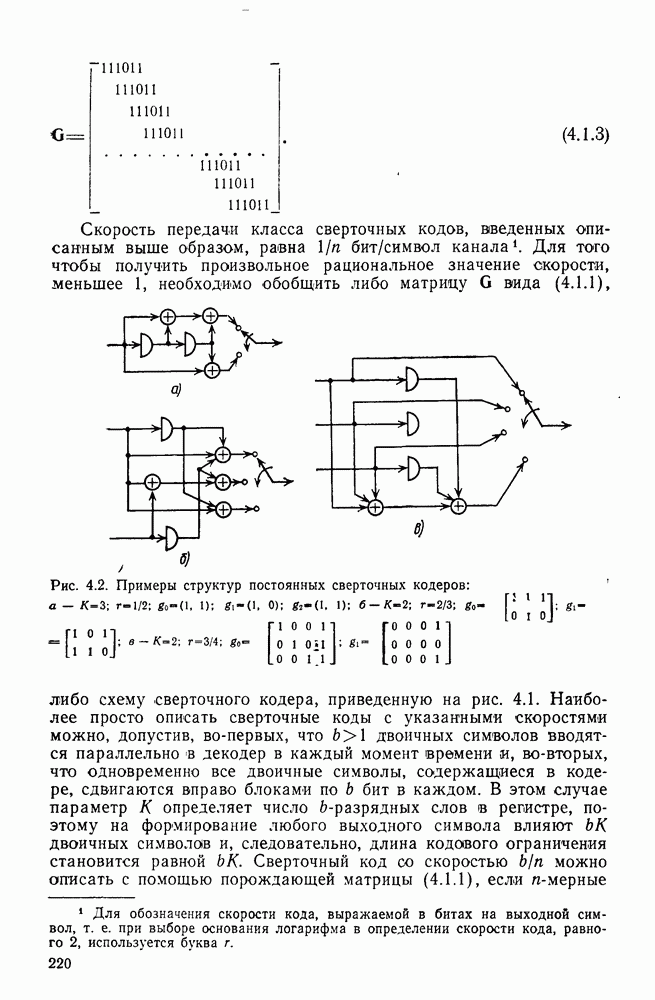
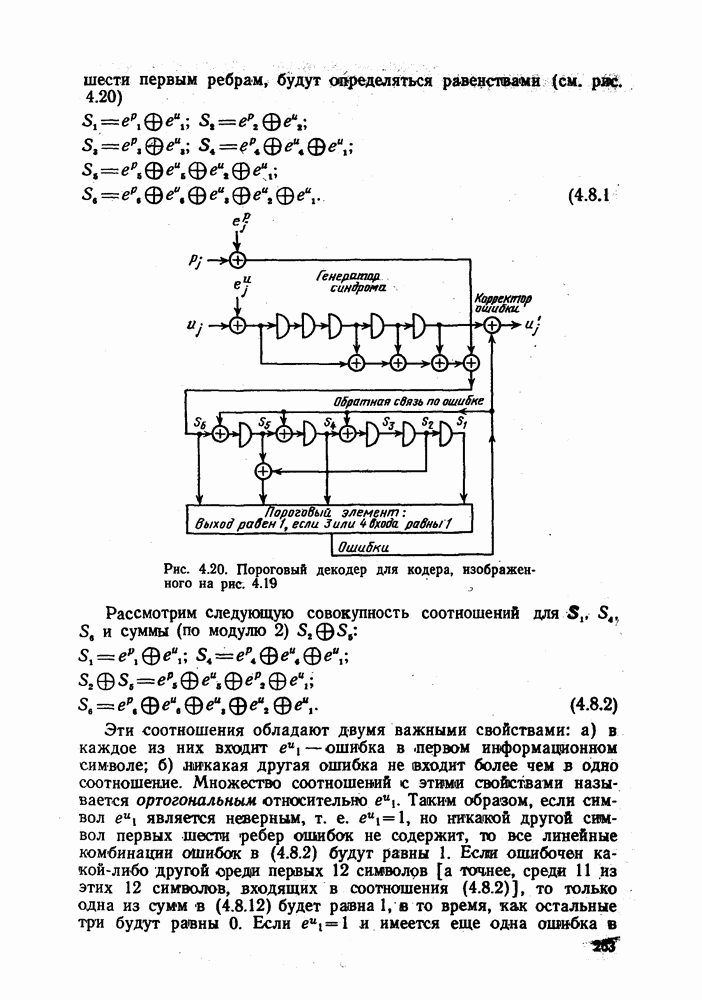
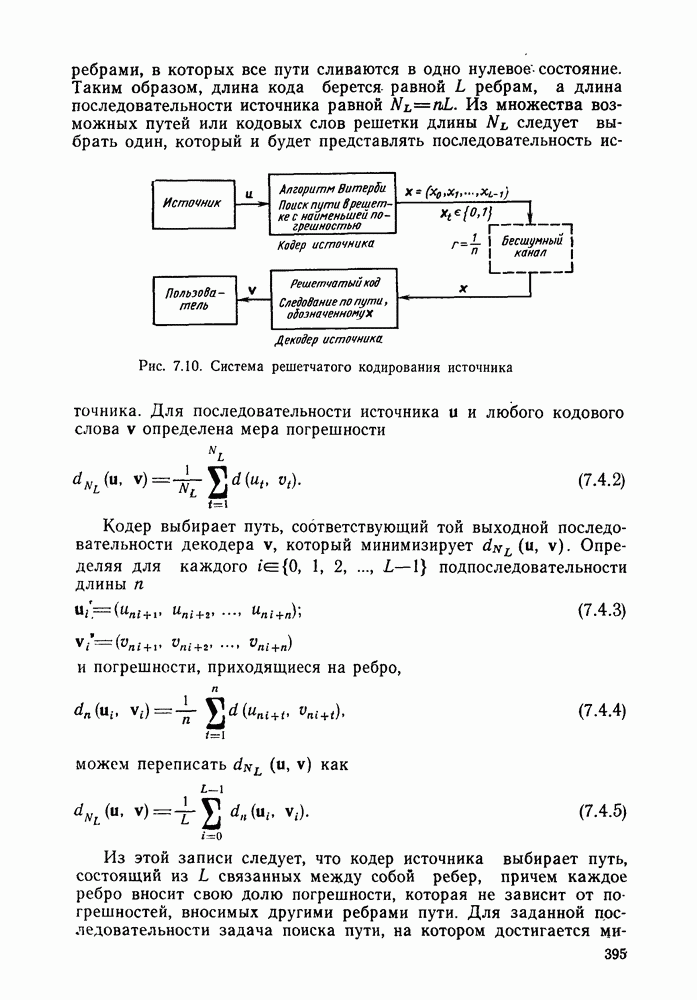
4.6. Структура кодов со скоростью 1/n. Ортогональные сверточные коды
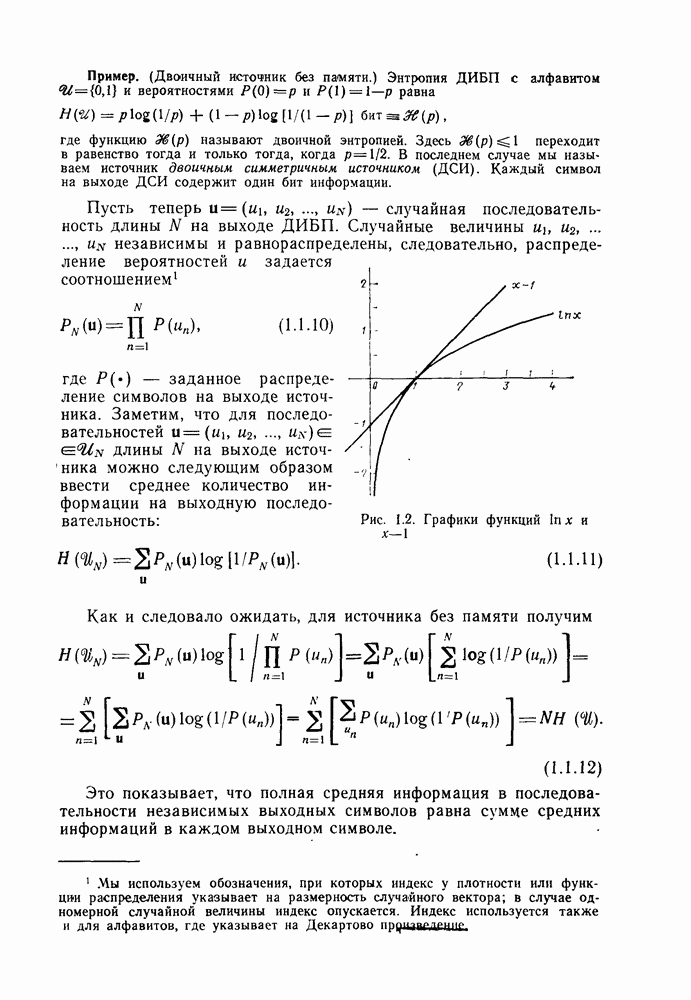
В то время как весовые и дистанционные свойства путей сверточного кода зависят от порождающих последовательностей кодера, длины сегментов несовпадения путей и число символов 1 в информационной последовательности конкретного кодового пути являются функциями только длины кодового ограничения К и числителя скорости  Так, например, для любого кода со скоростью
Так, например, для любого кода со скоростью  и длиной кодового ограничения 3 [ом. (4.3.3)]
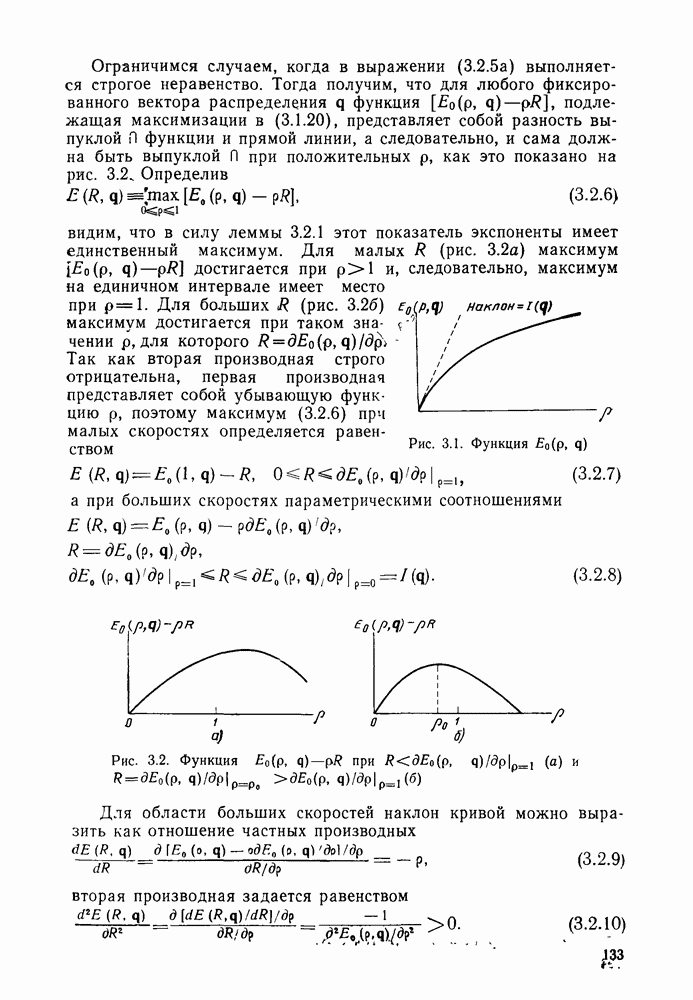
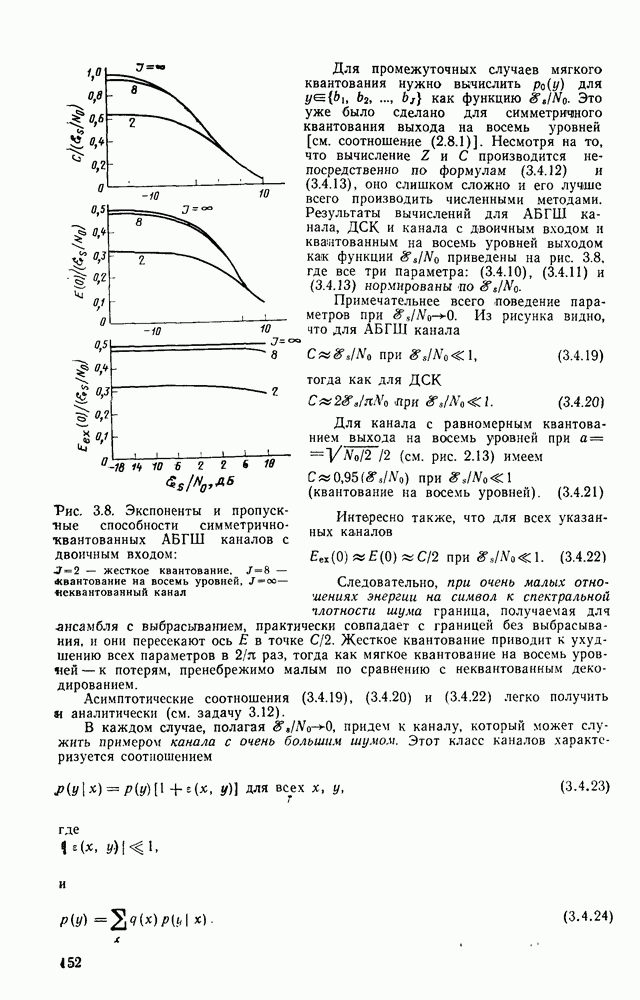
и длиной кодового ограничения 3 [ом. (4.3.3)]

Для того чтобы получить общую формулу для порождающей функции  произвольного кода со скоростью
произвольного кода со скоростью  и длиной кодового ограничения К, можно воспользоваться следующим подходом. На диаграмме состояний для «ода с длиной кодового ограничения К (см. рис. 4.10 для
и длиной кодового ограничения К, можно воспользоваться следующим подходом. На диаграмме состояний для «ода с длиной кодового ограничения К (см. рис. 4.10 для  рассмотрим состояние, непосредственно предшествующее конечному;
рассмотрим состояние, непосредственно предшествующее конечному;  -мерный вектор этого состояния имеет вид
-мерный вектор этого состояния имеет вид  Допустим, что это состояние является конечным и что путь, достигая этого состояния, поглощается (или сливается), не имея возможности следовать ни в состояние
Допустим, что это состояние является конечным и что путь, достигая этого состояния, поглощается (или сливается), не имея возможности следовать ни в состояние  ни в состояние
ни в состояние  В этом случае начальным символом, содержащимся в регистре кодера, можно пренебречь и получить код с длиной кодового ограничения
В этом случае начальным символом, содержащимся в регистре кодера, можно пренебречь и получить код с длиной кодового ограничения  Отсюда следует, что порождающей функцией для всех путей, ведущих из начального состояния в состояние, предшествующее конечному, является функция
Отсюда следует, что порождающей функцией для всех путей, ведущих из начального состояния в состояние, предшествующее конечному, является функция  При введении дополнительного символа 0 в кодер, находящийся в рассматриваемом состоянии, достигается конечное состояние. С другой стороны, при введении символа 1 кодер фактически возвращается в начало диаграммы состояния: строго говоря, символ 1 переводит кодер в состояние
При введении дополнительного символа 0 в кодер, находящийся в рассматриваемом состоянии, достигается конечное состояние. С другой стороны, при введении символа 1 кодер фактически возвращается в начало диаграммы состояния: строго говоря, символ 1 переводит кодер в состояние  а ребро, по которому осуществляется этот переход, играет ту же роль, что и ребро, исходящее из начального состояния. Это значит, что искомая порождающая функция может быть найдена по рекуррентной формуле
а ребро, по которому осуществляется этот переход, играет ту же роль, что и ребро, исходящее из начального состояния. Это значит, что искомая порождающая функция может быть найдена по рекуррентной формуле

Другими словами, для того чтобы достичь конечного состояния, вначале кодер должен попасть в состояние  Первое слагаемое в правой части равенства (4.62) соответствует поступлению символа 0 в кодер, находящийся в этом состоянии. При этом конечное состояние достигается присоединением еще одного ребра, соответствующего нулевому информационному символу. Второе слагаемое в правой части (4.6.2) соответствует введению
Первое слагаемое в правой части равенства (4.62) соответствует поступлению символа 0 в кодер, находящийся в этом состоянии. При этом конечное состояние достигается присоединением еще одного ребра, соответствующего нулевому информационному символу. Второе слагаемое в правой части (4.6.2) соответствует введению
символа 1, и в этом случае состояние  можно трактовать как начальное состояние, из которого конечное состояние может быть достигнуто только одним из путей
можно трактовать как начальное состояние, из которого конечное состояние может быть достигнуто только одним из путей  Из (4.6.2) непосредственно следует, что
Из (4.6.2) непосредственно следует, что

При  очевидно,
очевидно,

Решение уравнения (4.6.3) получается методом индукции по К:

Если интерес представляет только распределение длин путей, то можно ограничиться функцией

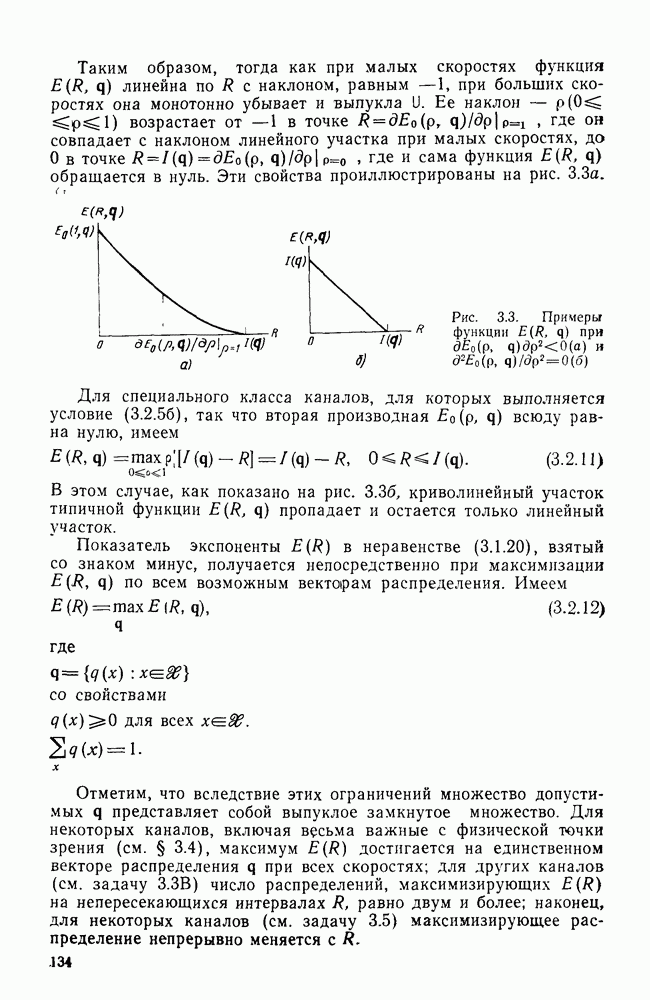
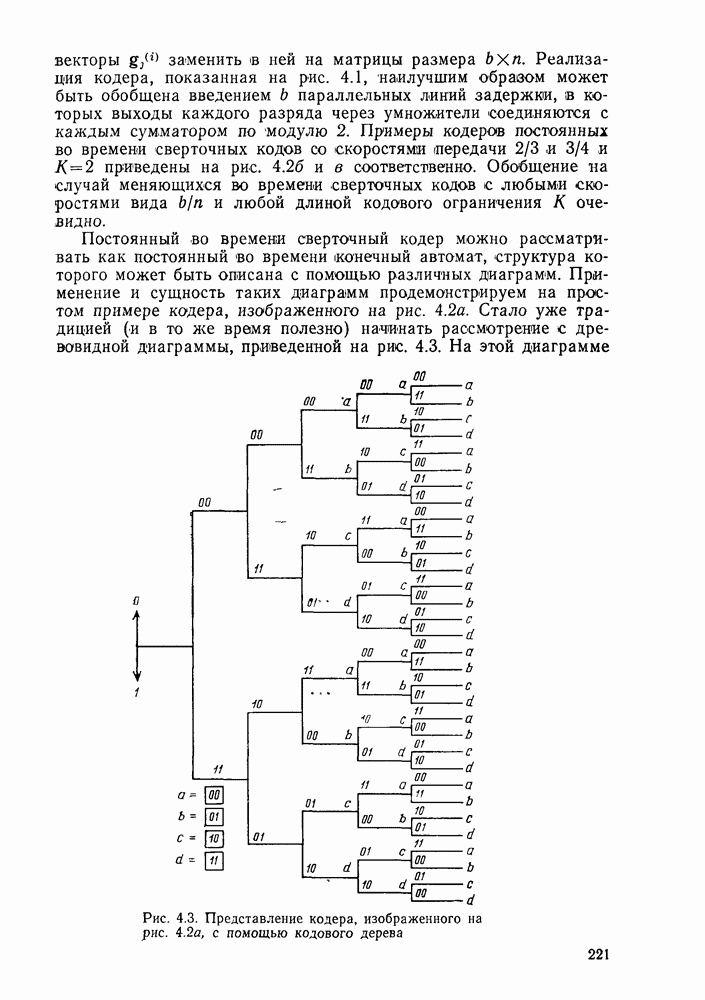
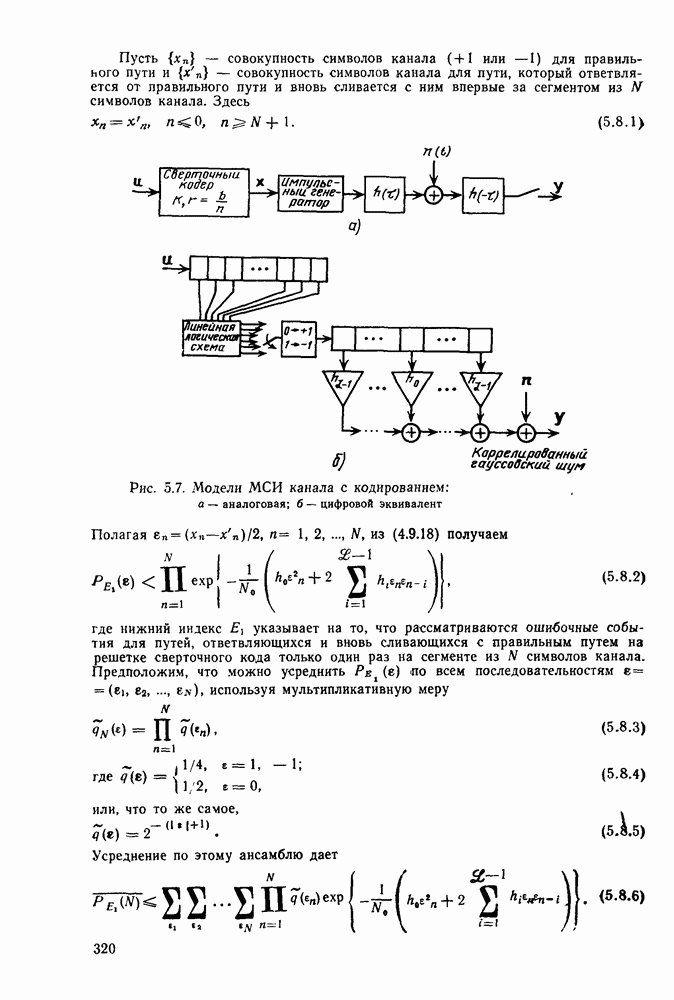
Эти результаты будут использованы в следующей главе при рассмотрении ансамблей сверточных кодов. В заключение параграфа рассмотрим класс кодов, у которых все ребра имеют одни и те же весовые и дистанционные свойства и, следовательно, характеристики которых зависят только от структуры путей. Речь идет о классе ортогональных сверточных кодов со скоростью  порождаемых кодером, приведенным на рис. 4.14.
порождаемых кодером, приведенным на рис. 4.14.

Рис. 4.14. Сверточный ортогональный кодер: длина кодового ограничения К, скорость передачи 
Изображенный на этом рисунке блочный ортогональный кодер порождает каждый раз одну из  ортогональных двоичных последовательностей размерности
ортогональных двоичных последовательностей размерности  (как это было описано в § 2.5). В результате вес любого ребра, соответствующего ненулевой информационной последовательности, оказывается равным в точности
(как это было описано в § 2.5). В результате вес любого ребра, соответствующего ненулевой информационной последовательности, оказывается равным в точности  Так как каждое ребро имеет вес
Так как каждое ребро имеет вес  то порождающая функция
то порождающая функция  для кодов из рассматриваемого класса может быть
для кодов из рассматриваемого класса может быть
получена из  заменой в последней
заменой в последней  на
на  Таким образом
Таким образом

Отсюда с помощью неравенства (4.4.7) и (4.4.12) для вероятностей ошибок на узел и на бит в АБГШ канале, для которого  получаем следующие границы:
получаем следующие границы:

Учитывая то, что для кода со скоростью  на каждый информационный двоичный символ приходится
на каждый информационный двоичный символ приходится  символов кодовой последовательности и, следовательно,
символов кодовой последовательности и, следовательно,  получаем:
получаем:

Напомним также следующий факт из § 2.5 [см. равенства {2.5.13) и (2.5.18)]:

где  скорость передачи,
скорость передачи,  пропускная способность, измеряемая в натах в секунду. Время передачи на один двоичный символ
пропускная способность, измеряемая в натах в секунду. Время передачи на один двоичный символ  с/бит. Поэтому выражения (4.6.11) переходят в неравенства
с/бит. Поэтому выражения (4.6.11) переходят в неравенства

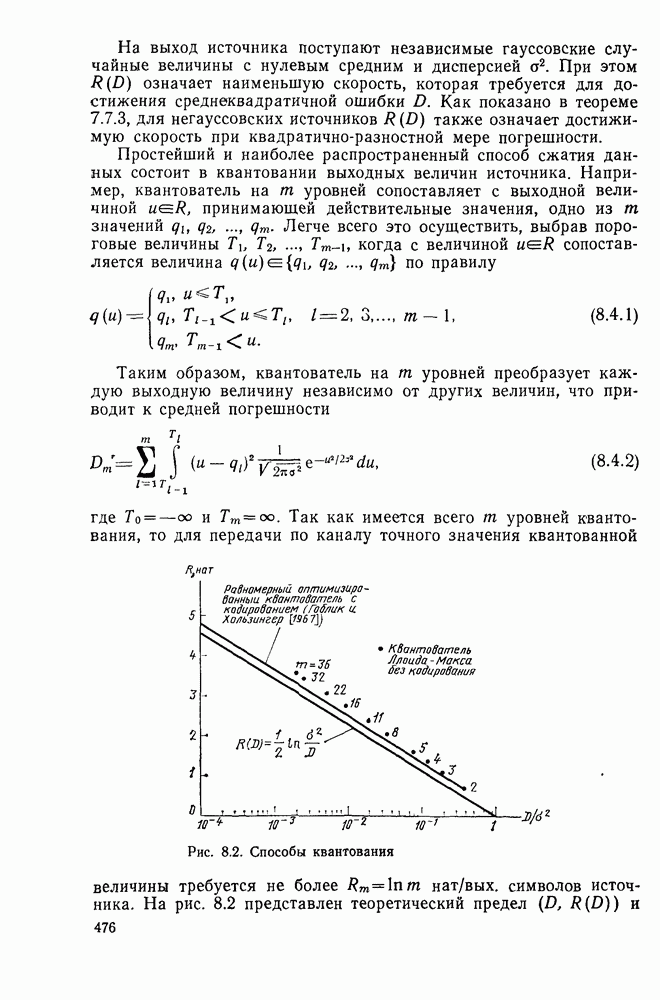
В § 2.5 было показано, что вероятность ошибки для блочных ортогональных кодов убывает экспоненциально с длиной блока при всех скоростях  Однако следует помнить, что для получения этого результата использовалась более точная, чем аддитивная граница, техника оценивания. Сейчас воспользуемся аналогичным подходом в случае сверточных кодов для того, чтобы получить экспоненциальную границу в терминах длины кодового ограничения для всех скоростей передачи вплоть до пропускной способности.
Однако следует помнить, что для получения этого результата использовалась более точная, чем аддитивная граница, техника оценивания. Сейчас воспользуемся аналогичным подходом в случае сверточных кодов для того, чтобы получить экспоненциальную границу в терминах длины кодового ограничения для всех скоростей передачи вплоть до пропускной способности.
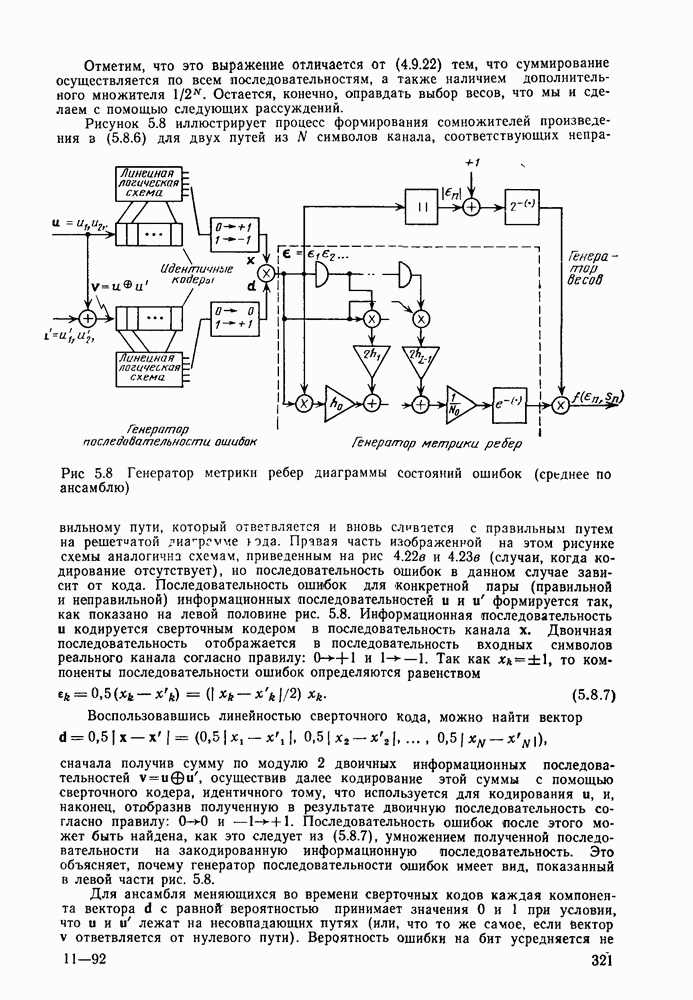
Начнем с вероятности ошибки на узел. Напомним, что в узле ошибка может произойти только в том случае, если путь, ответвляющийся от правильного в этом узле, до точки первого слияния с правильным путем имеет большую метрику, чем правильный путь. По порождающей функции  определяемой равенством (4.6.6), можно найти длины всех несливающихся с правильным путем и по ним — число ответвляющихся путей, которые сливаются с правильным путем через данное число ребер. Получающуюся формулу можно несколько упростить, если вместо равенства (5.6.6) воспользоваться следующим, вытекающим из него неравенством:
определяемой равенством (4.6.6), можно найти длины всех несливающихся с правильным путем и по ним — число ответвляющихся путей, которые сливаются с правильным путем через данное число ребер. Получающуюся формулу можно несколько упростить, если вместо равенства (5.6.6) воспользоваться следующим, вытекающим из него неравенством:

Таким образом, в совокупности путей, ответвляющихся от правильного пути в заданном узле, имеется не более  неправильных путей, которые сливаются с правильным после
неправильных путей, которые сливаются с правильным после  ребер; это завышение (приблизительно вдвое) числа путей, как увидим ниже, в асимптотике оказывает пренебрежимо малое влияние. В случае ортогонального сверточного кода все пути, которые не совпадают с правильным на сегменте из
ребер; это завышение (приблизительно вдвое) числа путей, как увидим ниже, в асимптотике оказывает пренебрежимо малое влияние. В случае ортогонального сверточного кода все пути, которые не совпадают с правильным на сегменте из  ребер, имеют кодовые векторы, ортогональные соответствующему кодовому вектору правильного пути на всем сегменте несовпадения. Вероятность ошибки на узел может быть ограничена сверху следующим образом:
ребер, имеют кодовые векторы, ортогональные соответствующему кодовому вектору правильного пути на всем сегменте несовпадения. Вероятность ошибки на узел может быть ограничена сверху следующим образом:

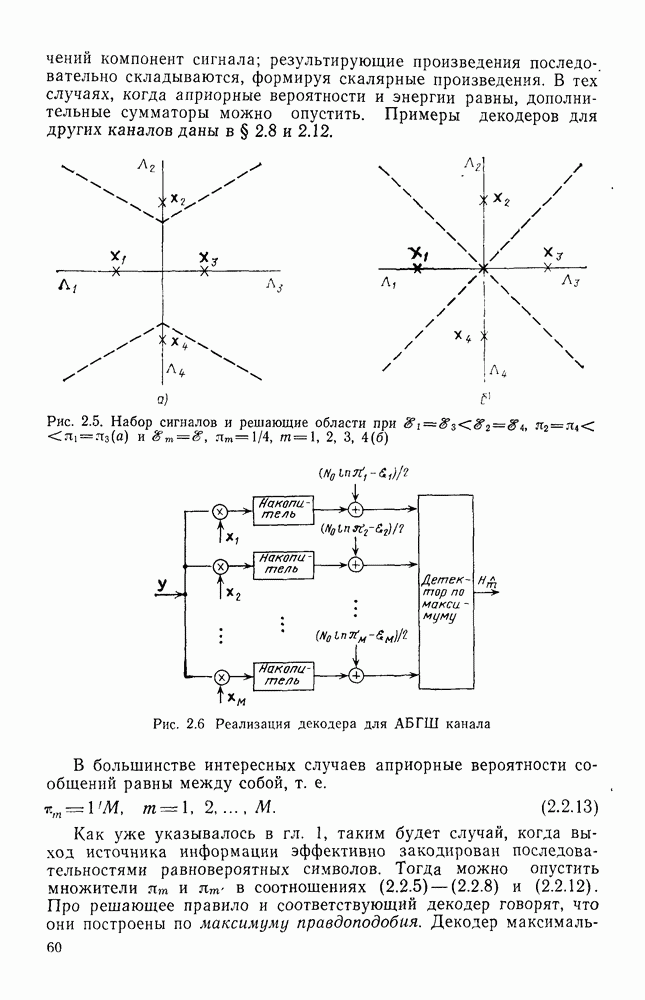
Это, конечно, аддитивная граница, но вместо суммирования по всем ошибочным исходам отдельных путей, как это делалось в § 4.4, здесь отнесены к отдельному исходу все ошибки, порожденные путями, несовпадающими с правильным на одном и том же числе ребер. Далее, вместо оценивания вероятности этих событий с помощью аддитивной границы, как это делалось ранее, воспользуемся границей Галлагера. Действительно, можно применить непосредственно результаты § 2.5, основанные на границе Галлагера (2.4.8), к множеству неправильных путей, несовпадающих с правильным путем, и, следовательно, ортогональных ему на сегменте из  ребер, мощность которого не превышает
ребер, мощность которого не превышает  Поскольку при этом не требуется, чтобы все кодовые векторы были взаимно ортогональными, а необходима лишь попарная ортогональность каждого неправильного и каждого правильного
Поскольку при этом не требуется, чтобы все кодовые векторы были взаимно ортогональными, а необходима лишь попарная ортогональность каждого неправильного и каждого правильного
кодового вектора, то из (2.5.12) для ортогональных кодов и АБГШ канала имеем

(здесь мы воспользовались также тем, что энергия, приходящаяся на рассматриваемый сегмент, в  раз больше энергии, приходящейся «а одно ребро и равной
раз больше энергии, приходящейся «а одно ребро и равной  для кодов со скоростью
для кодов со скоростью  Подставляя (4.6.17) в (4.6.16) и, далее, пользуясь (4.6.12), получаем
Подставляя (4.6.17) в (4.6.16) и, далее, пользуясь (4.6.12), получаем

Ясно, что если положим  то получим границу (4.6.13). С другой стороны, полагая
то получим границу (4.6.13). С другой стороны, полагая

для некоторого  лежащего в пределах
лежащего в пределах  находим
находим

Таким образом, доказано экспоненциальное убывание с ростом К вероятности ошибки на узел для всех скоростей  Так как асимптотически при больших К знаменатель в правой части последнего неравенства становится несущественным, то можно положить
Так как асимптотически при больших К знаменатель в правой части последнего неравенства становится несущественным, то можно положить 
Для того чтобы получить верхнюю границу вероятности ошибки на бит, учтем, что узловая ошибка, обусловленная неправильным путем, несовпадающим с правильным на сегменте из  ребер, может породить самое большее
ребер, может породить самое большее  двоичных ошибок. Это связано с тем, что неправильный путь может слиться с правильным путем только в том случае, если его
двоичных ошибок. Это связано с тем, что неправильный путь может слиться с правильным путем только в том случае, если его  последних информационных символов совпадают с соответствующими информационными символами правильного пути. (Вывод выражения для границы усложняется не намного.) Таким образом, если каждое слагаемое суммы в правой части (4.6.16) умножить на
последних информационных символов совпадают с соответствующими информационными символами правильного пути. (Вывод выражения для границы усложняется не намного.) Таким образом, если каждое слагаемое суммы в правой части (4.6.16) умножить на  то полученная в результате сумма в силу вышеизложенного будет оценкой сверху для вероятности ошибки на бит, т. е.
то полученная в результате сумма в силу вышеизложенного будет оценкой сверху для вероятности ошибки на бит, т. е.

Далее, используя (4.6.17) и равенство

получаем

Наконец, учитывая соотношение (4.6.19), по аналогии с (4.6.20), получаем следующую границу:

Из (4.6.13), (4.6.14), (4.6.20) и (4.6.22) следует, что

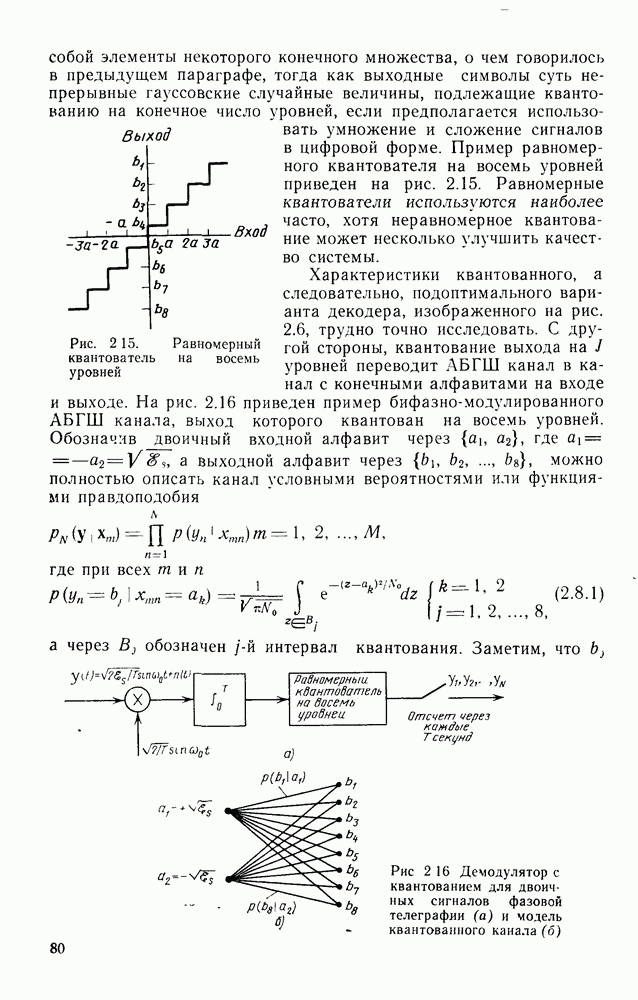
где  при
при 

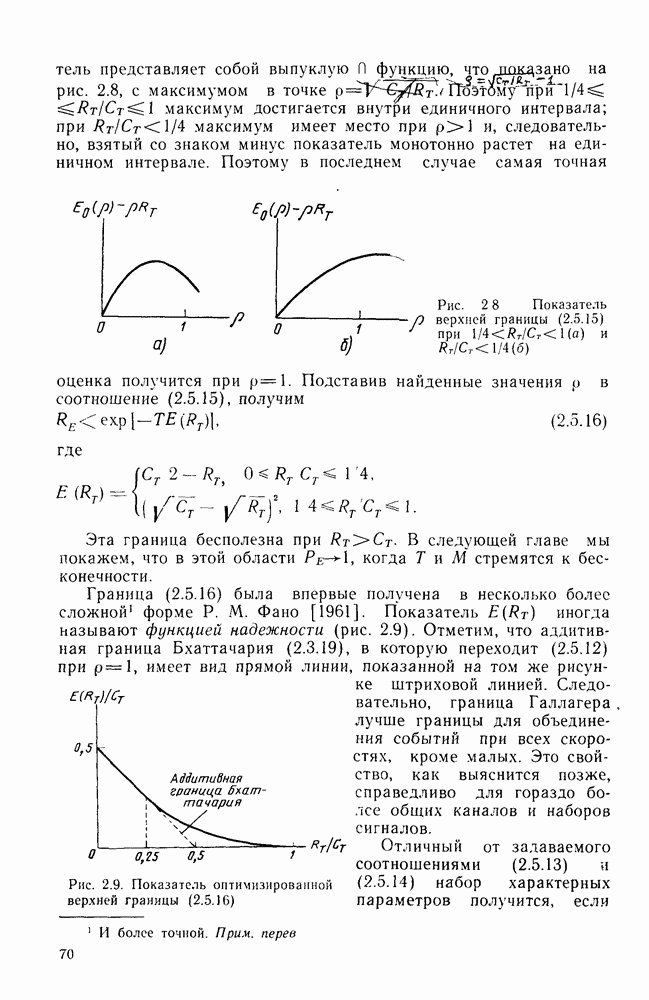
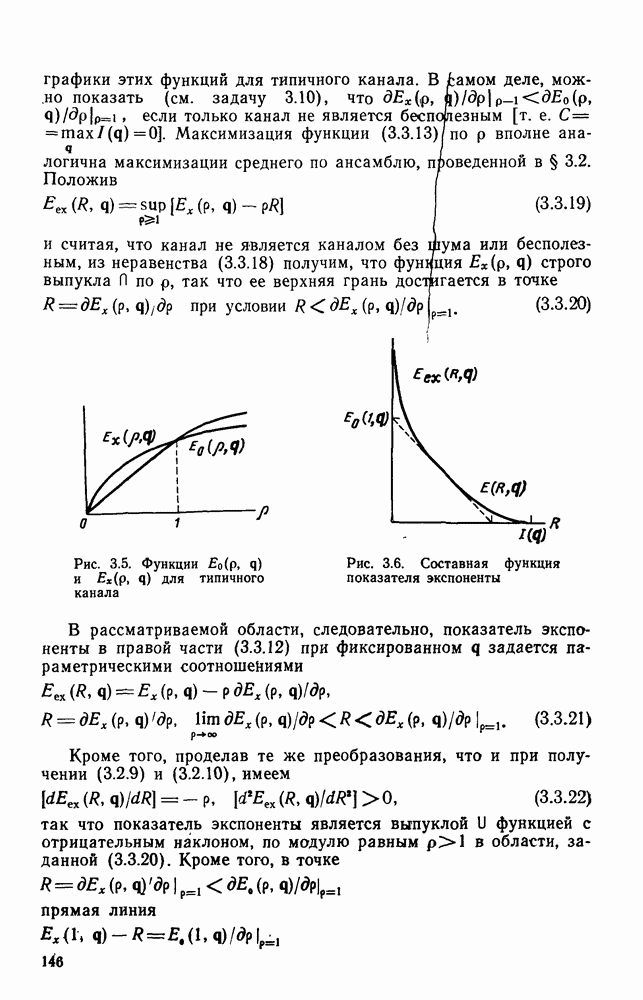
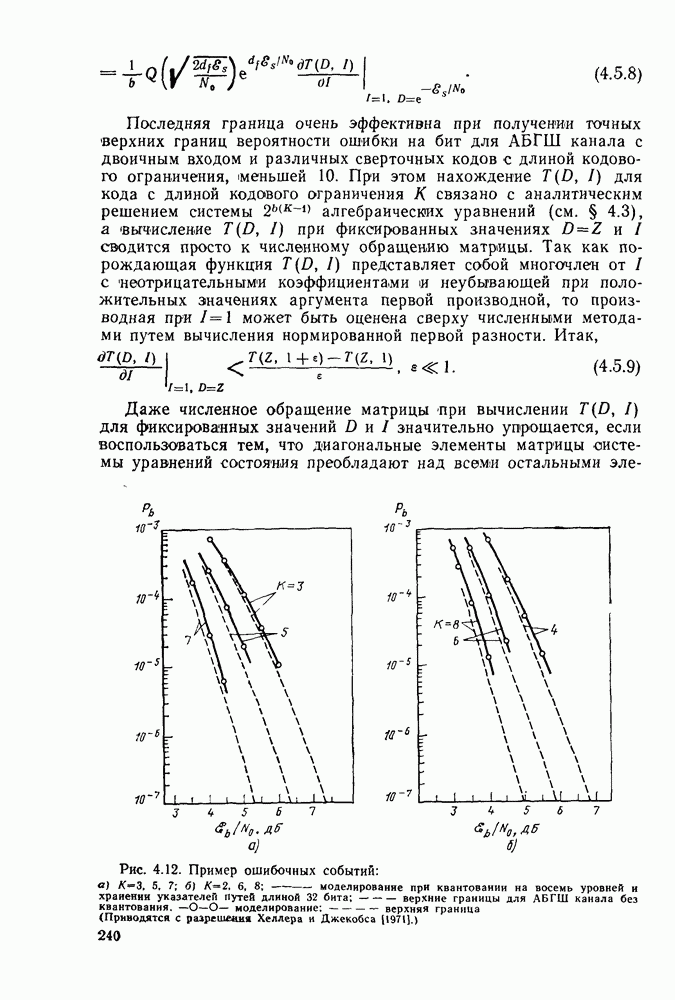
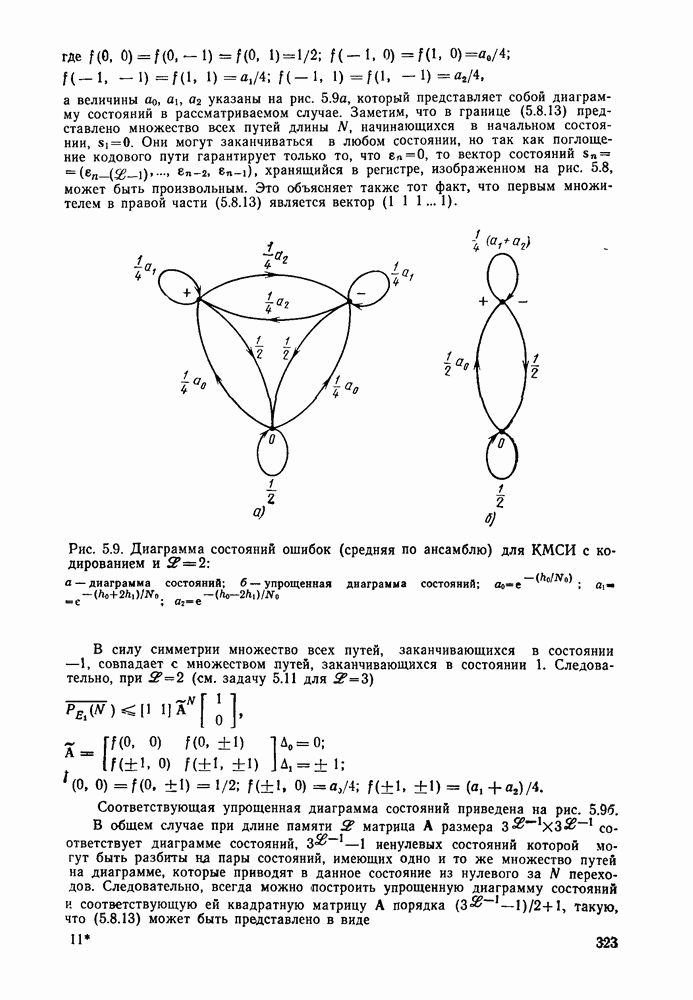
На рис. 4.15 приведены для сравнения показатель экспоненты.  для сверточных кодов (при
для сверточных кодов (при  и показатель экспоненты блочных (Кодов
и показатель экспоненты блочных (Кодов  определяющийся равенством (2.5.16) как функция
определяющийся равенством (2.5.16) как функция  Сравнивая последний с (4.6.23), видим, что для блочных кодов он равен времени передачи К двоичных символов, в то время как для сверточных кодов последняя величина равна
Сравнивая последний с (4.6.23), видим, что для блочных кодов он равен времени передачи К двоичных символов, в то время как для сверточных кодов последняя величина равна  Учитывая этот факт, (2.5.16) можно представить в виде
Учитывая этот факт, (2.5.16) можно представить в виде  где
где  функция, определенная раньше. Таким образом, как следует из сравнения
функция, определенная раньше. Таким образом, как следует из сравнения  с помощью рис. 4.15, показатель экспоненты сверточного кодирования
с помощью рис. 4.15, показатель экспоненты сверточного кодирования












































































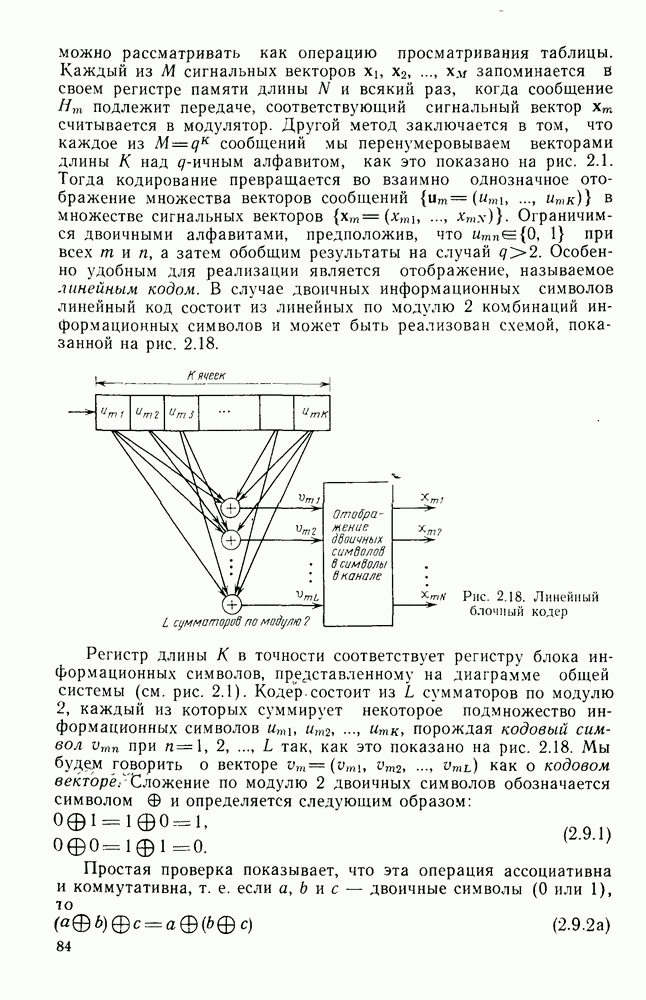














































































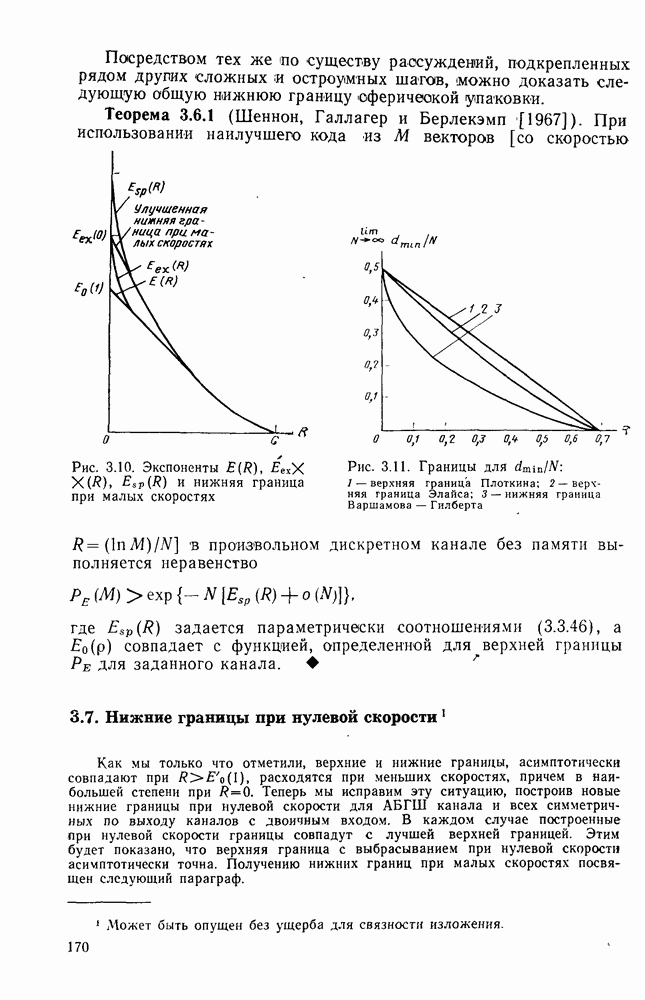









































































































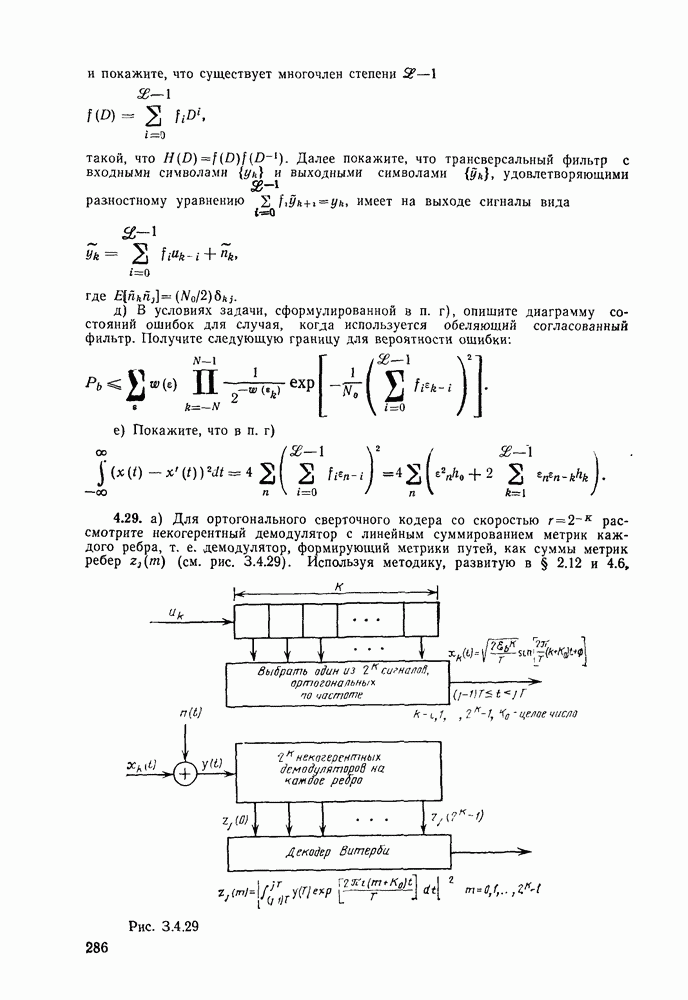






































































































































































































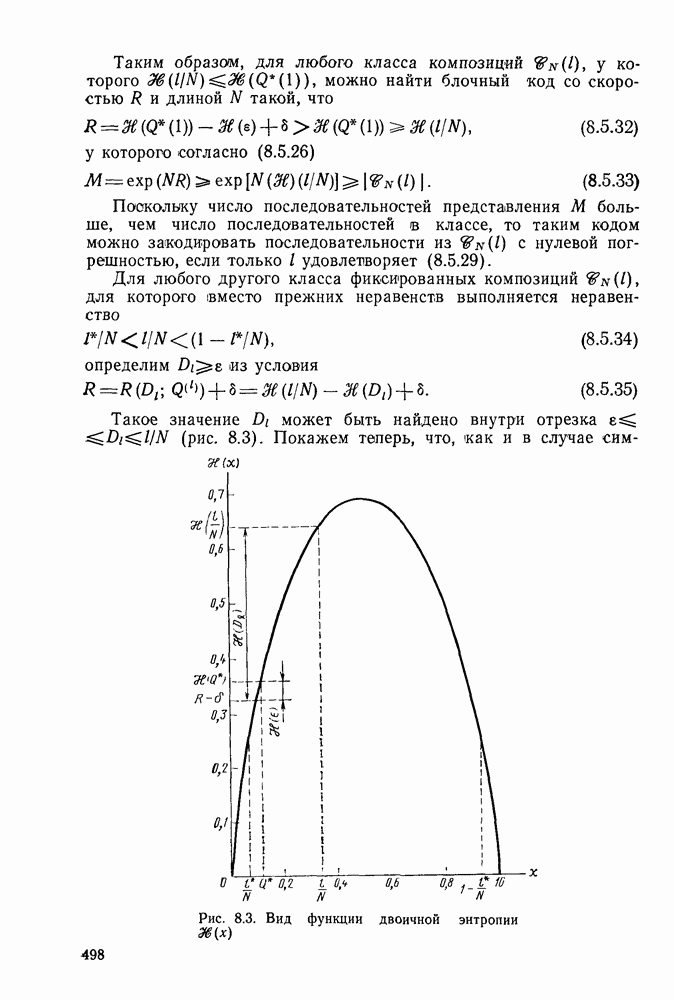






























 сравнений на каждые К бит или
сравнений на каждые К бит или  на один бит, в то время как декодер максимального правдоподобия Витерби для сверточных кодов выполняет
на один бит, в то время как декодер максимального правдоподобия Витерби для сверточных кодов выполняет  сравнений на бит; разница становится незначительной при больших
сравнений на бит; разница становится незначительной при больших 

 для ортогональных сверточных кодов и сравнение с показателем экспоненты ортогональных блочных кодов
для ортогональных сверточных кодов и сравнение с показателем экспоненты ортогональных блочных кодов
 для блочных кодов и
для блочных кодов и  для сверточных кодов, что является существенным недостатком последних. Однако этот недостаток характерен лишь для ортогональных кодов, и в следующей главе с помощью ансамблей кодов будет показано, что при той же ширине полосы (скорости передачи) показатель экспоненты сверточных кодов для всех каналов без памяти превосходит показатель экспоненты блочных кодов точно так же, как и в случае ортогональных кодов.
для сверточных кодов, что является существенным недостатком последних. Однако этот недостаток характерен лишь для ортогональных кодов, и в следующей главе с помощью ансамблей кодов будет показано, что при той же ширине полосы (скорости передачи) показатель экспоненты сверточных кодов для всех каналов без памяти превосходит показатель экспоненты блочных кодов точно так же, как и в случае ортогональных кодов.