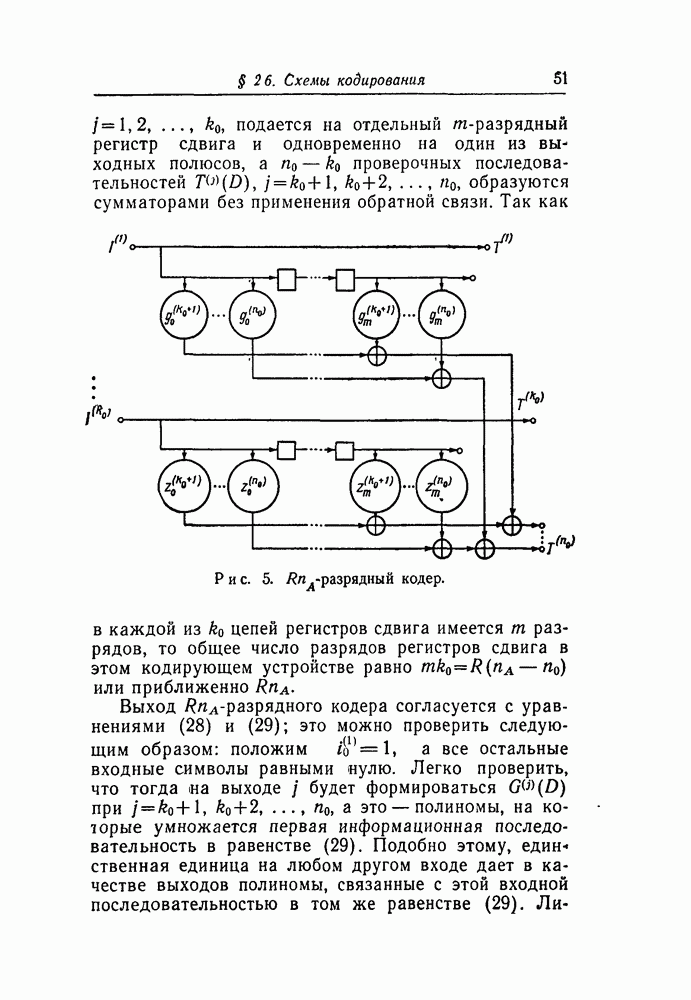
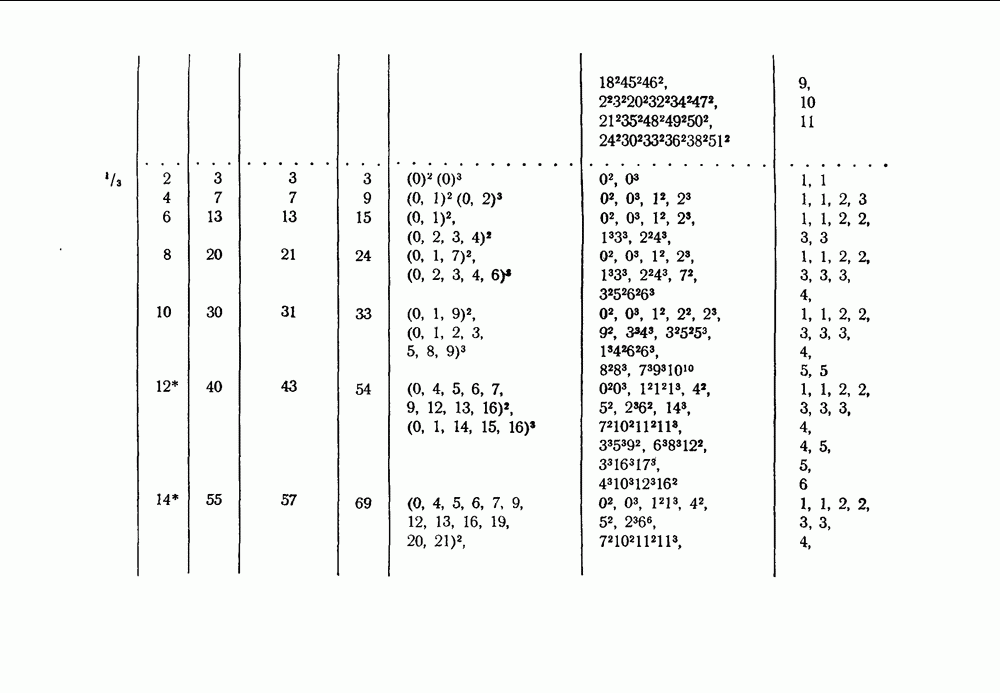
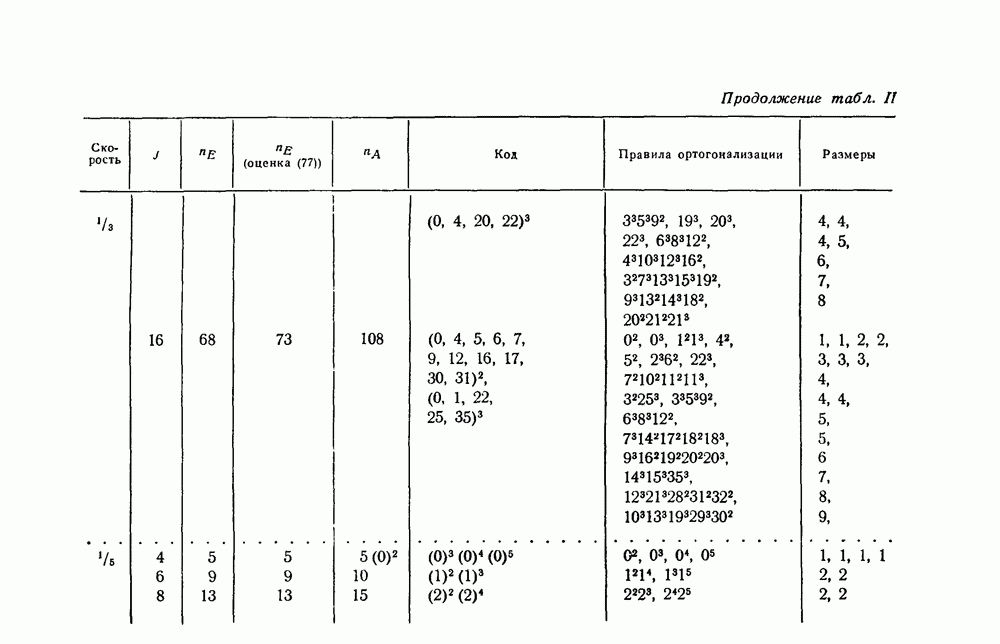
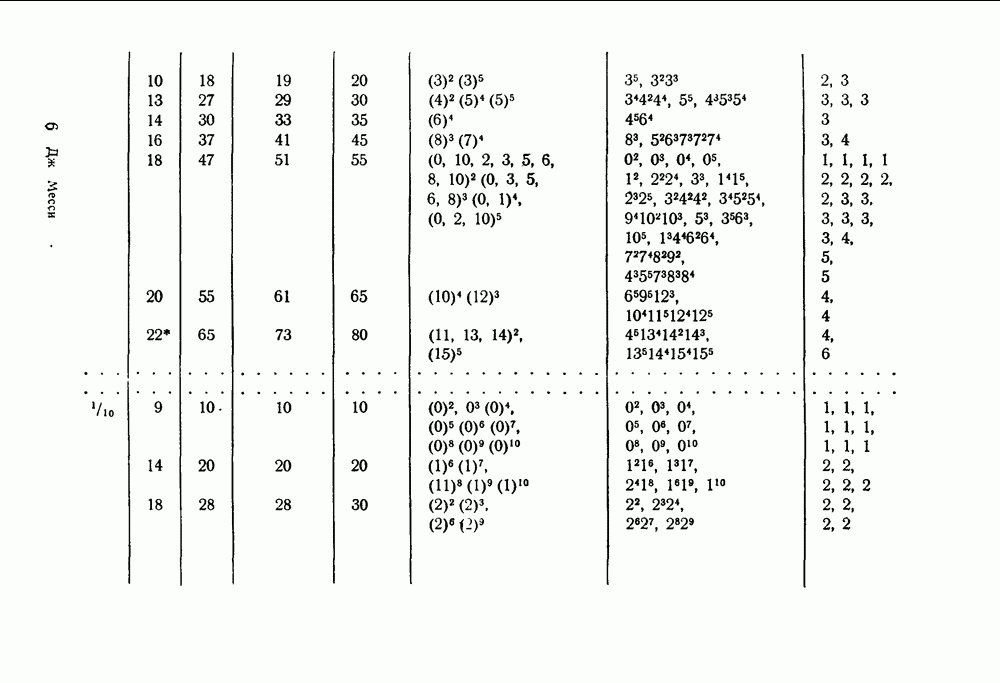
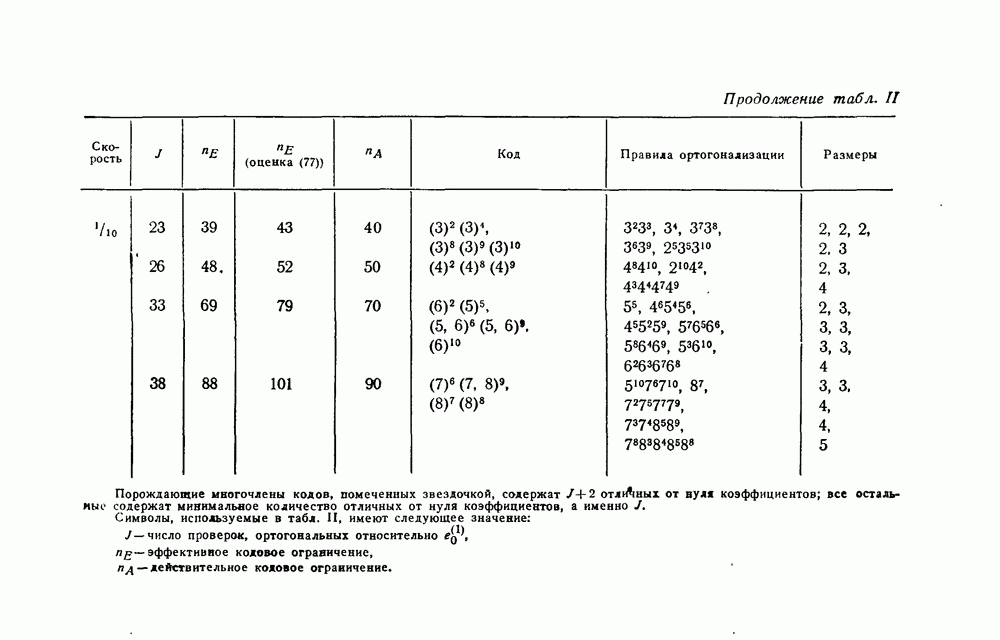
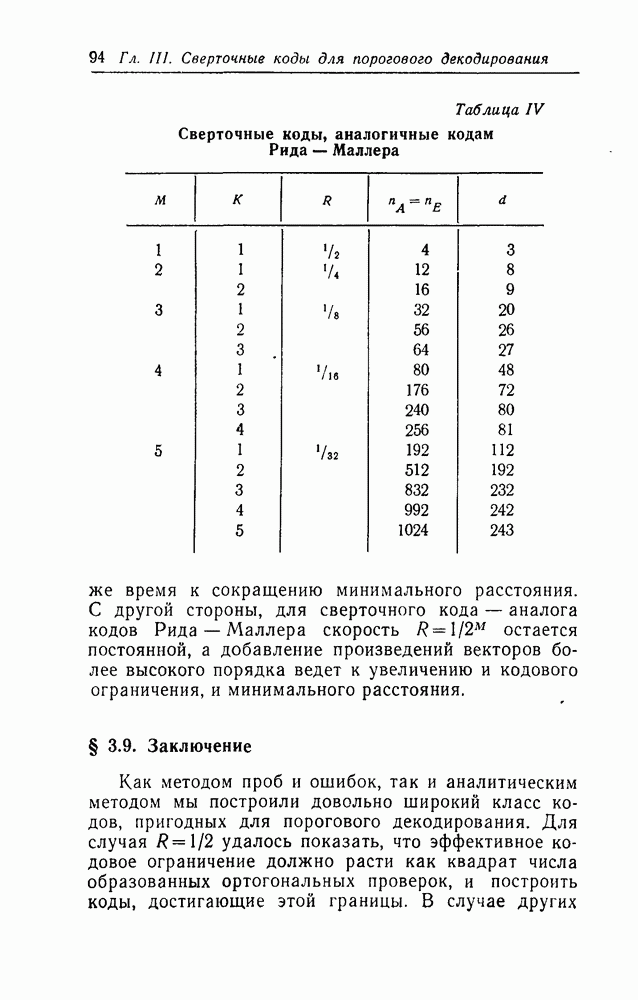
§ 5.1. Двоичный симметричный канал
Большая часть этого параграфа посвящена изучению величины  для двоичного симметричного канала (рис. 1). Особое внимание этому каналу мы уделяем по двум причинам. Во-первых, этот канал наиболее полно изучен связистами-теоретиками и теперь уже знаком всем инженерам-связистам. Во-вторых, естественно предположить, что результаты, получаемые при применении порогового декодирования, для этого канала в основном сохранятся и для более широкого класса двоичных каналов.
для двоичного симметричного канала (рис. 1). Особое внимание этому каналу мы уделяем по двум причинам. Во-первых, этот канал наиболее полно изучен связистами-теоретиками и теперь уже знаком всем инженерам-связистам. Во-вторых, естественно предположить, что результаты, получаемые при применении порогового декодирования, для этого канала в основном сохранятся и для более широкого класса двоичных каналов.
а. Границы вероятности ошибки
Мы хотим показать, что при использовании порогового декодирования величина  не может быть сделана сколь угодно малой. Доказательство будет облегчено использованием логарифма отношения правдоподобия
не может быть сделана сколь угодно малой. Доказательство будет облегчено использованием логарифма отношения правдоподобия  который определяется равенством
который определяется равенством

С помощью равенств (17) и (18) можно записать равенство (128) иначе

Наконец, с помощью формул (21) и (22) можно свести равенство (129) к виду

где  трактуются как действительные числа, а значения весовых множителей
трактуются как действительные числа, а значения весовых множителей  и порога
и порога  определены равенствами (109) и (111).
определены равенствами (109) и (111).
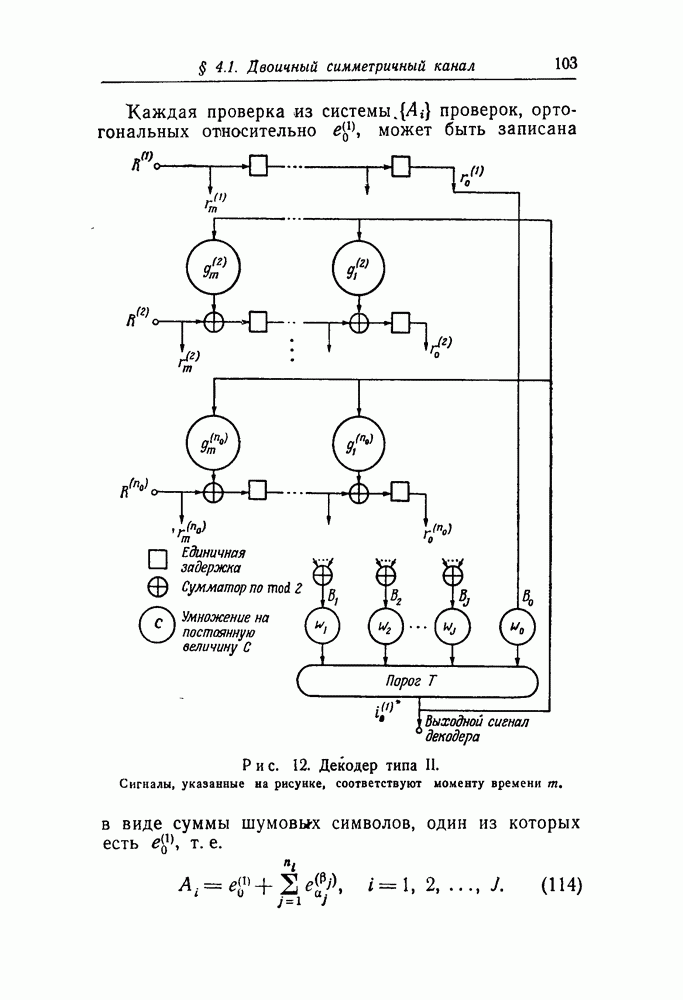
Равенство (130) выражает следующий интересный факт: когда применяется АВ-декодирование, логарифм отношения правдоподобия в точности равен разности между взвешенной суммой результатов ортогональных проверок и порогом.
Логарифм отношения правдоподобия представляет значительный интерес, так как если известно  то вероятность ошибки декодирования
то вероятность ошибки декодирования  символа можно определить из уравнения
символа можно определить из уравнения

Уравнение (131) непосредственно следует из уравнения (128), если заметить, что при 

тогда как при 

Теперь мы в состоянии доказать, что если построенный нами код удовлетворяет следствию из теоремы 10, то при применении порогового декодирования вероятность ошибки не может быть сделана произвольно малой.
Теорема 16. Пусть для двоичного сверточного кода со скоростью  образована система
образована система  проверок
проверок  ортогональных
ортогональных
относительно  Положим, что для любого
Положим, что для любого  найдется
найдется  проверок, для которых
проверок, для которых  Тогда, если код применяется в двоичном симметричном? канале с вероятностью перехода
Тогда, если код применяется в двоичном симметричном? канале с вероятностью перехода  то каково бы ни было
то каково бы ни было  величина
величина  полученная при пороговом декодировании, удовлетворяет неравенству
полученная при пороговом декодировании, удовлетворяет неравенству

Доказательство. При пороговом декодировании величина  минимальна, если используется АВ-декодирование. Кроме того,
минимальна, если используется АВ-декодирование. Кроме того,  монотонно убывает вместе с возрастанием
монотонно убывает вместе с возрастанием  так как при этом АВ-декодирование полнее использует информацию, заключенную в системе
так как при этом АВ-декодирование полнее использует информацию, заключенную в системе  и для более длинных кодов, построенных в соответствии с условием теоремы, система
и для более длинных кодов, построенных в соответствии с условием теоремы, система  всегда включает в качестве подсистемы систему
всегда включает в качестве подсистемы систему  каждого более короткого кода. Поэтому нам достаточно показать, что при АВ-деко-дировании величина
каждого более короткого кода. Поэтому нам достаточно показать, что при АВ-деко-дировании величина  удовлетворяет неравенству (132), если
удовлетворяет неравенству (132), если  Начнем с доказательства того, что
Начнем с доказательства того, что  ограничен.
ограничен.
Используя выражение (111), можно переписать равенство (130) в виде

откуда следует, что  получается, когда все
получается, когда все  -равны нулю, т. е. когда все ортогональные проверки удовлетворены. Таким образом,
-равны нулю, т. е. когда все ортогональные проверки удовлетворены. Таким образом,

Подставляя выражение (112) в (134) ), получаем

Пользуясь разложением в ряд логарифма

можем записать равенство (135) в виде

Так как ряд в скобках сходится абсолютно, для каждого члена ряда суммирование по I можно выполнить отдельно, используя формулу для суммы геометрической прогрессии

Ограничив сверху ряд справа, получим

В ряде справа мы узнаем разложение выражения

Поэтому соотношение (139) принимает вид

Из уравнения (131) следует, что величина  минимальна, когда
минимальна, когда  максимален, и что эта вероятность больше, чем
максимален, и что эта вероятность больше, чем  Учитывая неравенство (141), находим, что
Учитывая неравенство (141), находим, что  должно удовлетворять неравенству
должно удовлетворять неравенству

Но так как  - среднее значение вероятности
- среднее значение вероятности  по всем
по всем  то
то  должна быть, конечно, больше, чем минимальное значение
должна быть, конечно, больше, чем минимальное значение  и поэтому больше, чем правая часть неравенства (142), что и требуется доказать.
и поэтому больше, чем правая часть неравенства (142), что и требуется доказать.
Из теоремы 16 следует, что, пользуясь пороговым декодированием в случае кодов, удовлетворяющих следствию теоремы 10, величину  нельзя сделать сколь угодно малой. Согласно теореме 12, этот класс кодов является наилучшим из всех, которые могут быть построены для порогового декодирования при
нельзя сделать сколь угодно малой. Согласно теореме 12, этот класс кодов является наилучшим из всех, которые могут быть построены для порогового декодирования при  Таким образом, при пороговом декодировании в случае
Таким образом, при пороговом декодировании в случае  величину
величину  невозможно сделать произвольно малой. Можно предположить, что это верно и при других скоростях, однако мы не в состоянии этого доказать.
невозможно сделать произвольно малой. Можно предположить, что это верно и при других скоростях, однако мы не в состоянии этого доказать.
В действительности мы доказали больше, чем утверждается в теореме 16. Неравенство (142) показывает, что для класса кодов, рассмотренного в теореме 16, не существует алгоритма декодирования, который позволил бы сделать вероятность ошибки меньше правой части неравенств (142) или (132). Даже в самом благоприятном случае (когда удовлетворены все ортогональные проверки) вероятность ошибки при декодировании превосходит границу в правой части неравенства (132). По этой причине неравенство (132) не может считаться хорошей нижней границей величины  оно дает хорошую границу минимального значения величины
оно дает хорошую границу минимального значения величины 
б. Данные о ПО-кодах
Установив, что в общем случае при пороговом декодировании вероятность ошибки не может быть сделана сколь угодно малой, обратимся к вычислению  в частных случаях. Для этой цели выберем ПО-коды из табл. III. Эти коды обладают тем свойством, что значения
в частных случаях. Для этой цели выберем ПО-коды из табл. III. Эти коды обладают тем свойством, что значения  и
и  почти равны и что
почти равны и что  никогда не превышает границы, указанной в теореме 10.
никогда не превышает границы, указанной в теореме 10.
Прежде чем выражать  в форме, наиболее подходящей для двоичного симметричного канала, дадим общее выражение, которое годится для любого двоичного канала, независимо от того, изменяется он во времени или нет. Положим, как обычно,
в форме, наиболее подходящей для двоичного симметричного канала, дадим общее выражение, которое годится для любого двоичного канала, независимо от того, изменяется он во времени или нет. Положим, как обычно,  . В случае канала, параметры которого изменяются во времени,
. В случае канала, параметры которого изменяются во времени,  случайная величина. Общим выражением для
случайная величина. Общим выражением для  будет
будет

где черта указывает на усреднение по всем значениям весовых множителей, 
Равенство (143) выражает тот очевидный факт, что ошибка произошла тогда, когда встречается одно из двух несовместимых событий: или порог превзойден, когда  Не превзойден, когда
Не превзойден, когда  Но так как система
Но так как система  проверок, в которых
проверок, в которых  дополняет систему
дополняет систему  проверок, в
проверок, в
где  множество
множество  статистически независимых случайных величин, для которых
статистически независимых случайных величин, для которых 
Определение величины  из равенства (147) сводится к классической задаче вычисления вероятности того, что сумма статистически независимых случайных величин превосходит некоторую фиксированную величину. Однако мы не в состоянии получить для
из равенства (147) сводится к классической задаче вычисления вероятности того, что сумма статистически независимых случайных величин превосходит некоторую фиксированную величину. Однако мы не в состоянии получить для  точного выражения или даже хорошей нижней оценки по следующим причинам. Так как, согласно выражению (112), для двоичного симметричного канала
точного выражения или даже хорошей нижней оценки по следующим причинам. Так как, согласно выражению (112), для двоичного симметричного канала

то в общем случае величины  не являются равномерно распределенными. Более того, так как
не являются равномерно распределенными. Более того, так как  растет в прямой зависимости от
растет в прямой зависимости от  (по крайней мере для кодов, удовлетворяющих следствию из теоремы 10), при увеличении
(по крайней мере для кодов, удовлетворяющих следствию из теоремы 10), при увеличении  вероятность стремится к
вероятность стремится к  ; это означает, что при АВ-декодировании весовые множители стремятся к нулю. Для больших
; это означает, что при АВ-декодировании весовые множители стремятся к нулю. Для больших  распределение суммы величин
распределение суммы величин  определяется почти полностью несколькими первыми значениями
определяется почти полностью несколькими первыми значениями  при малых значениях По этим причинам для обработки сумм независимых случайных величин не могут быть применены обычные приемы, такие, как граница Чернова или центральная предельная теорема.
при малых значениях По этим причинам для обработки сумм независимых случайных величин не могут быть применены обычные приемы, такие, как граница Чернова или центральная предельная теорема.
Численное решение уравнения (147) облегчается использованием производящей функции, упомянутой в § 4.1. В случае двоичного симметричного канала производящая функция  для
для  такова:
такова:

Так как величины  статистически независимы, производящая функция
статистически независимы, производящая функция  их суммы равна произведению функций
их суммы равна произведению функций  или
или

Тогда, так как каждый коэффициент в производящей функции есть вероятность того, что случайная величина равна показателю при  в этом члене, равенство (147) можно написать так:
в этом члене, равенство (147) можно написать так:

Равенство (151) было использовано в качестве основы при определении величины  для ПО-кодов табл. III на вычислительной машине. Так как при мажоритарном декодировании
для ПО-кодов табл. III на вычислительной машине. Так как при мажоритарном декодировании  для всех
для всех  то
то  в равенстве (150) представляет собой обычный полином с
в равенстве (150) представляет собой обычный полином с  членами. В этом случае очень легко вычислить величину
членами. В этом случае очень легко вычислить величину  При АВ-декодировании все
При АВ-декодировании все  могут быть различными и тогда полином
могут быть различными и тогда полином  содержит
содержит  членов, и применение вычислительной машины становится необходимым даже в простейших случаях.
членов, и применение вычислительной машины становится необходимым даже в простейших случаях.
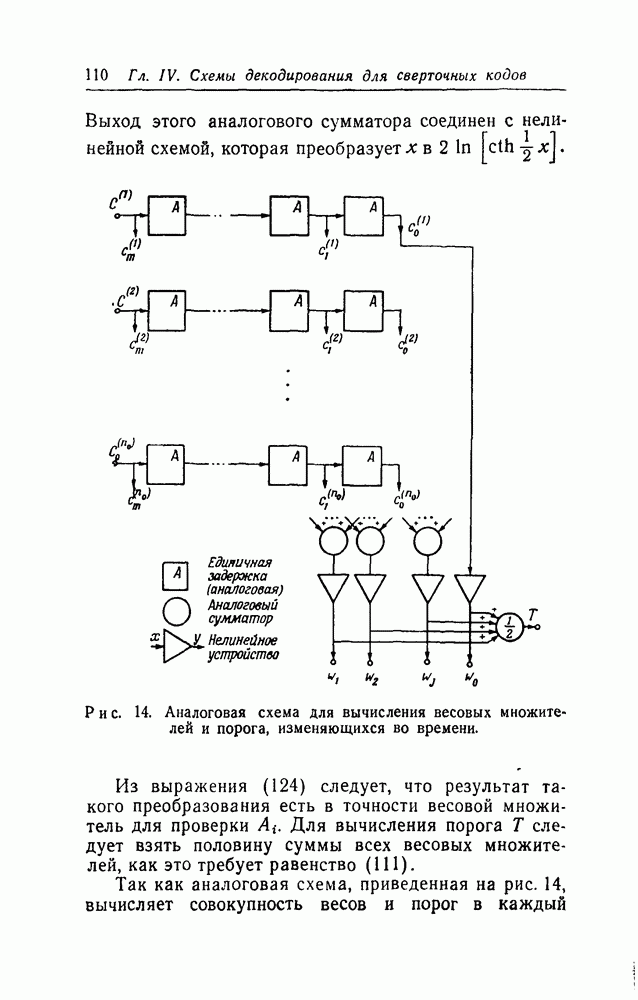
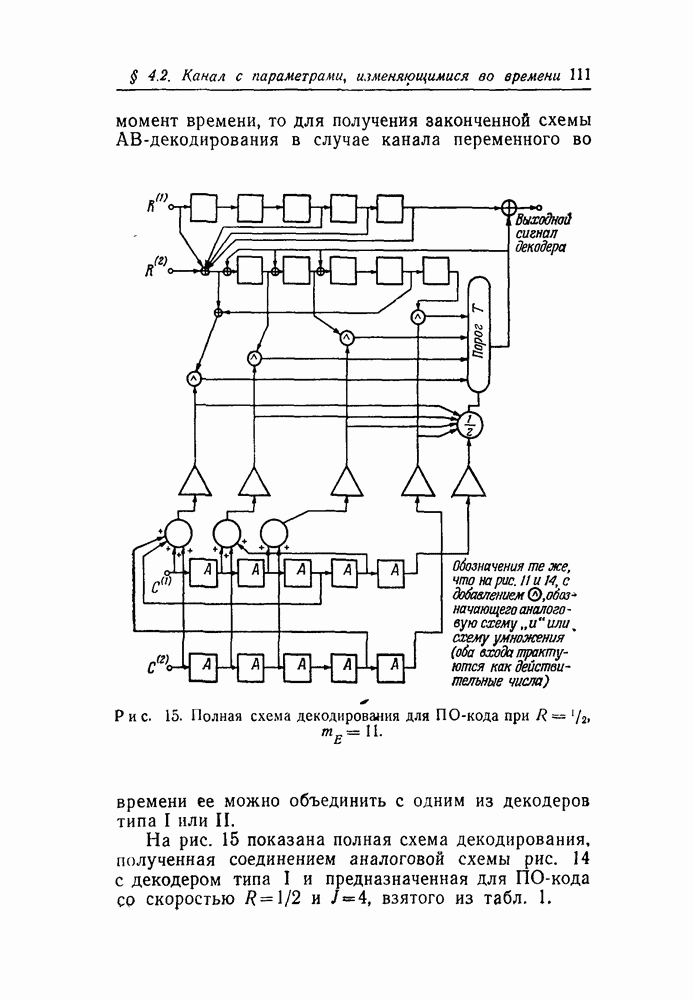
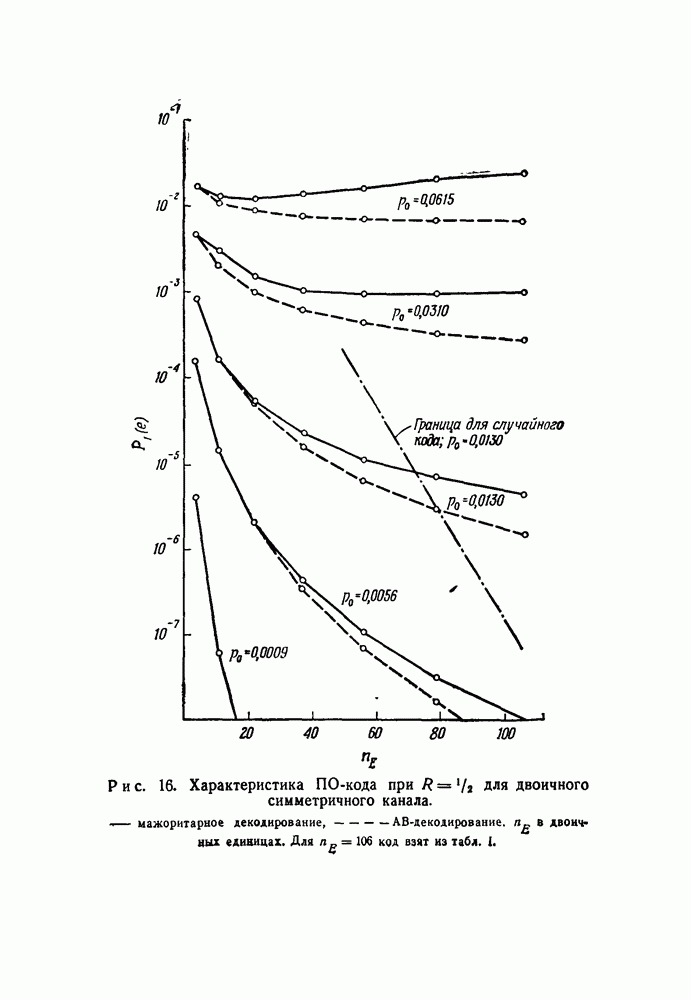
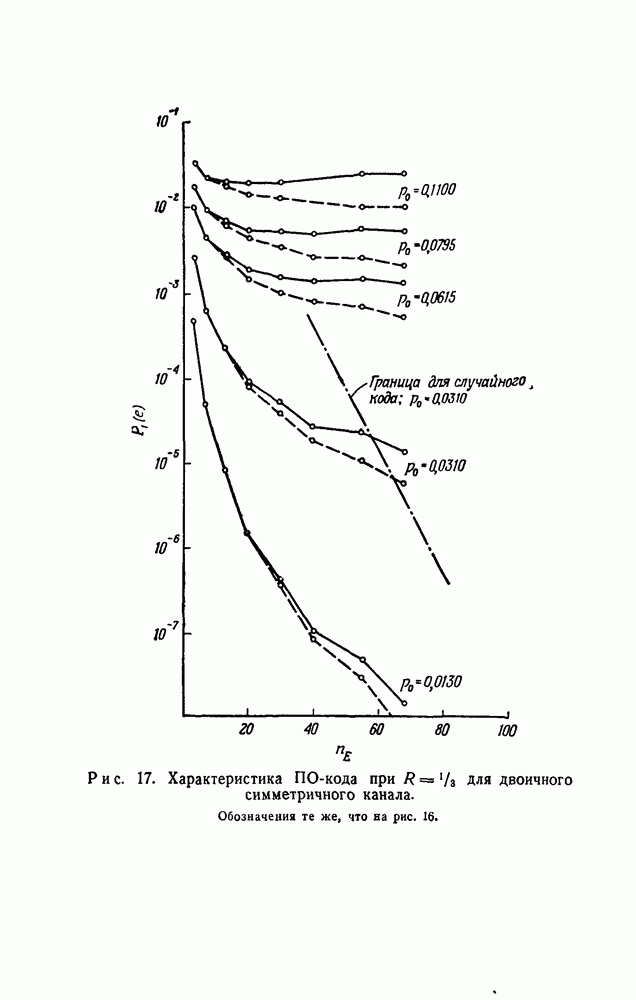
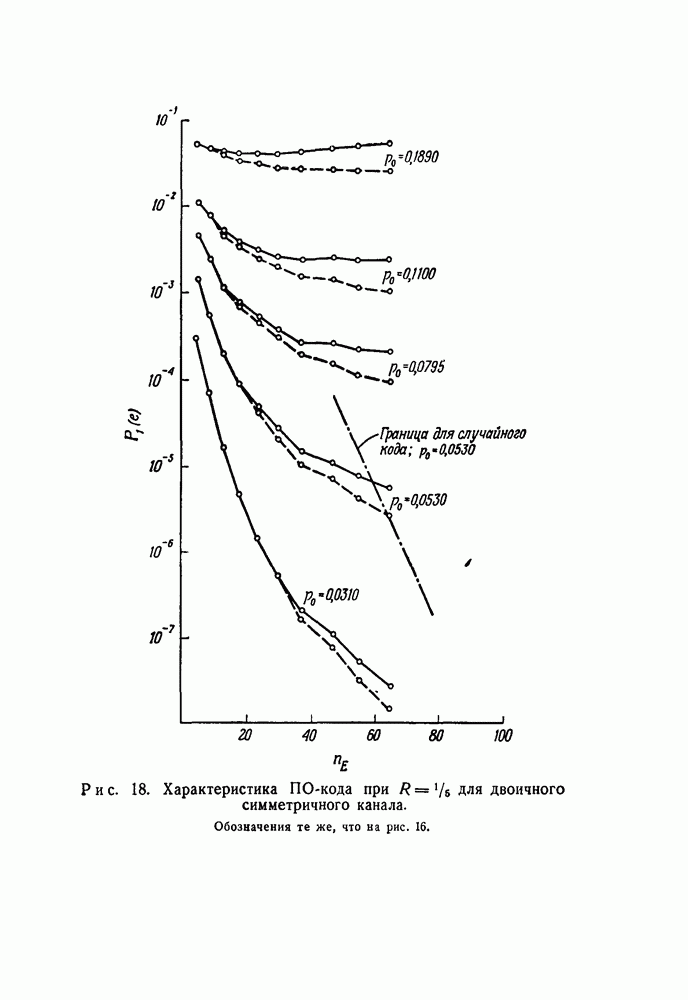
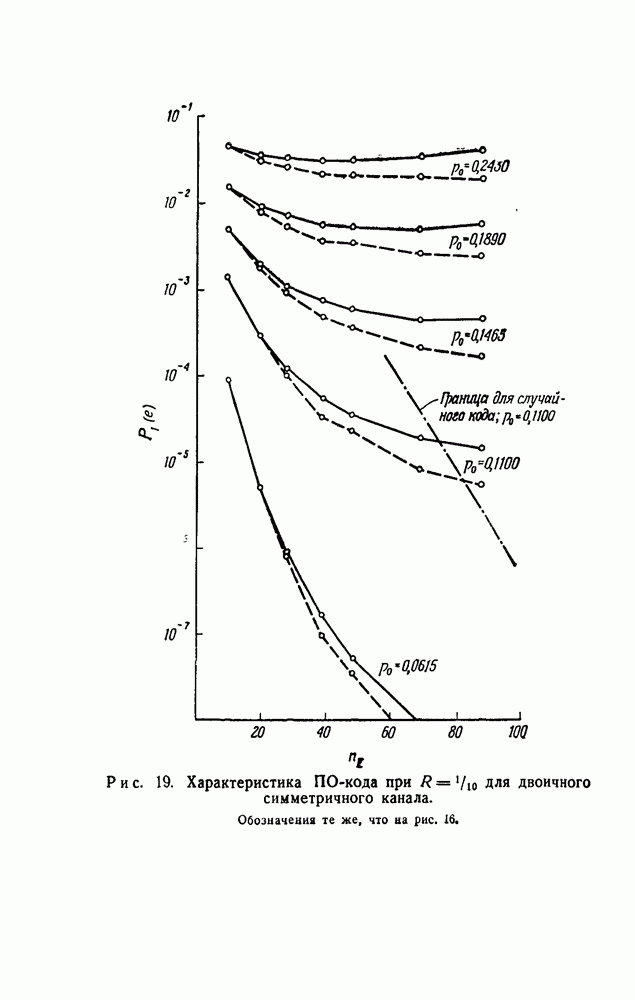
На рис. 16—19 показаны значения  в зависимости от
в зависимости от  для ПО-кодов со скоростями
для ПО-кодов со скоростями  соответственно. (Все эти данные были получены вычислением на машине
соответственно. (Все эти данные были получены вычислением на машине  вычислительного центра Массачусетского технологического института; на получение каждого графика требовалось приблизительно три минуты машинного времени.) Для каждого значения скорости было использовано пять различных каналов, и они были выбраны так, чтобы обеспечить широкий диапазон величин
вычислительного центра Массачусетского технологического института; на получение каждого графика требовалось приблизительно три минуты машинного времени.) Для каждого значения скорости было использовано пять различных каналов, и они были выбраны так, чтобы обеспечить широкий диапазон величин 
Несколько особенностей графиков, показанных на рис. 16—19, ясны сразу. Во-первых,  не убывает экспоненциально при увеличении
не убывает экспоненциально при увеличении  ни для мажоритарного, ни для АВ-декодирования. При АВ-декодировании
ни для мажоритарного, ни для АВ-декодирования. При АВ-декодировании  монотонно убывает с ростом
монотонно убывает с ростом  по
по

(кликните для просмотра скана)

(кликните для просмотра скана)

(кликните для просмотра скана)

(кликните для просмотра скана)
причине, которая была установлена в начале доказательства теоремы 16. Однако при мажоритарном декодировании в случае каналов с большим  при некоторых значениях
при некоторых значениях  величина
величина  имеет минимум и после него возрастает. Причина этого состоит в том, что для проверок с большим
имеет минимум и после него возрастает. Причина этого состоит в том, что для проверок с большим  в достаточно длинных кодах
в достаточно длинных кодах  близко к 1/2, но эти «плохие» проверки имеют такой же вес в принятии решения относительно
близко к 1/2, но эти «плохие» проверки имеют такой же вес в принятии решения относительно  как и «хорошие» проверки с малыми
как и «хорошие» проверки с малыми  . В конечном счете при любом значении
. В конечном счете при любом значении  вероятность
вероятность  для мажоритарного декодирования будет стремиться к 1/2, когда величина
для мажоритарного декодирования будет стремиться к 1/2, когда величина  бесконечно возрастает.
бесконечно возрастает.
Для первой оценки качества ПО-кодов при использовании порогового декодирования для одного канала «а каждом из рис. 16—19 нанесена верхняя граница величины  в том виде, как это дается границей
в том виде, как это дается границей  в приложении
в приложении  для случайного кода. (В каждом случае скорость передачи несколько меньше, чем
для случайного кода. (В каждом случае скорость передачи несколько меньше, чем  для выбранного канала.) При нанесении границы для случайного кода была использована величина
для выбранного канала.) При нанесении границы для случайного кода была использована величина  а не
а не  Это делалось потому, что
Это делалось потому, что  есть число символов, по которым, в случае порогового декодирования принимается решение относительно
есть число символов, по которым, в случае порогового декодирования принимается решение относительно  в то время как все
в то время как все  символов используются при декодировании по максимуму правдоподобия, как предполагается при выводе величины
символов используются при декодировании по максимуму правдоподобия, как предполагается при выводе величины  для случайного кода.
для случайного кода.
Во всех четырех случаях вероятность  для ПО-кодов достигает границы
для ПО-кодов достигает границы  для случайного кода при
для случайного кода при  Если используются более длинные ПО-коды, то получаемая при декодировании по максимуму правдоподобия вероятность ошибки превышает эту верхнюю границу для средней по ансамблю сверточных кодов вероятности ошибки.
Если используются более длинные ПО-коды, то получаемая при декодировании по максимуму правдоподобия вероятность ошибки превышает эту верхнюю границу для средней по ансамблю сверточных кодов вероятности ошибки.
Поскольку рассмотрение практического осуществления, проведенное в п. 1.1 а, показывает невыполнимость декодирования по максимуму правдоподобия в общем случае, более реалистичным критерием для оценки характеристики ПО-кодов является
вероятность ошибки, которой можно достичь при использовании других методов кодирования и декодирования. Для сравнения в случае скоростей  7з и 7з выбраны подходящие коды Боуза — Чоудхури [2], при декодировании которых для исправления любой комбинации ошибок веса не более
7з и 7з выбраны подходящие коды Боуза — Чоудхури [2], при декодировании которых для исправления любой комбинации ошибок веса не более  может быть использован алгоритм Питерсона [12, стр. 197-202] (d - минимальное расстояние). В случае скорости
может быть использован алгоритм Питерсона [12, стр. 197-202] (d - минимальное расстояние). В случае скорости  мы предположили существование блоковых кодов, для которых
мы предположили существование блоковых кодов, для которых  равно среднему весу ненулевого кодового слова. При вычислении вероятности
равно среднему весу ненулевого кодового слова. При вычислении вероятности  ошибки в блоке мы предполагали, что любая комбинация ошибок может быть исправлена тогда и только тогда, когда ее вес не превосходит
ошибки в блоке мы предполагали, что любая комбинация ошибок может быть исправлена тогда и только тогда, когда ее вес не превосходит  Наконец, так как при
Наконец, так как при  не существует кодов Боуза — Чоудхури с требуемыми скоростями, пришлось воспользоваться укороченными кодами: если скорость несколько превосходила заданную, то отбрасывалось столько информационных символов, что скорость укороченного таким образом кода уже не превосходила
не существует кодов Боуза — Чоудхури с требуемыми скоростями, пришлось воспользоваться укороченными кодами: если скорость несколько превосходила заданную, то отбрасывалось столько информационных символов, что скорость укороченного таким образом кода уже не превосходила
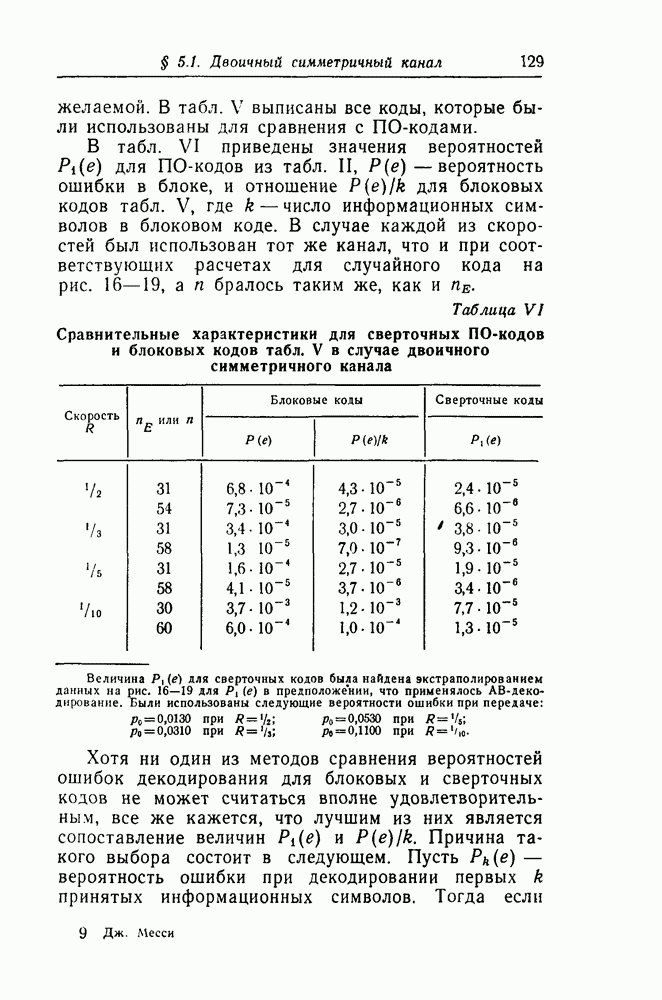
Таблица V (см. скан) Блоковые коды, использованные для сравнения с ПО-кодами
 то среднее число правильно декодированных (до первой ошибки) информационных символов приблизительно одинаково и для блокового, и для сверточного кодов. С другой стороны, величина
то среднее число правильно декодированных (до первой ошибки) информационных символов приблизительно одинаково и для блокового, и для сверточного кодов. С другой стороны, величина  заведомо подчинена неравенству
заведомо подчинена неравенству

в котором вероятность совместного наступления событий ограничена сверху суммой вероятностей каждого события. Таким образом, для сравнения блокового и сверточного декодирования сопоставление величин  или (что то же самое) величин
или (что то же самое) величин  представляется вполне разумным.
представляется вполне разумным.
Из таблицы VI видно, что результаты порогового декодирования для ПО-кодов выгодно отличаются от результатов декодирования блоковых кодов, используемых для сравнения. В случае высоких скоростей разница невелика. Заметное превосходство порогового декодирования в случае  объясняется тем, что при такой низкой скорости особенно важно исправлять большое количество комбинаций ошибок, вес которых больше, чем
объясняется тем, что при такой низкой скорости особенно важно исправлять большое количество комбинаций ошибок, вес которых больше, чем  Даже мажоритарное декодирование для многих таких комбинаций ошибок будет правильно декодировать символ
Даже мажоритарное декодирование для многих таких комбинаций ошибок будет правильно декодировать символ  Например, в случае ПО-кода при
Например, в случае ПО-кода при  ошибка декодирования произойдет при
ошибка декодирования произойдет при  только тогда, когда 14 или более ортогональных проверок окажутся равными единице. Таким образом, если искажены 14 символов из 48 входящих в систему ортогональных проверок, то при декодировании ошибка произойдет только в том неблагоприятном случае, когда все искаженные символы контролируются различными ортогональными проверками (в предположении, что
только тогда, когда 14 или более ортогональных проверок окажутся равными единице. Таким образом, если искажены 14 символов из 48 входящих в систему ортогональных проверок, то при декодировании ошибка произойдет только в том неблагоприятном случае, когда все искаженные символы контролируются различными ортогональными проверками (в предположении, что  если два символа в комбинации ошибок принадлежат одной и той же проверке, то ошибки декодирования не произойдет, пока вес комбинации ошибок не окажется равным по меньшей мере 16,
если два символа в комбинации ошибок принадлежат одной и той же проверке, то ошибки декодирования не произойдет, пока вес комбинации ошибок не окажется равным по меньшей мере 16,
в. Допустимые отклонения для весовых множителей и порога
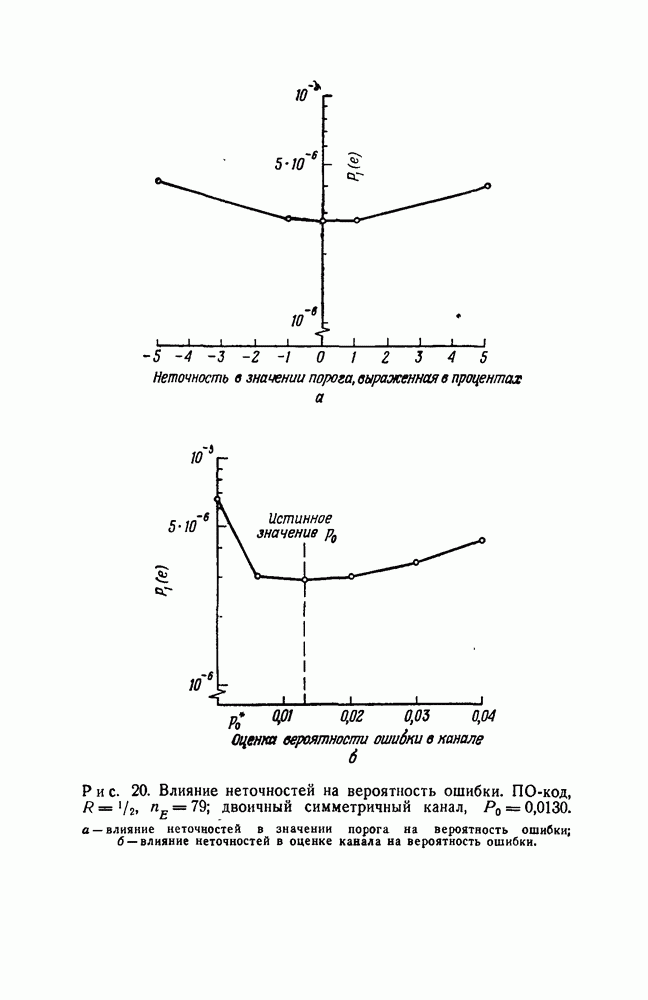
Характеристика порогового декодирования в применении к ПО-кодам табл. II оказывается вполне приемлемой, а простые схемы для реализации порогового декодирования могут сделать его при соответствующих длинах кодов в достаточной степени ценным для практических целей. Но, в то время как при рассмотрении схем декодирования и при вычислениях величины  предполагалось, что весовые множители и порог принимают свои истинные значения, с технической точки зрения важно знать, как отразятся неточности в их значениях на характеристике декодирования.
предполагалось, что весовые множители и порог принимают свои истинные значения, с технической точки зрения важно знать, как отразятся неточности в их значениях на характеристике декодирования.
Легко убедиться, что требования к отклонениям не строги. Из равенства (130) следует, что в критических случаях, когда взвешенная сумма ортогональных проверок приближается к порогу, L стремится к нулю и в соответствии с равенством (131) вероят ность ошибки при принятии решения стремится к 1/2. Таким образом, в этом случае несущественно, какое значение — нуль или единица приписывает декодер символу На рис. 20, а для типичного случая приведены числовые результаты, которые иллюстрируют влияние неточностей в значении порога. Характеристика не ухудшается сколько-нибудь заметно даже при  -процентном отклонении. Незначительные отклонения в значениях весовых множителей дают такой же результат.
-процентном отклонении. Незначительные отклонения в значениях весовых множителей дают такой же результат.
Более интересным является вопрос о влиянии ошибки при оценке свойств канала. В соответствии с равенством (112) весовые множители, а также порог получают значения, зависящие от оценки величины  которую мы будем обозначать через
которую мы будем обозначать через 
К счастью, слишком точного определения не требуется. Такое заключение позволяют сделать рис. 15—19, из которых ясно, что умножение всех проверок даже на одинаковые весовые множители, как это полагается при мажоритарном декодировании в

(кликните для просмотра скана)
большинстве случаев, не ухудшает характеристики сколько-нибудь заметно.
На рис. 20, б для типичного случая приведены числовые результаты, которые показывают, какое незначительное влияние оказывают умеренные неточности в определении свойств канала на значение 
В заключение отметим, что мажоритарное декодирование можно понимать как предельный случай АВ-декодирования, когда  Для этого рассмотрим две проверки, одну размера
Для этого рассмотрим две проверки, одну размера  другую размера
другую размера  Отношение весовых множителей
Отношение весовых множителей  в соответствии с формулой (112) будет
в соответствии с формулой (112) будет

Когда  оба весовых множителя стремятся к бесконечности, а их отношение стремится к пределу, который можно найти двукратным применением правила Лопиталя:
оба весовых множителя стремятся к бесконечности, а их отношение стремится к пределу, который можно найти двукратным применением правила Лопиталя:

при произвольных а и  В этом случае все проверки умножаются на одинаковые весовые множители, что является отличительной особенностью мажоритарного декодирования. Таким образом, можно ожидать, что характеристики мажоритарного и АВ-декодирования почти одинаковы в случае каналов с малыми
В этом случае все проверки умножаются на одинаковые весовые множители, что является отличительной особенностью мажоритарного декодирования. Таким образом, можно ожидать, что характеристики мажоритарного и АВ-декодирования почти одинаковы в случае каналов с малыми  Из рис. 16—19 видно, что это действительно так.
Из рис. 16—19 видно, что это действительно так.
г. Модификация порогового декодирования
Существует два основных пути, следуя которым можно модифицировать алгоритм порогового декодирования с целью повышения достоверности декодирования при передаче по двоичному симметричному (или по другому) каналу с обратной связью. (Основная идея этого раздела — повышение достоверности за счет декодирования только наиболее вероятных
комбинаций ошибок и переспроса во всех остальных случаях — впервые была предложена Возенкрафтом и Хорстейном 
Первый метод состоит в том, чтобы создать в пороговом устройстве область неопределенности шириной  симметричную относительно порога, т. е. всякий раз, когда
симметричную относительно порога, т. е. всякий раз, когда  устройство должно сигнализировать о необходимости переспроса.
устройство должно сигнализировать о необходимости переспроса.
Из равенства (131) следует, что при АВ-декодировании использование метода обнаружения ошибки эквивалентно тому, что решение принимается тогда и только тогда, когда вероятность ошибки меньше, чем  Область неопределенности можно применить также и при мажоритарном декодировании. А именно, пусть
Область неопределенности можно применить также и при мажоритарном декодировании. А именно, пусть  такое целое число, что
такое целое число, что  четно. Тогда будет декодироваться правильно всякий раз, когда среди
четно. Тогда будет декодироваться правильно всякий раз, когда среди  символов, контролируемых проверками
символов, контролируемых проверками  имеется не более
имеется не более  ошибок и не будет принято неправильного решения, если среди этих символов встретится не более чем
ошибок и не будет принято неправильного решения, если среди этих символов встретится не более чем  ошибок. При этом подразумевается следующее правило декодирования: выбрать
ошибок. При этом подразумевается следующее правило декодирования: выбрать  если более чем
если более чем  проверок
проверок  имеют значение единица; выбрать
имеют значение единица; выбрать  если не более чем
если не более чем  проверок
проверок  имеют значение единица. В противном случае подается сигнал об обнаружении ошибки. Доказательство этого утверждения представляет собой тривиальную модификацию доказательства теоремы 1.
имеют значение единица. В противном случае подается сигнал об обнаружении ошибки. Доказательство этого утверждения представляет собой тривиальную модификацию доказательства теоремы 1.
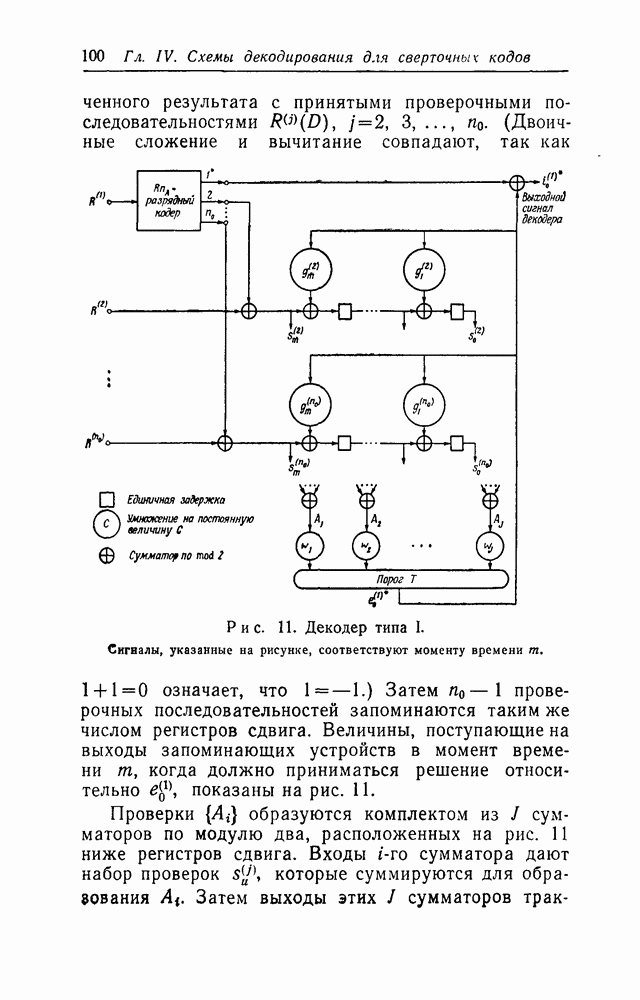
Второй метод повышения надежности при наличии обратной связи будем называть случайным дополнением сверточного кода. Этот метод предназначен для использования в сочетании с методом подсчета ошибок, описанным в § 3.2. Его идея состоит в том, чтобы заставить ошибку декодирования размножаться; затем это размножение может быть обнаружено методом подсчета ошибок, на основании чего можно потребовать повторения передачи. Этого можно
добиться добавлением к порождающим полиномам (65) членов степени, большей, чем  коэффициенты 0 и 1 при которых выбираются независимо друг от друга с вероятностью 1/2. (Так как
коэффициенты 0 и 1 при которых выбираются независимо друг от друга с вероятностью 1/2. (Так как  при этом возрастает, сложность кодера и декодера возрастает в той же пропорции.) Предположим, что к каждому порождающему полиному добавлено L таких членов. Из рис. 11 видно, что в случае ошибки декодирования влияние случайного дополнения состоит в введении в регистры сдвига проверок пачки из
при этом возрастает, сложность кодера и декодера возрастает в той же пропорции.) Предположим, что к каждому порождающему полиному добавлено L таких членов. Из рис. 11 видно, что в случае ошибки декодирования влияние случайного дополнения состоит в введении в регистры сдвига проверок пачки из  случайных символов. Когда эти символы поступают в ту часть регистра сдвига, которая используется для декодирования, т. е. в последние
случайных символов. Когда эти символы поступают в ту часть регистра сдвига, которая используется для декодирования, т. е. в последние  разрядов регистра сдвига в каждой цепи, то вероятность размножения ошибок возрастает. (Аналогичный анализ приложим к декодеру типа II на рис. 12.) Выбрав L достаточно большим, вероятность необнаружения ошибки можно сделать произвольно малой. Однако, так как число символов, подлежащих повторению, растет пропорционально
разрядов регистра сдвига в каждой цепи, то вероятность размножения ошибок возрастает. (Аналогичный анализ приложим к декодеру типа II на рис. 12.) Выбрав L достаточно большим, вероятность необнаружения ошибки можно сделать произвольно малой. Однако, так как число символов, подлежащих повторению, растет пропорционально  растет и расход времени на переспрос. (Мы здесь не будем рассматривать таких важных вопросов, как запоминание данных для повторения, количество символов, подлежащих повторению, и т. д. Для полного ознакомления с ними отошлем читателя к статье Возенкрафта и Хорстейна [5]. Наша цель — указать главным образом на те особенности применения обратной связи, которые характерны для порогового декодирования.)
растет и расход времени на переспрос. (Мы здесь не будем рассматривать таких важных вопросов, как запоминание данных для повторения, количество символов, подлежащих повторению, и т. д. Для полного ознакомления с ними отошлем читателя к статье Возенкрафта и Хорстейна [5]. Наша цель — указать главным образом на те особенности применения обратной связи, которые характерны для порогового декодирования.)
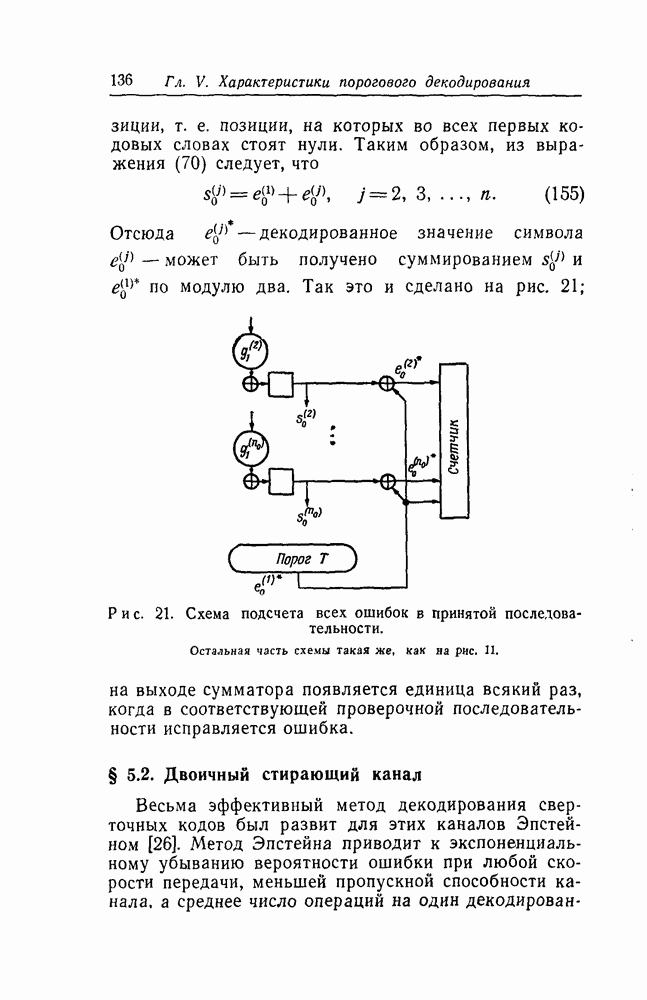
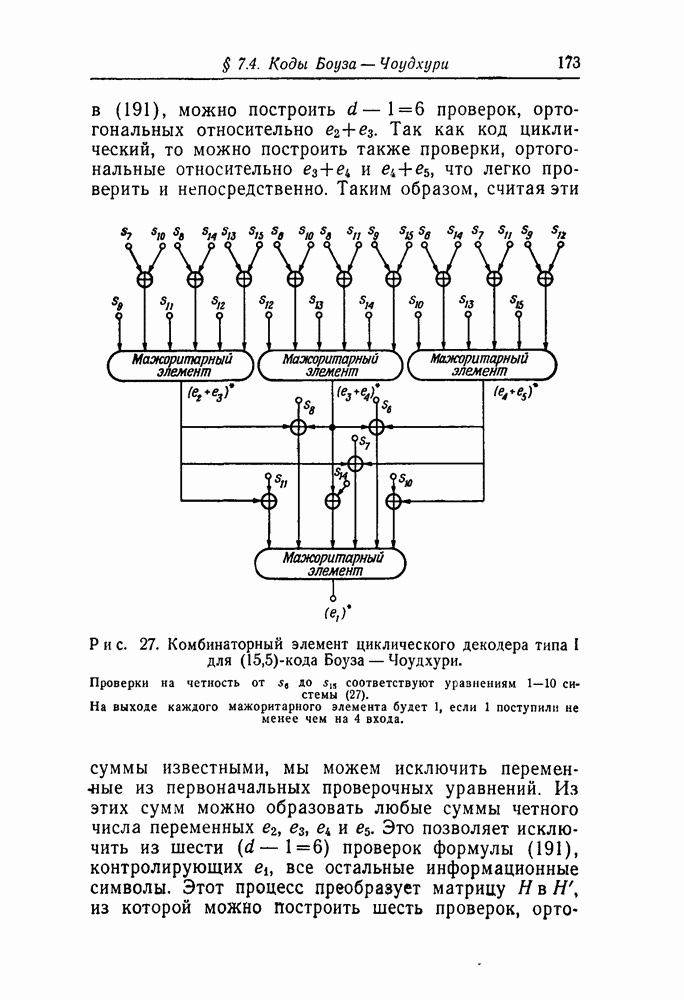
Наконец, для осуществления метода подсчета ошибок необходимы средства для подсчета всех ошибок, исправленных в принятой последовательности. На выходе порогового устройства в декодере типа I появляется единица всякий раз, когда исправляется ошибка в информационной последовательности. Число ошибок, исправленных в проверочной последовательности, может быть получено посредством модификации декодера типа I, показанной на рис. 21. Порождающие полиномы всегда выбираются так, что  в противном случае в червом кодовом слове найдутся неиспользованные
в противном случае в червом кодовом слове найдутся неиспользованные
позиции, т. е. позиции, на которых во всех первых кодовых словах стоят нули. Таким образом, из выражения (70) следует, что

Отсюда  декодированное значение символа — может быть получено суммированием и
декодированное значение символа — может быть получено суммированием и  по модулю два. Т
по модулю два. Т

Рис. 21. Схема подсчета всех ошибок в принятой последовательности. Остальная часть схемы такая же, как на рис. 11.
ак это и сделано на рис. 21; на выходе сумматора появляется единица всякий раз, когда в соответствующей проверочной последовательности исправляется ошибка.




















































































































































































 то имеем
то имеем


 проверок только при условии
проверок только при условии  Для двоичного симметричного канала черта над правой частью равенства (145) может быть опущена, так как все весовые множители постоянны.
Для двоичного симметричного канала черта над правой частью равенства (145) может быть опущена, так как все весовые множители постоянны.
 , что система
, что система  проверок, в которых
проверок, в которых  суть система статистически независимых случайных величин, для которых
суть система статистически независимых случайных величин, для которых  Определим случайную величину
Определим случайную величину  равенством
равенством

 трактуется как вещественное число. Тогда равенство (145) можно переписать в виде
трактуется как вещественное число. Тогда равенство (145) можно переписать в виде

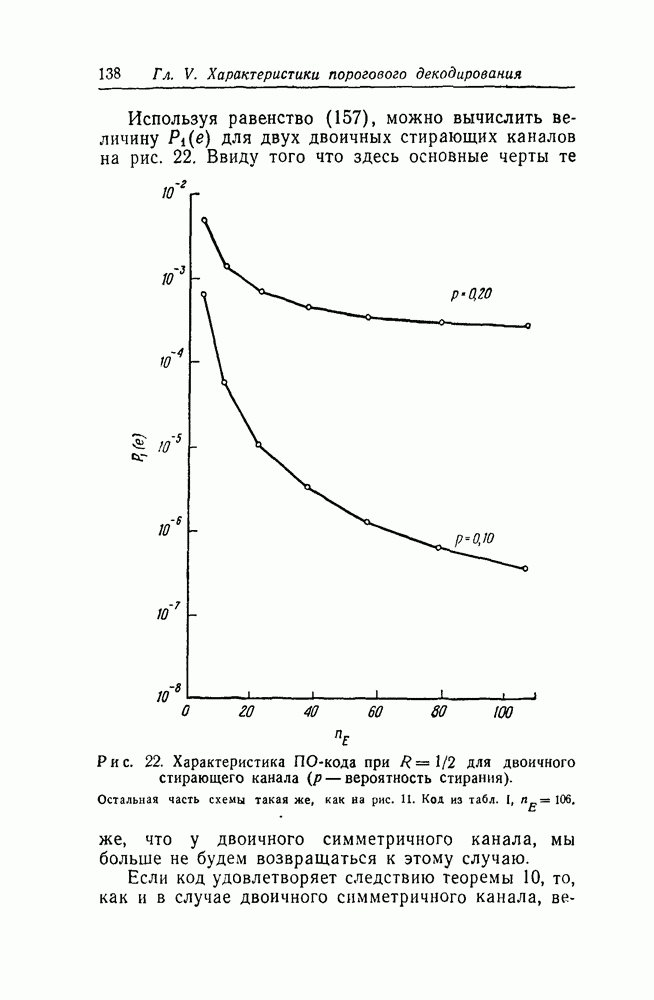
 для ПО-кодов из табл.
для ПО-кодов из табл.  -вероятность ошибки в блоке, и отношение
-вероятность ошибки в блоке, и отношение  для блоковых кодов табл. V, где
для блоковых кодов табл. V, где  число информационных символов в блоковом коде. В случае каждой из скоростей был использован тот же канал, что и при соответствующих расчетах для случайного кода на рис. 16—19, а
число информационных символов в блоковом коде. В случае каждой из скоростей был использован тот же канал, что и при соответствующих расчетах для случайного кода на рис. 16—19, а  бралось таким же, как и
бралось таким же, как и 
 Причина такого выбора состоит в следующем. Пусть
Причина такого выбора состоит в следующем. Пусть  вероятность ошибки при декодировании первых
вероятность ошибки при декодировании первых  принятых информационных символов. Тогда если
принятых информационных символов. Тогда если