Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
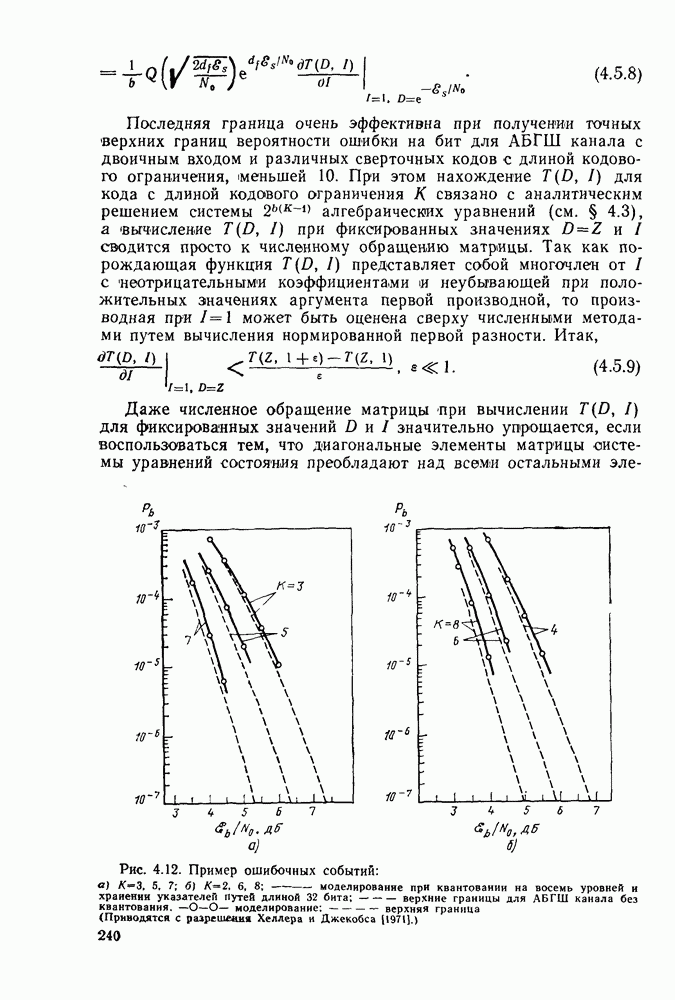
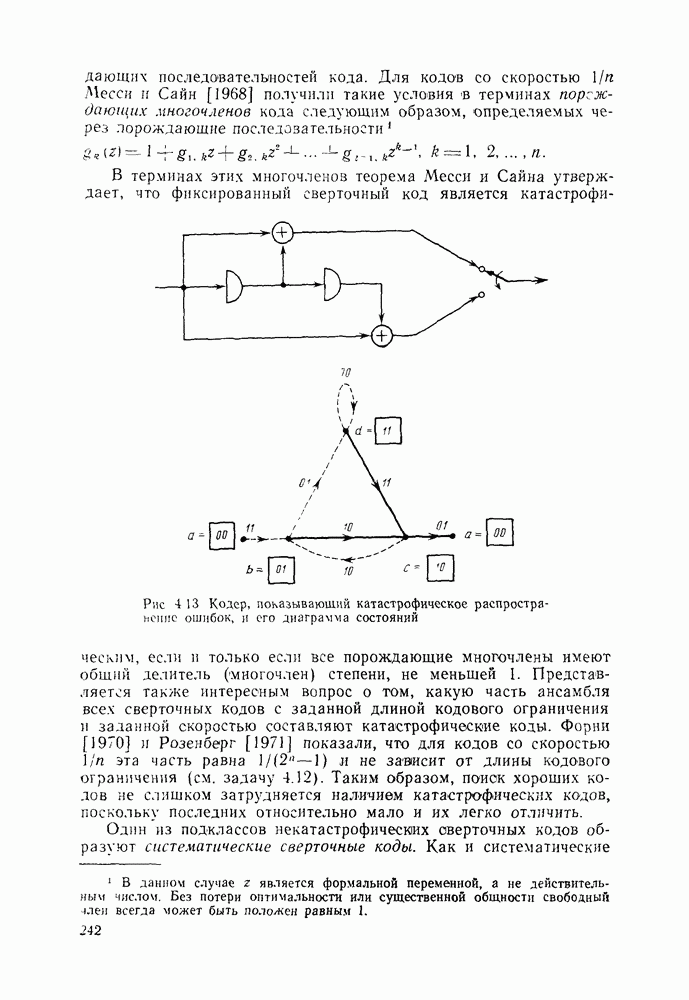
ZADANIA.TO
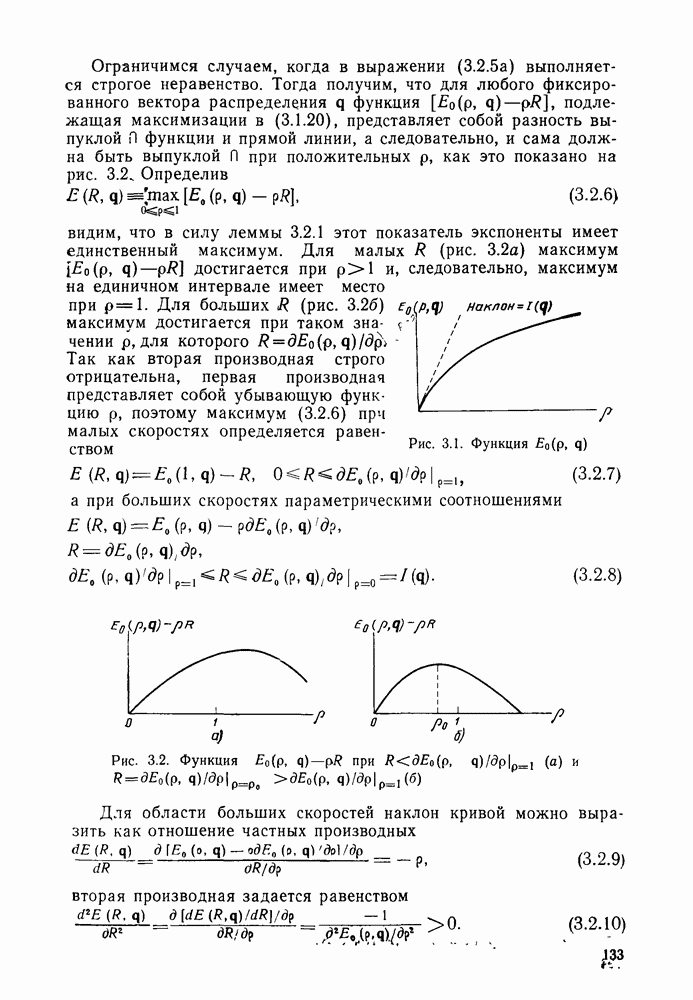
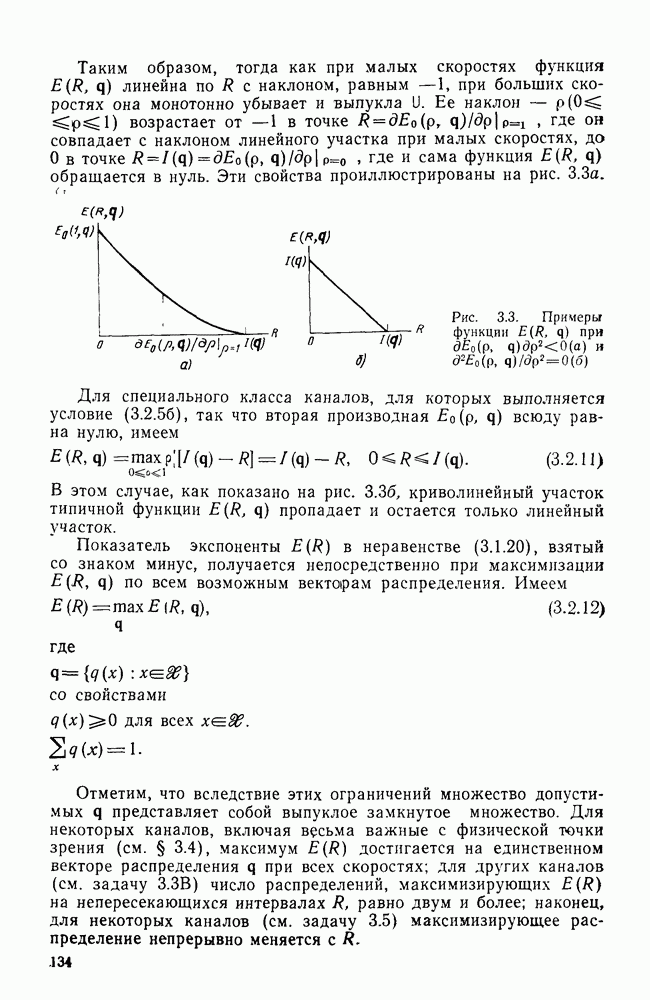
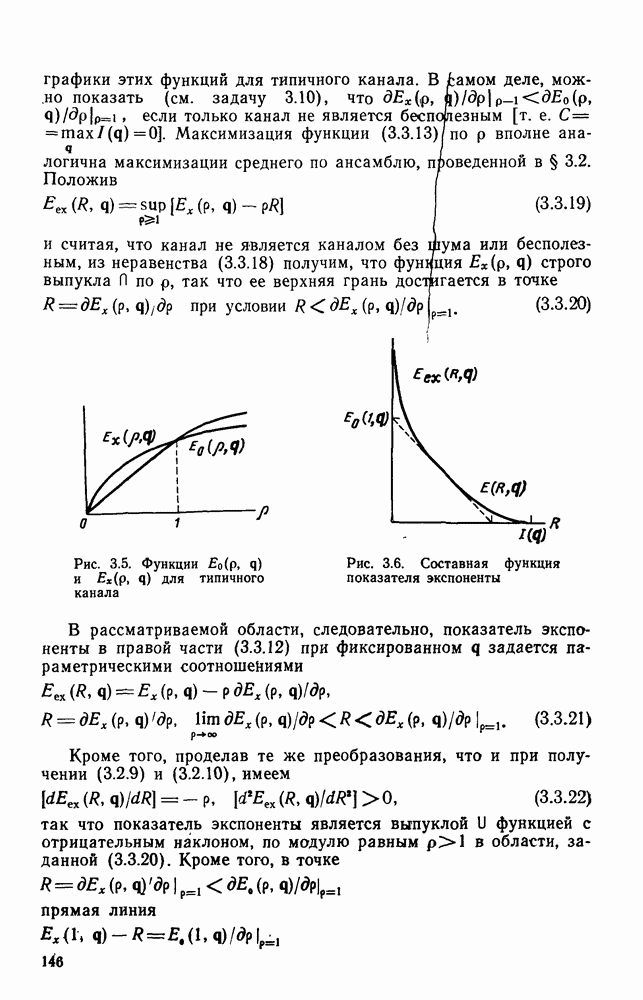
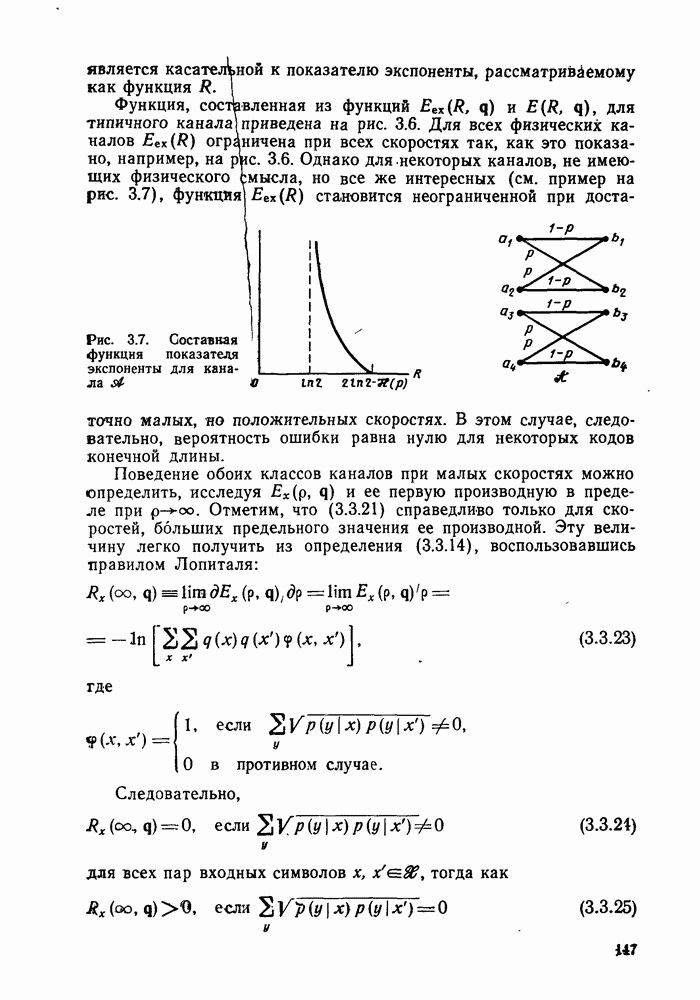
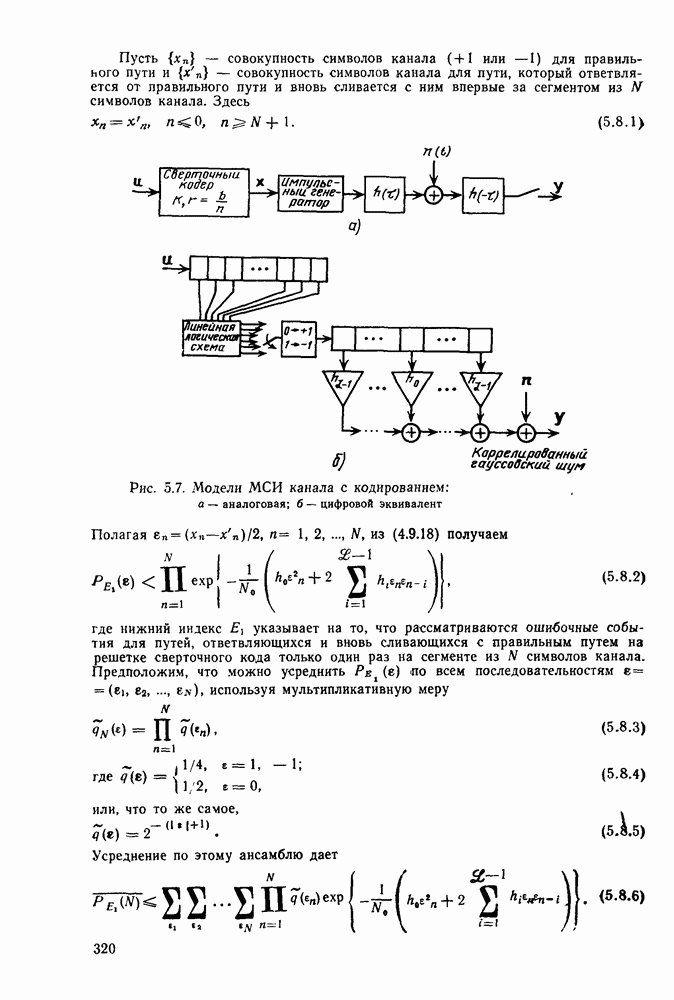
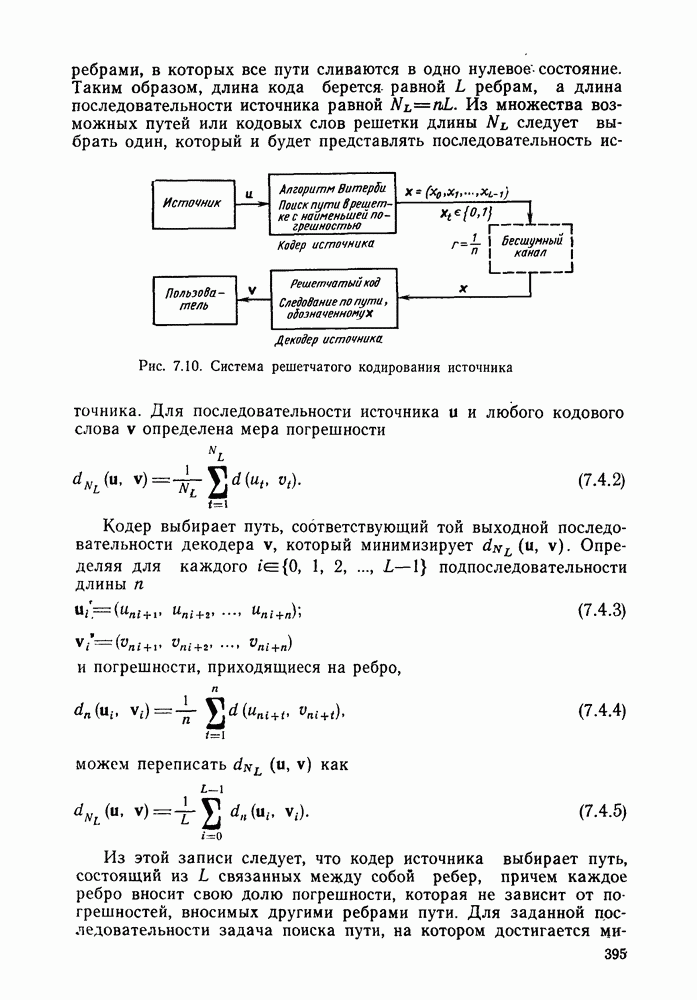
Глава 6. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕ СВЕРТОЧНЫХ КОДОВ6.1. Основные понятия и базовый стек-алгоритмВ последних двух главах были описаны и проанализированы декодеры максимального правдоподобия для сверточных кодов. Их характеристики оказались значительно лучше, чем у блочных кодов, но им присущ тот же недостаток, что и блочным кодам: их вычислительная сложность растет экспоненциально с длиной кодового ограничения. Таким образом, хотя вероятность ошибки для сверточных кодов убывает экспоненциально с ростом длины кодового ограничения, с ростом вычислительной сложности она оказывается убывающей лишь алгебраически. То же наблюдается и для блочных кодов, но скорость убывания для сверточных кодов оказывается много большей. Было бы еще лучше, если бы можно было избежать вычисления отношения правдоподобия (метрики) для каждого из путей решетки и сконцентрировать вычислительные ресурсы только на тех из них, которые имеют большие значения метрики и, по-видимому, включают правильный путь. Основанная на предыдущем анализе интуиция показывает, что когда неправильный путь не совпадает с правильным, приращения его метрики оказываются много меньше, чем соответствующие приращения метрики правильного пути на том же сегменте. Можно обосновать этот вывод количественно, снова рассмотрев ансамбль всевозможных сверточных кодов с заданной длиной кодового ограничения в данном канале. Пусть
Прежде всего заметим, что выбор этой метрики согласуется с метрикой максимального правдоподобия, использовавшейся ранее. При декодировании по максимуму правдоподобия используется только разность между метриками сравниваемых путей. Согласно введенным в (4.4.1) и (5.1.1) определениям, разность метрик
где сумма берется по символам сегмента несовпадения. Таким образом, величины стороны, для любого алгоритма, который не требует для принятия решения обследования каждого возможного пути, а должен осуществлять выбор среди путей с различными длинами, указанные величины приводят к появлению смещения, которое играет существенную роль при оптимизации алгоритма. Для иллюстрации влияния этих величин рассмотрим среднее приращение метрики для произвольного символа правильного пути. Как обычно, проведем усреднение вначале по условному распределению на выходе канала
Если выбрать весовой вектор
для всех
[здесь мы воспользовались (6.1.3) и неравенством —1]. Так как последняя сумма в этом неравенстве равна нулю, то
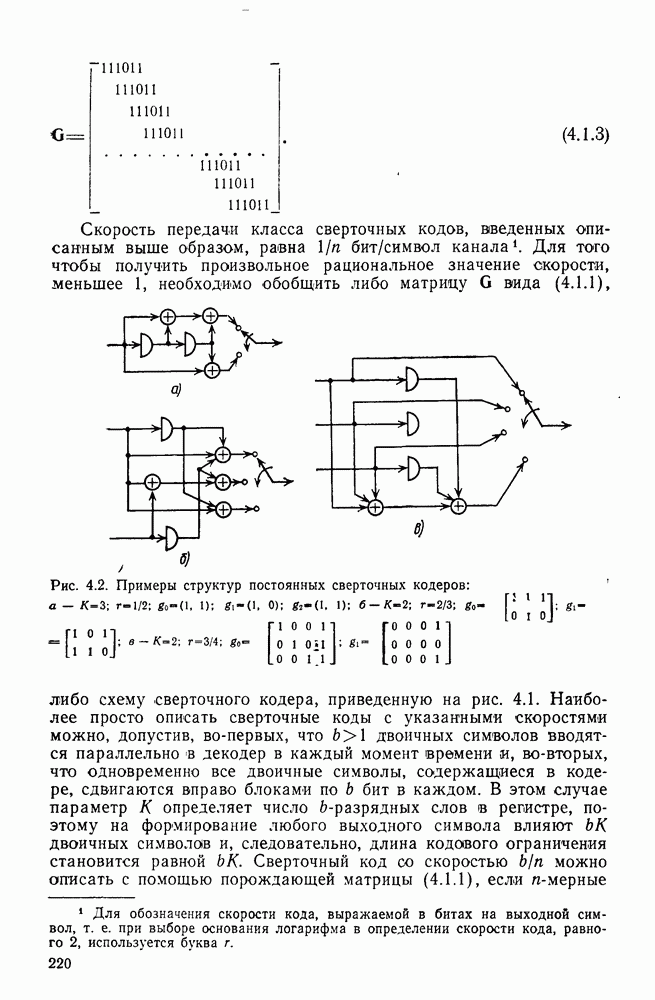
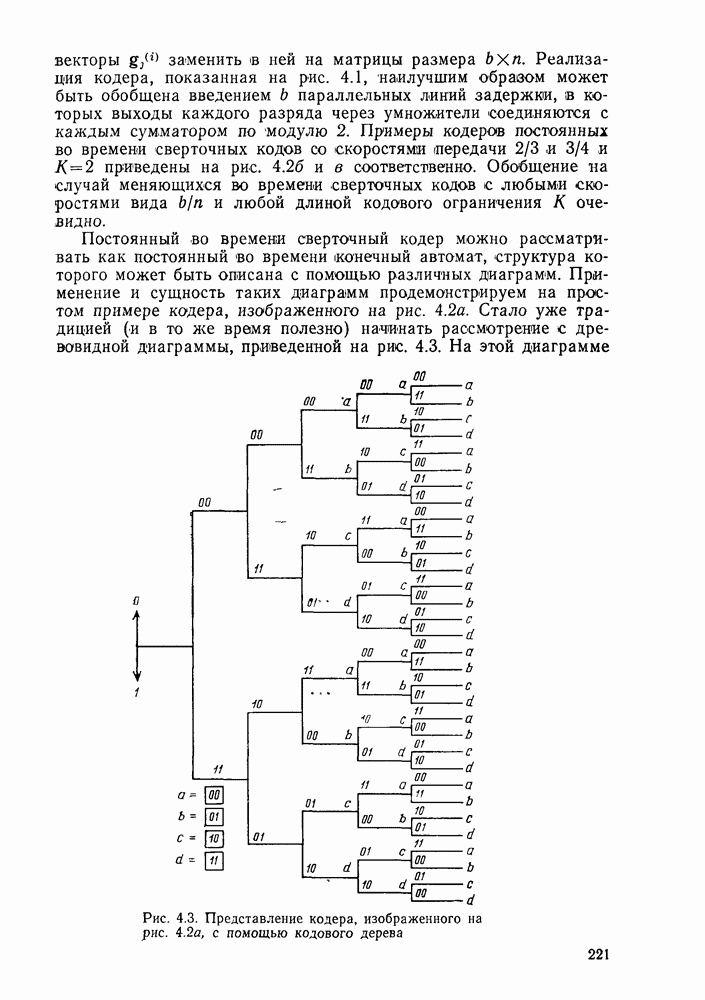
Необходимость усреднения по символам правильного пути Таким образом, эвристическим путем приходим к тому, что «среднее» приращение метрики на символ правильного пути при Прежде чем воспользоваться этими эвристическими закономерностями, необходимо описать алгоритм, который некоторым образом реализует эти свойства. Начнем с того, что определим алгоритм последовательного декодирования как алгоритм, который вычисляет метрику путей, продолжая каждый раз ровно на одно ребро уже обследованный путь, и который принимает решение о том, какой путь должен быть продолжен, только на основании значений метрик путей, уже обследовавшихся ранее. Основным алгоритмом этого класса, к тому же наиболее простым в описании, представляется стек-алгоритм последовательного декодирования, блок-схема которого для сверточных кодов со скоростью Пример поиска с помощью базового стек-алгоритма приведен на рис. 6.1, где изображено дерево с метриками путей для сверточного кода с Таблица 6.1
Таким образом, из (6.1.2) получаем
Так как ход поиска не изменится, если все метрики символов умножить на одну и ту же положительную константу, можно с равным успехом использовать метрику
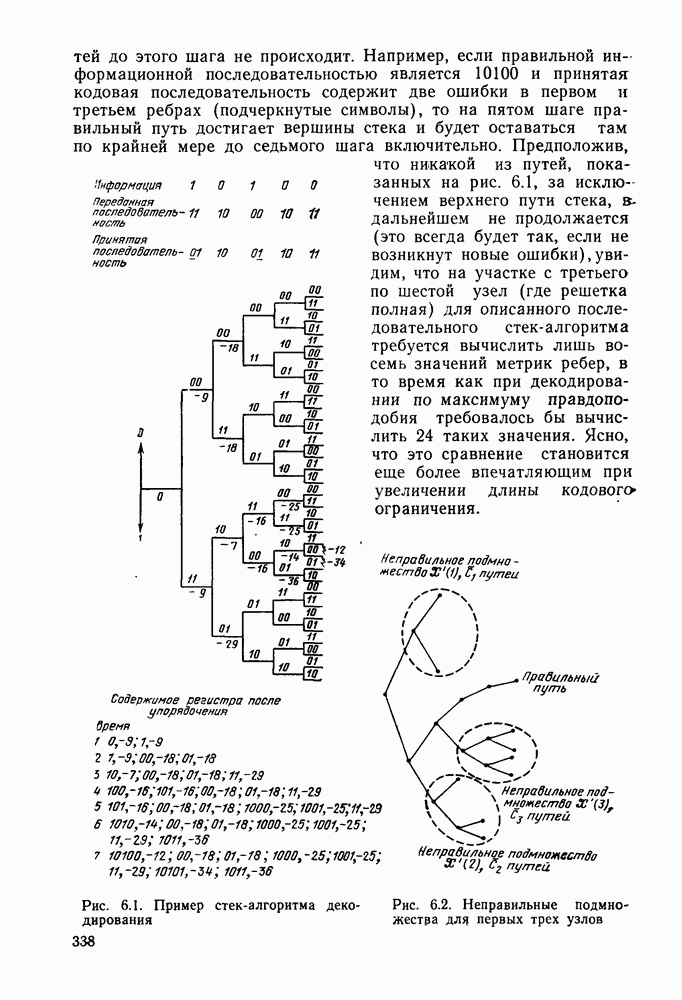
и таким образом упростить записи и диаграмму. На рис. 6.1 показаны первые семь шагов поиска, а именно приведены пути и значения метрик после обследования каждой новой пары путей и упорядочивания стека. Так как в стеке вплоть до седьмого шага путей до этого шага не происходит. Например, если правильной информационной последовательностью является 10100 и принятая кодовая последовательность содержит две ошибки в первом и третьем ребрах (подчеркнутые символы), то на пятом шаге правильный путь достигает вершины стека и будет оставаться там по крайней мере до седьмого шага включительно. Предположив, что никакой из путей, показанных на рис. 6.1, за исключением верхнего пути стека, в дальнейшем не продолжается (это всегда будет так, если не возникнут новые ошибки), увидим, что на участке с третьего по шестой узел (где решетка полная) для описанного последовательного стек-алгоритма требуется вычислить лишь восемь значений метрик ребер, в то время как при декодировании по максимуму правдоподобия требовалось бы вычислить 24 таких значения. Ясно, что это сравнение становится еще более впечатляющим при увеличении длины кодового ограничения. Рис. 6.1. (см. скан) Пример стек-алгоритма декодирования Рис. 6.2. (см. скан) Неправильные подмножества для первых трех узлов Однако последовательный стек-алгоритм совсем не обязательно на каждом шаге продвигается вперед на одно ребро. Как это видно из приведенного примера, число обследуемых путей меняется от узла к узлу. Для каждого узла правильного пути определим неправильное подмножество как совокупность всех путей, которые ответвляются от правильного пути в этом узле. Для кодов со скоростью Анализ распределения числа вычислений проведен в § 6.2, а анализ вероятности ошибки в § 6.3.
|
 |
Оглавление
|








































































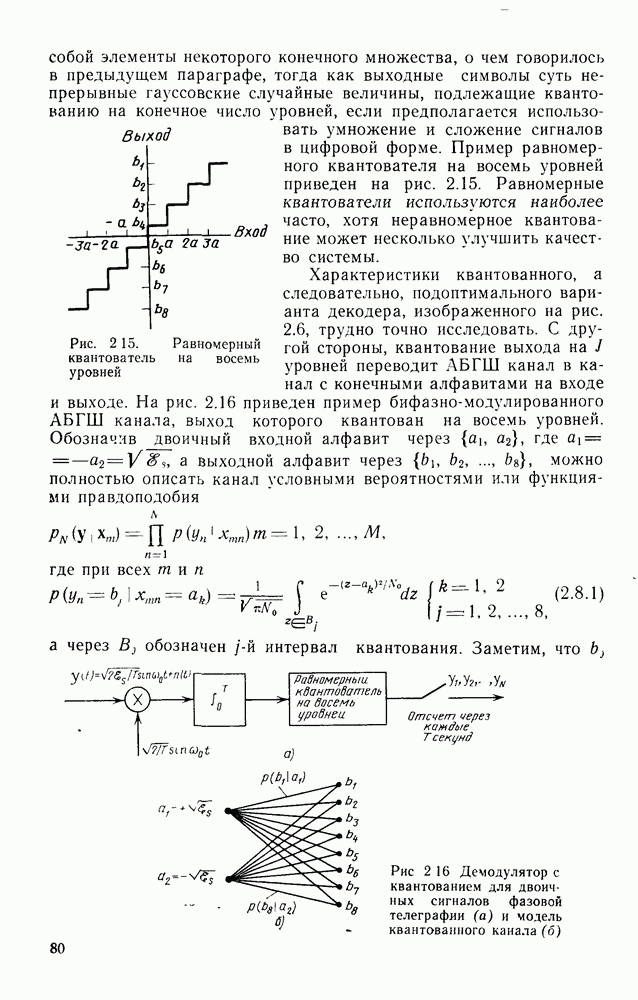



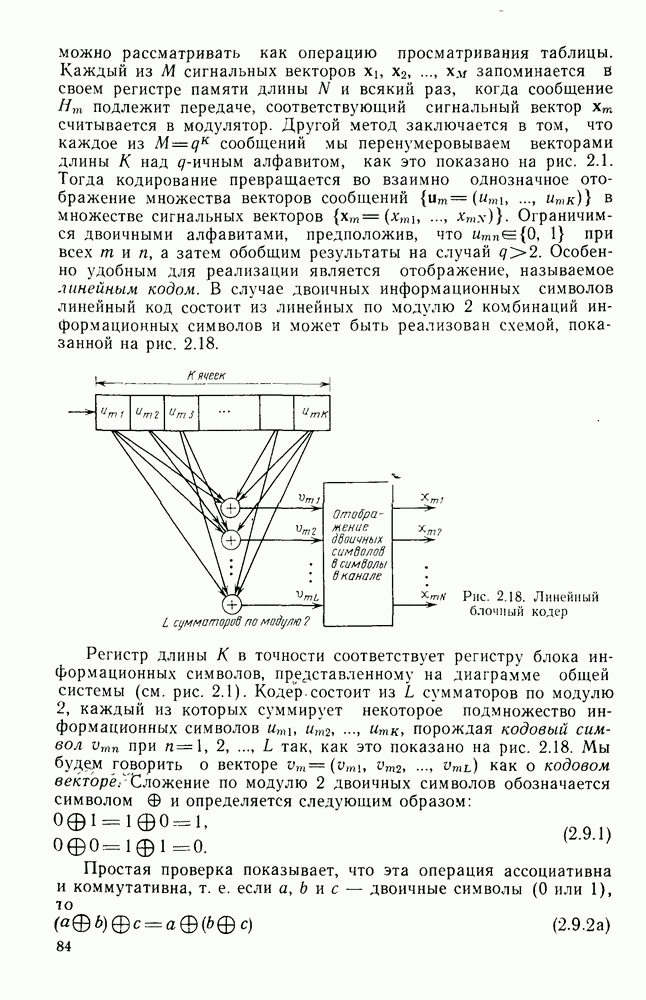













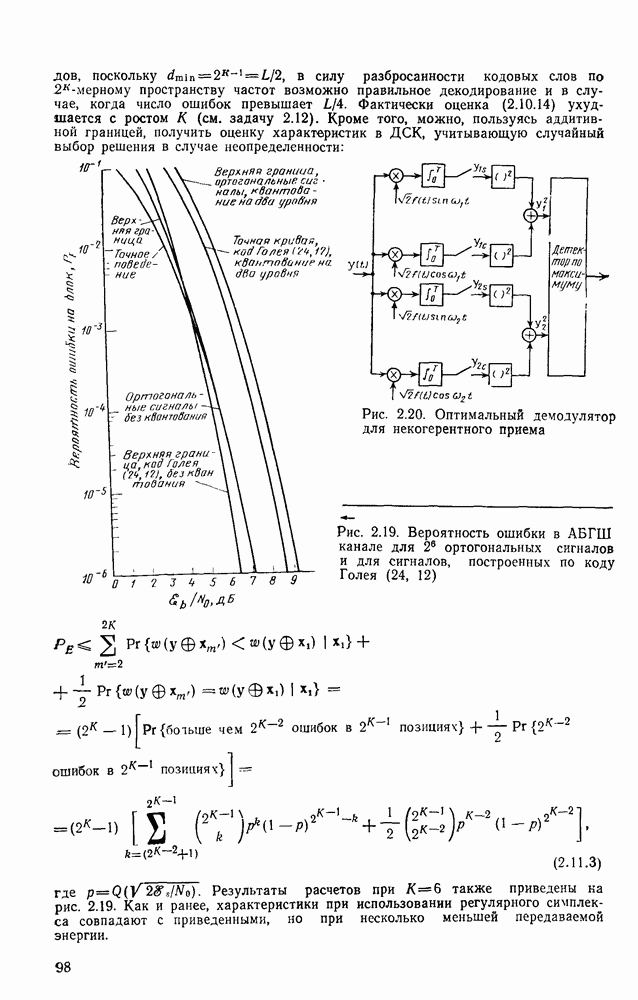












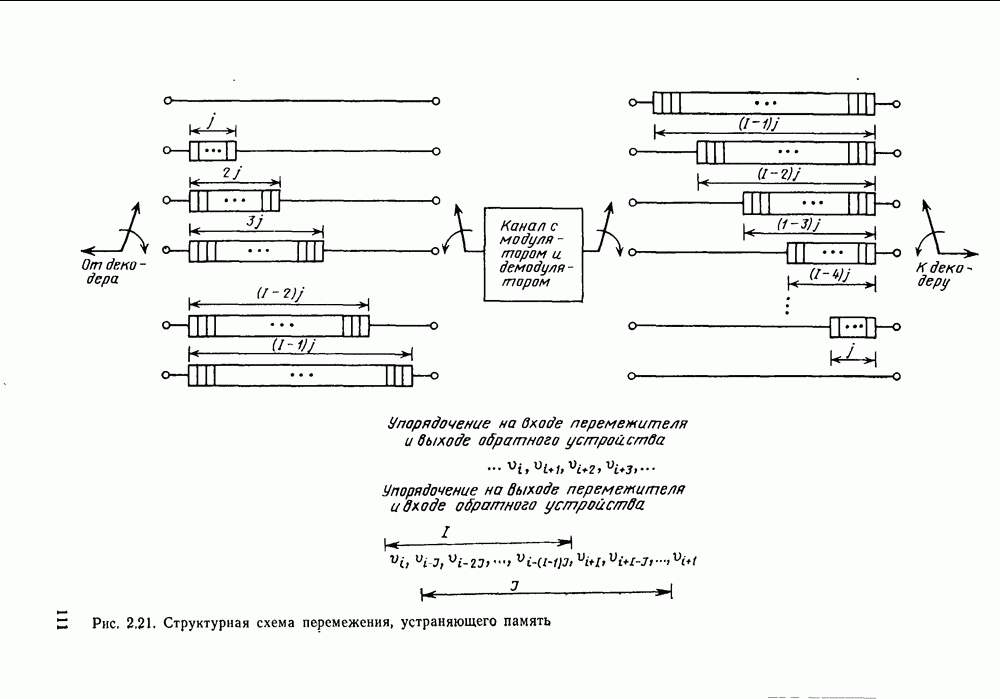




































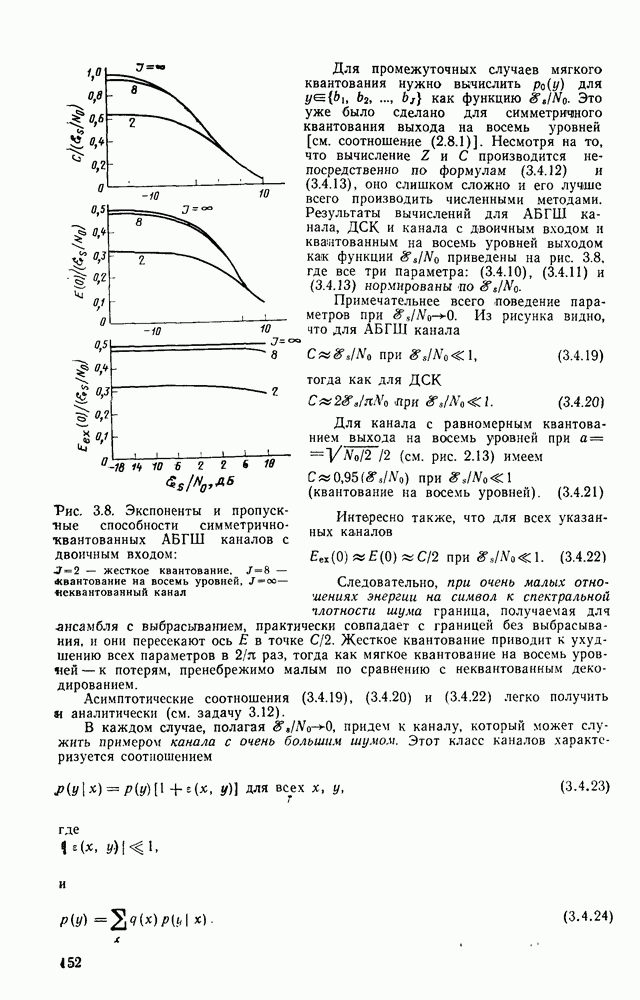

















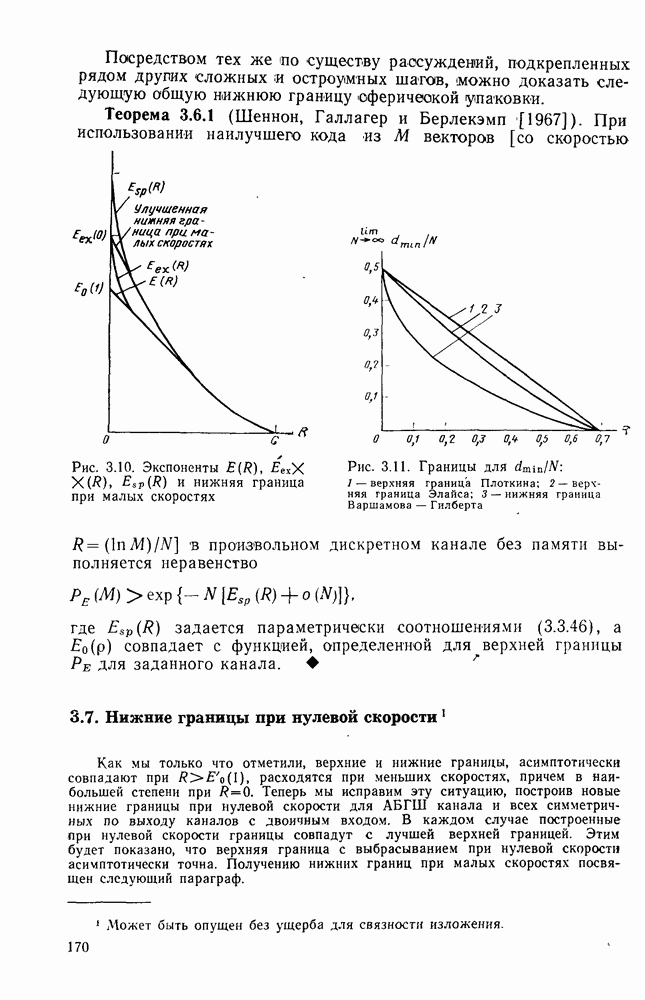














































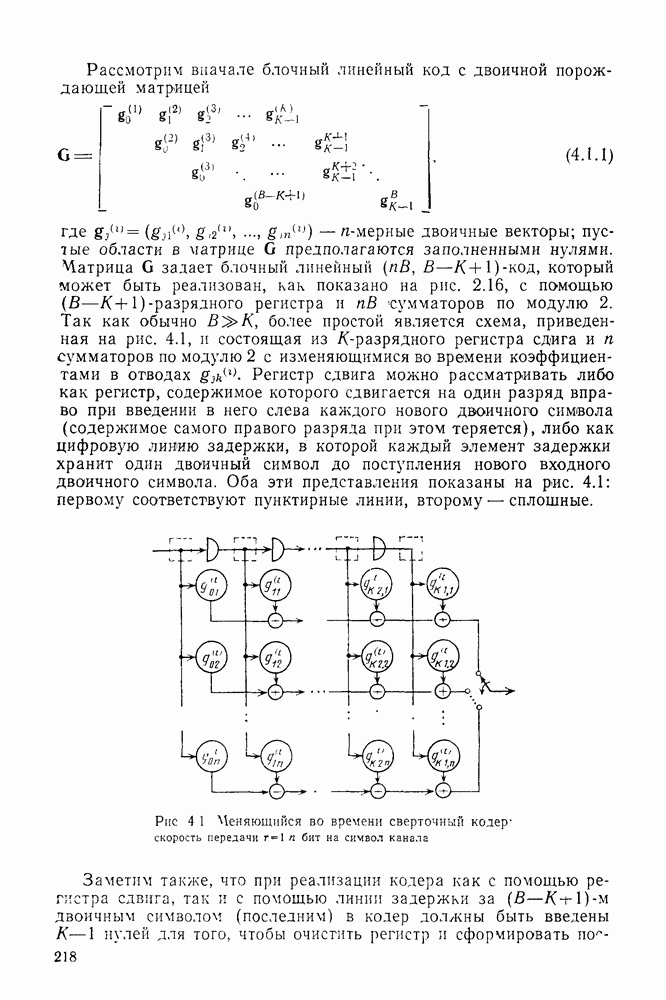



























































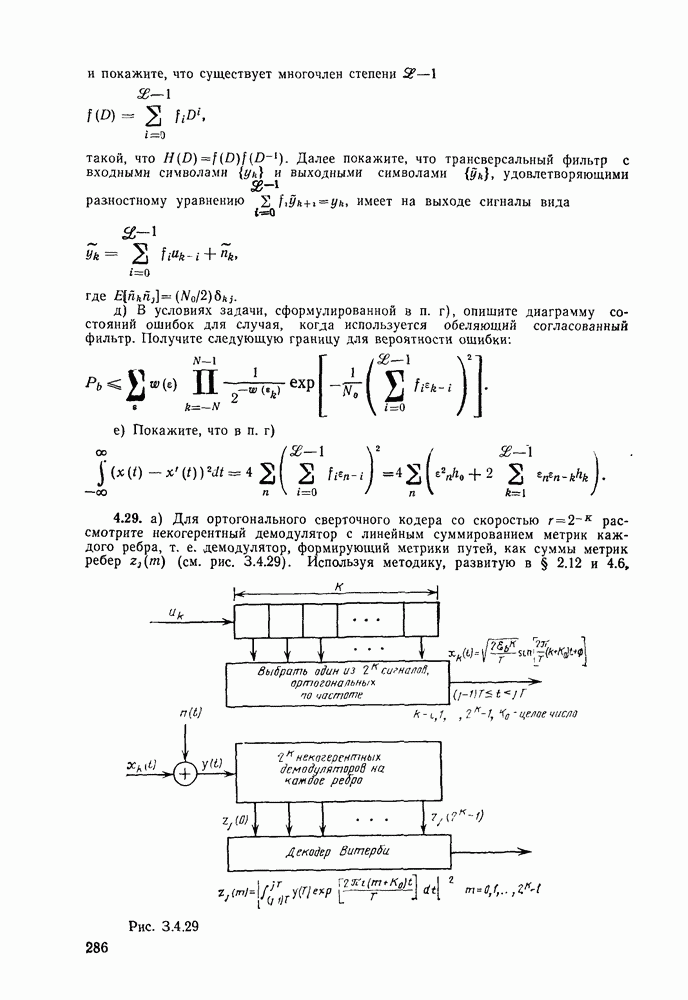
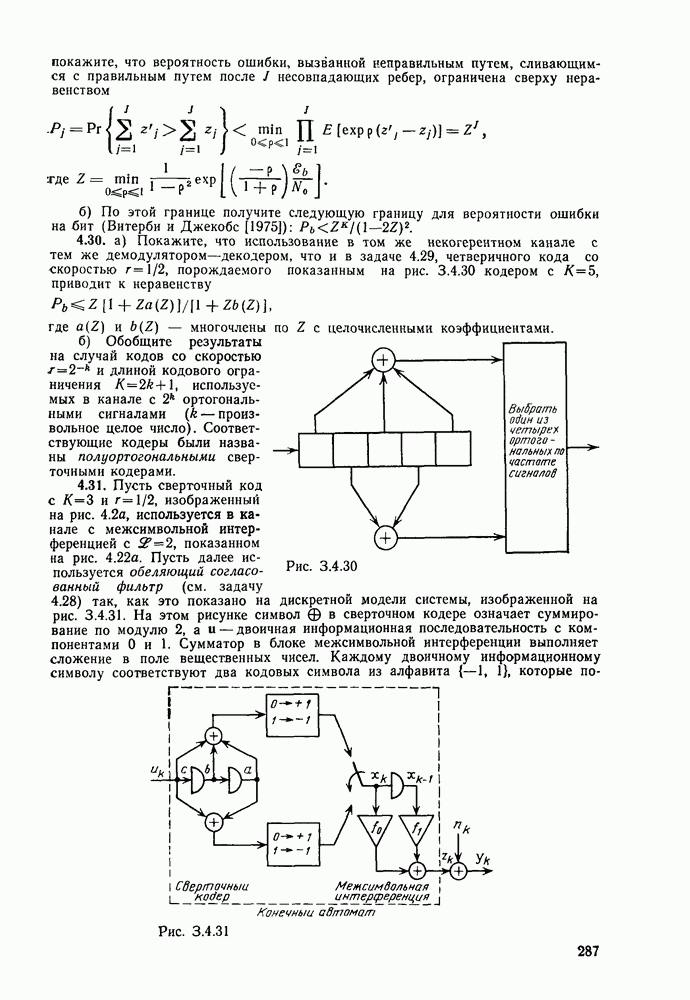











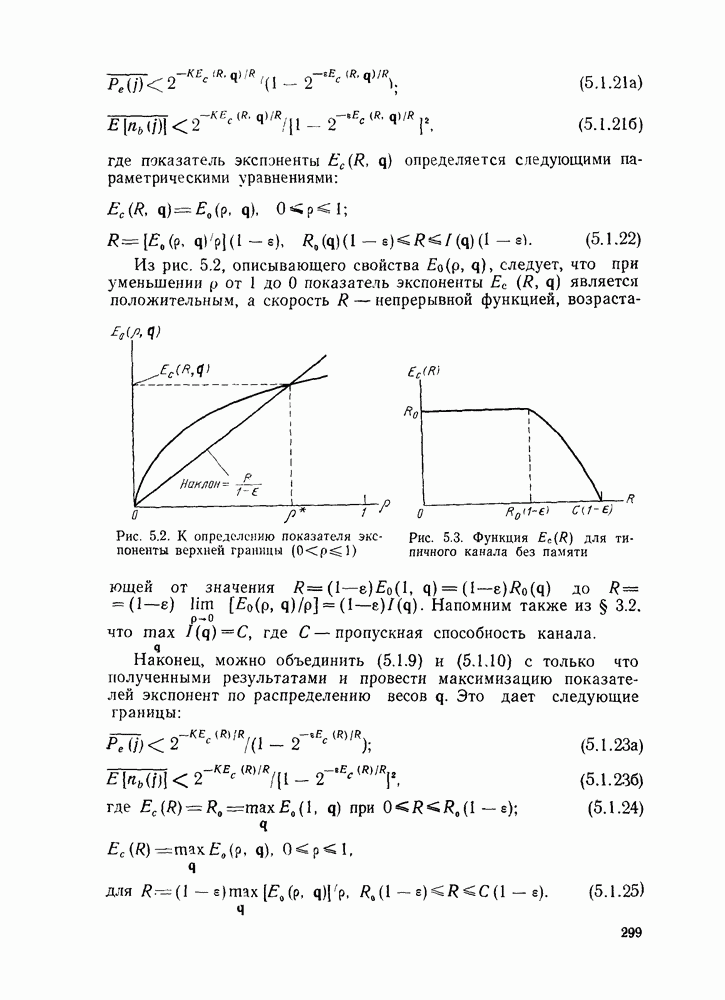







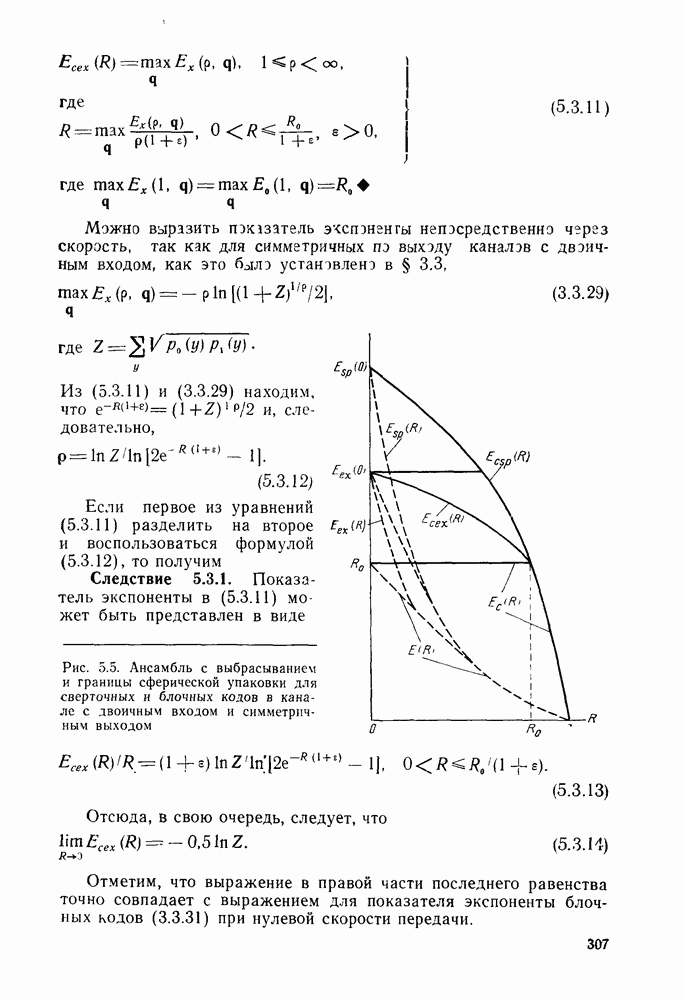












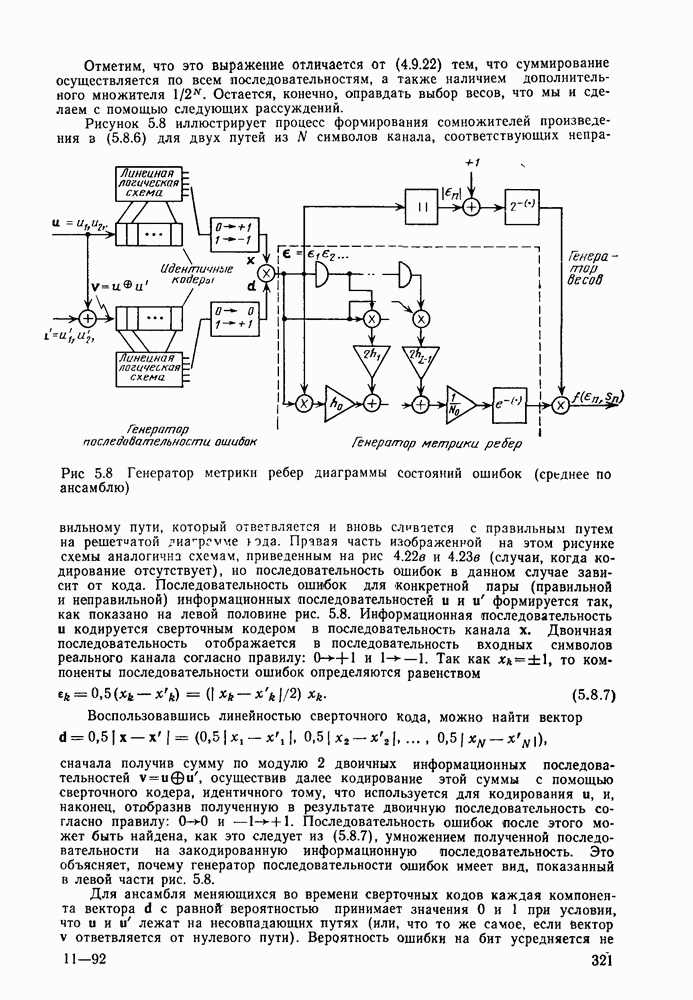






























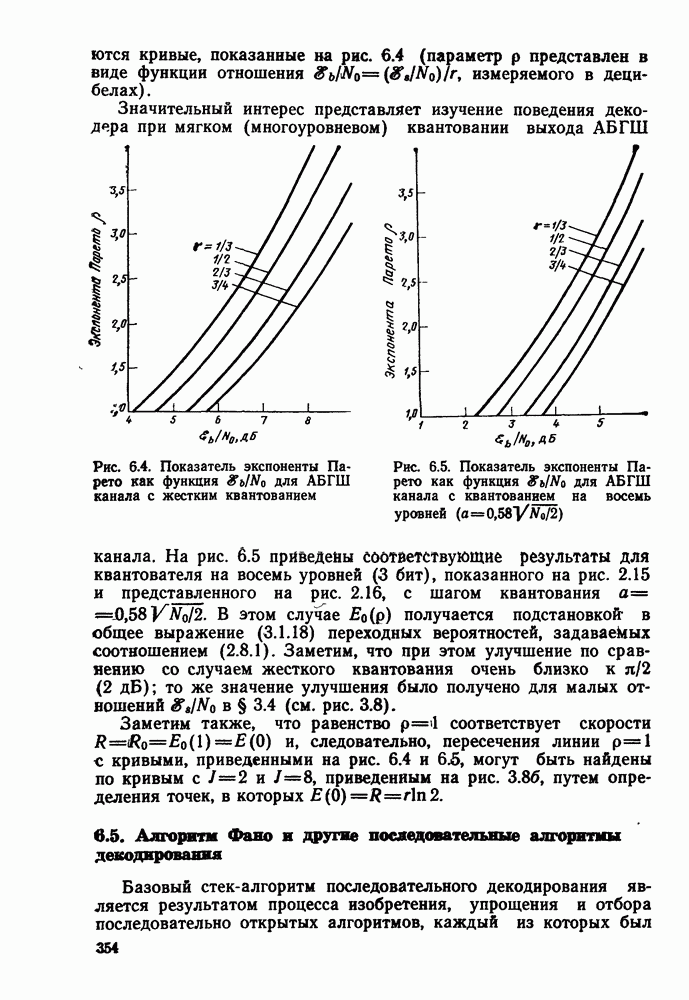


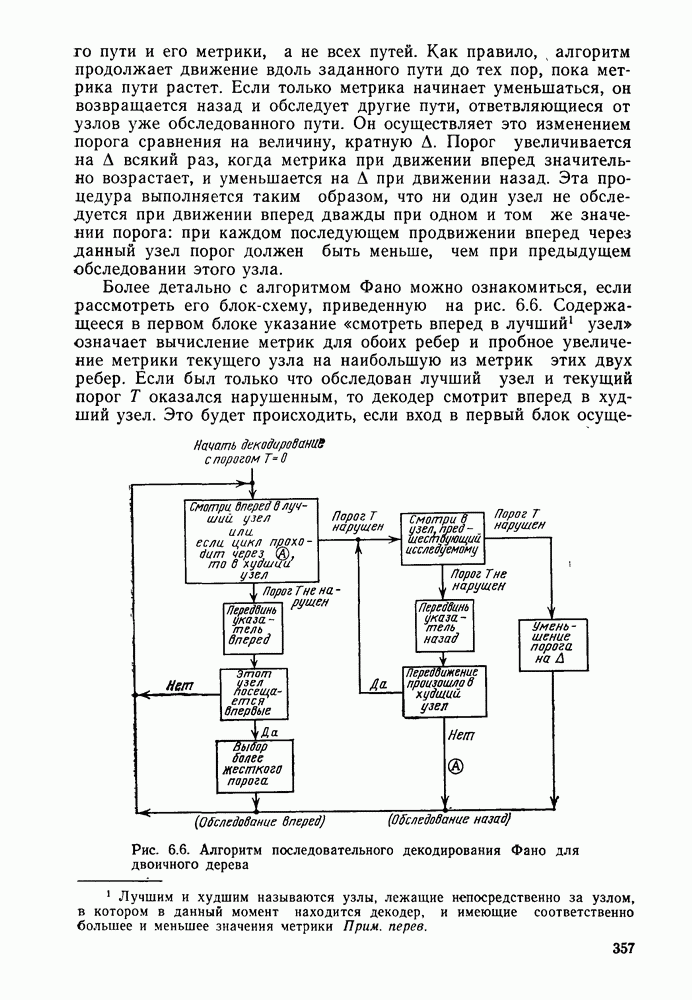























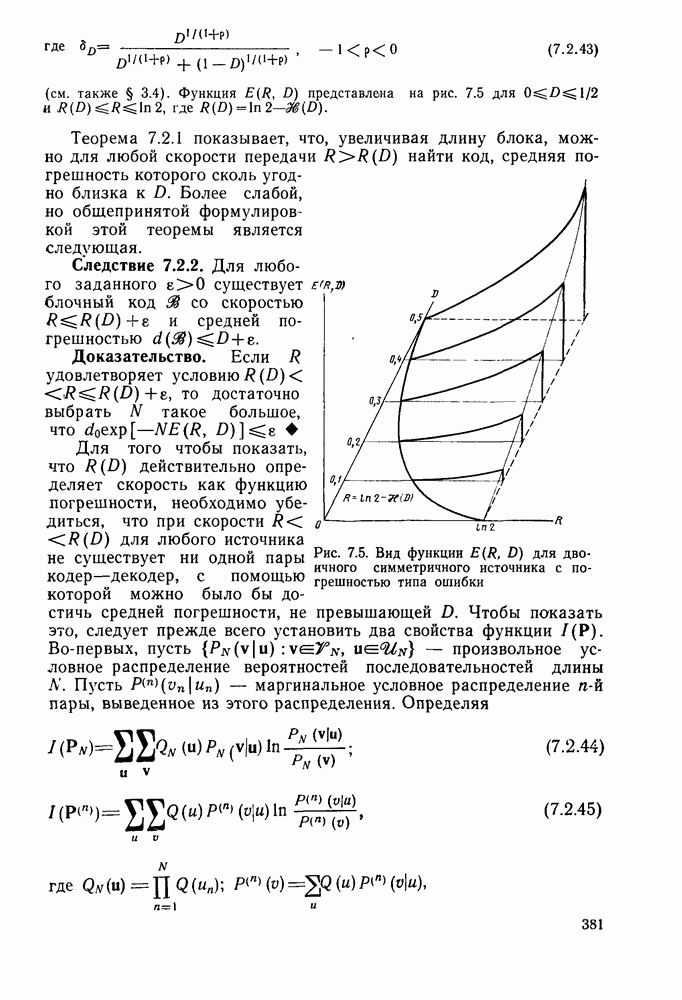












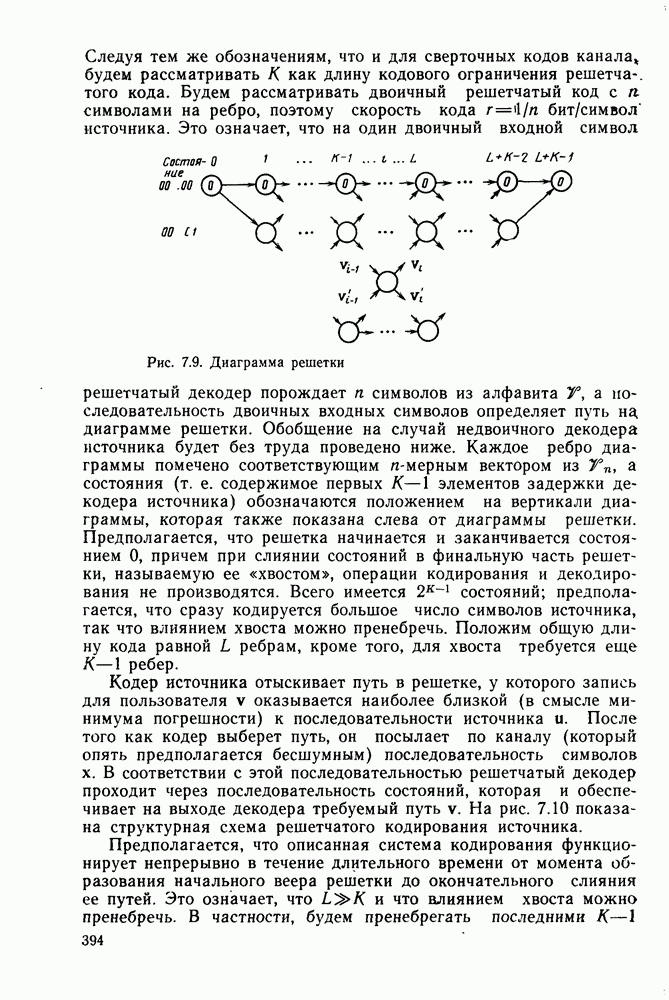



































































































































 кодовые векторы правильного и неправильного путей на сегменте, где эти пути не совпадают, и пусть у — вектор, принятый на этом сегменте на выходе канала без памяти. С помощью нижнего индекса
кодовые векторы правильного и неправильного путей на сегменте, где эти пути не совпадают, и пусть у — вектор, принятый на этом сегменте на выходе канала без памяти. С помощью нижнего индекса  будем обозначать
будем обозначать  символ каждого вектора. Предположим, что выбрана метрика
символ каждого вектора. Предположим, что выбрана метрика

 — произвольное распределение весов, задаваемое на ансамбле кодов (см. § 5.1).
— произвольное распределение весов, задаваемое на ансамбле кодов (см. § 5.1).

 не входят в выражение для разности метрик и, следовательно, оказываются несущественными при декодировании по максимуму правдоподобия. Однако, с другой
не входят в выражение для разности метрик и, следовательно, оказываются несущественными при декодировании по максимуму правдоподобия. Однако, с другой
 а затем по ансамблю кодов с входным распределением
а затем по ансамблю кодов с входным распределением  В результате получим
В результате получим

 так, чтобы он максимизировал
так, чтобы он максимизировал  то последняя величина будет равна пропускной способности канала и
то последняя величина будет равна пропускной способности канала и

 При этом для любого символа неправильного пути на сегменте несовпадения выполняется соотношение
При этом для любого символа неправильного пути на сегменте несовпадения выполняется соотношение


 обусловлена тем, что распределение выходных символов канала
обусловлена тем, что распределение выходных символов канала  задается при условии, что символ правильного пути фиксирован.
задается при условии, что символ правильного пути фиксирован.
 всегда положительно, но всегда отрицательно для неправильного пути, не совпадающего с правильным. Очевидно, что вместо
всегда положительно, но всегда отрицательно для неправильного пути, не совпадающего с правильным. Очевидно, что вместо  в качестве смещения можно было бы взять любое число, меньшее С, но сделанный выбор минимизирует вычислительную сложность. Основной вывод, который отсюда следует, состоит в том, что для сверточных кодов с большими длинами кодового ограничения правильный путь может быть выделен из других путей, так как в среднем будет расти только его метрика, в то время как метрика любого не совпадающего с ним неправильного пути будет в среднем убывать. При выборе достаточно большой длины кодового ограничения К убывание метрики на любом сегменте несовпадения можно обнаружить и исключить соответствующий путь из рассмотрения (как правило) после его ответвления от правильного.
в качестве смещения можно было бы взять любое число, меньшее С, но сделанный выбор минимизирует вычислительную сложность. Основной вывод, который отсюда следует, состоит в том, что для сверточных кодов с большими длинами кодового ограничения правильный путь может быть выделен из других путей, так как в среднем будет расти только его метрика, в то время как метрика любого не совпадающего с ним неправильного пути будет в среднем убывать. При выборе достаточно большой длины кодового ограничения К убывание метрики на любом сегменте несовпадения можно обнаружить и исключить соответствующий путь из рассмотрения (как правило) после его ответвления от правильного.
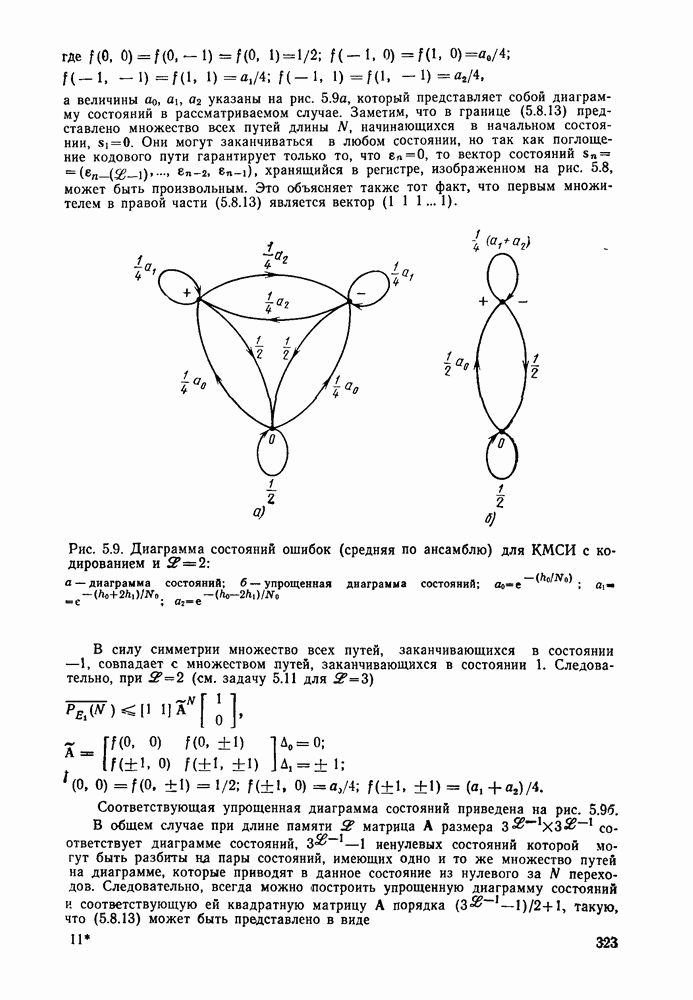
 приведена в табл. 6.1. Обозначим через
приведена в табл. 6.1. Обозначим через  метрики ребер, представляющие собой суммы
метрики ребер, представляющие собой суммы  метрик символов ребра, каждый из которых зависит от
метрик символов ребра, каждый из которых зависит от  информационных символов
информационных символов  заданного ребра в
заданного ребра в  предшествующих им информационных символов
предшествующих им информационных символов  пути, которые определяют состояние узла. Алгоритм основан на стеке, образуемом обследованными путями переменной длины, упорядоченными в порядке убывания значений их метрик. На каждом шаге путь, находящийся на вершине стека, заменяется на
пути, которые определяют состояние узла. Алгоритм основан на стеке, образуемом обследованными путями переменной длины, упорядоченными в порядке убывания значений их метрик. На каждом шаге путь, находящийся на вершине стека, заменяется на  путей, получающихся из него продолжением на одно ребро, располагаемых в соответствии с приращенными значениями метрик. Если какой-либо из вновь вводимых в стек путей сливается с одним из путей решетки, уже находящимся в стеке, то тот из этих путей, который имеет меньшее значение метрики, из стека удаляется. Алгоритм применяется описанным выше образом до тех пор, пока не будет достигнут конечный узел решетки.
путей, получающихся из него продолжением на одно ребро, располагаемых в соответствии с приращенными значениями метрик. Если какой-либо из вновь вводимых в стек путей сливается с одним из путей решетки, уже находящимся в стеке, то тот из этих путей, который имеет меньшее значение метрики, из стека удаляется. Алгоритм применяется описанным выше образом до тех пор, пока не будет достигнут конечный узел решетки.
 и
и  изучавшегося в гл. 4 (см. рис. 4.2), и
изучавшегося в гл. 4 (см. рис. 4.2), и  Для того чтобы определить метрики символов, отметим вначале, что
Для того чтобы определить метрики символов, отметим вначале, что  для
для  и 1.
и 1.



 появилось двух путей одинаковой длины с одним и тем же конечным состоянием, то вычеркиваний из стека из-за слияния
появилось двух путей одинаковой длины с одним и тем же конечным состоянием, то вычеркиваний из стека из-за слияния
 ровно половина путей, исходящих из данного узла, принадлежит неправильному подмножеству этого узла. Вернувшись к примеру и вновь предположив, что в пределах первых шести уровней ветвления дальнейший поиск не ведется, видим, что три пути обследуются в неправильном подмножестве первого узла, один путь в неправильном подмножестве второго узла и три в неправильном подмножестве четвертого узла. Определим вычисление ребра как операцию вычисления метрики пути, получающегося при продолжении на одно ребро обследованного ранее пути. Таким образом, число вычислений ребер, приходящихся на один уровень узлов, просто на единицу больше, чем число вычислений ребер в неправильном подмножестве этого узла. На рис. 6.2 показано, что в общем случае имеется
ровно половина путей, исходящих из данного узла, принадлежит неправильному подмножеству этого узла. Вернувшись к примеру и вновь предположив, что в пределах первых шести уровней ветвления дальнейший поиск не ведется, видим, что три пути обследуются в неправильном подмножестве первого узла, один путь в неправильном подмножестве второго узла и три в неправильном подмножестве четвертого узла. Определим вычисление ребра как операцию вычисления метрики пути, получающегося при продолжении на одно ребро обследованного ранее пути. Таким образом, число вычислений ребер, приходящихся на один уровень узлов, просто на единицу больше, чем число вычислений ребер в неправильном подмножестве этого узла. На рис. 6.2 показано, что в общем случае имеется  путей (вычислений ребер) в неправильном подмножестве узла
путей (вычислений ребер) в неправильном подмножестве узла  следовательно, необходимо выполнить в конечном счете
следовательно, необходимо выполнить в конечном счете  вычислений для того, чтобы из узла
вычислений для того, чтобы из узла  достичь
достичь  уровень узлов без повторного обследования. Ясно, что
уровень узлов без повторного обследования. Ясно, что  случайная величина и, как увидим в следующем параграфе, ее распределение не зависит от длины кодового ограничения (от скорости
случайная величина и, как увидим в следующем параграфе, ее распределение не зависит от длины кодового ограничения (от скорости  оно зависит). Столь же важно и то, что хотя этот алгоритм и является субоптимальным, асимптотически при больших длинах кодового ограничения он работает, по существу, столь же хорошо, как алгоритмы декодирования по максимуму правдоподобия.
оно зависит). Столь же важно и то, что хотя этот алгоритм и является субоптимальным, асимптотически при больших длинах кодового ограничения он работает, по существу, столь же хорошо, как алгоритмы декодирования по максимуму правдоподобия.