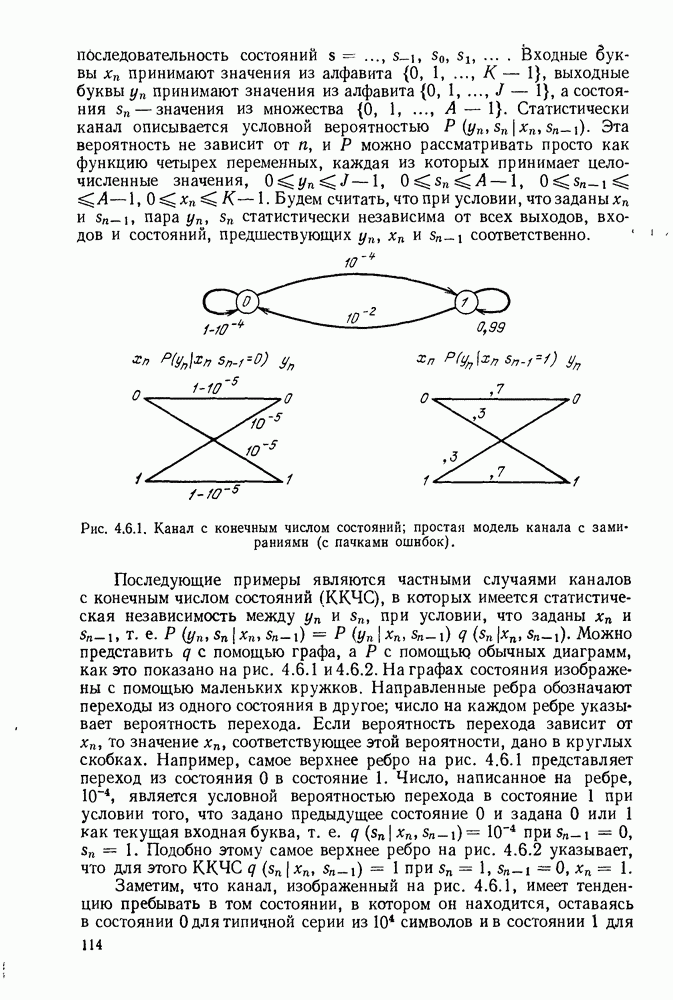
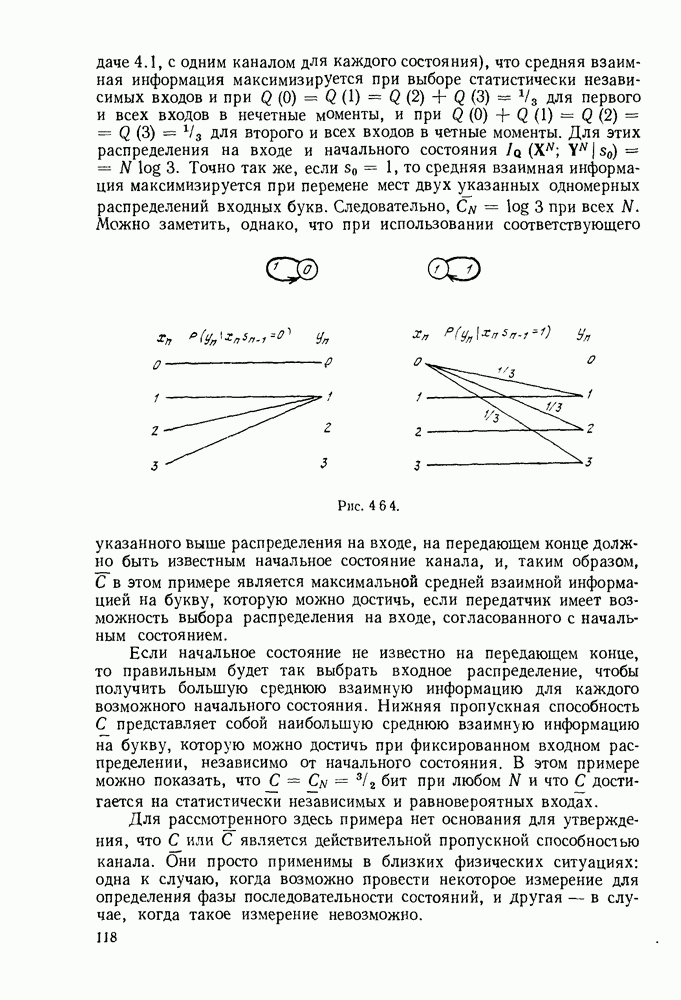
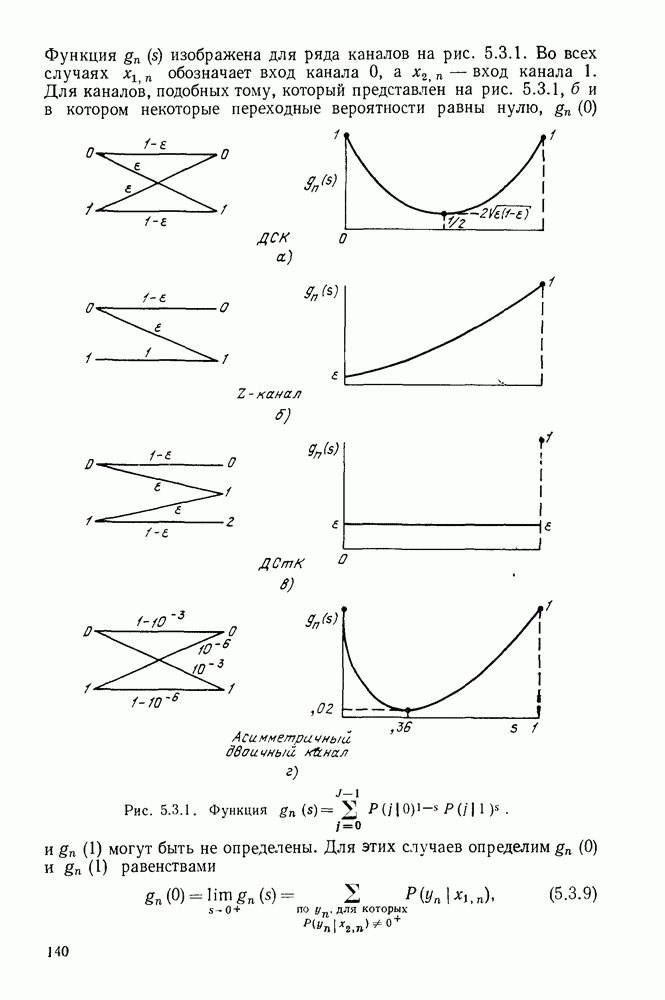
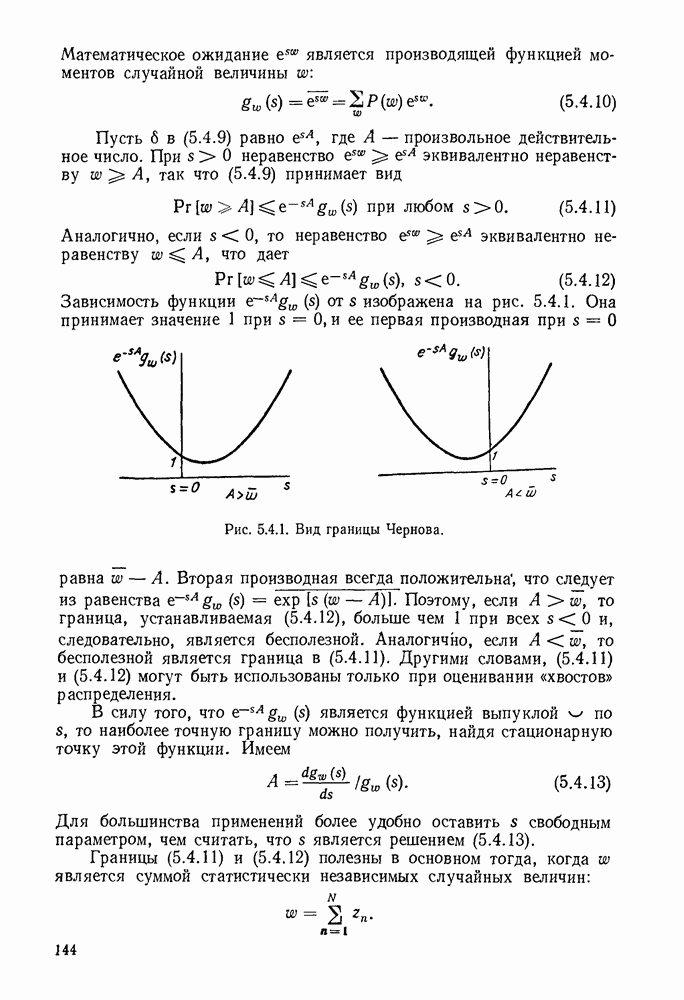
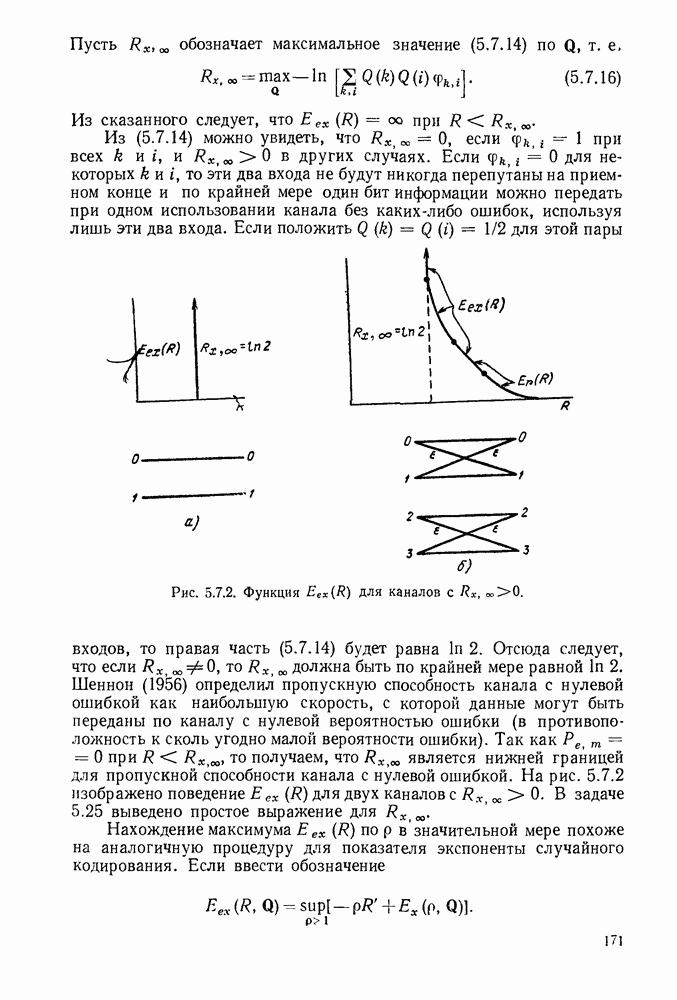
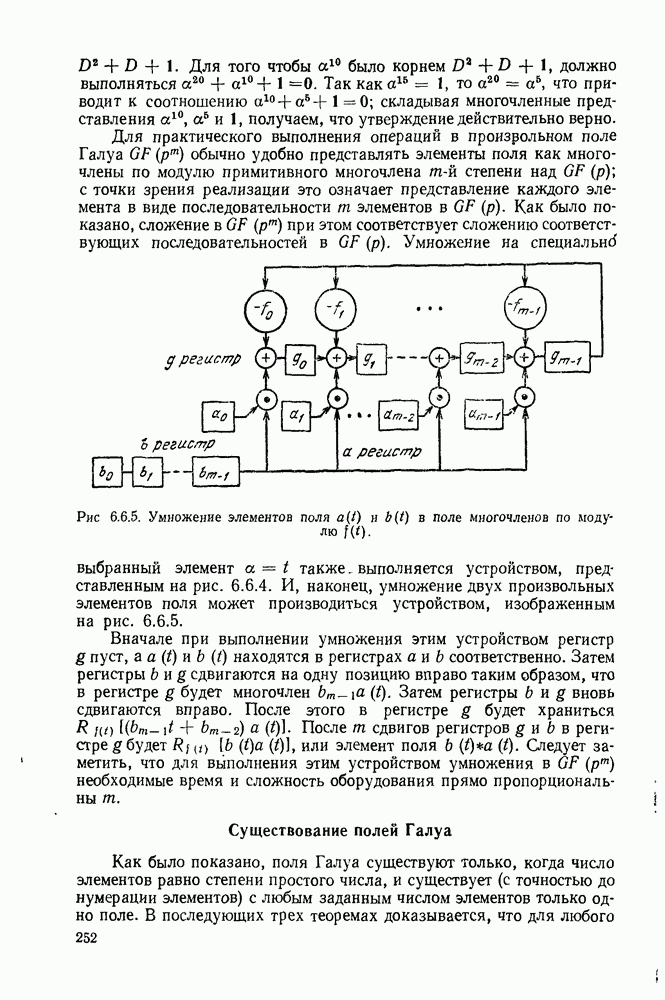
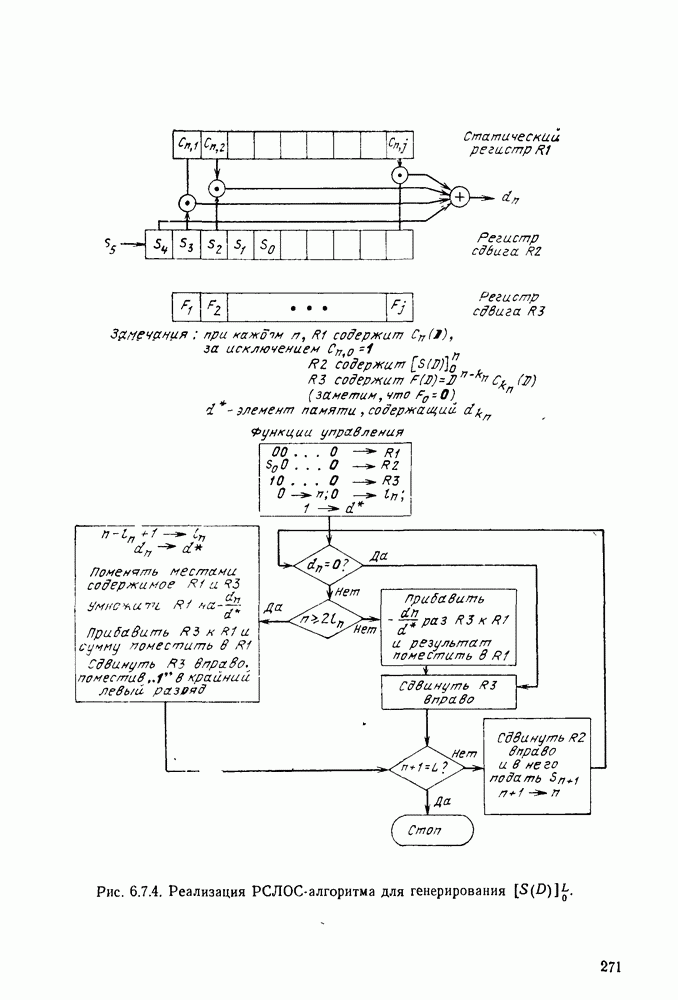
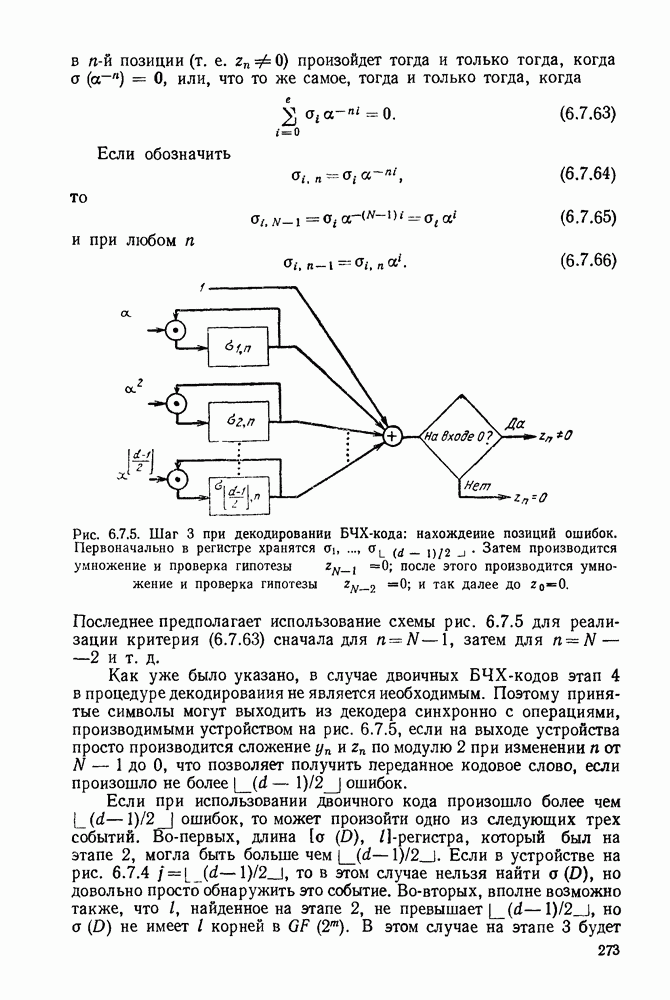
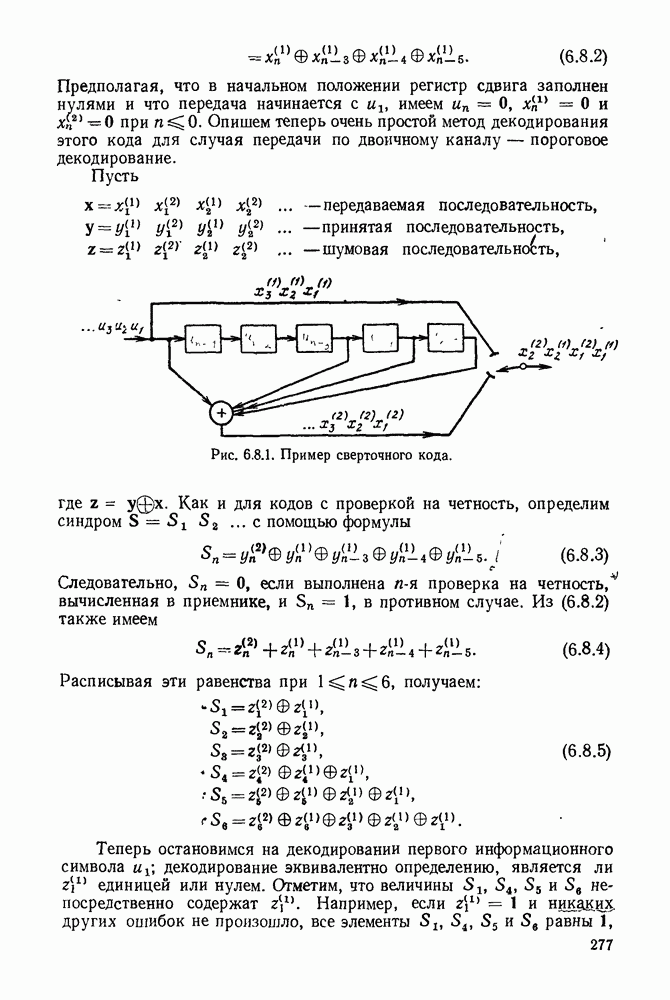
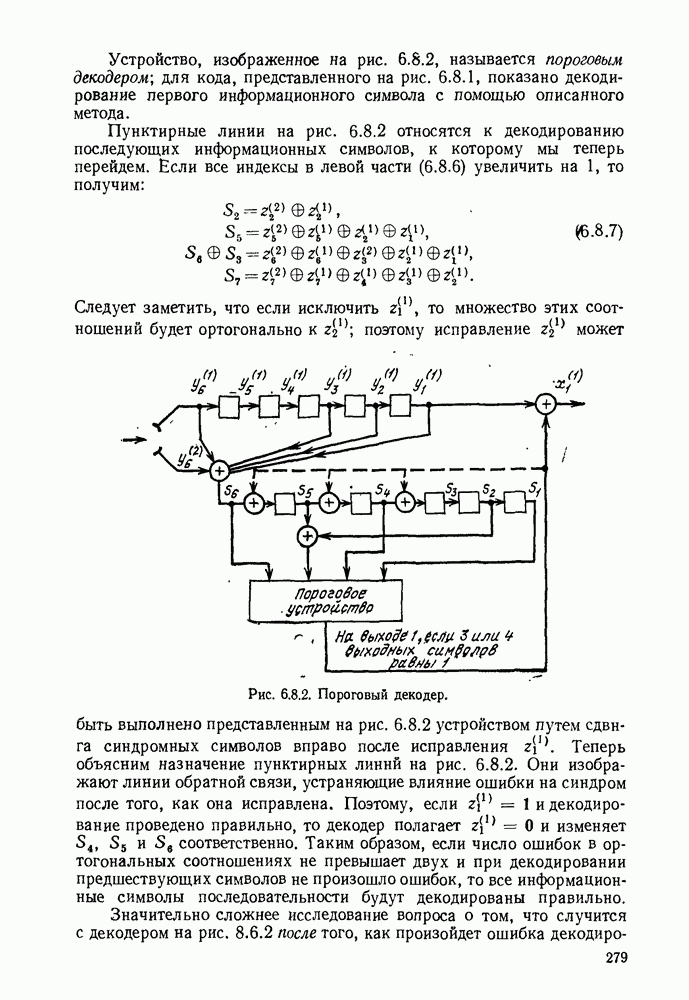
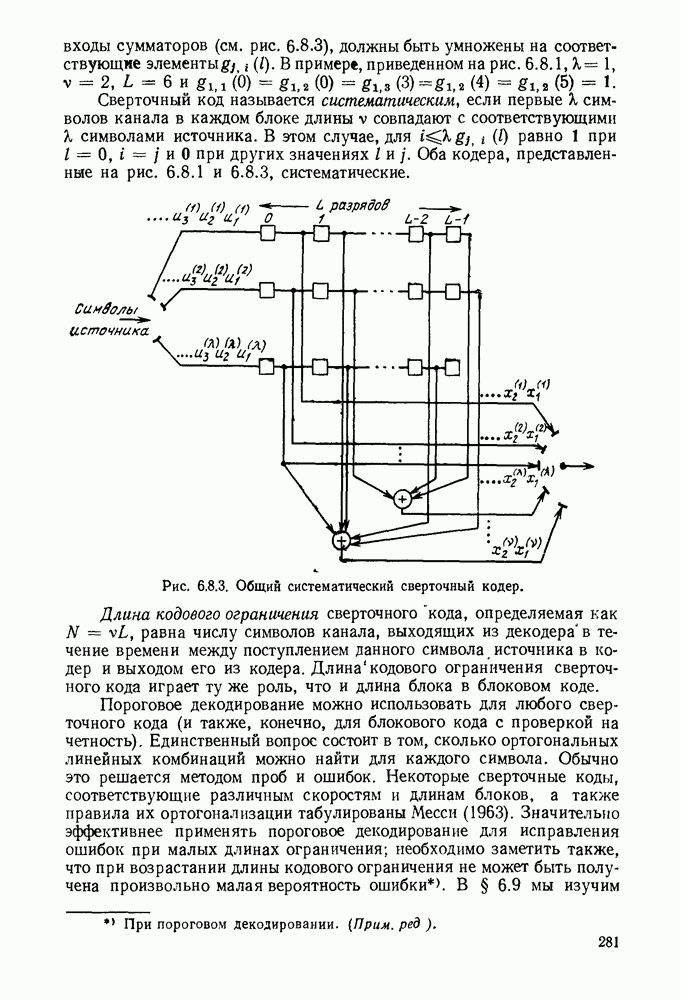
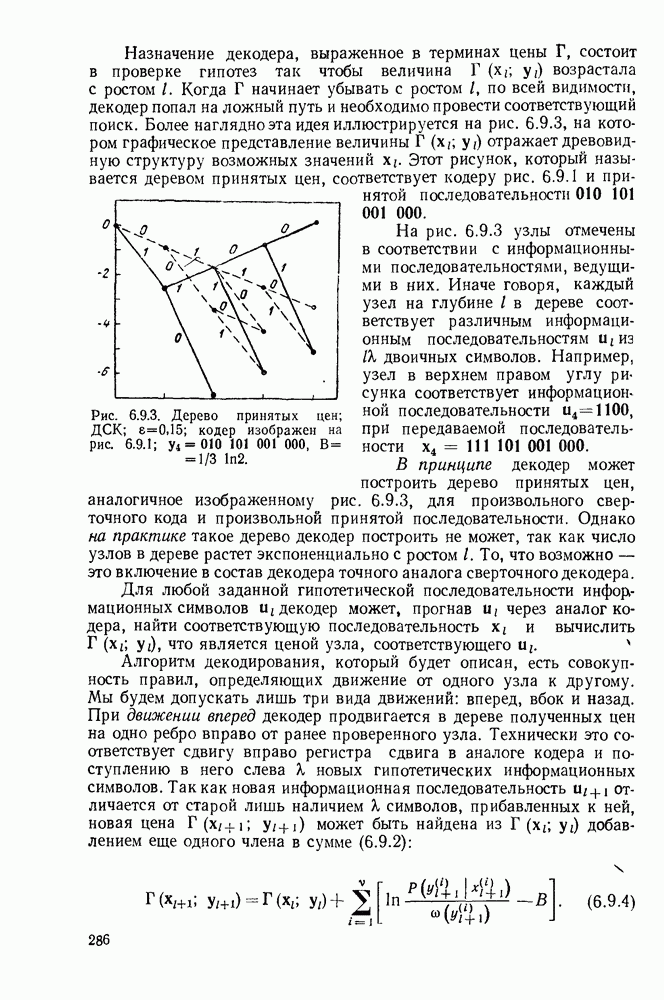
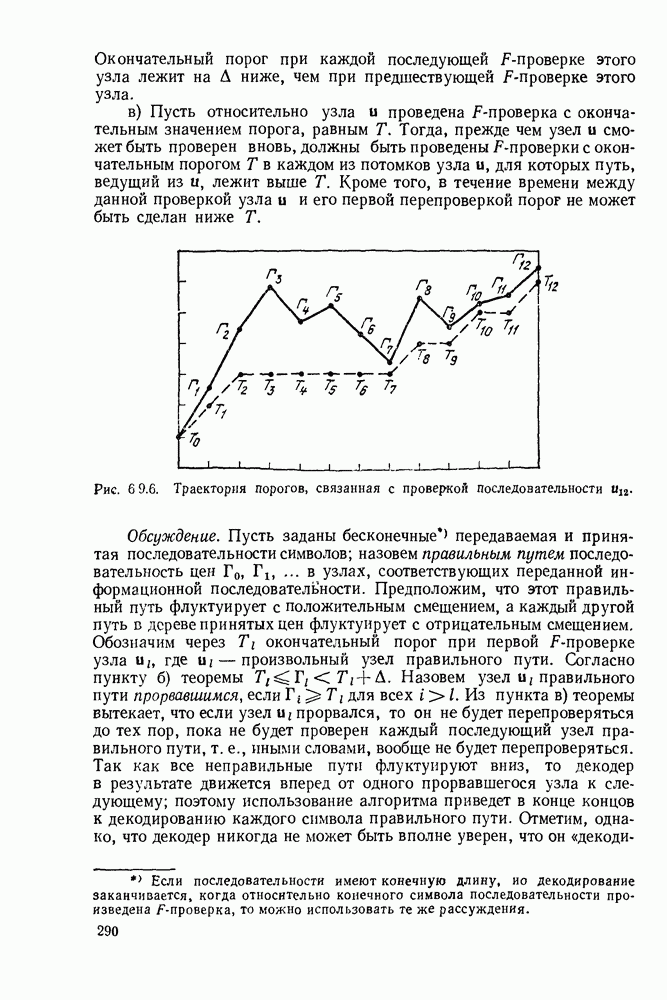
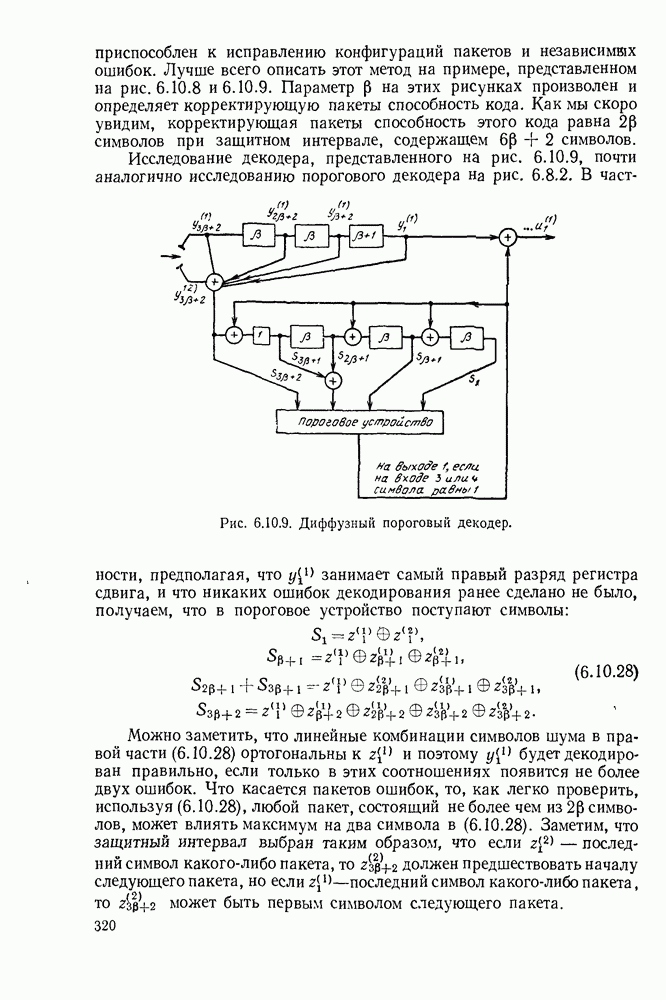
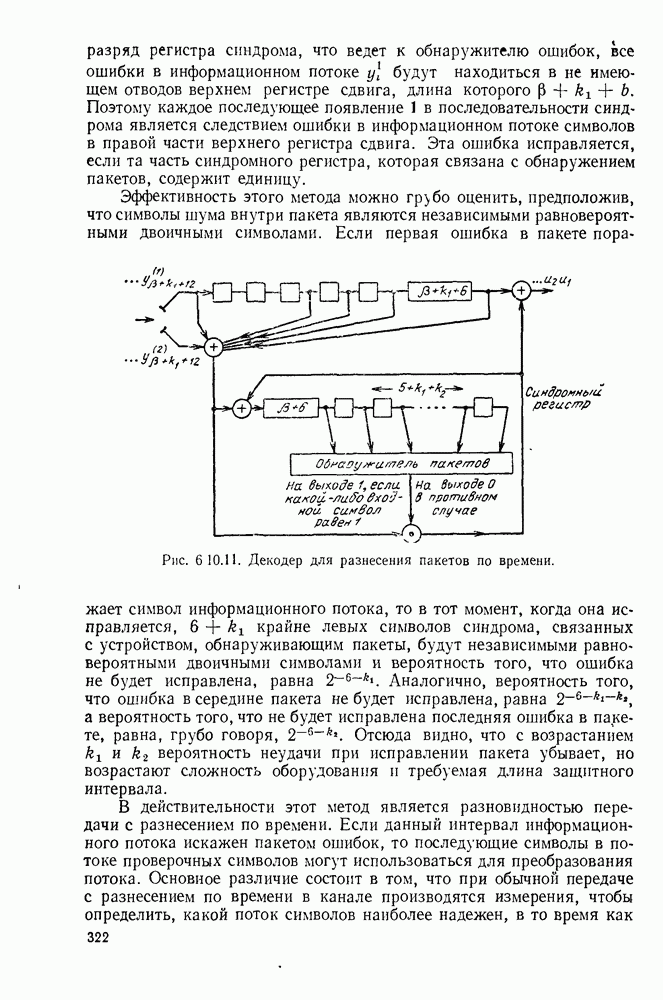
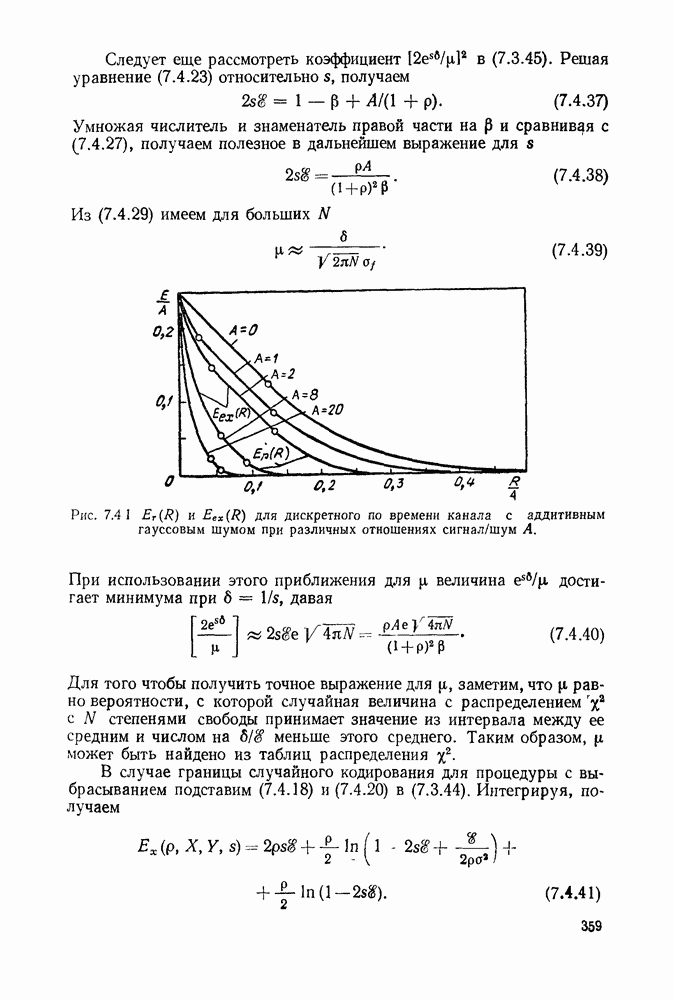
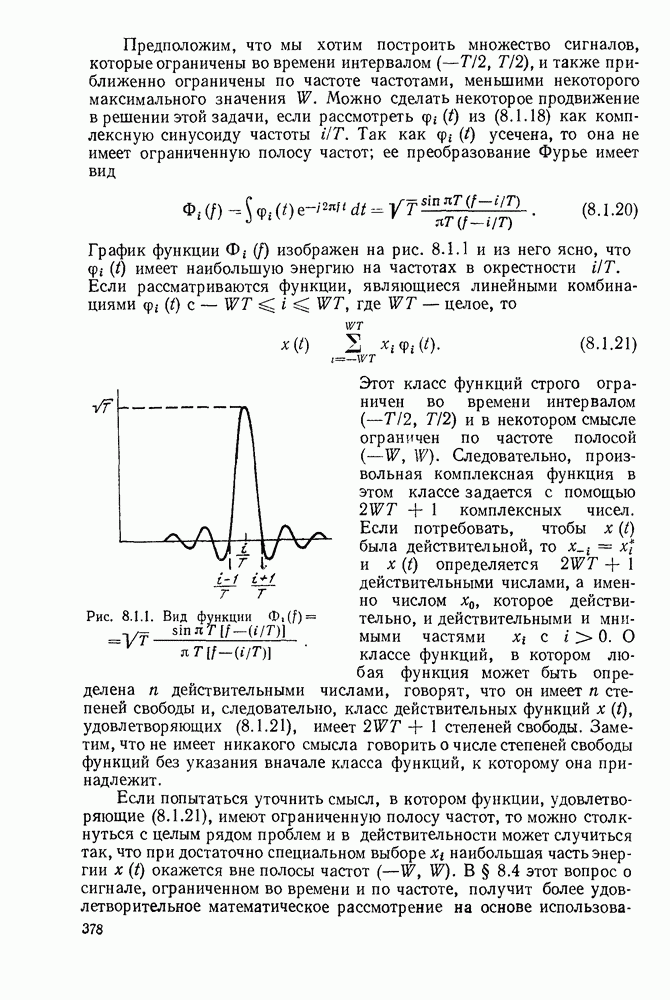
6. МЕТОДЫ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ
6.1. КОДЫ С ПРОВЕРКОЙ НА ЧЕТНОСТЬ
В предыдущей главе было рассмотрено использование блокового кодирования для надежной передачи данных по дискретным каналам. Было доказано, что для соответствующим образом выбранных кодов и при любой заданной скорости передачи, меньшей пропускной способности, вероятность ошибочного декодирования ограничена неравенством  где
где  длина блока,
длина блока,  определяется соотношением (5.6.16). Вместе с тем число кодовых слов и число возможных принятых последовательностей являются экспоненциально растущими функциями
определяется соотношением (5.6.16). Вместе с тем число кодовых слов и число возможных принятых последовательностей являются экспоненциально растущими функциями  поэтому при больших N практически невозможно осуществить хранение в памяти кодера всех кодовых слов и хранение в памяти декодера способа отображения принятых последовательностей в сообщения.
поэтому при больших N практически невозможно осуществить хранение в памяти кодера всех кодовых слов и хранение в памяти декодера способа отображения принятых последовательностей в сообщения.
В настоящей главе будут рассмотрены методы кодирования и декодирования, позволяющие избежать упомянутой проблемы памяти путем использования алгоритмов для построения кодовых слов по сообщениям и сообщений по принятым последовательностям. Почти все известные методы кодирования и декодирования основаны на идеях, лежащих в основе кодов с проверкой на четность, и поэтому мы начнем изучение с этих кодов. Полезно начать описание таких кодов применительно к двоичному симметричному каналу (ДСК), хотя позднее будет показано, что это ограничение не является обязательным.
Код с проверкой на четность является частным случаем отображения двоичной последовательности длины  в двоичную последовательность некоторой большей длины
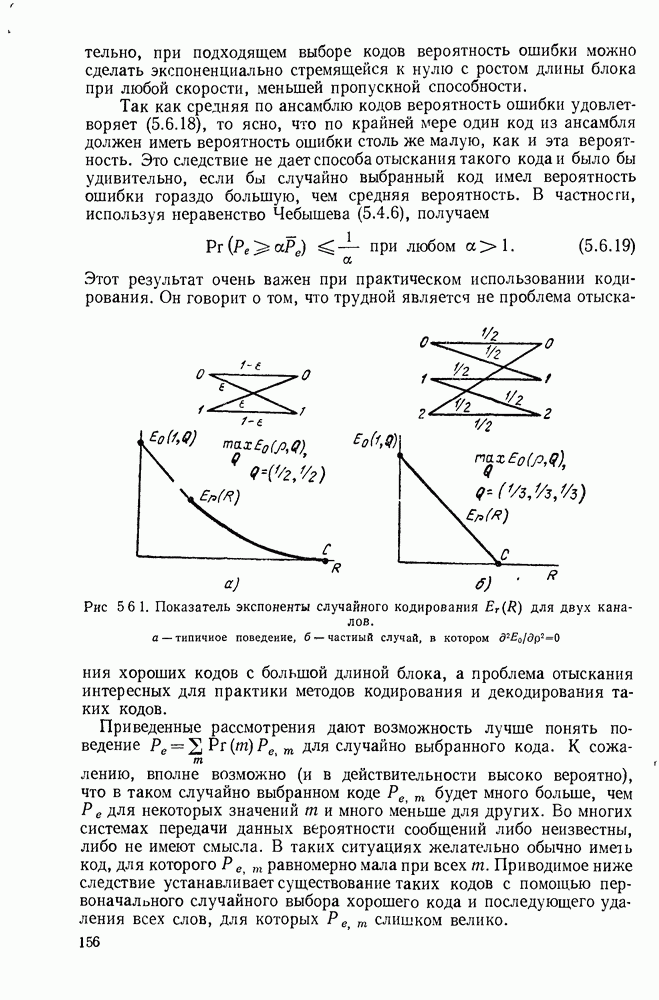
в двоичную последовательность некоторой большей длины  Прежде чем определять коды с проверкой на четность, приведем довольно простой, но широко используемый пример проверки на четность. Допустим, что последовательность двоичных символов кодируется с помощью простого добавления одного двоичного символа в конце последовательности; этот последний символ выбирается таким образом, чтобы общее число единиц в кодовой последовательности было четным. Назовем первоначальные символы информационными символами, а добавленный в конце последовательности символ — проверочным символом. Легко видеть, что если затем изменить один из символов последовательности, то общее число единиц станет нечетным, что обнаруживает факт наступления ошибки. Однако, если произойдут две ошибки, число единиц вновь станет четным и ошибки не будут обнаружены. Кодирование такого типа широко используется при записи на магнитные ленты, а также и в других случаях, когда желательна некоторая небольшая возможность обнаружения ошибок при минимальных затратах на оборудование.
Прежде чем определять коды с проверкой на четность, приведем довольно простой, но широко используемый пример проверки на четность. Допустим, что последовательность двоичных символов кодируется с помощью простого добавления одного двоичного символа в конце последовательности; этот последний символ выбирается таким образом, чтобы общее число единиц в кодовой последовательности было четным. Назовем первоначальные символы информационными символами, а добавленный в конце последовательности символ — проверочным символом. Легко видеть, что если затем изменить один из символов последовательности, то общее число единиц станет нечетным, что обнаруживает факт наступления ошибки. Однако, если произойдут две ошибки, число единиц вновь станет четным и ошибки не будут обнаружены. Кодирование такого типа широко используется при записи на магнитные ленты, а также и в других случаях, когда желательна некоторая небольшая возможность обнаружения ошибок при минимальных затратах на оборудование.
Удобно рассматривать эти проверки на четность или нечетность в терминах арифметических действий по модулю 2. В арифметике по модулю 2 существуют лишь два числа 0 и 1; сложение (обозначаемое  ) определяется по правилу
) определяется по правилу

Нетрудно заметить, что это сложение совпадает с обычным, если не считать того, что  Умножение аналогично умножению в обычной арифметике и обозначается тем же знаком.
Умножение аналогично умножению в обычной арифметике и обозначается тем же знаком.
Легко убедиться (кто сомневается, может это непосредственно проверить), что обычные ассоциативный, коммутативный и дистрибутивный арифметические законы справедливы в арифметике по модулю 2. Это значит, что если  и с — двоичные числа, то
и с — двоичные числа, то

Существует несколько интерпретаций арифметических действий по модулю 2. Если интерпретировать 0 как четное, а 1 как нечетное число, то эти действия сложения и умножения задают правила комбинирования четных и нечетных чисел. Кроме того, можно интерпретировать сумму по модулю 2 последовательности двоичных чисел как остаток от деления на 2 их суммы в обычном смысле. Тогда легко убедиться, что проверочный символ в рассмотренном выше примере выбирается таким образом, чтобы сумма по модулю 2 всех символов равнялась 0. Если сумма по модулю 2 информационных символов равна 0, то проверочный символ выбирается равным 0; если сумма по модулю 2 информационных символов равна 1, то проверочный символ выбирается равным 1. Поэтому проверочный символ равен сумме по модулю 2 информационных символов.
- В качестве простого (но чрезвычайно сильного) обобщения использования одной проверки на четность применительно к проверке последовательности информационных символов рассмотрим такое использование множества символов проверки на четность, при котором каждый из символов проверяет некоторое предварительно определенное множество информационных символов. Точнее, пусть и  обозначает последовательность
обозначает последовательность  двоичных информационных символов; рассмотрим образование кодового слова х с длиной блока
двоичных информационных символов; рассмотрим образование кодового слова х с длиной блока  из последовательности и по правилу
из последовательности и по правилу

где  означает здесь сумму по модулю 2.
означает здесь сумму по модулю 2.
Элементы  при
при  в соотношении (6.1.2) представляют собой фиксированные двоичные символы, не
в соотношении (6.1.2) представляют собой фиксированные двоичные символы, не

Рис. 6.1.1.
зависящие от и; поэтому соотношения (6.1.1) и (6.1.2) задают отображение множества  возможных информационных последовательностей в множество
возможных информационных последовательностей в множество  кодовых слов с длиной блока
кодовых слов с длиной блока  Назовем первые
Назовем первые  символов в каждом кодовом слове информационными символами, а последние
символов в каждом кодовом слове информационными символами, а последние  символов проверочными символами.
символов проверочными символами.
Систематическим кодом с проверкой на четность называется двоичный блоковый код с произвольной длиной блока  для которого множество сообщений представляет собой множество
для которого множество сообщений представляет собой множество  двоичных последовательностей некоторой фиксированной длины
двоичных последовательностей некоторой фиксированной длины  и в котором каждому сообщению
и в котором каждому сообщению  сопоставлено кодовое слово
сопоставлено кодовое слово  определяемое соотношениями (6.1.1) и (6.1.2), где множество двоичных символов
определяемое соотношениями (6.1.1) и (6.1.2), где множество двоичных символов  для
для  является произвольным, но фиксированным и независимым от и. Разумеется, при каждом выборе совокупности
является произвольным, но фиксированным и независимым от и. Разумеется, при каждом выборе совокупности  получаются различные систематические коды с проверкой на четность.
получаются различные систематические коды с проверкой на четность.
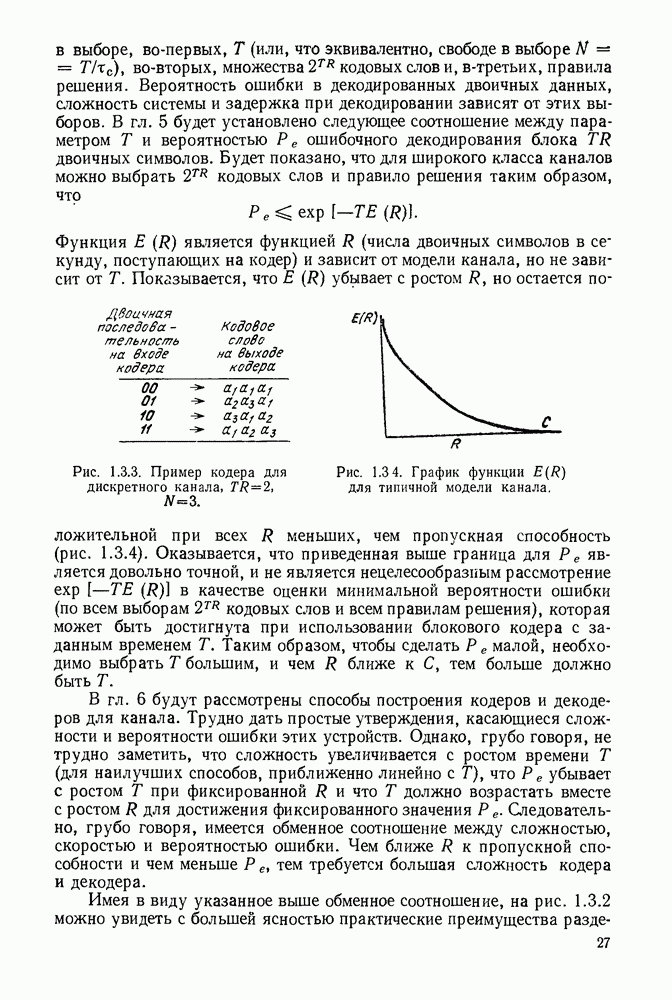
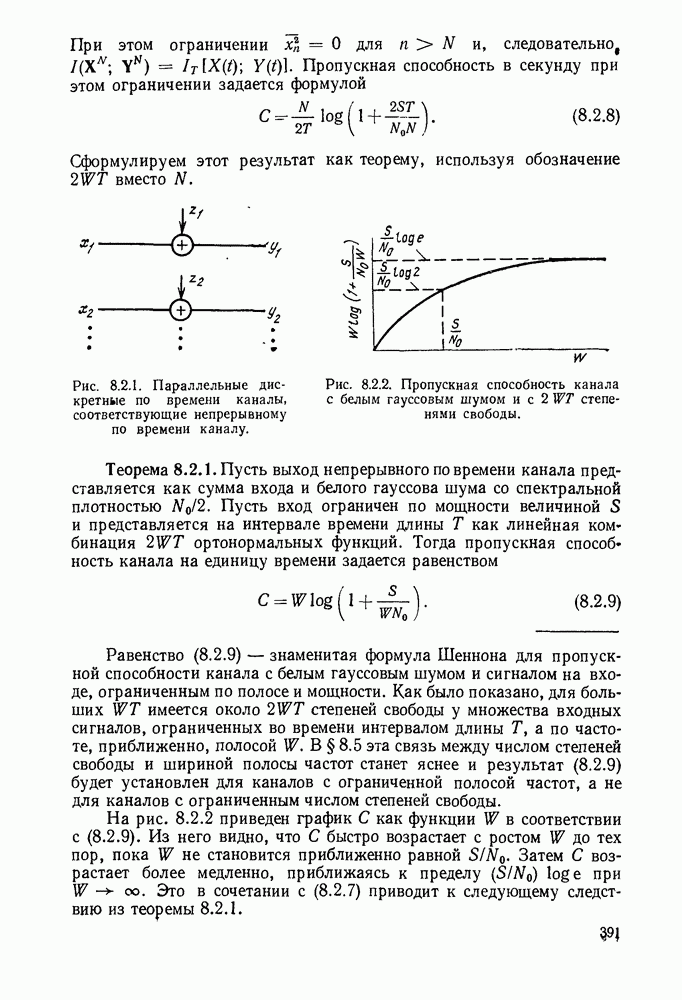
Например, пусть для  вектор
вектор  обозначает информационную последовательность, а вектор
обозначает информационную последовательность, а вектор  соответствующее кодовое слово, образуемое так, как показано на рис. 6.1.1.
соответствующее кодовое слово, образуемое так, как показано на рис. 6.1.1.
Общий код с проверкой на четность определяется так же, как систематический код с проверкой на четность, за исключением того, что при вычислении в нем кодовых слов по последовательностям сообщений используются не соотношения (6.1.1) и (6.1.2), а соотношение

где  произвольное, но фиксированное множество двоичных чисел
произвольное, но фиксированное множество двоичных чисел  Из сравнения (6.1.1) и (6.1.3) видно, что систематический код с проверкой на четность представляет собой частный случай общего кода с проверкой на четность, в котором
Из сравнения (6.1.1) и (6.1.3) видно, что систематический код с проверкой на четность представляет собой частный случай общего кода с проверкой на четность, в котором

В тех случаях, когда при использовании некоторого кода с проверкой на четность нужно будет специально обратить внимание на длину
блока N и на длину последовательности сообщения  код будем называть
код будем называть  -кодом с проверкой на четность (или систематическим
-кодом с проверкой на четность (или систематическим  -кодом с проверкой на четность).
-кодом с проверкой на четность).
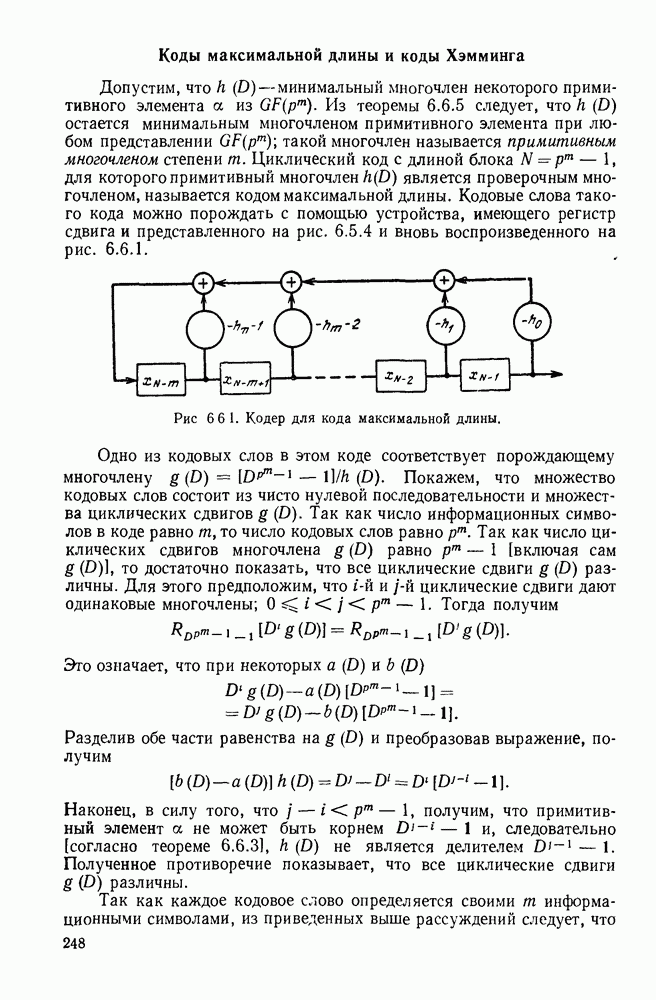
Одну из причин рассмотрения кодов с проверкой на четность как систематических, так и несистематических, можно понять, если рассмотреть реализации кодера. Для кодера с проверкой на четность необходимы регистр для запоминания последовательности сообщения и, регистр для запоминания кодового слова х и сумматоры по модулю 2, число которых пропорционально  Поэтому использование кодеров с проверкой на четность позволяет избежать экспоненциального роста объема памяти с ростом
Поэтому использование кодеров с проверкой на четность позволяет избежать экспоненциального роста объема памяти с ростом  неизбежного при использовании произвольного блокового кода с
неизбежного при использовании произвольного блокового кода с  кодовыми словами, структура которого не выбиралась специальным образом.
кодовыми словами, структура которого не выбиралась специальным образом.
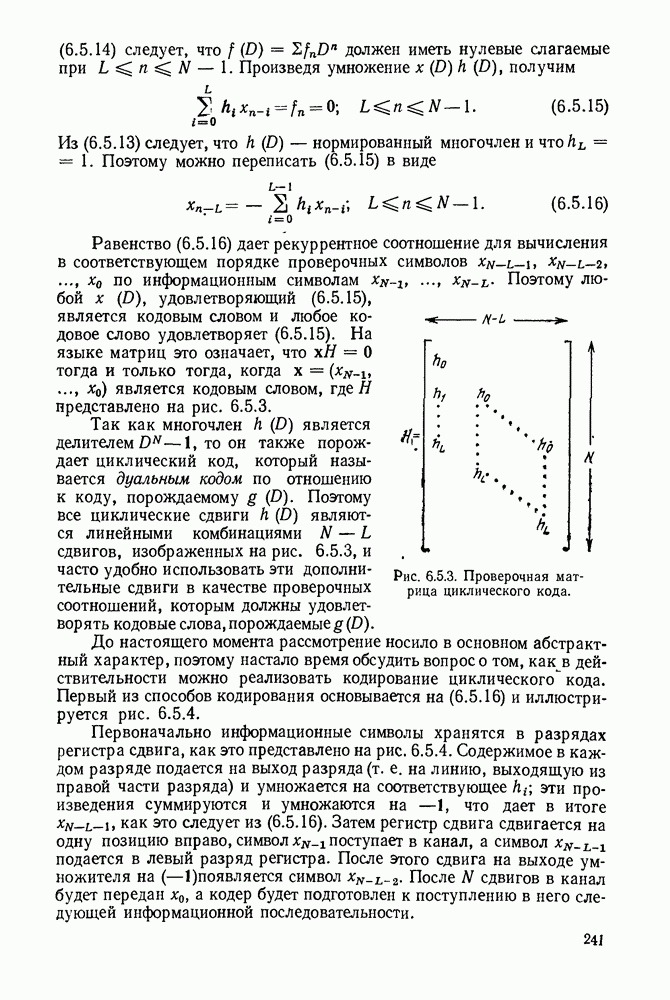
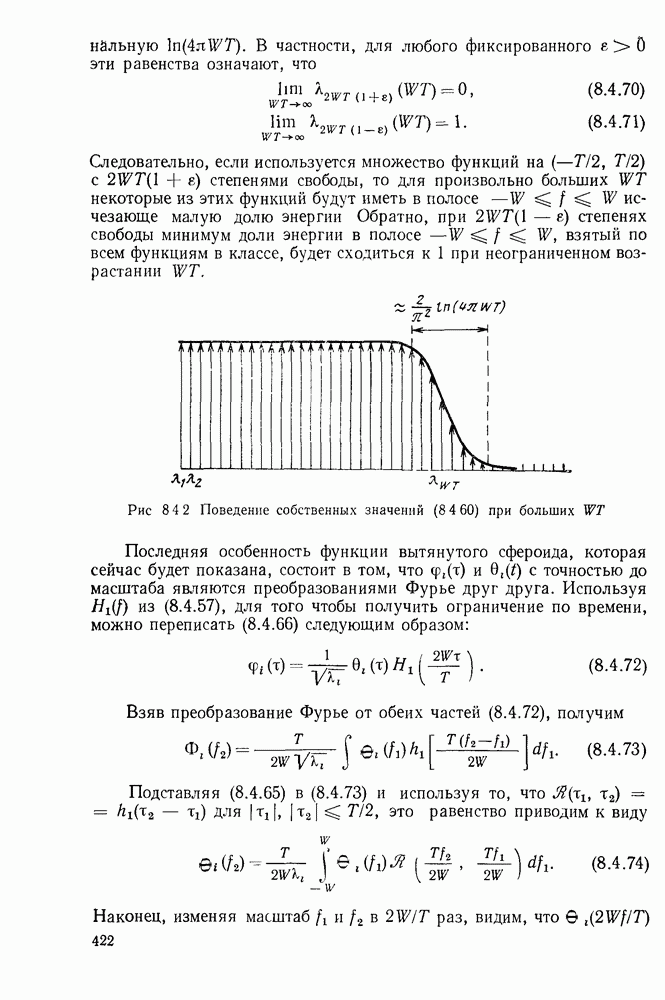
Порождающие матрицы
Соотношение (6.1.3) можно выразить в более компактной форме, если ввести понятие порождающей матрицы  -кода с проверкой на четность. Эта матрица, как показано на рис. 6.1.2, представляет собой двоичную матрицу с разменами
-кода с проверкой на четность. Эта матрица, как показано на рис. 6.1.2, представляет собой двоичную матрицу с разменами  на N и компонентами
на N и компонентами  определяемыми соотношениями (6.1.3).
определяемыми соотношениями (6.1.3).

Рис. 6.1.2 Порождающая матрица а — произвольный код с проверкой на четность, б - систематический код с проверкой на четность.
Из (6.1.4) следует, что в случае систематического кода с проверкой на четность подматрица, соответствующая первым  столбцам, является единичной матрицей.
столбцам, является единичной матрицей.
Рассматривая  как вектор-строки, получаем
как вектор-строки, получаем

где  представляет собой матричное произведение, использующее сложение по модулю 2 [это означает, что
представляет собой матричное произведение, использующее сложение по модулю 2 [это означает, что  определяется таким образом, чтобы (6.1.5) было эквивалентно
определяется таким образом, чтобы (6.1.5) было эквивалентно 
Пусть теперь  две информационные последовательности; определим сумму по модулю 2 двоичных векторов соотношением
две информационные последовательности; определим сумму по модулю 2 двоичных векторов соотношением
 Тогда, если
Тогда, если 

Последнее равенство в (6.1.6) вытекает из ассоциативного, коммутативного и дистрибутивного законов сложения по модулю 2 и может быть доказано с помощью соотношения (6.1.3). Из (6.1.7) следует, что сумма по модулю 2 двух кодовых слов равна другому кодовому слову, соответствующему информационной последовательности 
Заметим далее, что если в информационной последовательности имеется лишь один символ 1, скажем на 1-я позиции, то результирующее кодовое слово равно I-й строке матрицы  которую обозначим через
которую обозначим через  Отсюда, учитывая соотношение (6.1.6), получаем, что произвольное кодовое слово можно представить в виде
Отсюда, учитывая соотношение (6.1.6), получаем, что произвольное кодовое слово можно представить в виде

Другими словами, множество кодовых слов является пространством строк матрицы  т. е. совокупностью линейных по модулю 2 комбинаций строк
т. е. совокупностью линейных по модулю 2 комбинаций строк  как
как  определяется соотношением (6.1.8).
определяется соотношением (6.1.8).
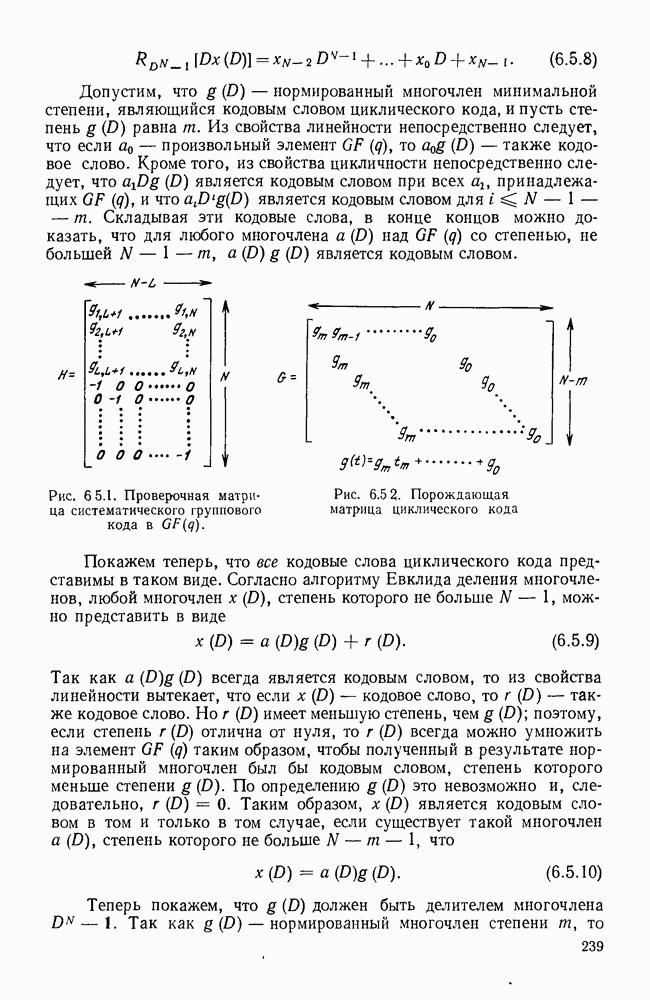
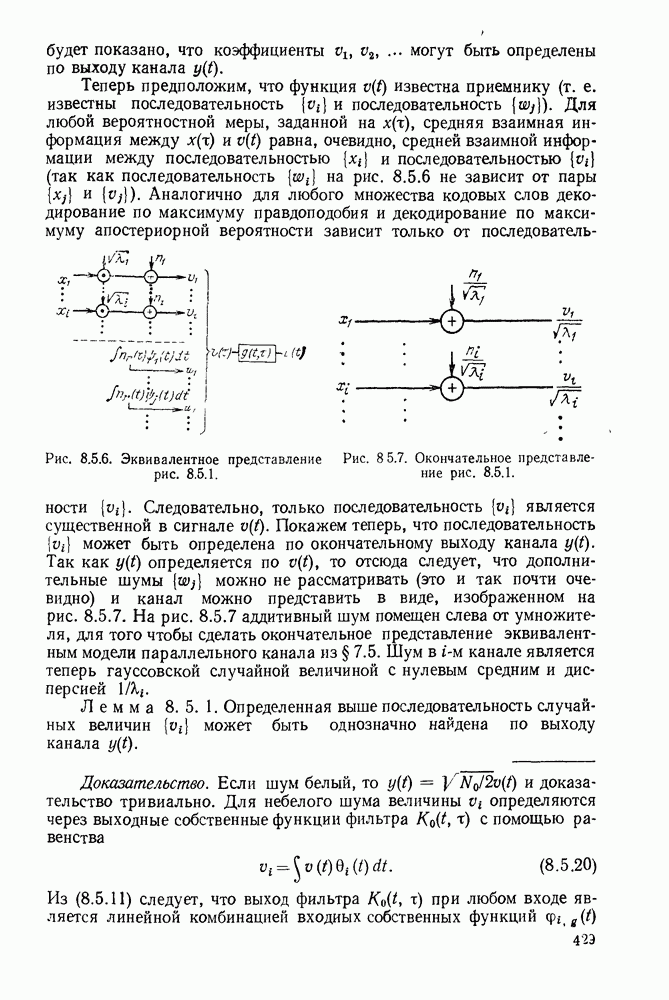
Проверочные матрицы систематических кодов с проверкой на четность
Временно ограничимся рассмотрением систематических  -кодов с проверкой на четность и введем в рассмотрение новую матрицу
-кодов с проверкой на четность и введем в рассмотрение новую матрицу  называемую проверочной матрицей. Она представляет собой матрицу с размерами N на
называемую проверочной матрицей. Она представляет собой матрицу с размерами N на  и определяется, как показано на рис. 6.1.3, через коэффициенты
и определяется, как показано на рис. 6.1.3, через коэффициенты  введенные в (6.1.2).
введенные в (6.1.2).
Чтобы понять значение матрицы Я, перепишем (6.1.2), используя соотношение (6.1.1), в виде

Прибавляя  к обеим частям (или вычитая
к обеим частям (или вычитая  что эквивалентно в арифметике по модулю 2), получим для каждого кодового слова
что эквивалентно в арифметике по модулю 2), получим для каждого кодового слова 

Путем сравнения этого равенства с матрицей на рис. 6.1.3 нетрудно убедиться, что оно может быть переписано в следующей матричной форме: для каждого кодового слова х

Обратно, если произвольная последовательность х удовлетворяет соотношению (6.1.11), она также удовлетворяет (6.1.9). Эта последовательность должна быть кодовым словом, соответствующим
информационной последовательности, определяемой первыми  символами вектора х. Таким образом, множество кодовых слов — это множество последовательностей х, для которых
символами вектора х. Таким образом, множество кодовых слов — это множество последовательностей х, для которых  нуль в пространстве столбцов матрицы
нуль в пространстве столбцов матрицы  ; множество кодовых слов является также множеством линейных комбинаций строк
; множество кодовых слов является также множеством линейных комбинаций строк  пространством строк матрицы
пространством строк матрицы 

Рис. 6.1.3.
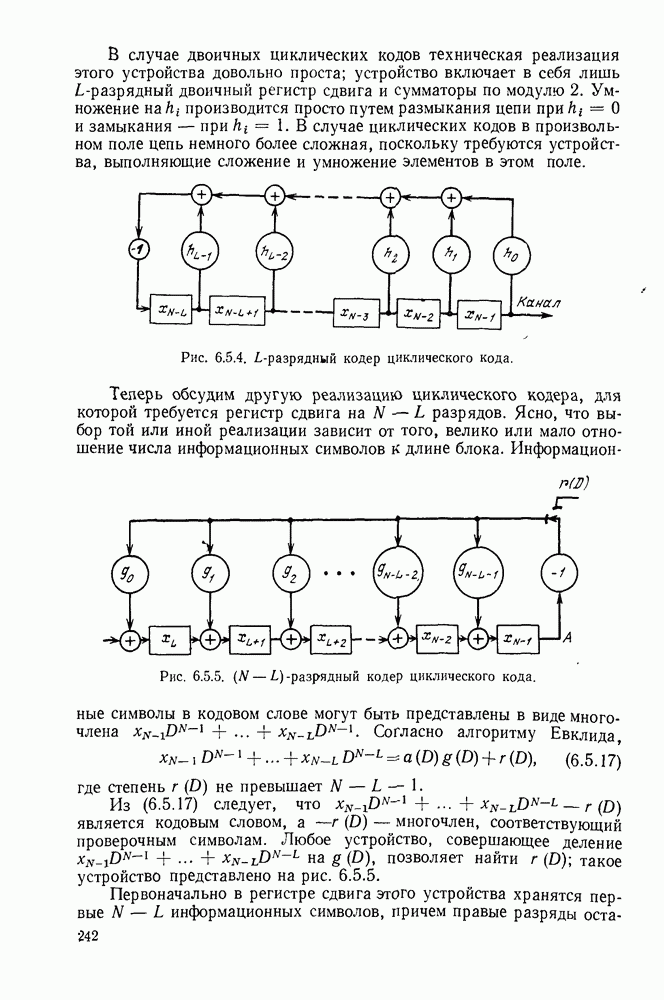
Матрица Я используется в основном для декодирования. Пусть при передаче по двоичному каналу используется некоторый заданный систематический код с проверкой на четность, и у — принятая последовательность; определим соответствующий у синдром  равенством
равенством

Синдром  это вектор-строка
это вектор-строка  компонентами, по одной для каждого проверочного символа. Поскольку
компонентами, по одной для каждого проверочного символа. Поскольку

то нетрудно убедиться, что  равно 1 тогда и только тогда, когда принятый
равно 1 тогда и только тогда, когда принятый  проверочный символ отличается от
проверочный символ отличается от  проверочного символа, вычисленного по принятым информационным символам. Отметим, что если
проверочного символа, вычисленного по принятым информационным символам. Отметим, что если  является каким-либо кодовым словом, то
является каким-либо кодовым словом, то

Если  переданный, а у — принятый вектор, то последовательность
переданный, а у — принятый вектор, то последовательность  содержит 1 на тех позициях, на которых отличаются
содержит 1 на тех позициях, на которых отличаются  Эта последовательность называется шумовой последовательностью
Эта последовательность называется шумовой последовательностью  соответствующей
соответствующей  из (6.1.13) получаем
из (6.1.13) получаем

Так как  тогда и только тогда, когда х кодовое слово, из (6.1.13) следует, что для выполнения соотношения
тогда и только тогда, когда х кодовое слово, из (6.1.13) следует, что для выполнения соотношения  необходимо и достаточно, чтобы
необходимо и достаточно, чтобы  была одной из определенных выше шумовых последовательностей.
была одной из определенных выше шумовых последовательностей.
Нужно отметить, что соотношение (6.1.14) не позволяет точно установить, какая шумовая последовательность действительно имела место при передаче? Оно представляет собой соотношение, справедливое для всех  возможных последовательностей ошибок, соответствующих
возможных последовательностей ошибок, соответствующих  кодовым словам. Выбор
кодовым словам. Выбор  (или выбор кодового слова) зависит от канала.
(или выбор кодового слова) зависит от канала.
Предположим теперь, что при передаче по ДСК (см. рис. 5.3.1, а) с переходной вероятностью  используется систематический код с проверкой на четность. Тогда, если кодовое слово
используется систематический код с проверкой на четность. Тогда, если кодовое слово  и принятая последовательность у отличаются в
и принятая последовательность у отличаются в  позициях, то
позициях, то  Число позиций, в которых отличаются две двоичные последовательности, называется расстоянием Хэмминга между этими последовательностями. Нетрудно видеть, что
Число позиций, в которых отличаются две двоичные последовательности, называется расстоянием Хэмминга между этими последовательностями. Нетрудно видеть, что  убывающая функция от расстояния Хэмминга между
убывающая функция от расстояния Хэмминга между  и поэтому декодирование по максимуму правдоподобия эквивалентно выбору кодового слова, находящегося на минимальном расстоянии от у. Отметим также, что расстояние между
и поэтому декодирование по максимуму правдоподобия эквивалентно выбору кодового слова, находящегося на минимальном расстоянии от у. Отметим также, что расстояние между  равно числу единиц (называемому весом) в шумовой последовательности
равно числу единиц (называемому весом) в шумовой последовательности  Декодирование по максимуму правдоподобия состоит в выборе кодового слова
Декодирование по максимуму правдоподобия состоит в выборе кодового слова  , для которого
, для которого  имеет минимальный вес. Эти результаты можно сформулировать в виде следующей теоремы.
имеет минимальный вес. Эти результаты можно сформулировать в виде следующей теоремы.
Теорема 6.1.1. Пусть систематический код с проверкой на четность имеет проверочную матрицу  и пусть этот код используется в ДСК с переходной вероятностью
и пусть этот код используется в ДСК с переходной вероятностью  Тогда при заданной принятой последовательности у декодирование по максимуму правдоподобия состоит в вычислении синдрома
Тогда при заданной принятой последовательности у декодирование по максимуму правдоподобия состоит в вычислении синдрома  нахождении среди последовательностей, удовлетворяющих соотношению
нахождении среди последовательностей, удовлетворяющих соотношению  последовательности
последовательности  с минимальным весом и декодировании кодового слова
с минимальным весом и декодировании кодового слова 
Таблицы декодирования
Доказанная теорема оставляет нерешенной задачу нахождения решения уравнения  которое обладает минимальным весом. Один из путей решения этой задачи основан на таблице декодирования. Мы можем составить список из
которое обладает минимальным весом. Один из путей решения этой задачи основан на таблице декодирования. Мы можем составить список из  возможных значений
возможных значений  и каждому из них поставить в соответствие последовательность
и каждому из них поставить в соответствие последовательность  с минимальным весом. Проще всего реализовать эту идею, если начать с последовательностей нулевого веса, затем составить список всех
с минимальным весом. Проще всего реализовать эту идею, если начать с последовательностей нулевого веса, затем составить список всех  обладающих единичным весом, затем весом 2 и т. д. Для каждого из
обладающих единичным весом, затем весом 2 и т. д. Для каждого из  можно вычислить синдром
можно вычислить синдром  если в дальнейшем в списке появится уже вычисленный синдром
если в дальнейшем в списке появится уже вычисленный синдром  то соответствующий ему новый вектор
то соответствующий ему новый вектор  опускается. Составление таблицы заканчивается, как только все возможные
опускается. Составление таблицы заканчивается, как только все возможные  векторов
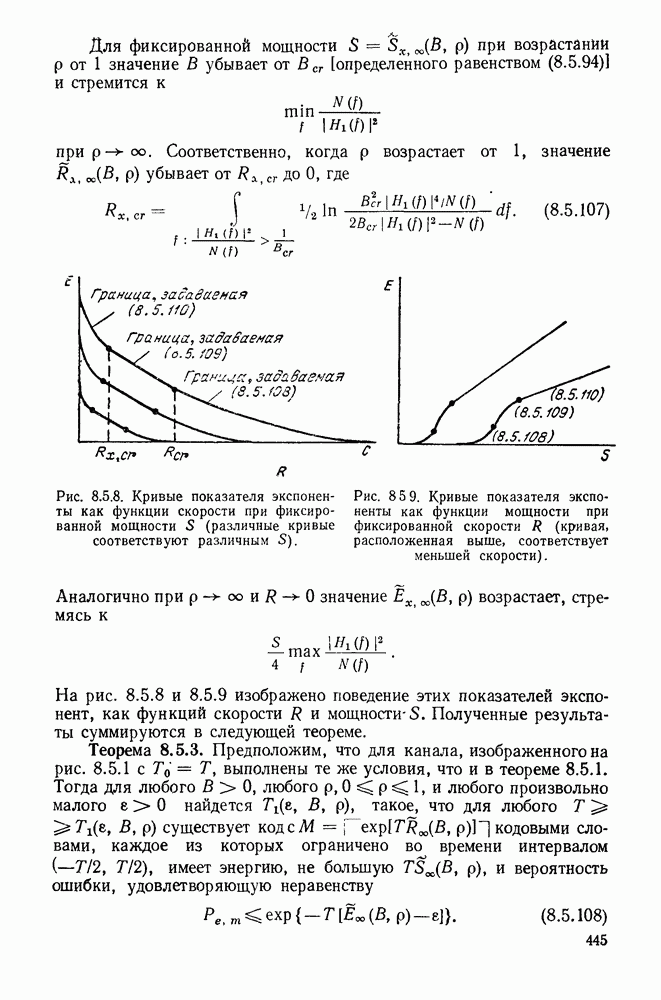
векторов  появятся в таблице. На рис. 6.1.4 представлена такая таблица декодирования для кода, приведенного на рис. 6.1.1.
появятся в таблице. На рис. 6.1.4 представлена такая таблица декодирования для кода, приведенного на рис. 6.1.1.
Если при использовании этого кода принята последовательность  то
то  Согласно приведенной таблице
Согласно приведенной таблице  и наиболее вероятное кодовое слово равно
и наиболее вероятное кодовое слово равно  Поэтому декодированным сообщением будет
Поэтому декодированным сообщением будет 
Из дальнейшего ясно, что приведенное в таблице множество шумовых последовательностей точно совпадает с множеством ошибок, которые будут исправлены (независимо от переданного кодового слова). В тех случаях, когда в канале появляется любая из этих шумовых

Рис. 6.1.4. Таблица декодирования для кода, приведенного на рис. 6.1.1.
последовательностей, декодер вычисляет соответствующий синдром и отыскивает в таблице декодирования эту самую шумовою последовательность. В тех случаях, когда появляется шумовая последовательность, не содержащаяся в таблице, декодер выбирает по таблице некоторую шумовую последовательность, и результат декодирования получается ошибочным. Для кода, представленного на рис. 6.1.1, и для декодирующей таблицы, представленной на рис. 6.1.4, исправляются все единичные ошибки, а также одна из двойных ошибок. Синдром 111 в таблице на рис. 6.1.4 имеет несколько конфигураций двойных ошибок, однако в таблицу может быть включена лишь одна из них; совершенно ясно, что в случае двоичного симметричного канала безразлично, какую из них включать.
Рассуждая подобным образом, можно убедиться, что для систематического кода с проверкой на четность, использующего таблицу декодирования, вероятность ошибочного декодирования в двоичном симметричном канале равна вероятности появления шумовой последовательности, не включенной в таблицу. Поскольку в таблице на рис. 6.1.4 содержатся одна безошибочная последовательность, шесть последовательностей, содержащих единичные ошибки, и одна последовательность, содержащая двойную ошибку, то вероятность ошибки для этого случая дается соотношением

Коды Хэмминга
Как было выяснено, синдром, соответствующий шумовой последовательности  определяется соотношением
определяется соотношением  Если
Если  содержит лишь одну ошибку, скажем на
содержит лишь одну ошибку, скажем на  позиции, то
позиции, то  совпадает с
совпадает с  строкой матрицы
строкой матрицы  Если все строки матрицы Я ненулевые и различные, то безошибочная последовательность и все последовательности, содержащие единичные ошибки, имеют различные синдромы и поэтому код может исправлять все единичные ошибки. Для кодов с
Если все строки матрицы Я ненулевые и различные, то безошибочная последовательность и все последовательности, содержащие единичные ошибки, имеют различные синдромы и поэтому код может исправлять все единичные ошибки. Для кодов с  проверочными символами существует
проверочными символами существует  различных ненулевых последовательностей, которые могут быть выбраны в качестве
различных ненулевых последовательностей, которые могут быть выбраны в качестве

Рис. 6.1.5.
строк матрицы  поэтому при
поэтому при  строки
строки  можно выбирать ненулевыми и различными.
можно выбирать ненулевыми и различными.
Коды Хэмминга — это коды, для которых строки матрицы  различны и включают все ненулевые последовательности длины
различны и включают все ненулевые последовательности длины  Поэтому ясно, что для таких кодов
Поэтому ясно, что для таких кодов  связаны соотношением
связаны соотношением

На рис. 6.1.5 приведены небольшая таблица значений  удовлетворяющих соотношению (6.1.15), и матрица
удовлетворяющих соотношению (6.1.15), и матрица  для случая
для случая 
Так как таблица декодирования для кодов Хэмминга не содержит ничего, кроме безошибочной последовательности и всех последовательностей с единичными ошибками, то ясно, что любая возможная принятая последовательность является либо кодовым словом, либо лежит на расстоянии 1 от одного и только от одного из кодовых слов.
Эти коды являются примером сферически упакованных кодов. Сферой радиуса  вокруг некоторой последовательности назовем множество всех последовательностей, лежащих на расстоянии
вокруг некоторой последовательности назовем множество всех последовательностей, лежащих на расстоянии  или меньшем от этой последовательности. Сферически упакованным кодом с исправляющей способностью
или меньшем от этой последовательности. Сферически упакованным кодом с исправляющей способностью  назовем код, у которого сферы радиуса
назовем код, у которого сферы радиуса  вокруг кодовых слов взаимно не пересекаются и любая последовательность лежит на расстоянии, не большем
вокруг кодовых слов взаимно не пересекаются и любая последовательность лежит на расстоянии, не большем  от какого-либо кодового слова. При декодировании принятой последовательности в ближайшее кодовое слово исправляются все конфигурации не более чем
от какого-либо кодового слова. При декодировании принятой последовательности в ближайшее кодовое слово исправляются все конфигурации не более чем  ошибок и некоторые конфигурации
ошибок и некоторые конфигурации  ошибок; ни одна из конфигураций большего числа ошибок не исправляется. Легко видеть (см. § 5.8), что для двоичного симметричного канала сферически упакованный код с такой схемой декодирования обладает минимальной вероятностью ошибки среди всех кодов с той же самой длиной блока и с тем же самым числом кодовых слов.
ошибок; ни одна из конфигураций большего числа ошибок не исправляется. Легко видеть (см. § 5.8), что для двоичного симметричного канала сферически упакованный код с такой схемой декодирования обладает минимальной вероятностью ошибки среди всех кодов с той же самой длиной блока и с тем же самым числом кодовых слов.
Если сферически упакованный код, исправляющий  ошибок, удовлетворяет более сильному условию, состоящему в том, что любая последовательность удалена от некоторого кодового слова на расстояние, не большее
ошибок, удовлетворяет более сильному условию, состоящему в том, что любая последовательность удалена от некоторого кодового слова на расстояние, не большее  то он называется совершенным кодом. В этом случае рассмотренный выше декодер исправляет все конфигурации
то он называется совершенным кодом. В этом случае рассмотренный выше декодер исправляет все конфигурации  ошибок и не исправляет ни одной конфигурации большего числа ошибок.
ошибок и не исправляет ни одной конфигурации большего числа ошибок.
Единственными найденными двоичными совершенными кодами являются: коды Хэмминга (исправляющие единичные ошибки), все коды из двух кодовых слов с нечетной длиной блока, у которых кодовые слова отличаются во всех позициях, и код с проверкой на четность, исправляющий тройные ошибки с  открытый Голеем (1949). Как показал Элайс, для любой скорости
открытый Голеем (1949). Как показал Элайс, для любой скорости  выраженной в битах, не существуют двоичные сферически упакованные коды с длиной блока, большей
выраженной в битах, не существуют двоичные сферически упакованные коды с длиной блока, большей  где N зависит от
где N зависит от 

Рис. 6.1.6.
Проблема отыскания сферически упакованных кодов является, к сожалению, проблемой отыскания оптимальных (обладающих минимальной вероятностью ошибки) кодов среди кодов с проверкой на четность и среди произвольных кодов. Питерсон (1961) для двоичного симметричного канала составил таблицу известных оптимальных кодов с проверкой на четность, но ее расширение на большие длины блоков при произвольных скоростях не представляется возможным. Вместе с тем с практической точки зрения решение этой проблемы нельзя считать настоятельно необходимым. Известно, что вероятность ошибки при заданной скорости может быть сделана произвольно малой с помощью увеличения длины блока. Более важной чем проблема отыскания наилучшего кода при заданной длине блока является проблема отыскания наиболее легко практически реализуемого кода с какой-либо длиной блока, дающего требуемую вероятность ошибки.
Далее изучим здесь связь между различными кодами с проверкой на четность и, в частности, связь между систематическими и несистематическими кодами. Если две порождающие матрицы имеют одно и то же пространство строк, то они порождают одно и то же множество кодовых слов, хотя и с различными отображениями информационных последовательностей на кодовые слова. Назовем такие порождающие матрицы эквивалентными. Отметим, что если две строки  порождающей матрицы переставить местами, то результирующая матрица будет эквивалентна первоначальной. Аналогично, если строку
порождающей матрицы переставить местами, то результирующая матрица будет эквивалентна первоначальной. Аналогично, если строку 
Прибавить к  как показано на рис. 6.1.6, то результирующая матрица также будет эквивалентна первоначальной.
как показано на рис. 6.1.6, то результирующая матрица также будет эквивалентна первоначальной.
Произвольная порождающая матрица  может быть приведена к эквивалентной матрице в «приведенно-ступенчатой форме» следующим образом. Выбирается первый ненулевой столбец, затем строки переставляются таким образом, чтобы первая строка имела в этом столбце 1, и, наконец, эта строка добавляется ко всем другим строкам, имеющим единицы в этом столбце, после чего единица остается лишь в первой строке рассматриваемого столбца. Аналогичная процедура может быть проделана со следующим столбцом, имеющим хотя бы одну единицу в оставшихся
может быть приведена к эквивалентной матрице в «приведенно-ступенчатой форме» следующим образом. Выбирается первый ненулевой столбец, затем строки переставляются таким образом, чтобы первая строка имела в этом столбце 1, и, наконец, эта строка добавляется ко всем другим строкам, имеющим единицы в этом столбце, после чего единица остается лишь в первой строке рассматриваемого столбца. Аналогичная процедура может быть проделана со следующим столбцом, имеющим хотя бы одну единицу в оставшихся  строках, после чего в этом столбце единица остается лишь во второй строке, и т. д. Процесс заканчивается либо тем, что в каждом из
строках, после чего в этом столбце единица остается лишь во второй строке, и т. д. Процесс заканчивается либо тем, что в каждом из  столбцов останется по одной единице в различных строках, либо тем, что в нижней части матрицы останутся одна или несколько строк, целиком состоящих из нулей. Последний случай, который произойдет, если строки
столбцов останется по одной единице в различных строках, либо тем, что в нижней части матрицы останутся одна или несколько строк, целиком состоящих из нулей. Последний случай, который произойдет, если строки  линейно зависимы, неинтересен, так как означает, что имеются меньше чем 21 различных кодовых слов и для каждого сообщения существует по крайней мере одно другое сообщение с тем же кодовым словом (см. задачу
линейно зависимы, неинтересен, так как означает, что имеются меньше чем 21 различных кодовых слов и для каждого сообщения существует по крайней мере одно другое сообщение с тем же кодовым словом (см. задачу
6.10). В первом же случае каждый из столбцов, содержащих одну единицу, можно интерпретировать как столбец, соответствующий информационным символам, а остальные  столбцов — как соответствующие проверочным символам.
столбцов — как соответствующие проверочным символам.
Таким образом, для любой порождающей матрицы  существует эквивалентная матрица
существует эквивалентная матрица  которая, если не принимать во внимание расположение информационных символов, соответствует систематическому коду. Проверочная матрица
которая, если не принимать во внимание расположение информационных символов, соответствует систематическому коду. Проверочная матрица  для эквивалентного систематического кода имеет вид, аналогичный представленному на рис. 6.1.3, с той разницей, что единичная подматрица занимает те
для эквивалентного систематического кода имеет вид, аналогичный представленному на рис. 6.1.3, с той разницей, что единичная подматрица занимает те  строк, которые соответствуют положению проверочных символов, и эти строки не обязательно являются последними
строк, которые соответствуют положению проверочных символов, и эти строки не обязательно являются последними  строками. Так как первоначальный код имеет то же самое множество кодовых слов, что и эквивалентный систематический код, кодовые слова в обоих случаях удовлетворяют соотношению
строками. Так как первоначальный код имеет то же самое множество кодовых слов, что и эквивалентный систематический код, кодовые слова в обоих случаях удовлетворяют соотношению  Синдром принятой последовательности у, как и прежде, определяется равенством
Синдром принятой последовательности у, как и прежде, определяется равенством  и можно, как и прежде, проводить декодирование на основе синдромной таблицы декодирования.
и можно, как и прежде, проводить декодирование на основе синдромной таблицы декодирования.
Нетрудно убедиться, что имеет место следующее полезное свойство проверочной матрицы: последовательность х является кодовым словом тогда и только тогда, когда  Было показано, как найти одну такую проверочную матрицу
Было показано, как найти одну такую проверочную матрицу  для любой порождающей матрицы с линейно независимыми строками. Легко проверить (задача
для любой порождающей матрицы с линейно независимыми строками. Легко проверить (задача
6.11), что для всякой матрицы  столбцы которой порождают то же пространство, что и столбцы матрицы
столбцы которой порождают то же пространство, что и столбцы матрицы  является кодовым словом тогда и только тогда, когда
является кодовым словом тогда и только тогда, когда  По этой причине будем называть любую такую матрицу проверочной матрицей для данного кода.
По этой причине будем называть любую такую матрицу проверочной матрицей для данного кода.