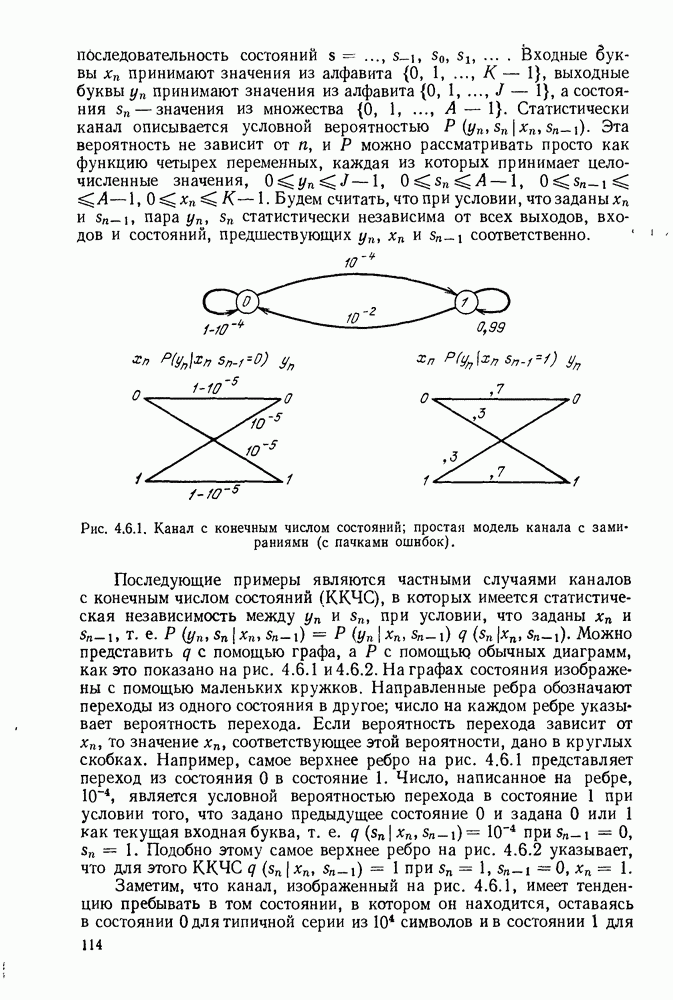
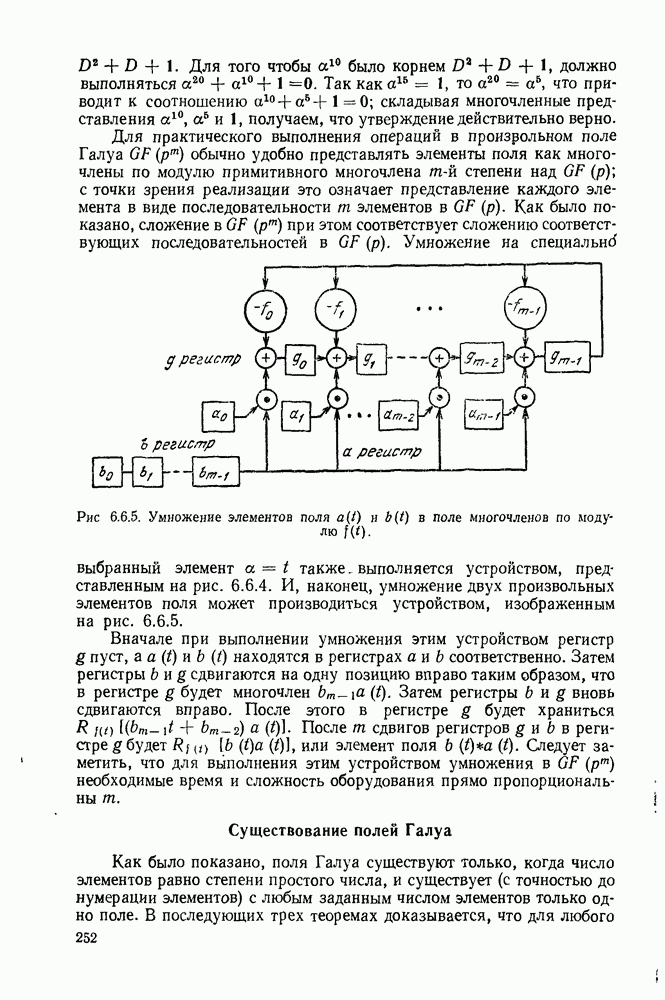
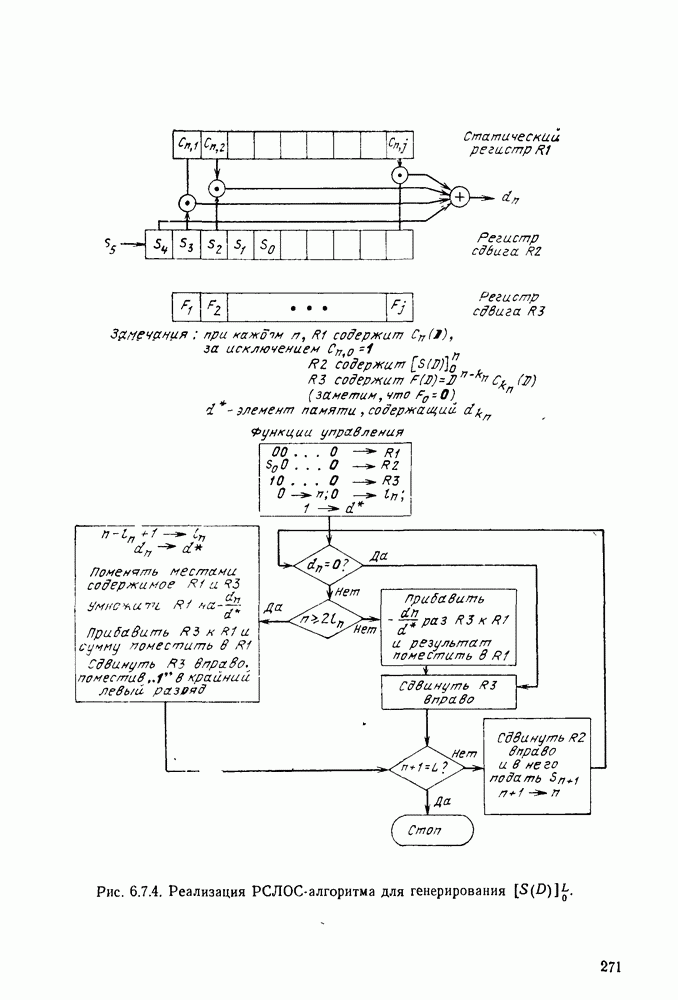
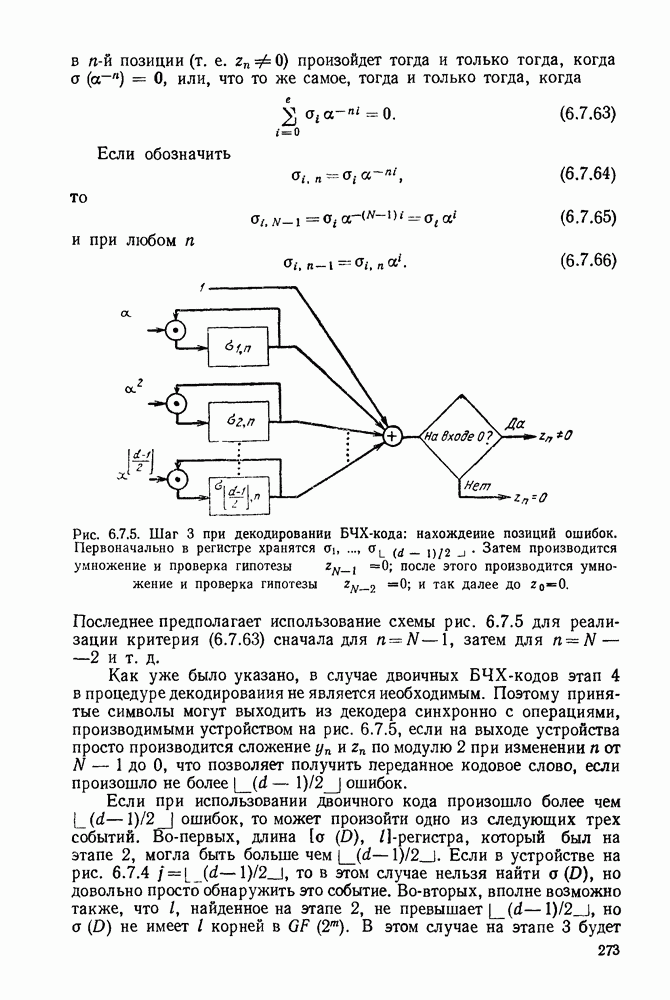
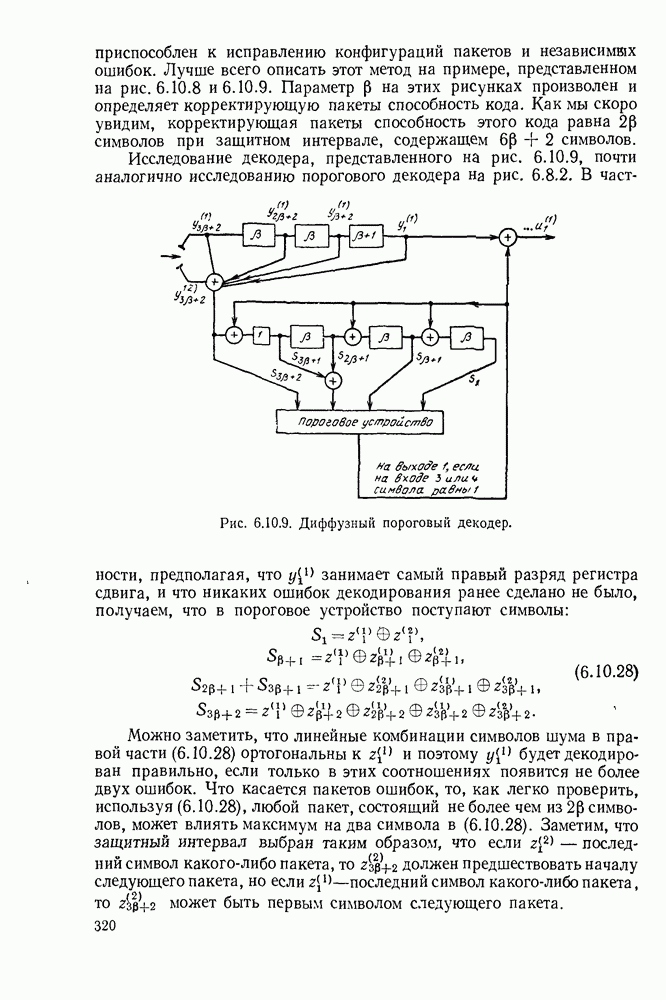
6.8. СВЕРТОЧНЫЕ КОДЫ И ПОРОГОВОЕ ДЕКОДИРОВАНИЕ
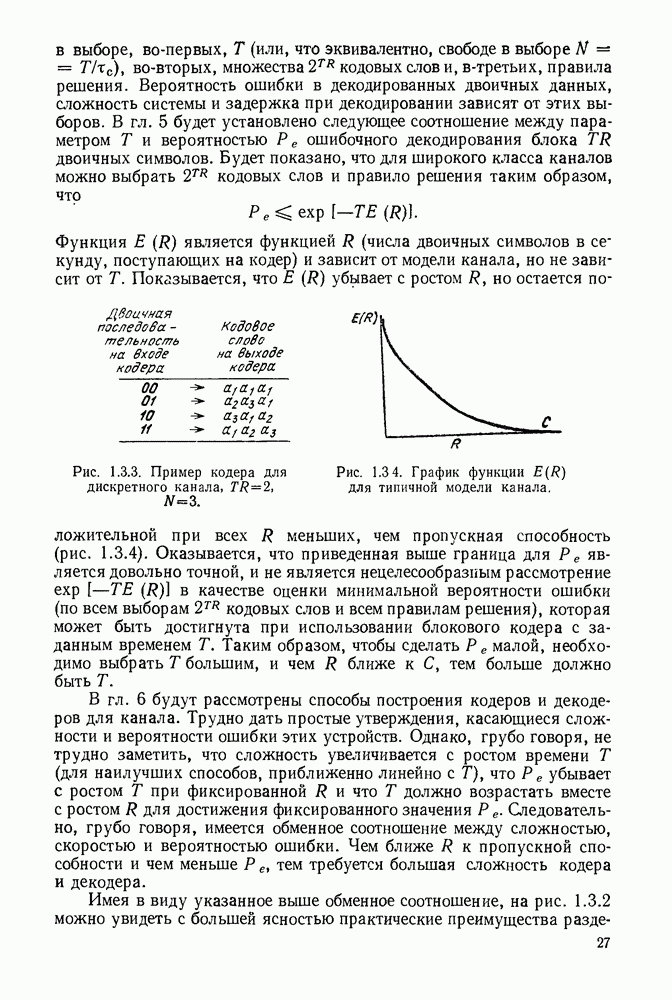
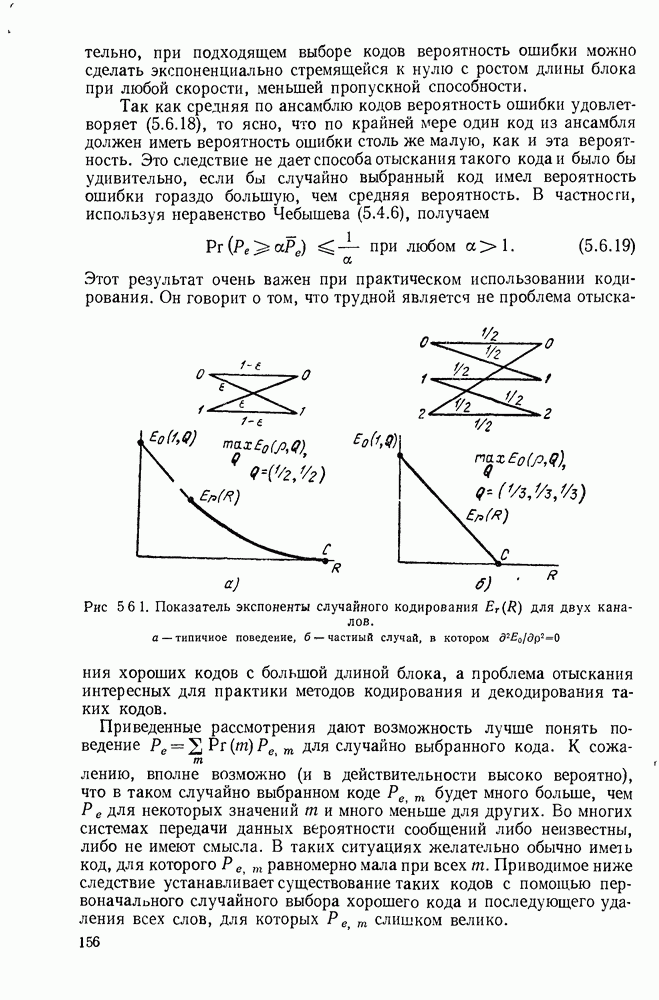
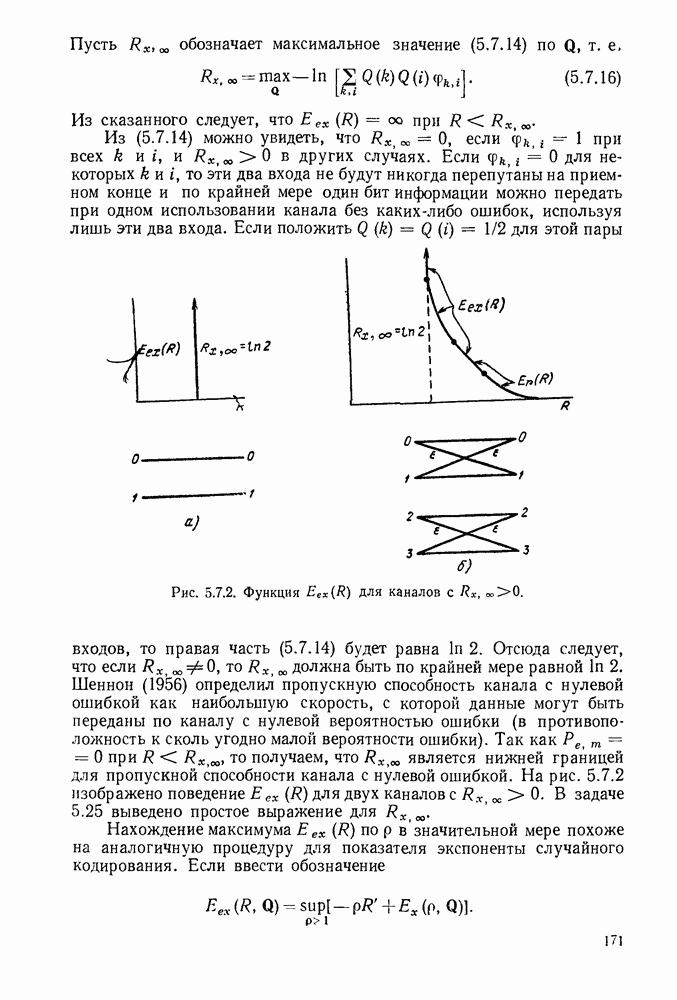
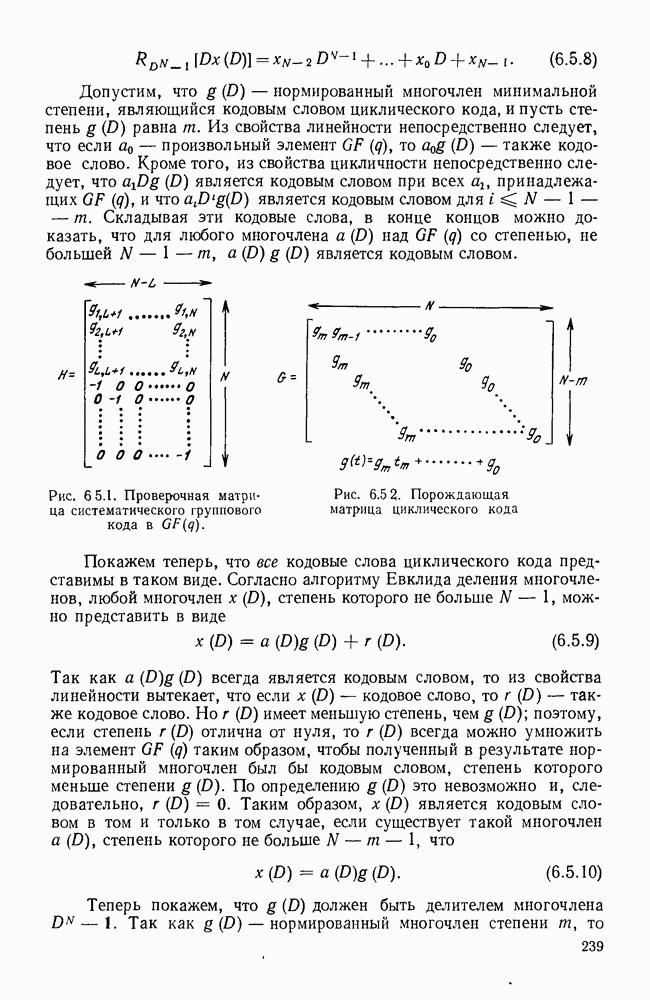
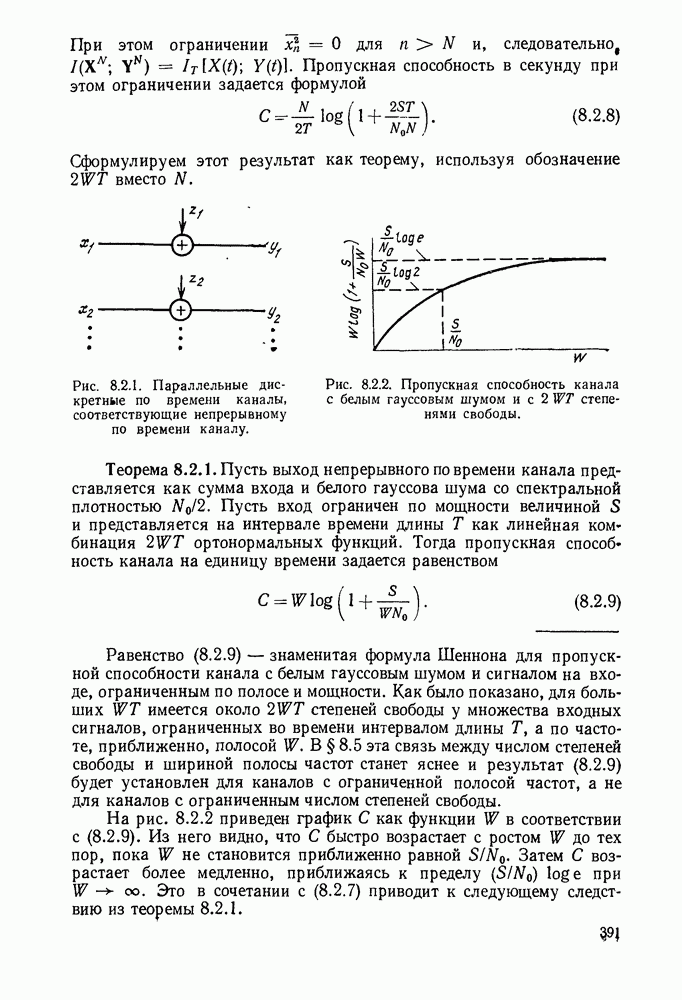
Сверточные коды, которые будут определены в этом параграфе, отличаются от всех ранее рассмотренных кодов тем, что они являются «еблоковыми кодами. Прежде чем определять эти коды, рассмотрим простой пример сверточного кода, иллюстрируемый рис. 6.8.1. В каждую единицу времени в кодер поступает новый двоичный символ источника  а каждый из ранее поступивших символов источника сдвигается в регистре сдвига на один разряд вправо. Новый символ источника поступает непосредственно в канал, так что
а каждый из ранее поступивших символов источника сдвигается в регистре сдвига на один разряд вправо. Новый символ источника поступает непосредственно в канал, так что  За каждым таким информационным символом следует проверочный символ
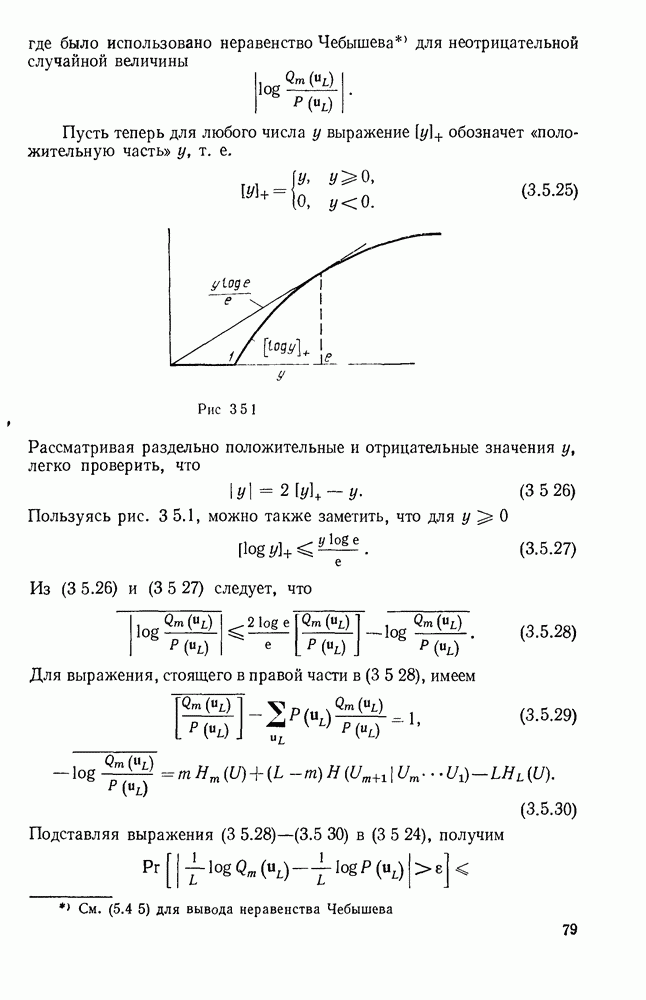
За каждым таким информационным символом следует проверочный символ


Предполагая, что в начальном положении регистр сдвига заполнен нулями и что передача начинается с  имеем
имеем  при
при  . Опишем теперь очень простой метод декодирования этого кода для случая передачи по двоичному каналу — пороговое декодирование.
. Опишем теперь очень простой метод декодирования этого кода для случая передачи по двоичному каналу — пороговое декодирование.

Рис. 6.8.1. Пример сверточного кода.
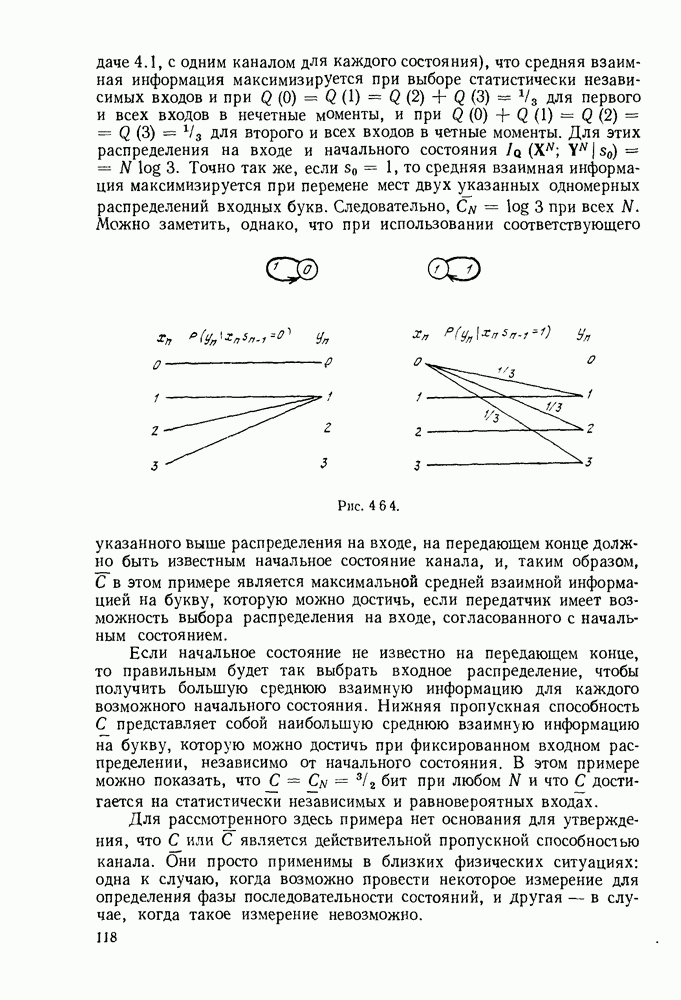
Пусть

где  Как и для кодов с проверкой на четность, определим синдром
Как и для кодов с проверкой на четность, определим синдром  с помощью формулы
с помощью формулы

Следовательно,  если выполнена
если выполнена  проверка на четность, вычисленная в приемнике, и
проверка на четность, вычисленная в приемнике, и  в противном случае. Из (6.8.2) также имеем
в противном случае. Из (6.8.2) также имеем

Расписывая эти равенства при получаем:

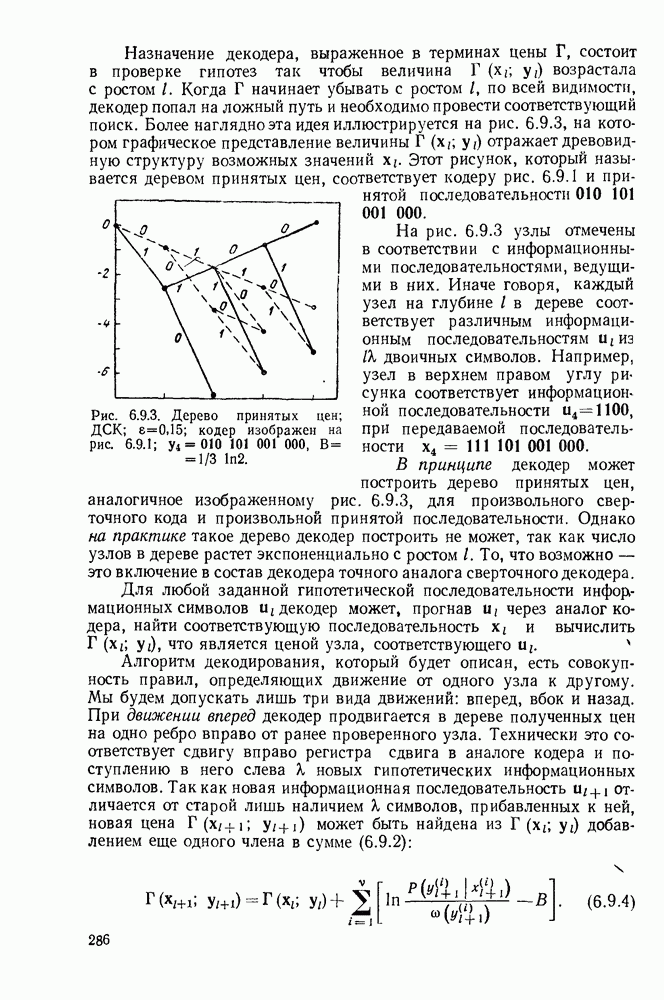
Теперь остановимся на декодировании первого информационного символа их, декодирование эквивалентно определению, является ли  единицей или нулем. Отметим, что величины
единицей или нулем. Отметим, что величины  непосредственно содержат
непосредственно содержат  Например, если
Например, если  и никоих, других ошибок не произошло, все элементы
и никоих, других ошибок не произошло, все элементы  равны 1,
равны 1,
тогда как, если ни одной ошибки не произошло, все они равны 0. Это позволяет применить следующую стратегию декодирования: если большинство из элементов  и 56 равно 1, то полагаем
и 56 равно 1, то полагаем  в противном случае полагаем
в противном случае полагаем 
К описанной выше стратегии декодирования можно применить следующее простое усовершенствование. Легко видеть, что  содержится в выражениях как для
содержится в выражениях как для  так и для 5в, поэтому если
так и для 5в, поэтому если  то
то  и 56 будут равны
и 56 будут равны  и 54 будут равны 1, и в результате декодирование будет неправильным. Этой трудности можно избежать, суммируя
и 54 будут равны 1, и в результате декодирование будет неправильным. Этой трудности можно избежать, суммируя  что приводит к соотношениям:
что приводит к соотношениям:

Множество линейных комбинаций шумовых символов называется ортогональным к одному из шумовых символов, если этот символ входит (с ненулевыми коэффициентами) в каждую из линейных комбинаций того множества и ни один другой символ не входит (с ненулевыми коэффициентами) более чем в одну из этих линейных комбинаций. Таким образом, множество четырех линейных комбинаций в правой части (6.8.6) ортогонально к  Заметим, что если
Заметим, что если  и все остальные
и все остальные  входящие в линейные комбинации из множества, равны 0, то значения всех четырех линейных комбинаций отличны от нуля. Если произойдет одна дополнительная ошибка (т. е.
входящие в линейные комбинации из множества, равны 0, то значения всех четырех линейных комбинаций отличны от нуля. Если произойдет одна дополнительная ошибка (т. е.  для одного из других символов), то в силу ортогональности по меньшей мере значения трех линейных комбинаций будут отличны от нуля. Вместе с тем, если
для одного из других символов), то в силу ортогональности по меньшей мере значения трех линейных комбинаций будут отличны от нуля. Вместе с тем, если  и по крайней мере два других шумовых символа, входящих в совокупность, ненулевые, то значения не более чем двух линейных комбинаций отличны от нуля. Поэтому, если декодер после вычисления значений элементов, стоящих в левой части (6.8.6), положит
и по крайней мере два других шумовых символа, входящих в совокупность, ненулевые, то значения не более чем двух линейных комбинаций отличны от нуля. Поэтому, если декодер после вычисления значений элементов, стоящих в левой части (6.8.6), положит  равным 1, когда большинство из этих символов равно 1, и положит
равным 1, когда большинство из этих символов равно 1, и положит  в противном случае, то
в противном случае, то  будет декодировано правильно, если число ненулевых шумовых символов в (6.8.6) не превышает два. Этот принцип непосредственно обобщает следующая теорема, утверждение которой справедливо для произвольного поля, хотя здесь будет рассматриваться
будет декодировано правильно, если число ненулевых шумовых символов в (6.8.6) не превышает два. Этот принцип непосредственно обобщает следующая теорема, утверждение которой справедливо для произвольного поля, хотя здесь будет рассматриваться 
Теорема 6.8.1. Предположим, что при произвольном положительном целом  декодер может вычислить значения
декодер может вычислить значения  линейных комбинаций шумовых символов, образующих множество, ортогональное к
линейных комбинаций шумовых символов, образующих множество, ортогональное к  Тогда если число ненулевых шумовых символов, входящих в линейные комбинации, не превышает
Тогда если число ненулевых шумовых символов, входящих в линейные комбинации, не превышает  то к правильному декодированию
то к правильному декодированию  приводит следующее правило. Если более половины линейных комбинаций имеют одно и то же значение а, то декодер полагает
приводит следующее правило. Если более половины линейных комбинаций имеют одно и то же значение а, то декодер полагает  в противном случае декодер полагает
в противном случае декодер полагает 
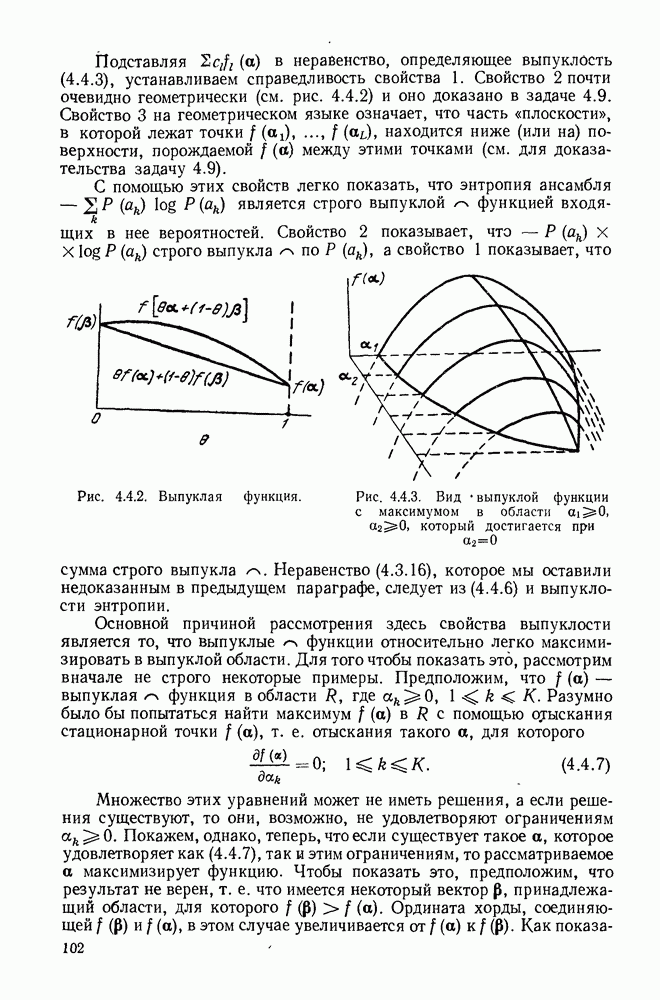
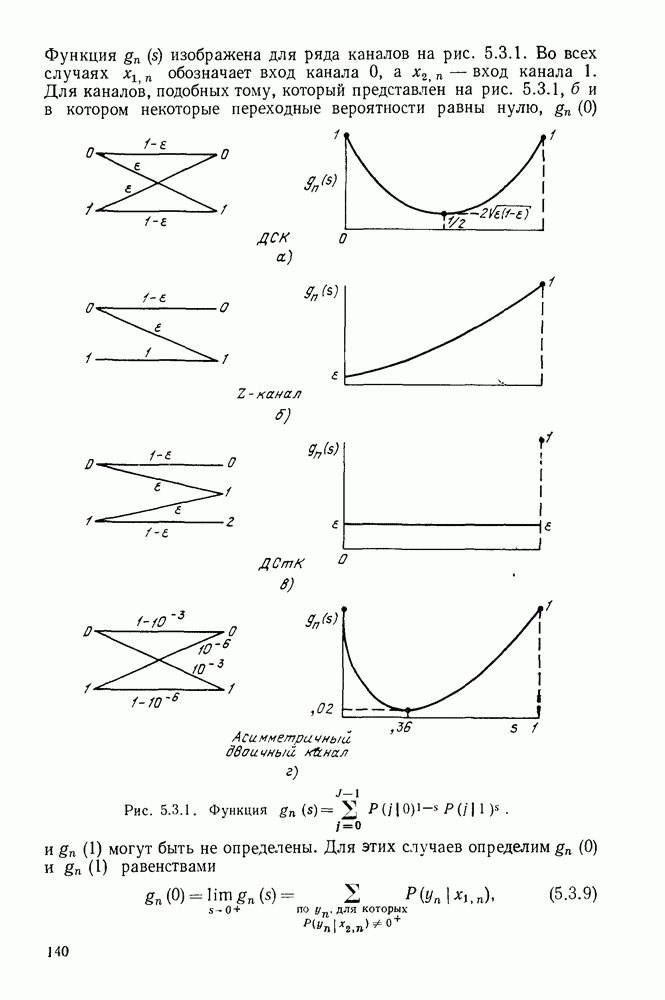
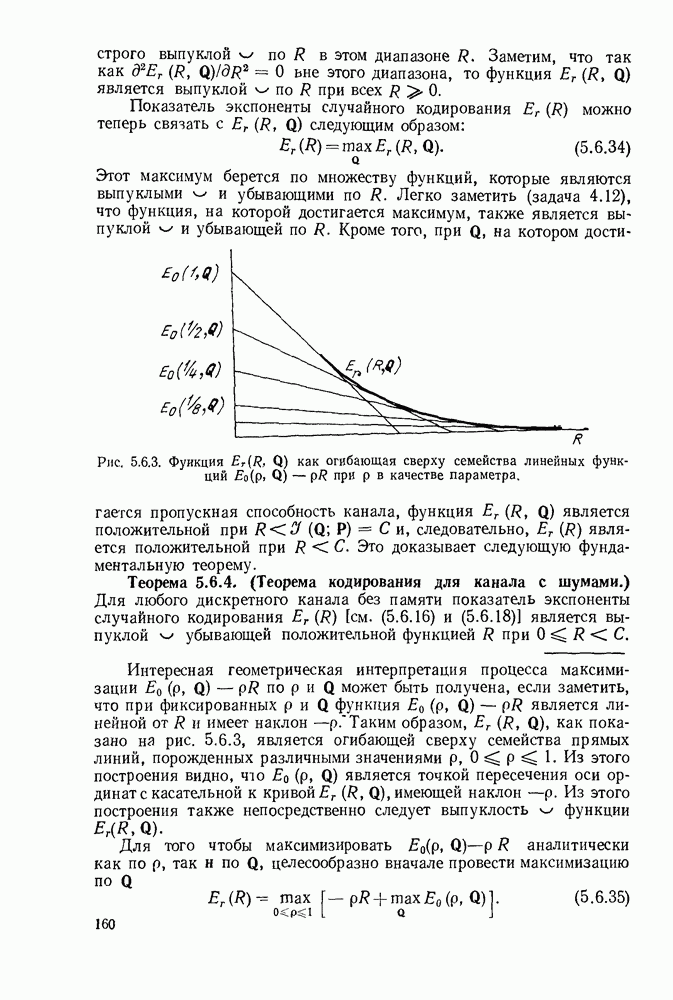
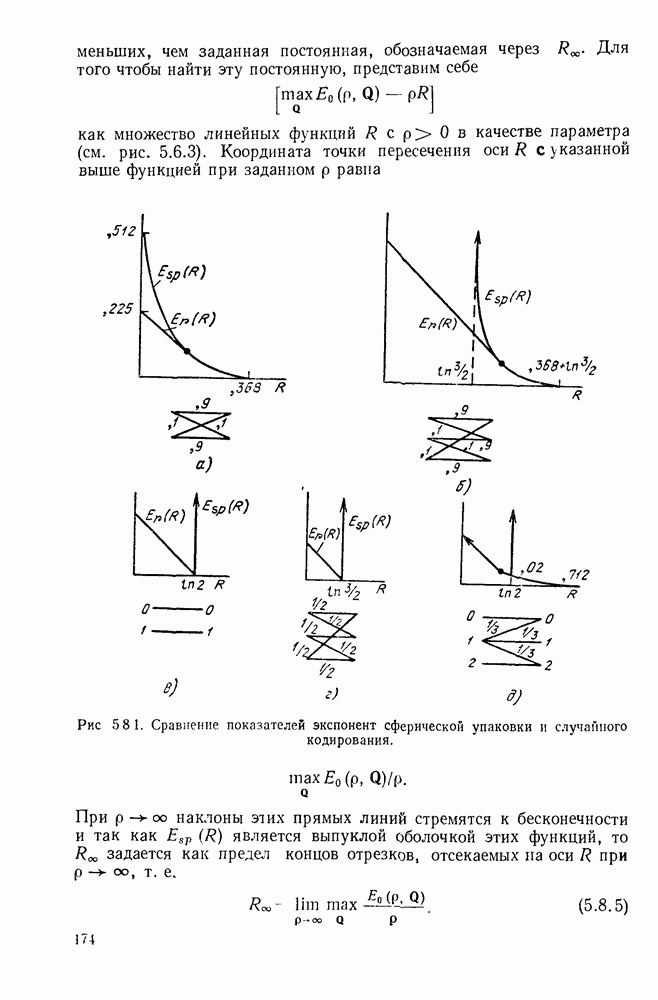
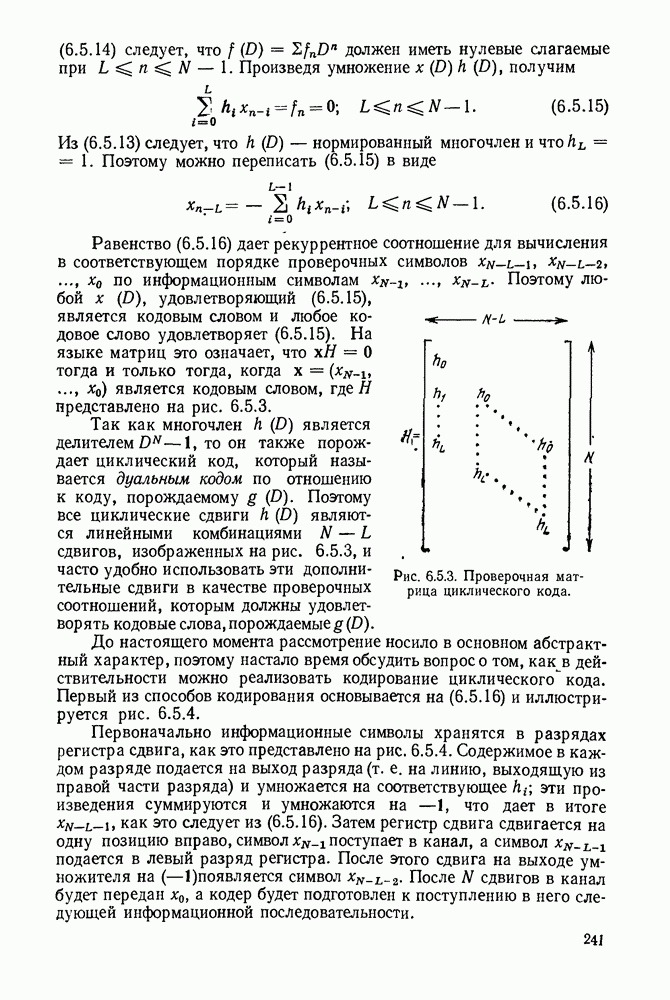
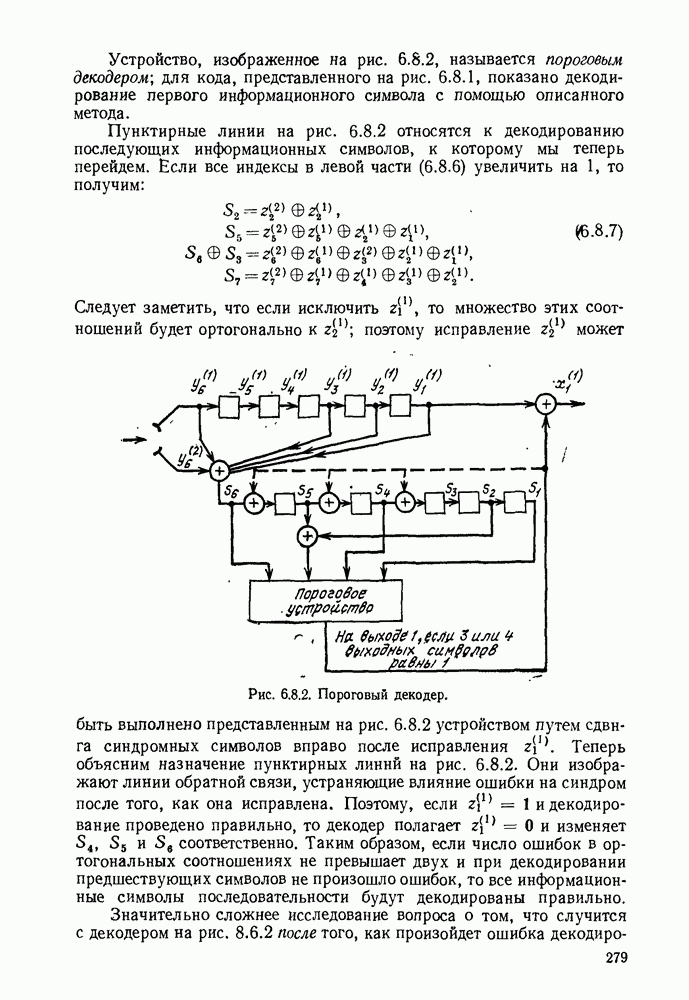
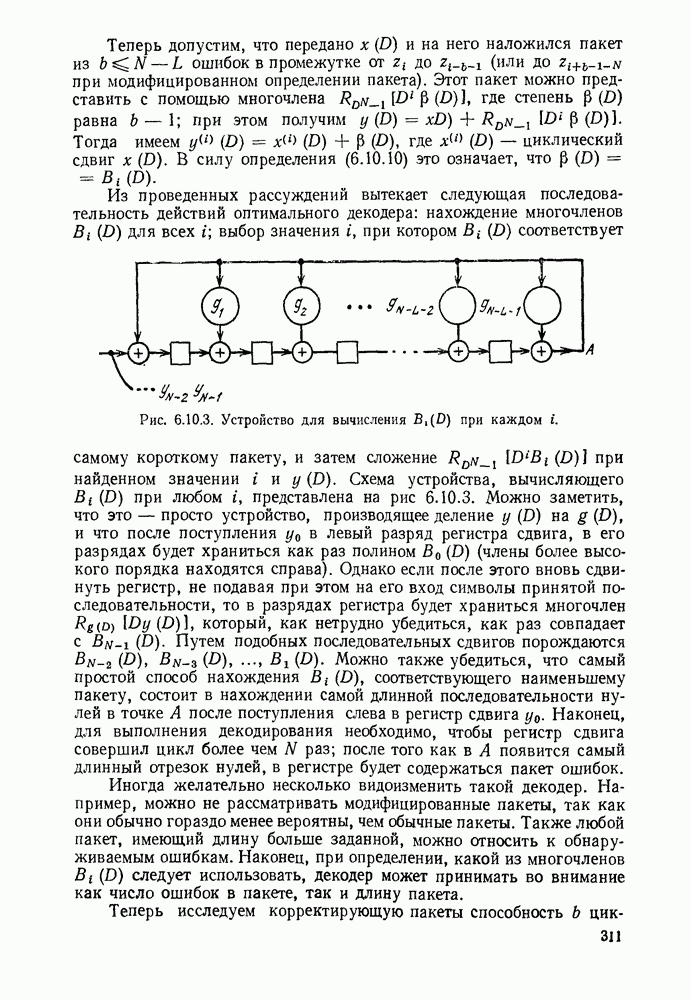
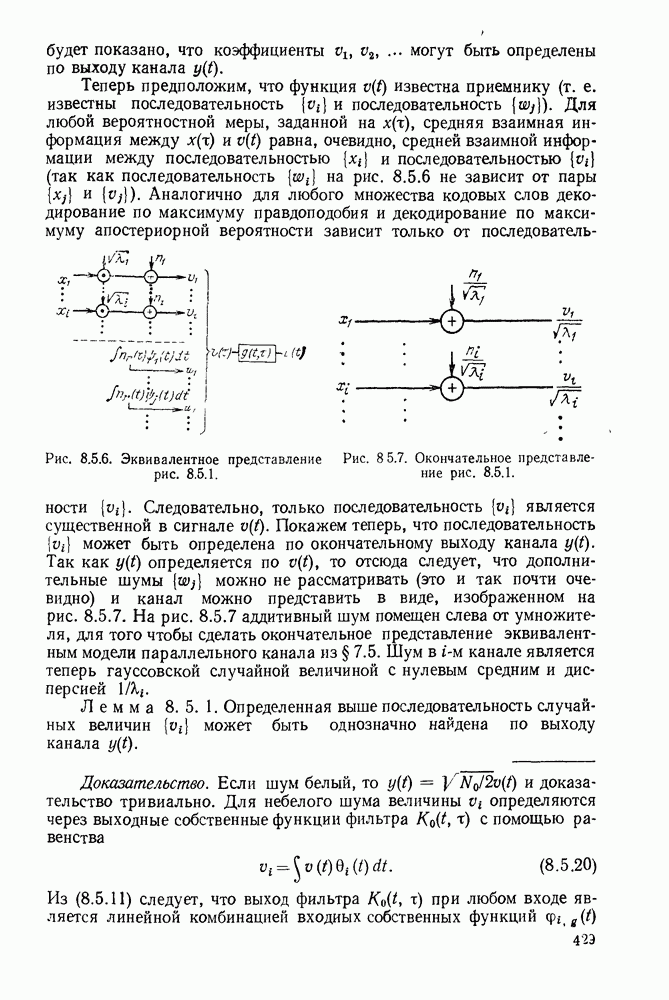
Устройство, изображенное на рис. 6.8.2, называется пороговым декодером-, для кода, представленного на рис. 6.8.1, показано декодирование первого информационного символа с помощью описанного метода.
Пунктирные линии на рис. 6.8.2 относятся к декодированию последующих информационных символов, к которому мы теперь перейдем. Если все индексы в левой части (6.8.6) увеличить на 1, то получим:

Следует заметить, что если исключить  то множество этих соотношений будет ортогонально к
то множество этих соотношений будет ортогонально к  поэтому исправление
поэтому исправление  может быть выполнено представленным на рис. 6.8.2 устройством путем сдвига синдромных символов вправо после исправления
может быть выполнено представленным на рис. 6.8.2 устройством путем сдвига синдромных символов вправо после исправления 

Рис. 6.8.2. Пороговый декодер.
Теперь объясним назначение пунктирных линнй на рис. 6.8.2. Они изображают линии обратной связи, устраняющие влияние ошибки на синдром после того, как она исправлена. Поэтому, если  и декодирование проведено правильно, то декодер полагает
и декодирование проведено правильно, то декодер полагает  и изменяет
и изменяет  соответственно. Таким образом, если число ошибок в ортогональных соотношениях не превышает двух и при декодировании предшествующих символов не произошло ошибок, то все информационные символы последовательности будут декодированы правильно.
соответственно. Таким образом, если число ошибок в ортогональных соотношениях не превышает двух и при декодировании предшествующих символов не произошло ошибок, то все информационные символы последовательности будут декодированы правильно.
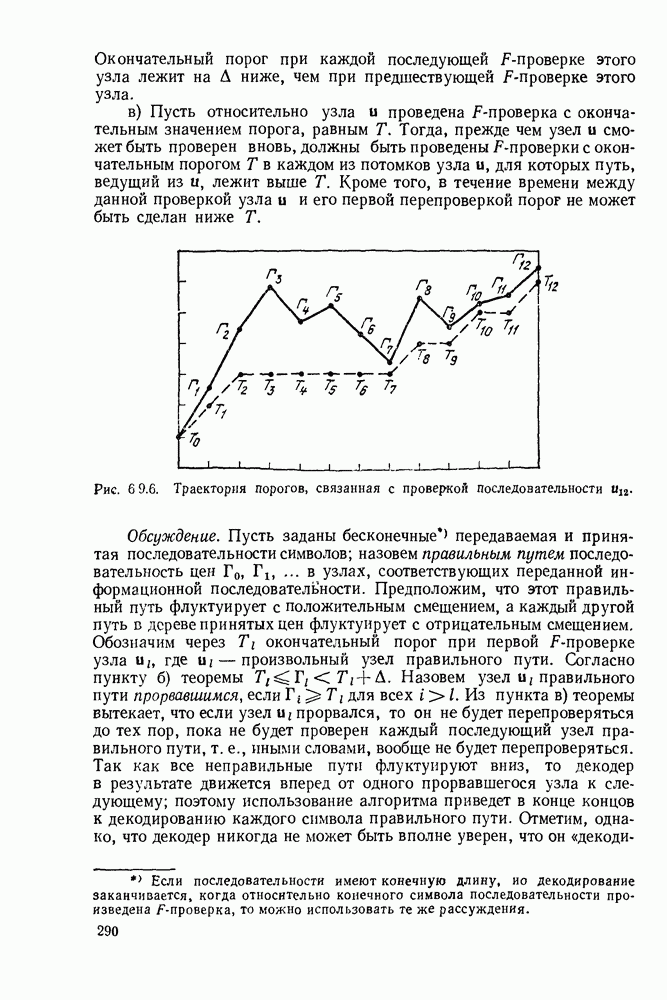
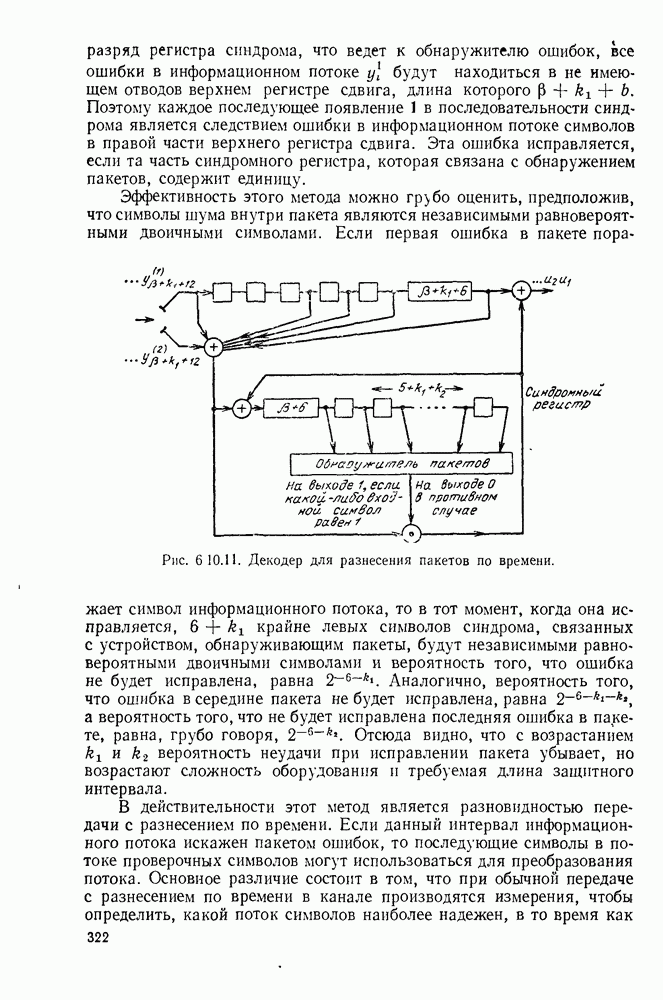
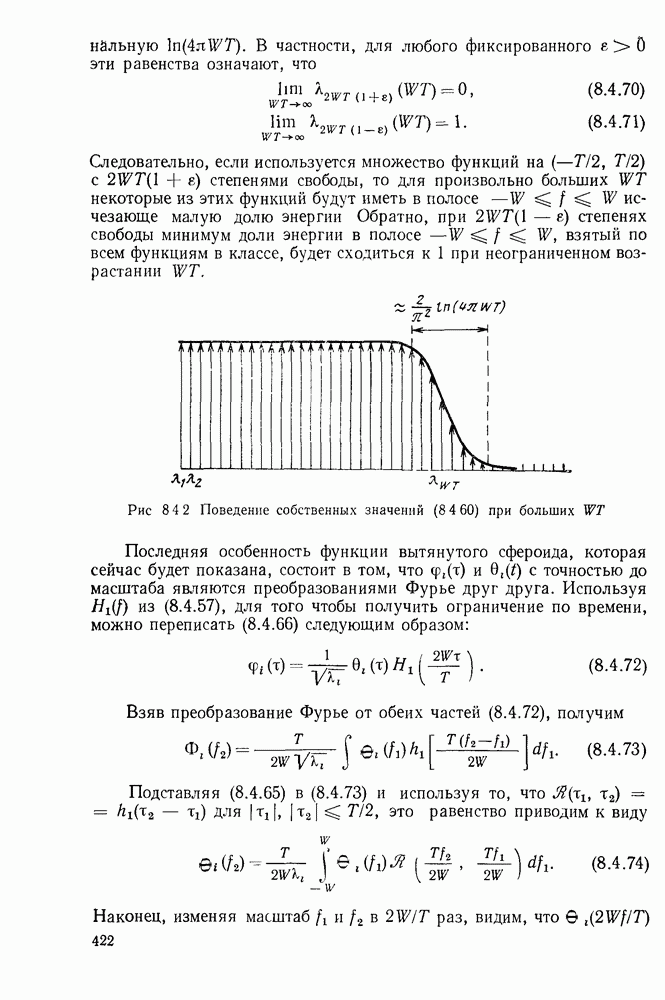
Значительно сложнее исследование вопроса о том, что случится с декодером на рис. 8.6.2 после того, как произойдет ошибка
декодирования. Экспериментальные исследования показали, что, как правило, после того как декодер совершит ошибку декодирования, он сделает еще  ошибки при декодировании последующих примерно пяти символов, а затем вновь будет декодировать правильно. Для рассмотренного частного кода Месси (1964) теоретически показал, что поступление в декодер достаточно длинной последовательности неискаженных символов после ошибки декодирования возвращает декодер к правильному декодированию. Это стремление к размножению ошибок характерно для схем декодирования сверточных кодов. Для очень простых кодов и декодеров типа рассмотренных выше это размножение ошибок не слишком серьезно и обычно приводит лишь к коротким пакетам ошибок декодирования. Однако если увеличивать длину кодового ограничения и усложнять схему декодирования, то это размножение ошибок приводит к более серьезным последствиям. Вместе с тем, чем серьезнее становится проблема размножения ошибок, тем легче декодеру распознать наличие ошибки декодирования. Если декодер имеет обратную связь с передатчиком, то передатчик может затем повторить передачу пропавших данных. Кроме того, в кодер можно периодически подавать известную последовательность нулей, после чего декодер может начинать декодирование сначала.
ошибки при декодировании последующих примерно пяти символов, а затем вновь будет декодировать правильно. Для рассмотренного частного кода Месси (1964) теоретически показал, что поступление в декодер достаточно длинной последовательности неискаженных символов после ошибки декодирования возвращает декодер к правильному декодированию. Это стремление к размножению ошибок характерно для схем декодирования сверточных кодов. Для очень простых кодов и декодеров типа рассмотренных выше это размножение ошибок не слишком серьезно и обычно приводит лишь к коротким пакетам ошибок декодирования. Однако если увеличивать длину кодового ограничения и усложнять схему декодирования, то это размножение ошибок приводит к более серьезным последствиям. Вместе с тем, чем серьезнее становится проблема размножения ошибок, тем легче декодеру распознать наличие ошибки декодирования. Если декодер имеет обратную связь с передатчиком, то передатчик может затем повторить передачу пропавших данных. Кроме того, в кодер можно периодически подавать известную последовательность нулей, после чего декодер может начинать декодирование сначала.
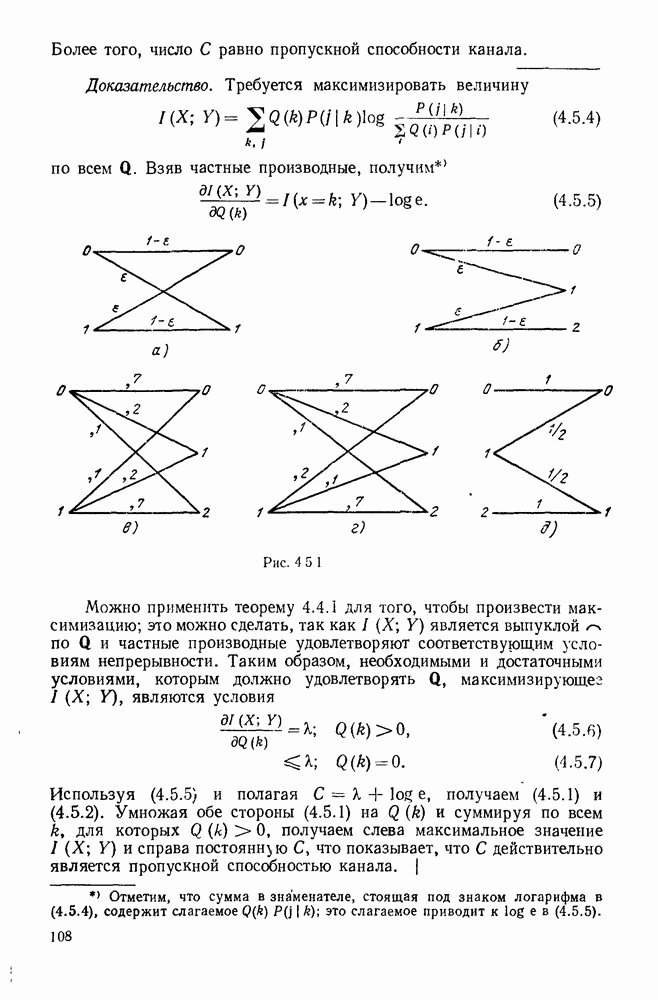
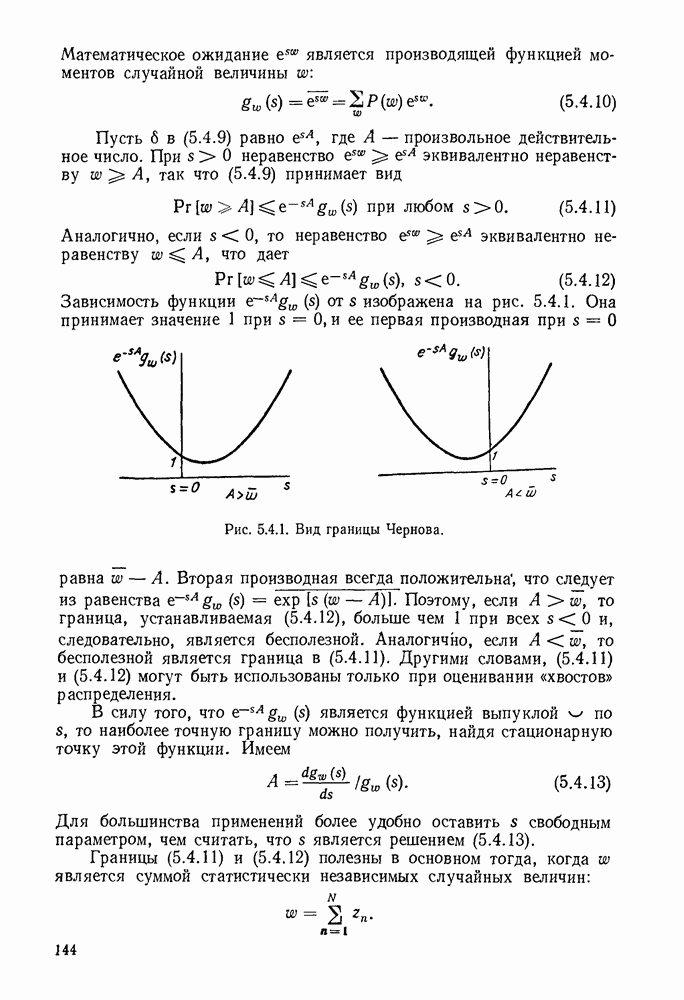
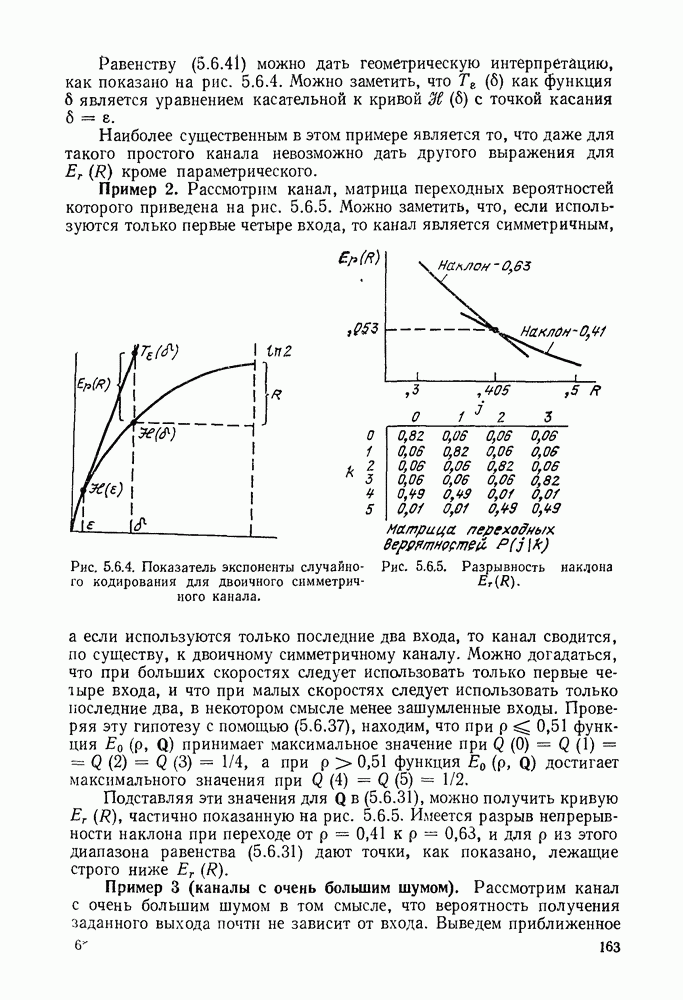
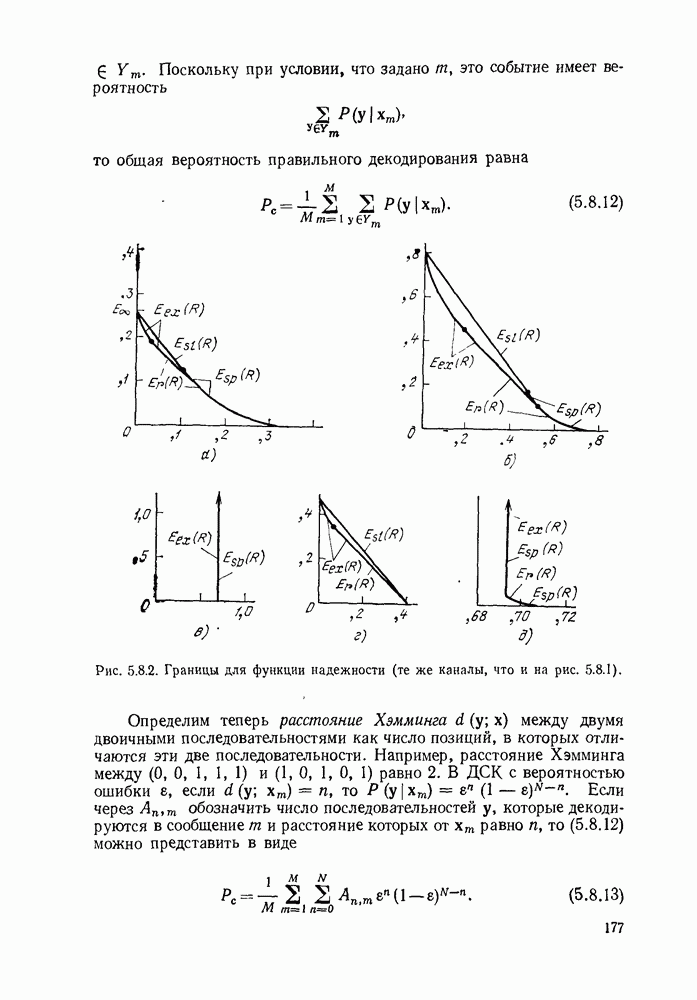
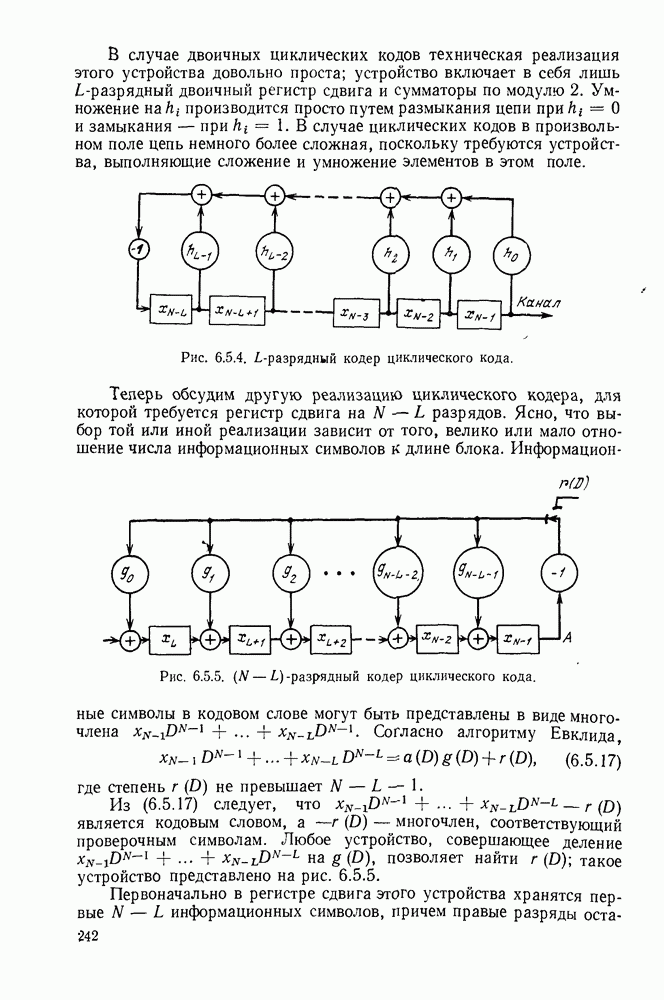
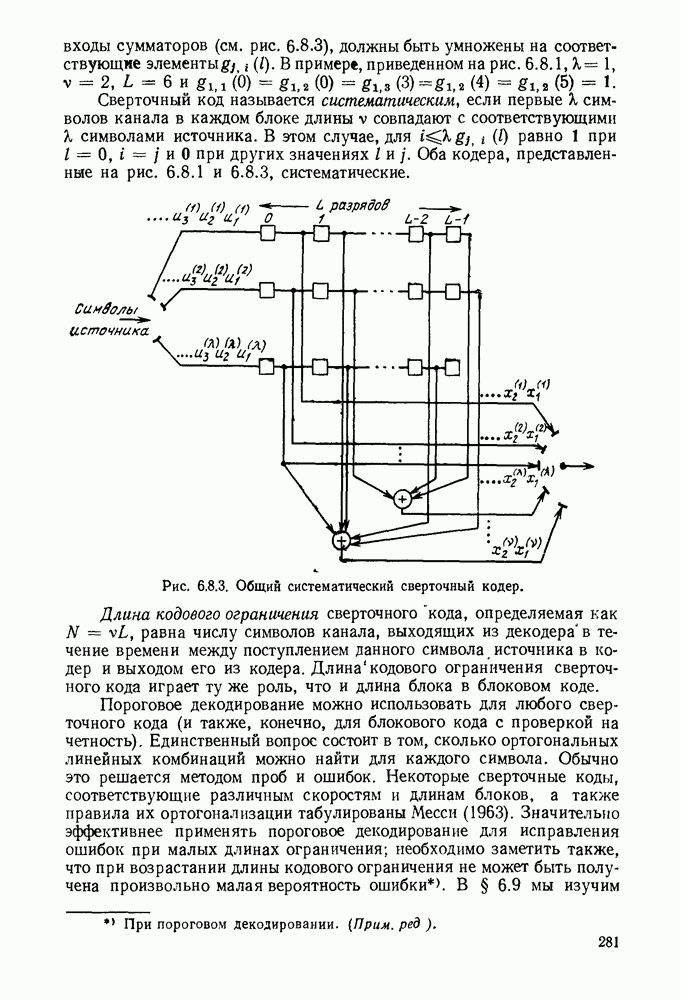
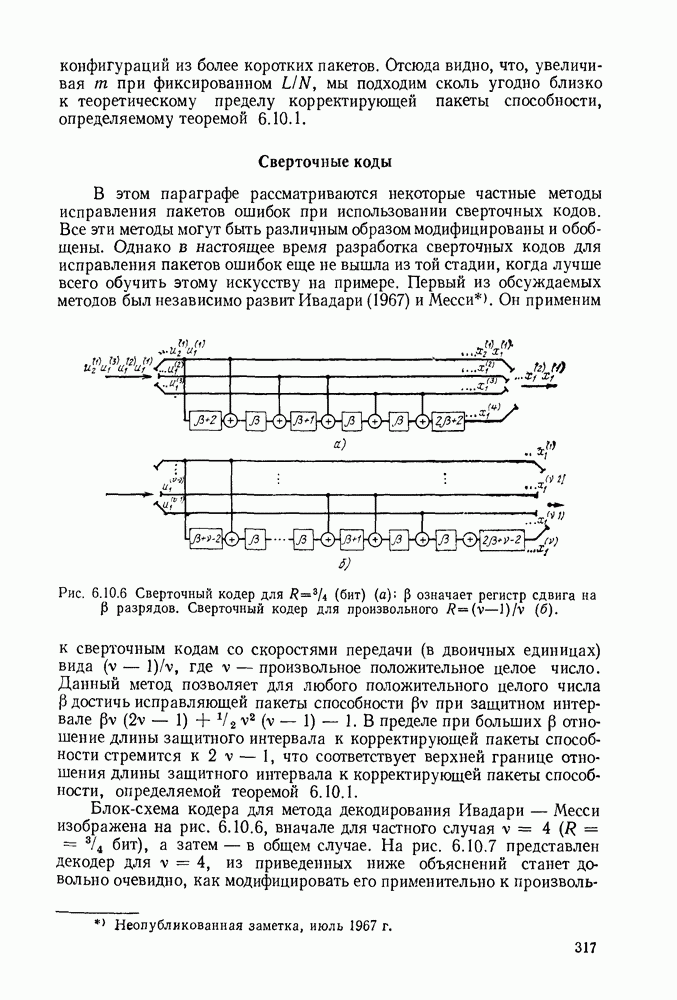
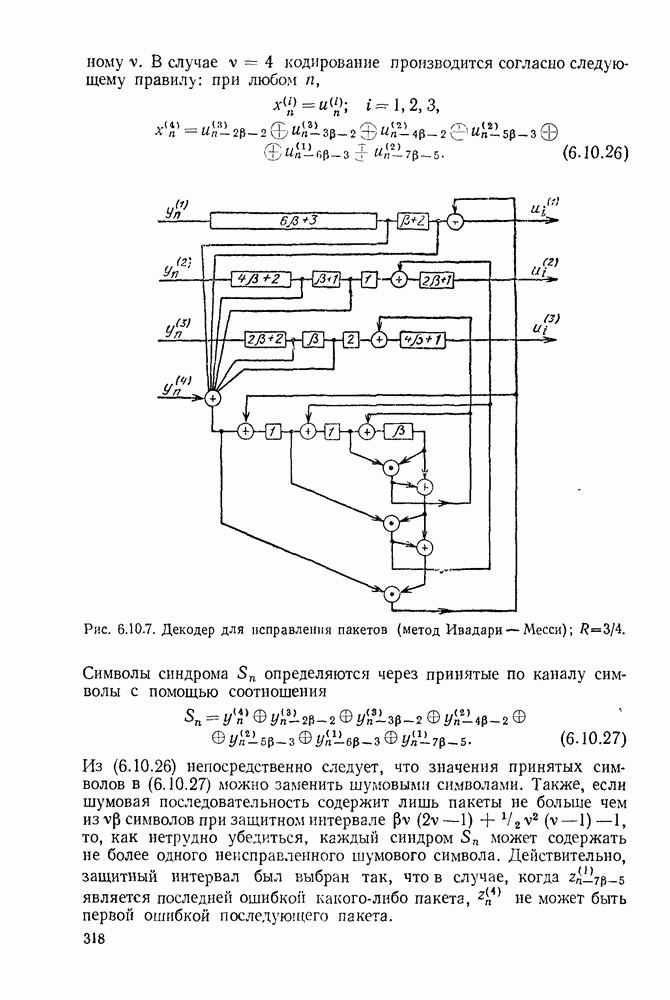
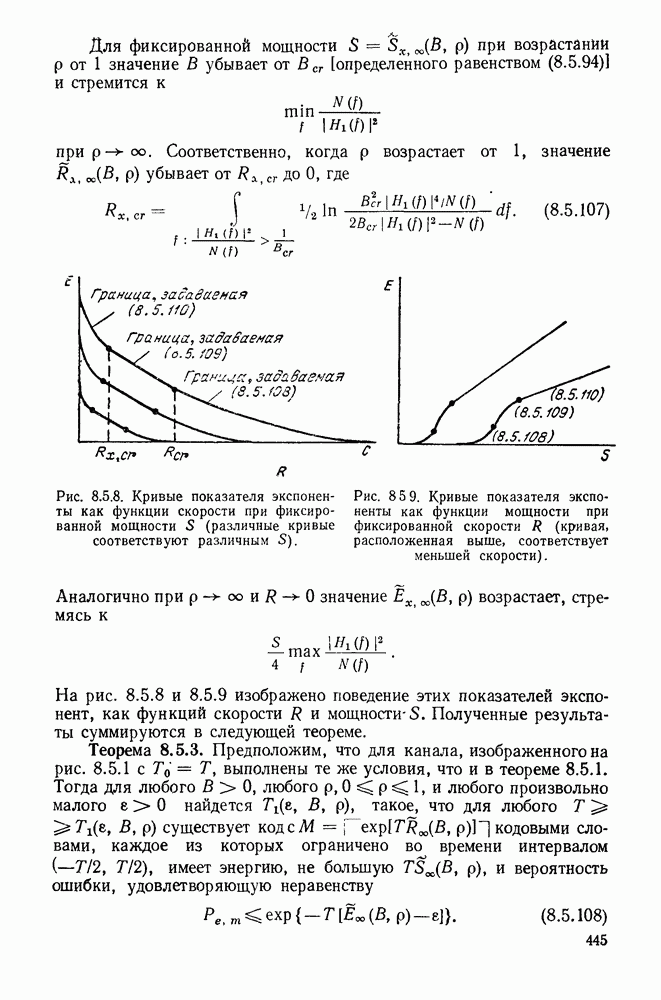
Пример сверточного кодера, представленный на рис. 6.8.1, можно теперь обобщить в трех направлениях. Во-первых, можно произвольно выбрать длину регистра сдвига и его отводы, определяющие проверочные символы. Во-вторых, можно сделать так, чтобы символы источника и символы канала были бы элементами произвольного поля Галуа. Наконец, можно обобщить коды на скорости, отличные от скорости «один символ источника на два символа канала». Для того чтобы провести это последнее обобщение, разделим последовательность символов источника на блоки заданной длины  Каждому множеству символов источника кодер ставит в соответствие данное число
Каждому множеству символов источника кодер ставит в соответствие данное число  символов канала, как показано на рис. 6.8.3. Если обозначить последовательность источника
символов канала, как показано на рис. 6.8.3. Если обозначить последовательность источника  и последовательность символов канала
и последовательность символов канала  правило образования символов канала по символам источника можно записать в виде
правило образования символов канала по символам источника можно записать в виде

где  (как показано на рис. 6.8.3) — длина регистра сдвига, а элементы
(как показано на рис. 6.8.3) — длина регистра сдвига, а элементы  определяют связи между регистрами сдвига и сумматорами. При суммировании по модулю 2 коэффициент
определяют связи между регистрами сдвига и сумматорами. При суммировании по модулю 2 коэффициент  если 1-й разряд
если 1-й разряд  регистра сдвига связан с сумматором, образующим
регистра сдвига связан с сумматором, образующим  поток символов канала. В общем случае все элементы
поток символов канала. В общем случае все элементы  принадлежат данному полю Галуа и элементы, поступающие на
принадлежат данному полю Галуа и элементы, поступающие на
входы сумматоров (см. рис. 6.8.3), должны быть умножены на соответствующие элементы  . В примере, приведенном на рис.
. В примере, приведенном на рис. 
Сверточный код называется систематическим, если первые  символов канала в каждом блоке длины
символов канала в каждом блоке длины  совпадают с соответствующими X символами источника. В этом случае, для
совпадают с соответствующими X символами источника. В этом случае, для  равно 1 при
равно 1 при  и 0 при других значениях
и 0 при других значениях  Оба кодера, представленные на рис. 6.8.1 и 6.8.3, систематические.
Оба кодера, представленные на рис. 6.8.1 и 6.8.3, систематические.

Рис. 6.8.3. Общин систематический сверточный кодер.
Длина кодового ограничения сверточного кода, определяемая как  равна числу символов канала, выходящих из декодера в течение времени между поступлением данного символа источника в кодер и выходом его из кодера. Длинакодового ограничения сверточного кода играет ту же роль, что и длина блока в блоковом коде.
равна числу символов канала, выходящих из декодера в течение времени между поступлением данного символа источника в кодер и выходом его из кодера. Длинакодового ограничения сверточного кода играет ту же роль, что и длина блока в блоковом коде.
Пороговое декодирование можно использовать для любого сверточного кода (и также, конечно, для блокового кода с проверкой на четность). Единственный вопрос состоит в том, сколько ортогональных линейных комбинаций можно найти для каждого символа. Обычно это решается методом проб и ошибок. Некоторые сверточные коды, соответствующие различным скоростям и длинам блоков, а также правила их ортогонализации табулированы Месси (1963). Значительно эффективнее применять пороговое декодирование для исправления ошибок при малых длинах ограничения; необходимо заметить также, что при возрастании длины кодового ограничения не может быть получена произвольно малая вероятность ошибки. В § 6.9 мы изучим
другой метод декодирования сверточных кодов — последовательное декодирование, для которого вероятность ошибки может быть сделана произвольно малой с помощью увеличения длины кодового ограничения.