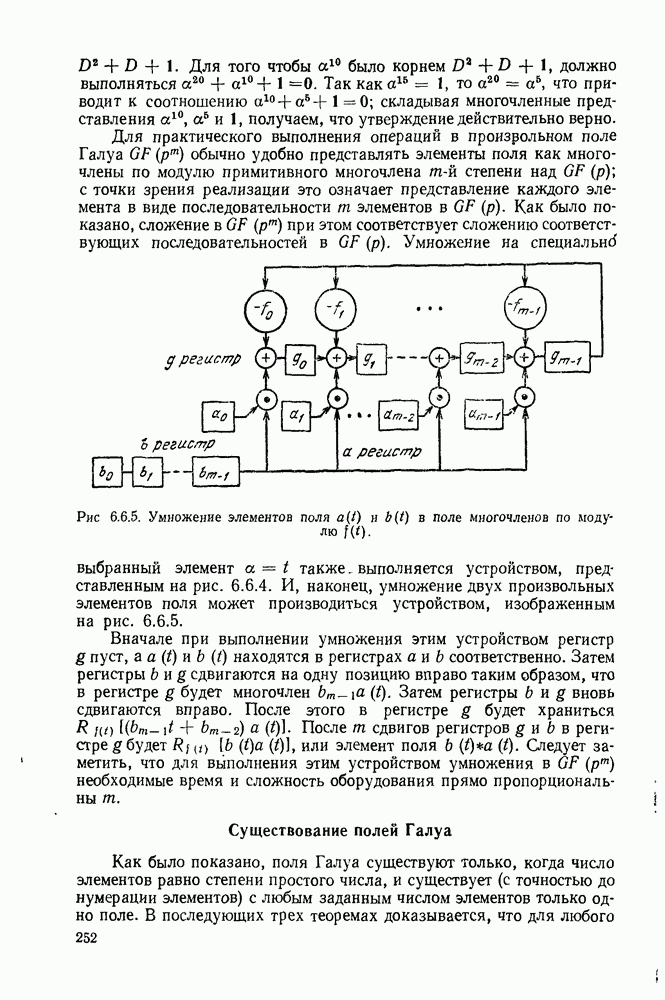
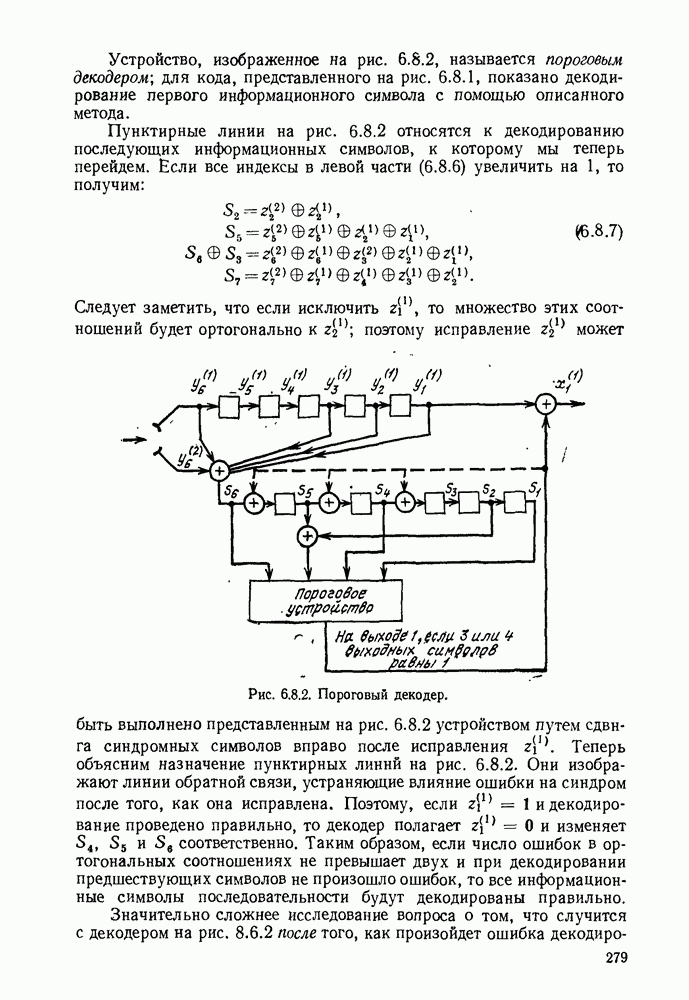
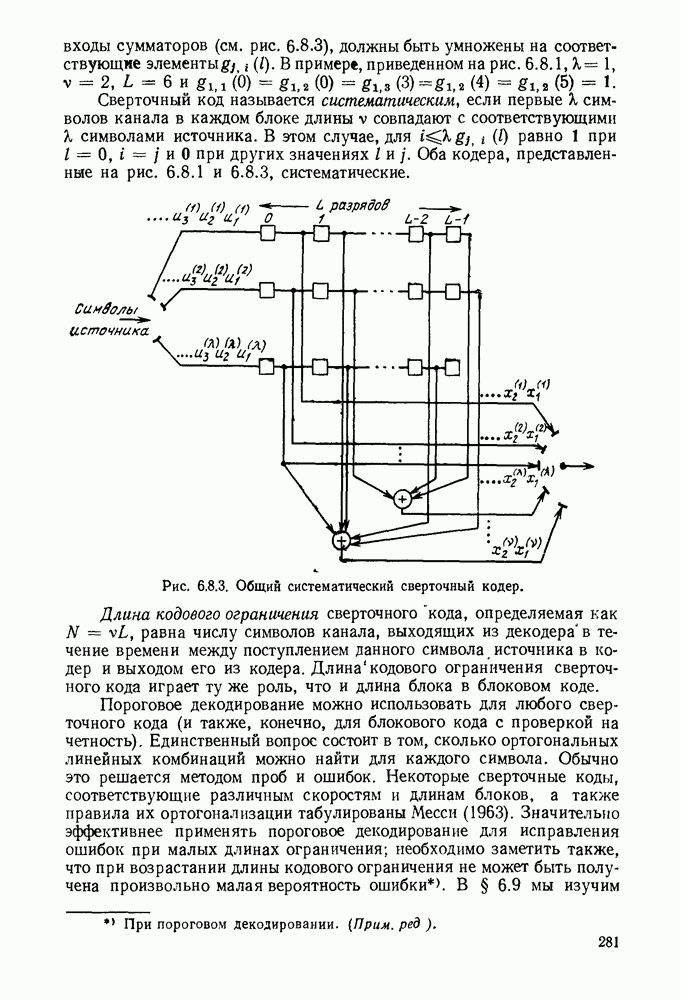
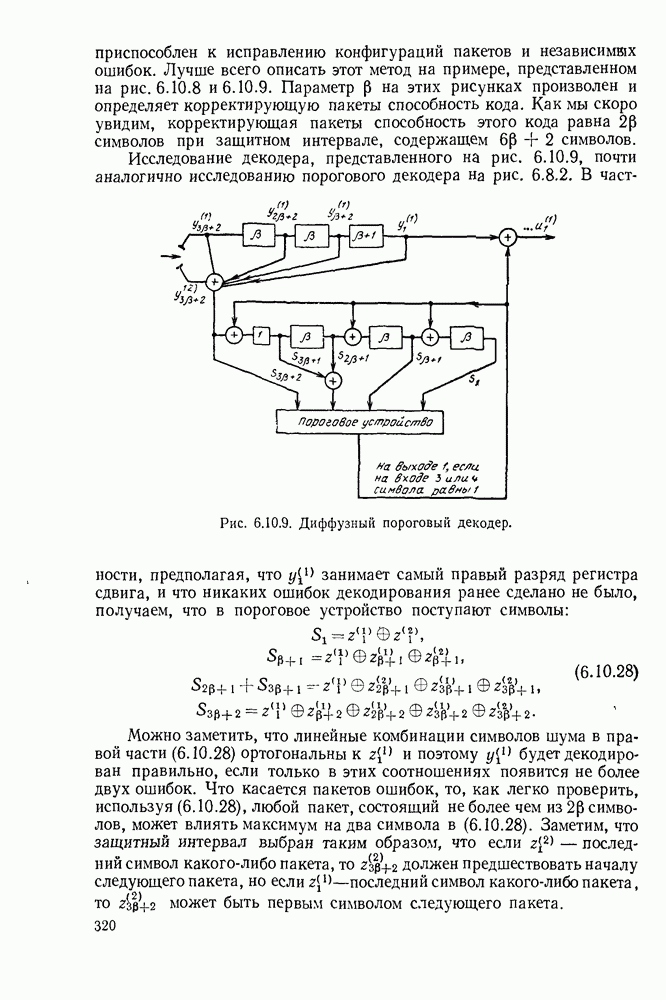
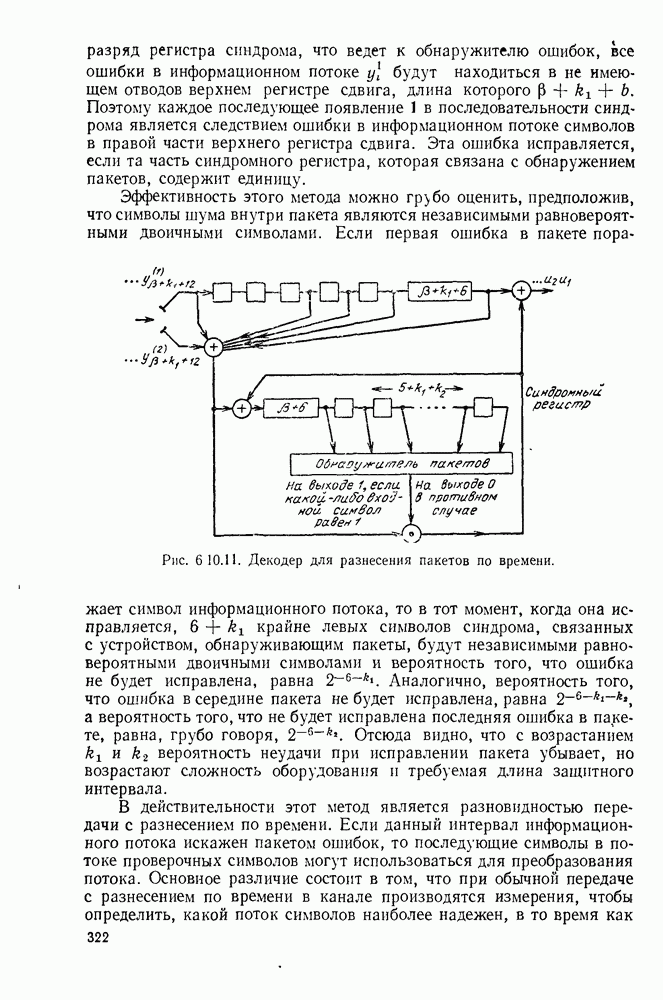
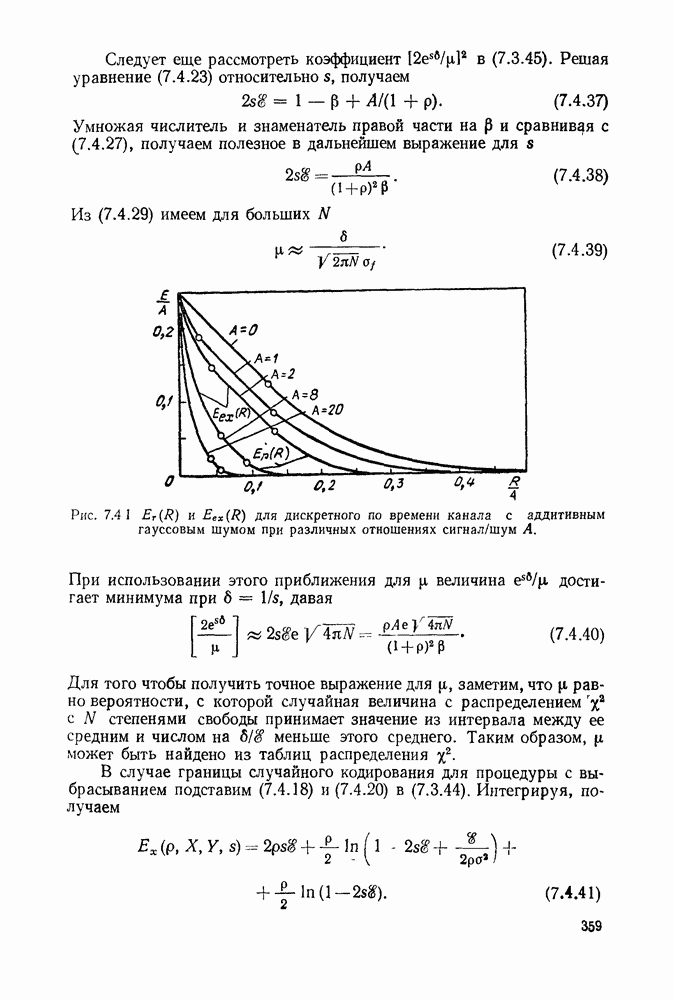
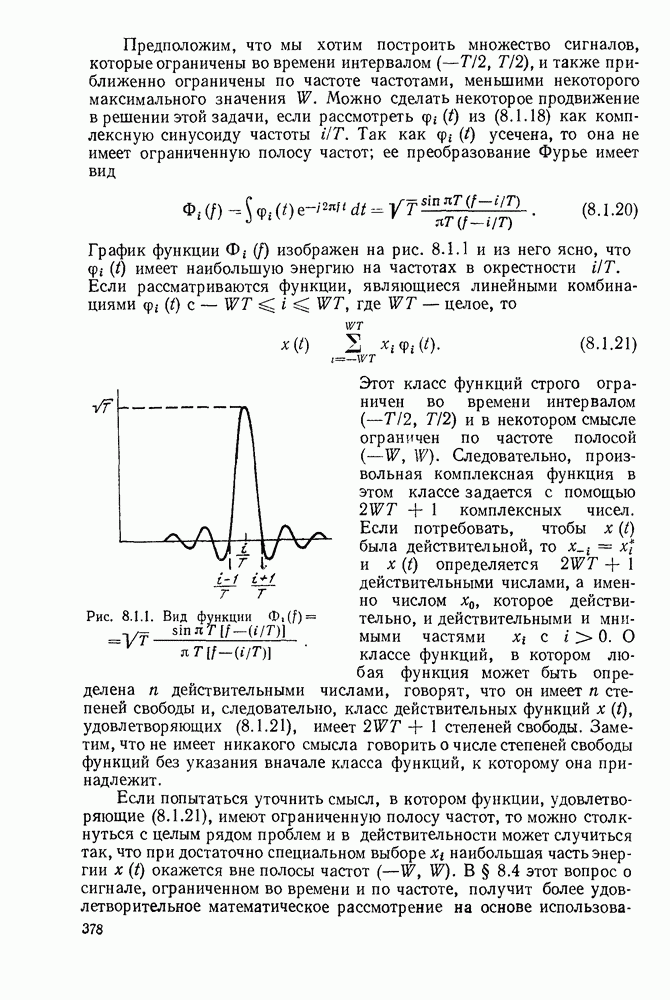
6.9. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕ
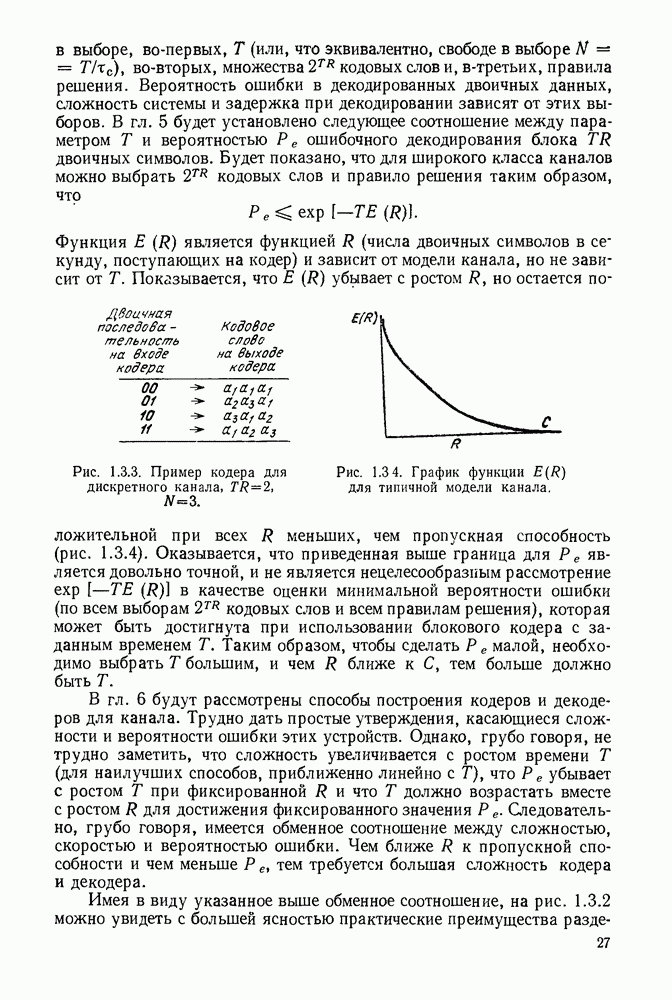
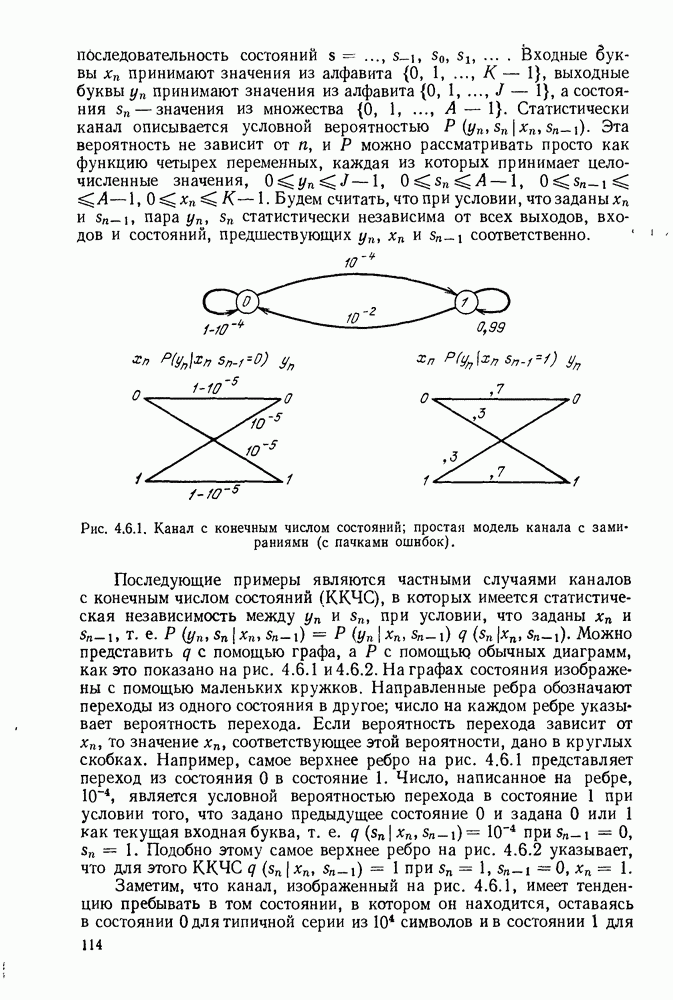
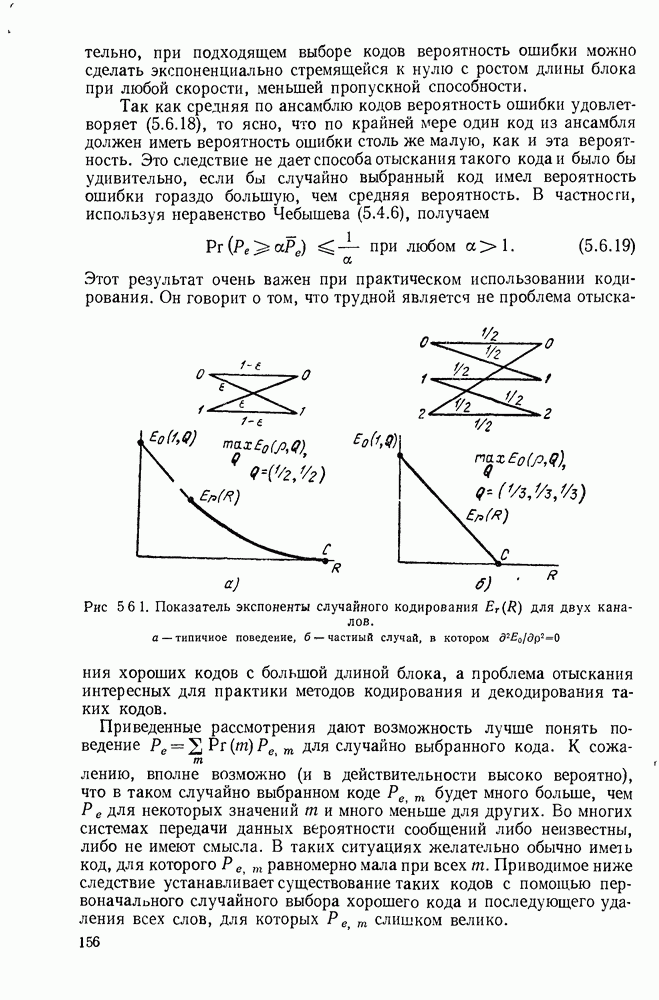
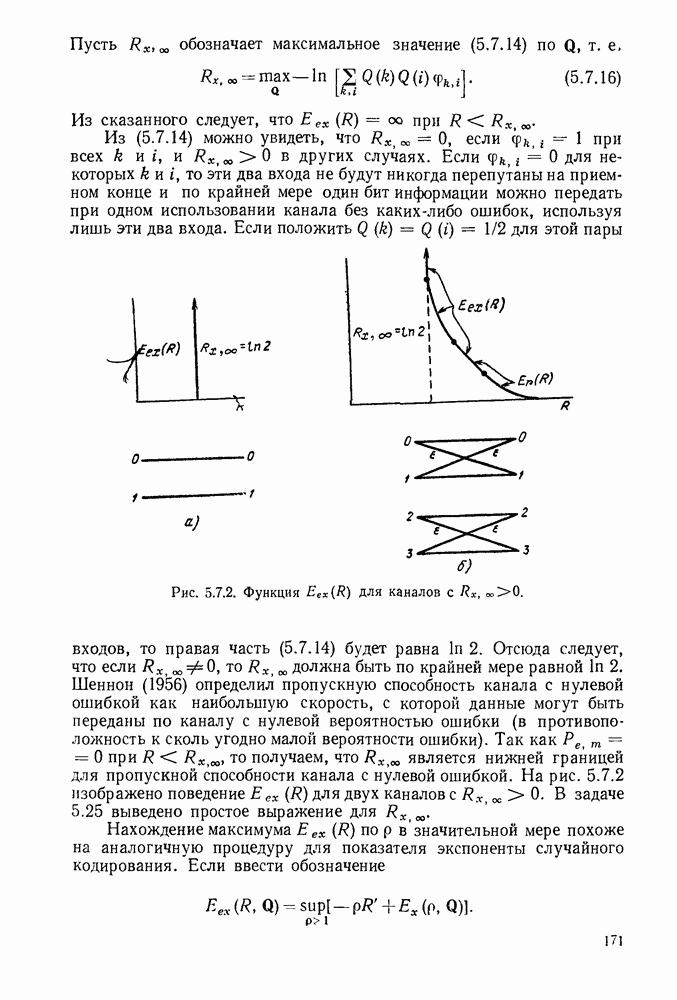
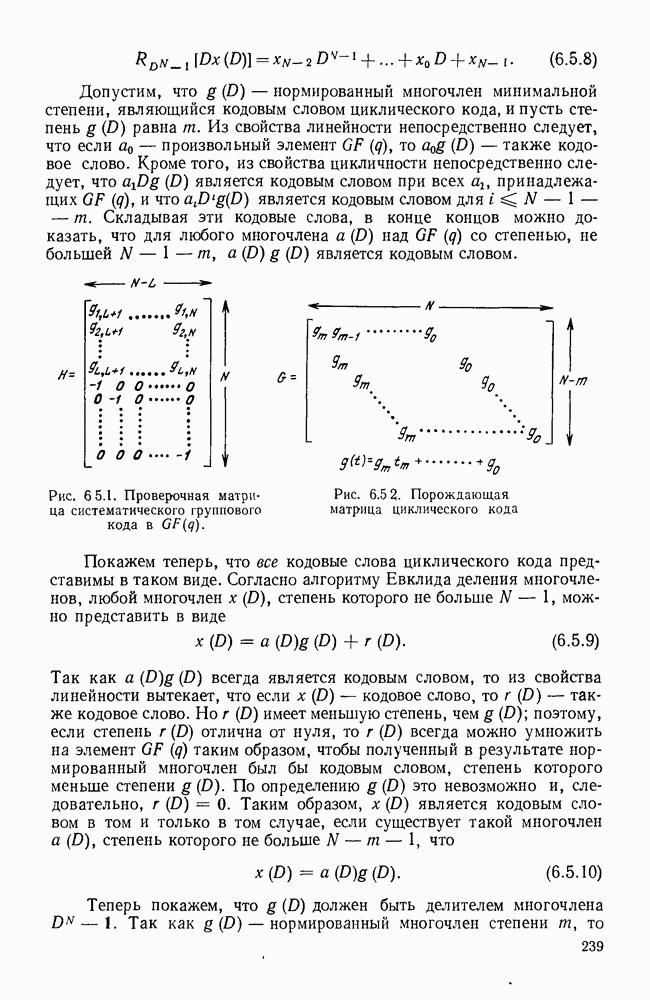
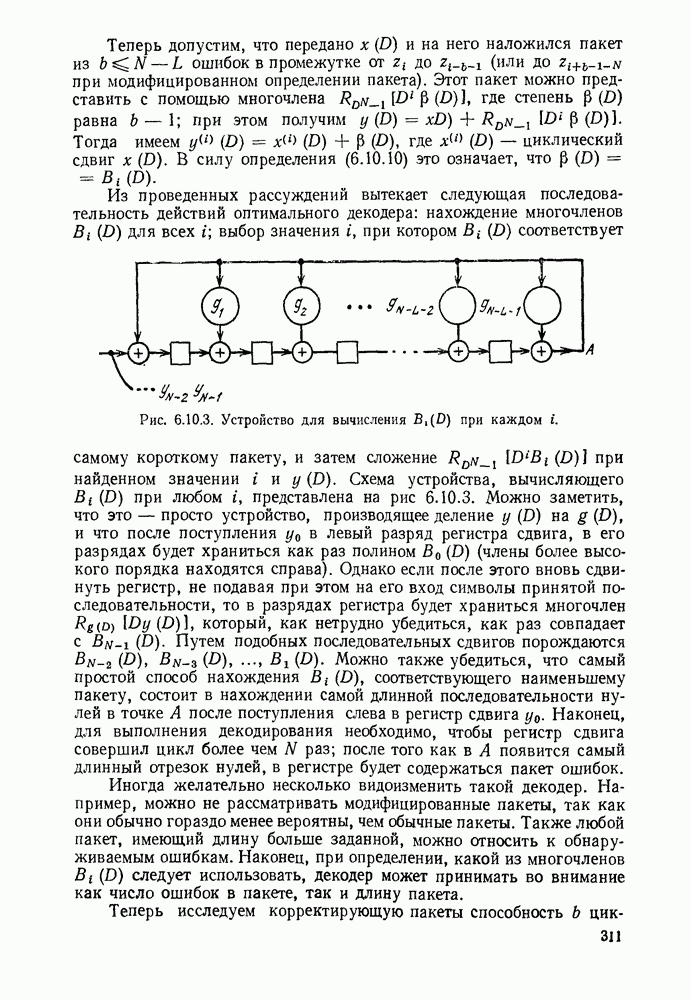
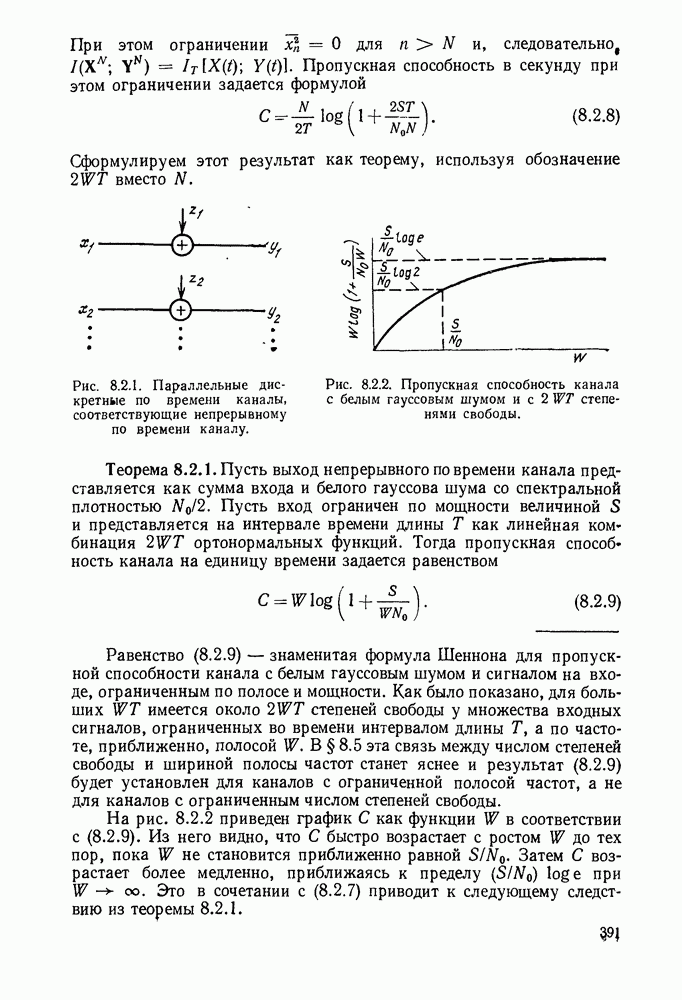
Идею последовательного декодирования можно лучше всего понять на следующем простом примере. Рассмотрим двоичный сверточный кодер, схема которого представлена на рис. 6.9.1. Как обычно, предполагается, что до поступления первого символа источника их он содержит лишь нули. Первые три символа канала  полностью определяются значением
полностью определяются значением 

Рис. 6.9.1. Пример сверточного кода.
Следующие за ними три символа канала являются функциями обоих символов  а последующие три символа — функции
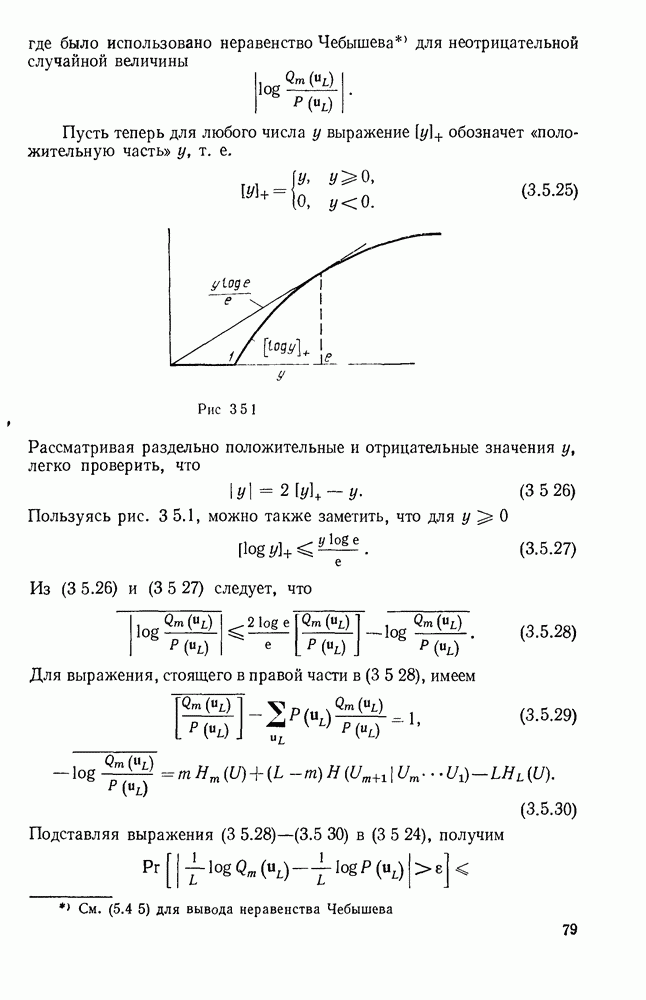
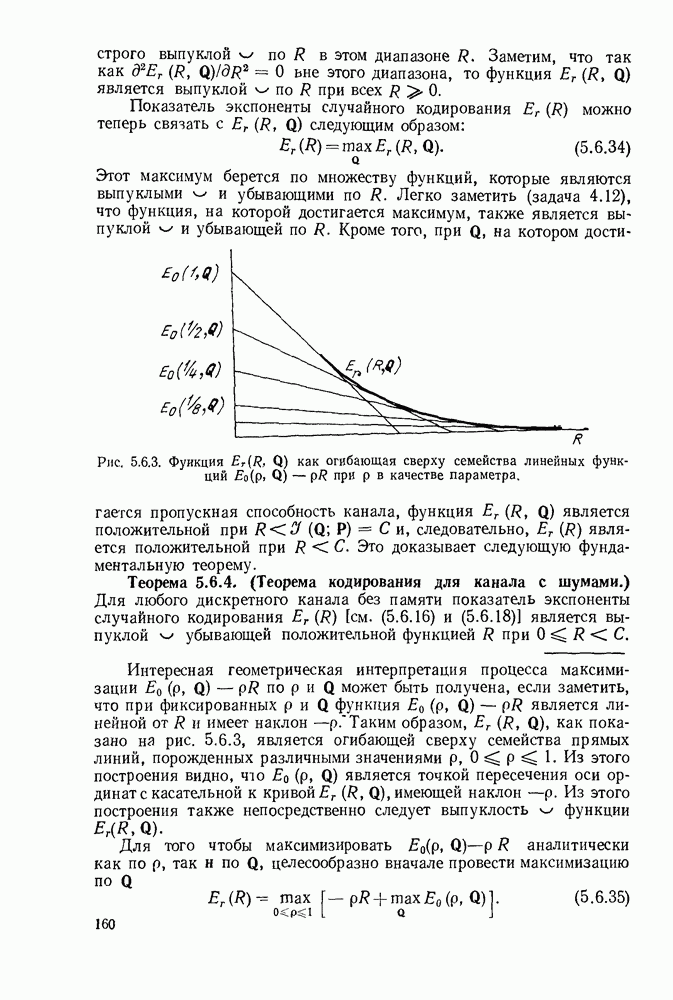
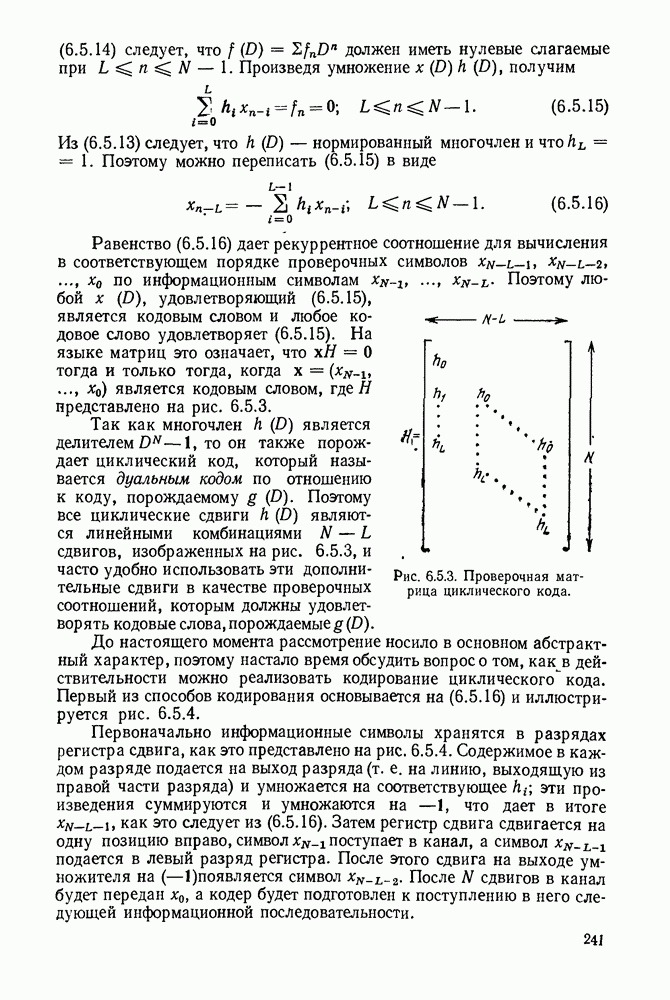
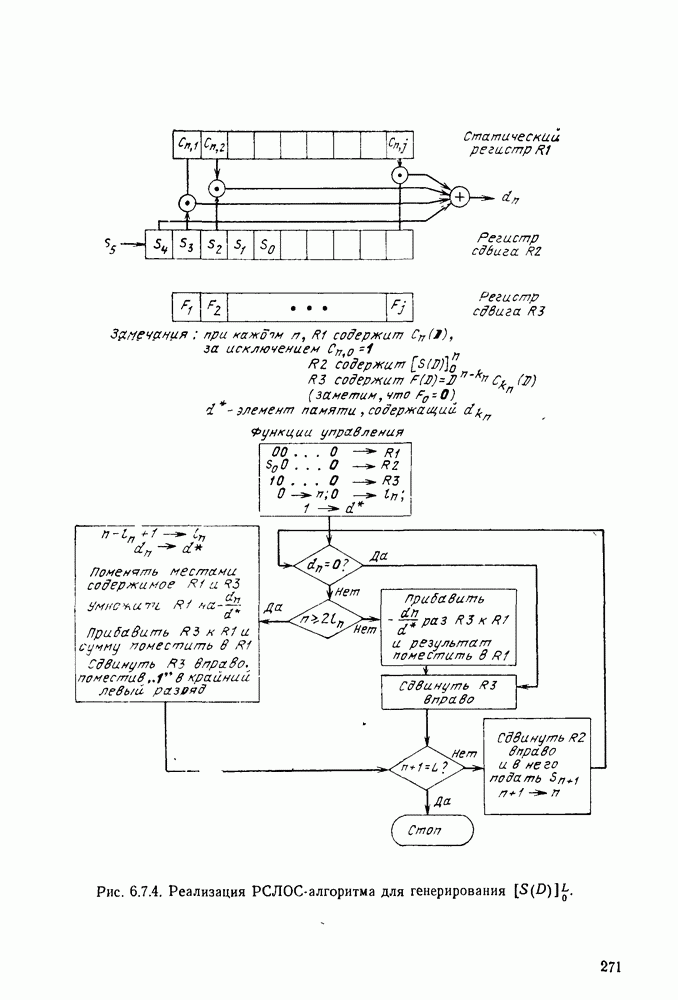
а последующие три символа — функции  Эта зависимость объясняется древовидной структурой множества кодовых последовательностей в канале, выявляемой из рассмотрения рис. 6.9.2.
Эта зависимость объясняется древовидной структурой множества кодовых последовательностей в канале, выявляемой из рассмотрения рис. 6.9.2.
Крайние слева тройки двоичных символов на рис. 6.9.2 соответствуют отклику кодера на поступление в него первого символа 1, или 0. Отходящие вправо от множества 111, соответствующего отклику кодера на поступление в него первого символа 1, тройки символов являются откликами на поступление вслед за первой 1 новой 1 или 0, и т. д. Например, пунктиром на рис. 6.9.2 обозначен отклик кодера на поступление 
Исследуем теперь качественно, как можно использовать при декодировании эту древовидность структуры. Позднее мы определим последовательное декодирование формально, развивая довольно простой по смыслу подход, который будет сейчас рассмотрен.
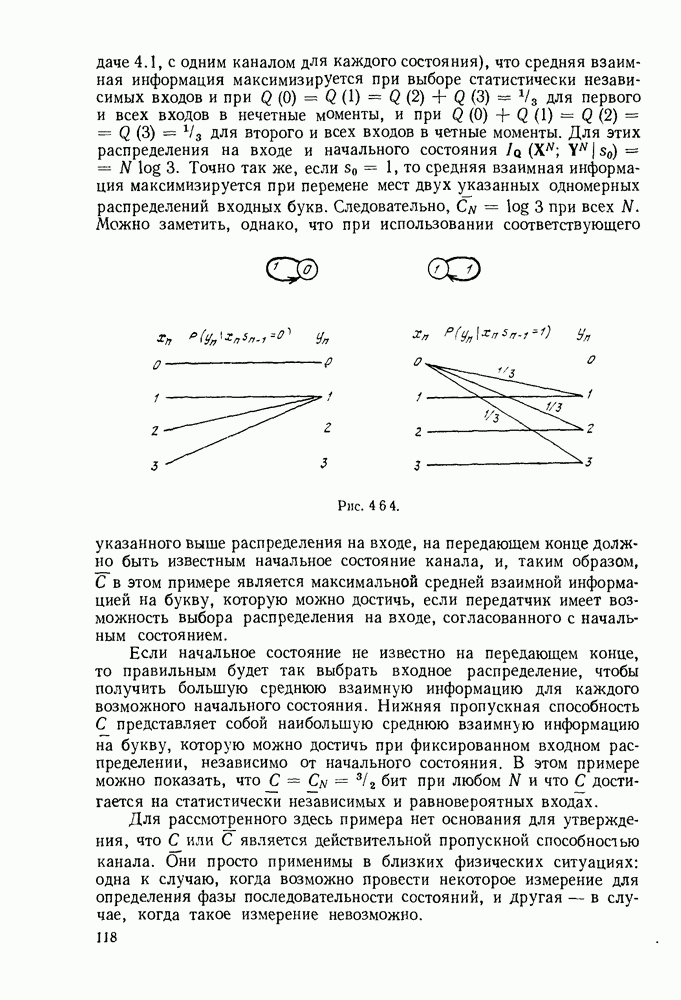
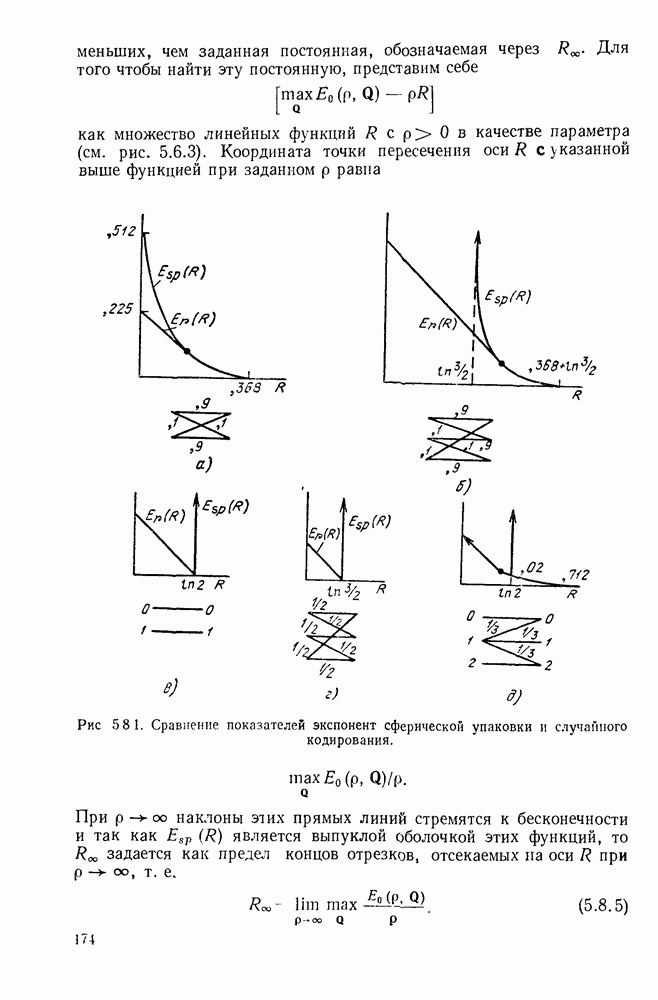
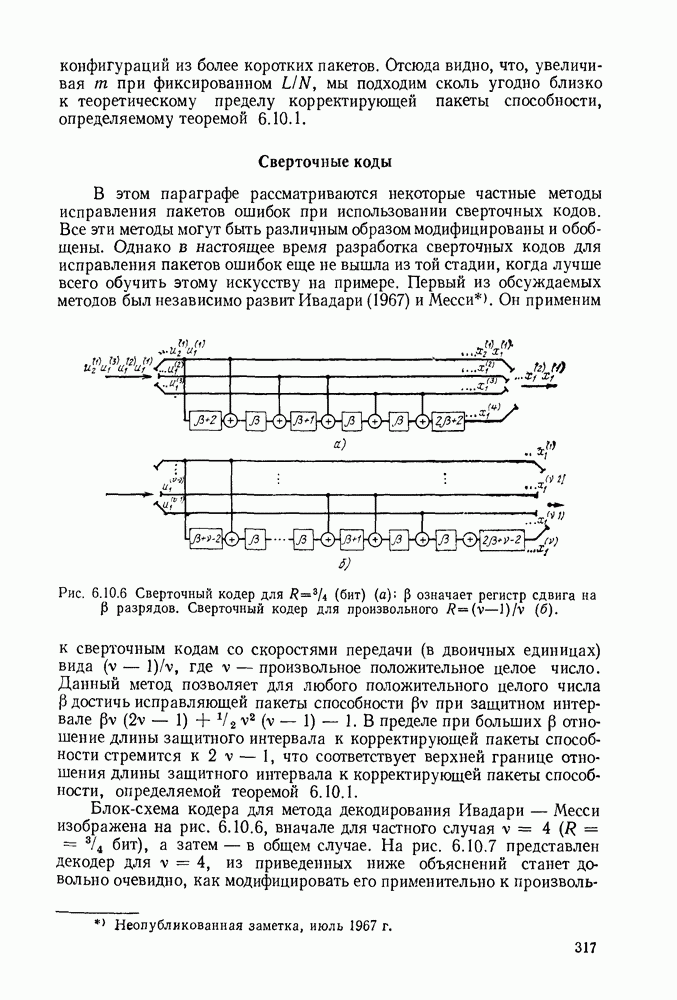
Допустим, что кодер, представленный на рис. 6.9.1, используется в двоичном симметричном канале и что первыми двенадцатью символами принятой последовательности являются 101 101 001 000. Из рассмотрения дерева на рис. 6.9.2 видно, что первая тройка переданных символов может быть либо 111, либо 000. Поэтому, основываясь на первой тройке принятых символов, мы можем попробовать принять
гипотезу, что передано множество 111, соответствующее верхнему разветвлению первого ребра дерева. Пусть принята эта гипотеза; тогда следующие три символа должны быть символами одной из двух верхних троек символов, обозначенных на рис. 6.9.2 как  Очевидно, что предпочтительнее принятие гипотезы 101, соответствующей верхнему разветвлению. Продолжая таким же образом, мы принимаем гипотезу, что третья тройка переданных символов равна 001, а четвертая 000.
Очевидно, что предпочтительнее принятие гипотезы 101, соответствующей верхнему разветвлению. Продолжая таким же образом, мы принимаем гипотезу, что третья тройка переданных символов равна 001, а четвертая 000.

Рис. 6 9.2. Древовидная структура сверточного кода.
Этим гипотезам соответствует пунктирная линия на рис. 6.9.2. Метод, который был продемонстрирован — это, по существу, декодирование символ за символом, при котором выбор гипотезы при декодировании тройки символов используется для уменьшения числа возможных выборов при декодировании последующей тройки. В рассмотренном примере совпадение всех, начиная с третьего, символов последовательности, которую мы на основании нашей гипотезы считаем переданной, с символами принятой последовательности подтверждает, что принятые ранее гипотезы правильны.
Теперь рассмотрим второй пример, который иллюстрирует, что случится, если была принята неправильная гипотеза. Предположим, что передана та же самая первоначальная последовательность 111 101
 но принята последовательность
но принята последовательность  Декодер, которому не известно, что было передано, принимает гипотезу, что первые три переданные символа равны 000, что соответствует нижнему ребру, выходящему из первой точки ветвления. Две следующие принятые гипотезы тогда соответствуют символам 111 и 101. Из этих первых девяти символов последовательности, которую мы считаем переданной, три символа не совпадают с символами принятой последовательности. Случившееся является следствием того, что декодер, приняв однажды неправильную гипотезу, вынужден выбирать последующие гипотезы среди последовательностей, не имеющих отношения к принятой последовательности. Поэтому в конце концов декодер, как правило, способен распознать, что он, по-видимому, принял неправильную гдпотезу. Тогда можно вернуться назад, проверить альтернативные гипотезы, после чего, вероятно, декодирование будет правильным. Таким образом, принятие каждой гипотезы упрощает дальнейший процесс проверки гипотез путем уменьшения числа возможных выборов и в то же время дает дополнительные данные для проверки правильности ранее принятых гипотез.
Декодер, которому не известно, что было передано, принимает гипотезу, что первые три переданные символа равны 000, что соответствует нижнему ребру, выходящему из первой точки ветвления. Две следующие принятые гипотезы тогда соответствуют символам 111 и 101. Из этих первых девяти символов последовательности, которую мы считаем переданной, три символа не совпадают с символами принятой последовательности. Случившееся является следствием того, что декодер, приняв однажды неправильную гипотезу, вынужден выбирать последующие гипотезы среди последовательностей, не имеющих отношения к принятой последовательности. Поэтому в конце концов декодер, как правило, способен распознать, что он, по-видимому, принял неправильную гдпотезу. Тогда можно вернуться назад, проверить альтернативные гипотезы, после чего, вероятно, декодирование будет правильным. Таким образом, принятие каждой гипотезы упрощает дальнейший процесс проверки гипотез путем уменьшения числа возможных выборов и в то же время дает дополнительные данные для проверки правильности ранее принятых гипотез.
Последовательный декодер является декодером, предназначенным для кодов с древовидной структурой, который декодирует их путем принятия пробных гипотез относительно последовательных ребер дерева и изменяет эти гипотезы, если последующий выбор указывает на неправильность ранее принятых гипотез. К сожалению, чрезвычайная простота этой концепции исчезнет при четкой формулировке правила о том, должен ли декодер продолжать принимать новые гипотезы, или он должен вернуться для изменения старой гипотезы. Нашим целям отвечают три требования к стратегии поиска при последовательном декодировании. Во-первых, стратегия должна в конце концов с высокой вероятностью привести к правильному декодированию последовательности источника. Во-вторых, количество вычислений, требуемых декодером, не должно быть чрезмерным. Наконец (это требование не возникает для действующих систем), стратегия должна допускать математическое исследование. Первая такая стратегия (или алгоритм) была предложена Возенкрафтом (1957), который к тому же явился автором идеи последовательного декодирования. Мы ограничимся здесь рассмотрением усовершенствованного более позднего алгоритма, принадлежащего Фано (1963).
Предполагается, что канал является дискретным каналом без памяти с переходными вероятностями  Детальное рассмотрение кодера будет проведено позднее; коротко говоря, он состоит из трех блоков. Первый из них является двоичным сверточным кодером, аналогичным представленному на рис. 6.8.3 или описываемому соотношением (6.8.8). Каждую единицу времени в двоичный кодер поступают от источника к двоичных символов, а он производит на выходе
Детальное рассмотрение кодера будет проведено позднее; коротко говоря, он состоит из трех блоков. Первый из них является двоичным сверточным кодером, аналогичным представленному на рис. 6.8.3 или описываемому соотношением (6.8.8). Каждую единицу времени в двоичный кодер поступают от источника к двоичных символов, а он производит на выходе  двоичных символов, где
двоичных символов, где  целые. Второй блок осуществляет сложение фиксированной двоичной последовательности и этой двоичной последовательности. В-третьих, полученная сумма разбивается на подблоки из а символов каждый, и каждый подблок отображается во входную букву канала с помощью отображения, аналогичного представленному
целые. Второй блок осуществляет сложение фиксированной двоичной последовательности и этой двоичной последовательности. В-третьих, полученная сумма разбивается на подблоки из а символов каждый, и каждый подблок отображается во входную букву канала с помощью отображения, аналогичного представленному
на рис. 6.2.1. Мы видим, что при таком кодировании каждые к символов источника порождают  символов канала и что скорость кода, вычисленная в натуральных единицах на символ канала, равна
символов канала и что скорость кода, вычисленная в натуральных единицах на символ канала, равна

Графически можно представить такое кодирование в виде древовидной структуры, аналогичной изображенной на рис. 6.9.2, отличающейся, однако, тем, что из каждой точки ветвления выходит не 2 возможных ребра, как на рисунке, а  и что каждое ребро состоит из
и что каждое ребро состоит из  символов канала.
символов канала.
Обозначим теперь через  первые
первые  символов кодовой последовательности, и через
символов кодовой последовательности, и через  первые
первые  символов принятой последовательности. Определим функцию
символов принятой последовательности. Определим функцию  следующим образом:
следующим образом:

В этом выражении В есть произвольное число, определяющее смещение, значение которого будет выбрано позднее, и о)  есть вероятность появления
есть вероятность появления  буквы выходного алфавита канала,
буквы выходного алфавита канала,

где  относительная частота
относительная частота  буквы при отображении двоичных символов во входные символы канала [см. (6.2.6)]. Назовем
буквы при отображении двоичных символов во входные символы канала [см. (6.2.6)]. Назовем  ценой гипотезы
ценой гипотезы  и будем использовать ее как меру согласования
и будем использовать ее как меру согласования  с принятой последовательностью у. Это разумная мера, так как при фиксированном
с принятой последовательностью у. Это разумная мера, так как при фиксированном  величина
величина  является возрастающей функцией вероятности
является возрастающей функцией вероятности  При таком подходе довольно трудно понять назначение члена
При таком подходе довольно трудно понять назначение члена  в соотношении (6.9.2); грубо говоря, он вводится для того, чтобы уменьшить зависимость источника от безусловных вероятностей символов выходной последовательности.
в соотношении (6.9.2); грубо говоря, он вводится для того, чтобы уменьшить зависимость источника от безусловных вероятностей символов выходной последовательности.
В случае двоичного симметричного канала с переходной вероятностью  последние два блока описанного выше кодера могут быть отброшены и соотношение (6.8.8) полностью описывает кодирование. Тогда
последние два блока описанного выше кодера могут быть отброшены и соотношение (6.8.8) полностью описывает кодирование. Тогда  является постоянной и
является постоянной и  упрощается:
упрощается:

где  расстояние Хэмминга между
расстояние Хэмминга между 
Назначение декодера, выраженное в терминах цены  состоит в проверке гипотез так чтобы величина
состоит в проверке гипотез так чтобы величина  возрастала с ростом
возрастала с ростом  Когда
Когда  начинает убывать с ростом
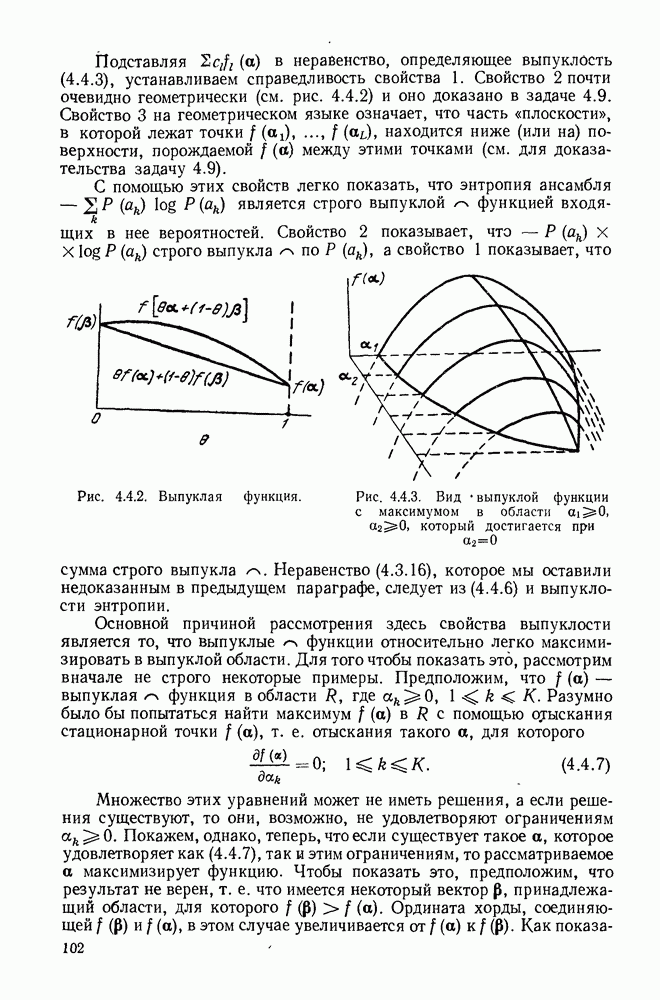
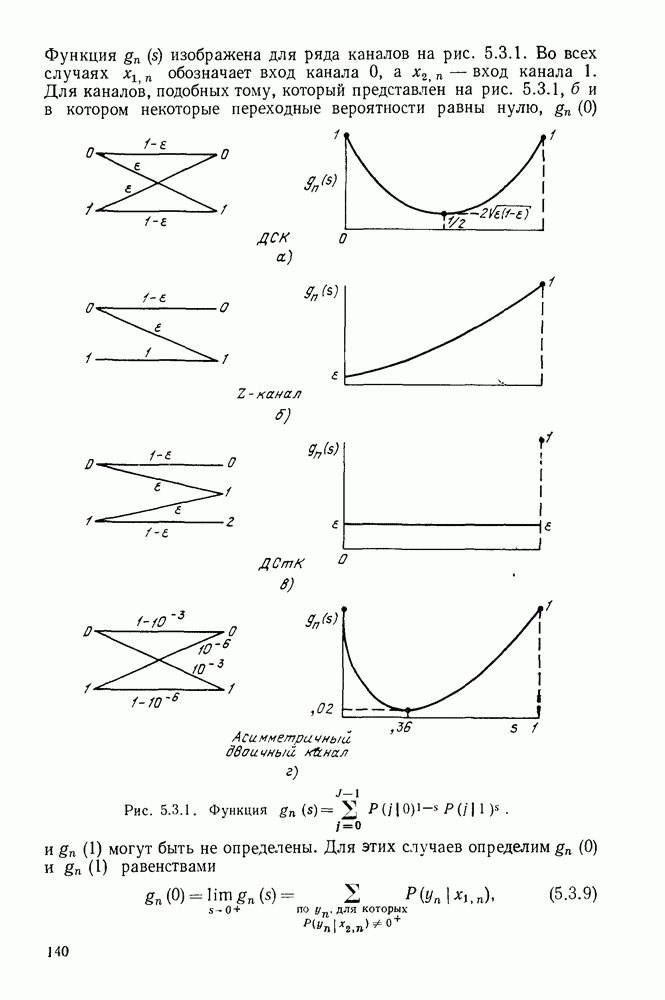
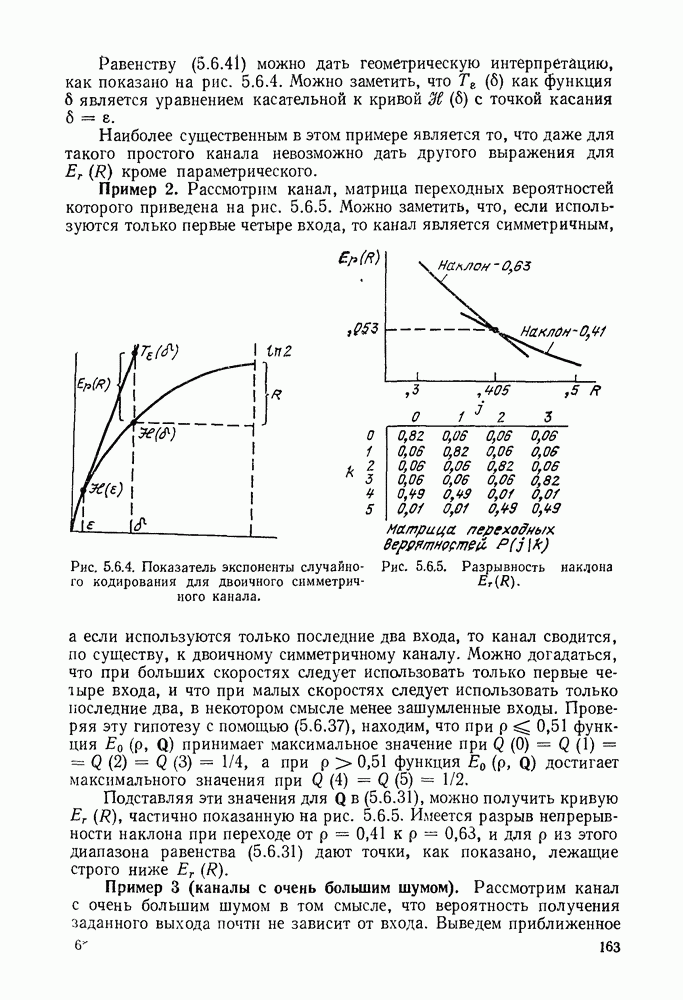
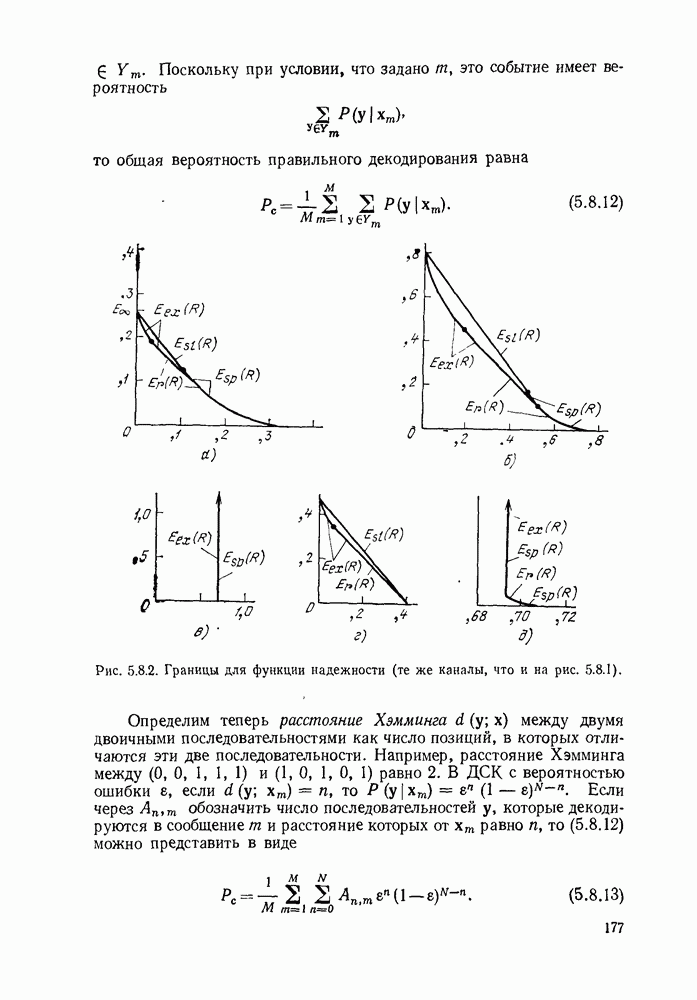
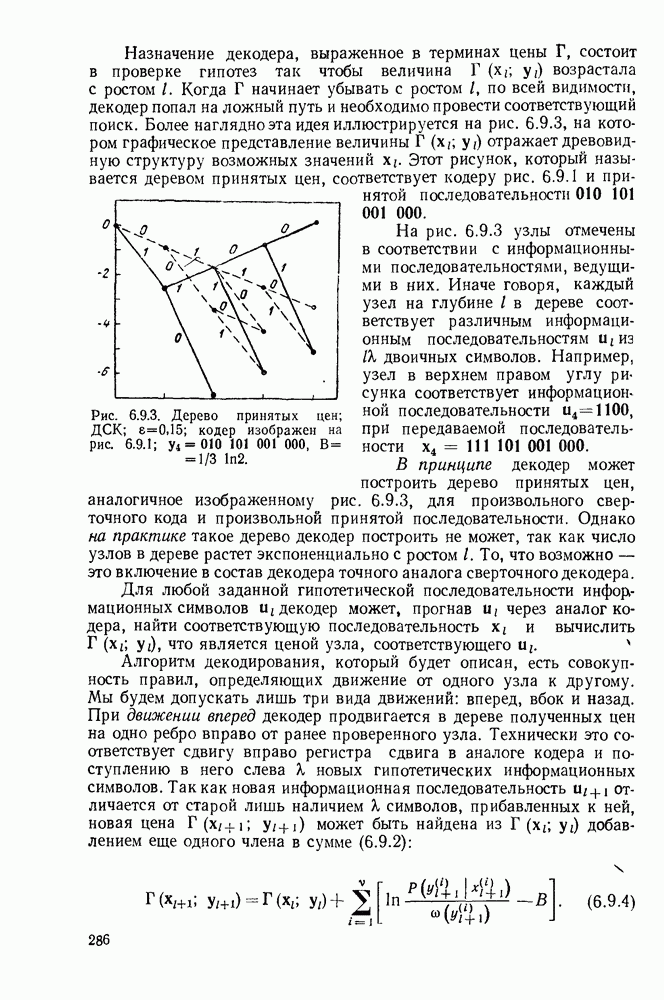
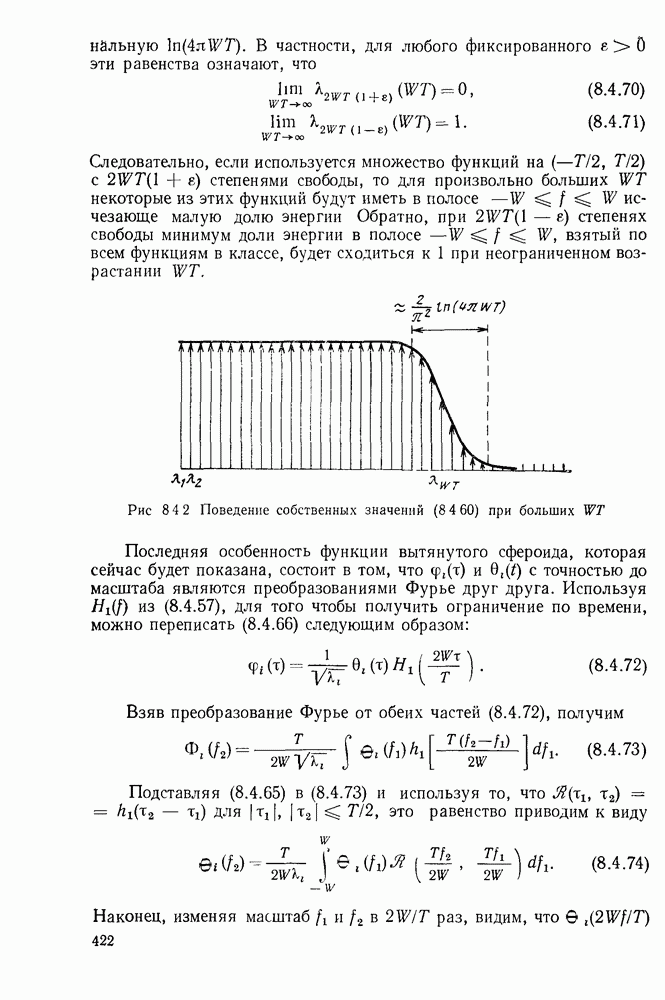
начинает убывать с ростом  по всей видимости, декодер попал на ложный путь и необходимо провести соответствующий поиск. Более наглядно эта идея иллюстрируется на рис. 6.9.3, на котором графическое представление величины
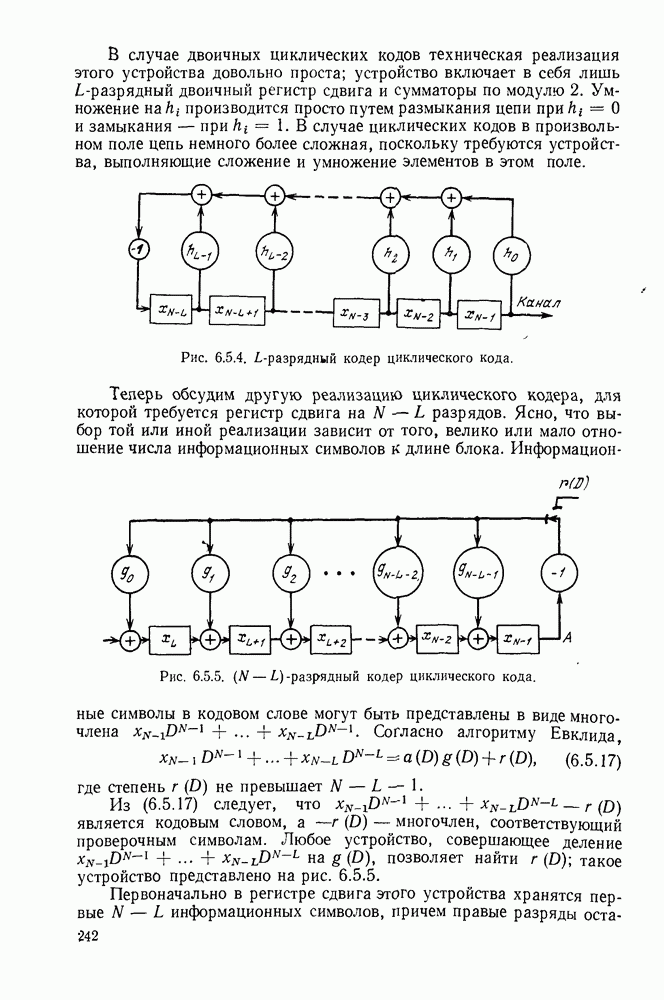
по всей видимости, декодер попал на ложный путь и необходимо провести соответствующий поиск. Более наглядно эта идея иллюстрируется на рис. 6.9.3, на котором графическое представление величины  отражает древовидную структуру возможных значений
отражает древовидную структуру возможных значений  Этот рисунок, который называется деревом принятых цен, соответствует кодеру рис. 6.9.1 и принятой последовательности
Этот рисунок, который называется деревом принятых цен, соответствует кодеру рис. 6.9.1 и принятой последовательности 
На рис. 6.9.3 узлы отмечены в соответствии с информационными последовательностями, ведущими в них. Иначе говоря, каждый узел на глубине  в дереве соответствует различным информационным последовательностям
в дереве соответствует различным информационным последовательностям  двоичных символов. Например, узел в верхнем правом углу рисунка соответствует информационной последовательности
двоичных символов. Например, узел в верхнем правом углу рисунка соответствует информационной последовательности  при передаваемой последовательности
при передаваемой последовательности  .
.

Рис. 6.9.3. Дерево принятых цен;  кодер изображен на рис. 6.9.1;
кодер изображен на рис. 6.9.1; 
В принципе декодер может построить дерево принятых цен, аналогичное изображенному рис. 6.9.3, для произвольного сверточного кода и произвольной принятой последовательности. Однако на практике такое дерево декодер построить не может, так как число узлов в дереве растет экспоненциально с ростом  То, что возможно — это включение в состав декодера точного аналога сверточного декодера.
То, что возможно — это включение в состав декодера точного аналога сверточного декодера.
Для любой заданной гипотетической последовательности информационных символов  декодер может, прогнав и? через аналог кодера, найти соответствующую последовательность
декодер может, прогнав и? через аналог кодера, найти соответствующую последовательность  и вычислить
и вычислить  что является ценой узла, соответствующего
что является ценой узла, соответствующего 
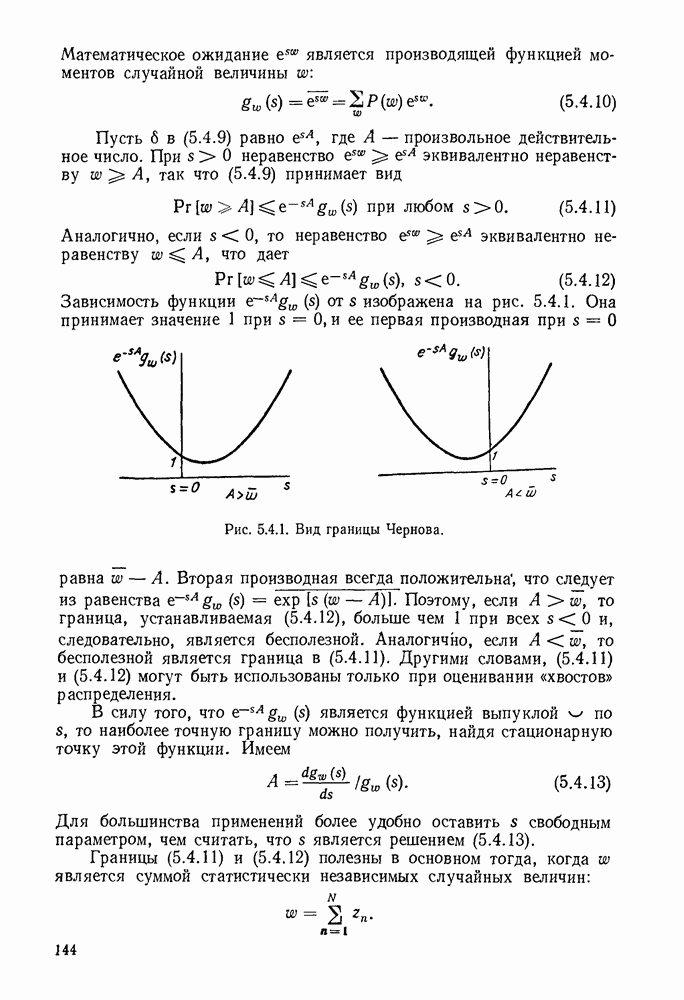
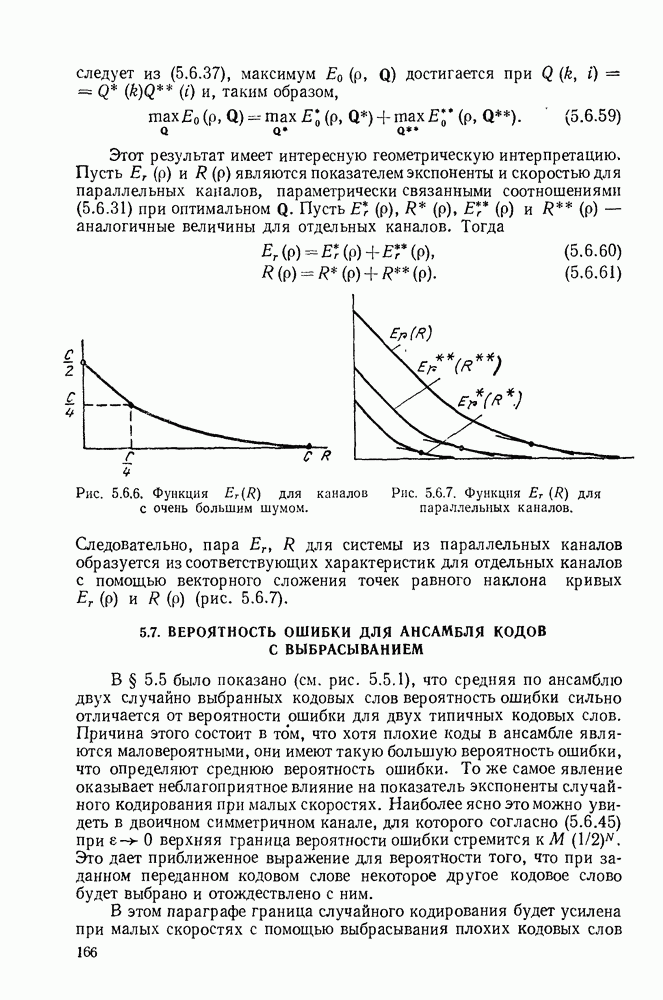
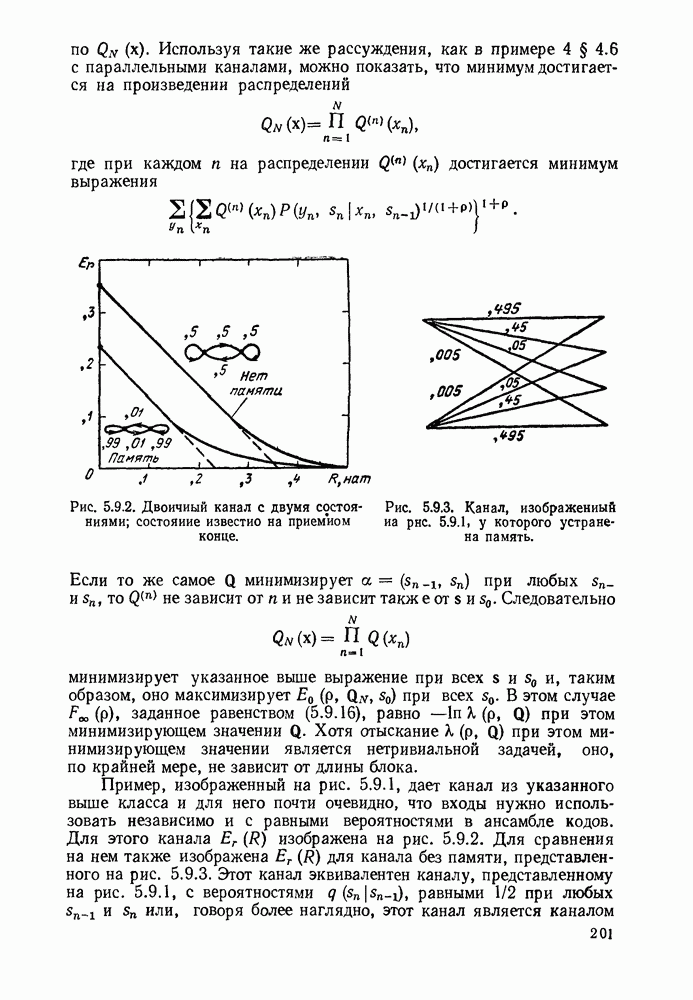
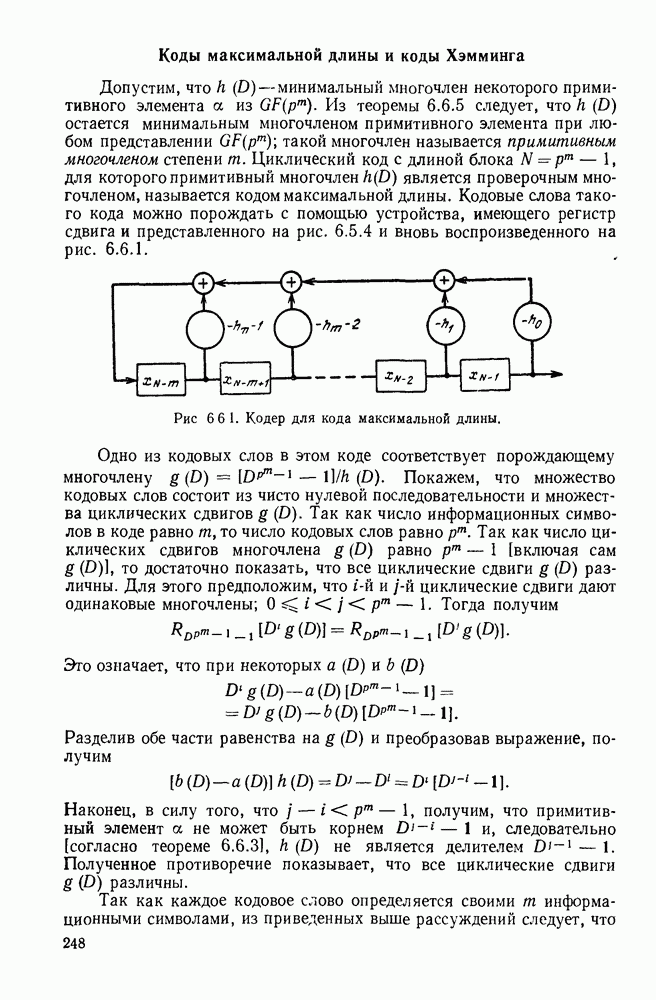
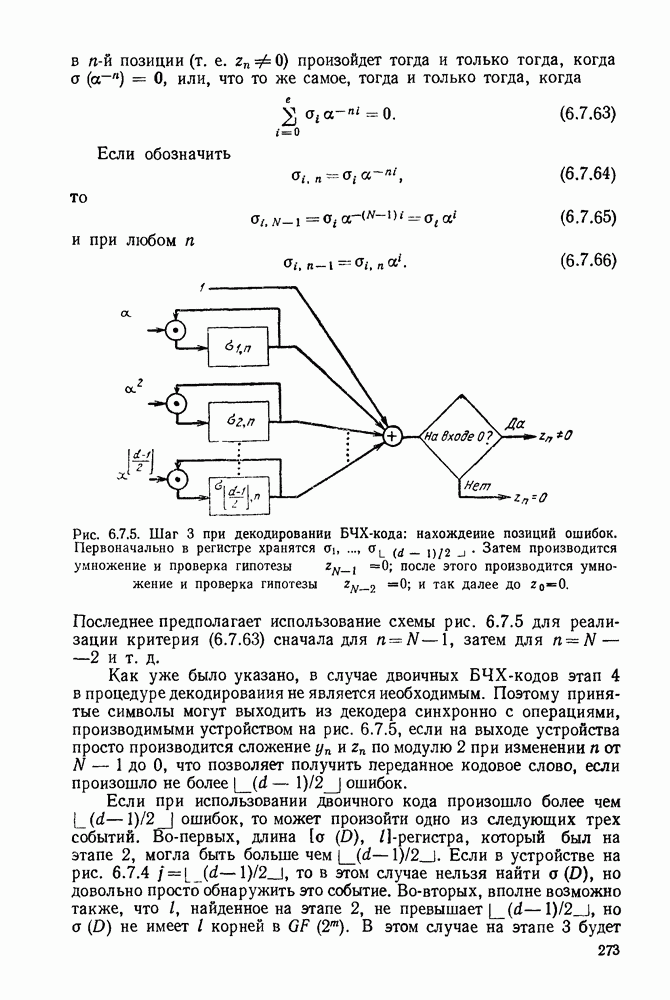
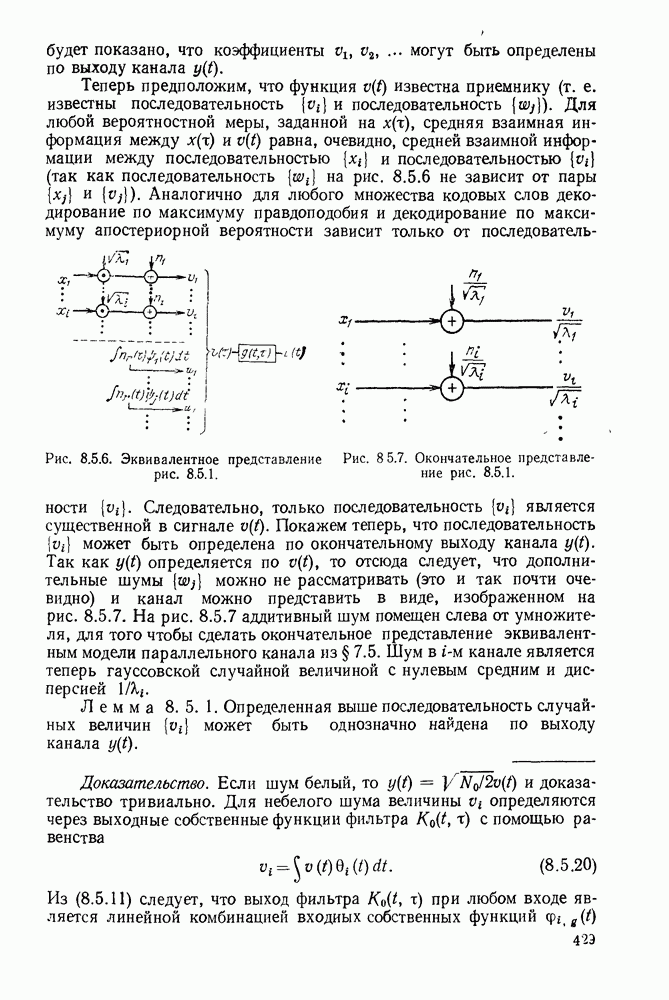
Алгоритм декодирования, который будет описан, есть совокупность правил, определяющих движение от одного узла к другому. Мы будем допускать лишь три вида движений: вперед, вбок и назад. При движении вперед декодер продвигается в дереве полученных цен на одно ребро вправо от ранее проверенного узла. Технически это соответствует сдвигу вправо регистра сдвига в аналоге кодера и поступлению в него слева  новых гипотетических информационных символов. Так как новая информационная последовательность
новых гипотетических информационных символов. Так как новая информационная последовательность  отличается от старой лишь наличием X символов, прибавленных к ней, новая цена
отличается от старой лишь наличием X символов, прибавленных к ней, новая цена  может быть найдена из
может быть найдена из  добавлением еще одного члена в сумме (6.9.2):
добавлением еще одного члена в сумме (6.9.2):

Символы, входящие в эту сумму, есть просто  входных символов канала, порождаемых аналогом кодера. Движение вбок определяется как движение из одного узла в другой, отличающийся лишь в последнем ребре дерева. Технически это соответствует изменению крайне левых
входных символов канала, порождаемых аналогом кодера. Движение вбок определяется как движение из одного узла в другой, отличающийся лишь в последнем ребре дерева. Технически это соответствует изменению крайне левых  символов в регистре сдвига аналога кодера. Как и ранее, изменение в цене при переходе от одного узла к другому определяется изменением последних
символов в регистре сдвига аналога кодера. Как и ранее, изменение в цене при переходе от одного узла к другому определяется изменением последних  входных символов канала. Движение назад определяется как движение на одно ребро влево в дереве принятых цен. Технически это соответствует сдвигу регистра сдвига кодера влево и восстановлению последних
входных символов канала. Движение назад определяется как движение на одно ребро влево в дереве принятых цен. Технически это соответствует сдвигу регистра сдвига кодера влево и восстановлению последних  символов, вышедших из регистра сдвига вправо.
символов, вышедших из регистра сдвига вправо.

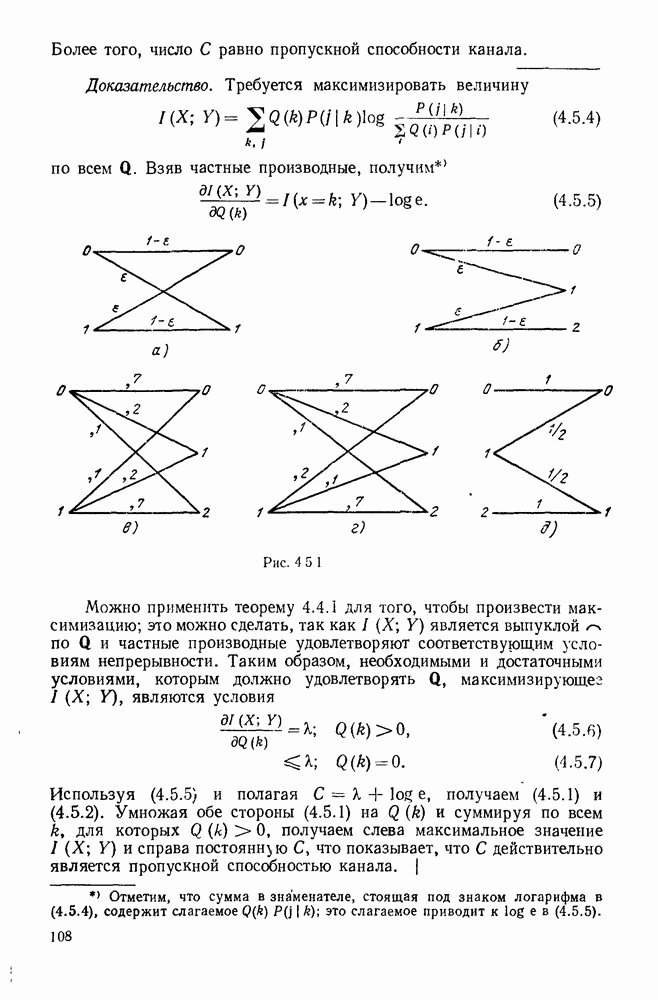
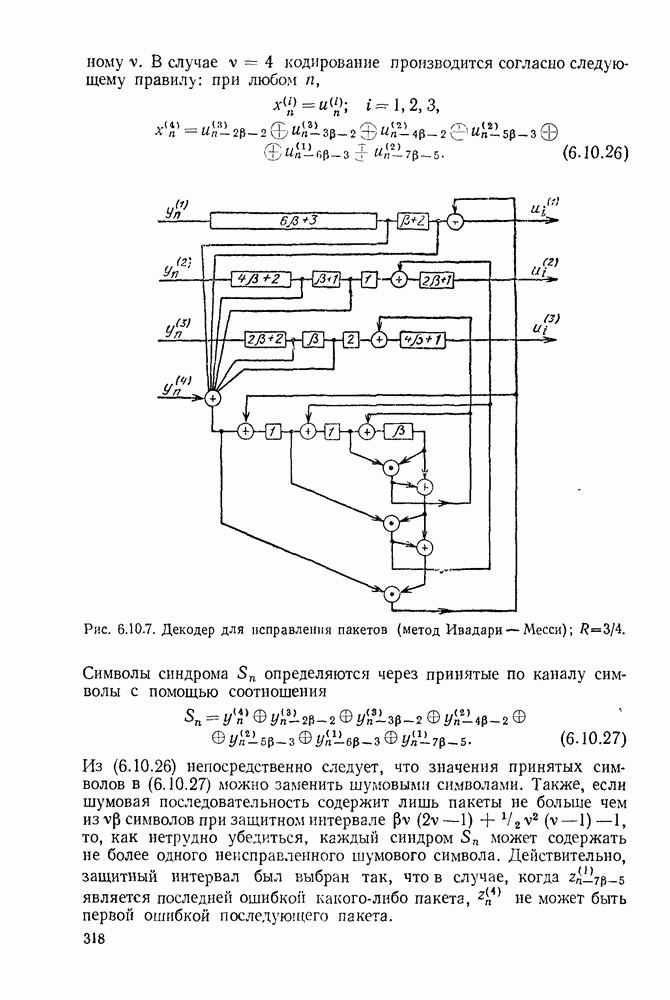
Рис. 6.9.4. Правила движения декодера.
Новое значение цены вычисляется из старого вычитанием последнего слагаемого из суммы по  в (6.9.2). Поэтому для каждого возможного движения изменение цены при переходе от старого узла к новому зависит лишь от последних
в (6.9.2). Поэтому для каждого возможного движения изменение цены при переходе от старого узла к новому зависит лишь от последних  гипотетических входных символов канала.
гипотетических входных символов канала.
Алгоритм, использующий движение от одного узла к другому, является модификацией алгоритма Фано и представлен на рис. 6.9.4. В формулировку правила входит цена  текущего узла, который проверяется в данный момент, цена
текущего узла, который проверяется в данный момент, цена  узла, находящегося на одно ребро слева от текущего узла, и порог
узла, находящегося на одно ребро слева от текущего узла, и порог  На порог Т наложено ограничение, состоящее в том, что при увеличении он изменяется на некоторое фиксированное число А, величина которого определяется алгоритмом.
На порог Т наложено ограничение, состоящее в том, что при увеличении он изменяется на некоторое фиксированное число А, величина которого определяется алгоритмом.
В начале декодирования устанавливается следующие начальные условия: проверяется исходный узел  что соответствует тому, что регистр сдвига содержит лишь нули, причем ни один информационный
что соответствует тому, что регистр сдвига содержит лишь нули, причем ни один информационный

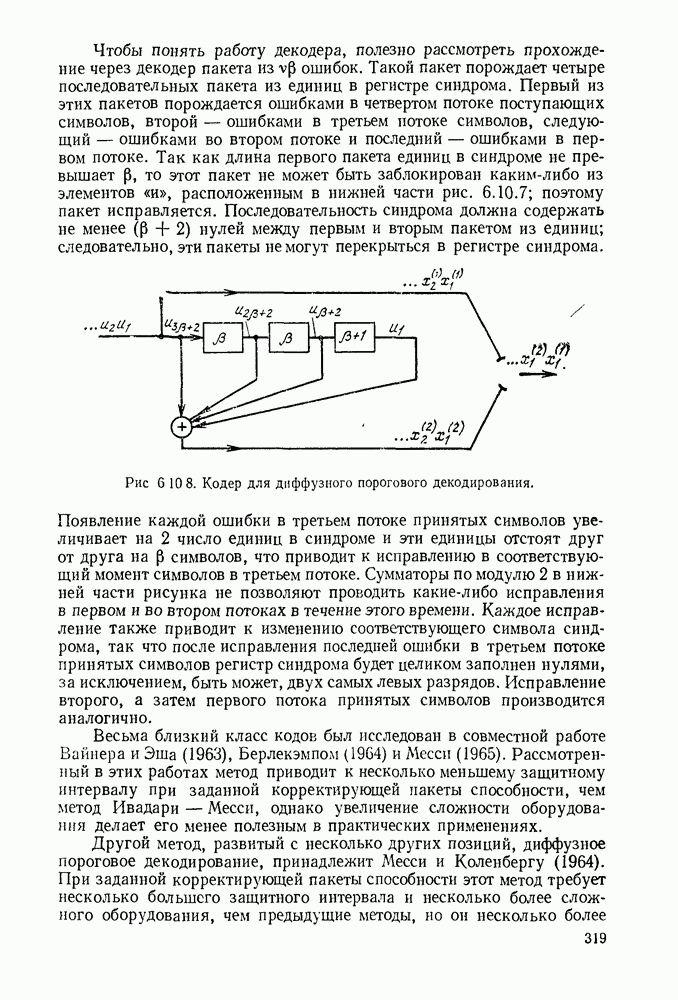
Рис. 6 9.5. Запись поиска декодера, изображенного на рис. 
символ еще не проверялся. Значение  выбирается равным 0 и по определению
выбирается равным 0 и по определению  Начальное значение порога не определено, но условимся считать, что декодер при начальной проверке следует правилу 1 с конечным порогом, равным 0.
Начальное значение порога не определено, но условимся считать, что декодер при начальной проверке следует правилу 1 с конечным порогом, равным 0.
Легко видеть, что движение вперед может быть предпринято в любой из  узлов, отстоящих на одно ребро вправо от текущего. Предполагается, что узлы предварительно упорядочены и движение вперед всегда совершается в первый по порядку узел, а движение вбок — в следующий по порядку после текущего. Эта упорядоченность несущественна для исследования, но здесь мы будем предполагать лексикографическую упорядоченность гипотетических информационных подпоследовательностей длины считая
узлов, отстоящих на одно ребро вправо от текущего. Предполагается, что узлы предварительно упорядочены и движение вперед всегда совершается в первый по порядку узел, а движение вбок — в следующий по порядку после текущего. Эта упорядоченность несущественна для исследования, но здесь мы будем предполагать лексикографическую упорядоченность гипотетических информационных подпоследовательностей длины считая  первой,
первой,  следующей и
следующей и  последней последовательностью.
последней последовательностью.
В дальнейшем мы увидим, что правило 1 алгоритма декодирования является правилом, обычно используемым при проверке декодером узлов, соответствующих действительно переданной последовательности, когда действие шума не слишком велико. В этих условиях порог будет подниматься таким образом, чтобы разность между ценой узла и величиной порога не была бы больше  После движения вперед цена этого прежнего узла будет появляться как
После движения вперед цена этого прежнего узла будет появляться как  то обстоятельство, что
то обстоятельство, что  вновь обеспечивает нам возможность применения правила 1 и нового повышения порога, если только новая цена
вновь обеспечивает нам возможность применения правила 1 и нового повышения порога, если только новая цена  выше, чем старая цена
выше, чем старая цена  Если первоначально проверялся ложный узел, то скорее всего цена узла будет меньше порога и декодер будет совершать движения вбок до тех пор, пока не перейдет к проверке правильного узла, а порог будет повышен вновь.
Если первоначально проверялся ложный узел, то скорее всего цена узла будет меньше порога и декодер будет совершать движения вбок до тех пор, пока не перейдет к проверке правильного узла, а порог будет повышен вновь.
Если действие шумов сильнее обычного, поведение алгоритма существенно сложнее, что иллюстрируется схемой рис. 6.9.5. Грубо говоря, ситуация, представленная на рисунке, вызвана тем, что декодер пытается найти путь в дереве принятых цен, который находится выше текущего порога. Как мы позднее увидим, если такого пути не существует, декодер вынужден двигаться назад к узлу, где порог согласовывался бы с его текущей ценой. В этом узле порог понижается (по правилу 4) и декодер снова движется вперед, пытаясь найти узел, остающийся выше этого пониженного порога. Ограничение  в правиле 1 введено с целью предохранить порог от нового повышения в одном из тех узлов, которые были предварительно проверены. В самом деле, если бы это ограничение не было введено, декодер быстро вошел бы в цикл, проверяя снова и снова один и тот же узел при одном и том же пороге.
в правиле 1 введено с целью предохранить порог от нового повышения в одном из тех узлов, которые были предварительно проверены. В самом деле, если бы это ограничение не было введено, декодер быстро вошел бы в цикл, проверяя снова и снова один и тот же узел при одном и том же пороге.
Прежде чем сформулировать эту идею точнее, необходимо ввести дополнительные определения. Назовем  -проверкой проверку по правилам 1, 2 или 4 (т. е. по тем правилам, для которых последующее движение совершается вперед). Предшественниками узла и
-проверкой проверку по правилам 1, 2 или 4 (т. е. по тем правилам, для которых последующее движение совершается вперед). Предшественниками узла и  являются узлы, связывающие
являются узлы, связывающие  с началом
с началом  узлы, соответствующие префиксам информационной последовательности и
узлы, соответствующие префиксам информационной последовательности и  Путь цен
Путь цен  относящийся к узлу и
относящийся к узлу и  образован ценами предшественников узла
образован ценами предшественников узла  и ценой самого
и ценой самого  Путь порогов
Путь порогов  относящийся к проверке иобразован окончательными порогами при последних проверках гипотез относительно их предшественников
относящийся к проверке иобразован окончательными порогами при последних проверках гипотез относительно их предшественников  это окончательный порог для текущей проверки). Потомками узла
это окончательный порог для текущей проверки). Потомками узла  называются узлы, для которых
называются узлы, для которых  является предшествующим узлом, т. е. узлы, расположенные направо от
является предшествующим узлом, т. е. узлы, расположенные направо от  Непосредственными потомками
Непосредственными потомками  называются
называются  потомков, отстоящих от и
потомков, отстоящих от и  на одно ребро. Путь из узла
на одно ребро. Путь из узла  к потомку
к потомку  лежит выше порога
лежит выше порога  если цены в узлах пути удовлетворяют неравенству при
если цены в узлах пути удовлетворяют неравенству при 
Следующая теорема, которая доказывается в приложении  описывает работу алгоритма. С точки зрения последующего анализа наиболее важными пунктами теоремы являются пункты
описывает работу алгоритма. С точки зрения последующего анализа наиболее важными пунктами теоремы являются пункты  эти пункты лучше всего понять, связав чтение теоремы с последующим обсуждением.
эти пункты лучше всего понять, связав чтение теоремы с последующим обсуждением.
Теорема 6.9.1.
а) Путь порогов  и путь цен
и путь цен  связанные с проверкой узла
связанные с проверкой узла  удовлетворяют следующим соотношениям при
удовлетворяют следующим соотношениям при  :
:

б) Для каждого узла, относительно которого когда-либо проводилась  -проверка, окончательный порог Т при первой
-проверка, окончательный порог Т при первой  -проверке связан с ценой
-проверке связан с ценой  этого узла соотношением
этого узла соотношением

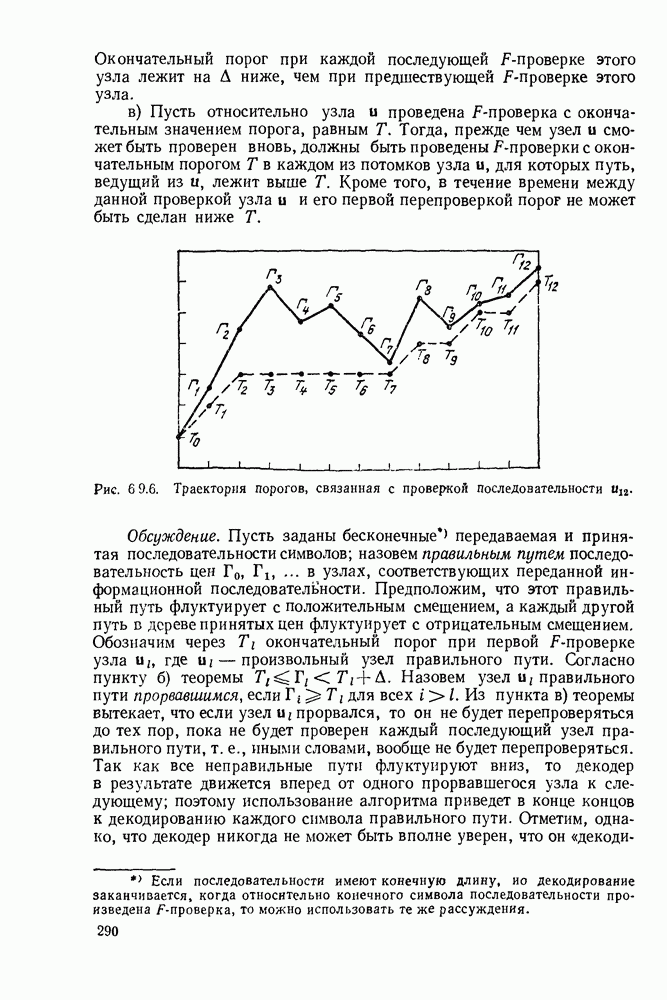
Окончательный порог при каждой последующей  -проверке этого узла лежит на
-проверке этого узла лежит на  ниже, чем при предшествующей проверке этого узла.
ниже, чем при предшествующей проверке этого узла.
в) Пусть относительно узла и проведена  -проверка с окончательным значением порога, равным
-проверка с окончательным значением порога, равным  Тогда, прежде чем узел и сможет быть проверен вновь, должны быть проведены
Тогда, прежде чем узел и сможет быть проверен вновь, должны быть проведены  -проверки с окончательным порогом Т в каждом из потомков узла и, для которых путь, ведущий из и, лежит выше
-проверки с окончательным порогом Т в каждом из потомков узла и, для которых путь, ведущий из и, лежит выше  Кроме того, в течение времени между данной проверкой узла
Кроме того, в течение времени между данной проверкой узла  и его первой перепроверкой порог не может быть сделан ниже
и его первой перепроверкой порог не может быть сделан ниже 

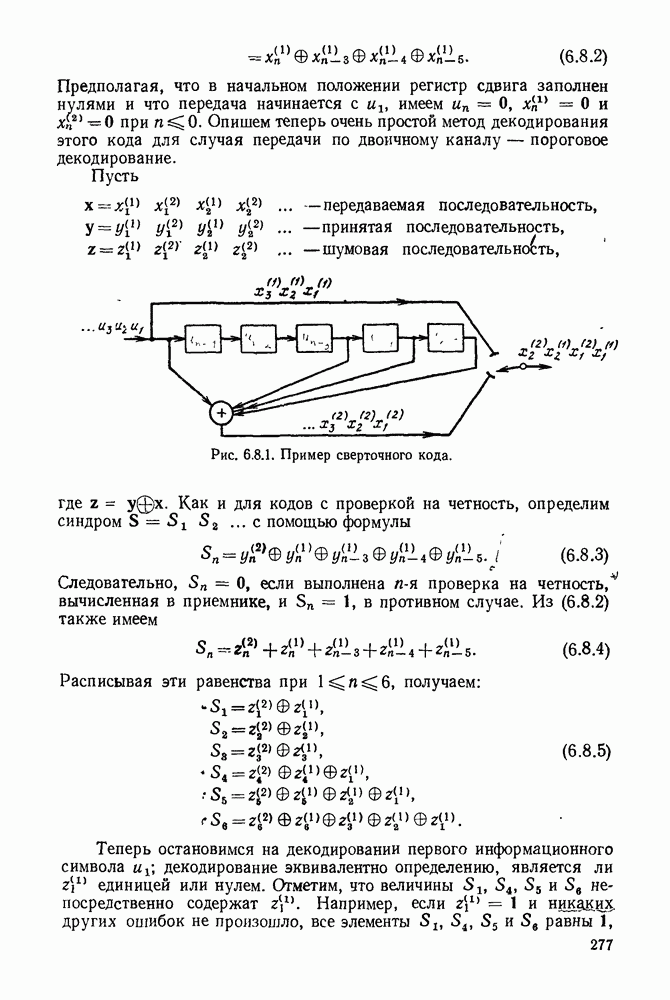
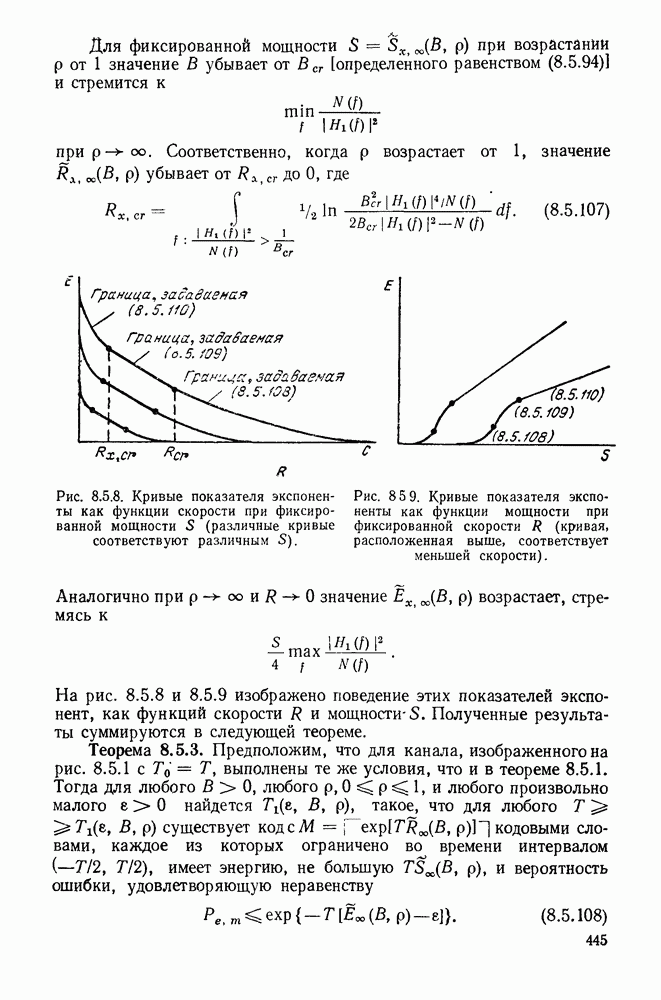
Рис. 6 9.6. Траектория порогов, связанная с проверкой последовательности 
Обсуждение. Пусть заданы бесконечные передаваемая и принятая последовательности символов; назовем правильным пущем последовательность цен  в узлах, соответствующих переданной информационной последовательности. Предположим, что этот правильный путь флуктуирует с положительным смещением, а каждый другой путь в дереве принятых цен флуктуирует с отрицательным смещением. Обозначим через
в узлах, соответствующих переданной информационной последовательности. Предположим, что этот правильный путь флуктуирует с положительным смещением, а каждый другой путь в дереве принятых цен флуктуирует с отрицательным смещением. Обозначим через  окончательный порог при первой
окончательный порог при первой  -проверке узла
-проверке узла  где и; — произвольный узел правильного пути. Согласно пункту б) теоремы
где и; — произвольный узел правильного пути. Согласно пункту б) теоремы  Назовем узел и, правильного пути прорвавшимся, если
Назовем узел и, правильного пути прорвавшимся, если  для всех
для всех  Из пункта в) теоремы вытекает, что если узел
Из пункта в) теоремы вытекает, что если узел  прорвался, то он не будет перепроверяться до тех пор, пока не будет проверен каждый последующий узел правильного пути, т. е., иными словами, вообще не будет перепроверяться. Так как все неправильные пути флуктуируют вниз, то декодер в результате движется вперед от одного прорвавшегося узла к следующему; поэтому использование алгоритма приведет в конце концов к декодированию каждого символа правильного пути. Отметим, однако, что декодер никогда не может быть вполне уверен, что он
прорвался, то он не будет перепроверяться до тех пор, пока не будет проверен каждый последующий узел правильного пути, т. е., иными словами, вообще не будет перепроверяться. Так как все неправильные пути флуктуируют вниз, то декодер в результате движется вперед от одного прорвавшегося узла к следующему; поэтому использование алгоритма приведет в конце концов к декодированию каждого символа правильного пути. Отметим, однако, что декодер никогда не может быть вполне уверен, что он
«декодировал» узел, так как всегда не исключена возможность, что последующие узлы упадут ниже данного порога. В дальнейшем мы подробнее обсудим этот момент.
На рис. 6.9.6 представлена типичная последовательность узлов вдоль правильного пути. Предположим, что  для всех
для всех  тогда прорвавшимися узлами будут
тогда прорвавшимися узлами будут  На рис. 6.9.6 также изображен путь порогов до прорыва в
На рис. 6.9.6 также изображен путь порогов до прорыва в  Эти пороги полностью определяются пунктом
Эти пороги полностью определяются пунктом  теоремы 6.9.1 через путь цен и окончательный порог в последовательности. Чтобы убедиться в этом, начнем с рассмотрения окончательного порога
теоремы 6.9.1 через путь цен и окончательный порог в последовательности. Чтобы убедиться в этом, начнем с рассмотрения окончательного порога  на рис. 6.9.6) и продвинемся по горизонтали влево. Согласно (6.9.8) пороги понижаются только, если необходимо избежать пересечения с траекторией пути; согласно (6.9.7) понижение не больше чем это необходимо для того, чтобы избежать пересечения.
на рис. 6.9.6) и продвинемся по горизонтали влево. Согласно (6.9.8) пороги понижаются только, если необходимо избежать пересечения с траекторией пути; согласно (6.9.7) понижение не больше чем это необходимо для того, чтобы избежать пересечения.
Сложность последовательного декодирования
Чнсло проверок, которое последовательный декодер должен произвести при декодировании последовательности принятых символов, является случайной величиной, зависящей от принятой последовательности, последовательности на выходе источника и сверточного кодера. Если принятые символы поступают в декодер с фиксированной по времени скоростью, и проверки проводятся с фиксированной скоростью, на входе декодера образуется очередь из принятых символов. Ясно, что изучение поведения этой очереди имеет первостепенное значение при рассмотрении работы последовательного декодера.
Чтобы лучше понять поведение этой очереди, удобно представить себе дерево принятых цен (соответствующее данной последовательности источника, данному кодеру и данной принятой последовательности) состоящим из правильного пути, соответствующего передаваемой последовательности источника, и множества деревьев неправильных путей, причем из каждого узла правильного пути исходят различные деревья. Обозначим через  число
число  -проверок, проведенных в
-проверок, проведенных в  узле правильного пути и во всех узлах дерева неправильных путей, исходящих из
узле правильного пути и во всех узлах дерева неправильных путей, исходящих из  узла. Сумма по
узла. Сумма по  величин
величин  равна общему числу
равна общему числу  -проверок, которые необходимо провести для декодирования последовательности;
-проверок, которые необходимо провести для декодирования последовательности;  можно интерпретировать как число
можно интерпретировать как число  -проверок, которые необходимо провести для декодирования
-проверок, которые необходимо провести для декодирования  подблока. Если
подблока. Если  узел правильного дерева — прорвавшийся, то все
узел правильного дерева — прорвавшийся, то все  -проверки, входящие в
-проверки, входящие в  будут выполнены раньше любой
будут выполнены раньше любой  -проверки, входящей в
-проверки, входящей в 
В дальнейшем нас будет интересовать исследование распределения  Это позволит нам лучше понять статистическое поведение очереди; если вероятность того, что
Это позволит нам лучше понять статистическое поведение очереди; если вероятность того, что  примет очень большое значение не мала, то будет существовать тенденция к созданию больших очередей. Оправданием для рассмотрения только
примет очень большое значение не мала, то будет существовать тенденция к созданию больших очередей. Оправданием для рассмотрения только  -проверок и пренебрежения движениями - вбок и назад могут служить следующие соображения. Каждый узел имеет
-проверок и пренебрежения движениями - вбок и назад могут служить следующие соображения. Каждый узел имеет  непосредственных потомков и на каждую проверку данного узла из каждого из этих потомков приходится
непосредственных потомков и на каждую проверку данного узла из каждого из этих потомков приходится
лишь одно движение вбок или назад. Поэтому при любой фиксированной длине I дерева общее число боковых и обратных движений на длине I не более чем в  раз превышает число движений вперед на длине
раз превышает число движений вперед на длине  Суммируя по I, получаем, что общее число проверок за некоторое фиксированное время не более чем в
Суммируя по I, получаем, что общее число проверок за некоторое фиксированное время не более чем в  раз превышает число
раз превышает число  -проверок.
-проверок.
В свете доказательства теоремы кодирования не должно показаться неожиданным, что поведение случайной величины  легче исследовать для ансамбля кодов, чем для некоторого частного кода. В каждом из кодов ансамбля, который будет рассматриваться, кодовые последовательности получаются следующим образом: информационная последовательность подается в двоичный несистематический сверточный кодер, выходная последовательность этого кодера суммируется с произвольной двоичной последовательностью, а сумма затем преобразуется во входные символы канала. Точнее, двоичная последовательность сообщения разбивается на подблоки по X символов в каждом,
легче исследовать для ансамбля кодов, чем для некоторого частного кода. В каждом из кодов ансамбля, который будет рассматриваться, кодовые последовательности получаются следующим образом: информационная последовательность подается в двоичный несистематический сверточный кодер, выходная последовательность этого кодера суммируется с произвольной двоичной последовательностью, а сумма затем преобразуется во входные символы канала. Точнее, двоичная последовательность сообщения разбивается на подблоки по X символов в каждом,  Каждым X входным символам сверточного кодера соответствуют
Каждым X входным символам сверточного кодера соответствуют  выходных символов (для соответствующим образом выбранных
выходных символов (для соответствующим образом выбранных  образующих двоичную последовательность
образующих двоичную последовательность  Как и в соотношении (6.8.8) (и на рис. 6.8.3), выходные символы образуются из входных по правилу
Как и в соотношении (6.8.8) (и на рис. 6.8.3), выходные символы образуются из входных по правилу

где 
Для простоты исследования будем считать  (длину кодового ограничения в блоке) бесконечной. Позднее, при изучении вероятности ошибки мы, естественно, будем рассматривать кодовые ограничения конечной длины. Выходная последовательность сверточного кодера
(длину кодового ограничения в блоке) бесконечной. Позднее, при изучении вероятности ошибки мы, естественно, будем рассматривать кодовые ограничения конечной длины. Выходная последовательность сверточного кодера  суммируется далее по модулю 2 с произвольной двоичной последовательностью
суммируется далее по модулю 2 с произвольной двоичной последовательностью  при этом образуется последовательность
при этом образуется последовательность

Эта последовательность затем разбивается на подблоки по а символов в каждом, и каждая двоичная последовательность из а символов отображается во входную букву канала с помощью отображения, аналогичного представленному на рис. 6.2.1; при этом  буква входного алфавита канала используется с относительной частотой
буква входного алфавита канала используется с относительной частотой  определенной как и в (6.2.6). Так же как и в (6.2.6), используемое значение а определяется по значениям
определенной как и в (6.2.6). Так же как и в (6.2.6), используемое значение а определяется по значениям  Можно заметить, что после выполнения этих этапов кодирования на каждые X на двоичных символов источника будет приходиться
Можно заметить, что после выполнения этих этапов кодирования на каждые X на двоичных символов источника будет приходиться  символов канала, поэтому скорость кода равна
символов канала, поэтому скорость кода равна  нат на символ канала.
нат на символ канала.
Пусть заданы значения  и а и отображение
и а и отображение  -символьной двоичной последовательности в символы канала; рассмотрим ансамбль кодов, в котором значения всех элементов
-символьной двоичной последовательности в символы канала; рассмотрим ансамбль кодов, в котором значения всех элементов  и всех элементов последовательности
и всех элементов последовательности  являются значениями незавиеимых равновероятных двоичных символов.
являются значениями незавиеимых равновероятных двоичных символов.
Лемма 6.9.1. Для рассмотренного выше ансамбля кодов кодовая последовательность  соответствующая какой-либо данной информационной последовательности, является случайной последовательностью с символами, статистически независящими один от другого и выбираемыми с вероятностями
соответствующая какой-либо данной информационной последовательности, является случайной последовательностью с символами, статистически независящими один от другого и выбираемыми с вероятностями  Более того, если две информационные последовательности
Более того, если две информационные последовательности  и совпадают в первых
и совпадают в первых  подблоках и отличаются в
подблоках и отличаются в  подблоке, то соответствующие кодовые последовательности совпадают в первых
подблоке, то соответствующие кодовые последовательности совпадают в первых  подблоках и статистически независимы во всех последующих подблоках.
подблоках и статистически независимы во всех последующих подблоках.
Доказательство. Если задана некоторая произвольная выходная последовательность двоичного сверточного кодера  то из независимости и равновероятности двоичных символов последовательности
то из независимости и равновероятности двоичных символов последовательности  вытекает, что
вытекает, что  состоит из независимых равновероятных двоичных символов, поэтому любая кодовая последовательность состоит из независимых букв с вероятностями появления
состоит из независимых равновероятных двоичных символов, поэтому любая кодовая последовательность состоит из независимых букв с вероятностями появления  Предположим, что
Предположим, что  и
и  совпадают в первых
совпадают в первых  подблоках и отличаются в
подблоках и отличаются в  подблоке, и что
подблоке, и что  соответствующие им выходные последовательности двоичного сверточного кодера. Тогда
соответствующие им выходные последовательности двоичного сверточного кодера. Тогда  является выходной последовательностью сверточного кодера при входной последовательности
является выходной последовательностью сверточного кодера при входной последовательности  поскольку первые
поскольку первые  подблоков последовательности
подблоков последовательности  целиком состоят из нулей, то первые
целиком состоят из нулей, то первые  подблоков
подблоков  также нулевые. Пусть теперь, по крайней мере при одном значении
также нулевые. Пусть теперь, по крайней мере при одном значении  например
например  величина
величина  и при любых
и при любых 

Так как  является двоичной случайной величиной с равновероятными значениями, не зависящей от всех остальных
является двоичной случайной величиной с равновероятными значениями, не зависящей от всех остальных  то
то  также двоичная случайная величина с равновероятными значениями. Точно так же величина
также двоичная случайная величина с равновероятными значениями. Точно так же величина  статистически не зависит от всех
статистически не зависит от всех  при
при  и всех
и всех  при
при  так как они не зависят от
так как они не зависят от  Поэтому все подблоки последовательности
Поэтому все подблоки последовательности  кроме первых
кроме первых  образуются независимыми и равновероятными двоичными символами. Следовательно,
образуются независимыми и равновероятными двоичными символами. Следовательно,  статистически независимы во всех подблоках, кроме первых
статистически независимы во всех подблоках, кроме первых  и поэтому
и поэтому  статистически независимы во всех подблоках, кроме первых
статистически независимы во всех подблоках, кроме первых 
Найдем теперь верхнюю границу  среднего числа
среднего числа  -проверок, выполняемых последовательным декодером в начальном узле и в дереве неправильных путей, исходящем из начального узла. Усреднение будет проводиться по ансамблю кодов, шумам канала и последовательностям сообщения. После этого найдем верхнюю границу для
-проверок, выполняемых последовательным декодером в начальном узле и в дереве неправильных путей, исходящем из начального узла. Усреднение будет проводиться по ансамблю кодов, шумам канала и последовательностям сообщения. После этого найдем верхнюю границу для  момента
момента  величины
величины  при всех
при всех  Те же границы, как мы увидим, справедливы для
Те же границы, как мы увидим, справедливы для  в каждом узле правильного пути.
в каждом узле правильного пути.
Случайные величины  зависят как от цен узлов вдоль правильного пути, так и от цен узлов в неправильном поддереве, исходящем из начального узла. Число непосредственных потомков начального
зависят как от цен узлов вдоль правильного пути, так и от цен узлов в неправильном поддереве, исходящем из начального узла. Число непосредственных потомков начального
узла, принадлежащих неправильному поддереву, равно  (оставшийся непосредственный потомок принадлежит правильному пути). Число узлов в данном неправильном поддереве, лежащих на глубине 2, равно
(оставшийся непосредственный потомок принадлежит правильному пути). Число узлов в данном неправильном поддереве, лежащих на глубине 2, равно  и вообще число узлов на глубине I в данном неправильном поддереве равно
и вообще число узлов на глубине I в данном неправильном поддереве равно  Обозначим через
Обозначим через  узел среди этих узлов, лежащих на глубине
узел среди этих узлов, лежащих на глубине  при некотором произвольном упорядочении; пусть
при некотором произвольном упорядочении; пусть 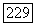 является ценой этого узла. Обозначим через
является ценой этого узла. Обозначим через 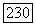 цену
цену 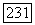 узла на правильном пути и через
узла на правильном пути и через  нижнюю грань
нижнюю грань  при
при 
Лемма 6.9.2. Узел  может проверяться в
может проверяться в  раз,
раз,  лишь в том случае, когда
лишь в том случае, когда 
Доказательство. Согласно пункту б) теоремы 6.9.1, при первой  -проверке узла
-проверке узла  окончательный порог не может превысить
окончательный порог не может превысить  Аналогично, окончательный порог при
Аналогично, окончательный порог при  -проверке узла
-проверке узла  не превышает
не превышает  Лемма будет доказана, если показать, что порог никогда не может быть сделан ниже чем Гтгп —
Лемма будет доказана, если показать, что порог никогда не может быть сделан ниже чем Гтгп — 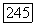 Согласно пункту б) теоремы 6.9.1 порог при последовательных
Согласно пункту б) теоремы 6.9.1 порог при последовательных 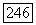 -проверках в начальном узле уменьшается от 0 скачками, равными
-проверках в начальном узле уменьшается от 0 скачками, равными 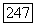 Согласно пункту в) теоремы в любом другом узле порог не может быть сделан ниже финального порога при последней
Согласно пункту в) теоремы в любом другом узле порог не может быть сделан ниже финального порога при последней 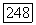 -проверке в начальном узле. Следовательно, впервые порог принимает значение, равное
-проверке в начальном узле. Следовательно, впервые порог принимает значение, равное 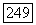 или меньше, при
или меньше, при 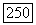 -проверке в начальном узле и этот порог больше чем
-проверке в начальном узле и этот порог больше чем 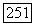 Так как траектория правильного пути проходит всюду не ниже этого порога, то начальный узел в дальнейшем никогда не будет проверен вновь и порог никогда не будет сделан ниже
Так как траектория правильного пути проходит всюду не ниже этого порога, то начальный узел в дальнейшем никогда не будет проверен вновь и порог никогда не будет сделан ниже 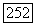
Определим теперь двоичную случайную величину  с помощью соотношения
с помощью соотношения

Так как  раз
раз  -проверка в
-проверка в  узле может быть выполнена только в том случае, если
узле может быть выполнена только в том случае, если  то легко видеть, что число
то легко видеть, что число  -проверок в
-проверок в  узле ограничено сверху суммой
узле ограничено сверху суммой

Поэтому общее число проверок в исходном узле и всех узлах, которые принадлежат неправильному поддереву, исходящему из начального узла, ограничено неравенством

По условию, в сумму по  при
при  войдет только одно слагаемое, соответствующее исходному узлу. При
войдет только одно слагаемое, соответствующее исходному узлу. При  в сумму по
в сумму по  войдут слагаемые, соответствующие
войдут слагаемые, соответствующие  узлам неправильного поддерева, лежащим на глубине
узлам неправильного поддерева, лежащим на глубине  Оценим теперь сверху
Оценим теперь сверху
математическое ожидание величины  Так как математическое ожидание суммы равно сумме математических ожиданий, то
Так как математическое ожидание суммы равно сумме математических ожиданий, то

С другой стороны, согласно (6.9.11)

В силу статистической независимости передаваемой кодовой последовательности и кодовой последовательности, соответствующей  , задача нахождения вероятности в правой части (6.9.14) аналогична задаче нахождения вероятности ошибки при передаче двух случайно выбираемых кодовых слов. Единственное различие заключается в том, что должны рассматриваться последовательности вдоль правильного пути различной длины. Принимая во внимание эту аналогию с задачами передачи двух кодовых слов, не следует удивляться, что в ответе появляется значение функции
, задача нахождения вероятности в правой части (6.9.14) аналогична задаче нахождения вероятности ошибки при передаче двух случайно выбираемых кодовых слов. Единственное различие заключается в том, что должны рассматриваться последовательности вдоль правильного пути различной длины. Принимая во внимание эту аналогию с задачами передачи двух кодовых слов, не следует удивляться, что в ответе появляется значение функции  при
при 

Следующая лемма доказана в приложении 
Лемма 6.9.3. Рассмотрим ансамбль кодов, в котором кодовая последовательность, соответствующая каждой последовательности сообщения, представляет собой последовательность статистически независимых символов, принимающих значения с вероятностями 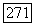 Обозначим через Гтгп нижнюю грань цен вдоль правильного пути в дереве принятых цен и через
Обозначим через Гтгп нижнюю грань цен вдоль правильного пути в дереве принятых цен и через 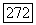 цену в узле
цену в узле 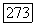 где
где 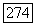 последовательность сообщения из
последовательность сообщения из 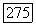 подблоков, такая, что первые
подблоков, такая, что первые 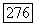 подблоков кодовой последовательности, соответствующей
подблоков кодовой последовательности, соответствующей 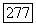 статистически независимы от переданной кодовой последовательности. Тогда, если смещение В удовлетворяет неравенству
статистически независимы от переданной кодовой последовательности. Тогда, если смещение В удовлетворяет неравенству 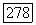 то
то

Сравнивая (6.9.13), (6.9.14) и (6.9.16), получаем

Из (6.9.1) видно, что 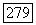 и поэтому приведенная выше сумма по
и поэтому приведенная выше сумма по 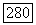 содержит менее чем
содержит менее чем 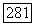 одинаковых членов; следовательно,
одинаковых членов; следовательно,

Эти ряды могут быть без труда просуммированы, если использовать разложение

и его производную

Эти ряды сходятся, если

при этом получим

Приведенная граница дает некоторое представление о том, какие значения должны выбираться для смещения В и порогового интервала А. Граница убывает с возрастанием В, но справедлива лишь при 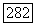 Поэтому граница имеет минимум при
Поэтому граница имеет минимум при 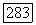 Аналогично, минимизируя по А, находим, что минимум достигается при
Аналогично, минимизируя по А, находим, что минимум достигается при  или
или 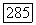 Используя эти значения, убеждаемся, что при
Используя эти значения, убеждаемся, что при 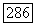

Эти рассуждения оставляют некоторое сомнение в том, что минимум  достигается при этих значениях
достигается при этих значениях  поскольку они минимизируют лишь границу для
поскольку они минимизируют лишь границу для  -Для слагаемых, соответствующих малым значениям
-Для слагаемых, соответствующих малым значениям  которые доминируют в сумме (6.9.13), использованная нами экспоненциальная граница является довольно грубой. Блюстейн и Жордан (1963) экспериментально показали, что, как правило, величина
которые доминируют в сумме (6.9.13), использованная нами экспоненциальная граница является довольно грубой. Блюстейн и Жордан (1963) экспериментально показали, что, как правило, величина  на два порядка меньше, чем приведенная здесь граница, и что она мало зависит от смещения и от порогового интервала. Важное значение неравенства (6.9.23) состоит не в том, что оно задает явную границу, а в доказательстве того, что граница конечна при
на два порядка меньше, чем приведенная здесь граница, и что она мало зависит от смещения и от порогового интервала. Важное значение неравенства (6.9.23) состоит не в том, что оно задает явную границу, а в доказательстве того, что граница конечна при 
Рассмотрим теперь произвольный узел правильного пути, например  узел. Заметим, что статистическое описание неправильного поддерева и правильного пути, исходящих из этого узла, совершенно аналогично статистическому описанию неправильного поддерева и правильного пути, исходящих из начального узла. Единственная разница состоит в том, что к множеству цен узлов добавлена цена
узел. Заметим, что статистическое описание неправильного поддерева и правильного пути, исходящих из этого узла, совершенно аналогично статистическому описанию неправильного поддерева и правильного пути, исходящих из начального узла. Единственная разница состоит в том, что к множеству цен узлов добавлена цена  Лемма применяется здесь точно так же, как и раньше, и (6.9.23) позволяет получить верхнюю границу для
Лемма применяется здесь точно так же, как и раньше, и (6.9.23) позволяет получить верхнюю границу для  Поэтому (6.9.23) оценивает сверху среднее число
Поэтому (6.9.23) оценивает сверху среднее число  -проверок на декодированный подблок.
-проверок на декодированный подблок.
Из этой границы можно также увидеть довольно ясно, почему «работает» метод последовательного декодирования. Число узлов в неправильном поддереве растет экспоненциально с глубиной дерева, а вероятность проверки узла является экспоненциально убывающей функцией глубины дерева. До тех пор пока скорость остается меньше, чем  убывание вероятности более чем компенсирует возрастание числа узлов. Ясно, что именно древовидная структура сверточных кодов делает возможным такой обмен.
убывание вероятности более чем компенсирует возрастание числа узлов. Ясно, что именно древовидная структура сверточных кодов делает возможным такой обмен.
Теперь найдем верхнюю границу  Из (6.9.12) имеем
Из (6.9.12) имеем

Применяя в правой части (6.9.24) неравенство Минковского (см. задачу 4.15 (е)), получаем

Так как  принимает лишь значения 0 и 1, то
принимает лишь значения 0 и 1, то  и из (6.9.14) и (6.9.16) имеем
и из (6.9.14) и (6.9.16) имеем

Оценивая сверху величиной и суммируя эти ряды таким же образом, как и ряды в (6.9.17), убеждаемся, что суммы сходятся, если

и

К вновь применима та же самая граница. Если смещение В равно то как нетрудно убедиться, конечно при меньших, чем Границу (6.9.28) можно использовать для оценки функции распределения Применяя обобщенное неравенство Чебышева, имеем

Наши результаты можно сформулировать в виде следующей теоремы.
Теорема 6.9.2. При применении последовательного декодирования в дискретном канале без памяти среднее число -проверок,
приходящихся на декодированный подблок, удовлетворяет неравенству

при
Здесь означает число символов канала, приходящихся на подблок, является скоростью кода в натах на символ канала, определяется соотношением (6.9.15). Смещение В выбирается равным а пороговый интервал — равным Усреднение проводится по ансамблю кодов бесконечной длины, определенных на стр. 292. Кроме того, при любом для которого величина также конечна.
Севэдж (1966) получил более сильные оценки для с помощью рассмотрения большего ансамбля кодов. Он рассмотрел ансамбль случайно выбираемых древовидных кодов, в котором кодовые последовательности имеют такую же древовидную структуру, как и на рис. 6.9.2, но где каждый символ в дереве выбирается независимо с вероятностями Севэдж показал, что в этом ансамбле при целых величина конечна, если Отсюда не обязательно следует, что для этих скоростей существуют сверточные коды, для которых конечно. Однако довольно правдоподобно, что при всех положительных и всех величина конечна, где усреднение производится по ансамблю сверточных кодов с бесконечной длиной кодового ограничения и скоростью Это предположение было доказано Фэлконером (1966) для случая
Вопрос о том, что произойдет с при детально исследован Джекобсом и Берлекэмпом (1967). Их результаты применимы к произвольным древовидным кодам (т. е. кодам, структура которых описывается рис. 6.9.2) и к классу последовательных алгоритмов, включающему описанный здесь алгоритм Фано. Пусть и пусть выпуклая оболочка т. е. - минимальная выпуклая функция, равная или большая чем Она образуется заменой всех невыпуклых участков прямолинейными сегментами. Джекобе и Берлекэмп показали, что в наших обозначениях для любого древовидного кода со скоростью

Бесконечность моментов высокого порядка указывает на то, что длинные очереди являются трудной проблемой в последовательном декодировании. Джекобе и Берлекэмп показали, что вероятность того, что либо очередь при декодировании символа превысит данную длину либо будет сделана ошибка, не может убывать с ростом быстрее, чем для скорости кода, равной
Вероятность ошибки при последовательном декодировании
Чтобы оценить вероятность ошибки при последовательном декодировании, следует рассмотреть коды с конечной длиной кодового ограничения. Если для кодов с бесконечной длиной кодового ограничения конечно при любом то из (6.9.18) следует, что вероятность проверки узла на глубине I дерева неправильных путей стремится к нулю с возрастанием и вероятность ошибки, очевидно, равна нулю.
Предположим, что длина ограничения кодера равна подблокам. Предположим также, что в кодер вместо бесконечной последовательности подблоков поступает от источника конечное число подблоков где как правило, гораздо больше После того как в кодер поступит подблоков сообщения, в него подается известная последовательность подблоков, состоящих из нулей. В такой ситуации каждый узел дерева принятых цен, лежащий на глубине не больше имеет непосредственных потомков, а каждый узел на глубине, не меньшей только одного непосредственного потомка. Декодирование проводится согласно правилам, указанным на рис. 6.9.4, за исключением того, что декодер распознает, что узел порядка или больше имеет лишь одного непосредственного потомка и поэтому правила 3 и 5 всегда приводят к движению назад для узлов порядка, большего чем Декодирование заканчивается при первой проверке в узле порядка и гипотетическая последовательность источника при этой проверке выбирается в качестве декодированной последовательности. При конечных декодирование в конце концов должно закончиться.
Из рассмотрения ансамбля кодов, введенных после соотношения (6.9.10), с конечным следует, что две кодовые последовательности, соответствующие двум заданным последовательностям источника, статистически независимы в первых подблоках, исходящих из первого подблока, в котором они отличаются, но зависимы в остальных. Вероятность ошибки декодирования для этого ансамбля может быть ограничена сверху величиной, по существу, эквивалентной границе случайного кодирования для блоковых кодов (см. задачу 6.42). Однако интереснее здесь слегка модифицировать ансамбль и затем вывести гораздо меньшую верхнюю границу для вероятности ошибки. Для этого рассмотрим двоичный сверточный кодер, изменяющийся во времени; двоичная выходная последовательность кодера образуется по правилу [сравнить с

В данном ансамбле каждый элемент выбирается так, что он является статистически независимой от других величин двоичной случайной величиной, принимающей оба значения с одинаковыми вероятностями. В остальном ансамбль аналогичен прежнему; суммируется со случайной двоичной последовательностью после чего сумма отображается во входные буквы канала. В обозначениях
рис. 6.8.3 это соответствует случайному перемешиванию связей между X регистрами сдвига и сумматорами по модулю 2, порождающими двоичную выходную последовательность; перемешивание производится после поступления в кодер каждого из подблоков символов сообщения.
Лемма 6.9.4. В рассмотренном выше ансамбле кодов кодовая последовательность, соответствующая какой-либо данной информационной последовательности, представляет собой последовательность статистически независимых букв, выбираемых с вероятностями, равными где относительная частота появления входной буквы при отображении двоичной последовательности длины а во входную букву канала. Пусть далее кодовые последовательности соответствуют последовательности сообщений ; тогда совпадают в некотором подблоке, если совпадают в этом подблоке и предыдущих. Во всех остальных подблоках последовательности статистически независимы.
Доказательство этой леммы почти идентично доказательству леммы 6.9.1 и потому опускается.
Утверждение леммы в обозначениях рис. 6.8.3 означает, что совпадают в тех подблоках, которые соответствуют одним и тем же символам в регистре сдвига. В других случаях независимы.
Пусть задан код из рассмотренного выше ансамбля. Обозначим через и переданную последовательность сообщения и через и — декодированную методом последовательного декодирования последовательность сообщения. Как правило, ошибки декодирования, если они происходят, имеют тенденцию группироваться в пакеты. Точнее, пакетом ошибок декодирования называется последовательность одного и более подблоков, обладающих следующими свойствами: первый и последний подблоки последовательности содержат ошибки (т. е. и отличаются в этих подблоках), никакие последовательных подблоков внутри этой последовательности не являются одновременно безошибочными по подблоков с каждой стороны последовательности не содержат ошибки. Это определение однозначно определяет множество одного или более пакетов ошибок для любого
Обозначим через вероятность (в ансамбле кодов, сообщений и шумов в канале) того, что с началом в подблоке и концом в подблоке имел место пакет ошибок. Обозначим через вероятность ошибочного декодирования подблока. Согласно нашему определению пакета любой подблок, ошибочно декодированный, должен входить в некоторый пакет ошибок декодирования, поэтому

Чтобы найти верхнюю границу рассмотрим сначала простейший случай, т. е. случай Пусть и — переданная информационная последовательность и пусть — первые с подблоков декодированной последовательности. Для того чтобы в промежутке от до подблока появился пакет ошибок
декодирования, должно быть исфиси. Так как каждый внутренний подблок может быть выбран не более чем способами, то последовательность содержащая пакет ошибок декодирования в промежутке от до подблока, может быть выбрана менее чем способами.
Обозначим через путь цен вдоль правильного пути в дереве полученных цен, и пусть

Пусть далее является ценой узла где выбрано таким образом, что он соответствует пакету ошибок декодирования в промежутке от до подблока. Совершенно ясно, что проведение в узле -проверки необходимо для того, чтобы было декодировано. Вместе с тем согласно лемме -проверка может наступить только тогда, когда поэтому

Согласно лемме 6.9.4 с подблоков кодовой последовательности, соответствующей последовательности статистически не зависят от переданной последовательности и поэтому из леммы 6.9.3 вытекает

при Так как число способов выбора соответствующих пакету ошибок в промежутке от до подблока, меньше чем то получим

Теперь найдем эквивалентную границу для при произвольных Рассмотрим некоторый конкретный код ансамбля; обозначим через и переданное сообщение, а через переданную кодовую последовательность. Пусть первые подблоков произвольной последовательности сообщения, удовлетворяющей условию при Рассмотрим потомков в дереве принятых цен. Один из путей потомков, выходящий из соответствует подблокам переданного сообщения Кодовая последовательность, соответствующая совпадает в подблоках с кодовой последовательностью, соответствующей переданной последовательности сообщения и, так как в регистре сдвига, порождающем кодовые последовательности, в обоих случаях будут храниться одни и те же символы. Поэтому изменение вдоль пути цен от узла до потомка совпадают с (изменением вдоль пути цен от до
Пусть потомок лежащий на глубине в с подблоков, и пусть изменение цены при переходе в дереве принятых цен от узла к Чтобы декодировать узел необходимо произвести в нем, по крайней мере, -проверку, а для того чтобы провести в этом узле -проверку, необходимо, чтобы

Справедливость этого следует из того, что в противном случае последовательность не даст возможности понизить порог настолько, чтобы была возможна -проверка Если декодирование приводит к пакету ошибок в промежутке от до подблока, то необходимо, чтобы исфис и при — 1. Поэтому последовательность содержащая пакет ошибок декодирования в промежутке от до подблока, может быть выбрана менее чем способами. Наконец, выполнение неравенства (6.9.37) для некоторой выбранной подпоследовательности зависит лишь от кодовых последовательностей, начинающихся с подблока, и не зависит от выбора [удовлетворяющих ограничению, состоящему в том, что для Поэтому вероятность появления пакета ошибок декодирования в промежутке от до подблока ограничена сверху вероятностью того, что неравенство (6.9.37) не выполняется при всех рассмотренных выше способах выбора число этих способов меньше чем Так как эта вероятность не зависит от удобно выбрать
В ансамбле кодов подблоки до кодовой последовательности, соответствующей какому-либо из рассмотренных выше узлов статистически не зависят от подблоков от до кодовой последовательности, которая соответствует последовательности и (см. лемму 6.9.4). Поэтому согласно лемме 6.9.3 имеем при

Подставляя (6.9.39) в (6.9.33) и по получаем границу вероятности ошибки на подблок. Далее можно получить верхнюю границу, суммируя по от до и по с от до эти суммы можно вычислить согласно формуле суммы геометрической прогрессии
объясняется тем, что ограничения на блок данных в сверточном коде простираются вне данного блока, а отчасти тем, что декодеру разрешается проводить поиск во всем блоке принятых символов, прежде чем он примет какое-либо решение.
Юдкин (1964) с помощью более тонких методов, чем применявшиеся при выводе (6.9.43), получил верхнюю границу вероятности ошибки для последовательного декодирования при всех скоростях вплоть до пропускной способности, и его экспонента также представлена на рис. 6.9.7. Витерби (1967) недавно нашел нижнюю границу минимальной вероятности ошибки, которая может быть достигнута для сверточных кодов, и график соответствующего показателя экспоненты также изображен на рис. 6.9.7. Заметим, что последовательное декодирование имеет вероятность ошибки с наилучшей возможной экспонентой при и фактически наилучшую экспоненту при несколько меньших когда также конечно.
Граница вероятности ошибки (6.9.40) не зависит от общей длины и поэтому нет необходимости периодически вставлять концевую последовательность при последовательном декодировании. Вместе с тем при практическом применении, особенно если больше или равно 20, желательно выбирать конечным; это позволяет декодеру в тех редких случаях, когда поиск очень затягивается, считать принятый блок стертым и переходить к следующему блоку. Вероятность такого стирания, конечно, тесно связана с функцией распределения