Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
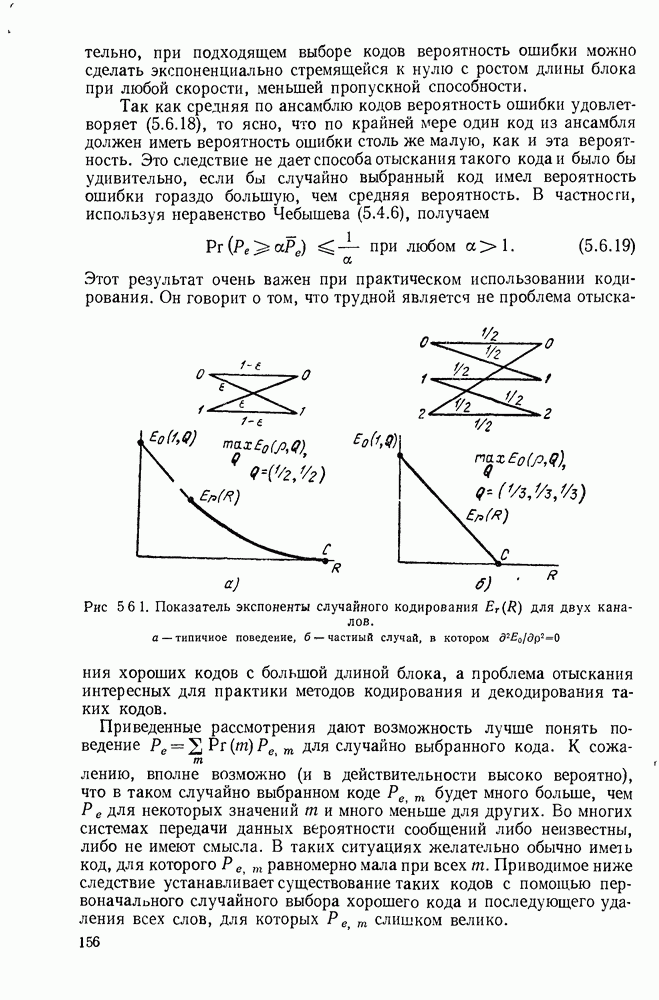
3.2. НЕРАВНОМЕРНЫЕ КОДОВЫЕ СЛОВАПредположим, что дискретный источник без памяти В дальнейшем мы будем главным образом интересоваться величиной
Согласно закону больших чисел, если кодируется очень длинная последовательность букв источника с помощью описанной выше процедуры кодирования, то число кодовых букв на одну букву источника будет с большой вероятностью близко к До того как изучить вопрос о том, на сколько мало может быть Заметим, что код I имеет неудачное свойство, состоящее в том, что буквы
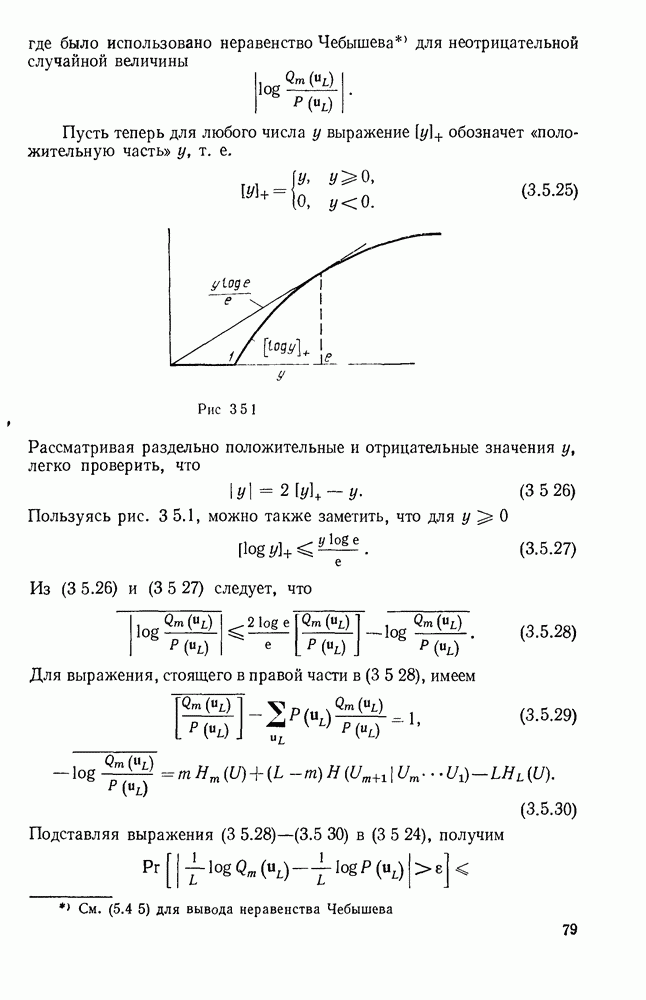
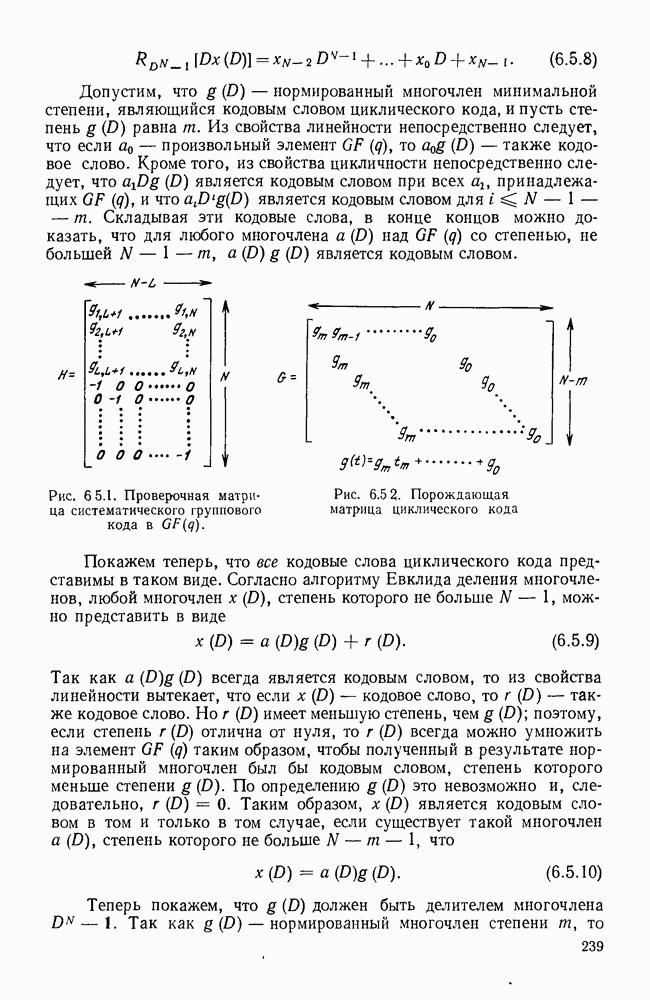
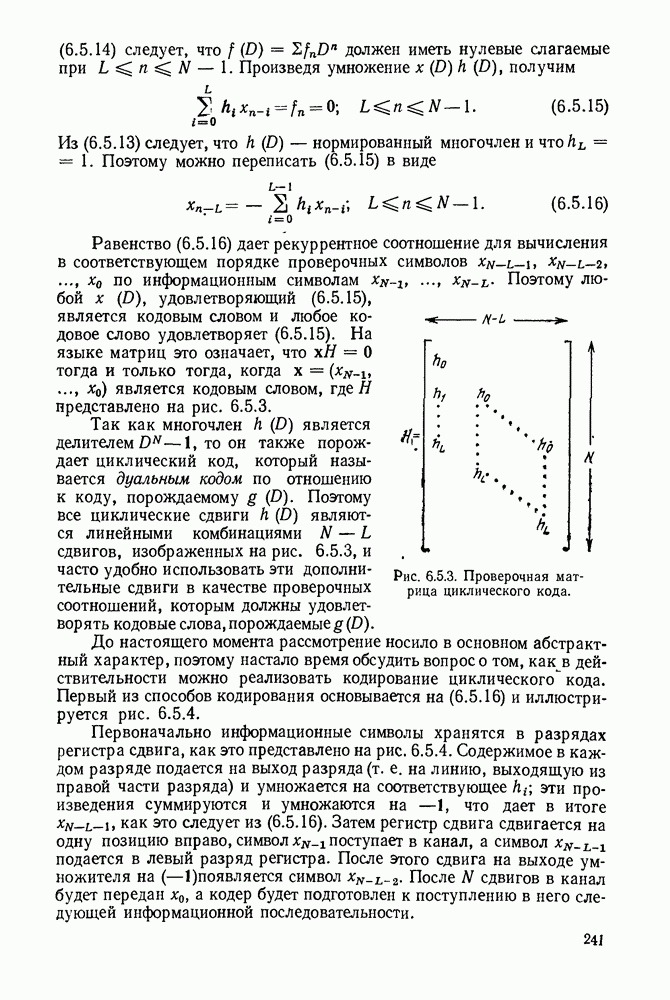
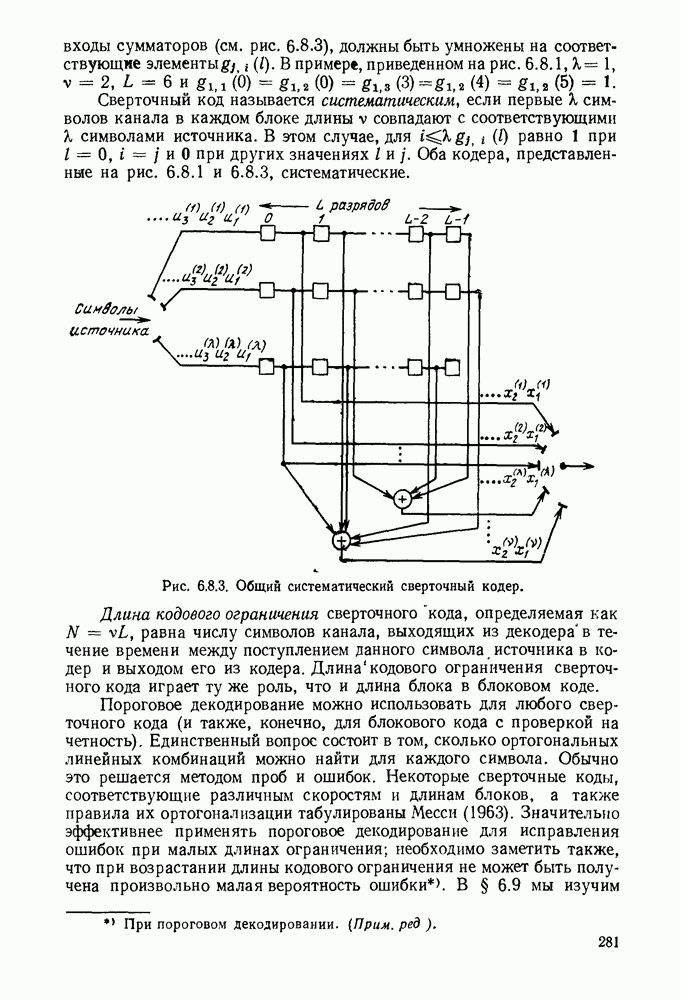
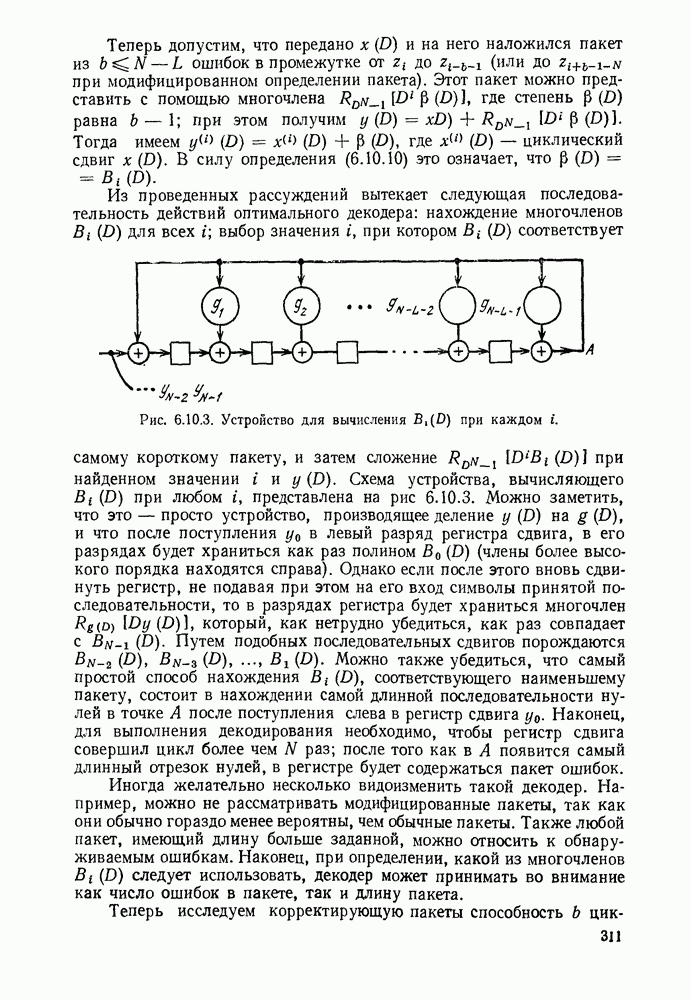
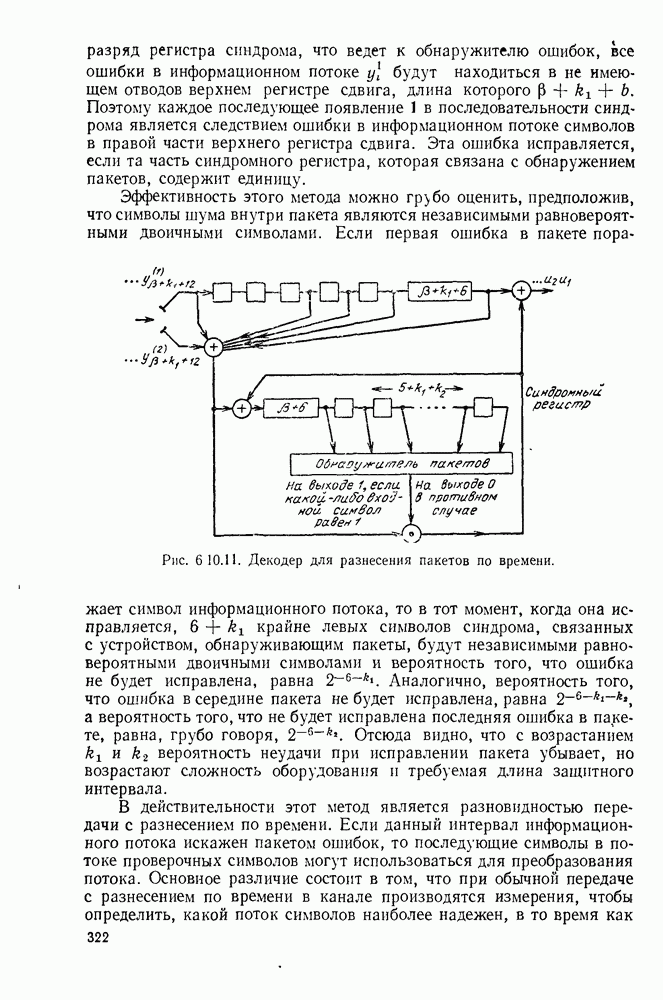
Рис. Код II на рис. 3.2.1 обладает тем же самым недостатком что и код I, хотя и выраженным более тонким образом. Если источник порождает последовательность а, то она будет закодирована в 00, что совпадает с кодовым словом для Как было отмечено, коды I и II из рис. 3.2.1 не могут быть использованы для представления источника, так как они не являются однозначно декодируемыми. Это приводит к следующему определению. Код является однозначно декодируемым, если последовательности кодовых букв, соответствующие различным последовательностям источника конечной длины, являются различными. Приведенное выше определение непосредственно не дает какого-либо способа определить, является ли некоторый код однозначно декодируемым или нет. Однако нас будет главным образом интересовать частный класс кодов, которые удовлетворяют условию, известному под названием «свойство префикса», легко показывается, что эти коды однозначно декодируемы. Для того чтобы определить свойство префикса, допустим, что На рис. 3.2.1. можно заметить, что код I не обладает свойством префикса, так как 1, кодовое слово для Для того чтобы декодировать последовательность кодовых слов из кода, обладающего свойством префикса, следует просто начать с начала последовательности и декодировать одно слово сразу. Когда дойдем до конца кодового слова, мы будем знать, что это конец, так как это кодовое слово не является префиксом какого-либо другого кодового слова. Таким образом, можно однозначно декодировать любую последовательность кодовых букв, соответствующую последовательности букв источника и, тем самым доказано, что любой код, удовлетворяющий свойству префикса, является однозначно декодируемым кодом. Так, например, последовательность источника Не любой однозначно декодируемый код обладает свойством префикса. Чтобы заметить это, рассмотрим код IV на рис. 3.2.1. В нем каждое кодовое слово является префиксом каждого более длинного кодового слова. Вместе с тем единственность декодирования является тривиальной, так как символ 0 всегда означает начало нового кодового слова. Коды, обладающие свойством префикса, отличаются, однако, от других однозначно декодируемых кодов тем, что конец кодового слова всегда может быть опознан, так что декодирование может быть выполнено без задержки наблюдаемой последовательности кодовых слов. По этой причине коды, обладающие свойством префикса, называются иногда мгновенными кодами. Удобное графическое представление множества кодовых слов, удовлетворяющих свойству префикса, можно получить, представляя каждое кодовое слово концевым узлом на дереве. Дерево, представляющее кодовые слова кода III рис. 2.3.1, показано на рис. 3.2.2. Начиная с основания дерева, два ребра, ведущие к узлам первого порядка, соответствуют выбору между 0 и 1, рассматриваемым в качестве первой буквы кодовых слов. Подобно этому два ребра, исходящие из правого узла первого порядка, соответствуют выбору между 0 и 1 для второй буквы кодового слова, если первая буква была 1; такое же представление применимо и для других ребер. Последовательность символов каждого кодового слова можно рассматривать как правило восхождения от основания дерева к концевому узлу, представляющему желаемую букву источника. Дерево можно также использовать для представления кодовых слов кода, который не обладает свойством префикса, однако в этом случае некоторые промежуточные узлы дерева будут соответствовать кодовым словам. Обратим теперь наше внимание на задачу выбора кода, обладающего свойством префикса, так чтобы минимизировать Для префиксного кода приемник можно представить себе как устройство, наблюдающее последовательность кодовых букв и прослеживающее их путь вверх по дереву, как изображено рис. 3.2.2, чтобы декодировать сообщение источника.
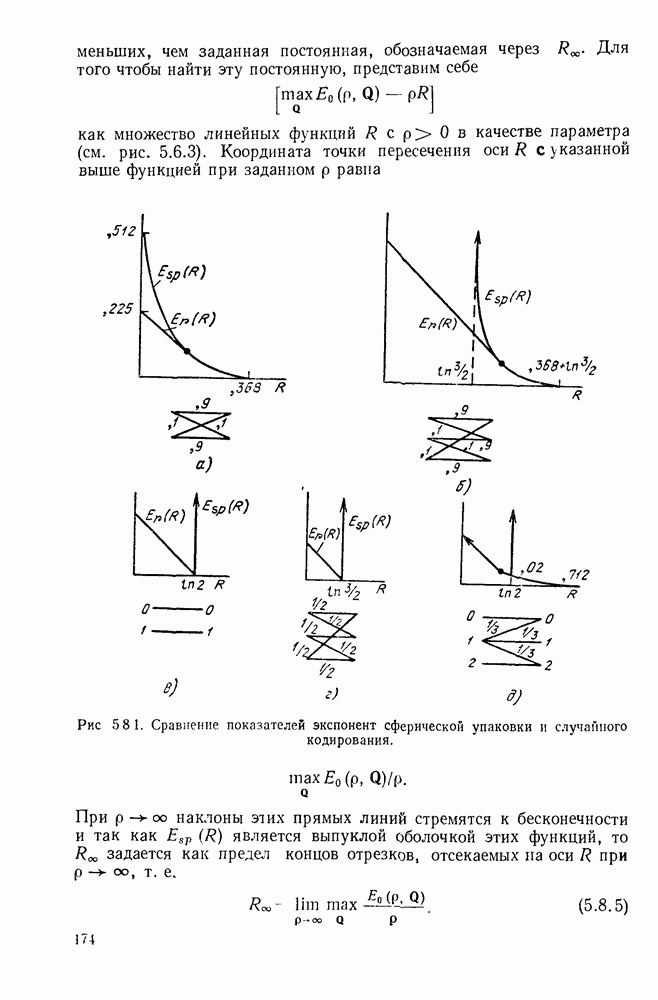
Рис. 3.2.2. Представление в виде дерева кодовых слов кода III, изображенного на рис. 3.2.1. В каждом узле этого дерева следующий кодовый символ дает информацию о том, какое нужно взять ребро. Можно заметить, что сумма взаимных информаций в последовательных узлах, ведущих к некоторому данному концевому узлу, равна в точности собственной информации символа источника, соответствующего этому узлу. Таким образом, чтобы достичь малого значения Этот пример дает возможность произвести очевидное обобщение, позволяющее построить префиксные коды для общего множества букв источника. Разобьем вначале множество букв на
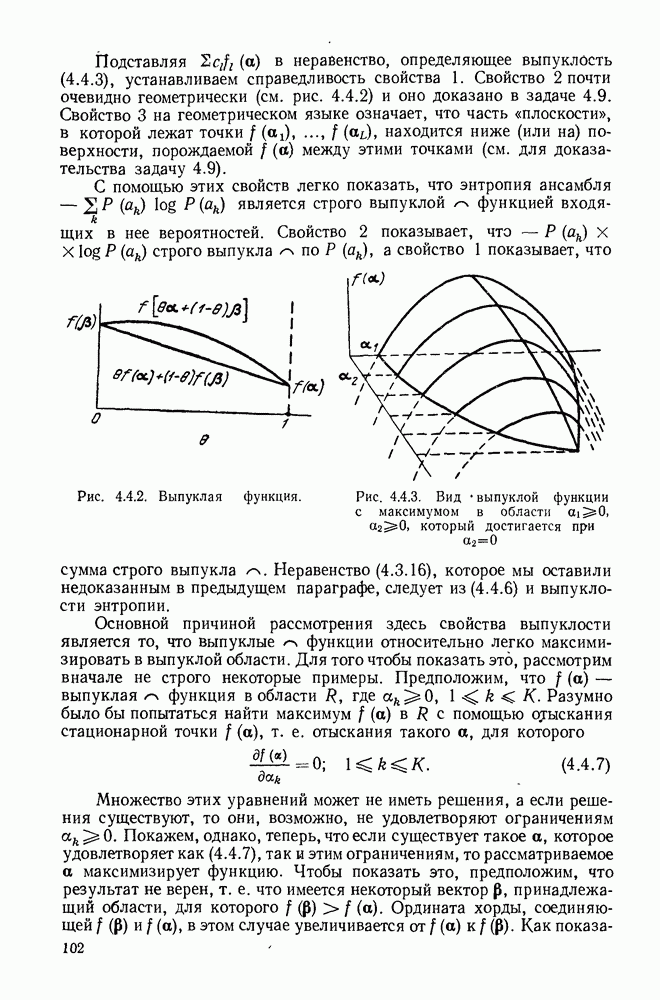
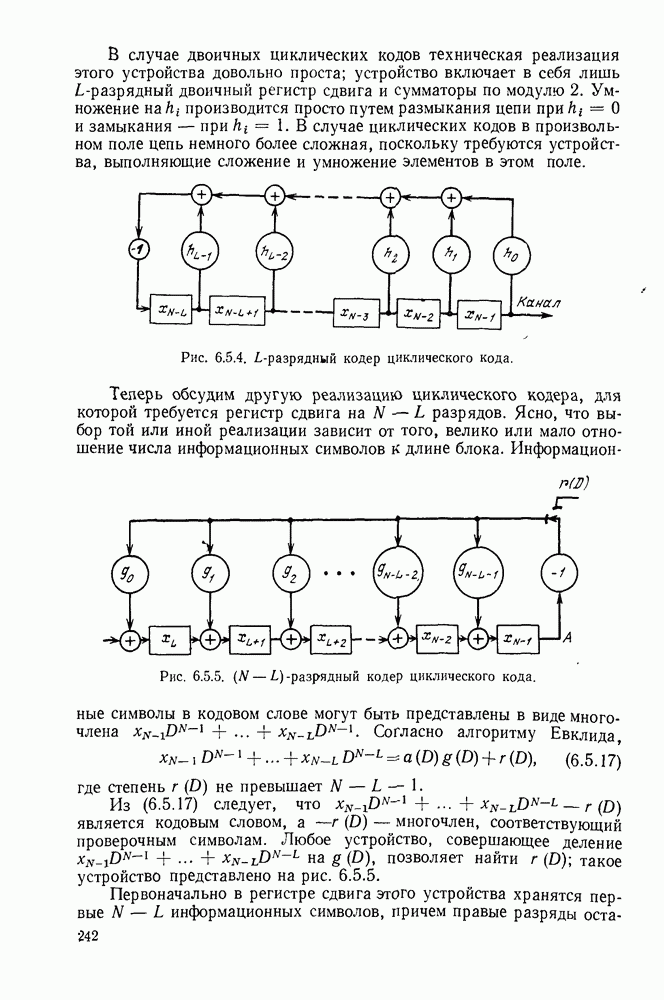
До того как обратиться к деталям процедуры минимизации средней длины множества кодовых слов, исследуем ограничения на длины кодовых слов префиксного кода. Теорема 3.2.1. [Неравенство Крафта (1949)]. Если целые числа
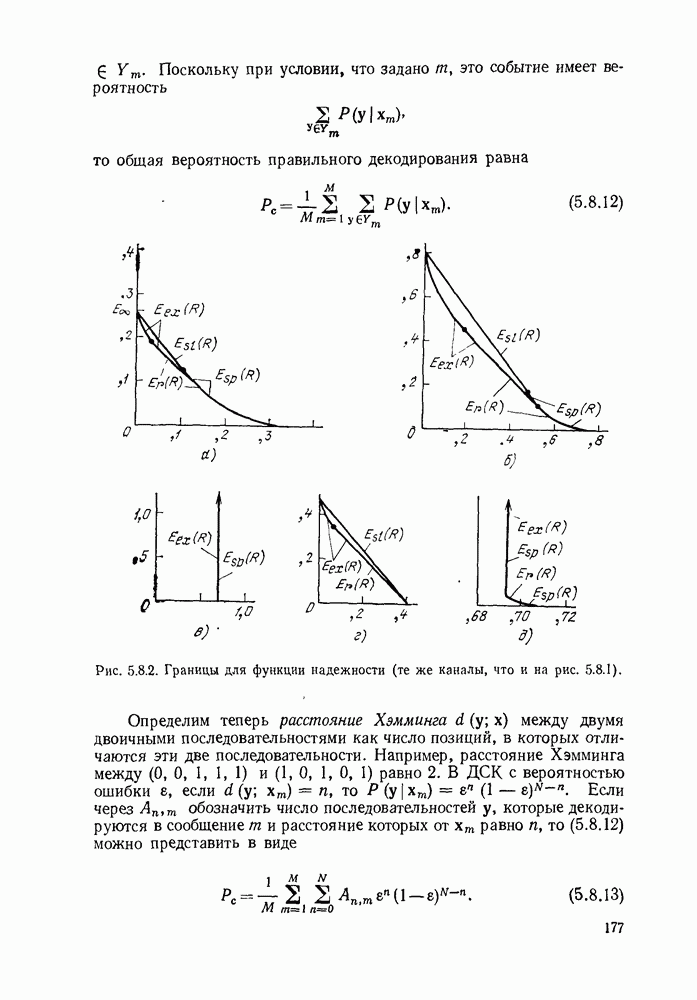
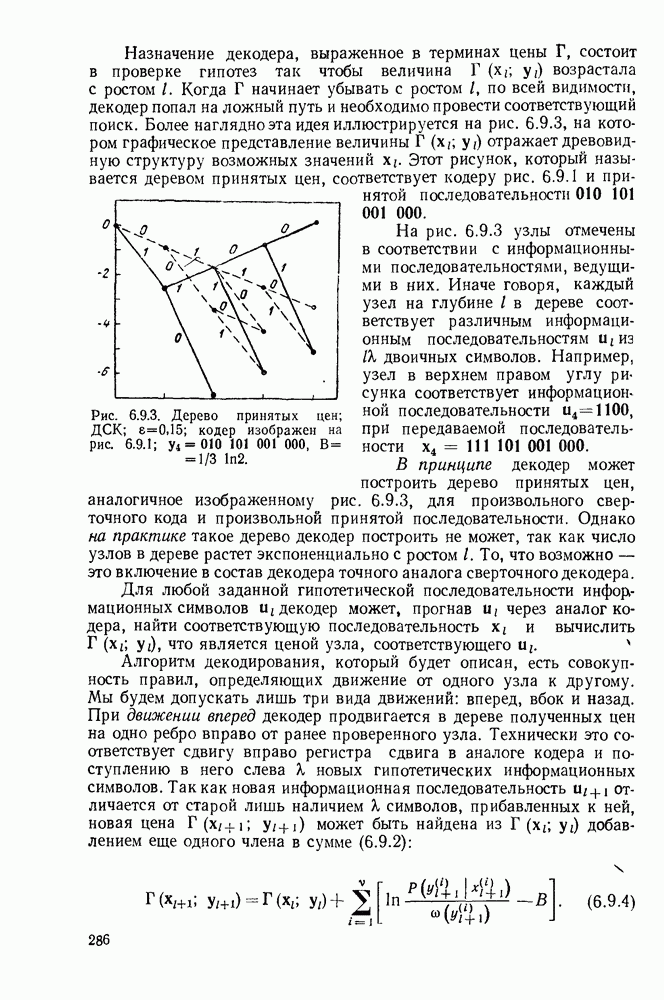
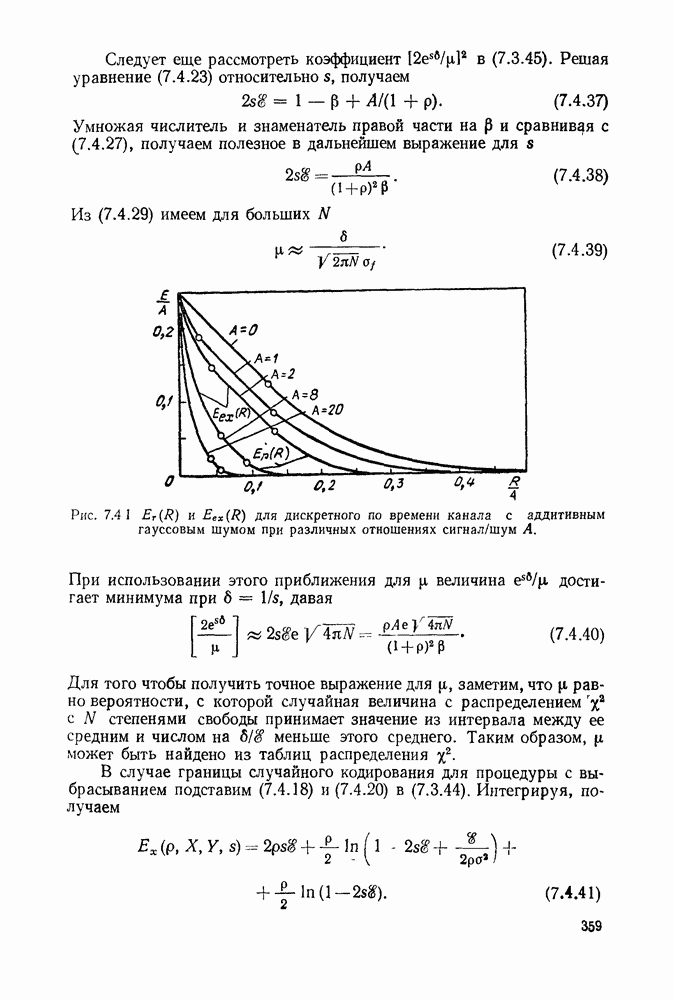
то существует код, обладающий свойством префикса, с алфавитом объема Доказательство. Назовем полным деревом порядка Пусть теперь построение будет закончено, кодовое дерево будет вложено в полное дерево, как показано на рис. 3.2.3. Для простоты обозначений, предположим, что
Рис. 3.2.3. Двоичное кодовое дерево (сплошные линии), дополненное до полного дерева (пунктирные линии) порядка 3. Продолжая этот процесс, после образования Чтобы доказать вторую часть теоремы, заметим, что кодовое дерево, соответствующее любому префиксному коду, может быть вложено в полное дерево, порядок которого равен наибольшей длине кодового слова. Из концевого узла порядка Докажем теперь теорему о длинах кодовых слов однозначно декодируемых кодов, которая оправдает наше рассмотрение кодов, обладающих свойством префикса. Теорема 3.2.2. Пусть задан код с длинами кодовых слов Доказательство. Пусть
Заметим, что в выражении, стоящем в правой части (3.2.4), различные слагаемые соответствуют каждой возможной последовательности из
где Если код однозначно декодируем, то все последовательности кодовых слов из
Неравенство (3.2.7) справедливо для всех положительных целых чисел Так как длины кодовых слов любого однозначно декодируемого кода удовлетворяют (3.2.3) и так как можно построить префиксный код для любого множества длин, удовлетворяющих (3.2.3), то любой однозначно декодируемый код можно заменить на префиксный код без изменения длин кодовых слов. Таким образом, последующие теоремы относительно средней длины кодового слова приложимы как к однозначно декодируемым кодам, так и к подклассу префиксных кодов.
|
 |
Оглавление
|






































































































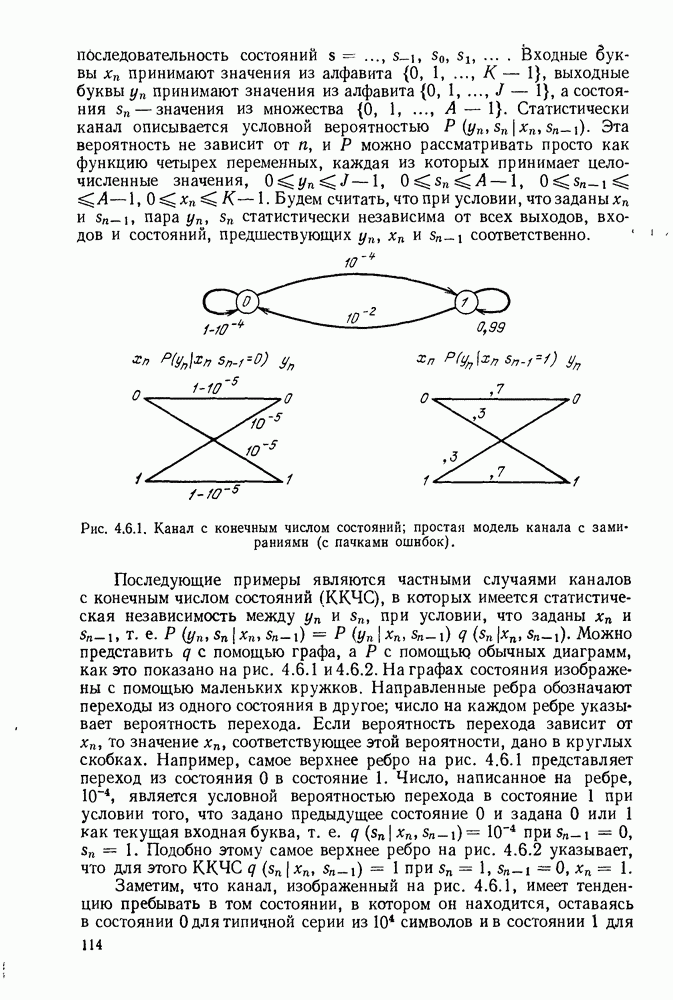



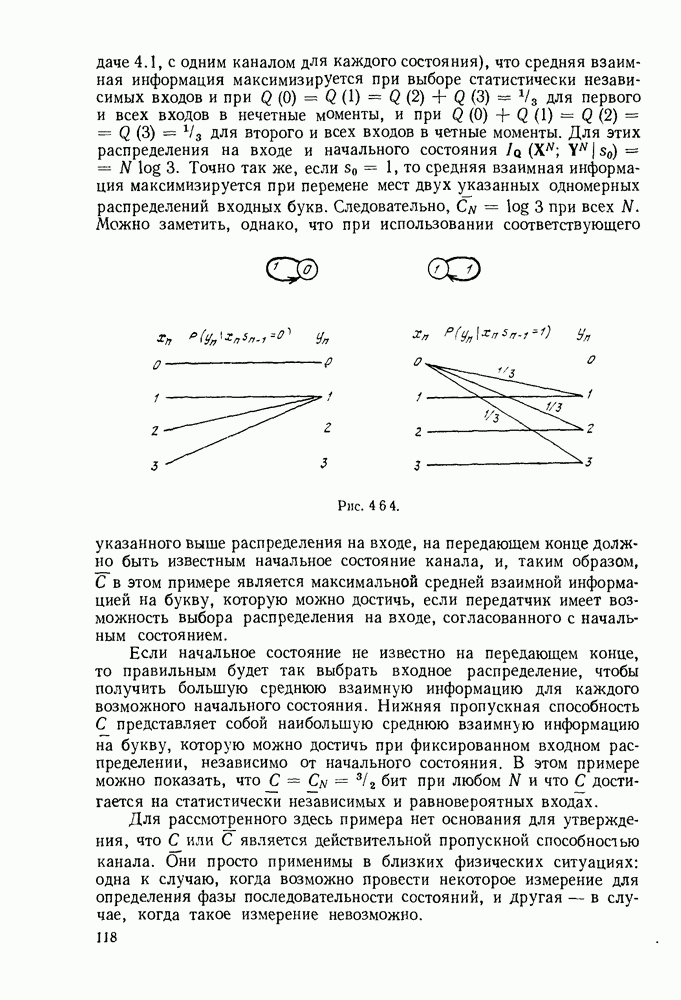





















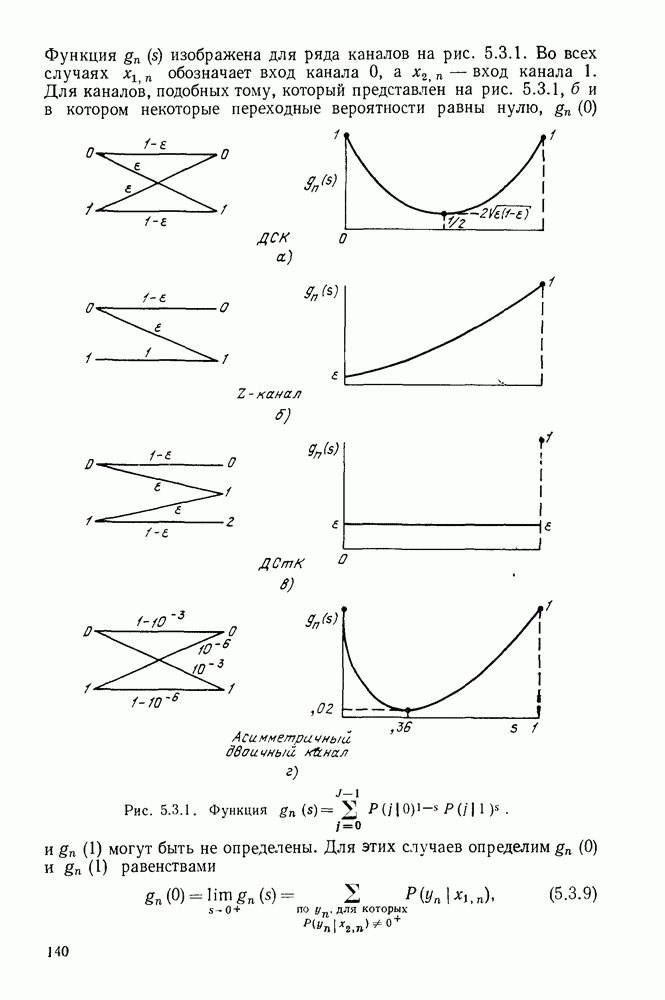



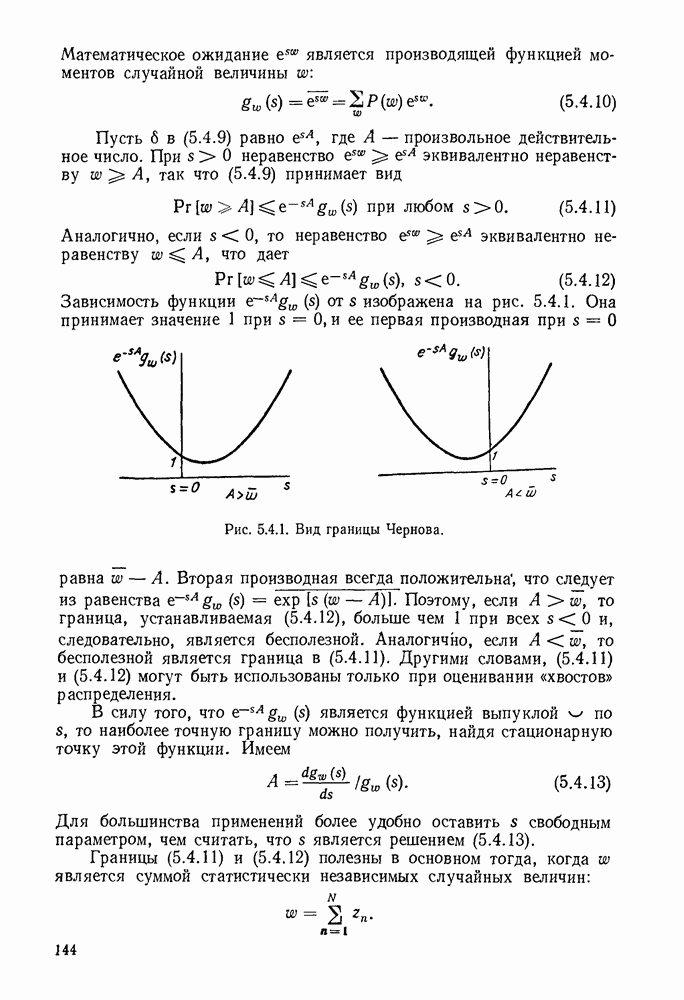































































































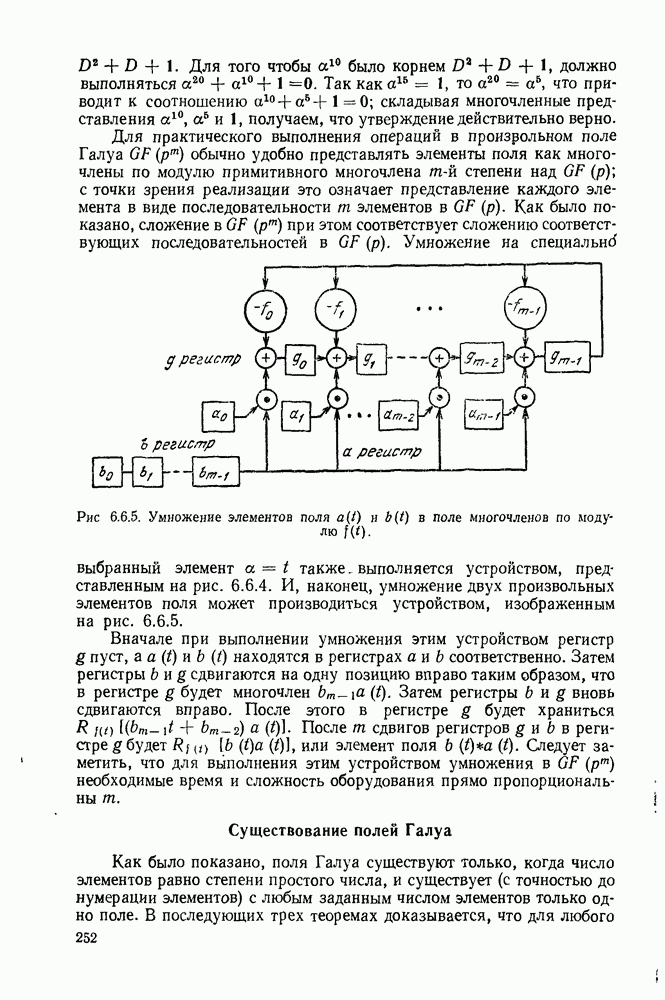


















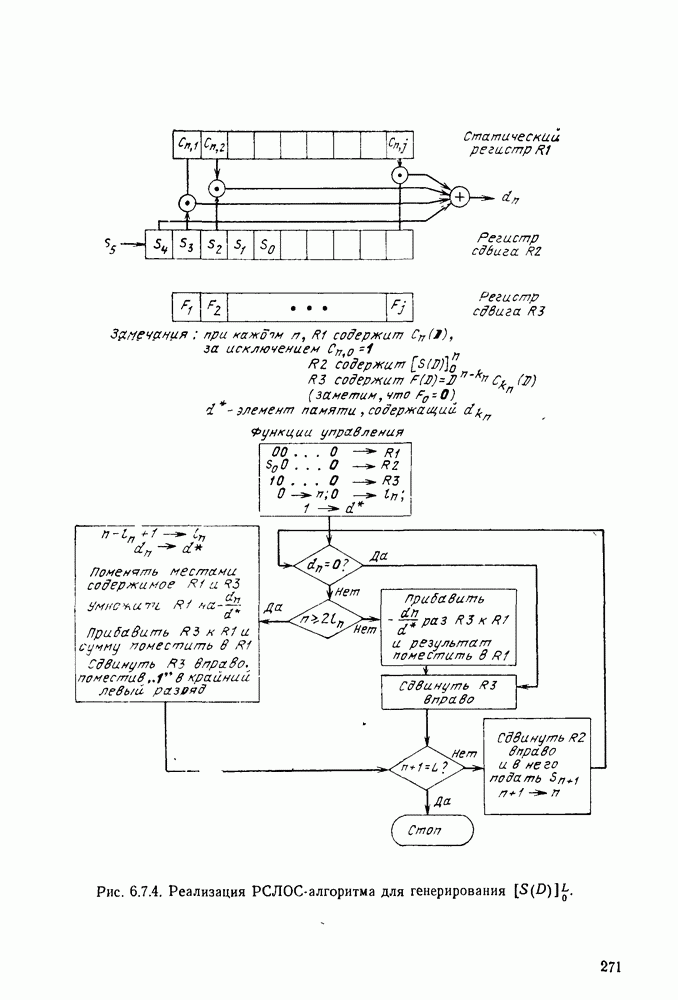

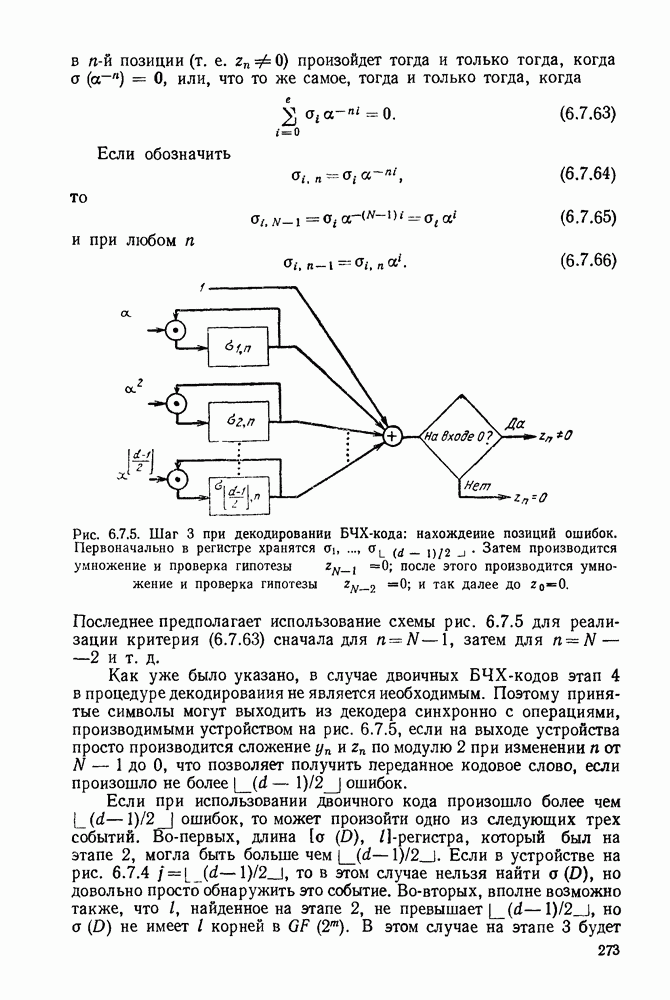



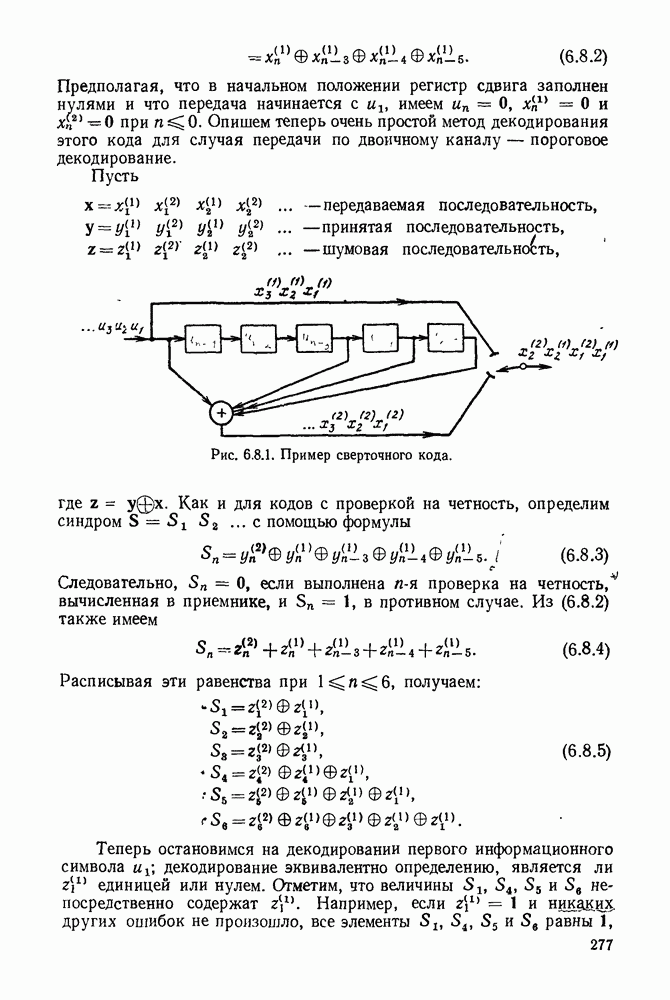

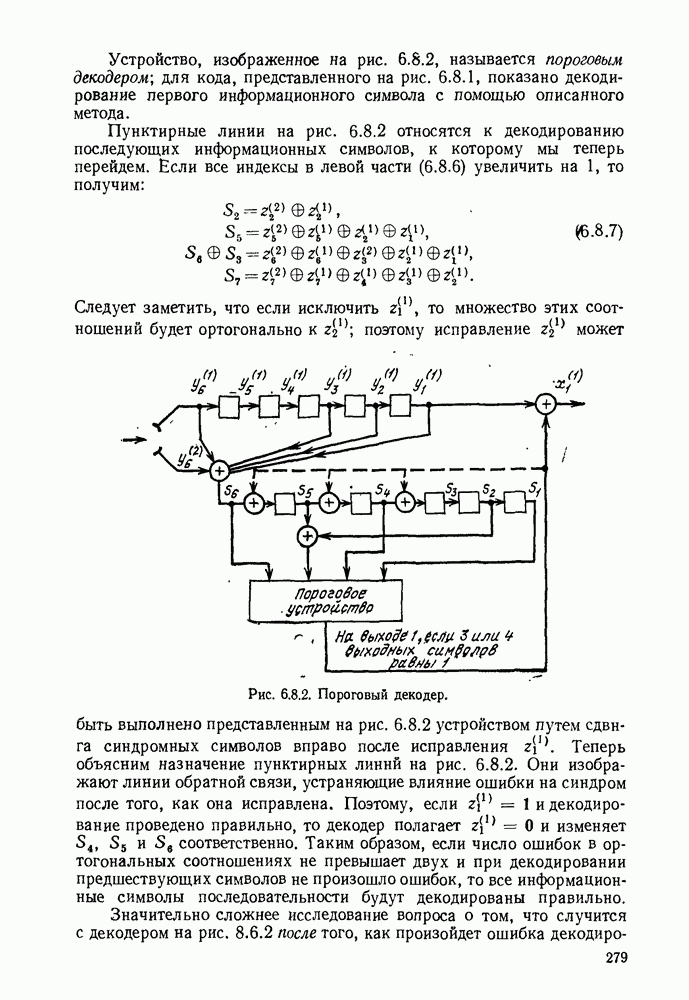

































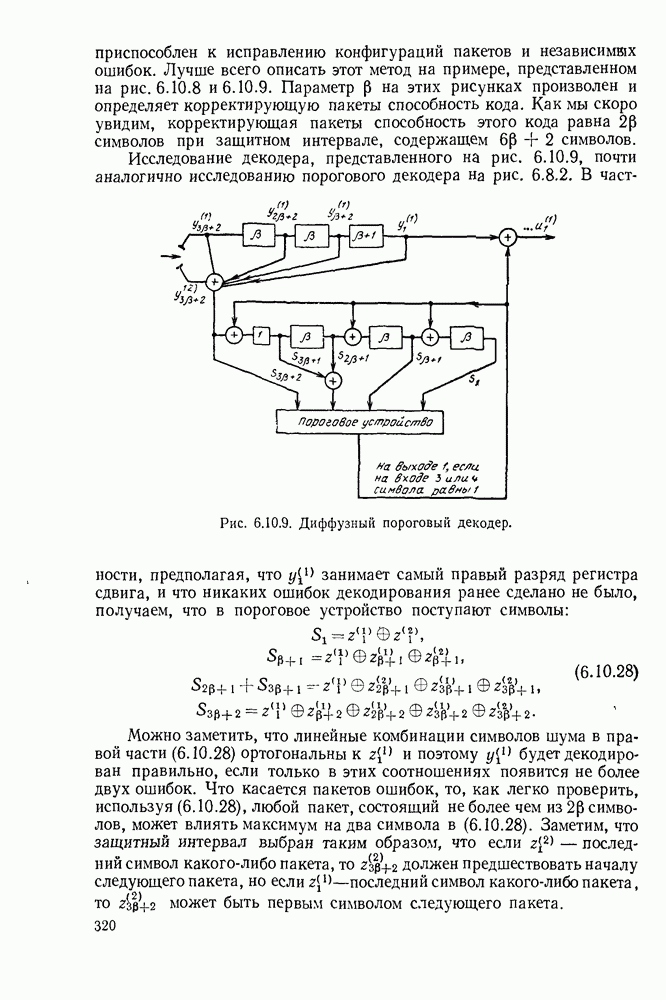





































































































































































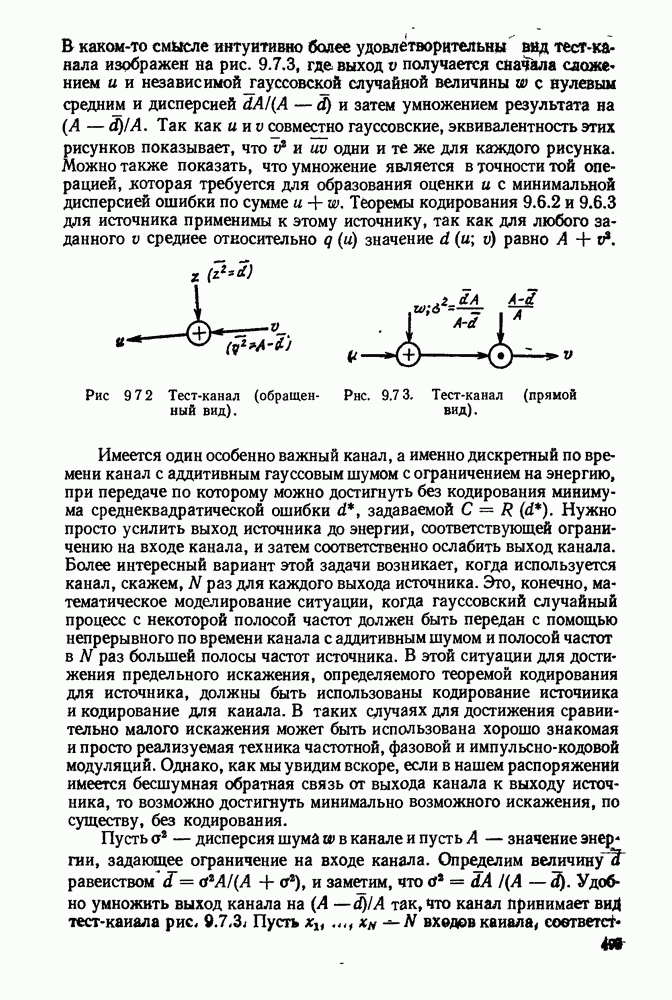









































 имеет алфавит из
имеет алфавит из  букв
букв  с вероятностями
с вероятностями  Каждая буква источника должна быть представлена кодовым словом, состоящим из последовательности букв, принадлежащих заданному кодовому алфавиту. Обозначим
Каждая буква источника должна быть представлена кодовым словом, состоящим из последовательности букв, принадлежащих заданному кодовому алфавиту. Обозначим  число различных символов в кодовом алфавите, а через
число различных символов в кодовом алфавите, а через  число букв в кодовом слове, соответствующем
число букв в кодовом слове, соответствующем  Позднее будут рассмотрены буквы источника, являющиеся последовательностями букв более простого источника, и, таким образом, мы получим существенное обобщение описанной выше ситуации.
Позднее будут рассмотрены буквы источника, являющиеся последовательностями букв более простого источника, и, таким образом, мы получим существенное обобщение описанной выше ситуации.
 средним числом кодовых букв на одну букву источника:
средним числом кодовых букв на одну букву источника:


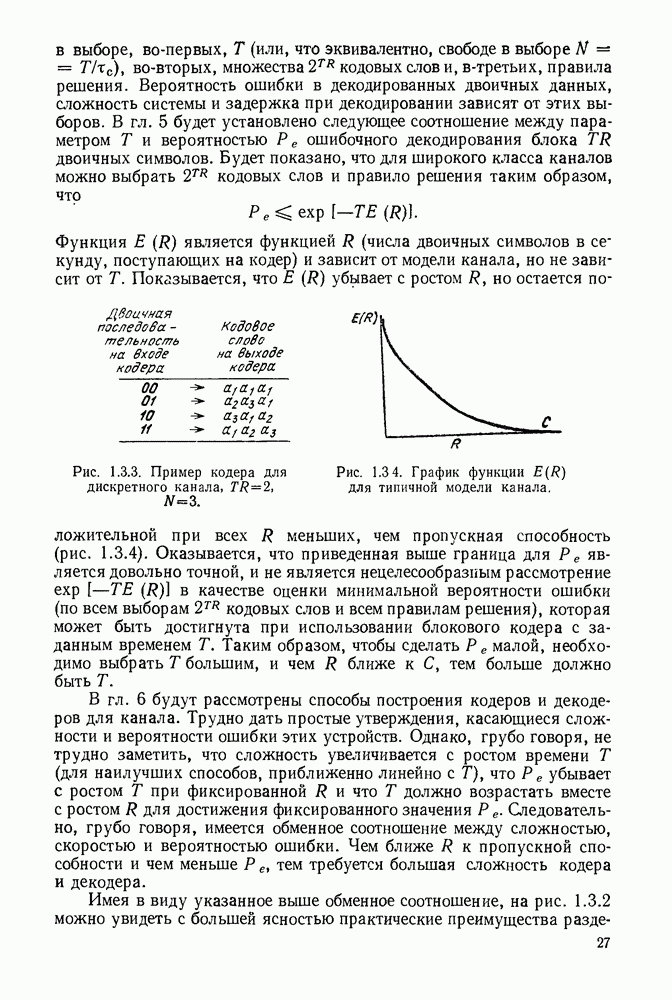
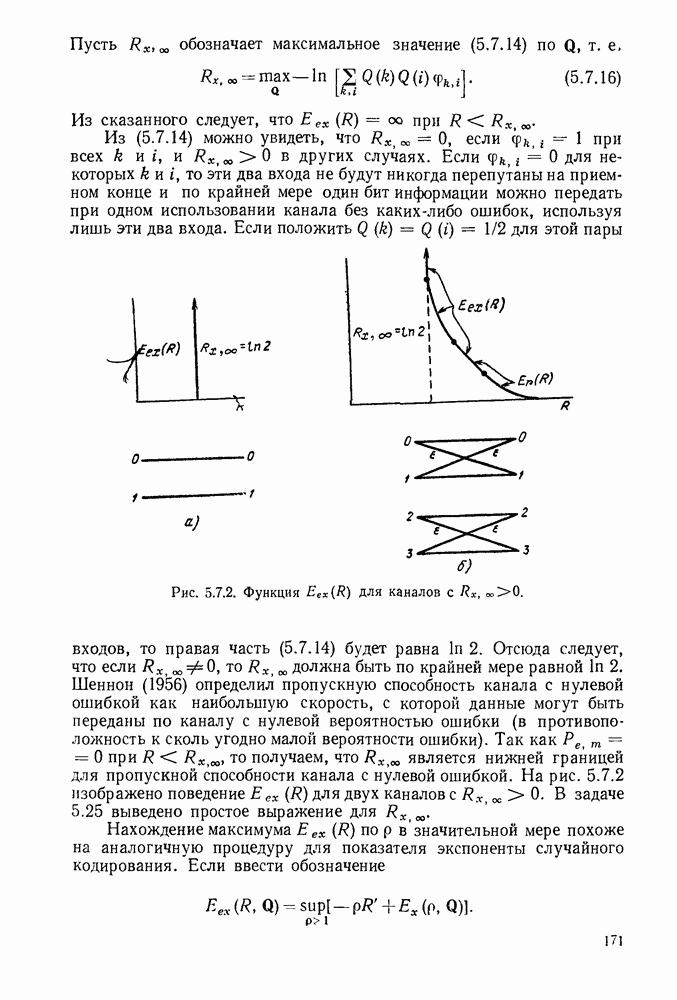
 рассмотрим некоторые ограничения на неравномерные коды, которые иллюстрируются рис. 3.2.1.
рассмотрим некоторые ограничения на неравномерные коды, которые иллюстрируются рис. 3.2.1.
 кодируются в одно и то же кодовое слово 0. Таким образом, это кодовое слово не может быть однозначно декодировано в букву источника, которая привела к этому слову. Так как такие коды не могут представлять буквы источника, они будут исключены из дальнейшего рассмотрения.
кодируются в одно и то же кодовое слово 0. Таким образом, это кодовое слово не может быть однозначно декодировано в букву источника, которая привела к этому слову. Так как такие коды не могут представлять буквы источника, они будут исключены из дальнейшего рассмотрения.

 Это не вызовет затруднения при декодировании, если между последовательными кодовыми словами имеется какой-то интервал или разделение. Однако если такой интервал допустим, то он должен быть рассмотрен как отдельный символ
Это не вызовет затруднения при декодировании, если между последовательными кодовыми словами имеется какой-то интервал или разделение. Однако если такой интервал допустим, то он должен быть рассмотрен как отдельный символ  кодового алфавита и кодовые слова в коде II должны быть
кодового алфавита и кодовые слова в коде II должны быть  Вводя обозначение для интервала (для ясности), когда это требуется, можно рассматривать такие коды просто как частные случаи кодов без интервала. По этой причине в дальнейшем такие коды не будут рассматриваться отдельно.
Вводя обозначение для интервала (для ясности), когда это требуется, можно рассматривать такие коды просто как частные случаи кодов без интервала. По этой причине в дальнейшем такие коды не будут рассматриваться отдельно.
 кодовое слово в коде представляется как
кодовое слово в коде представляется как  где
где  отдельные кодовые буквы, составляющие кодовое слово. Любая последовательность, составленная из начальной части
отдельные кодовые буквы, составляющие кодовое слово. Любая последовательность, составленная из начальной части  т. е.
т. е.  для некоторого
для некоторого  называется префиксом
называется префиксом  Код, обладающий свойством префикса, определяется как код, в котором никакое кодовое слово не является префиксом никакого другого кодового слова.
Код, обладающий свойством префикса, определяется как код, в котором никакое кодовое слово не является префиксом никакого другого кодового слова.
 является префиксом 10, кодового слова для
является префиксом 10, кодового слова для  Аналогично, если внимательно просмотреть определение префикса, то можно заметить, что 0, кодовое слово для
Аналогично, если внимательно просмотреть определение префикса, то можно заметить, что 0, кодовое слово для  является префиксом 0, кодового слова для
является префиксом 0, кодового слова для  Иными словами, любой код, два или более кодовых слова которого совпадают, не являются кодом, обладающим свойством префикса. Читателю предлагается проверить, что коды II и IV на рис. 3.2.1 не обладают свойством префикса, а код III обладает.
Иными словами, любой код, два или более кодовых слова которого совпадают, не являются кодом, обладающим свойством префикса. Читателю предлагается проверить, что коды II и IV на рис. 3.2.1 не обладают свойством префикса, а код III обладает.
 кодируется кодом III рис. 3.2.1 в
кодируется кодом III рис. 3.2.1 в  Так как первая буква в кодовой последовательности есть 0 и она соответствует
Так как первая буква в кодовой последовательности есть 0 и она соответствует  и не является начальным отрезком любой другой последовательности, то декодируется
и не является начальным отрезком любой другой последовательности, то декодируется  и остается кодовая последовательность 111100. Как 1, так 11 не соответствуют никакому кодовому слову, а 111 соответствует и декодируется в
и остается кодовая последовательность 111100. Как 1, так 11 не соответствуют никакому кодовому слову, а 111 соответствует и декодируется в  после чего остается 100. Далее 10 декодируется в
после чего остается 100. Далее 10 декодируется в  остается только 0, который декодируется в
остается только 0, который декодируется в 
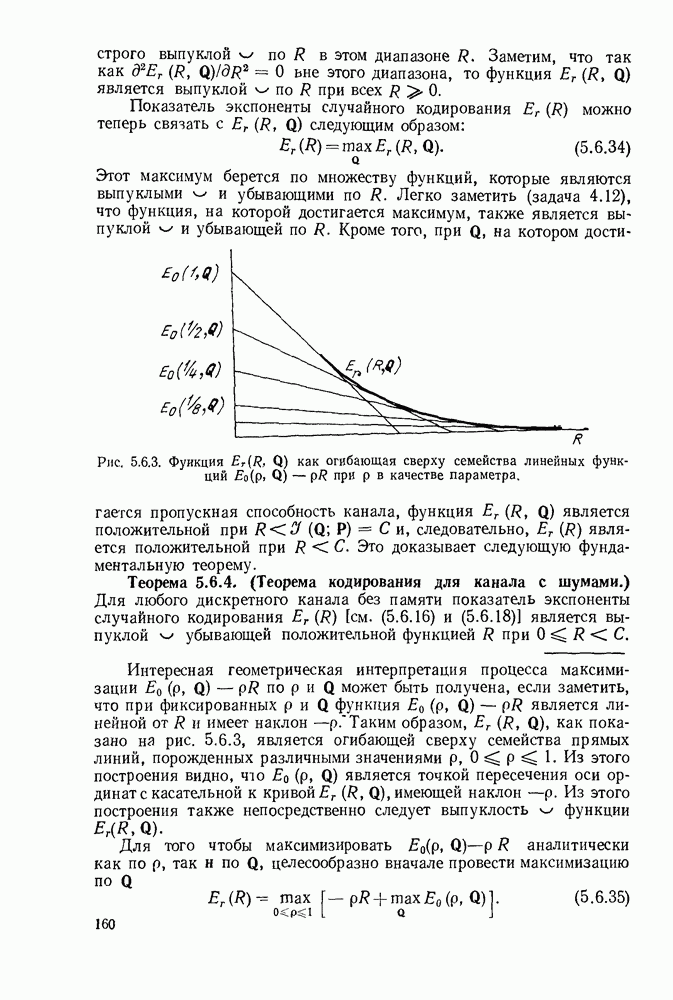
 В начале приведем эвристическое рассмотрение этой задачи, затем докажем некоторые общие теоремы относительно длин кодовых слов и, наконец, дадим алгоритм построения кода, который минимизирует
В начале приведем эвристическое рассмотрение этой задачи, затем докажем некоторые общие теоремы относительно длин кодовых слов и, наконец, дадим алгоритм построения кода, который минимизирует 

 следует достичь большого значения средней взаимной информации во всех промежуточных узлах дерева. Это в свою очередь говорит о том, что нужно попытаться выбрать кодовые слова таким образом, чтобы все ребра, исходящие из узла, в соответствующем дереве, были равновероятными. Сопоставляя дерево рис. 3.2.2 с вероятностями букв источника для кода III рис. 3.2.1, можно заметить, что каждое ребро дерева берется с вероятностью 1/2. Для этого примера
следует достичь большого значения средней взаимной информации во всех промежуточных узлах дерева. Это в свою очередь говорит о том, что нужно попытаться выбрать кодовые слова таким образом, чтобы все ребра, исходящие из узла, в соответствующем дереве, были равновероятными. Сопоставляя дерево рис. 3.2.2 с вероятностями букв источника для кода III рис. 3.2.1, можно заметить, что каждое ребро дерева берется с вероятностью 1/2. Для этого примера  В длинной последовательности
В длинной последовательности  букв источника значение
букв источника значение  с большой вероятностью близко к числу кодовых букв на одну букву источника. Следовательно, если бы существовал код с
с большой вероятностью близко к числу кодовых букв на одну букву источника. Следовательно, если бы существовал код с  можно было бы при больших
можно было бы при больших  закодировать большинство последовательностей источника длины
закодировать большинство последовательностей источника длины  с помощью меньше чем
с помощью меньше чем  кодовых букв на одну букву источника, в нарушение теоремы 3.1.1. Это означает, что 1,75 является минимальной возможной величиной
кодовых букв на одну букву источника, в нарушение теоремы 3.1.1. Это означает, что 1,75 является минимальной возможной величиной  для этого кода. Это не удивительно, так как мы смогли построить код так, что каждая кодовая буква содержит в точности 1 бит информации о выходе источника.
для этого кода. Это не удивительно, так как мы смогли построить код так, что каждая кодовая буква содержит в точности 1 бит информации о выходе источника.
 подмножеств так, чтобы вероятность каждого подмножества была по возможности наиболее близкой к
подмножеств так, чтобы вероятность каждого подмножества была по возможности наиболее близкой к  Припишем различные начальные кодовые буквы каждому из этих подмножеств. Затем разобьем вновь каждое подмножество
Припишем различные начальные кодовые буквы каждому из этих подмножеств. Затем разобьем вновь каждое подмножество  приближенно равновероятных групп и припишем вторую букву, соответствующую этому разделению. Продолжим этот процесс до тех пор, пока каждая группа не будет содержать только одну букву источника. Полученный в результате код удовлетворяет, очевидно, свойству префикса. Эта процедура не обязательно минимизирует
приближенно равновероятных групп и припишем вторую букву, соответствующую этому разделению. Продолжим этот процесс до тех пор, пока каждая группа не будет содержать только одну букву источника. Полученный в результате код удовлетворяет, очевидно, свойству префикса. Эта процедура не обязательно минимизирует  так как достижение большого значения средней собственной информации на одной кодовой букве может привести к обедненному выбору для последующих кодовых букв. Заметим, что если это разбиение может быть выполнено так, что группы будут в точности равновероятными на каждом этапе, то вероятности букв источника и длины кодовых слов будут связаны равенством
так как достижение большого значения средней собственной информации на одной кодовой букве может привести к обедненному выбору для последующих кодовых букв. Заметим, что если это разбиение может быть выполнено так, что группы будут в точности равновероятными на каждом этапе, то вероятности букв источника и длины кодовых слов будут связаны равенством

 удовлетворяют неравенству
удовлетворяют неравенству

 длины кодовых слов в котором равны этим числам. Обратно, длины кодовых слов любого кода, обладающего свойством префикса, удовлетворяют неравенству (3.2.3). (Замечание. Теорема не утверждает, что любой код с длинами кодовых слов, удовлетворяющими (3.2.3), является префиксным. Так, например, множество двоичных кодовых слов 0, 00, 11 удовлетворяет (3.2.3), но не обладает свойством префикса. Теорема утверждает, что существует некоторый префиксный код с такими длинами, например, 0, 10 и 11).
длины кодовых слов в котором равны этим числам. Обратно, длины кодовых слов любого кода, обладающего свойством префикса, удовлетворяют неравенству (3.2.3). (Замечание. Теорема не утверждает, что любой код с длинами кодовых слов, удовлетворяющими (3.2.3), является префиксным. Так, например, множество двоичных кодовых слов 0, 00, 11 удовлетворяет (3.2.3), но не обладает свойством префикса. Теорема утверждает, что существует некоторый префиксный код с такими длинами, например, 0, 10 и 11).
 с алфавитом объема
с алфавитом объема  дерево, содержащее
дерево, содержащее  концевых узлов порядка
концевых узлов порядка  в котором
в котором  узлов порядка
узлов порядка  появляются из каждого узла порядка
появляются из каждого узла порядка  для каждого
для каждого  Заметим, что доля
Заметим, что доля  узлов любого порядка
узлов любого порядка  исходит из каждого из
исходит из каждого из  узлов первого порядка. Точно так же доля
узлов первого порядка. Точно так же доля  узлов любого порядка
узлов любого порядка  исходит из каждого из
исходит из каждого из  узлов порядка
узлов порядка  узлов любого порядка, большего или равного
узлов любого порядка, большего или равного  исходит из каждого из
исходит из каждого из  узлов порядка
узлов порядка 
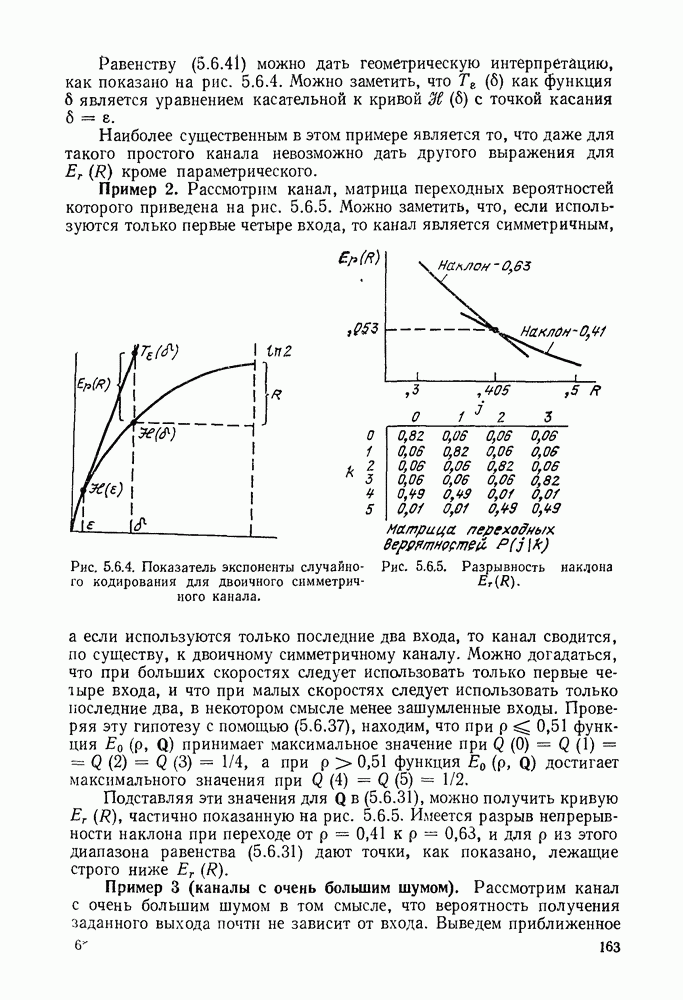
 удовлетворяют (3.2.3). Покажем, как построить префиксный код с этими длинами, исходя из полного дерева порядка
удовлетворяют (3.2.3). Покажем, как построить префиксный код с этими длинами, исходя из полного дерева порядка  равного наибольшемулз
равного наибольшемулз  и полагая различные узлы в этом
и полагая различные узлы в этом  полном дереве концевыми узлами кодового дерева. Так что, когда
полном дереве концевыми узлами кодового дерева. Так что, когда
 упорядочены в порядке возрастания
упорядочены в порядке возрастания  Выберем какой-либо узел порядка
Выберем какой-либо узел порядка  допустим
допустим  в полном дереве в качестве первого концевого узла кодового дерева. Все узлы полного дерева любого порядка, большего или равного
в полном дереве в качестве первого концевого узла кодового дерева. Все узлы полного дерева любого порядка, большего или равного  еще можно использовать как концевые узлы кодового дерева, за исключением доли
еще можно использовать как концевые узлы кодового дерева, за исключением доли  узлов, которые исходят из узла х Далее выберем какой-нибудь оставшийся узел порядка
узлов, которые исходят из узла х Далее выберем какой-нибудь оставшийся узел порядка  например
например  в качестве следующего концевого узла кодового дерева. Все узлы полного дерева
в качестве следующего концевого узла кодового дерева. Все узлы полного дерева  любого порядка, большего или равного
любого порядка, большего или равного  еще можно использовать как концевые узлы, за исключением доли
еще можно использовать как концевые узлы, за исключением доли  узлов, которые исходят из узлов
узлов, которые исходят из узлов 

 концевого узла кодового дерева все узлы полного дерева любого порядка, большего или равного
концевого узла кодового дерева все узлы полного дерева любого порядка, большего или равного  все еще можно использовать, за исключением доли
все еще можно использовать, за исключением доли  исходящей из
исходящей из  Согласно (3.2.3) эта доля всегда строго меньше, чем 1 при
Согласно (3.2.3) эта доля всегда строго меньше, чем 1 при  следовательно, всегда существует некоторый оставшийся узел, который может быть рассмотрен как следующий концевой узел.
следовательно, всегда существует некоторый оставшийся узел, который может быть рассмотрен как следующий концевой узел.
 кодового дерева исходит доля
кодового дерева исходит доля  концевых узлов полного дерева. Так как множества концевых узлов полного дерева, исходящие из различных концевых узлов кодового дерева, являются непересекающимися, то эти доли в сумме не могут превосходить 1, давая (3.2.3).
концевых узлов полного дерева. Так как множества концевых узлов полного дерева, исходящие из различных концевых узлов кодового дерева, являются непересекающимися, то эти доли в сумме не могут превосходить 1, давая (3.2.3).
 с кодовым алфавитом из
с кодовым алфавитом из  символов. Если код однозначно декодируем, неравенство Крафта (3.2.3) удовлетворяется.
символов. Если код однозначно декодируем, неравенство Крафта (3.2.3) удовлетворяется.
 произвольное положительное целое число. Рассмотрим тождество
произвольное положительное целое число. Рассмотрим тождество

 кодовых слов. Более того, сумма
кодовых слов. Более того, сумма  равна общему числу кодовых букв, соответствующему последовательности кодовых слов. Следовательно, если через
равна общему числу кодовых букв, соответствующему последовательности кодовых слов. Следовательно, если через  обозначить число последовательностей из
обозначить число последовательностей из  кодовых слов, имеющих общую длину
кодовых слов, имеющих общую длину  число кодовых букв, то (3.2.4) можно переписать в виде
число кодовых букв, то (3.2.4) можно переписать в виде

 является наибольшим из
является наибольшим из 
 кодовых букв являются различными и, следовательно,
кодовых букв являются различными и, следовательно,  Подставляя это неравенство в (3.2.5), получаем
Подставляя это неравенство в (3.2.5), получаем

 переходя к пределу при
переходя к пределу при  получаем (3.2.3), что доказывает теорему.)
получаем (3.2.3), что доказывает теорему.)