Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.3. ТЕОРЕМА КОДИРОВАНИЯ ДЛЯ ИСТОЧНИКАТеорема 3.3.1. При заданных конечном ансамбле источника
Более того для любого однозначно декодируемого множества кодовых слов
Доказательство. Покажем вначале справедливость (3.3.2), установив, что
Пусть
Помещая
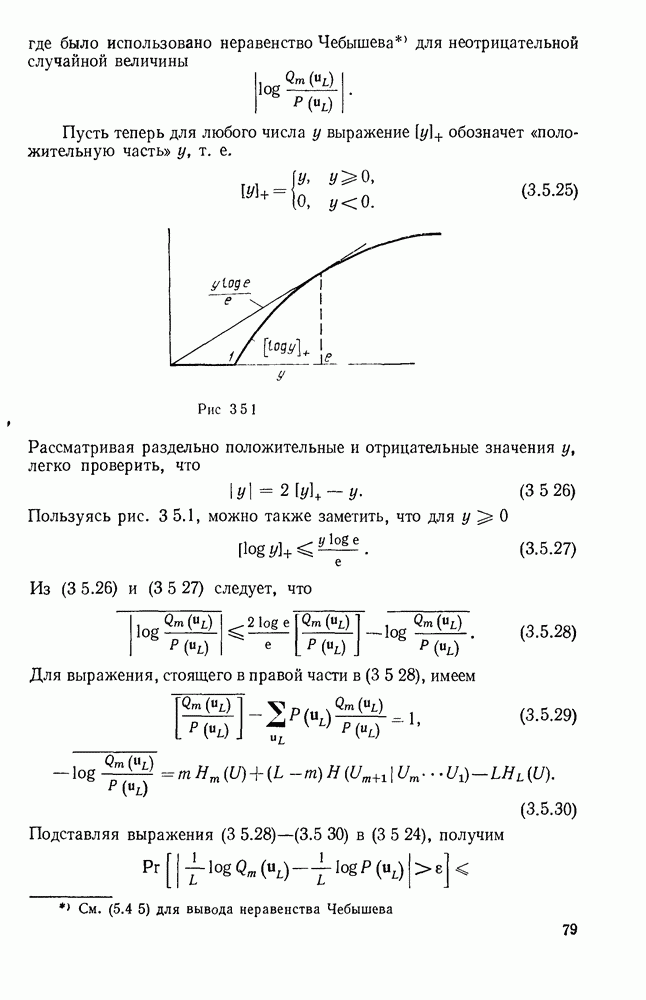
Используя неравенство
Последнее неравенство в (3.3.6) следует из неравенства Крафта (3.2.3), которое справедливо для любого однозначно декодируемого кода. Это доказывает (3.3.2). Заметим, что равенство в (3.3.2) имеет место тогда и только тогда, когда
Это условие совпадает с ранее полученным условием (3.2.2) для каждой кодовой буквы и приводит к максимуму энтропии. Покажем далее, как выбрать код, удовлетворяющий (3.3.1). Если бы длины кодовых слов не обязательно были целыми числами, то можно было бы просто подобрать
Суммирование (3.3.8) по
Умножая (3.3.9) на Можно получить более сильные результаты, если кодовые слова приписывать не отдельным буквам источника, а прямо последовательностям Теорема 3.3.2. Для заданных дискретного источника без памяти будет выполняться свойство префикса и средняя длина кодовых слов на одну букву источника
Более того, левое неравенство справедливо для любого однозначно декодируемого множества кодовых слов. Доказательство. Рассмотрим произведение ансамблей для последовательностей
Разделив эти выражения на Теорема 3.3.2 очень похожа на теорему 3.1.1. Если выбрать
|
 |
Оглавление
|



















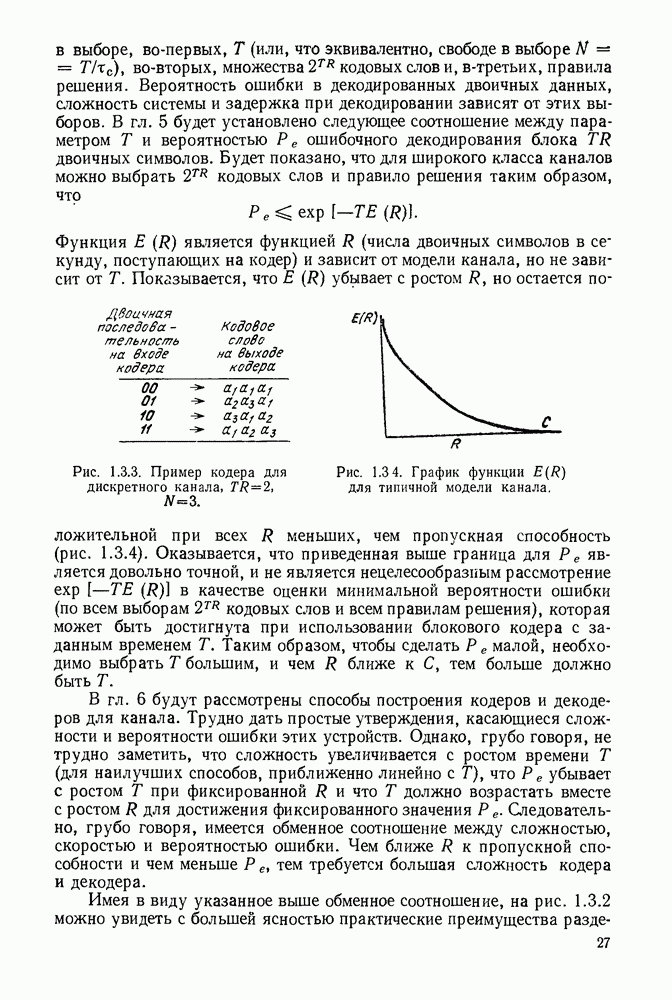




































































































































































































































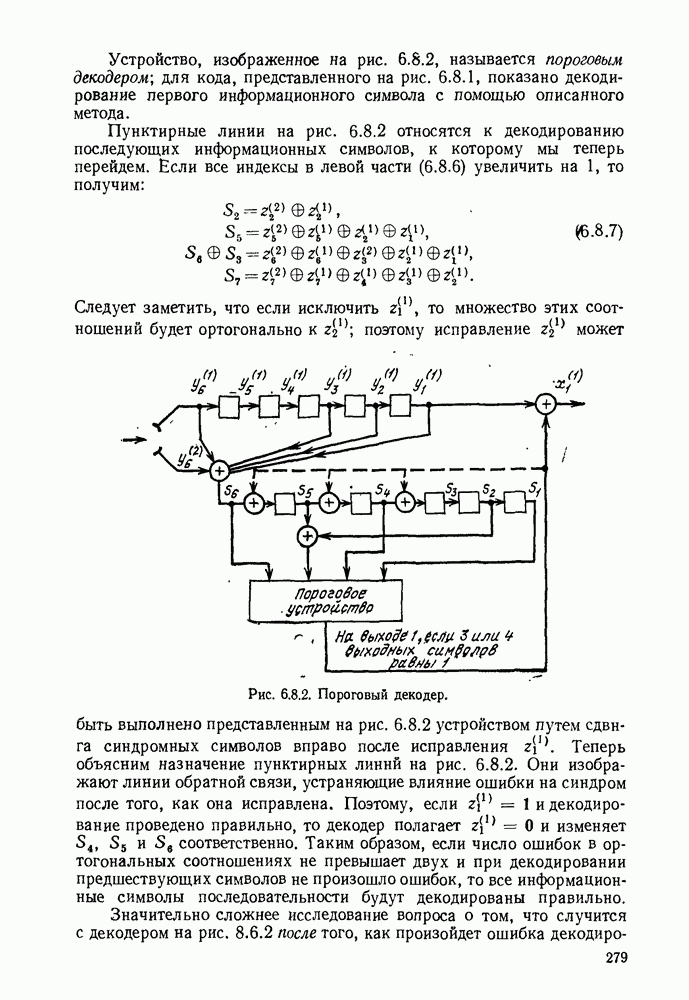

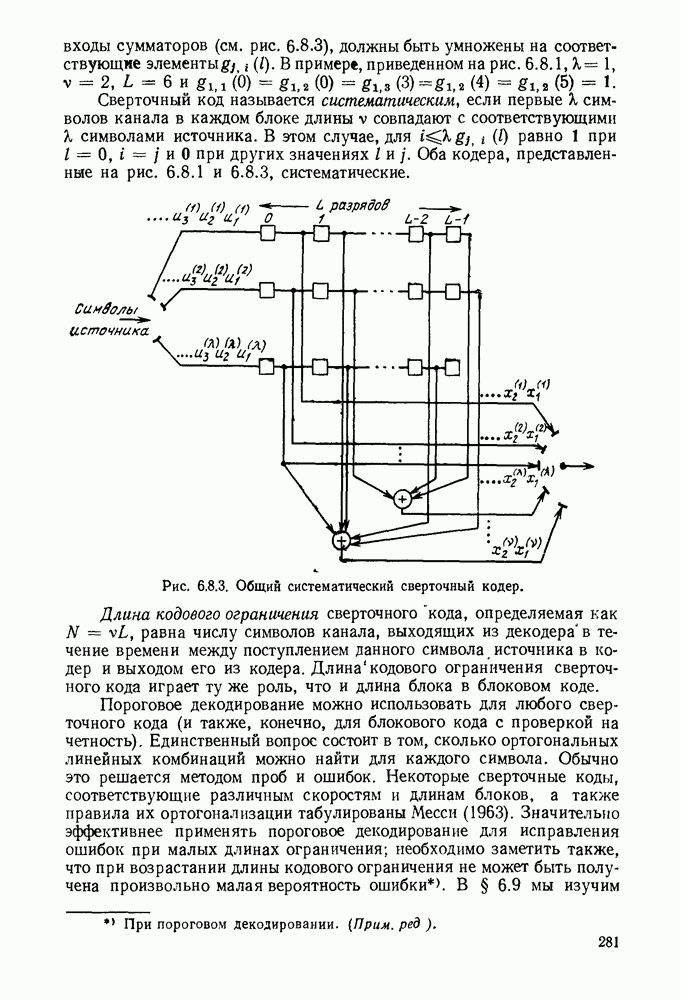




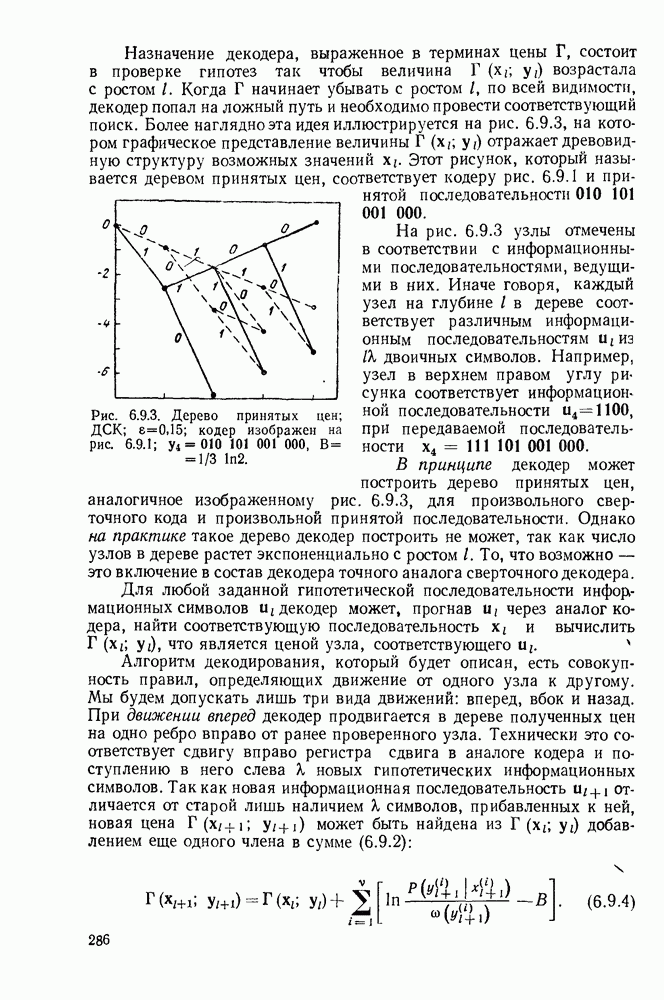



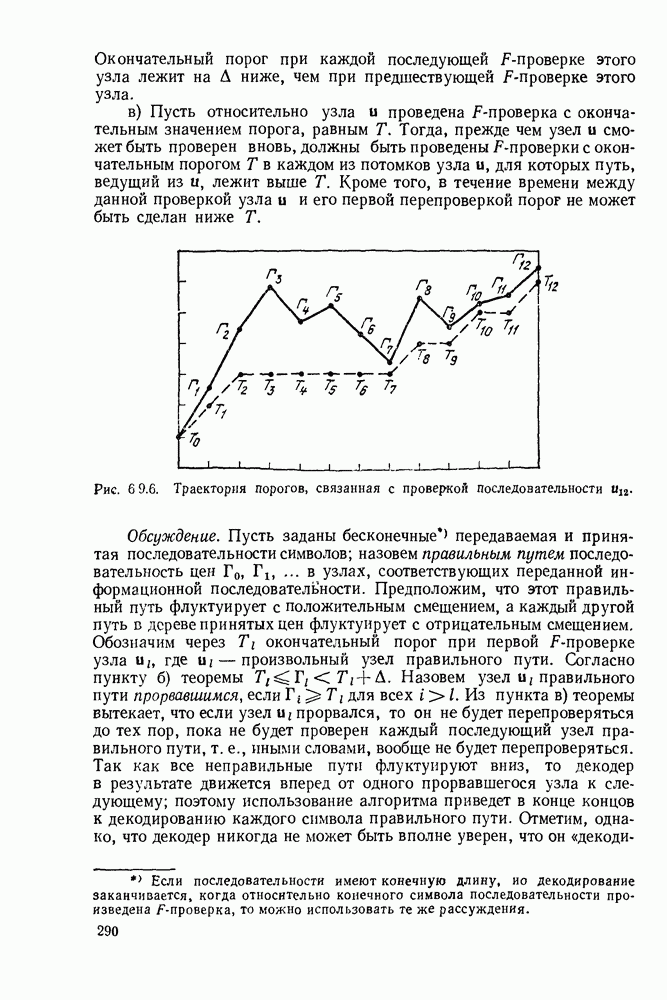

























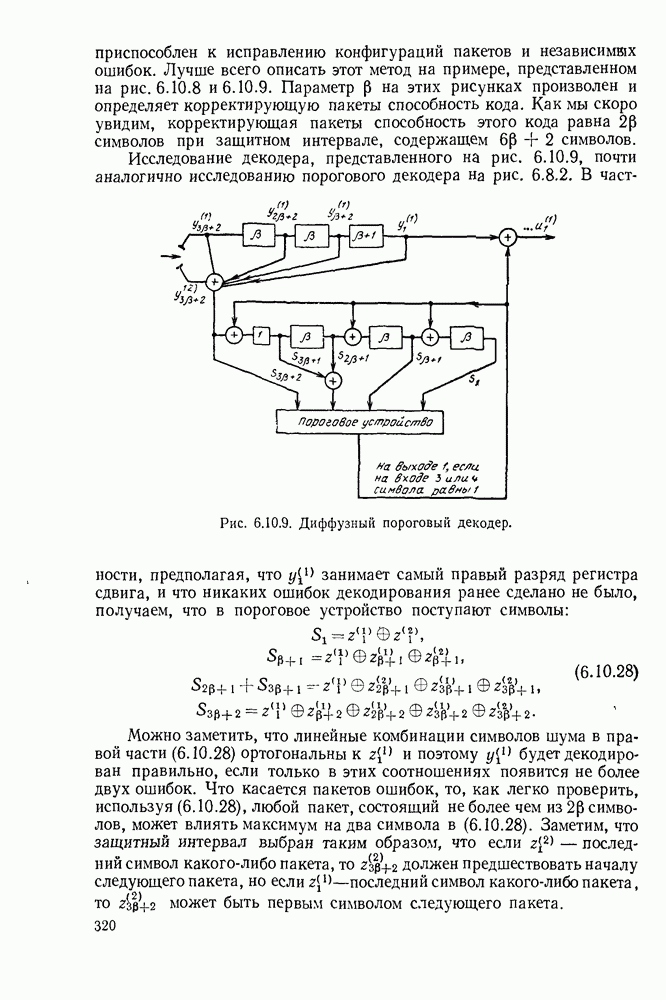

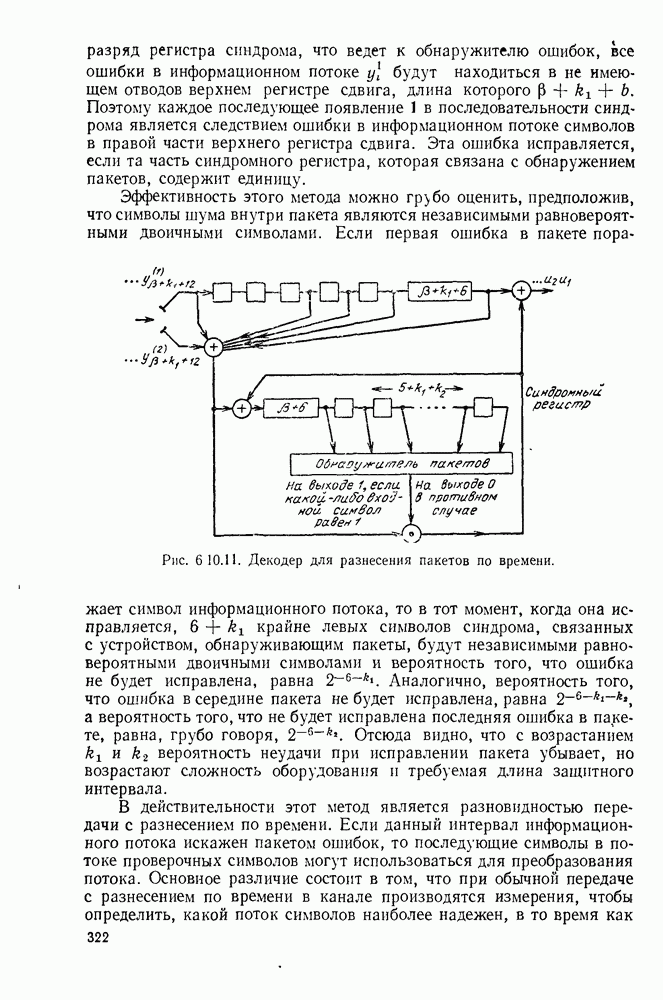




































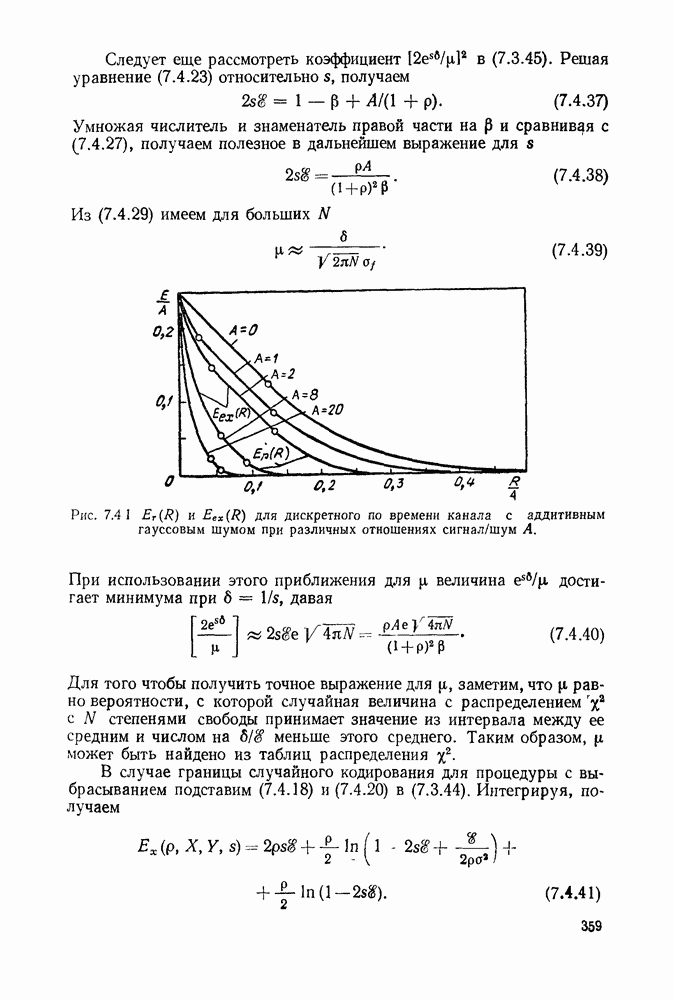


















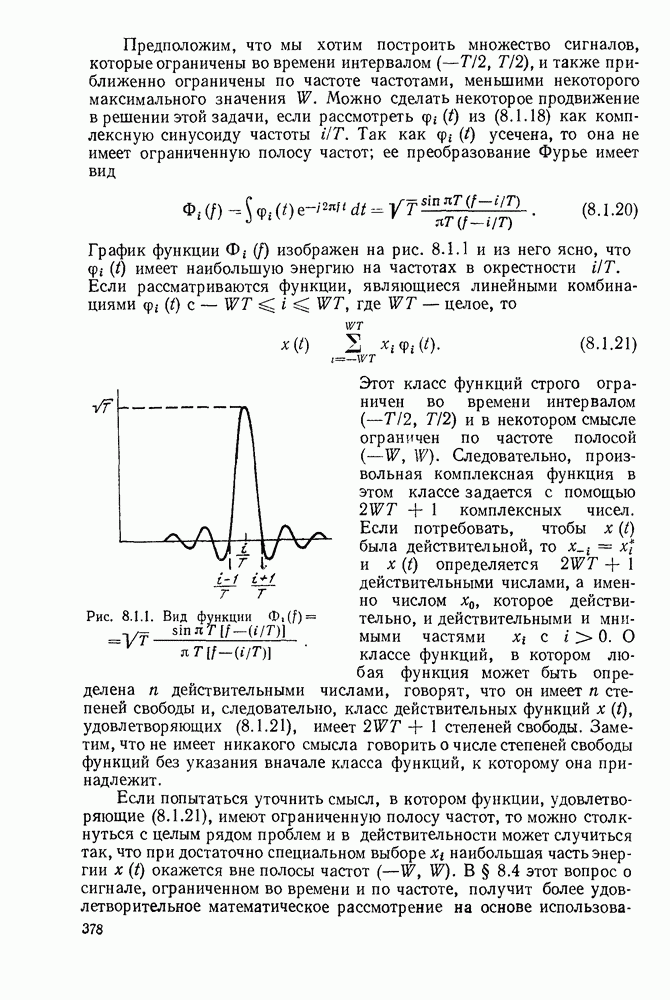












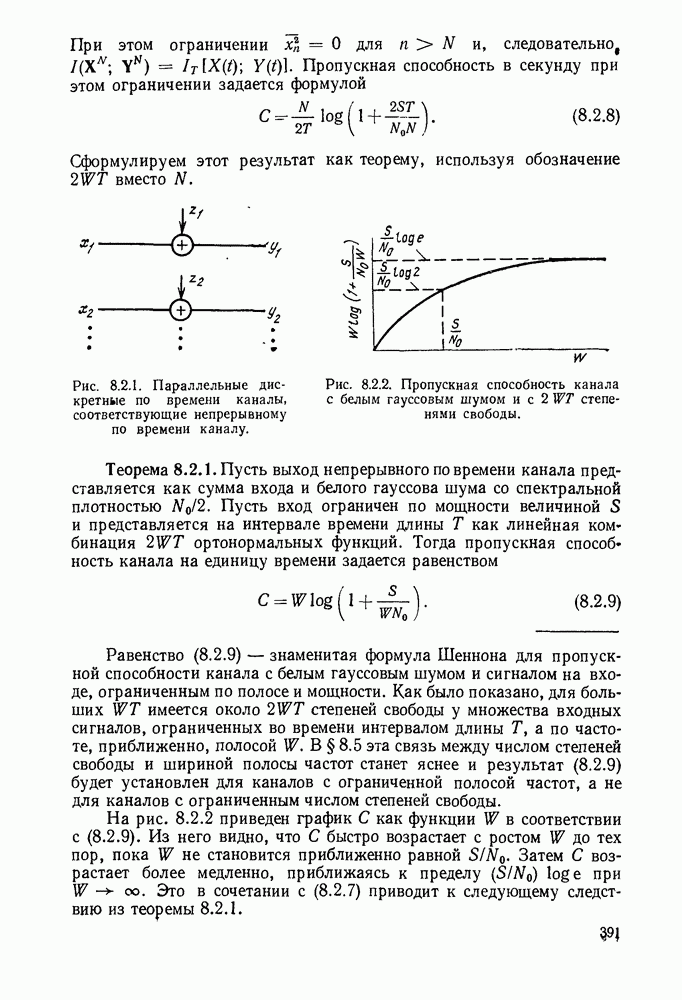






























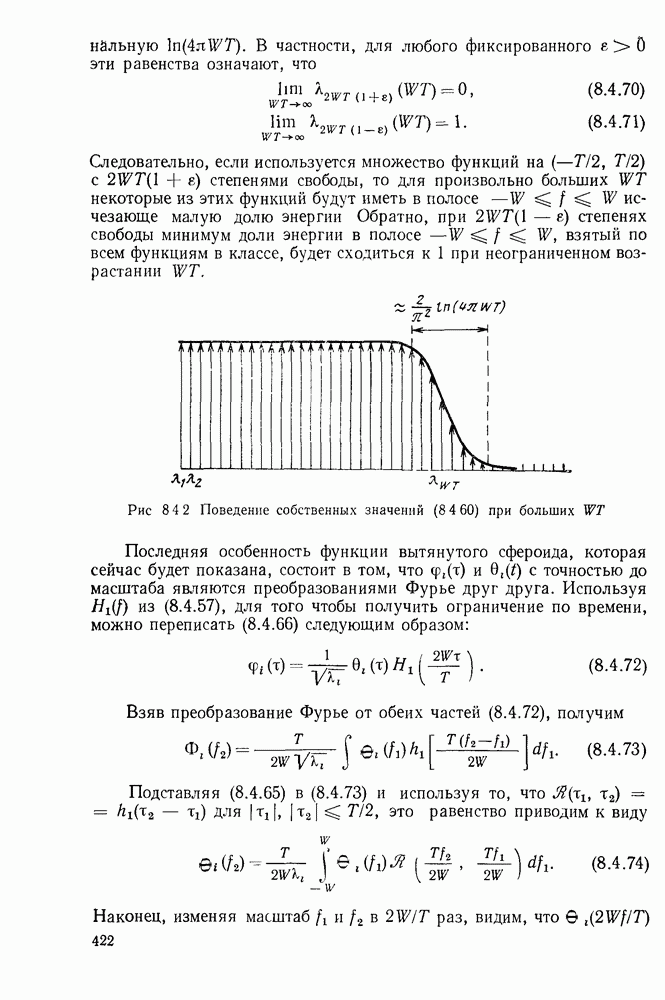






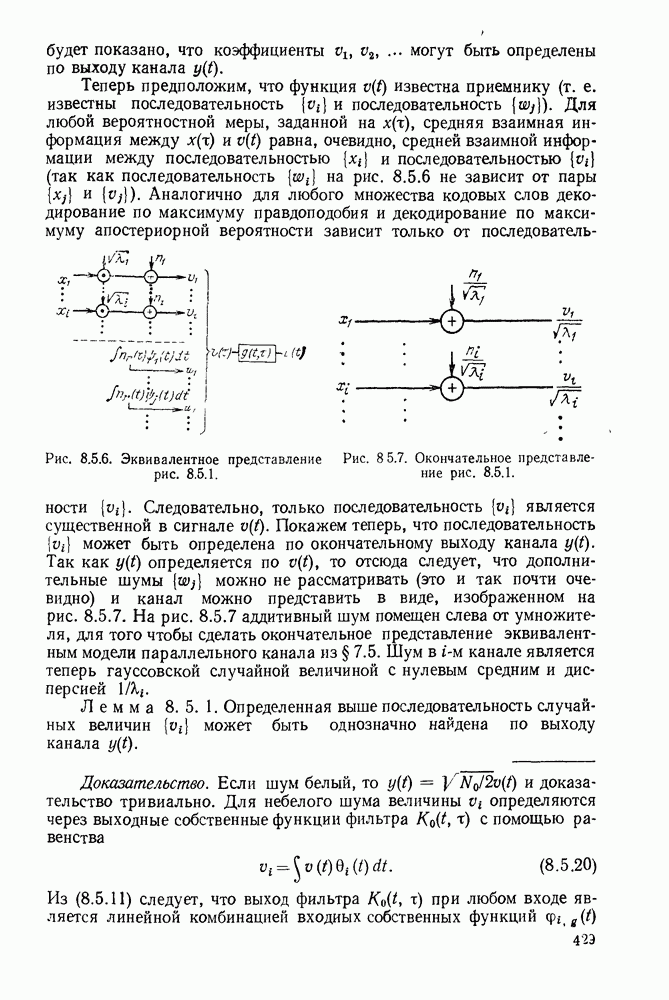















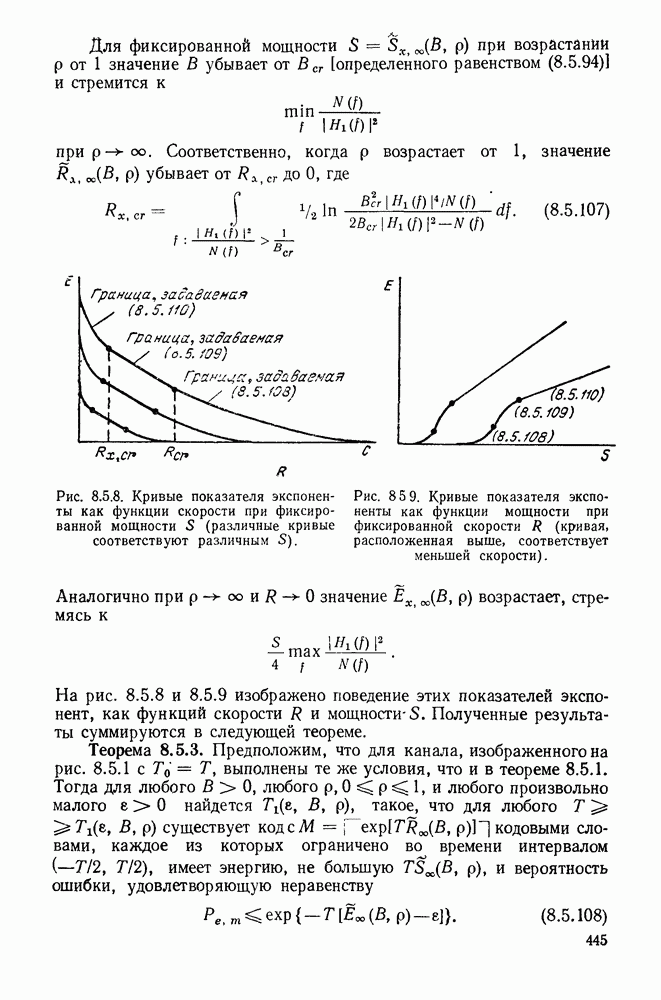
























































































 с энтропией
с энтропией  и кодовом алфавите из
и кодовом алфавите из  символов можно так приписать кодовые слова буквам источника, что будет выполняться свойство префикса и средняя длина кодового слова
символов можно так приписать кодовые слова буквам источника, что будет выполняться свойство префикса и средняя длина кодового слова  будет удовлетворять условию
будет удовлетворять условию



 вероятности букв источника и пусть
вероятности букв источника и пусть  длины кодовых слов. Имеем
длины кодовых слов. Имеем

 под знак логарифма и объединяя слагаемые, будем иметь
под знак логарифма и объединяя слагаемые, будем иметь

 при
при  получаем
получаем


 чтобы удовлетворить условию (3.3.7). Однако можно приближенно удовлетворить (3.3.7), выбирая целые числа так, чтобы удовлетворялись неравенства
чтобы удовлетворить условию (3.3.7). Однако можно приближенно удовлетворить (3.3.7), выбирая целые числа так, чтобы удовлетворялись неравенства

 превращает левое неравенство в неравенство Крафта (3.2.3), и существует префиксный код с этими длинами. Логарифмируя правое неравенство в (3.3.8), получаем
превращает левое неравенство в неравенство Крафта (3.2.3), и существует префиксный код с этими длинами. Логарифмируя правое неравенство в (3.3.8), получаем

 и суммируя по всем
и суммируя по всем  получаем (3.3.1), что завершает доказательство теоремы.
получаем (3.3.1), что завершает доказательство теоремы. 
 букв источника.
букв источника.
 с энтропией
с энтропией  и кодового алфавита из
и кодового алфавита из  символов возможно так приписать кодовые слова последовательностям
символов возможно так приписать кодовые слова последовательностям  букв источника, что
букв источника, что
 будет удовлетворять условию
будет удовлетворять условию

 букв источника. Энтропия произведения ансамблей равна
букв источника. Энтропия произведения ансамблей равна  а средняя длина кодовых слов равна
а средняя длина кодовых слов равна  где
где  означает среднюю длину на одну букву источника. Теорема 3.3.1 утверждает, что минимально достижимое значение
означает среднюю длину на одну букву источника. Теорема 3.3.1 утверждает, что минимально достижимое значение  (при сопоставлении кодового слова неравномерного кода каждой последовательности
(при сопоставлении кодового слова неравномерного кода каждой последовательности  букв источника) удовлетворяет неравенствам
букв источника) удовлетворяет неравенствам

 получим результат теоремы.
получим результат теоремы. 
 достаточно большим и затем применить закон больших чисел к длинной последовательности, состоящей, в свою очередь, из последовательностей
достаточно большим и затем применить закон больших чисел к длинной последовательности, состоящей, в свою очередь, из последовательностей  букв источника, то можно заметить, что из теоремы 3.3.2 следует первая часть теоремы 3.1.1. Однако теорема 3.3.2 немного сильнее, чем теорема 3.1.1, так как она предлагает относительно простой метод кодирования, а также альтернативу случайным ошибкам, а именно случайные длинные задержки.
букв источника, то можно заметить, что из теоремы 3.3.2 следует первая часть теоремы 3.1.1. Однако теорема 3.3.2 немного сильнее, чем теорема 3.1.1, так как она предлагает относительно простой метод кодирования, а также альтернативу случайным ошибкам, а именно случайные длинные задержки.