Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
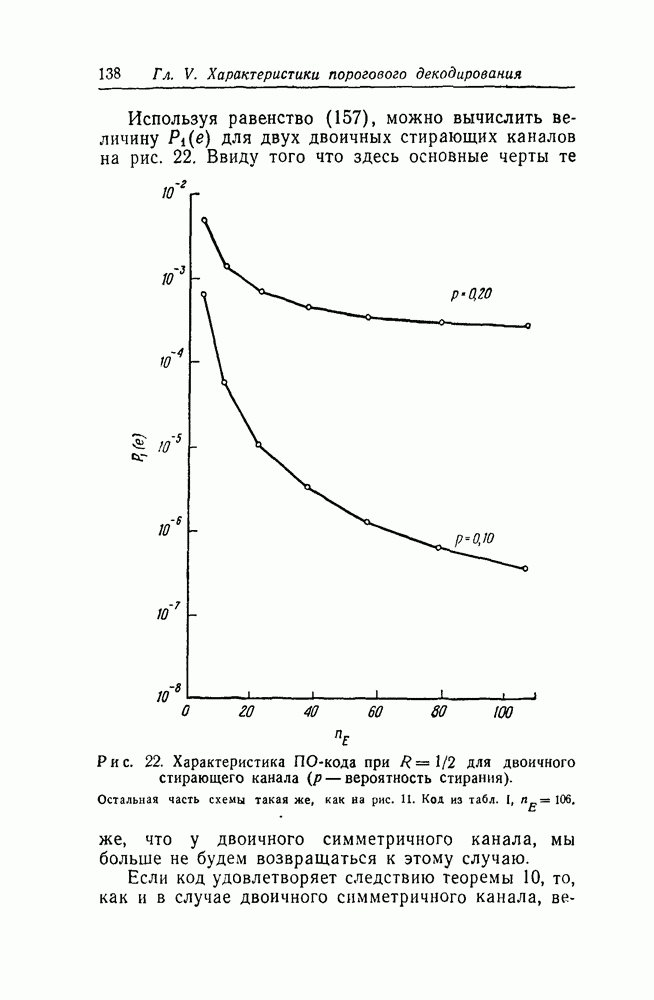
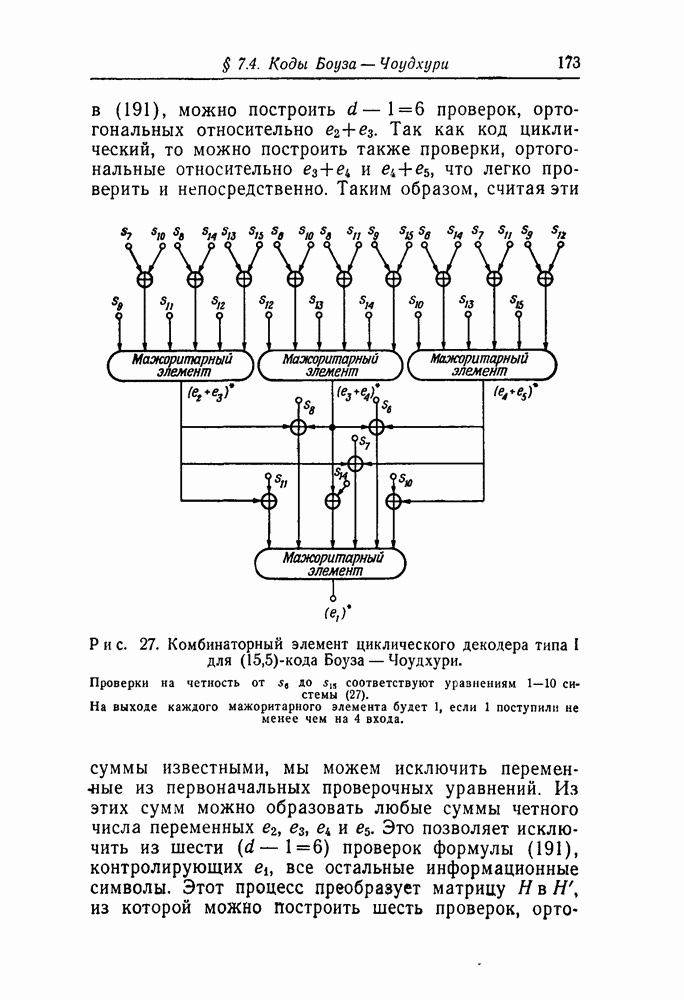
§ 1.1. Пороговое декодирование линейных кодовОпираясь на вышеизложенное, можно описать, в каком отношении к уже известным подходам к проблеме декодирования находится идея порогового декодирования, предлагаемая в этой работе. Как и в случае вероятностных методов, мы начнем с алгоритма декодирования, а не с конкретных кодов. Однако наш алгоритм будет в основном алгебраическим и потребует фиксированного количества вычислений на один декодируемый символ. Вследствие того что этот алгоритм требует от кода специальной алгебраической структуры, он не может быть применен ко всем ансамблям кодов; точнее говоря, должны быть построены специальные коды, к которым он применим. Наконец, — и это самое важное — в качестве нашего алгоритма мы выбираем такой, который допускает простую реализацию на вычислительной машине. Перед тем как обрисовать метод декодирования, мы сделаем некоторые предварительные замечания относительно линейных или групповых кодов. а. Линейные коды и проблема декодирования [8]Нас будут интересовать в основном линейные коды в систематической форме. Множество кодовых слов такого кода есть подмножество множества всех последовательностей длины
где каждое
где множество коэффициентов Предположим теперь, что после передачи по некоторому каналу полученная последовательность «шумовой последовательностью»
где Нетрудно показать, что множество передаваемых кодовых слов образует аддитивную абелеву группу порядка Пусть представляет собой последовательность
и совпадает с последовательностью, которая получится, если в качестве информационных символов выбрать Для линейного систематического кода, описываемого системой (2), мы всегда будем пользоваться обозначением Систему (2) можно переписать в виде
при этом говорят, что каждое из этих Мы назовем проверкой на четность сумму в (5), образованную на приемном конце, т. е.
Используя (3) и (5), проверки можно переписать в виде
откуда видно, что для которых определены
Это общее решение включает
Рис. 2. Модель источника шума для двоичного симметричного канала. Каждая из этих произвольных постоянных может принимать любые из Мы еще не рассмотрели механизма, посредством которого порождаются шумовые символы Основная проблема декодирования для линейных кодов состоит в том, чтобы найти наиболее вероятное решение системы (7) для данного канала. Например, при передаче двоичной информации по двоичному симметричному каналу задача состоит в нахождении такого решения системы (7), которое содержит наименьшее число единиц. На практике из-за большого числа возможностей обычно не удается найти наиболее вероятное решение системы (7) для произвольного сочетания значений проверок
|
 |
Оглавление
|














































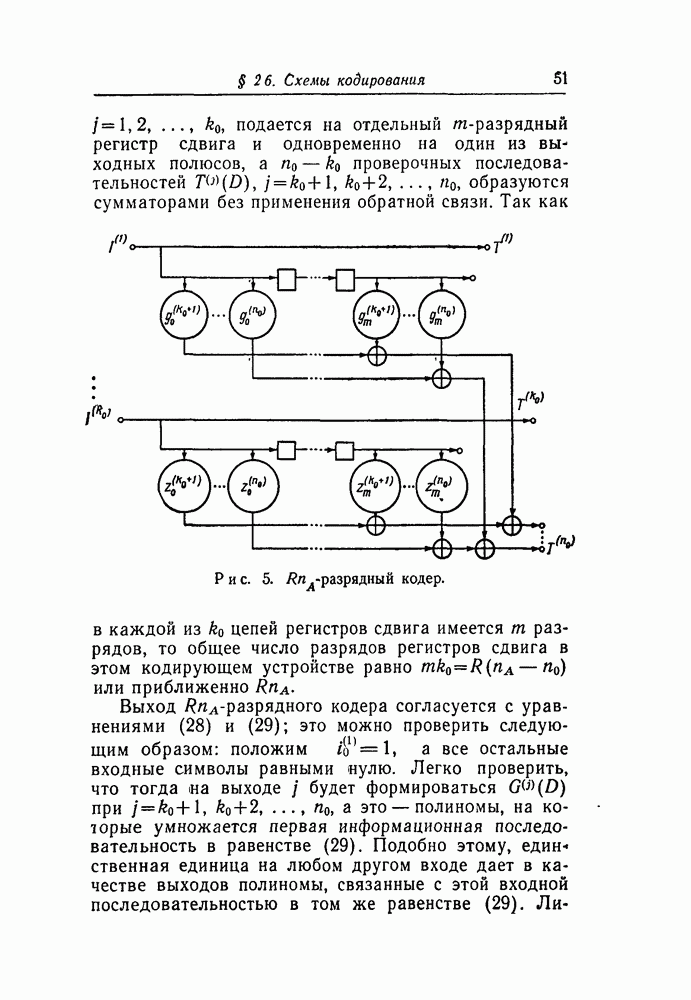
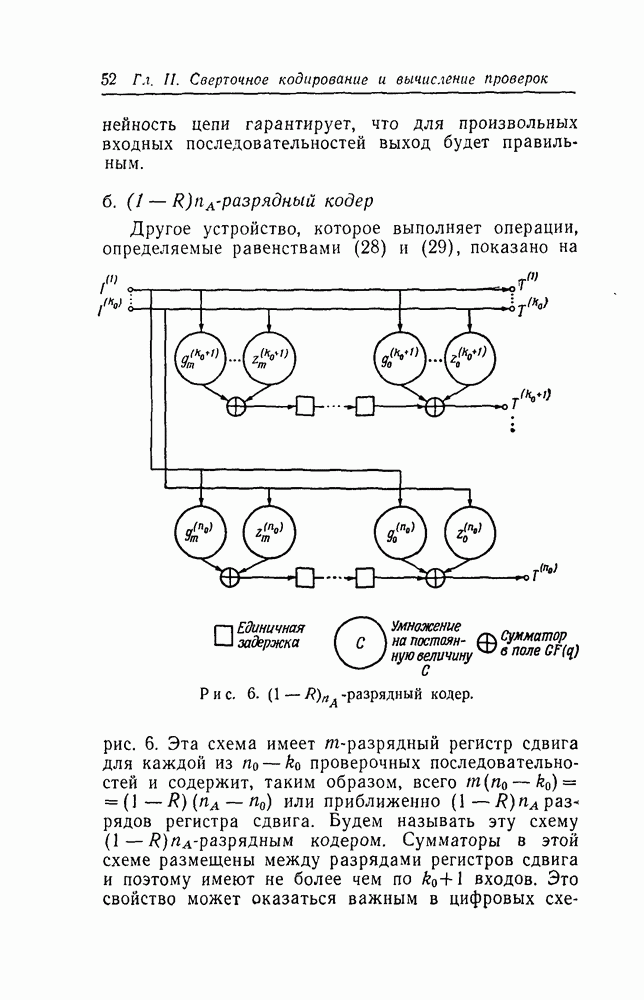















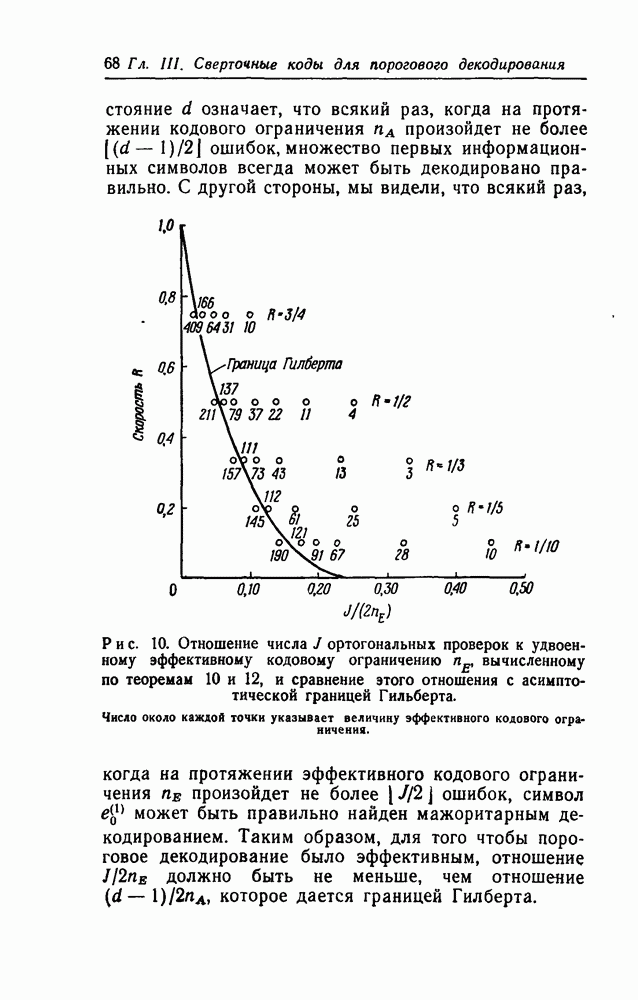









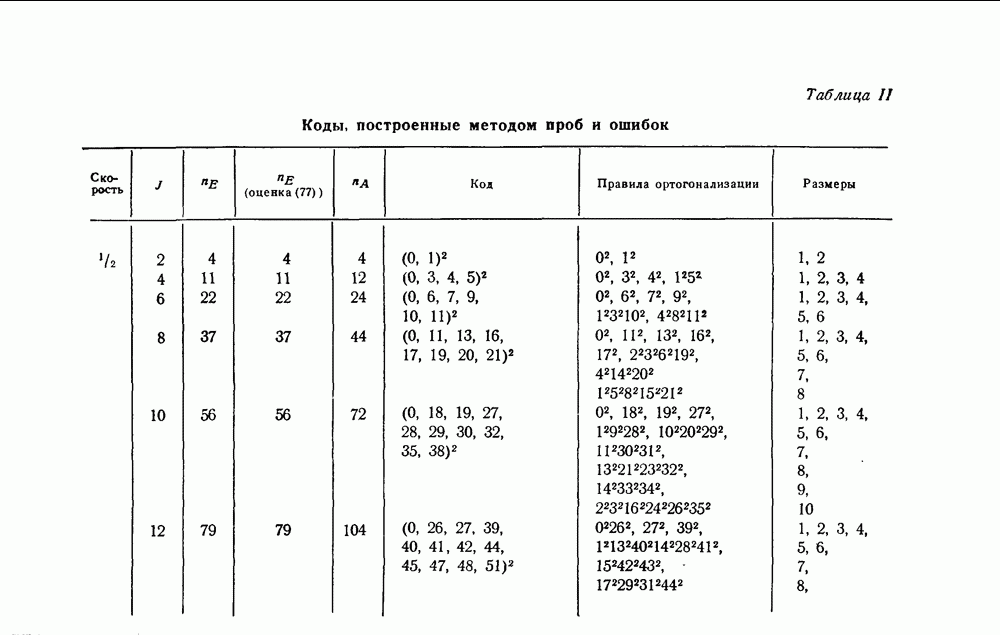
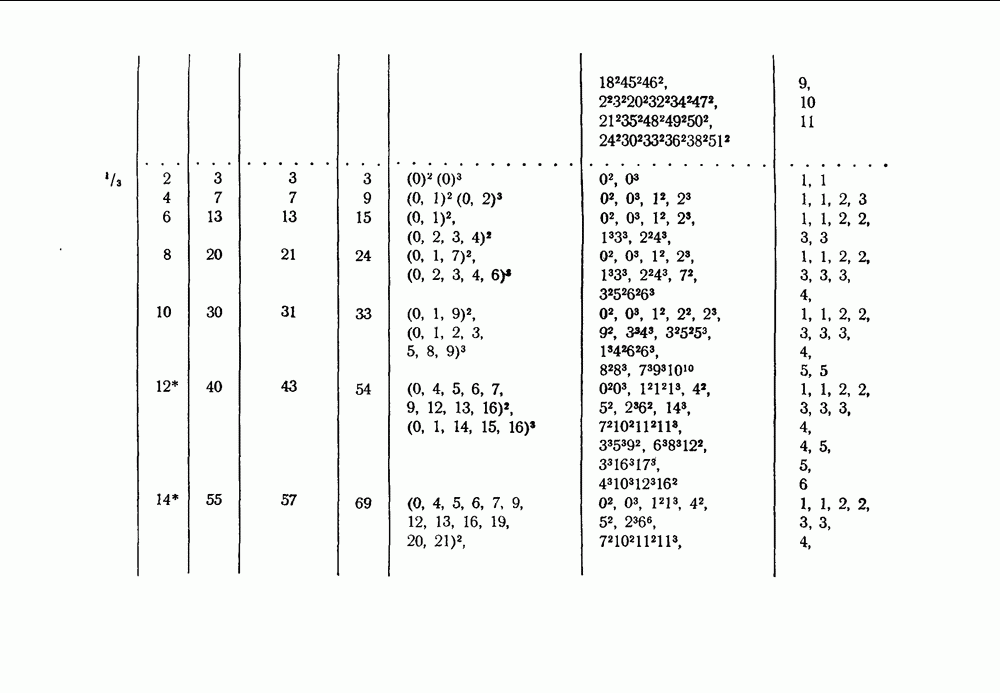
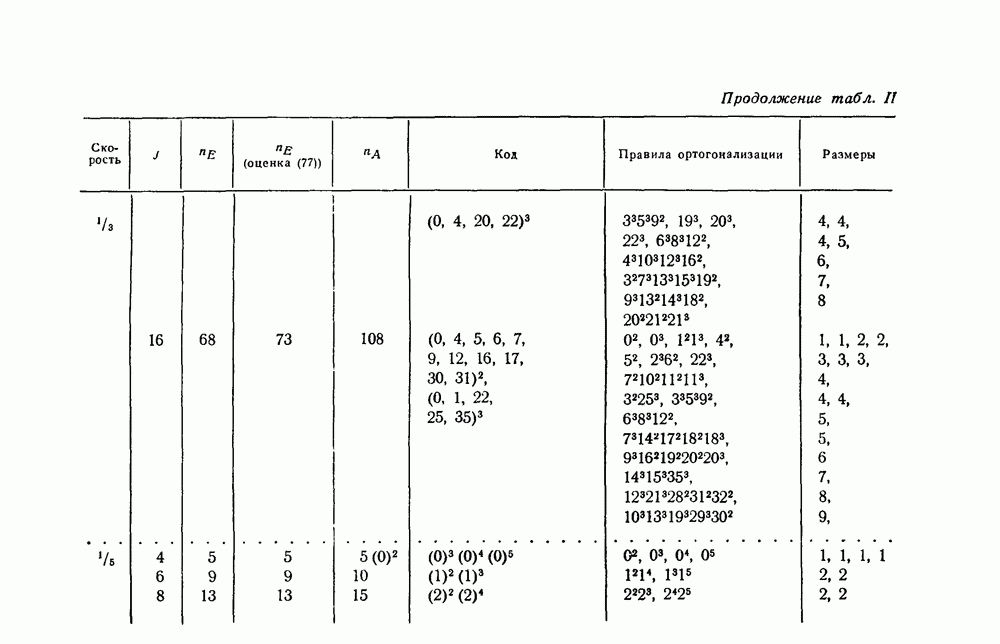
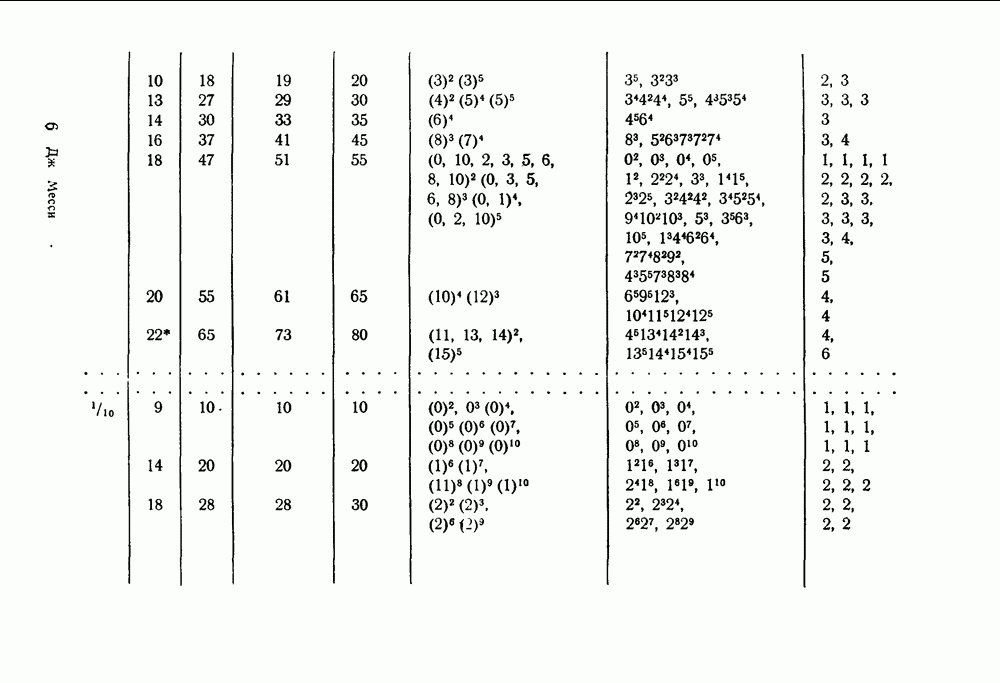
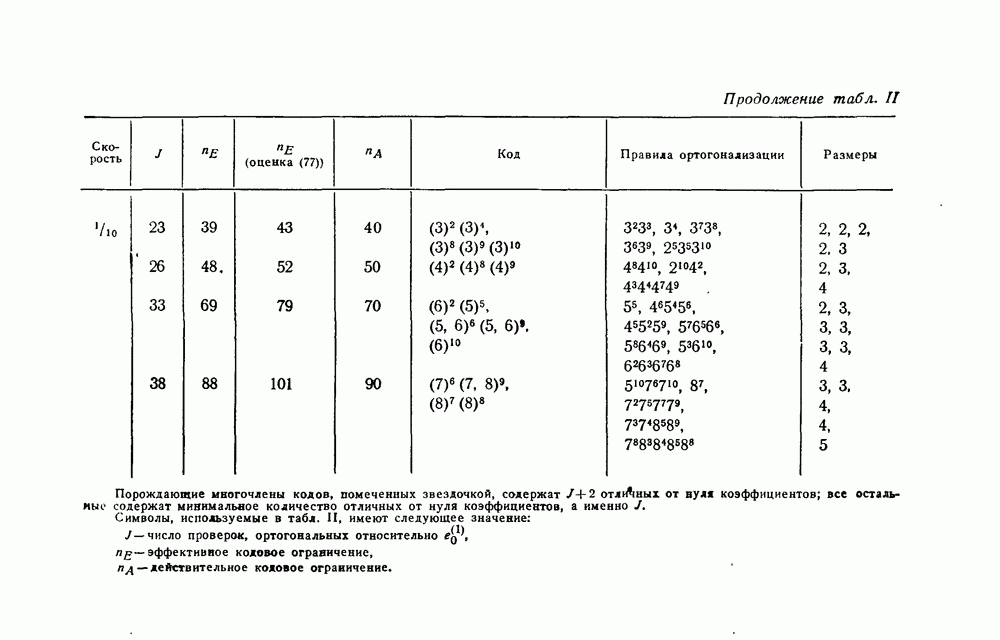











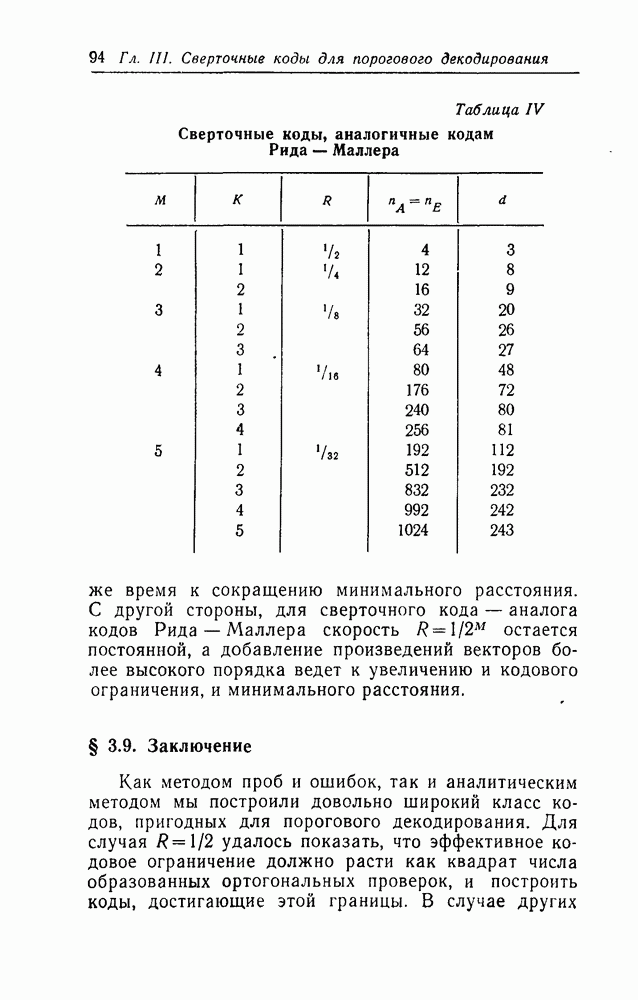





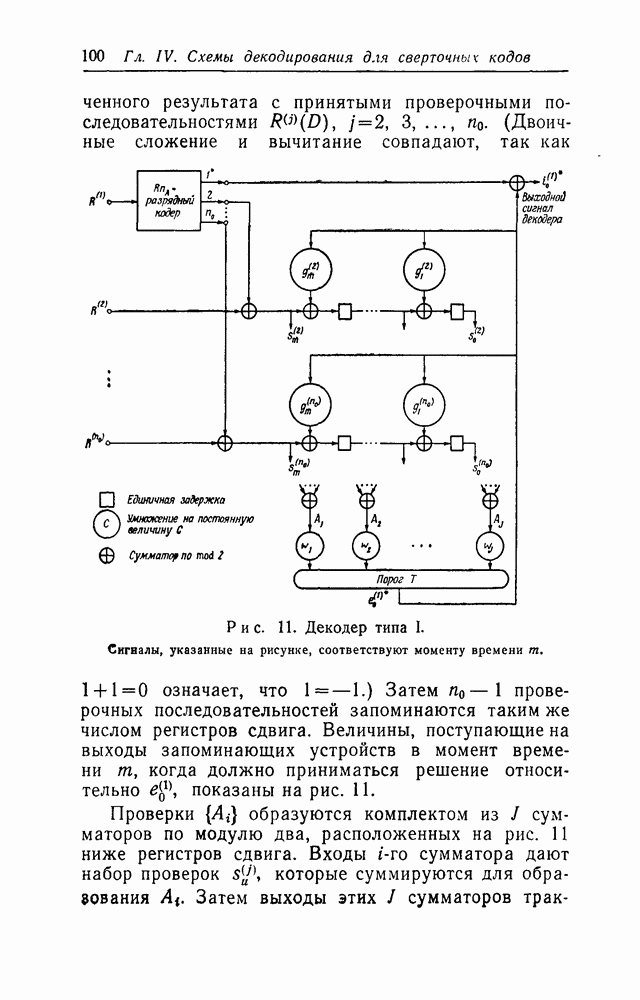


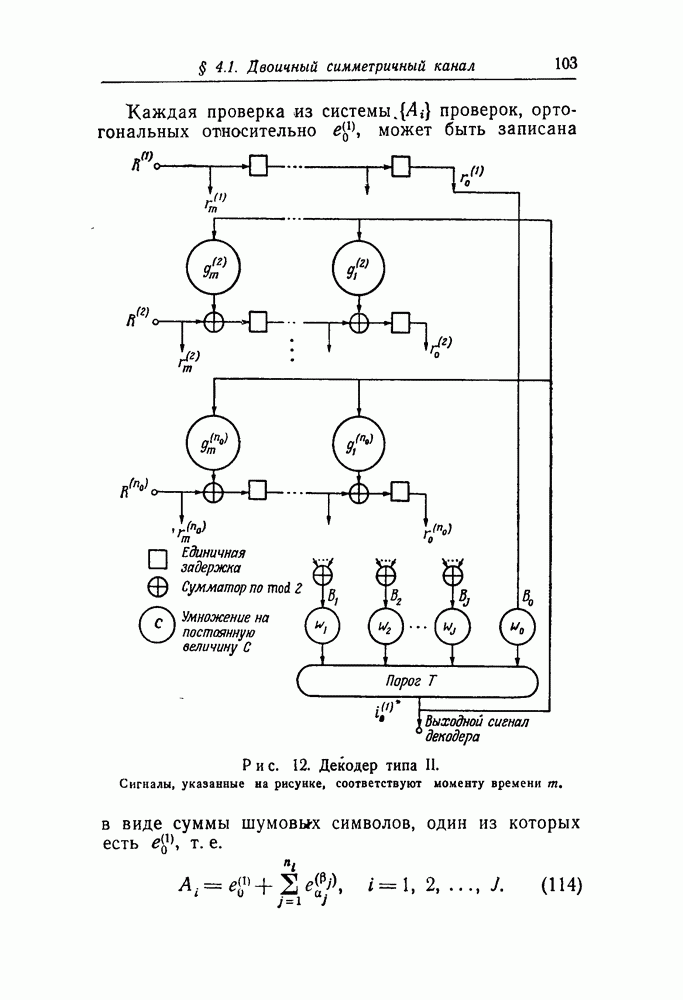






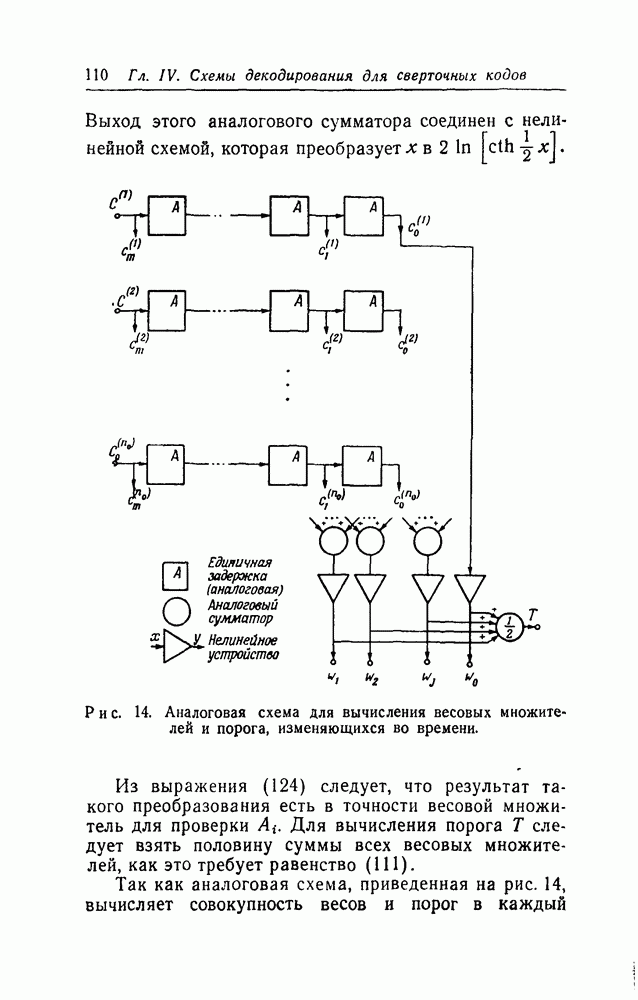
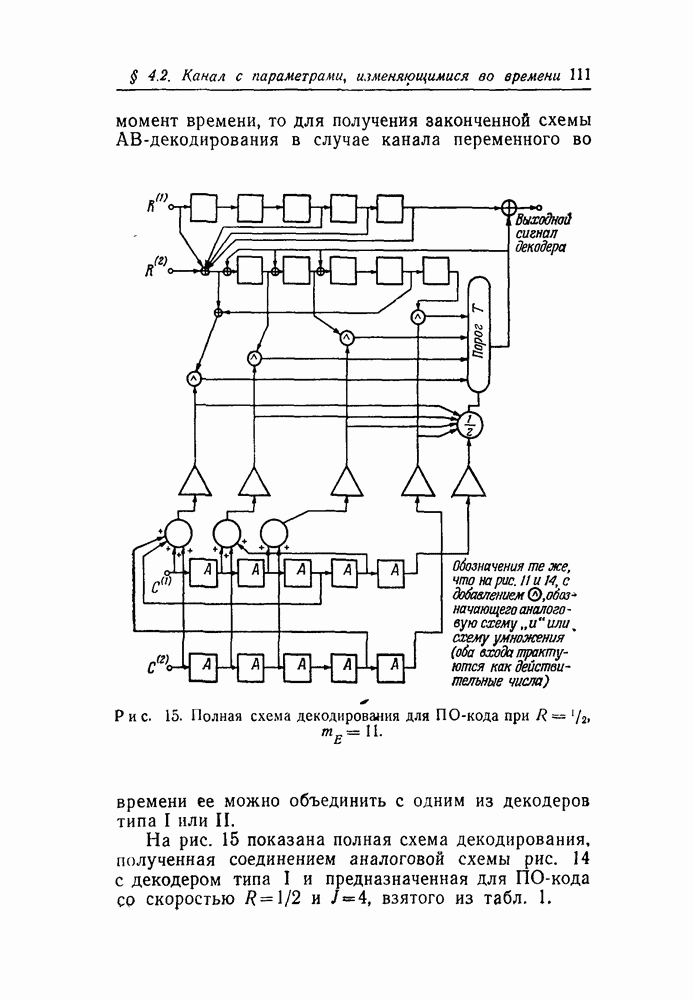











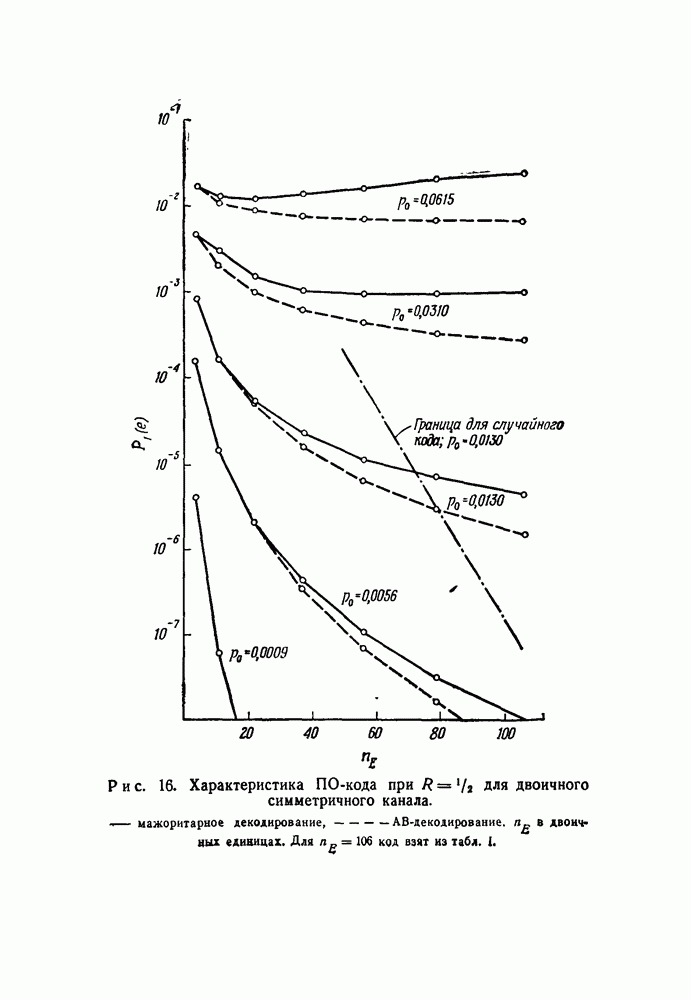
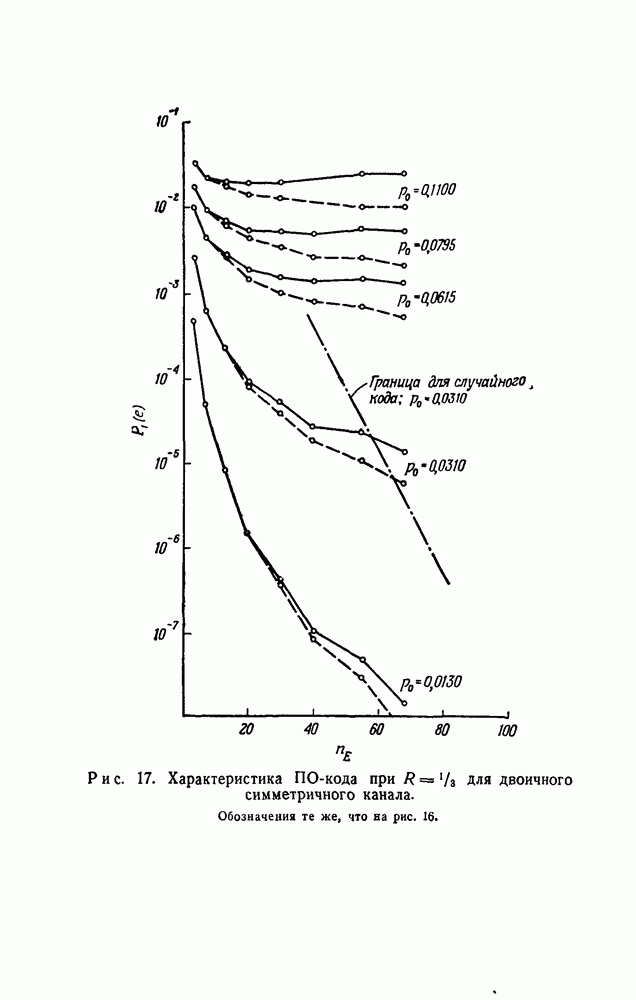
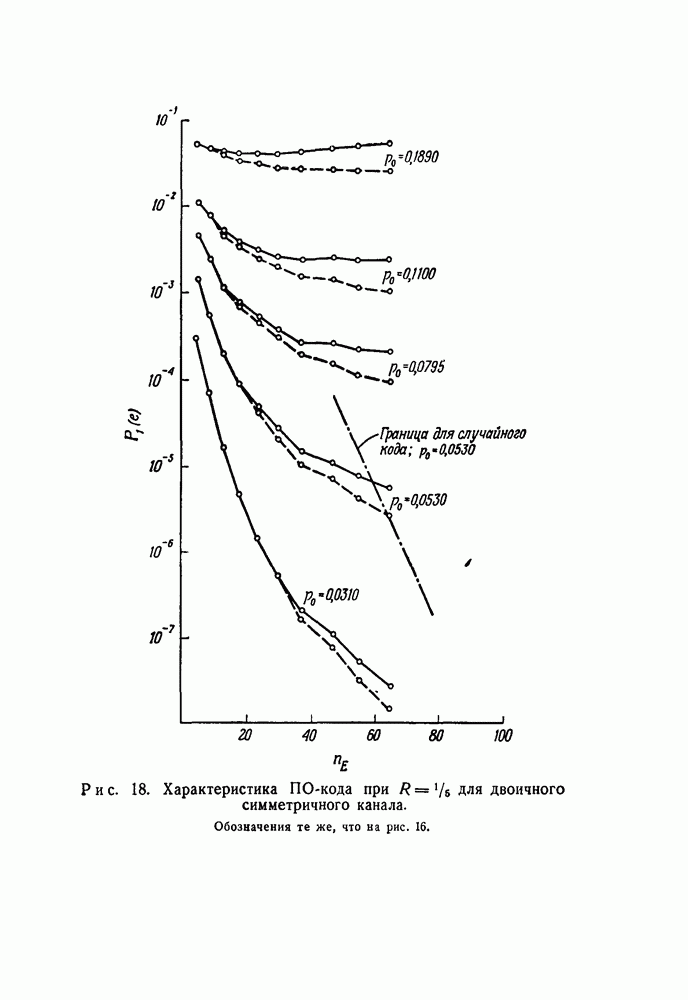
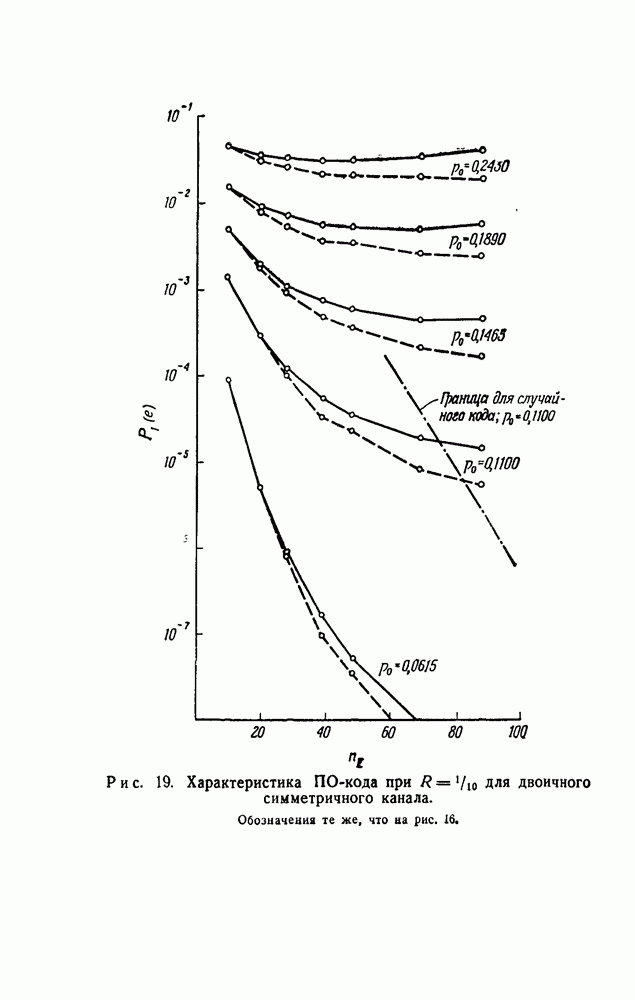


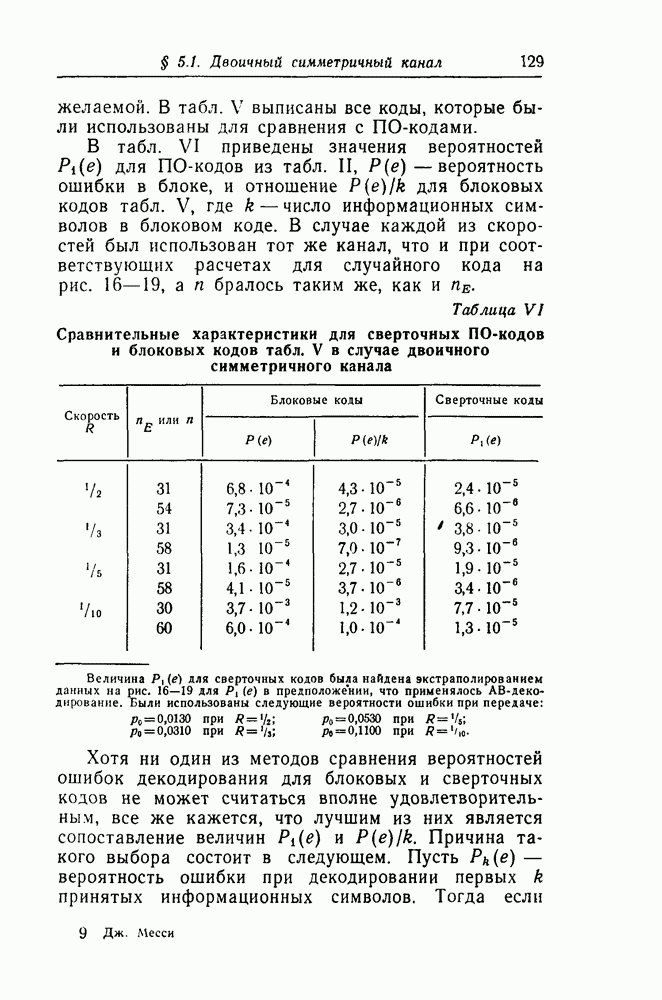


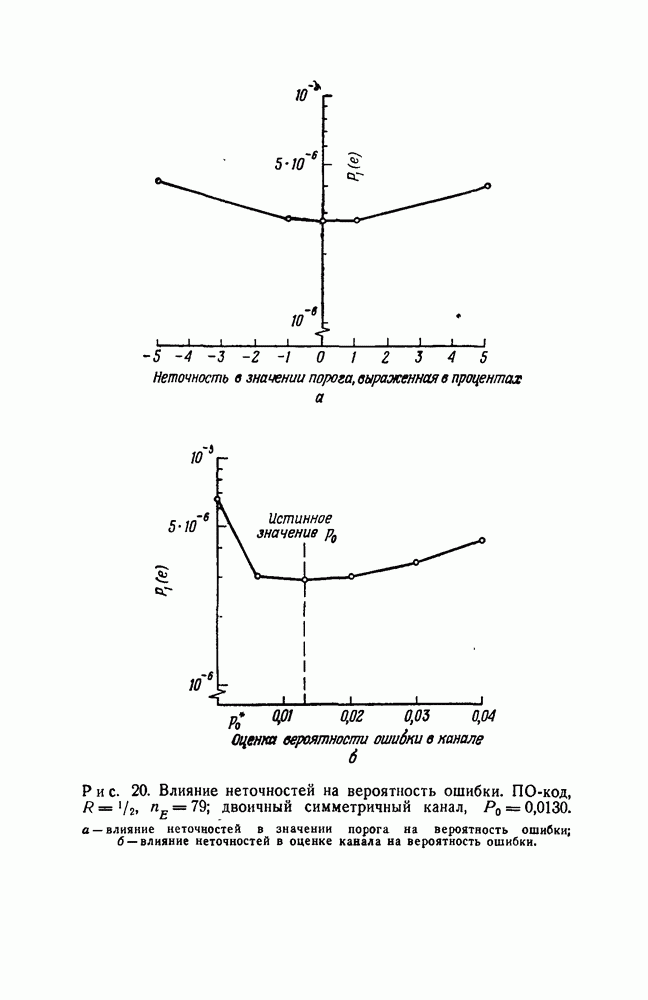



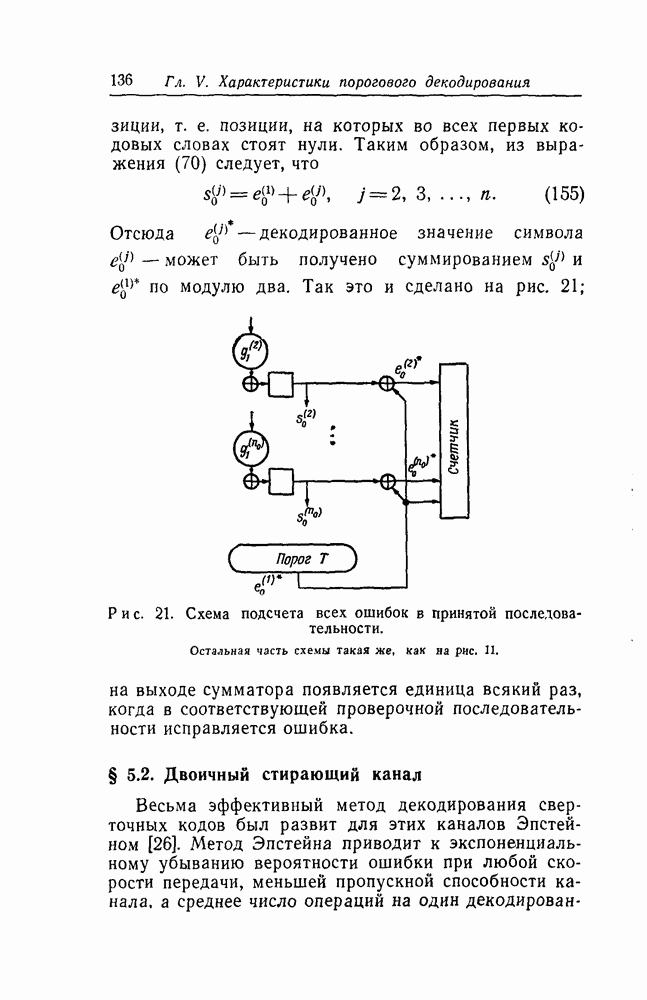



































































 вида
вида

 элемент поля
элемент поля  конечного поля из
конечного поля из  элементов (см. приложение А). Символы
элементов (см. приложение А). Символы  выбираются в качестве информационных символов. Остальные
выбираются в качестве информационных символов. Остальные  символов называются проверочными и находятся по информационным символам из системы линейных уравнений
символов называются проверочными и находятся по информационным символам из системы линейных уравнений 

 являющихся элементами поля
являющихся элементами поля  полностью определяется данным кодом. (Все операции над этими символами, если не сделано специальных оговорок, выполняются в поле
полностью определяется данным кодом. (Все операции над этими символами, если не сделано специальных оговорок, выполняются в поле 
 отличается от переданной
отличается от переданной 


 также принадлежат полю
также принадлежат полю  и все операции выполняются в этом поле. Тогда из (3) следует, что для определения переданной последовательности достаточно знать принятую и шумовую последовательности.
и все операции выполняются в этом поле. Тогда из (3) следует, что для определения переданной последовательности достаточно знать принятую и шумовую последовательности.
 (см. приложение А). Существует
(см. приложение А). Существует  кодовых слов, так как каждый информационный символ может принимать любые из
кодовых слов, так как каждый информационный символ может принимать любые из  значений.
значений.
 два кодовых слова; тогда, согласно (2), их сумма
два кодовых слова; тогда, согласно (2), их сумма
 где
где

 Таким образом, первая групповая аксиома удовлетворена; легко проверить, что удовлетворяются и другие аксиомы.
Таким образом, первая групповая аксиома удовлетворена; легко проверить, что удовлетворяются и другие аксиомы.
 -код.
-код.

 уравнений определяет для кода проверку на четность (всюду ниже — просто проверка), т. е. некоторую взвешенную сумму кодовых символов, которая для всех кодовых слов равна нулю.
уравнений определяет для кода проверку на четность (всюду ниже — просто проверка), т. е. некоторую взвешенную сумму кодовых символов, которая для всех кодовых слов равна нулю.


 составляет систему
составляет систему  линейных уравнений относительно неизвестных
линейных уравнений относительно неизвестных  (символ
(символ  мы будем использовать для обозначения множества объектов
мы будем использовать для обозначения множества объектов  где
где  пробегает все значения,
пробегает все значения,
 Общее решение системы (7) может быть сразу записано в виде
Общее решение системы (7) может быть сразу записано в виде 

 произвольных постоянных, именно значения
произвольных постоянных, именно значения 

 значений; таким образом, существует
значений; таким образом, существует  различных решений системы (7).
различных решений системы (7).
 Эти символы можно рассматривать как некоторую реализацию случайного процесса, параметры которого определяются каналом связи. Например, легко видеть, что двоичный симметричный канал, изображенный на рис. 1, вполне эквивалентен модели на рис. 2, в которой источником шума является источник независимых символов, выдающий 1 с вероятностью
Эти символы можно рассматривать как некоторую реализацию случайного процесса, параметры которого определяются каналом связи. Например, легко видеть, что двоичный симметричный канал, изображенный на рис. 1, вполне эквивалентен модели на рис. 2, в которой источником шума является источник независимых символов, выдающий 1 с вероятностью  с вероятностью
с вероятностью  В этом случае шумовая последовательность длины
В этом случае шумовая последовательность длины  содержащая
содержащая  единиц, встречается с вероятностью
единиц, встречается с вероятностью  последняя является монотонно убывающей функцией от
последняя является монотонно убывающей функцией от  числа ошибок в принятой последовательности длины
числа ошибок в принятой последовательности длины  (предполагается, что
(предполагается, что 
 Эффективное решение проблемы декодирования зависит от возможности нахождения простого метода определения наиболее вероятного решения системы (7) лишь для некоторого высоковероятного подмножества всех возможных сочетаний значений проверок.
Эффективное решение проблемы декодирования зависит от возможности нахождения простого метода определения наиболее вероятного решения системы (7) лишь для некоторого высоковероятного подмножества всех возможных сочетаний значений проверок.