Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
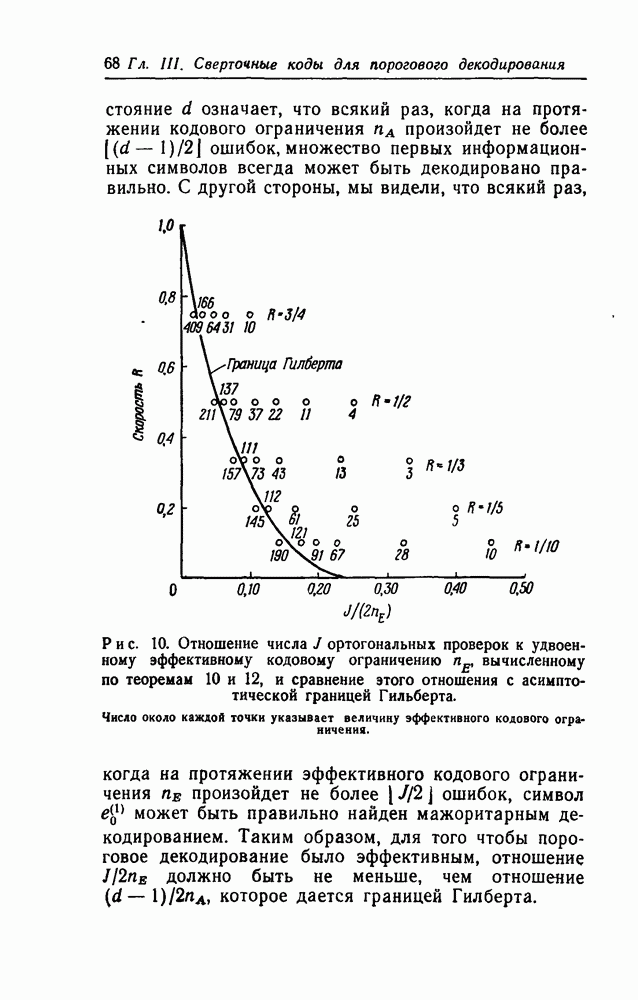
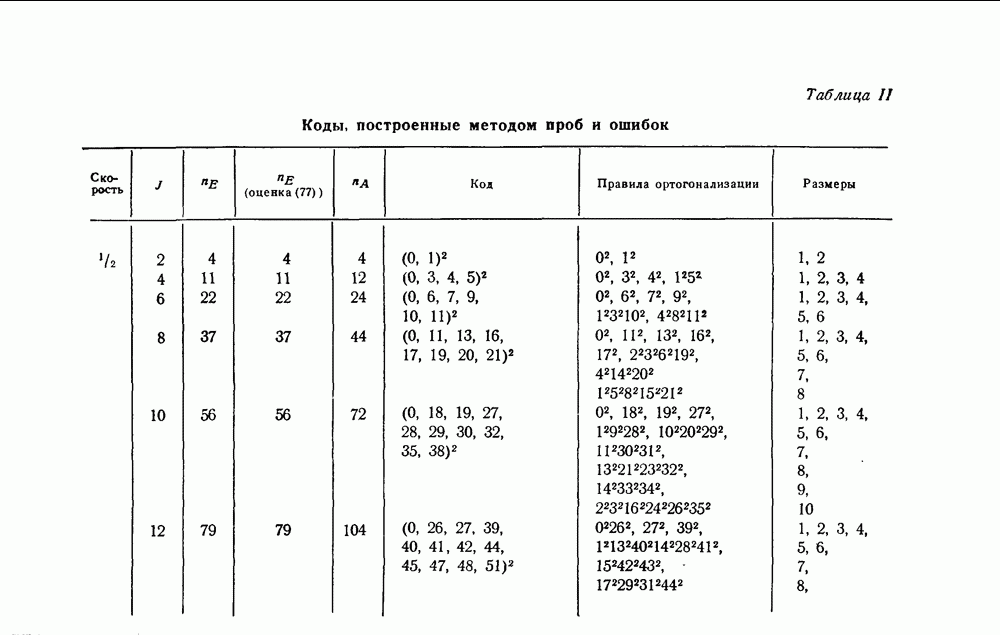
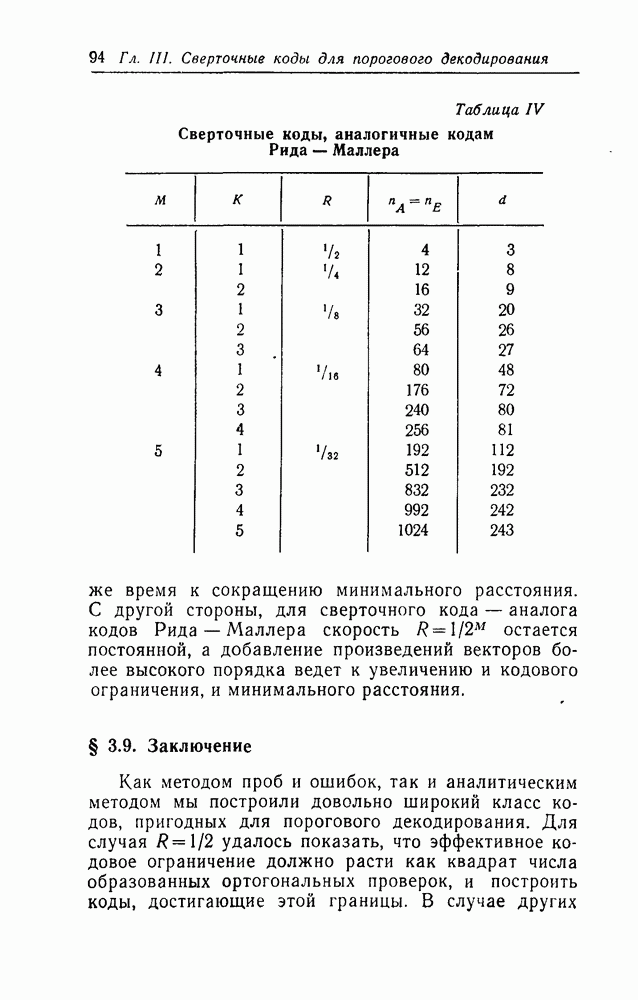
Глава III. СВЕРТОЧНЫЕ КОДЫ ДЛЯ ПОРОГОВОГО ДЕКОДИРОВАНИЯ§ 3.1. ВведениеПринцип порогового декодирования, сформулированный в гл. I, будет использован теперь в применении к сверточным кодам. Этому же вопросу будут посвящены гл. IV и V. Мы построим коды, к которым можно эффективно применить алгоритм порогового декодирования; для них же будут предложены декодирующие схемы и приведены данные о характеристиках кодов для нескольких каналов связи. § 3.2. Проблема декодирования для сверточных кодовИзложим характерные черты проблемы декодирования для сверточных кодов, необходимые для понимания основ построения кодов, к которым применимо пороговое декодирование. В § 2.2 было показано, что начальные кодовые слова сверточного кода (т. е. все возможные совокупности из Для определения множества первых информационных символов можно, разумеется, воспользоваться меньшим или большим, чем используется большее число, то при декодировании множества первых информационных символов может быть уменьшена вероятность ошибки Положим, что мы располагаем алгоритмом, который позволяет по
и
Из соотношений (28) и (29) следует, что если декодирование было правильным, т. е. Если при декодировании произошла ошибка, то возникает очевидная трудность. Действительно, предположим, что множество первых информационных символов декодировано неверно; тогда выполнение операций равенства (65) приведет к появлению в принятых проверочных последовательностях искаженных символов, а именно:
Эти искаженные символы влияют на выполнение алгоритма декодирования примерно так же, как пачка ошибок длины В методе ресинхронизации произвольные информационные символы кодируются только в течение фиксированного числа
где Более изящным приемом борьбы с размножением ошибок является метод «подсчета ошибок». Он предложен Возенкрафтом и Рейффеном (в несколько иной, чем здесь, форме), чтобы обратить размножение ошибок в полезное свойство двусторонней системы связи [4, стр. 96]. Короче говоря, метод заключается в следующем. Если для некоторой совокупности принятых символов используемый алгоритм декодирования «исправляет больше ошибок», чем это возможно при существующей исправляющей способности кода, то полагают, что при декодировании произошла ошибка или что интенсивность шумов в канале временно настолько возросла, что канал нельзя использовать с требуемой надежностью. В этом случае «а приемном конце просят повторить передачу с того момента, когда шумы в канале резко возросли. Более детально этот метод рассматривается в п. 4.2 в. Основной смысл предыдущих рассуждений состоит в том, что тщательная разработка алгоритма порогового декодирования нужна только в той его части, где речь идет об определении ошибок
|
 |
Оглавление
|














































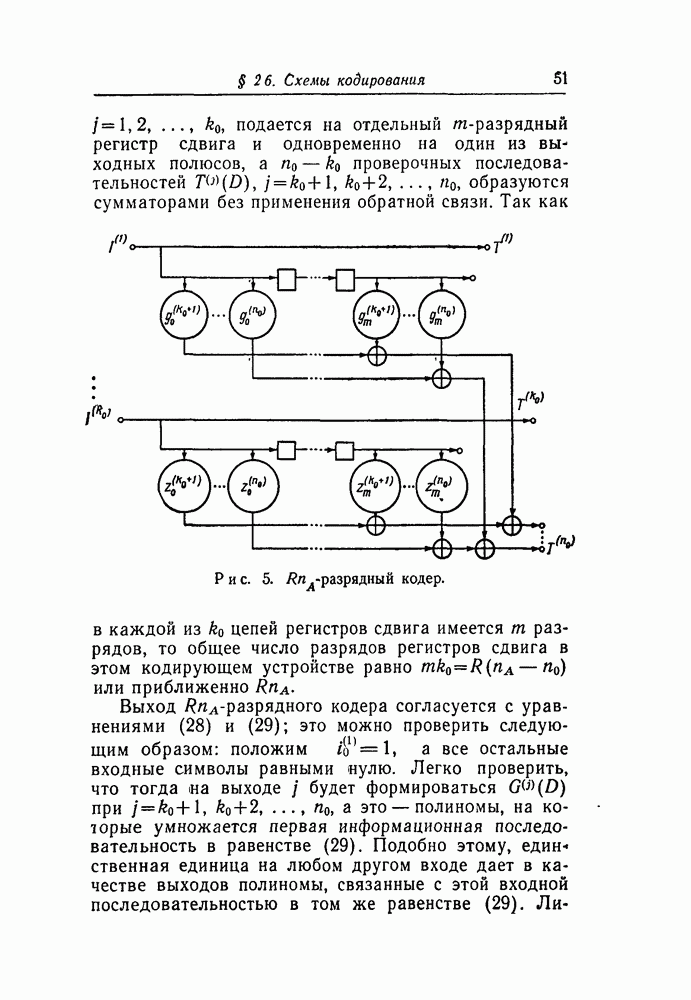
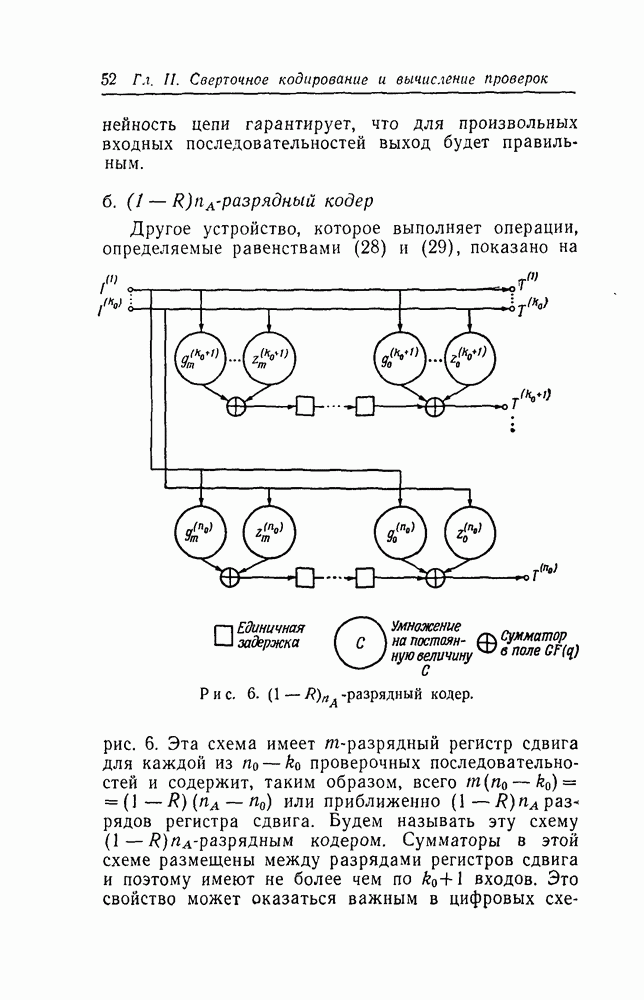
















































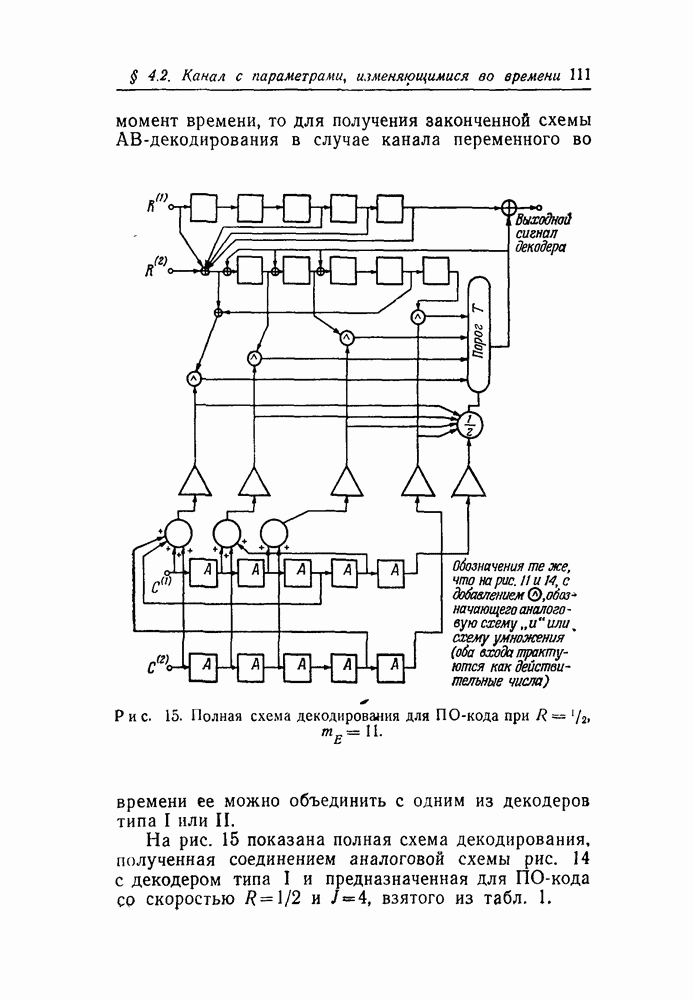











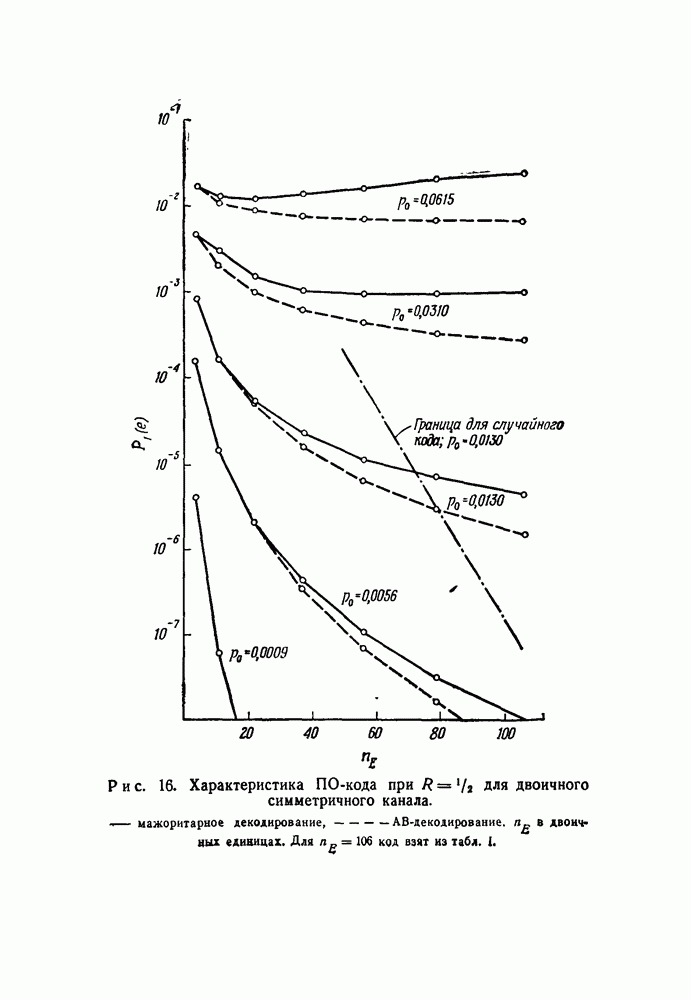
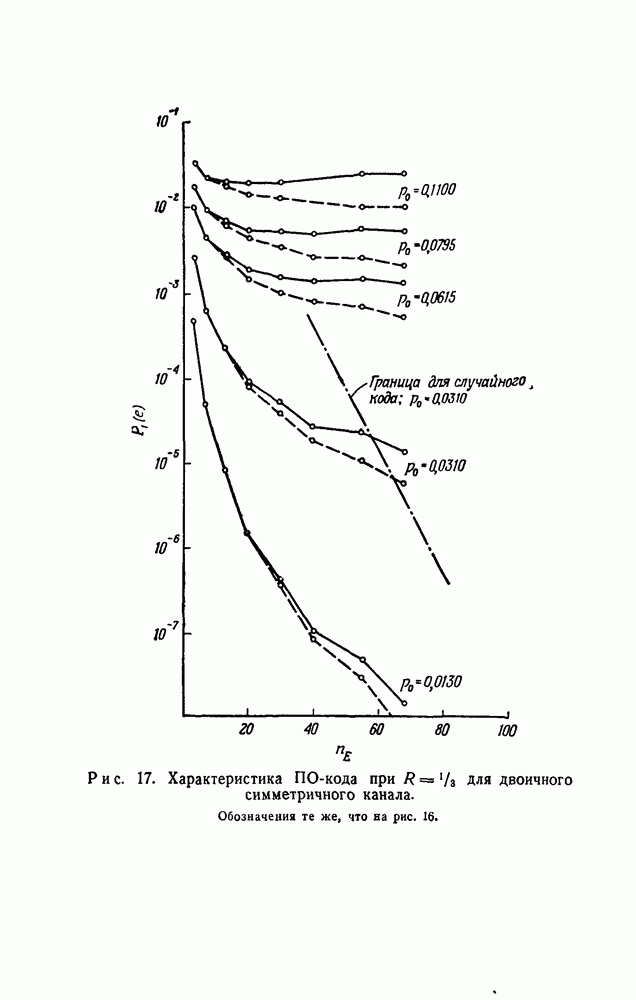
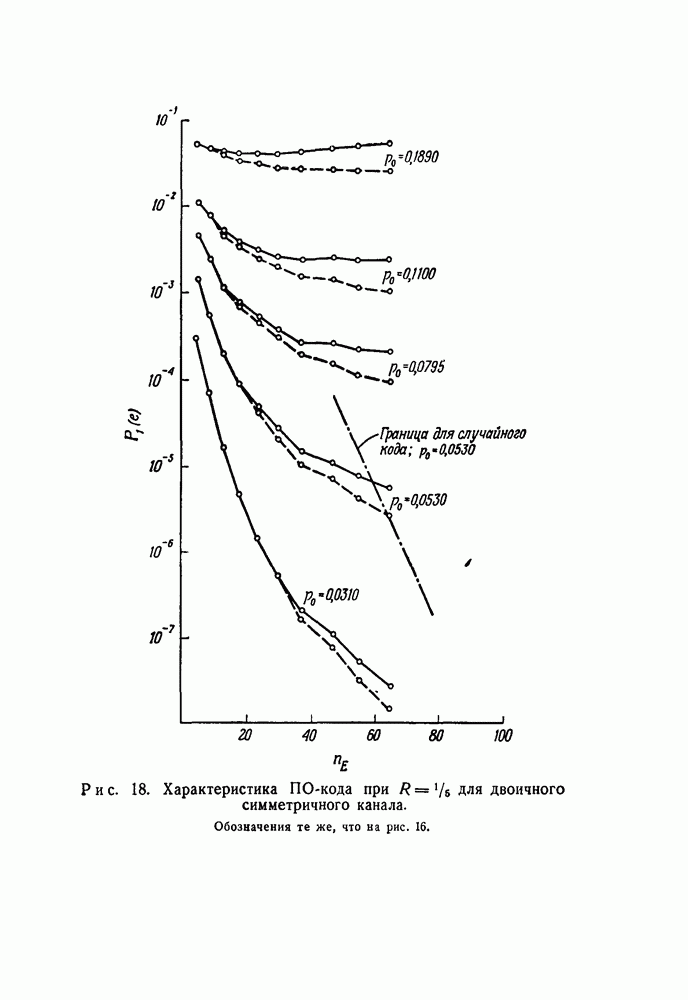
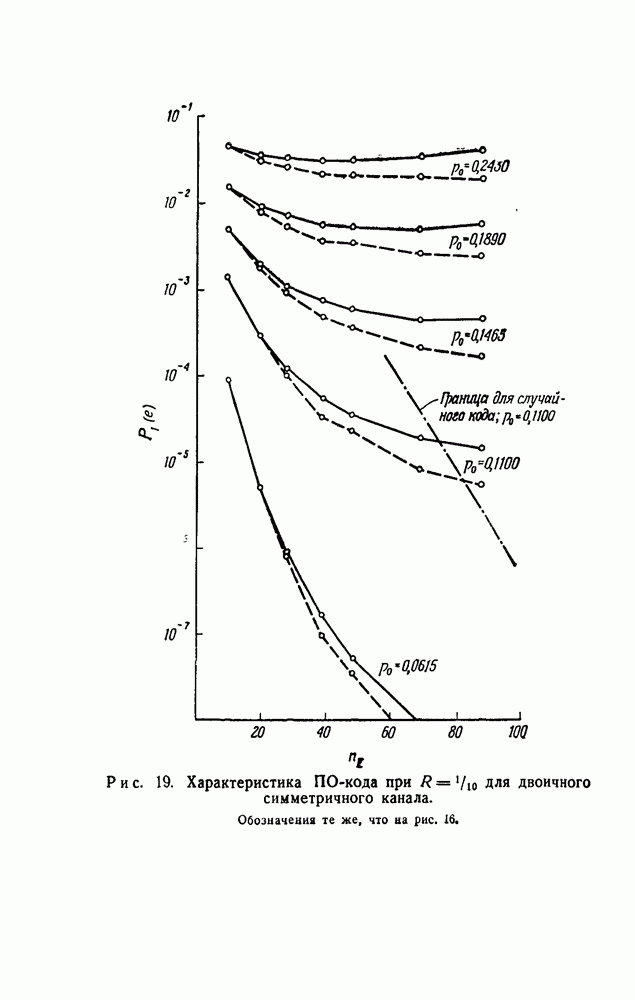


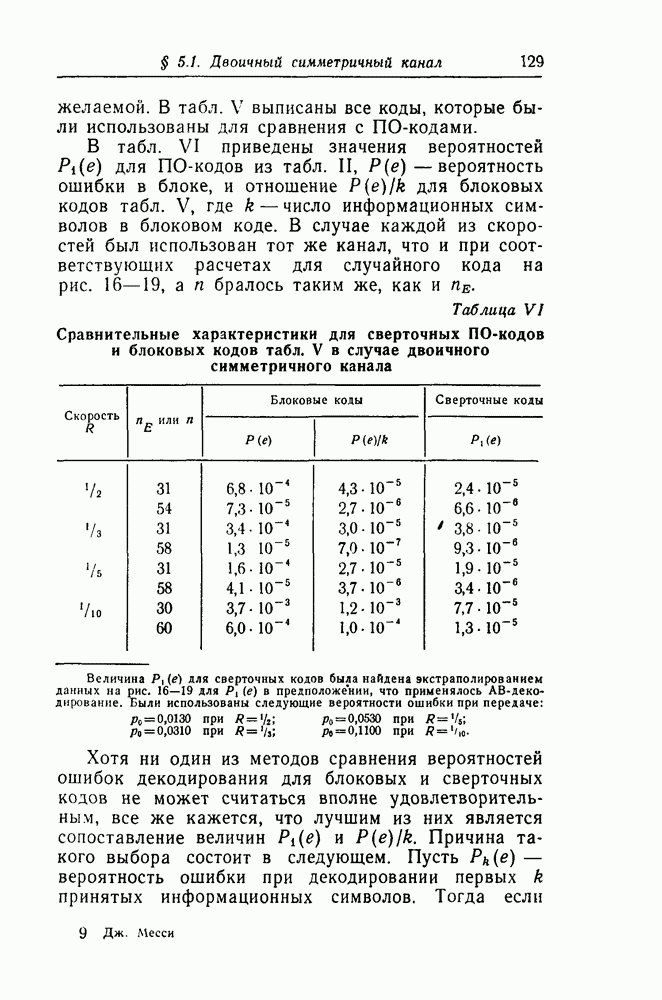


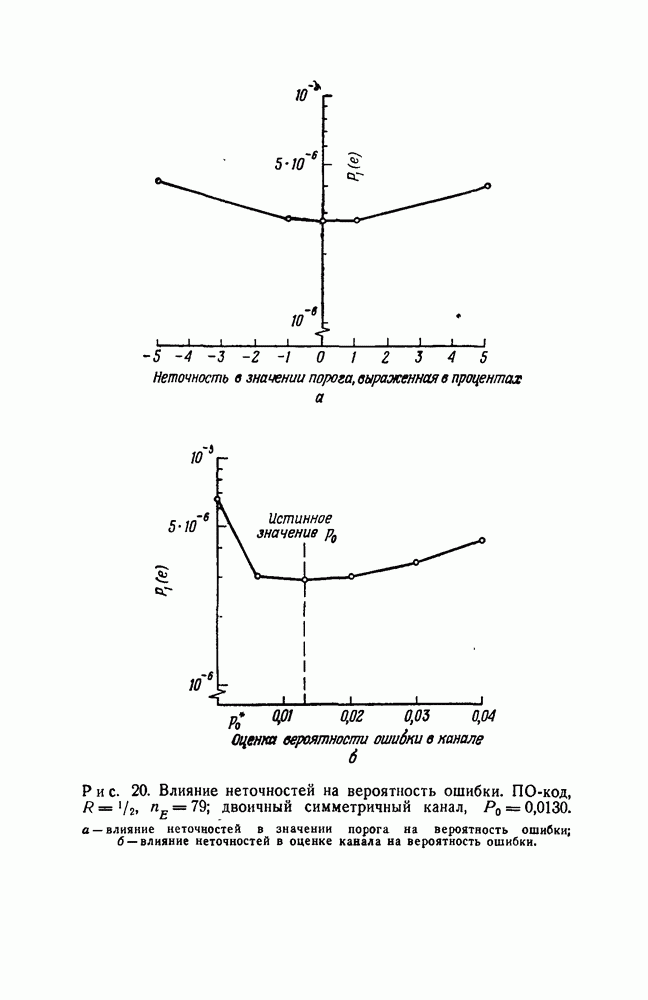



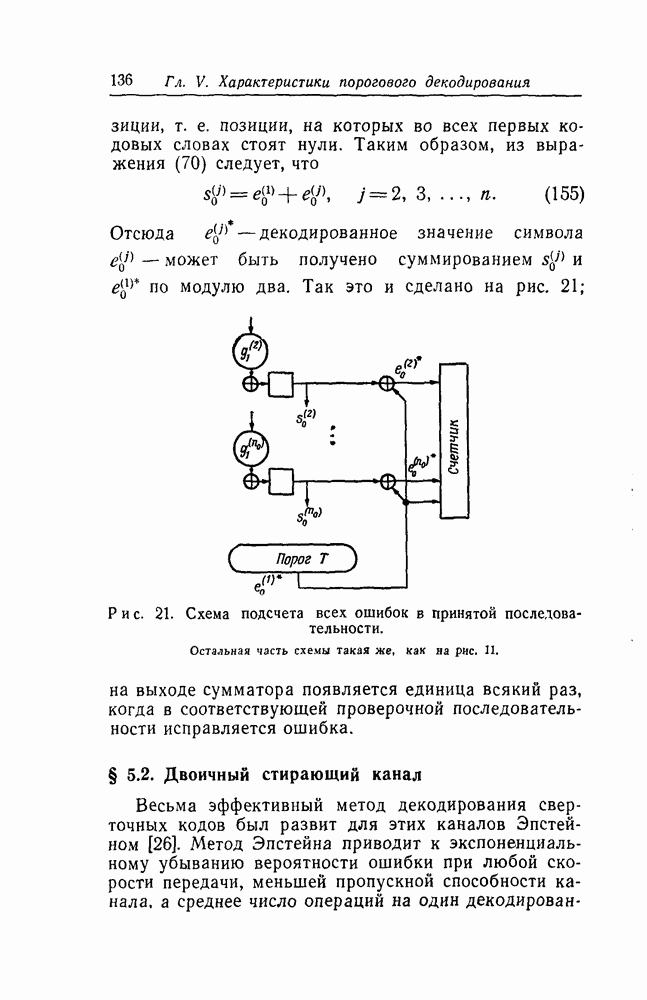

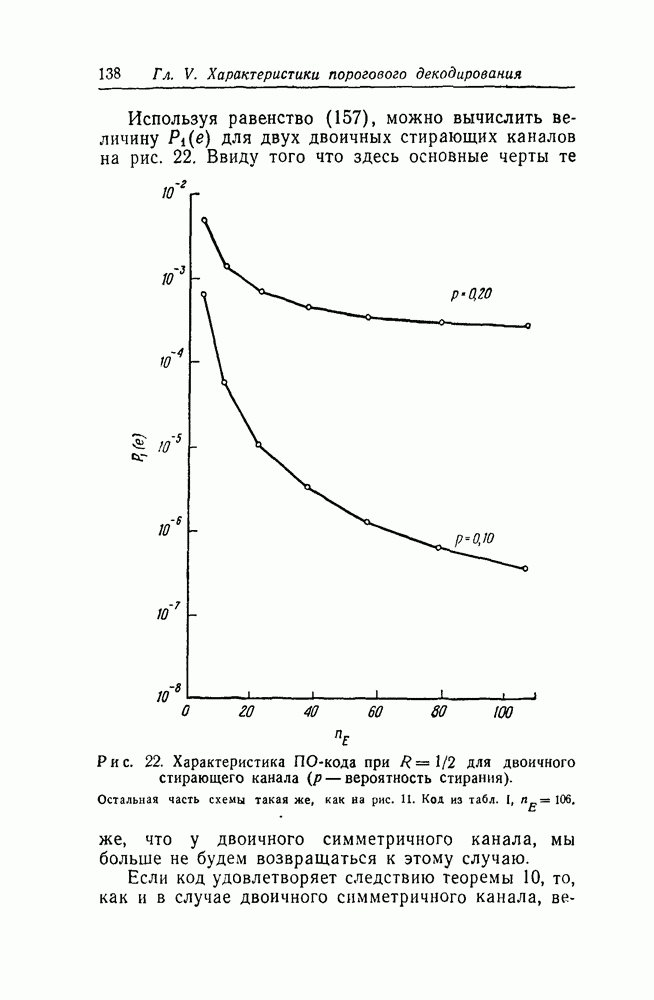


































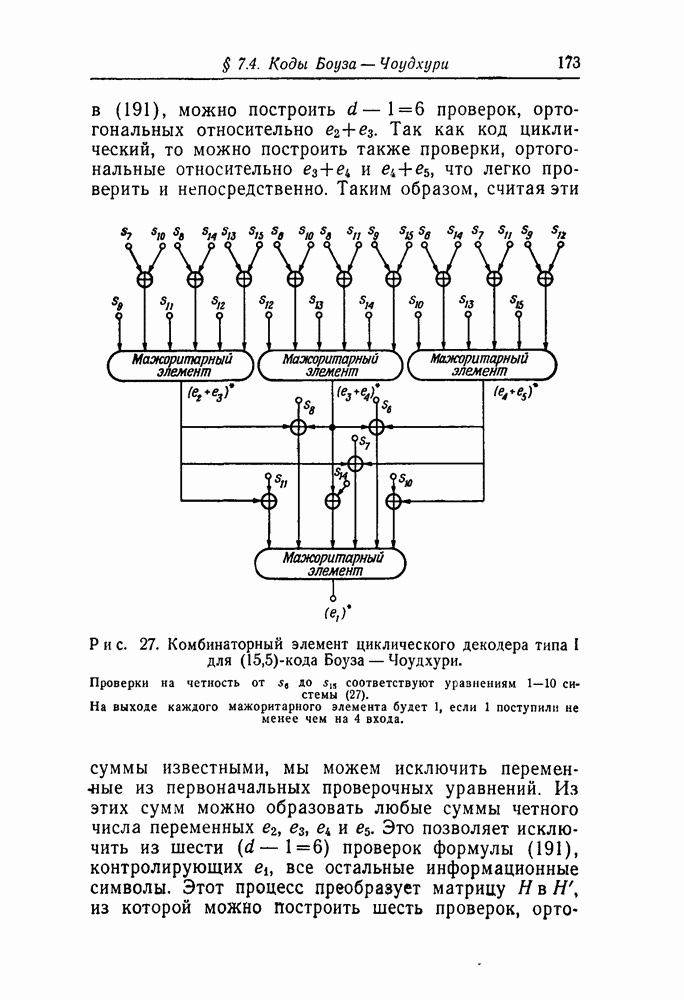
































 символов, передаваемых от начального момента времени 0 до момента
символов, передаваемых от начального момента времени 0 до момента  образуют линейный
образуют линейный  -код. Таким образом, замечания п. 1.2 относительно проблемы декодирования линейных кодов справедливы и для сверточных кодов. Кроме этого, декодирование сверточных кодов отличается одной характерной особенностью, состоящей в том, что по
-код. Таким образом, замечания п. 1.2 относительно проблемы декодирования линейных кодов справедливы и для сверточных кодов. Кроме этого, декодирование сверточных кодов отличается одной характерной особенностью, состоящей в том, что по  символам принятого начального кодового слова нужно определить только множество первых информационных символов
символам принятого начального кодового слова нужно определить только множество первых информационных символов 
 числом принятых символов. Если используется меньшее число, то достаточно было бы более короткого кода. Если
числом принятых символов. Если используется меньшее число, то достаточно было бы более короткого кода. Если
 однако, как указал
однако, как указал  Галлагер (частное сообщение), уменьшение вероятности ошибки может быть достигнуто более просто использованием кода с большим
Галлагер (частное сообщение), уменьшение вероятности ошибки может быть достигнуто более просто использованием кода с большим 
 символам принятого начального кодового слова определить множество первых информационных символов. Обозначим это множество через
символам принятого начального кодового слова определить множество первых информационных символов. Обозначим это множество через  подчеркивая тем самым, что эти величины могут отличаться от истинных значений. Рассмотрим измененные принятые последовательности
подчеркивая тем самым, что эти величины могут отличаться от истинных значений. Рассмотрим измененные принятые последовательности  заданные в виде
заданные в виде


 при
при  то влияние множества первых информационных символов на переданную (а потому и на принятую) последовательность устраняется. Таким образом, декодирование символа
то влияние множества первых информационных символов на переданную (а потому и на принятую) последовательность устраняется. Таким образом, декодирование символа  может быть выполнено по
может быть выполнено по  символам измененных) последовательностей
символам измененных) последовательностей  принятых от момента 1 до момента
принятых от момента 1 до момента  посредством того же алгоритма, который был использован для декодирования символа
посредством того же алгоритма, который был использован для декодирования символа  по
по  символам первоначальных последовательностей
символам первоначальных последовательностей  принятых от момента 0 до момента
принятых от момента 0 до момента  Продолжая этот процесс, декодирование можно вести последовательно, в каждый момент времени декодируя новое множество информационных символов.
Продолжая этот процесс, декодирование можно вести последовательно, в каждый момент времени декодируя новое множество информационных символов.

 в канале с шумами, а потому можно ожидать, что последующие множества информационных символов будут с высокой вероятностью декодированы неправильно. Это известный «эффект размножения» ошибок при декодировании сверточных кодов. Изложим два основных метода, с помощью которых эту неприятность можно обойти, а именно методы «ресинхронизации» и «подсчета ошибок».
в канале с шумами, а потому можно ожидать, что последующие множества информационных символов будут с высокой вероятностью декодированы неправильно. Это известный «эффект размножения» ошибок при декодировании сверточных кодов. Изложим два основных метода, с помощью которых эту неприятность можно обойти, а именно методы «ресинхронизации» и «подсчета ошибок».
 моментов времени. В течение следующих
моментов времени. В течение следующих  моментов времени кодируются нули. Так как в процессе декодирования используются символы, посланные не более чем
моментов времени кодируются нули. Так как в процессе декодирования используются символы, посланные не более чем  моментов времени тому назад, декодирование производится независимо от символов, принятых в соответствующие
моментов времени тому назад, декодирование производится независимо от символов, принятых в соответствующие  моментов времени; по прошествии этого времени декодирующее устройство становится свободным и процесс декодирования начинается снова по следующим принятым символам. Таким образом, любое размножение ошибок ограничивается
моментов времени; по прошествии этого времени декодирующее устройство становится свободным и процесс декодирования начинается снова по следующим принятым символам. Таким образом, любое размножение ошибок ограничивается  моментами времени или
моментами времени или  принятыми символами. Применение метода ресинхронизации уменьшает скорость передачи. Новая скорость передачи равна
принятыми символами. Применение метода ресинхронизации уменьшает скорость передачи. Новая скорость передачи равна

 номинальная скорость сверточного кода. Если
номинальная скорость сверточного кода. Если  то скорость снижается несущественно.
то скорость снижается несущественно.
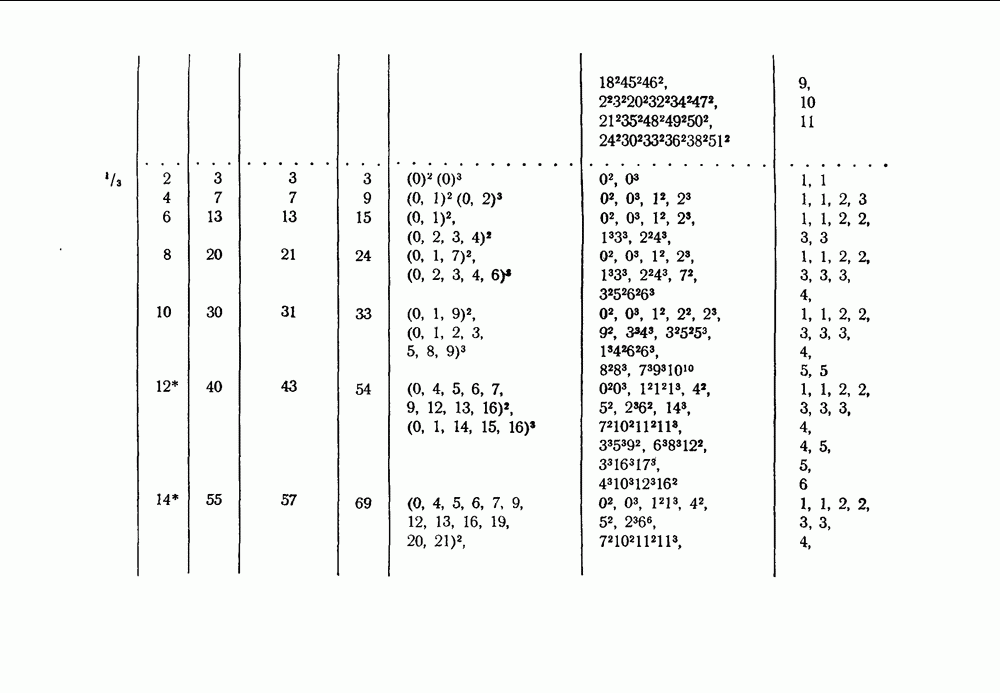
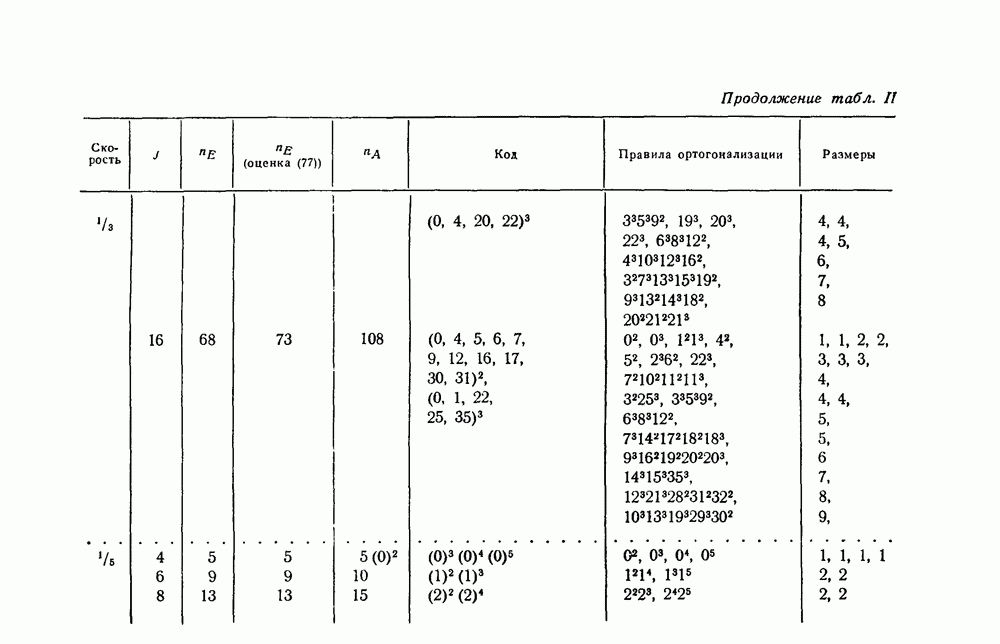
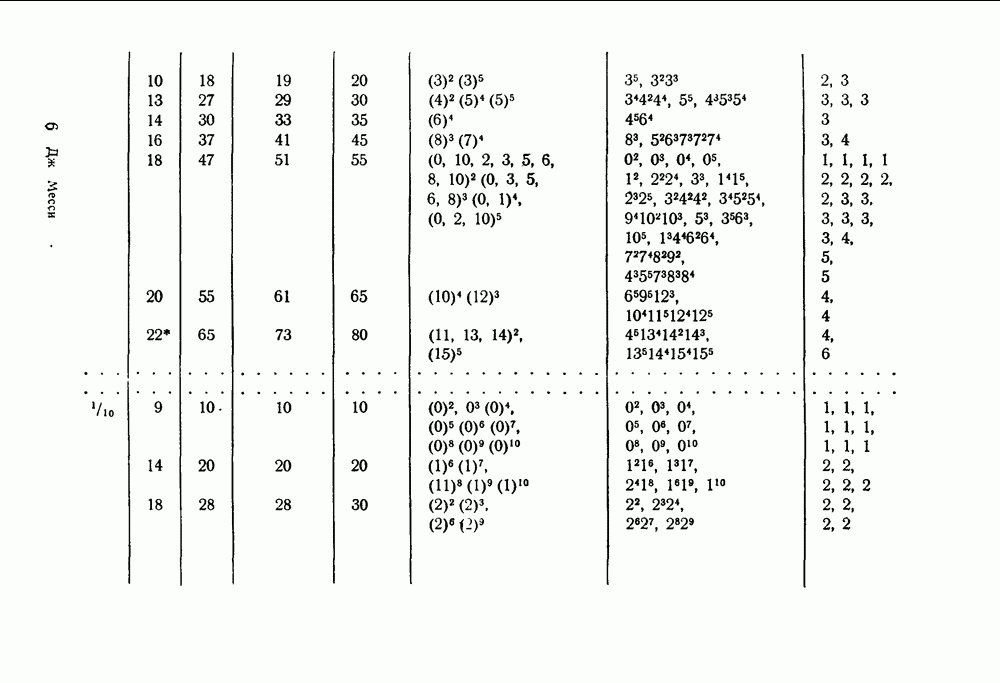
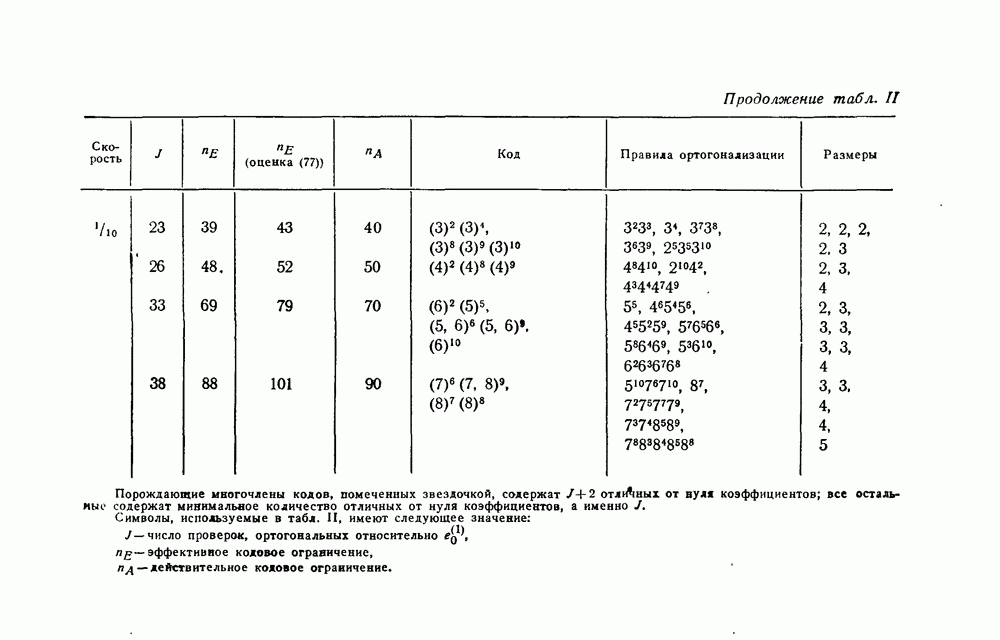
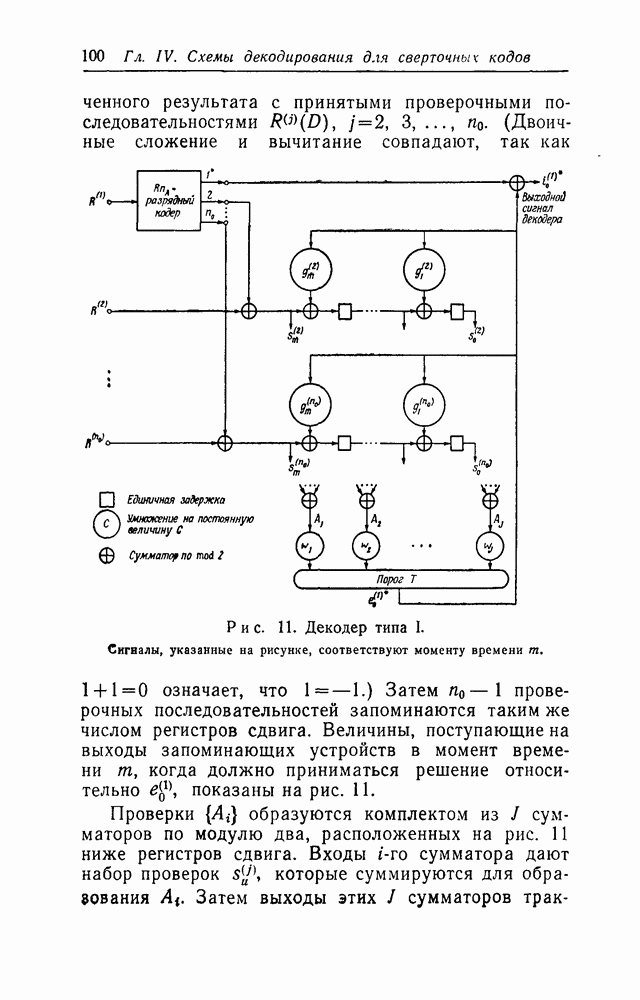
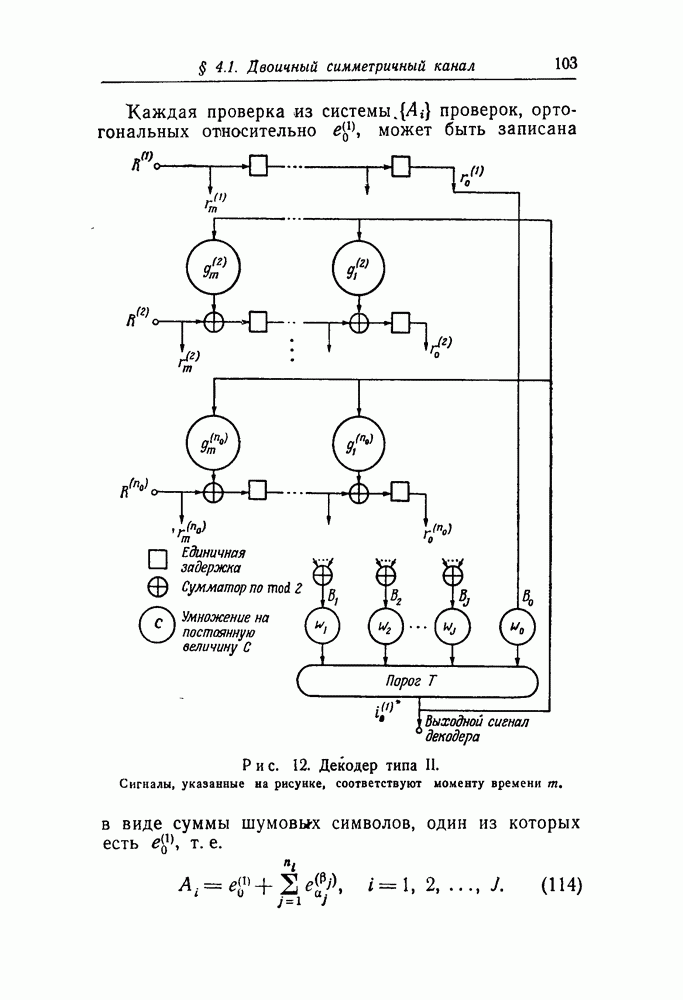
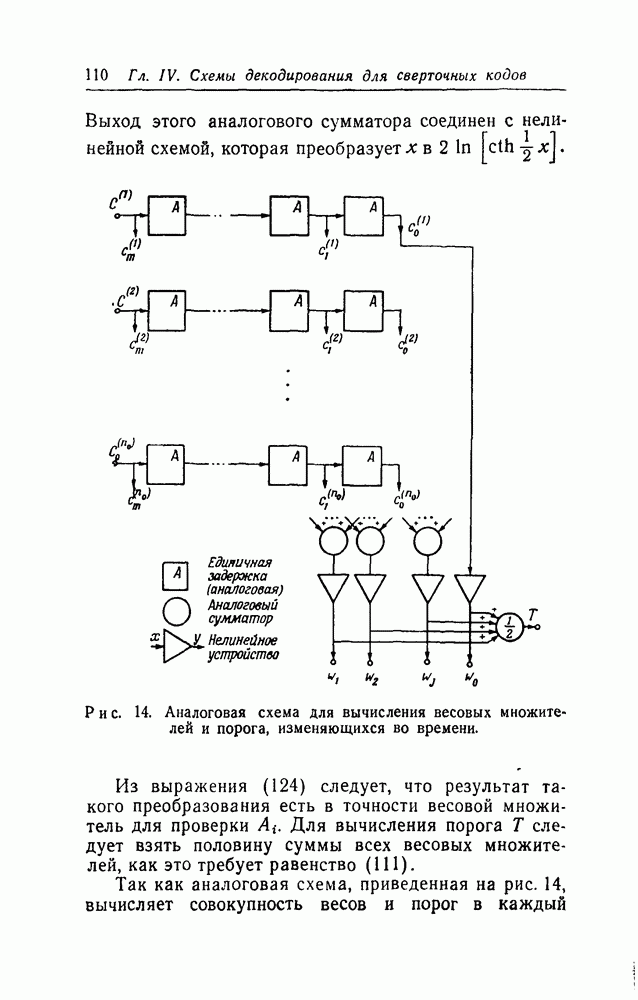
 в множестве первых информационных символов. Остальные этапы процесса декодирования, а именно изменение принятых последовательностей для устранения влияния первых символов и контроль за размножением ошибок, могут быть выполнены обычными способами. Таким образом, проблема построения сверточного кода, допускающего пороговое декодирование, сводится к нахождению кодов, для которых эффективным способом может быть выполнен переход от обычных проверок к системе проверок, ортогональных относительно
в множестве первых информационных символов. Остальные этапы процесса декодирования, а именно изменение принятых последовательностей для устранения влияния первых символов и контроль за размножением ошибок, могут быть выполнены обычными способами. Таким образом, проблема построения сверточного кода, допускающего пороговое декодирование, сводится к нахождению кодов, для которых эффективным способом может быть выполнен переход от обычных проверок к системе проверок, ортогональных относительно  так как только эти ошибки и должны быть определены в процессе декодирования.
так как только эти ошибки и должны быть определены в процессе декодирования.