Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 2.5. Граница, основанная на случайном выборе кодаОбратимся теперь к задаче вычисления вероятности ошибки на приемном конце, которой можно добиться, пользуясь сверточным кодом при передаче по двоичному симметричному каналу. Прежде чем непосредственно приступить к делу, выведем более общую оценку, основанную на случайном выборе кода, которая справедлива не только для ансамбля сверточных кодов, но также и для нескольких других ансамблей линейных кодов. Сосредоточим внимание на двоичных Для примера возьмем случай
Здесь в качестве подгруппы Заметим далее, что если к информационным позициям добавить проверочные, то полученные последовательности длины
Разбиение группы информационных последовательностей есть не что иное, как «стандартное расположение» подгруппы и ее смежных классов, введенное в теорию кодирования еще Слепяном [15]. Несколько иная терминология используется здесь по следующей причине. В стандартном расположении Слепяна подгруппой является сама группа кодовых слов, а исходной группой — группа всех последовательностей длины Разбиение группы интересует нас по следующим причинам. Во-первых, множество расстояний между элементами собственного смежного класса совпадает с множеством весов элементов подгруппы. Это тривиальным образом следует из определения смежного класса, приведенного в приложении А. Во-вторых, множество расстояний от любого элемента одного смежного класса до каждого из элементов другого смежного класса совпадает с множеством весов элементов некоторого фиксированного собственного смежного класса и не зависит от выбора элемента из первого смежного класса. Это следует из того факта, что элементы любого смежного класса отличаются друг от друга на элемент подгруппы. Например, в коде, использованном в приведенном выше примере, элементы смежного класса находятся друг от друга на расстоянии 2, но любой элемент из В приложении Теорема 8. Если заданы ансамбль равновероятных двоичных
где К и а — коэффициент и показатель соответственно в обычном выражении для границы, основанной на случайном выборе кода (точные значения — в приложении Назовем первой вероятностью полученным символам. Это определение позволяет сформулировать следствие из теоремы 8. Следствие 1. Средняя по ансамблю двоичных сверточных кодов вероятность ошибки Доказательство. Мы видели (§ 2.1), что множество начальных кодовых слов сверточного кода образует Установлен, следовательно, факт, что в ансамбле сверточных кодов должен существовать хотя бы один код, для которого последовательность первых информационных символов может быть определена с вероятностью ошибки, удовлетворяющей неравенству (56). В § 4.1 мы покажем, что для сверточного кода декодирование может быть выполнено последовательно с помощью алгоритма, который определяет последующие множества информационных символов таким же образом, как и множество первых информационных символов. Таким образом, если все предшествующие последовательности декодированы правильно, то последующие информационные символы могут быть определены с вероятностью ошибки, удовлетворяющей неравенству (56). Хотя в этой книге, вообще говоря, не исследуются другие ансамбли, мы применим теорему 8 к рассмотренному Возенкрафтом ансамблю кодов со случайными сдвигами (ср. гл. I), чтобы показать ее пригодность вообще при доказательстве границы для случайных линейных кодов. Следствие 2. Вероятность ошибки на блок для ансамбля кодов со случайными сдвигами удовлетворяет неравенству (56). Доказательство. Коды со случайными сдвигами могут быть описаны следующим образом. Рассмотрим Кодирование для кодов со случайными сдвигами выполняется так: последовательность может быть определена с вероятностью ошибки, удовлетворяющей неравенству (56). (Этот ансамбль кодов интересен тем, что из всех ансамблей, для которых можно показать, что к ним применима граница, основанная на случайном выборе кода, он содержит меньше всего кодов.) Интересно, что для вывода границы для ансамбля сверточных кодов и для ансамбля блоковых кодов используется одна и та же основная теорема. Теорему 8 можно использовать также для доказательства того, что ансамбль скользящих кодов и ансамбль всех систематических кодов удовлетворяют границе случайных кодов. Доказательство этого последнего факта вполне аналогично доказательству следствия 2 и потому здесь не приводится.
|
 |
Оглавление
|














































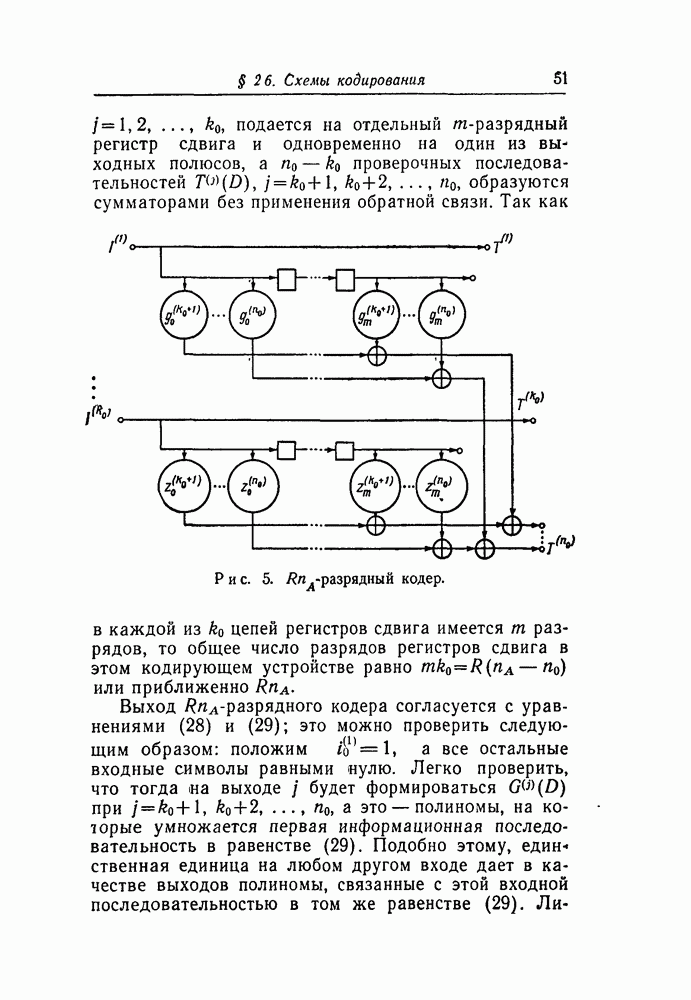
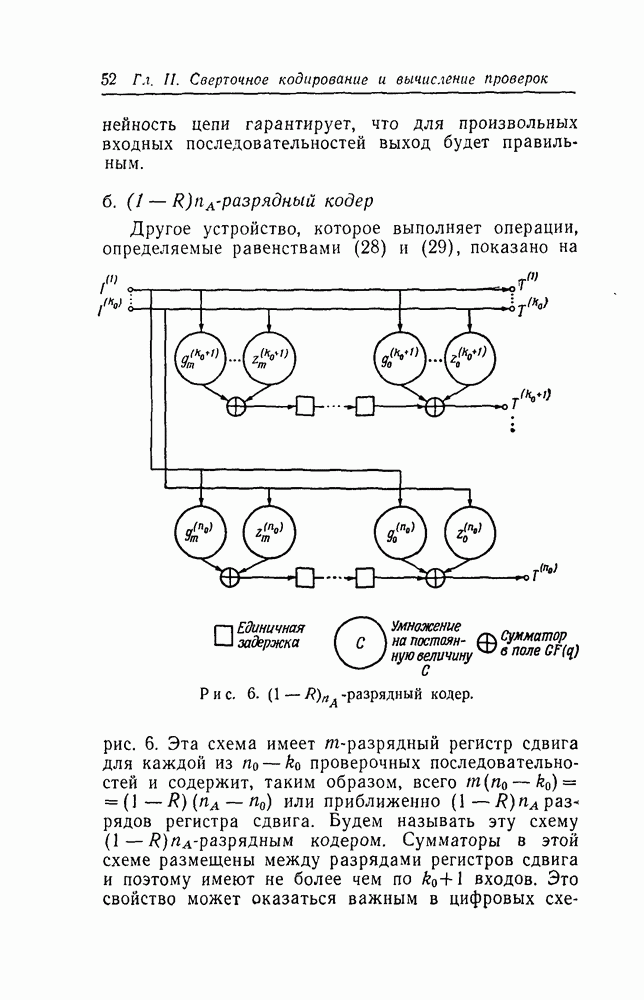
























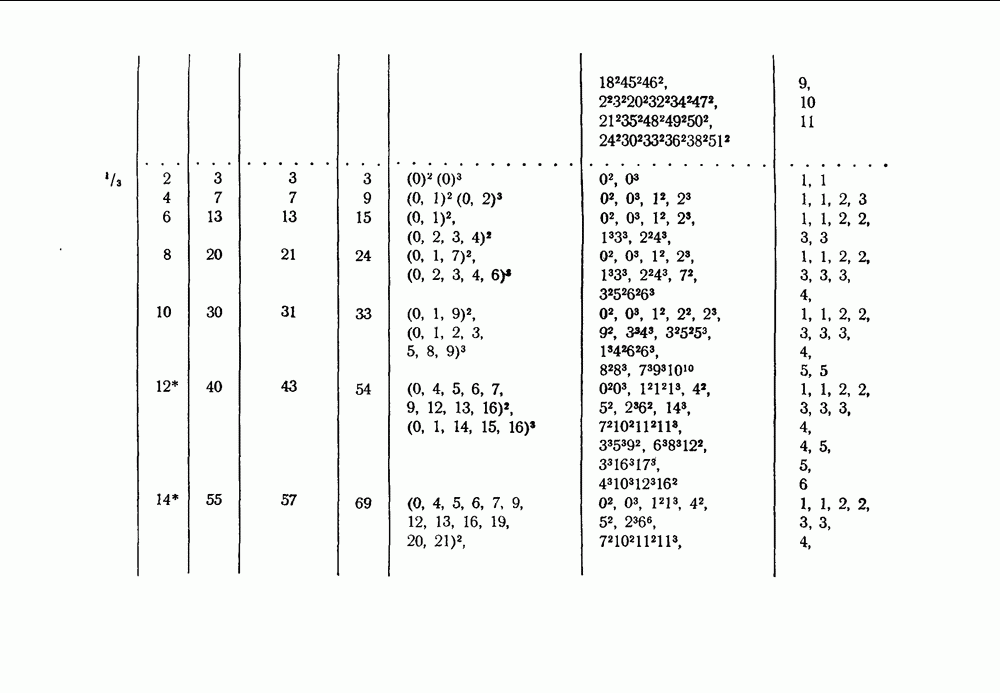
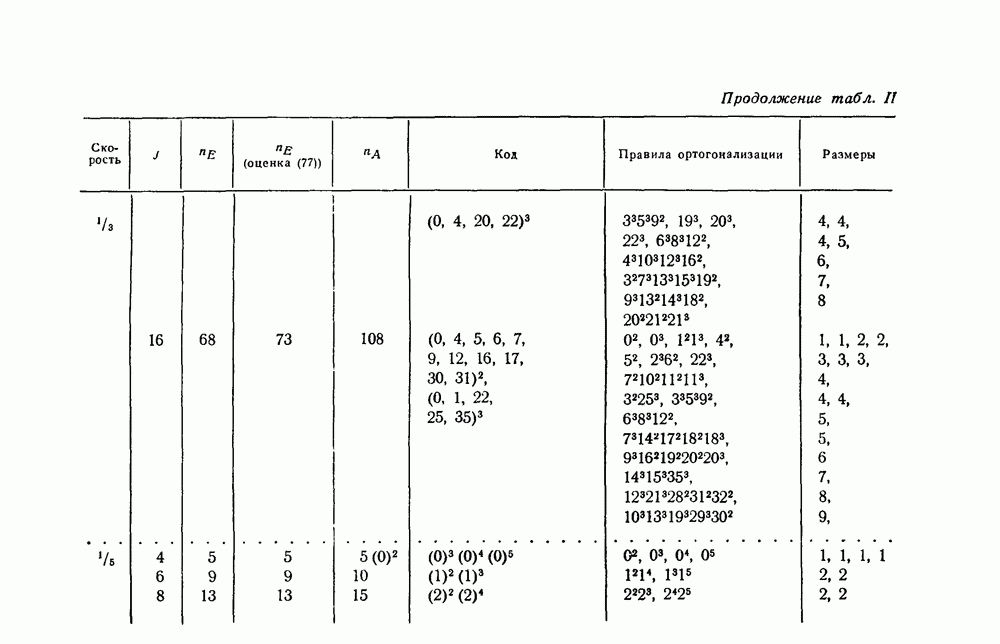
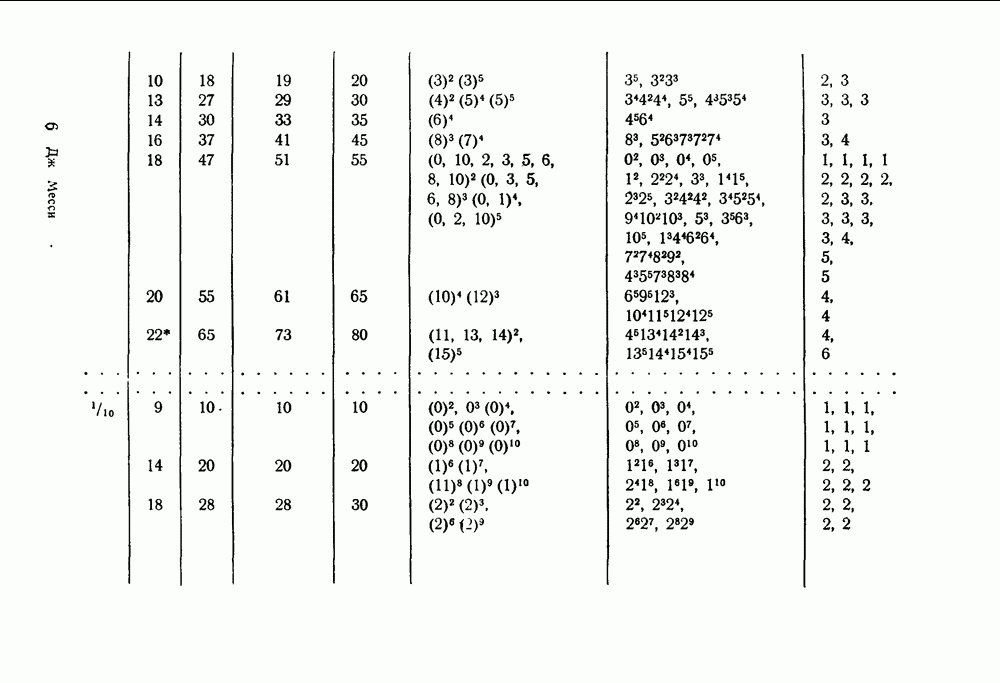
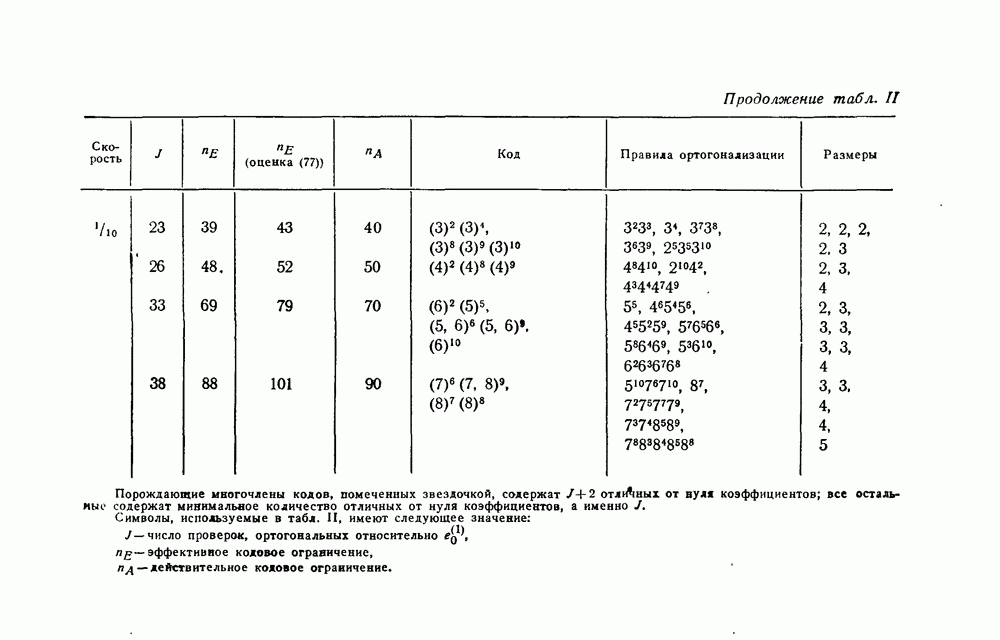
























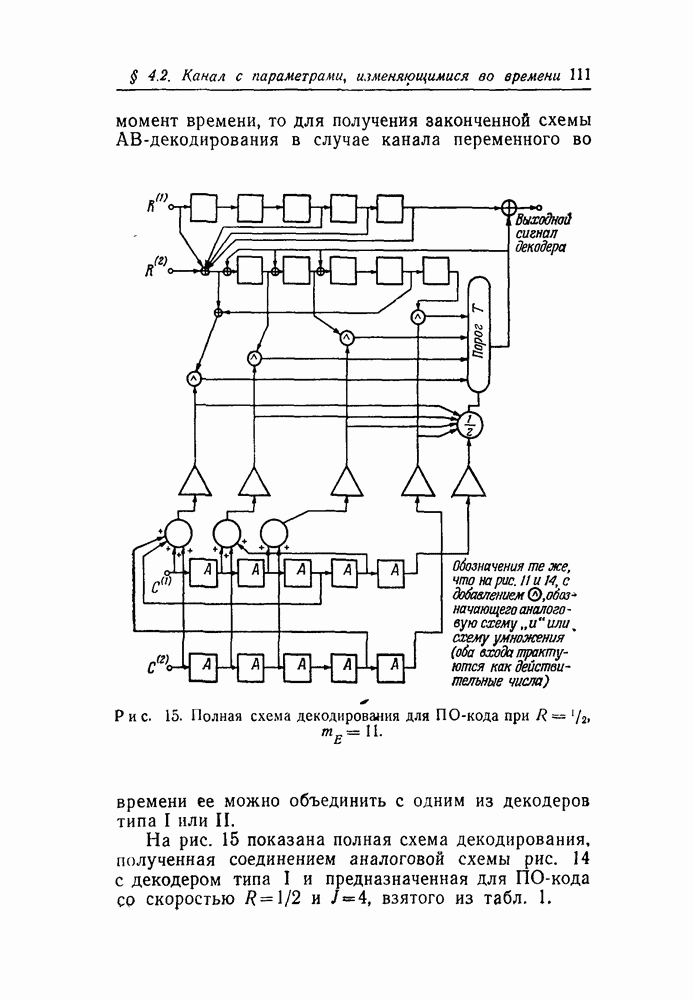











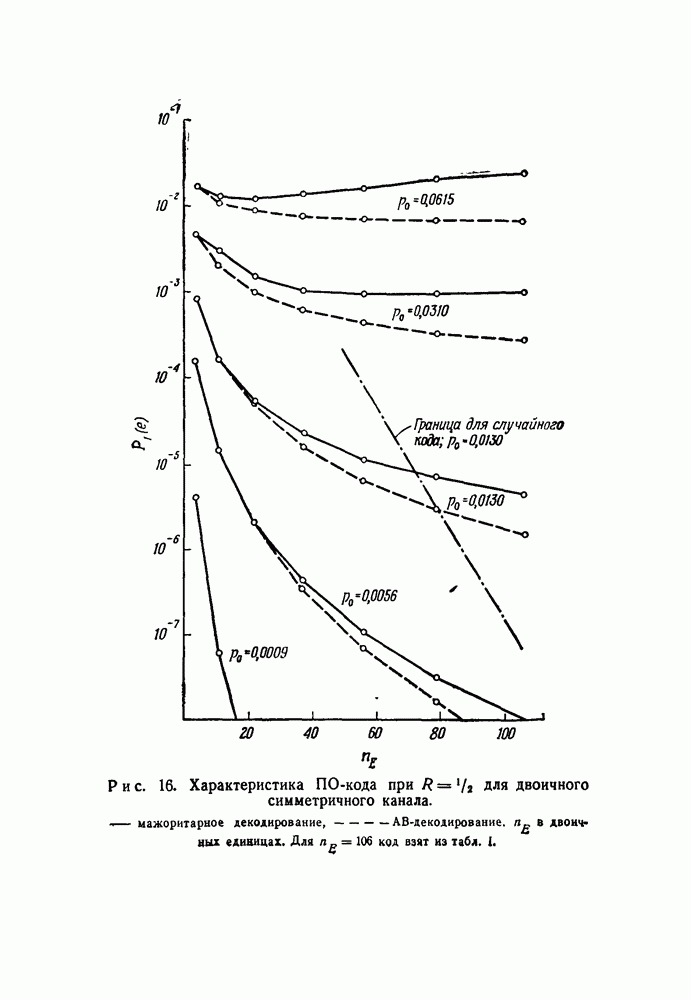
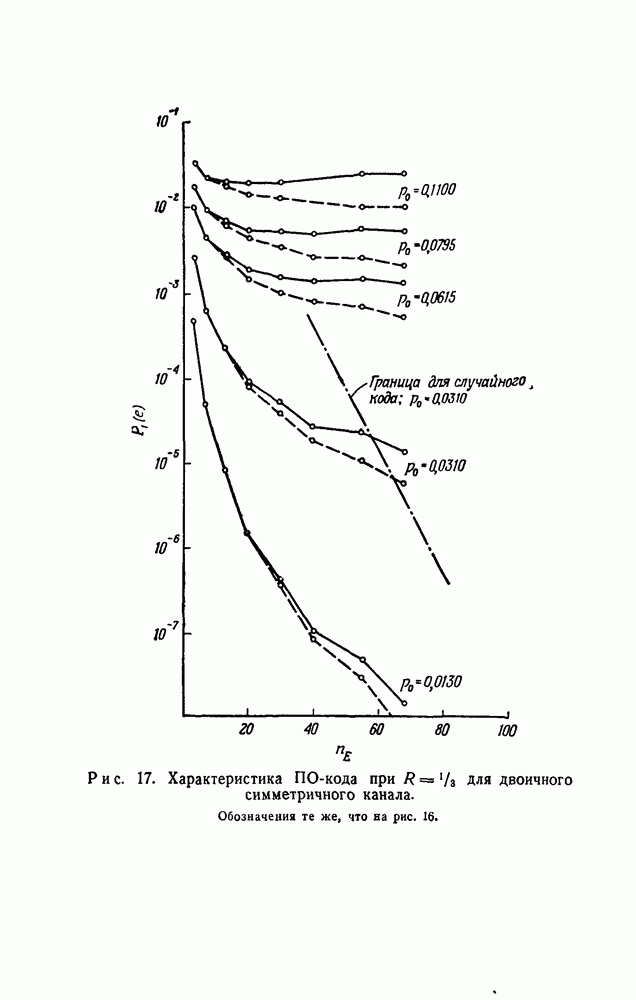
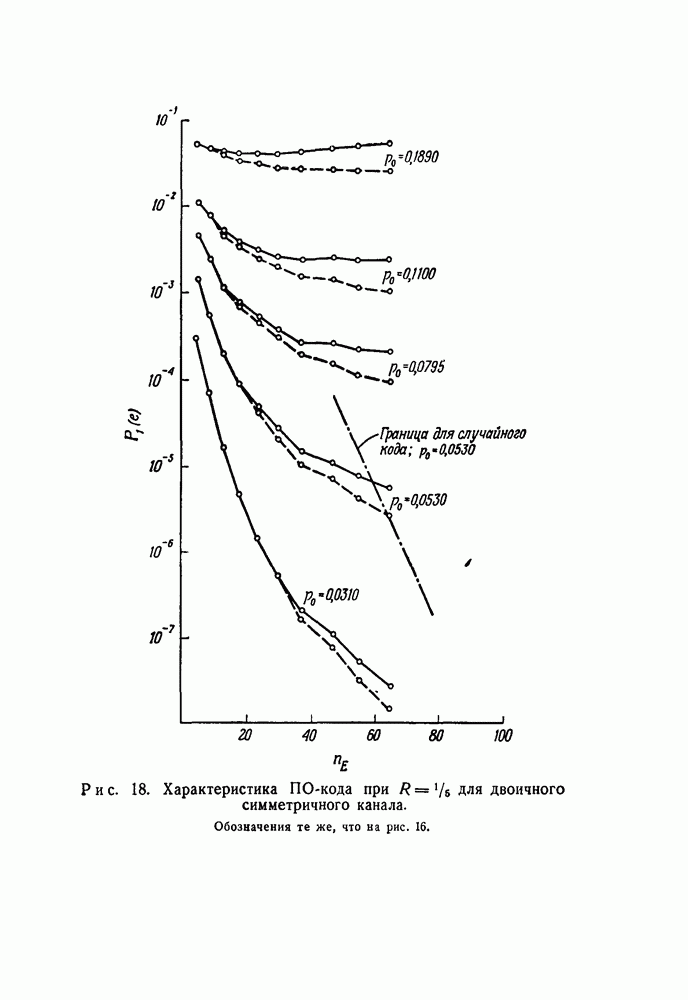
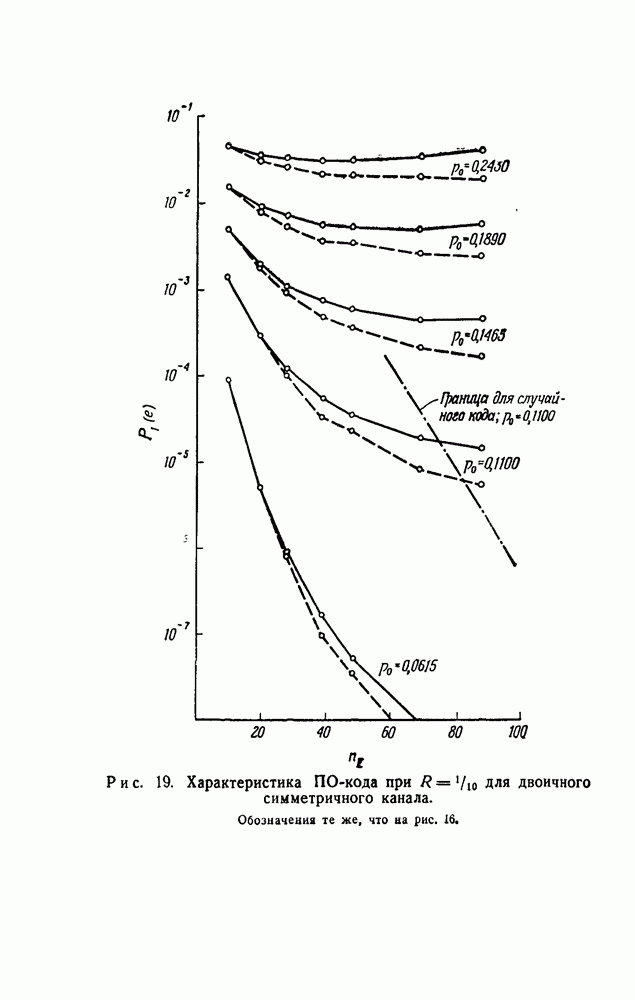


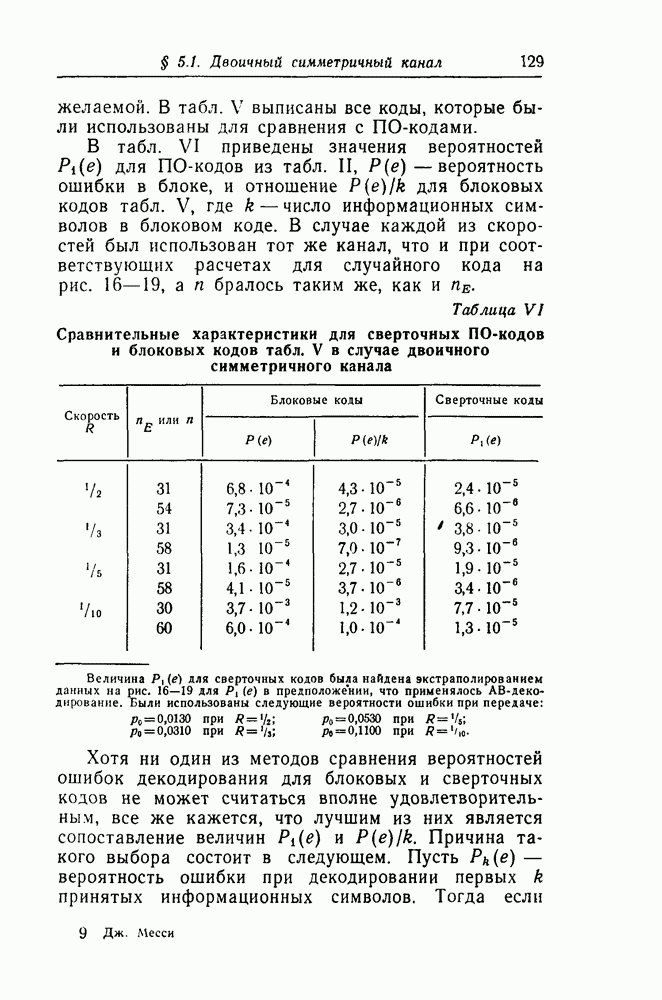


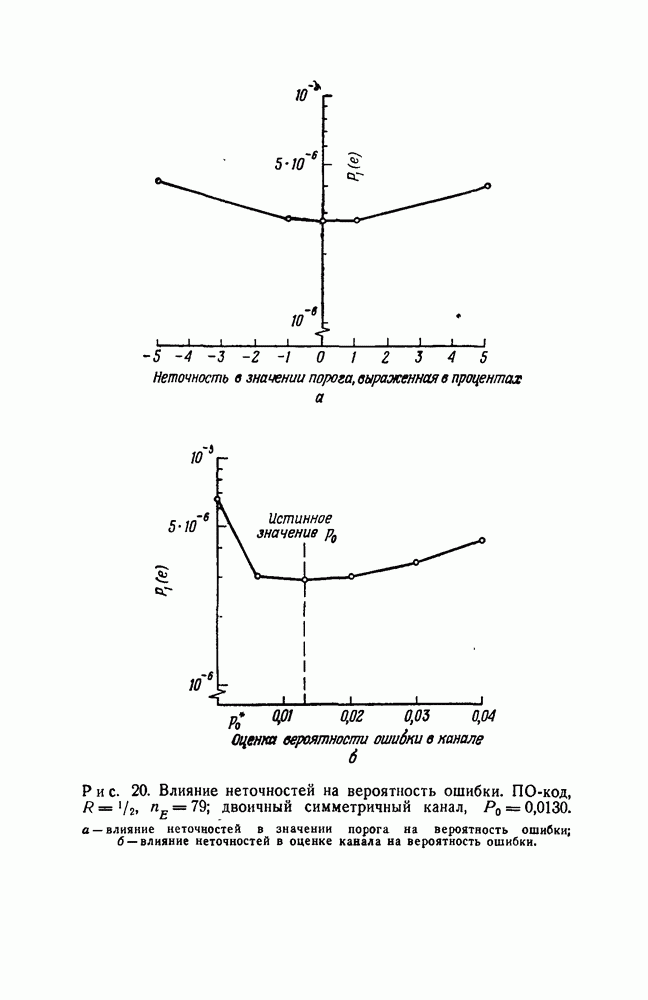



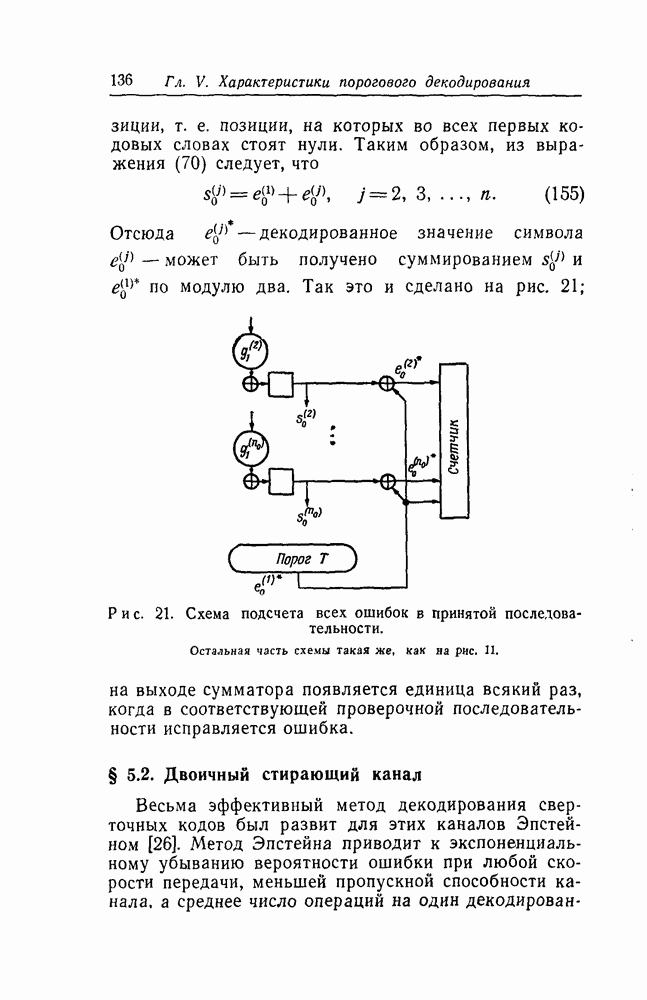

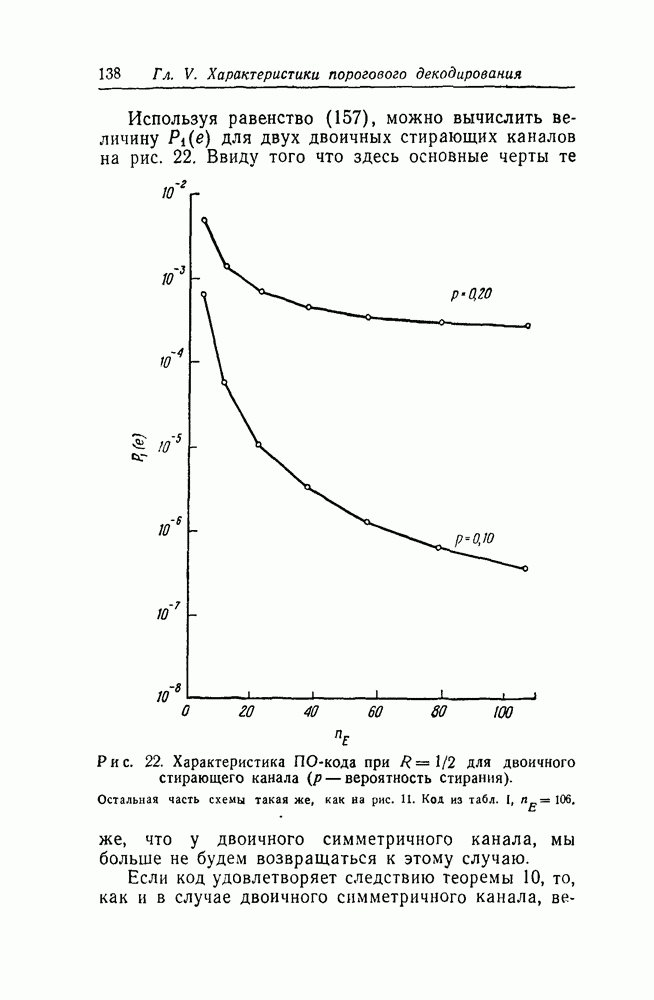


































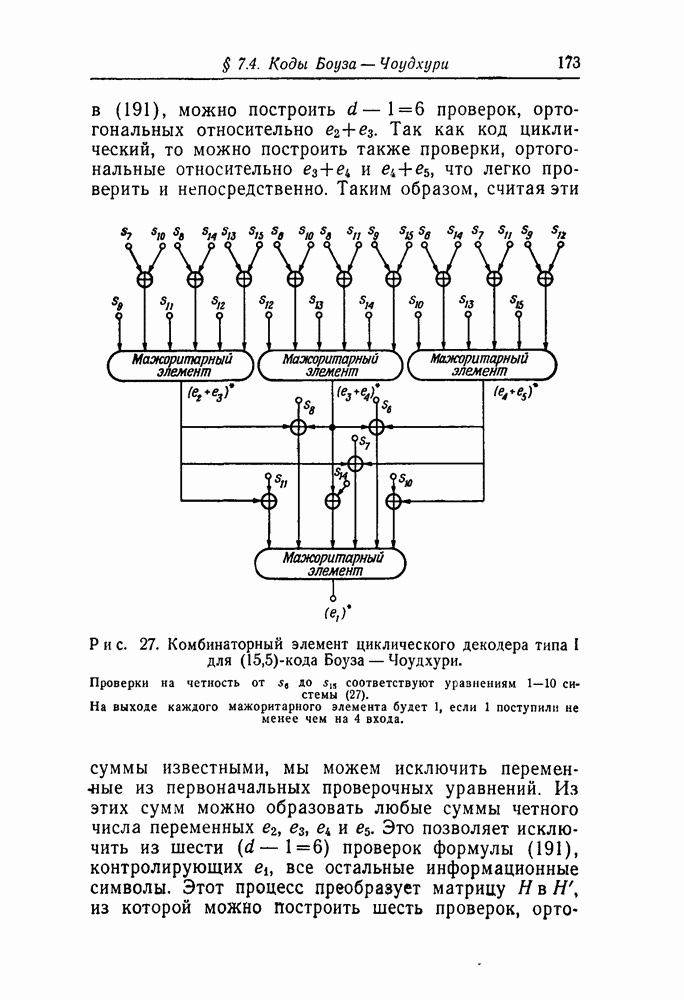
































 -кодах. В любом таком коде множество
-кодах. В любом таком коде множество  всевозможных информационных последовательностей образует группу всех двоичных последовательностей длины
всевозможных информационных последовательностей образует группу всех двоичных последовательностей длины  Назовем разбиением группы отображение этой группы последовательностей длины
Назовем разбиением группы отображение этой группы последовательностей длины  в любую ее подгруппу и ее собственные смежные классы (ср. приложение А).
в любую ее подгруппу и ее собственные смежные классы (ср. приложение А).
 Одним из возможных разбиений группы будет
Одним из возможных разбиений группы будет

 взяты последовательности длины 2, первый символ которых есть 0; в этом случае существует единственный собственный смежный класс
взяты последовательности длины 2, первый символ которых есть 0; в этом случае существует единственный собственный смежный класс  состоящий из всех последовательностей длины 2 с первым символом единицей.
состоящий из всех последовательностей длины 2 с первым символом единицей.
 можно распределить в подгруппу группы кодовых слов и в ее собственные смежные классы так, что прежнее разбиение группы информационных последовательностей сохранится. Если мы продолжим приведенный выше пример, положим
можно распределить в подгруппу группы кодовых слов и в ее собственные смежные классы так, что прежнее разбиение группы информационных последовательностей сохранится. Если мы продолжим приведенный выше пример, положим  и сделаем первый проверочный символ равным первому информационному, а второй проверочный — сумме информационных, то получим
и сделаем первый проверочный символ равным первому информационному, а второй проверочный — сумме информационных, то получим

 Когда же к информационным символам в разбиении группы добавляются проверочные символы, подгруппой оказывается множество кодовых слов, информационные последовательности которых образуют подгруппу в первоначальном разбиении группы, а исходной группой — группа всех кодовых слов.
Когда же к информационным символам в разбиении группы добавляются проверочные символы, подгруппой оказывается множество кодовых слов, информационные последовательности которых образуют подгруппу в первоначальном разбиении группы, а исходной группой — группа всех кодовых слов.
 находится на расстоянии 3 от любого элемента из
находится на расстоянии 3 от любого элемента из  так как все кодовые слова в единственном собственном смежном классе имеют вес 3.
так как все кодовые слова в единственном собственном смежном классе имеют вес 3.
 устанавливается следующая нижняя граница вероятности ошибки, которая получается при решении вопроса, к какому смежному классу разбиения группы принадлежит информационная последовательность, если кодовые слова передаются по двоичному симметричному каналу.
устанавливается следующая нижняя граница вероятности ошибки, которая получается при решении вопроса, к какому смежному классу разбиения группы принадлежит информационная последовательность, если кодовые слова передаются по двоичному симметричному каналу.
 -кодов и разбиение группы информационных последовательностей, обладающее тем свойством, что любая информационная последовательность в любом собственном смежном классе имеет одинаковую вероятность иметь в качестве проверочной последовательности любую из
-кодов и разбиение группы информационных последовательностей, обладающее тем свойством, что любая информационная последовательность в любом собственном смежном классе имеет одинаковую вероятность иметь в качестве проверочной последовательности любую из  всевозможных последовательностей длины
всевозможных последовательностей длины  то при передаче по двоичному симметричному каналу с любой скоростью
то при передаче по двоичному симметричному каналу с любой скоростью  меньшей пропускной способности С, средняя вероятность
меньшей пропускной способности С, средняя вероятность  ошибки, с которой может быть определен смежный класс, включающий в себя передаваемую информационную последовательность, удовлетворяет неравенству
ошибки, с которой может быть определен смежный класс, включающий в себя передаваемую информационную последовательность, удовлетворяет неравенству

 .
.
 ошибки сверточного кода среднюю вероятность ошибки декодирования последовательности первых информационных символов
ошибки сверточного кода среднюю вероятность ошибки декодирования последовательности первых информационных символов  по первым
по первым
 удовлетворяет неравенству (56), если в нем
удовлетворяет неравенству (56), если в нем  заменить на
заменить на 
 -код, где
-код, где  и
и  Рассмотрим следующее разбиение группы: в качестве подгруппы возьмем все информационные последовательности, для которых последовательность всех первых информационных символов состоит из нулей, т. е.
Рассмотрим следующее разбиение группы: в качестве подгруппы возьмем все информационные последовательности, для которых последовательность всех первых информационных символов состоит из нулей, т. е.  Эта подгруппа имеет
Эта подгруппа имеет  собственных смежных классов, и каждый собственный смежный класс содержит все те информационные последовательности, которые имеют одинаковые множества не всех равных нулю первых информационных символов. Для такого разбиения группы теорема 5 означает, что по ансамблю всех сверточных кодов любая информационная последовательность в собственном смежном классе имеет одинаковую вероятность быть присоединенной к любой возможной проверочной последовательности. Таким образом, все условия теоремы 8 выполнены и (56) справедливо для ансамбля двоичных сверточных кодов.
собственных смежных классов, и каждый собственный смежный класс содержит все те информационные последовательности, которые имеют одинаковые множества не всех равных нулю первых информационных символов. Для такого разбиения группы теорема 5 означает, что по ансамблю всех сверточных кодов любая информационная последовательность в собственном смежном классе имеет одинаковую вероятность быть присоединенной к любой возможной проверочной последовательности. Таким образом, все условия теоремы 8 выполнены и (56) справедливо для ансамбля двоичных сверточных кодов.
 -разрядный регистр сдвига, где
-разрядный регистр сдвига, где  Если этот регистр содержит вначале некоторую ненулевую последовательность, то после
Если этот регистр содержит вначале некоторую ненулевую последовательность, то после  сдвигов в регистре будут получаться для каждого
сдвигов в регистре будут получаться для каждого  различные ненулевые последовательности длины
различные ненулевые последовательности длины 
 информационных символов помещаются в
информационных символов помещаются в  младших разрядов регистра сдвига, который затем сдвигается некоторое фиксированное число раз
младших разрядов регистра сдвига, который затем сдвигается некоторое фиксированное число раз  Содержимое
Содержимое  младших разрядов регистра тогда трактуется как проверочная последовательность. Так как кодирующая цепь линейна, то и код будет
младших разрядов регистра тогда трактуется как проверочная последовательность. Так как кодирующая цепь линейна, то и код будет  -кодом. В ансамбле имеется
-кодом. В ансамбле имеется  кодов, по одному для каждого выбора числа
кодов, по одному для каждого выбора числа  Отождествим случай
Отождествим случай  со случаем, когда регистр содержит только нули. Рассмотрим такое разбиение группы информационных последовательностей: подгруппой будет нулевая последовательность, и каждый собственный смежный класс содержит единственную, отличную от других информационную последовательность. Если все
со случаем, когда регистр содержит только нули. Рассмотрим такое разбиение группы информационных последовательностей: подгруппой будет нулевая последовательность, и каждый собственный смежный класс содержит единственную, отличную от других информационную последовательность. Если все  равновероятны, то ясно, что ненулевые информационные последовательности с одинаковой вероятностью могут быть присоединены к любой проверочной последовательности. Таким образом, условия теоремы 8 выполнены и поэтому переданная информационная
равновероятны, то ясно, что ненулевые информационные последовательности с одинаковой вероятностью могут быть присоединены к любой проверочной последовательности. Таким образом, условия теоремы 8 выполнены и поэтому переданная информационная