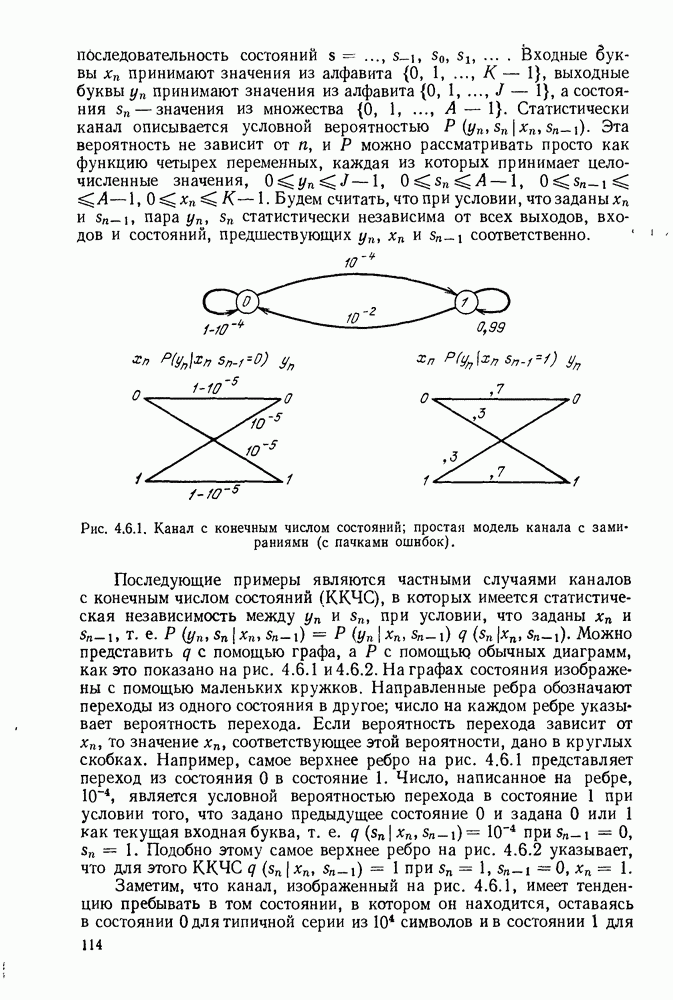
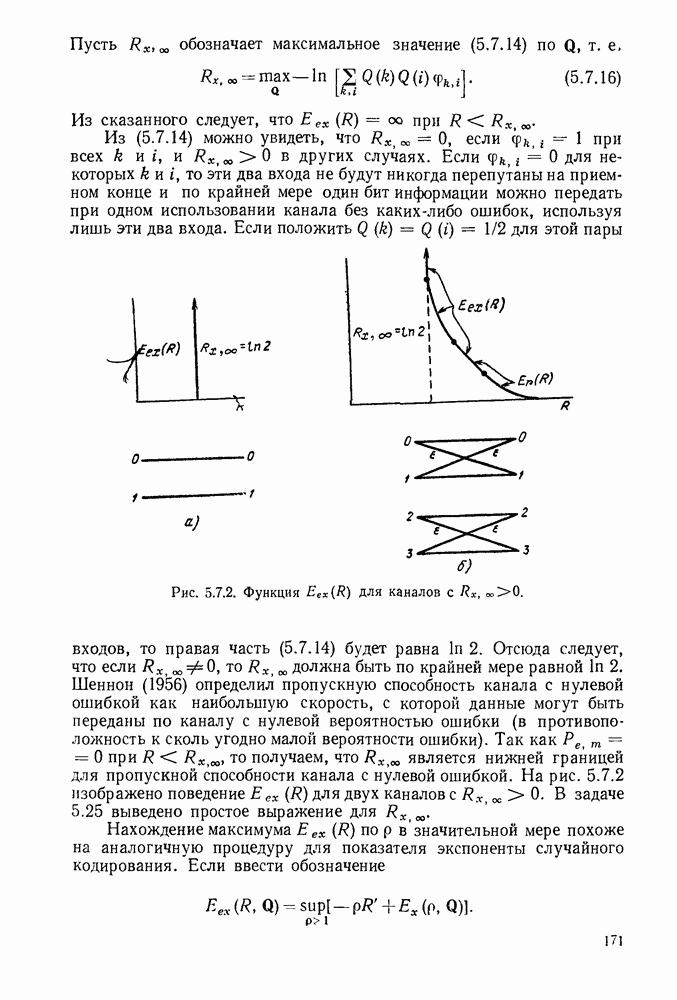
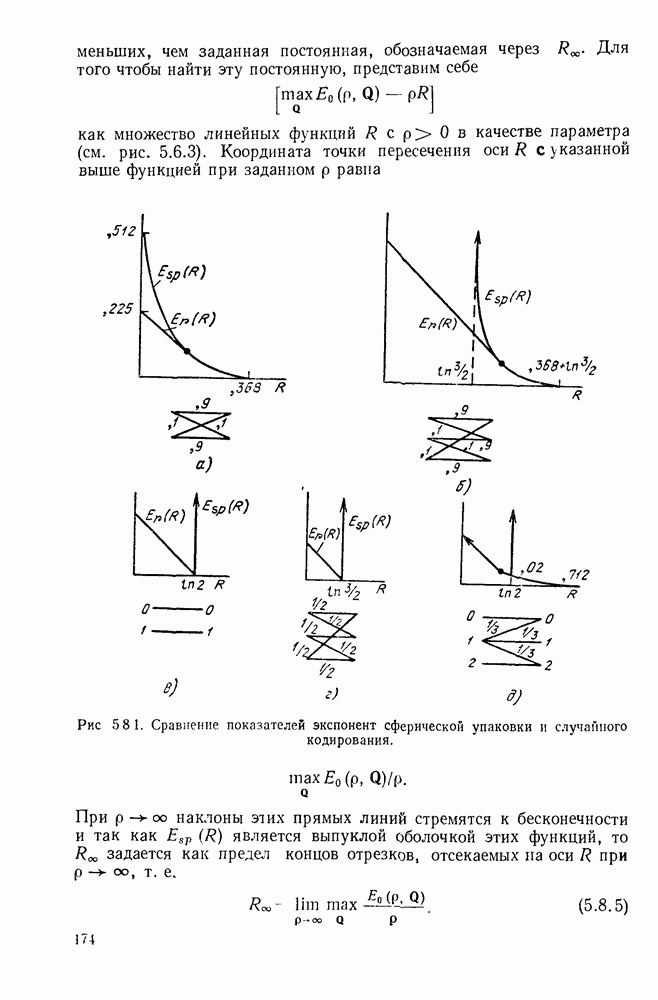
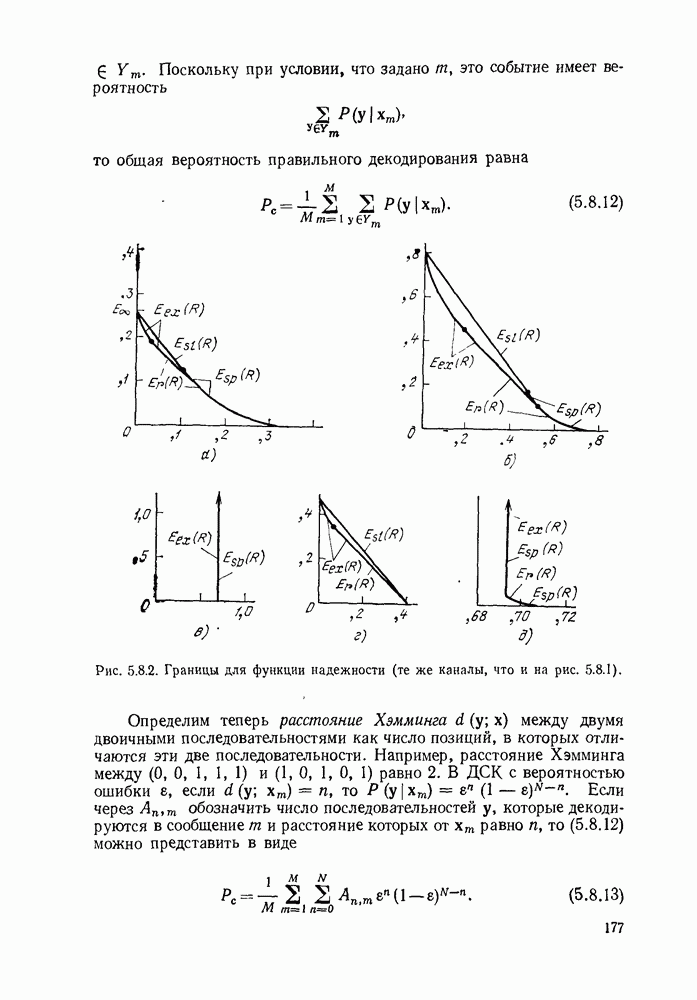
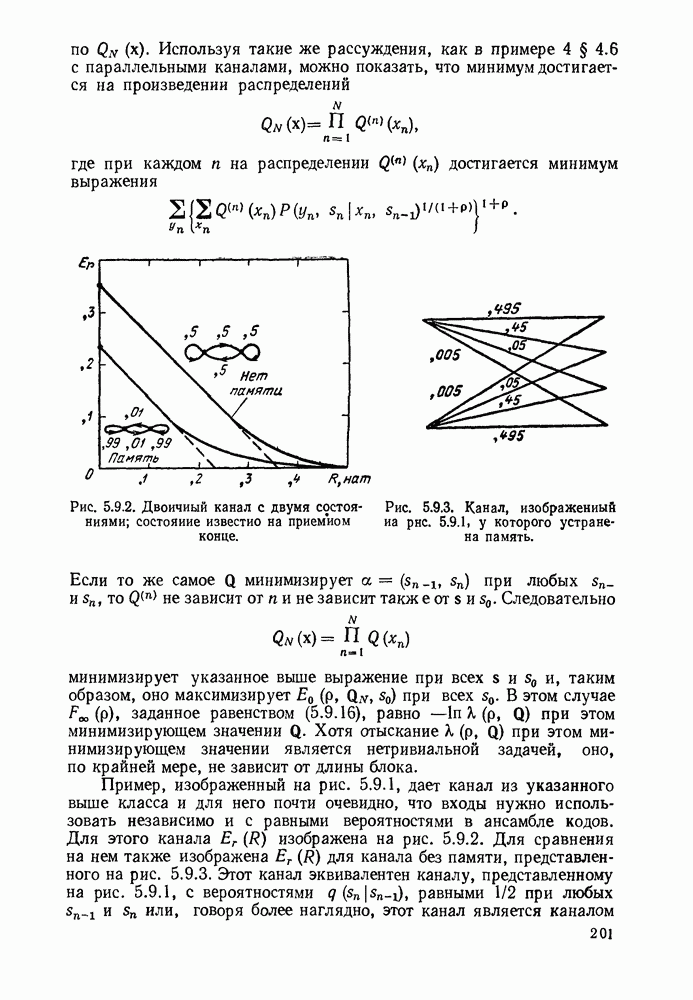
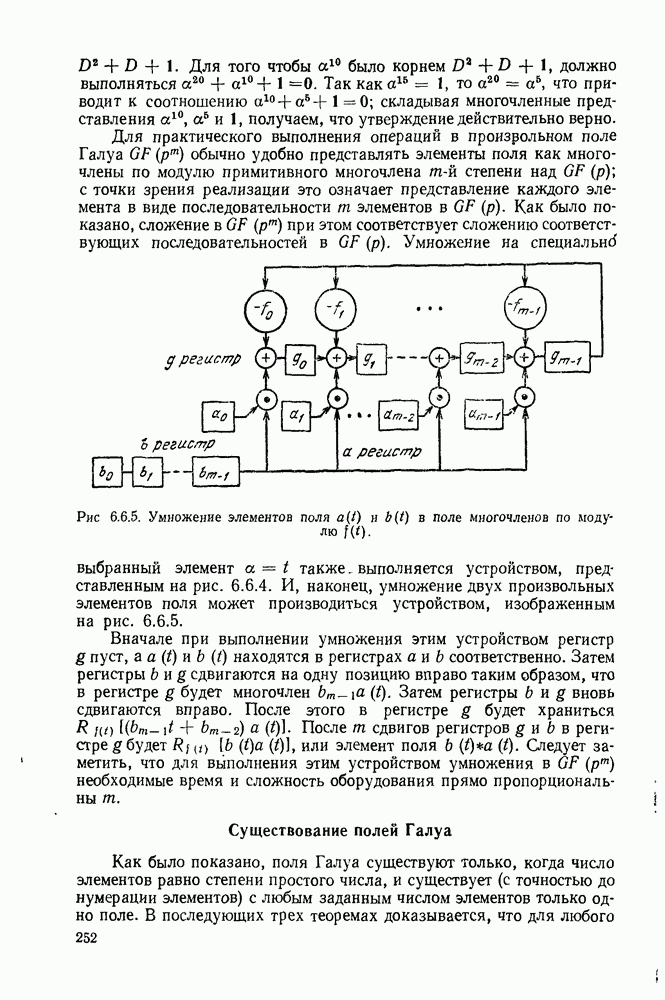
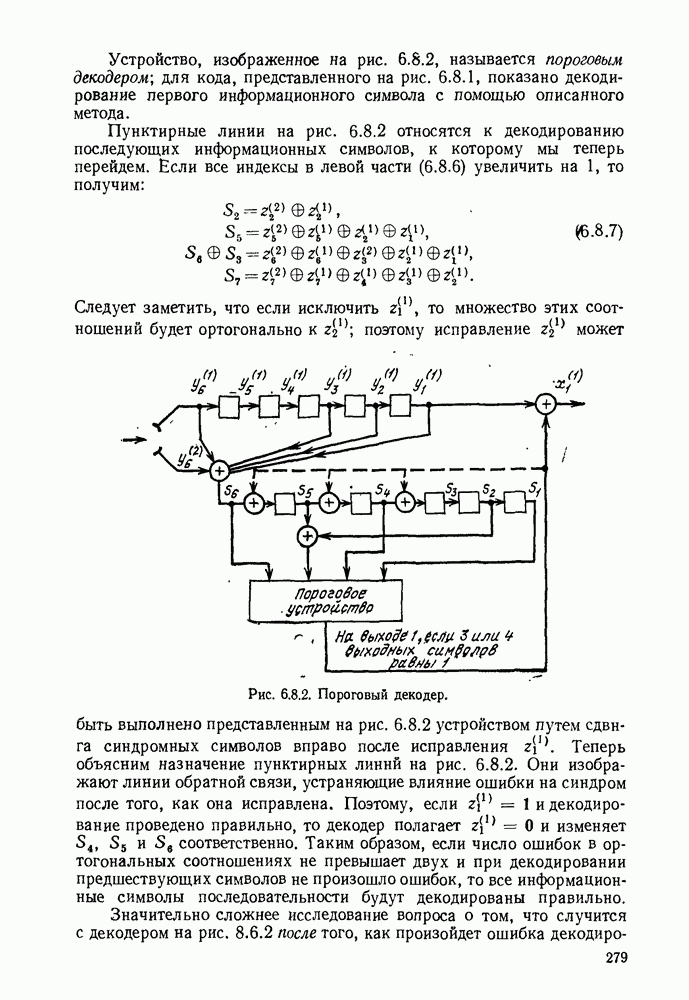
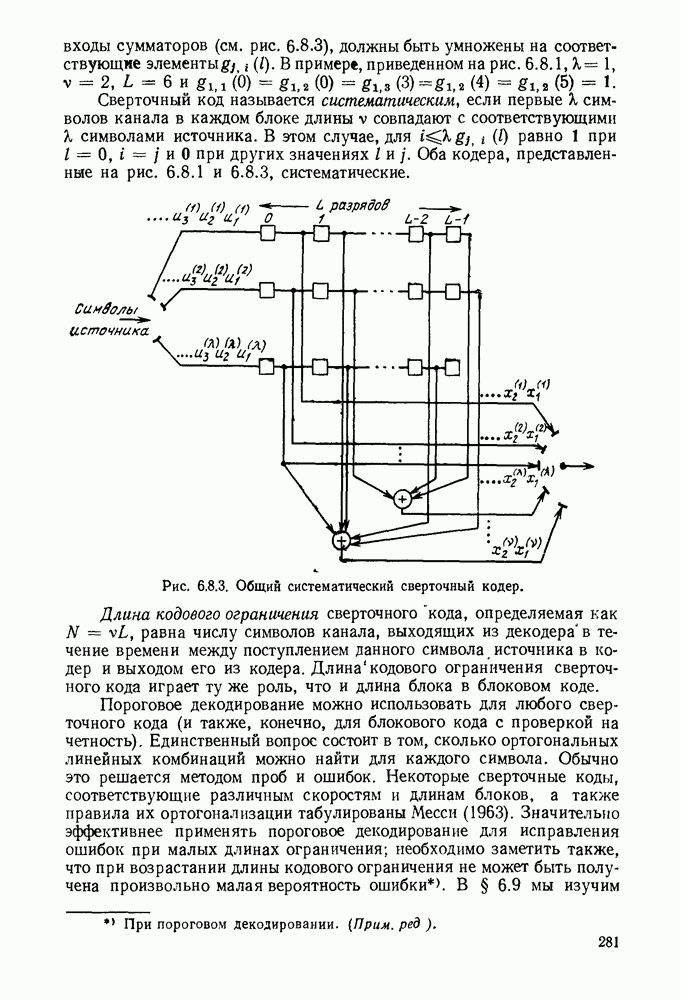
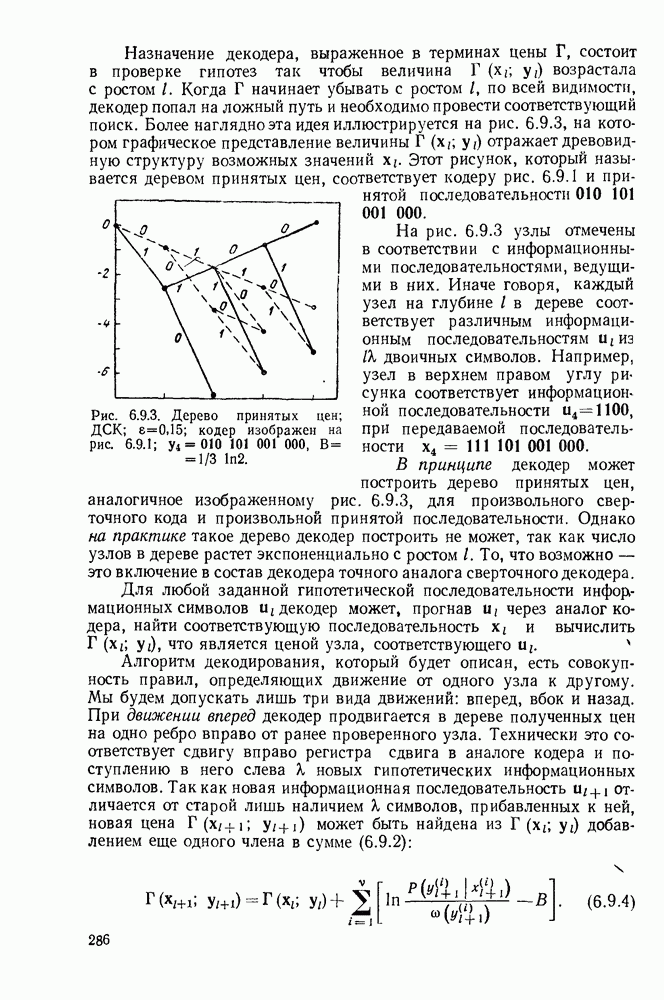
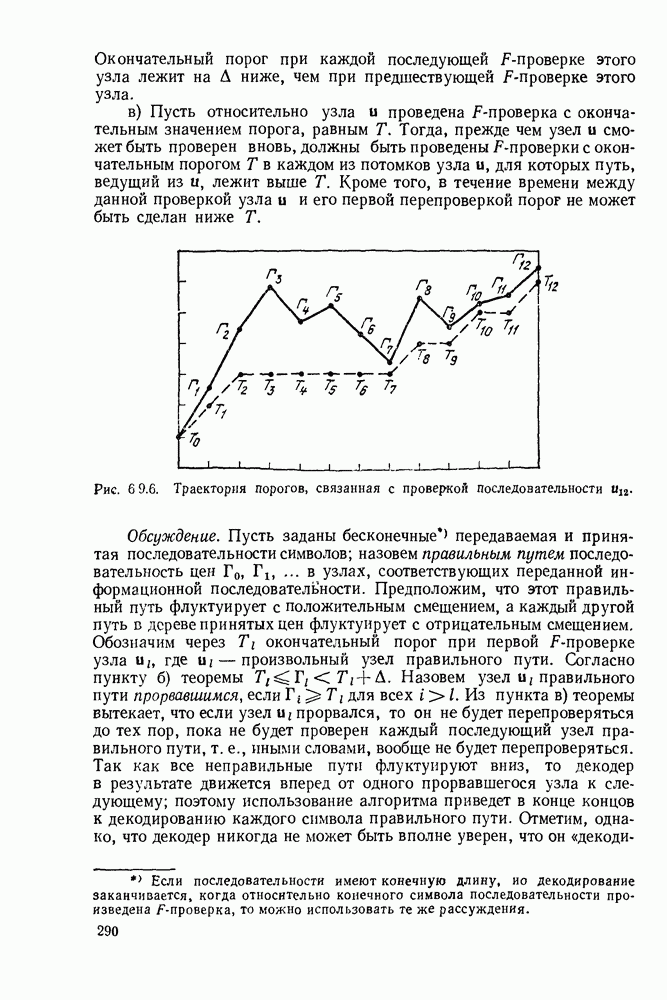
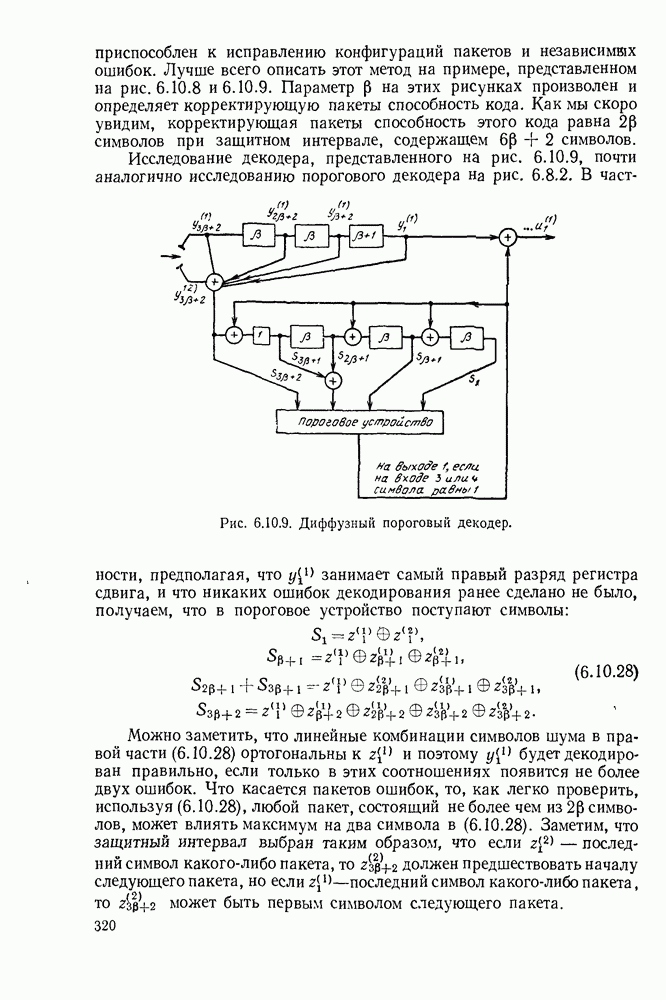
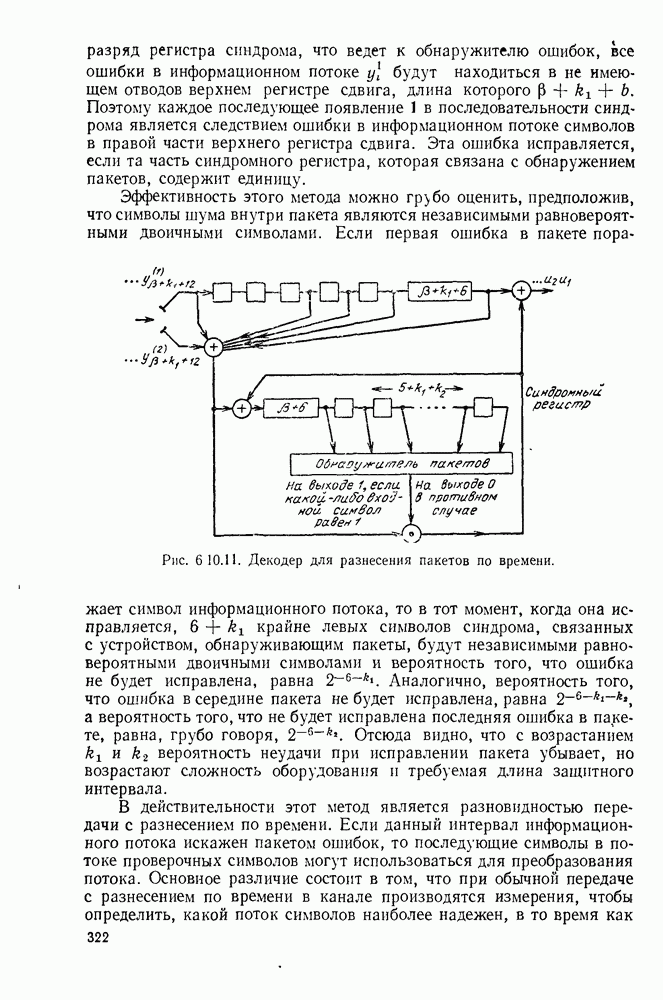
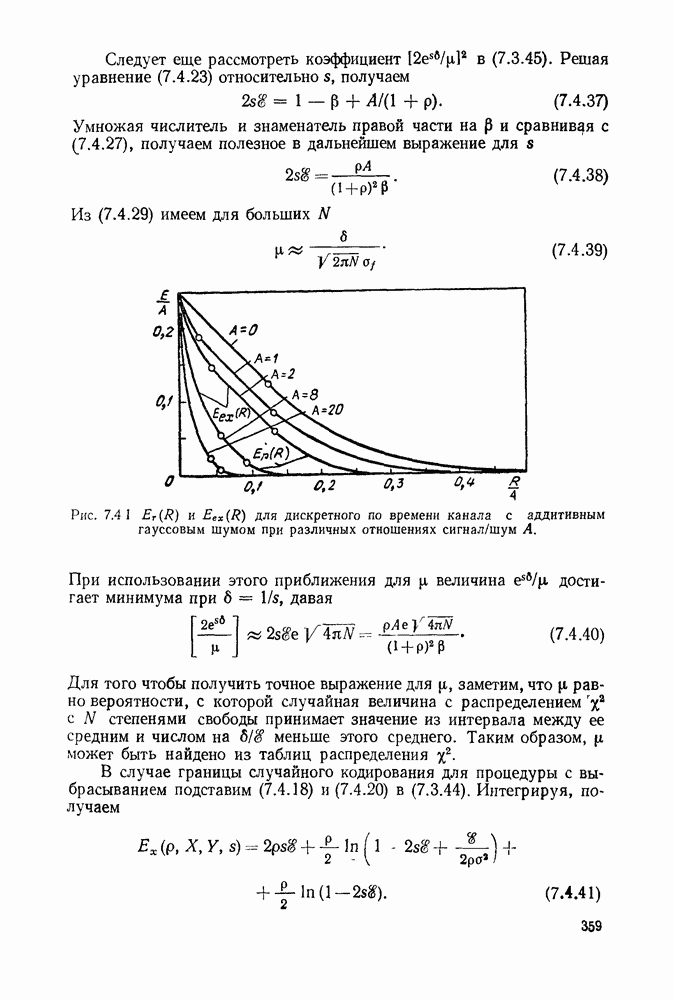
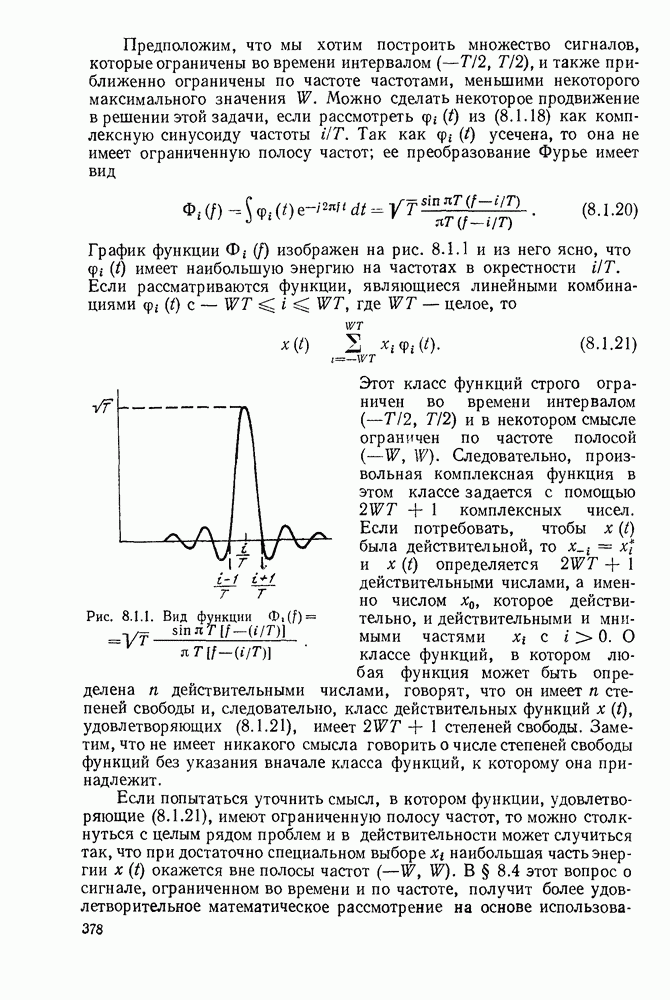
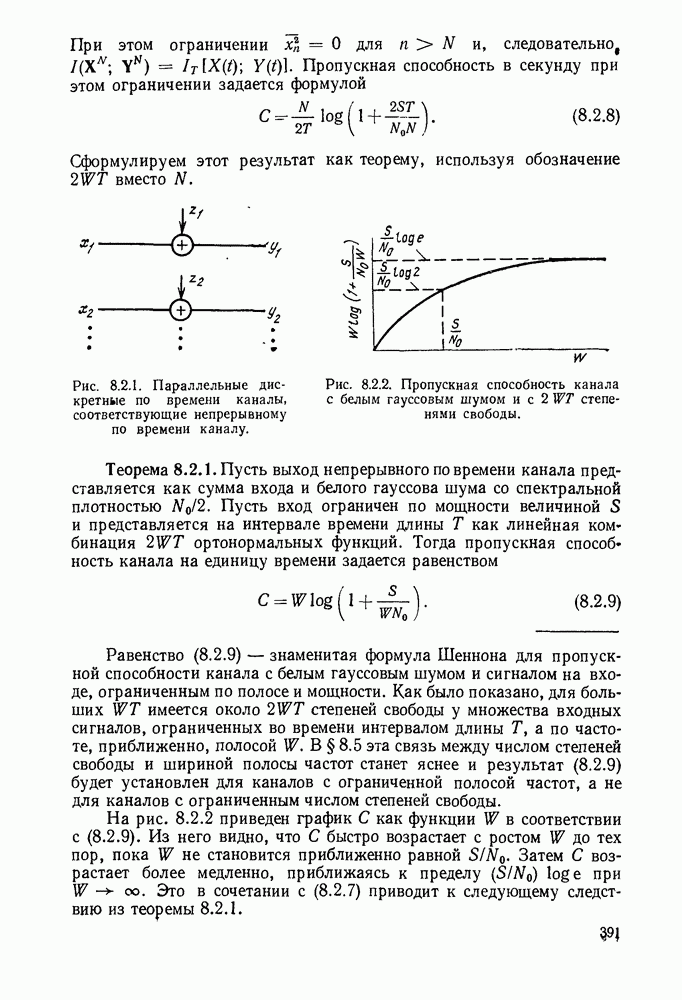
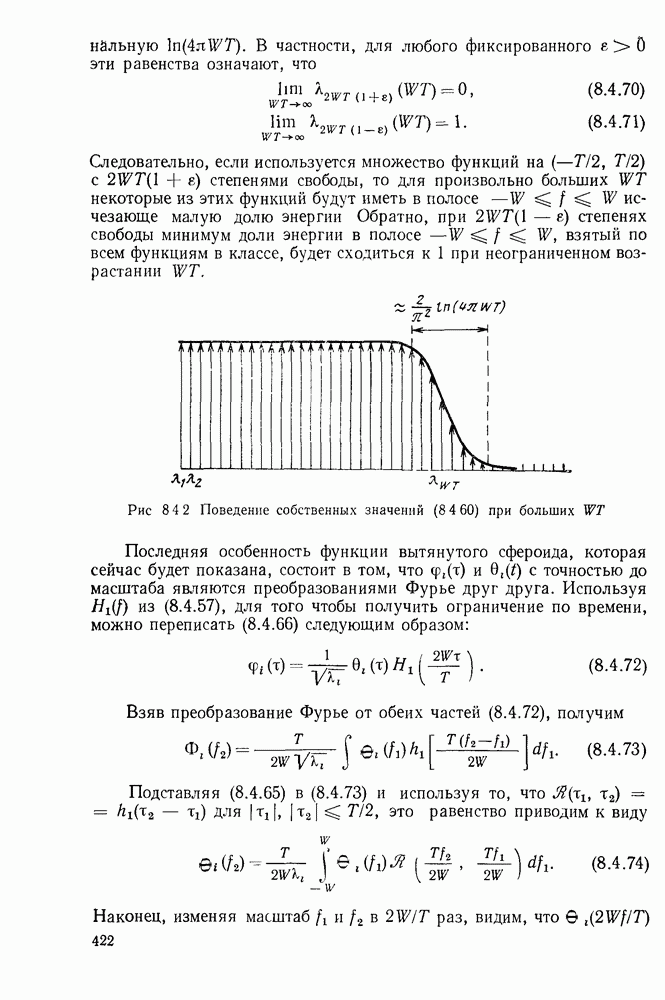
определенного класса назовем аддитивными инвариантными во времени мерами искажения.
В последующем изложении сначала определим скорость как функцию искажения для таких источников и мер искажения. Затем докажем теорему кодирования для источника, показав, что эта скорость как функция искажения допускает такое же истолкование, что и скорость как функция искажения для дискретных источников без памяти с мерой искажения для одиночной буквы.
Пусть  обозначает бесконечную последовательность источника и пусть
обозначает бесконечную последовательность источника и пусть  обозначает последовательность
обозначает последовательность  букв из
букв из  . Аналогично пусть
. Аналогично пусть  обозначает соответствующую последовательность букв адресата. Рассмотрим передачу последовательности
обозначает соответствующую последовательность букв адресата. Рассмотрим передачу последовательности  по каналу с шумами; пусть
по каналу с шумами; пусть  принимаемая последовательность. Канал и любые преобразования, сопровождающие передачу, можно описать с помощью переходной вероятности
принимаемая последовательность. Канал и любые преобразования, сопровождающие передачу, можно описать с помощью переходной вероятности  порядка
порядка  Примем, что при заданном
Примем, что при заданном  принятая последовательность статистически не зависит от других букв последовательности бесконечной длины и, т. е. что
принятая последовательность статистически не зависит от других букв последовательности бесконечной длины и, т. е. что  В соединении с вероятностной мерой источника
В соединении с вероятностной мерой источника  определяет среднюю взаимную информацию
определяет среднюю взаимную информацию  между последовательностями
между последовательностями  Аналогично
Аналогично  определяет среднее значение общего искажения между
определяет среднее значение общего искажения между  т. е.
т. е. 
Скорость как функция искажения  порядка для заданных источника и меры искажения определяется как
порядка для заданных источника и меры искажения определяется как

Минимизация проводится по всем заданиям переходных вероятностей  таким, что среднее искажение на букву
таким, что среднее искажение на букву  не превосходит
не превосходит  Для тех ситуаций, когда
Для тех ситуаций, когда  не равен 0 при всех и, множество ограничений в приведенной выше минимизации может быть пусто для малых
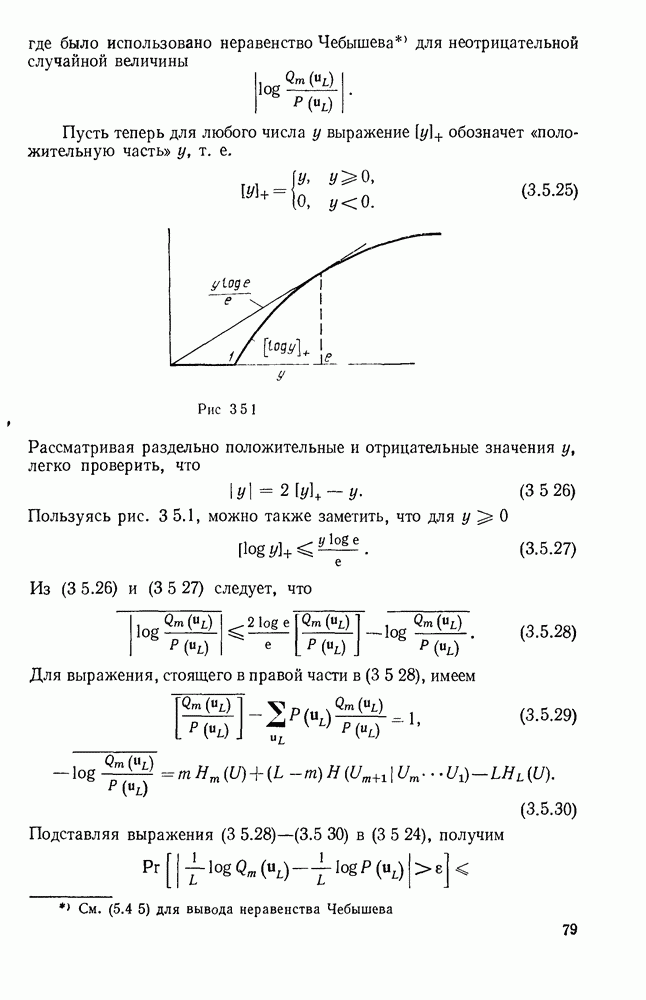
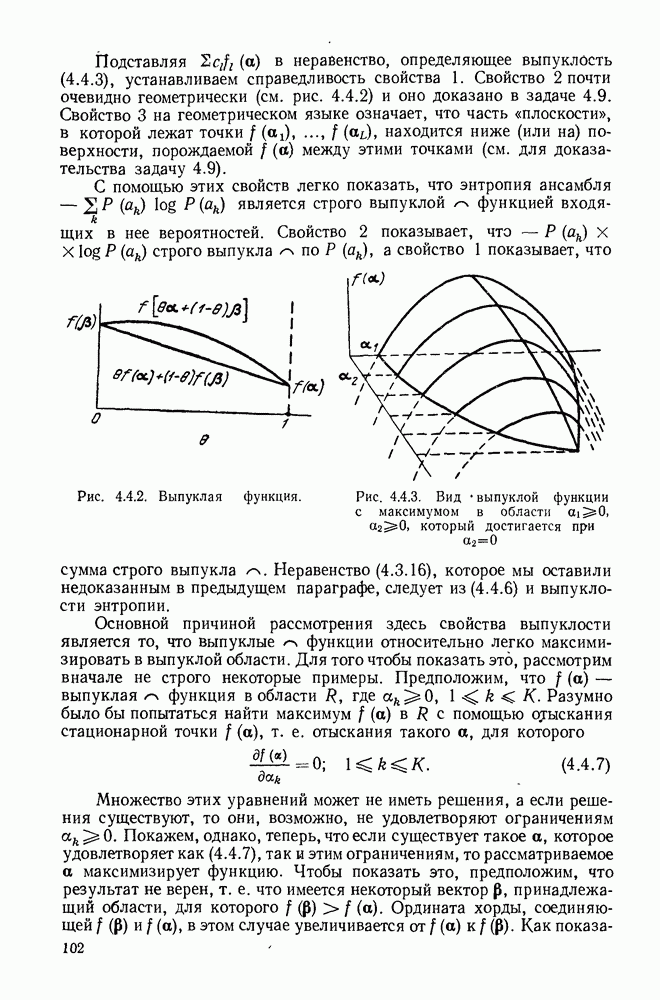
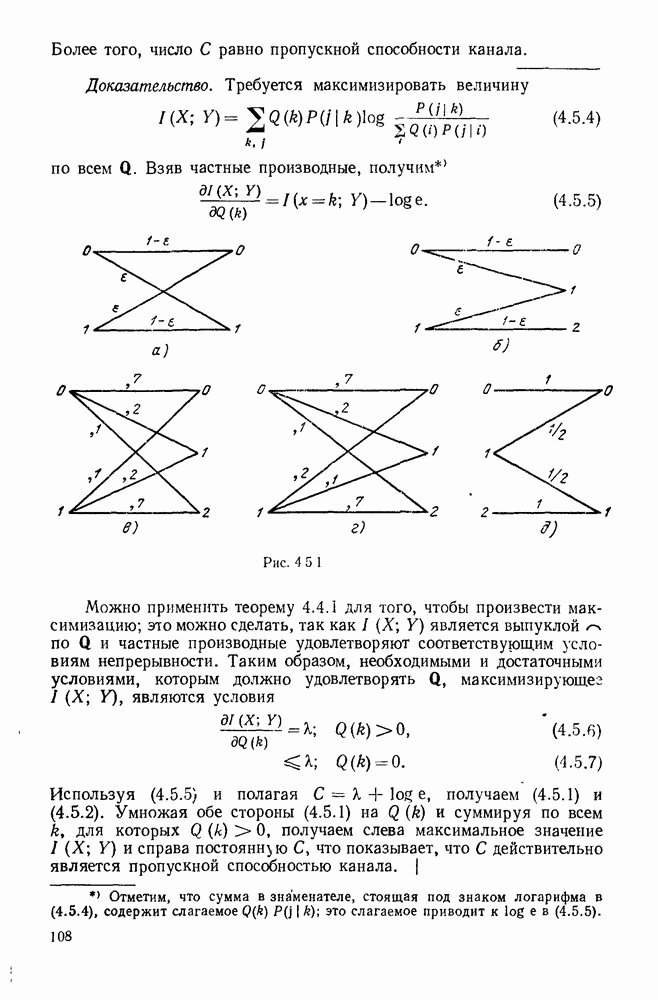
не равен 0 при всех и, множество ограничений в приведенной выше минимизации может быть пусто для малых  и в этих случаях полагаем
и в этих случаях полагаем  равной
равной  Так же как и в § 9.2, показывается, что функция
Так же как и в § 9.2, показывается, что функция  неотрицательная невозрастающая и выпуклая
неотрицательная невозрастающая и выпуклая  по
по  Скорость как функция искажения для источника определяется как
Скорость как функция искажения для источника определяется как

Следующая простая теорема утверждает, что этот предел существует, а также что для любого  значение
значение  ограничивает сверху
ограничивает сверху 
Теорема 9.8.1.

Доказательство. Пусть  произвольные положительные целые числа и для заданного
произвольные положительные целые числа и для заданного  пусть
пусть  переходные вероятности, на которых достигаются
переходные вероятности, на которых достигаются  соответственно. Рассмотрим тест-канал, по которому передаются
соответственно. Рассмотрим тест-канал, по которому передаются  символов и используется
символов и используется  для первых
для первых  символов и независимо
символов и независимо  для последних
для последних  т. е.
т. е.

Обозначим через  ансамбль первых
ансамбль первых  букв источника
букв источника  и через
и через  ансамбль последующих
ансамбль последующих  букв
букв  Аналогично, пусть
Аналогично, пусть  и
и  обозначают ансамбли первых
обозначают ансамбли первых  и последующих
и последующих  букв адресата соответственно. С помощью тех же рассуждений, как в теореме 4.2.1, имеем
букв адресата соответственно. С помощью тех же рассуждений, как в теореме 4.2.1, имеем

А также из независимости каналов вытекает [см. (9.8.5)]

Отсюда следует, что

По определению  и
и  и в силу стационарности источника правая часть (9.8.6) равна
и в силу стационарности источника правая часть (9.8.6) равна  Также из (9.8.1) вытекает, что общее среднее искажение
Также из (9.8.1) вытекает, что общее среднее искажение  символов равно общему среднему искажению первых
символов равно общему среднему искажению первых  символов, сложенному с общим средним искажением последних
символов, сложенному с общим средним искажением последних  символов. Следовательно, среднее искажение на символ для
символов. Следовательно, среднее искажение на символ для  символов не более
символов не более  является нижней границей левой части (9.8.6). Следовательно,
является нижней границей левой части (9.8.6). Следовательно,

Теорема вытекает из леммы 
Теперь легко видеть, что функция  так же как и
так же как и  не отрицательная не возрастающая с
не отрицательная не возрастающая с  и выпуклая
и выпуклая 
Обращение теоремы кодирования для источника, данное в теореме 9.2.2, применимо без изменения для источников и мер искажения, рассмотренных здесь. Однако сама теорема кодирования требует некоторых дополнительных рассмотрений. Сначала установим вспомогательный результат, который полезен сам по себе.
Теорема 9.8.2. Пусть  скорость как функция искажения первого порядка для дискретного эргодического источника с аддитивной инвариантной во времени мерой искажения. Для любого
скорость как функция искажения первого порядка для дискретного эргодического источника с аддитивной инвариантной во времени мерой искажения. Для любого  такого
такого
что  любого
любого  и любого достаточно большого
и любого достаточно большого  существует блоковый код источника длины
существует блоковый код источника длины  кодовыми словами, для которого среднее искажение на букву удовлетворяет неравенству
кодовыми словами, для которого среднее искажение на букву удовлетворяет неравенству

Для доказательства теоремы нам потребуется следующая лемма.
Лемма 9.8.1. Пусть выход  дискретного эргодического источника пропускается через дискретный канал без памяти с выходом
дискретного эргодического источника пропускается через дискретный канал без памяти с выходом  Тогда совместный процесс
Тогда совместный процесс  им,
им,  является эргодическим.
является эргодическим.
Мы опустим формальное доказательство этой леммы, обобщение которой доказано Вольфовицем (1961) (§ 10.3) и Файнстейном (1958). Идея доказательства состоит в следующем. Пусть  любая частная последовательность I букв источника и
любая частная последовательность I букв источника и  какая-либо последовательность I выходов канала. Так как источник эргодический, то относительная частота появления
какая-либо последовательность I выходов канала. Так как источник эргодический, то относительная частота появления  на всех начальных позициях в последовательности источника длины
на всех начальных позициях в последовательности источника длины  стремится к
стремится к  т. е. к вероятности
т. е. к вероятности  с вероятностью 1 при
с вероятностью 1 при  Так как канал без памяти, то относительная частота
Так как канал без памяти, то относительная частота  по тем начальным позициям, где
по тем начальным позициям, где  появляется, стремится к
появляется, стремится к  с вероятностью 1. Следовательно, относительная частота
с вероятностью 1. Следовательно, относительная частота  сходится к
сходится к  что достаточно для эргодичности.
что достаточно для эргодичности.
Доказательство теоремы. Пусть  переходная вероятностная мера, на которой достигается
переходная вероятностная мера, на которой достигается  для заданного
для заданного  и пусть
и пусть  обозначает вероятность отдельной буквы источника. Пусть
обозначает вероятность отдельной буквы источника. Пусть

Для любого  рассмотрим ансамбль кодов с
рассмотрим ансамбль кодов с  кодовыми словами, в которых каждая буква каждого кодового слова выбрана независимо с распределением вероятностей
кодовыми словами, в которых каждая буква каждого кодового слова выбрана независимо с распределением вероятностей  В любом коде из ансамбля каждая последовательность источника и отображается в кодовое слово, которое минимизирует искажение с и. Пусть
В любом коде из ансамбля каждая последовательность источника и отображается в кодовое слово, которое минимизирует искажение с и. Пусть

пусть

и определим

Заметим, что  не является взаимной информацией между
не является взаимной информацией между  при использовании источника на входе тест-канала без памяти
при использовании источника на входе тест-канала без памяти
с переходными вероятностями, задаваемыми  , так как
, так как  не является вероятностью
не является вероятностью  выхода тест-канала. Пусть
выхода тест-канала. Пусть  произвольны
произвольны  определим
определим

Пусть  вероятность А в ансамбле тест-канала. Заметим, что этот ансамбль содержит бесконечные последовательности на выходе источника, но содержит последовательности адресата
вероятность А в ансамбле тест-канала. Заметим, что этот ансамбль содержит бесконечные последовательности на выходе источника, но содержит последовательности адресата  только конечной длины. Пусть
только конечной длины. Пусть  вероятность в ансамбле кодов и ансамбле выходов источника того, что искажение (между
вероятность в ансамбле кодов и ансамбле выходов источника того, что искажение (между  и кодовым слоеом, в которое оно отображается) превысит
и кодовым слоеом, в которое оно отображается) превысит  Тогда из доказательства леммы 9.3.1 следует, что
Тогда из доказательства леммы 9.3.1 следует, что

Читателю сейчас следует просмотреть это доказательство. Существенная разница состоит в том, что  было в лемме как выходной вероятностной мерой для тест-канала, так и вероятностной мерой, с которой выбирались кодовые слова. Если заметить, что только последнее свойство было использовано в доказательстве, то становится очевидным, что здесь применимо неравенство (9.8.10).
было в лемме как выходной вероятностной мерой для тест-канала, так и вероятностной мерой, с которой выбирались кодовые слова. Если заметить, что только последнее свойство было использовано в доказательстве, то становится очевидным, что здесь применимо неравенство (9.8.10).
Теперь пусть  Как и в теореме 9.3.1, среднее искажение на букву
Как и в теореме 9.3.1, среднее искажение на букву  по ансамблю кодов удовлетворяет неравенству
по ансамблю кодов удовлетворяет неравенству

Так как  по предположению ограниченно, то теорема будет доказана, если будет показано, что
по предположению ограниченно, то теорема будет доказана, если будет показано, что  сходится к 0 при
сходится к 0 при  Как в теореме 9.3.1 последнее слагаемое в (9.8.10) стремится к 0 с возрастанием
Как в теореме 9.3.1 последнее слагаемое в (9.8.10) стремится к 0 с возрастанием  Первое слагаемое оценивается сверху выражениями
Первое слагаемое оценивается сверху выражениями

Вместе с тем, так как совместный процесс  является эргодическим, то из (3.5.13) вытекает, что с вероятностью 1
является эргодическим, то из (3.5.13) вытекает, что с вероятностью 1

Следовательно, вероятность в (9.8.13) стремится к 0 с возрастанием  Такие же рассуждения применимы к последнему слагаемому в (9.8.12), что завершает доказательство.
Такие же рассуждения применимы к последнему слагаемому в (9.8.12), что завершает доказательство.
Один из наиболее интересных аспектов предыдущей теоремы состоит в том, что как  так и ансамбль кодов, использованный в доказательстве, зависит только от меры искажения и вероятностей отдельной буквы источника. Это указывает весьма ясно, что если хороший код источника конструируется только на основе знания вероятностей отдельной буквы источника, то можно с уверенностью сказать, что любая память в источнике только уменьшит среднее искажение по отношению к тому, которое ожидается в случае источника без памяти. К сожалению, это утверждение нельзя сделать точным и не очень трудно указать примеры кодов, для которых среднее искажение источника с памятью превышает среднее искажение для источника без памяти с теми же самыми вероятностями отдельных букв.
так и ансамбль кодов, использованный в доказательстве, зависит только от меры искажения и вероятностей отдельной буквы источника. Это указывает весьма ясно, что если хороший код источника конструируется только на основе знания вероятностей отдельной буквы источника, то можно с уверенностью сказать, что любая память в источнике только уменьшит среднее искажение по отношению к тому, которое ожидается в случае источника без памяти. К сожалению, это утверждение нельзя сделать точным и не очень трудно указать примеры кодов, для которых среднее искажение источника с памятью превышает среднее искажение для источника без памяти с теми же самыми вероятностями отдельных букв.
Было показано, что для дискретного эргодического источника можно найти коды источника со скоростями, произвольно близкими к  и со средними искажениями на букву, сколь угодно близкими к
и со средними искажениями на букву, сколь угодно близкими к  Перейдем теперь к изложению более сильного результата, когда
Перейдем теперь к изложению более сильного результата, когда  может быть заменена на
может быть заменена на  Путь доказательства заключается в том, что сначала выбирается
Путь доказательства заключается в том, что сначала выбирается  достаточно большим, так чтобы
достаточно большим, так чтобы  было близко к
было близко к  Затем рассматриваются последовательности из
Затем рассматриваются последовательности из  букв источника как единые буквы «суперисточника», который порождает одну букву каждые
букв источника как единые буквы «суперисточника», который порождает одну букву каждые  единиц времени. Затем применим предыдущую теорему к этому суперисточнику и после соответствующей нормировки по
единиц времени. Затем применим предыдущую теорему к этому суперисточнику и после соответствующей нормировки по  получим требуемый результат. Имеется небольшая трудность в этой процедуре: суперисточник не обязательно будет эргодическим. Чтобы обойти ее, сначала покажем, что суперисточник может быть разбит не более чем на
получим требуемый результат. Имеется небольшая трудность в этой процедуре: суперисточник не обязательно будет эргодическим. Чтобы обойти ее, сначала покажем, что суперисточник может быть разбит не более чем на  «эргодических компонент» и затем применим предыдущую теорему в каждой компоненте отдельно.
«эргодических компонент» и затем применим предыдущую теорему в каждой компоненте отдельно.
Предположим теперь, что дискретный эргодический источник имеет алфавит объема К и рассмотрим суперисточник  порядка с алфавитом объема
порядка с алфавитом объема  где каждая буква суперисточника является последовательностью
где каждая буква суперисточника является последовательностью  букв первоначального источника. Каждой последовательности
букв первоначального источника. Каждой последовательности  первоначального источника соответствует последовательность
первоначального источника соответствует последовательность  суперисточника, где
суперисточника, где  Обозначим это соответствие между последовательностями первоначального источника и суперисточника в виде
Обозначим это соответствие между последовательностями первоначального источника и суперисточника в виде  Так как сдвиг на
Так как сдвиг на  единиц времени в первоначальном источнике соответствует сдвигу на одну единицу времени для суперисточника, то имеем
единиц времени в первоначальном источнике соответствует сдвигу на одну единицу времени для суперисточника, то имеем  и для
и для  Аналогично, любое множество
Аналогично, любое множество  последовательностей первоначального источника соответствует множеству
последовательностей первоначального источника соответствует множеству  суперисточника и
суперисточника и  Напомним, что, как указано в § 3.5, инвариантное множество
Напомним, что, как указано в § 3.5, инвариантное множество  является множеством, для которого
является множеством, для которого  и что источник эргодический тогда и только тогда, когда любое измеримое инвариантное множество имеет вероятность 1 или 0.
и что источник эргодический тогда и только тогда, когда любое измеримое инвариантное множество имеет вероятность 1 или 0.
Предположим теперь, что  — инвариантное множество последовательностей суперисточника и что его вероятность
— инвариантное множество последовательностей суперисточника и что его вероятность  больше 0. Соответствующее множество
больше 0. Соответствующее множество  первоначального источника имеет вероятность
первоначального источника имеет вероятность  и удовлетворяет равенству
и удовлетворяет равенству  Определим множества
Определим множества  равенствами
равенствами

Так как источник стационарный, то  для
для  Пусть теперь множество А является объединением множеств
Пусть теперь множество А является объединением множеств  Тогда имеем
Тогда имеем

Поскольку  то это сводится к равенству
то это сводится к равенству  Так как источник эргодический и
Так как источник эргодический и  то должно быть
то должно быть  следовательно,
следовательно,  Таким образом, показано, что каждое измеримое инвариантное множество для суперисточника имеет вероятность 0 или вероятность, не меньшую
Таким образом, показано, что каждое измеримое инвариантное множество для суперисточника имеет вероятность 0 или вероятность, не меньшую 
Далее предположим, что  инвариантное множество последовательностей суперисточника и что В — инвариантное подмножество
инвариантное множество последовательностей суперисточника и что В — инвариантное подмножество  Пусть
Пусть  последовательности, содержащиеся в
последовательности, содержащиеся в  но не содержащиеся в В, заметим, что
но не содержащиеся в В, заметим, что  так что
так что  также инвариантное подмножество
также инвариантное подмножество  Из предыдущего результата следует, что
Из предыдущего результата следует, что  Если теперь представить, что В играет роль
Если теперь представить, что В играет роль  и повторить приведенные выше рассуждения, то увидим, что постепенно мы должны попасть в
и повторить приведенные выше рассуждения, то увидим, что постепенно мы должны попасть в  которое не имеет инвариантного подмножества В с
которое не имеет инвариантного подмножества В с  Будем называть такое
Будем называть такое  эргодической компонентой суперисточника. Источник, который порождает супербуквы в соответствии с условной вероятностной мерой
эргодической компонентой суперисточника. Источник, который порождает супербуквы в соответствии с условной вероятностной мерой  при условии, что задано
при условии, что задано  является, очевидно, эргодическим источником, так как при условии, что задано
является, очевидно, эргодическим источником, так как при условии, что задано  каждое инвариантное подмножество
каждое инвариантное подмножество  имеет вероятность 0 или 1.
имеет вероятность 0 или 1.
Пусть теперь  пусть
пусть  и пусть
и пусть  Каждое
Каждое  должно также образовывать эргодическую компоненту суперисточника, т. е. если
должно также образовывать эргодическую компоненту суперисточника, т. е. если  подмножество
подмножество  то для соответствующего множества
то для соответствующего множества  первоначального источника имеем
первоначального источника имеем  Положив, что
Положив, что  получаем, что
получаем, что  подмножество
подмножество  Следовательно,
Следовательно,  подмножество
подмножество  Так как
Так как  то будет или
то будет или  или
или  Наконец, рассмотрим пересечение
Наконец, рассмотрим пересечение  Это пересечение является инвариантным множеством и является подмножеством как множества
Это пересечение является инвариантным множеством и является подмножеством как множества  так и множества
так и множества  Таким образом, или
Таким образом, или  или
или  В последнем случае
В последнем случае  одни и те же множества (исключая, быть может, разность вероятности нуль). Легко видеть, что если
одни и те же множества (исключая, быть может, разность вероятности нуль). Легко видеть, что если  совпадают, то совпадают
совпадают, то совпадают  где
где  взяты по модулю
взяты по модулю  Отсюда легко следует, что число различных эргодических компонент, скажем
Отсюда легко следует, что число различных эргодических компонент, скажем  является делителем
является делителем  и что в качестве эргодических компонент могут быть взяты
и что в качестве эргодических компонент могут быть взяты  В этом случае каждая эргодическая компонента имеет вероятность
В этом случае каждая эргодическая компонента имеет вероятность  В случае, представляющем наибольший физический интерес,
В случае, представляющем наибольший физический интерес,  и суперисточник с самого начала эргодический.
и суперисточник с самого начала эргодический.
Следующая лемма подытоживает результаты.
Лемма 9. 8. 2. Рассмотрим суперисточник  порядка, буквы которого — последовательности из
порядка, буквы которого — последовательности из  букв дискретного эргодического источника. Множество последовательностей суперисточника может быть разбито на
букв дискретного эргодического источника. Множество последовательностей суперисточника может быть разбито на  эргодических компонент, каждая из которых имеет вероятность
эргодических компонент, каждая из которых имеет вероятность  где
где  является делителем
является делителем  Компоненты не пересекаются, за исключением, быть может, множеств вероятности нуль. Множества последовательностей
Компоненты не пересекаются, за исключением, быть может, множеств вероятности нуль. Множества последовательностей  первоначального источника, соответствующие этим эргодическим компонентам, можно связать соотношениями
первоначального источника, соответствующие этим эргодическим компонентам, можно связать соотношениями 
В качестве примера рассмотрим двоичный источник, для которого выход образован парами одних и тех же символов. С вероятностью 1/2 каждый символ на четной позиции получается в результате независимого равновероятного выбора символов алфавита, а каждый символ с нечетным номером совпадает с предыдущим символом с четным номером. Аналогично с вероятностью 1/2 каждый символ с нечетным номером получается в результате независимого равновероятного выбора символов, а каждый символ с четным номером совпадает с предыдущим символом с нечетным номером. Это эргодический источник, однако суперисточник второго порядка имеет две компоненты. На одной компоненте суперисточник не имеет памяти и порождает 00 с вероятностью 1/2 и 11 с вероятностью 1/2 .На второй компоненте все четыре пары символов равновероятны, однако последний символ любой пары совпадает с первым символом следующей пары. Очевидно,  в этом примере выход какой-либо компоненты (в символах первоначального источника) статистически эквивалентен выходу другой компоненты, сдвинутой во времени на один символ.
в этом примере выход какой-либо компоненты (в символах первоначального источника) статистически эквивалентен выходу другой компоненты, сдвинутой во времени на один символ.
Как было показано, вообще суперисточник  порядка, соответствующий эргодическому источнику, может быть разбит на
порядка, соответствующий эргодическому источнику, может быть разбит на 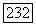 эргодических компонент, где
эргодических компонент, где 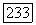 является делителем
является делителем 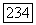 В последующем изложении удобно рассматривать их как
В последующем изложении удобно рассматривать их как 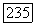 эргодических компонент, где только
эргодических компонент, где только 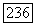 среди них различны. Определим суперисточник
среди них различны. Определим суперисточник 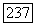 фазы
фазы 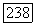 как источник, который порождает последовательности из
как источник, который порождает последовательности из 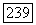 в соответствии с первоначальной вероятностной мерой на последовательностях супербукв при условии наступления
в соответствии с первоначальной вероятностной мерой на последовательностях супербукв при условии наступления 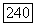 Тогда для
Тогда для 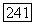 суперисточники
суперисточники 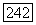 фаз и т. д. тождественны. Первоначальный суперисточник моделируется как совокупность
фаз и т. д. тождественны. Первоначальный суперисточник моделируется как совокупность 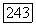 эргодических суперисточников, каждый из которых используется во всей бесконечной последовательности с вероятностью
эргодических суперисточников, каждый из которых используется во всей бесконечной последовательности с вероятностью 
Используем теперь эту модель в конструкции кодов эргодического источника. Для заданного 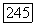 пусть
пусть 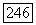 -скорость как функция искажения
-скорость как функция искажения 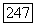 порядка и для заданного
порядка и для заданного 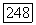 пусть
пусть 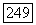 Ил) обозначает множество переходных вероятностей, на которых достигается
Ил) обозначает множество переходных вероятностей, на которых достигается 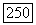 В терминах суперисточника
В терминах суперисточника 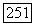 порядка
порядка 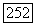 является единичной буквой
является единичной буквой 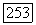 и аналогично можно рассматривать
и аналогично можно рассматривать 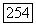 как отдельную букву
как отдельную букву  в супералфавите последовательностей
в супералфавите последовательностей 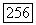 букв адресата. Полагая, что
букв адресата. Полагая, что 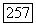 ансамбль отдельных супербукв и
ансамбль отдельных супербукв и 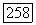 ансамбль отдельных супербукв адресата, определяемый
ансамбль отдельных супербукв адресата, определяемый 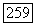
имеем

Аналогично

где 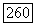 определяется равенством
определяется равенством 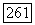 и неравенство возникает из-за возможности
и неравенство возникает из-за возможности 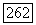
Пусть теперь 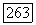 средняя взаимная информация между супербуквой суперисточника
средняя взаимная информация между супербуквой суперисточника 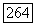 фазы,
фазы, 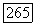 и буквой супералфавита адресата при использовании переходных вероятностей
и буквой супералфавита адресата при использовании переходных вероятностей 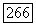 Так как средняя взаимная информация в канале — выпуклая
Так как средняя взаимная информация в канале — выпуклая 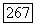 функция входных вероятностей, то
функция входных вероятностей, то

Аналогично среднее значение 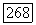 является линейной функцией вероятностной меры на и, так что
является линейной функцией вероятностной меры на и, так что

где 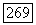 среднее значение
среднее значение 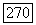 для суперисточника
для суперисточника 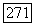 фазы.
фазы.
Заметим теперь, что 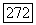 является верхней границей для скорости как функции искажения первого порядка для суперисточника
является верхней границей для скорости как функции искажения первого порядка для суперисточника 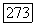 фазы, вычисленной при среднем искажении
фазы, вычисленной при среднем искажении 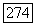 Так как суперисточник
Так как суперисточник 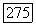 фазы является эргодическим, то теорема 9.8.2 применима и для любого
фазы является эргодическим, то теорема 9.8.2 применима и для любого 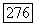 при любом достаточно большом
при любом достаточно большом 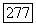 имеется множество
имеется множество 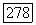 кодовых слов длины
кодовых слов длины 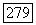 (супербукв), для которых среднее искажение на супербукву для этого источника не больше
(супербукв), для которых среднее искажение на супербукву для этого источника не больше 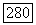 Для заданного
Для заданного 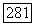 пусть
пусть 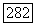 достаточно велико, так что для каждой из
достаточно велико, так что для каждой из 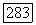 фаз такой код может быть выбран, и рассмотрим это множество из
фаз такой код может быть выбран, и рассмотрим это множество из  кодов.
кодов.
Удобно представлять себе кодовые слова в этих кодах не как последовательности 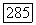 супербукв, а как последовательности
супербукв, а как последовательности 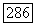 букв первоначального алфавита адресата. Будем рассматривать такой
букв первоначального алфавита адресата. Будем рассматривать такой  код, выбранный выше для суперисточника
код, выбранный выше для суперисточника  фазы, как
фазы, как  малый код. Используем теперь эти
малый код. Используем теперь эти  малых кодов для построения нового множества
малых кодов для построения нового множества  больших кодов с длиной блока
больших кодов с длиной блока  как показано на рис. 9.8.1. Построенный
как показано на рис. 9.8.1. Построенный 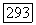 большой код,
большой код, 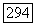 кодирует выход суперисточника
кодирует выход суперисточника 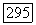 фазы. Как показано на рис. 9.8.1, для каждого
фазы. Как показано на рис. 9.8.1, для каждого 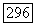 множество букв на позициях от
множество букв на позициях от 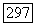 до
до 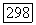 является произвольным кодовым словом из
является произвольным кодовым словом из 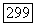 малого кода, где
малого кода, где 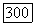 берется по модулю
берется по модулю  Буквы на позициях
Буквы на позициях  являются фиксированными буквами алфавита адресата. Таким образом, общее число кодовых слов
являются фиксированными буквами алфавита адресата. Таким образом, общее число кодовых слов
в  -м большом коде равно
-м большом коде равно  где
где  число кодовых слов в
число кодовых слов в  -м малом коде. Напомним теперь, что из леммы 9.8.2 следует, что если
-м малом коде. Напомним теперь, что из леммы 9.8.2 следует, что если  множество последовательностей букв первоначального алфавита источника, порожденное суперисточником
множество последовательностей букв первоначального алфавита источника, порожденное суперисточником  фазы, то
фазы, то  Отсюда следует, что для суперисточника
Отсюда следует, что для суперисточника  фазы вероятностная мера на буквах позиций от
фазы вероятностная мера на буквах позиций от  до
до  такая же, как для суперисточника
такая же, как для суперисточника  фазы на позициях от 1 до
фазы на позициях от 1 до  Следовательно, среднее искажение на букву между суперисточником
Следовательно, среднее искажение на букву между суперисточником  фазы и
фазы и  большим кодом на позициях
большим кодом на позициях  до
до  составляет
составляет  часть среднего искажения на супербукву между суперисточником фазы и малым кодом (где взята по модулю ).
часть среднего искажения на супербукву между суперисточником фазы и малым кодом (где взята по модулю ).

Рис. 9.8.1. Конструирование большого кода из малого кода;
Выберем малые коды так, чтобы среднее искажение на букву было ограничено сверху выражением Замечая, что искажение между каждой из фиксированных позиций в коде и источником ограничено сверху находим, что среднее искажение на букву между суперисточником и большим кодом ограничено сверху выражением

Можно дальше построить границу сверху, уменьшая знаменатель до и применяя (9.8.18) и (9.8.20), в результате получим

Следовательно, для достаточно больших среднее искажение на букву между суперисточником фазы и большим кодом ограничено сверху где произвольно.
Если все кодовые слова этих больших кодов объединить в один код, то независимо от того, какой эргодический суперисточник действует, среднее искажение на букву будет не больше Общее число кодовых слов равно

Таким образом показано, что для любого любого и достаточно большого можно найти коды длины с

и средним искажением на букву, меньшим или равным Кроме того, очевидно, ограничение, состоящее в том, что длина блока должна иметь вид не является необходимым, так как для блока любой достаточно большой длины V можно найти наибольшее такое, что далее для этого найти код, удовлетворяющий (9.8.22) и (9.8.23), и затем добавить последовательность, содержащую не более фиксированных символов, к концу каждого кодового слова. Среднее искажение на букву возрастает, таким образом, не более чем на что для больших пренебрежимо мало. Наконец, так как может быть выбрано достаточно большим, так чтобы было сколь угодно близко к то тем самым доказана следующая фундаментальная теорема.
Теорема 9.8.3. Пусть скорость как функция искажения для дискретного эргодического источника с аддитивной инвариантной во времени мерой искажения. Для любого любого и достаточно больших существует блоковый код источника длины кодовыми словами и средним искажением на букву, не большим
При желании терпеливый и настойчивый читатель может соединить метод доказательства этой теоремы с результатами § 9.3 и 9.6 и снять как условие, что ограничено, так и условие, что источник дискретный.