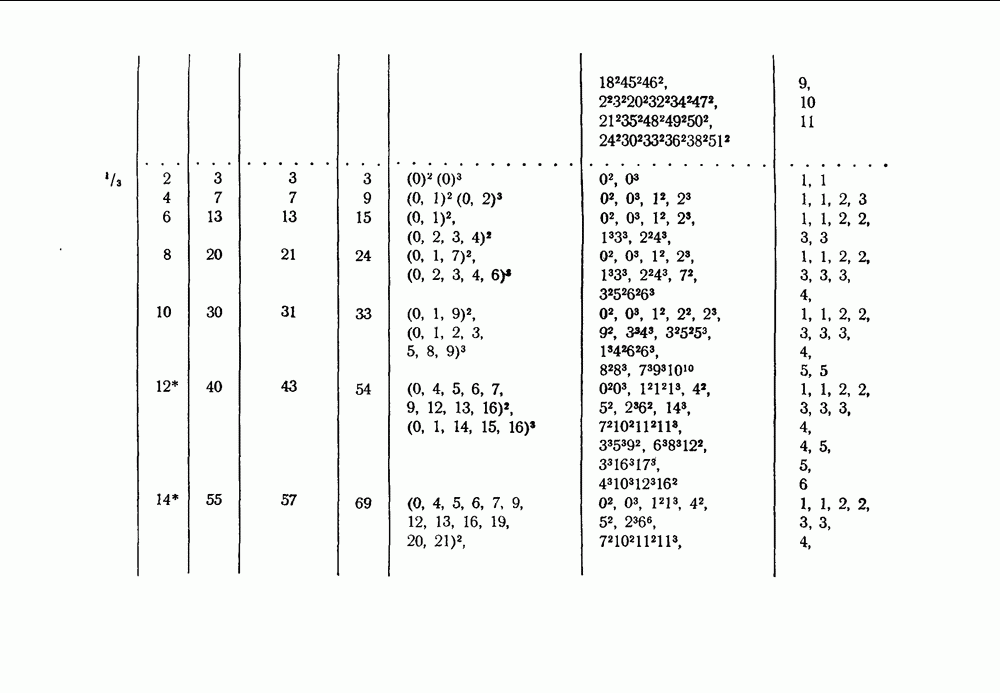
§ 4.1. Декодирование для двоичного симметричного канала
Начнем с простейшего случая, когда вероятность искажения одна и та же для всех принятых символов, т. е.  для всех
для всех  Единственным каналом, удовлетворяющим этому требованию, является двоичный симметричный канал, рассмотренный в гл. I. В этом случае схемы АВ-декодирования особенно просты, так как весовые множители
Единственным каналом, удовлетворяющим этому требованию, является двоичный симметричный канал, рассмотренный в гл. I. В этом случае схемы АВ-декодирования особенно просты, так как весовые множители  и значение порога
и значение порога  представляют собой постоянные величины (разумеется, в случае мажоритарного декодирования эти величины всегда постоянны, и потому схемы, приведенные в этом параграфе, пригодны для мажоритарного декодирования при любом двоичном канале). Например, рассмотрим конкретную проверку
представляют собой постоянные величины (разумеется, в случае мажоритарного декодирования эти величины всегда постоянны, и потому схемы, приведенные в этом параграфе, пригодны для мажоритарного декодирования при любом двоичном канале). Например, рассмотрим конкретную проверку  размера
размера  Применяя лемму 2, получаем
Применяя лемму 2, получаем

Это выражение зависит только от  так как
так как  постоянно. Поэтому
постоянно. Поэтому  в (109) и
в (109) и  в (111) также постоянные величины.
в (111) также постоянные величины.
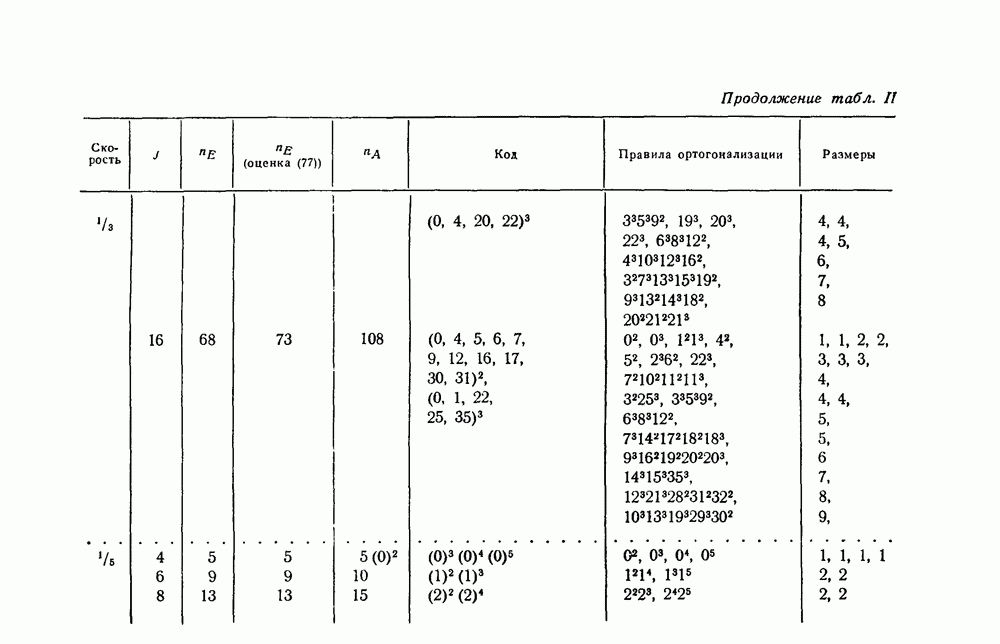
а. Декодер типа I
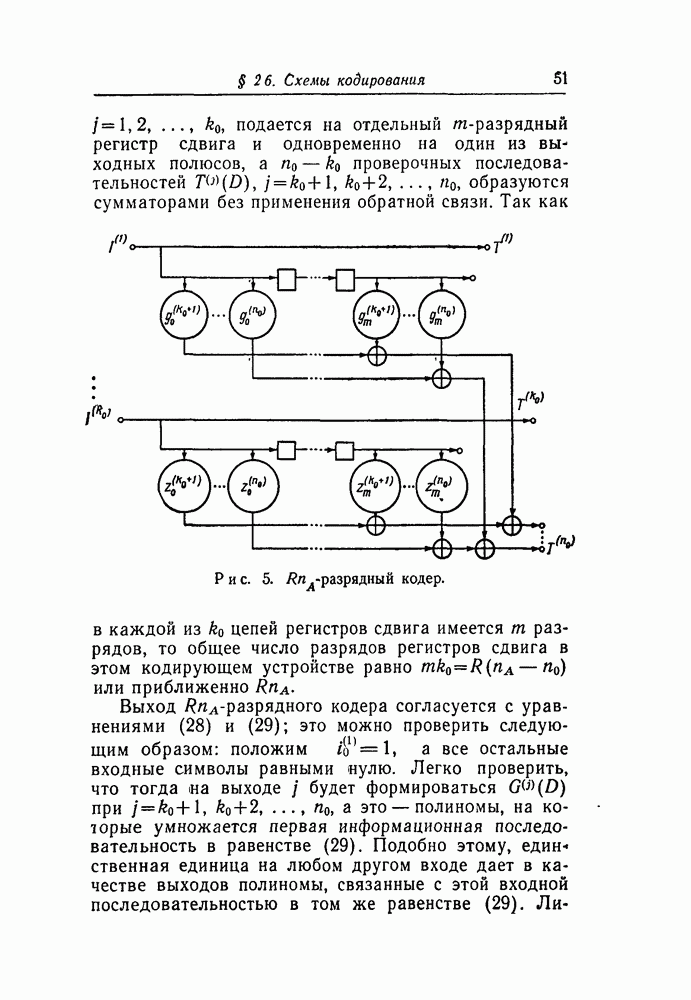
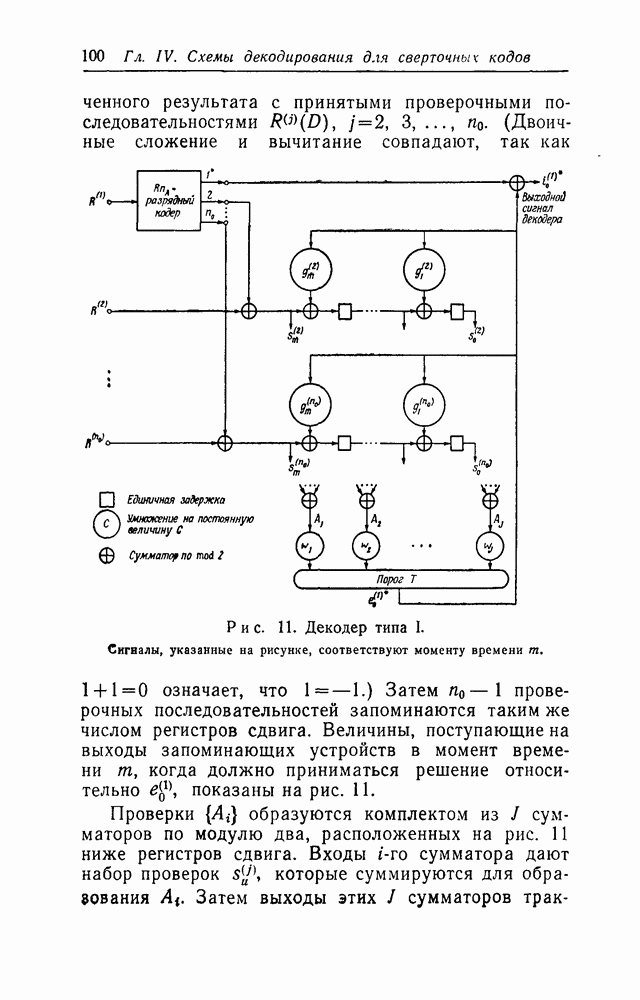
Первая схема, предлагаемая для реализации соотношения (107), показана на рис. 11. В том, что это действительно пороговый декодер, можно убедиться следующим образом.
Проверочные последовательности  образуются, как это объяснено в § 2.7, кодированием принятой информационной последовательности
образуются, как это объяснено в § 2.7, кодированием принятой информационной последовательности  и последующим сложением
и последующим сложением
трактуются как действительные числа; весовые множители  имеют значения (108) или (109) в зависимости от типа декодирования. После этого взвешенная сумма сравнивается с константой
имеют значения (108) или (109) в зависимости от типа декодирования. После этого взвешенная сумма сравнивается с константой  определяемой выражениями (110) или (111). Таким образом, на выходе порогового устройства появляется
определяемой выражениями (110) или (111). Таким образом, на выходе порогового устройства появляется  значение символа полученное в результате декодирования. Далее, для получения декодированного значения эта величина складывается по модулю два с величиной
значение символа полученное в результате декодирования. Далее, для получения декодированного значения эта величина складывается по модулю два с величиной  которая благодаря задержке как раз в момент времени
которая благодаря задержке как раз в момент времени  появляется на выходном полюсе кодера.
появляется на выходном полюсе кодера.
Наконец, рассмотрим измененные проверочные последовательности

Из выражения (63) следует, что если декодирование произведено верно, т. е. если  то влияние ошибки
то влияние ошибки  на измененные проверочные последовательности должно быть устранено. Более того, выражения (113) в моменты времени от 1 до
на измененные проверочные последовательности должно быть устранено. Более того, выражения (113) в моменты времени от 1 до  имеют в точности такую же структуру по отношению к
имеют в точности такую же структуру по отношению к  как первоначальные члены в моменты времени от 0 до
как первоначальные члены в моменты времени от 0 до  по отношению к Но это значит, что декодирование символа может быть выполнено применением к измененной проверочной последовательности в моменты временя от 1 до
по отношению к Но это значит, что декодирование символа может быть выполнено применением к измененной проверочной последовательности в моменты временя от 1 до  того же алгоритма, что и при декодировании символа из первоначальных проверочных последовательностей в моменты времени от 0 до
того же алгоритма, что и при декодировании символа из первоначальных проверочных последовательностей в моменты времени от 0 до 
Таким образом, если не произошло ошибочного декодирования, то в последующие моменты времени декодер типа I будет работать правильно, если проверочные последовательности будут изменяться в соответствии с равенством (113). Из рисунка 11 видно, что это можно выполнить посредством обратных связей от выхода порогового элемента к сумматорам
по модулю два, расположенным между разрядами регистров сдвигов, которые запоминают проверочные последовательности. Связи с сумматорами соответствуют, порождающим полиномам 
Относительно декодера типа I следует сделать еще несколько замечаний.
Во-первых, регистры сдвига, используемые для запоминания проверочных последовательностей, содержат всего

разрядов. Вдобавок входящий в схему кодер содержит  разрядов. Всего, таким образом, в декодере типа I имеется
разрядов. Всего, таким образом, в декодере типа I имеется  разрядов регистров сдвига. Во-вторых, принятые последовательности могут быть введены в декодер, начиная с нулевого момента времени, так как последовательности, состоящие сплошь из «улей, в любом сверточном коде образуют вполне правомерное начальное кодовое слово.
разрядов регистров сдвига. Во-вторых, принятые последовательности могут быть введены в декодер, начиная с нулевого момента времени, так как последовательности, состоящие сплошь из «улей, в любом сверточном коде образуют вполне правомерное начальное кодовое слово.
При этом не требуется отключать пороговое устройство вплоть до момента времени  когда должно быть принято решение относительно
когда должно быть принято решение относительно 
Кроме того, все информационные символы на выходе декодера должны быть нулями до момента времени  если декодирование производится правильно. В течение всего этого времени декодер находится под контролем, и любая «единица» на выходе должна истолковываться как указание на то, что символ
если декодирование производится правильно. В течение всего этого времени декодер находится под контролем, и любая «единица» на выходе должна истолковываться как указание на то, что символ  декодирован неверно.
декодирован неверно.
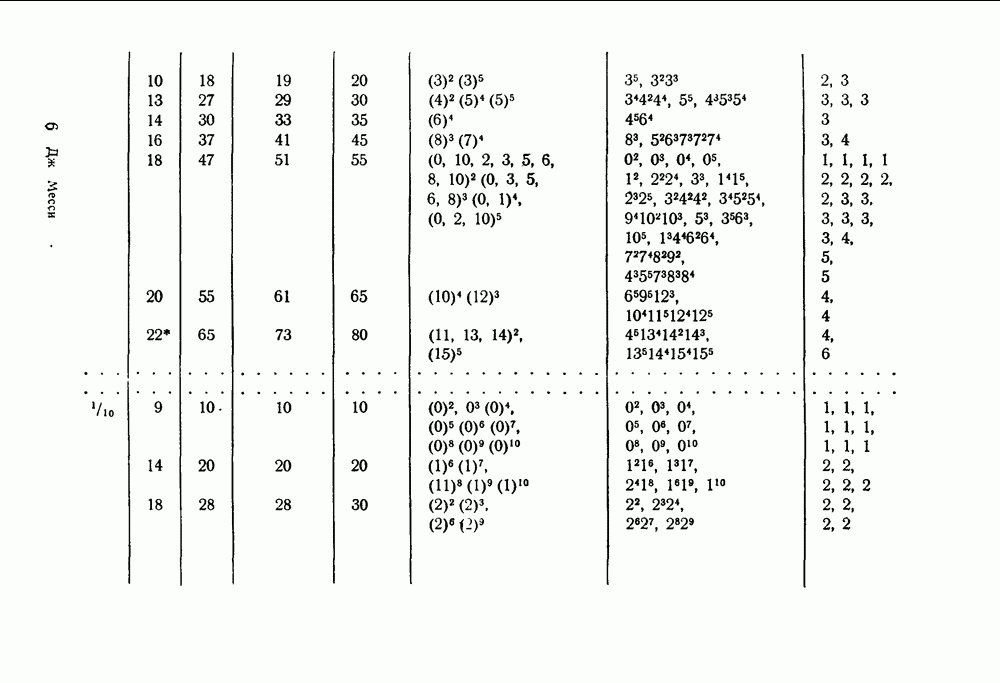
б. Декодер типа II
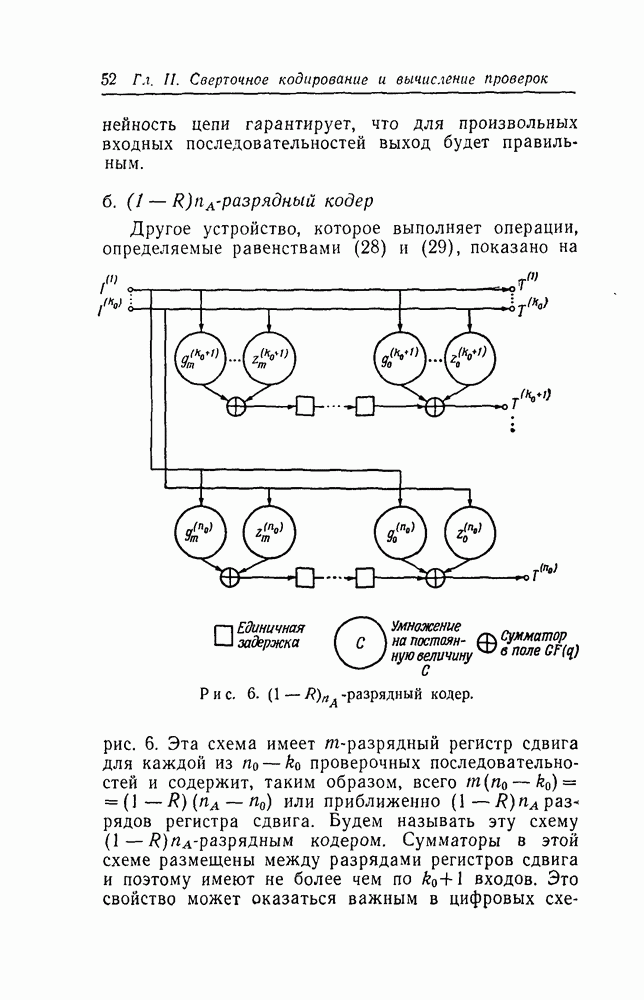
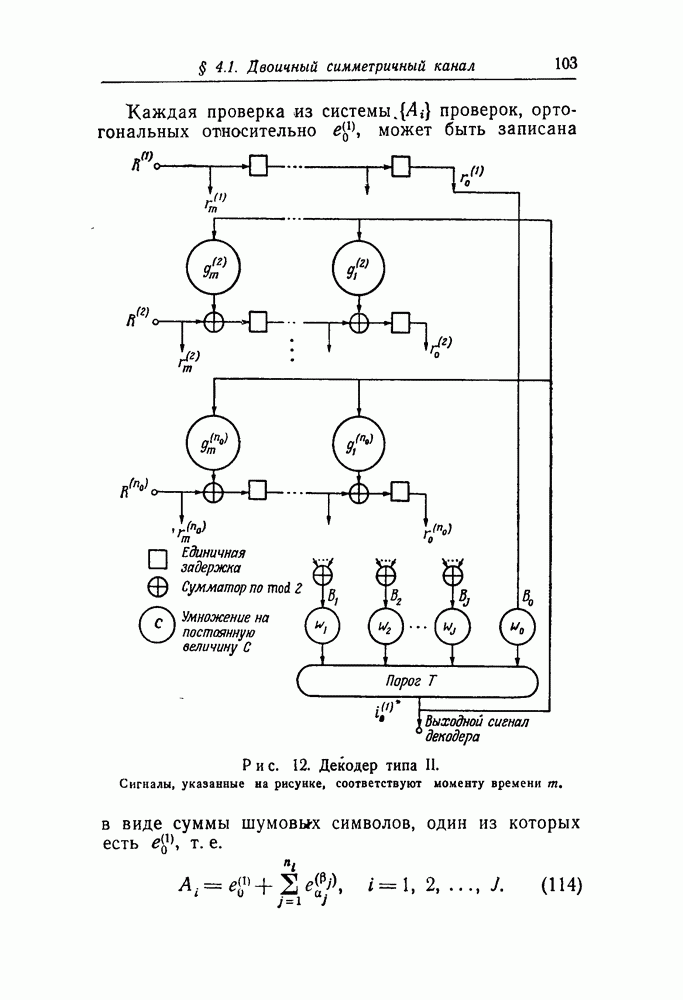
Вторая схема, реализующая алгоритмы порогового декодирования, показана на рис. 12. Форма, в которой эта схема реализует алгоритмы, совершенно отлична от приведенной выше. Поэтому сейчас необходимо изложить теорию, на которую опирается схема, изображенная на рис. 12.
Каждая проверка из системы  проверок, ортогональных относительно может быть записана в виде суммы шумовых символов, один из которых есть
проверок, ортогональных относительно может быть записана в виде суммы шумовых символов, один из которых есть  т. е.
т. е.

Рис. 12. (см. скан) Декодер типа II. Сигналы, указанные на рисунке, соответствуют моменту времени 
Так как  проверка, то равенство (114) можно переписать так:
проверка, то равенство (114) можно переписать так:

Обозначим через  сумму принятых символов, кроме
сумму принятых символов, кроме  которые входят в выражение
которые входят в выражение  т. е.
т. е.

Вспомним, что  и подставим выражения (114) и (115) в (116)
и подставим выражения (114) и (115) в (116)

Пусть для удобства

Из равенства (117) и (118) видно, что  образует систему
образует систему  уравнений (но не проверок!), каждое из которых есть сумма
уравнений (но не проверок!), каждое из которых есть сумма  и множества шумовых символов, таких, что ни один из них не входит более чем в одно уравнение. Поступая так же, как и в начале главы, найдем, что правила порогового декодирования будут выглядеть следующим образом.
и множества шумовых символов, таких, что ни один из них не входит более чем в одно уравнение. Поступая так же, как и в начале главы, найдем, что правила порогового декодирования будут выглядеть следующим образом.
Выбрать  тогда и только тогда, когда
тогда и только тогда, когда

где  трактуются как действительные числа,
трактуются как действительные числа,  и
и  имеют тот же смысл, что в формулах (108) — (111). Если
имеют тот же смысл, что в формулах (108) — (111). Если  нечетно, то правило мажоритарного декодирования, изложенное здесь, не совпадает в точности с формулой (107). Для полного
нечетно, то правило мажоритарного декодирования, изложенное здесь, не совпадает в точности с формулой (107). Для полного 
нообразия также и в этом случае правило (119) должно звучать так: выбрать

Этот алгоритм выполняет те же операции декодирования, что и алгоритм (107), с той единственной разницей, что первый прямо дает символ (значение символа полученное при декодировании), тогда как второй дает  откуда декодированное значение символа может быть найдено из равенства
откуда декодированное значение символа может быть найдено из равенства 
Теперь можно легко объяснить работу декодера типа II, показанного «а рис. 12. Принятые последовательности запоминаются в  регистрах сдвига так, что принятые символы могут быть использованы для образования множества
регистрах сдвига так, что принятые символы могут быть использованы для образования множества  Величины
Величины  образуются в сумматорах, расположенных на рисунке ниже регистров сдвига; входы
образуются в сумматорах, расположенных на рисунке ниже регистров сдвига; входы  сумматора суть
сумматора суть  принятых символов в равенстве (116), сумма которых равна
принятых символов в равенстве (116), сумма которых равна  Выходы сумматоров, т. е.
Выходы сумматоров, т. е.  умножаются на весовые множители и сравниваются с порогом в соответствии с неравенством (119). Выходом порогового элемента является
умножаются на весовые множители и сравниваются с порогом в соответствии с неравенством (119). Выходом порогового элемента является  Наконец, для подготовки схемы к правильной работе в последующие моменты времени принятые последовательности меняются в соответствии с (65). Это достигается обратными связями от выхода
Наконец, для подготовки схемы к правильной работе в последующие моменты времени принятые последовательности меняются в соответствии с (65). Это достигается обратными связями от выхода  порогового устройства к сумматорам по модулю два, расположенным между разрядами регистра сдвига, с соединениями, соответствующими порождающим полиномам
порогового устройства к сумматорам по модулю два, расположенным между разрядами регистра сдвига, с соединениями, соответствующими порождающим полиномам 
Декодер типа II содержит  регистров сдвига по
регистров сдвига по  разрядов в каждом, т. е. всего
разрядов в каждом, т. е. всего  разрядов регистров сдвига. Столько же разрядов и в декодере типа
разрядов регистров сдвига. Столько же разрядов и в декодере типа  Более того, как и в случае декодера типа I, тот факт, что последовательности, состоящие
Более того, как и в случае декодера типа I, тот факт, что последовательности, состоящие
сплошь из нулей, являются кодовыми словами, означает, что с момента времени 0, когда входы впервые вступают в действие, до момента времени  когда принимается решение относительно пороговый элемент не должен отключаться. Однако в противоположность декодеру типа I декодер типа II не может служить также и кодером, если не произвести в нем некоторых изменений.
когда принимается решение относительно пороговый элемент не должен отключаться. Однако в противоположность декодеру типа I декодер типа II не может служить также и кодером, если не произвести в нем некоторых изменений.
в. Заключение
Содержание предыдущих разделов можно сформулировать в виде теоремы.
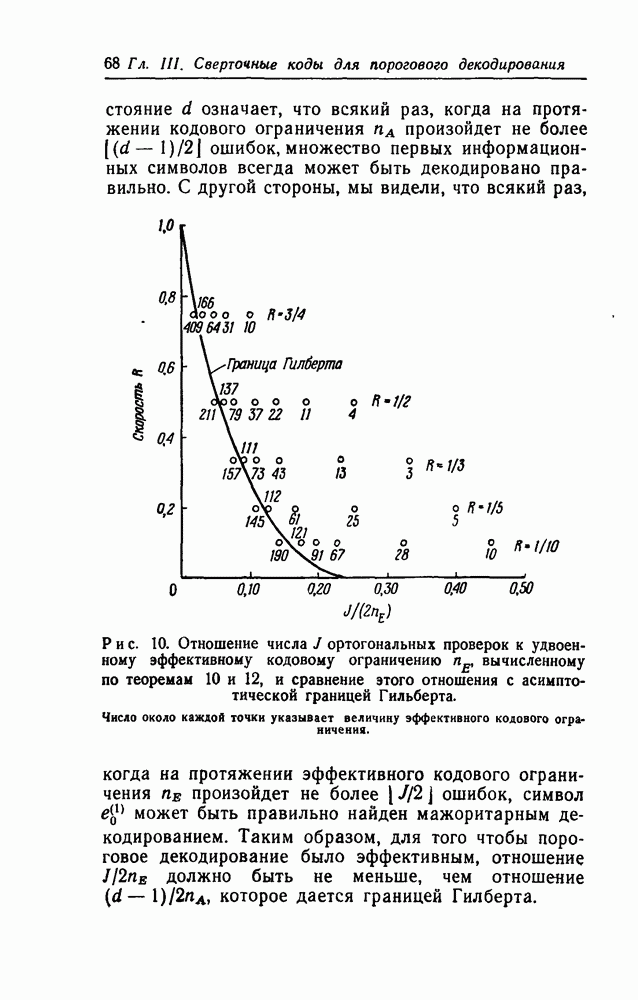
Теорема 15. Для двоичного сверточного кода со скоростью передачи  и кодовым ограничением
и кодовым ограничением  мажоритарное декодирование (в случае любого двоичного канала) или АВ-декодирование (в случае двоичного симметричного канала) может быть выполнено последовательной схемой, содержащей
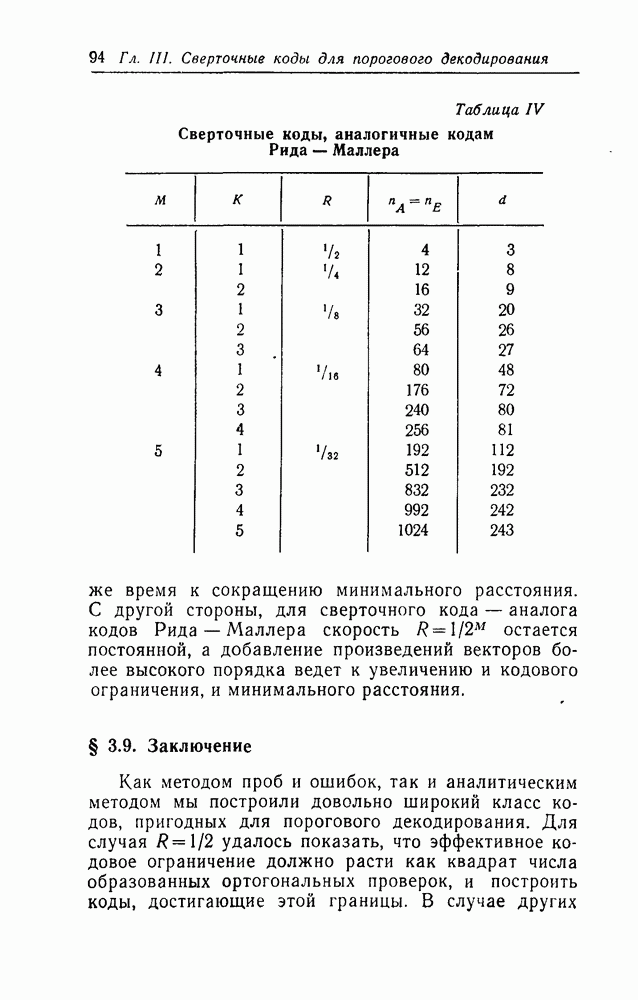
мажоритарное декодирование (в случае любого двоичного канала) или АВ-декодирование (в случае двоичного симметричного канала) может быть выполнено последовательной схемой, содержащей  разрядов регистров сдвига и один пороговый логический элемент.
разрядов регистров сдвига и один пороговый логический элемент.
Интересно отметить, что элементы декодеров обоих типов работают со скоростью одна операция в единицу времени, в то время как принимаемые символы поступают со скоростью  символов в единицу времени. Этот факт позволяет снизить требования к быстродействию элементов декодеров.
символов в единицу времени. Этот факт позволяет снизить требования к быстродействию элементов декодеров.
Представляется правдоподобным, что эти декодеры содержат минимальное для сверточного декодера число элементов памяти. Это можно показать следующим образом. Так как для принятия решения относительно требуется  принятых символов, а в единицу времени поступает
принятых символов, а в единицу времени поступает  символов, то декодер должен запомнить не менее
символов, то декодер должен запомнить не менее  принятых символов (или их эквивалентов).
принятых символов (или их эквивалентов).
Наконец, теперь должно быть ясно, что в случае  декодеры типов I и II каждый со своим собственным комплектом сумматоров для образования системы проверок, ортогональных относительно
декодеры типов I и II каждый со своим собственным комплектом сумматоров для образования системы проверок, ортогональных относительно 







































































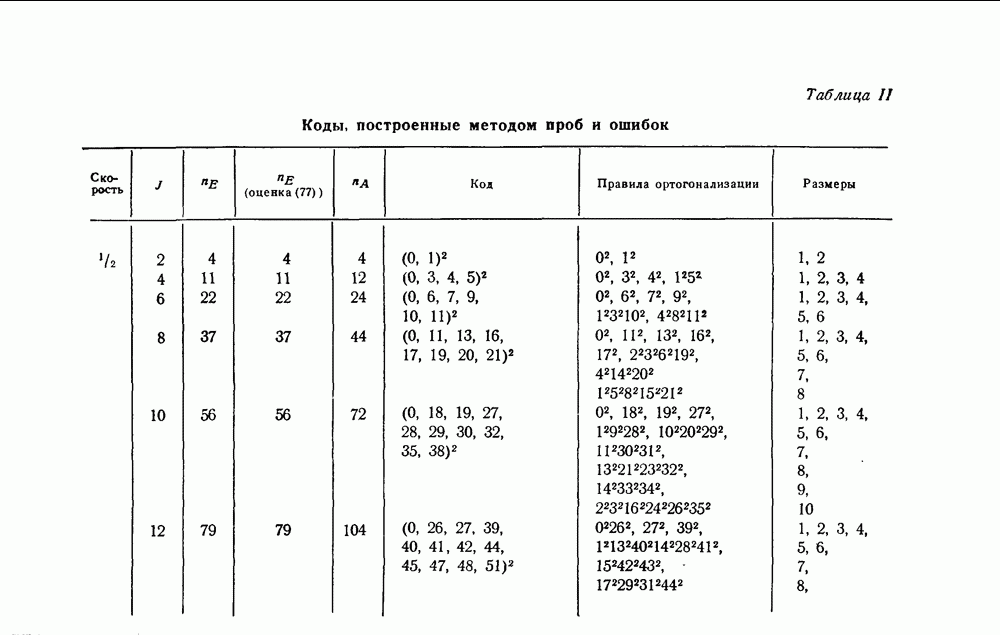
























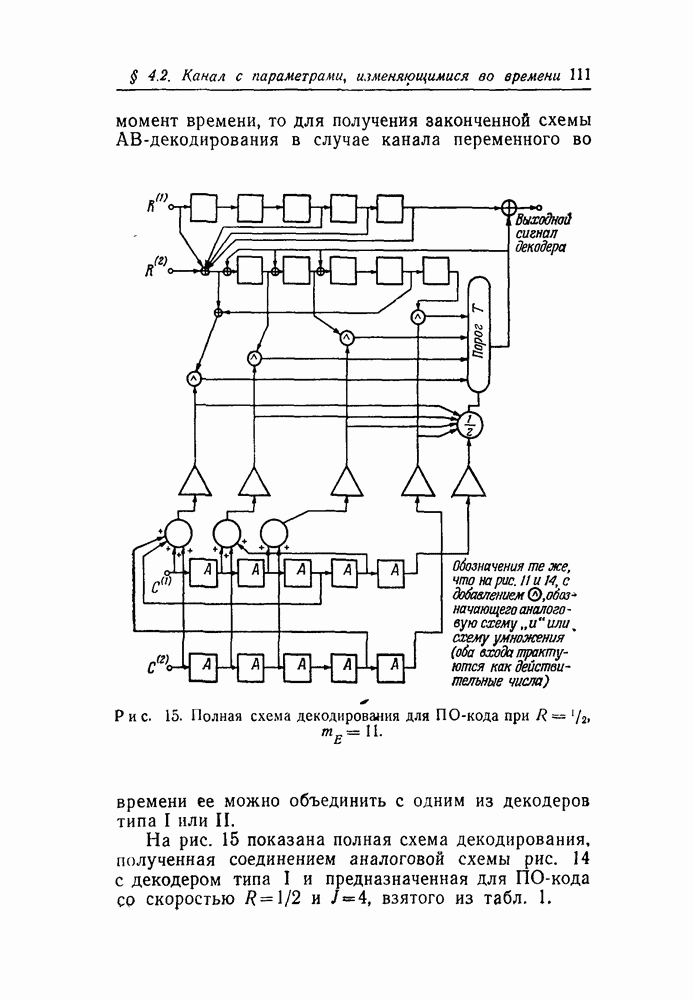











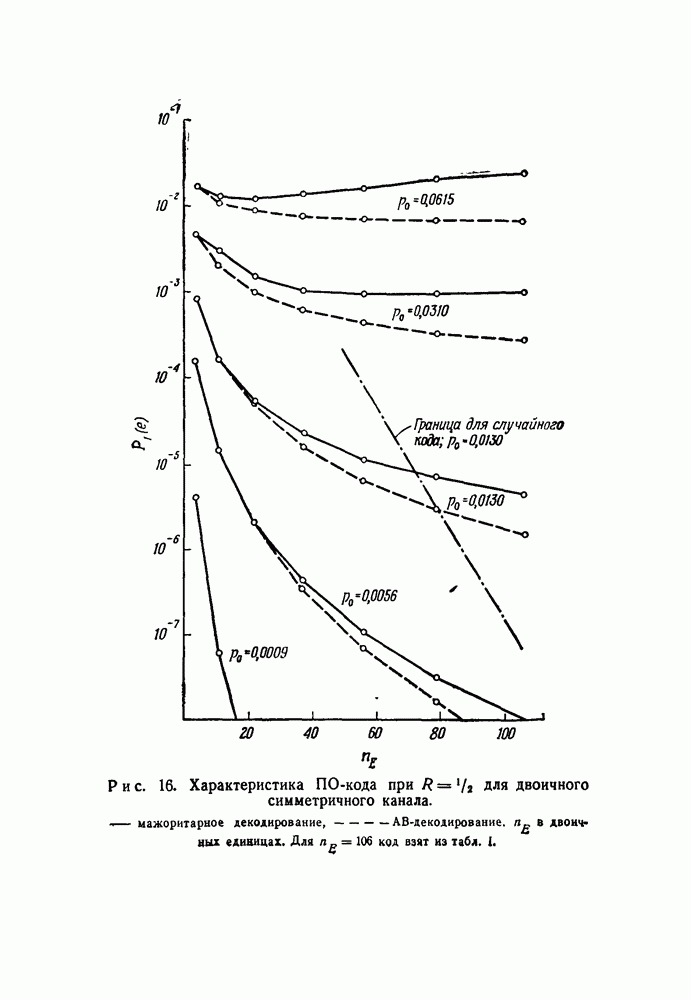
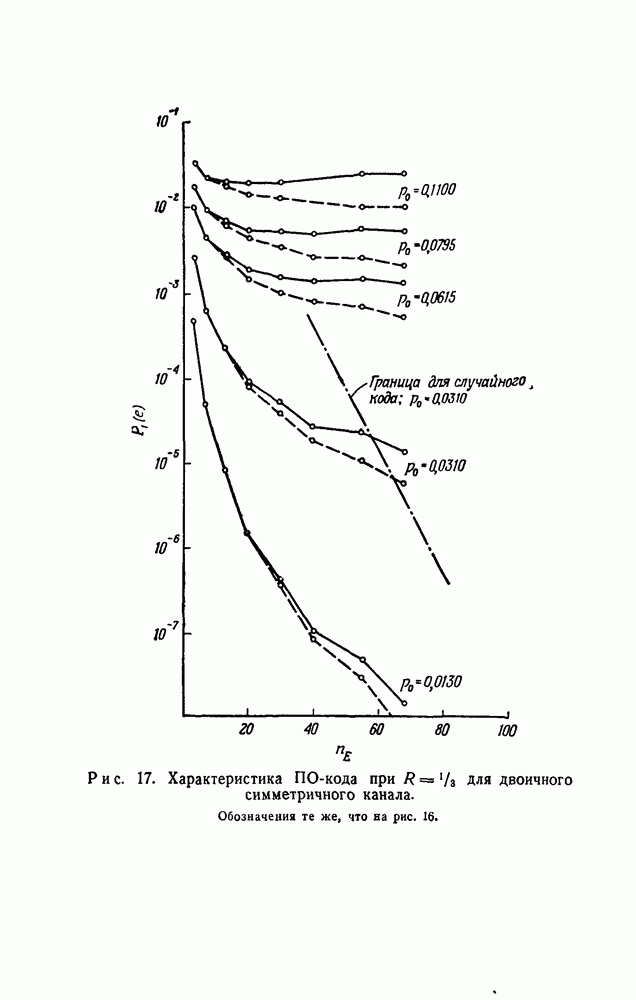
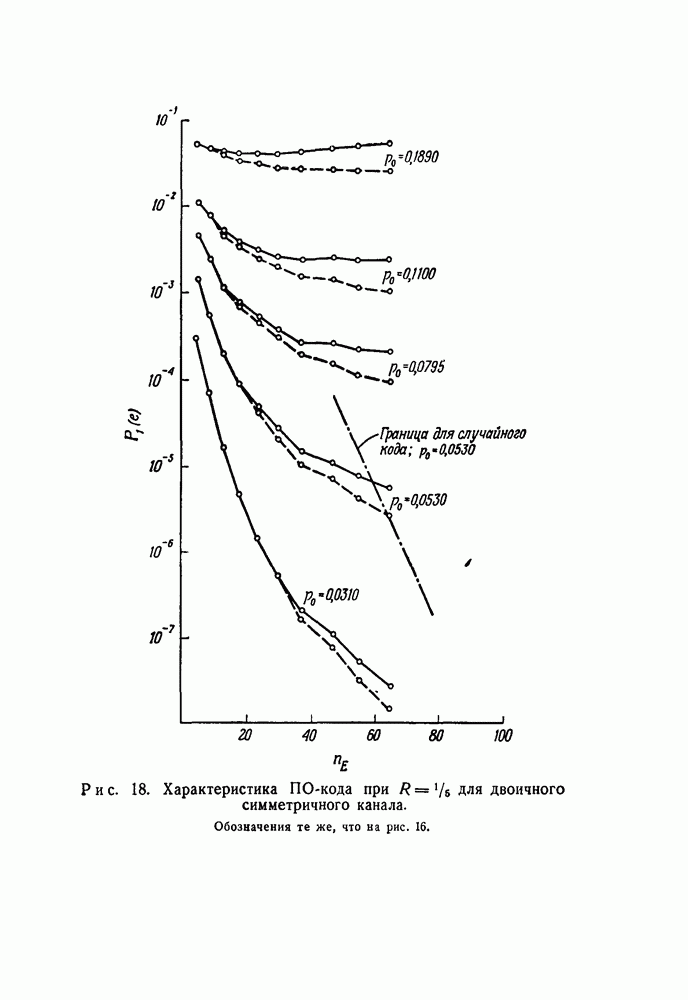







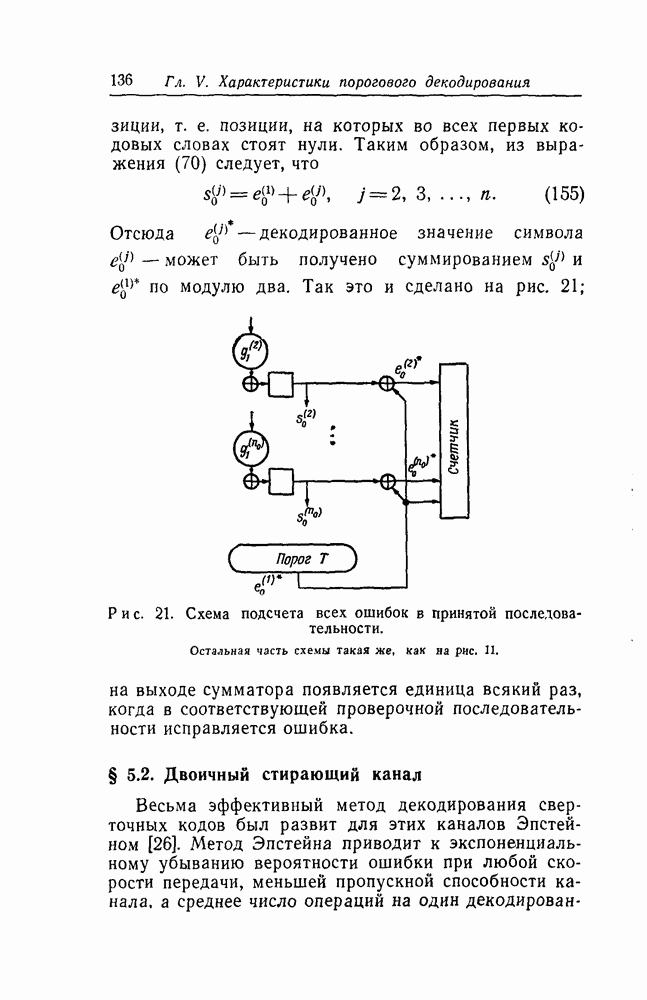



































































 (Двоичные сложение и вычитание совпадают, так как
(Двоичные сложение и вычитание совпадают, так как  означает, что
означает, что  Затем
Затем  проверочных последовательностей запоминаются таким же числом регистров сдвига.
проверочных последовательностей запоминаются таким же числом регистров сдвига.


 когда должно приниматься решение относительно
когда должно приниматься решение относительно  показаны на рис. 11.
показаны на рис. 11.
 образуются комплектом из
образуются комплектом из  сумматоров по модулю два, расположенных на рис. 11 ниже регистров сдвига. Входы
сумматоров по модулю два, расположенных на рис. 11 ниже регистров сдвига. Входы  сумматора дают набор проверок
сумматора дают набор проверок  которые суммируются для образования
которые суммируются для образования  Затем выходы этих
Затем выходы этих  сумматоров
сумматоров
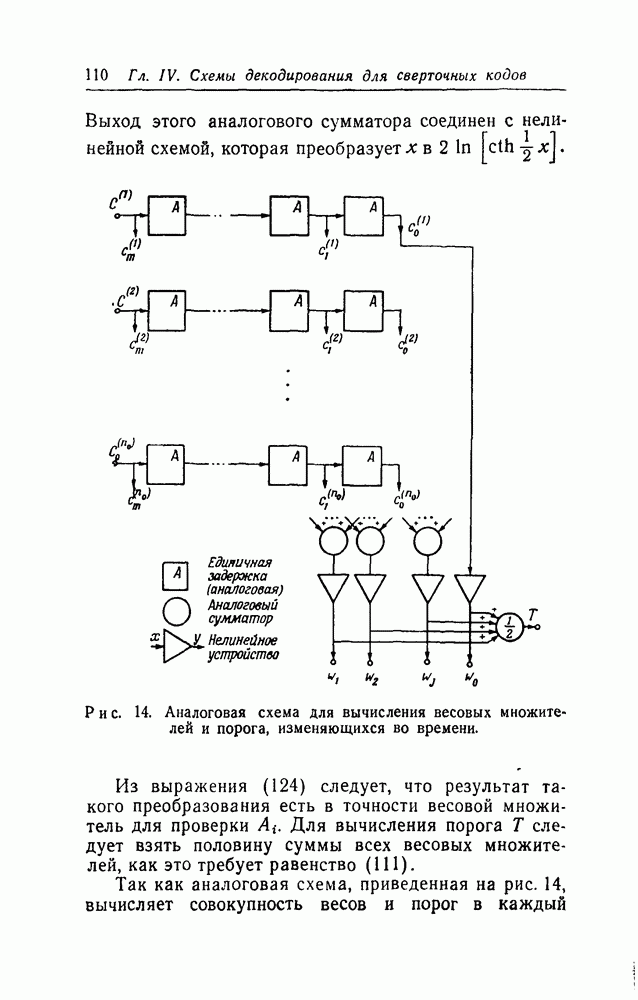
 должны быть изменены так, чтобы содержать
должны быть изменены так, чтобы содержать  пороговых устройств. Выходами пороговых элементов должны быть символы в декодере типа I или символы
пороговых устройств. Выходами пороговых элементов должны быть символы в декодере типа I или символы  в декодере типа II. Таким образом, в случае
в декодере типа II. Таким образом, в случае  теорема 15 остается неизменной, кроме последних слов, которые следует читать
теорема 15 остается неизменной, кроме последних слов, которые следует читать  пороговых логических элементов».
пороговых логических элементов».