Пред.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
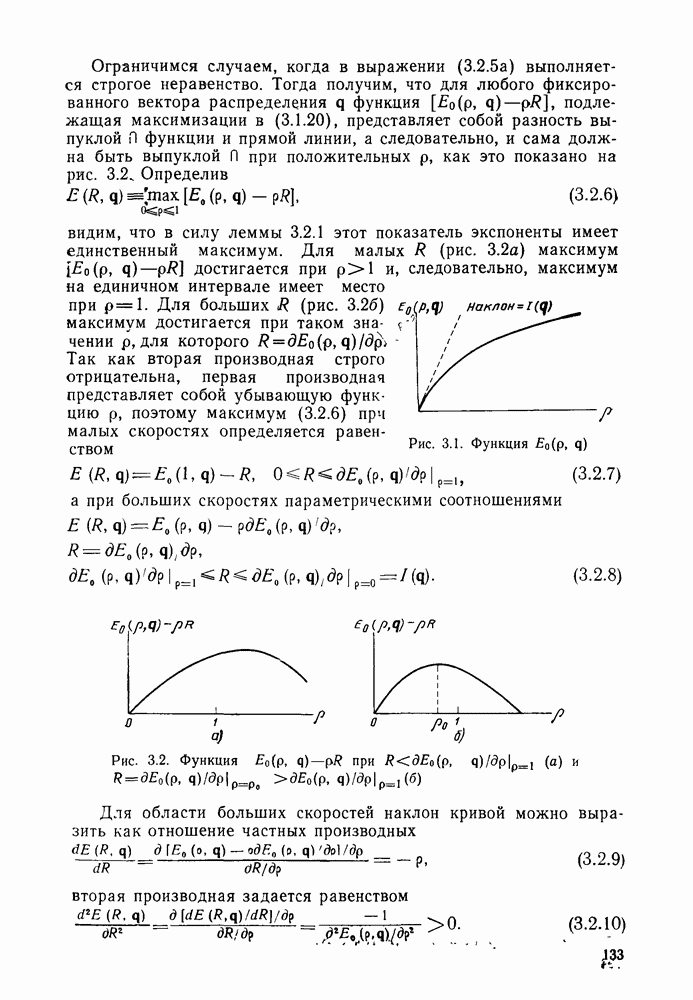
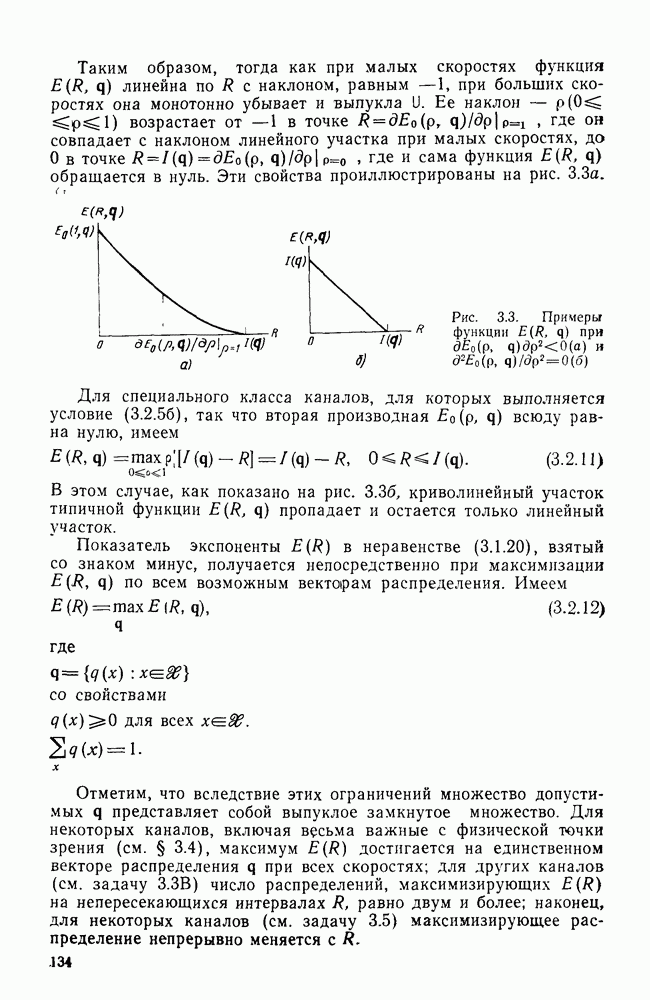
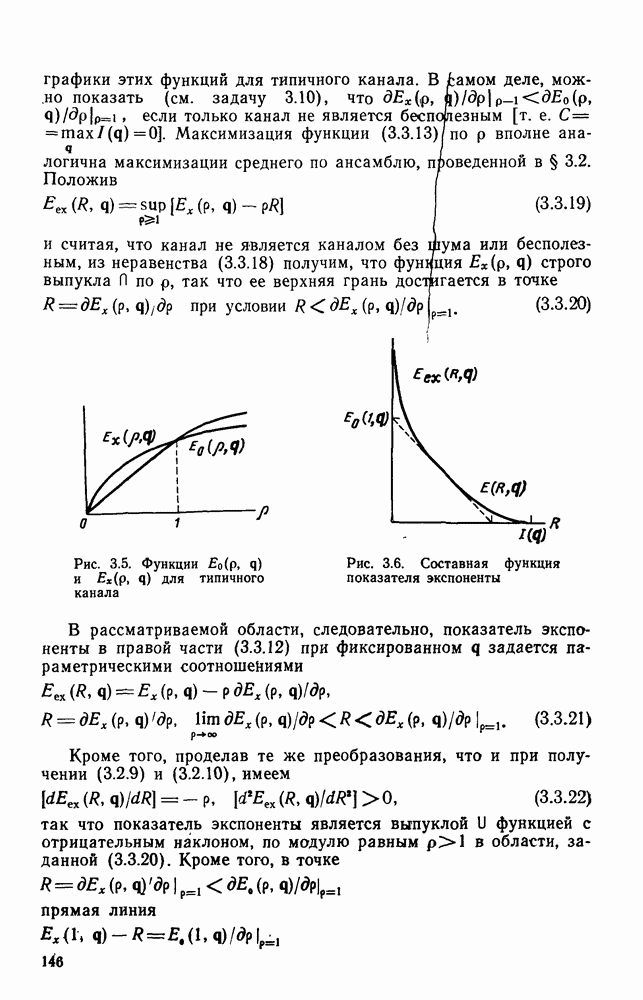
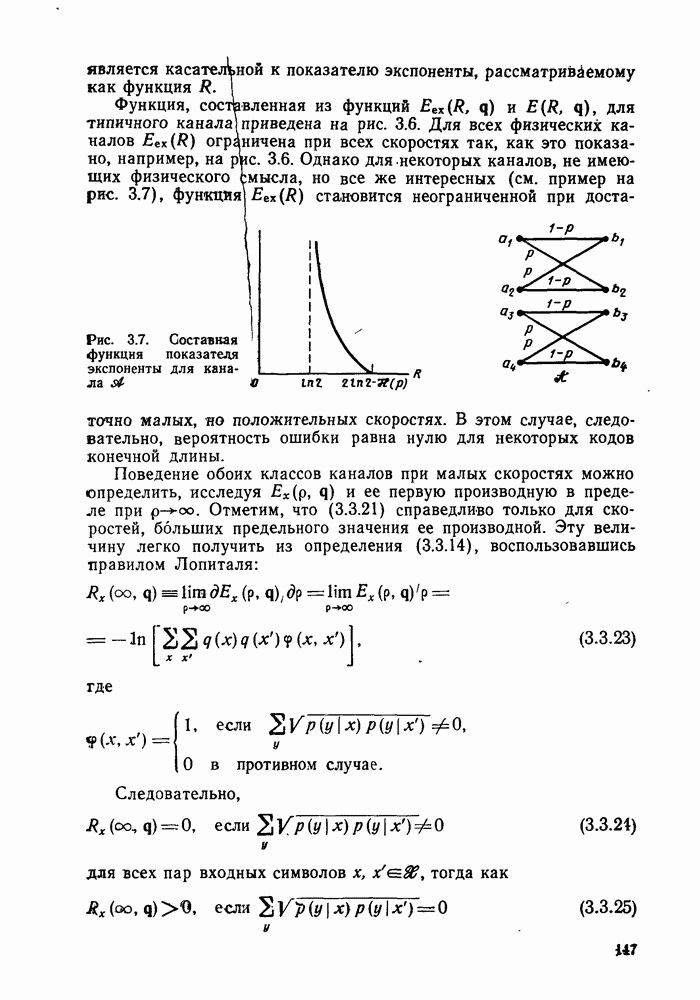
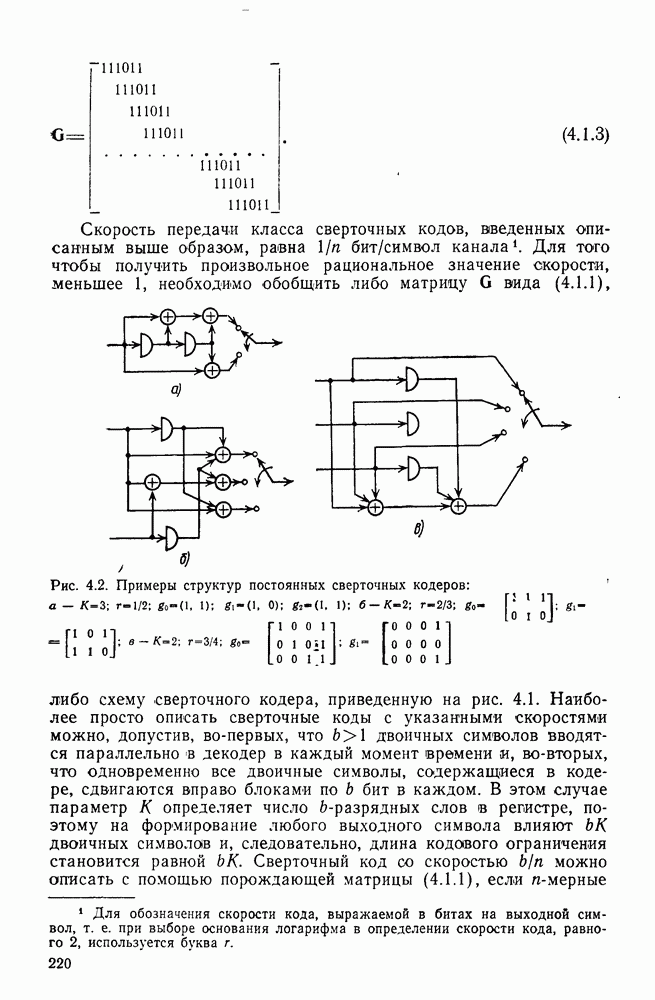
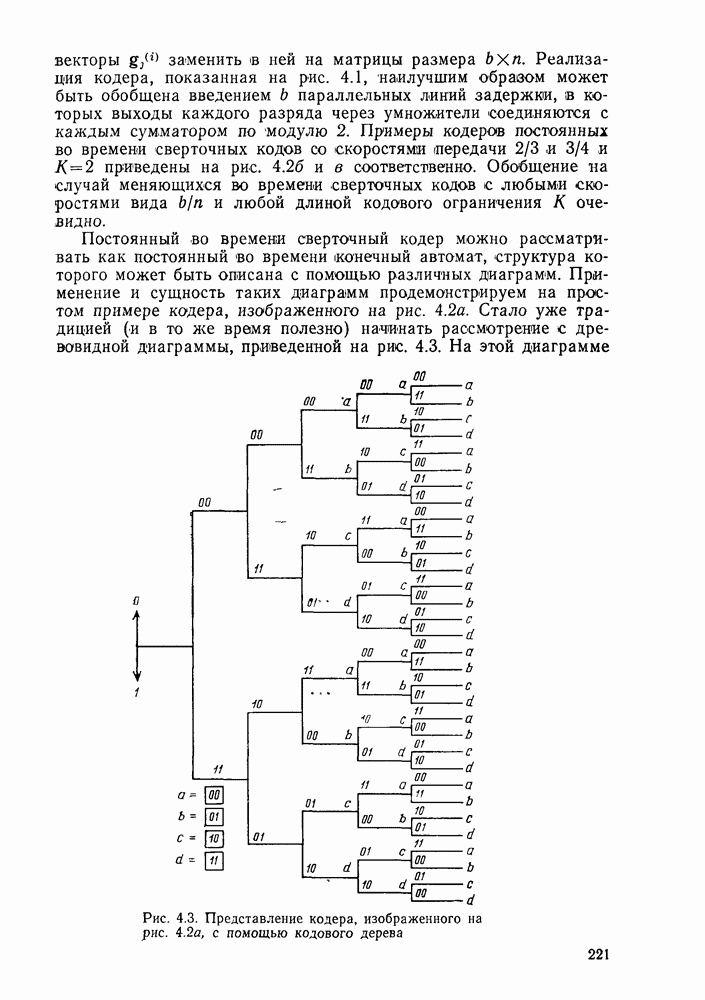
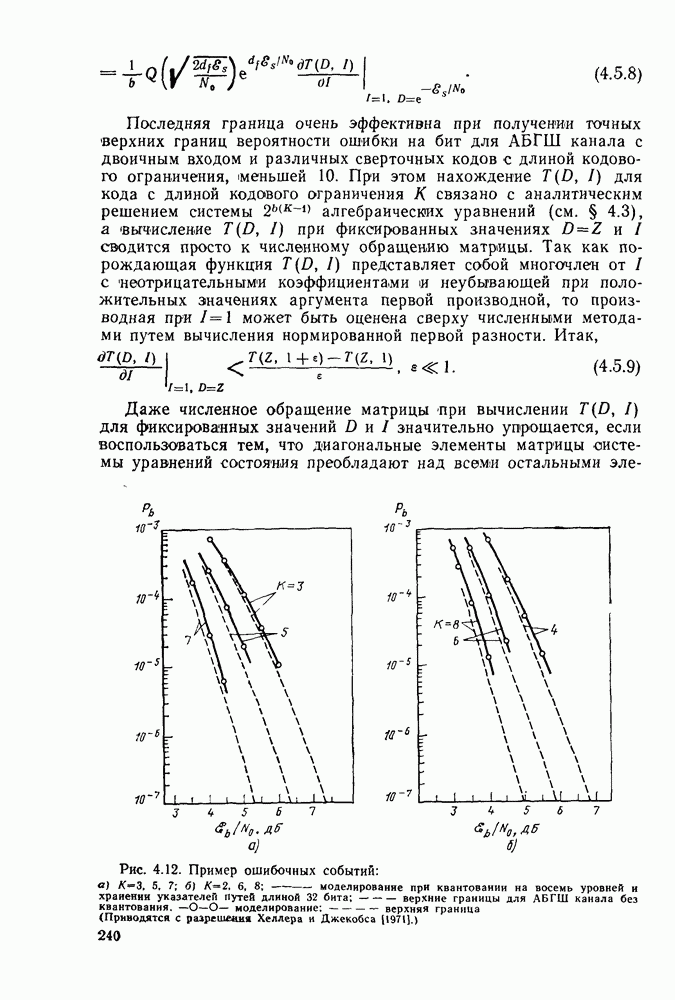
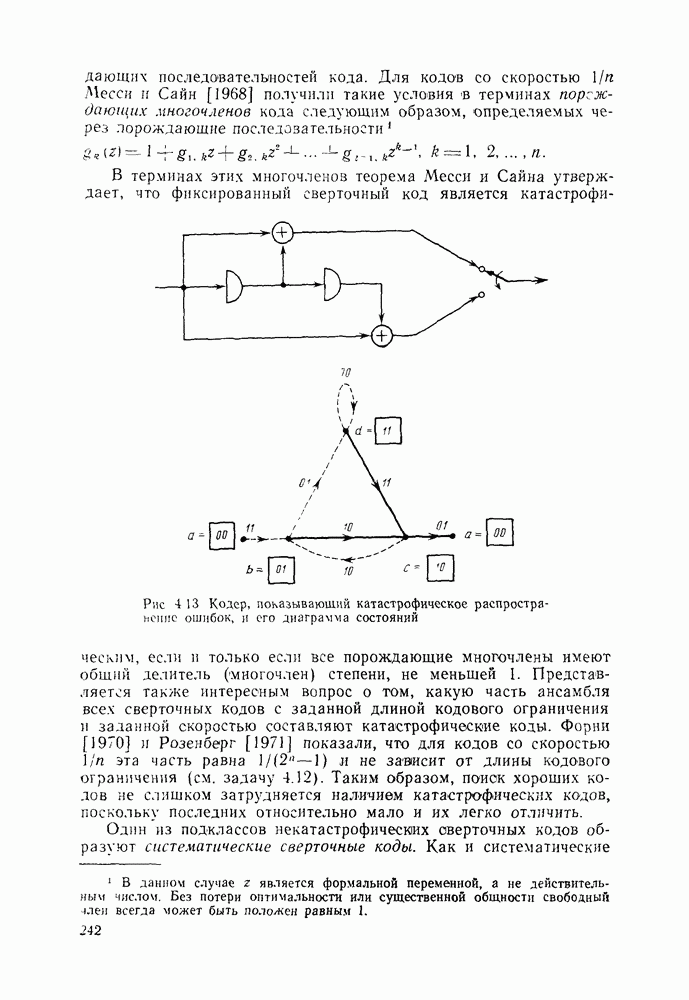
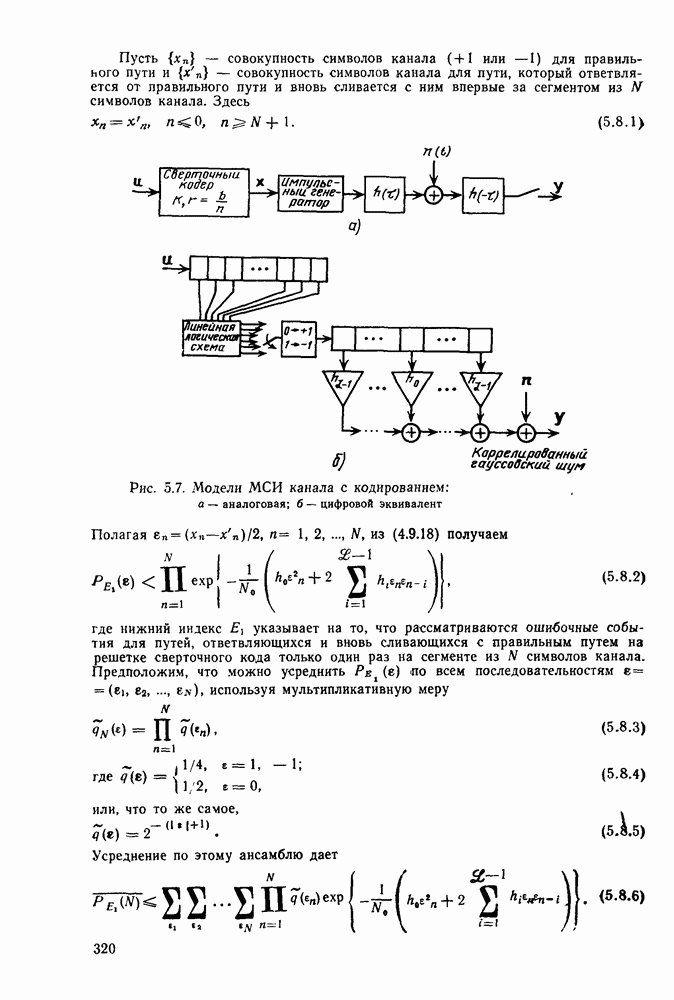
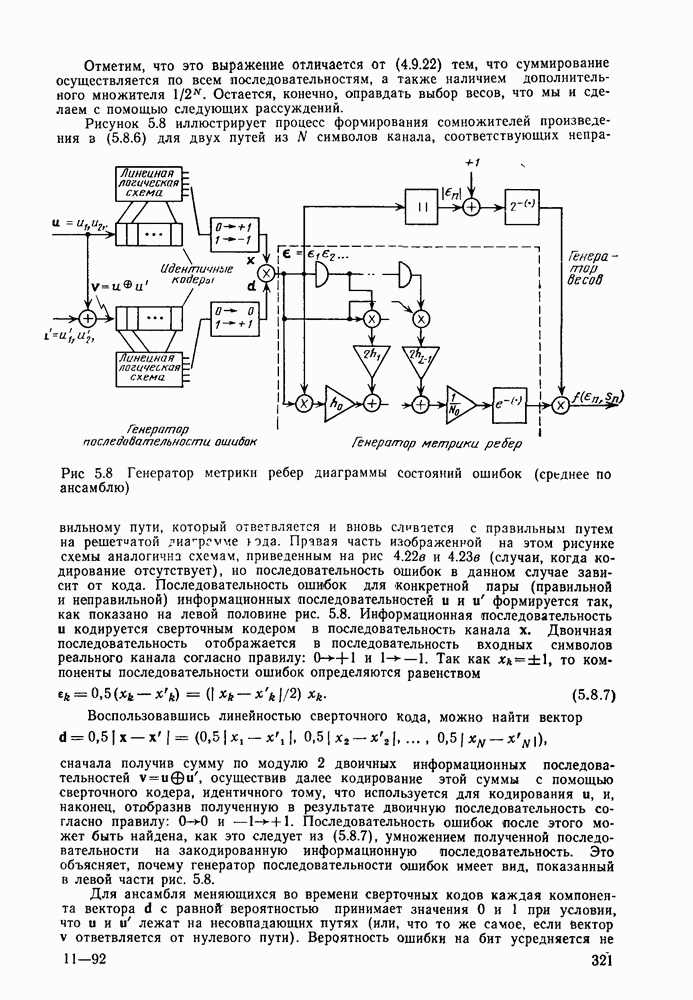
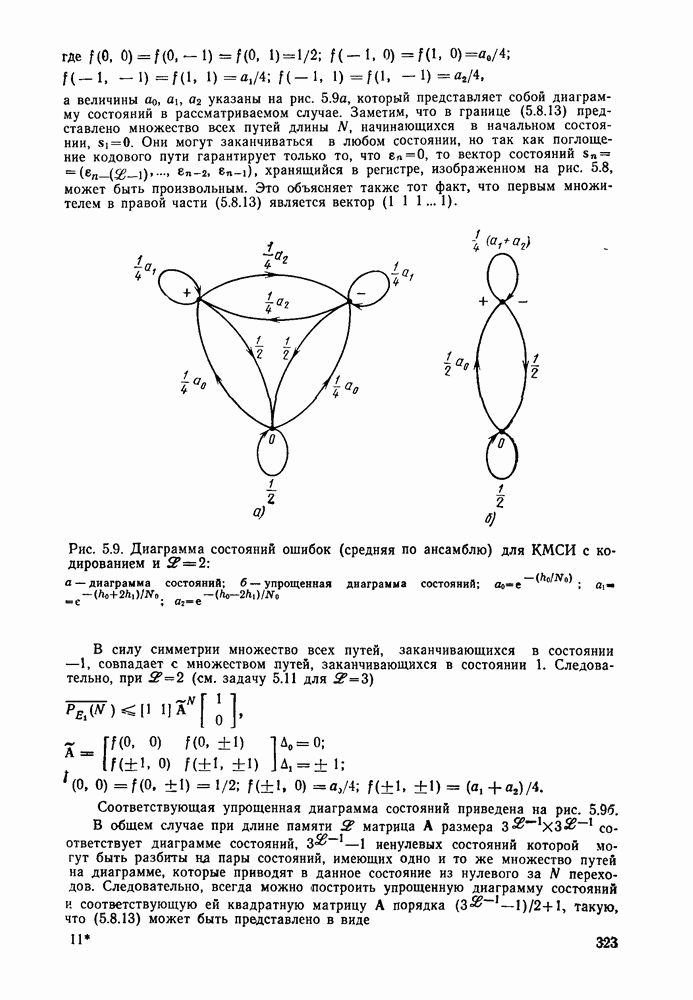
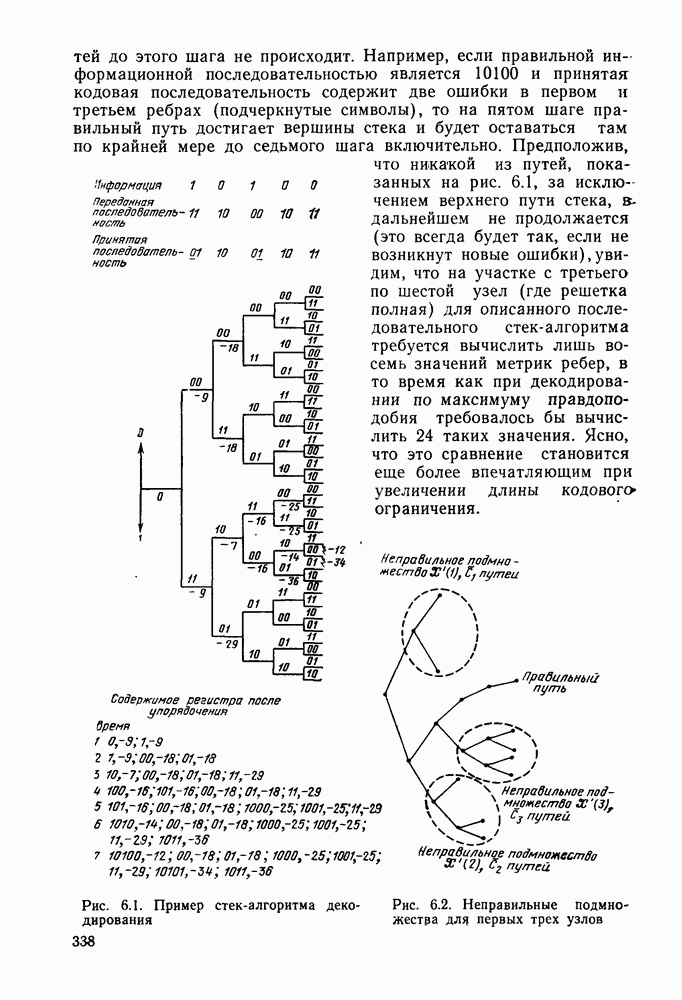
6.6. Вопросы сложности, переполнения буфера и устройства других системСложность декодирования по максимуму правдоподобия сверточных кодов с помощью алгоритма Витерби определяется легко: так, если длина кодового ограничения равна К, а скорость кода
то, как это следует из (5.1.32) и (5.4.13), вероятность ошибки на бит асимптотически при больших х и скоростях
где Как было показано в § 5.2, характеристики сверточного кода как функции сложности выглядят гораздо привлекательнее, чем характеристики блочных кодов. В данном рассмотрении
Так как означает превосходство сверточных кодов с декодированием Витерби. Определение сложности последовательного декодирования является несколько менее очевидным. Одним из возможных определений могло бы быть максимальное число вычислений метрики ребер, приходящееся на один бит, т. е. максимальное число вычислений в неправильном подмножестве каждого узла, нормированное числом
При этом согласно (6.2.20) и (6.4.9) вероятность того, что декодер не может выполнить декодирование в заданном узле из-за того, что для этого требуется большее число вычислений, чем это допустимо, оценивается соотношением
где Сравнивая (6.6.5) с (6.6.2), видим, что вероятность отказа от продолжения последовательного декодирования в случае, когда число вычислений на одно ребро ограничено, асимптотически связана со сложностью декодирования точно так же, как вероятность ошибки на бит при декодировании по максимуму правдоподобия (по Витерби). Заметим, однако, что в последовательном декодировании длина кодового ограничения непосредственно не фигурирует, а поэтому может показаться, что ее можно сделать произвольно большой (так как сложность не зависит от К), исключая таким образом, возможность появления обычных ошибок и в некотором смысле заменяя их отказом от декодирования, описанным выше. Сравнение (6.6.2) с (6.6.5) или (6.6.1) с (6.6.4) показывает, что при декодировании Витерби. Таким образом, эффективная длина кодового ограничения при последовательном декодировании Однако наше определение сложности последовательного декодирования является до некоторой степени обманчивым, так как основано на максимальном числе вычислений, приходящихся на один бит, хотя обычно для большинства узлов Начнем с установления объема памяти буфера, в котором хранятся символы принятого кодового вектора у; в буфере символы ожидают своей очереди быть обследованными декодером. Предположим, что объем буфера выбран таким, что в нем могут храниться В ребер или
то ясно, что произойдет отказ. Действительно, если даже буфер оказывается пустым при приеме из канала символов, необходимых для принятые символы
где
Из теоремы 6.2.1 известно также, что эта граница является асимптотически точной для
где
где Так как явление переполнения представляет собой в некотором смысле «катастрофой», то единственным возможным условием нормальной работы последовательного декодера с конечным объемом буфера и конечной скоростью вычислений является деление данных на блоки длиной 3? ребер хвостов из Из сравнения (6.6.9) с (6.6.2) видно, что произведение исключением случая передачи по каналу с двоичным выходом. На даже и в этом случае требуются быстродействующие логические схемы. В то же время при использовании декодирования Витерб» и раздельных схем вычисления метрик для каждого состояния требуется лишь выполнение условия Другим фактором, который следует учитывать, является задержка декодирования. При последовательном декодировании она должна равняться Последним важным фактором, который должен учитываться всегда, когда делается выбор между декодированием Витерби и последовательным декодированием, является относительная чувствительность декодирования к изменению параметров канала, т. е. его робастность. В этом последовательный декодер уступает декодеру Витерби, так как его характеристики сильно зависят
|
 |
Оглавление
|








































































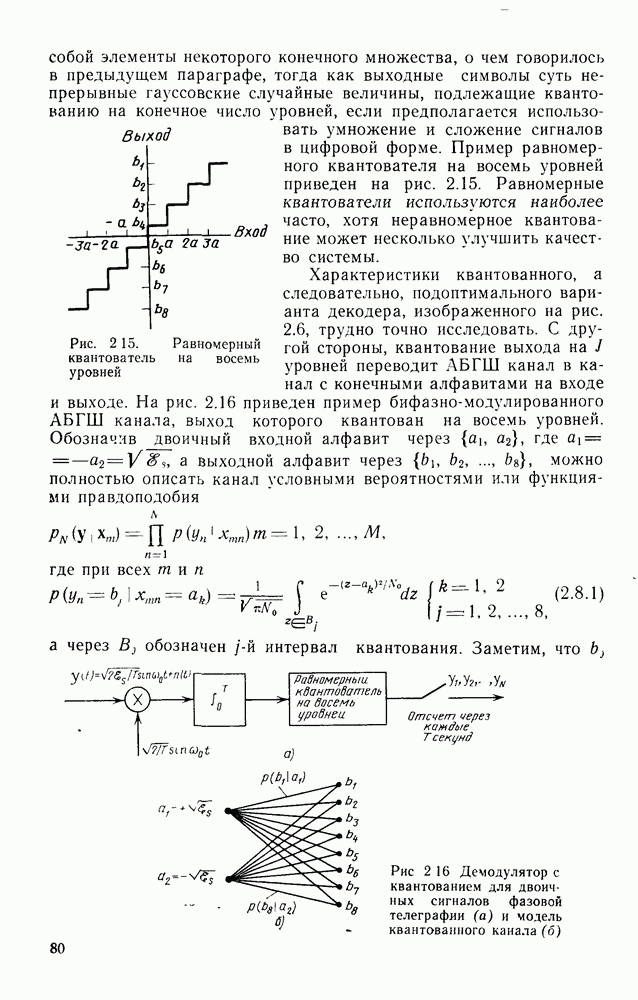



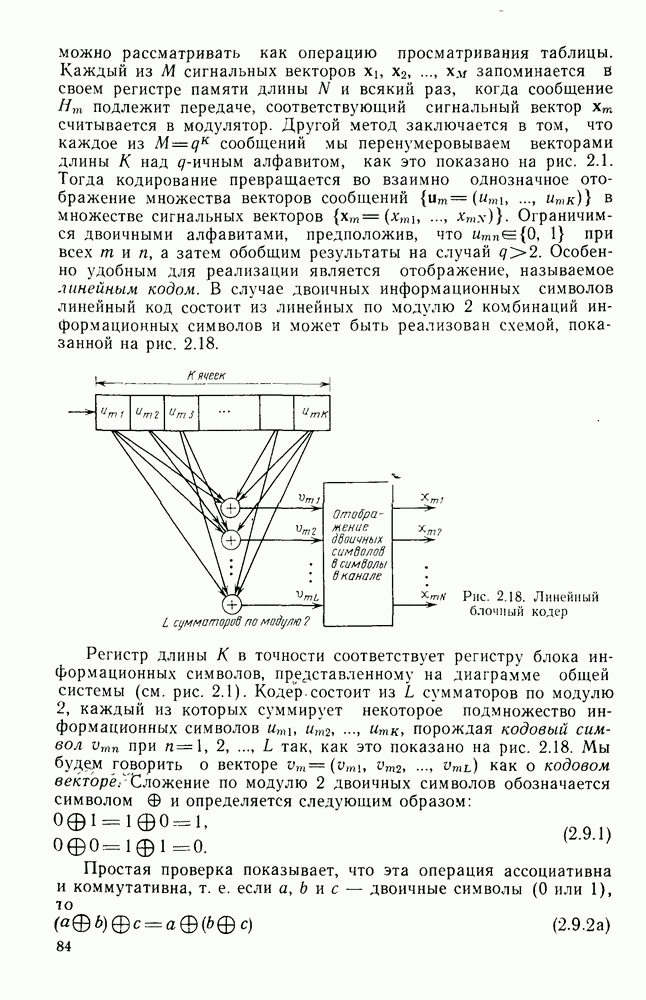













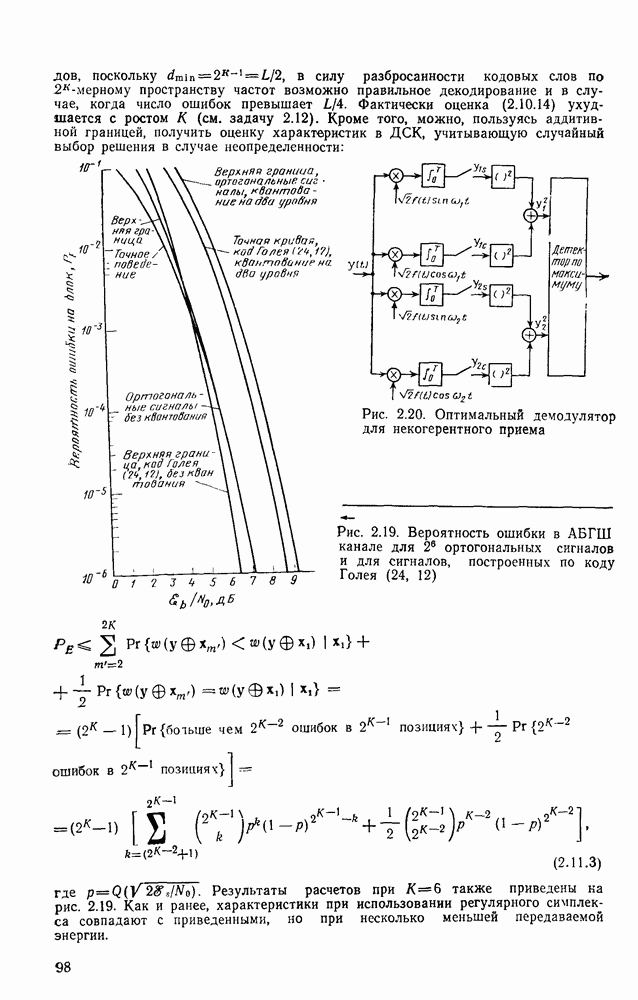












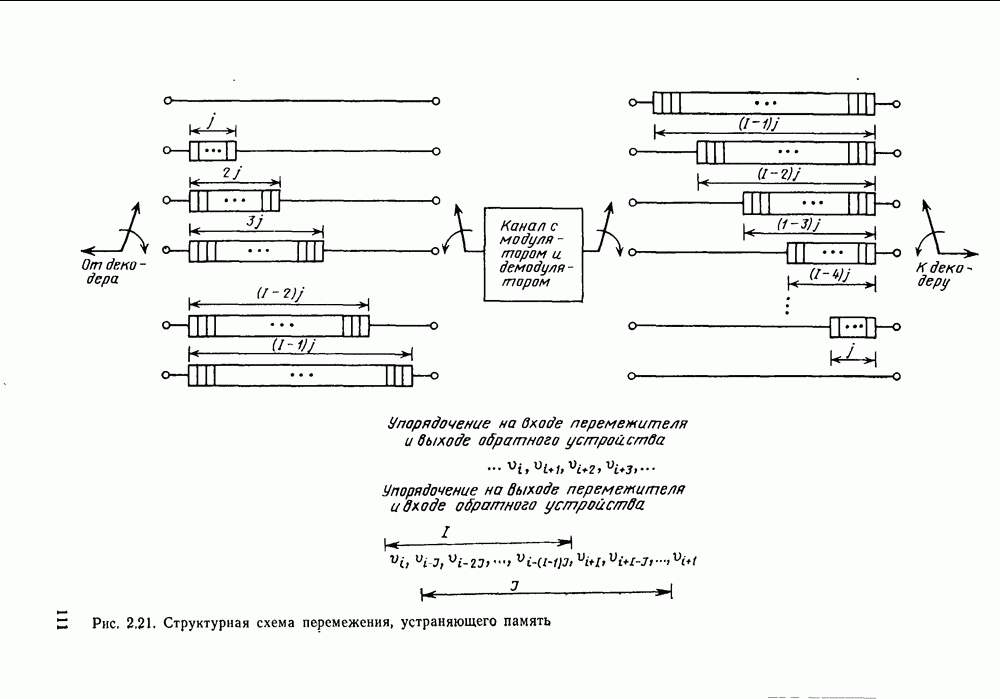




































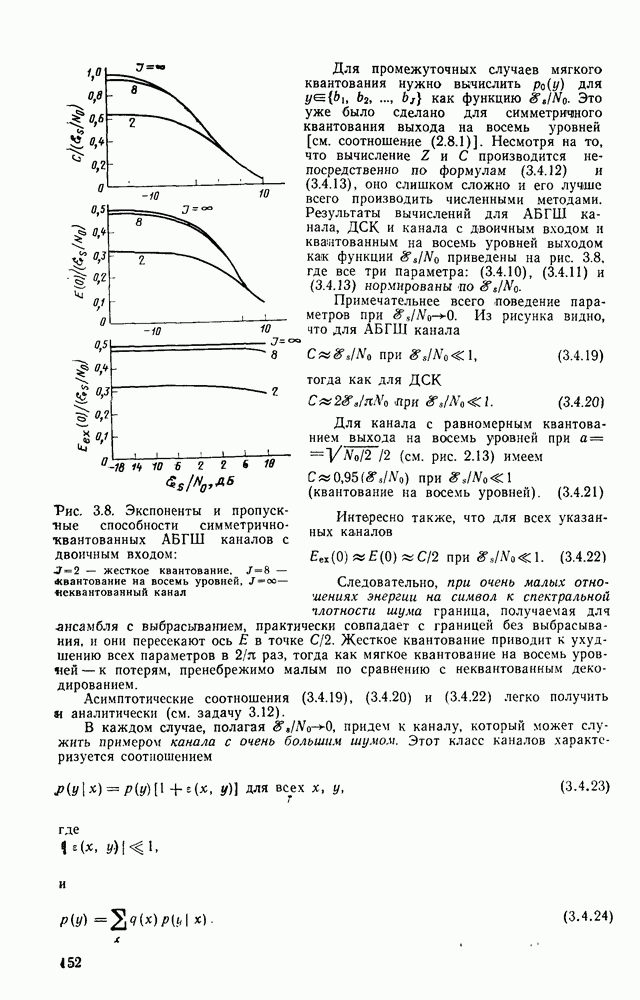

















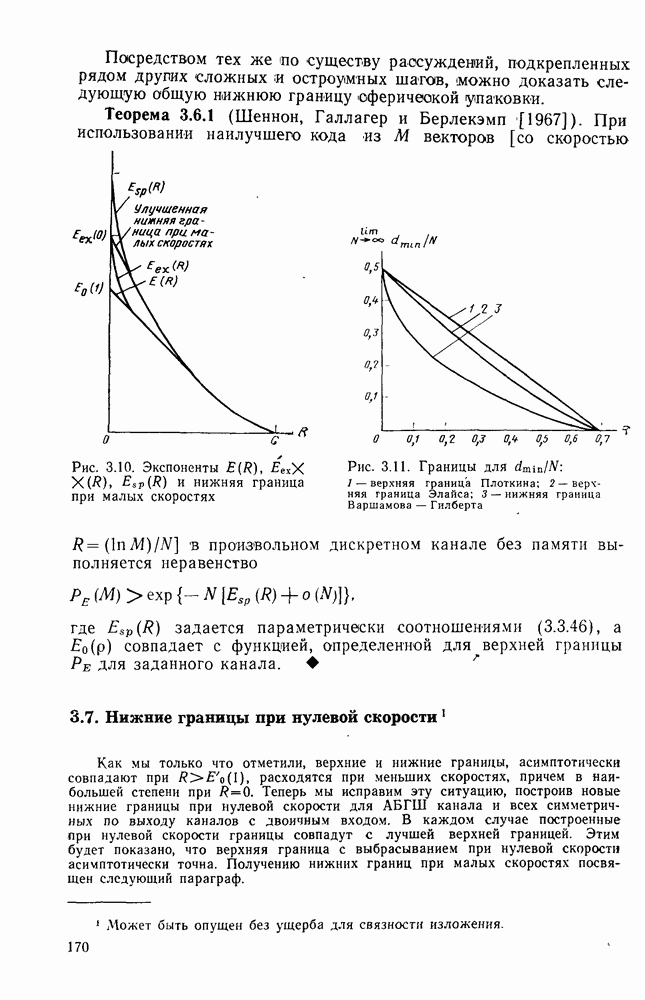
































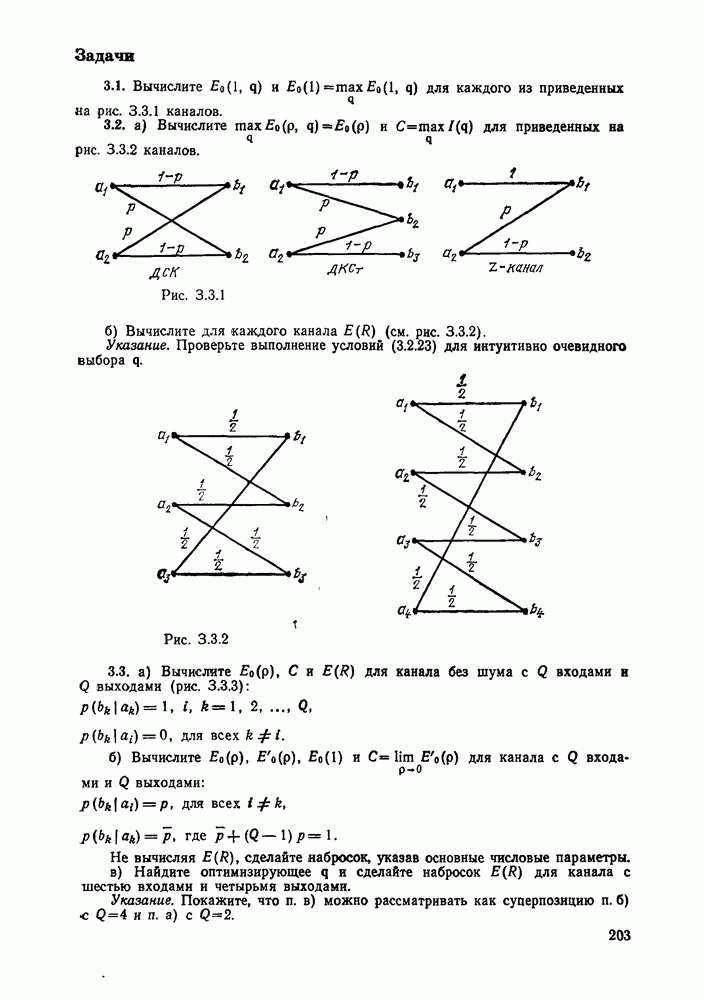














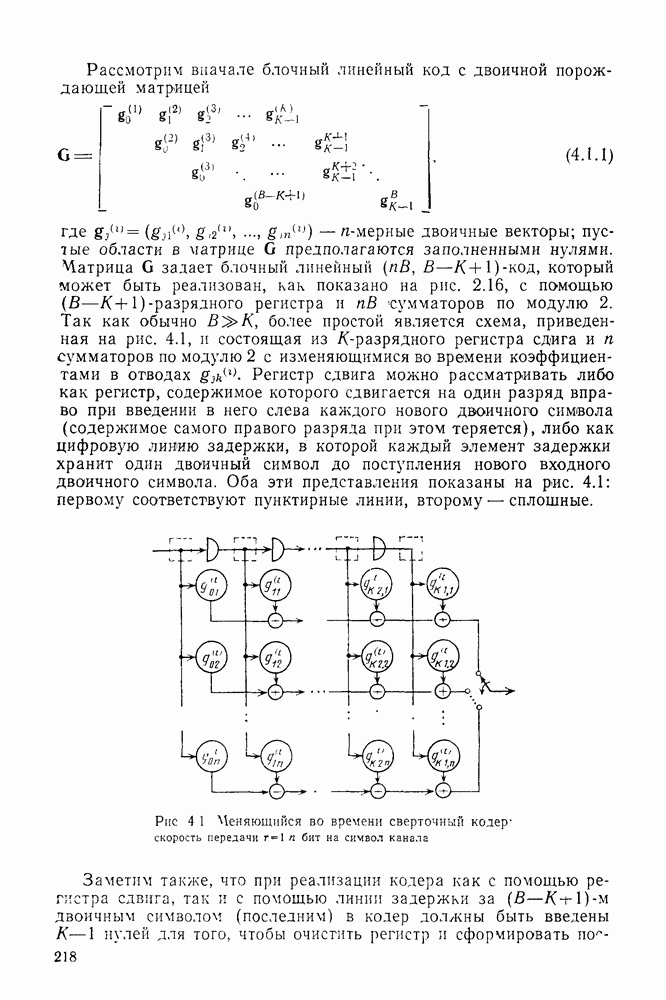



























































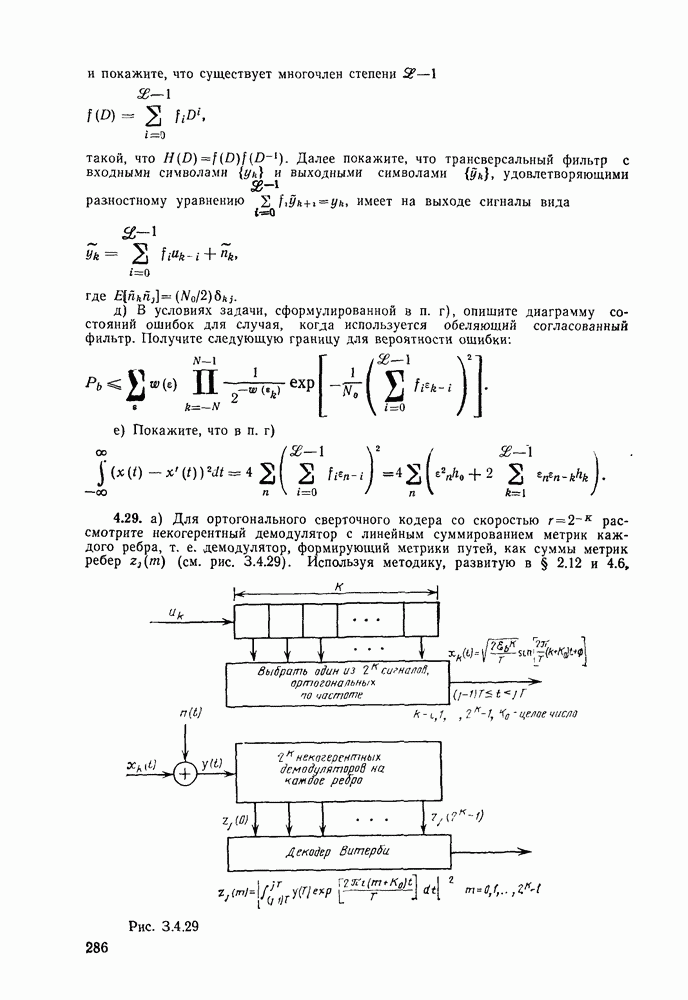
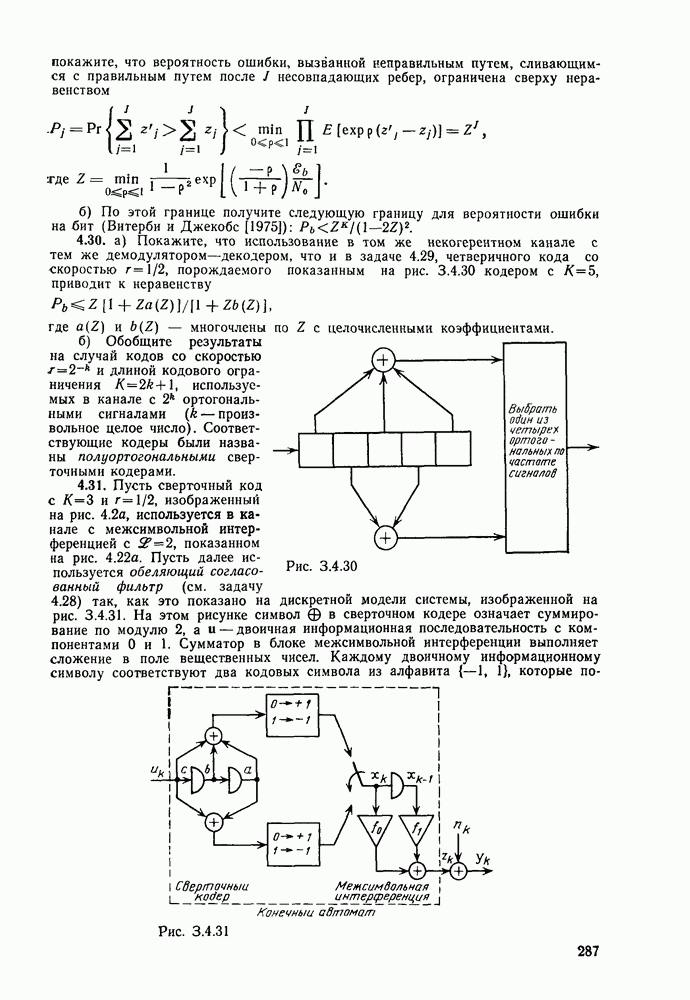











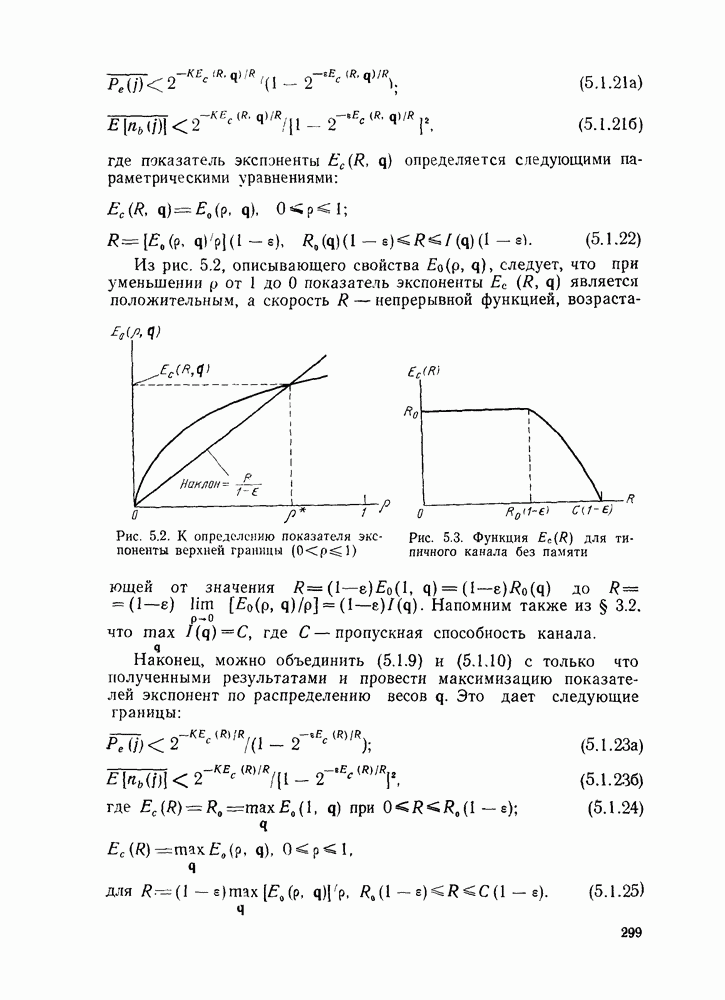







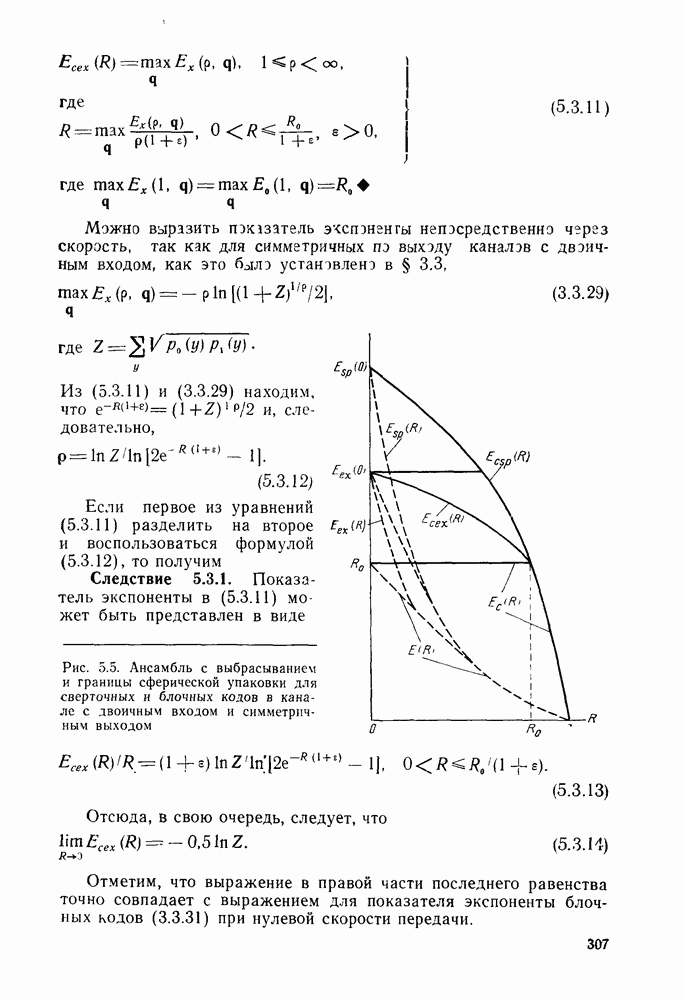










































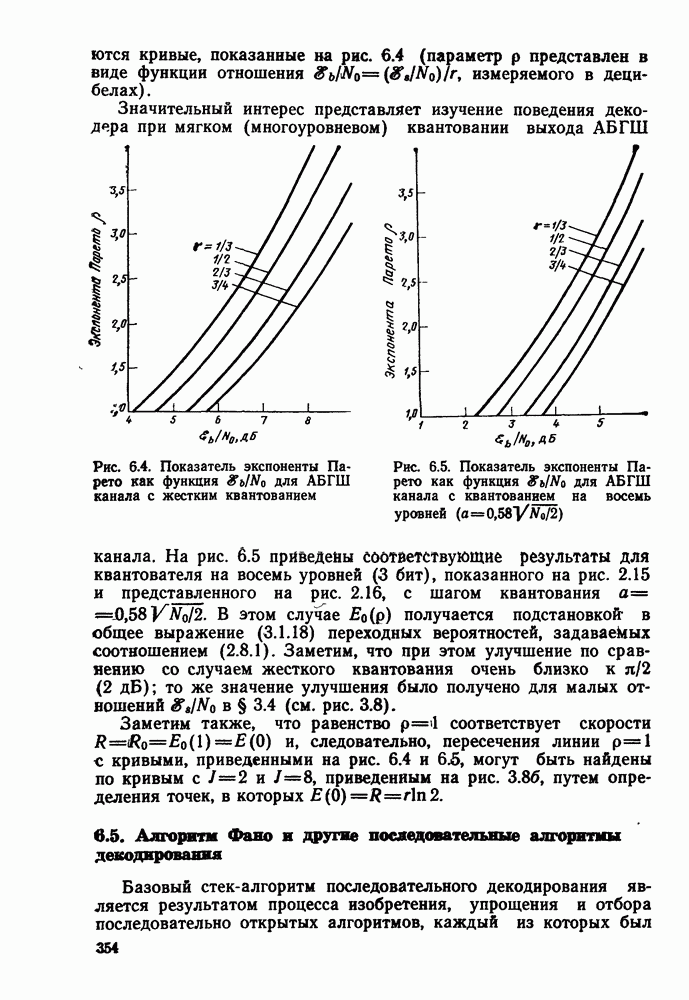


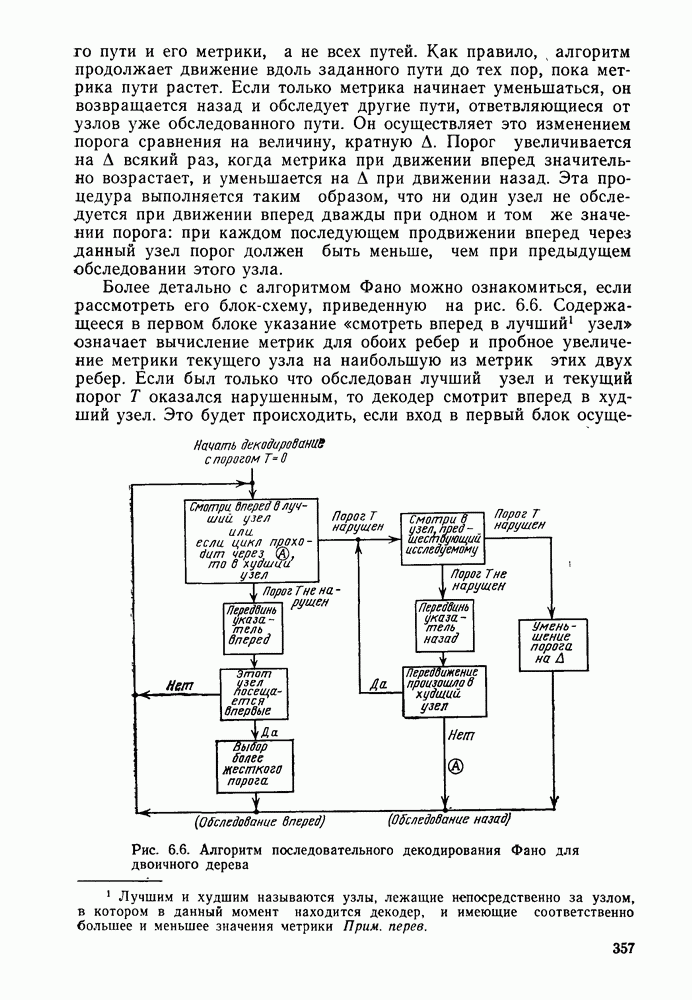























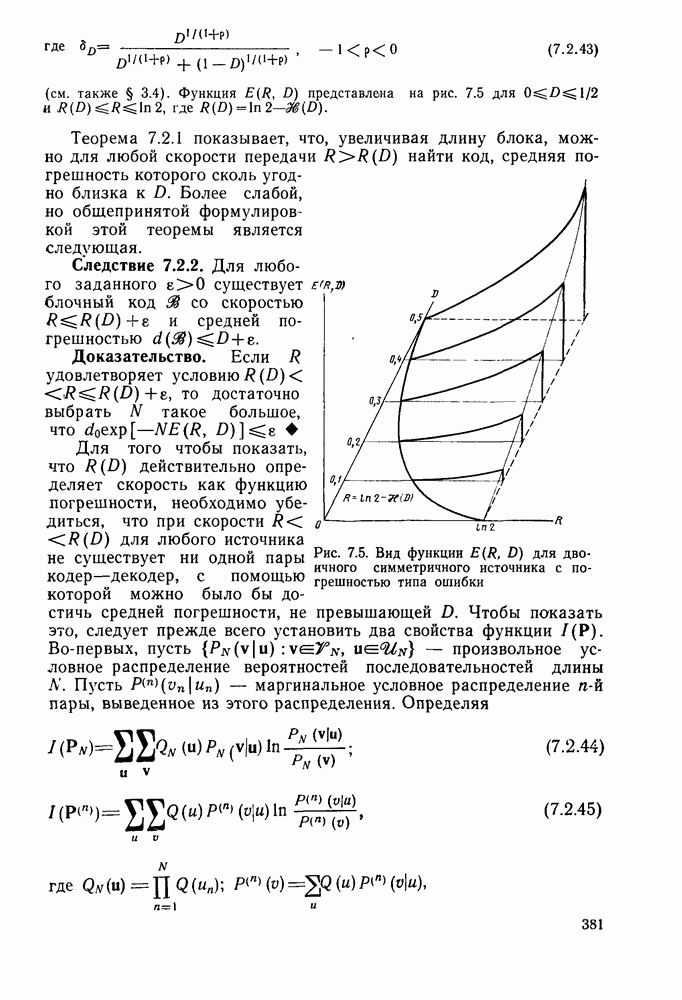












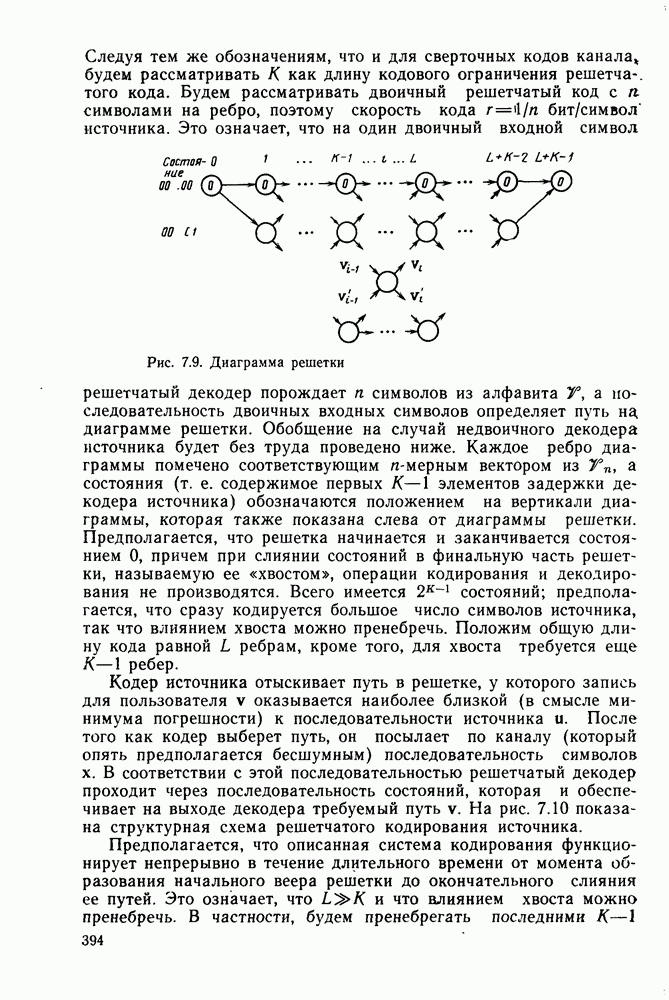



































































































































 то число вычислений метрики ребер, приходящееся на одно ребро
то число вычислений метрики ребер, приходящееся на одно ребро  бит), равно
бит), равно  при этом число сравнений и число регистров памяти, необходимых для хранения указателей пути и метрик, равно
при этом число сравнений и число регистров памяти, необходимых для хранения указателей пути и метрик, равно  Таким образом, если определить сложность декодирования Витерби как число вычислений метрики ребер на один бит, т. е. через отношение
Таким образом, если определить сложность декодирования Витерби как число вычислений метрики ребер на один бит, т. е. через отношение



 -разрядного блочного кода необходимо было бы положить х равным
-разрядного блочного кода необходимо было бы положить х равным  числу вычислений метрики кодовых векторов, приходящемуся на один бит. При этом из (3.2.14) и (3.6.45) следовало бы, что для
числу вычислений метрики кодовых векторов, приходящемуся на один бит. При этом из (3.2.14) и (3.6.45) следовало бы, что для  справедливо асимптотическое равенство
справедливо асимптотическое равенство

 при
при  значительно меньше, чем
значительно меньше, чем  то абсолютное значение показателя экспоненты из (6.6.2) значительно больше, чем соответствующая величина из (6.6.3), что
то абсолютное значение показателя экспоненты из (6.6.2) значительно больше, чем соответствующая величина из (6.6.3), что
 декодируемых в каждом узле двоичных символов. Проблема связана с тем, что число
декодируемых в каждом узле двоичных символов. Проблема связана с тем, что число  является
является  для каждого неправильного
для каждого неправильного 


 Для последовательного декодирования должно выбираться следующим образом:
Для последовательного декодирования должно выбираться следующим образом:  где К аналогично используемому
где К аналогично используемому
 является такой же мерой эффективной сложности алгоритма, как и обычная длина кодового ограничения для декодера Витерби.
является такой же мерой эффективной сложности алгоритма, как и обычная длина кодового ограничения для декодера Витерби.
 много меньше, чем
много меньше, чем  Эта схема ограничения
Эта схема ограничения  непрактична сама по себе, так как сбой при декодировании может казаться катастрофическим в том смысле, что после него декодер, быть может, уже никогда не вернется в нормальное состояние и не начнет декодировать правильно. Эти замечания показывают, что любой реальный последовательный декодер должен быть снабжен дополнительными функциями и дополнительными устройствами, прежде чем можно будет реально оценить его характеристики и сложность.
непрактична сама по себе, так как сбой при декодировании может казаться катастрофическим в том смысле, что после него декодер, быть может, уже никогда не вернется в нормальное состояние и не начнет декодировать правильно. Эти замечания показывают, что любой реальный последовательный декодер должен быть снабжен дополнительными функциями и дополнительными устройствами, прежде чем можно будет реально оценить его характеристики и сложность.
 канальных символов. При использовании канала с
канальных символов. При использовании канала с  выходом или, что эквивалентно, канала с непрерывным выходом, квантуемым на
выходом или, что эквивалентно, канала с непрерывным выходом, квантуемым на  уровней, такой буфер должен содержать самое большее
уровней, такой буфер должен содержать самое большее  бит памяти. (Сюда не входит память, необходимая для организации стека, но, как указывалось выше, можно обойтись без нее, воспользовавшись алгоритмом Фано.) Далее, предположим, что декодер может выполнять
бит памяти. (Сюда не входит память, необходимая для организации стека, но, как указывалось выше, можно обойтись без нее, воспользовавшись алгоритмом Фано.) Далее, предположим, что декодер может выполнять  вычислений ребер за время между поступлением двух последовательных ребер; другими словами,
вычислений ребер за время между поступлением двух последовательных ребер; другими словами,  число вычислений, выполняемых за время передачи
число вычислений, выполняемых за время передачи  бит информации, и оно обычно называется скоростью вычислений декодера. Если число вычислений, которые должны быть выполнены в
бит информации, и оно обычно называется скоростью вычислений декодера. Если число вычислений, которые должны быть выполнены в  неправильном подмножестве,
неправильном подмножестве,


 то, очевидно,
то, очевидно,
 ребра не могут быть сброшены из буфера в течение по крайней мере
ребра не могут быть сброшены из буфера в течение по крайней мере  единичных (соответствующих одному ребру) интервалов времени, так как они могут потребоваться для вычислений метрики в любой момент до того, как будет принято окончательное решение о
единичных (соответствующих одному ребру) интервалов времени, так как они могут потребоваться для вычислений метрики в любой момент до того, как будет принято окончательное решение о  ребре. Однако за это время поступит более чем В ребер, для хранения которых необходима память, и она не освободится до тех пор, пока не будет сброшено
ребре. Однако за это время поступит более чем В ребер, для хранения которых необходима память, и она не освободится до тех пор, пока не будет сброшено  ребро. Явление этого типа по понятным причинам называется переполнением буфера. Как это следует из (6.6.6) и нижней границы, приведенной в теореме 6.4.1,
ребро. Явление этого типа по понятным причинам называется переполнением буфера. Как это следует из (6.6.6) и нижней границы, приведенной в теореме 6.4.1,  узле удовлетворяет неравенству
узле удовлетворяет неравенству


 при условии, что первоначально буфер пуст. Более того, если расширить класс рассматриваемых кодов, включив в него произвольные меняющиеся во времени решетчатые (нелинейные сверточные) коды, то, как следует из (6.2.23) и работы Сэвиджа [1966], эта граница будем асимптотически точной во всем диапазоне скоростей. В предположении, что рассматривается этот расширенный класс кодов,
при условии, что первоначально буфер пуст. Более того, если расширить класс рассматриваемых кодов, включив в него произвольные меняющиеся во времени решетчатые (нелинейные сверточные) коды, то, как следует из (6.2.23) и работы Сэвиджа [1966], эта граница будем асимптотически точной во всем диапазоне скоростей. В предположении, что рассматривается этот расширенный класс кодов,  узла при первоначально пустом буфере оценивается соотношением
узла при первоначально пустом буфере оценивается соотношением

 константа. Эксперименты (Форни и Боуэр [1971], Джилхаузен и др. [ 1971]) показывают, что
константа. Эксперименты (Форни и Боуэр [1971], Джилхаузен и др. [ 1971]) показывают, что  имеет порядок от 1 до 10 и длительный поиск является довольно редким явлением при условии, что предположение о пустоте буфера в начале поиска выполняется достаточно точно. При достаточно малых
имеет порядок от 1 до 10 и длительный поиск является довольно редким явлением при условии, что предположение о пустоте буфера в начале поиска выполняется достаточно точно. При достаточно малых  фективной работы декодера, получаем
фективной работы декодера, получаем

 параметр, связанный с
параметр, связанный с  параметрическим соотношением (6.6.8).
параметрическим соотношением (6.6.8).
 бит) и введение между ними
бит) и введение между ними
 ребер, состоящих из
ребер, состоящих из  нулей. В этом случае если даже в некотором блоке из
нулей. В этом случае если даже в некотором блоке из  ребер произойдет катастрофическое переполнение буфера, то хвост позволит привести декодер в нормальное состояние и снова начать декодирование, потеряв при этом самое большее
ребер произойдет катастрофическое переполнение буфера, то хвост позволит привести декодер в нормальное состояние и снова начать декодирование, потеряв при этом самое большее  бит. Конечно, введение хвостов приводит к снижению вычислений скорости в
бит. Конечно, введение хвостов приводит к снижению вычислений скорости в  раз и усложнению синхронизации декодера. Поэтому, чтобы ухудшение было небольшим, отношение
раз и усложнению синхронизации декодера. Поэтому, чтобы ухудшение было небольшим, отношение  должно выбираться достаточно малым. С другой стороны, параметр
должно выбираться достаточно малым. С другой стороны, параметр  не может быть выбран чрезмерно большим, поскольку он входит в виде мультипликативной константы в выражение (6.6.10) для
не может быть выбран чрезмерно большим, поскольку он входит в виде мультипликативной константы в выражение (6.6.10) для  размер буфера в ребрах В та
размер буфера в ребрах В та  Скорость вычислений
Скорость вычислений  зависит от скорости поступления данных, измеряемой в битах на секунду, а также от быстродействия и сложности логических схем, используемых для выполнения вычислений. Например, если максимальное быстродействие логических схем составляет
зависит от скорости поступления данных, измеряемой в битах на секунду, а также от быстродействия и сложности логических схем, используемых для выполнения вычислений. Например, если максимальное быстродействие логических схем составляет  вычислений ребер/с, а скорость поступления данных равна
вычислений ребер/с, а скорость поступления данных равна  то
то  Ясно, что необходимо всегда иметь
Ясно, что необходимо всегда иметь  хотя бы для того, чтобы просто справляться с поступающими данными. Поэтому при относительно малых скоростях передачи данных (меньших 100 Кбит/с) можно получить произведения
хотя бы для того, чтобы просто справляться с поступающими данными. Поэтому при относительно малых скоростях передачи данных (меньших 100 Кбит/с) можно получить произведения  большие 107. Конечно,
большие 107. Конечно,  зависит также от сложности вычисления метрики. Например, вычисление метрики Хэмминга для ДСК много проще, чем вычисление метрики для канала с восьмеричным выходом; отсюда следует, что для ДСК
зависит также от сложности вычисления метрики. Например, вычисление метрики Хэмминга для ДСК много проще, чем вычисление метрики для канала с восьмеричным выходом; отсюда следует, что для ДСК  будет в несколько раз больше.
будет в несколько раз больше.
 при последовательном декодировании играет ту же роль, что и величина
при последовательном декодировании играет ту же роль, что и величина  для декодера Витерби. Конечно, как уже отмечалось, при малых скоростях
для декодера Витерби. Конечно, как уже отмечалось, при малых скоростях  может иметь величину порядка 107, в то время как число регистров, необходимых для хранения указателей пути и метрик при декодировании по максимуму правдоподобия, равное
может иметь величину порядка 107, в то время как число регистров, необходимых для хранения указателей пути и метрик при декодировании по максимуму правдоподобия, равное  невозможно сделать большим чем 103. С другой стороны, при больших скоростях передачи данных (
невозможно сделать большим чем 103. С другой стороны, при больших скоростях передачи данных ( бит/с и выше) практически трудно сделать
бит/с и выше) практически трудно сделать  больше единицы, как это требуется для эффективного последовательного декодирования, за
больше единицы, как это требуется для эффективного последовательного декодирования, за
 Кроме того, высокая степень однородности структуры декодера Витерби, которая уже отмечалась в гл. 4, позволяет уменьшить сложность его аппаратурной реализации.
Кроме того, высокая степень однородности структуры декодера Витерби, которая уже отмечалась в гл. 4, позволяет уменьшить сложность его аппаратурной реализации.
 битам, так как для того, чтобы данные можно было вывести в том же порядке, в каком они вводятся в кодер, одна и та же (максимальная) задержка должна быть предусмотрена для всех двоичных символов. Для декодирования Витерби в § 5.6 было найдено, что максимальная задержка должна иметь порядок нескольких
битам, так как для того, чтобы данные можно было вывести в том же порядке, в каком они вводятся в кодер, одна и та же (максимальная) задержка должна быть предусмотрена для всех двоичных символов. Для декодирования Витерби в § 5.6 было найдено, что максимальная задержка должна иметь порядок нескольких  с другой стороны, В обычно на два порядка больше, чем К.
с другой стороны, В обычно на два порядка больше, чем К.
 выбора метрики, в свою очередь, зависящей от параметров канала (например от
выбора метрики, в свою очередь, зависящей от параметров канала (например от