Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
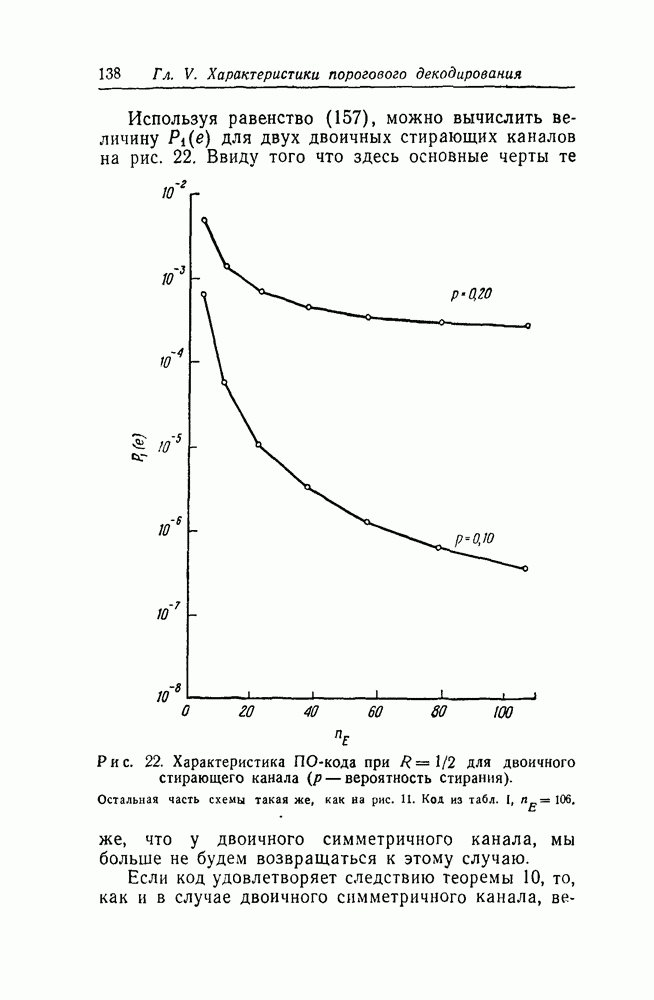
Глава I. ПРИНЦИП ПОРОГОВОГО ДЕКОДИРОВАНИЯВ 1948 году Шеннон [23] впервые показал, что при передаче информации по каналу с шумами ошибки могут быть сведены к любому желаемому уровню без ущерба для скорости передачи. Его «теорема кодирования для канала с шумами» устанавливает, что такой канал характеризуется величиной С, называемой пропускной способностью канала, и при соответствующем кодировании и декодировании вероятность ошибки на приемном конце можно сделать произвольно малой тогда и только тогда, когда (i) построение хороших легко реализуемых кодов, (ii) создание для таких кодов простой и эффективной аппаратуры декодирования. Первая из этих задач сама по себе не связана с реальными трудностями. Для удобства ограничимся пока двоичными кодами и передачей по двоичному симметричному каналу без памяти. Математическая модель такого канала показана на рис. 1. Если по такому каналу передаются символы 0 или 1, то они правильно принимаются с вероятностью
представляет собой энтропию [23]. Каждое сообщение, подлежащее передаче по этому каналу, кодируется блоком из
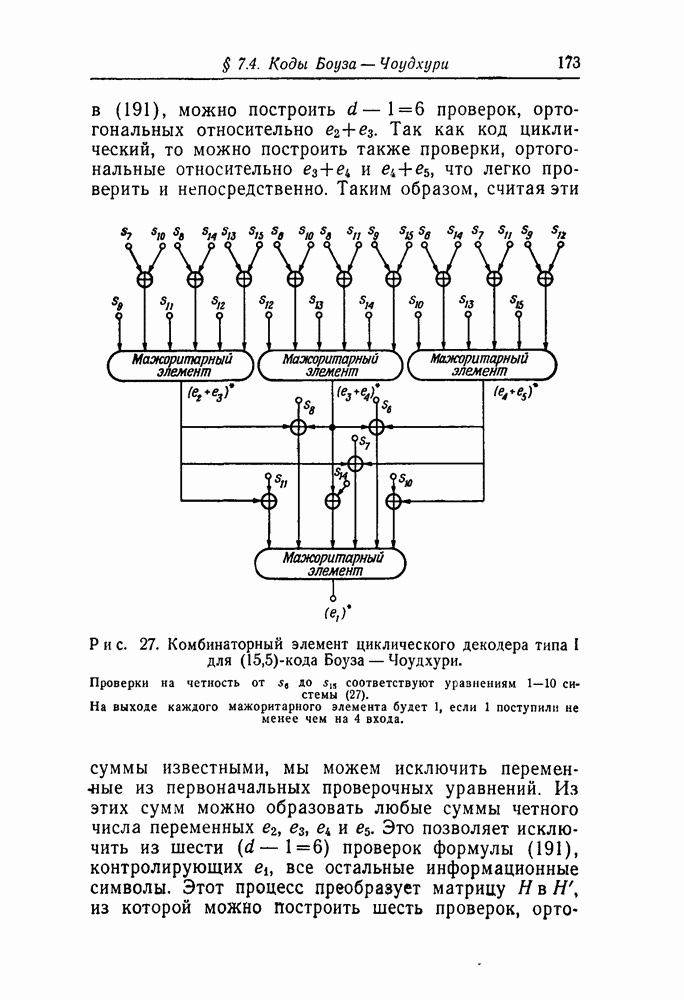
Рис. 1. Двоичный симметричный канал. В доказательстве своей «теоремы кодирования для канала с шумами» в случае двоичного симметричного канала Шеннон показал, что при Поскольку код, выбранный случайно из такого ансамбля, с вероятностью, меньшей Элайес [24] показал, что значительно более узкий ансамбль скользящих кодов с проверками на четность обладает той же средней вероятностью ошибки, что и ансамбль кодов, каждое слово в которых выбрано случайно, и, более того, эта вероятность ошибки убывает экспоненциально вместе с ростом длины блока Таким образом, из ансамбля скользящих кодов с проверками на четность или ансамбля кодов со случайными сдвигами вполне возможно случайным образом выбрать хороший и легко реализуемый код. Однако в настоящее время не известен ни один способ решения второй задачи для этих ансамблей, т. е. задачи построения простого и эффективного декодера. (Сложность общей проблемы декодирования будет обсуждаться ниже.) В высшей степени эффективные методы декодирования были найдены для некоторых ансамблей случайно выбранных кодов. Для ансамбля сверточных кодов Возенкрафт [3] разработал метод последовательного декодирования. Возенкрафт и Рейффен [4] показали, что, действуя этим методом, можно добиться экспоненциального убывания вероятности ошибки с помощью декодера, сложность которого и среднее число выполняемых операций растут пропорционально небольшой степени длины кода. Галлагер [6] получил аналогичный результат, относящийся к его итеративному методу декодирования кодов с проверкой на четность, построенных таким образом, что проверочная матрица имеет малую плотность единиц. В обоих случаях сложность декодирования невелика лишь тогда, когда скорость передачи информации меньше некоторой «вычислительной скорости», которая в свою очередь меньше пропускной способности канала. Два эти метода декодирования (и модификации метода последовательного декодирования, предложенные Зивом [7] и Фано [неопубликованные сообщения на двух семинарах, проведенных в течение весеннего семестра 1962 г. в Массачусетском технологическом институте]) являются единственными известными достаточно общими решениями описанных выше двух сторон проблемы кодирования. Недостатки обоих методов заключаются в том, что объем вычислений на один декодированный символ является случайной величиной и что в случае коротких кодов декодеры оказываются сложнее, чем те, которые можно было бы построить для некоторых специальных кодов при использовании иных методов. Другой подход к проблеме декодирования резко отличается от вероятностного подхода Возенкрафта и Галлагера. Основываясь на первых работах Хемминга [21] и Слепяна [15], алгебраисты берут в качестве отправной точки формальную математическую структуру, обеспечивающую нужные для целей кодирования метрические свойства. Часто методы декодирования находят только через некоторое время после того, как найдены коды; наиболее ярко это иллюстрируется алгоритмом Рида [14] для кодов Маллера [9] и алгоритмом Питерсона [11] для кодов Боуза — Чоудхури [2]. Благодаря систематической структуре кодов, полученных алгебраическим путем, метод декодирования обычно требует фиксированного числа операций. Весьма вероятно, что по той же причине коды любого из известных типов всегда становятся плохими, если их длина возрастает, а скорость передачи остается постоянной (единственным исключением из этого правила являются итеративные коды Элайеса [25], которые с ростом длины блока обеспечивают стремление вероятности ошибки к нулю, правда, более медленное, чем оптимальное, и только для скоростей, существенно меньших, чем пропускная способность канала).
|
 |
Оглавление
|






































































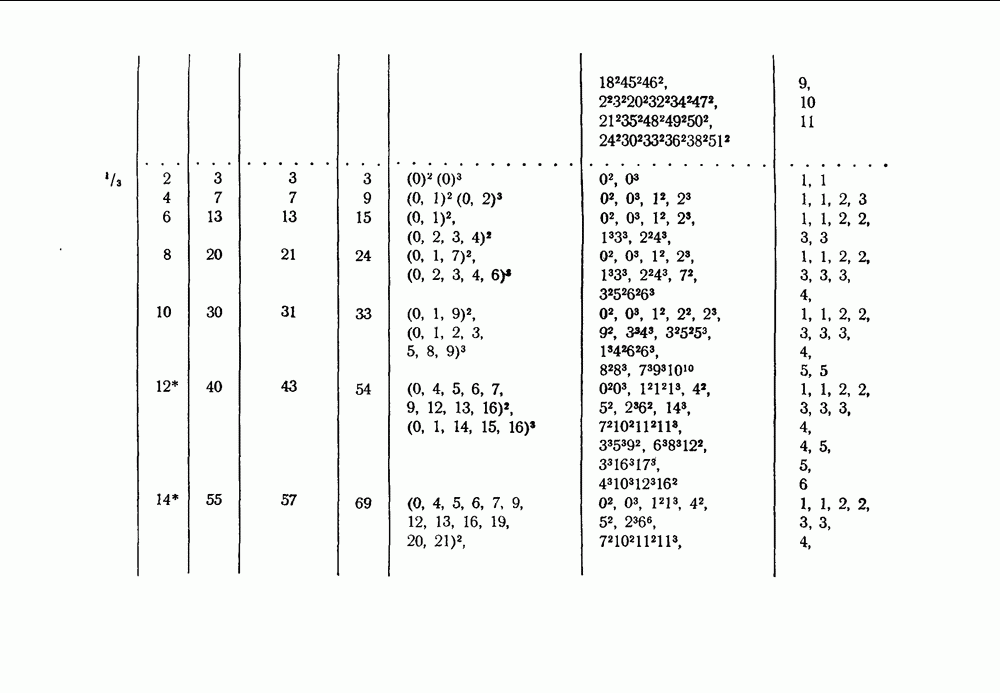
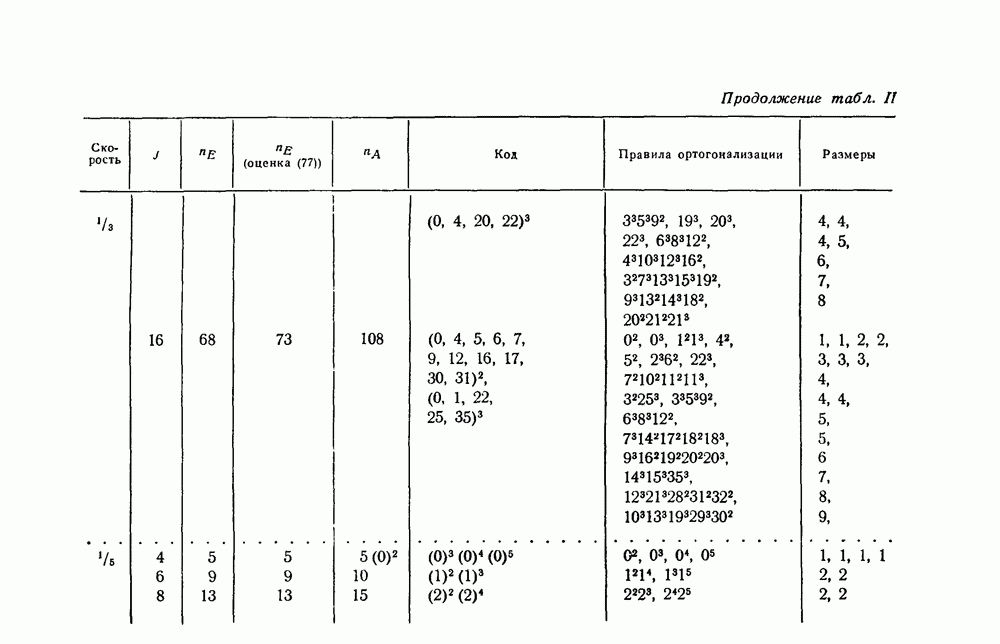
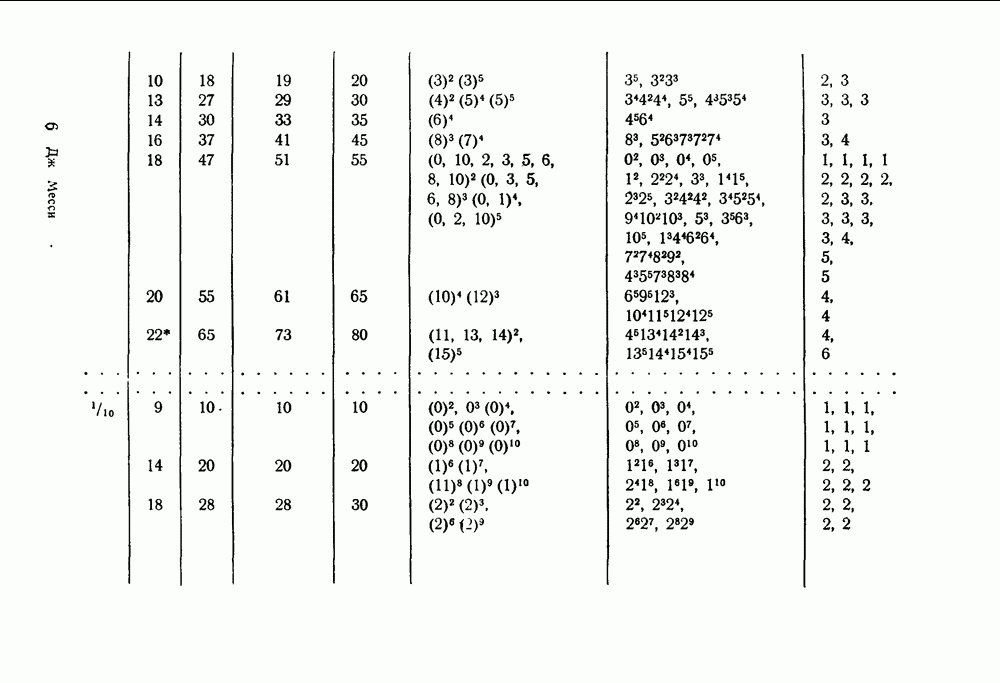
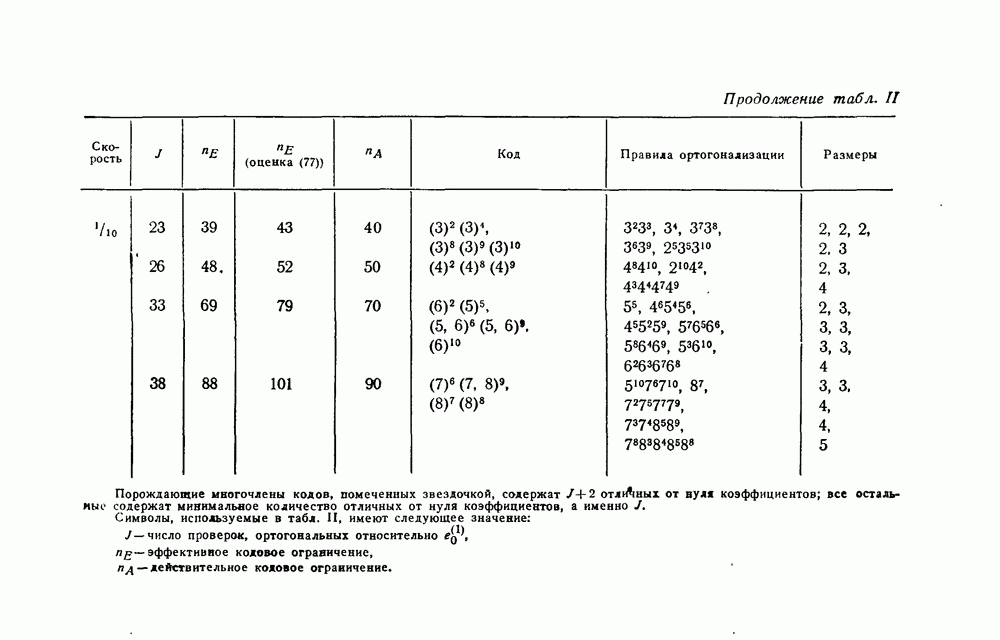
























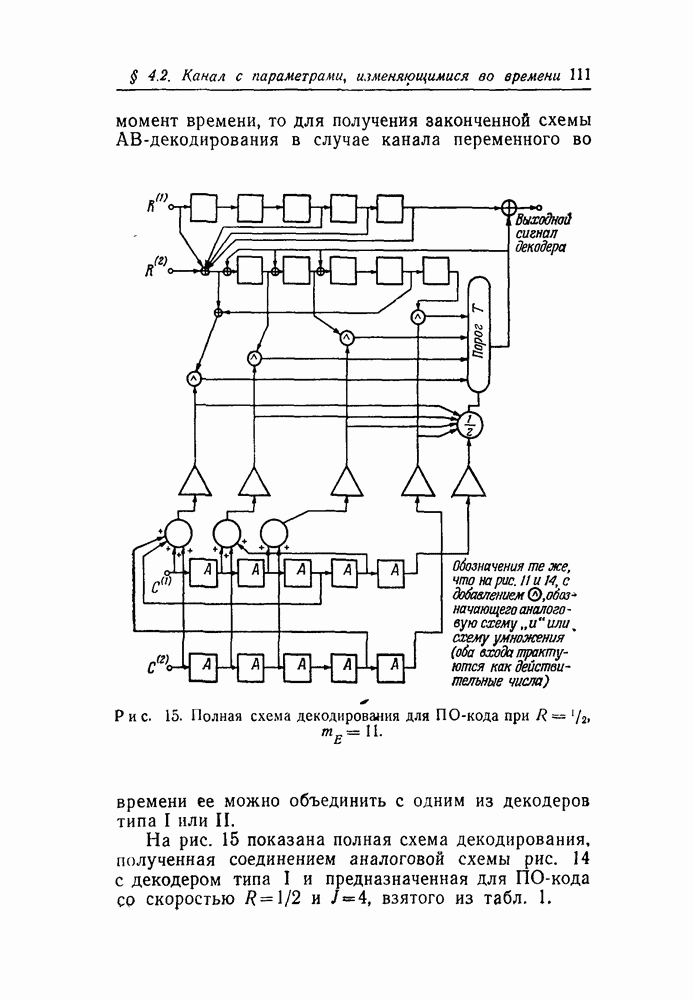











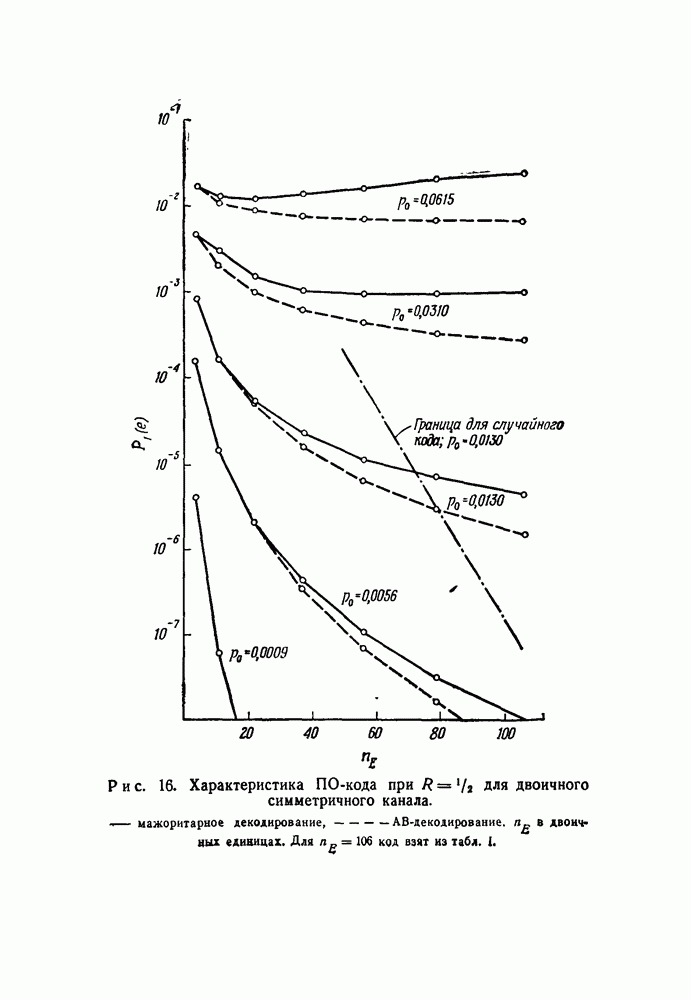
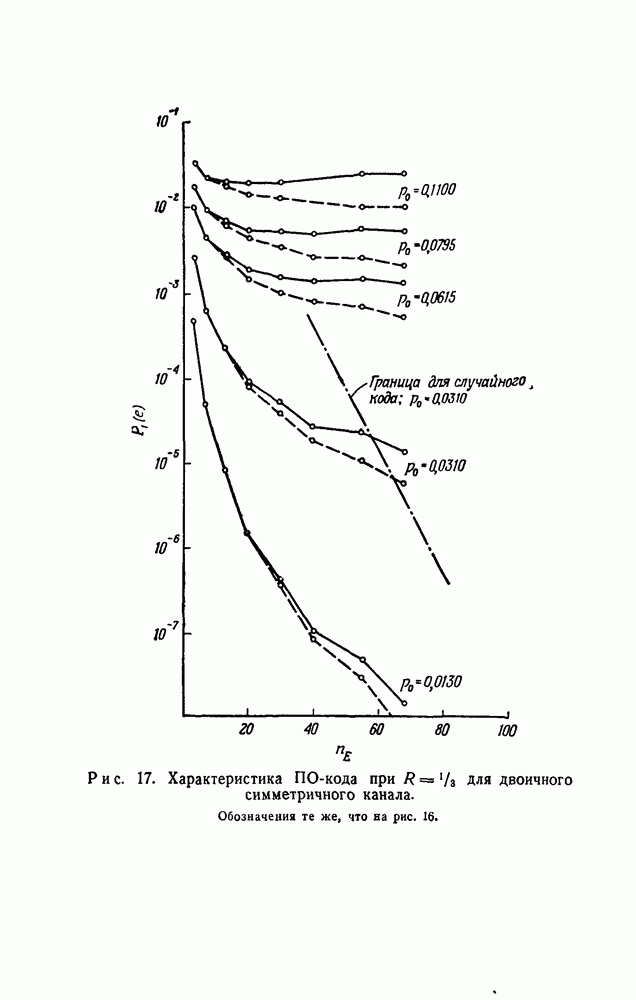
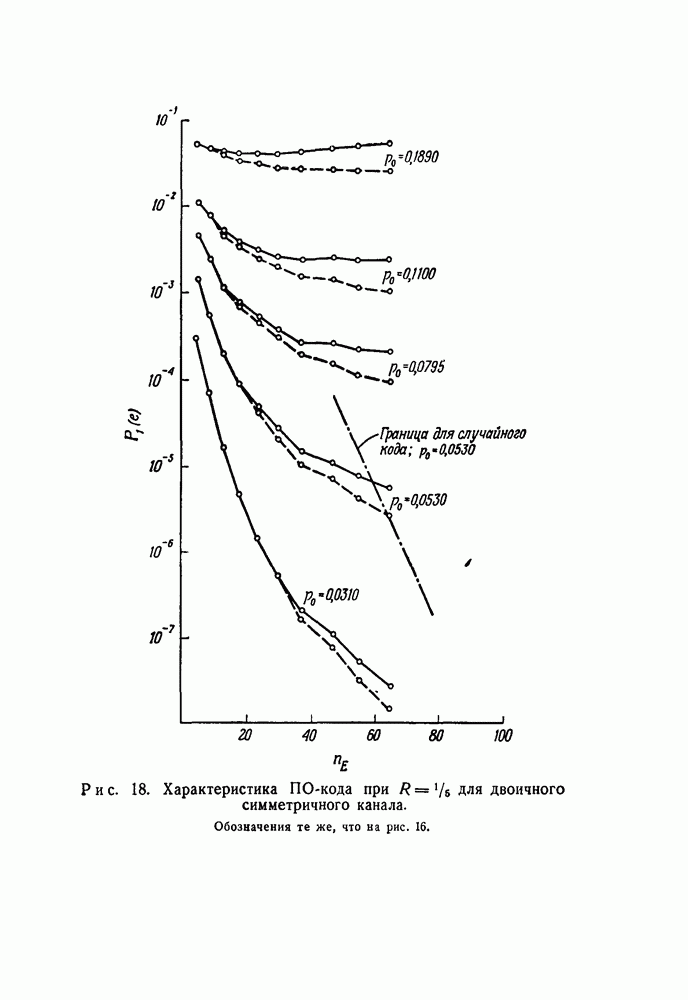










































































 скорость передачи — будет меньше, чем С. Получив в его работах четкое определение целей и возможностей передачи информации, инженеры-связисты сосредоточили значительные усилия, часто приводившие к остроумным результатам, на проблеме наиболее полного применения теоремы Шеннона к решению двух взаимосвязанных задач:
скорость передачи — будет меньше, чем С. Получив в его работах четкое определение целей и возможностей передачи информации, инженеры-связисты сосредоточили значительные усилия, часто приводившие к остроумным результатам, на проблеме наиболее полного применения теоремы Шеннона к решению двух взаимосвязанных задач:
 и неправильно — с вероятностью
и неправильно — с вероятностью  Можно показать, что пропускная способность канала равна
Можно показать, что пропускная способность канала равна
 двоичных единиц на передаваемый символ, где функция
двоичных единиц на передаваемый символ, где функция

 двоичных символов. Число возможных сообщений равно
двоичных символов. Число возможных сообщений равно  где
где  скорость передачи информации, измеряемая числом двоичных единиц на передаваемый символ, если все входные сообщения равновероятны.
скорость передачи информации, измеряемая числом двоичных единиц на передаваемый символ, если все входные сообщения равновероятны.

 вероятность ошибки, средняя по ансамблю двоичных блоковых кодов, стремится к нулю с ростом
вероятность ошибки, средняя по ансамблю двоичных блоковых кодов, стремится к нулю с ростом  если каждая из
если каждая из  передаваемых последовательностей случайно и с равной вероятностью выбрана из множества
передаваемых последовательностей случайно и с равной вероятностью выбрана из множества  двоичных последовательностей длины
двоичных последовательностей длины 
 имеет в
имеет в  раз большую вероятность ошибки, чем средняя по ансамблю, вполне можно случайным выбором получить хороший код. Понадобится, однако, недопустимо сложная кодирующая аппаратура, так как нужно запомнить каждое из
раз большую вероятность ошибки, чем средняя по ансамблю, вполне можно случайным выбором получить хороший код. Понадобится, однако, недопустимо сложная кодирующая аппаратура, так как нужно запомнить каждое из  кодовых слов длины
кодовых слов длины 
 при этом экспонента оптимальна для скоростей, близких к С. Фано [16] показал, что кодирующим устройством для скользящих кодов с проверкой на четность может служить линейная последовательная цепь, содержащая всего лишь
при этом экспонента оптимальна для скоростей, близких к С. Фано [16] показал, что кодирующим устройством для скользящих кодов с проверкой на четность может служить линейная последовательная цепь, содержащая всего лишь  ячеек регистра сдвига. Недавно Возенкрафт (частное сообщение) нашел еще более узкий ансамбль кодов — назовем их кодами со случайными сдвигами, — которые обладают такой же средней (по ансамблю) вероятностью ошибки, что и другие случайные коды. Кодирование для кодов Возенкрафта можно выполнить линейной последовательной цепью, содержащей
ячеек регистра сдвига. Недавно Возенкрафт (частное сообщение) нашел еще более узкий ансамбль кодов — назовем их кодами со случайными сдвигами, — которые обладают такой же средней (по ансамблю) вероятностью ошибки, что и другие случайные коды. Кодирование для кодов Возенкрафта можно выполнить линейной последовательной цепью, содержащей  ячеек регистра сдвига (ср. § 2.5).
ячеек регистра сдвига (ср. § 2.5).