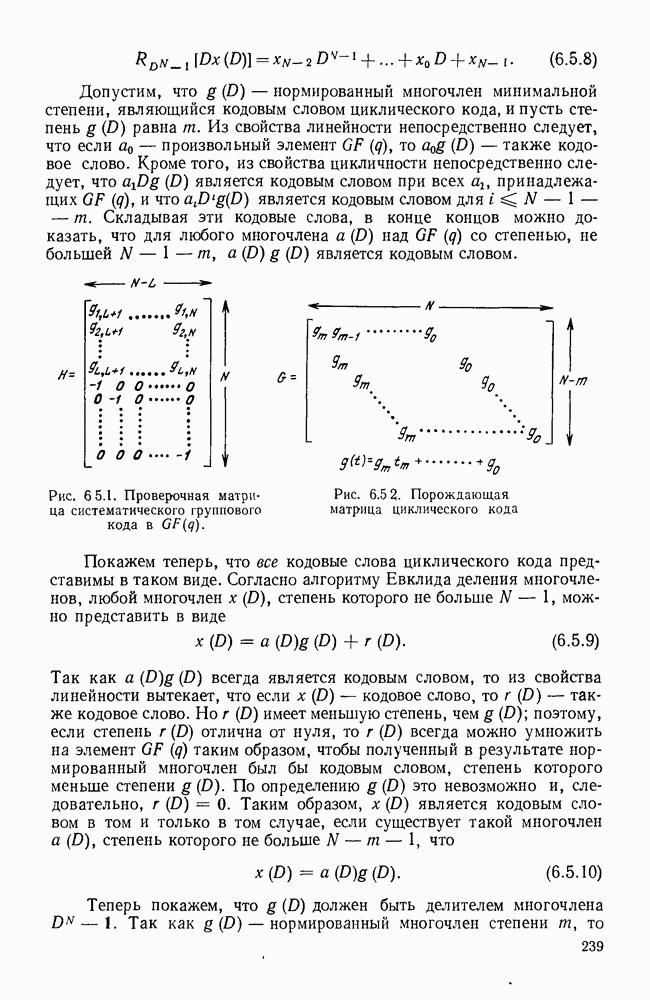
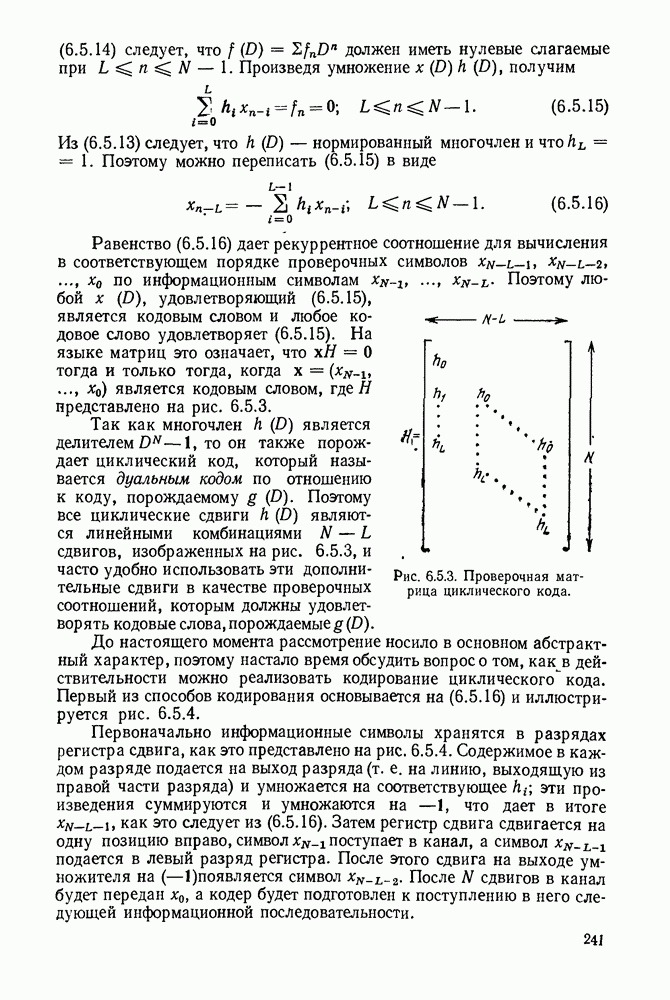
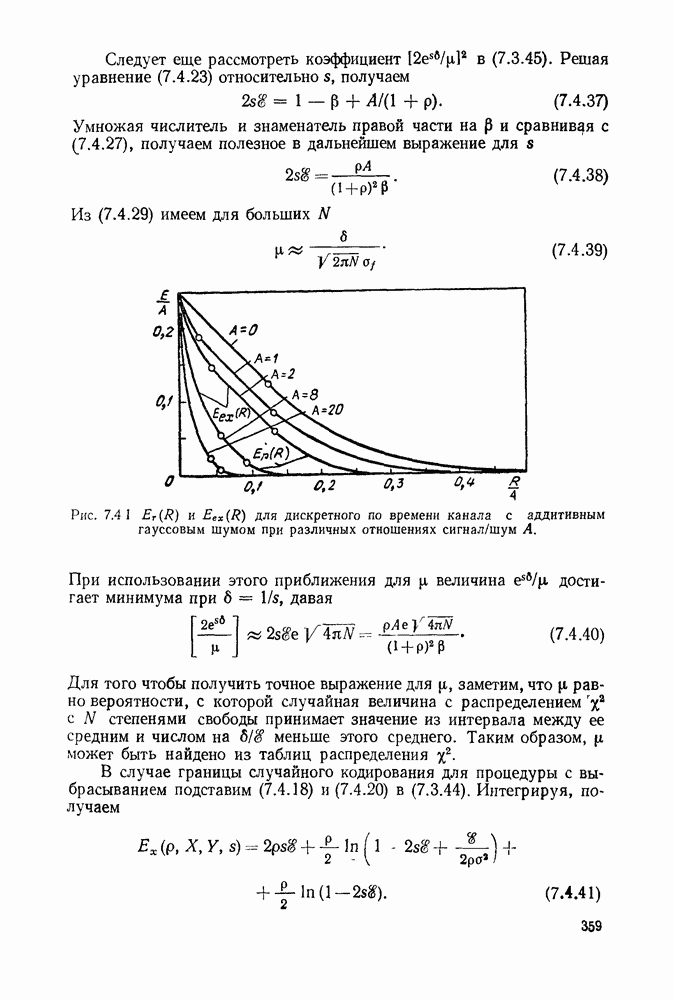
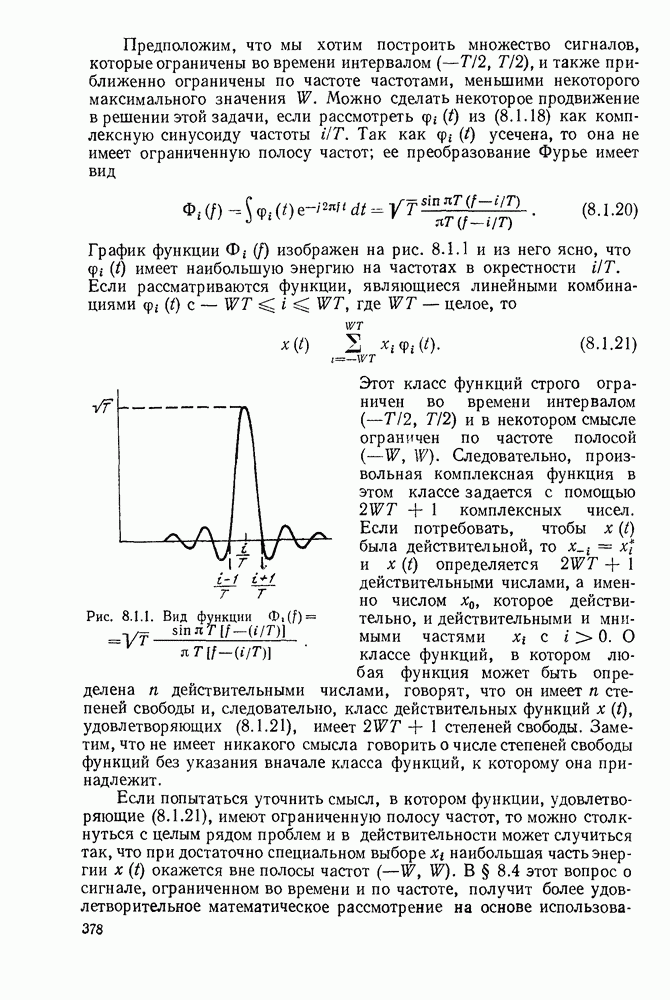
6.10. КОДИРОВАНИЕ В КАНАЛАХ С ПАКЕТАМИ ОШИБОК
В предыдущих параграфах в основном рассматривались методы кодирования в каналах без памяти. В этом параграфе рассматриваются каналы с двоичными входными и выходным алфавитами, в которых ошибки передачи имеют тенденцию к объединению в пакеты. Большинство двоичных систем связи (за исключением космических каналов) ведет себя именно таким образом. Трудно найти вероятностные модели этих каналов, которые подходили бы для целей изучения в них кодирования. Недостаточно найти модель, которая описывала бы типичное поведение канала, поскольку при отклонении поведения канала от типичного любой разумный метод кодирования приведет к ошибке декодирования. Причинами нетипичного поведения канала служат различные редкие события, которые по своей природе затрудняют вероятностное моделирование. По этой причине не будем исследовать вероятность ошибки для различных методов кодирования в этих каналах, а найдем другие меры их характеристики.
Наиболее естественным методом кодирования, используемым в каналах с пакетами ошибок, является обнаружение ошибок и переспрос. В этом случае данные на выходе источника кодируются кодом с проверкой на четность (лучше всего, в силу простоты реализации, использовать циклический код). Приемник вычисляет для принятой последовательности синдром  и если
и если  то считается, что информационные символы приняты без ошибок. Если
то считается, что информационные символы приняты без ошибок. Если  , приемник запрашивает, чтобы передатчик повторил данное кодовое слово. При этом
, приемник запрашивает, чтобы передатчик повторил данное кодовое слово. При этом
ошибка декодирования произойдет только в том случае, если в передаче произойдут ошибки и последовательность ошибок совпадает с одним из кодовых слов. Для  -кода с проверкой на четность кодовыми словами являются лишь
-кода с проверкой на четность кодовыми словами являются лишь  последовательностей из общего числа
последовательностей из общего числа  последовательностей длины N или лишь одна из каждых
последовательностей длины N или лишь одна из каждых  последовательностей. Отсюда видно, что ошибками декодирования можно пренебречь уже при не слишком больших значениях
последовательностей. Отсюда видно, что ошибками декодирования можно пренебречь уже при не слишком больших значениях  и что число ошибок декодирования слабо зависит от конкретной статистики шумов. Кодер и декодер для такого рода циклического кода могут быть реализованы при помощи регистров сдвига с
и что число ошибок декодирования слабо зависит от конкретной статистики шумов. Кодер и декодер для такого рода циклического кода могут быть реализованы при помощи регистров сдвига с  разрядами (см. рис. 6.5.5).
разрядами (см. рис. 6.5.5).

Рис. 6.10.1. Кодирование с перемежением.
Наряду с простотой этот метод имеет несколько недостатков. Во-первых, необходимо иметь надежную линию обратной связи от приемника к передатчику для передачи запросов о повторении передачи. Во-вторых, возникают проблемы хранения данных как в передатчике, так и в приемнике в моменты, когда необходимо повторение передачи. В-третьих, если канал сильно зашумлен, принимается лишь малое число кодовых слов. Существенны или нет первые два недостатка — это зависит от наличия линии обратной связи и от природы источника (т. е. от того, порождает ли источник данные по запросу передатчика, или он порождает их с постоянной по времени скоростью). Если существенным является третий недостаток, то описанная выше схема повторной передачи может быть дополнена каким-либо методом исправления ошибок, рассмотренным ниже. Следует отметить здесь, что если модулятор и демодулятор цифровых данных предназначены для эффективной передачи большого числа двоичных символов в секунду, то в передаче будут происходить частые ошибки, исправление которых совершенно необходимо вне зависимости от того, используется повторение передачи или нет.
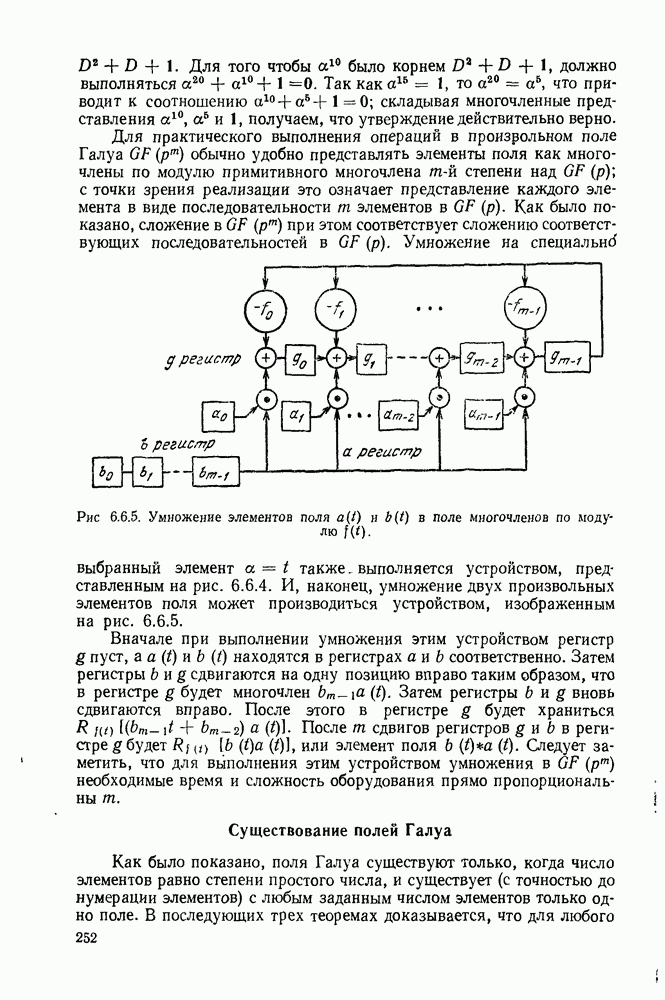
Другой простой метод достижения надежной передачи в канале с пакетами ошибок состоит в перемежеиии или перемешивании символов. В принципе этот метод сводится к тому, что поступающий поток двоичных данных разбивается на фиксированное число, допустим на  потоков данных, как показано на рис. 6.10.1. После этого каждый из
потоков данных, как показано на рис. 6.10.1. После этого каждый из  потоков данных кодируется отдельно, а закодированные
потоков данных кодируется отдельно, а закодированные
последовательности объединяются для передачи по каналу. На выходе канала принятый поток данных вновь разделяется на  потоков, каждый поток декодируется отдельно и, наконец, декодированные данные вновь объединяются.
потоков, каждый поток декодируется отдельно и, наконец, декодированные данные вновь объединяются.
Идея рассмотренного метода состоит в том, что следующие друг за другом буквы в любом кодовом слове отделены в канале промежутком в  единиц времени. Поэтому, если влияние памяти в канале исчезает с увеличением времени разделения символов, шумы в канале, действующие на следующие
единиц времени. Поэтому, если влияние памяти в канале исчезает с увеличением времени разделения символов, шумы в канале, действующие на следующие  за другом буквы кодового слова, практически становятся независимыми при достаточно больших
за другом буквы кодового слова, практически становятся независимыми при достаточно больших  Таким образом, в канале с пакетами ошибок можно использовать в со четании с перемежением символов любой из методов кодирования, ранее рассмотренных применительно к каналам без памяти.
Таким образом, в канале с пакетами ошибок можно использовать в со четании с перемежением символов любой из методов кодирования, ранее рассмотренных применительно к каналам без памяти.
Эти рассуждения показывают, что наличие памяти в канале не уменьшает его пропускной способности. Чтобы сделать это утверждение более точным, предположим, что в данном дискретном канале с памятью можно задать переходные вероятности  отдельных букв. Тогда, если память в канале уменьшается достаточно быстро по времени, то любой метод кодирования, который приводит к данной вероятности ошибки в дискретном канале без памяти с переходными вероятностями
отдельных букв. Тогда, если память в канале уменьшается достаточно быстро по времени, то любой метод кодирования, который приводит к данной вероятности ошибки в дискретном канале без памяти с переходными вероятностями  будет иметь практически ту же самую вероятность ошибки в данном канале с памятью, если только использовать перемежение с достаточно большим
будет иметь практически ту же самую вероятность ошибки в данном канале с памятью, если только использовать перемежение с достаточно большим  Поэтому канал с памятью имеет пропускную способность, по меньшей мере равную пропускной способности соответствующего канала без памяти. Мы не формулируем этот результат в виде теоремы, поскольку точно указать, как быстро память должна убывать со временем, довольно трудно.
Поэтому канал с памятью имеет пропускную способность, по меньшей мере равную пропускной способности соответствующего канала без памяти. Мы не формулируем этот результат в виде теоремы, поскольку точно указать, как быстро память должна убывать со временем, довольно трудно.
Для реализации перемежения символов не всегда необходимо использовать  отдельных кодеров и декодеров. Например, если кодеры, представленные на рис. 6.10.1, являются циклическими
отдельных кодеров и декодеров. Например, если кодеры, представленные на рис. 6.10.1, являются циклическими  кодерами, каждый с производящим многочленом
кодерами, каждый с производящим многочленом  то изображенные на рис. 6.10.1 перемежение и кодирование могут быть произведены с помощью
то изображенные на рис. 6.10.1 перемежение и кодирование могут быть произведены с помощью  циклического кодера с производящим многочленом
циклического кодера с производящим многочленом  Аналогично, если
Аналогично, если  нечетно и кодирование производится одинаковыми сверточными кодерами, каждый из которых рассчитан на скорость
нечетно и кодирование производится одинаковыми сверточными кодерами, каждый из которых рассчитан на скорость  (в битах), как и на рис. 6.8.1, то перемежение и кодирование могут быть выполнены единственным сверточным кодером, у которого между каждыми двумя соседними разрядами регистра сдвига, представленного на рис 6.8.1, добавлено
(в битах), как и на рис. 6.8.1, то перемежение и кодирование могут быть выполнены единственным сверточным кодером, у которого между каждыми двумя соседними разрядами регистра сдвига, представленного на рис 6.8.1, добавлено  разрядов и каждый проверочный символ проходит через
разрядов и каждый проверочный символ проходит через  -разрядный регистр сдвига.
-разрядный регистр сдвига.
С практической точки зрения основное преимущество перемежения состоит в том, что оно мало чувствительно по отношению к статистике памяти в канале и требует лишь настолько большого  чтобы почти все действие памяти в канале исчезло. Недостаток перемежения (или по крайней мере декодера, использующего перемежения) состоит в том,
чтобы почти все действие памяти в канале исчезло. Недостаток перемежения (или по крайней мере декодера, использующего перемежения) состоит в том,
что при принятии решения о декодировании не принимается во внимание память канала.
Прежде чем перейти к дальнейшему изложению, необходимо условиться о критерии оценки методов кодирования в каналах с пакетами ошибок. Для простоты будем в дальнейшем предполагать, что входные  и выходные у-последовательности канала являются двоичными. Шумовая последовательность
и выходные у-последовательности канала являются двоичными. Шумовая последовательность  равна
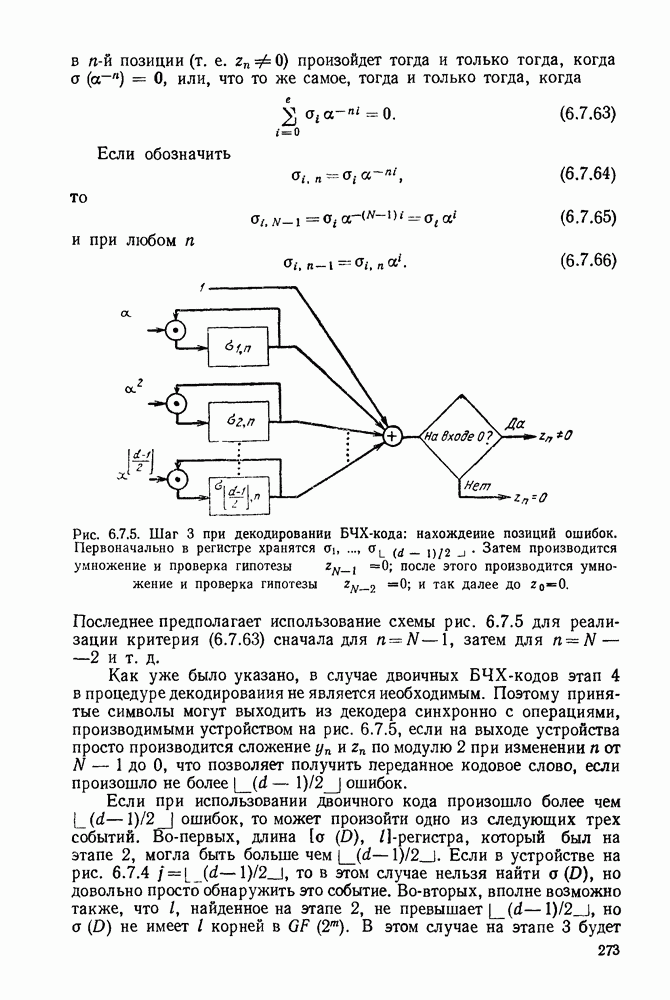
равна  При попытке определить, что такое пакет, заметим, что две ошибки (т. е. две единицы) в последовательности
При попытке определить, что такое пакет, заметим, что две ошибки (т. е. две единицы) в последовательности  отделенные несколькими нулями, могут рассматриваться либо как две изолированные ошибки, либо как пакет, состоящий из двух ошибок.
отделенные несколькими нулями, могут рассматриваться либо как две изолированные ошибки, либо как пакет, состоящий из двух ошибок.

Рис. 6.10 2. Два типа шумовых последовательностей,  произвольные двоичные символы.
произвольные двоичные символы.
Чтобы разрешить такого вида неопределенность, условимся считать совокупность последовательных символов шумовой последовательности  пакетом ошибок относительно
пакетом ошибок относительно  интервала
интервала  если, во-первых,
если, во-первых,  во-вторых, если по
во-вторых, если по  символов с каждой стороны множества
символов с каждой стороны множества  равны 0, и, в-третьих, если в множестве
равны 0, и, в-третьих, если в множестве  нет
нет  последовательных символов, одновременно равных 0. Длиной пакета
последовательных символов, одновременно равных 0. Длиной пакета  является мощность рассматриваемого множества. Заметим, что все символы шумовой последовательности в пакете не обязательно являются ошибками. В частном случае
является мощность рассматриваемого множества. Заметим, что все символы шумовой последовательности в пакете не обязательно являются ошибками. В частном случае  пакетом является изолированная ошибка, с каждой стороны которой расположены по
пакетом является изолированная ошибка, с каждой стороны которой расположены по  безошибочных символов. Данное выше определение однозначно разбивает любую последовательность
безошибочных символов. Данное выше определение однозначно разбивает любую последовательность  на множество пакетов, отделенных друг от друга интервалами по крайней мере из
на множество пакетов, отделенных друг от друга интервалами по крайней мере из  безошибочных символов.
безошибочных символов.
Условимся говорить, что кодер и декодер имеют при защитном интервале  корректирующую пакеты способность
корректирующую пакеты способность  если
если  равно максимальному целому числу, при котором любая шумовая последовательность
равно максимальному целому числу, при котором любая шумовая последовательность  содержащая лишь пакеты длины
содержащая лишь пакеты длины  или меньше при защитном интервале
или меньше при защитном интервале  декодируется правильно. Аналогично, корректирующей пакеты способностью кодера (или кода) при защитном интервале
декодируется правильно. Аналогично, корректирующей пакеты способностью кодера (или кода) при защитном интервале  называется наибольшее целое
называется наибольшее целое  для которого существует декодер, такой, что корректирующая пакеты способность этих кодера и декодера при защитном интервале
для которого существует декодер, такой, что корректирующая пакеты способность этих кодера и декодера при защитном интервале  равна
равна  Будем использовать величину корректирующей пакеты способности кода при данном защитном интервале в качестве критерия эффективности кода при исправлении пакетов ошибок. Следует заметить, что это лишь грубый
Будем использовать величину корректирующей пакеты способности кода при данном защитном интервале в качестве критерия эффективности кода при исправлении пакетов ошибок. Следует заметить, что это лишь грубый
критерий. Например, в канале, в котором длинные пакеты, содержащие относительно мало ошибок, гораздо более вероятны, чем болеё короткие пакеты, содержащие большое число ошибок, предпочтительнее использовать код, способный к исправлению высоко вероятных длинных пакетов за счет менее вероятных коротких пакетов.
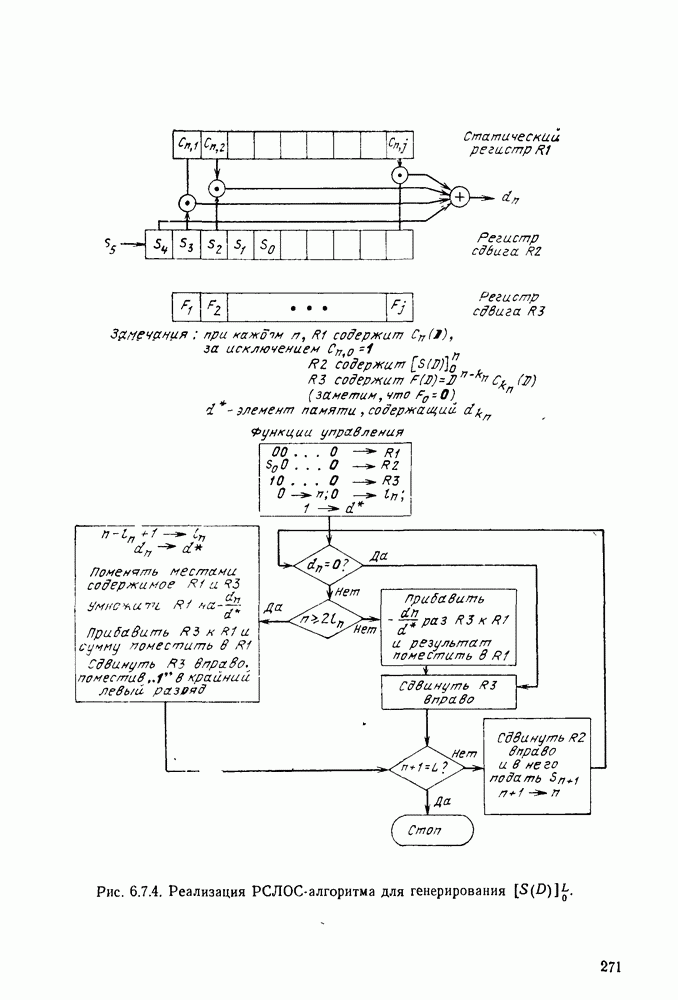
Теперь исследуем верхнюю границу корректирующей пакеты способности кода в зависимости от его скорости R и защитного интервала  Эта граница справедлива для блоковых кодов, сверточных кодов и любых других классов кодов. Предположим, однако, что существует произвольная, но конечная задержка декодирования в N символов источника, т. е. в тот момент, когда
Эта граница справедлива для блоковых кодов, сверточных кодов и любых других классов кодов. Предположим, однако, что существует произвольная, но конечная задержка декодирования в N символов источника, т. е. в тот момент, когда  символ источника поступает в кодер, по крайней мере
символ источника поступает в кодер, по крайней мере  символов источника должны быть декодированы. Вспоминая, что скорость R (измеряемая числом двоичных символов) определяется как отношение числа символов источника к числу символов канала, можно трактовать это условие как требование, чтобы за время, в течение которого принято
символов источника должны быть декодированы. Вспоминая, что скорость R (измеряемая числом двоичных символов) определяется как отношение числа символов источника к числу символов канала, можно трактовать это условие как требование, чтобы за время, в течение которого принято  символов канала, декодировалось бы не менее
символов канала, декодировалось бы не менее  символов источника. Теперь предположим, что используется код, имеющий корректирующую пакеты способность
символов источника. Теперь предположим, что используется код, имеющий корректирующую пакеты способность  при защитном интервале
при защитном интервале  и рассмотрим случай, когда число принятых символов
и рассмотрим случай, когда число принятых символов  кратно
кратно  т. е.
т. е. 
Рассмотрим далее два типа шумовых последовательностей, представленных на рис. 6.10.2. В каждом из этих двух случаев шумовые последовательности таковы, что имеют нули на указанных на рисунке позициях и могут иметь произвольные значения в позициях, обозначенных символами х (мы предполагаем здесь, что  Пусть
Пусть  кодовые последовательности, соответствующие двум различным наборам первых
кодовые последовательности, соответствующие двум различным наборам первых  символов источника и
символов источника и  шумовые последовательности первого и второго типа соответственно Так как по предположению эти шумовые последовательности не могут привести к ошибке декодирования, то имеем
шумовые последовательности первого и второго типа соответственно Так как по предположению эти шумовые последовательности не могут привести к ошибке декодирования, то имеем

Более обще, если  шумовые последовательности первого типа и
шумовые последовательности первого типа и  шумовые последовательности второго типа, то должно выполняться соотношение
шумовые последовательности второго типа, то должно выполняться соотношение

Чтобы доказать (6.10.2), предположим, что (6.10.2) не выполняется при каком-либо выборе последовательностей, и убедимся, что такое предположение приводит к противоречию. Если в (6.10.2) имеет место знак равенства, то, прибавив к обеим сторонам этого равенства  получим в результате
получим в результате

Поскольку  шумовая последовательность первого типа,
шумовая последовательность первого типа,  — шумовая последовательность второго типа, то равенство (6.10.3) противоречит (6.10.1) и, следовательно, соотношение (6.10.2) верно. Наконец, заметим, что если
— шумовая последовательность второго типа, то равенство (6.10.3) противоречит (6.10.1) и, следовательно, соотношение (6.10.2) верно. Наконец, заметим, что если  одинаковы и соответствуют
одинаковы и соответствуют
одним и тем же  первым символам источника, но или или
первым символам источника, но или или  то соотношение (6.10.2) вновь сохраняет силу.
то соотношение (6.10.2) вновь сохраняет силу.
Теперь легко понять, что  можно выбрать по крайней мере
можно выбрать по крайней мере  различными способами, каждый из которых соответствует различным выборам первых
различными способами, каждый из которых соответствует различным выборам первых  символов источника. Аналогично имеется
символов источника. Аналогично имеется  различных способов выбора
различных способов выбора  различных способов выбора
различных способов выбора  Согласно (6.10.2) при различных выборах тройки
Согласно (6.10.2) при различных выборах тройки  получаем различные последовательности
получаем различные последовательности  Поскольку двоичную последовательность длины
Поскольку двоичную последовательность длины  можно выбрать
можно выбрать  различными способами, то имеют место неравенства:
различными способами, то имеют место неравенства:

Так как N фиксировано, а неравенство (6.10.5) должно выполняться при всех 1, то можно перейти к пределу при  при этом получим
при этом получим

Аналогичные расчеты в предположении, что шумовые последовательности второго типа (рис. 6.10.2) имеют пакеты длины  могут быть проведены при
могут быть проведены при  В результате получим, что
В результате получим, что  (см. задачу 6.46).
(см. задачу 6.46).
Преобразовывая (6.10.6) в выражение (6.10.7), приведенное ниже, получаем следующую теорему.
Теорема 6.10.1. Для того чтобы двоичные кодер и декодер с ограниченной задержкой декодирования и скоростью  (в двоичных символах на символ канала) имели корректирующую пакеты способность
(в двоичных символах на символ канала) имели корректирующую пакеты способность  относительно защитного интервала
относительно защитного интервала  необходимо, чтобы
необходимо, чтобы

В дальнейшем будут рассмотрены сначала циклический, а затем сверточный коды, исправляющие пакеты ошибок. Будет показано, что (по крайней мере для сверточных кодов) в пределе при больших  можно приблизиться к границе (6.10.7) сколь угодно близко. Мы также увидим, что большинство пакетов, имеющих длины, гораздо большие, чем значение
можно приблизиться к границе (6.10.7) сколь угодно близко. Мы также увидим, что большинство пакетов, имеющих длины, гораздо большие, чем значение  определяемое (6.10.7), может быть исправлено при больших
определяемое (6.10.7), может быть исправлено при больших 
Циклические коды
Для исправления пакетов ошибок рассмотрим использование двоичного циклического  -кода с порождающим многочленом
-кода с порождающим многочленом  степени
степени  Пусть
Пусть  многочлен, соответствующий передаваемому кодовому слову,
многочлен, соответствующий передаваемому кодовому слову,  многочлен, соответствующий,
многочлен, соответствующий,
шумовой последовательности, и  многочлен; соответствующий принятой последовательности.
многочлен; соответствующий принятой последовательности.
В случае циклического кода пакет ошибок удобно определить несколько иначе, чем это сделано выше. Найдем в шумовой последовательности  самый длинный интервал циклически следующих друг за другом нулей и рассмотрим оставшуюся часть последовательности как пакет. Например, если
самый длинный интервал циклически следующих друг за другом нулей и рассмотрим оставшуюся часть последовательности как пакет. Например, если

то согласно этому определению  состоит не из одиночных пакетов, а из пакета длины 2, состоящего из
состоит не из одиночных пакетов, а из пакета длины 2, состоящего из  и из
и из  Чтобы хотя бы частично убедиться в разумности этого довольно странного определения, предположим, что циклический код способен исправлять все пакеты длины
Чтобы хотя бы частично убедиться в разумности этого довольно странного определения, предположим, что циклический код способен исправлять все пакеты длины  или меньше. Тогда согласно нашему старому определению корректирующая пакеты способность кода при защитном интервале
или меньше. Тогда согласно нашему старому определению корректирующая пакеты способность кода при защитном интервале  не меньше
не меньше  Однако если код не исправляет пакеты в циклическом смысле, то он не будет исправлять и два пакета в канале, отделенные участком из
Однако если код не исправляет пакеты в циклическом смысле, то он не будет исправлять и два пакета в канале, отделенные участком из  неискаженных символов в середине блока.
неискаженных символов в середине блока.
В случае циклического кода оптимальным декодером для пакетов ошибок называется такой декодер, который при заданном  выбирает кодовое слово
выбирает кодовое слово  при котором
при котором  состоит из самых коротких пакетов. Такой декодер минимизирует вероятность ошибки декодирования в канале, для которого любой пакет данной длины менее вероятен, чем любой пакет меньшей длины. Покажем теперь, что задача построения оптимального декодера для пакетов оказывается удивительно простой.
состоит из самых коротких пакетов. Такой декодер минимизирует вероятность ошибки декодирования в канале, для которого любой пакет данной длины менее вероятен, чем любой пакет меньшей длины. Покажем теперь, что задача построения оптимального декодера для пакетов оказывается удивительно простой.
При любом  назовем
назовем  циклическим сдвигом многочлена
циклическим сдвигом многочлена  соответствующего принятой последовательности, многочлен
соответствующего принятой последовательности, многочлен

Кроме того, введем многочлен 

Так как многочлен  делится на
делится на  то он соответствует кодовому слову. Поскольку при каждом циклическом сдвиге кодового слова также получается кодовое слово, то можно, сдвигая полином
то он соответствует кодовому слову. Поскольку при каждом циклическом сдвиге кодового слова также получается кодовое слово, то можно, сдвигая полином  назад к
назад к  и одновременно полином
и одновременно полином  на
на  позиций в том же направлении, убедиться, что многочлен
позиций в том же направлении, убедиться, что многочлен  также соответствует кодовому слову. Иначе говоря, многочлен
также соответствует кодовому слову. Иначе говоря, многочлен  при заданном
при заданном  и при любом
и при любом  определяет возможную шумовую последовательность, которая могла бы наложиться на переданное слово, давая в итоге
определяет возможную шумовую последовательность, которая могла бы наложиться на переданное слово, давая в итоге  Из (6.10.10) следует, что каждый из полиномов
Из (6.10.10) следует, что каждый из полиномов  имеет степень не больше
имеет степень не больше  и потому
и потому  соответствует последовательности, у которой все ненулевые символы циклически следуют друг за другом в ряду, состоящем не более чем из
соответствует последовательности, у которой все ненулевые символы циклически следуют друг за другом в ряду, состоящем не более чем из  символов.
символов.
Теперь допустим, что передано  и на него наложился пакет из
и на него наложился пакет из  ошибок в промежутке от
ошибок в промежутке от  до
до  до
до  при модифицированном определении пакета). Этот пакет можно представить с помощью многочлена
при модифицированном определении пакета). Этот пакет можно представить с помощью многочлена  где степень
где степень  равна
равна  при этом получим
при этом получим  Тогда имеем
Тогда имеем  где
где  циклический сдвиг
циклический сдвиг  В силу определения (6.10.10) это означает, что
В силу определения (6.10.10) это означает, что 
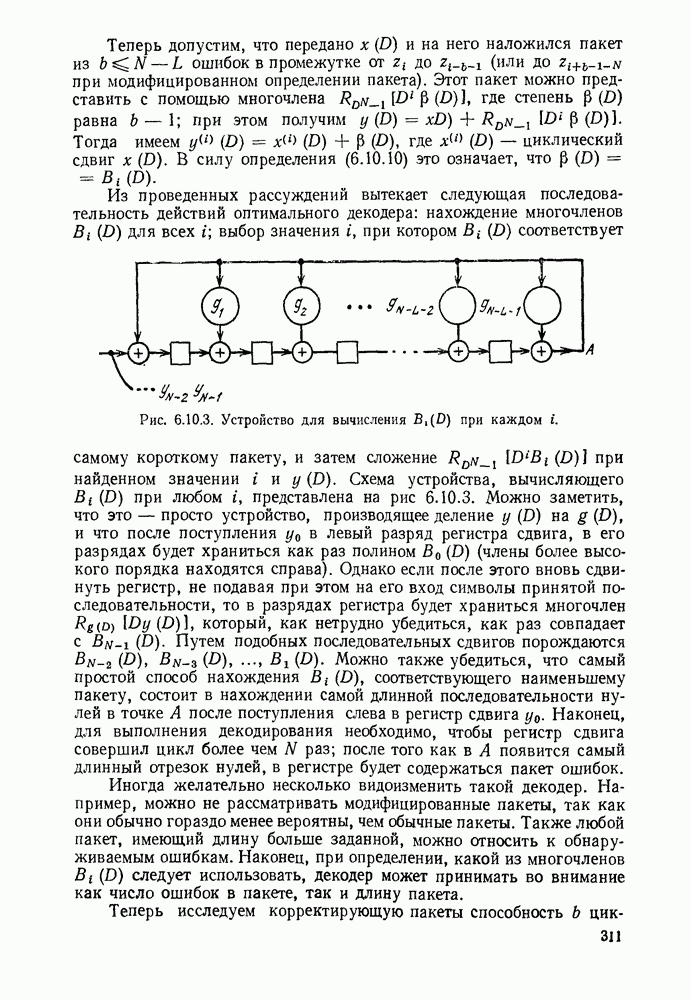
Из проведенных рассуждений вытекает следующая последовательность действий оптимального декодера: нахождение многочленов  для всех
для всех  выбор значения
выбор значения  при котором
при котором  соответствует самому короткому пакету, и затем сложение
соответствует самому короткому пакету, и затем сложение  при найденном значении
при найденном значении  и
и 

Рис. 6.10.3. Устройство для вычисления  при каждом
при каждом 
Схема устройства, вычисляющего  при любом
при любом  представлена на рис 6.10.3. Можно заметить, что это — просто устройство, производящее деление
представлена на рис 6.10.3. Можно заметить, что это — просто устройство, производящее деление  на
на  и что после поступления
и что после поступления  в левый разряд регистра сдвига, в его разрядах будет храниться как раз полином
в левый разряд регистра сдвига, в его разрядах будет храниться как раз полином  (члены более высокого порядка находятся справа). Однако если после этого вновь сдвинуть регистр, не подавая при этом на его вход символы принятой последовательности, то в разрядах регистра будет храниться многочлен
(члены более высокого порядка находятся справа). Однако если после этого вновь сдвинуть регистр, не подавая при этом на его вход символы принятой последовательности, то в разрядах регистра будет храниться многочлен  который, как нетрудно убедиться, как раз совпадает с
который, как нетрудно убедиться, как раз совпадает с  Путем подобных последовательных сдвигов порождаются
Путем подобных последовательных сдвигов порождаются  Можно также убедиться, что самый простой способ нахождения
Можно также убедиться, что самый простой способ нахождения  соответствующего наименьшему пакету, состоит в нахождении самой длинной последовательности нулей в точке А после поступления слева в регистр сдвига
соответствующего наименьшему пакету, состоит в нахождении самой длинной последовательности нулей в точке А после поступления слева в регистр сдвига  Наконец, для выполнения декодирования необходимо, чтобы регистр сдвига совершил цикл более чем N раз; после того как в А появится самый длинный отрезок нулей, в регистре будет содержаться пакет ошибок.
Наконец, для выполнения декодирования необходимо, чтобы регистр сдвига совершил цикл более чем N раз; после того как в А появится самый длинный отрезок нулей, в регистре будет содержаться пакет ошибок.
Иногда желательно несколько видоизменить такой декодер. Например, можно не рассматривать модифицированные пакеты, так как они обычно гораздо менее вероятны, чем обычные пакеты. Также любой пакет, имеющий длину больше заданной, можно относить к обнаруживаемым ошибкам. Наконец, при определении, какой из многочленов  следует использовать, декодер может принимать во внимание как число ошибок в пакете, так и длину пакета.
следует использовать, декодер может принимать во внимание как число ошибок в пакете, так и длину пакета.
Теперь исследуем корректирующую пакеты способность b
циклических кодах, где  наибольшее целое число, такое, что все пакеты длины
наибольшее целое число, такое, что все пакеты длины  или меньше могут быть исправлены оптимальным декодером. Если корректирующая пакеты способность циклического кода равна
или меньше могут быть исправлены оптимальным декодером. Если корректирующая пакеты способность циклического кода равна  то существует некоторый пакет длины
то существует некоторый пакет длины  который может быть декодирован как некоторый другой пакет длины
который может быть декодирован как некоторый другой пакет длины  или меньше; следовательно, сумма этих пакетов является кодовым словом. Произведя циклический сдвиг этого кодового слова так, чтобы пакет неисправимых ошибок начинался с нулевой позиции, представим это сдвинутое кодовое слово в виде
или меньше; следовательно, сумма этих пакетов является кодовым словом. Произведя циклический сдвиг этого кодового слова так, чтобы пакет неисправимых ошибок начинался с нулевой позиции, представим это сдвинутое кодовое слово в виде

где степень  равна
равна  и степень
и степень  не больше
не больше 
Так как  кодовое слово, то его можно представить в виде
кодовое слово, то его можно представить в виде  где степень
где степень  равная, например, а, представляется в виде разности степени члена самого высокого порядка в
равная, например, а, представляется в виде разности степени члена самого высокого порядка в  и
и  Поэтому, для того чтобы степень
Поэтому, для того чтобы степень  не превосходила
не превосходила  необходимо, чтобы коэффициенты при
необходимо, чтобы коэффициенты при  в многочлене
в многочлене  были бы равны нулю для
были бы равны нулю для

Другими словами, для того чтобы существовал неисправимый пакет длины  необходимо, чтобы существовали некоторое целое число а,
необходимо, чтобы существовали некоторое целое число а,  и некоторый ненулевой многочлен
и некоторый ненулевой многочлен  степени а, такой, что коэффициенты членов многочлена
степени а, такой, что коэффициенты членов многочлена  равны нулю при всех
равны нулю при всех  удовлетворяющих (6.10.12). Длиной исправимого пакета циклического кода называется такое наименьшее
удовлетворяющих (6.10.12). Длиной исправимого пакета циклического кода называется такое наименьшее  при котором такое решение существует. При любых заданных
при котором такое решение существует. При любых заданных  нахождение такого решения эквивалентно нахождению совокупности
нахождение такого решения эквивалентно нахождению совокупности  коэффициентов
коэффициентов  которые удовлетворяли бы
которые удовлетворяли бы  линейным уравнениям, указанным в (6.10.12). Легко видеть, что
линейным уравнениям, указанным в (6.10.12). Легко видеть, что  поскольку пакет
поскольку пакет  образуемый с помощью усечения
образуемый с помощью усечения  до первых
до первых  членов, всегда может быть воспринят как
членов, всегда может быть воспринят как  Также легко увидеть, что граница
Также легко увидеть, что граница  справедливая для циклических кодов, эквивалентна более общей границе, приведенной в теореме 6.10.1.
справедливая для циклических кодов, эквивалентна более общей границе, приведенной в теореме 6.10.1.
К сожалению, довольно мало изучена проблема нахождения при заданных  многочлена
многочлена  максимизирующего
максимизирующего  Файр (1959) нашел большой класс циклических кодов со сравнительно большими значениями
Файр (1959) нашел большой класс циклических кодов со сравнительно большими значениями  а Элспас и Шорт (1962) опубликовали небольшую таблицу циклических кодов с оптимальными значениями
а Элспас и Шорт (1962) опубликовали небольшую таблицу циклических кодов с оптимальными значениями  Казами (1963, 1964) также указал упрощенную процедуру решения данных выше уравнений и также привел таблицу укороченных циклических кодов с оптимальными значениями
Казами (1963, 1964) также указал упрощенную процедуру решения данных выше уравнений и также привел таблицу укороченных циклических кодов с оптимальными значениями  Для любого циклического
Для любого циклического  кода укороченный циклический коде длиной блока
кода укороченный циклический коде длиной блока  образуется с помощью отбрасывания первых
образуется с помощью отбрасывания первых  информационных символов циклического кода и заменой этих отброшенных символов нулями при вычислении проверочных символов.
информационных символов циклического кода и заменой этих отброшенных символов нулями при вычислении проверочных символов.
Теперь исследуем долю исправимых пакетов ошибок, имеющих длины, большие, чем корректирующая пакеты способность.
Теорема 6.10.2. Пусть циклический  -код имеет корректирующую пакеты способность, равную
-код имеет корректирующую пакеты способность, равную  Тогда при
Тогда при  доля
доля  пакетов длины
пакетов длины  неправильно декодированных оптимальным для пакетов декодером, ограничена неравенствами
неправильно декодированных оптимальным для пакетов декодером, ограничена неравенствами

где

Обсуждение. Наибольший интерес эта теорема представляет для больших  и
и  когда величина коэффициентов в (6.10.14) не имеет большого значения. Весьма интересно, что при
когда величина коэффициентов в (6.10.14) не имеет большого значения. Весьма интересно, что при  исправляется большинство пакетов. При фиксированном значении скорости
исправляется большинство пакетов. При фиксированном значении скорости  и возрастании N отношение этой оценки к верхней границе корректирующей пакеты способности стремится к 2. График функции
и возрастании N отношение этой оценки к верхней границе корректирующей пакеты способности стремится к 2. График функции  приведен на рис. 6.10.4. Можно заметить, что при возрастании корректирующей пакеты способности
приведен на рис. 6.10.4. Можно заметить, что при возрастании корректирующей пакеты способности  горизонтальный участок функции
горизонтальный участок функции  поднимается, уменьшая долю неисправимых пакетов в окрестности
поднимается, уменьшая долю неисправимых пакетов в окрестности 

Рис. 6.10.4. Показатель экспоненты доли неисправных пакетов длины 
Доказательство. Назовем синдромом  соответствующим шумовой последовательности
соответствующим шумовой последовательности  многочлен
многочлен

где  Заметим, что две шумовые последовательности имеют один и тот же синдром, если их сумма является кодовым словом. Отметим также, что множество всех синдромов, соответствующих всем различным
Заметим, что две шумовые последовательности имеют один и тот же синдром, если их сумма является кодовым словом. Отметим также, что множество всех синдромов, соответствующих всем различным  просто совпадает с множеством кодовых слов в дуальном коде, порождаемом многочленом
просто совпадает с множеством кодовых слов в дуальном коде, порождаемом многочленом  Пакет ошибок называется путающим, если его синдром совпадает с синдромом другого пакета меньшей или равной длины. Отметим, что любой неисправимый пакет будет путающим и по крайней мере половина путающих пакетов любой длины декодируется оптимальным декодером неправильно. Наконец, доля путающих пакетов длины
Пакет ошибок называется путающим, если его синдром совпадает с синдромом другого пакета меньшей или равной длины. Отметим, что любой неисправимый пакет будет путающим и по крайней мере половина путающих пакетов любой длины декодируется оптимальным декодером неправильно. Наконец, доля путающих пакетов длины  расположенных на позициях от 0 до
расположенных на позициях от 0 до  совпадает с долей путающих пакетов длины
совпадает с долей путающих пакетов длины  начинающихся в любой другой позиции.
начинающихся в любой другой позиции.
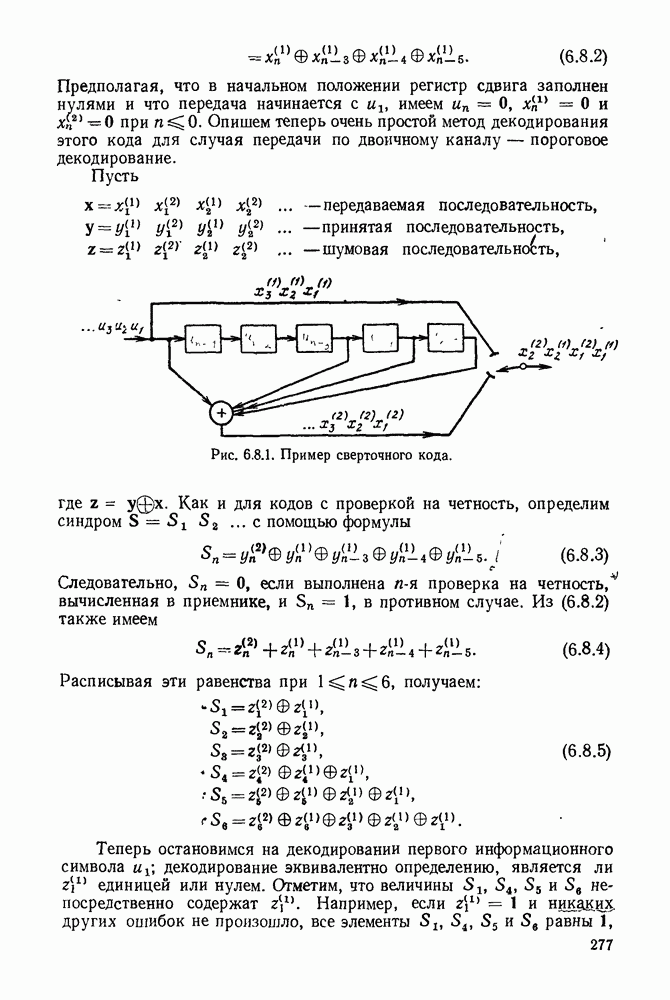
При любых целых значениях  и любых
и любых  обозначим через
обозначим через  (рис. 6.10.5) множество
(рис. 6.10.5) множество
синдромов  для которых
для которых  при
при  Коэффициенты здесь выбираются как вычеты по модулю
Коэффициенты здесь выбираются как вычеты по модулю 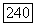 Из рассмотрения положений интервалов нулей на рис. 6.10.5 видно, что каждый синдром
Из рассмотрения положений интервалов нулей на рис. 6.10.5 видно, что каждый синдром 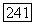 может быть представлен как в виде
может быть представлен как в виде 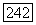 так и в виде
так и в виде 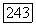 где каждый из полиномов
где каждый из полиномов  имеет степень
имеет степень  Найдем сначала границу числа элементов в этих множествах синдромов, а затем укажем ее связь с числом неисправимых пакетов длины
Найдем сначала границу числа элементов в этих множествах синдромов, а затем укажем ее связь с числом неисправимых пакетов длины  Заметим, что
Заметим, что  всегда содержит все нулевые синдромы и образует подгруппу множества всех синдромов относительно сложения многочленов по модулю 2.
всегда содержит все нулевые синдромы и образует подгруппу множества всех синдромов относительно сложения многочленов по модулю 2.

Рис. 6.10.5. Множество синдромов  произвольные двоичные символы.
произвольные двоичные символы.
Заметим также, что при любых  множество
множество  или пусто или образует смежный класс для
или пусто или образует смежный класс для  Так как общее число синдромов является степенью 2, то из теоремы Лагранжа (теорема 6.3.1) следует, что каждая из этих подгрупп и каждый из этих смежных классов имеют число элементов, равное степени 2. Определим множество
Так как общее число синдромов является степенью 2, то из теоремы Лагранжа (теорема 6.3.1) следует, что каждая из этих подгрупп и каждый из этих смежных классов имеют число элементов, равное степени 2. Определим множество  следующим образом:
следующим образом:

Из рассмотрения рис. 6.10.3 непосредственно проверяется, что

Отсюда следует, что

где  равно числу комбинаций
равно числу комбинаций  для которых
для которых  непусто. Так как
непусто. Так как  являются степенью 2, то а
являются степенью 2, то а  равно 1,2 или 4.
равно 1,2 или 4.
Далее заметим, что согласно рис. 6.10.5, если 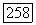 то
то 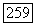 Поэтому, если множество
Поэтому, если множество 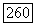 не пусто для одного из значений
не пусто для одного из значений 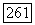 то оно не пусто и для всех больших значений
то оно не пусто и для всех больших значений  Следовательно, а
Следовательно, а  не убывает с ростом
не убывает с ростом 
Согласно определению величины 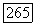 (корректирующей пакеты способности кода) существует некоторый пакет длины
(корректирующей пакеты способности кода) существует некоторый пакет длины 
простирающийся от 0-й до  позиций, который имеет такой же синдром, что и некоторый пакет с длиной, не превышающей
позиций, который имеет такой же синдром, что и некоторый пакет с длиной, не превышающей  начинающийся, например, на позиции
начинающийся, например, на позиции  Этот синдром принадлежит
Этот синдром принадлежит 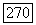 Более того,
Более того,

Доказательство этого опирается на тот факт, что большее число синдромов содержат ненулевой синдром из 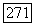 такой синдром содержал бы два интервала, каждый из которых целиком состоит не менее чем из
такой синдром содержал бы два интервала, каждый из которых целиком состоит не менее чем из 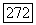 нулей, либо сливающихся, либо нет. Если интервалы сливаются в один, то длина получающегося интервала должна быть не менее
нулей, либо сливающихся, либо нет. Если интервалы сливаются в один, то длина получающегося интервала должна быть не менее 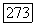 что влечет за собой требование, чтобы синдром был равен 0. Если интервалы не сливаются, то существуют два пакета, длина которых не превышает
что влечет за собой требование, чтобы синдром был равен 0. Если интервалы не сливаются, то существуют два пакета, длина которых не превышает  с таким синдромом, что противоречит определению
с таким синдромом, что противоречит определению 
Учитывая, что эти множества являются смежными классами и используя (6.10.16) и (6.10.17), получаем

Наконец, отметим, что при  все синдромы принадлежат
все синдромы принадлежат  и
и

Так как величина а 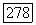 входящая в соотношение (6.10.18), не убывает с ростом
входящая в соотношение (6.10.18), не убывает с ростом 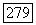 и принимает при
и принимает при 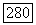 лишь значения 2 или 4, соотношения (6.10.20) и (6.10.21) полностью определяют
лишь значения 2 или 4, соотношения (6.10.20) и (6.10.21) полностью определяют 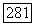 при всех промежуточных значениях величины
при всех промежуточных значениях величины 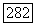

Используя равенство (6.10.17) и равенство! 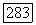 получаем
получаем

Каждый синдром  для которого 50 — 1, соответствует путающему пакету длины
для которого 50 — 1, соответствует путающему пакету длины 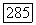 расположенному на позициях от 0 до
расположенному на позициях от 0 до 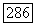 При
При 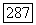 единственный синдром из
единственный синдром из  имеет
имеет 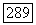 а при больших
а при больших 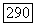 ровно половина синдромов из
ровно половина синдромов из  имеет
имеет 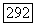 Чтобы показать это, заметим, что если
Чтобы показать это, заметим, что если 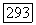 принадлежит
принадлежит 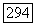 принадлежит
принадлежит 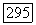 Так как множество
Так как множество 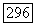 и аналогичное множество с
и аналогичное множество с 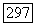 являются оба смежными классами подгруппы
являются оба смежными классами подгруппы 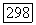 то эти множества имеют одинаковую мощность. Далее, так как существует всего
то эти множества имеют одинаковую мощность. Далее, так как существует всего 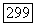 различных пакетов, занимающих позиции от 0 до
различных пакетов, занимающих позиции от 0 до 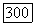 то доля
то доля
путающих пакетов, занимающих позиции от 0 до ограничена снизу величинами

Так как по крайней мере половина путающих пакетов декодируется неправильно, последнее соотношение в сочетании с (6.10.23) приводит к нижней границе вида (6.10.13).
Чтобы получить верхнюю границу следует прежде всего оценить при каждом значении Пусть при любом заданном наибольшее целое число, для которого Тогда при некоторой ненулевой паре значений Если то, повторяя предыдущие рассуждения, можно получить

Вместе с тем, если то при всех таких, что Следовательно,

и поэтому (6.10.24) справедливо, при всех
Любой неисправимый пакет длины занимающий позиции от 0 до соответствует синдрому в при некотором Поэтому общее число неисправимых пакетов длины занимающих позиции от 0 до ограничено сверху величиной для и величиной для других значений Учитывая (6.10.23), отсюда получаем верхнюю оценку вида (6.10.14).
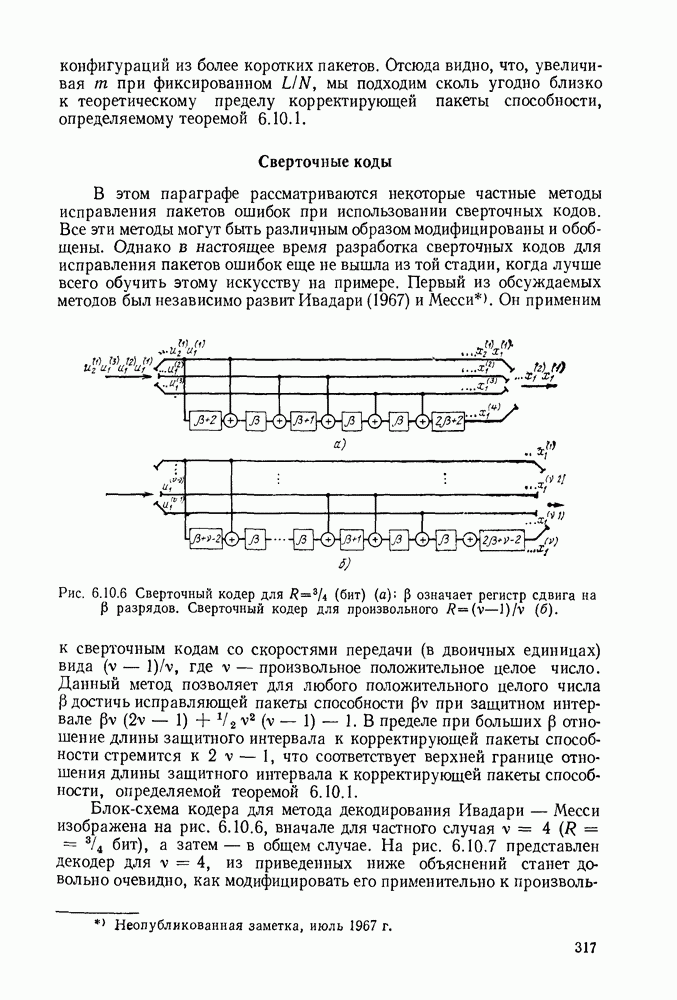
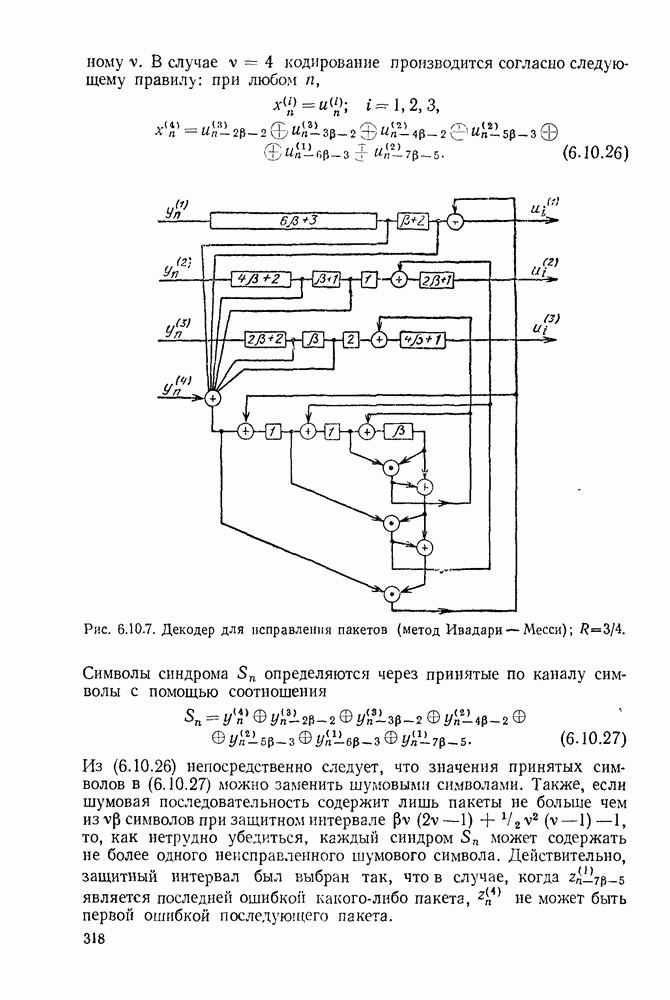
Другой метод блокового кодирования для каналов с пакетами ошибок основан на использовании кодов Рида-Соломона (1961). Используемые символы принадлежат полю при некотором длина блока равна Для произвольно выбранного минимального расстояния кода, заданного нечетным числом число информационных символов равно и любая конфигурация ошибок может быть исправлена. Если представить каждую букву кодового слова двоичными символами, то получим двоичный код с информационными символами и длиной блока Любая шумовая последовательность, которая искажает не более чем из этих последовательностей длины исправляется; поэтому корректирующая пакеты способность этого кода равна при этом код исправляет большое число
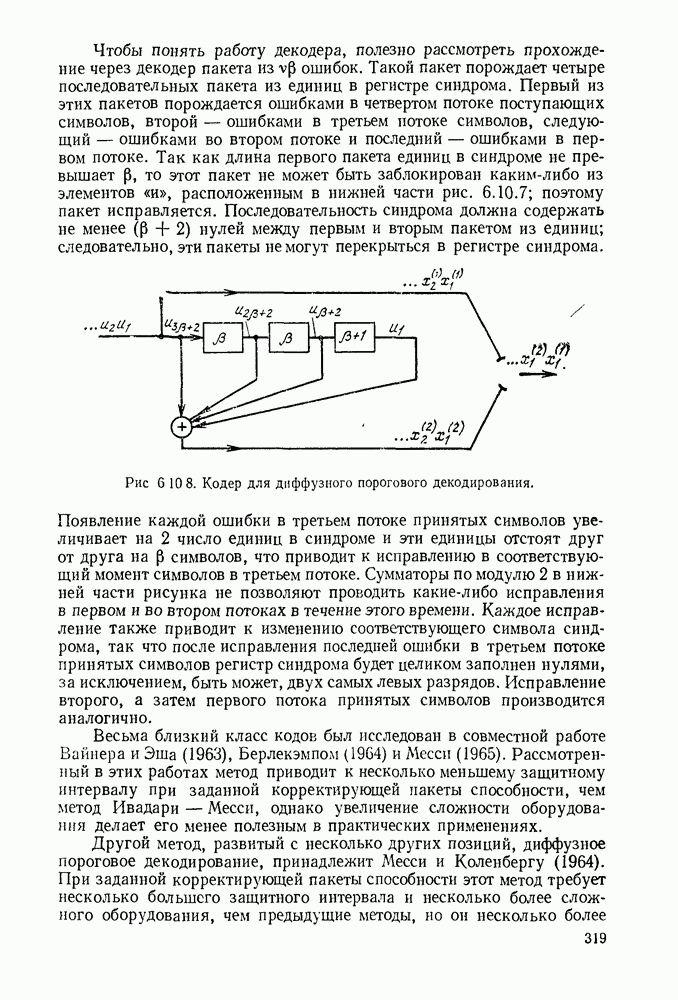
Чтобы понять работу декодера, полезно рассмотреть прохождение через декодер пакета из ошибок. Такой пакет порождает четыре последовательных пакета из единиц в регистре синдрома. Первый из этих пакетов порождается ошибками в четвертом потоке поступающих символов, второй — ошибками в третьем потоке символов, следующий — ошибками во втором потоке и последний — ошибками в первом потоке. Так как длина первого пакета единиц в синдроме не превышает то этот пакет не может быть заблокирован каким-либо из элементов расположенным в нижней части рис. 6.10.7; поэтому пакет исправляется. Последовательность синдрома должна содержать не менее нулей между первым и вторым пакетом из единиц; следовательно, эти пакеты не могут перекрыться в регистре синдрома.

Рис. 6.10.8. Кодер для диффузного порогового декодирования.
Появление каждой ошибки в третьем потоке принятых символов увеличивает на 2 число единиц в синдроме и эти единицы отстоят друг от друга на символов, что приводит к исправлению в соответствующий момент символов в третьем потоке. Сумматоры по модулю 2 в нижней части рисунка не позволяют проводить какие-либо исправления в первом и во втором потоках в течение этого времени. Каждое исправление также приводит к изменению соответствующего символа синдрома, так что после исправления последней ошибки в третьем потоке принятых символов регистр синдрома будет целиком заполнен нулями, за исключением, быть может, двух самых левых разрядов. Исправление второго, а затем первого потока принятых символов производится аналогично.
Весьма близкий класс кодов был исследован в совместной работе Вайнера и Эша (1963), Берлекэыпом (1964) и Месси (1965). Рассмотренный в этих работах метод приводит к несколько меньшему защитному интервалу при заданной корректирующей пакеты способности, чем метод Ивадари — Месси, однако увеличение сложности оборудования делает его менее полезным в практических применениях.
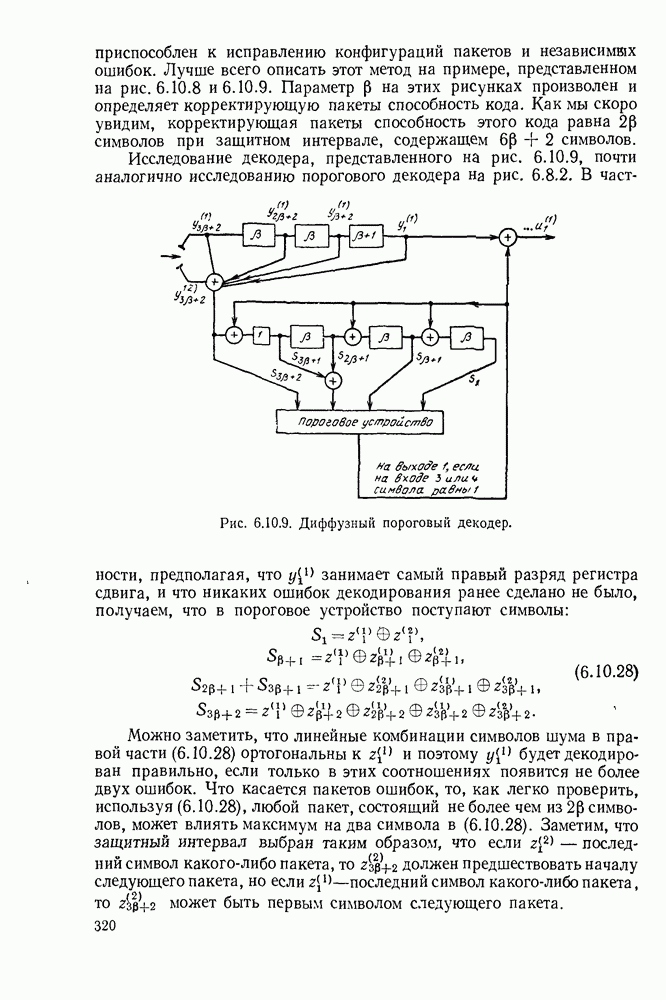
Другой метод, развитый с несколько других позиций, диффузное пороговое декодирование, принадлежит Месси и Коленбергу (1964). При заданной корректирующей пакеты способности этот метод требует несколько большего защитного интервала и несколько более сложного оборудования, чем предыдущие методы, но он несколько более
приспособлен к исправлению конфигураций пакетов и независимых ошибок. Лучше всего описать этот метод на примере, представленном на рис. 6.10.8 и 6.10.9. Параметр на этих рисунках произволен и определяет корректирующую пакеты способность кода. Как мы скоро увидим, корректирующая пакеты способность этого кода равна символов при защитном интервале, содержащем символов.
Исследование декодера, представленного на рис. 6.10.9, почти аналогично исследованию порогового декодера на рис. 6.8.2.

Рис. 6.10.9. Диффузный пороговый декодер.
В частности, предполагая, что занимает самый правый разряд регистра сдвига, и что никаких ошибок декодирования ранее сделано не было, получаем, что в пороговое устройство поступают символы:

Можно заметить, что линейные комбинации символов шума в правой части (6.10.28) ортогональны к и поэтому будет декодирован правильно, если только в этих соотношениях появится не более двух ошибок. Что касается пакетов ошибок, то, как легко проверить, используя (6.10.28), любой пакет, состоящий не более чем из символов, может влиять максимум на два символа в (6.10.28). Заметим, что защитный интервал выбран таким образом, что если последний символ какого-либо пакета, то должен предшествовать началу следующего пакета, но если -последний символ какого-либо пакета, то может быть первым символом следующего пакета.
Можно заметить, что этот метод и метод перемежения символов основаны на близких идеях. В обоих методах символы, рассматриваемые кодером совместно, в канале разнесены так, что пакеты, по существу, преобразуются в независимые ошибки. Однако можно убедиться, что отношение длины защитного интервала к длине пакета для декодера, представленного на рис. 6.10.9, гораздо меньше, чем то, которое может быть получено с помощью перемежения символов в коде, изображенном на рис. 6.8.1.
Существует также тесная связь между методом Ивадари — Месси и диффузным пороговым декодированием. В терминах независимых ошибок декодер, представленный на рис. 6.10.7, может рассматриваться как пороговый декодер, исправляющий одиночную ошибку, а декодер на рис. 6.10.9 — как пороговый декодер, исправляющий двойные ошибки.

Рис. 6.10.10. Кодер для разнесения пакетов по времени,
Поэтому не удивительно, что диффузный пороговый декодер, исправляющий двойные ошибки, имеет большую сложность, будучи при этом более приспособлен к исправлению различных типов ошибок, чем декодер Ивадари — Месси.
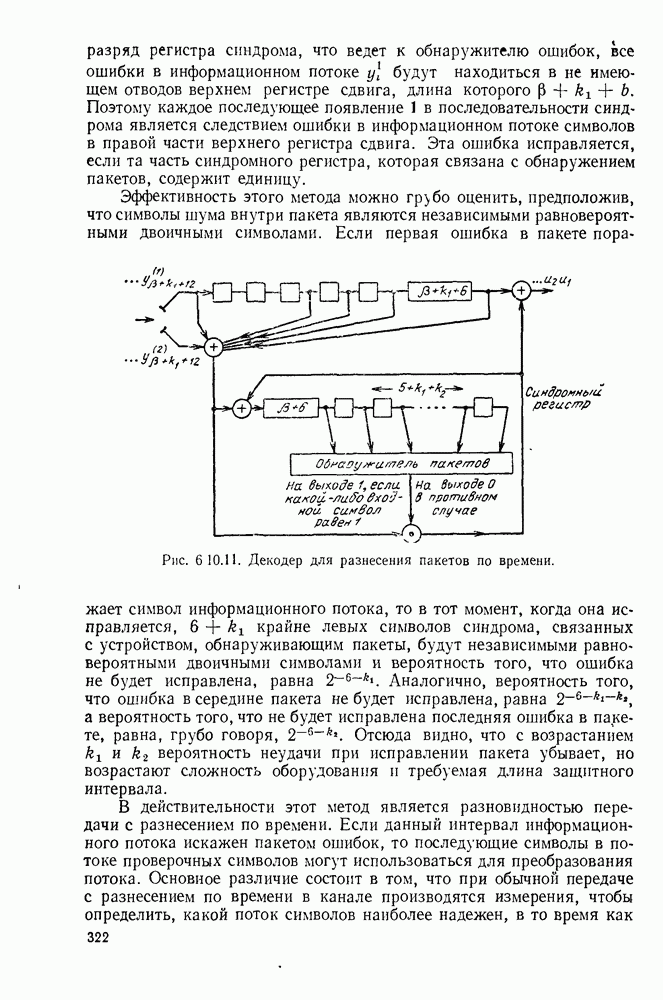
В качестве последнего примера исправления пакетов ошибок с помощью сверточных кодов рассмотрим следующий метод, принадлежащий Галлагеру (19656). Сначала рассмотрим частный пример, представленный на рис. 6.10.10 и 6.10.11. Изображенные здесь кодер и декодер предназначены для исправления большинства пакетов с длиной не более при защитном интервале длины - Параметры произвольны, но можно считать, что обычно имеет порядок величины меньше чем 10. Заметим, что поскольку мы пытаемся исправлять пакеты с длиной, почти в три раза большей верхней оценки корректирующей пакеты способности, определяемой теоремой 6.10.1, то не все пакеты длины могут быть исправлены.
Чтобы понять качественно работу декодера, представленного на рис. 6.10.11, рассмотрим, что произойдет, если пакет длины поступит в декодер. Поступление пакета ошибок в декодер приводит к тому, что многие из символов синдрома примут значение 1; фактически ошибки, проходя через первые пять разрядов верхнего регистра сдвига, порождают пакеты единиц в последовательностях синдрома, длина которых не превышает Однако в тот момент, когда начало этого пакета единиц в последовательности синдрома поступает в первый
разряд регистра синдрома, что ведет к обнаружителю ошибок, все ошибки в информационном потоке будут находиться в не имеющем отводов верхнем регистре сдвига, длина которого Поэтому каждое последующее появление 1 в последовательности синдрома является следствием ошибки в информационном потоке символов в правой части верхнего регистра сдвига. Эта ошибка исправляется, если та часть синдромного регистра, которая связана с обнаружением пакетов, содержит единицу.
Эффективность этого метода можно оценить, предположив, что символы шума внутри пакета являются независимыми равновероятными двоичными символами.

Рис. 6.10.11. Декодер для разнесения пакетов по времени.
Если первая ошибка в пакете поражает символ информационного потока, то в тот момент, когда она исправляется, крайне левых символов синдрома, связанных с устройством, обнаруживающим пакеты, будут независимыми равновероятными двоичными символами и вероятность того, что ошибка не будет исправлена, равна Аналогично, вероятность того, что ошибка в середине пакета не будет исправлена, равна а вероятность того, что не будет исправлена последняя ошибка в пакете, равна, грубо говоря, Отсюда видно, что с возрастанием вероятность неудачи при исправлении пакета убывает, но возрастают сложность оборудования и требуемая длина защитного интервала.
В действительности этот метод является разновидностью передачи с разнесением по времени. Если данный интервал информационного потока искажен пакетом ошибок, то последующие символы в потоке проверочных символов могут использоваться для преобразования потока. Основное различие состоит в том, что при обычной передаче с разнесением по времени в канале производятся измерения, чтобы определить, какой поток символов наиболее надежен, в то время как
здесь для этого используются кодовые связи. Во многих физических каналах существует столь много причин, приводящих к пакетам ошибок, что трудно надежно определить по измерениям в канале место пакета, поэтому использование для этого кодовых связей более надежно и более просто.
В описанном методе могут быть сделаны некоторые изменения. Ясно, что можно изменить данное отдельное множество разрядов регистра в левой части рис. 6.10 10, выходные символы которых суммируются при вычислении проверочных символов. Более существенная модификация состоит в использовании устройства (рис. 6.10.11), обнаруживающего пакеты как для исправления относительно изолированных ошибок, так и для обнаружения более крупных пакетов. Наконец, можно использовать тот же метод при произвольных скоростях, представимых в виде для исправления большинства пакетов длины с длиной защитного интервала, чуть большей