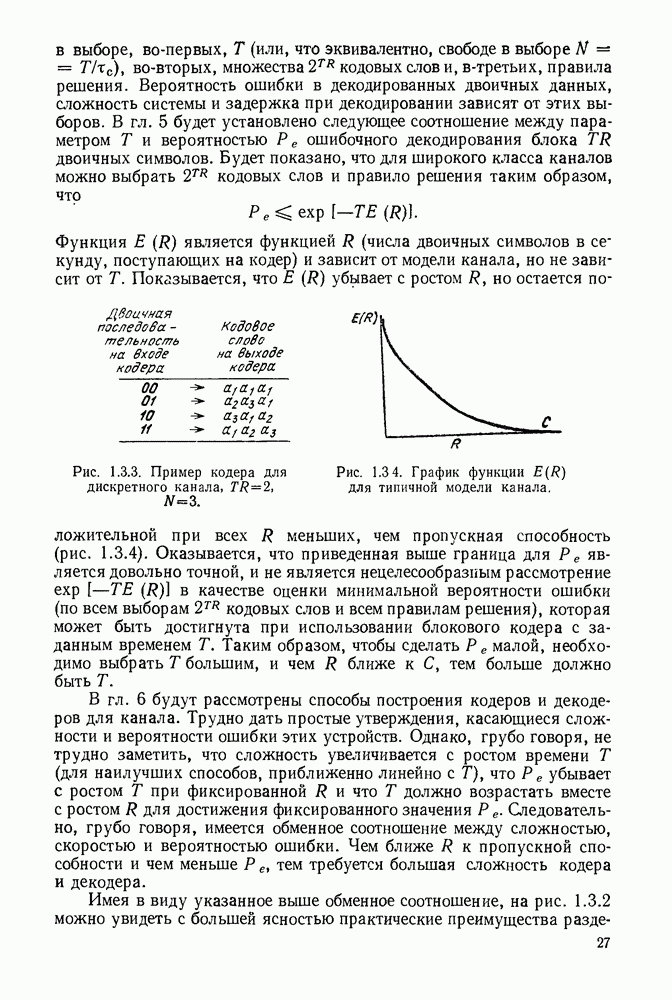
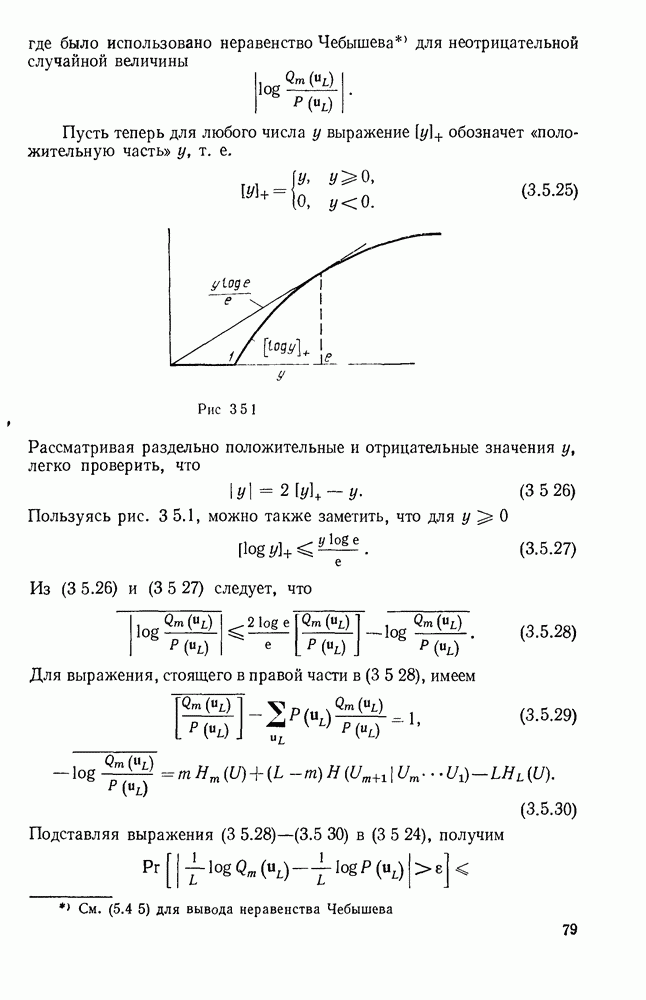
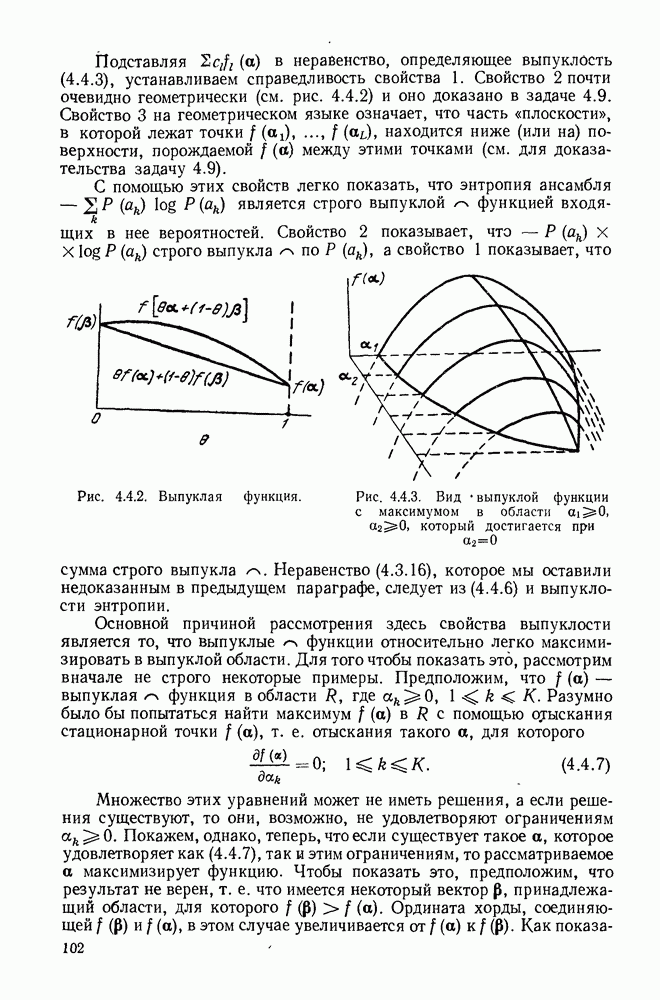
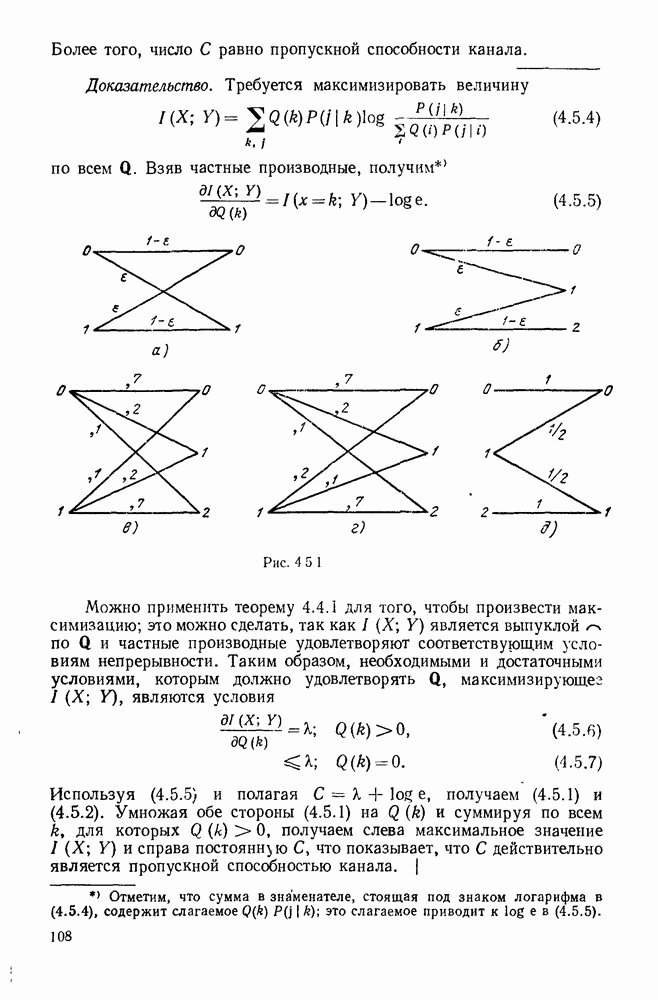
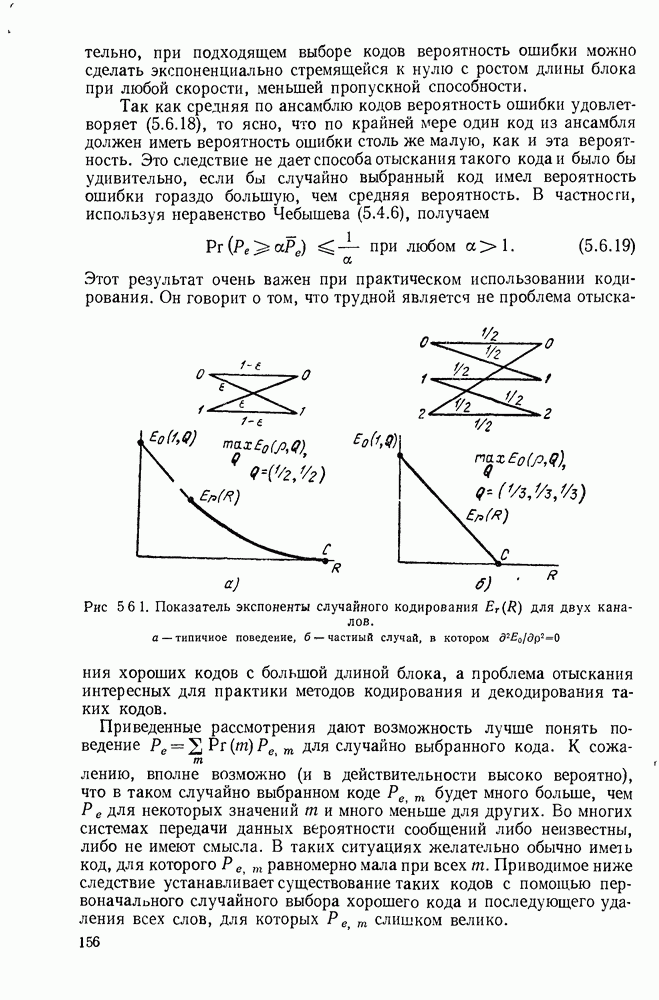
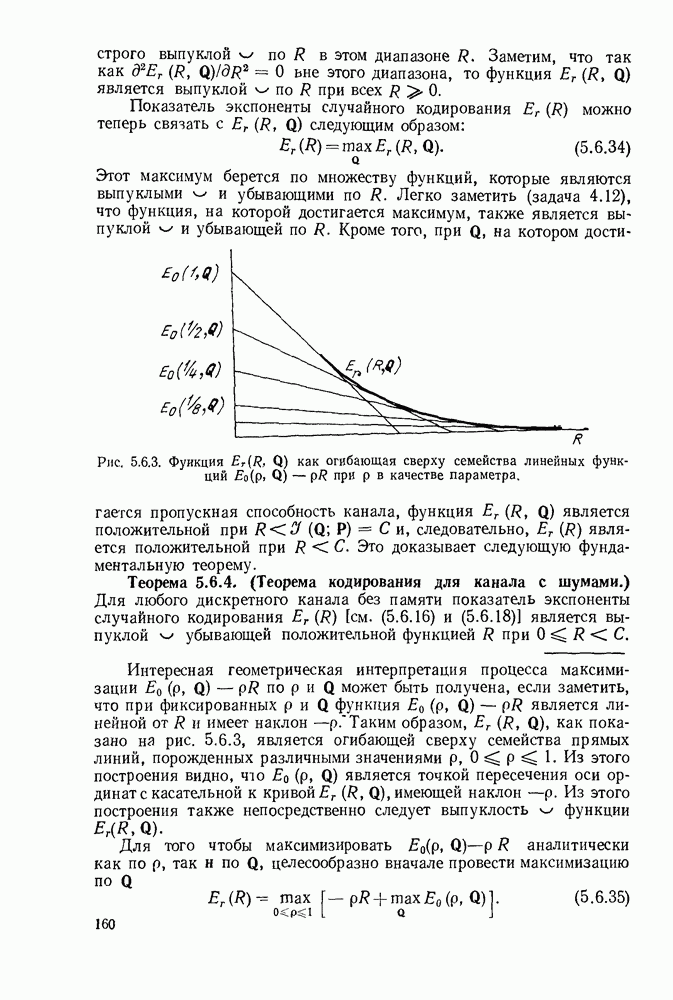
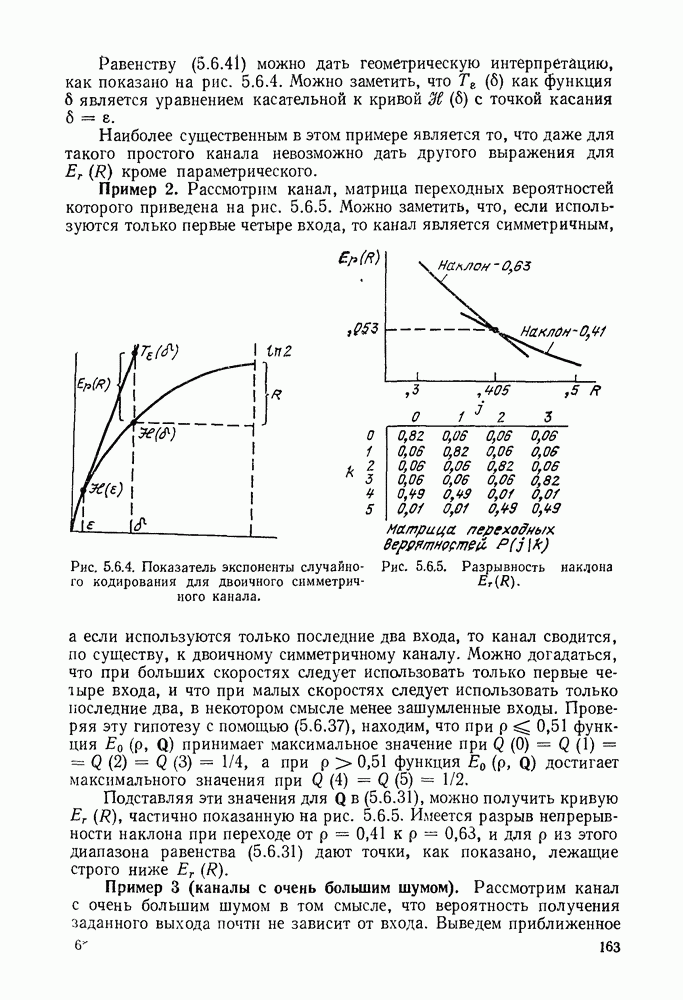
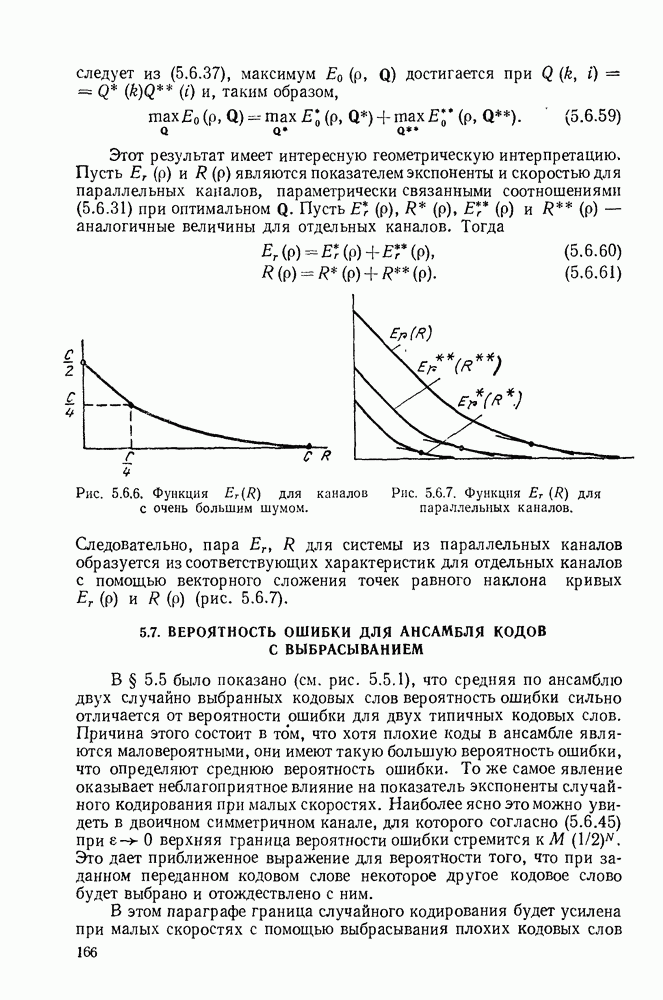
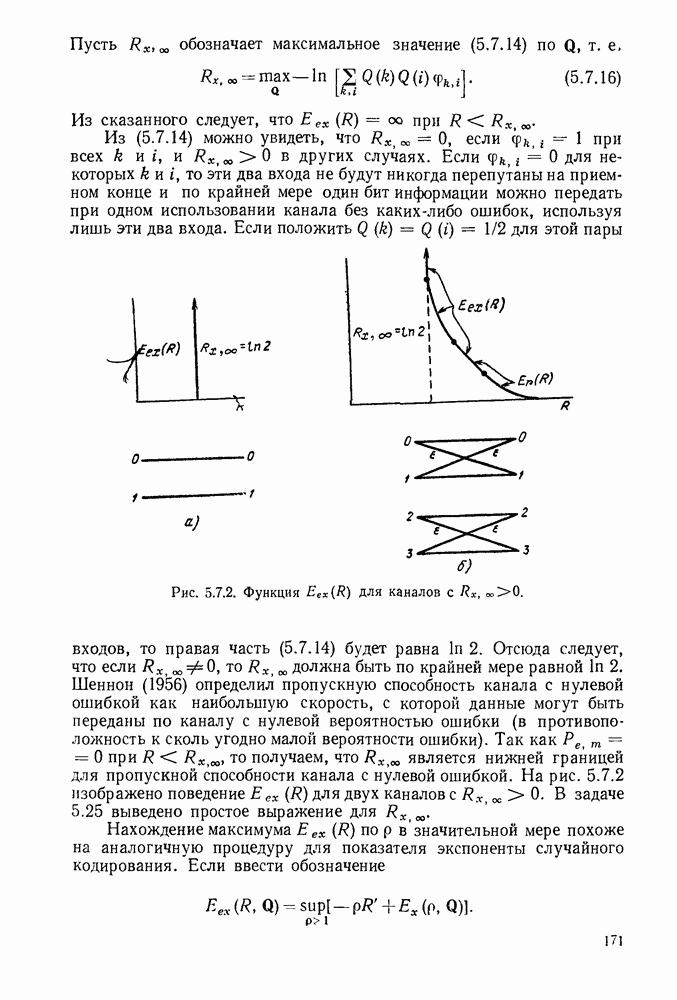
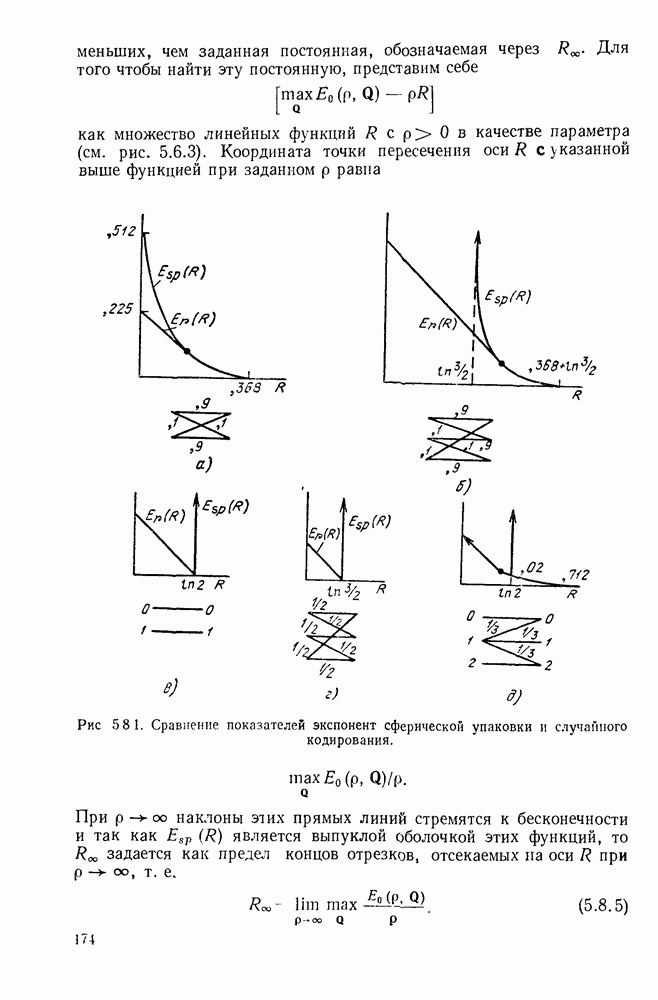
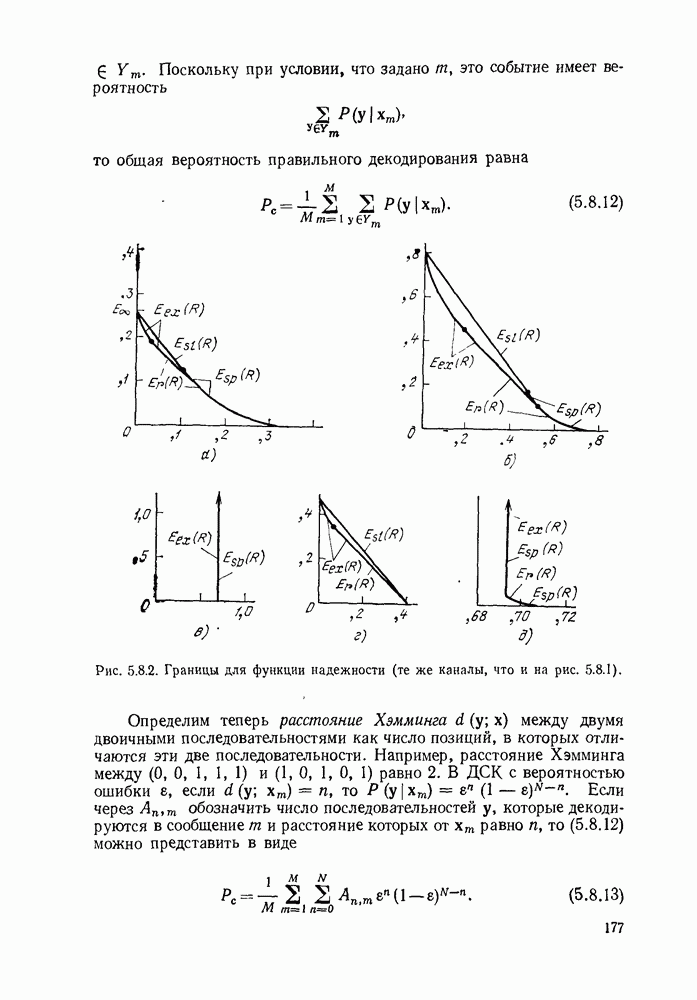
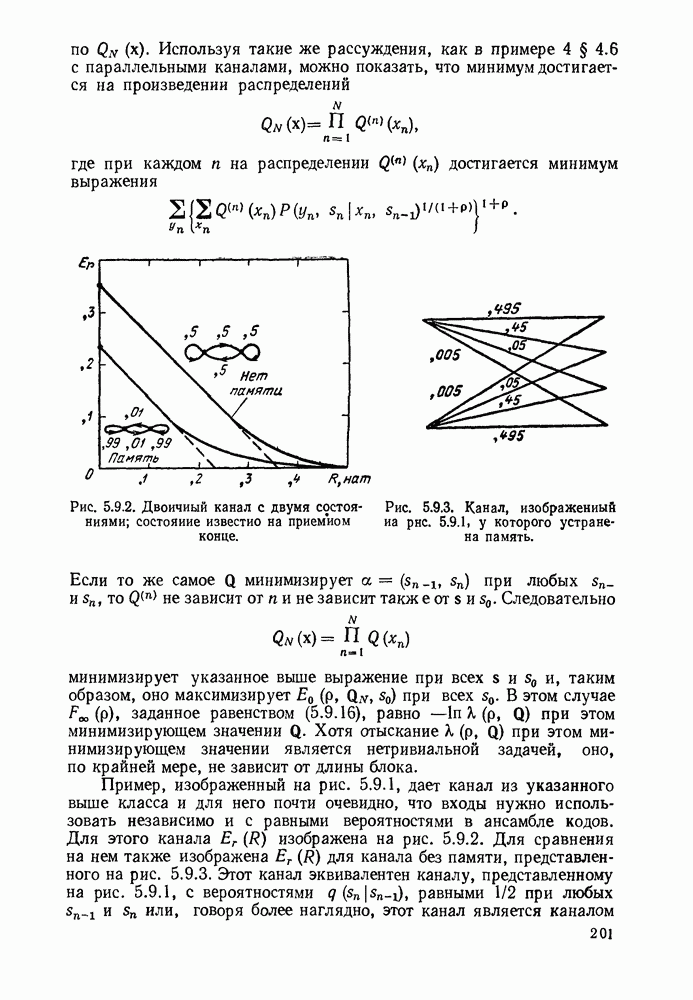
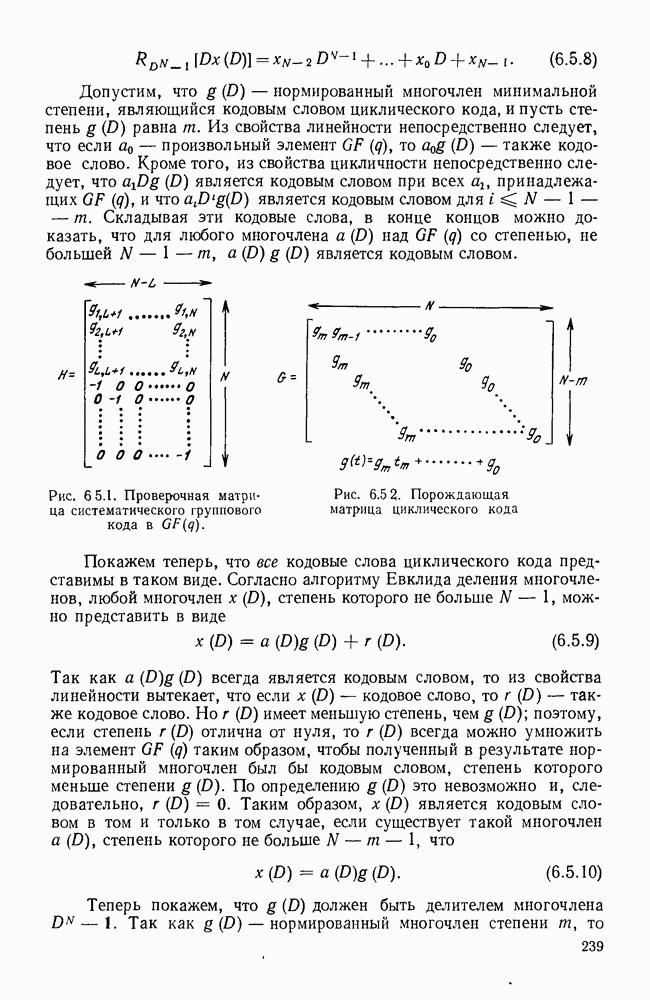
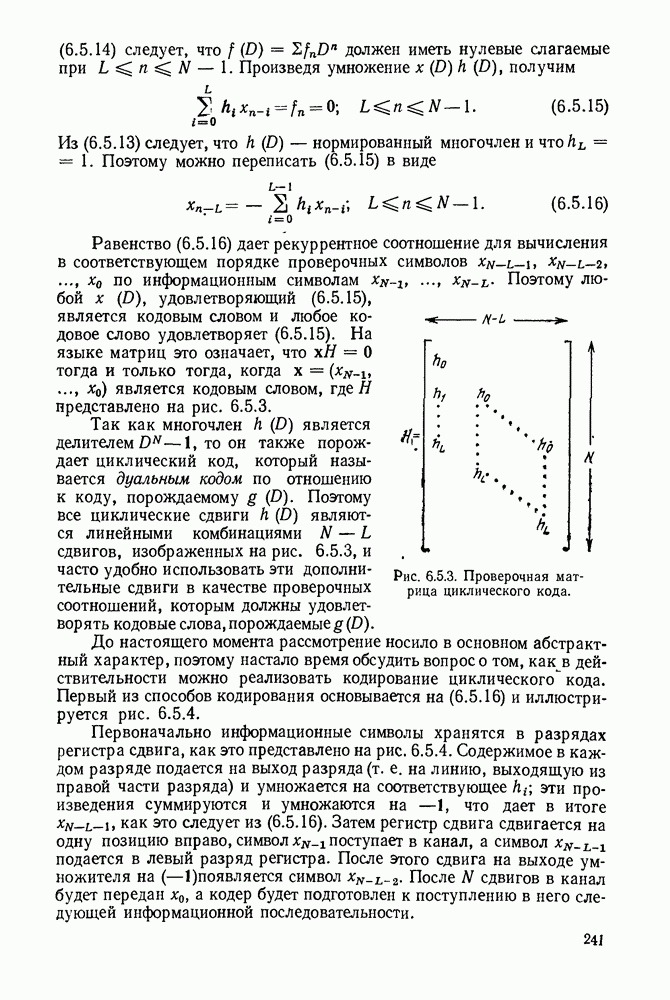
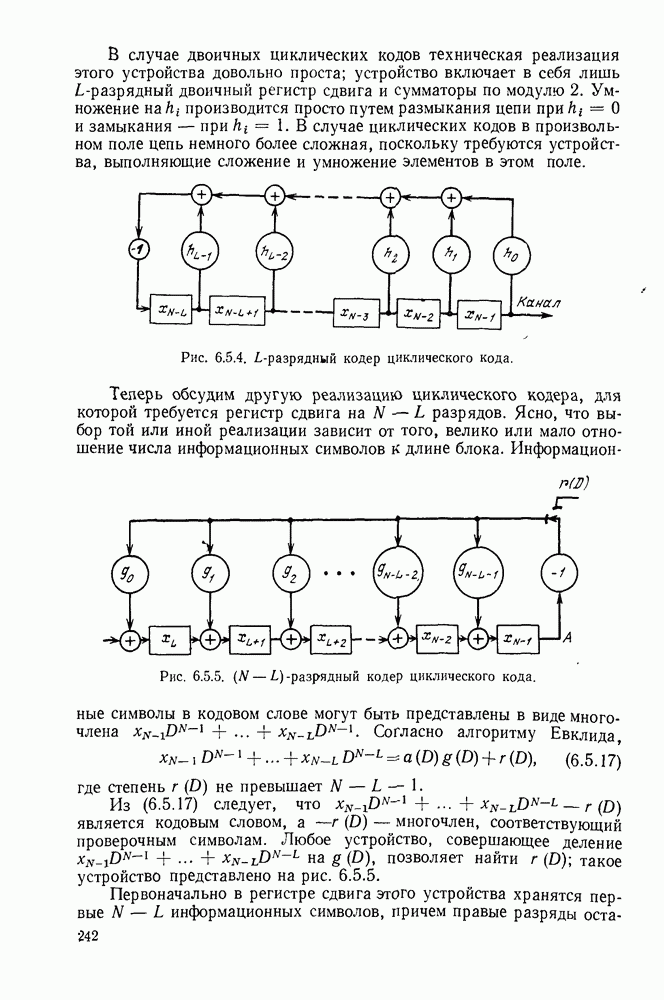
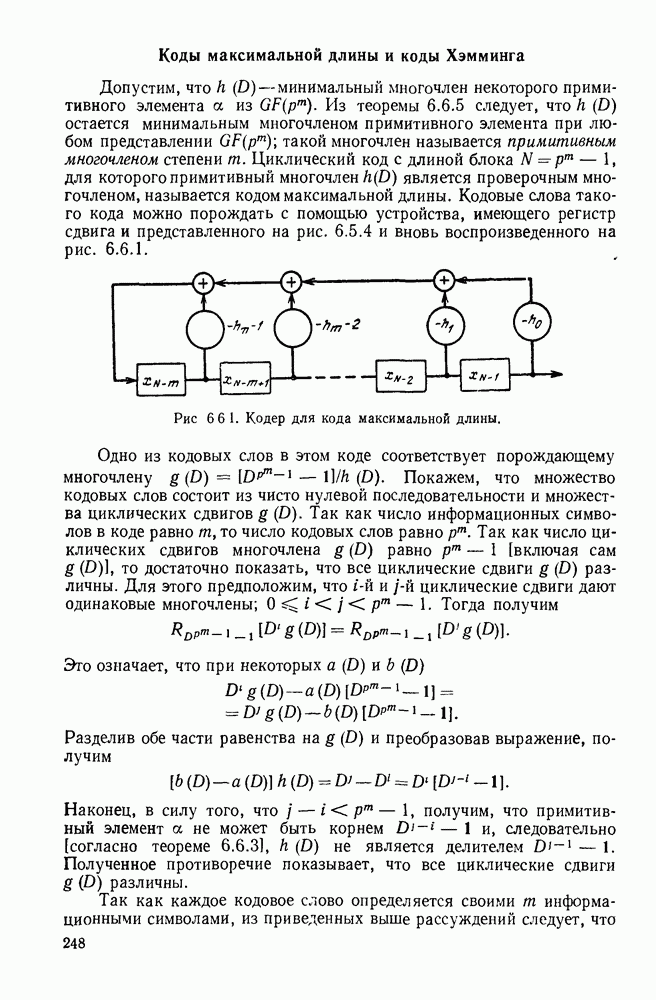
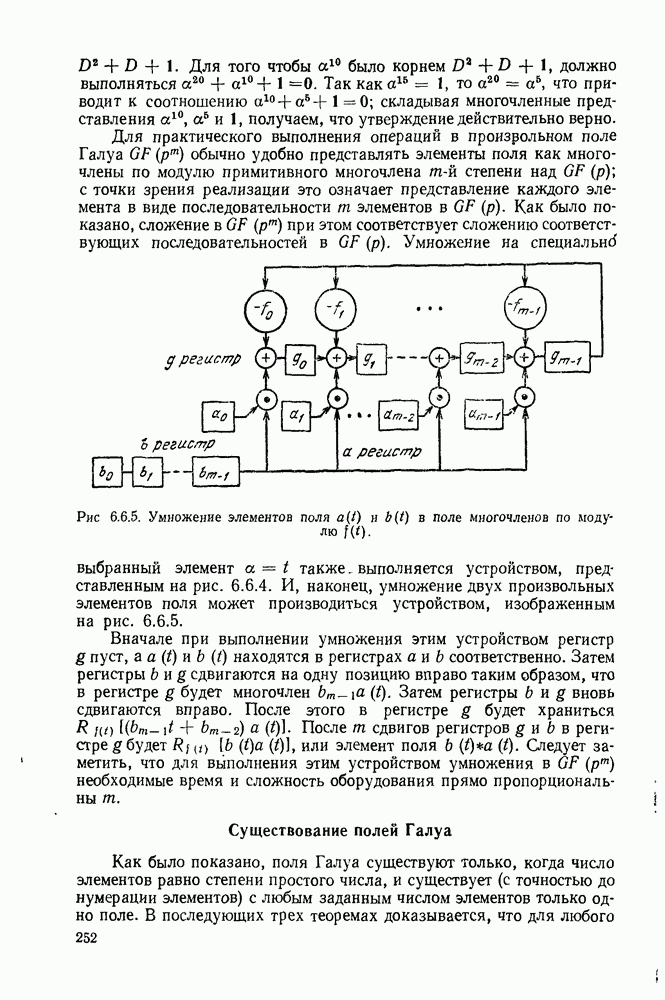
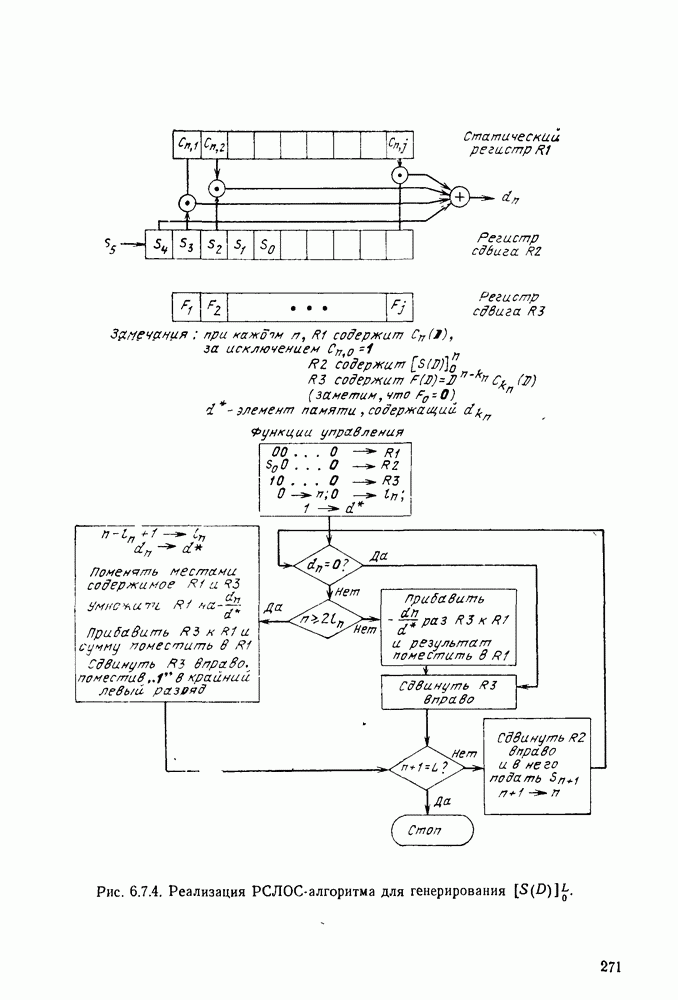
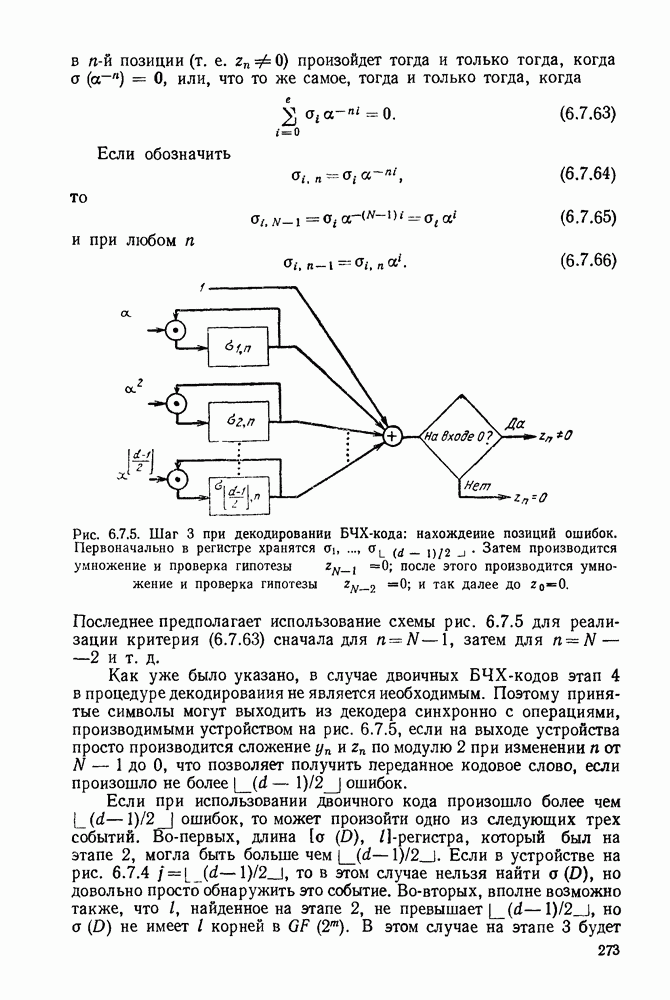
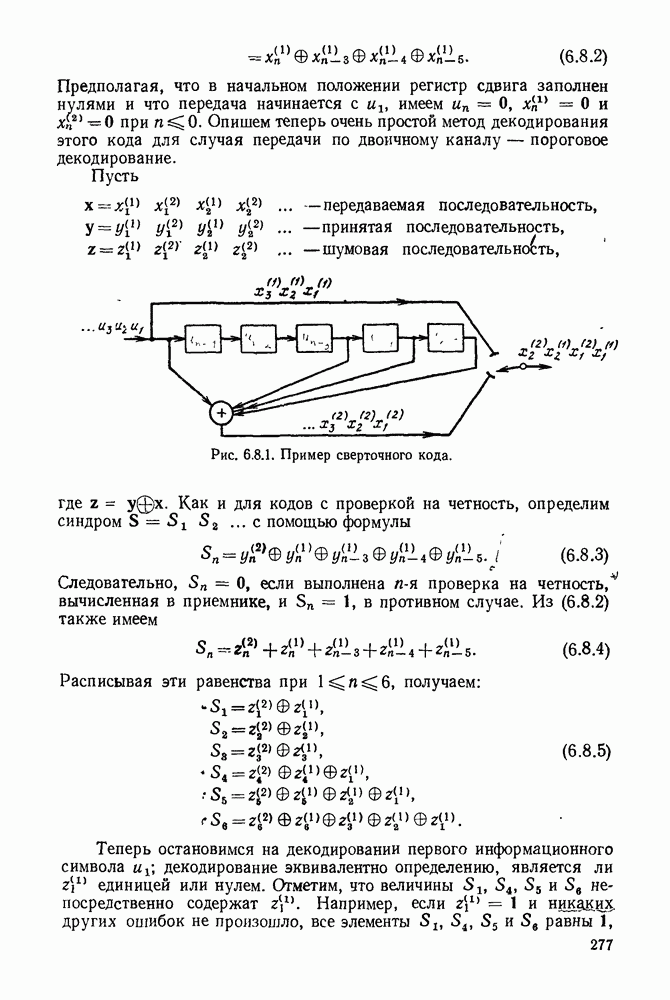
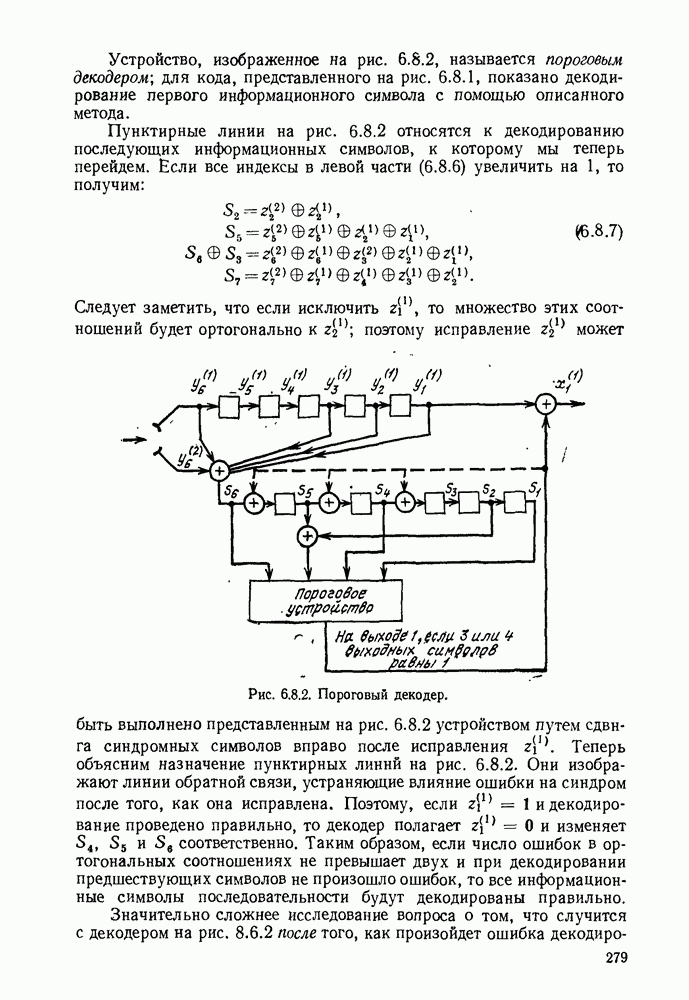
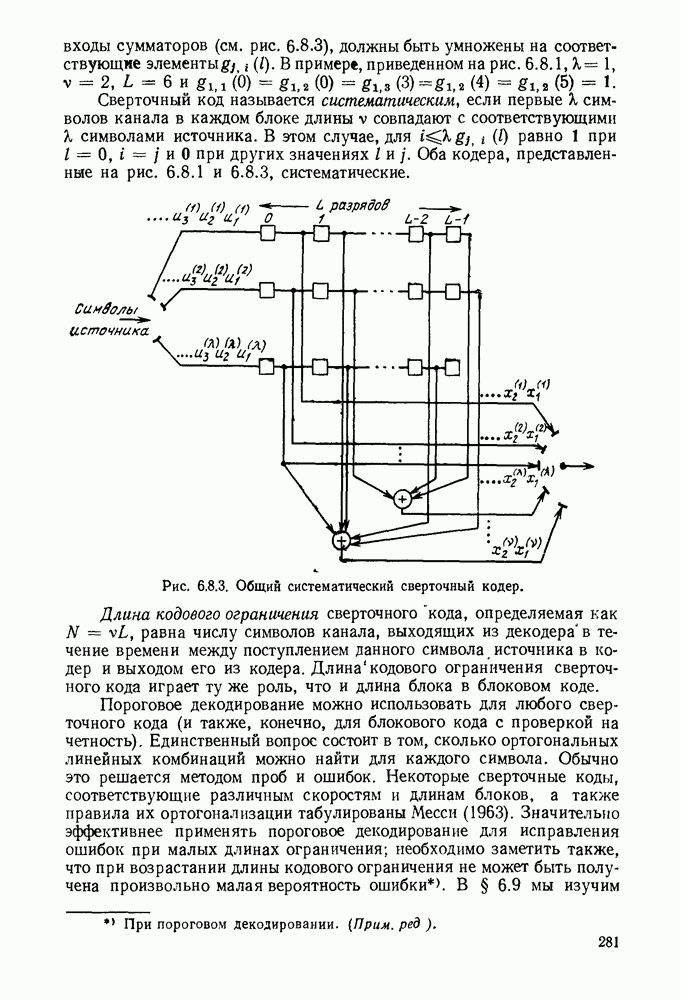
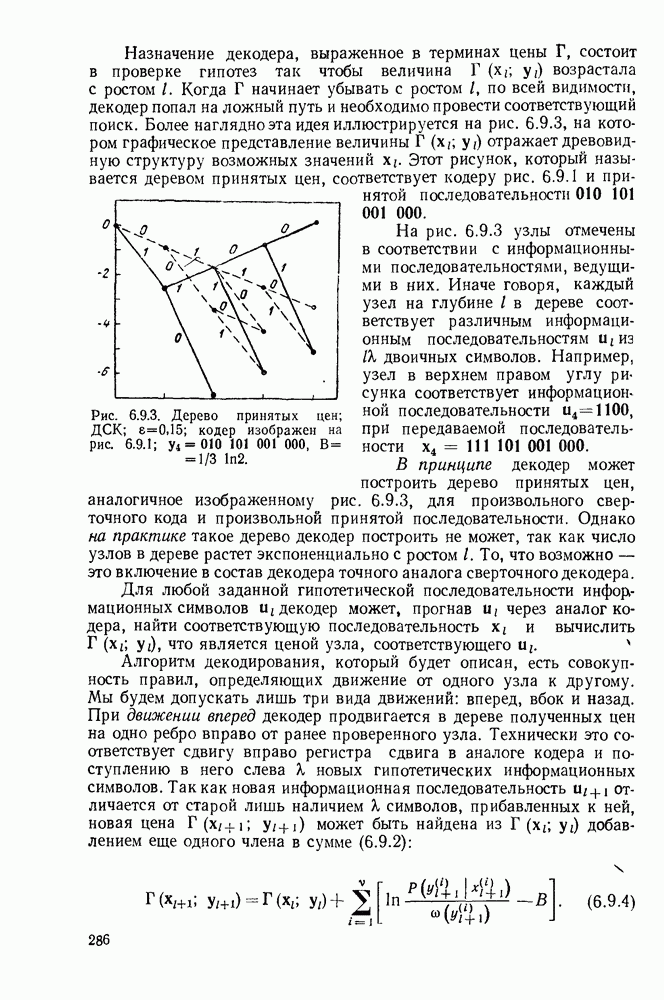
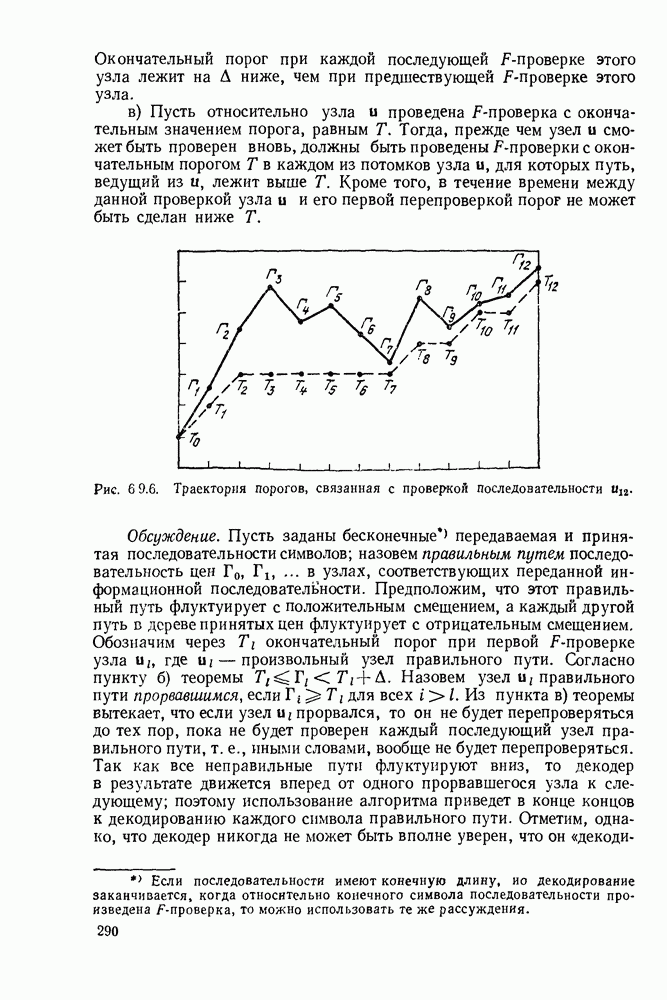
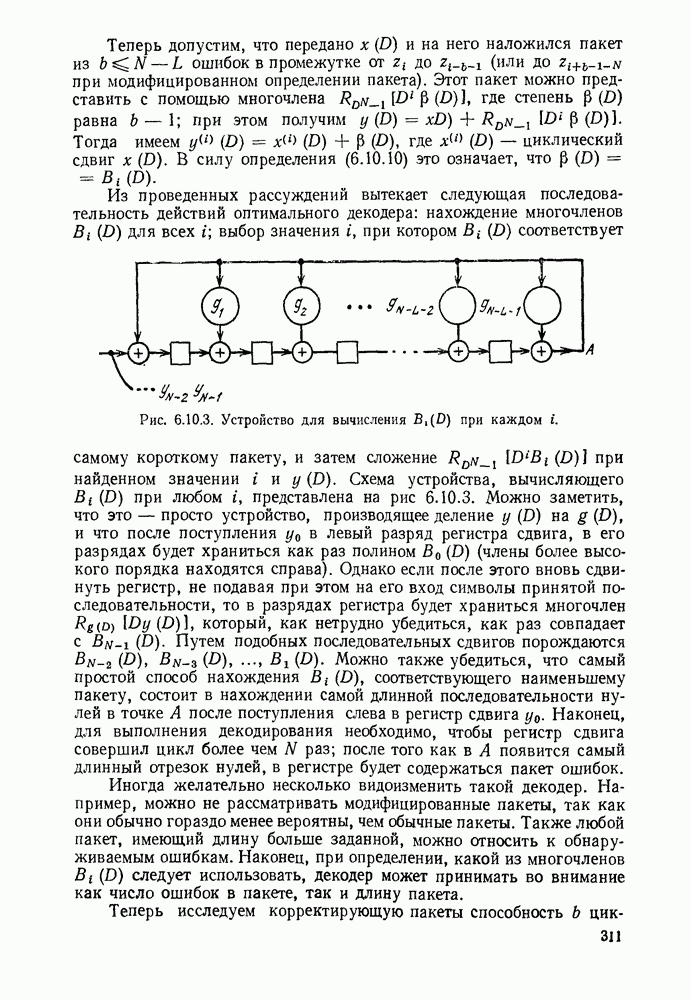
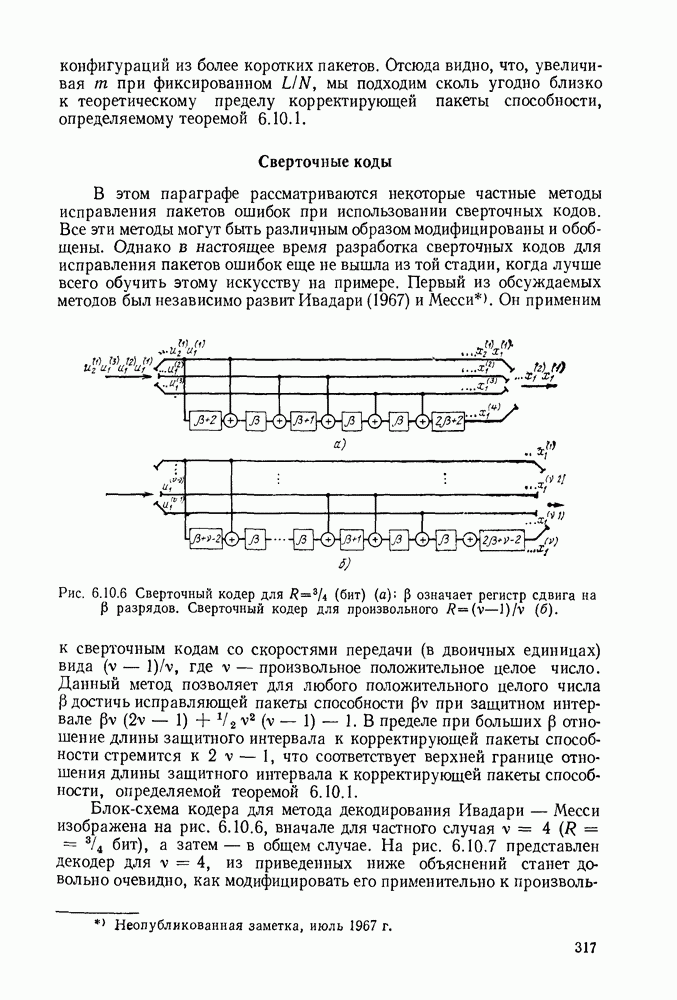
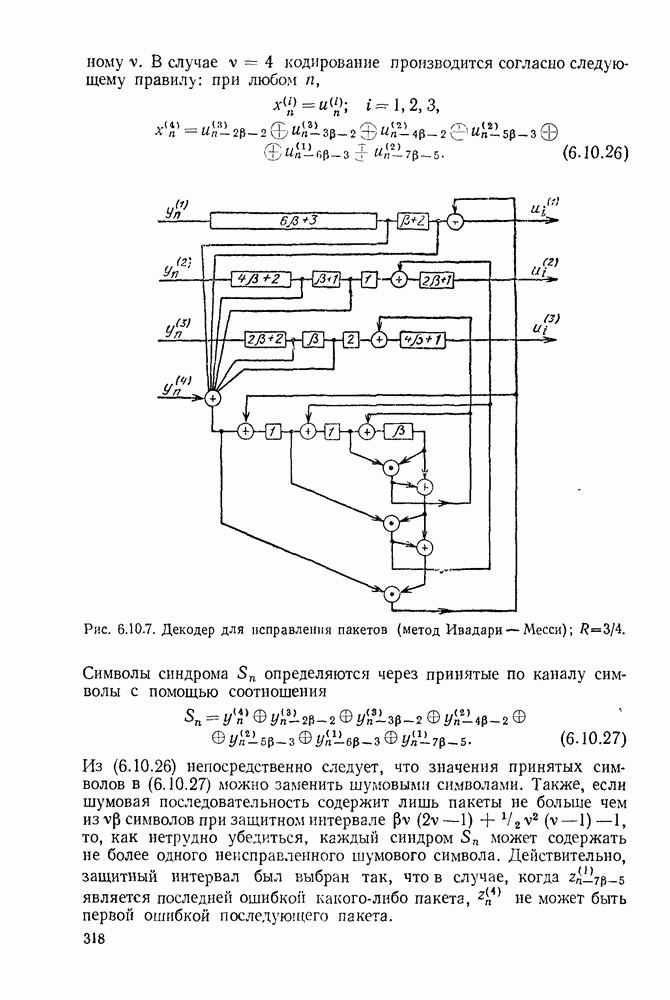
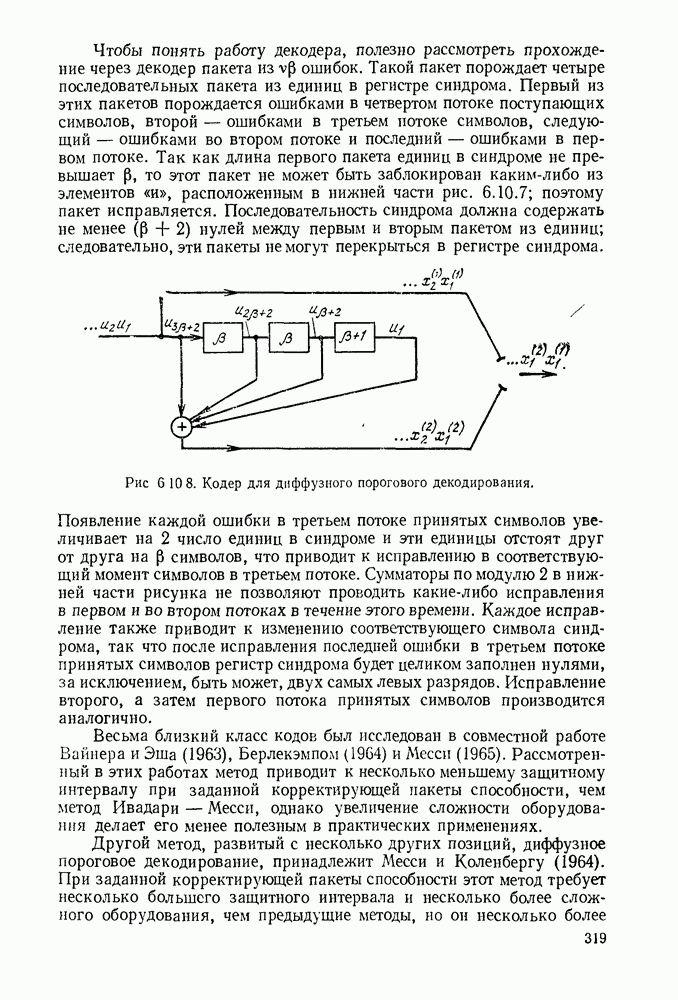
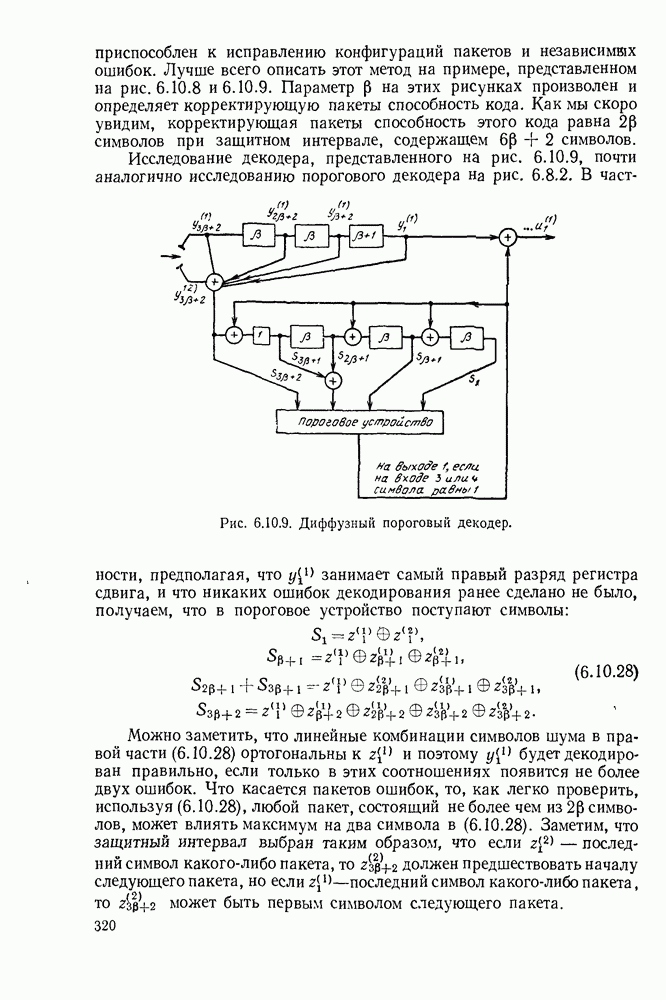
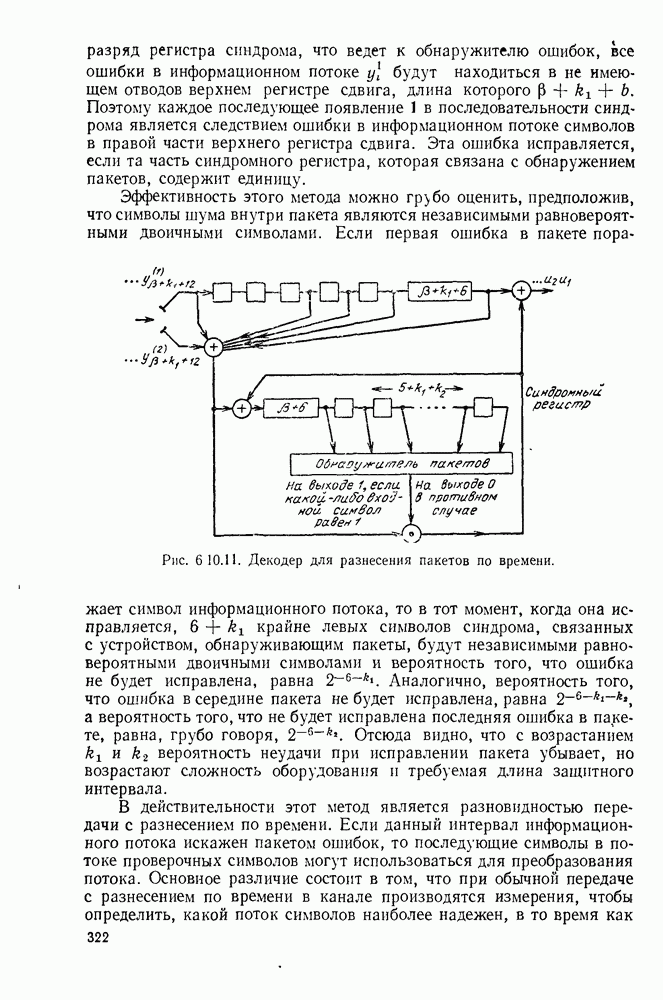
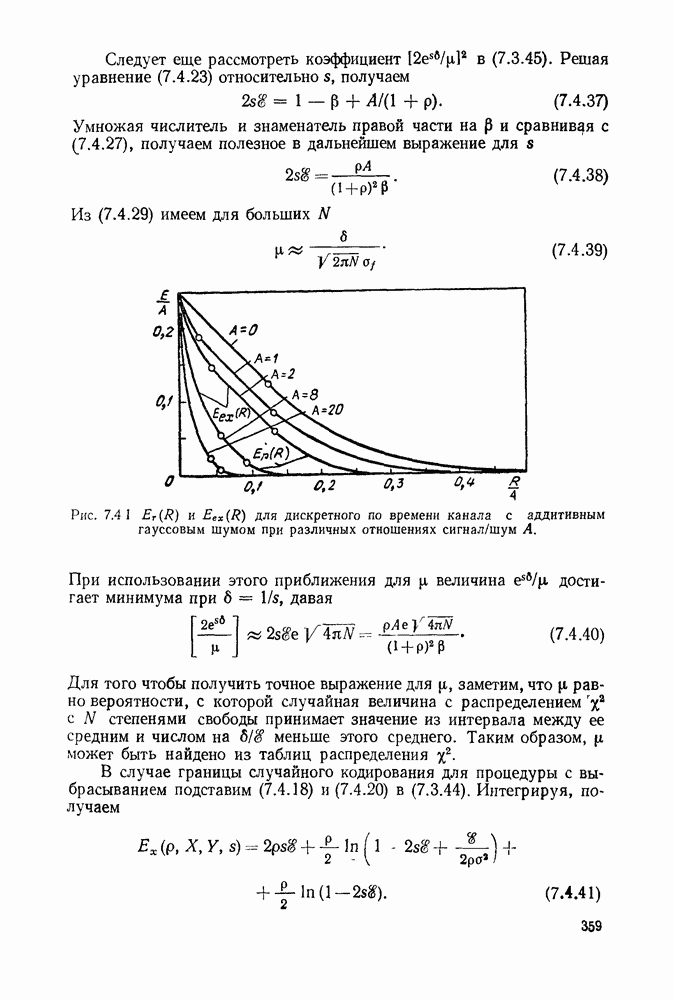
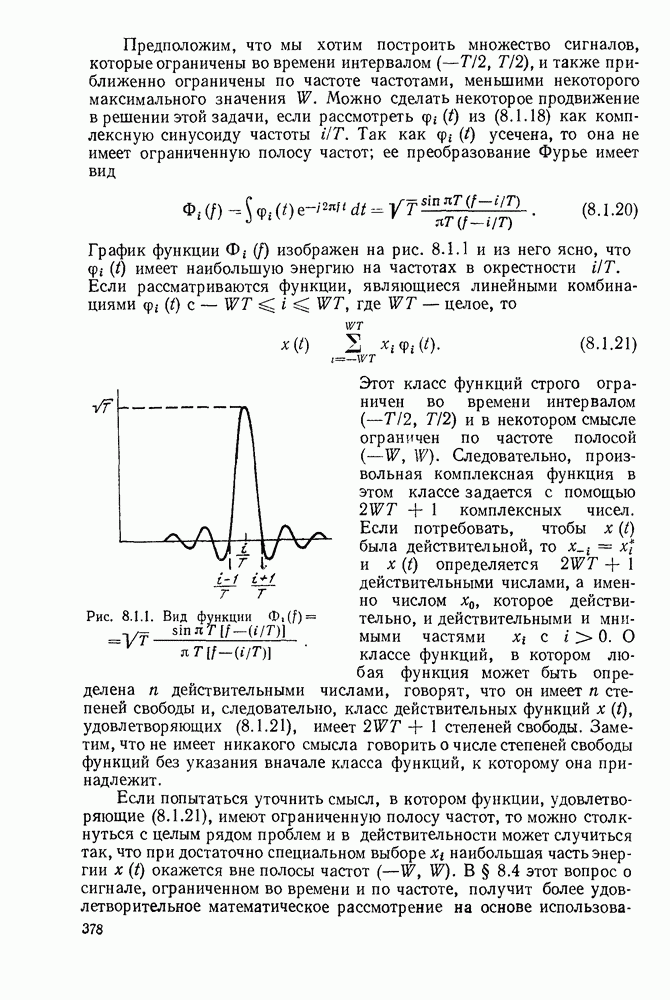
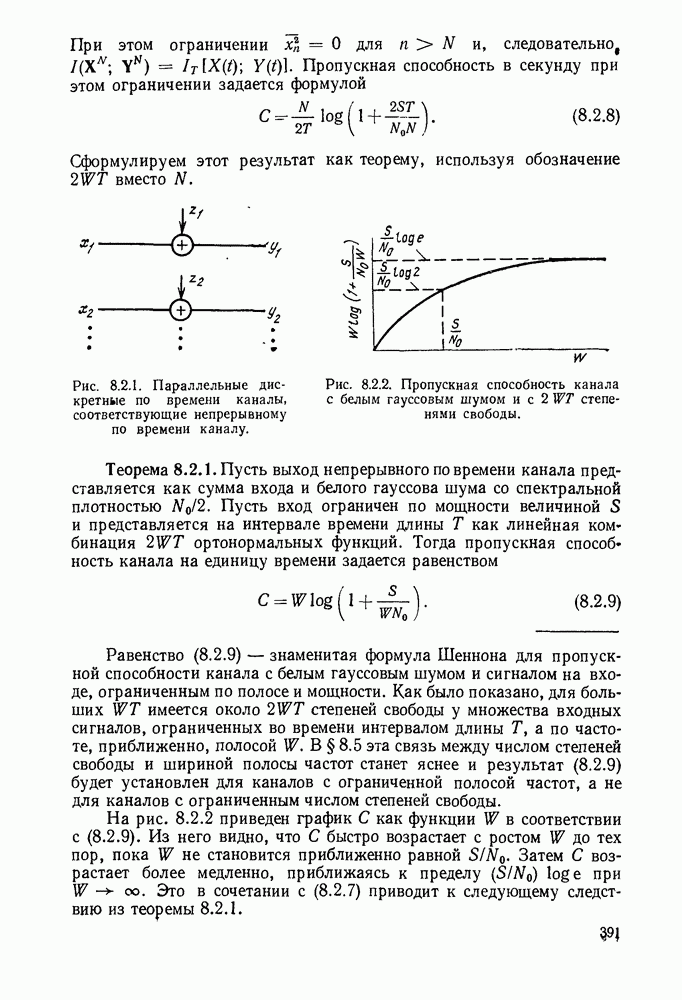
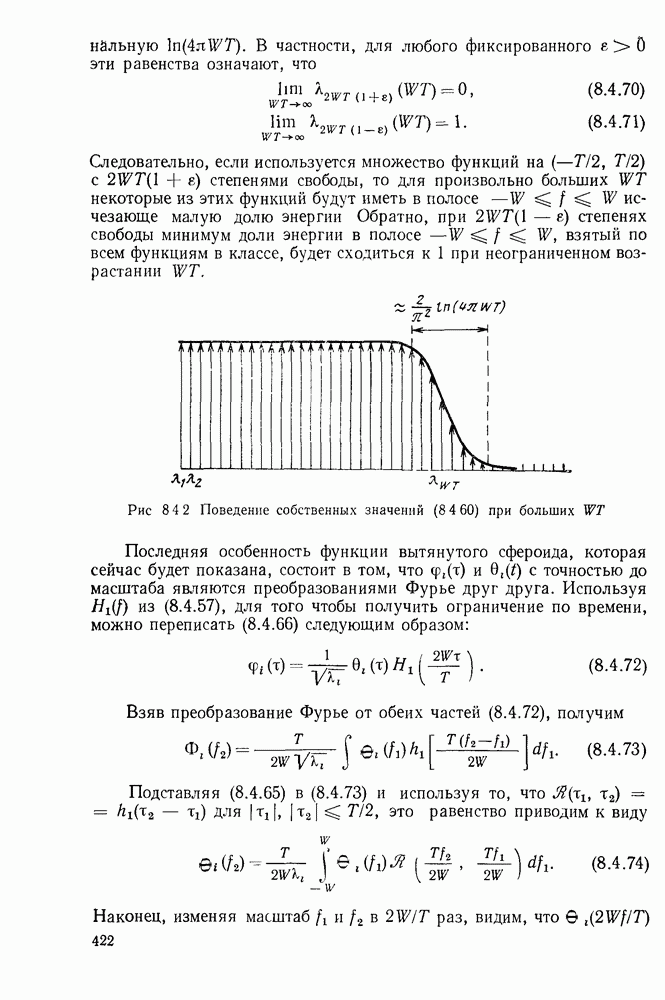
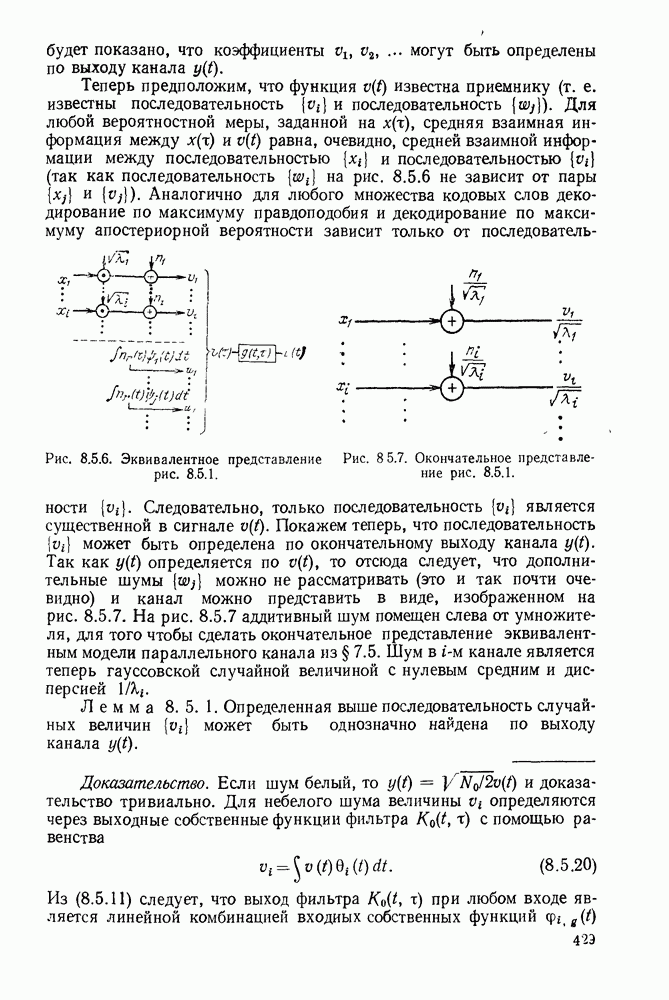
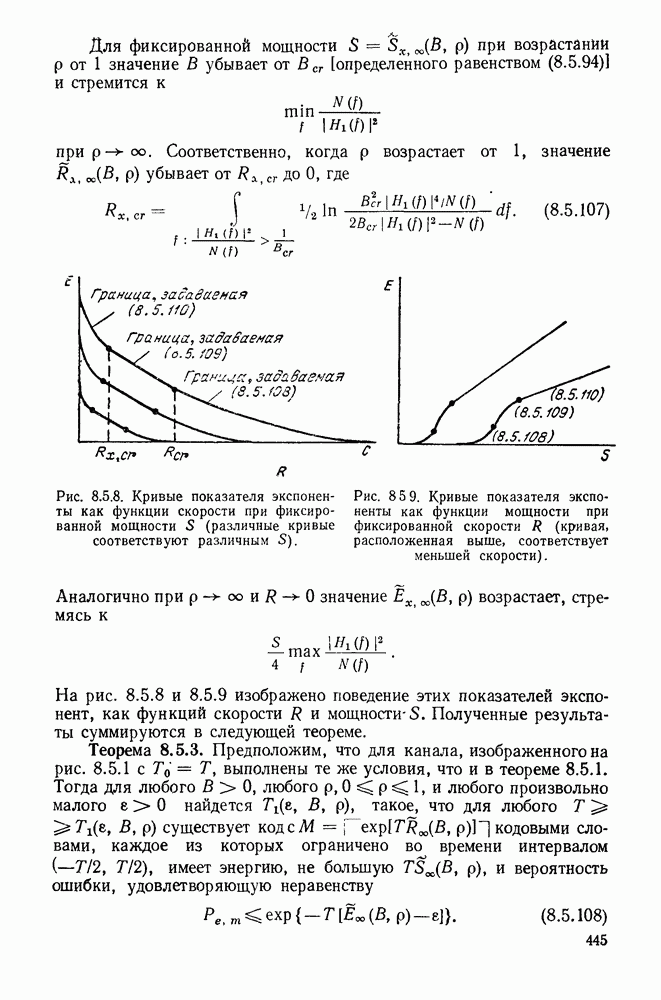
3.1. КОДЫ С ФИКСИРОВАННОЙ ДЛИНОЙ
Обозначим через  последовательность
последовательность  последовательных букв дискретного источника. Каждая буква выбирается из алфавита
последовательных букв дискретного источника. Каждая буква выбирается из алфавита  таким образом, имеются
таким образом, имеются  различных последовательностей длины
различных последовательностей длины  которые могут появляться на выходе источника. Предположим, что нужно закодировать эти последовательности в слова кода с фиксированной длиной. Если кодовый алфавит состоит из
которые могут появляться на выходе источника. Предположим, что нужно закодировать эти последовательности в слова кода с фиксированной длиной. Если кодовый алфавит состоит из  символов и если длина каждого кодового слова равна
символов и если длина каждого кодового слова равна  то существуют
то существуют  различных последовательностей кодовых букв, которые могут быть рассмотрены как кодовые слова. Следовательно, если нужно сопоставить различные кодовые слова разным последовательностям источника (это необходимо сделать, если требуется восстановить каждую возможную последовательность источника по ее кодовому слову), то получаем
различных последовательностей кодовых букв, которые могут быть рассмотрены как кодовые слова. Следовательно, если нужно сопоставить различные кодовые слова разным последовательностям источника (это необходимо сделать, если требуется восстановить каждую возможную последовательность источника по ее кодовому слову), то получаем

Таким образом, для кодов с фиксированной длиной всегда, когда требуется декодировать последовательность источника по кодовому слову, необходимо иметь по меньшей мере  кодовых букв на одну букву источника. Так, например, в случае телетайпа источник
кодовых букв на одну букву источника. Так, например, в случае телетайпа источник
имеет алфавит из  символов (26 английских букв и 6 специальных символов). Кодируя одну букву источника
символов (26 английских букв и 6 специальных символов). Кодируя одну букву источника  в буквы двоичного кода
в буквы двоичного кода  нужно иметь
нужно иметь  двоичных символов на один символ источника для того, чтобы удовлетворить условию (3.1.1).
двоичных символов на один символ источника для того, чтобы удовлетворить условию (3.1.1).
Если мы хотим использовать меньше чем  кодовых букв на один символ источника, то, очевидно, нужно ослабить требование того, чтобы всегда было возможно декодировать последовательность источника по кодовой последовательности. Отсюда следует, что мы должны приписать кодовые слова только некоторому подмножеству последовательностей источника длины
кодовых букв на один символ источника, то, очевидно, нужно ослабить требование того, чтобы всегда было возможно декодировать последовательность источника по кодовой последовательности. Отсюда следует, что мы должны приписать кодовые слова только некоторому подмножеству последовательностей источника длины  Далее будет показано, что для достаточно больших
Далее будет показано, что для достаточно больших  вероятность получения последовательности источника, которая не соответствует никакому слову, может быть сделана произвольно малой и в то же самое время число кодовых букв на один символ источника может быть сделано сколь угодно близким к
вероятность получения последовательности источника, которая не соответствует никакому слову, может быть сделана произвольно малой и в то же самое время число кодовых букв на один символ источника может быть сделано сколь угодно близким к 
Для источника без памяти вероятность данной последовательности  из
из  букв источника равна произведению вероятностей отдельных букв источника
букв источника равна произведению вероятностей отдельных букв источника

В этом равенстве каждая буква выбирается из алфавита  с вероятностью
с вероятностью  Так, например, если источник имеет алфавит из двух букв
Так, например, если источник имеет алфавит из двух букв  то вероятность последовательности
то вероятность последовательности  при
при  равна
равна  Собственная информация последовательности
Собственная информация последовательности  имеет вид
имеет вид

Каждая буква  представляет собой статистически независимую выборку для одного и того же источника и, следовательно, (3.1.2) утверждает, что
представляет собой статистически независимую выборку для одного и того же источника и, следовательно, (3.1.2) утверждает, что  является суммой
является суммой  независимых одинаково распределенных случайных величин. Так как среднее значение каждой из случайных величин
независимых одинаково распределенных случайных величин. Так как среднее значение каждой из случайных величин  является энтропией источника
является энтропией источника  то из закона больших чисел следует, что, если
то из закона больших чисел следует, что, если  велико, то
велико, то  будет с большой вероятностью близко к
будет с большой вероятностью близко к 

Символ в равенстве (3.1.3) используется как для того, чтобы показать приближенность равенства, так и для того, чтобы подчеркнуть, что мы не хотим указать точный смысл этого приближения. В начале
рассмотрим следствия равенства (3.1.3), а затем возвратимся, чтобы дать необходимые математические уточнения. Из (3.1.3) имеем

Здесь и до конца этой главы все энтропии будут выражаться в битах, т. е. будут определены логарифмами с основанием 2. Из равенства (3.1.5) вероятность любой типичной достаточно длинной последовательности источника длины  в некотором смысле приближенно равна
в некотором смысле приближенно равна  следовательно, число таких типичных последовательностей
следовательно, число таких типичных последовательностей  должно быть приближенно равно
должно быть приближенно равно

Если требуется сопоставить двоичные кодовые слова всем этим типичным последовательностям, то следует отметить, что имеется  различных двоичных последовательностей и, следовательно, требуется, чтобы N было приближенно равно
различных двоичных последовательностей и, следовательно, требуется, чтобы N было приближенно равно  для того, чтобы представить все типичные последовательности источника.
для того, чтобы представить все типичные последовательности источника.
Приведенные эвристические соображения дают три различных толкования энтропии источника; одно с помощью вероятности типичных длинных последовательностей источника; другое с помощью числа типичных длинных последовательностей источника и третье с помощью числа двоичных символов, требуемых для представления типичных последовательностей источника. Эти эвристические идеи очень полезны для получения простой картины поведения источников, и они легко обобщаются на источники, в которых имеется статистическая зависимость между последовательными буквами. Однако до того как развить эти идеи, необходимо привести ряд уточнений.
Как было показано,  является суммой
является суммой  независимых одинаково распределенных случайных величин, каждая из которых имеет конечное математическое ожидание
независимых одинаково распределенных случайных величин, каждая из которых имеет конечное математическое ожидание  Закон больших чисел утверждает при этом, что для любого
Закон больших чисел утверждает при этом, что для любого  существует такое
существует такое  что
что

и

Это означает, что вероятность того, что выборочное среднее  отличается от
отличается от  более чем на произвольную фиксированную
более чем на произвольную фиксированную
величину  стремится к нулю при увеличении
стремится к нулю при увеличении  Для некоторых заданных
Для некоторых заданных  пусть
пусть  множество последовательностей
множество последовательностей  для которых
для которых

Это множество ранее мы называли множеством типичных последовательностей; из (3.1.7) получаем

Преобразуя (3.1.9), получаем для 

Можно ограничить число  последовательностей в
последовательностей в  заметив, что
заметив, что

Отсюда, используя (3.1.12) в качестве нижней границы  для
для  принадлежащих
принадлежащих  получаем
получаем

Точно так же, используя (3.1.10), получаем

и, используя (3.1.12) в качестве верхней границы  для
для  принадлежащих
принадлежащих  находим
находим

Неравенства  дают точные утверждения, соответствующие (3.1.5) и (3.1.6).
дают точные утверждения, соответствующие (3.1.5) и (3.1.6).
Предположим далее, что требуется закодировать последовательности источника  в последовательности длины
в последовательности длины  представляющие собой кодовые слова с алфавитом из
представляющие собой кодовые слова с алфавитом из  букв. Будем отображать только одну последовательность источника сообщений в каждую кодовую последовательность, при этом часто будут возникать последовательности из множества последовательностей сообщения, которым не будет сопоставлено никакое кодовое слово. Определим вероятность ошибки
букв. Будем отображать только одну последовательность источника сообщений в каждую кодовую последовательность, при этом часто будут возникать последовательности из множества последовательностей сообщения, которым не будет сопоставлено никакое кодовое слово. Определим вероятность ошибки  как вероятность множества, которому не сопоставлены кодовые слова. Выберем вначале
как вероятность множества, которому не сопоставлены кодовые слова. Выберем вначале  так, чтобы удовлетворить неравенству
так, чтобы удовлетворить неравенству

Тогда из (3.1.13) следует, что общее число кодовых слов  больше, чем
больше, чем  и можно сопоставить кодовые слова всем
и можно сопоставить кодовые слова всем  принадлежащим
принадлежащим  Используя этот метод, получаем
Используя этот метод, получаем

Если теперь считать, что  достаточно велико и, одновременно увеличивая
достаточно велико и, одновременно увеличивая  удовлетворить
удовлетворить  то можно увидеть из (3.1.8) и (3.1.16), что
то можно увидеть из (3.1.8) и (3.1.16), что  стремится к 0 при любом
стремится к 0 при любом  Покажем теперь, что, если
Покажем теперь, что, если  фиксировать равным любому числу, меньшему
фиксировать равным любому числу, меньшему  то вероятность ошибки должна стремиться к 1 при
то вероятность ошибки должна стремиться к 1 при  стремящемся к
стремящемся к  Выберем теперь N так, чтобы
Выберем теперь N так, чтобы

Таким образом, число кодовых слов  не больше чем
не больше чем  Так как любая последовательность
Так как любая последовательность  из Т имеет вероятность, не большую чем то полная вероятность последовательностей, принадлежащих
из Т имеет вероятность, не большую чем то полная вероятность последовательностей, принадлежащих  которым можно сопоставить кодовые слова, не больше чем
которым можно сопоставить кодовые слова, не больше чем  Можно было бы также сопоставить кодовые слова некоторым последовательностям источника, не принадлежащим множеству
Можно было бы также сопоставить кодовые слова некоторым последовательностям источника, не принадлежащим множеству  в частности тем, которые имеют большую вероятность. Вместе с тем общая вероятность последовательностей, не принадлежащих
в частности тем, которые имеют большую вероятность. Вместе с тем общая вероятность последовательностей, не принадлежащих  не больше
не больше  Следовательно, вероятность множества всех последовательностей, принадлежащих и не принадлежащих
Следовательно, вероятность множества всех последовательностей, принадлежащих и не принадлежащих  которым могут быть сопоставлены кодовые слова, ограничена сверху в случае, если удовлетворяется (3.1.7), следующим образом:
которым могут быть сопоставлены кодовые слова, ограничена сверху в случае, если удовлетворяется (3.1.7), следующим образом:

Таким образом, если  то
то  должна стремиться к 1 при любом
должна стремиться к 1 при любом  Можно подытожить эти результаты следующей фундаментальной теоремой.
Можно подытожить эти результаты следующей фундаментальной теоремой.
Теорема 3.1.1. (Теорема кодирования для источника.) Пусть дискретный источник без памяти имеет конечную энтропию  Рассмотрим кодирование последовательностей из
Рассмотрим кодирование последовательностей из  букв источника в последовательности из N кодовых букв, принадлежащих кодовому алфавиту объема
букв источника в последовательности из N кодовых букв, принадлежащих кодовому алфавиту объема  Каждой кодовой последовательности может быть сопоставлена только одна последовательность источника. Пусть
Каждой кодовой последовательности может быть сопоставлена только одна последовательность источника. Пусть  вероятность появления последовательности источника, которой не сопоставлена никакая кодовая последовательность. Тогда, если при каком-либо
вероятность появления последовательности источника, которой не сопоставлена никакая кодовая последовательность. Тогда, если при каком-либо 

то  можно сделать произвольно малой, выбирая
можно сделать произвольно малой, выбирая  достаточно большим. Обратно, если
достаточно большим. Обратно, если

то  становится сколь угодно близкой к 1, когда
становится сколь угодно близкой к 1, когда  становится достаточно большим.
становится достаточно большим.
Теореме 3.1.1 можно дать очень простое и полезное эвристическое толкование. Так как кодовые слова дают попросту другое представление вероятных последовательностей источника, то они должны иметь в точности такую же энтропию, как последовательности источника.
Кроме того, как было показано в гл.  представляет собой наибольшую энтропию на одну букву, которой может обладать последовательность букв алфавита объема
представляет собой наибольшую энтропию на одну букву, которой может обладать последовательность букв алфавита объема  такая энтропия возникает, когда буквы равновероятны и статистически независимы. Теорема 3.1.1 утверждает, таким образом, что можно закодировать буквы произвольного дискретного источника без памяти так, что энтропия кодовых букв будет, по существу, максимальной.
такая энтропия возникает, когда буквы равновероятны и статистически независимы. Теорема 3.1.1 утверждает, таким образом, что можно закодировать буквы произвольного дискретного источника без памяти так, что энтропия кодовых букв будет, по существу, максимальной.
В интерпретации этой теоремы можно представлять себе  как общее число сообщений, которые выходят из источника во время его работы, и представлять себе N как общее число кодовых букв, которые мы пожелали использовать для представления источника. Затем любой метод може быть использован для кодирования и теорема утверждает, что
как общее число сообщений, которые выходят из источника во время его работы, и представлять себе N как общее число кодовых букв, которые мы пожелали использовать для представления источника. Затем любой метод може быть использован для кодирования и теорема утверждает, что  является наименьшим числом кодовых букв на одну букву источника, которые можно использовать, чтобы все еще представлять источник с высокой вероятностью. То, что такое кодирование последовательностей фиксированной длины в последовательности фиксированной длины при очень больших длинах является довольно непрактичным, несущественно для рассматриваемого общего толкования.
является наименьшим числом кодовых букв на одну букву источника, которые можно использовать, чтобы все еще представлять источник с высокой вероятностью. То, что такое кодирование последовательностей фиксированной длины в последовательности фиксированной длины при очень больших длинах является довольно непрактичным, несущественно для рассматриваемого общего толкования.