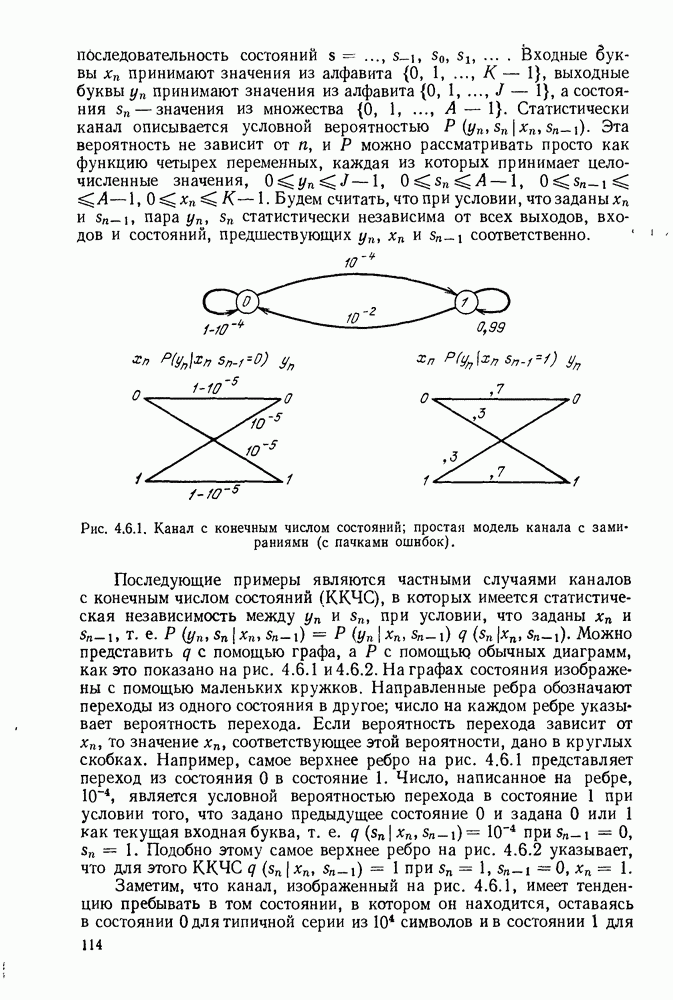
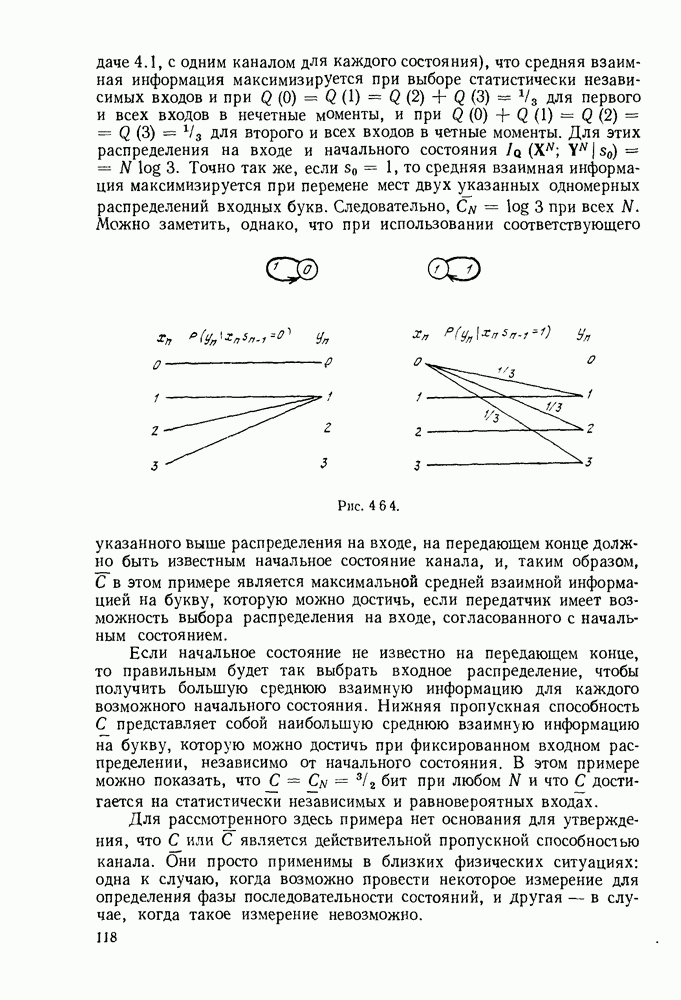
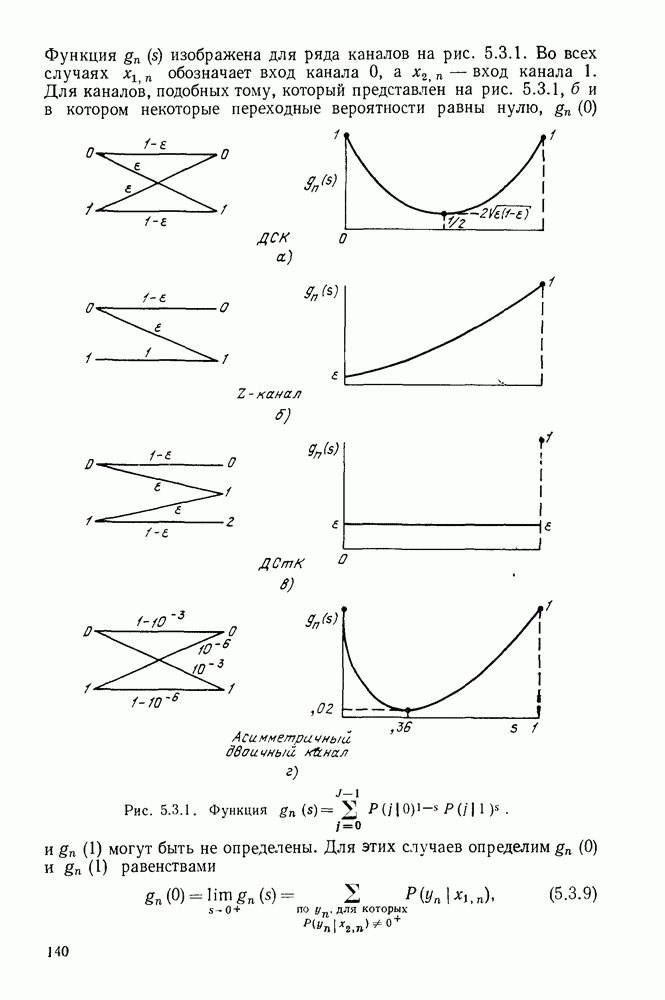
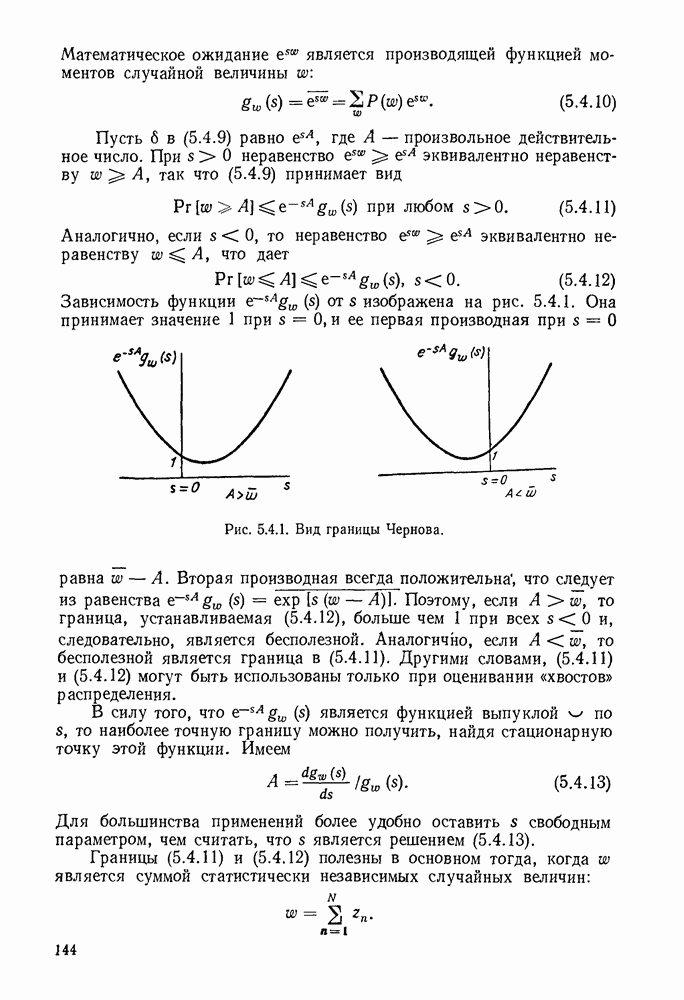
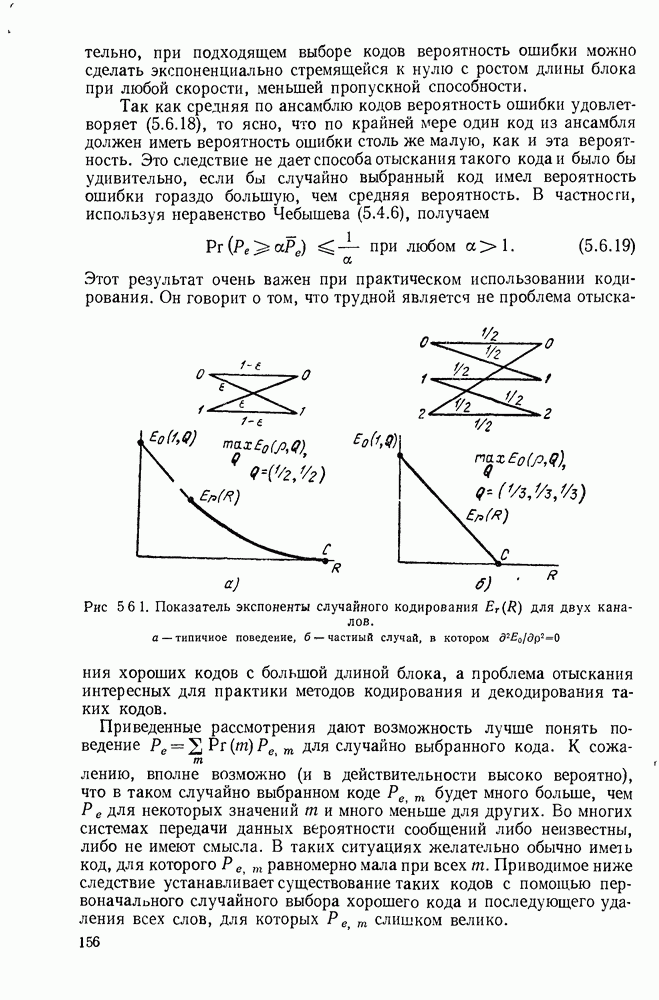
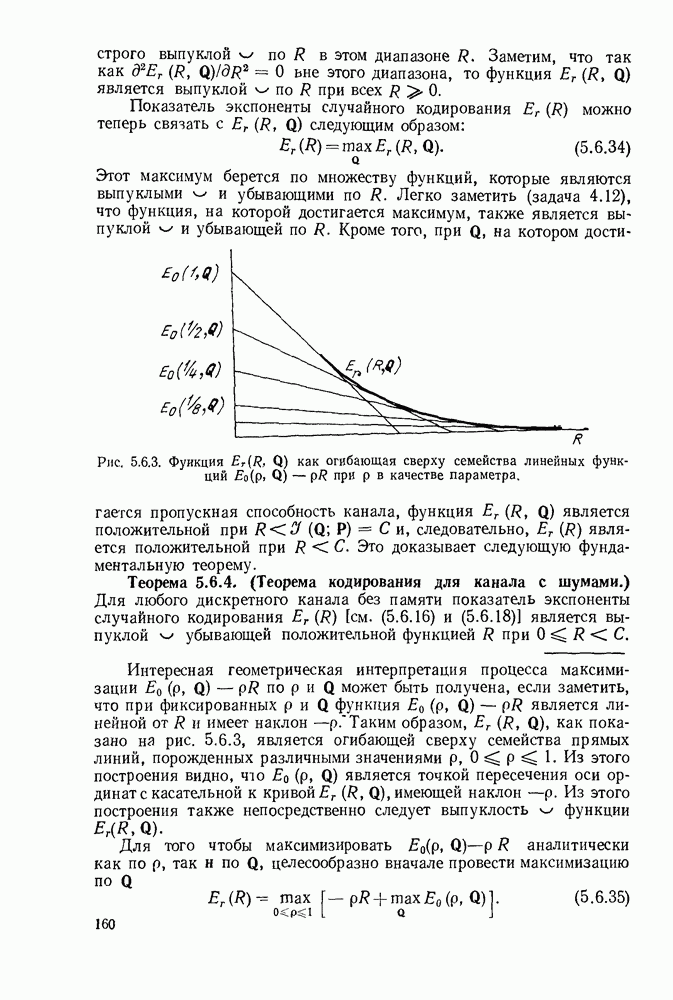
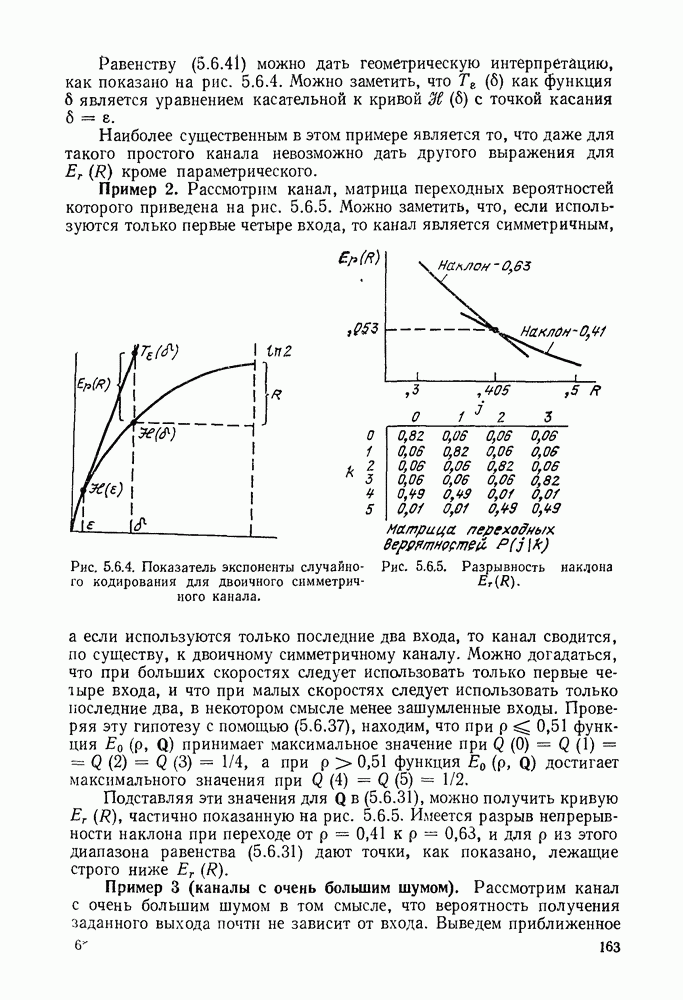
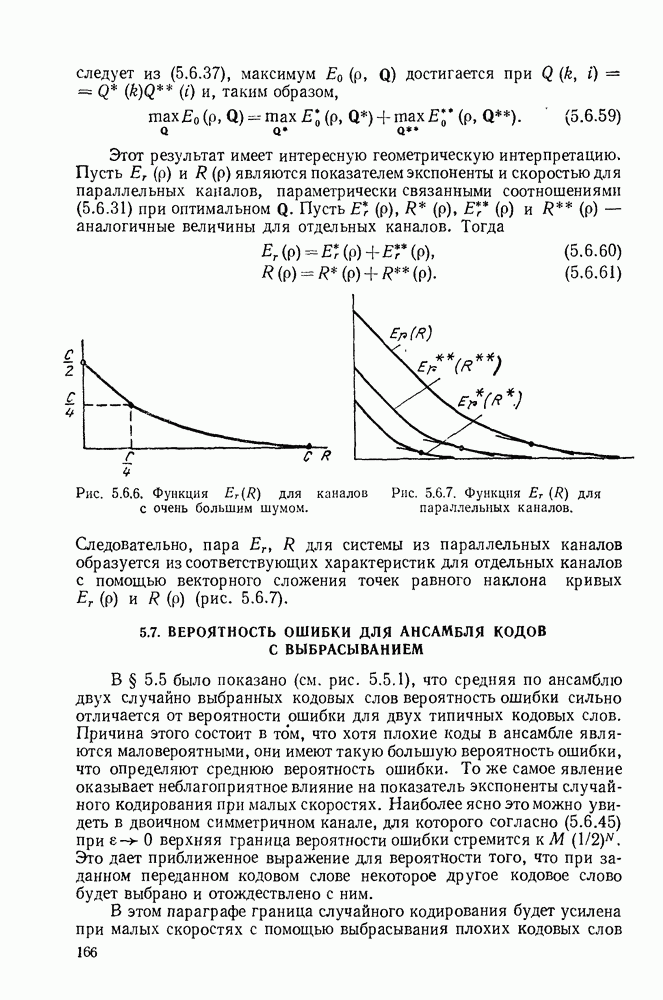
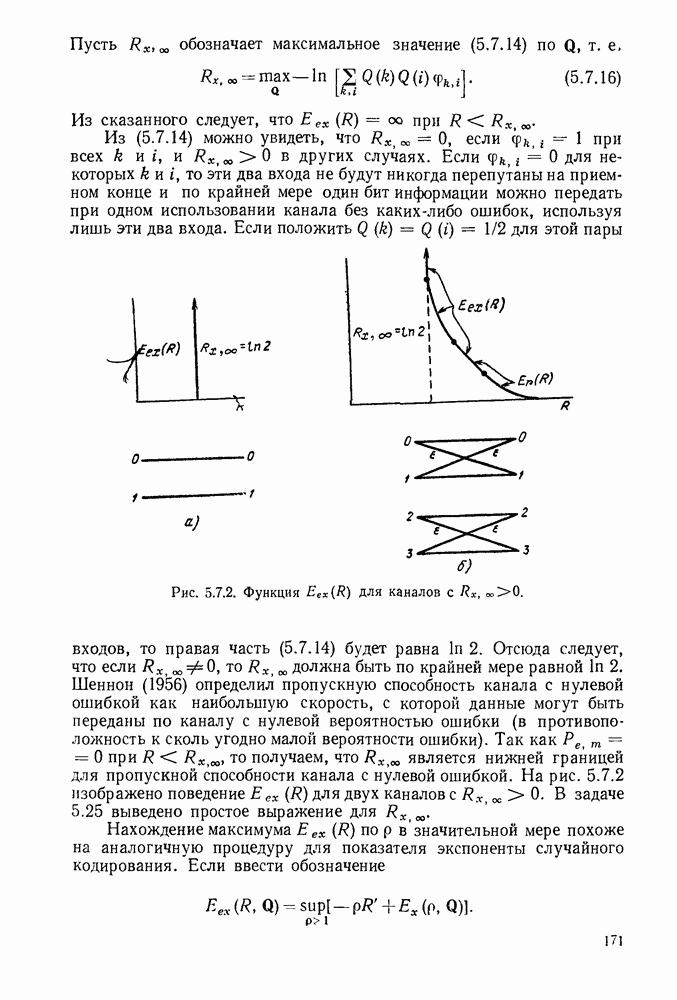
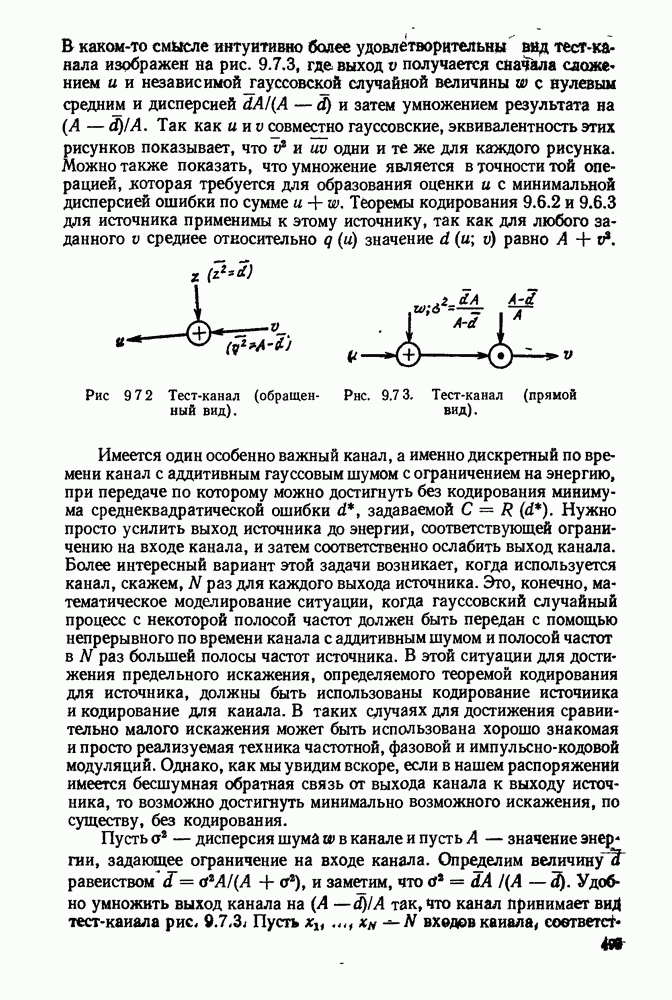
3.4. ПРОЦЕДУРА ВЫБОРА ОПТИМАЛЬНОГО НЕРАВНОМЕРНОГО КОДА
В этом параграфе будет дана предложенная Д. А. Хаффманом (1952) конструктивная процедура отыскания оптимального множества кодовых слов для кодирования данного множества сообщений. Под оптимальностью будет подразумеваться то, что никакое другое однозначно декодируемое множество кодовых слов не имеет меньшую среднюю длину кодового слова, чем заданное множество. Множество длин, задаваемое (3.3.8), обычно не минимизирует  даже если на нем достигается граница в теореме 3.3.1. Вначале будут рассмотрены двоичные коды и затем будет дано обобщение на произвольный кодовый алфавит.
даже если на нем достигается граница в теореме 3.3.1. Вначале будут рассмотрены двоичные коды и затем будет дано обобщение на произвольный кодовый алфавит.
Пусть буквы источника  имеют вероятности
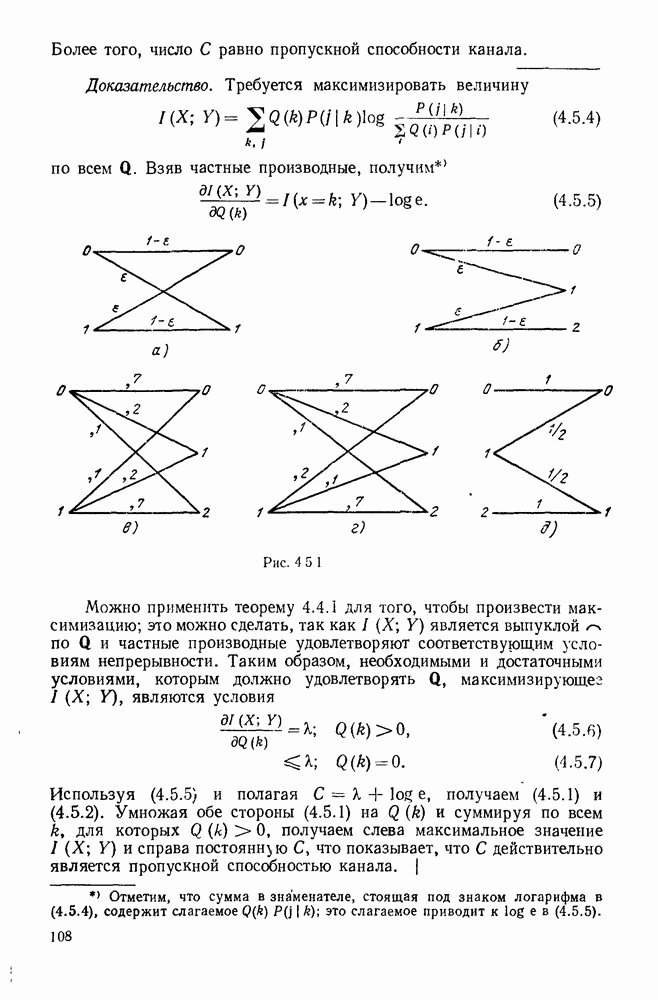
имеют вероятности  предположим для простоты обозначений, что буквы упорядочены так, что
предположим для простоты обозначений, что буквы упорядочены так, что  Пусть
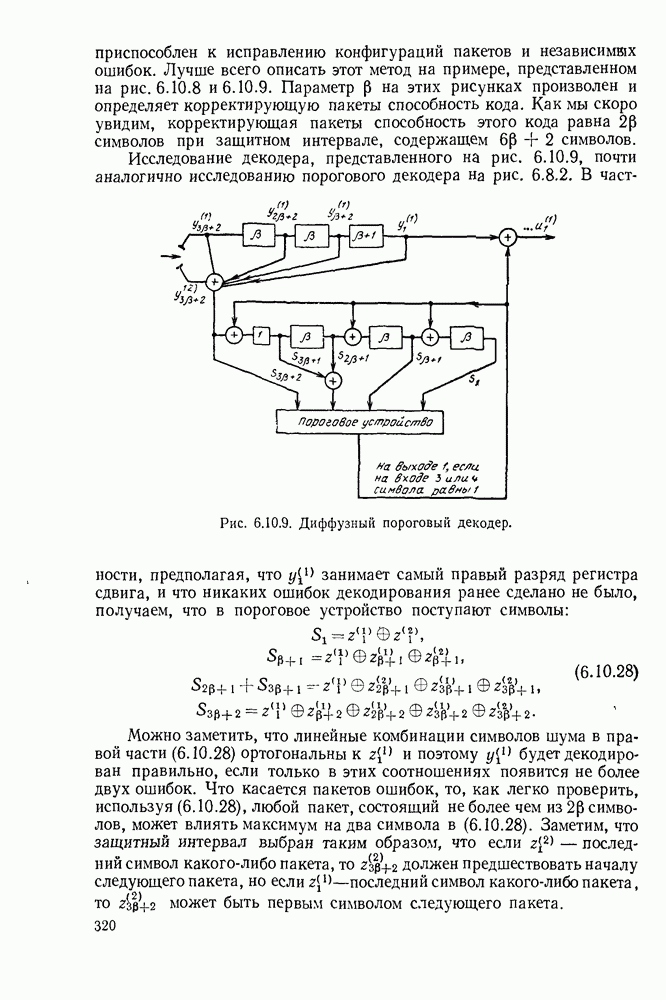
Пусть  множество двоичных кодовых слов для этого источника и пусть
множество двоичных кодовых слов для этого источника и пусть  длины кодовых слов. Кодовые слова
длины кодовых слов. Кодовые слова  соответствующие оптимальному коду, в общем случае не являются единственными и часто длины
соответствующие оптимальному коду, в общем случае не являются единственными и часто длины  не являются единственными (см. задачу 3.13). Далее будут получены некоторые условия, которым должен удовлетворять по крайней мере один оптимальный код, и затем будет показано, как построить код, удовлетворяющий этим условиям. Мы ограничимся
не являются единственными (см. задачу 3.13). Далее будут получены некоторые условия, которым должен удовлетворять по крайней мере один оптимальный код, и затем будет показано, как построить код, удовлетворяющий этим условиям. Мы ограничимся
рассмотрением префиксных кодов, так как любое множество длин, получаемых на однозначно декодируемом коде, можно получить на префиксном коде.
Лемма 1. Для любого заданного источника с К 2 буквами существует оптимальный двоичный код, в котором два наименее вероятных кодовых слова  имеют одну и ту же длину и отличаются лишь последним символом:
имеют одну и ту же длину и отличаются лишь последним символом:  оканчивается на
оканчивается на 
Доказательство. Во-первых, заметим, что по крайней мере для одного оптимального кода  больше или равно остальным длинам кодовых слов. Чтобы показать это, рассмотрим код, в котором
больше или равно остальным длинам кодовых слов. Чтобы показать это, рассмотрим код, в котором  для некоторого
для некоторого  Если кодовые слова
Если кодовые слова  заменить одно другим, то а изменится на величину
заменить одно другим, то а изменится на величину

Следовательно, любой код может быть изменен так, чтобы сделать  максимальной длиной, не увеличивая
максимальной длиной, не увеличивая  Далее заметим, что в любом оптимальном коде, для которого
Далее заметим, что в любом оптимальном коде, для которого  является наибольшей длиной, должно быть другое кодовое слово, отличающееся от
является наибольшей длиной, должно быть другое кодовое слово, отличающееся от  лишь в последнем символе, в противном случае последний символ
лишь в последнем символе, в противном случае последний символ  мог бы быть отброшен без нарушения свойства префикса. Наконец, если
мог бы быть отброшен без нарушения свойства префикса. Наконец, если  есть кодовое слово, отличающееся от
есть кодовое слово, отличающееся от  лишь в одной позиции, то должно быть
лишь в одной позиции, то должно быть  как показывает (3.4.1),
как показывает (3.4.1),  можно поменять местами без увеличения
можно поменять местами без увеличения  Таким образом, существует оптимальный код, в котором
Таким образом, существует оптимальный код, в котором  отличаются лишь в последнем символе. Эти слова, если необходимо, можно поменять местами, чтобы получить
отличаются лишь в последнем символе. Эти слова, если необходимо, можно поменять местами, чтобы получить  оканчивающимся на
оканчивающимся на 
С помощью этой леммы задача построения оптимального кода сводится к задаче построения  и отысканию первых
и отысканию первых  символов
символов  Определим теперь редуцированный ансамбль
Определим теперь редуцированный ансамбль  как ансамбль, состоящий из букв
как ансамбль, состоящий из букв  с вероятностями
с вероятностями

Любой префиксный код для  можно превратить в соответствующий префиксный код для
можно превратить в соответствующий префиксный код для  простым добавлением концевого символа 0 к
простым добавлением концевого символа 0 к  для получения
для получения  и добавлением концевого символа 1 к
и добавлением концевого символа 1 к  для получения
для получения  Это устанавливает взаимно однозначное соответствие между множеством префиксных кодов для
Это устанавливает взаимно однозначное соответствие между множеством префиксных кодов для  и множеством тех префиксных кодов для
и множеством тех префиксных кодов для  в которых
в которых  отличаются лишь последним символом;
отличаются лишь последним символом;  кончается на
кончается на  кончается на 0.
кончается на 0.
Лемма 2. Если некоторый префиксный код для  является оптимальным, то соответствующий ему префиксный код для
является оптимальным, то соответствующий ему префиксный код для  является оптимальным.
является оптимальным.
Доказательство. Длины  кодовых слов для V связаны с длинами
кодовых слов для V связаны с длинами  соответствующего кода для
соответствующего кода для  соотношениями
соотношениями

Следовательно, средние длины  связаны равенством
связаны равенством

Так как  отличаются лишь на фиксированное число, не зависящее от кода для
отличаются лишь на фиксированное число, не зависящее от кода для  то можно минимизировать
то можно минимизировать  в классе кодов, у которых
в классе кодов, у которых  и 1 отличаются лишь в последнем символе, минимизируя
и 1 отличаются лишь в последнем символе, минимизируя  Но согласно лемме 1 код из этого класса минимизирует
Но согласно лемме 1 код из этого класса минимизирует  по всем кодам, обладающим свойством префикса.
по всем кодам, обладающим свойством префикса. 
Задача отыскания оптимального кода сведена теперь к задаче отыскания оптимального кода для ансамбля, имеющего на одно сообщение меньше. Но теперь редуцированный ансамбль может иметь свои два наименее вероятные сообщения сгруппированными вместе, и может быть произведен следующий редуцированный ансамбль. Продолжая таким образом, мы постепенно достигнем того, что получится ансамбль, состоящий только из двух сообщений, и тогда оптимальный код, очевидно, получается приписыванием 1 одному сообщению и 0 другому.
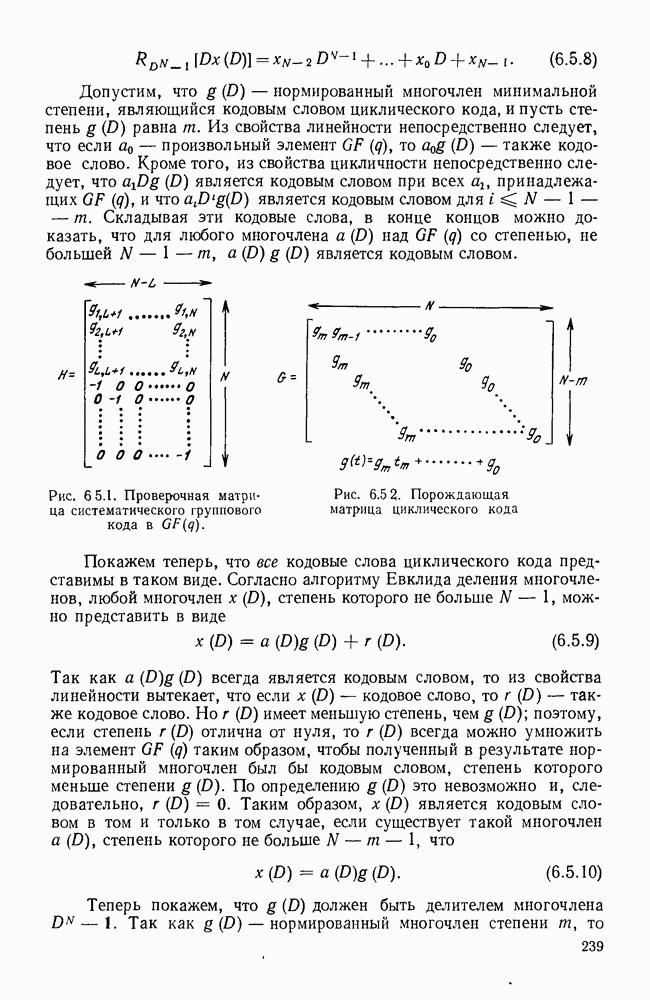
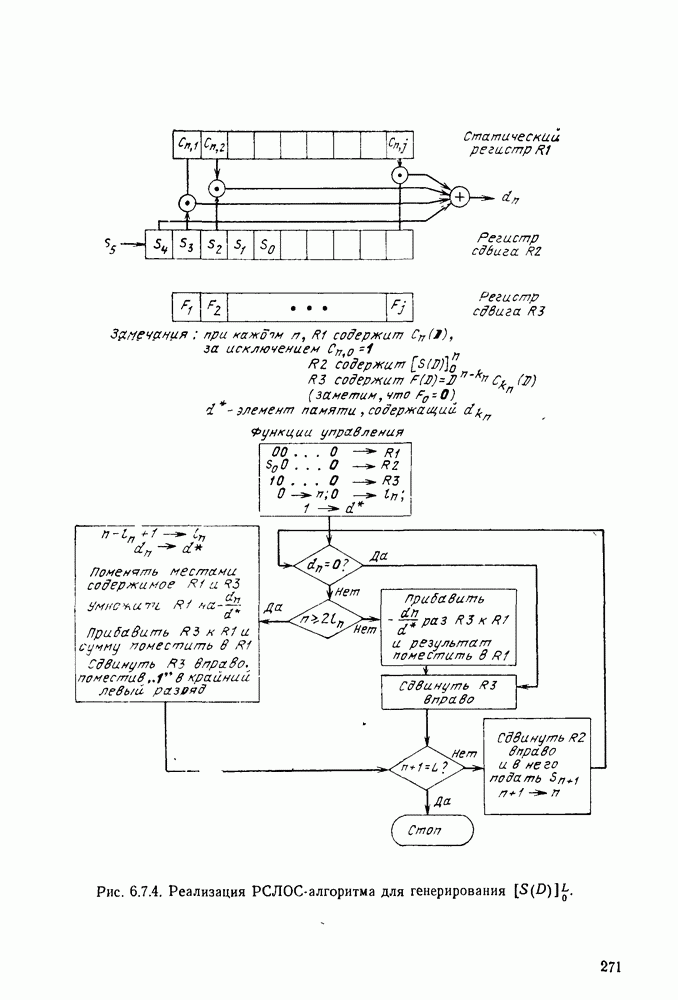
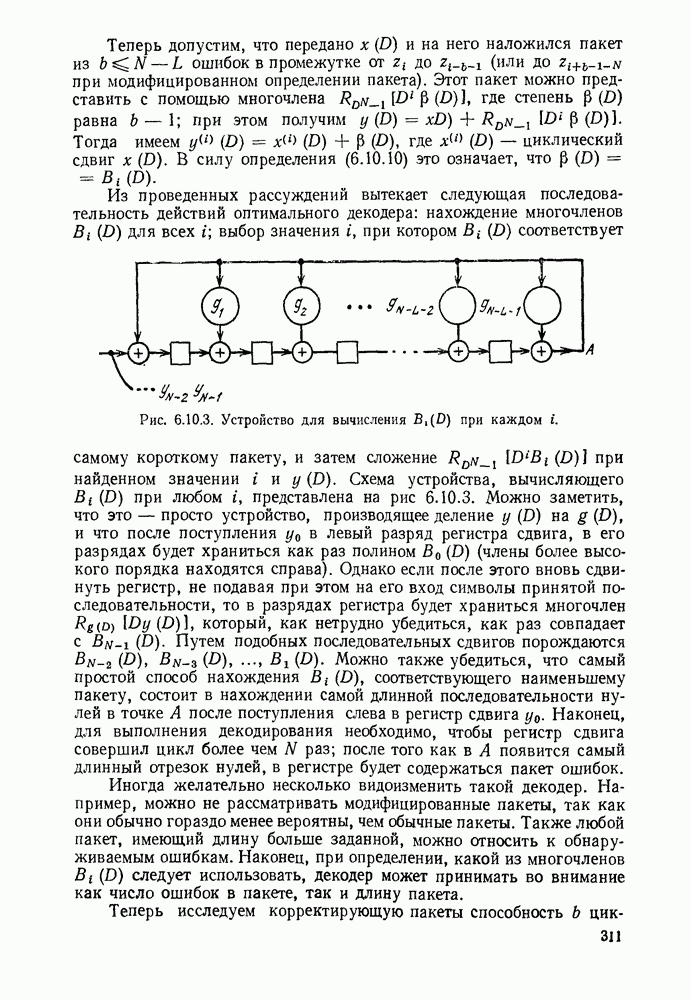
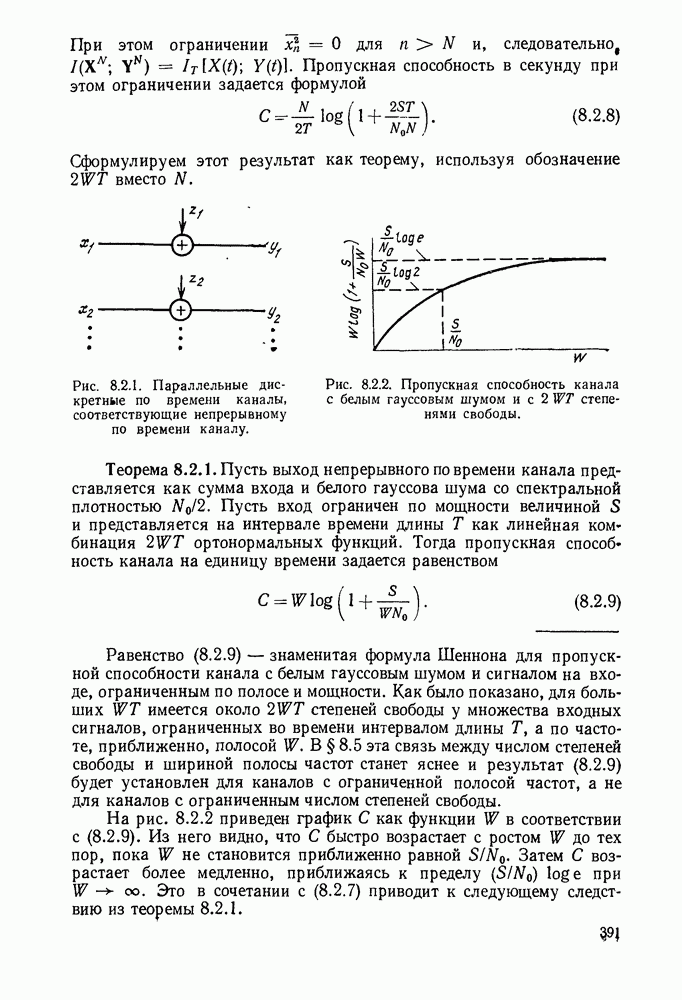
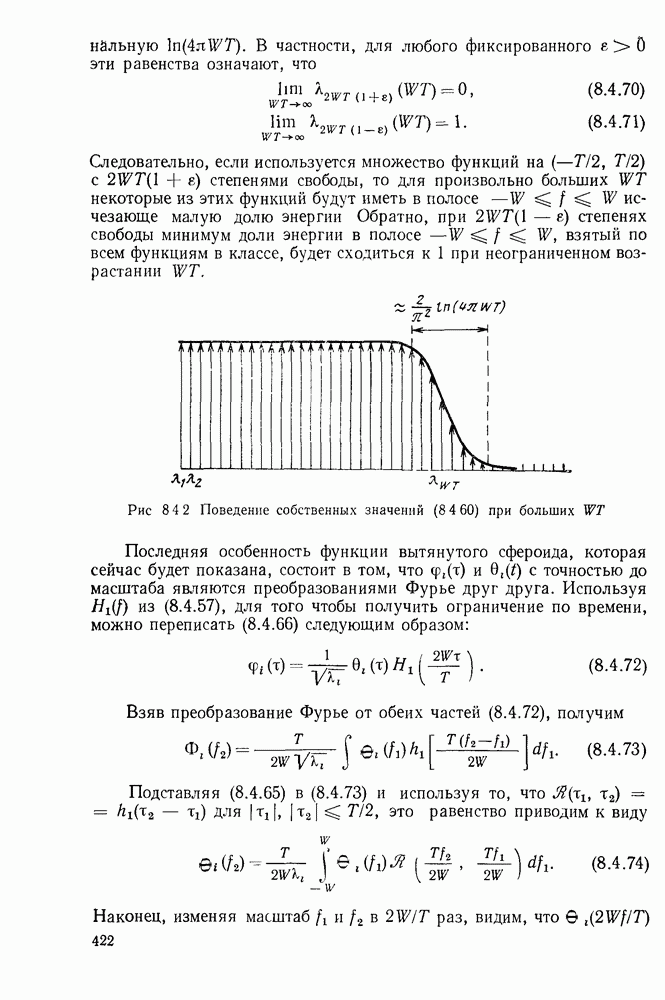
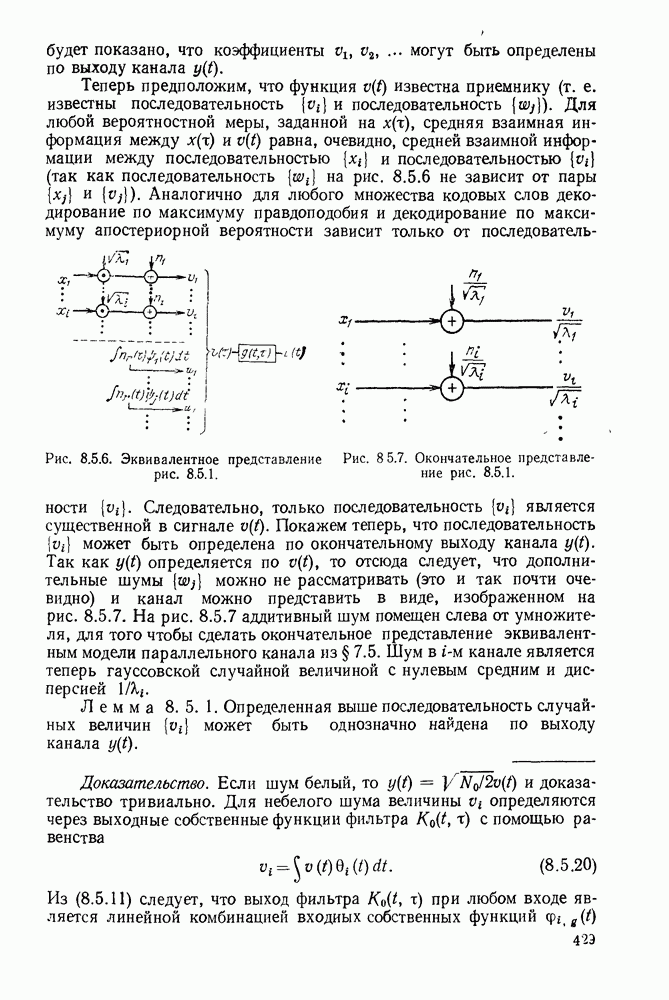
Систематическая процедура для выполнения описанных выше операций приведена на рис. 3.4.1. Вначале свяжем вместе два наименее вероятных сообщения (в рассматриваемом случае  полагая, что последним символом для
полагая, что последним символом для  является 0 и последним символом
является 0 и последним символом  является 1. Складывая вероятности сообщений
является 1. Складывая вероятности сообщений  находим, что два наименее вероятных сообщения в редуцированном ансамбле будут
находим, что два наименее вероятных сообщения в редуцированном ансамбле будут  На следующем этапе двумя наименее вероятными сообщениями будут
На следующем этапе двумя наименее вероятными сообщениями будут  но на этот раз остались только два сообщения. Рассматривая получающийся в результате рисунок, видим, что мы построили кодовое дерево для
но на этот раз остались только два сообщения. Рассматривая получающийся в результате рисунок, видим, что мы построили кодовое дерево для  начав с наиболее удаленных ребер и спускаясь вниз с основанию. Кодовые слова считаются по этому дереву справа налево.
начав с наиболее удаленных ребер и спускаясь вниз с основанию. Кодовые слова считаются по этому дереву справа налево.
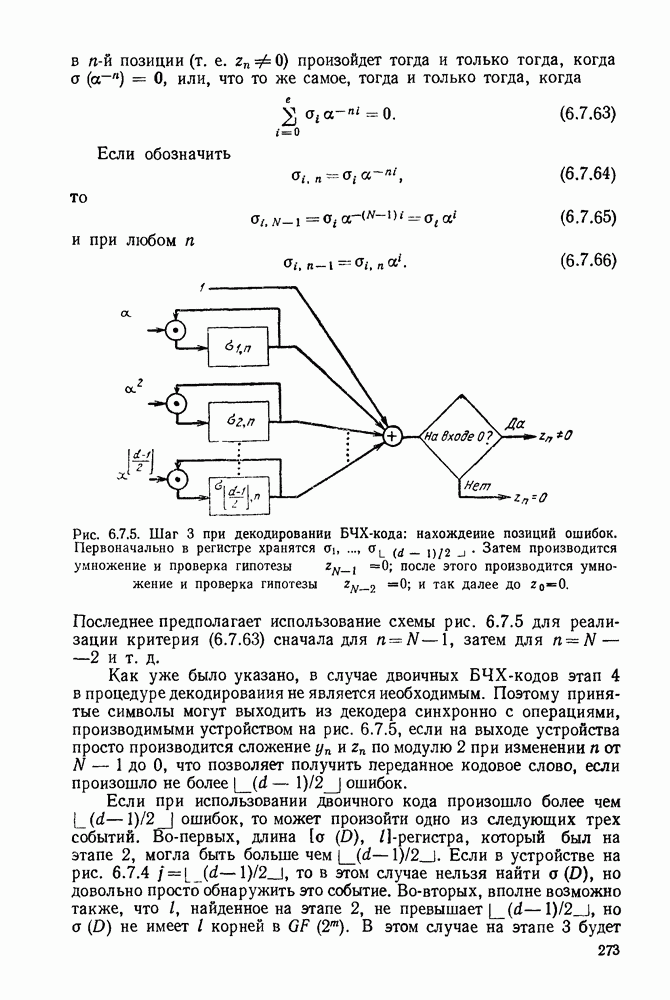
Имеется некоторая трудность при распространении этой процедуры на недвоичные коды. Лемма 1 остается справедливой для недвоичного кодового алфавита. А лемма 2 не остается справедливой и возникает вопрос, имеются ли еще кодовые слова помимо  которые должны отличаться от в последнем символе.
которые должны отличаться от в последнем символе.
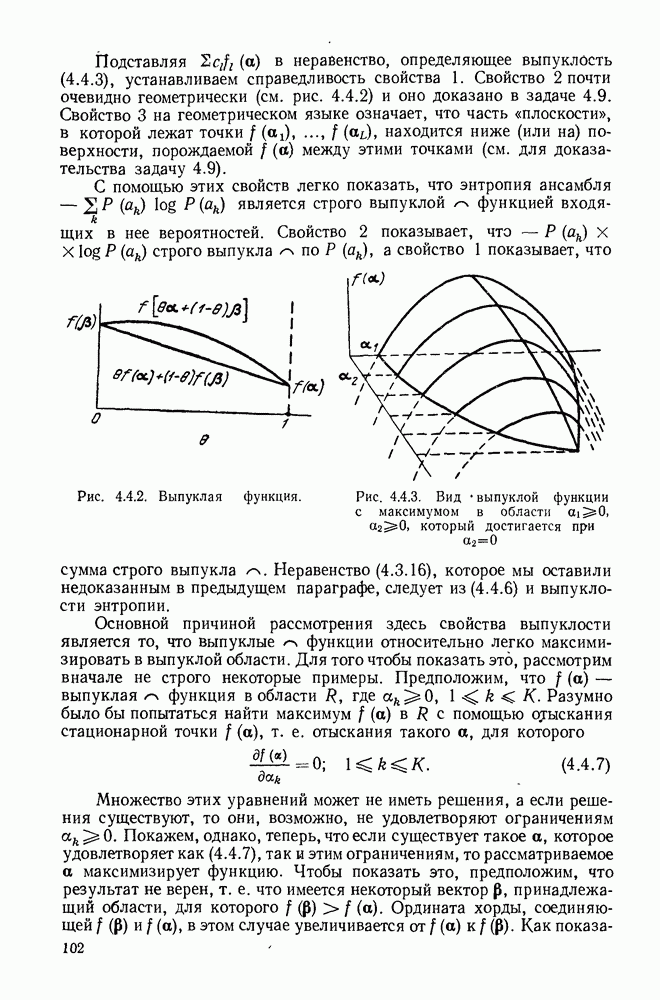
Определим полное кодовое дерево как конечное кодовое дерево, в  тором из каждого промежуточного узла исходят
тором из каждого промежуточного узла исходят  узлов следующего более высокого порядка. Как можно заметить из доказательства неравенства Крафта, для полного кодового дерева неравенство Крафта удовлетворяется с равенством.
узлов следующего более высокого порядка. Как можно заметить из доказательства неравенства Крафта, для полного кодового дерева неравенство Крафта удовлетворяется с равенством.
Лемма 3. Число концевых узлов полного кодового дерева с алфавитом объема  имеет вид
имеет вид  где
где  некоторое целое число.
некоторое целое число.
Доказательство. Наименьшее полное дерево с алфавитом объема  имеет
имеет  концевых узлов. Если один из этих концевых узлов превращается в промежуточный узел, то образуется
концевых узлов. Если один из этих концевых узлов превращается в промежуточный узел, то образуется  новых концевых узлов и один узел теряется, в результате получаем приращение
новых концевых узлов и один узел теряется, в результате получаем приращение  Так как любое полное дерево может быть построено с помощью таких последовательных преобразований концевых узлов в промежуточные узлы и так как каждое такое преобразование увеличивает число узлов на
Так как любое полное дерево может быть построено с помощью таких последовательных преобразований концевых узлов в промежуточные узлы и так как каждое такое преобразование увеличивает число узлов на  то окончательное число узлов должно иметь вид
то окончательное число узлов должно иметь вид 

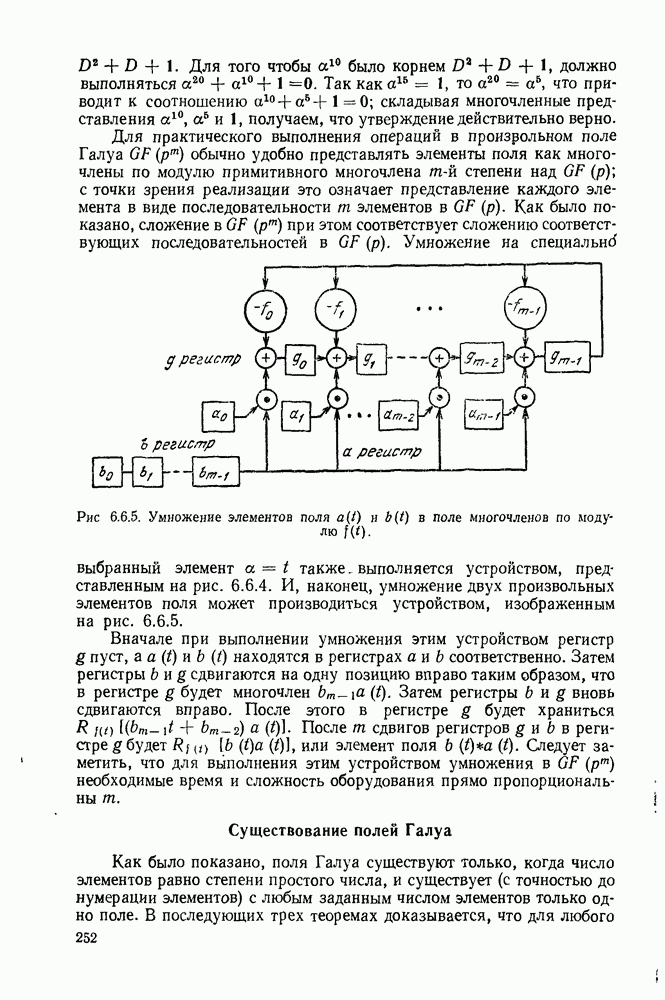
Рис. 3.4.1. Процедура кодирования Хаффмана.
Условимся теперь рассматривать каждое кодовое дерево как полное дерево, может быть, с некоторым числом В неиспользуемых концевых узлов, добавленных для полноты дерева. Ясно, что в оптимальном коде все неиспользуемые концевые узлы имеют ту же самую длину, что и самое длинное кодовое слово. Точно так же, меняя местами используемые и неиспользуемые концевые узлы, можно добиться того, чтобы неиспользуемые концевые узлы отличались лишь в последнем символе. Следовательно, оптимальное кодовое дерево должно иметь не более чем  неиспользуемых концевых узлов, так как если бы
неиспользуемых концевых узлов, так как если бы  неиспользуемых узлов группировались вместе, то соответствующее кодовое слово могло бы быть укорочено без нарушения свойства префикса. Число кодовых слов, сложенное с числом неиспользуемых узлов, имеет вид
неиспользуемых узлов группировались вместе, то соответствующее кодовое слово могло бы быть укорочено без нарушения свойства префикса. Число кодовых слов, сложенное с числом неиспользуемых узлов, имеет вид  это выражение однозначно определяет число неиспользуемых узлов полного дерева. Например, если
это выражение однозначно определяет число неиспользуемых узлов полного дерева. Например, если  то каждое полное дерево имеет нечетное число узлов. Если К четно, то число неиспользуемых концевых узлов В для оптимального кода равно 1, а если
то каждое полное дерево имеет нечетное число узлов. Если К четно, то число неиспользуемых концевых узлов В для оптимального кода равно 1, а если  нечетно, то
нечетно, то 
Для читателя, который лучше ориентируется в языке формул, мы получим точное выражение для В, замечая, что  Отсюда
Отсюда  Для оптимального кода
Для оптимального кода  и поэтому
и поэтому  следовательно,
следовательно,  равно остатку от деления
равно остатку от деления  на
на  ; обозначим его через
; обозначим его через  Отсюда
Отсюда  Используя те же рассуждения, что и в лемме 1, получаем, что существует оптимальный код, у которого имеются В неиспользуемых
Используя те же рассуждения, что и в лемме 1, получаем, что существует оптимальный код, у которого имеются В неиспользуемых
узлов и  наименее вероятных узлов, соответствующих кодовым словам, отличающихся лишь в последнем символе. Таким образом, первый этап процедуры декодирования состоит в группировании
наименее вероятных узлов, соответствующих кодовым словам, отличающихся лишь в последнем символе. Таким образом, первый этап процедуры декодирования состоит в группировании  наименее вероятных узлов.
наименее вероятных узлов.
После этого начального этапа построение оптимального кода проходит так же, как и раньше. Производится редуцированный ансамбль с помощью объединения вероятностей предварительно сгруппированных кодовых слов. Легко проверить, что число сообщений в редуцированном ансамбле имеет вид  и мы полагаем, что
и мы полагаем, что  менее вероятных из них отличаются лишь в последнем символе.
менее вероятных из них отличаются лишь в последнем символе.

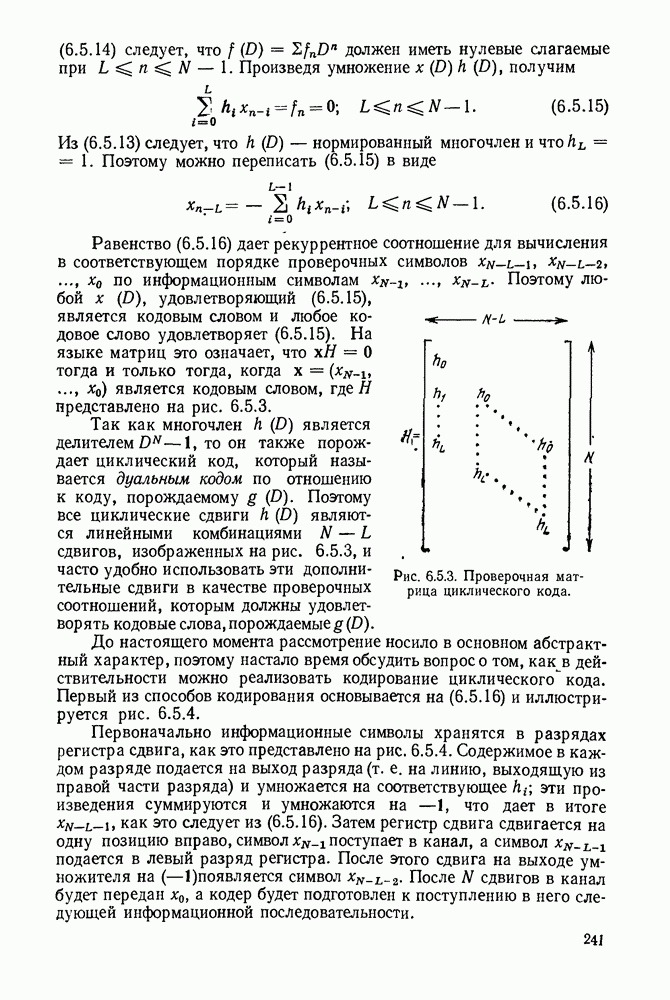
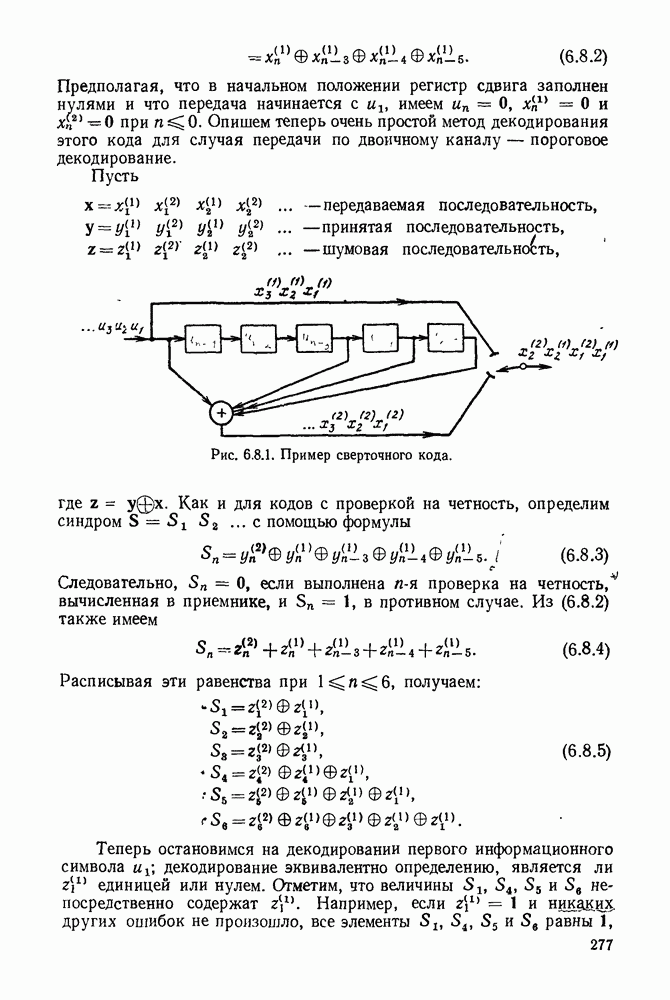
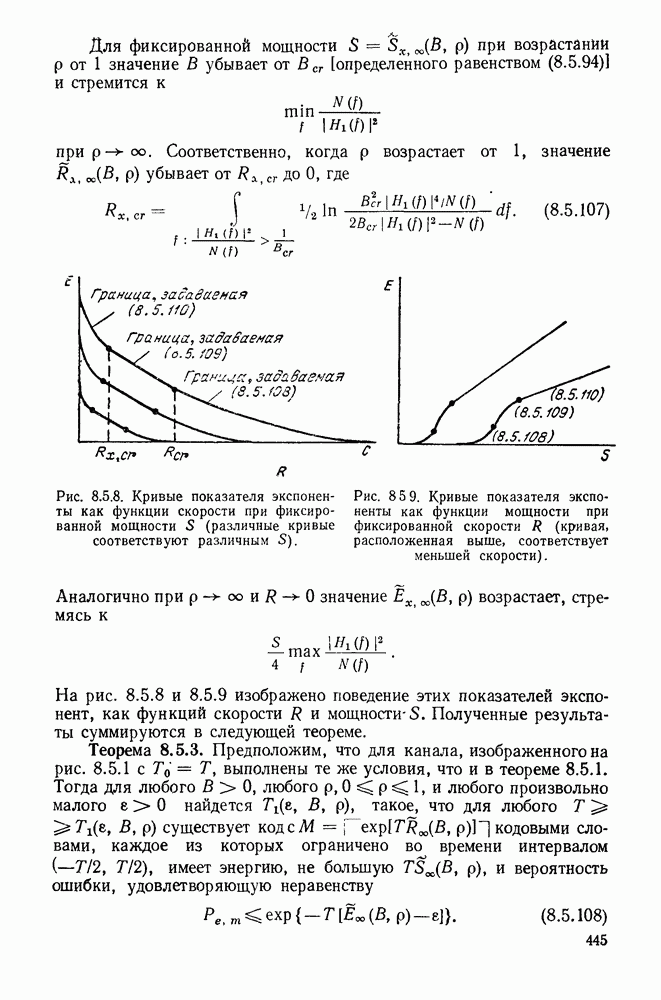
Рис. 3.4.2. Кодирование по Хаффману при 
Продолжая процедуру таким образом, в итоге получаем редуцированный ансамбль из  сообщений, для которого оптимальный код очевиден. Рис. 3.4.2 доказывает построение в случае
сообщений, для которого оптимальный код очевиден. Рис. 3.4.2 доказывает построение в случае  Так как
Так как  то число сообщений, группируемых на начальном этапе, равно
то число сообщений, группируемых на начальном этапе, равно