Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
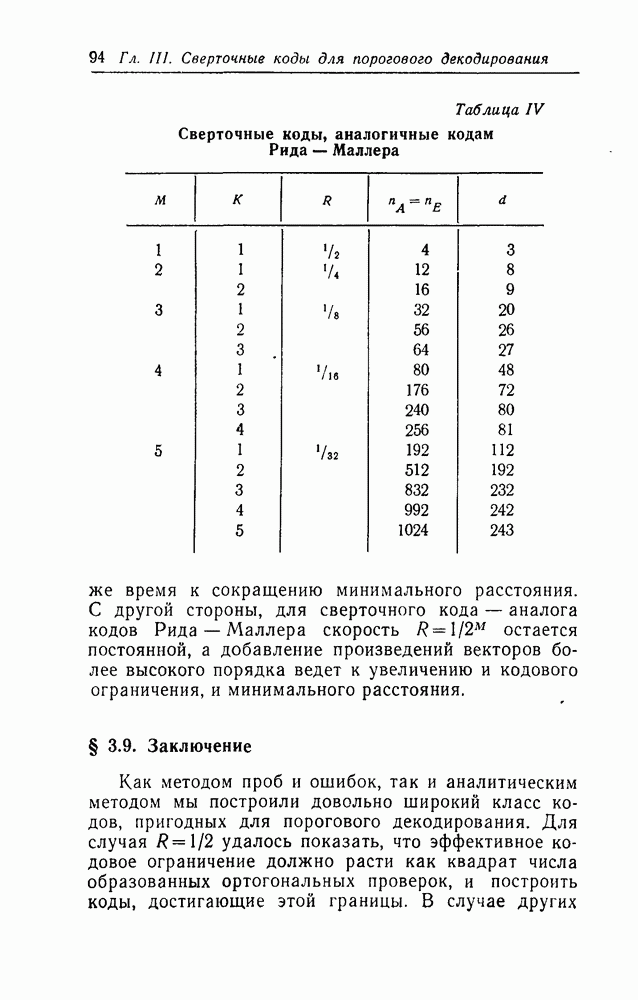
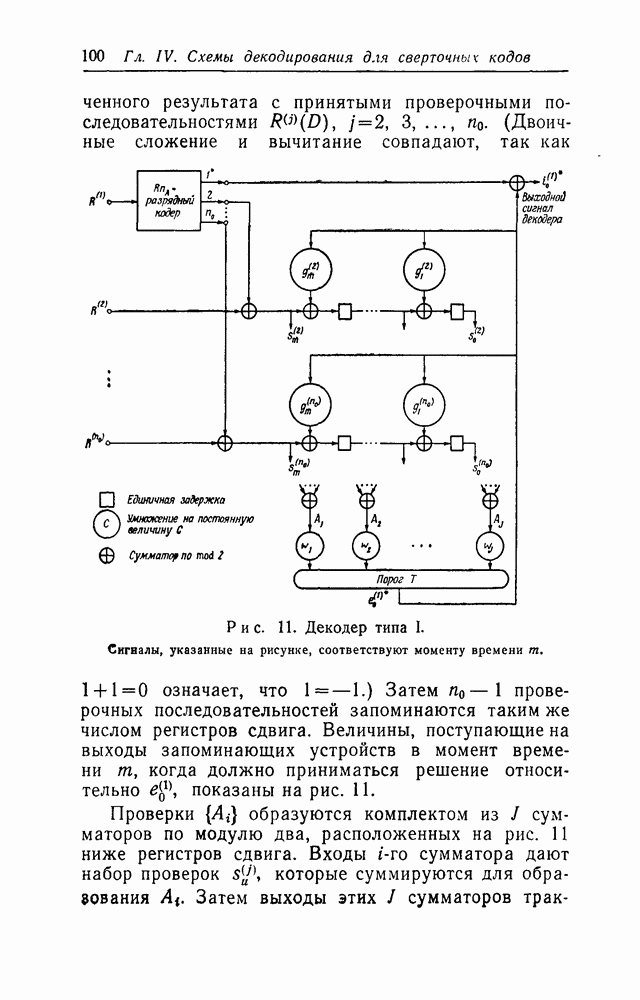
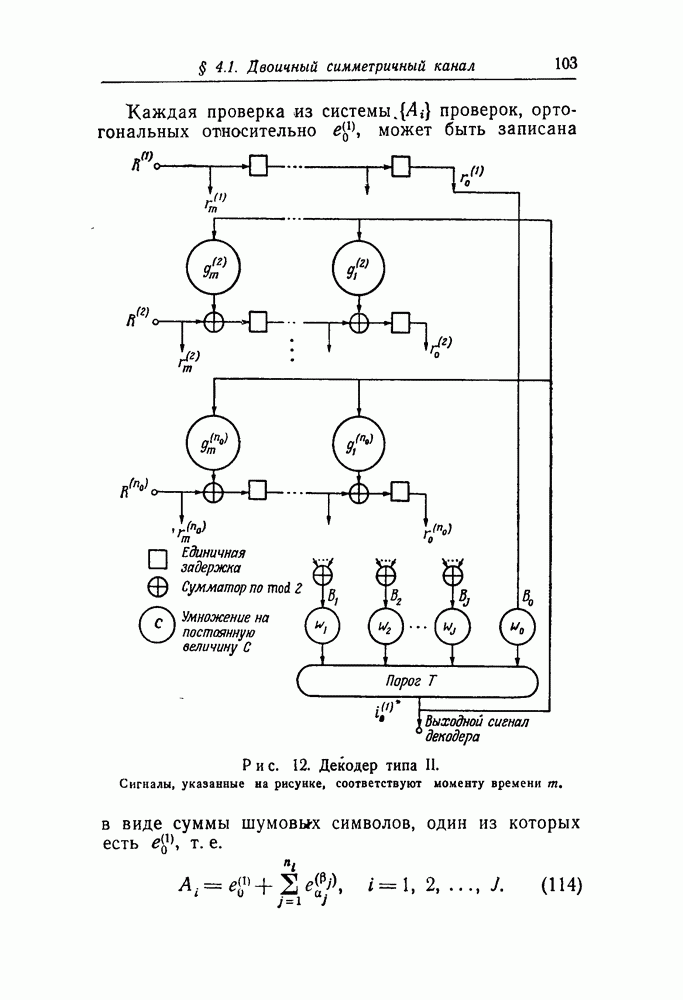
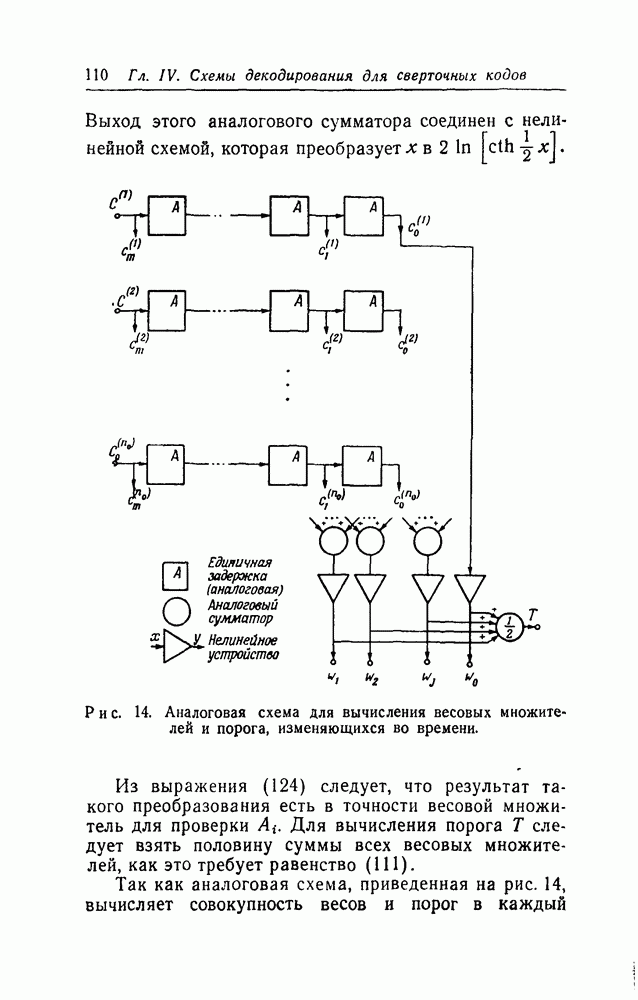
§ 8.3. Рекомендации к дальнейшим исследованиямДальнейшие исследования рекомендуется проводить особенно в следующих областях: (i) Построение хороших систематических классов сверточных кодов для исправления случайных ошибок. Кроме некоторых классов кодов, построенных для исправления пачек ошибок [20], единственными известными систематическими классами сверточных кодов являются равномерные коды и коды, аналогичные кодам Рида — Маллера, которые были найдены в представленных исследованиях. К сожалению, оба эти класса кодов имеют низкую скорость передачи. Было бы желательным иметь несколько классов хороших кодов, пригодных для порогового декодирования (или другого алгоритма декодирования). (ii) Исследования размножения ошибок в сверточных кодах. Дополнительные усилия для изучения общих свойств порогового декодирования сверточных кодов пока, видимо, не целесообразны. Основные особенности вполне ясны из теорем 10—12. Точно так же вряд ли будут найдены более простые схемы декодирования. С другой стороны, некоторые другие особенности, главной среди которых является вопрос о размножении ошибок, вполне оправдывают дополнительные исследования. В § 3.1 были рассмотрены два метода контроля за размножением ошибок — ресинхронизация и подсчет ошибок. Существует также и третья возможность — автоматическое возвращение декодера после короткой пачки неверно декодированных символов. Как оказалось, автоматическое возвращение возможно при последовательном декодировании по крайней мере при высоких скоростях передачи [Дж. Возенкрафт, личное сообщение, 1962; Дж. Буссганг (J. J. Bussgang), личное сообщение, 1962]. Однако быстрый рост объема вычислений при декодировании, сопровождающих ошибку при последовательном декодировании, ограничивает практическое использование автоматического возвращения для борьбы с размножением ошибок. Пороговое же декодирование не страдает этим ограничением, так как объем вычислений всегда постоянен. По-видимому, следует смоделировать достаточно длинные коды (например, код табл. II с (iii) Изучение других нелинейных функций в применении к декодированию сверточных кодов. Вместо порогового элемента и связанных с ним сумматоров в декодере типа I на рис. 11 можно в качестве решающего элемента использовать любой комбинаторный элемент, лишь бы он был способен образовать декодированное значение символа (iv) Исследование всеобщности ортогонализации блоковых линейных кодов в L шагов. Это самая важная область для дополнительных исследований. Теоремы 21 и 23 наводят на мысль о возможности общей теоремы такого характера: «любой двоичный код длины
|
 |
Оглавление
|






































































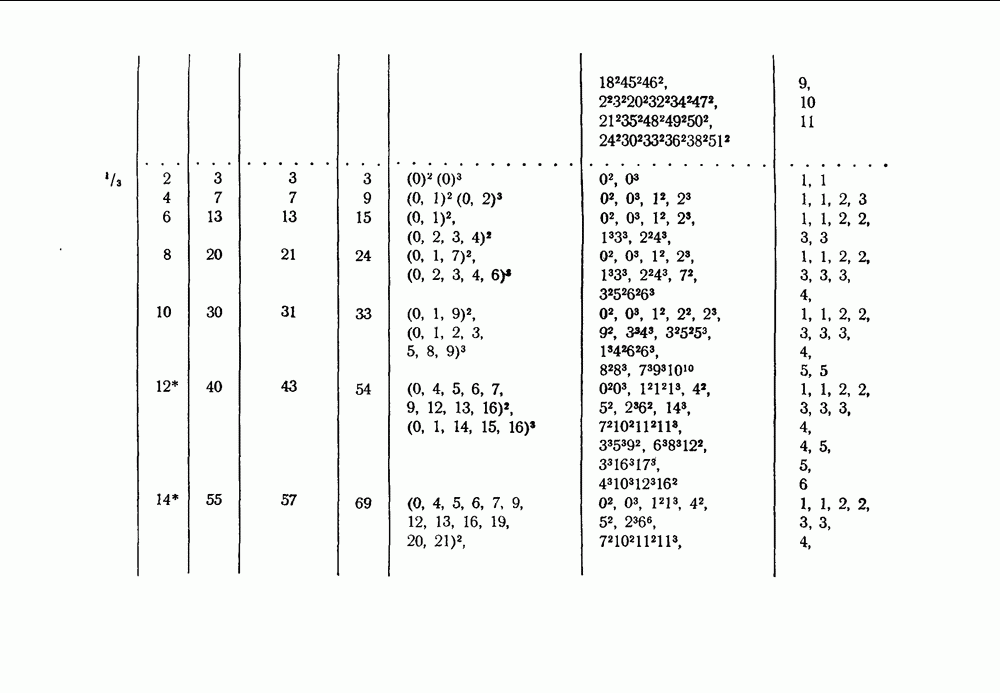
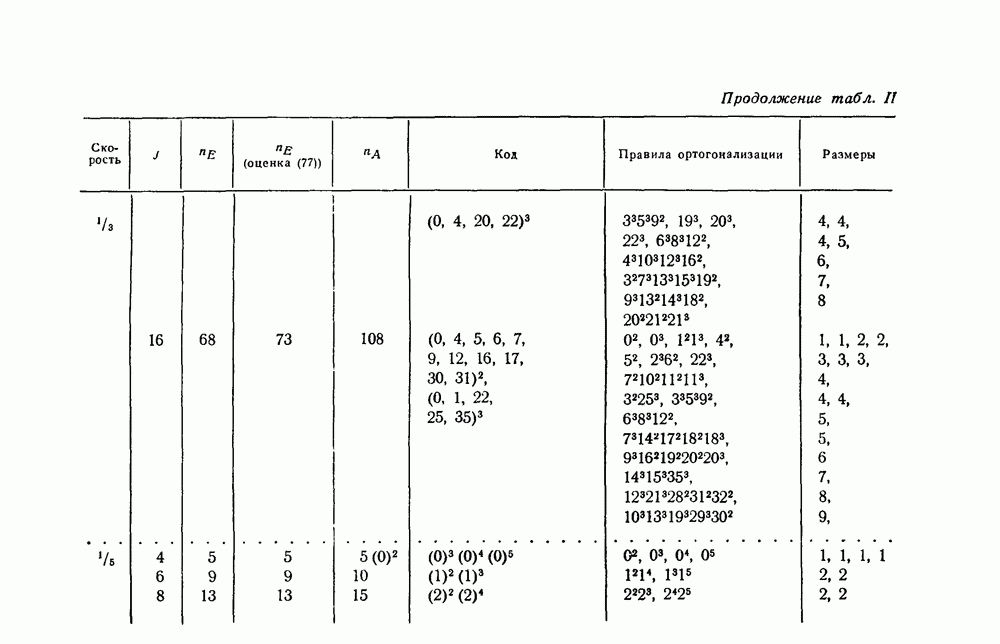
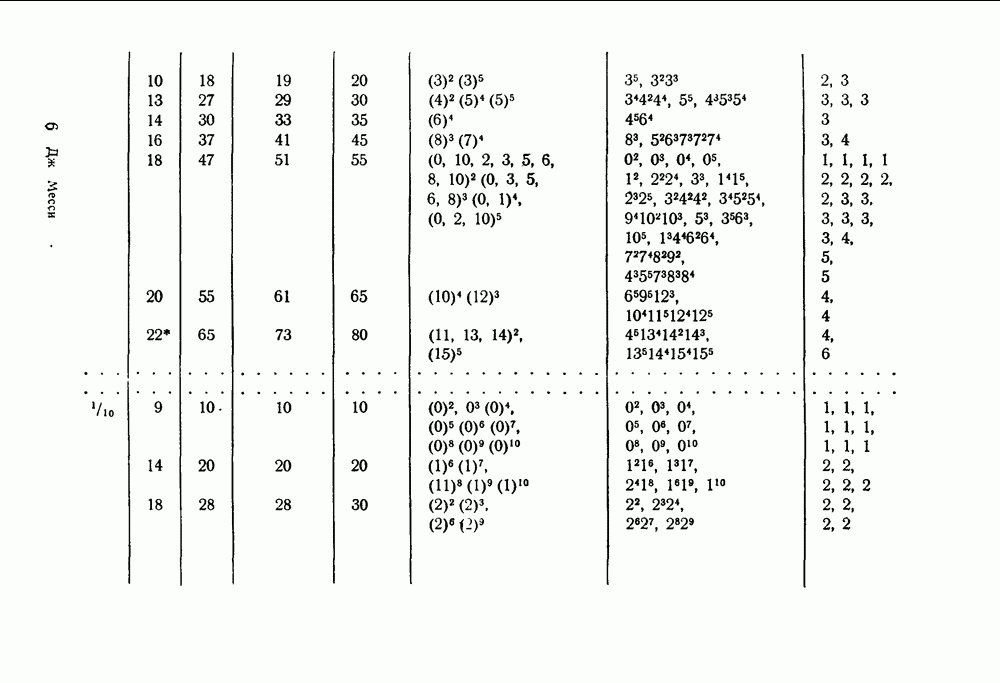
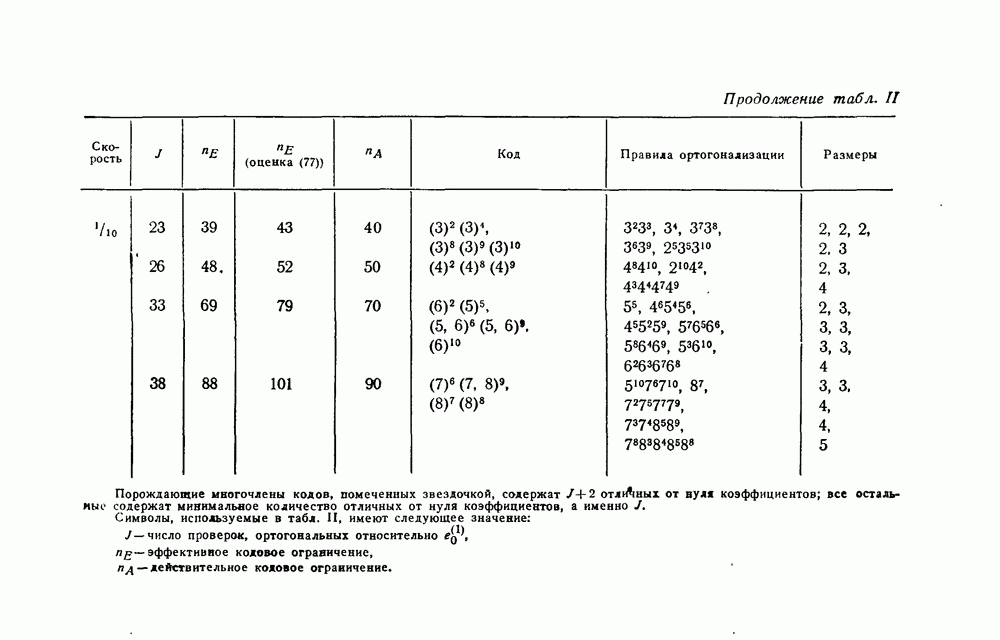
























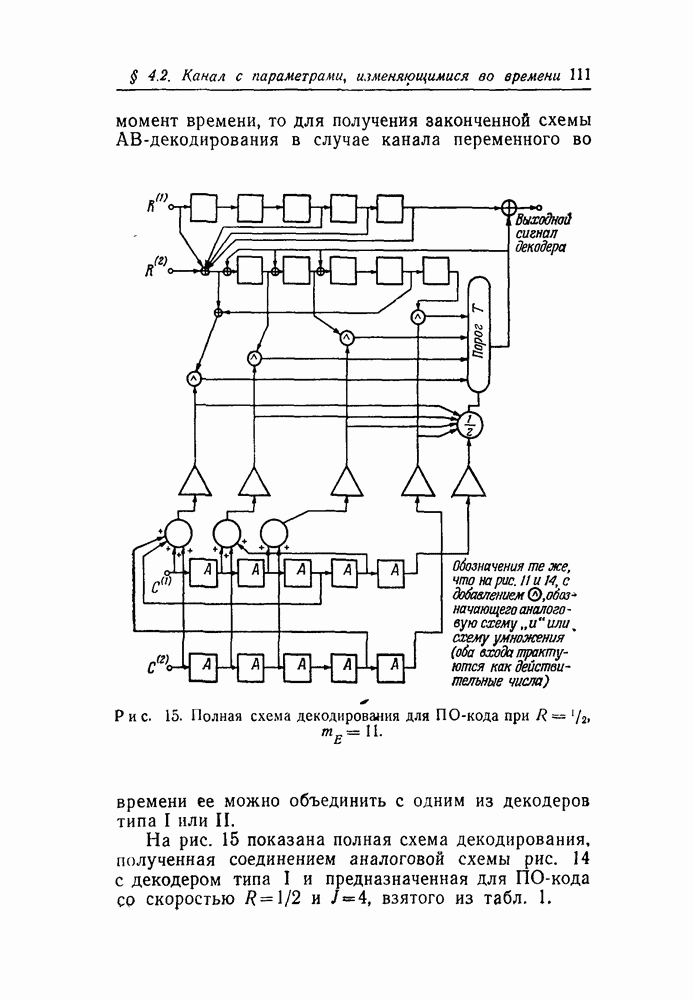











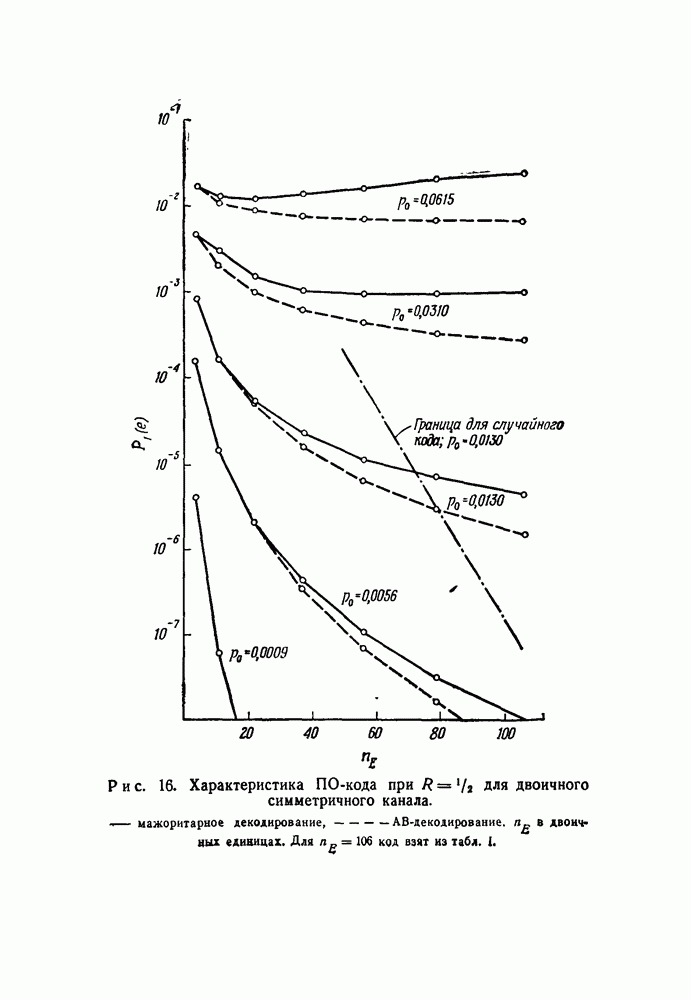
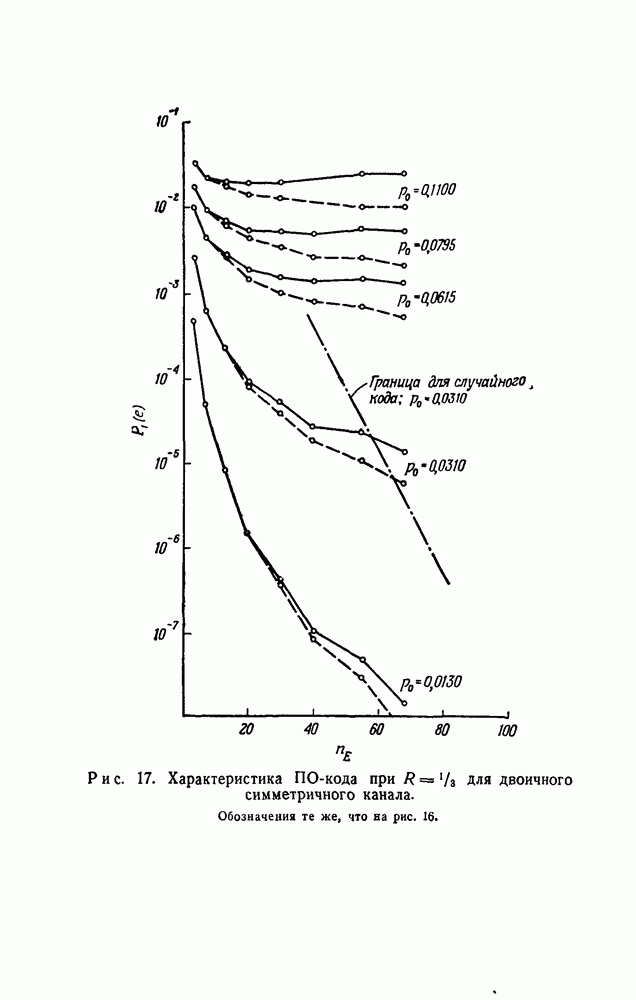
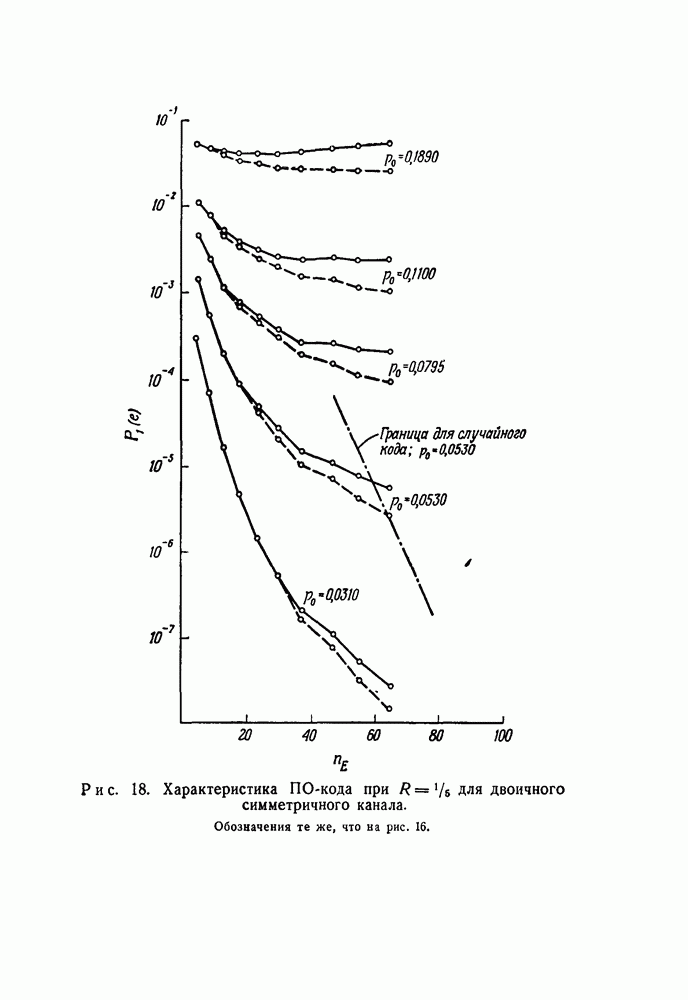
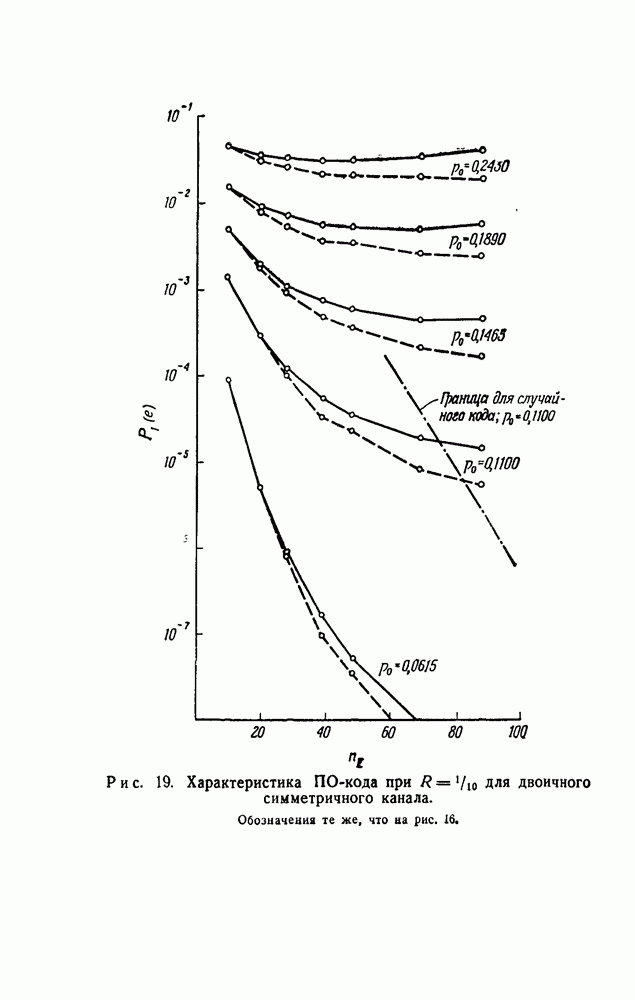


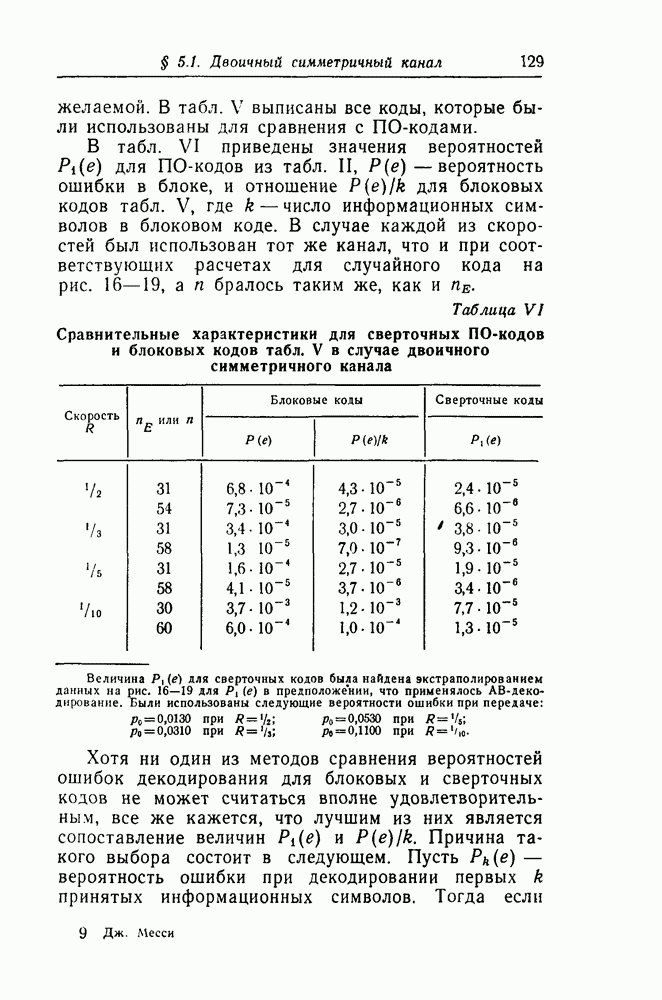


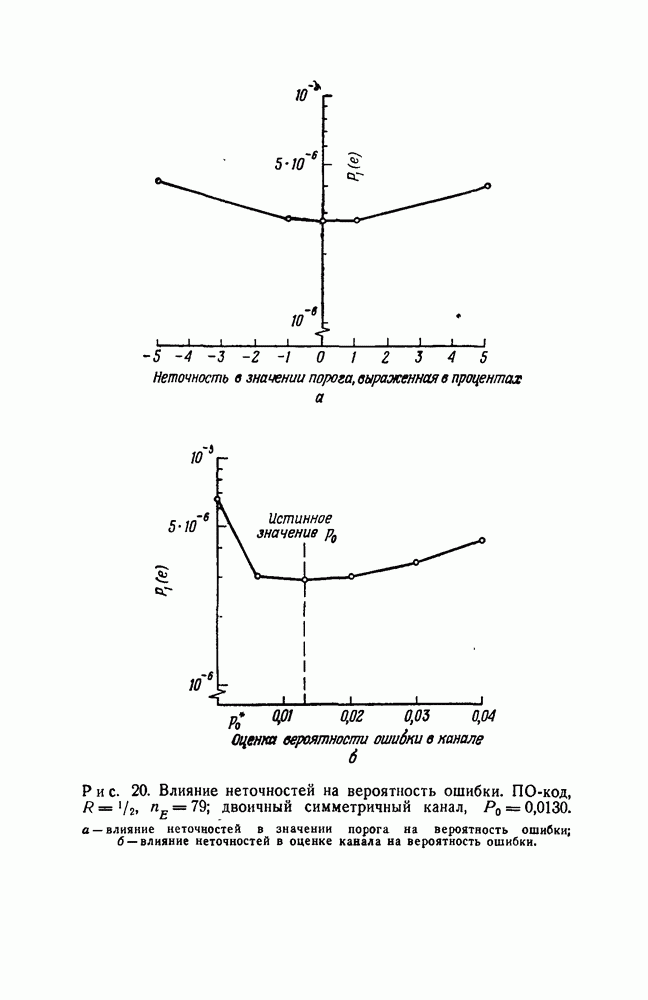



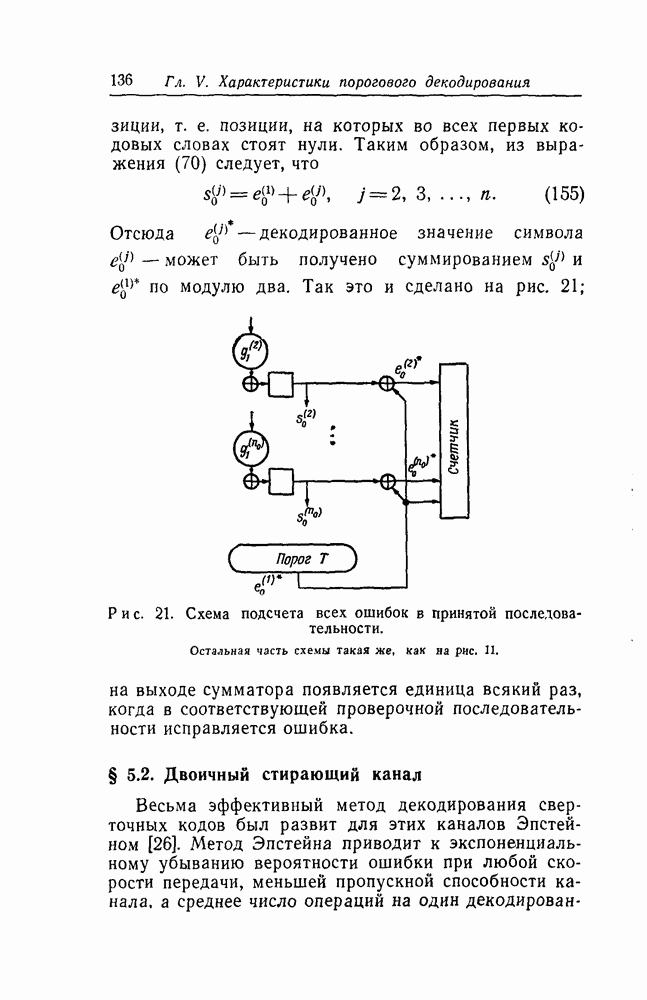

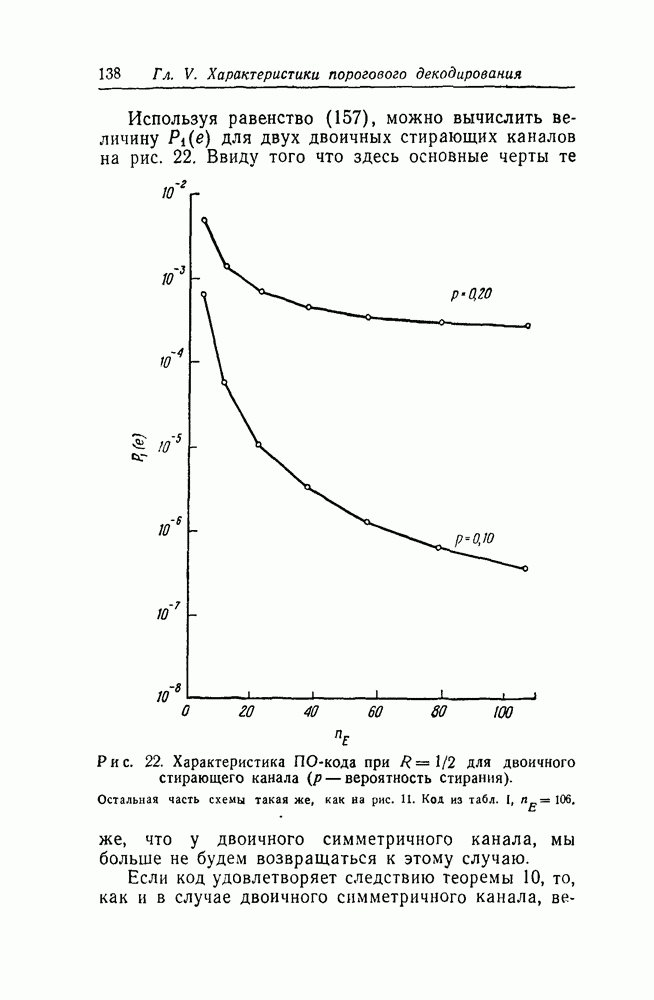


































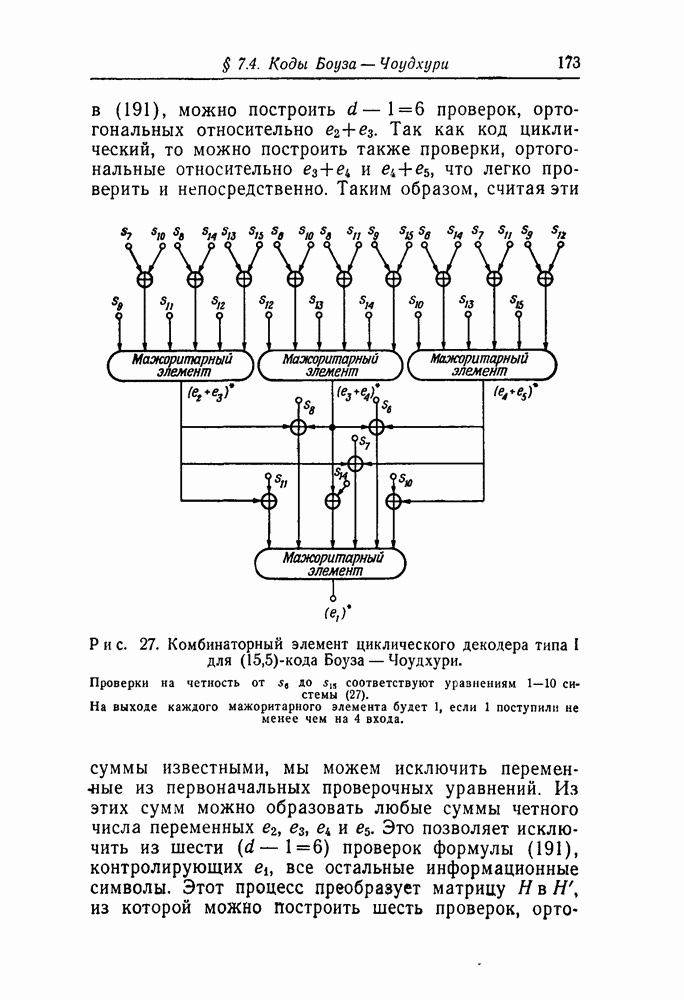
































 чтобы выяснить, в самом ли деле возможно при возникновении ошибки такое автоматическое возвращение. Если да, то на очереди дальнейшие исследования, которые должны показать, что пачка искаженных символов имеет довольно малую среднюю длину.
чтобы выяснить, в самом ли деле возможно при возникновении ошибки такое автоматическое возвращение. Если да, то на очереди дальнейшие исследования, которые должны показать, что пачка искаженных символов имеет довольно малую среднюю длину.
 Может быть, можно найти другую простую нелинейную функцию, пригодную к использованию для декодирования некоторых классов сверточных кодов. Несомненно, это будет очень трудной областью исследований.
Может быть, можно найти другую простую нелинейную функцию, пригодную к использованию для декодирования некоторых классов сверточных кодов. Несомненно, это будет очень трудной областью исследований.
 или менее может быть ортогонализован в
или менее может быть ортогонализован в  шагов». Такой результат, окажись он верным, был бы необычайно важным. Он означал бы, что в любом блоковом коде исправлять любую комбинацию не более чем
шагов». Такой результат, окажись он верным, был бы необычайно важным. Он означал бы, что в любом блоковом коде исправлять любую комбинацию не более чем  ошибок можно было бы всего одной операцией комбинаторной схемы, состоящей не более чем из
ошибок можно было бы всего одной операцией комбинаторной схемы, состоящей не более чем из  пороговых элементов кодера и не более чем
пороговых элементов кодера и не более чем  сумматоров по
сумматоров по  Попытки доказать это предположение или опровергнуть его имели бы большое значение.
Попытки доказать это предположение или опровергнуть его имели бы большое значение.