Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3. КОДИРОВАНИЕ ДЛЯ ДИСКРЕТНЫХ ИСТОЧНИКОВВ этой главе будет рассмотрено кодирование выхода дискретного источника информации в последовательность букв заданного кодового алфавита. Мы хотим выбрать правила кодирования таким образом, чтобы, по крайней мере с высокой вероятностью, последовательность на выходе источника могла быть восстановлена по закодированной последовательности, а также таким образом, чтобы число букв кода, требуемых на одну букву источника, было по возможности меньшим. Будет показано, что минимальное число двоичных букв кода на одну букву источника, требуемых для представления выхода источника, задается энтропией источника. Как было указано в § 1.2, выходом дискретной модели источника является случайная последовательность букв дискретного алфавита. Дискретная модель источника является подходящей для реальных источников, которые производят дискретные данные, а также для непрерывных источников, выход которых превращается в дискретные данные с помощью таких операций, как выборка и квантование. В гл. 9 будет проведено фундаментальное рассмотрение проблемы кодирования непрерывного источника в дискретные данные при ограничении средних искажений. Настоящая глава посвящена задаче кодирования (и декодирования) для математических моделей дискретных источников, определяемых как случайные последовательности. Построение математической модели реального источника является задачей более трудной и ее решение связано с детальным изучением внутренних закономерностей источника и их использованием; такое построение модели не может быть грамотно выполнено абстрактным образом. Предположим, что в каждую единицу времени источник вырабатывает одну букву из конечного множества букв источника связанные с кодированием источника, избегая математических трудностей, к которым приводит учет статистической зависимости. Во многих практических кодах для источника, таких, как код Морзе и стенография, короткие кодовые слова приписываются наиболее часто возникающим буквам или сообщениям, а длинные кодовые слова — более редким буквам или сообщениям. Например, в коде Морзе часто встречающаяся буква С практической точки зрения обычно желательно избежать эти проблемы, связанные с ожидающей очередью, с помощью кода с фиксированной длиной, т. е. кода, в котором каждое кодовое слово имеет одну и ту же длину. Число кодовых слов в таких практических кодах, в общем, довольно мало (так, например, 32 слова для телетайпа). Рассмотрением кодов с фиксированной длиной мы начнем следующий параграф, однако наибольший интерес для нас будут представлять коды очень большой длины. Такие коды имеют небольшую практическую значимость, но позволяют ясно обнаружить некоторые более глубокие свойства собственной информации и энтропии.
|
 |
Оглавление
|



















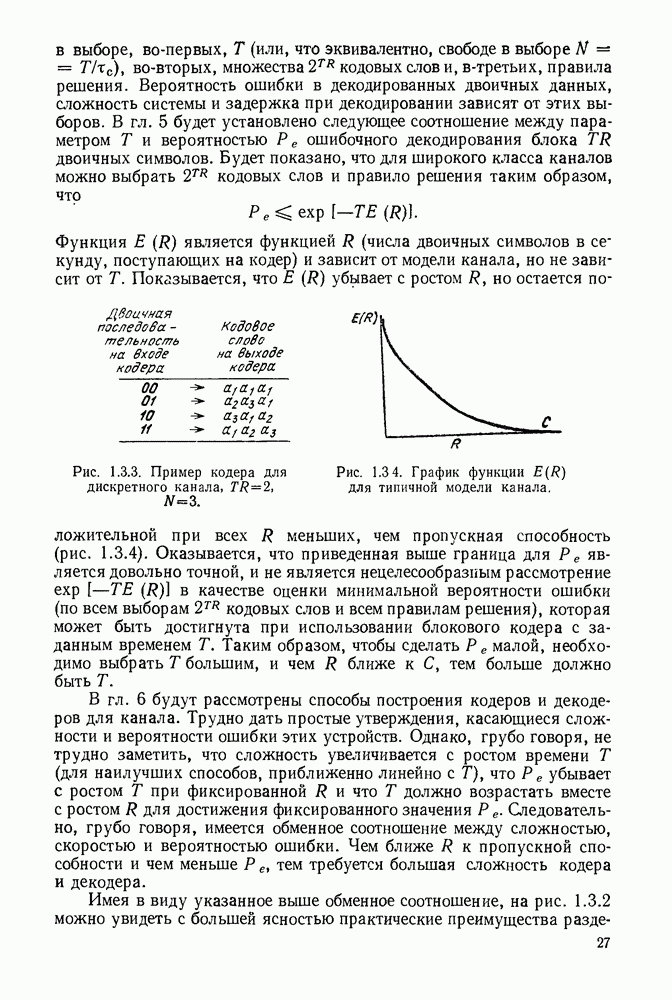



















































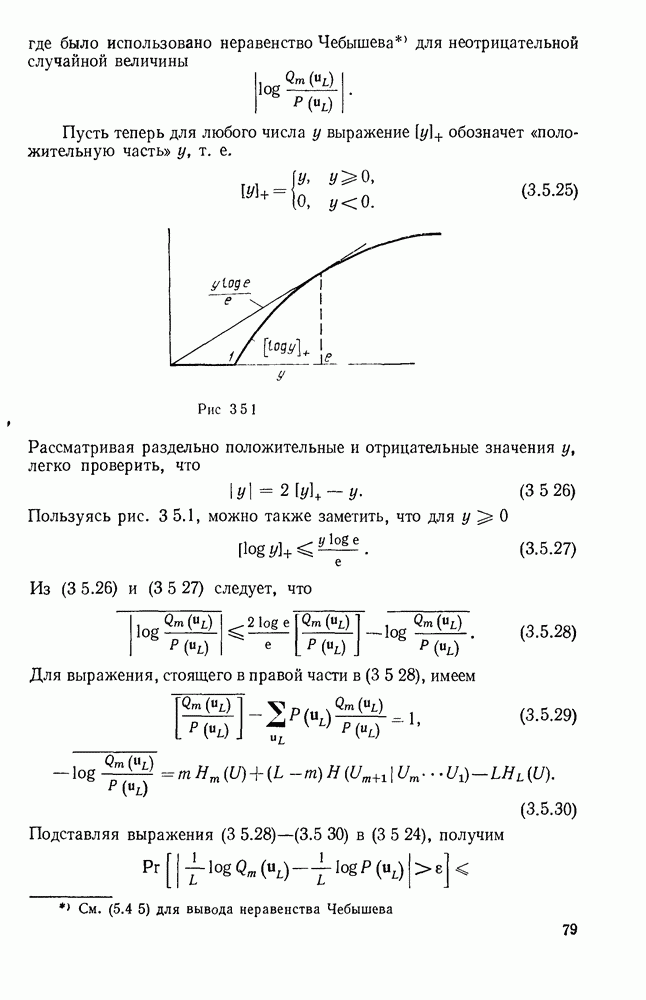






















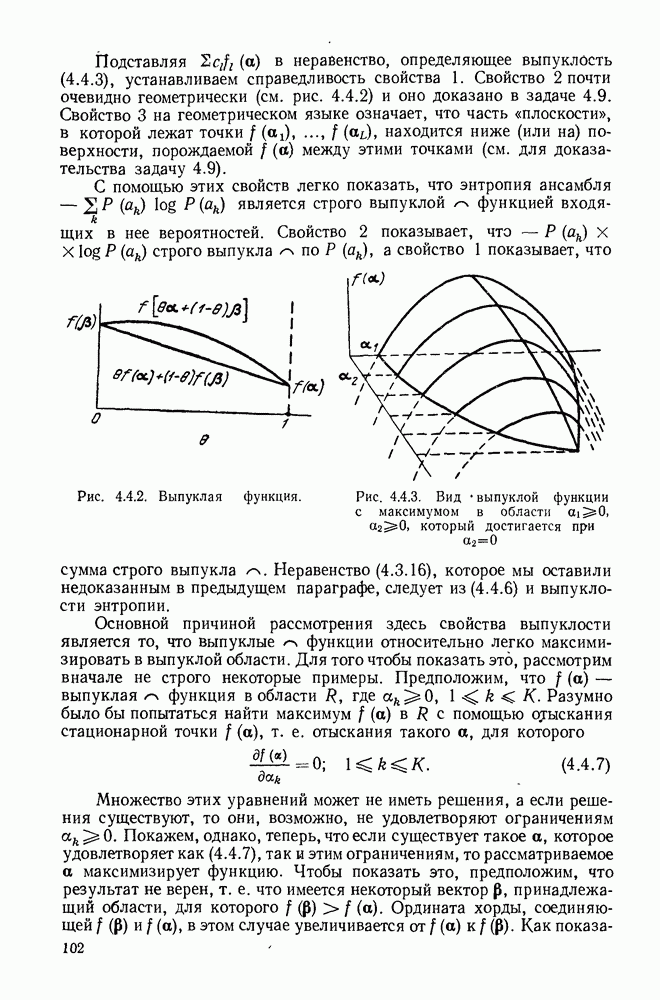





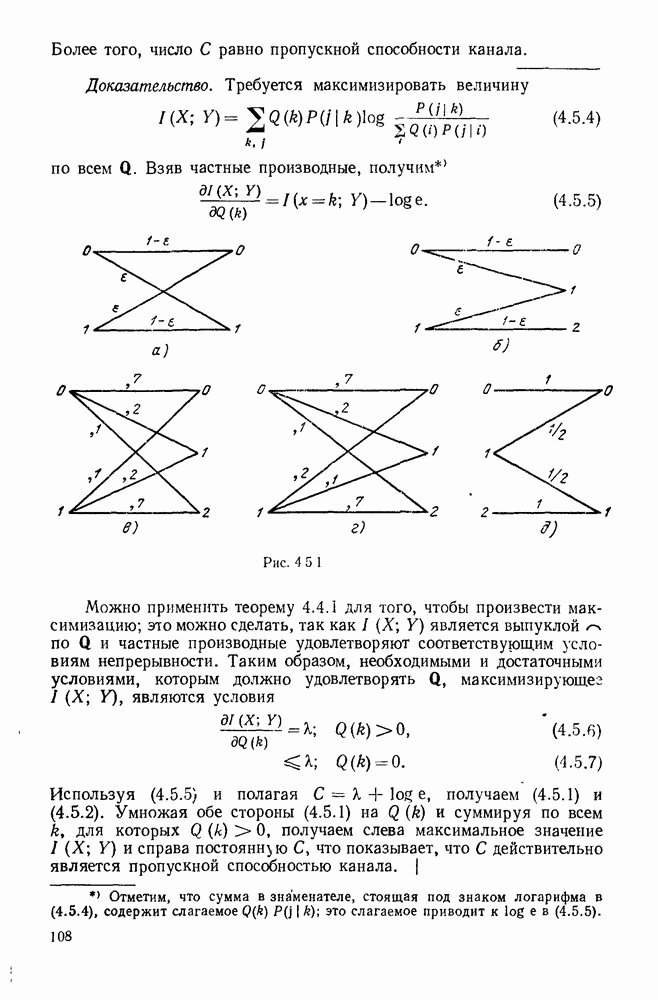





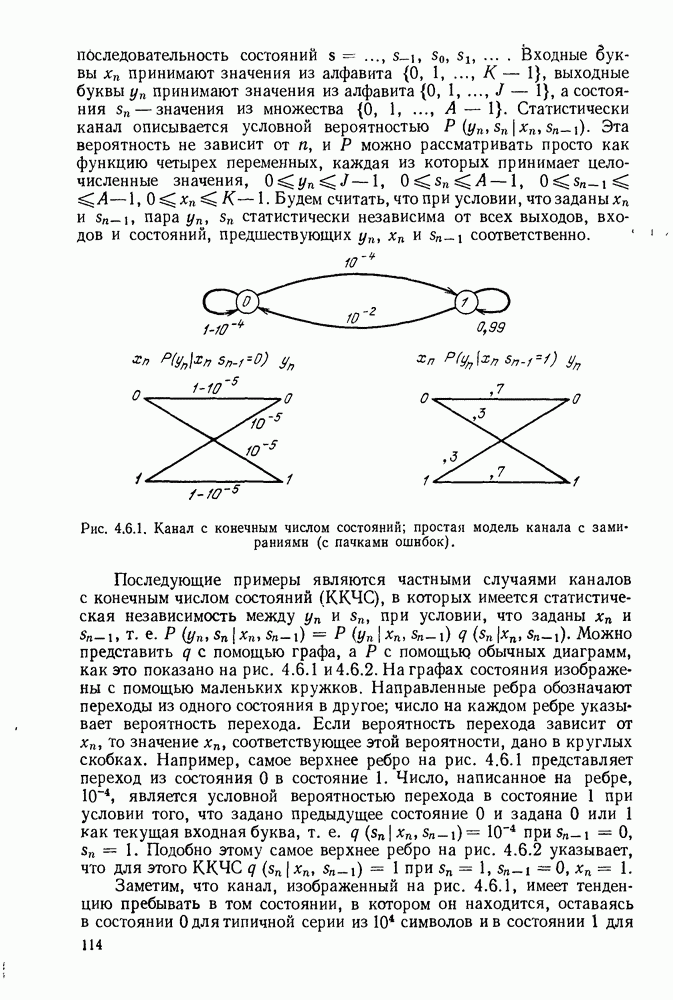



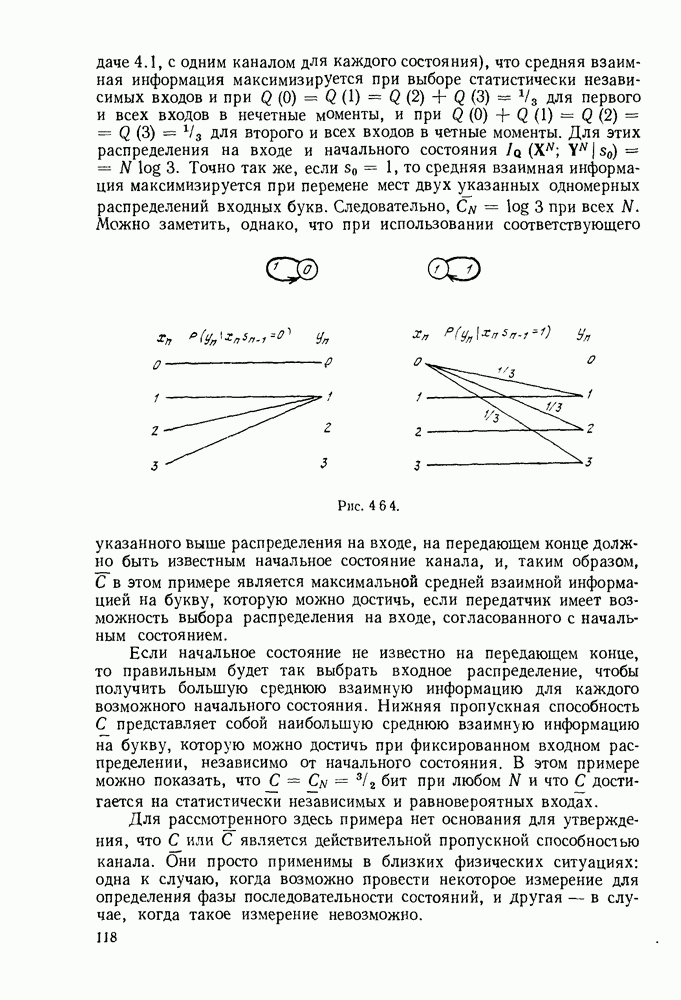





















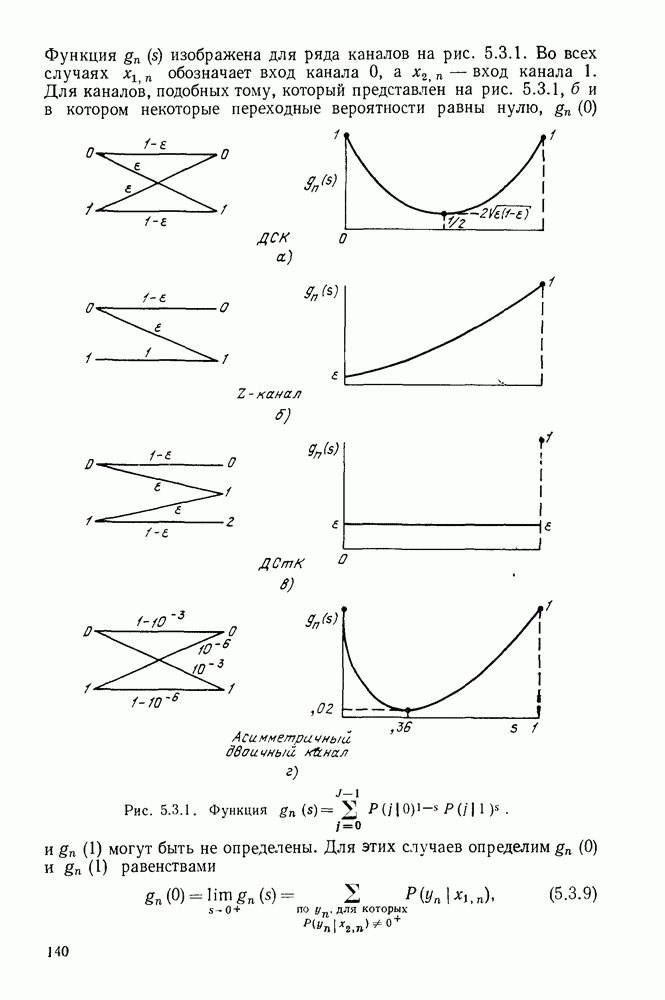



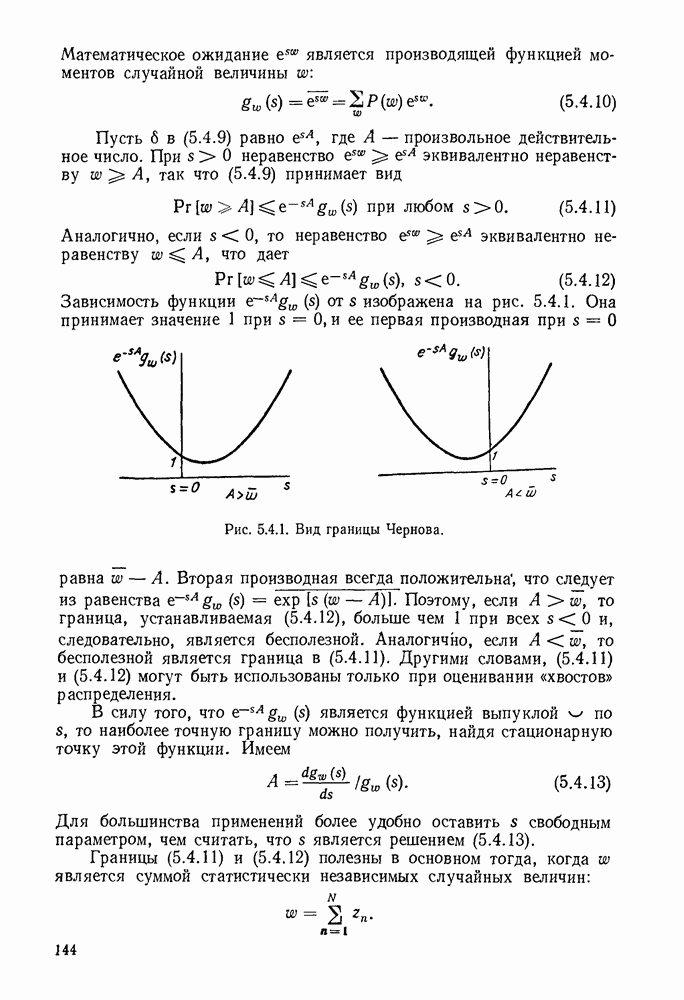






















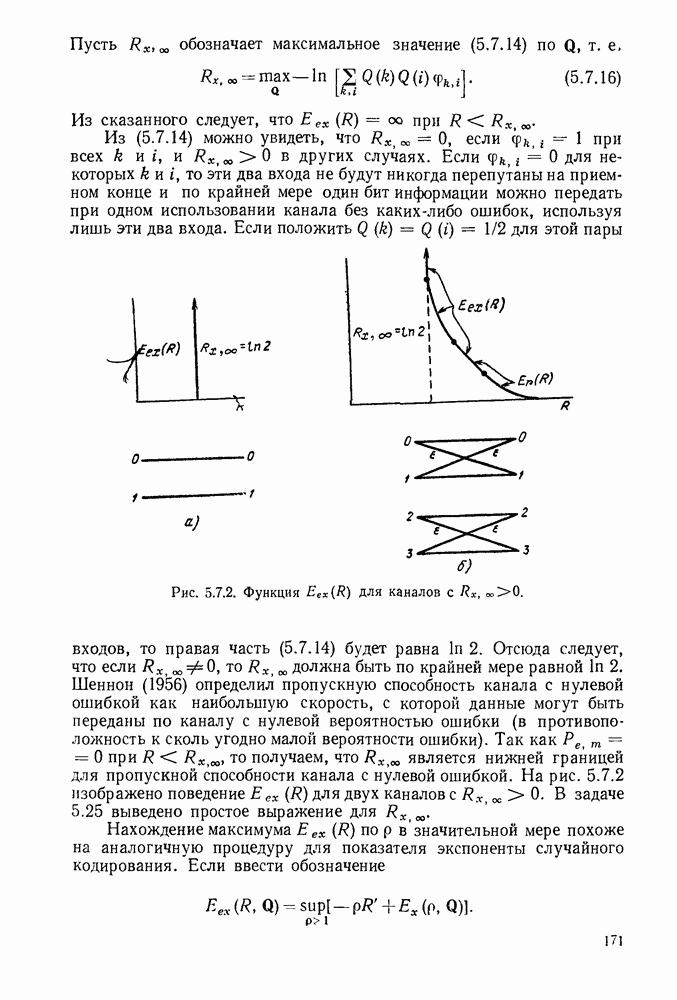


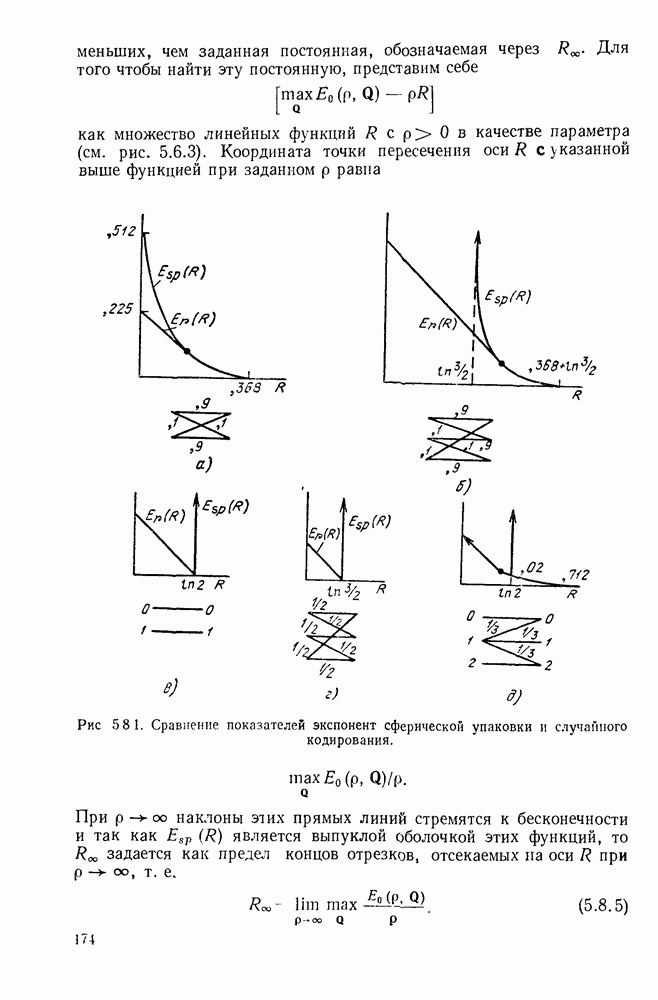


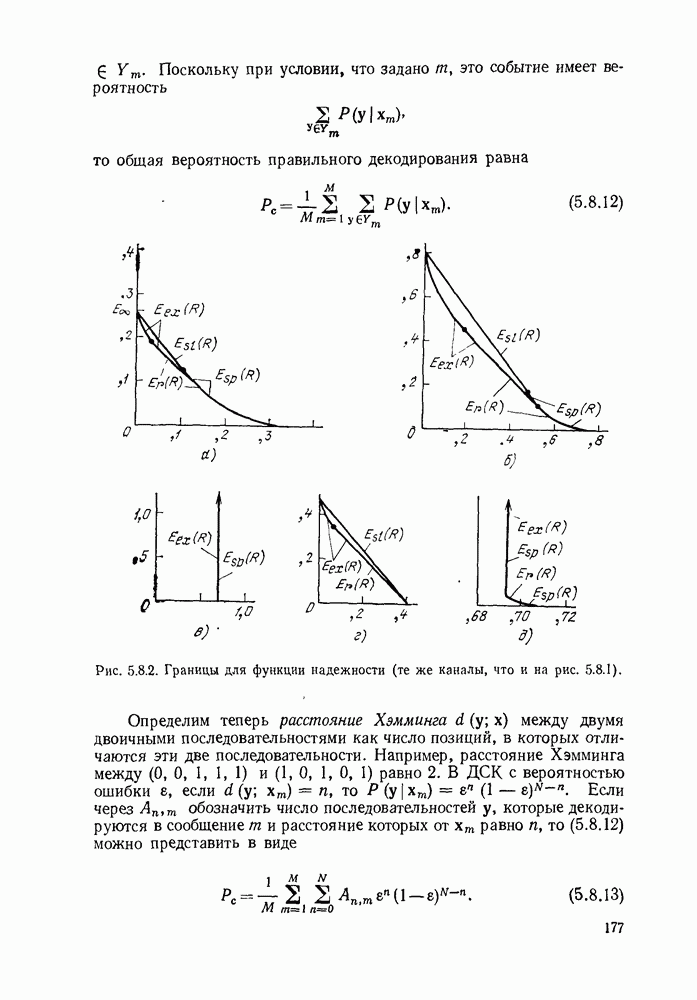























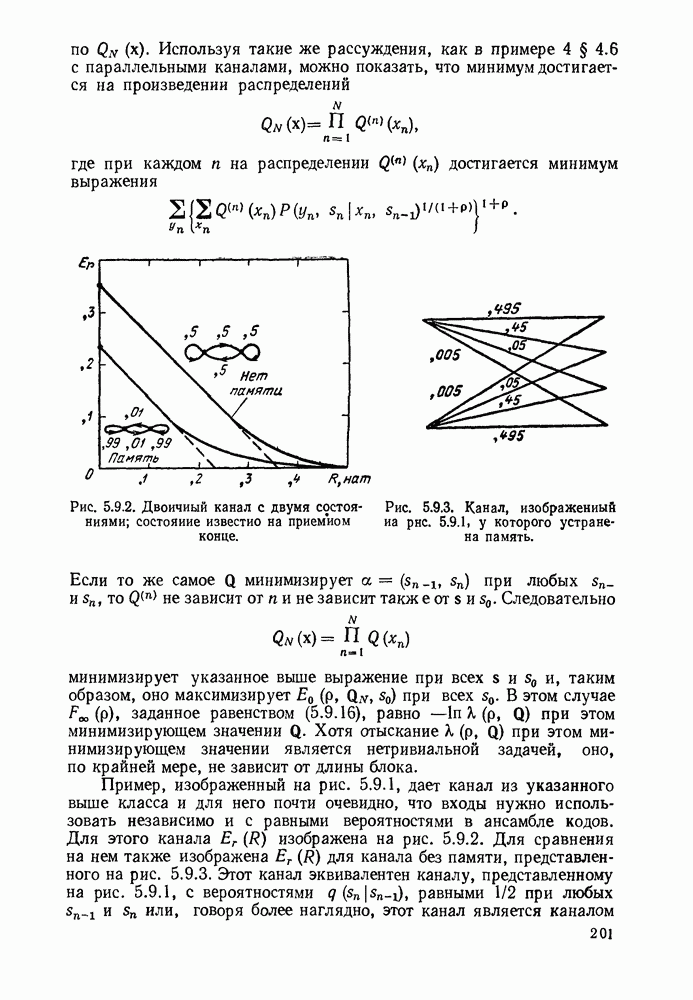














































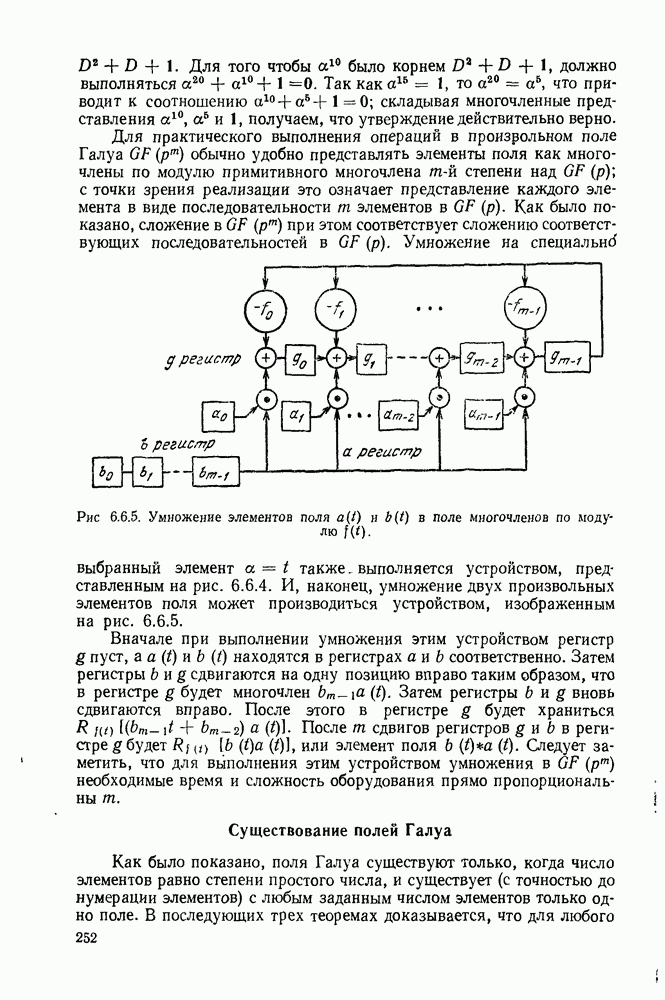


















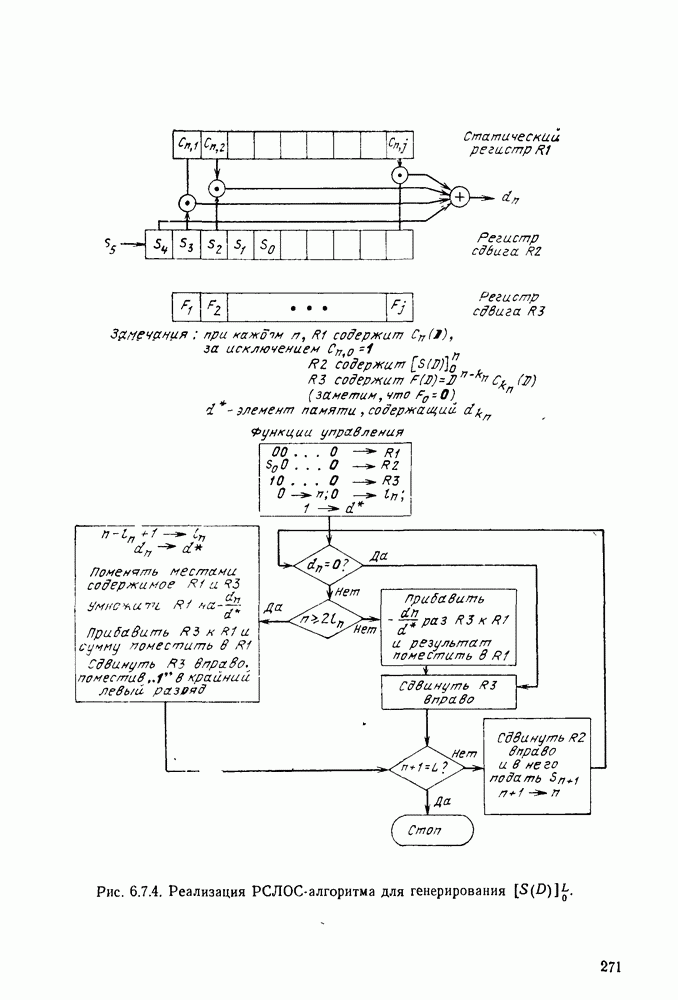

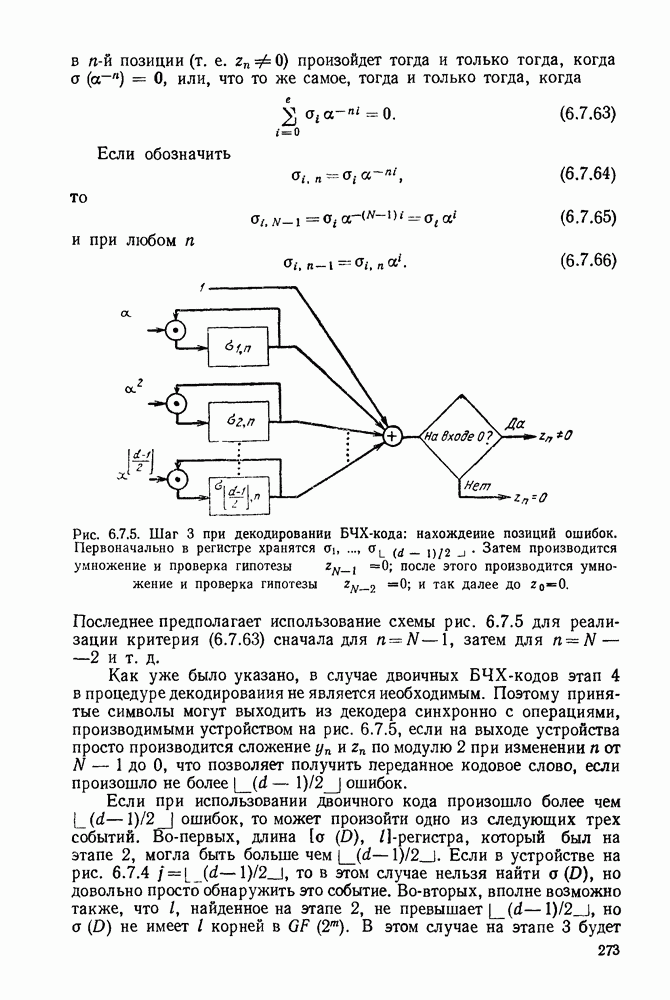



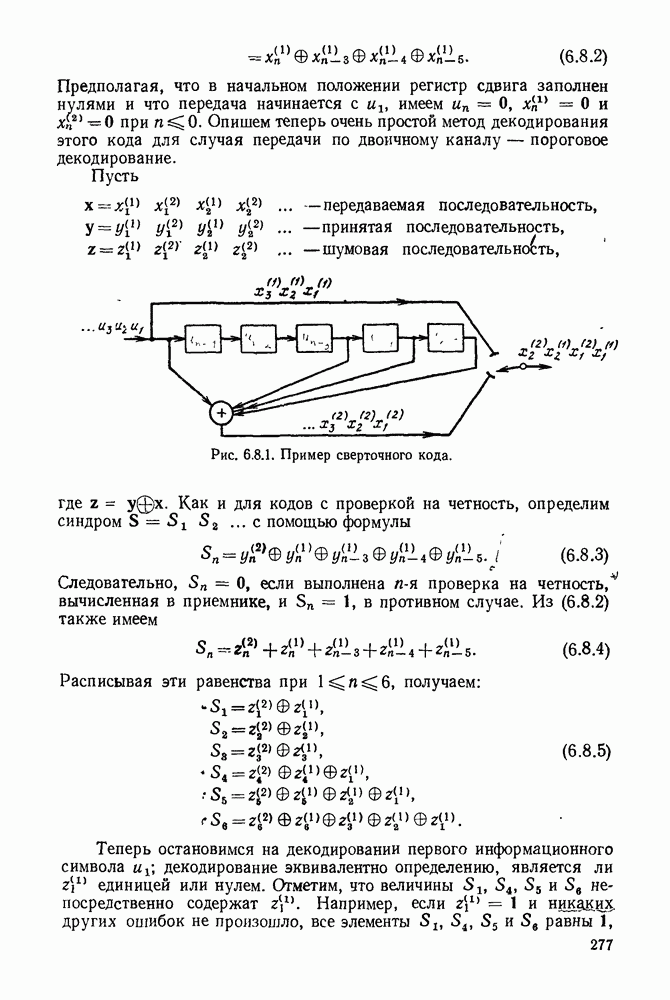





























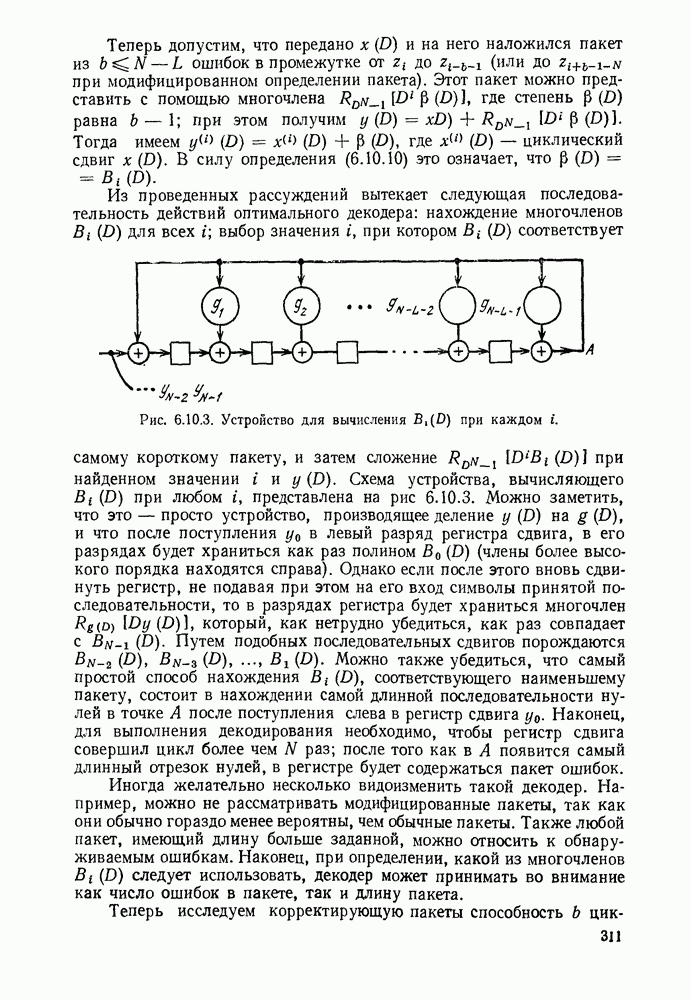





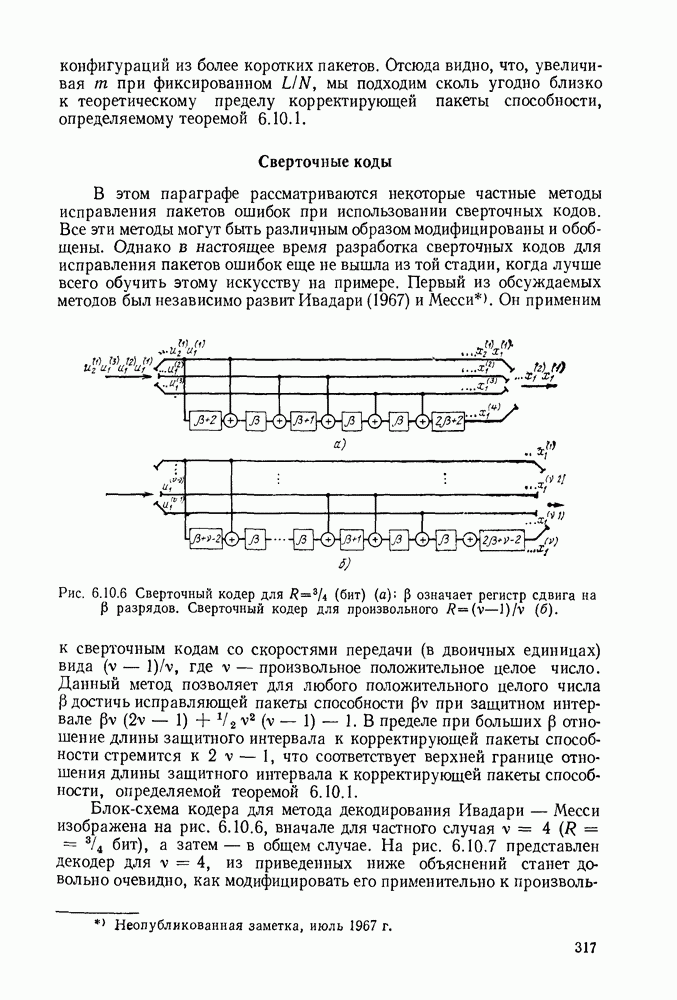
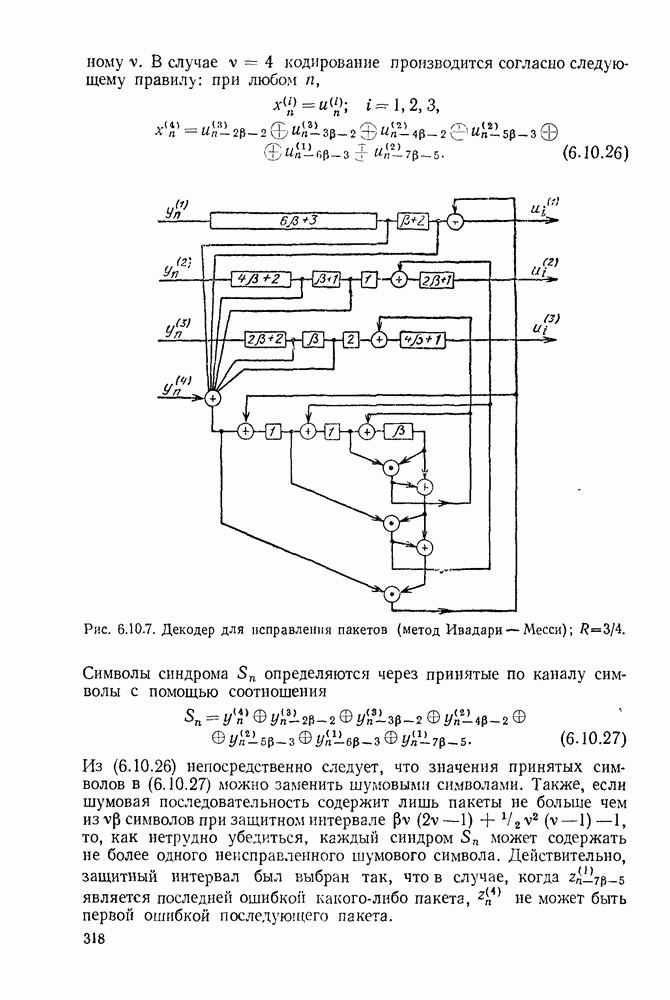
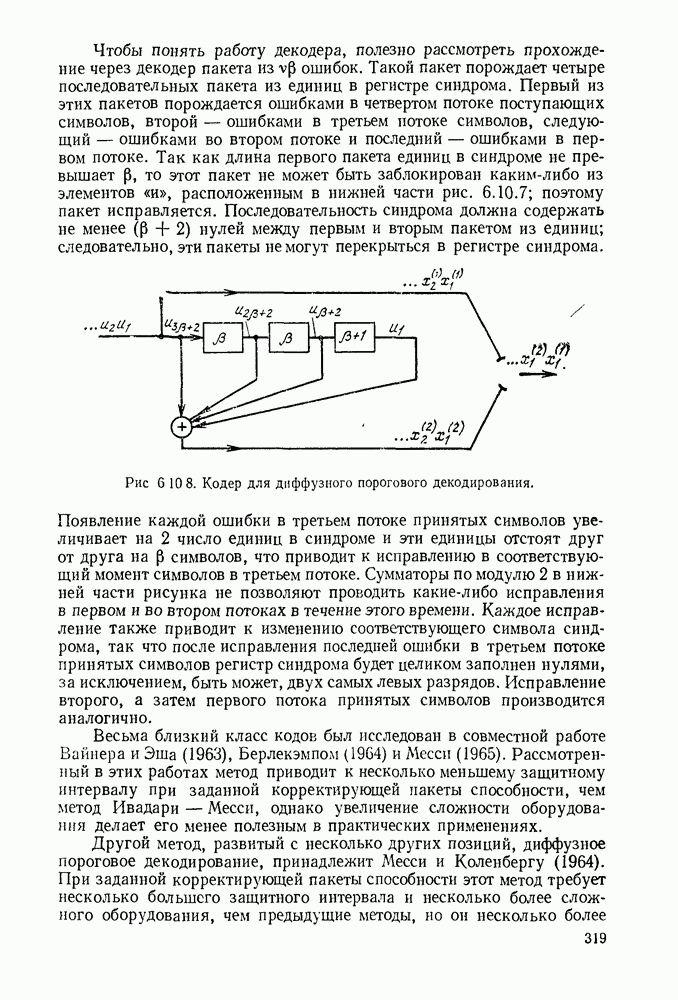
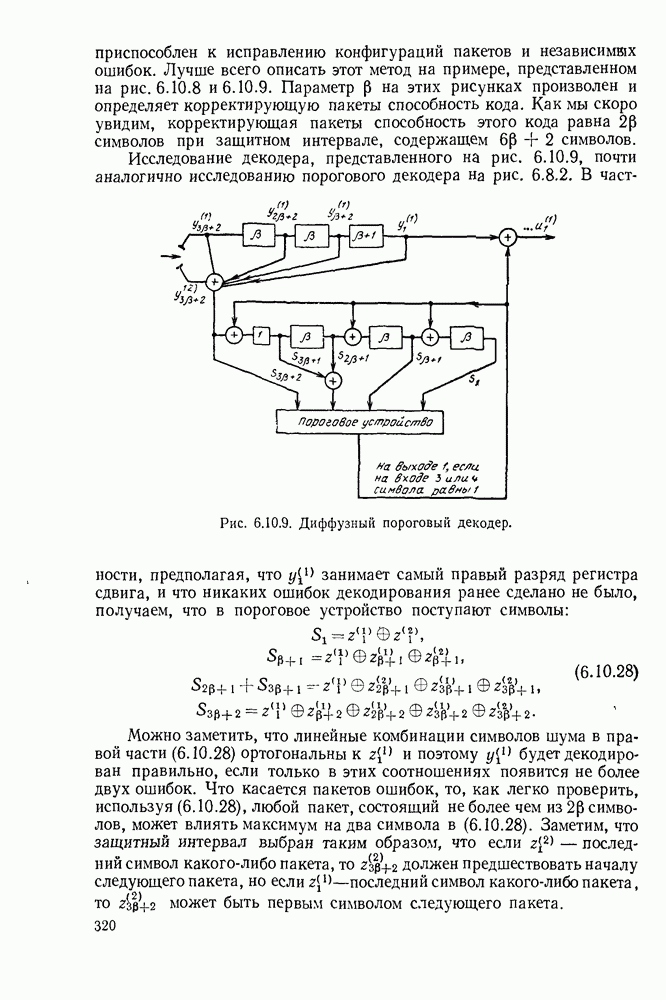

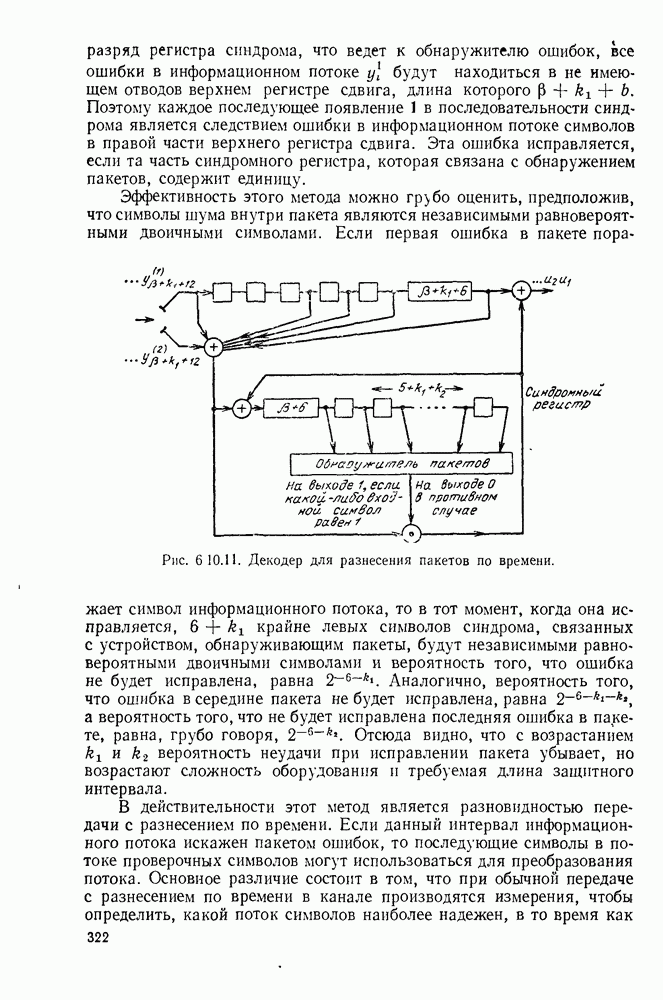




































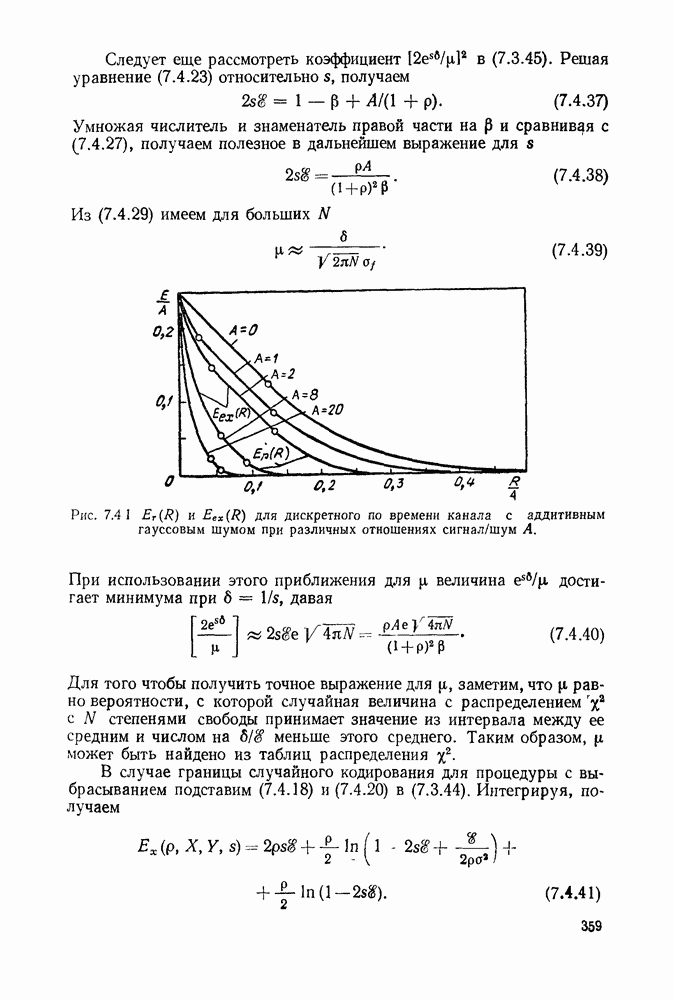


















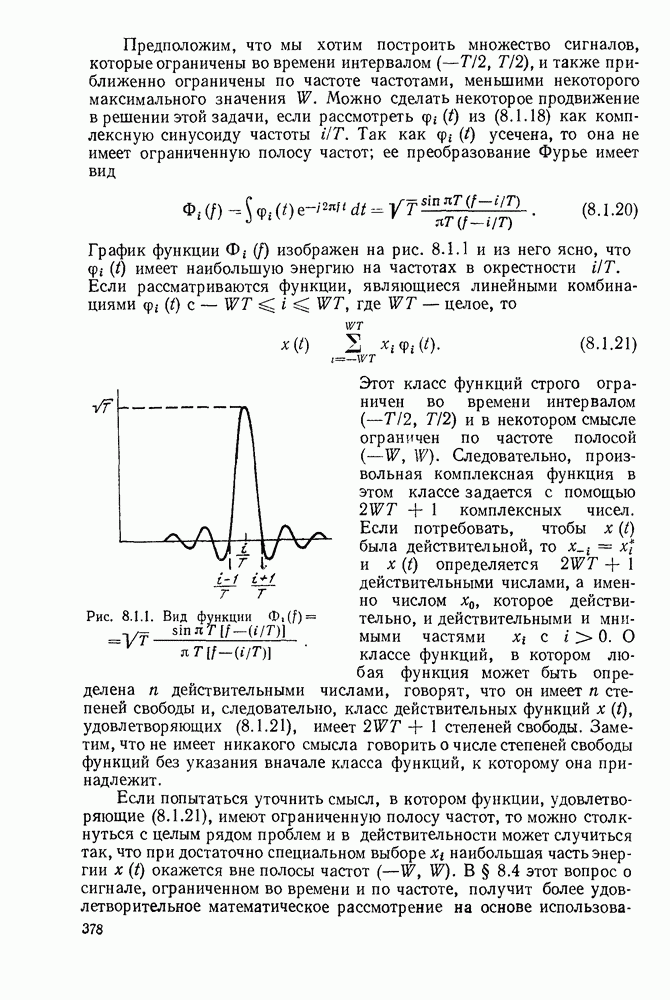












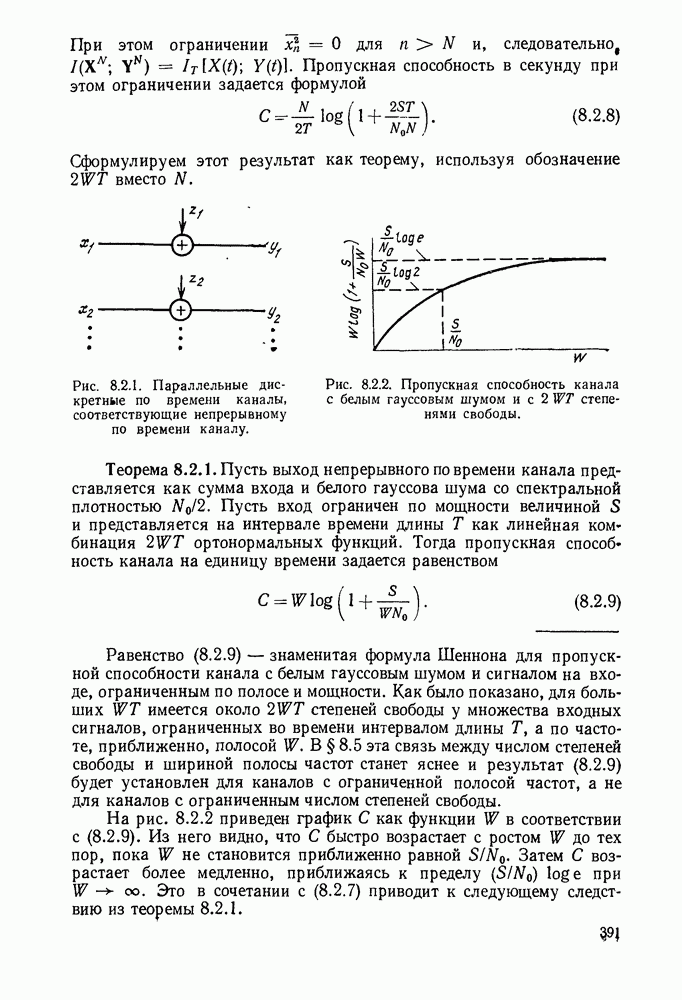






























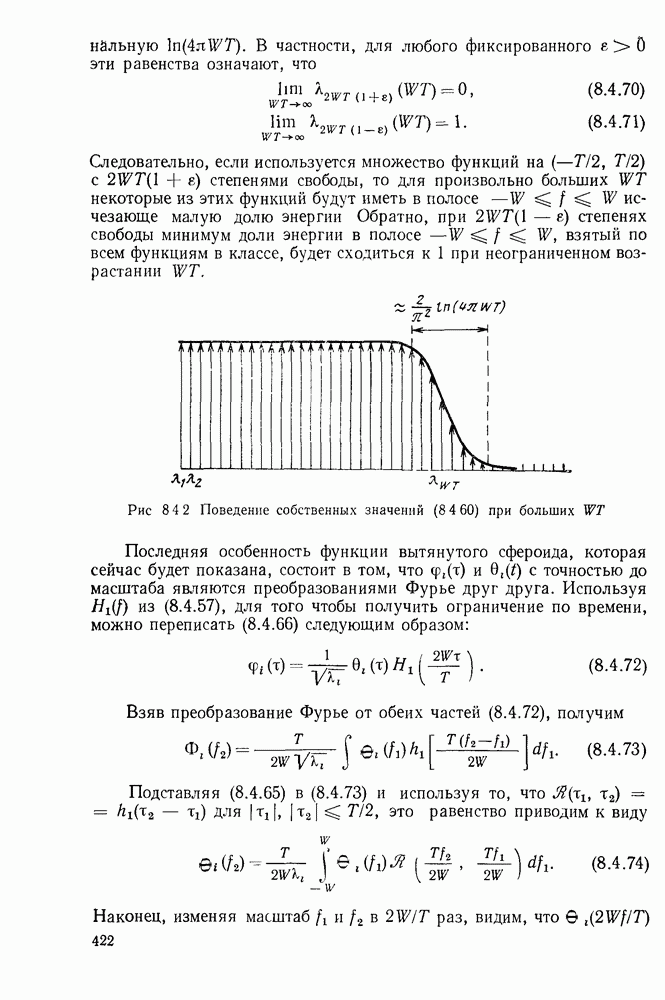






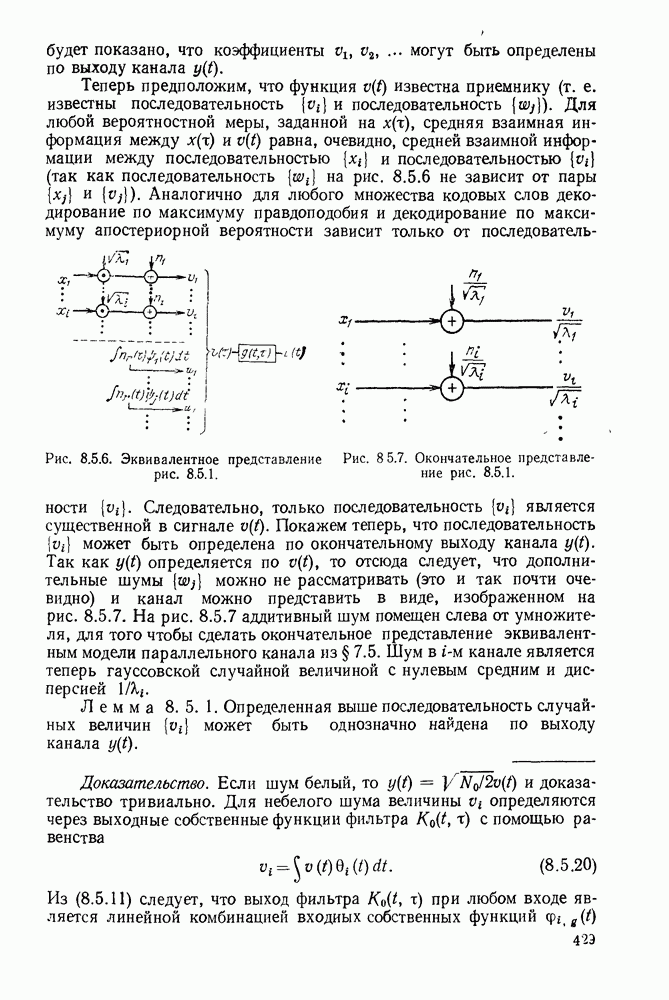















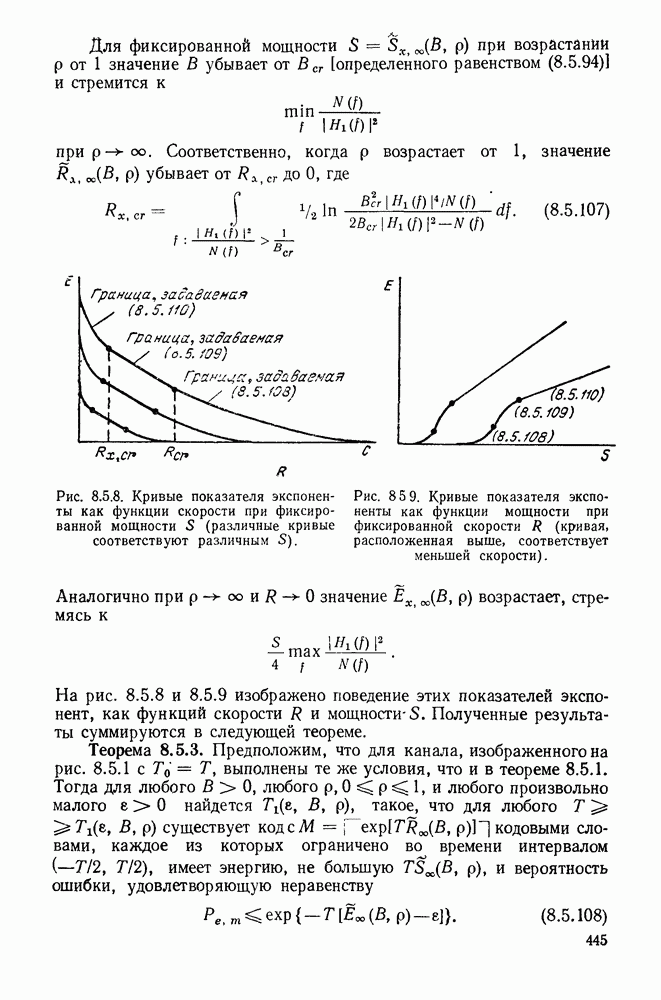















































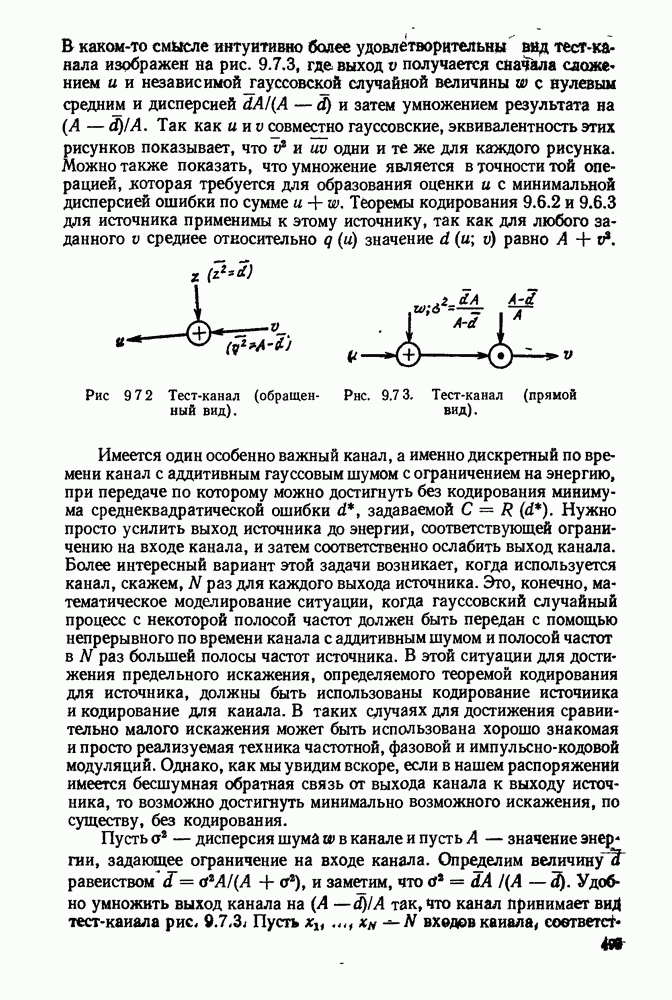









































 Вначале будем считать также, что эти буквы источника производятся с некоторыми фиксированными вероятностями
Вначале будем считать также, что эти буквы источника производятся с некоторыми фиксированными вероятностями  и что последовательные буквы статистически независимы. Такие источники называются дискретными источниками без памяти. Это предположение о статистической независимости, или отсутствии памяти, является в некотором смысле нереальным для большинства дискретных источников. Однако это предположение дает возможность развить важные понятия,
и что последовательные буквы статистически независимы. Такие источники называются дискретными источниками без памяти. Это предположение о статистической независимости, или отсутствии памяти, является в некотором смысле нереальным для большинства дискретных источников. Однако это предположение дает возможность развить важные понятия,
 имеет кодовое слово
имеет кодовое слово  а редкая буква
а редкая буква  имеет кодовое слово
имеет кодовое слово  Такие коды, в которых различные кодовые слова содержат различное число кодовых символов, называются неравномерными кодами. Если источник производит буквы с фиксированной во времени скоростью и если необходимо передавать закодированные символы с фиксированной во времени скоростью, то неравномерный код приводит к проблеме ожидающей очереди. Когда источник выдает редкую букву, производится длинное кодовое слово и ожидающая очередь увеличивается. Наоборот, часто встречающиеся буквы порождают короткие кодовые слова, сокращая ожидающую очередь.
Такие коды, в которых различные кодовые слова содержат различное число кодовых символов, называются неравномерными кодами. Если источник производит буквы с фиксированной во времени скоростью и если необходимо передавать закодированные символы с фиксированной во времени скоростью, то неравномерный код приводит к проблеме ожидающей очереди. Когда источник выдает редкую букву, производится длинное кодовое слово и ожидающая очередь увеличивается. Наоборот, часто встречающиеся буквы порождают короткие кодовые слова, сокращая ожидающую очередь.