Пред.
След.
Макеты страниц
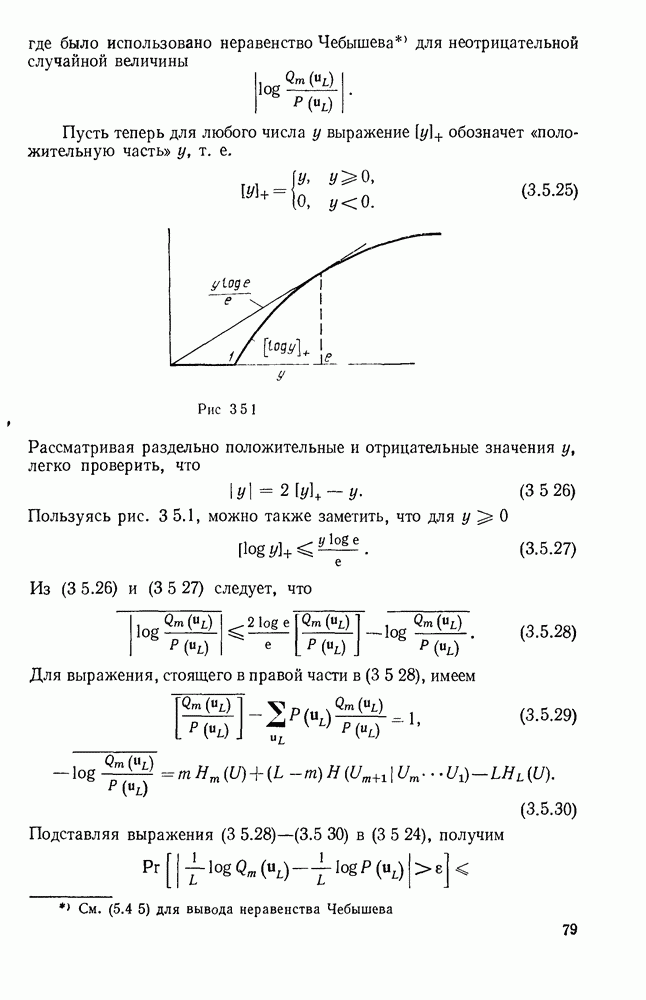
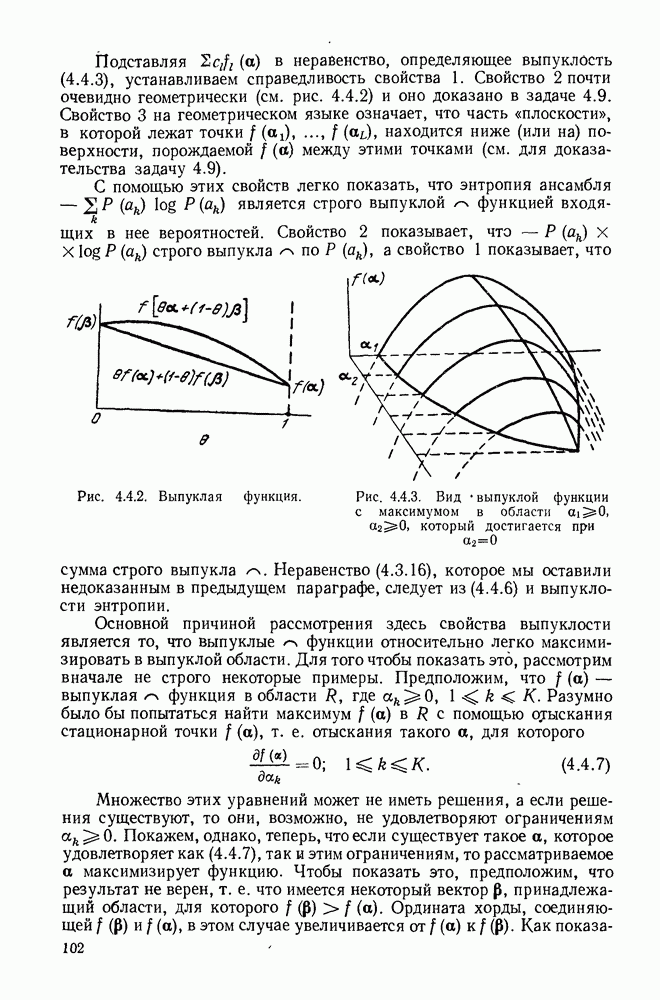
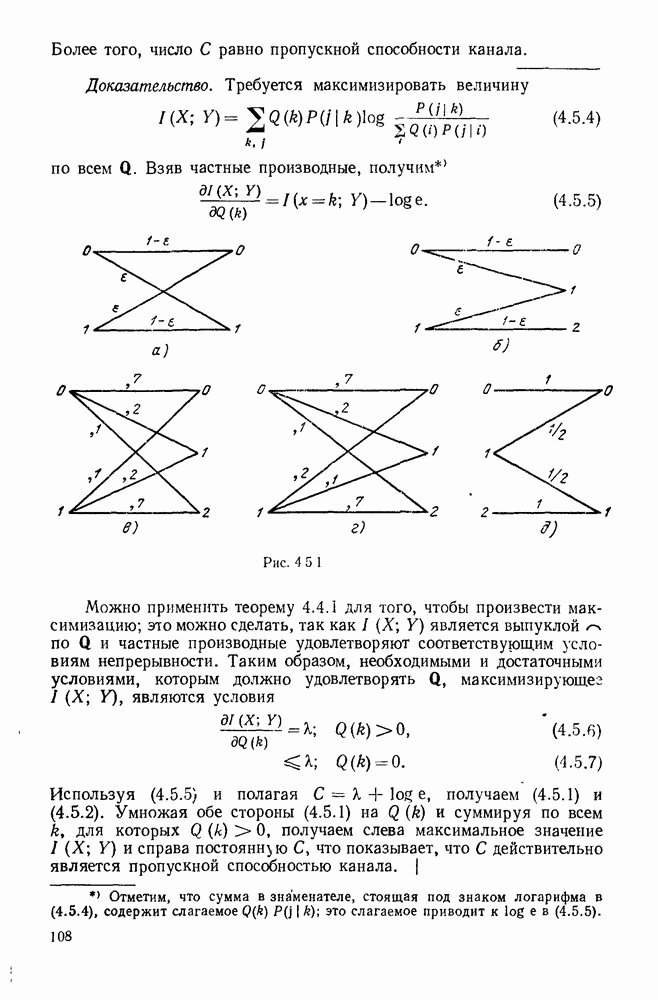
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
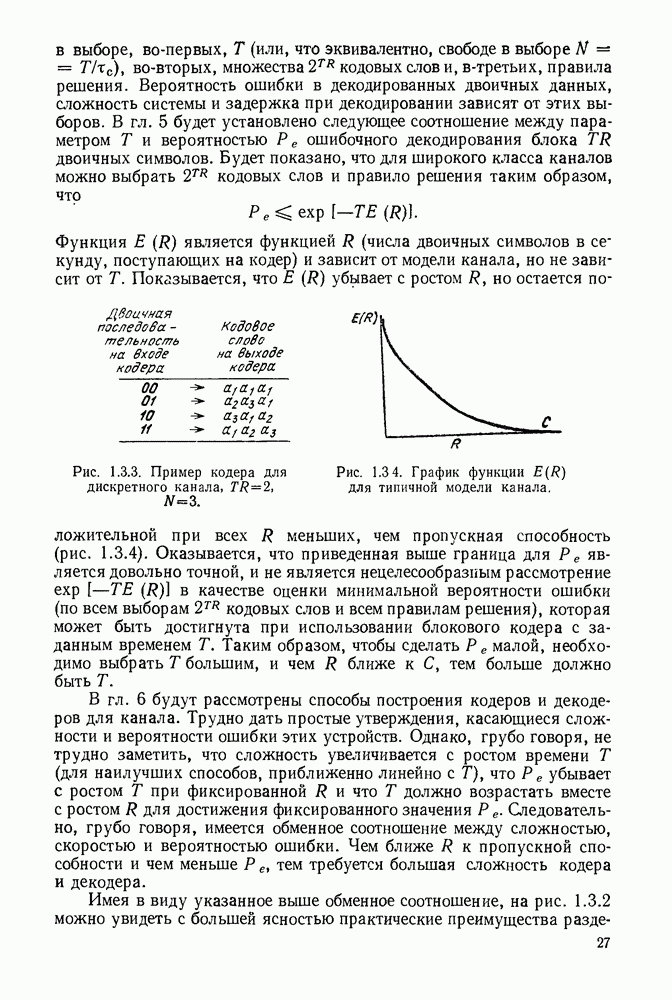
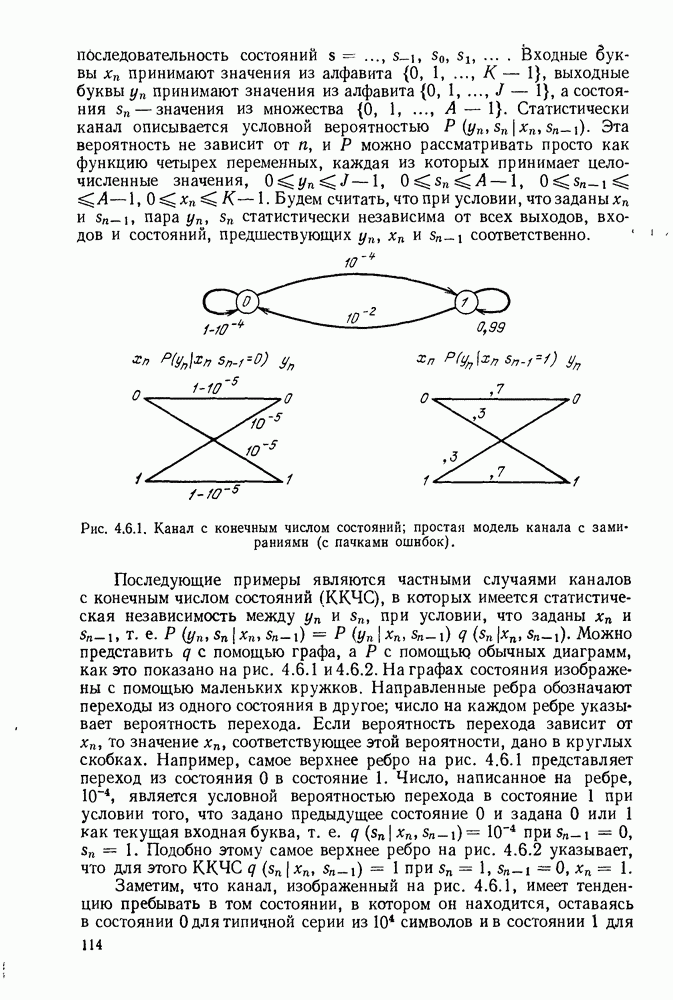
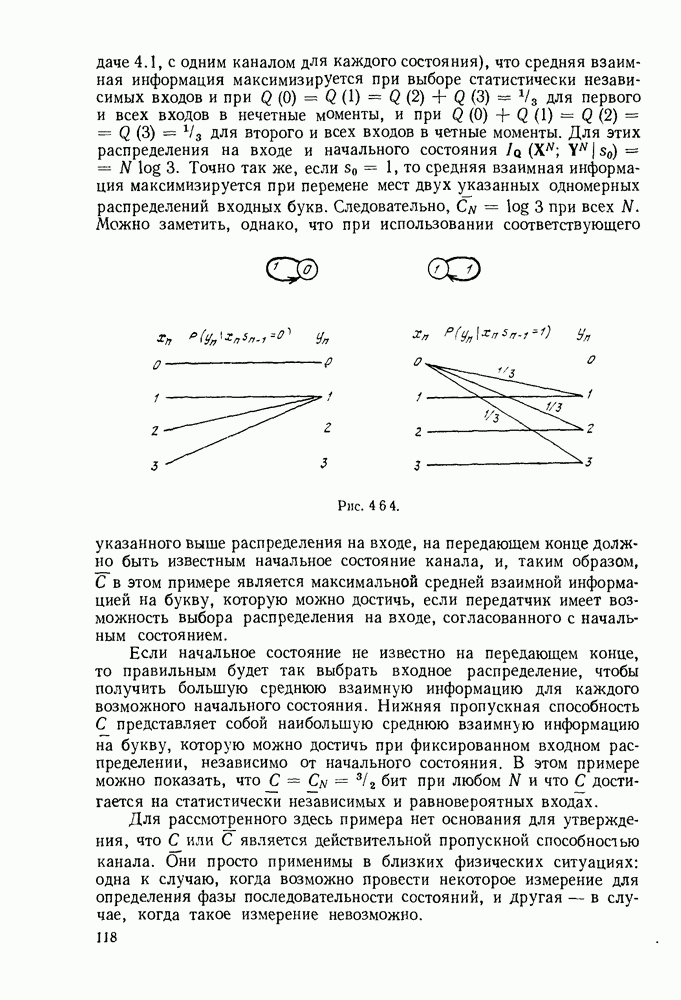
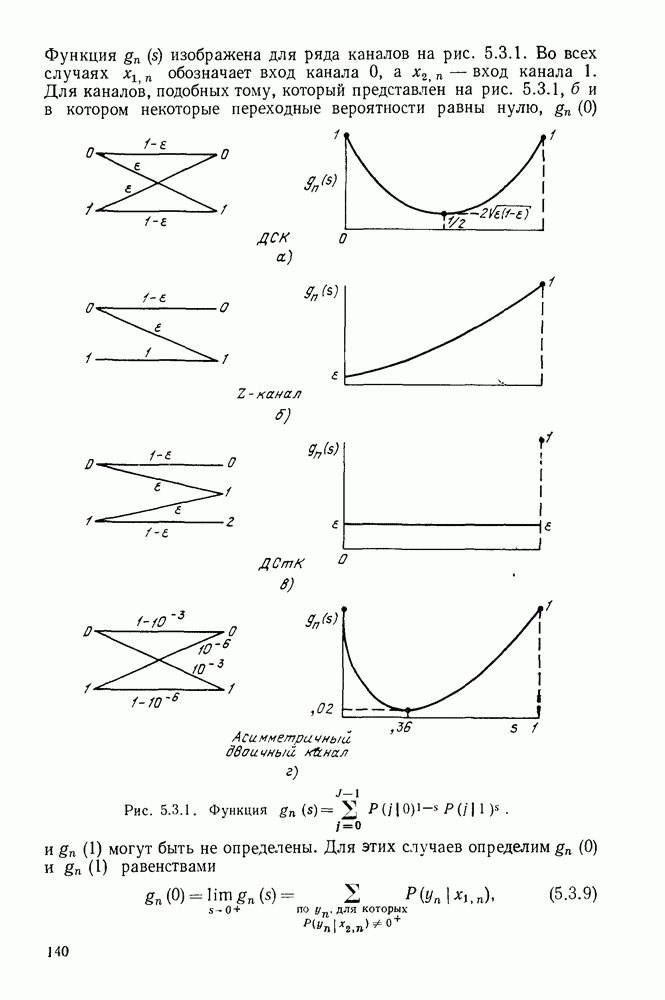
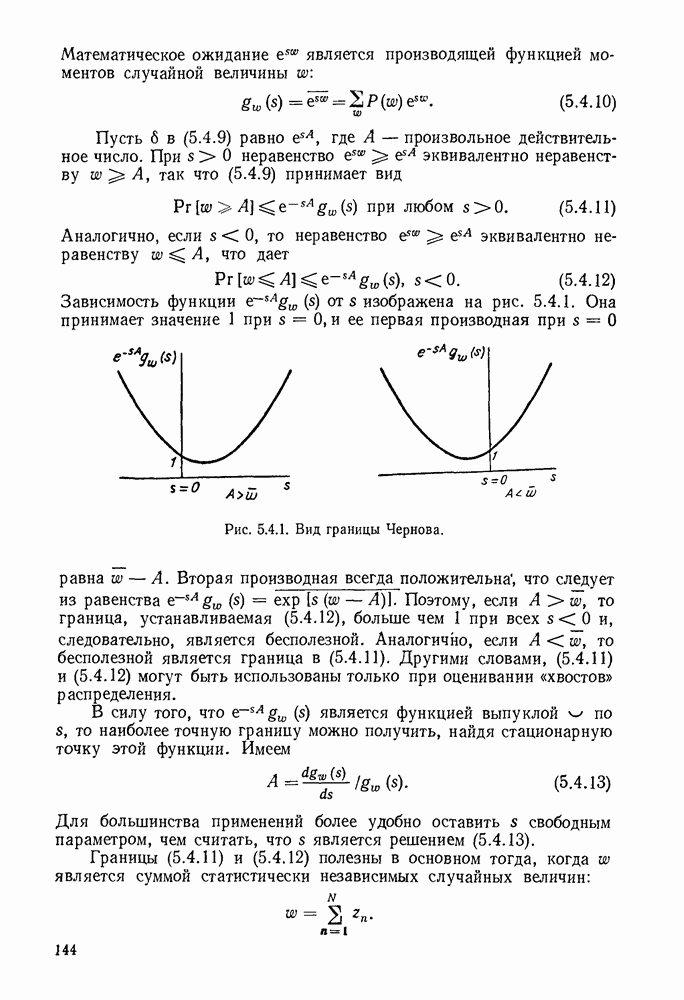
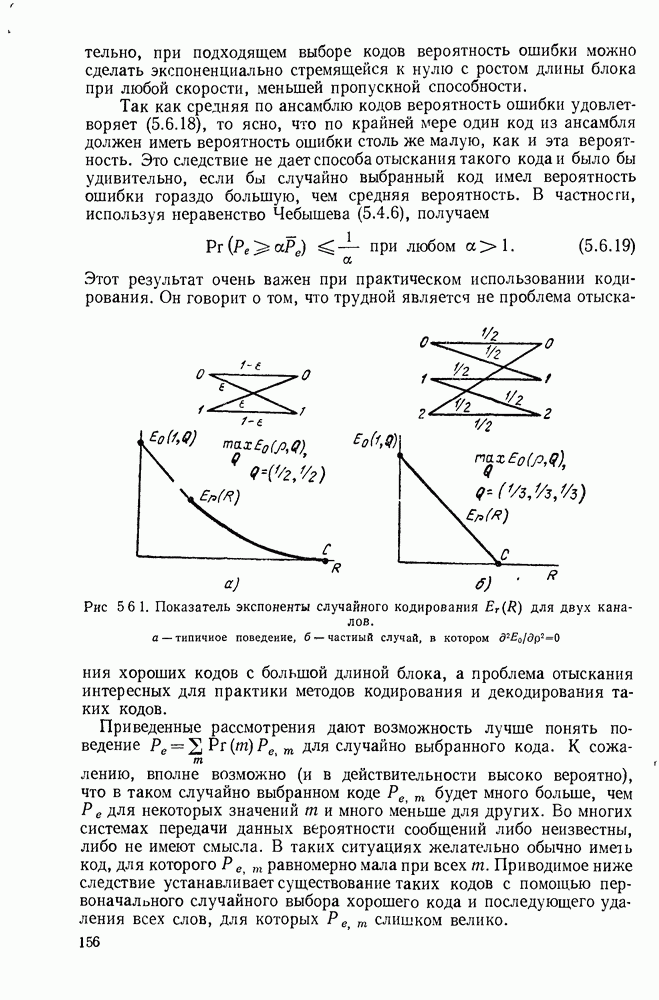
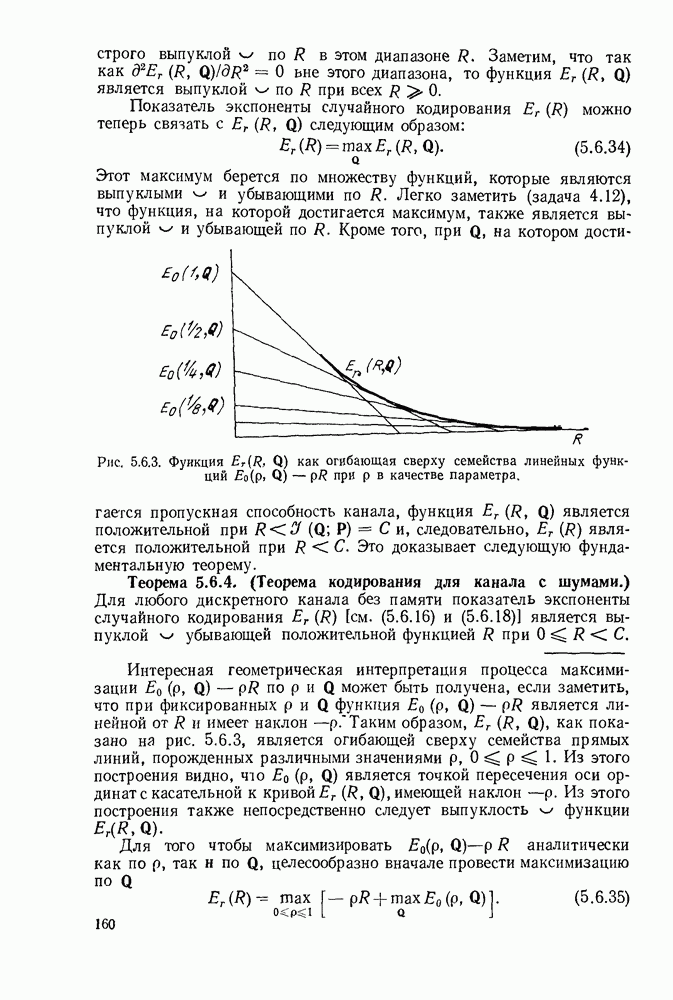
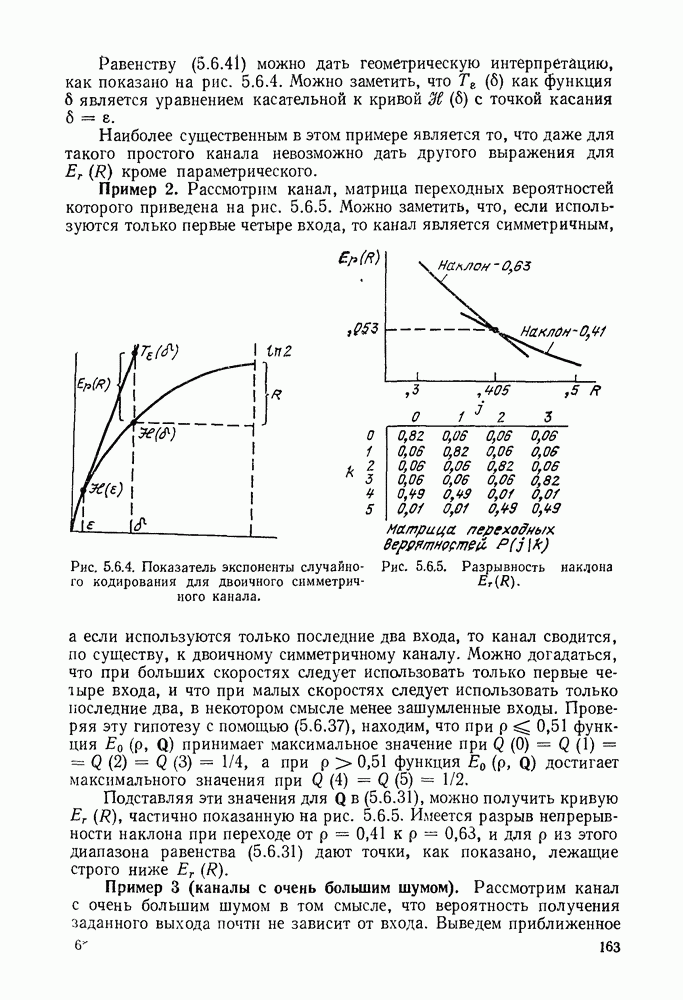
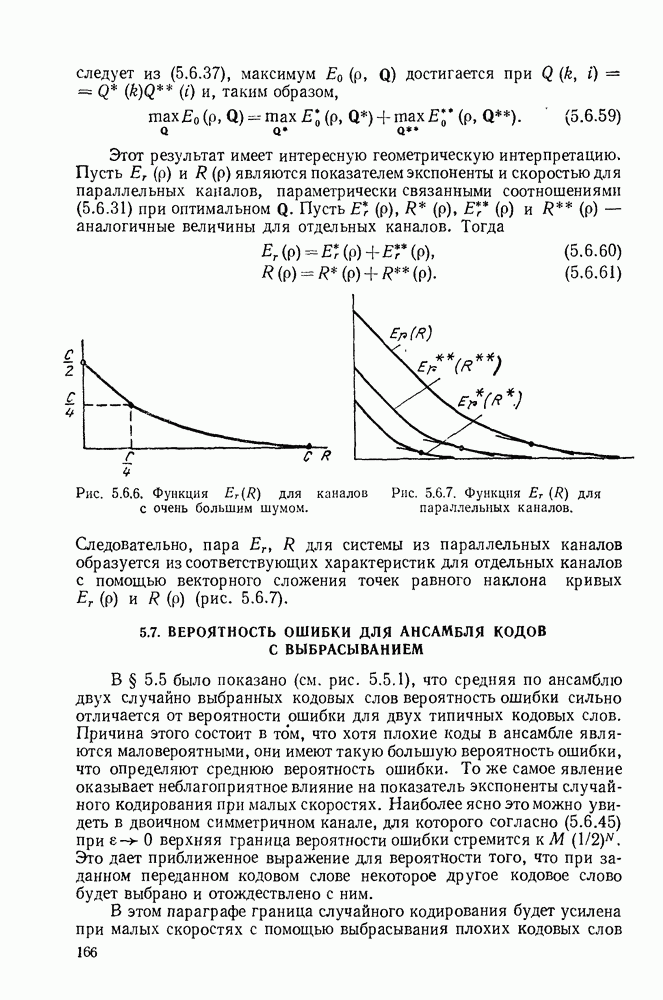
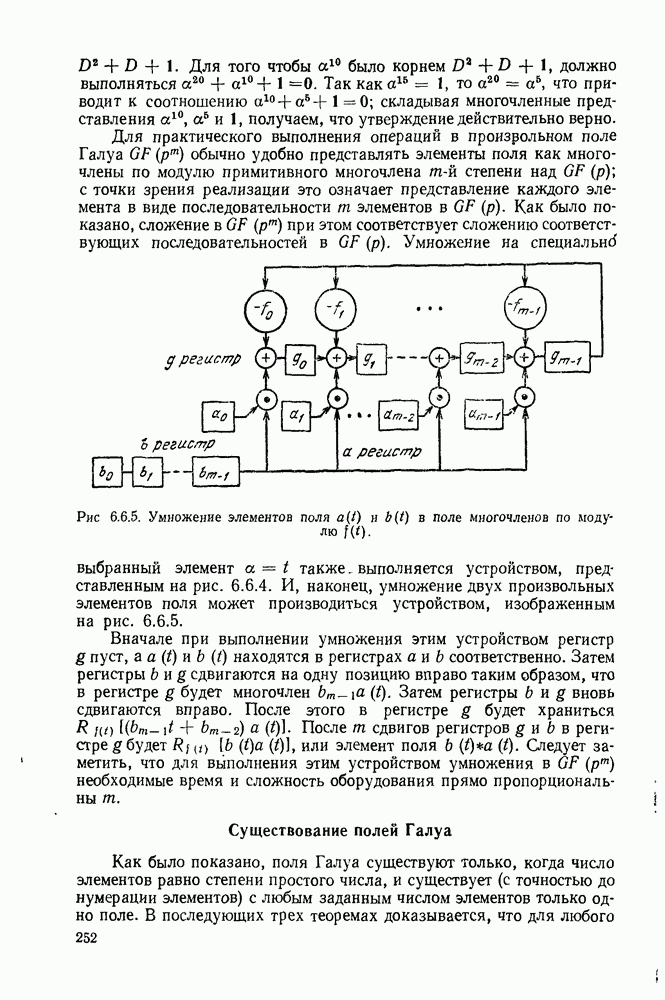
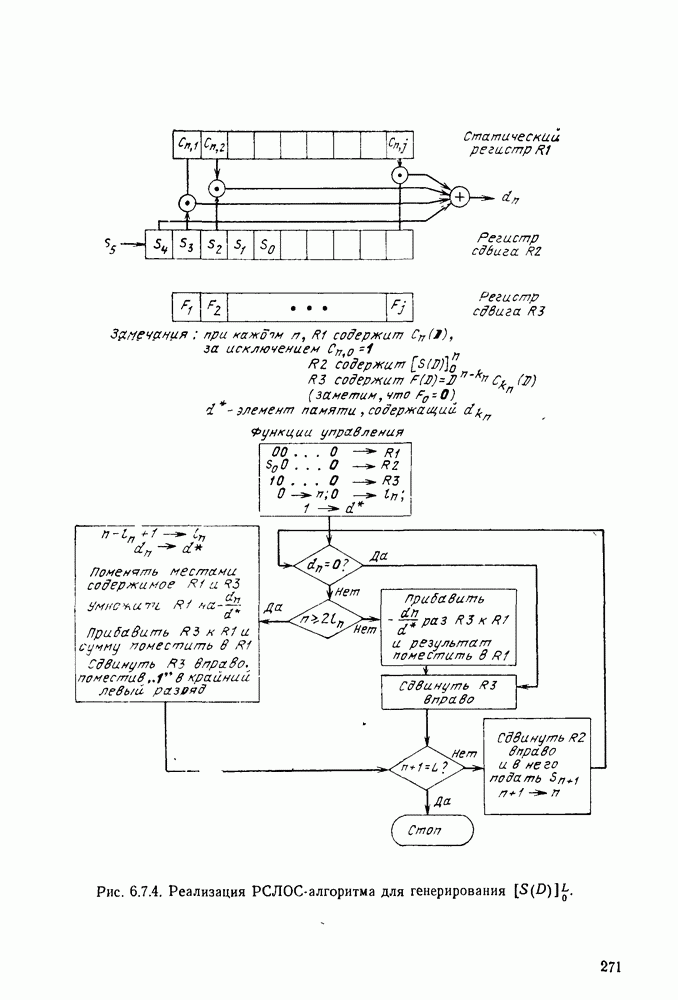
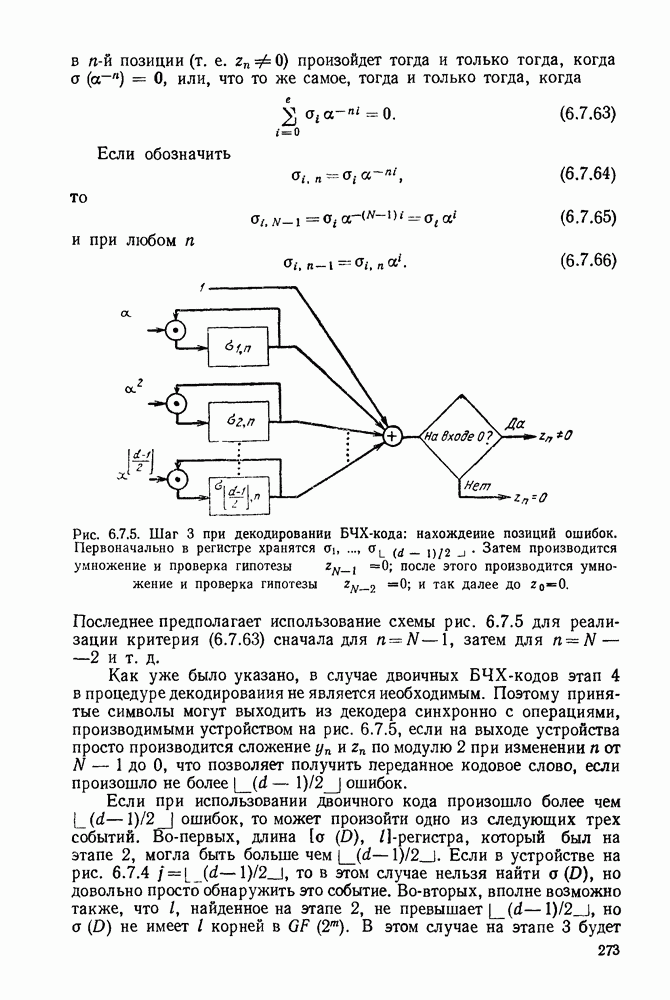
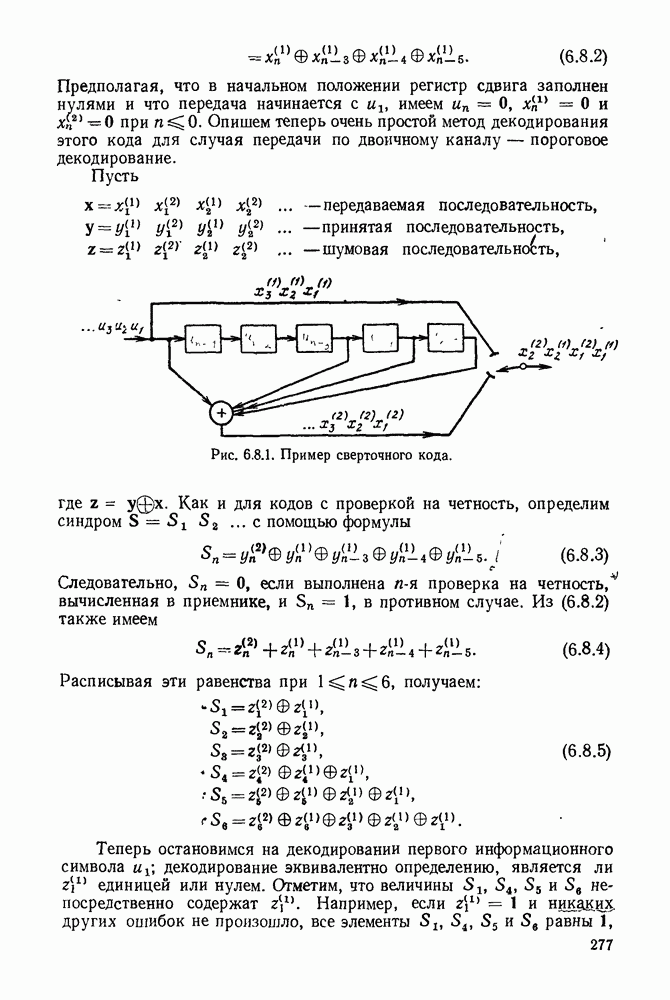
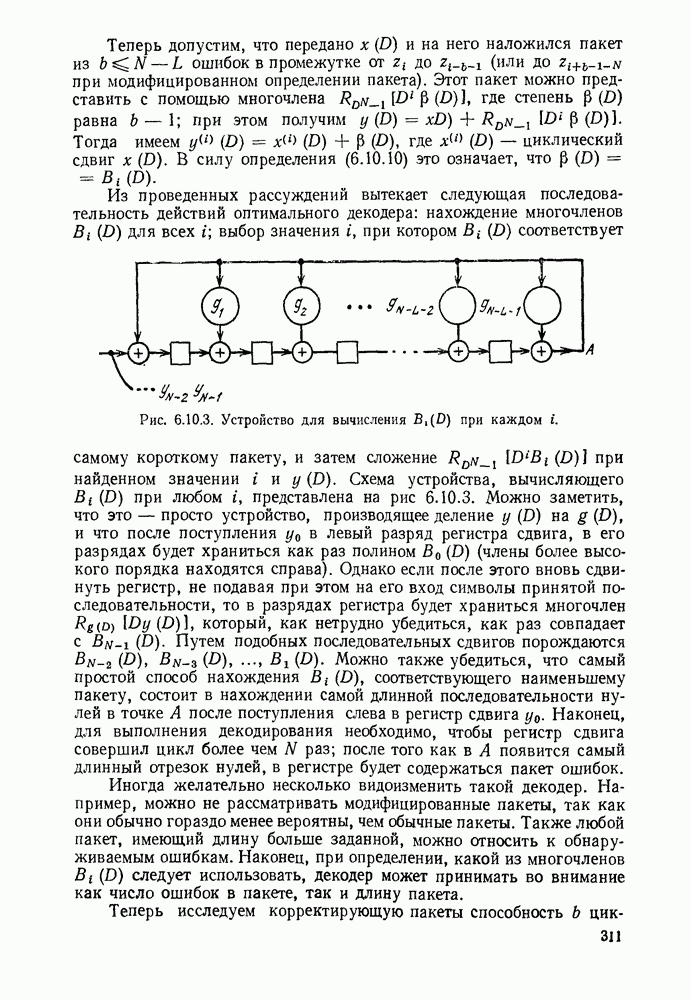
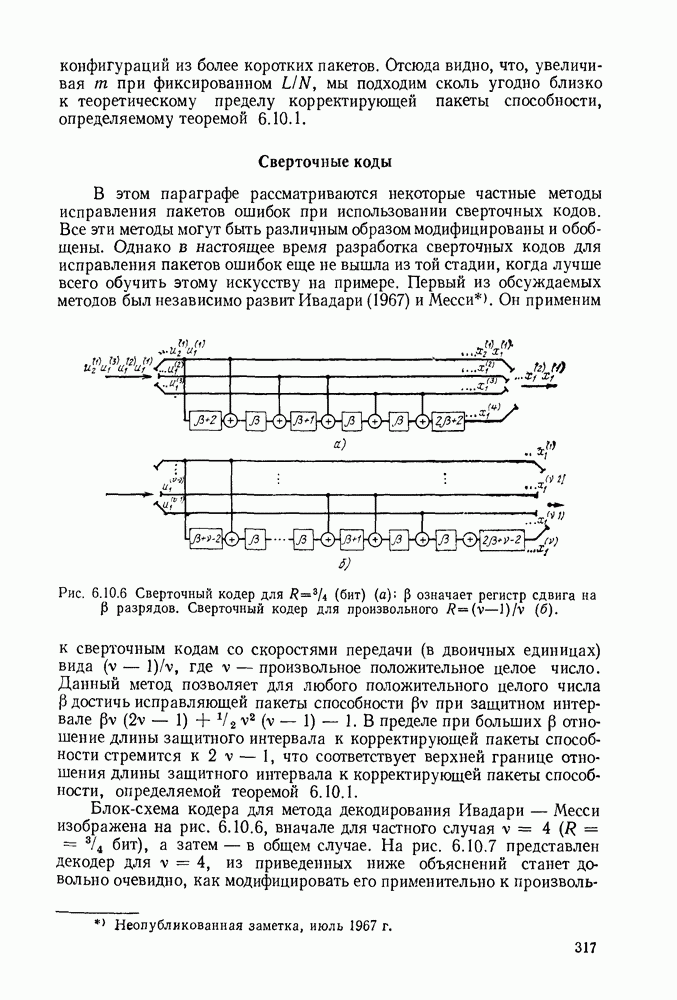
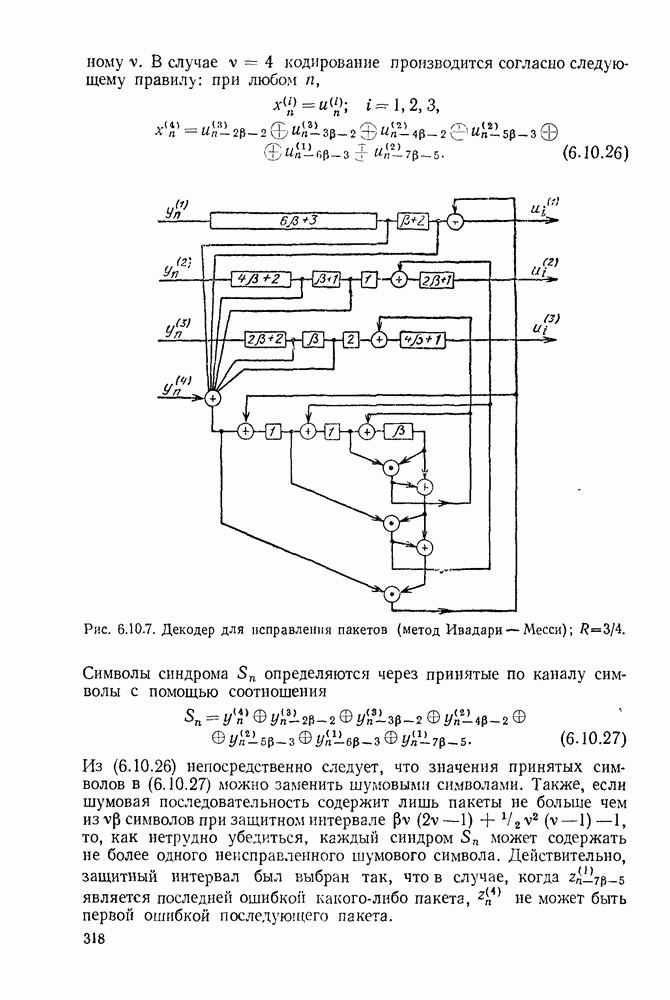
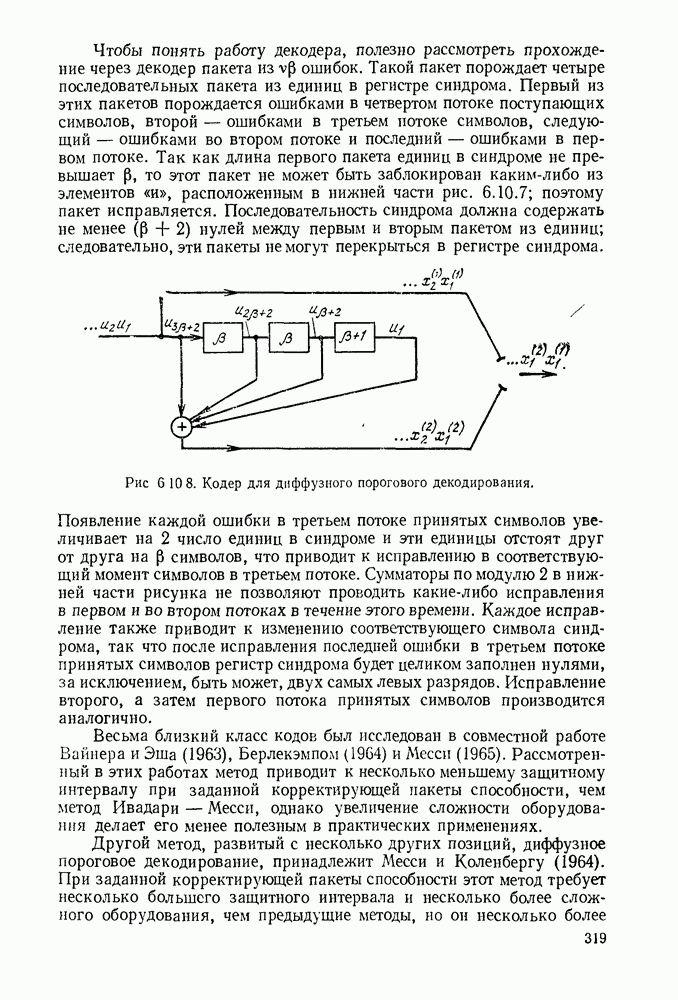
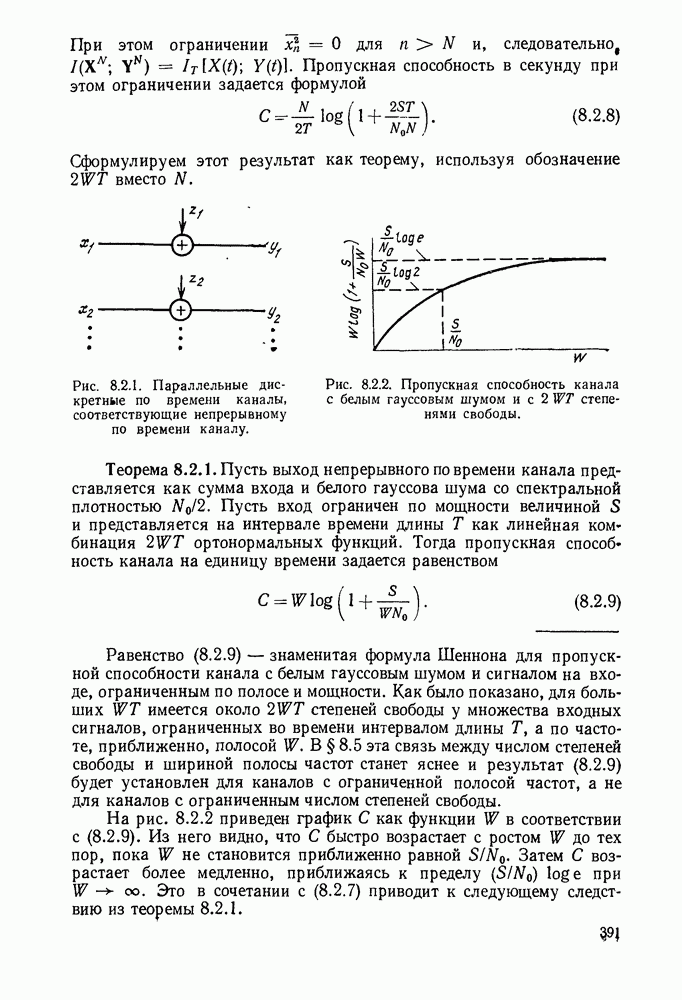
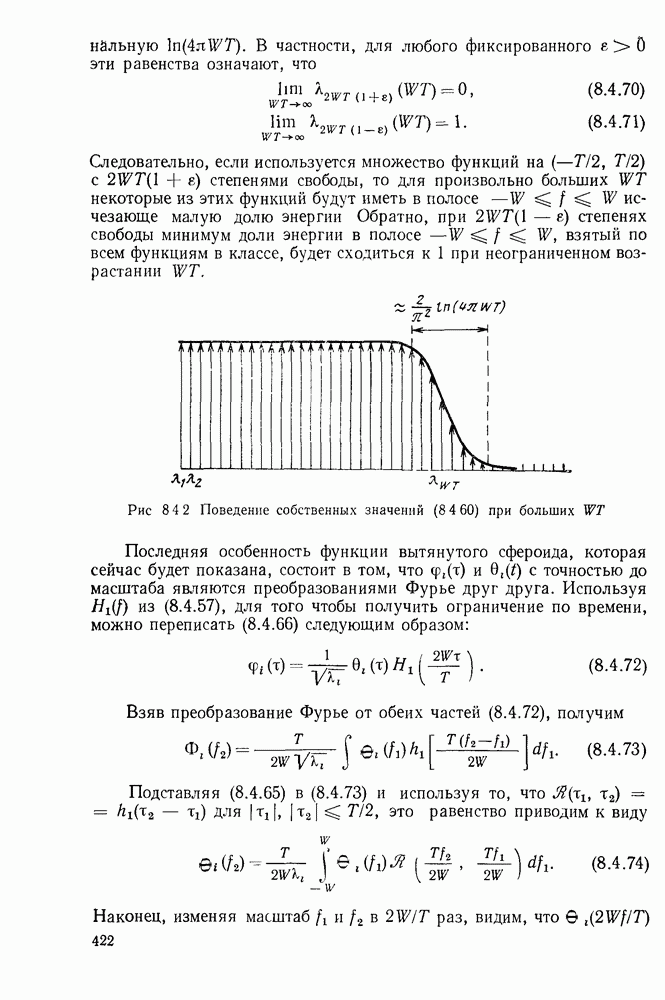
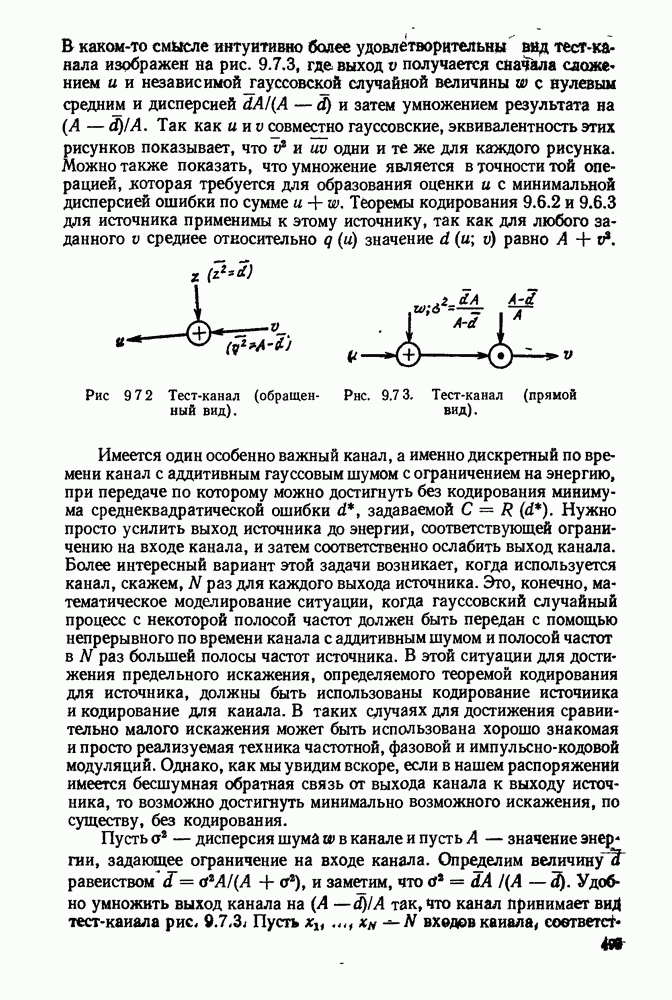
1.2. МОДЕЛИ ИСТОЧНИКОВ И КОДИРОВАНИЕ ДЛЯ ИСТОЧНИКОВЗдесь мы дадим краткое описание математических моделей источников, которые будут рассматриваться в дальнейшем. Естественно, что более подробно эти модели будут рассмотрены в последующих главах. Все источники в теории информации моделируются с помощью случайных процессов или случайных последовательностей. Простейший класс моделей источников составляют дискретные источники без памяти. В этих источниках выходом является последовательность (во времени) букв, каждая из которых выбрана из некоторого фиксированного алфавита, скажем, содержащего буквы
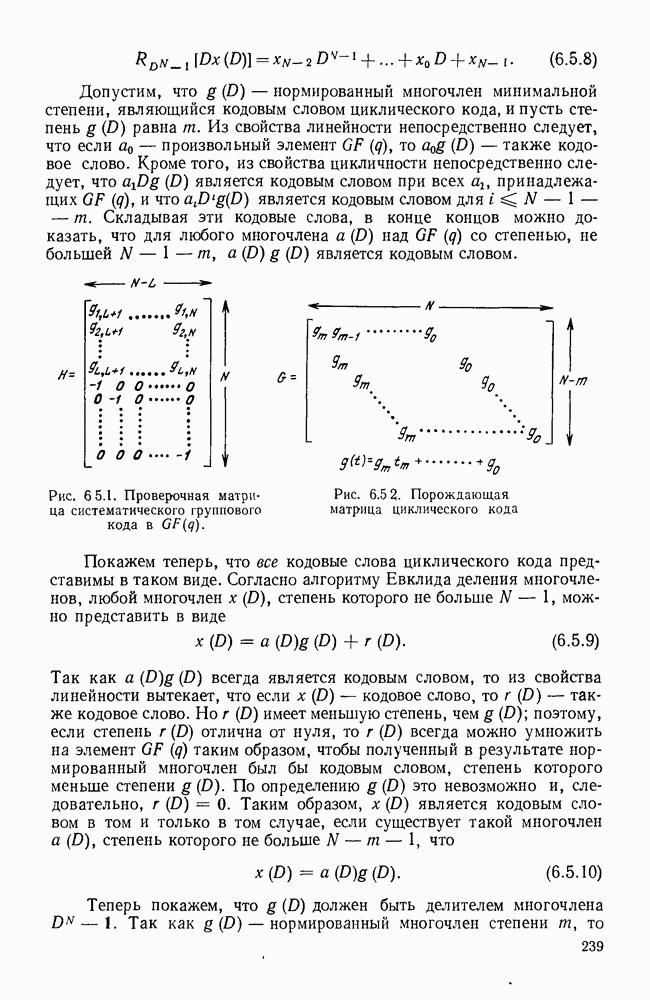
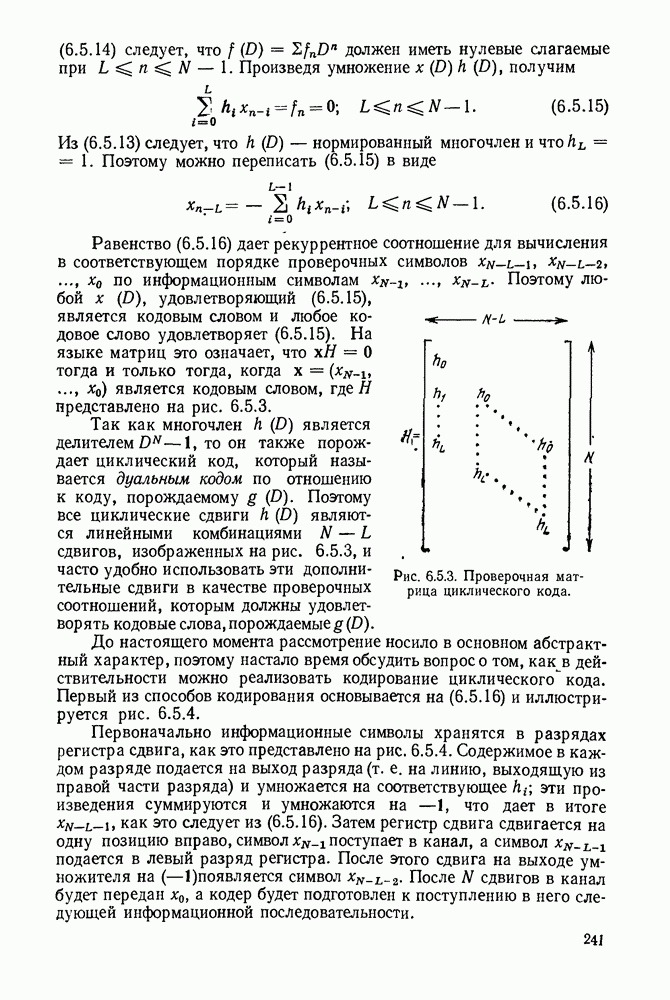
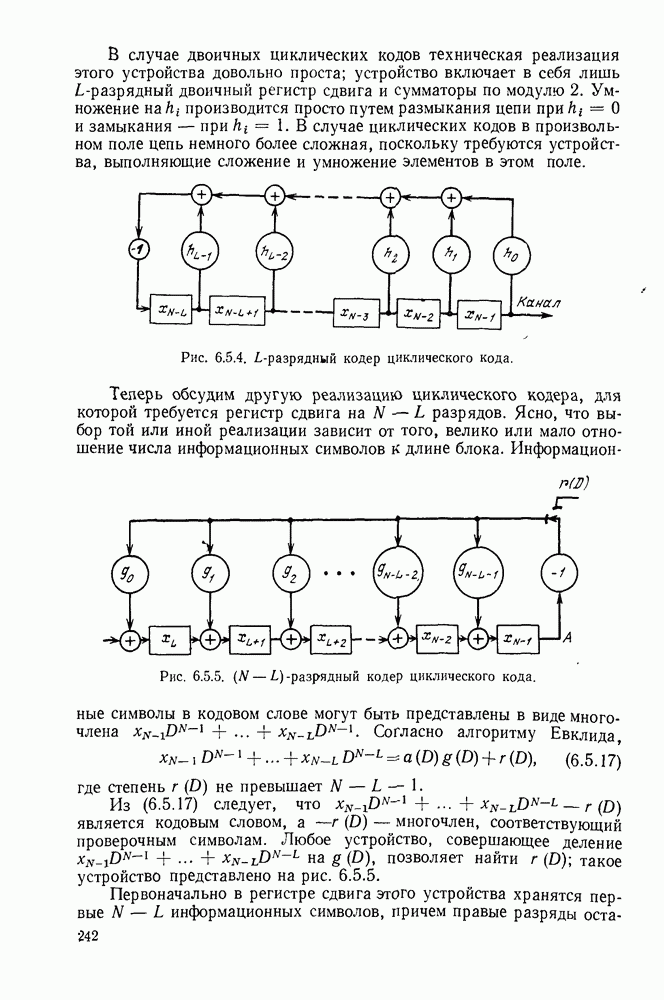
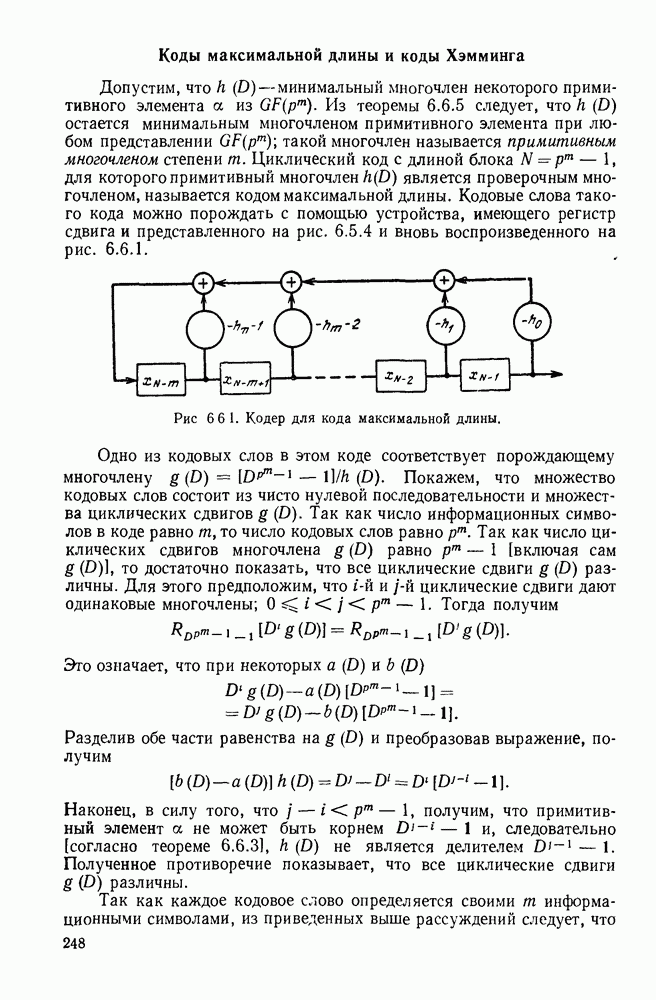
Рис. 1.2.1. Два способа преобразования алфавита из четырех букв в двоичные символы Последовательность на выходе источника состоит из этих букв, выбираемых из алфавита статистически независимо и случайно, и при этом выбор производится в соответствии с некоторым заданным распределением вероятностей Несомненно, что на первый взгляд кажется довольно странным моделирование реальных источников, которые по предположению производят осмысленную информацию, с помощью случайных процессов. Следующий пример поможет пояснить причину этого. Предположим, что нужно провести некоторое измерение несколько раз подряд и что результатом каждого измерения может быть одно из четырех событий В первом из представленных выше способов требуются два двоичных символа для представления каждой буквы источника, в то время как во втором способе требуется переменное число символов. Если известно, что в подавляющем большинстве измерений результатом будет С кодированием выхода источника в двоичные данные тесно связана мера информации (или неопределенности) букв алфавита источника, которая будет описана в гл. 2. Если Среднее по буквам алфавита значение собственной информации является особенно важной величиной, которая называется энтропией буквы источника-, энтропия задается выражением
Значение энтропии буквы источника определяется, главным образом, теоремой кодирования для источника, которая рассматривается в гл. 3. Она утверждает, что если Я — энтропия буквы источника в дискретном источнике без памяти, то последовательность на выходе источника не может быть представлена двоичной последовательностью, использующей в среднем меньше чем Я двоичных символов на букву источника, но она может быть представлена двоичной последовательностью, использующей в среднем сколь угодно близкое к Я число двоичных символов на букву источника. Некоторое ощущение справедливости этого результата может быть получено, если заметить, что в случае, когда для некоторого целого кое-что для понимания того, почему в определении собственной информации и энтропии появляется логарифм. Часто энтропия также выражается в битах в секунду. Если для дискретного источника без памяти энтропия буквы источника равна В качестве более сложного класса моделей источников можно рассмотреть дискретные источники с памятью, в которых последовательные буквы источника статистически зависимы. В § 3.5 аналогичным, но более сложным образом определяется энтропия этих источников (в битах на букву или в битах в секунду) и доказывается, что теорема кодирования для источников справедлива, если источник является эргодическим. Наконец, в гл. 9 будут рассмотрены недискретные источники. Наиболее известным примером недискретного источника является такой, у которого выходом источника является случайный процесс. При попытке закодировать случайный процесс случайной последовательностью возникает ситуация, по своей природе сильно отличающаяся от кодирования дискретных источников. Случайный процесс можно закодировать в двоичные данные, например, следующим образом: взять выборки случайной функции, затем проквантовать их и после этого закодировать проквантованные выборки в двоичные символы. Различие между этим кодированием и двоичным кодированием, описанным ранее, состоит в том, что выборочные функции не могут быть точно восстановлены по двоичной последовательности и, таким образом, это кодирование следует описывать как в терминах числа двоичных символов в секунду, так и в терминах некоторой меры искажения функции на выходе источника при представлении ее функцией, восстановленной по двоичной последовательности символов. В гл. 9 рассматривается проблема отыскания минимального числа двоичных символов в секунду, достаточного для того, чтобы закодировать выход источника так, чтобы среднее искажение выхода источника при его воспроизведении по двоичной последовательности находилось в заданных пределах. Основное здесь состоит в том, что недискретный источник может быть закодирован с некоторыми искажениями в двоичную последовательность и что требуемое число двоичных символов в единицу времени зависит от допустимого искажения.
|
 |
Оглавление
|























































































































































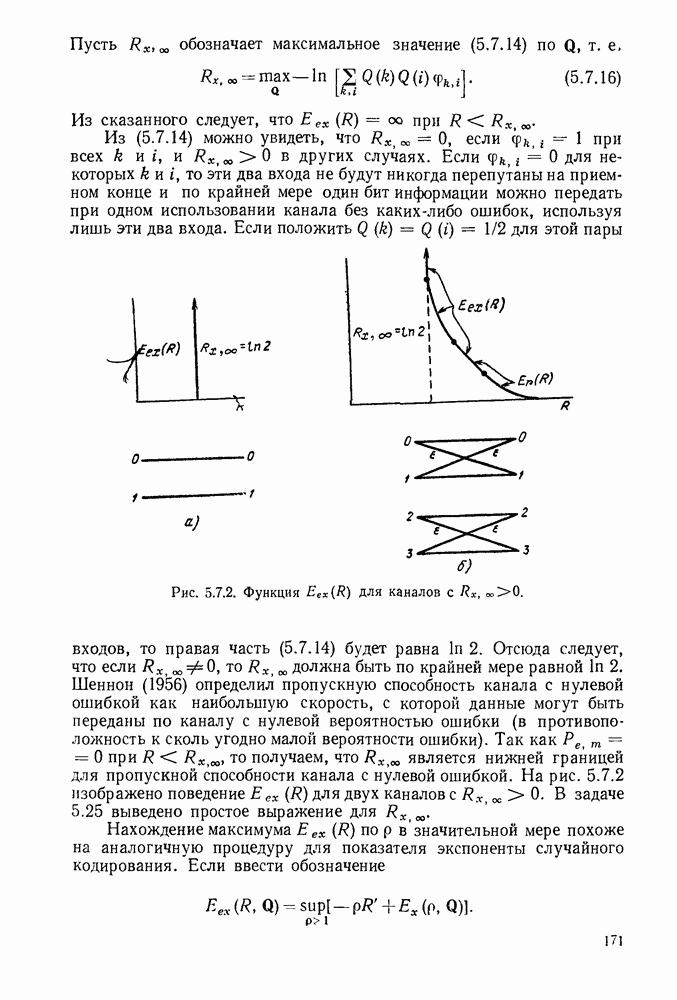


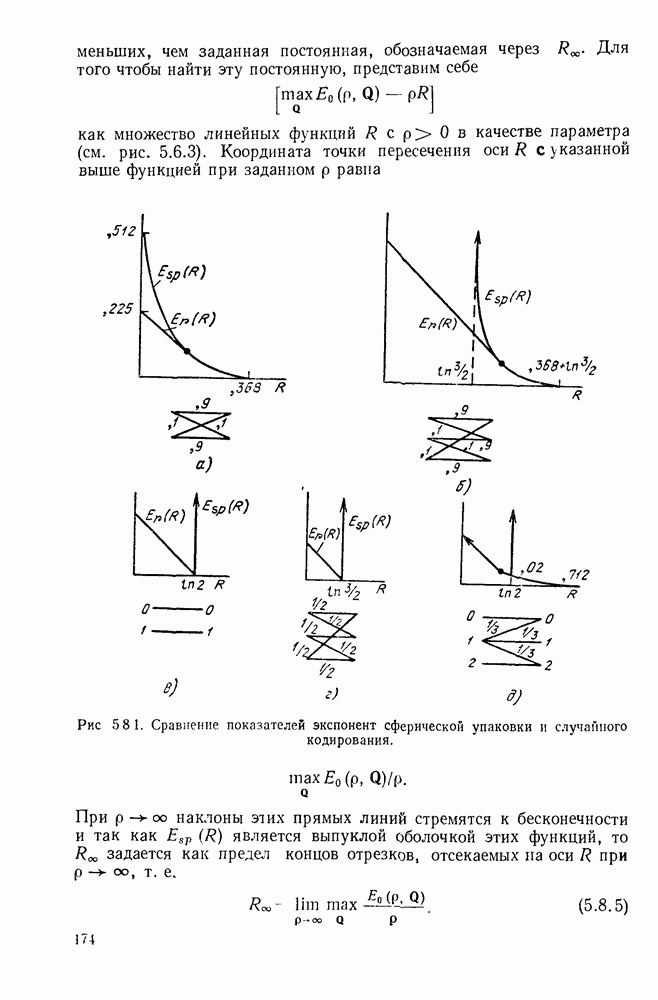


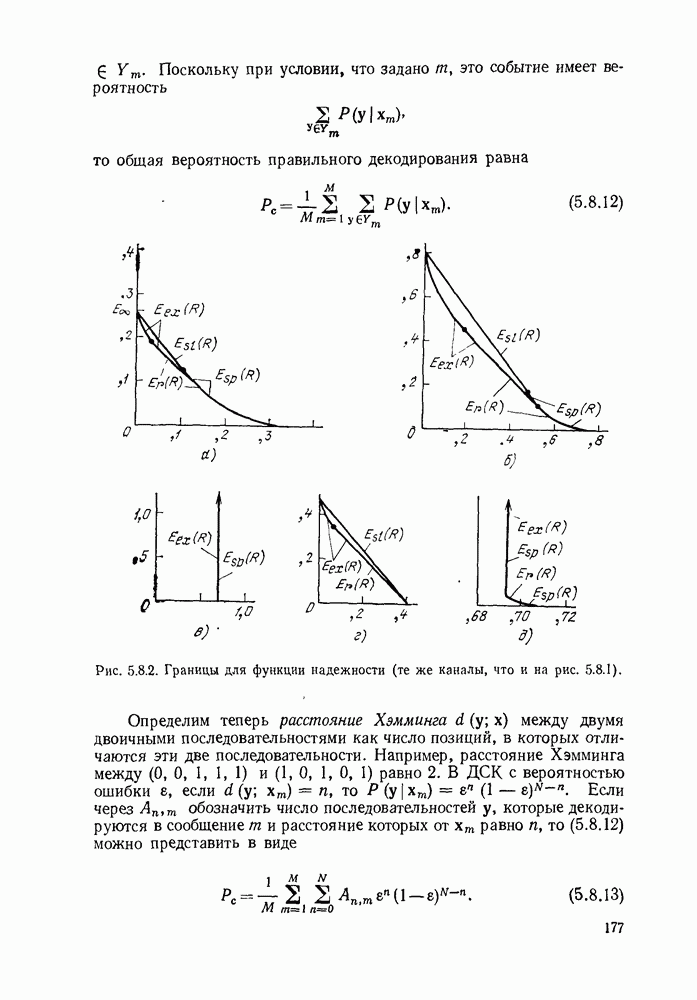























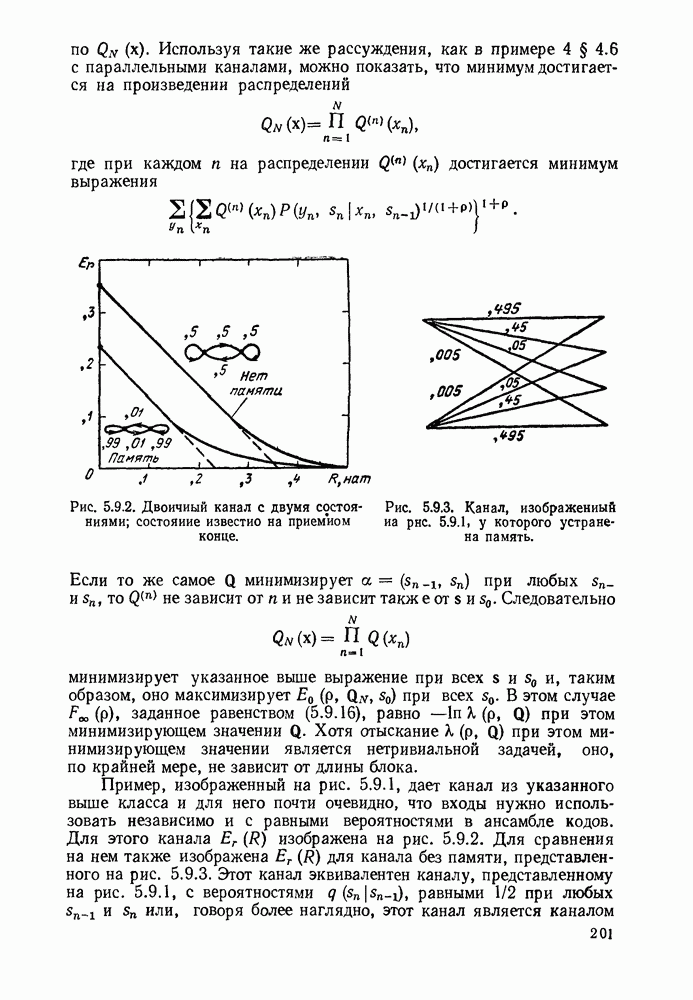






































































































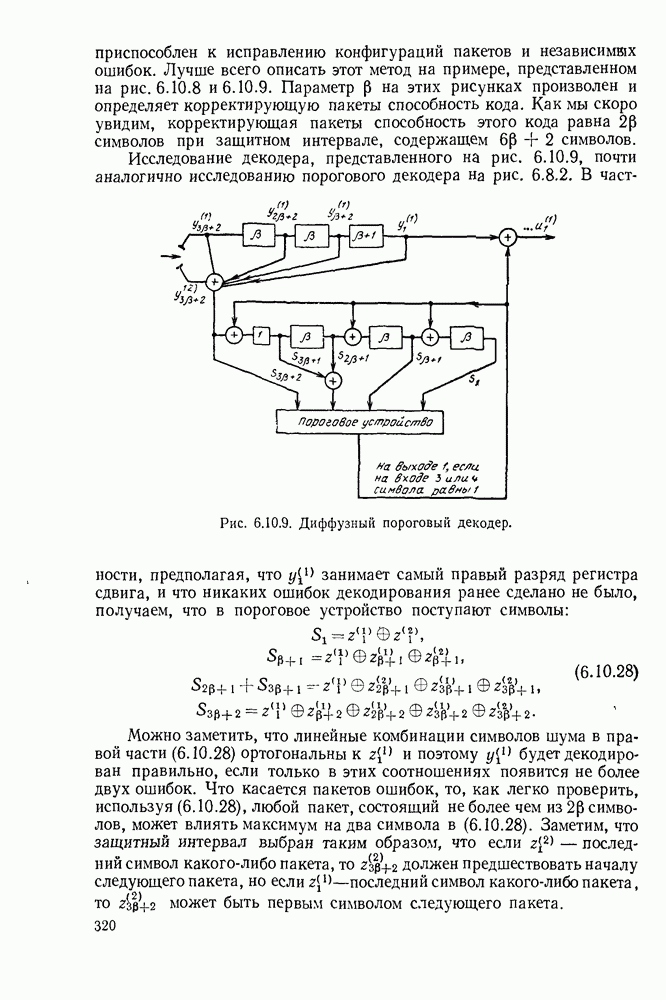

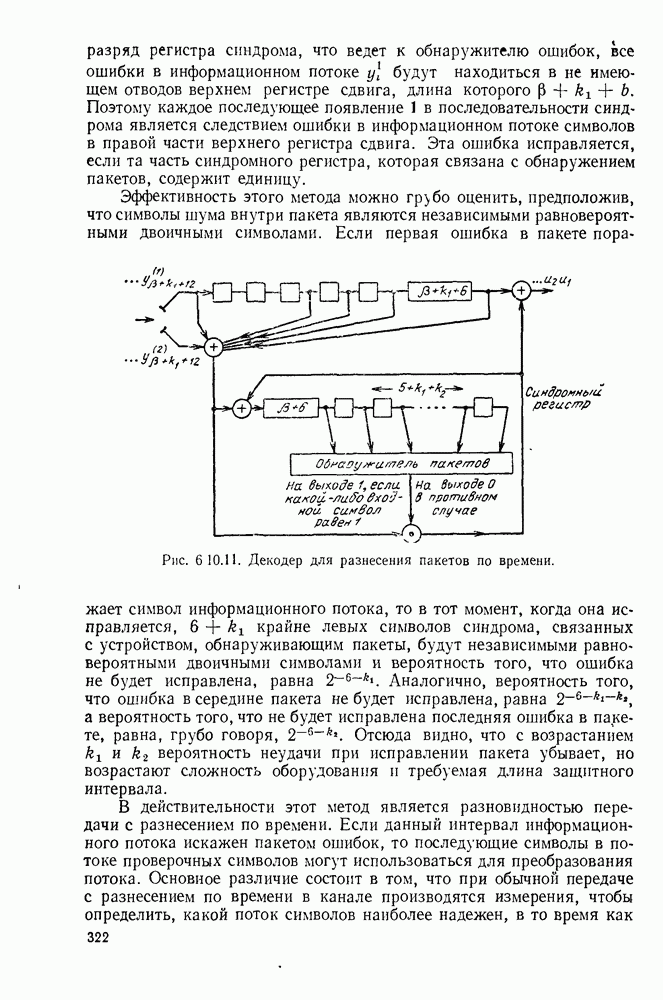




































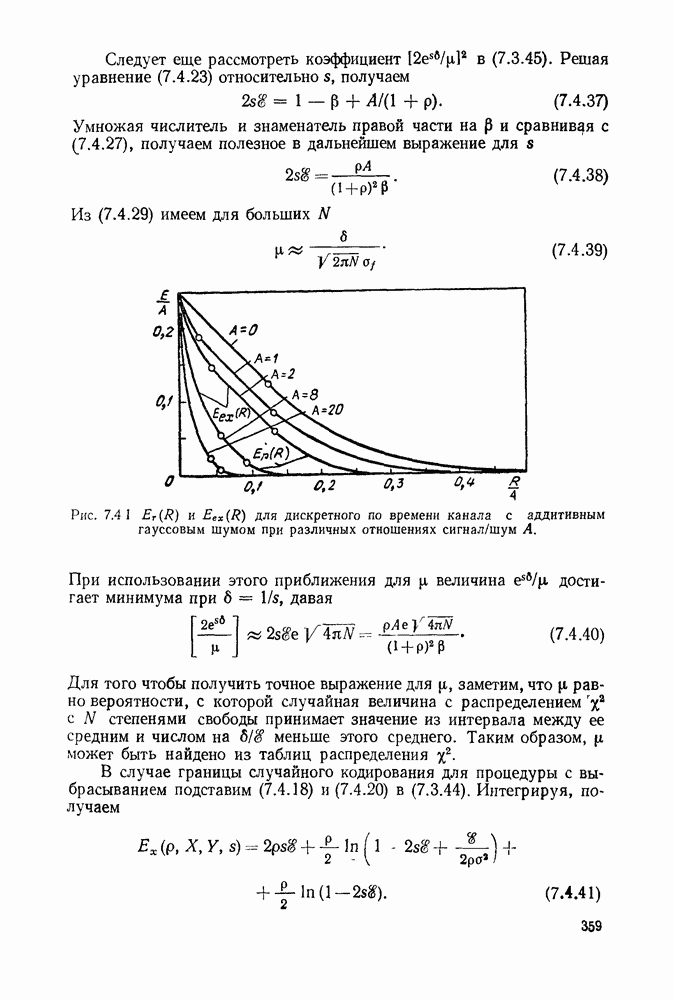


















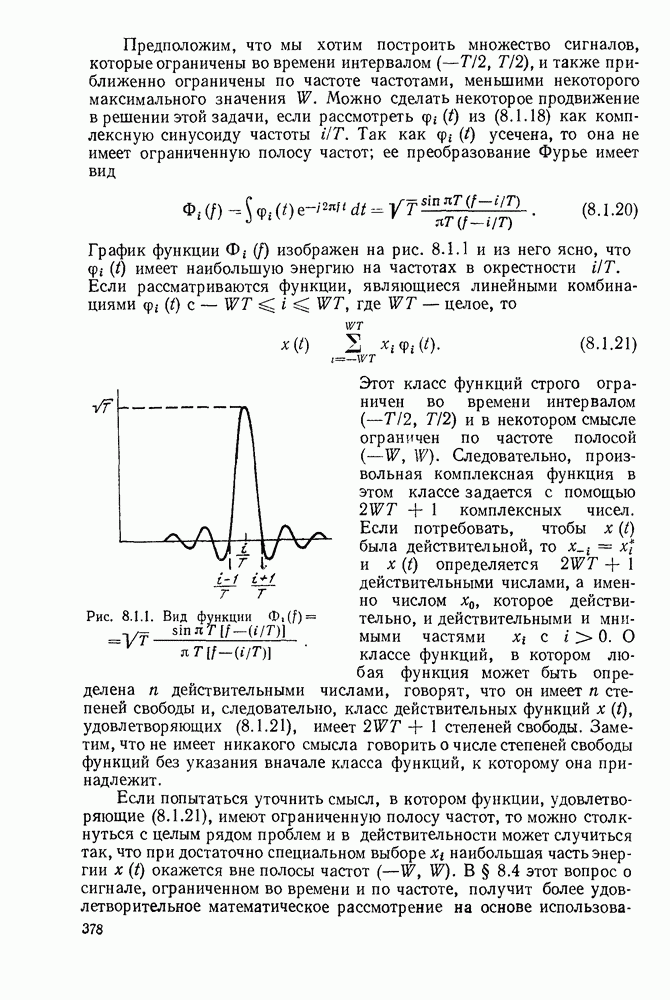


























































































































































 или
или  Пусть эта последовательность измерений должна быть накоплена в двоичной форме записи, и предположим, что предлагаются два способа перехода к двоичным символам, изображенные на рис. 1.2.1.
Пусть эта последовательность измерений должна быть накоплена в двоичной форме записи, и предположим, что предлагаются два способа перехода к двоичным символам, изображенные на рис. 1.2.1.
 тогда способ 2 позволит накопить длинную последовательность измерений с помощью значительно меньшего числа двоичных символов, чем способ 1. Методы кодирования выхода дискретного источника в двоичные данные будут подробно обсуждаться в гл. 3. Важным моментом здесь является то, что относительная эффективность методов, изображенных на рис. 1.2.1, критически зависит от частоты появления различных событий и что в математической модели источника последите определяются с помощью распределения вероятности на множестве букв источника. Хорошо известные, но более сложные примеры такого типа дает стенография, в которой короткие символы используются для наиболее употребительных слов, и код Морзе, в котором короткие последовательности точек и тире сопоставлены часто встречающимся буквам, а длинные последовательности — редким буквам.
тогда способ 2 позволит накопить длинную последовательность измерений с помощью значительно меньшего числа двоичных символов, чем способ 1. Методы кодирования выхода дискретного источника в двоичные данные будут подробно обсуждаться в гл. 3. Важным моментом здесь является то, что относительная эффективность методов, изображенных на рис. 1.2.1, критически зависит от частоты появления различных событий и что в математической модели источника последите определяются с помощью распределения вероятности на множестве букв источника. Хорошо известные, но более сложные примеры такого типа дает стенография, в которой короткие символы используются для наиболее употребительных слов, и код Морзе, в котором короткие последовательности точек и тире сопоставлены часто встречающимся буквам, а длинные последовательности — редким буквам.
 буква алфавита источника имеет вероятность
буква алфавита источника имеет вероятность  то собственная информация этой буквы (измеренная в битах) определяется как
то собственная информация этой буквы (измеренная в битах) определяется как  . С интуитивной точки зрения (подробнее это будет рассматриваться в гл. 2) это, связанное с техникой связи определение, имеет много качественных черт, свойственных общеупотребительному понятию информации. В частности, если
. С интуитивной точки зрения (подробнее это будет рассматриваться в гл. 2) это, связанное с техникой связи определение, имеет много качественных черт, свойственных общеупотребительному понятию информации. В частности, если  то
то  в соответствии с тем, что появление
в соответствии с тем, что появление  не несет никакой информации, так как оно неизбежно должно произойти. Точно также, чем меньше вероятность
не несет никакой информации, так как оно неизбежно должно произойти. Точно также, чем меньше вероятность  тем больше ее собственная информация. Вместе с тем, нетрудно заметить, что это специальное определение информации имеет некоторые качественные недостатки в сравнении с общеупотребительным понятием информации. Например, не имеет значения то, насколько редким является событие; мы не считаем это информативным (в общеупотребительном смысле), если само по себе наступление события не оказывается интересным для нас. Это не означает, что имеется какой-то недостаток в определении собственной информации; польза от того или иного определения в теории определяется тем, насколько оно дает возможность проникнуть в существо проблемы, и тем, как оно упрощает теоремы. Определение, которое дается здесь, оказывается полезным в теории, главным образом, именно потому, что оно позволяет отделить понятие неожиданности в информации от того, что представляет в информации интерес или смысл.
тем больше ее собственная информация. Вместе с тем, нетрудно заметить, что это специальное определение информации имеет некоторые качественные недостатки в сравнении с общеупотребительным понятием информации. Например, не имеет значения то, насколько редким является событие; мы не считаем это информативным (в общеупотребительном смысле), если само по себе наступление события не оказывается интересным для нас. Это не означает, что имеется какой-то недостаток в определении собственной информации; польза от того или иного определения в теории определяется тем, насколько оно дает возможность проникнуть в существо проблемы, и тем, как оно упрощает теоремы. Определение, которое дается здесь, оказывается полезным в теории, главным образом, именно потому, что оно позволяет отделить понятие неожиданности в информации от того, что представляет в информации интерес или смысл.

 источник имеет алфавит из
источник имеет алфавит из  равновероятных букв, то энтропия буквы источника равна
равновероятных букв, то энтропия буквы источника равна  бит. Вместе с тем, если заметить, что всего имеется
бит. Вместе с тем, если заметить, что всего имеется  различных последовательностей из
различных последовательностей из  двоичных символов, то можно понять, что каждая из этих последовательностей может быть сопоставлена различным буквам алфавита источника, представляя, таким образом, выход источника с помощью
двоичных символов, то можно понять, что каждая из этих последовательностей может быть сопоставлена различным буквам алфавита источника, представляя, таким образом, выход источника с помощью  двоичных символов на букву источника. Этот пример дает
двоичных символов на букву источника. Этот пример дает
 и если источник производит одну букву за каждые
и если источник производит одну букву за каждые  секунд, то энтропия в битах в секунду равна
секунд, то энтропия в битах в секунду равна  и теорема кодирования для источника указывает, что выход источника может быть представлен двоичной последовательностью, в которой число двоичных символов в секунду сколь угодно близко к
и теорема кодирования для источника указывает, что выход источника может быть представлен двоичной последовательностью, в которой число двоичных символов в секунду сколь угодно близко к 