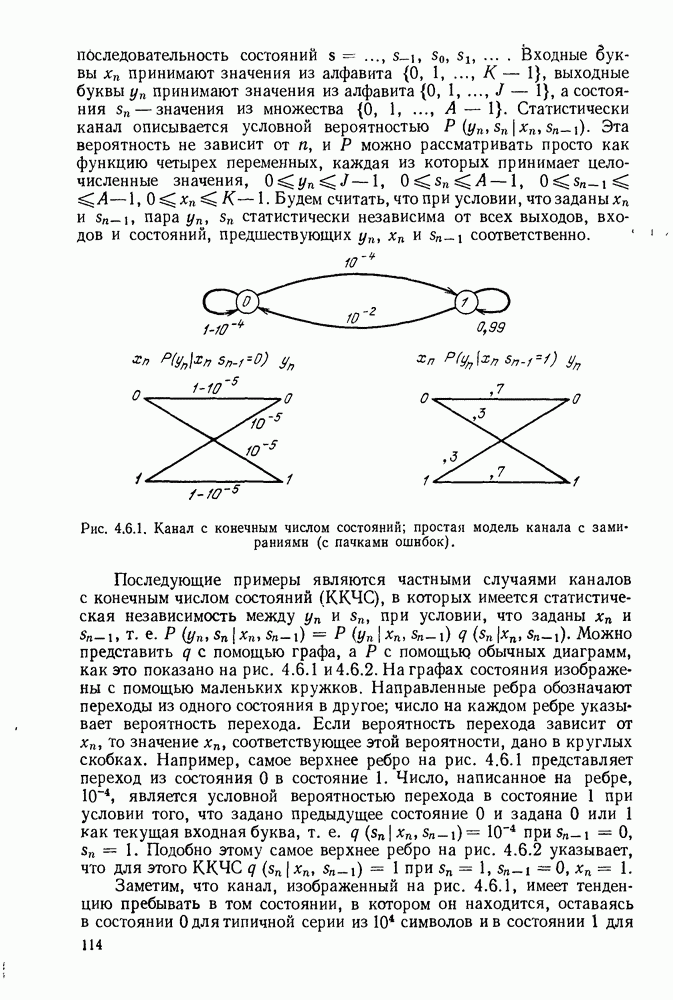
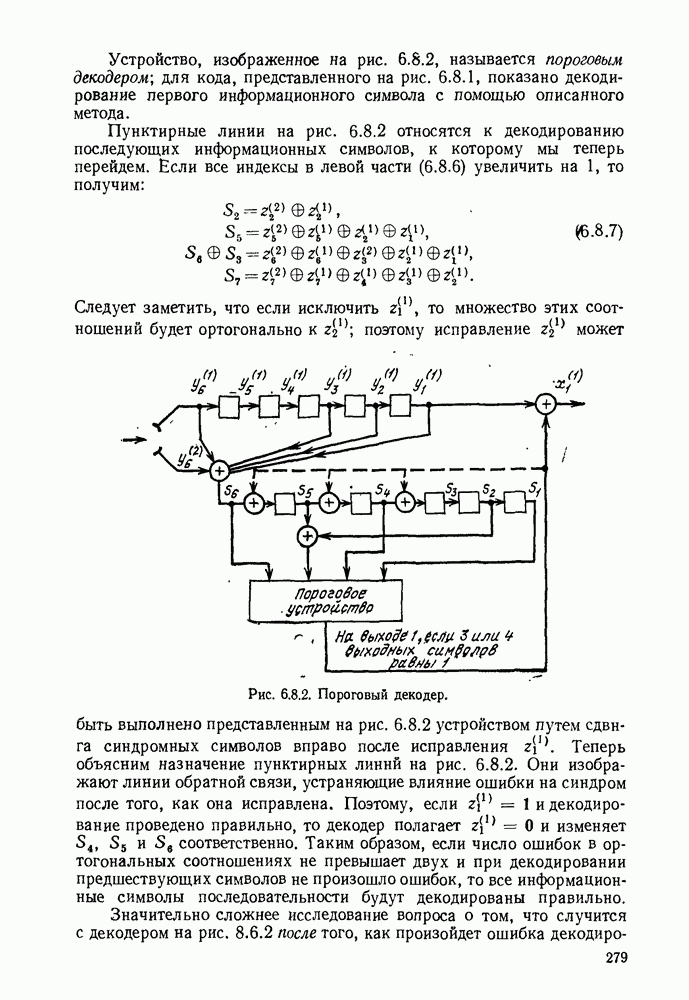
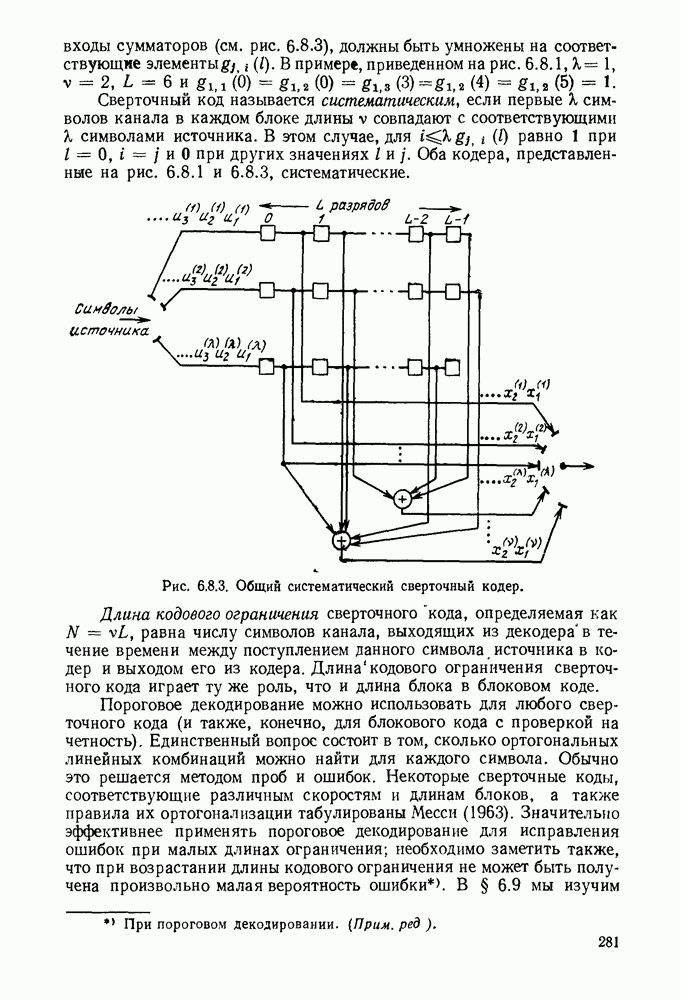
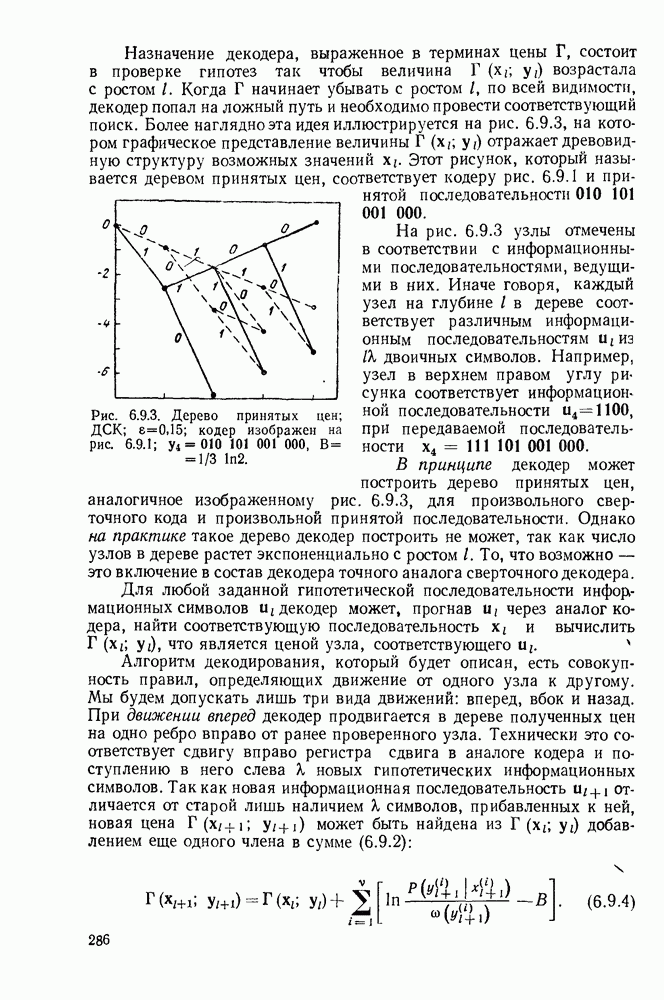
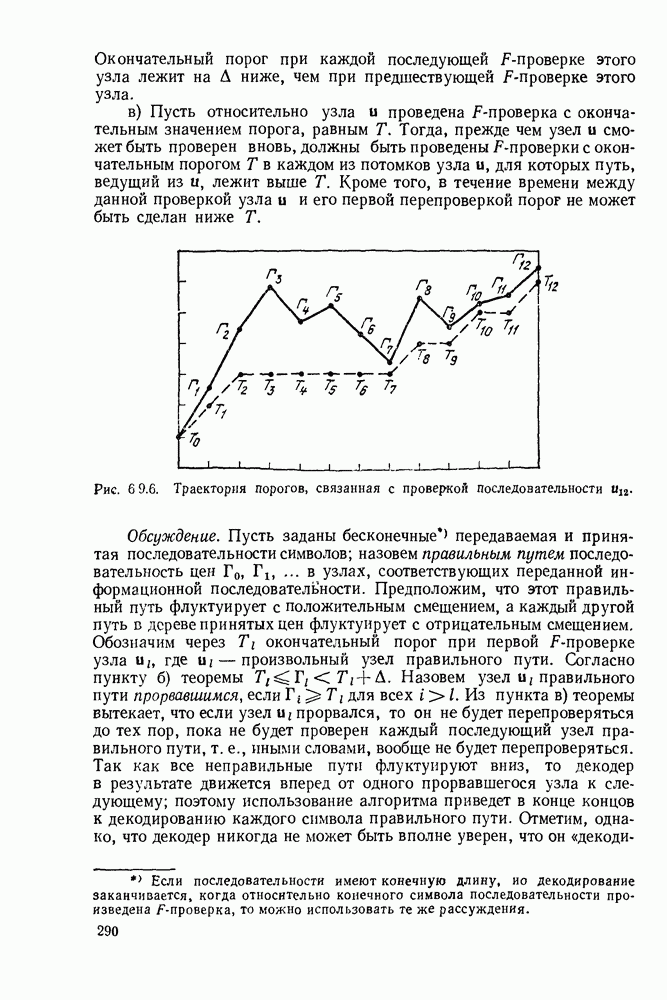
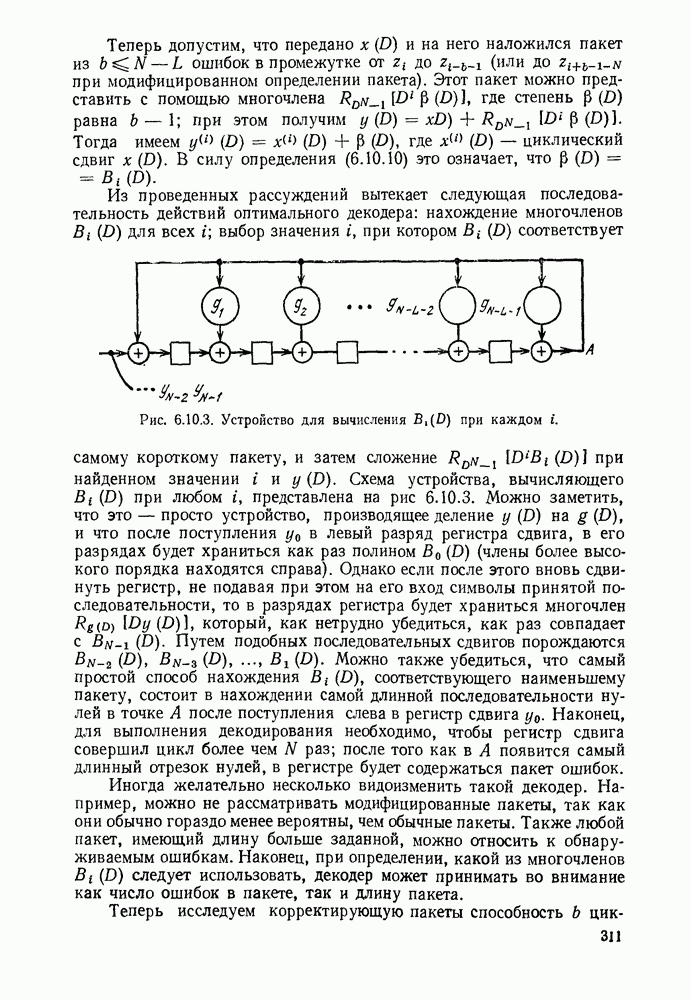
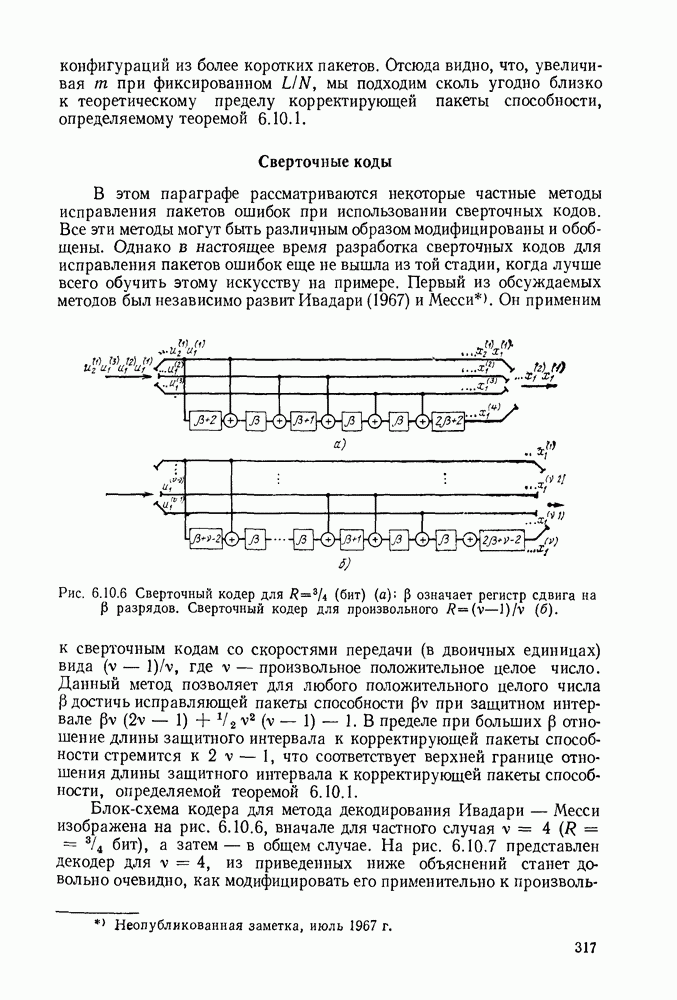
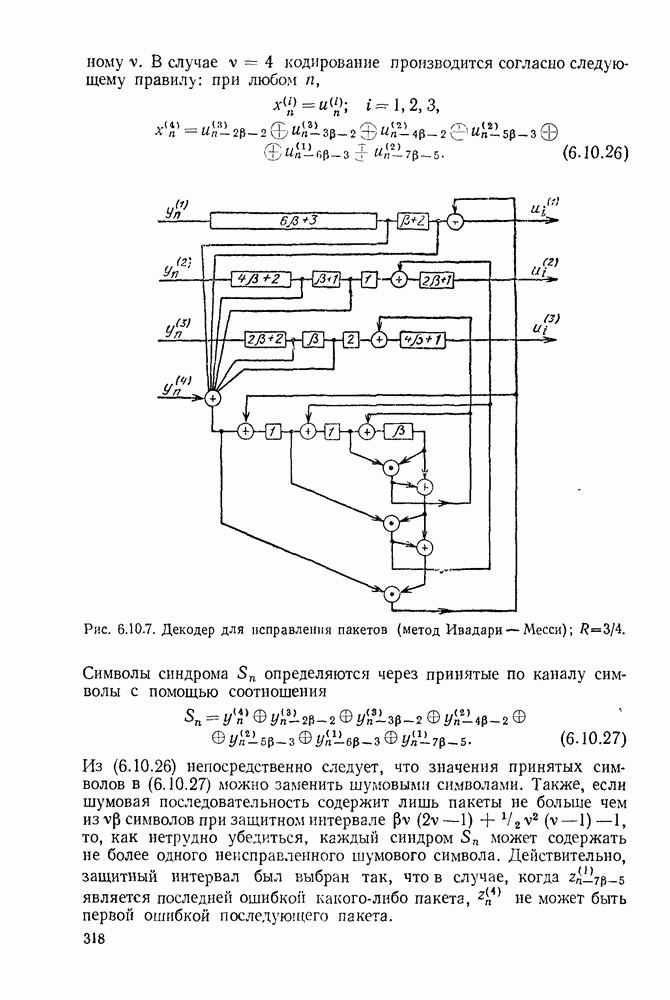
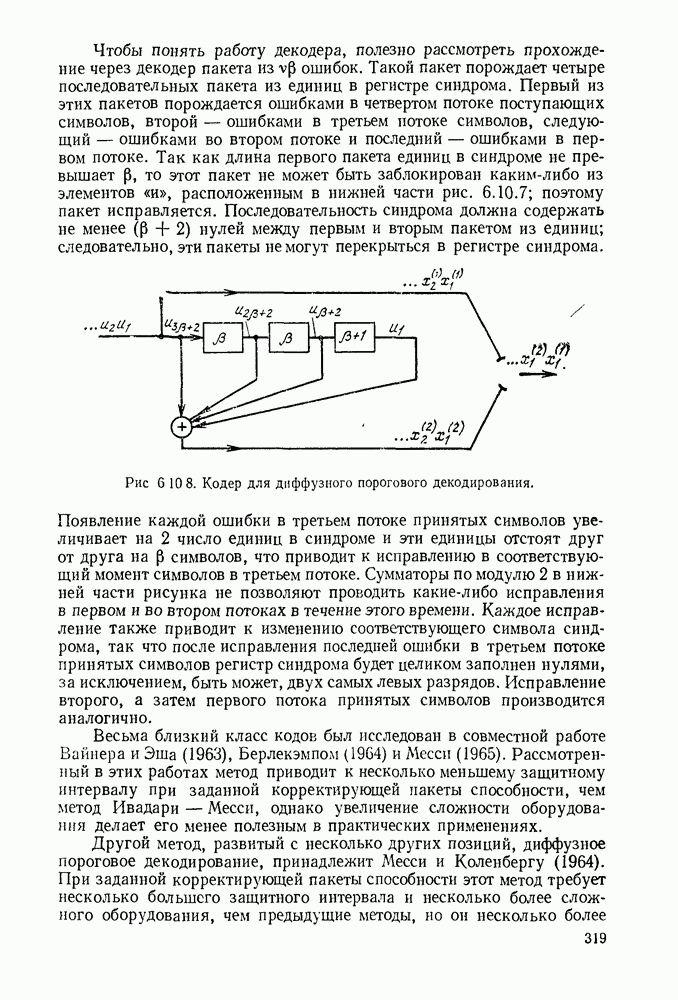
6.7. БЧХ-КОДЫ
Коды Боуза, Чоудхури и Хоквингема  открытые Хоквингемом (1959) и независимо от него Боузе и Чоудхури (1960), представляют собой класс циклических кодов, которые обладают весьма мощной способностью исправлять ошибки и одновременно допускают простые алгоритмы декодирования. Наиболее простым примером БЧХ-кодов являются двоичные коды, но совершенно аналогично можно в качестве алфавита выбирать элементы произвольного поля Галуа
открытые Хоквингемом (1959) и независимо от него Боузе и Чоудхури (1960), представляют собой класс циклических кодов, которые обладают весьма мощной способностью исправлять ошибки и одновременно допускают простые алгоритмы декодирования. Наиболее простым примером БЧХ-кодов являются двоичные коды, но совершенно аналогично можно в качестве алфавита выбирать элементы произвольного поля Галуа  Порождающий многочлен для этих кодов определяется в терминах некоторого расширения
Порождающий многочлен для этих кодов определяется в терминах некоторого расширения  поля
поля  Пусть а — элемент
Пусть а — элемент  мультипликативный порядок которого равен
мультипликативный порядок которого равен  числа
числа  произвольные целые числа; пусть далее
произвольные целые числа; пусть далее  минимальные многочлены для
минимальные многочлены для  Для каждого набора определенных выше параметров (т. е. для
Для каждого набора определенных выше параметров (т. е. для  существует БЧХ-код; его порождающий многочлен определяется равенством
существует БЧХ-код; его порождающий многочлен определяется равенством

где  означает наименьшее общее кратное.
означает наименьшее общее кратное.
Длина блока в коде по определению равна  мультипликативному порядку элемента а. Так как каждый из элементов
мультипликативному порядку элемента а. Так как каждый из элементов  является корнем
является корнем  то многочлен
то многочлен  делится на каждый из многочленов
делится на каждый из многочленов  (см. теорему 6.6.3) и, следовательно, на
(см. теорему 6.6.3) и, следовательно, на  что необходимо для циклических кодов. В неинтересном случае, когда
что необходимо для циклических кодов. В неинтересном случае, когда  последовательность, целиком состоящая из нулей, по определению, выбирается в качестве единого кодового слова.
последовательность, целиком состоящая из нулей, по определению, выбирается в качестве единого кодового слова.
Другое определение БЧХ-кода с параметрами, указанными выше, состоит в том, что последовательность  является кодовым словом тогда и только тогда, когда
является кодовым словом тогда и только тогда, когда  являются корнями
являются корнями  Чтобы убедиться в этом, заметим, что в силу определения (6.7.1) любой многочлен, соответствующий кодовому слову, делится на
Чтобы убедиться в этом, заметим, что в силу определения (6.7.1) любой многочлен, соответствующий кодовому слову, делится на  следовательно, на все минимальные многочлены
следовательно, на все минимальные многочлены  Поэтому
Поэтому  являются корнями многочлена,
являются корнями многочлена,
соответствующего кодовому слову. Обратно, если многочлен  не является кодовым словом, то он не делится на
не является кодовым словом, то он не делится на  следовательно, не делится, по крайней мере, на один из минимальных многочленов, допустим на
следовательно, не делится, по крайней мере, на один из минимальных многочленов, допустим на  Но тогда а не является корнем
Но тогда а не является корнем 
В большинстве приложений в качестве а выбирается примитивный элемент  так что
так что  качестве
качестве  обычно выбирается 1. Позднее будет показано, что параметр
обычно выбирается 1. Позднее будет показано, что параметр  имеет смысл нижней границы для минимального расстояния в коде.
имеет смысл нижней границы для минимального расстояния в коде.
Пример. Так как введенные выше определения, без сомнения, кажутся несколько абстрактными, рассмотрим конкретный пример  Пусть используется представление
Пусть используется представление  , определенное таблицей на рис. 6.6.3. Выберем в качестве элемента а тот элемент на рис. 6.6.3, который представляется многочленом
, определенное таблицей на рис. 6.6.3. Выберем в качестве элемента а тот элемент на рис. 6.6.3, который представляется многочленом  Как показано в § 6.6, минимальный многочлен для а над
Как показано в § 6.6, минимальный многочлен для а над  равен
равен  Тогда из (6.6.13) следует, что элементам
Тогда из (6.6.13) следует, что элементам  соответствует тот же самый минимальный многочлен, что и элементу а. Как показано в § 6.6, минимальный многочлен для
соответствует тот же самый минимальный многочлен, что и элементу а. Как показано в § 6.6, минимальный многочлен для  над
над  равен
равен  Тогда
Тогда

Интересная особенность, которую вскрывает данный пример, состоит в том, что при  и при любых
и при любых  имеем
имеем  Поэтому при
Поэтому при  и нечетном
и нечетном  можно переписать в виде
можно переписать в виде

Так как степень  равна числу проверочных символов в циклическом коде, порождаемом
равна числу проверочных символов в циклическом коде, порождаемом  то отсюда следует, что при нечетных
то отсюда следует, что при нечетных  число проверочных символов БЧХ-кода с
число проверочных символов БЧХ-кода с  и произвольными
и произвольными  не превышает
не превышает  Допустим на время, что
Допустим на время, что  равно нижней границе минимального расстояния в коде, тогда получим, что если число проверочных символов равно
равно нижней границе минимального расстояния в коде, тогда получим, что если число проверочных символов равно  то исправляются все комбинации
то исправляются все комбинации  ошибок. Если выбрать а примитивным, то длина блока в коде будет равна
ошибок. Если выбрать а примитивным, то длина блока в коде будет равна  Из (6.7.1) следует, что при
Из (6.7.1) следует, что при  или
или  все комбинации
все комбинации  ошибок могут быть исправлены, если число проверочных символов не меньше
ошибок могут быть исправлены, если число проверочных символов не меньше 
Так как БЧХ-коды являются циклическими кодами, то из результатов § 6.5 следует, что проверочную матрицу для БЧХ-кода можно вычислить, используя многочлен  Проверочную матрицу можно привести к более удобной для наших целей форме, если вспомнить, что
Проверочную матрицу можно привести к более удобной для наших целей форме, если вспомнить, что  является многочленом, соответствующим кодовому слову, тогда и только тогда, когда
является многочленом, соответствующим кодовому слову, тогда и только тогда, когда  при
при  Последнее соотношение можно переписать в виде
Последнее соотношение можно переписать в виде

Определяя проверочную матрицу как

можно переписать (6.7.4) в виде равенства

справедливого тогда и только тогда, когда  является кодовым словом. Если элементам
является кодовым словом. Если элементам  и а при некоторых значениях
и а при некоторых значениях  соответствуют одинаковые минимальные многочлены, то
соответствуют одинаковые минимальные многочлены, то  тогда и только тогда, когда
тогда и только тогда, когда  при этом столбцы, соответствующие а, могут быть опущены в (6.7.5). Таким образом, для только что рассмотренного примера
при этом столбцы, соответствующие а, могут быть опущены в (6.7.5). Таким образом, для только что рассмотренного примера

Напомним, что согласно § 6.6 элементы расширения  поля
поля  могут рассматриваться как
могут рассматриваться как  -компонентные векторы над
-компонентные векторы над  Умножение элемента а из
Умножение элемента а из  на элемент х, принадлежащий
на элемент х, принадлежащий  соответствует скалярному умножению вектора а на скаляр х из
соответствует скалярному умножению вектора а на скаляр х из  Поэтому, если рассматривать элементы Я в (6.7.5) как вектор-строки в поле
Поэтому, если рассматривать элементы Я в (6.7.5) как вектор-строки в поле  то при матричном умножении
то при матричном умножении  производятся лишь операции в
производятся лишь операции в  Например, для только что рассмотренного примера матрица
Например, для только что рассмотренного примера матрица  определяемая (6.7.7а), может быть переписана следующим образом (см. рис. 6.6.3):
определяемая (6.7.7а), может быть переписана следующим образом (см. рис. 6.6.3):

Теорема 6.7.1. Минимальное расстояние для БЧХ-кода с определенным выше параметром  не меньше чем
не меньше чем 
Доказательство. Пусть  последовательность символов из
последовательность символов из  предположим, что все значения этих символов, кроме
предположим, что все значения этих символов, кроме  выбираются равными 0, а остальные символы, например
выбираются равными 0, а остальные символы, например
 выбираются произвольно. Покажем, что при любых значениях целых чисел
выбираются произвольно. Покажем, что при любых значениях целых чисел  (удовлетворяющих
(удовлетворяющих  ), х может быть кодовым словом тогда и только тогда, когда
), х может быть кодовым словом тогда и только тогда, когда  при
при  Этим будет доказано, что все ненулевые кодовые слова отличаются от последовательности, целиком состоящей из нулей, не менее чем в
Этим будет доказано, что все ненулевые кодовые слова отличаются от последовательности, целиком состоящей из нулей, не менее чем в  позициях и, следовательно, минимальное расстояние в коде не меньше
позициях и, следовательно, минимальное расстояние в коде не меньше 
При заданном выборе целых чисел  вектор х является кодовым словом тогда и только тогда [см. (6.7.4)], когда
вектор х является кодовым словом тогда и только тогда [см. (6.7.4)], когда 

Упростим обозначения, определив

Тогда соотношение (6.7.8) переписывается в виде

Эти соотношения представляют собой систему  уравнений [над
уравнений [над  неизвестным
неизвестным  Одно решение данной системы тривиально:
Одно решение данной системы тривиально:  Для завершения доказательства необходимо показать, что это решение единственно [из того факта, что в
Для завершения доказательства необходимо показать, что это решение единственно [из того факта, что в  не существует другого решения, в действительности следует, что не существует другого решения в
не существует другого решения, в действительности следует, что не существует другого решения в  Вместе с тем это решение единственно, если уравнения линейно независимы (доказательство этого такое же, как в поле действительных чисел). Линейная зависимость уравнений означает, что существует такое множество не равных одновременно нулю элементов поля
Вместе с тем это решение единственно, если уравнения линейно независимы (доказательство этого такое же, как в поле действительных чисел). Линейная зависимость уравнений означает, что существует такое множество не равных одновременно нулю элементов поля  для которых
для которых

Предположим, что такое множество элементов поля существует, и пусть  Соотношение (6.7.11) выражается через
Соотношение (6.7.11) выражается через  следующим образом:
следующим образом:

Вместе с тем  является ненулевым многочленом, степень которого не больше
является ненулевым многочленом, степень которого не больше  из (6.7.12) следует, что число корней
из (6.7.12) следует, что число корней  не
не
меньше  Эти утверждения противоречивы и, следовательно, уравнения линейно не зависимы, что завершает доказательство.
Эти утверждения противоречивы и, следовательно, уравнения линейно не зависимы, что завершает доказательство. 
Так как минимальное расстояние в БЧХ-коде не меньше  то, как известно, любая комбинация из
то, как известно, любая комбинация из  или менее ошибок может быть исправлена; ниже получим алгоритм исправления всех таких комбинаций ошибок. В действительности этот код способен исправлять также много комбинаций более чем
или менее ошибок может быть исправлена; ниже получим алгоритм исправления всех таких комбинаций ошибок. В действительности этот код способен исправлять также много комбинаций более чем  ошибок, однако до сих пор неизвестен простой алгоритм их исправления.
ошибок, однако до сих пор неизвестен простой алгоритм их исправления.
Обозначим через  многочлен, соответствующий переданному кодовому слову, через
многочлен, соответствующий переданному кодовому слову, через  многочлен, соответствующий принятой последовательности, а через
многочлен, соответствующий принятой последовательности, а через  многочлен, соответствующий шумовой последовательности. Синдромом
многочлен, соответствующий шумовой последовательности. Синдромом  назовем вектор с компонентами
назовем вектор с компонентами

Отметим, что каждая из компонент  является элементом
является элементом  введя матрицу
введя матрицу  согласно (6.7.5), получим
согласно (6.7.5), получим  Так как
Так как  при
при  является корнем многочлена
является корнем многочлена  то
то

Теперь предположим, что при передаче произошло некоторое фиксированное число  ошибок, например на
ошибок, например на  позициях. Тогда
позициях. Тогда  при всех
при всех  кроме
кроме  и (6.7.14) принимает вид
и (6.7.14) принимает вид

Чтобы упростить обозначения, введем понятия значений ошибок  и локаторов ошибок
и локаторов ошибок  определяемых соотношениями:
определяемых соотношениями:

Соотношение ( принимает вид
принимает вид

Таким образом, Шкодер может вычислить синдром  по принятой последовательности у. Если декодер может решить (6.7.17) и определить значения ошибок и локаторы ошибок, то он может из (6.7.16) найти шумовую последовательность
по принятой последовательности у. Если декодер может решить (6.7.17) и определить значения ошибок и локаторы ошибок, то он может из (6.7.16) найти шумовую последовательность  (Напомним, что так как N равно мультипликативному порядку а, то все элементы
(Напомним, что так как N равно мультипликативному порядку а, то все элементы  различны.) Перейдем теперь к главной задаче, которая согласно принятой здесь схеме состоит в нахождении решения (6.7.17).
различны.) Перейдем теперь к главной задаче, которая согласно принятой здесь схеме состоит в нахождении решения (6.7.17).
Прежде всего определим многочлен бесконечной степени 
В введенных выше обозначениях

Так как члены в  степень которых больше
степень которых больше  влияют лишь на те члены многочлена
влияют лишь на те члены многочлена  степень которых больше чем
степень которых больше чем  то из (6.7.22) получим
то из (6.7.22) получим

Наконец, заметим, что согласно равенству (6.7.22), определяющему  степень
степень  не может превышать
не может превышать  Поэтому скобки вокруг
Поэтому скобки вокруг  в (6.7.25) могут быть опущены и, более того,
в (6.7.25) могут быть опущены и, более того,

Из соотношения (6.7.26) следует, что коэффициент при  в произведении а
в произведении а  равен 0 для
равен 0 для  При более подробной записи (6.7.26) эквивалентно следующей системе равенств:
При более подробной записи (6.7.26) эквивалентно следующей системе равенств:

Равенства (6.7.27) дают систему  линейных уравнений, по которым декодер может найти
линейных уравнений, по которым декодер может найти  неизвестных
неизвестных  [согласно (6.7.21),
[согласно (6.7.21),  Если эти уравнения разрешимы, то по
Если эти уравнения разрешимы, то по  могут быть найдены локаторы ошибок
могут быть найдены локаторы ошибок  поскольку
поскольку  являются корнями
являются корнями  Теперь общая картина процедуры декодирования ясна и можно сформулировать ее для последующих ссылок в виде четырех этапов.
Теперь общая картина процедуры декодирования ясна и можно сформулировать ее для последующих ссылок в виде четырех этапов.
Этап 1. Вычислить  по принятой последовательности у.
по принятой последовательности у.
Этап 2. Найти  из (6.7.26) или (6.7.27).
из (6.7.26) или (6.7.27).
Этап 3. Найти корни с  следовательно, локаторы ошибок.
следовательно, локаторы ошибок.
Этап 4. Найти значения ошибок  . Отметим, что в случае двоичных БЧХ-кодов все значения ошибок равны 1 (так как, по определению, они ненулевые) и, следовательно, этап 4 не нужен.
. Отметим, что в случае двоичных БЧХ-кодов все значения ошибок равны 1 (так как, по определению, они ненулевые) и, следовательно, этап 4 не нужен.
Теперь обсудим более подробно этап 2, а к рассмотрению реализации остальных этапов вернемся несколько позднее. Отметим, что при отыскании  из (6.7.26) декодеру неизвестно число ошибок
из (6.7.26) декодеру неизвестно число ошибок  Следующая теорема утверждает, что
Следующая теорема утверждает, что  может быть однозначно определен без предварительного знания
может быть однозначно определен без предварительного знания 
Теорема 6.7.2. Предположим, что произошло  ошибок и что
ошибок и что  определяется равенством (6.7.21). Пусть
определяется равенством (6.7.21). Пусть  минимальное целое число, для которого существует многочлен
минимальное целое число, для которого существует многочлен  степень которого не превышает
степень которого не превышает  и который удовлетворяет соотношению
и который удовлетворяет соотношению  Тогда
Тогда  и
и 
Доказательство. Соотношение  можно переписать в виде
можно переписать в виде

По определению  это означает
это означает

Равенство (6.7.29) можно рассматривать как систему  линейных уравнений относительное
линейных уравнений относительное  неизвестных
неизвестных  где
где  Так как
Так как  равно минимальному целому числу, для которого выполняется (6.7.28), и так как
равно минимальному целому числу, для которого выполняется (6.7.28), и так как  то должно выполняться
то должно выполняться  Аналогично, так как
Аналогично, так как  то справедливо неравенство
то справедливо неравенство  Теперь рассмотрим лишь
Теперь рассмотрим лишь  первых уравнений в (6.7.29) при
первых уравнений в (6.7.29) при  Эти
Эти  уравнений с
уравнений с  неизвестными
неизвестными  являются линейно независимыми по тем же причинам, которые были указаны при установлении линейной независимости (6.7.10) в теореме 6.7.1. Поэтому единственное решение этих уравнений:
являются линейно независимыми по тем же причинам, которые были указаны при установлении линейной независимости (6.7.10) в теореме 6.7.1. Поэтому единственное решение этих уравнений: 

Поскольку  при
при  величины
величины  являются корнями многочлена
являются корнями многочлена  при
при  Так как, во-первых, степень
Так как, во-первых, степень  не превышает
не превышает  во-вторых,
во-вторых,  имеет те же
имеет те же  корней, что и
корней, что и  и, в-третьих,
и, в-третьих,  то выполняется равенство
то выполняется равенство  Поскольку степень
Поскольку степень  равна
равна  мы получим
мы получим  что завершает доказательство.
что завершает доказательство. 
Теперь опишем весьма простой итеративный алгоритм нахождения 
Итеративный алгоритм для нахождения ...
Согласно предыдущей теореме, если число ошибок не превышает  то определим
то определим  через синдромные многочлены
через синдромные многочлены  разрешив уравнение
разрешив уравнение  для минимального
для минимального  и для
и для
многочлена  степени, не превышающей
степени, не превышающей 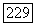 Эту задачу легче всего описать в терминах регистра сдвига с линейной обратной связью
Эту задачу легче всего описать в терминах регистра сдвига с линейной обратной связью 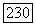 представленного на рис. 6.7.1.
представленного на рис. 6.7.1.
Первоначально в регистре хранится последовательность элементов  из данного поля. Затем регистр вычисляет новый элемент
из данного поля. Затем регистр вычисляет новый элемент  через величины обратных связей
через величины обратных связей  согласно соотношению
согласно соотношению

Числа  являются элементами того же поля, что и
являются элементами того же поля, что и  Затем регистр сдвигается на одну позицию вправо, после чего слева в регистр вводится
Затем регистр сдвигается на одну позицию вправо, после чего слева в регистр вводится 

Рис. 6.7.1. Регистр сдвига с лииейиой обратной связью (PCЛOC).
При каждом из последовательных сдвигов вправо вычисляется новый элемент, определяемый соотношением

Назовем длиной PCЛOC число разрядов в регистре сдвига  в обозначениях рис. 6.7.1). Назовем также многочленом связей РСЛОС многочлен
в обозначениях рис. 6.7.1). Назовем также многочленом связей РСЛОС многочлен  где
где  показанные на рис. 6.7.1 величины обратных связей, взятые со знаком минус. Поскольку РСЛОС полностью (если не считать первоначально хранящуюся в нем последовательность элементов) описывается заданием длины регистра и многочленом связей, то для обозначения PCЛOC с длиной регистра I и многочленом связей
показанные на рис. 6.7.1 величины обратных связей, взятые со знаком минус. Поскольку РСЛОС полностью (если не считать первоначально хранящуюся в нем последовательность элементов) описывается заданием длины регистра и многочленом связей, то для обозначения PCЛOC с длиной регистра I и многочленом связей 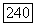 будем использовать название
будем использовать название 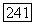 -регистр. Некоторые или все величины обратных связей
-регистр. Некоторые или все величины обратных связей 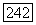 могут равняться нулю; поэтому
могут равняться нулю; поэтому 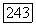 может быть произвольным многочленом, степень которого не превышает
может быть произвольным многочленом, степень которого не превышает  причем
причем 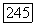 Наконец, для любого многочлена
Наконец, для любого многочлена 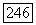 (конечного или бесконечного) будем говорить, что
(конечного или бесконечного) будем говорить, что 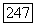 -регистр генерирует
-регистр генерирует 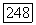 тогда и только тогда, когда регистр, первоначально хранивший
тогда и только тогда, когда регистр, первоначально хранивший  порождает оставшиеся элементы (если они есть)
порождает оставшиеся элементы (если они есть)  методом, определяемым соотношением (6.7.32). Поскольку (6.7.32) эквивалентно утверждению, что коэффициент при
методом, определяемым соотношением (6.7.32). Поскольку (6.7.32) эквивалентно утверждению, что коэффициент при  в произведении
в произведении  равен 0, то
равен 0, то  -регистр генерирует
-регистр генерирует  тогда и только тогда, когда
тогда и только тогда, когда

Теперь вырисовывается связь между устройством регистра сдвига с линейной обратной связью и задачей нахождения  Задача состоит в отыскании такого
Задача состоит в отыскании такого  -регистра с минимальной длиной
-регистра с минимальной длиной  который генерировал бы
который генерировал бы  Заметим, что определение
Заметим, что определение  -регистра включает в себя ограничение степени
-регистра включает в себя ограничение степени  максимальной величиной
максимальной величиной  и условие
и условие  Ниже дан алгоритм нахождения такого самого короткого регистра. Будет показано, что этот алгоритм работает в случае произвольного многочлена
Ниже дан алгоритм нахождения такого самого короткого регистра. Будет показано, что этот алгоритм работает в случае произвольного многочлена  над произвольным полем. Алгоритм состоит в нахождении последовательности регистров, первый из которых является самым коротким регистром, генерирующим
над произвольным полем. Алгоритм состоит в нахождении последовательности регистров, первый из которых является самым коротким регистром, генерирующим  второй — самым коротким регистром, генерирующим
второй — самым коротким регистром, генерирующим  Регистр, воспроизводящий алгоритм генерирования
Регистр, воспроизводящий алгоритм генерирования  назовем
назовем  Грубо говоря, алгоритм работает следующим образом: при заданном
Грубо говоря, алгоритм работает следующим образом: при заданном  генерирующем
генерирующем  проверяет, генерирует ли
проверяет, генерирует ли  также
также  выполняется ли
выполняется ли 
Так как по предположению  то вопрос состоит в том, равен ли нулю коэффициент при
то вопрос состоит в том, равен ли нулю коэффициент при  у многочлена
у многочлена  Эта сумма называется следующей разностью,
Эта сумма называется следующей разностью,  алгоритма; выражая
алгоритма; выражая  через
через 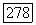 имеем
имеем

Обозначим через 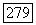 коэффициент при
коэффициент при 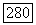 генерируемый регистром согласно (6.7.32); тогда получим
генерируемый регистром согласно (6.7.32); тогда получим 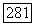 так что
так что 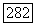 равно разности между благоприятным значением следующего выходного символа
равно разности между благоприятным значением следующего выходного символа 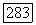 и действительным выходным символом регистра
и действительным выходным символом регистра  Если
Если 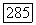 алгоритм увеличивает
алгоритм увеличивает 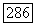 на 1, сохраняя неизменным регистр. Если
на 1, сохраняя неизменным регистр. Если 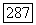 к многочлену связи добавляется поправочный член, так, чтобы
к многочлену связи добавляется поправочный член, так, чтобы  генерировалось правильно.
генерировалось правильно.
Более подробное описание алгоритма состоит в следующем: при любом 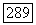 параметры
параметры 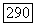 -регистра определяются через параметры
-регистра определяются через параметры  -регистра и параметры априорного регистра в последовательности
-регистра и параметры априорного регистра в последовательности 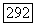 где
где 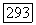 При любом
При любом 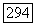 целое число
целое число 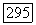 определяется следующим рекуррентным соотношением:
определяется следующим рекуррентным соотношением:

Многочлен 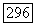 равны:
равны:

где  определяются (6.7.34) или, точнее,
определяются (6.7.34) или, точнее,

Алгоритм начинает работу с  при начальных условиях
при начальных условиях

Следующая ниже теорема утверждает, что  определяют
определяют  -регистр и что этот регистр генерирует В последующей теореме будет показано, что -регистр является самым коротким регистром, генерирующим
-регистр и что этот регистр генерирует В последующей теореме будет показано, что -регистр является самым коротким регистром, генерирующим
Теорема 6.7.3. При любом

Доказательство.
Утверждение а. Согласно начальным условиям при имеем При доказательство немедленно следует из (6.7.35) с помощью индукции по
Утверждение Согласно начальным условиям Теперь предположим, что любом заданном Так как то из (6.7.36) следует, что Поэтому по индукции получим, что при всех
Утверждения Вновь воспользуемся индукцией по Согласно начальным условиям соотношения (6.7.40) и (6.7.41) выполняются при Пусть задано некоторое предположим, что при

Доказательство будет завершено, если показать, что из этих соотношений следует справедливость (6.7.42) и (6.7.43) для Рассмотрим отдельно случаи При имеем Поэтому справедливость (6.7.42) при влечет за собой справедливость (6.7.42) при Аналогично из (6.7.43) для следует, что

Из (6.7.34) получим Поэтому откуда вытекает справедливость (6.7.43) для Теперь предположим, что Согласно (6.7.36) имеем:

где было использовано при и затем использовано (6.7.37).
Наконец, из (6.7.36) получим


Рис. 6.7.2. Действия алгоритма в для до
Так как то имеем

Что касается последнего выражения в (6.7.44), то нетрудно убедиться, что можно вынести за скобки, если уменьшить одновременно пределы на Таким образом,

где для доказательства того, что было использовано (6.7.37). Подставляя (6.7.45) и (6.7.46) в (6.7.44), получаем что завершает доказательство.
Суммируя эти равенства от до и учитывая, что получаем

Учитывая, что сравнительно близки друг к другу, видим, что или Взяв уравнение (3) можно решить относительно В, что дает Следовательно,

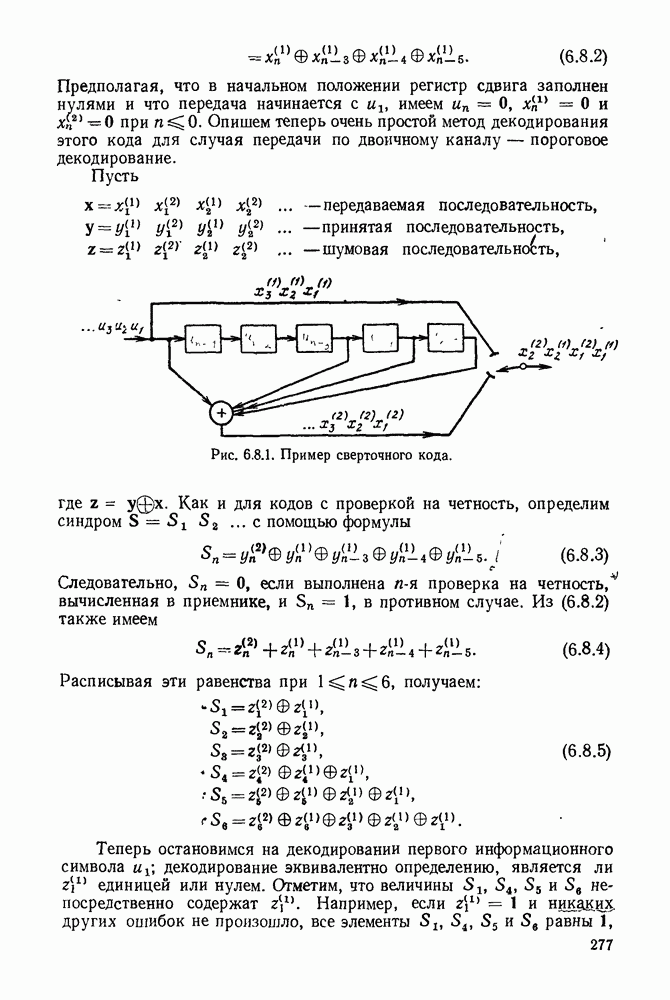
7.7. (а) Пусть принятая последовательность. Тогда

Декодер выбирает сообщение 1, если эта величина больше 0 и сообщение 2 в противном случае.
При условии, что сообщение 1 послано, пусть последовательность независимых гауссовских случайных величин имеющих средние и дисперсии Следовательно, имеет среднее дисперсию

где функция распределения гауссовской случайной величины с нулевым средним и единичной дисперсией. Из симметрии ясно, что и (1) дает вероятность ошибки.
(б) Вероятность минимизируется выбором таких которые максимизируют 2 при ограничении
Пусть номер канала с наименьшей дисперсией шума, так что для Тогда

с равенствами всегда, когда для всех Следовательно, для минимизируют вероятность ошибки и

для (см Феллер, т. 1, гл VII, § 1)
(в) Из (7.5.57) видим, что В — возрастающая функция Я и что при стремящемся к 0, В стремится к Следовательно, из (7.5.58) находим, что

Заметим, что этот показатель экспоненты равен половине показателя экспоненты, выведенного в пункте Если взглянуть более тщательно на связь между скоростью [см. (7.5.41) и (7.5.60)], то увидим, что только тогда,
Последнее доказывает справедливость (6.7.48) при что завершает доказательство.
Из этой леммы следует, что как функция имеет вид возрастающей последовательности пиков; величина для каждого указывает на местонахождение предшествующего пика, который превышает любой из предыдущих пиков (мы считаем, что в точке имеется пик, если
Прежде чем доказывать, что описанный алгоритм при любом приводит к самому короткому возможному регистру, необходимо привести две леммы.
Лемма 2. Предположим, что это два регистра, удовлетворяющие соотношениям

тогда при некотором существует -регистр, удовлетворяющий соотношению

Доказательство. Имеем

Пусть минимальное целое число, для которого и пусть Пусть определяется соотношением

Тогда и

Поэтому является регистром. Подставляя (6.7.59) в (6.7.58) и замечая, можно вынести за скобки, если одновременно уменьшить пределы на получим

Поскольку это завершает доказательство,
Лемма 3. Предположим, что при заданных и -регистр является самым коротким регистром, генерирующим при всех Тогда не существует такого -регистра, для которого при некотором одновременно выполняются соотношения

и

Доказательство. Покажем, что предположение о несправедливости леммы приводит к противоречию. Пусть самый короткий регистр, для которого при выполняются (6.7.60) и (6.7.61).
Случай а. Допустим, что Известно, что при и потому является самым коротким регистром, генерирующим при При отсюда следует, что Поэтому, поскольку то для -регистра выполняется равенство

Согласно предыдущей лемме из (6.7.61) и (6.7.62) следует существование -регистра, для которого при некотором выполняется равенство

Этот регистр короче, чем -регистр и удовлетворяет (6.7.60) и (6.7.61). Это противоречит сделанному предположению.
Случай Допустим, что По предложению, регистр является кратчайшим регистром, генерирующим и поэтому Следовательно, в силу (6.7.47),

что противоречит (6.7.60).
Теорема 6.7.4. При любом и всех не существует регистра, который генерирует и имеет длину, меньшую, чем -регистр, построенный с помощью описанного выше алгоритма.
Доказательство. Проведем индукцию по Очевидно, что теорема справедлива при Допустим, что она выполняется для любых заданных и некоторого данного Если то ясно, что -регистр имеет минимальную длину среди регистров, генерирующих поскольку он является самым коротким регистром, генерирующим а любой регистр, генерирующий генерирует также и -Теперь предположим, что так что

Рассмотрим какой-либо  -регистр, генерирующий
-регистр, генерирующий  Тогда имеем
Тогда имеем  и согласно лемме 2 из существования
и согласно лемме 2 из существования

(кликните для просмотра скана)
 -регистров следует существование при некотором
-регистров следует существование при некотором  такого
такого  -регистра для которого
-регистра для которого

Согласно лемме  Поэтому
Поэтому  Тогда
Тогда  -реги;гр не короче, чем
-реги;гр не короче, чем  -регистр, что завершает доказательство.
-регистр, что завершает доказательство.
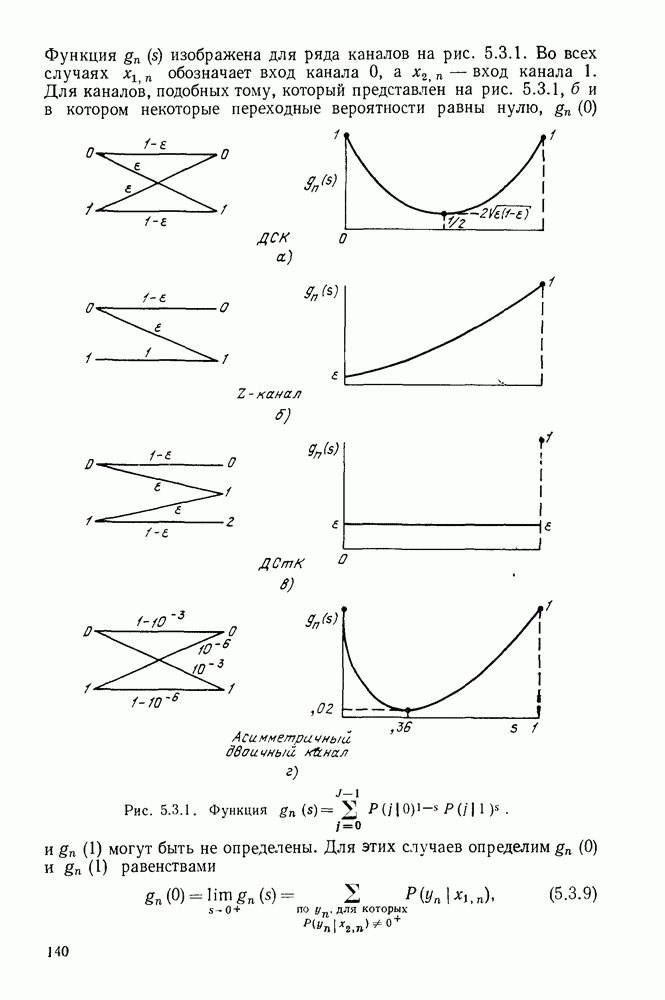
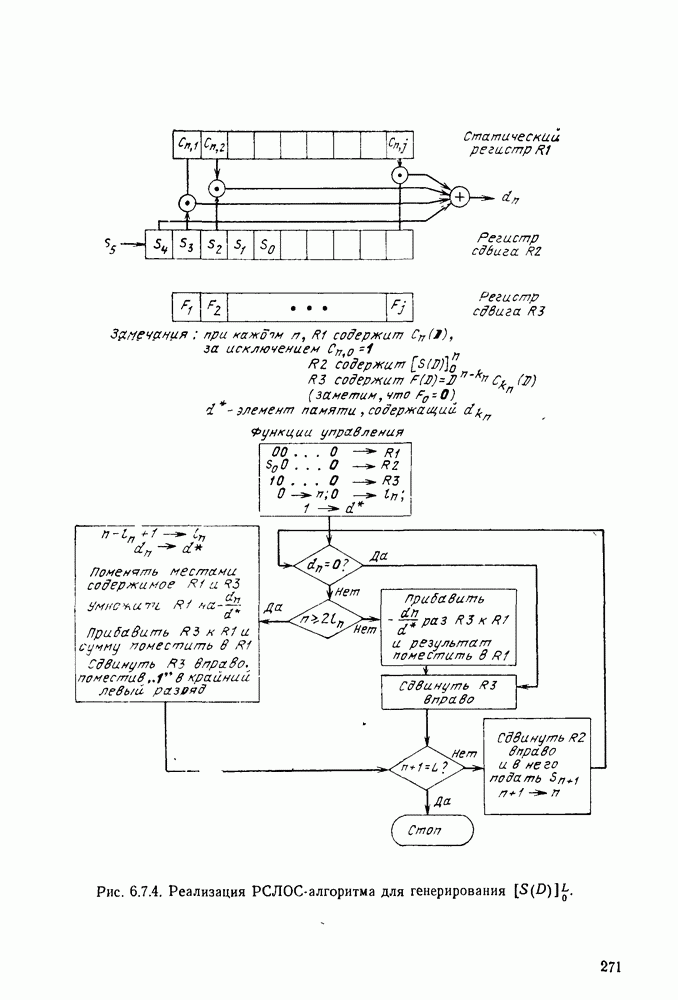
Блок-схема, представленная на рис. 6.7.4, автором которой является Месси (1968), предлагает способ реализации алгоритма. Отметим, что соотношение (6.7.49) используется здесь в качестве критерия для указания изменения  Длина регистров
Длина регистров  представленных на рис. 6.7.4, должна быть достаточной для хранения многочлена связей самого длинного ожидаемого регистра. Выберем для декодирования БЧХ-кодов
представленных на рис. 6.7.4, должна быть достаточной для хранения многочлена связей самого длинного ожидаемого регистра. Выберем для декодирования БЧХ-кодов  и расположим
и расположим  кроме коэффициента
кроме коэффициента  слева. Можно выбрать
слева. Можно выбрать  и тем самым гарантировать исправление всех комбинаций не более чем
и тем самым гарантировать исправление всех комбинаций не более чем  ошибок. В случае двоичных БЧХ-кодов элементы
ошибок. В случае двоичных БЧХ-кодов элементы  являются элементами
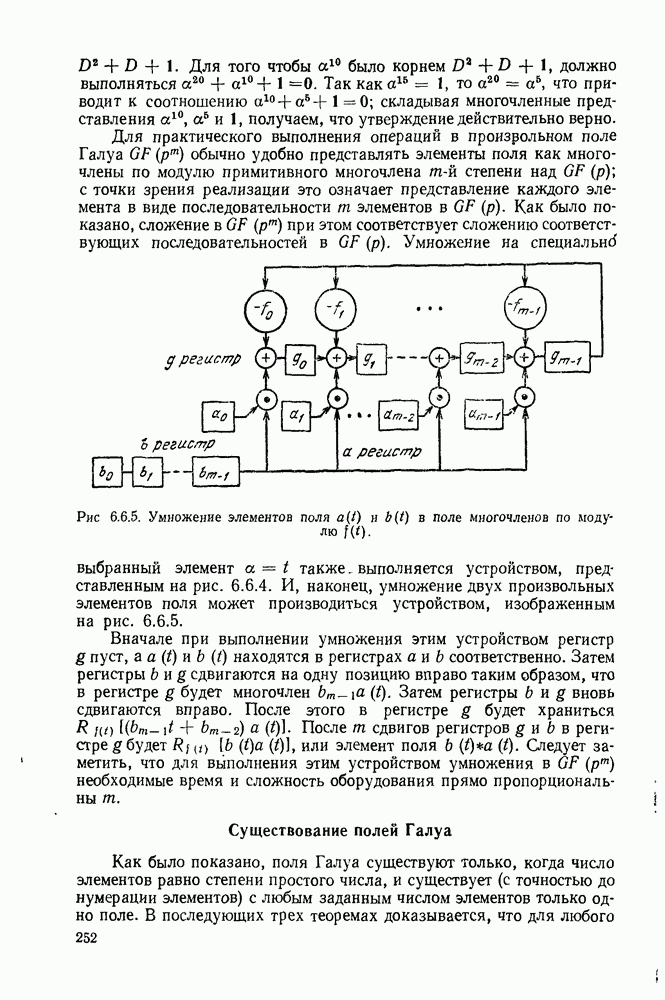
являются элементами  и каждый из регистров, представленных на рис. 6.7.4, может быть реализован при помощи двоичных регистров. Устройство, выполняющее умножение в можно сделать так, как показано на рис. 6.6.5. Легко видеть, что сложность оборудования, необходимого для регистров и умножителей, пропорциональна Также нетрудно убедиться, что время, необходимое для нахождения пропорционально [или чуть больше, что зависит от способа вычисления Безусловно, при построении такого устройства необходимо разрешить большое число технических вопросов; важно заметить, однако, что для такого устройства необходимо поразительно мало оборудования и поразительно мало вычислительного времени. Берлекэмп (1967) также доказал, что для двоичных кодов с и при нечетных величина всегда равна нулю. Использование этого обстоятельства, по существу, вдвое сокращает вычислительное время для нахождения На этом мы закончим обсуждение второго этапа процедуры декодирования БЧХ-кодов.
и каждый из регистров, представленных на рис. 6.7.4, может быть реализован при помощи двоичных регистров. Устройство, выполняющее умножение в можно сделать так, как показано на рис. 6.6.5. Легко видеть, что сложность оборудования, необходимого для регистров и умножителей, пропорциональна Также нетрудно убедиться, что время, необходимое для нахождения пропорционально [или чуть больше, что зависит от способа вычисления Безусловно, при построении такого устройства необходимо разрешить большое число технических вопросов; важно заметить, однако, что для такого устройства необходимо поразительно мало оборудования и поразительно мало вычислительного времени. Берлекэмп (1967) также доказал, что для двоичных кодов с и при нечетных величина всегда равна нулю. Использование этого обстоятельства, по существу, вдвое сокращает вычислительное время для нахождения На этом мы закончим обсуждение второго этапа процедуры декодирования БЧХ-кодов.
Теперь коротко рассмотрим реализации этапов 1, 3 и 4 для БЧХ-декодера. На этапе 1 можно вычислять элементы синдрома следующим способом:

Таким образом, возможный путь вычисления состоит в сложении всех последовательно принятых символов в первоначально пустом регистре; сумма затем должна быть умножена на и возвращена в регистр, ждущий следующего принятого символа.
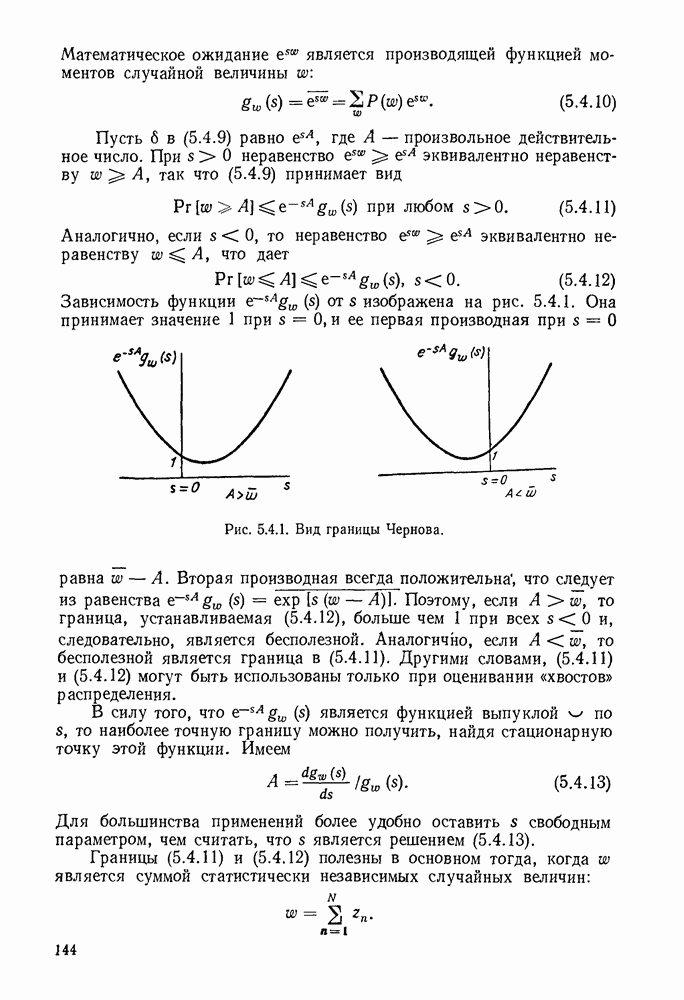
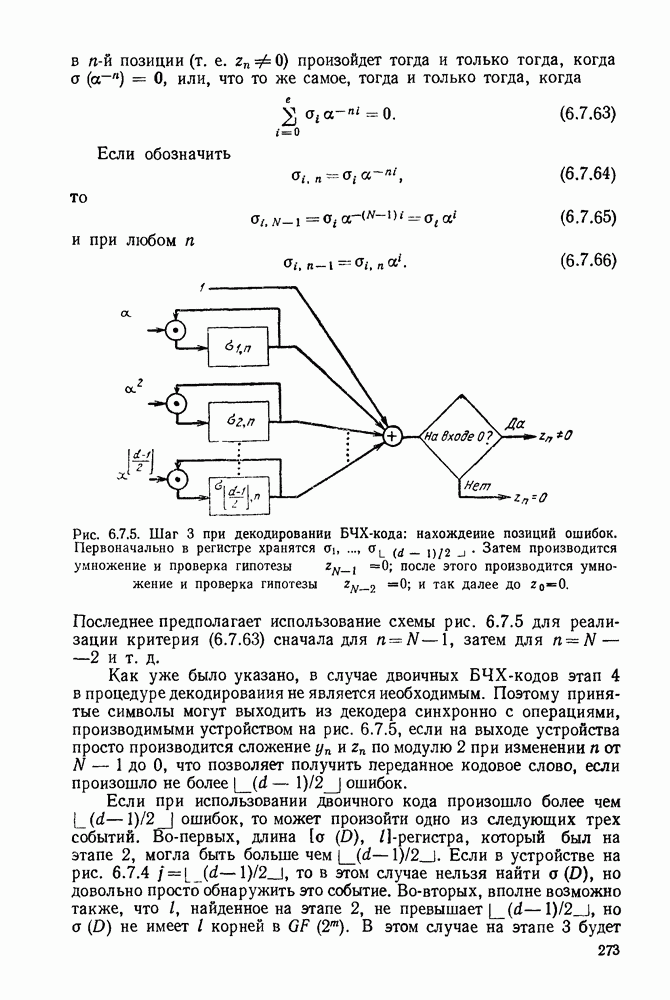
Этап 3 легче всего реализовать при помощи процедуры Ченя (1964). Если число ошибок не превышает то вычисленный на этапе 2, определяется соотношением (6.7.21), и ошибка
в позиции произойдет тогда и только тогда, когда а или, что то же самое, тогда и только тогда, когда

Если обозначить

то

и при любом


Рис. 6.7.5. Шаг 3 при декодировании БЧХ-кода: нахождение позиций ошибок. Первоначально в регистре хранятся Затем производится умножение и проверка гипотезы после этого производится умножение и проверка гипотезы и так далее до
Последнее предполагает использование схемы рис. 6.7.5 для реализации критерия (6.7.63) сначала для затем для и т. д.
Как уже было указано, в случае двоичных БЧХ-кодов этап 4 в процедуре декодирования не является необходимым. Поэтому принятые символы могут выходить из декодера синхронно с операциями, производимыми устройством на рис. 6.7.5, если на выходе устройства просто производится сложение по модулю 2 при изменении от до 0, что позволяет получить переданное кодовое слово, если произошло не более ошибок.
Если при использовании двоичного кода произошло более чем ошибок, то может произойти одно из следующих трех событий. Во-первых, длина Л-регистра, который был на этапе 2, могла быть больше чем Если в устройстве на рис. то в этом случае нельзя найти но довольно просто обнаружить это событие. Во-вторых, вполне возможно также, что найденное на этапе 2, не превышает но не имеет I корней в В этом случае на этапе 3 будет
сделано меньше, чем I исправлений, но декодированная последовательность не будет представлять собой кодовое слово. Это вновь может быть легко обнаружено или путем подсчета числа исправлений, или путем проверки, является ли декодированная последовательность кодовым словом. Наконец, вполне возможно, что -регистр имеет длину и что при декодировании будет найдено ошибок. В этом случае декодированная последовательность будет кодовым словом, которое отличается от принятой последовательности более чем в позициях. При этом нельзя обнаружить ошибку декодирования, но мы по крайней мере знаем, что декодер принял в двоичном симметричном канале решение по максимуму правдоподобия.
Обратимся теперь к отысканию значений ошибок (этап 4) в процессе декодирования недвоичных БЧХ-кодов. Определим многочлен в (6.7.22) как

Тогда согласно определяется следующим образом через

Многочлен можно найти непосредственно из (6.7.68) или, что более красиво, его вычисление можно включить в виде составной части в итеративный алгоритм нахождения В частности, из начальных условий вычислим при многочлен согласно формуле

где определяются (6.7.34) и (6.7.35). Для этого в блок-схему на рис. 6.7.4 необходимо включить два дополнительных регистра; никаких дополнительных логических элементов управления, по существу, не требуется, поскольку операции, производимые регистрами при вычислении аналогичны операциям, производимым регистрами при вычислении Доказательство того, что при любом почти аналогично доказательству теоремы 6.7.3 и это приведено в виде задачи 6.35.
После нахождения нетрудно убедиться, что согласно (6.7.67)

Можно упростить правую часть (6.7.70), если ввести производную

Легко реализовать вычисление по а если является степенью 2, то равна сумме членов в нечетных степенях, деленной на так как

то получим (см. задачу 6.36)

Подставляя (6.7.72) в (6.7.70), получаем

Используя определения данные в (6.7.16), получаем следующую формулу для нахождения каждого из ненулевых шумовых символов

Каждая из трех функций, входящих в правую часть (6.7.74), может быть последовательно вычислена для всех при изменении пот до 0 при помощи устройства того же типа, что и на рис. 6.7.5.
На этом заканчивается обсуждение декодирования БЧХ-кодов. Главный вывод состоит в том, что хотя по замыслу это декодирование является сложным, оно очень просто в смысле времени декодирования и требуемой сложности оборудования. Если не считать ячеек памяти, необходимых для запоминания принятого слова, и устройства вычисления обратных элементов в то количество требуемого оборудования пропорционально Время декодирования на этапе 2 пропорционально а на этапах 3 и 4 пропорционально
Давайте посмотрим, что можно сказать о поведении двоичных БЧХ-кодов в пределе при На время допустим, что является хорошей оценкой для числа проверочных символов в коде, так что

где скорость передачи в двоичных символах. Так как то при фиксированном R величина должна стремиться к 0 при стремлении N к бесконечности. Поэтому число ошибок, которые можно исправить описанным алгоритмом декодирования, в конце концов становится меньше среднего числа ошибок в канале. Питерсон (1961) точно вычислил число проверочных символов в различных двоичных БЧХ-кодах; из его результатов следует, что при
фиксированном R величина стремится к нулю с возрастанием Вместе с тем это уменьшение наступает при таких больших значениях что этот предел мало значит для практики.
Коды Рида-Соломона (1960) представляют собой интересный частный класс БЧХ-кодов с параметром равным 1; иначе говоря, в этом случае расширенное поле, в котором определено а, совпадает с полем символов для кодовых букв. Тогда минимальный многочлен для а равен а, так что имеем

Поэтому указанный код имеет проверочных символов и минимальное расстояние Нетрудно убедиться, что ни один групповой код с такими же объемом алфавита, длиной блока и числом проверочных символов не может иметь большего минимального расстояния, поскольку если выбрать все информационные символы, кроме одного, равными 0, то соответствующее кодовое слово будет иметь не более ненулевых символов.
Так как в коде Рида-Соломона длина блока N равна или делителю числа то нетрудно заметить, что эти коды полезны лишь при больших объемах алфавита. Их можно эффективно использовать в непрерывных по времени каналах, где входной алфавит составляет огромное множество сигналов. Форни (1965) эффективно использовал их также в каскадной схеме, где символы кода Рида-Соломона являлись кодовыми словами в меньшем внутреннем коде. Форни показал, что такие коды можно использовать при скоростях передачи, как угодно близких к пропускной способности. Вероятность ошибки для них экспоненциально убывает с ростом длины блока, а сложность декодирования пропорциональна малой степени длины слова. Коды Рида-Соломона можно также непосредственно использовать в канале с малым входным алфавитом путем представления каждой буквы в кодовом слове в виде последовательности букв канала. Эта техника полезна для применения в каналах, где ошибки объединяются в группы, поскольку число операций декодирования зависит лишь от числа последовательностей выходных символов канала, содержащих ошибки.