных узлах третьего яруса. то метрика (расстояние Хэмминга со знаком минус) равна —1 в узле с и имеет меньшие значения во всех остальных узлах третьего яруса.

Рис. 4.17. Пример кода для декодирования с обратной связью: а — кодер; б - решетчатая диаграмма; в — дерево
Рассматриваемый декодер примет решение о том, что первый символ был 1, и это решение уже пересматриваться не будет. С этого момента рассматриваются только пути, лежащие в нижней половине кодового дерева. Следующее решение принимается на основании путей в пунктирном прямоугольнике В, т. е. на основании метрик четырех узлов  Для данной последовательности у метрика, вычисляемая на основании ребер 2 и 3, принимает значение — 1 в узлах Для данной последовательности у метрика, вычисляемая на основании ребер 2 и 3, принимает значение — 1 в узлах  и меньшие значения в остальных узлах. Следовательно, решением о втором символе будет 0. Отметим, что вклад первого ребра в метрику можно было бы вычесть, поскольку все пути в прямоугольнике В имеют одно и то же первое ребро и решение в пользу последнего на предыдущем шаге было принято окончательное. Декодер может двигаться точно так же и дальше, оперируя, по существу, как «скользящий блочный декодер» с кодом из четырех кодовых слов, каждое из которых состоит из двух ребер. Этот декодер называется также декодером с обратной связью, поскольку принимаемые им решения вводятся «обратно» в него же, определяя подмножество кодовых путей, которое должно быть рассмотрено следующим. В ДСК этот декодер работает почти так же хорошо, как декодер Витерби, в том ймысле, что он исправляет все наиболее вероятные конфигурации и меньшие значения в остальных узлах. Следовательно, решением о втором символе будет 0. Отметим, что вклад первого ребра в метрику можно было бы вычесть, поскольку все пути в прямоугольнике В имеют одно и то же первое ребро и решение в пользу последнего на предыдущем шаге было принято окончательное. Декодер может двигаться точно так же и дальше, оперируя, по существу, как «скользящий блочный декодер» с кодом из четырех кодовых слов, каждое из которых состоит из двух ребер. Этот декодер называется также декодером с обратной связью, поскольку принимаемые им решения вводятся «обратно» в него же, определяя подмножество кодовых путей, которое должно быть рассмотрено следующим. В ДСК этот декодер работает почти так же хорошо, как декодер Витерби, в том ймысле, что он исправляет все наиболее вероятные конфигурации
ошибок, а именно те, что имеют вес, не превышающий  где где  свободное расстояние кода. Следовательно, некоторые (но не обязательно все) конфигурации ошибок минимального веса, которые приводят к ошибкам при принятии решений декодером с обратной связью, будут приводить свободное расстояние кода. Следовательно, некоторые (но не обязательно все) конфигурации ошибок минимального веса, которые приводят к ошибкам при принятии решений декодером с обратной связью, будут приводить  принятию ошибочных решений и при использовании декодера Витерби. принятию ошибочных решений и при использовании декодера Витерби.
Рассмотренный выше пример прост настолько, что может привести к ошибочному представлению о достаточности равенства длины памяти, которую обозначим через  длине кодового ограничения, для того чтобы минимальное расстояние между правильным путем и любым другим путем, ответвляющимся от него, было не меньше длине кодового ограничения, для того чтобы минимальное расстояние между правильным путем и любым другим путем, ответвляющимся от него, было не меньше  на длине в на длине в  ребер. Рассматривая изображенную на рис. 4.8 решетку кода со скоростью ребер. Рассматривая изображенную на рис. 4.8 решетку кода со скоростью  и длиной кодового ограничения и длиной кодового ограничения  для которого для которого  видим, что длина видим, что длина  должна быть равна шести ребрам, для того чтобы все пути (как сливающиеся, так и несливающиеся), ответвляющиеся от нулевого пути в первом узле, набрали вес должна быть равна шести ребрам, для того чтобы все пути (как сливающиеся, так и несливающиеся), ответвляющиеся от нулевого пути в первом узле, набрали вес  или более. Действительно, наихудшим в этом случае является путь с информационной последовательностью 101010, который достигает веса 5 только на шестом ребре. Таким образом, этот код гарантирует исправление всех конфигураций двойных ошибок в любой последовательности из 12 кодовых символов (из шести ребер). Для исправления всех тройных ошибок необходимо иметь код со свободным расстоянием или более. Действительно, наихудшим в этом случае является путь с информационной последовательностью 101010, который достигает веса 5 только на шестом ребре. Таким образом, этот код гарантирует исправление всех конфигураций двойных ошибок в любой последовательности из 12 кодовых символов (из шести ребер). Для исправления всех тройных ошибок необходимо иметь код со свободным расстоянием  равным самое меньшее 7, а при скорости 1/2 этот код будет иметь равным самое меньшее 7, а при скорости 1/2 этот код будет иметь  Лучший код с Лучший код с  требует, чтобы длина требует, чтобы длина  была равна 12, для того чтобы была равна 12, для того чтобы  невозвратные неправильные пути смогли достичь веса 7. Однако имеется систематический код с невозвратные неправильные пути смогли достичь веса 7. Однако имеется систематический код с  в котором все пути, ответвляющиеся от нулевого, достигают веса 7 при в котором все пути, ответвляющиеся от нулевого, достигают веса 7 при  Следовательно, декодер с обратной связью при использовании этого кода с Следовательно, декодер с обратной связью при использовании этого кода с  будет исправлять шее конфигурации тройных ошибок в любой последовательности из 22 символов. К дальнейшему обсуждению вопроса о систематических кодах мы вскоре вернемся. будет исправлять шее конфигурации тройных ошибок в любой последовательности из 22 символов. К дальнейшему обсуждению вопроса о систематических кодах мы вскоре вернемся.
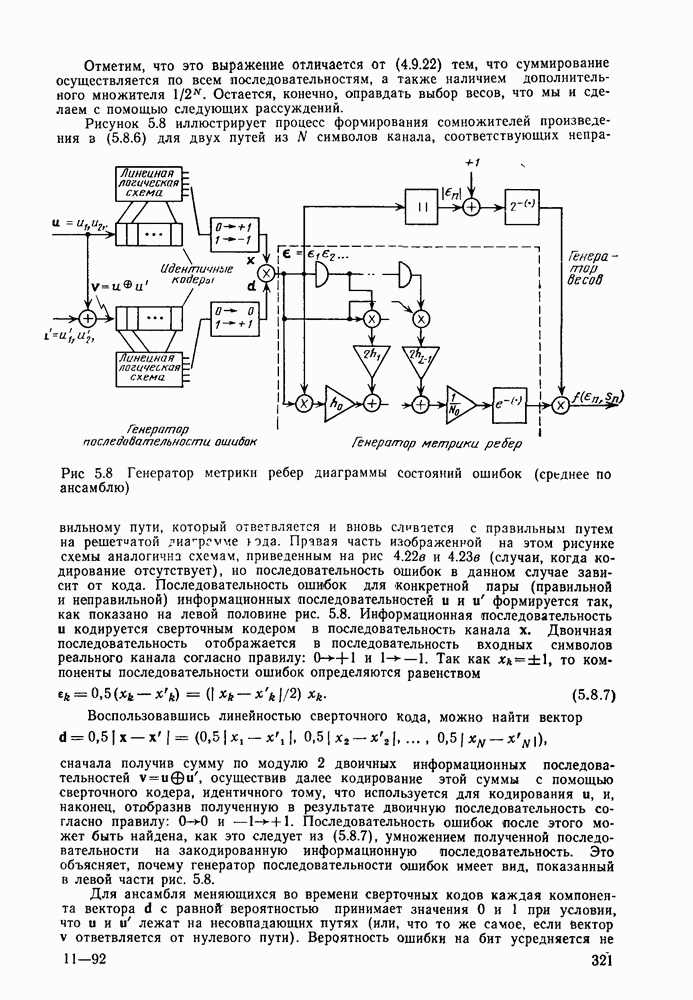
То, что рассмотренный выше декодер может рассматриваться как скользящий блочный декодер, позволяет упростить его реализацию для ДСК. Напомним, что, как показано в § 2.10, декодер максимального правдоподобия (минимального расстояния) для блочного систематического кода и ДСК может быть с успехом реализован на базе вычисления синдрома принятого вектора и нахождения наиболее правдоподобного вектора ошибок по полученному синдрому в таблице, содержащей для каждого синдрома наиболее вероятные векторы ошибок. Простой код, который сейчас рассматривается, является примером систематического
кода, поскольку один из генераторов его кодера представляет собой простое соединение выхода со входом, по которому информационные символы без изменений поступают со входа на выход. Для удобства передаваемый кодовый вектор представим в виде

где  информационный символ (генерируемый сверху), а информационный символ (генерируемый сверху), а  проверочный символ (генерируемый снизу). Этот вектор формируется по данным источника операцией проверочный символ (генерируемый снизу). Этот вектор формируется по данным источника операцией  где где

Здесь мы отошли от соглашения, принятого в § 4.1, записывать подряд все выходные символы, порождаемые при поступлении  входного символа, и разделили выходную последовательность на две подпоследовательности (в общем случае на входного символа, и разделили выходную последовательность на две подпоследовательности (в общем случае на  ), соответствующие отдельным порождающим последовательностям. Это повлекло необходимость разделения также порождающей матрицы на две подматрицы, соответствующие отдельным порождающим последовательностям. Из § 2.10 следует, что транспонированной проверочной матрицей этого кода является матрица ), соответствующие отдельным порождающим последовательностям. Это повлекло необходимость разделения также порождающей матрицы на две подматрицы, соответствующие отдельным порождающим последовательностям. Из § 2.10 следует, что транспонированной проверочной матрицей этого кода является матрица

Так как каждая подматрица проверочной матрицы также обладает тем свойством, что каждая ее строка является сдвигом предыдущей на один элемент, то ясно, что синдром  можно получить, пропустив принятые информационные символы, на которые действовал шум, через сверточный кодер с одной порождающей последовательностью и сложив получившиеся при этом на выходе кодера символы с принятыми проверочными символами, на которые воздействовал шум. На рис. 4.18 информационные и проверочные символы показаны так, как будто бы они передаются по двум отдельным каналам. можно получить, пропустив принятые информационные символы, на которые действовал шум, через сверточный кодер с одной порождающей последовательностью и сложив получившиеся при этом на выходе кодера символы с принятыми проверочными символами, на которые воздействовал шум. На рис. 4.18 информационные и проверочные символы показаны так, как будто бы они передаются по двум отдельным каналам.

Рис. 4.18. Декодер с обратной связью для кода, приведенного на рис. 4.17
В действительности, коммутатор на выходе кодера обеспечивает передачу символов  друг за другом по одному каналу, а другой коммутатор, устанавливаемый перед кодером, разделяет подверженную влиянию шума принятую последовательность на информационную и проверочную последовательности. Однако, поскольку канал является каналом без памяти, можно считать, что информационная и проверочная последовательности передаются по раздельным ДСК, но с одними и теми же статистическими характеристиками. друг за другом по одному каналу, а другой коммутатор, устанавливаемый перед кодером, разделяет подверженную влиянию шума принятую последовательность на информационную и проверочную последовательности. Однако, поскольку канал является каналом без памяти, можно считать, что информационная и проверочная последовательности передаются по раздельным ДСК, но с одними и теми же статистическими характеристиками.
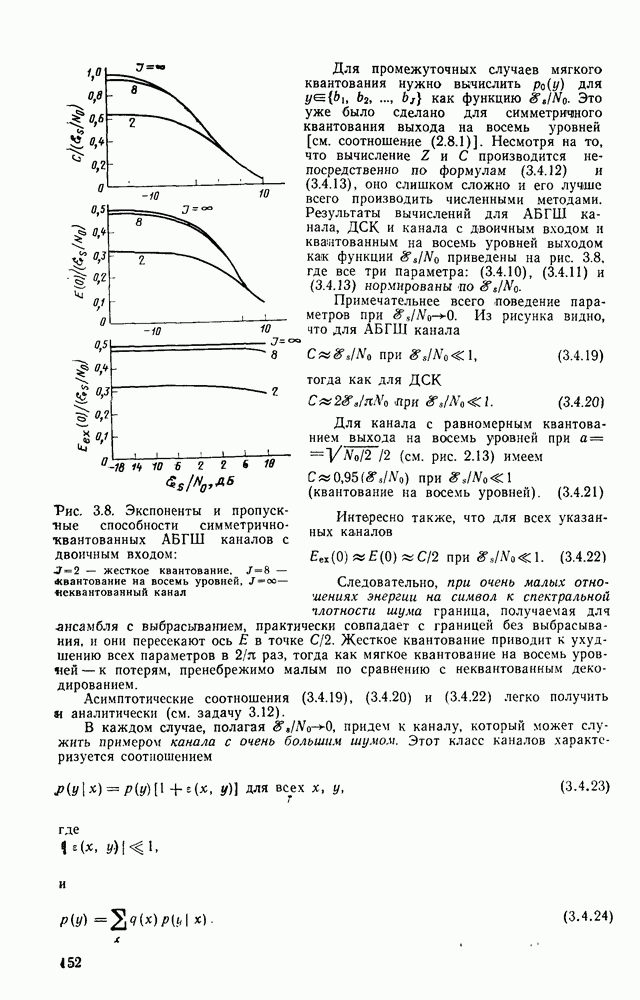
Ясно, что при отсутствии ошибок синдром всегда является нулевым, так как он представляет собой сумму по модулю 2 двух идентичных последовательностей. При появлении ошибок некоторые компоненты синдрома будут равны 1. Если сохранить лишь  символов синдрома, то с точки зрения «скользящего блочного» декодера эти символы будут синдромом блочного кода, соответствующего части кодового дерева глубиной в символов синдрома, то с точки зрения «скользящего блочного» декодера эти символы будут синдромом блочного кода, соответствующего части кодового дерева глубиной в  ребер. Каждому из ребер. Каждому из  значений синдрома этого блочного кода можно сопоставить с помощью таблицы наиболее вероятные конфигурации ошибок (минимального веса). Однако в действительности на каждом шаге декодер с обратной связью принимает лишь решение о том, какая из двух половин кодового дерева более вероятна. Другими словами, решение принимается о том, является ли принятый информационный символ, соответствующий первому ребру, правильно принятым или он содержит ошибку. Это требует хранения для каждого значения синдрома только одного символа: 0 или 1; при этом символ 1 соответствует ошибке и должен быть сложен по модулю 2 с соответствующим информационным символом, который также должен храниться в каскадном регистре сдвига. значений синдрома этого блочного кода можно сопоставить с помощью таблицы наиболее вероятные конфигурации ошибок (минимального веса). Однако в действительности на каждом шаге декодер с обратной связью принимает лишь решение о том, какая из двух половин кодового дерева более вероятна. Другими словами, решение принимается о том, является ли принятый информационный символ, соответствующий первому ребру, правильно принятым или он содержит ошибку. Это требует хранения для каждого значения синдрома только одного символа: 0 или 1; при этом символ 1 соответствует ошибке и должен быть сложен по модулю 2 с соответствующим информационным символом, который также должен храниться в каскадном регистре сдвига.
Для рассматриваемого кода значения синдрома, а также соответствующие ему наиболее вероятные последовательности
ошибок и необходимые выходные символы приведены в табл. 4.2. В общем случае такая таблица может быть реализована с помощью постоянной памяти с  адресными входами и одним выходом, который используется для коррекции информационного символа. адресными входами и одним выходом, который используется для коррекции информационного символа.
Таблица 4.2. Таблица поиска по синдрому для кода на рис. 4.17

В данном простом случае, как показано на рис. 4.18, постоянную память можно заменить элементом И. Имеется еще одна функция, которая должна быть реализована в декодере с обратной связью. Это введение обратно в декодер только что принятого решения. Если принимается решение о том, что символ  является ошибочным, то это проще всего может быть реализовано путем устранения влияния на решающий элемент ошибки в первом символе. Решающий элемент в данном случае состоит из регистра окндрома, где хранится синдром для последних является ошибочным, то это проще всего может быть реализовано путем устранения влияния на решающий элемент ошибки в первом символе. Решающий элемент в данном случае состоит из регистра окндрома, где хранится синдром для последних  ребер, и неизменяющейся во времени таблицы. Ошибка в символе ребер, и неизменяющейся во времени таблицы. Ошибка в символе  в данном случае порождает символы 1 в обоих каскадах регистра синдрома, но для принятия следующего решения в данном случае порождает символы 1 в обоих каскадах регистра синдрома, но для принятия следующего решения  содержимое самого правого каскада выводится и заменяется содержимым предыдущего каскада. Таким образом, чтобы устранить влияние ошибки в символе содержимое самого правого каскада выводится и заменяется содержимым предыдущего каскада. Таким образом, чтобы устранить влияние ошибки в символе  необходимо сложить по модулю 2 выходной символ решающего элемента с содержимым самого правого каскада регистра оиндрома и хранить полученный результат до поступления следующей компоненты синдрома. необходимо сложить по модулю 2 выходной символ решающего элемента с содержимым самого правого каскада регистра оиндрома и хранить полученный результат до поступления следующей компоненты синдрома.
До тех пор пока при принятии решений не происходит ошибок, декодер функционирует так, как было описано выше, исправляя все одиночные ошибки в любой последовательности из четырех оимволов. Однако, если некоторые два из произвольных четырех следующих друг за другом символов оказываются ошибочными, то будет принято неверное решение и эта ошибка может начать распространяться дальше, поскольку она вновь вводится в декодер и влияет на принятие последующих решений. Это явление называется эффектом распространения ошибок, и оно в той или иной степени присуще всем декодерам сверточных кодов. В данном случае распространение ошибки будет происходить на конечное расстояние по следующей причине. Очевидно, что при отсутствии
ошибок при передаче двух смежных ребер оба разряда регистра синдрома не могут одновременно содержать символ 1, а следовательно, как можно проверить по табл. 4.2, никакая ошибка декодирования уже не будет введена в декодер по цепи обратной связи, что приведет к возвращению регистра синдрома в нулевое состояние и беспрепятственному (прохождению правильных информационных символов. Рассмотренный выше пример кода со скоростью  исправляющего одиночные ошибки, может быть обобщен на случай кодов, исправляющих одиночные ошибки, с произвольной скоростью исправляющего одиночные ошибки, может быть обобщен на случай кодов, исправляющих одиночные ошибки, с произвольной скоростью  задачу 4.13). задачу 4.13).
Обобщение на случай произвольного систематического кода с любой скоростью  получить несложно. Для такого кода информационная последовательность делится на подпоследовательности (блоки) длиной получить несложно. Для такого кода информационная последовательность делится на подпоследовательности (блоки) длиной  бит. Каждый символ информационного блока длиной бит. Каждый символ информационного блока длиной  передается по каналу и одновременно вводится в соответствующую ячейку памяти первых разрядов передается по каналу и одновременно вводится в соответствующую ячейку памяти первых разрядов  регистров кодера, каждый из которых имеет длину К.. После каждого ввода информационных символов формируются регистров кодера, каждый из которых имеет длину К.. После каждого ввода информационных символов формируются  проверочных символов, которые являются линейными комбинациями (но модулю 2) содержимого этих регистров. Генератор синдрома в декодере работает почти точно так же, как и кодер, а именно, проверочных символов, которые являются линейными комбинациями (но модулю 2) содержимого этих регистров. Генератор синдрома в декодере работает почти точно так же, как и кодер, а именно,  возможно искаженных ошибками информационных символов «новь так же, как и ранее, кодируются в возможно искаженных ошибками информационных символов «новь так же, как и ранее, кодируются в  символов, которые далее складываются с соответствующими принятыми проверочными символами, и в результате получаются символы синдрома. Таким образом, для каждого блока из символов, которые далее складываются с соответствующими принятыми проверочными символами, и в результате получаются символы синдрома. Таким образом, для каждого блока из  информационных символов порождается информационных символов порождается  символов синдрома, равных нулю при отсутствии ошибок. Если декодирование осуществляется по максимуму правдоподобия на основании символов синдрома, равных нулю при отсутствии ошибок. Если декодирование осуществляется по максимуму правдоподобия на основании  последних ребер, то в памяти декодера должны храниться последних ребер, то в памяти декодера должны храниться  двоичных компонент синдрома и, в общем случае, таблица поиска по синдрому, состоящая из двоичных компонент синдрома и, в общем случае, таблица поиска по синдрому, состоящая из  строк строк  бит в каждой. Символ 1 на любом из бит в каждой. Символ 1 на любом из  выходов устройства, реализующего обращение к таблице поиска, означает, что должна быть исправлена ошибка в соответствующем информационном символе и проведена соответствующая коррекция синдрома. выходов устройства, реализующего обращение к таблице поиска, означает, что должна быть исправлена ошибка в соответствующем информационном символе и проведена соответствующая коррекция синдрома.
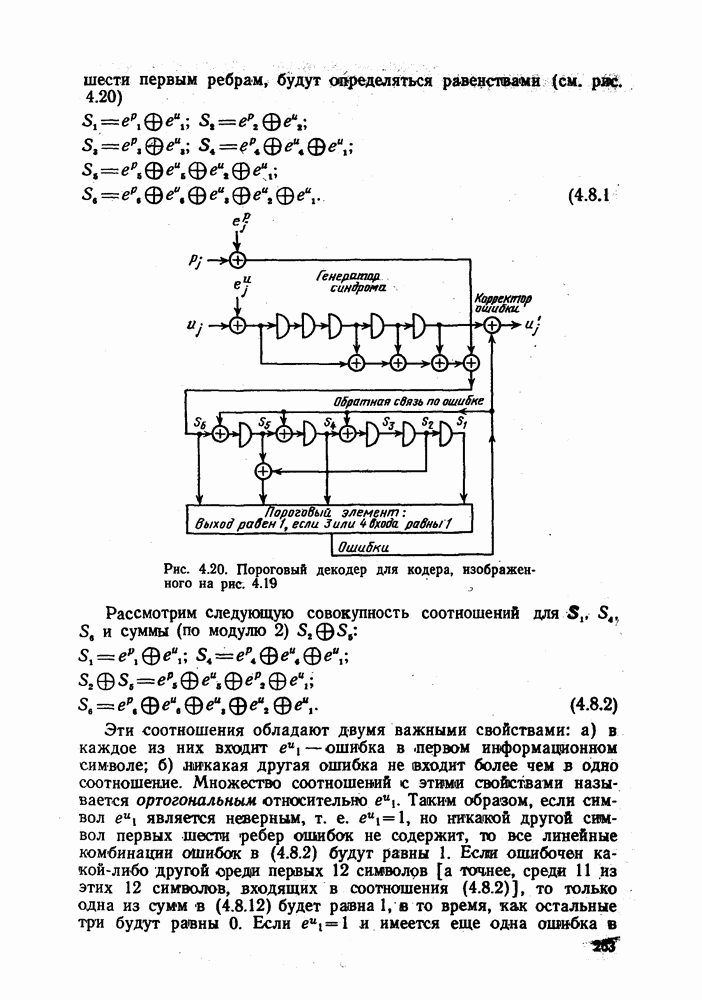
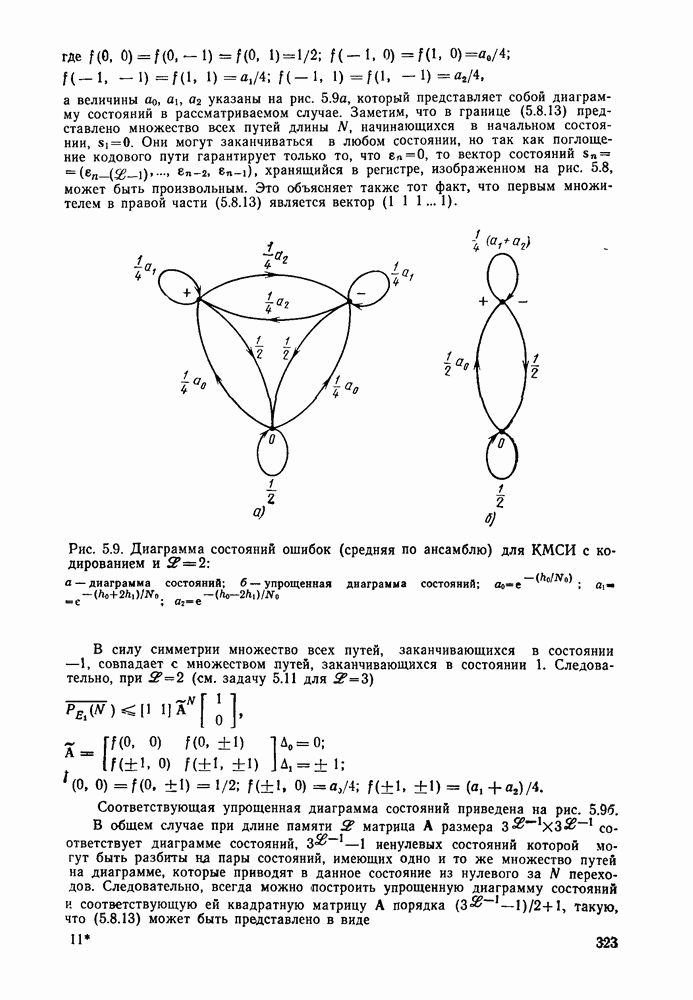
В качестве примера кода с несколько более высокой корректирующей способностью, а также для иллюстрации возможности дальнейшего упрощения декодера для некоторых подклассов сверточных кодов, рассмотрим код со скоростью  исправляющий двойные ошибки. Как указывалось выше, несистематический код исправляющий двойные ошибки. Как указывалось выше, несистематический код  скоростью скоростью  изображенный на рис. 4.2а, требует памяти на шесть ребер для того, чтобы все неправильные невозвратные пути находились от правильного пути на свободном расстоянии, равном 5. Сложность декодера с обратной связью определяется почти исключительно сложностью логических схем синдрома, а совсем не длиной кодового ограничения. Более того, с точки зрения исправления ошибок в информационных символах более естественно было бы работать с изображенный на рис. 4.2а, требует памяти на шесть ребер для того, чтобы все неправильные невозвратные пути находились от правильного пути на свободном расстоянии, равном 5. Сложность декодера с обратной связью определяется почти исключительно сложностью логических схем синдрома, а совсем не длиной кодового ограничения. Более того, с точки зрения исправления ошибок в информационных символах более естественно было бы работать с
систематичеокими кодами, чем с несистематическими. (Вообще говоря, при декодирования по максимуму правдоподобия, сложность которого зависит непосредственно и почти исключительно от длины кодового ограничения, как уже указывалось в § 4.5, несистематические сверточные коды лучше, чем систематические, поскольку при заданном К они имеют большее свободное расстояние. С другой стороны, так как, во-первых, декодер с обратной связью, по существу, представляет собой скользящий блочный декодер блочного кода длиной  ребер и; во-вторых, любому несистематическому блочному ребер и; во-вторых, любому несистематическому блочному  соответствует систематический блочный код с теми же характеристиками, использование систематического сверточного кода в сочетании с декодером с обратной связью представляется весьма привлекательным. Систематический код, который может быть декодирован декодером с обратной связью и с памятью синдрома на шесть ребер, показан на рис. 4.19. соответствует систематический блочный код с теми же характеристиками, использование систематического сверточного кода в сочетании с декодером с обратной связью представляется весьма привлекательным. Систематический код, который может быть декодирован декодером с обратной связью и с памятью синдрома на шесть ребер, показан на рис. 4.19.

Рис. 4.19. Систематический кодер, позволяющий исправлять двойные ошибки 
С помощью кодового дерева можно проверить, что для этого кода  и что все пути, ответвляющиеся в некотором узле от нулевого пути, находятся от последнего на расстоянии не менее 5 на сегменте из шести ребер. Следовательно, декодер с обратной связью и памятью на; шесть ребер исправляет ошибки в любых двух символах любой последовательности из 12 символов этого кода. и что все пути, ответвляющиеся в некотором узле от нулевого пути, находятся от последнего на расстоянии не менее 5 на сегменте из шести ребер. Следовательно, декодер с обратной связью и памятью на; шесть ребер исправляет ошибки в любых двух символах любой последовательности из 12 символов этого кода.
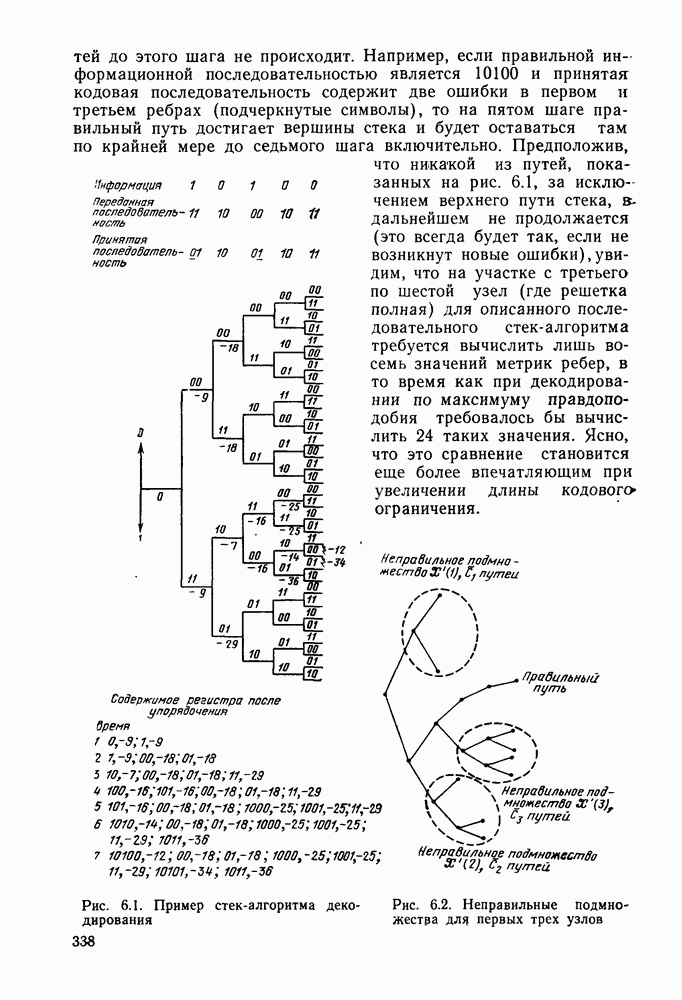
Поскольку общая структура декодера с обратной связью уже описана, покажем возможность значительного упрощения процедуры обращения к таблице поиска по синдрому для некоторых частных классов, кодов, к которым относится и рассматриваемый код. Предположим, что возможные ошибки в информационном и проверочном символах  ребра обозначены через ребра обозначены через  соответственно; каждый из этих символов принимает значение О, если соответствующий символ принят правильно, и 1, если он принят с ошибкой. Так как все компоненты синдрома равны О при отсутствии ошибок (предполагается, что ранее ошибок также не было), то первые шесть компонент синдрома, соответствующйе соответственно; каждый из этих символов принимает значение О, если соответствующий символ принят правильно, и 1, если он принят с ошибкой. Так как все компоненты синдрома равны О при отсутствии ошибок (предполагается, что ранее ошибок также не было), то первые шесть компонент синдрома, соответствующйе
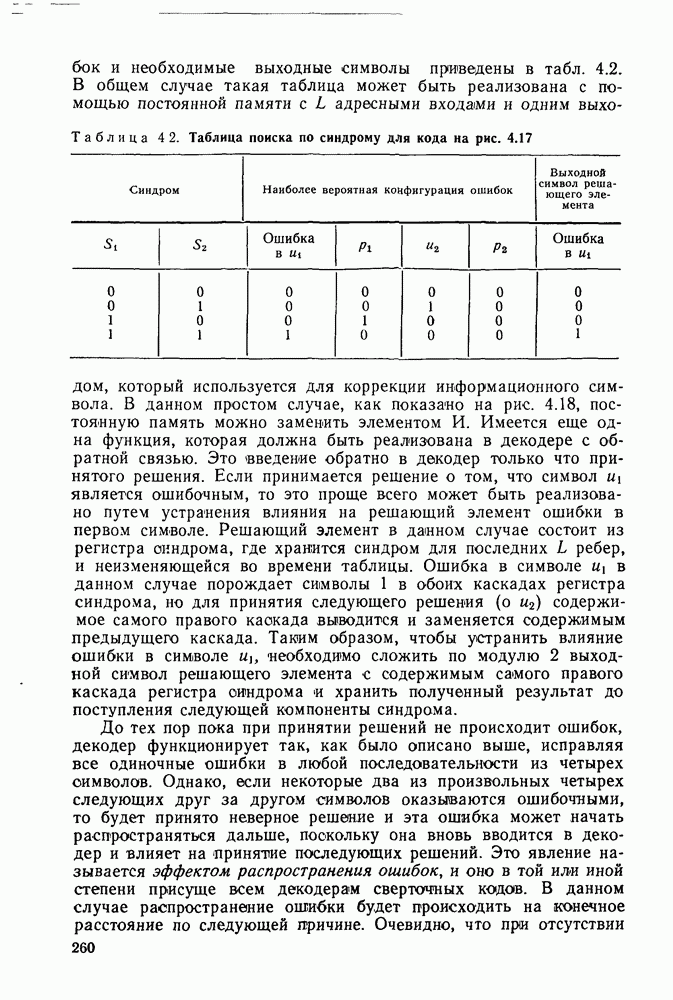
шести первым ребрам, будут определяться раовенстаа (см. рис. 4.20)


Рис. 4.20. Пороговый декодер для кодера, изображенного на рис. 4.19
Рассмотрим следующую совокупность соотношений для  и суммы (по модулю 2) и суммы (по модулю 2) 

Эти соотношения обладают двумя важными свойствами: а) в каждое из них входит  ошибка в первом информационном символе; б) никакая другая ошибка не входит более чем в одно соотношение. Множество соотношений с этими свойствами называется ортогональным относительно ошибка в первом информационном символе; б) никакая другая ошибка не входит более чем в одно соотношение. Множество соотношений с этими свойствами называется ортогональным относительно  Таким образом, если символ Таким образом, если символ  является неверным, т. е. является неверным, т. е.  но никэной другой символ первых шести ребер ошибок не содержит, то все линейные комбинации ошибок в (4.8.2) будут равны 1. Если ошибочен какой-либо другой среди первых 12 символрв [а точнее, среди 11 из этих 12 символов, входящих в соотношения (4.8.2)], то только одна из сумм в (4.8.12) будет равна 1, в то время, кале остальные три будут равны 0. Бели но никэной другой символ первых шести ребер ошибок не содержит, то все линейные комбинации ошибок в (4.8.2) будут равны 1. Если ошибочен какой-либо другой среди первых 12 символрв [а точнее, среди 11 из этих 12 символов, входящих в соотношения (4.8.2)], то только одна из сумм в (4.8.12) будет равна 1, в то время, кале остальные три будут равны 0. Бели  и имеется еще одна ошибка в и имеется еще одна ошибка в
первых 12 символах, то три суммы будут равны 1, а четвертая будет равна 0. И, наконец, если  но какие-либо два других символа ошибочны, то, самое большее, две суммы будут равны 1, так но какие-либо два других символа ошибочны, то, самое большее, две суммы будут равны 1, так  каждая из этих двух ошибок входит не более чем в одно соотношение (быть может, в одно и то же). Следовательно, каждая из этих двух ошибок входит не более чем в одно соотношение (быть может, в одно и то же). Следовательно,  тогда и только тогда, когда три или четыре суммы в (4.8.2) равны тогда и только тогда, когда три или четыре суммы в (4.8.2) равны  только в том случае, если равны 1 менее чем три суммы. Это позволяет использовать вместо таблицы поиска по синдрому схему декодирования, показанную на рис. 4.20. Эта схема содержит более простой основной логический блок, а в остальном она в точности повторяет описанный выше декодер с обратной связью по синдрому. Этот частный вид декодера с обратной связью называется пороговым декодером, поскольку принятие решений в нем осуществляется с помощью порогового (иногда называемого также мажоритарным) элемента. Класс сверточных кодов, допускающих пороговое декодирование, впервые был описан и исследован Месси [1963]. только в том случае, если равны 1 менее чем три суммы. Это позволяет использовать вместо таблицы поиска по синдрому схему декодирования, показанную на рис. 4.20. Эта схема содержит более простой основной логический блок, а в остальном она в точности повторяет описанный выше декодер с обратной связью по синдрому. Этот частный вид декодера с обратной связью называется пороговым декодером, поскольку принятие решений в нем осуществляется с помощью порогового (иногда называемого также мажоритарным) элемента. Класс сверточных кодов, допускающих пороговое декодирование, впервые был описан и исследован Месси [1963].
Ясно, что все описанное выше для первого ребра применимо и ко всем последующим ребрам с той разницей, что коррекция информационных символов и, производится путем .их сложения с  Кроме того, всякий раз когда Кроме того, всякий раз когда  должен быть также устранен эффект последействия этой ошибки путем прибавления проверочных символов, порождаемых должен быть также устранен эффект последействия этой ошибки путем прибавления проверочных символов, порождаемых  искаженном информационном символе, в соответствующие разряды регистра синдрома. Ясно, что при этом любая ошибка или пара ошибок в шести следующих друг за другом ребрах исправляется. Однако, так как имеется 64 возможных конфигурации синдрома и лишь искаженном информационном символе, в соответствующие разряды регистра синдрома. Ясно, что при этом любая ошибка или пара ошибок в шести следующих друг за другом ребрах исправляется. Однако, так как имеется 64 возможных конфигурации синдрома и лишь  конфигурации ошибок веса 2 и менее, то следует признать, что рассмотренная процедура декодирования, вообще говоря, не заменяет полностью обращения к таблице поиска по синдрому, соответствующего усеченному декодированию по максимуму правдоподобия. Это связано с тем, что хотя данная процедура гарантирует исправление всех конфигураций ошибок веса конфигурации ошибок веса 2 и менее, то следует признать, что рассмотренная процедура декодирования, вообще говоря, не заменяет полностью обращения к таблице поиска по синдрому, соответствующего усеченному декодированию по максимуму правдоподобия. Это связано с тем, что хотя данная процедура гарантирует исправление всех конфигураций ошибок веса  возможны конфигурации из трех ошибок, которые исправляются при декодировании с обращением к таблице поиска и не исправляются в рассмотренном случае. Также очевидно, что не все систематические сверточные коды могут быть декодированы с помощью порогового декодера. Как это должно быть ясно из приведенного выше примера, код исправляет возможны конфигурации из трех ошибок, которые исправляются при декодировании с обращением к таблице поиска и не исправляются в рассмотренном случае. Также очевидно, что не все систематические сверточные коды могут быть декодированы с помощью порогового декодера. Как это должно быть ясно из приведенного выше примера, код исправляет  ошибок с помощью порогового декодера тогда и только тогда, когда могут быть сформированы ошибок с помощью порогового декодера тогда и только тогда, когда могут быть сформированы  линейных комбинаций символов синдрома, ортогональных относительно ошибки в информационном символе. При этом пороговая логическая схема выдает сигнал ошибки всякий раз, когда более чем линейных комбинаций символов синдрома, ортогональных относительно ошибки в информационном символе. При этом пороговая логическая схема выдает сигнал ошибки всякий раз, когда более чем  из этих линейных комбинаций оказываются равными 1. Очевидно, что рассмотренный в первом примере декодер, изображенный на рис. 4.18, является пороговым декодером кода со скоростью из этих линейных комбинаций оказываются равными 1. Очевидно, что рассмотренный в первом примере декодер, изображенный на рис. 4.18, является пороговым декодером кода со скоростью  при при 
Другая трудность использования порогового декодирования для исправления ошибок кратности больше, чем 3, связана с очень
быстрым ростом объема памяти, необходимой для хранения таблицы поиска по синдрому при увеличении гарантированной кратности исправляемых ошибок. Как указывалось выше, существует систематический сверточный код со скоростью 1/2 (Бусганг [1965]), для которого все неправильные пути на сегменте из  ребер находятся на расстоянии 1 от правильного пути, что открывает возможность для исправления любой конфигурации из трех и меньшего числа ошибок в любой последовательности из 22 символов. Однако этот код неортогонализуем и, следовательно, не может быть декодирован с помощью порогового декодера. Наличие в настоящее время запоминающих устройств, предназначенных только для считывания записанной информации (read-only memory) объемом 211 бит, которые выпускаются в виде одной интегральной схемы, позволяет очень просто реализовать функцию обращения к таблице поиска (схема имеет 11 двоичных входов и 1 выход). Минимальное значение ребер находятся на расстоянии 1 от правильного пути, что открывает возможность для исправления любой конфигурации из трех и меньшего числа ошибок в любой последовательности из 22 символов. Однако этот код неортогонализуем и, следовательно, не может быть декодирован с помощью порогового декодера. Наличие в настоящее время запоминающих устройств, предназначенных только для считывания записанной информации (read-only memory) объемом 211 бит, которые выпускаются в виде одной интегральной схемы, позволяет очень просто реализовать функцию обращения к таблице поиска (схема имеет 11 двоичных входов и 1 выход). Минимальное значение  для ортогонализуемого сверточного кода, имеющего скорость для ортогонализуемого сверточного кода, имеющего скорость  и исправляющего тройные ошибки, равно 12, что позволяет организовать исправление тройных ошибок в последовательностях из 24 символов. Однако гораздо хуже обстоит дело с кодами со скоростью 1/2, исправляющие ошибки кратности 4, для которых все неправильные пути должны находиться от правильного на расстоянии, самое меньшее, 9. Поиск, проведенный Бусгангом с помощью и исправляющего тройные ошибки, равно 12, что позволяет организовать исправление тройных ошибок в последовательностях из 24 символов. Однако гораздо хуже обстоит дело с кодами со скоростью 1/2, исправляющие ошибки кратности 4, для которых все неправильные пути должны находиться от правильного на расстоянии, самое меньшее, 9. Поиск, проведенный Бусгангом с помощью  показал, что минимальное значение показал, что минимальное значение  в этом случае равно 16. Найденный им код неортогонализуем, так что для реализации декодирования по синдрому с помощью таблицы поиска требуется память объемом 216 бит. При этом самый короткий ортогонализуемый и, следовательно, допускающий пороговое декодирование код со скоростью в этом случае равно 16. Найденный им код неортогонализуем, так что для реализации декодирования по синдрому с помощью таблицы поиска требуется память объемом 216 бит. При этом самый короткий ортогонализуемый и, следовательно, допускающий пороговое декодирование код со скоростью  исправляющий ошибки кратности 4, требует, чтобы исправляющий ошибки кратности 4, требует, чтобы  После этого После этого  растет очень быстро; так, растет очень быстро; так,  для допускающего пороговое декодирование сверточного кода, исправляющего ошибки кратности 5 (Лаки, Салц, Велдон [1968]). для допускающего пороговое декодирование сверточного кода, исправляющего ошибки кратности 5 (Лаки, Салц, Велдон [1968]).
Хотя декодирование с обратной связью или, что то же самое, скользящее блочное декодирование применимо не только в ДСК, но и в других каналах, его привлекательность значительно падает всякий раз, когда двоичные операции должны быть заменены на операции с более сложными метриками. Более того, как только что было показано, даже для ДСК сложность процедур декодирования вряд ли оправдывает их применение для исправления большого числа ошибок. Однако эта процедура декодирования обладает одним очень важным достоинством, а именно, она может быть очень просто модифицирована для лрименения в сочетании с операцией разнесения символов в каналах с памятью, где преобладают пакеты ошибок. Универсальное устройство разнесения, предназначенное для произвольного канала, было описано в § 2.12; это устройство является внешним по отношению к кодеру и декодеру и служит, по существу, интерфейсом между ними и
каналом. Более естественный подход к реализации принципа разнесения при использовании сверточных кодов заключается в том, что все одноразрядные элементы задержки в регистре сдвига кодера заменяются на  -разрядные, где -разрядные, где  степень разнесения. В результате кодер оказывается состоящим из степень разнесения. В результате кодер оказывается состоящим из  кодеров, каждый из которых работает со своей собственной последовательностью информационных символов кодеров, каждый из которых работает со своей собственной последовательностью информационных символов  где где  целое число между целое число между  Этот метод называется внутренним разнесением. Основным его недостатком является то, что объем памяти декодера увеличивается в Этот метод называется внутренним разнесением. Основным его недостатком является то, что объем памяти декодера увеличивается в  раз. Так, для декодера Витерби раз. Так, для декодера Витерби  значений метрик состояний и такое же число путей должны храниться для каждого из значений метрик состояний и такое же число путей должны храниться для каждого из  разнесенных кодов, в результате чего требования к объему памяти при значениях разнесенных кодов, в результате чего требования к объему памяти при значениях  порядка сотен и тысяч оказываются неприемлемыми. В то же время декодер с обратной связью оказывается состоящим просто из копии кодера, предназначенной для формирования синдрома и регистра сдвига для хранения синдрома. При этом декодирование с разнесением, соответствующее порядка сотен и тысяч оказываются неприемлемыми. В то же время декодер с обратной связью оказывается состоящим просто из копии кодера, предназначенной для формирования синдрома и регистра сдвига для хранения синдрома. При этом декодирование с разнесением, соответствующее  последовательным декодерам, может быть реализовано так же, как и в случае с кодером, заменой всех одноразрядных элементов задержки на последовательным декодерам, может быть реализовано так же, как и в случае с кодером, заменой всех одноразрядных элементов задержки на  -разрядные в генераторе синдрома и регистре синдрома; схема, реализующая обращение к таблице поиска по синдрому, «ли пороговая логическая схема, остаются прежними. Таким образом, для сверточного кода со скоростью -разрядные в генераторе синдрома и регистре синдрома; схема, реализующая обращение к таблице поиска по синдрому, «ли пороговая логическая схема, остаются прежними. Таким образом, для сверточного кода со скоростью  длиной кодового ограничения К, степенью разнесения длиной кодового ограничения К, степенью разнесения  и длиной регистра синдрома и длиной регистра синдрома  требуется требуется  -разрядных элементов задержки для кодера и -разрядных элементов задержки для кодера и  таких же элементов для декодера. Использование таких декодеров является одним из простых подходов к решению проблемы организации высокоэффективного декодирования для каналов с группированием ошибок, какими являются, например, коротковолновые каналы с ионосферным распространением. Несколько модификаций описанного метода (кодирования с разнесением было предложено Галлагером [1969], Колленбергом и Форни [1968], Питерсоном и Велдоном [1972], но все они приводили лишь к его незначительному улучшению. таких же элементов для декодера. Использование таких декодеров является одним из простых подходов к решению проблемы организации высокоэффективного декодирования для каналов с группированием ошибок, какими являются, например, коротковолновые каналы с ионосферным распространением. Несколько модификаций описанного метода (кодирования с разнесением было предложено Галлагером [1969], Колленбергом и Форни [1968], Питерсоном и Велдоном [1972], но все они приводили лишь к его незначительному улучшению.
|
1 |
|