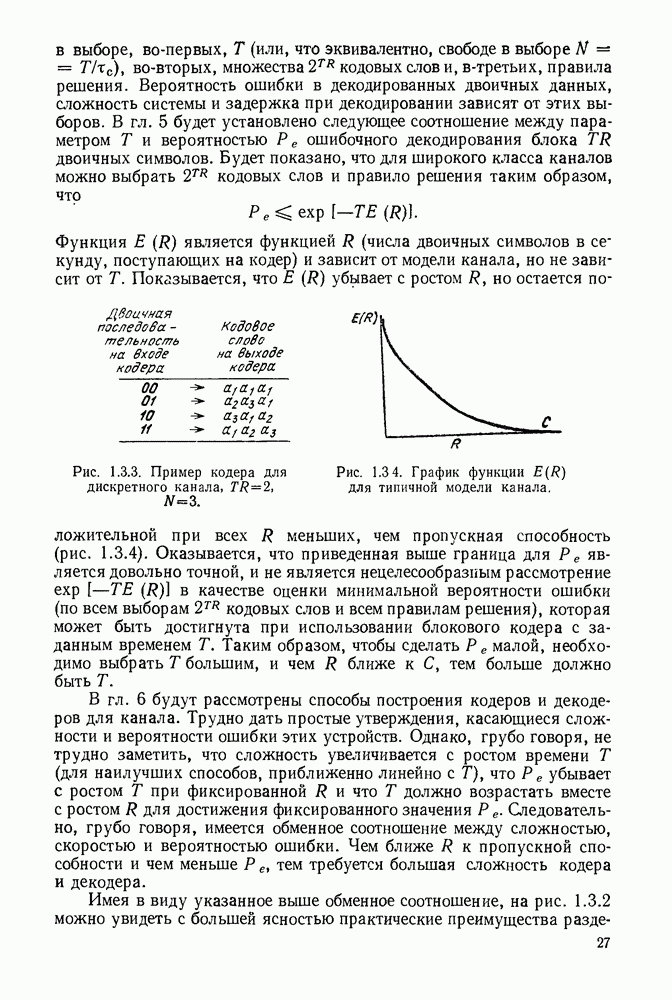
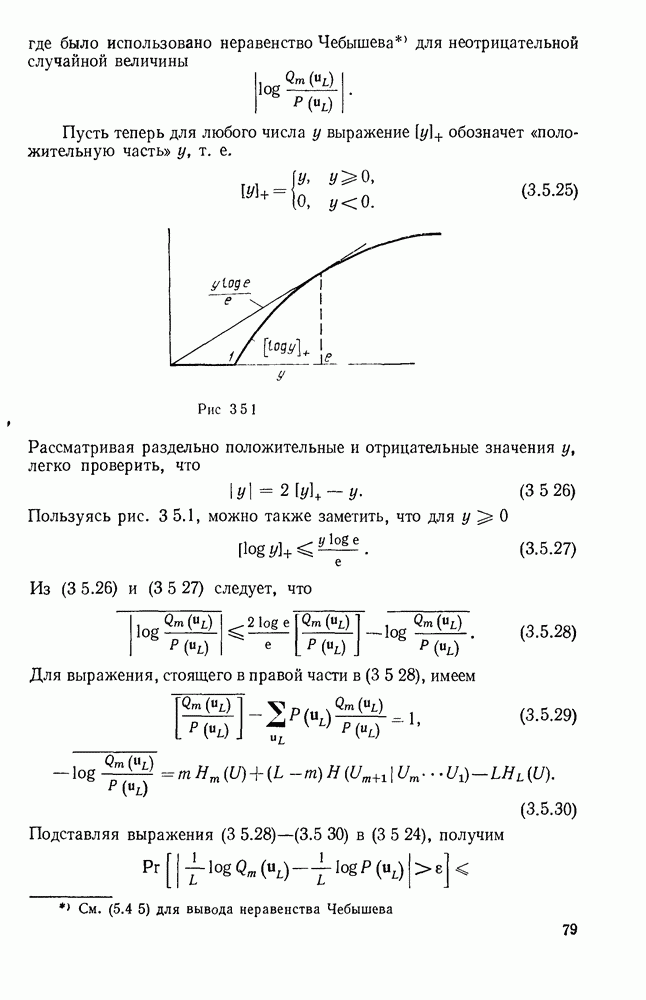
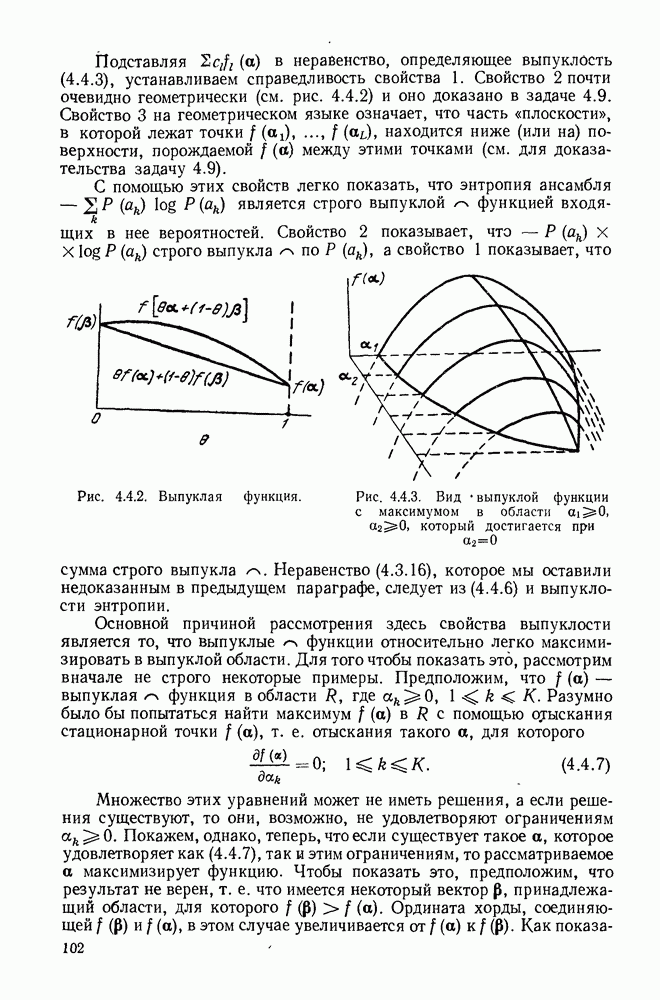
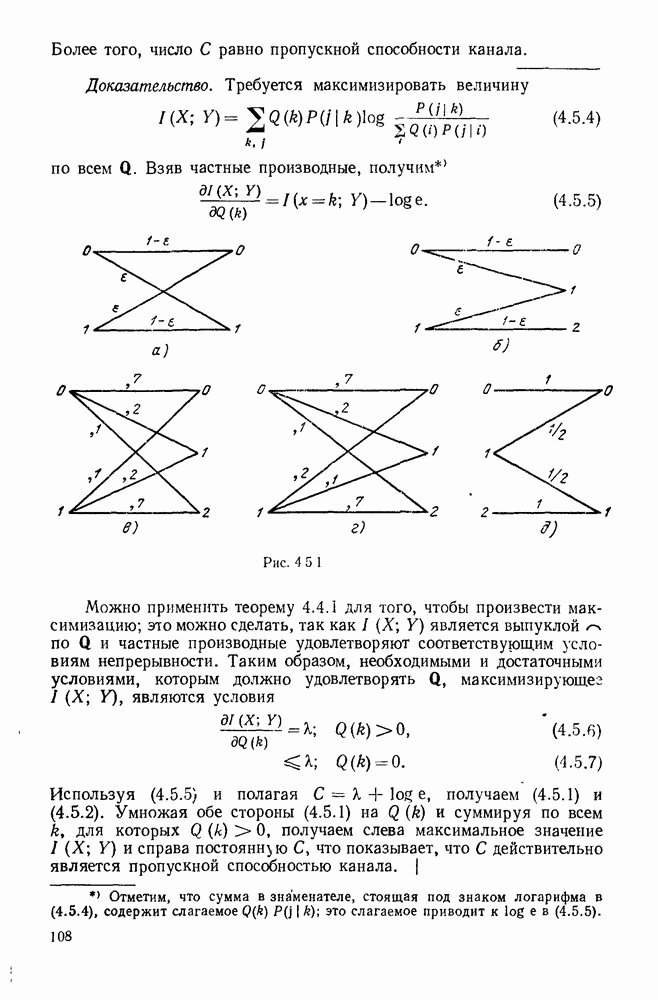
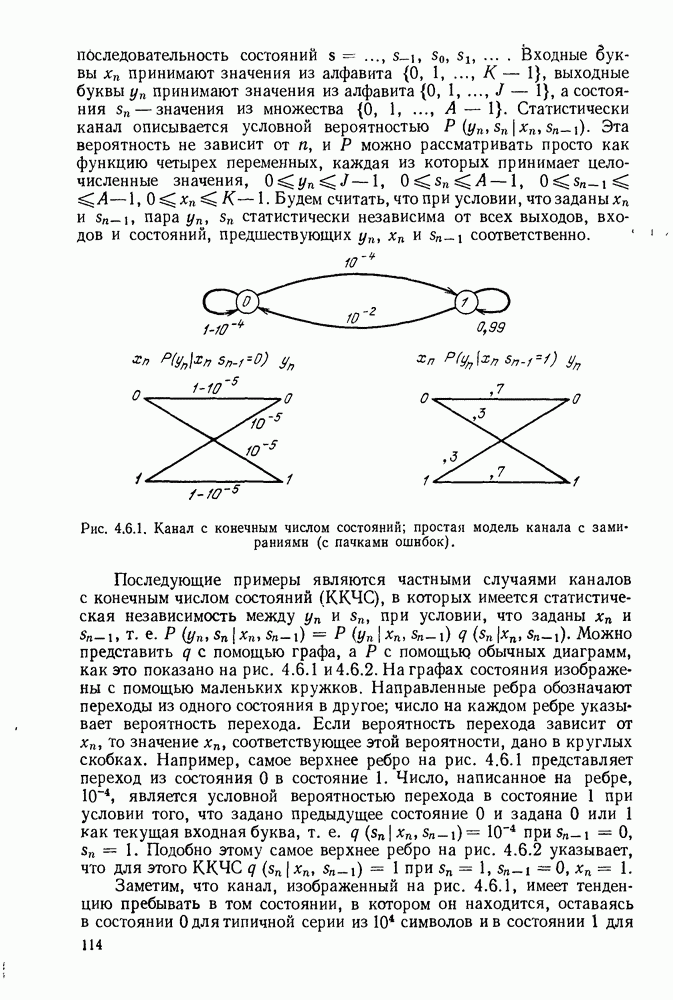
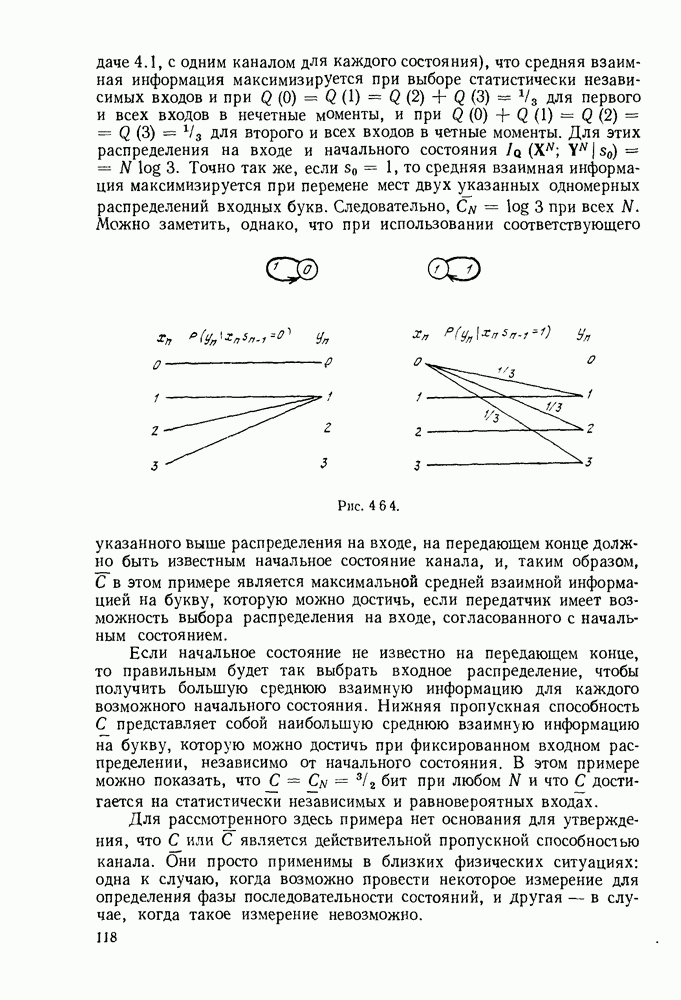
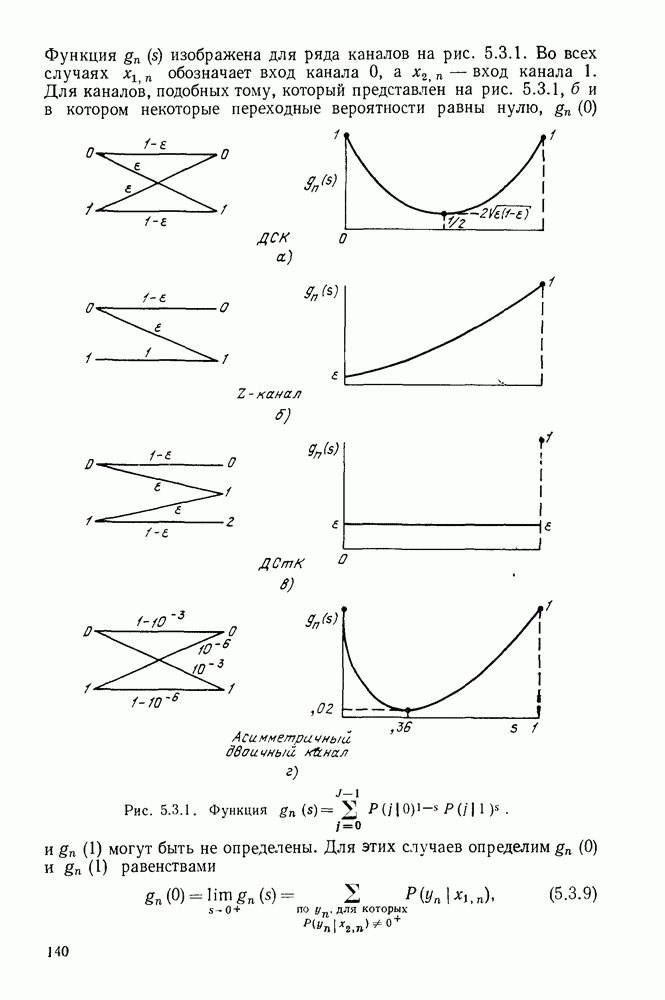
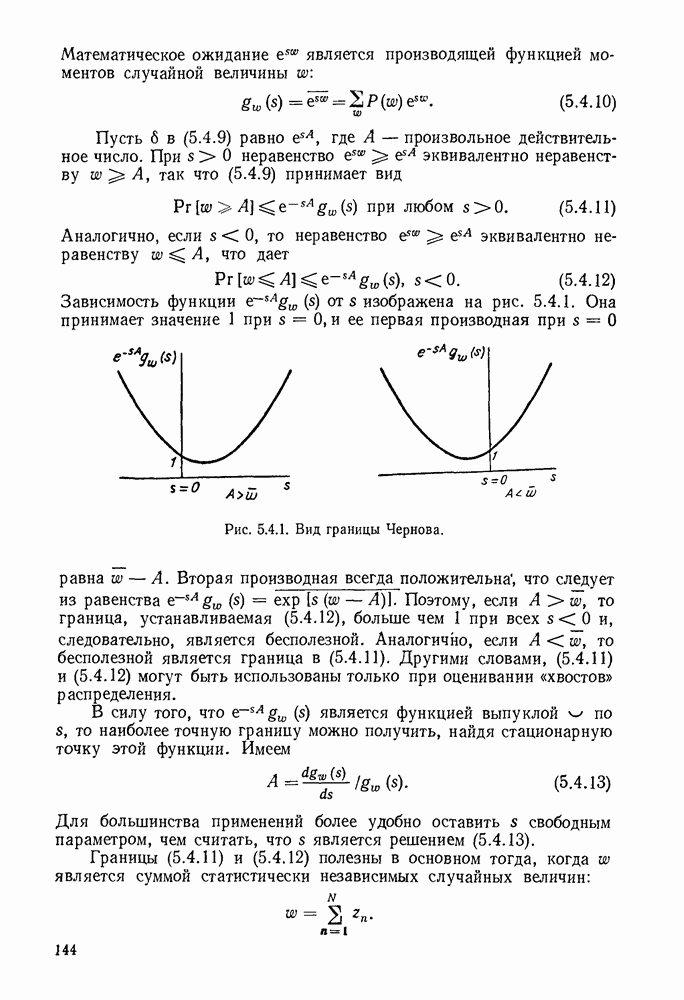
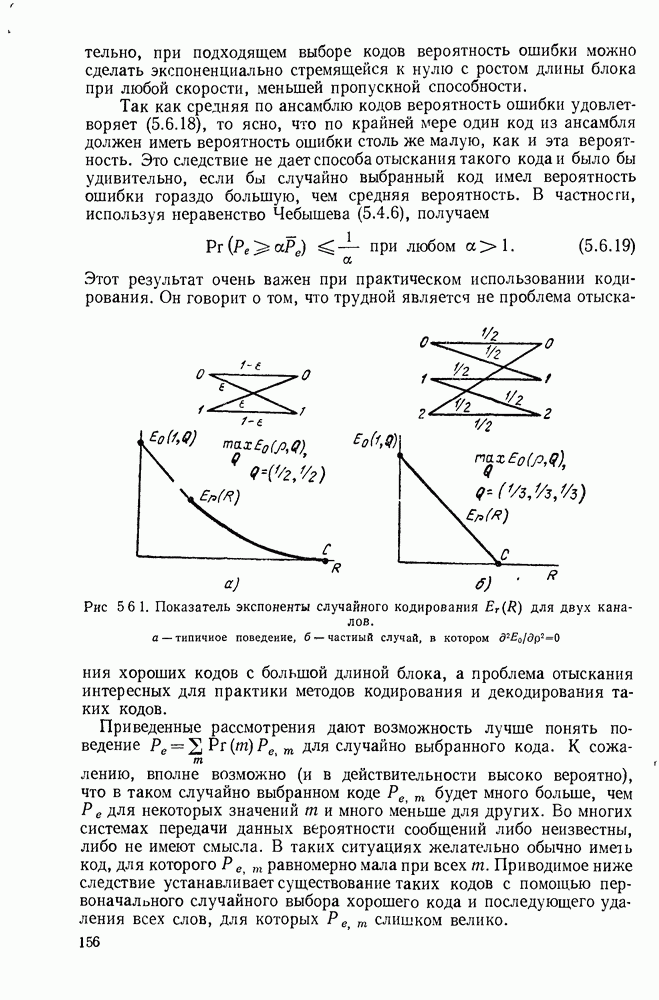
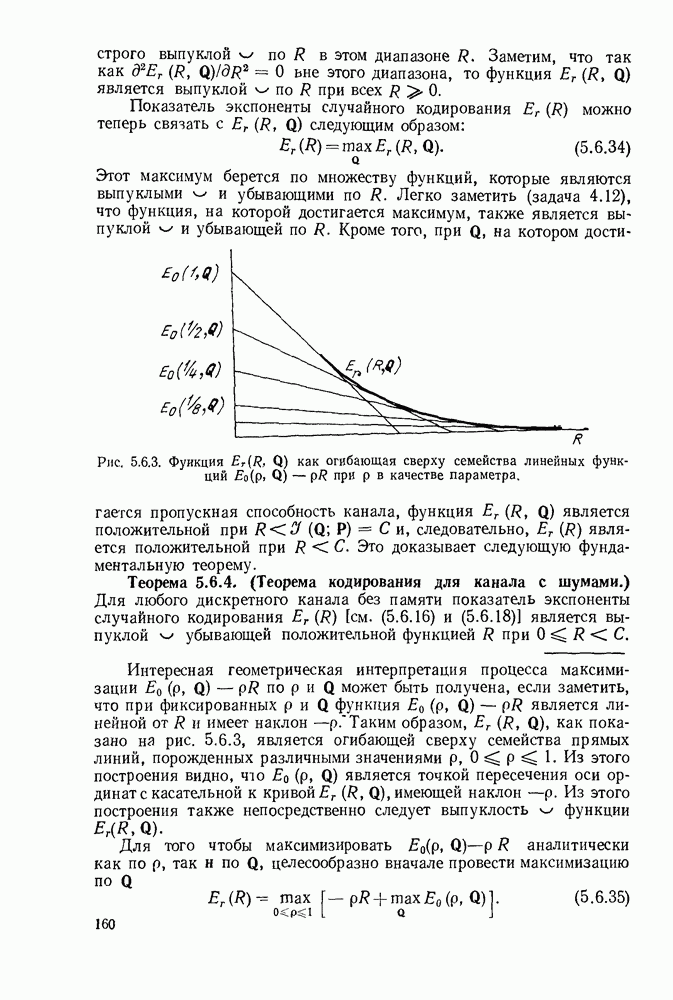
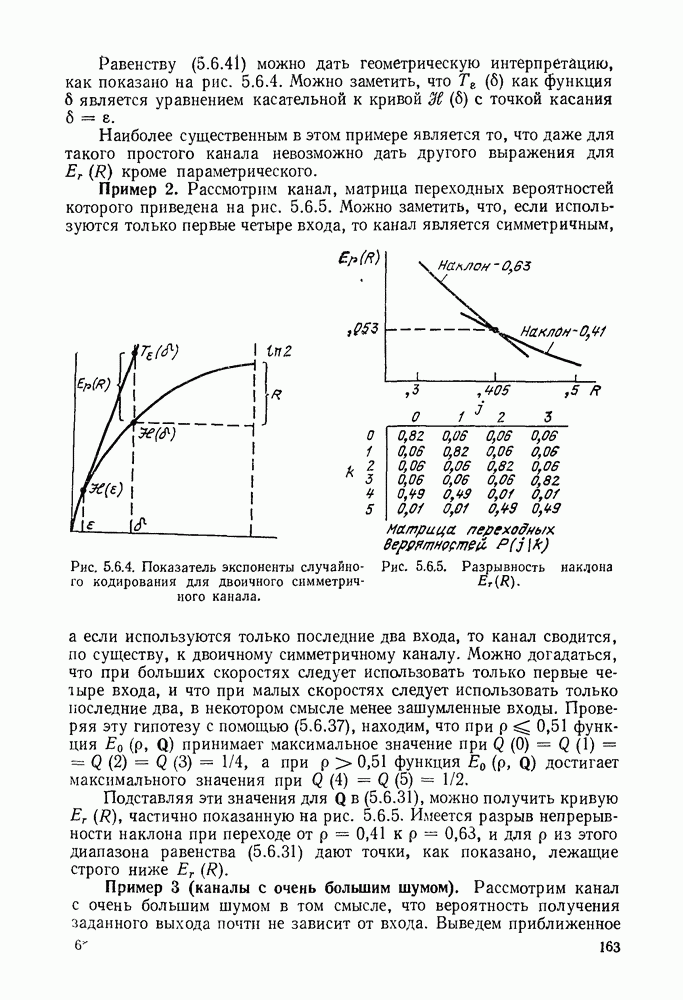
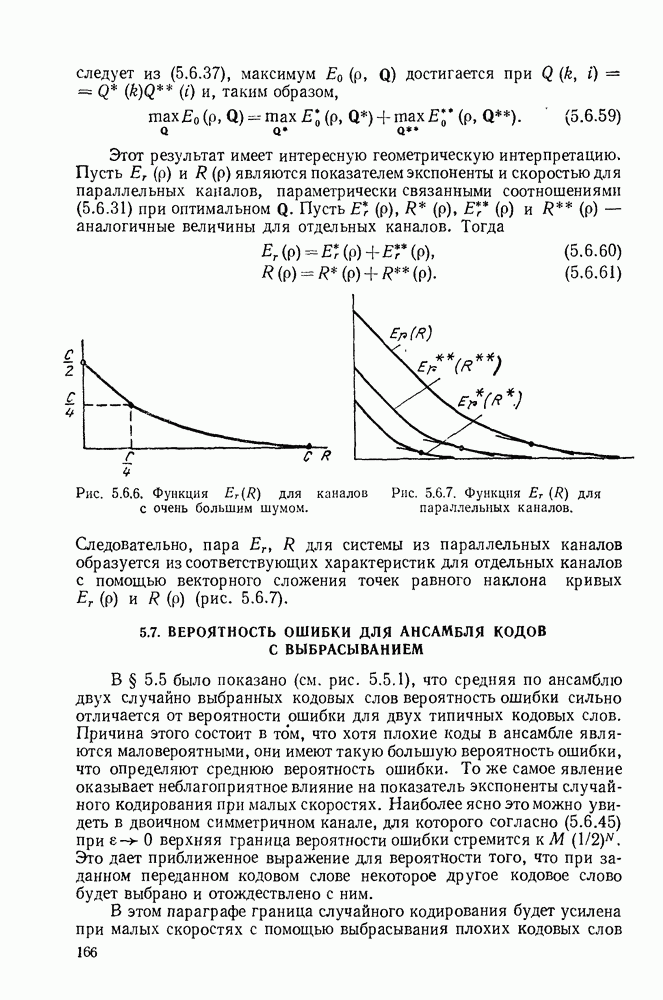
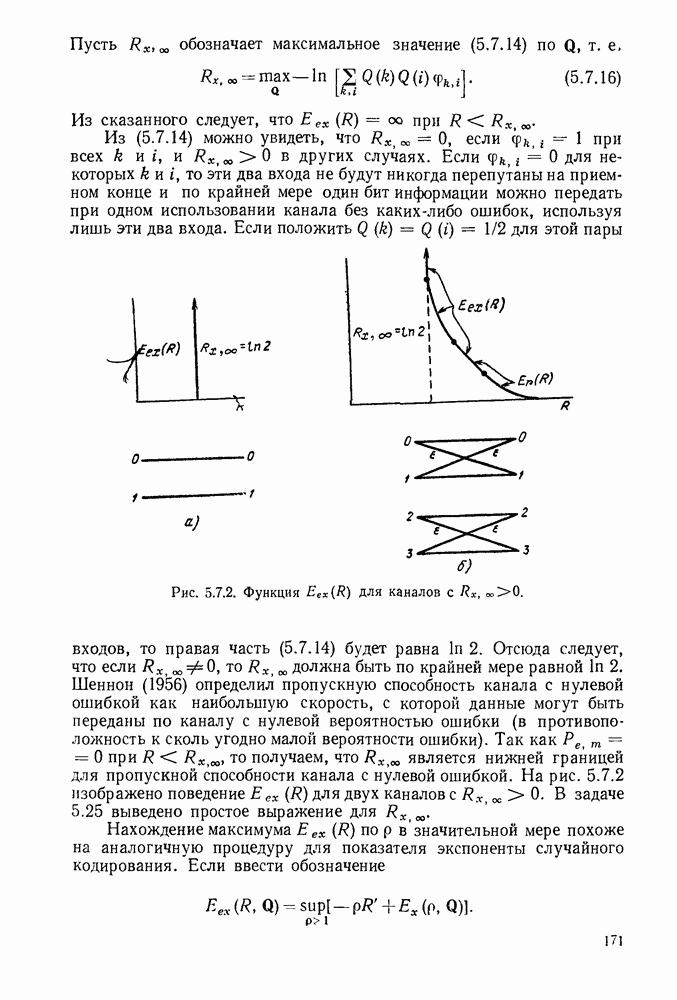
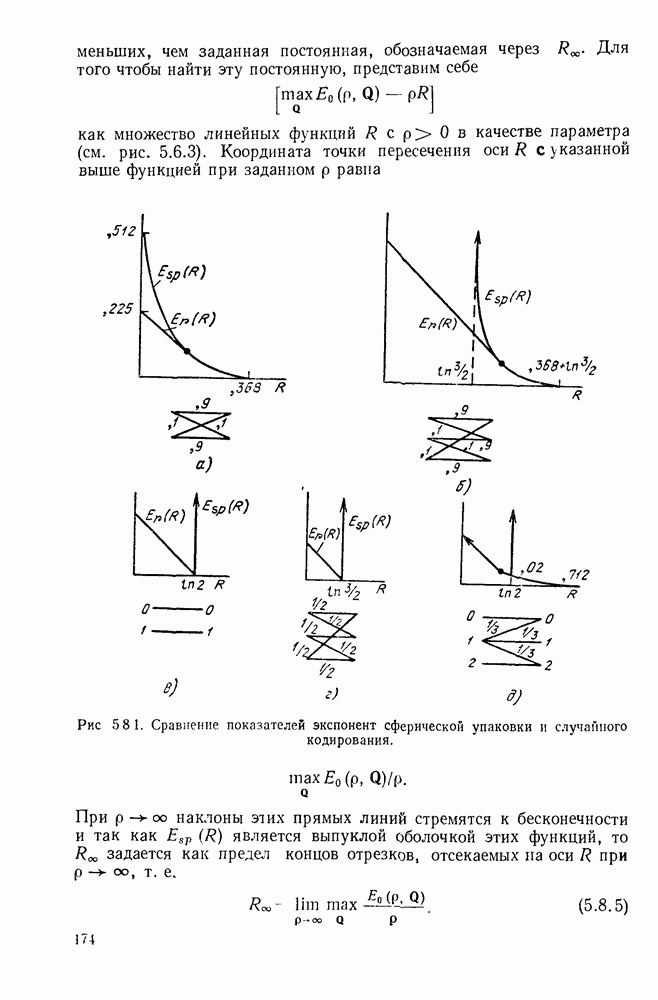
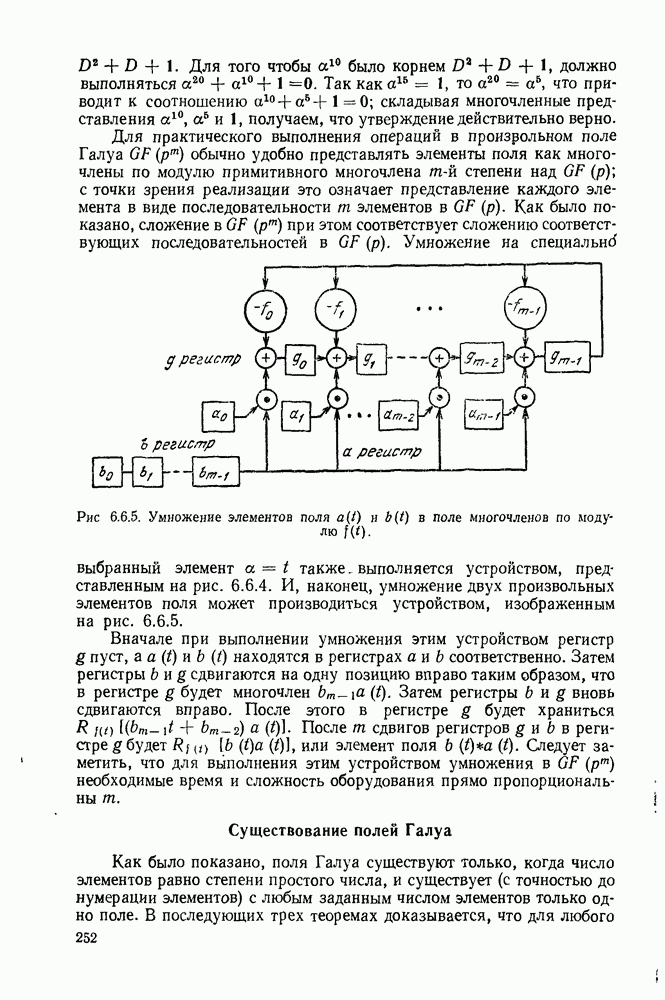
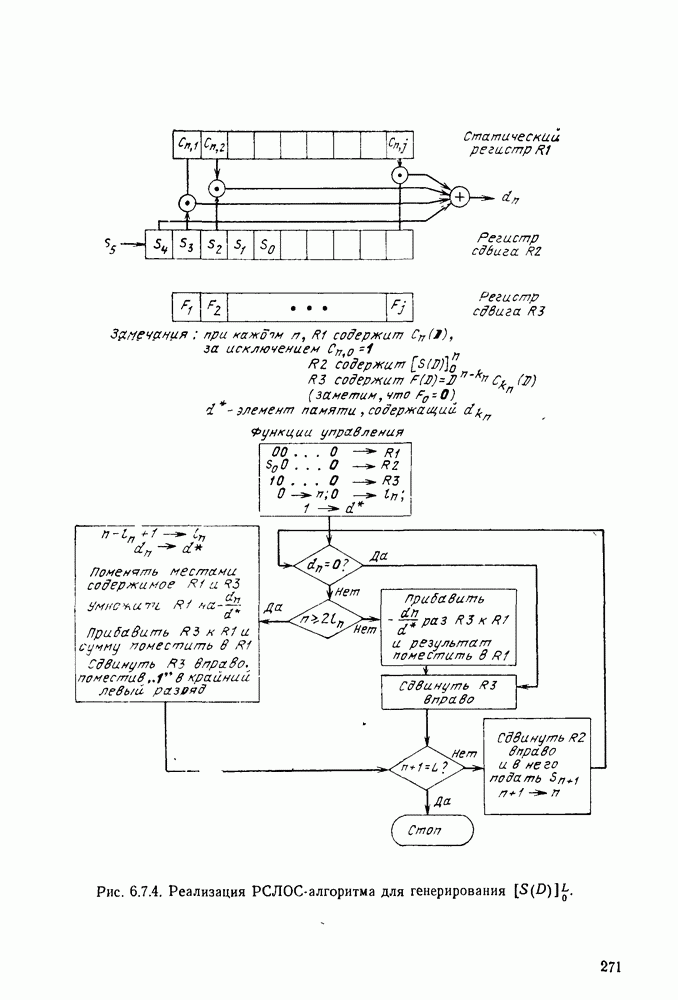
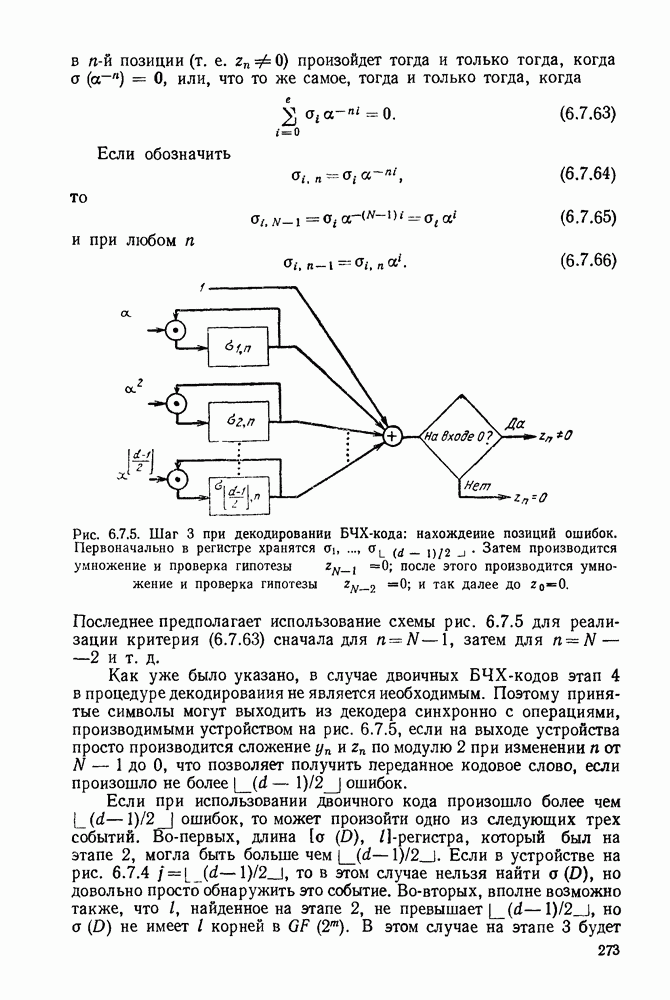
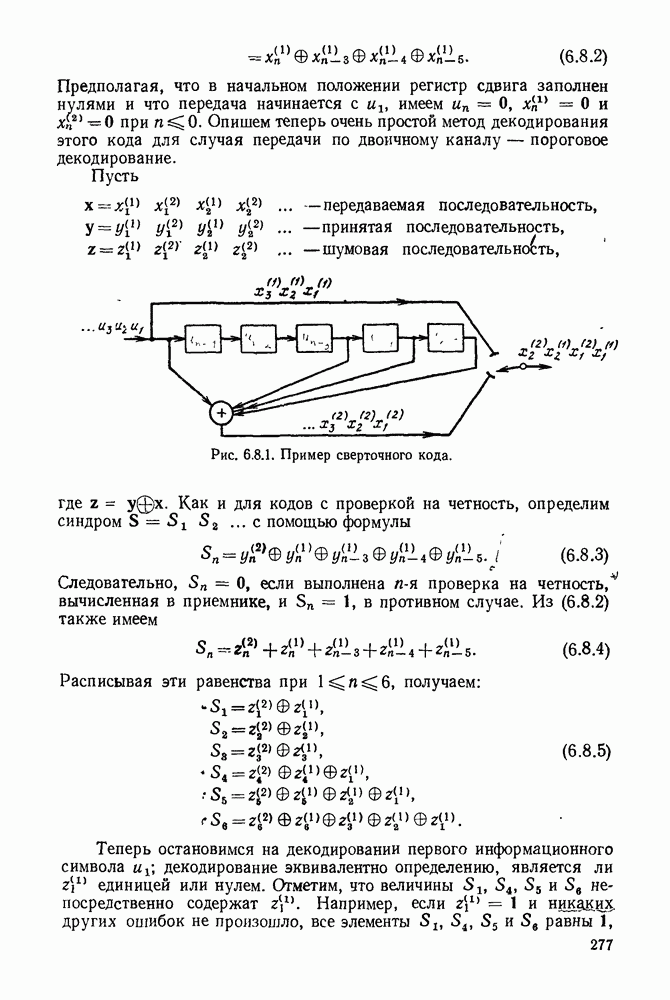
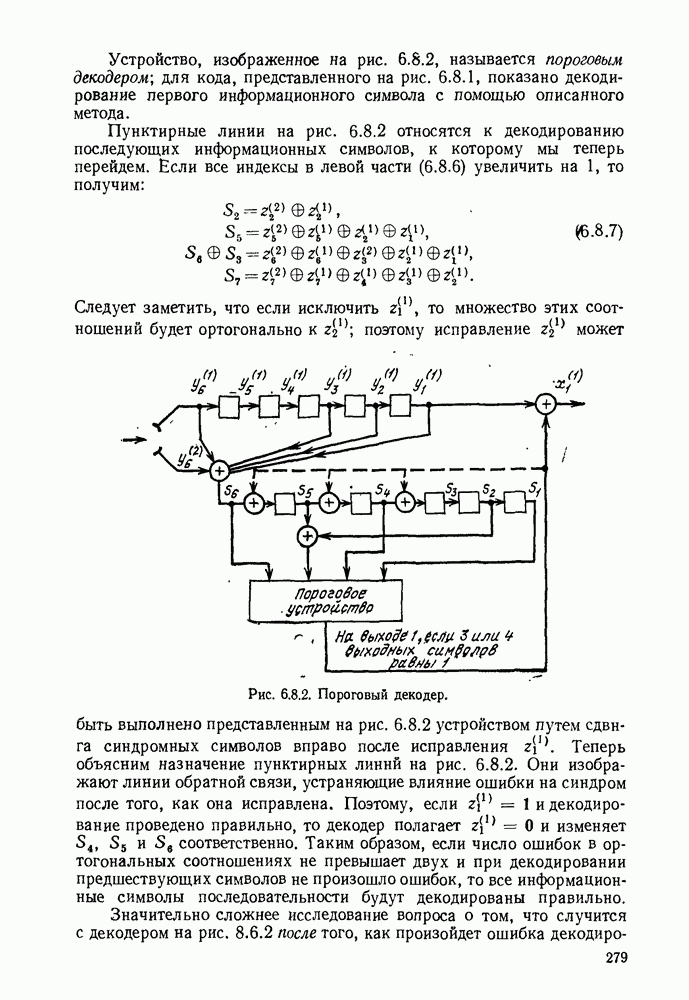
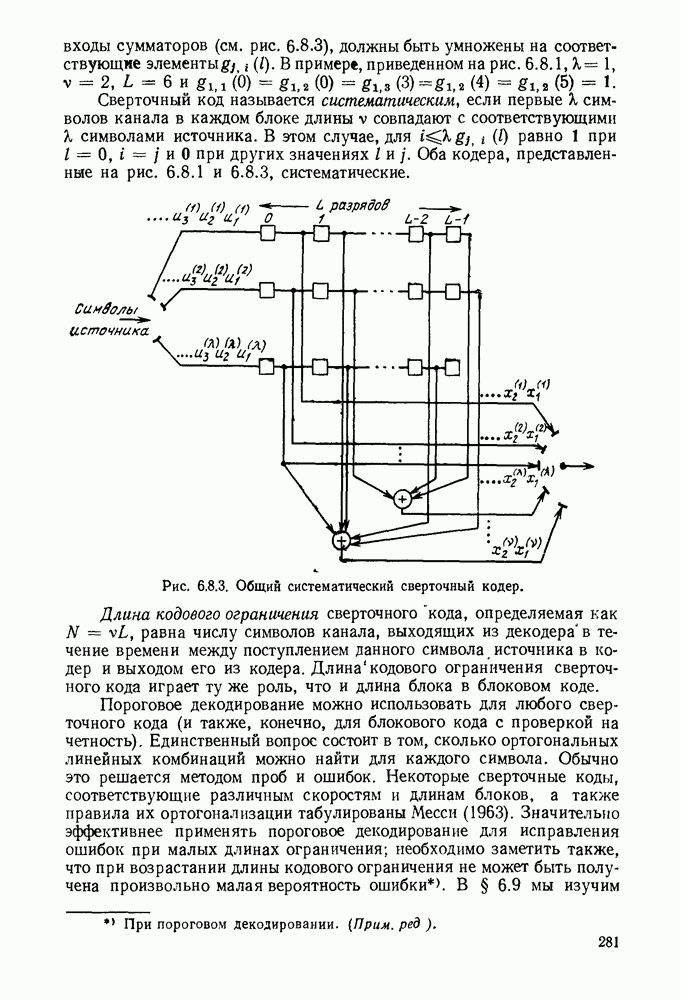
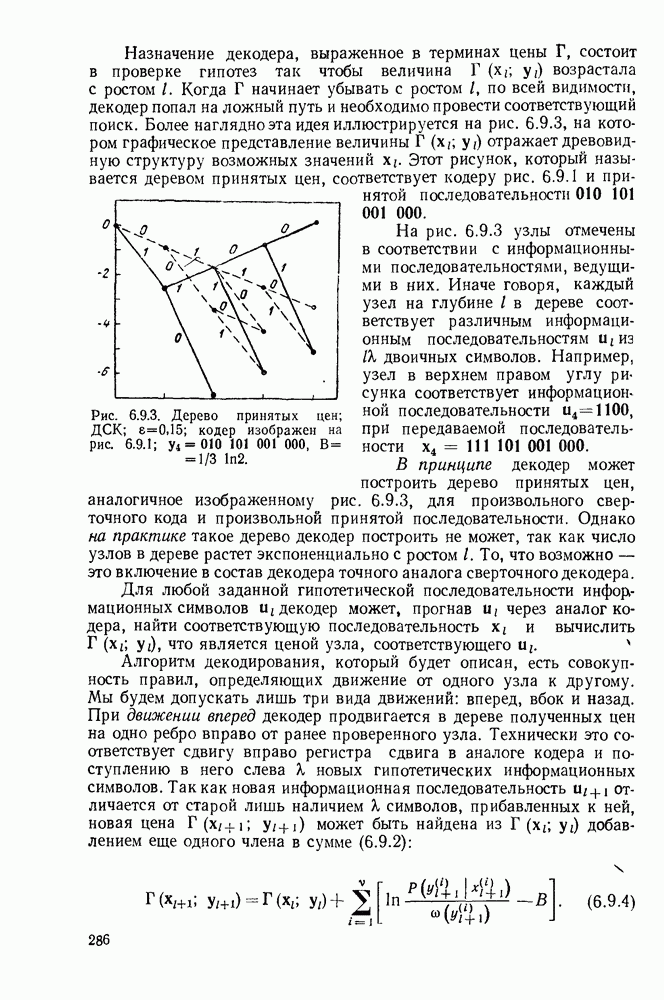
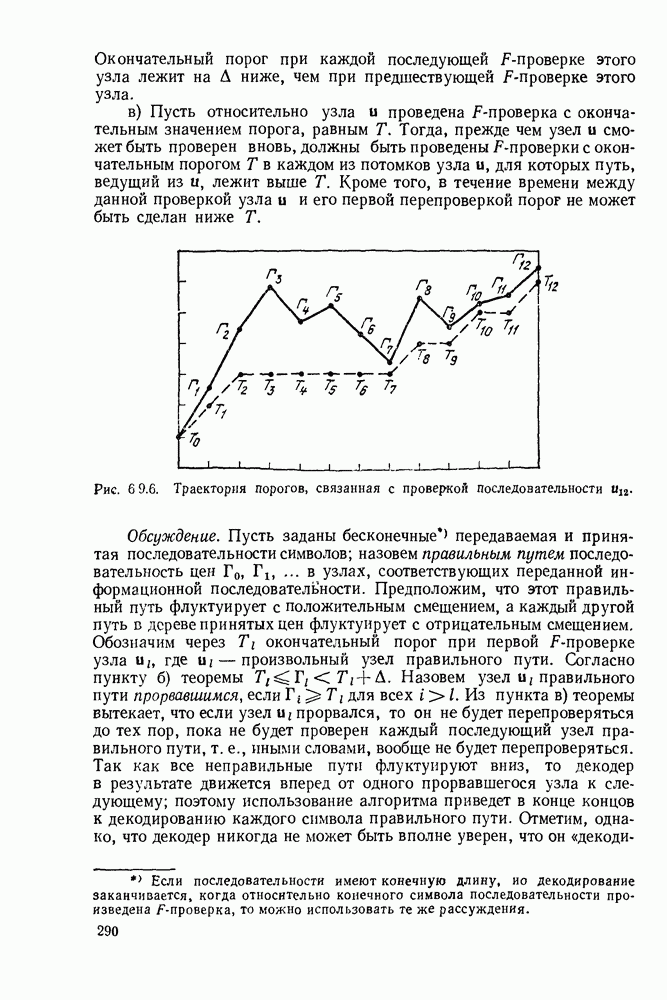
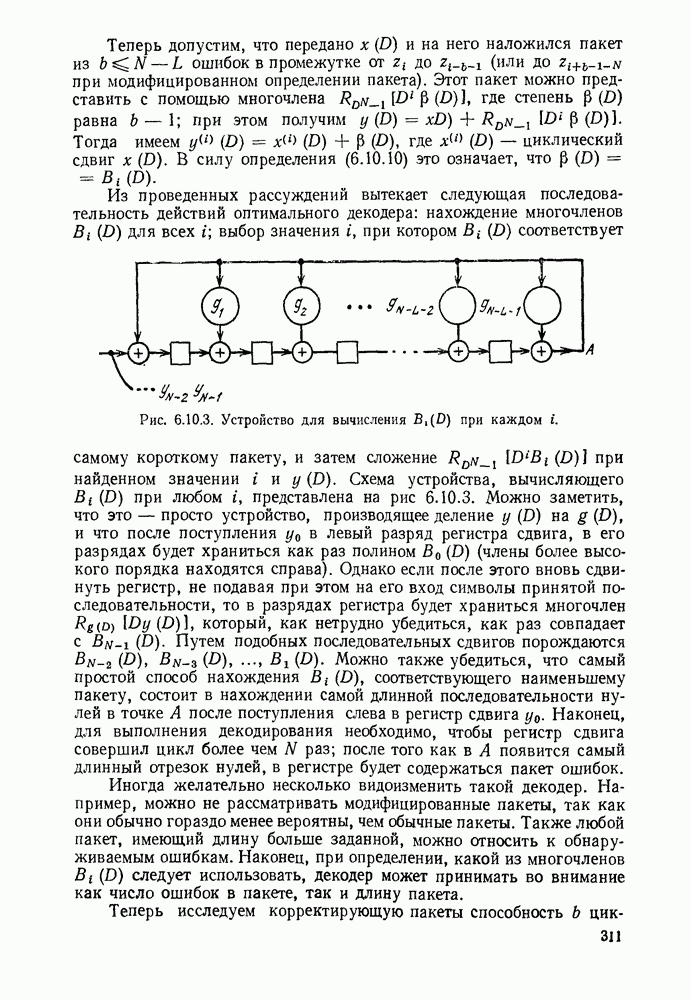
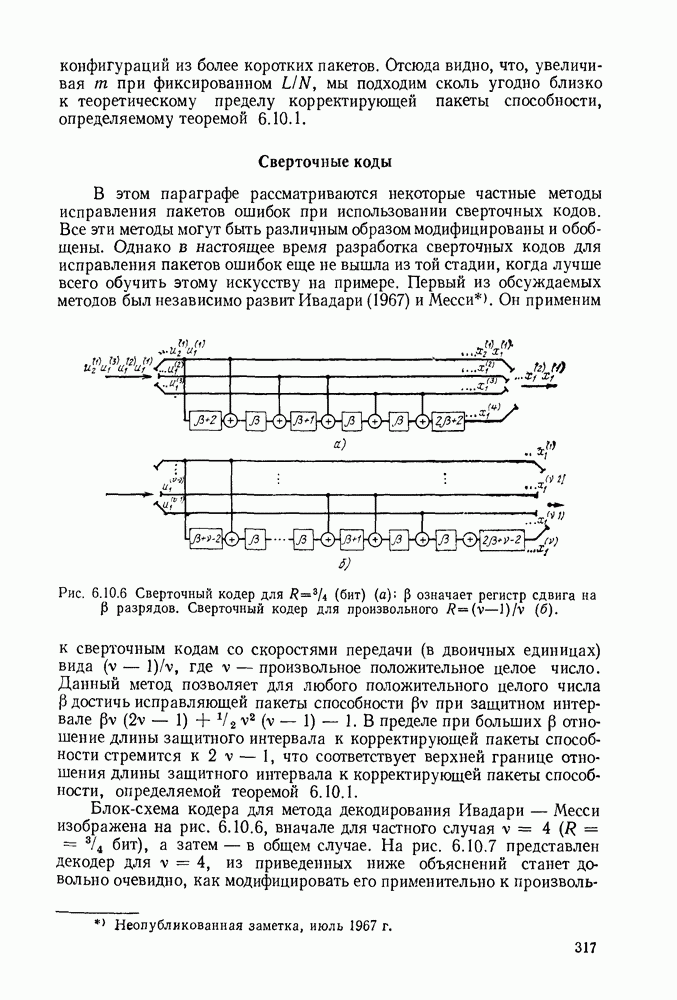
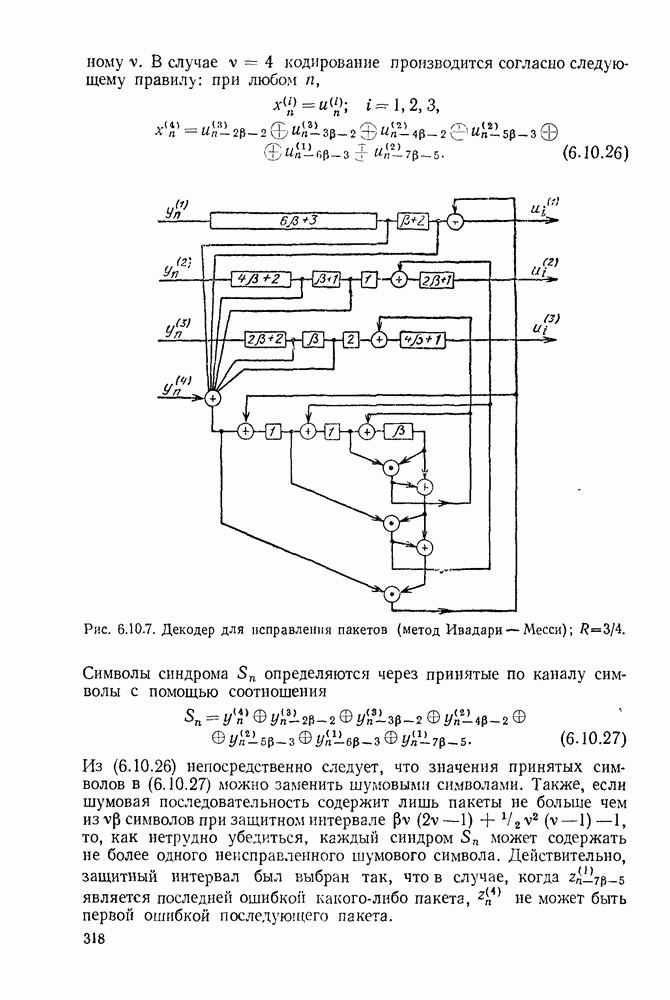
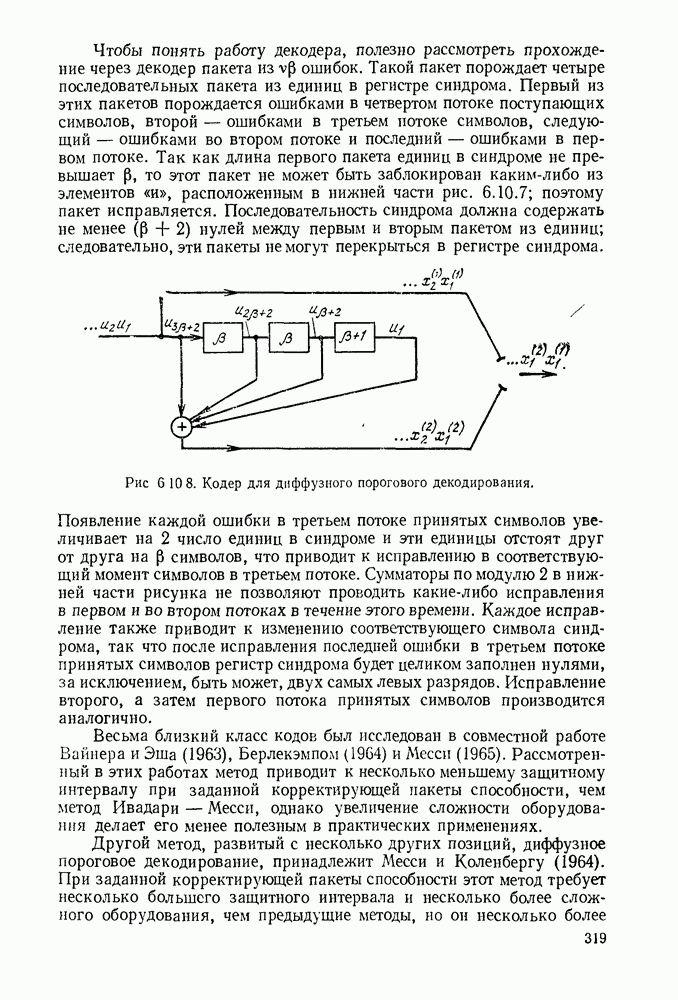
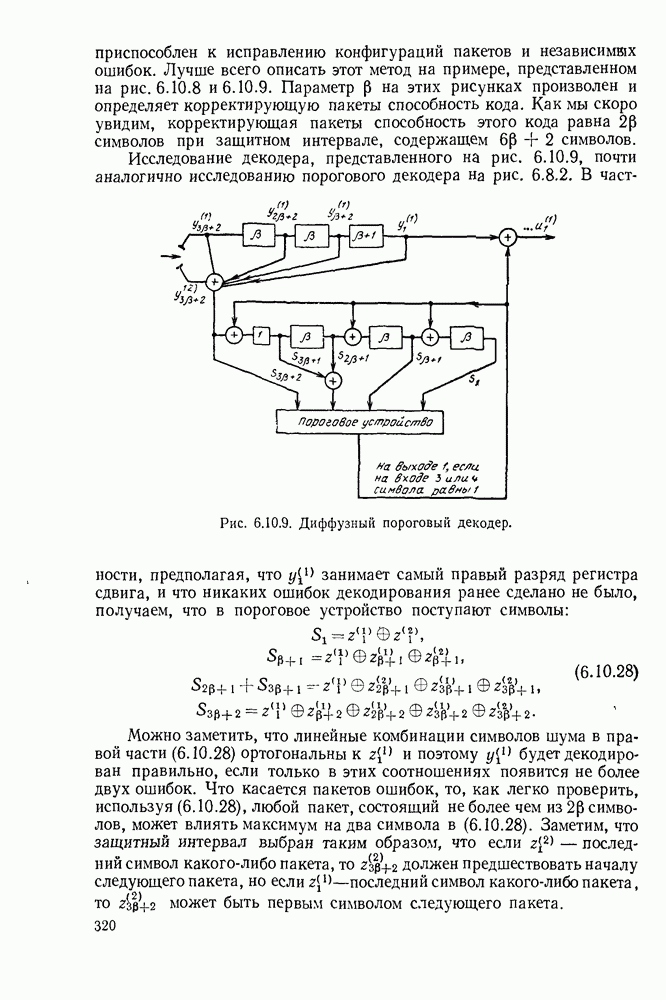
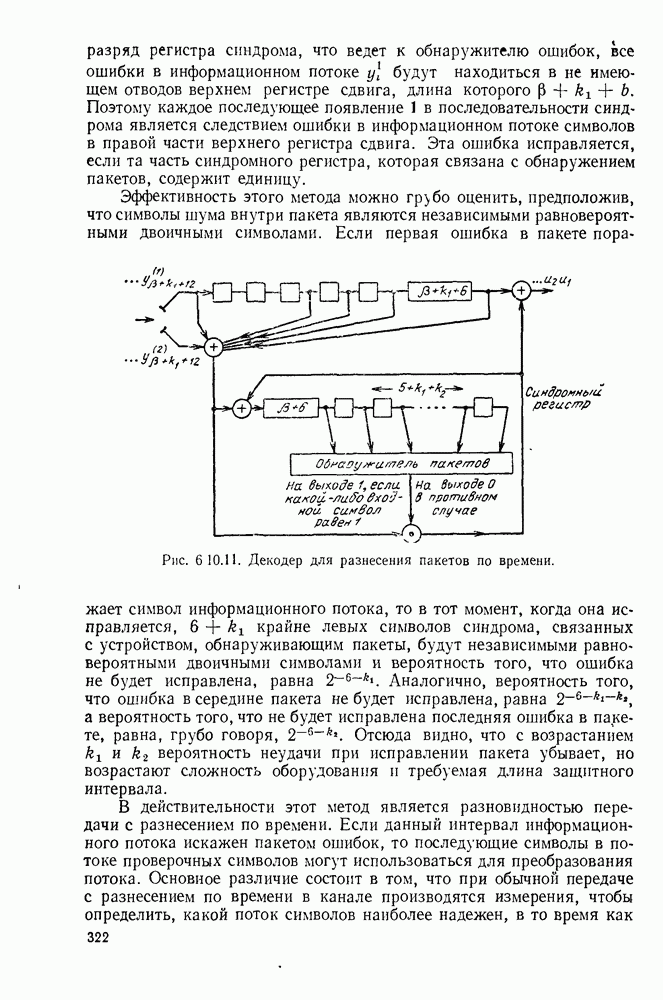
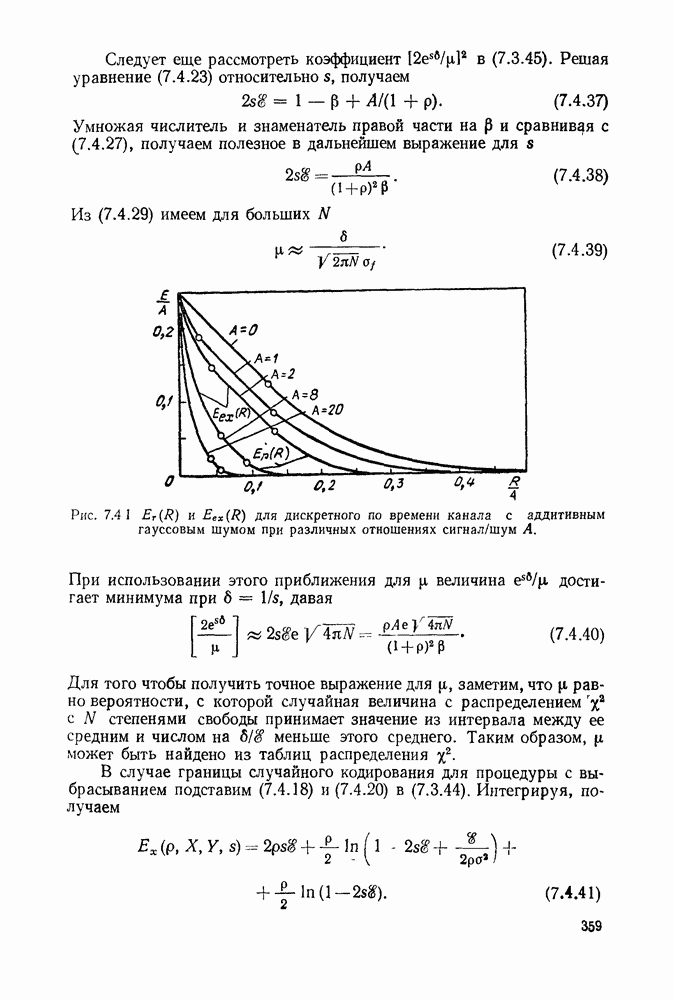
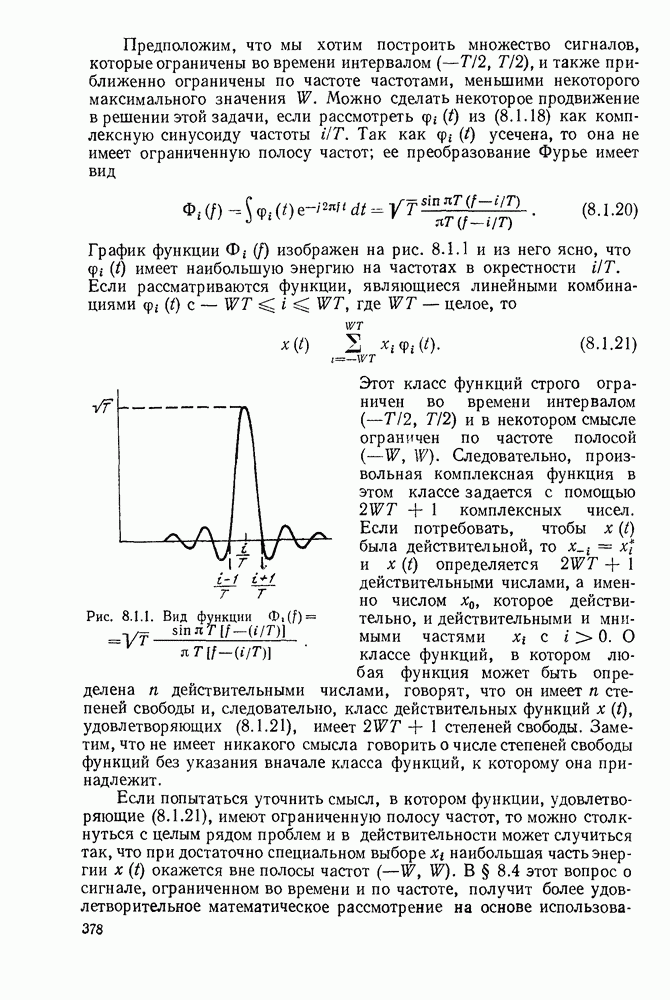
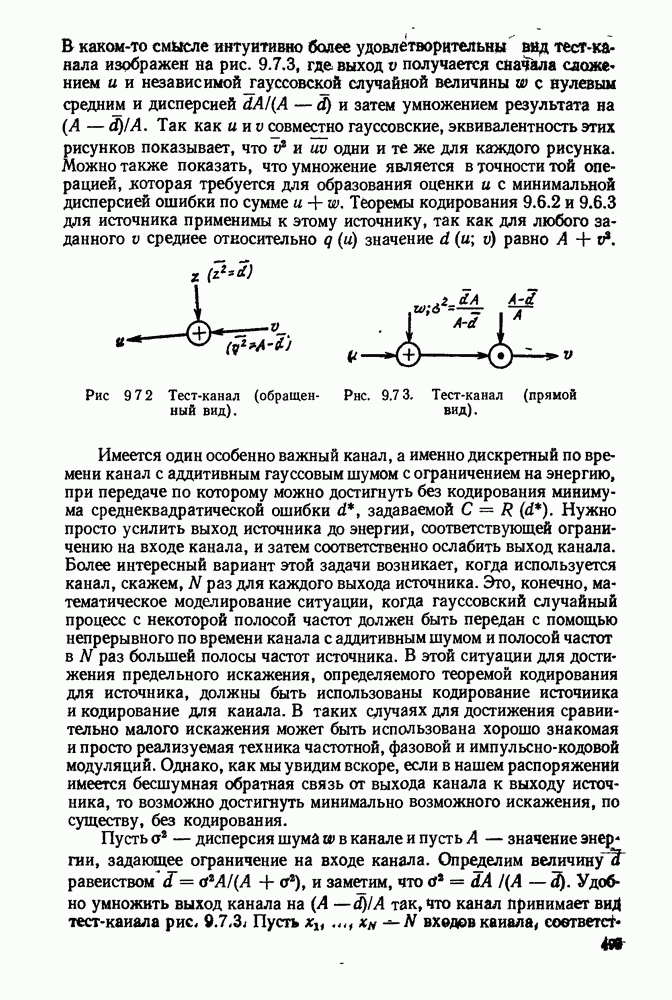
5.5. СЛУЧАЙНЫЕ КОДОВЫЕ СЛОВА
В последнем параграфе было показано, что вероятность ошибочного декодирования для двух кодовых слов стремится к нулю экспоненциально с ростом длины блока. Вместе с тем в этом случае передается только один двоичный символ источника на блок, так что вероятность ошибки уменьшается только за счет скорости передачи. Ясно, что единственной возможностью для снижения вероятности ошибки без уменьшения скорости передачи является рассмотрение большего множества кодовых слов.
Мы хотим исследовать минимально достижимую вероятность ошибочного декодирования как функцию скорости  длины блока N и канала. Будет найдена верхняя граница для этой вероятности ошибочного декодирования, которая убывает экспоненциально с длиной блока для всех скоростей, меньших пропускной способности. Эта граница выводится с помощью рассмотрения ансамбля кодов, а не
длины блока N и канала. Будет найдена верхняя граница для этой вероятности ошибочного декодирования, которая убывает экспоненциально с длиной блока для всех скоростей, меньших пропускной способности. Эта граница выводится с помощью рассмотрения ансамбля кодов, а не
одного-единственного хорошего кода. Этот своеобразный подход продиктован тем, что для представляющих интерес значений  не известно метода отыскания кодов, которые минимизируют вероятность ошибочного декодирования; и даже, если бы такие коды могли быть найдены, прямое вычисление вероятности ошибки было бы невозможным из-за большого числа последовательностей, возможных на приемном конце. В следующей главе будут рассмотрены несколько конкретных методов блокового кодирования и декодирования, которые интересны в силу относительной простоты их реализаций. Для некоторых из этих методов можно подсчитать вероятность ошибки, но при больших значениях N эта вероятность ошибки будет на много больше, чем верхняя граница для минимальной вероятности ошибки, выведенная здесь.
не известно метода отыскания кодов, которые минимизируют вероятность ошибочного декодирования; и даже, если бы такие коды могли быть найдены, прямое вычисление вероятности ошибки было бы невозможным из-за большого числа последовательностей, возможных на приемном конце. В следующей главе будут рассмотрены несколько конкретных методов блокового кодирования и декодирования, которые интересны в силу относительной простоты их реализаций. Для некоторых из этих методов можно подсчитать вероятность ошибки, но при больших значениях N эта вероятность ошибки будет на много больше, чем верхняя граница для минимальной вероятности ошибки, выведенная здесь.
Для того чтобы определить ансамбль блоковых кодов, обозначим через  произвольное распределение вероятности на множестве последовательностей длины N на входе канала и будем считать, что все кодовые слова выбираются независимо с одними и теми же вероятностями. Таким образом, вероятность некоторого частного кода
произвольное распределение вероятности на множестве последовательностей длины N на входе канала и будем считать, что все кодовые слова выбираются независимо с одними и теми же вероятностями. Таким образом, вероятность некоторого частного кода  в этом ансамбле кодов равна
в этом ансамбле кодов равна  Каждый код из ансамбля имеет свою собственную вероятность ошибочного декодирования, возникающую при декодировании по максимуму правдоподобия для этого кода. Мы оценим сверху математическое ожидание (по ансамблю) этой вероятности ошибки. Так как по крайней мере один код из ансамбля должен иметь такую же вероятность ошибки, как среднее по ансамблю, это даст границу для вероятности ошибки наилучшего кода (т. е. кода с минимальной
Каждый код из ансамбля имеет свою собственную вероятность ошибочного декодирования, возникающую при декодировании по максимуму правдоподобия для этого кода. Мы оценим сверху математическое ожидание (по ансамблю) этой вероятности ошибки. Так как по крайней мере один код из ансамбля должен иметь такую же вероятность ошибки, как среднее по ансамблю, это даст границу для вероятности ошибки наилучшего кода (т. е. кода с минимальной 
Для того чтобы понять, почему этот подход является разумным, рассмотрим опять двоичный симметричный канал. Если выбрать для этого канала два кодовых слова длины N случайно, выбирая символы каждого слова независимо и принимающими значения 0 или 1 с равными вероятностями, то при больших N эти два кодовых слова будут с большой вероятностью отличаться приближенно в половине позиций блока. Из (5.3.12) следует, что если  то
то  Если
Если  при
при  Следовательно, для двух кодовых слов, отличающихся в
Следовательно, для двух кодовых слов, отличающихся в  позициях, вероятность ошибки ограничена выражением
позициях, вероятность ошибки ограничена выражением

Это не является средней вероятностью ошибки по ансамблю кодов; это просто вероятность ошибки для типичного кода из ансамбля. Это отличие в дальнейшем будет обсуждено более детально.
Показатель степени в (5.5.1) равен половине показателя для двух кодовых слов, отличающихся в каждой позиции, но  все еще стремится к 0 экспоненциально по
все еще стремится к 0 экспоненциально по  В качестве компенсации за это уменьшение показателя степени появляется способ рассмотрения больших множеств кодовых слов, не требующий заботы о детальном выборе слов. Однако для больших множеств кодовых слов каждое кодовое слово не может отличаться от любого другого кодового слова во всех
В качестве компенсации за это уменьшение показателя степени появляется способ рассмотрения больших множеств кодовых слов, не требующий заботы о детальном выборе слов. Однако для больших множеств кодовых слов каждое кодовое слово не может отличаться от любого другого кодового слова во всех
позициях и, как будет показано, отмеченного уменьшения показателя не возникает.
Рассмотрим теперь произвольный дискретный канал, в котором  является вероятностью получения последовательности у при условии, что была послана последовательность х. Как следует из (5.3.4), для двух заданных кодовых слов
является вероятностью получения последовательности у при условии, что была послана последовательность х. Как следует из (5.3.4), для двух заданных кодовых слов  вероятность ошибки при передаче какого-либо слова ограничена следующим образом:
вероятность ошибки при передаче какого-либо слова ограничена следующим образом:

Если рассмотреть теперь ансамбль кодов, в котором кодовые слова выбираются независимо в соответствии с распределением вероятности  то вероятность кода с некоторыми частными кодовыми словами
то вероятность кода с некоторыми частными кодовыми словами  равна
равна  Следовательно, средняя вероятность ошибки по ансамблю имеет вид
Следовательно, средняя вероятность ошибки по ансамблю имеет вид

Минимум  имеет место при
имеет место при  Для того чтобы показать это, заметим, что
Для того чтобы показать это, заметим, что  в (5.5.5) являются просто глухими индексами суммирования. Поэтому, если поменять местами
в (5.5.5) являются просто глухими индексами суммирования. Поэтому, если поменять местами  то функция не изменится и, следовательно, она является симметричной относительно
то функция не изменится и, следовательно, она является симметричной относительно  Так же в силу того, что (как уже было показано) правая часть (5.5.2) является выпуклой
Так же в силу того, что (как уже было показано) правая часть (5.5.2) является выпуклой  по
по  то правая часть (5.5.5) также является выпуклой
то правая часть (5.5.5) также является выпуклой  по
по  Из симметрии и выпуклости следует, что минимум должен быть в точке
Из симметрии и выпуклости следует, что минимум должен быть в точке  и поэтому
и поэтому

Если канал является каналом без памяти, то

В этом случае (5.5.6) можно упростить, если положить

где  произвольное распределение вероятности для буквы. Другими словами, рассматривается ансамбль, в котором каждая буква любого кодового слова выбирается независимо с распределением вероятности
произвольное распределение вероятности для буквы. Другими словами, рассматривается ансамбль, в котором каждая буква любого кодового слова выбирается независимо с распределением вероятности  При этом (5.5.6) можно представить в виде
При этом (5.5.6) можно представить в виде

После раздельного суммирования по  каждого сомножителя в произведении [аналогично тому, как это было в (5.3.5)], получим
каждого сомножителя в произведении [аналогично тому, как это было в (5.3.5)], получим

Изменяя порядок возведения в квадрат, умножения и суммирования по  точно так же, как это было сделано для
точно так же, как это было сделано для  получаем
получаем

Так как в (5.5.9) суммирование по  производится по входному алфавиту
производится по входному алфавиту  и суммирование по
и суммирование по  производится по выходному алфавиту
производится по выходному алфавиту  то это дает
то это дает

Это представляет собой границу сверху для средней вероятности ошибки по ансамблю кодов с двумя кодовыми словами длины  Буквы кодовых слов выбираются независимо с вероятностями
Буквы кодовых слов выбираются независимо с вероятностями  и канал является дискретным каналом без памяти с переходными вероятностями
и канал является дискретным каналом без памяти с переходными вероятностями  . В двоичном симметричном канале, положив
. В двоичном симметричном канале, положив  из (5.5.10) получаем
из (5.5.10) получаем

Можно заметить, что граница в (5.5.11) отличается от границы в (5.5.1). На рис. 5.5.1 проиллюстрировано это отличие в зависимости от 
Причина этого отличия может быть понята с наибольшей ясностью в пределе при стремлении  к 0. Вероятность ошибки для типичного кода с кодовыми словами, отличающимися в половине позиций, очевидно, стремится к нулю. Вместе с тем вероятность того, что в ансамбле кодов два выбранных кодовых слова будут совпадать; равна
к 0. Вероятность ошибки для типичного кода с кодовыми словами, отличающимися в половине позиций, очевидно, стремится к нулю. Вместе с тем вероятность того, что в ансамбле кодов два выбранных кодовых слова будут совпадать; равна  это дает границу для
это дает границу для  в (5.5.11). Другими словами, при малых
в (5.5.11). Другими словами, при малых  средняя вероятность ошибки
средняя вероятность ошибки  определяется не типичными кодами, а в высшей степени специфическими кодами, для которых
определяется не типичными кодами, а в высшей степени специфическими кодами, для которых  велика.
велика.
Приведенное рассуждение довольно просто, но оно часто используется в теории информации. Если требуется получить надежную передачу по каналу с шумами, то нужно сконцентрировать внимание
на специфических событиях, которые вызывают ошибки, а не на типичных событиях, которые не вызывают ошибок. К сожалению, этим важным принципом часто пренебрегают при построении моделей физических каналов связи.

Рис. 5.5.1. Граница ошибочного декодирования для двух кодовых слов. Сравнение между случайным выбором и случаем, когда имеется отличие в  позициях.
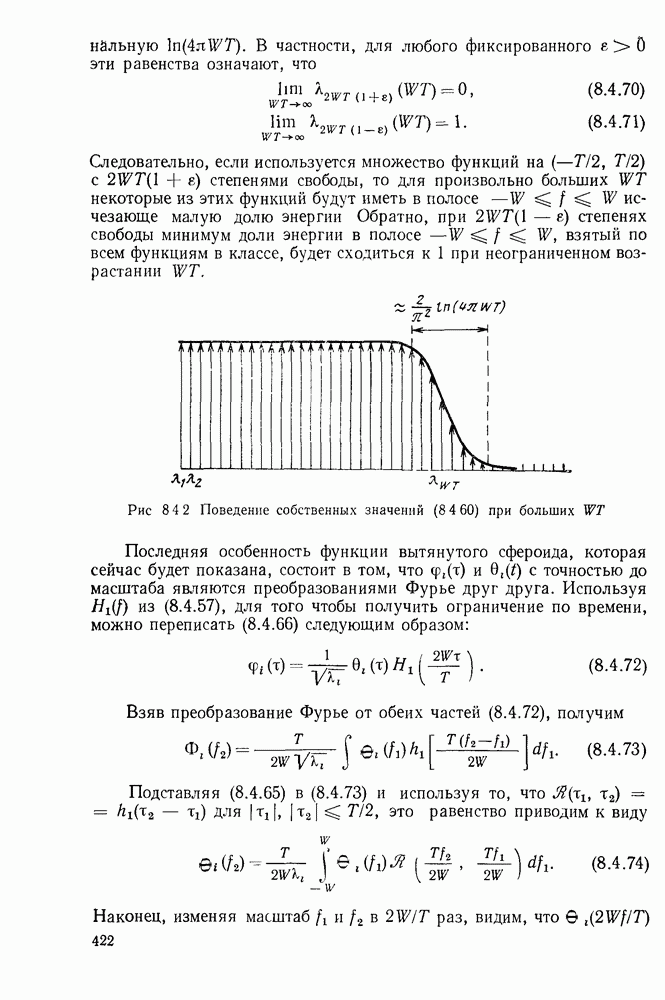
позициях.
Теперь мы почти подготовлены для отыскания верхней границы  для более чем двух кодовых слов, но вначале приведем другой вывод границы (5.5.4). Заметим, что
для более чем двух кодовых слов, но вначале приведем другой вывод границы (5.5.4). Заметим, что  является средним по
является средним по  Когда сообщение 1 кодируется в
Когда сообщение 1 кодируется в  то у происходит с вероятностью
то у происходит с вероятностью  и будем считать, что ошибка возникает, если
и будем считать, что ошибка возникает, если  Таким образом,
Таким образом,  можно записать в виде
можно записать в виде

где  [ошибка
[ошибка  ] - вероятность (по ансамблю выборов
] - вероятность (по ансамблю выборов  того, что произойдет ошибка, при условии, что на кодер поступило сообщение 1, первым кодовым словом является
того, что произойдет ошибка, при условии, что на кодер поступило сообщение 1, первым кодовым словом является  и было принято у. Имеем
и было принято у. Имеем

При  выражение (5.5.13) можно ограничить сверху, умножая каждое слагаемое на
выражение (5.5.13) можно ограничить сверху, умножая каждое слагаемое на  при любом
при любом  Далее, строя границу с помощью суммирования по всем
Далее, строя границу с помощью суммирования по всем  получаем
получаем

Вместе с тем этот результат можно интерпретировать как границу Чернова для

где в качестве вероятностной меры используется 
Подставляя (5.5.14) в (5.5.12), получаем снова (5.5.4). Другое доказательство понадобилось здесь потому, что оно может быть легко обобщено на случай произвольного числа кодовых слов.