Пред.
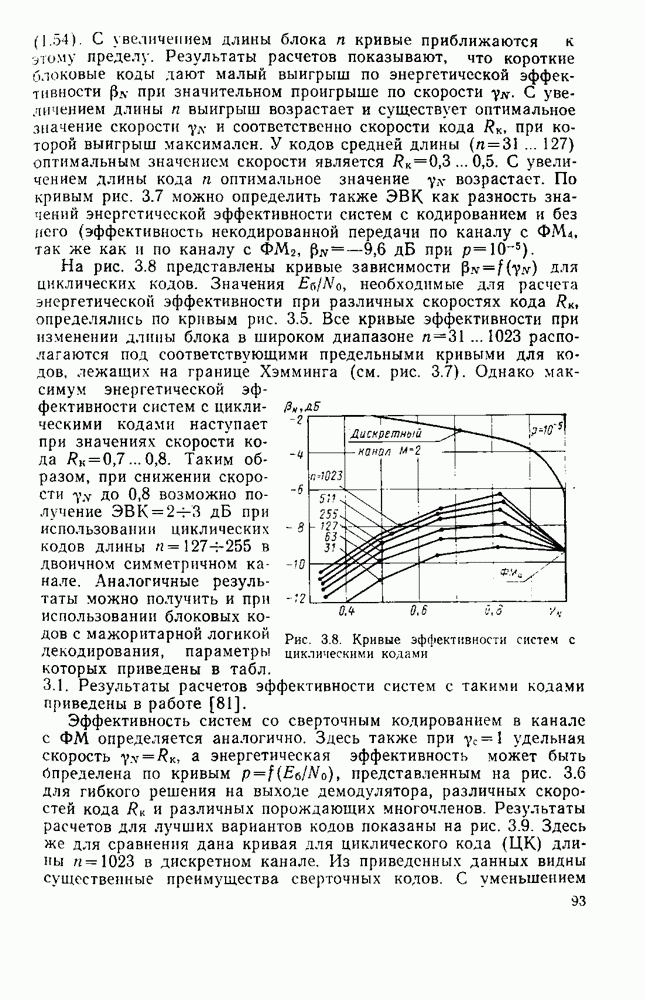
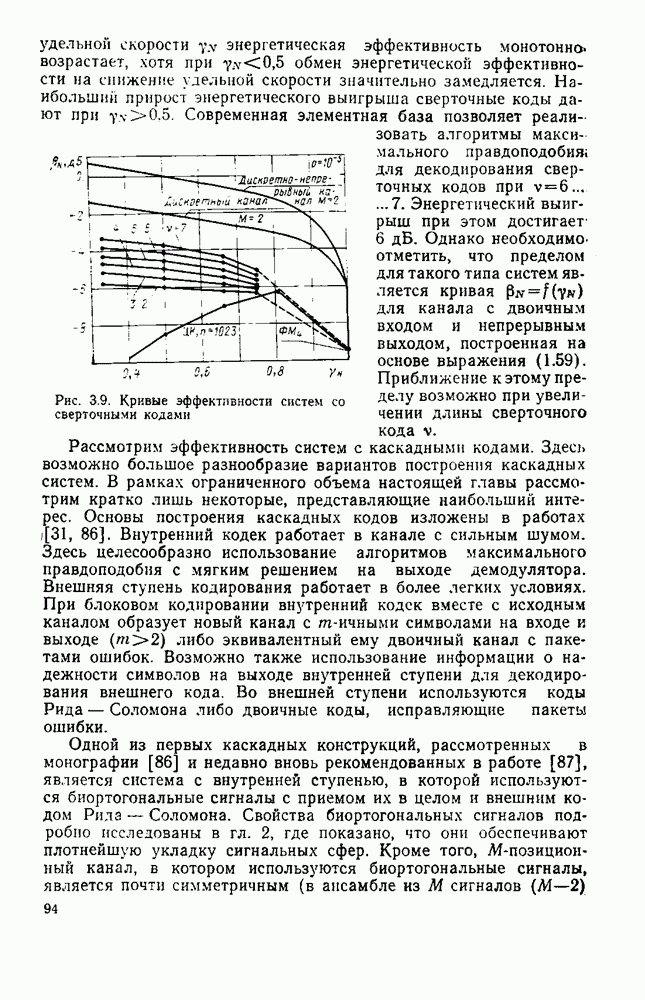
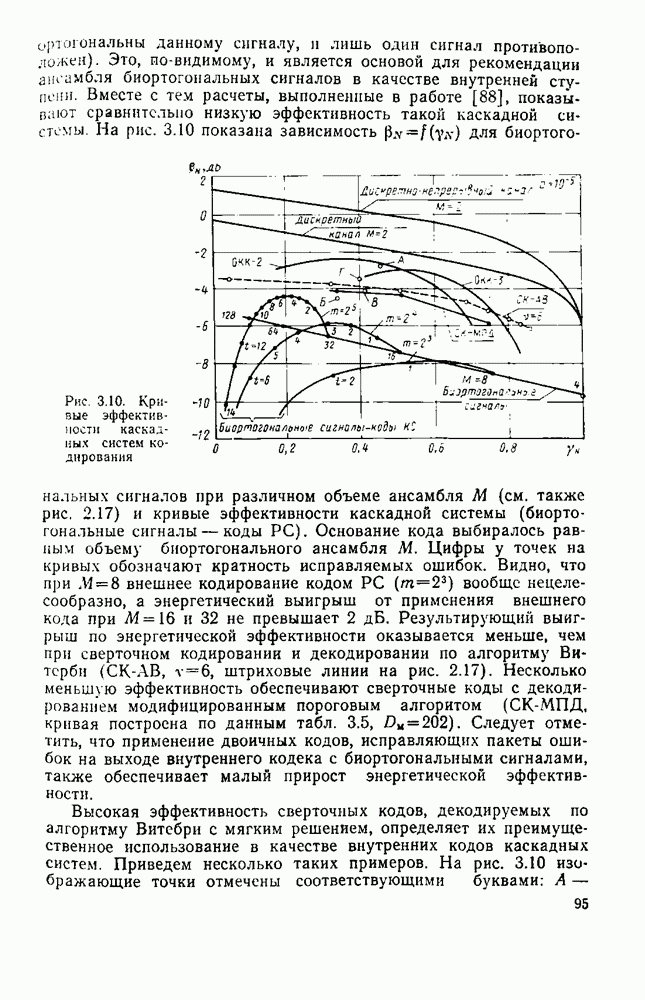
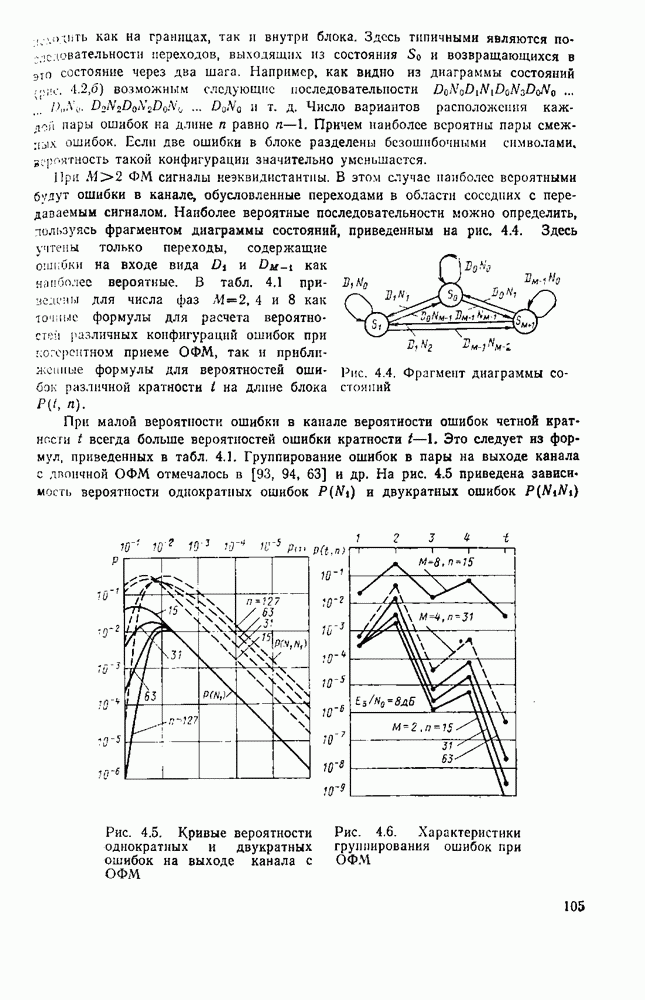
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
8.2. ИНФОРМАЦИОННЫЕ ХАРАКТЕРИСТИКИ ИСТОЧНИКА ДИСКРЕТНЫХ СООБЩЕНИЙРассмотрим источник, который вырабатывает сообщения в виде последовательности дискретных элементов (букв), выбираемых из конечного множества (алфавита)
где К — объем алфавита источника. Выбор букв происходит с некоторыми вероятностями, зависящими, как от предыдущих выборов, так и от конкретно рассматриваемого сообщения. Типичным примером такого сообщения является обычная телеграмма, представляющая собой последовательность букв (знаков), имеющих разную вероятность и статистически связанных между собой. При таком подходе в качестве математической модели источника принимается дискретный случайный процесс. Источник дискретных сообщений называется стационарным, если его вероятностное описание не зависит от падала отсчета времени. Количество информации, вырабатываемое источником, определяется его энтропией. Если сообщения (буквы) статистически независимы (источник без памяти), то энтропия источника, равная среднему количеству информации на букву, определяется известным выражением
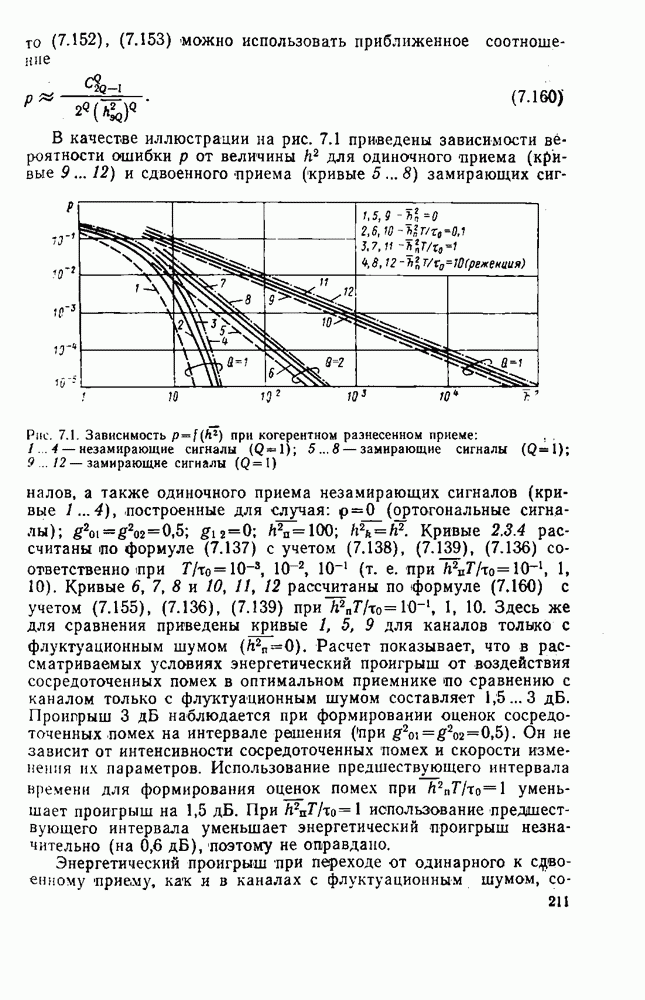
где Энтропия источника максимальна, когда все его сообщения имеют одинаковую вероятность
Следовательно, величину энтропии Важным частным случаем является источник двоичных сообщений, для которого
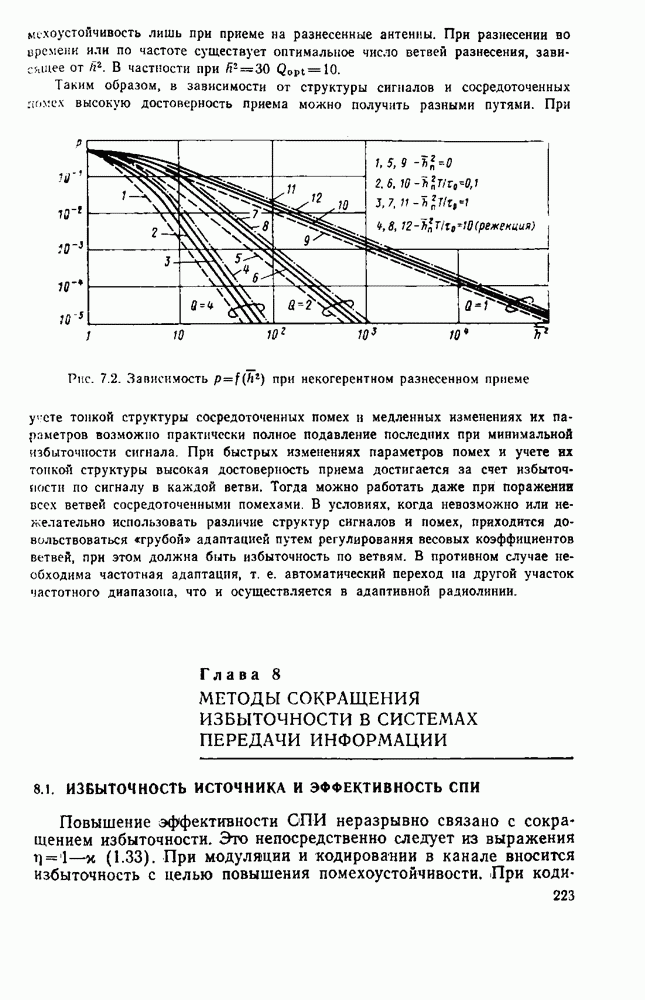
В общем случае сообщения, поступающие от источника, статистически зависимы. Примером «может быть обычный текст, в котором появление той или иной буквы зависит от предыдущих букв. Так, после сочетания В ряде случаев последовательность сообщений на выходе источника образуют цепь Маркова. Стационарный источник, для которою каждая буква на выходе зависит лишь от I предыдущих букв, является марковским источником, состояниями которого являются все возможные последовательности из Для стационарного источника зависимых дискретных сообщений энтропию можно определить как предел совместной энтрошии
где
В теории информации доказывается, что энтропия источника зависимых сообщений всегда меньше энтропии источника независимых сообщений при том же объеме алфавита и тех же безусловных вероятностях сообщений. Очевидно, имеют место следующие неравенства:
Дцесь Но — максимальная энтропия (8.2); — энтропия источника независимых сообщений (8.1); (буквами); Величина
называется избыточностью источника, а
определяет эффективность кодека источника. Для оиенки эффективности устройств сжатия данных часто вводится величина
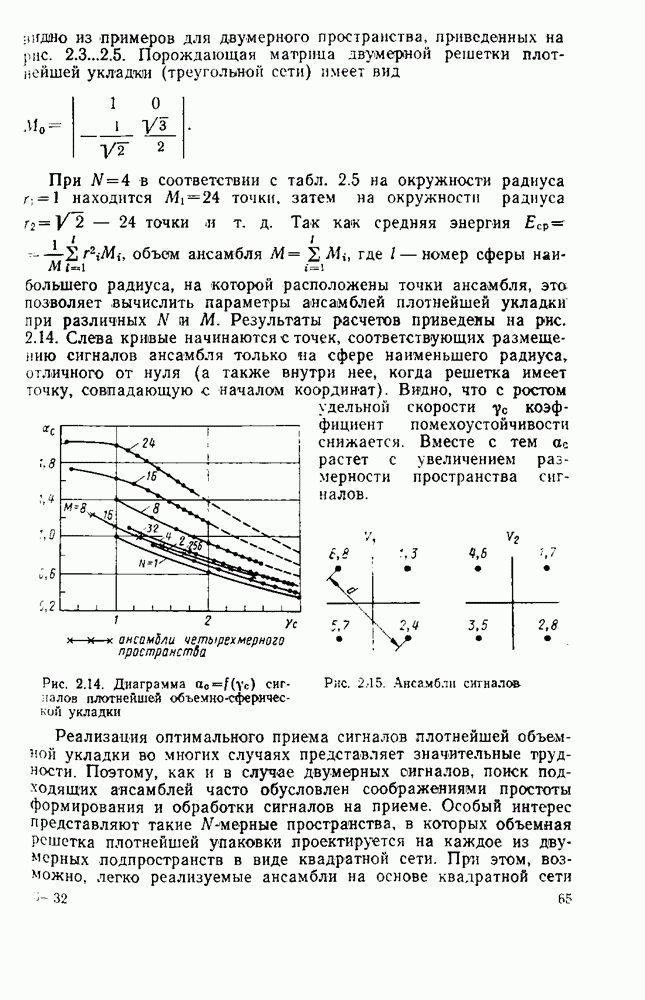
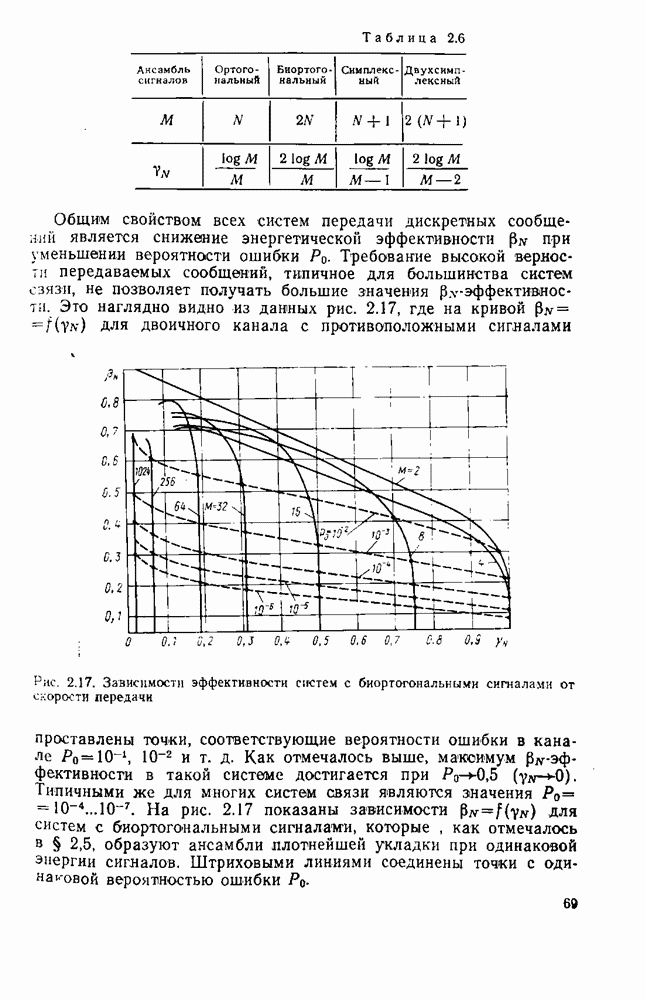
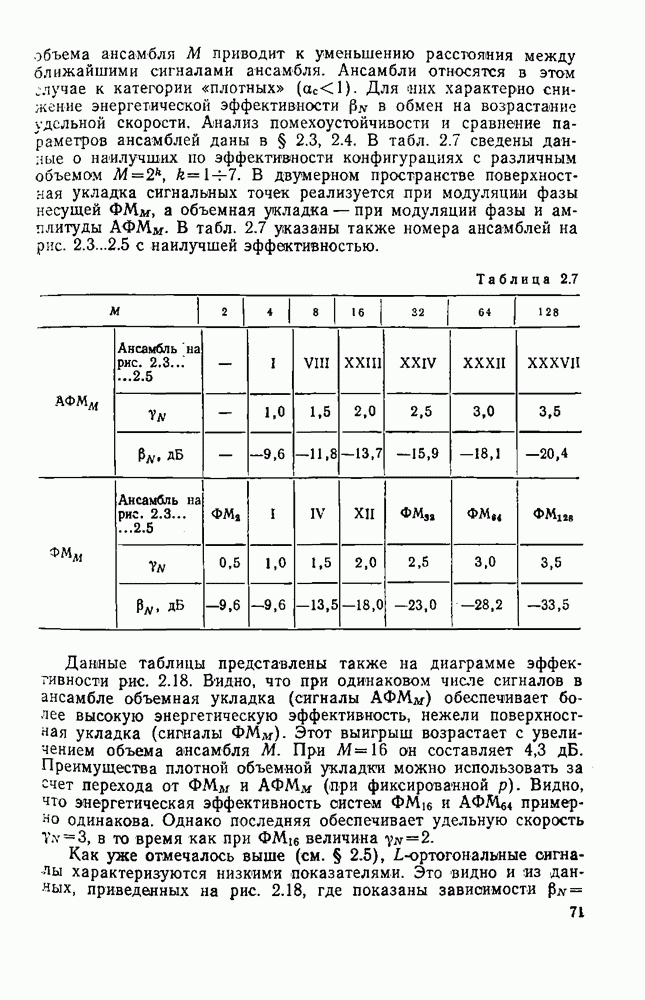
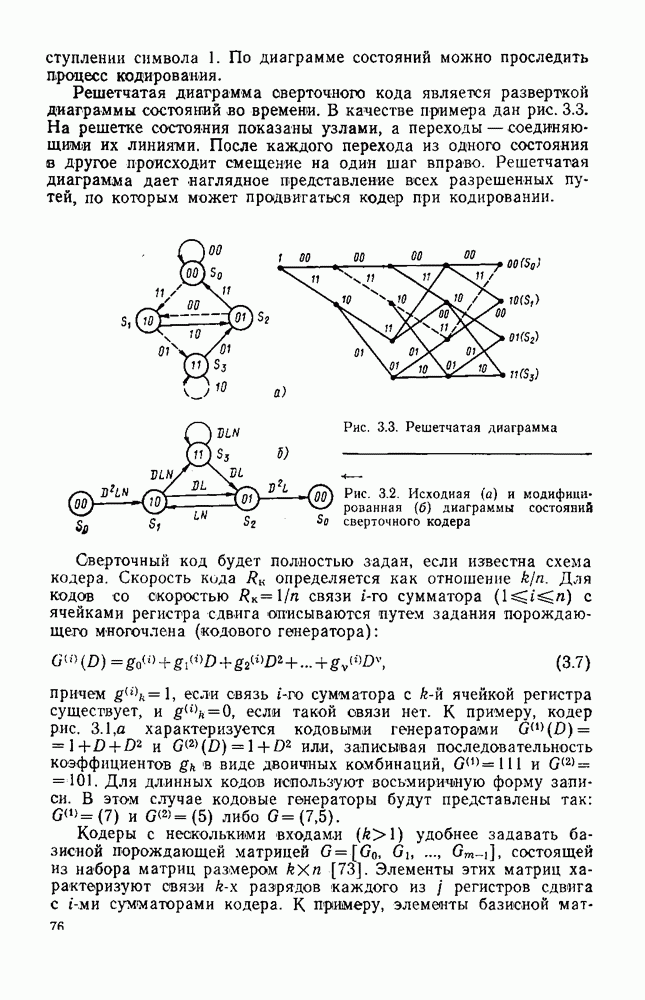
которая называется коэффициентом сжатия. В табл. 8.2 приведены значения энтропии для литературного текста на русском, английском и французском языках [179]. Оценка энтропии Таблица 8.2. (см. скан) Следовательно, избыточность русского литературного языка близка к 80%. Избыточность поэтических произведений еще больше (энтропия меньше 1 бита на букву), так «как в них имеются дополнительные вероятностные связи, обусловленные ритмом и рифмами. Деловые тексты, телеграммы весьма однообразны, и поэтому их избыточность очень большая. Так, энтропия источника телеграфных сообщений не превышает 0,8 бит на букву (избыточность порядка Избыточность дискретного источника к обусловлена тем, что элементы сообщения (буквы) не равновероятны
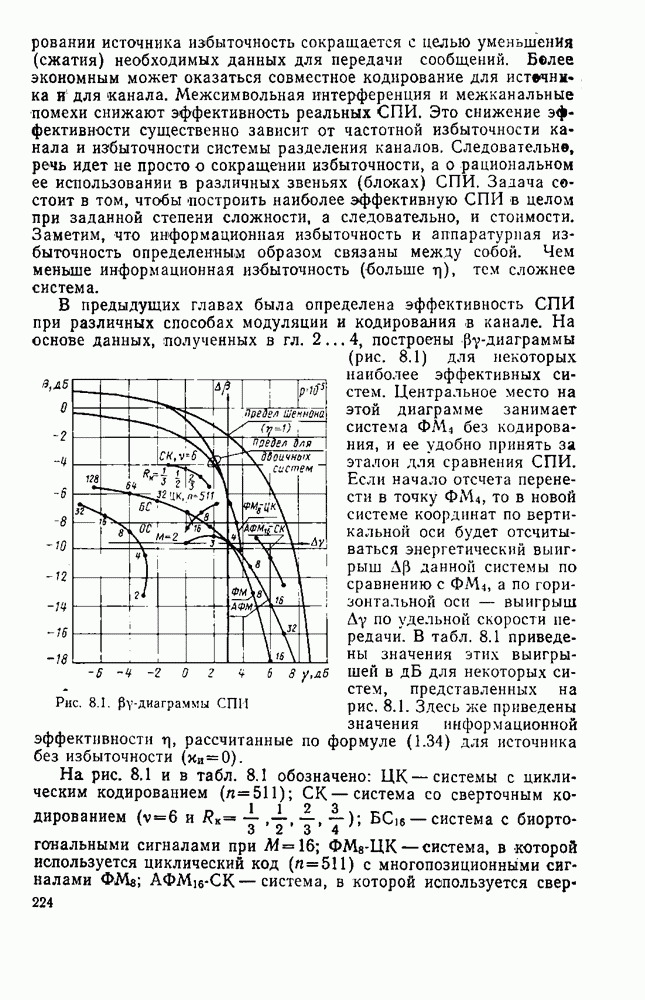
Согласно табл. 8.2 для русского языка Для передачи по дискретному каналу сообщения источника представляют (кодируют) последовательностями кодовых (чаще всего двоичных) символов так, чтобы по этим последовательностям можно было однозначно (без ошибок) восстановить исходные сообщения при декодировании. Задача состоит в том, чтобы эффективно закодировать сообщения, т. е. обеспечить наиболее экономное представление букв источника бинарными последовательностями При этом стремятся минимизировать среднее число битов Теорема 1 К При любом способе кодирования: 1) Таким образом, энтропия источника Таким образом, равномерный код, который широко используется в телеграфии (код Бодо), не является оптимальным для передачи текста телеграмм. При таком кодировании не учитывают статистические свойства источника и на передачу каждой из 32 букв русского языка тратится максимальное число двоичных символов, равное 5 бит. Согласно теореме 1 и статистике языка (см. табл. 8.2) возможно более аффективное кодирование, при котором в среднем на букву русского текста будет затрачено не более 1,5 бит, т. е. примерно в 3 раза меньше, чем в коде Бодо. Для реализации этих возможностей необходимо кодировать не отдельные буквы, а целые достаточно длинные последовательности букв (слова или даже фразы) и использовать для этого неравномерное кодирование, при котором более вероятным буквам (словам) присваивать короткие кодовые комбинации, а тем буквам (словам), которые встречаются редко, присваивать более длинные кодовые комбинации. В настоящее время разработано много методов эффективного кодирования для различных источников. Известные код Хаффмэна и код Шеннона — Фано, учитывающие только распределения вероятностей букв, не являются эффективными [178]. Коды же, учитывающие статистические связи между буквами, оказываются сложными и требуют значительной задержки передачи при кодировании и декодировании длинных последовательностей сообщений источника. Задача эффективного кодирования наиболее актуальна не для передачи текста (телеграфии), а для других источников, обладающих большой избыточностью. К ним, в частности, относятся источники звуковых, видео- и телеметрических сообщений. В большинстве случаев эти источники относятся к классу источников непрерывных сообщений, которые рассматриваются в § 8.5.
|
 |
Оглавление
|











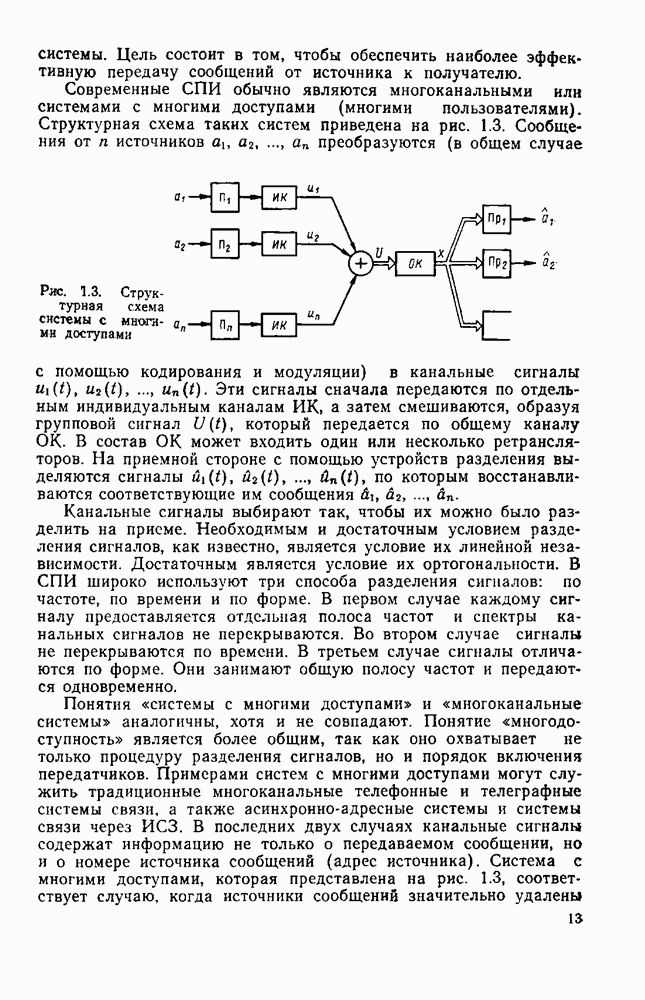









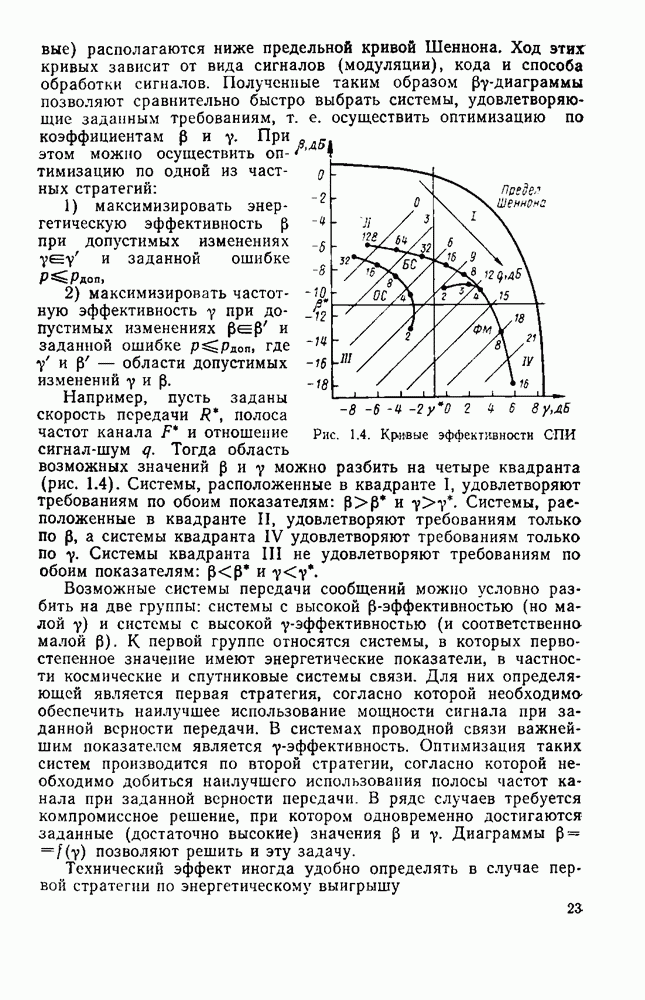





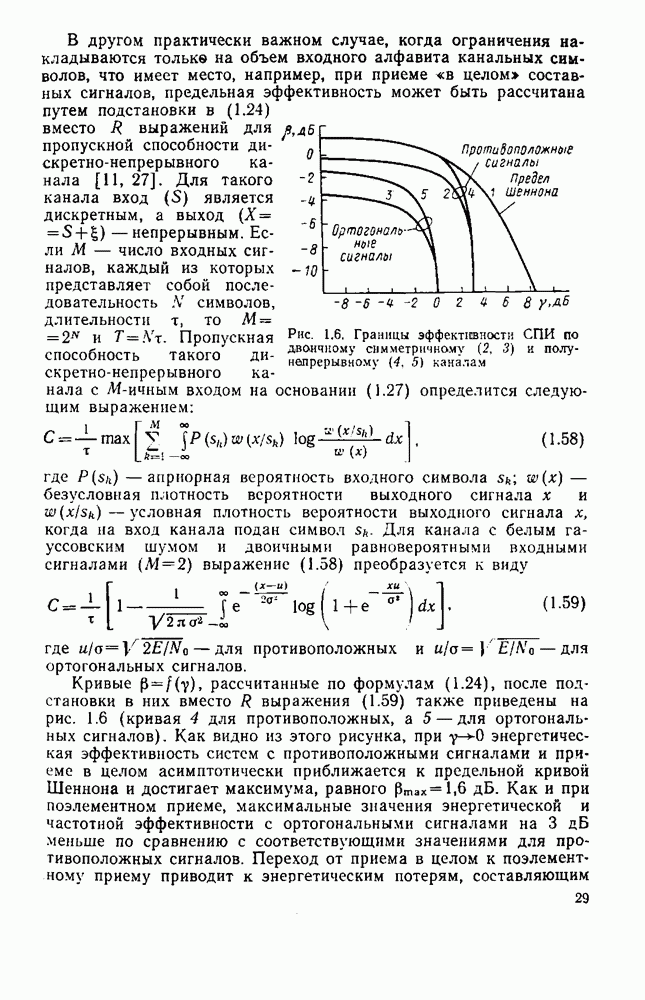









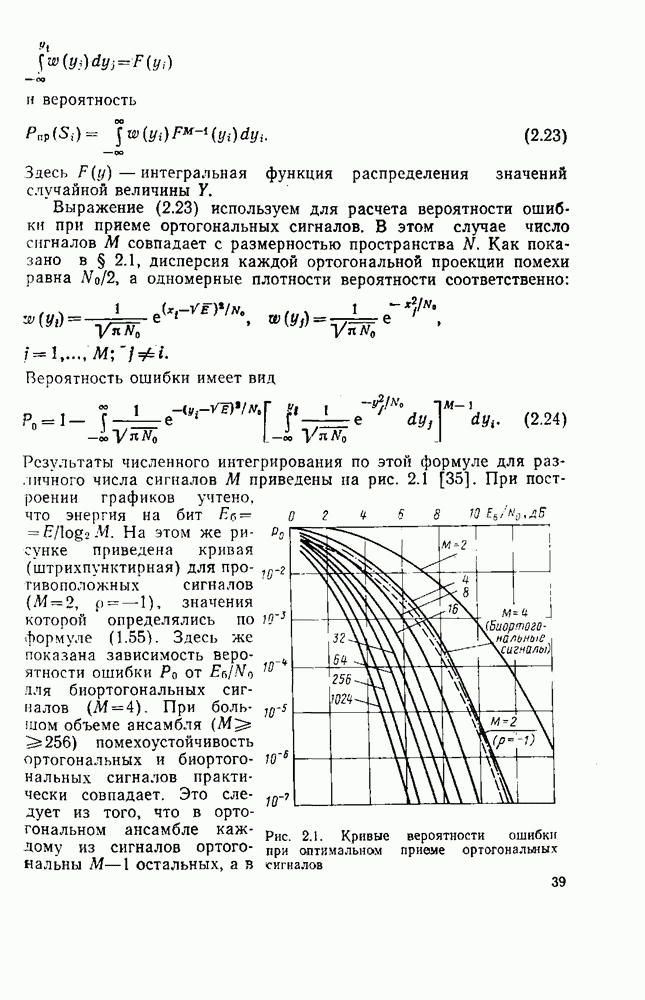




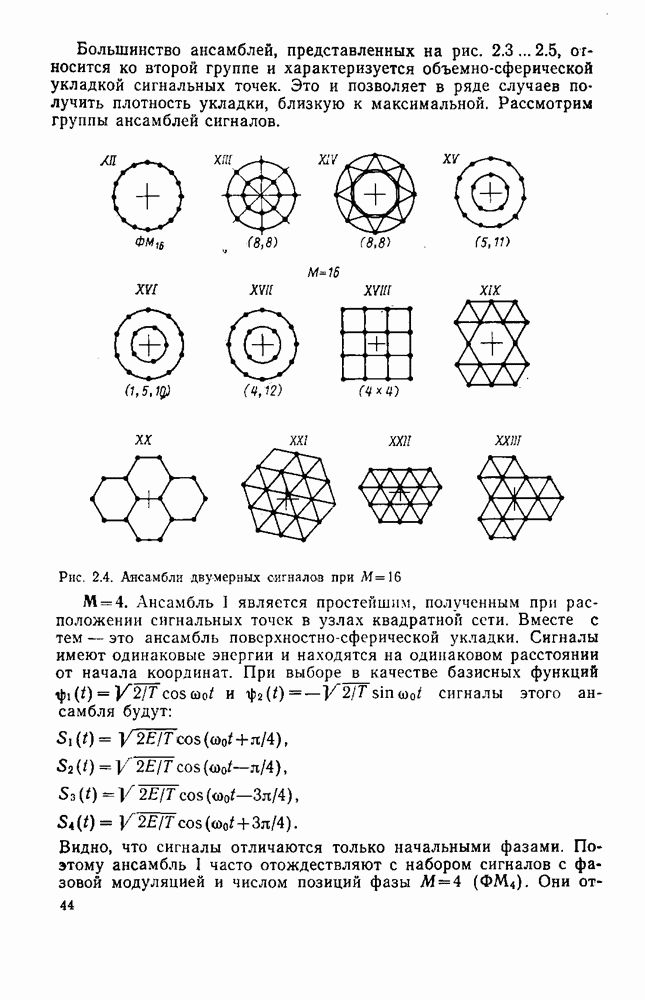
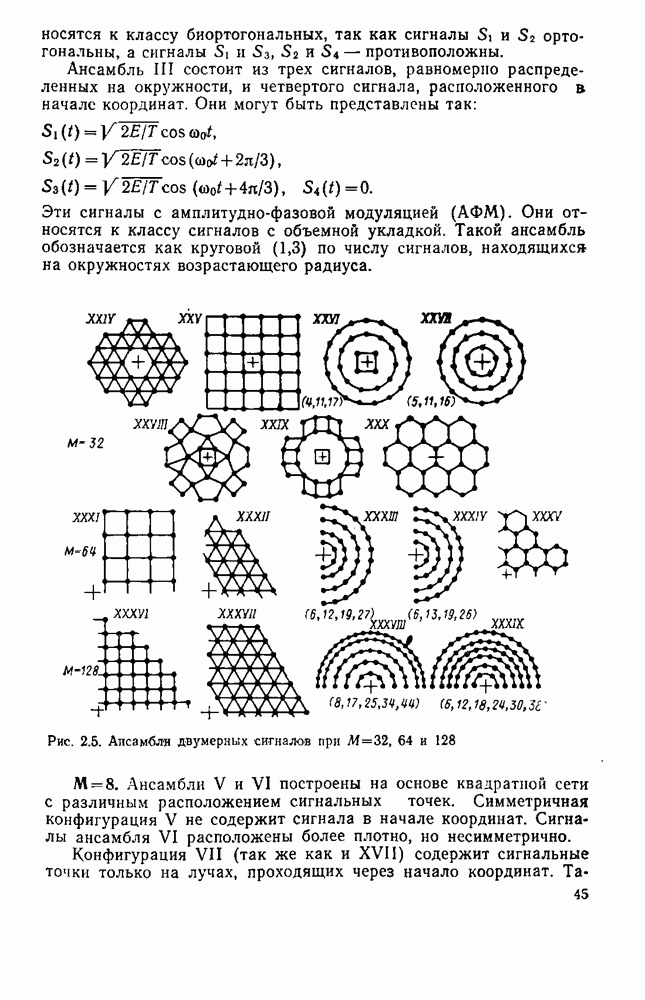

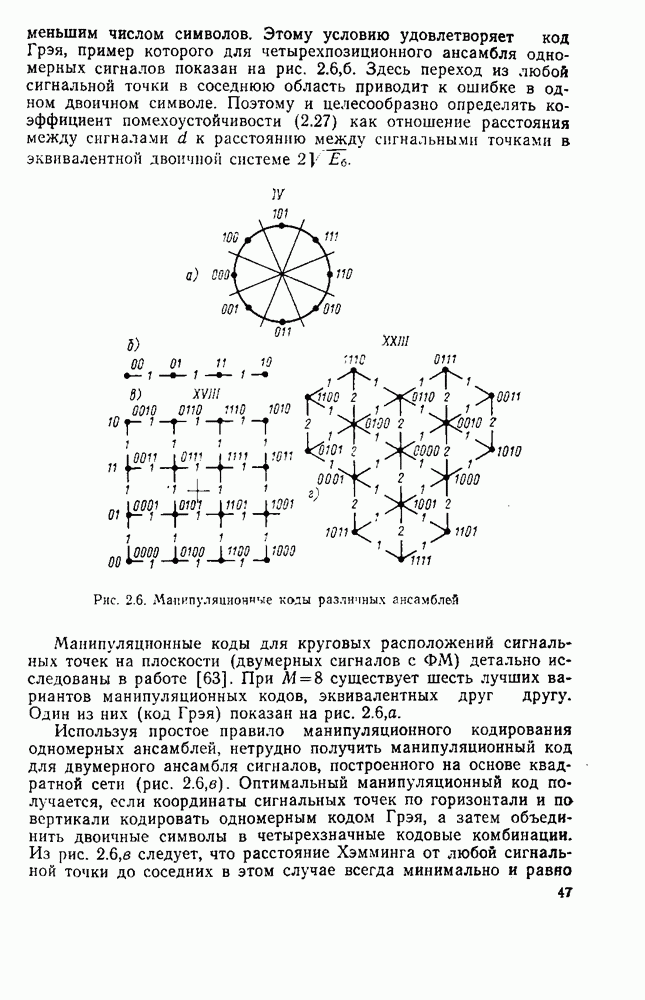

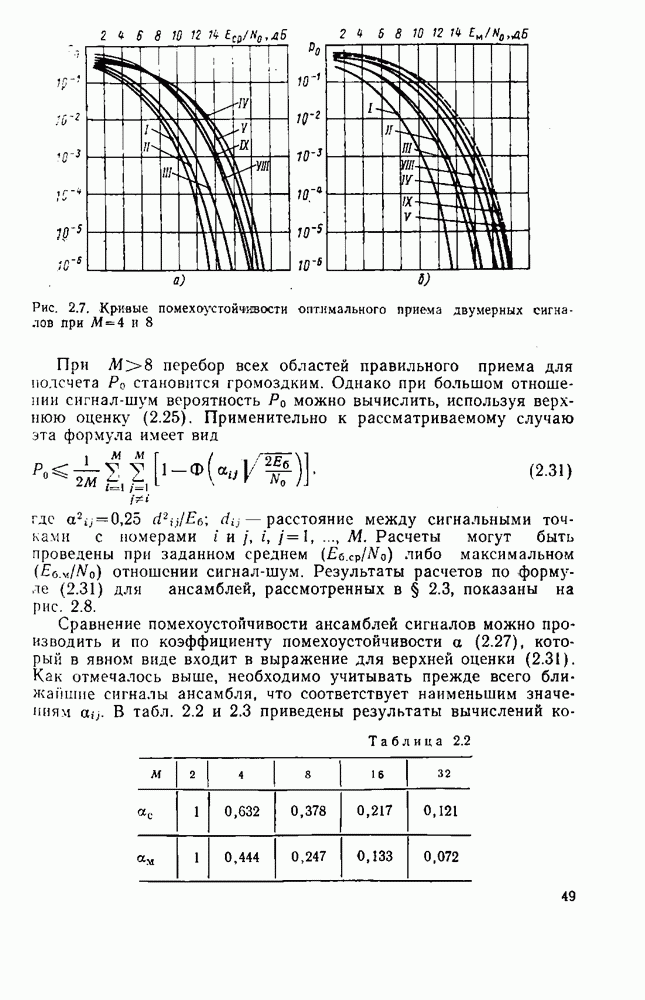
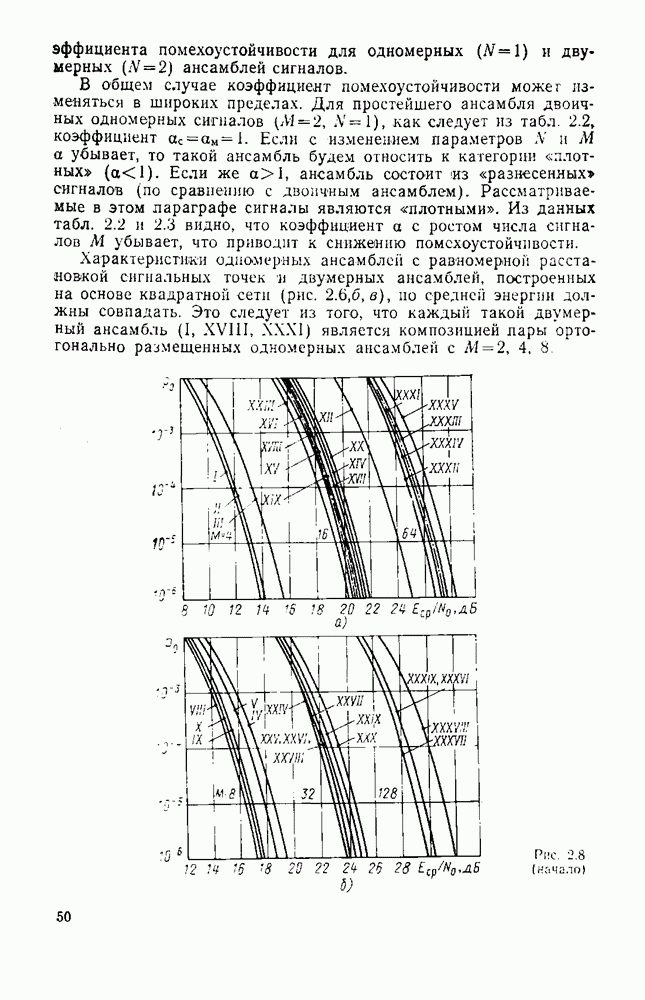
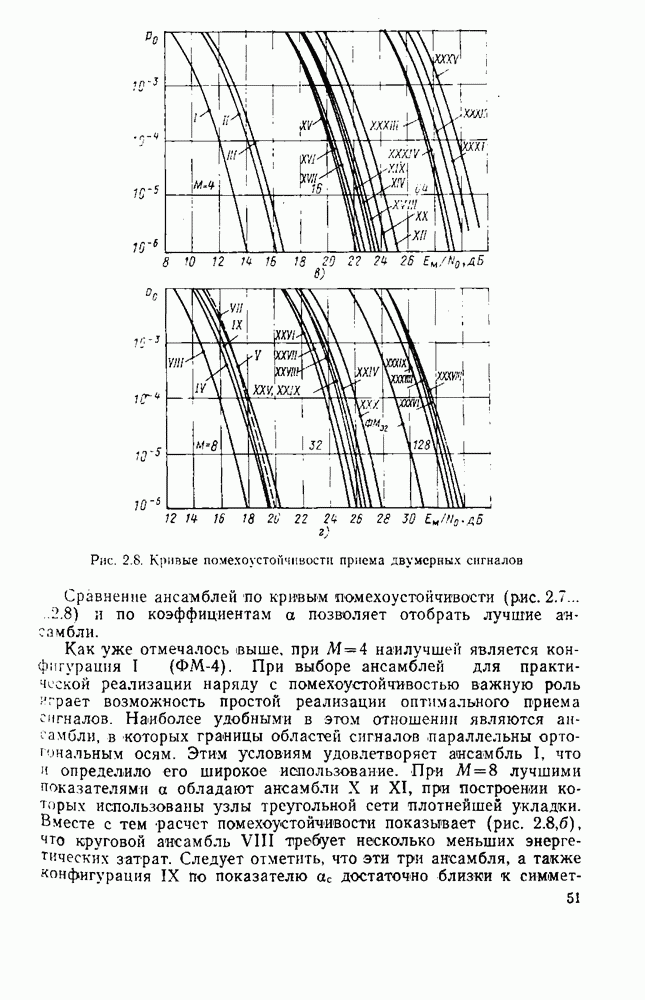




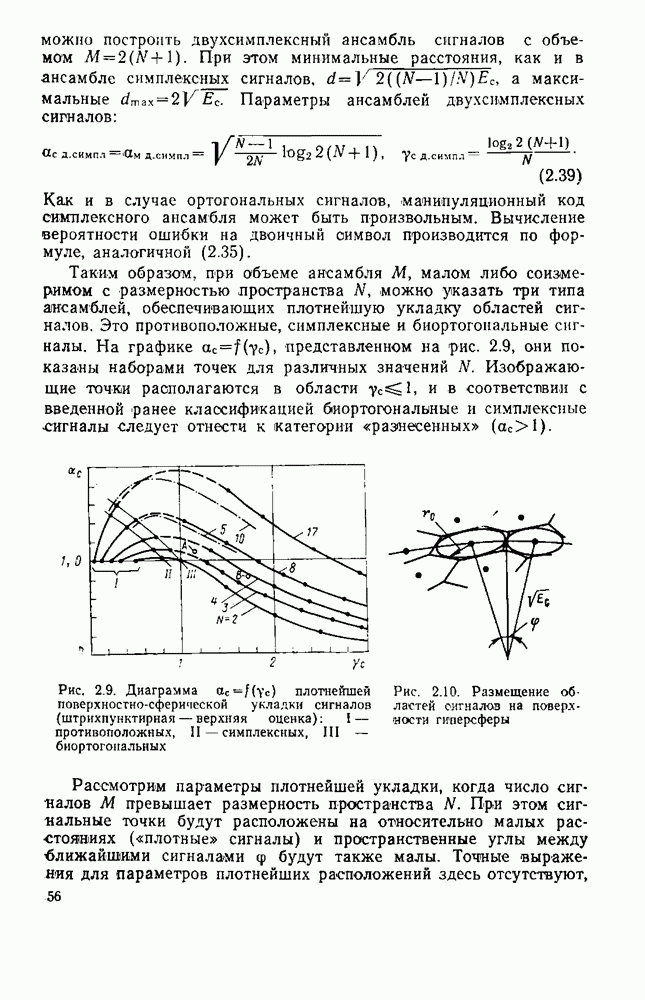



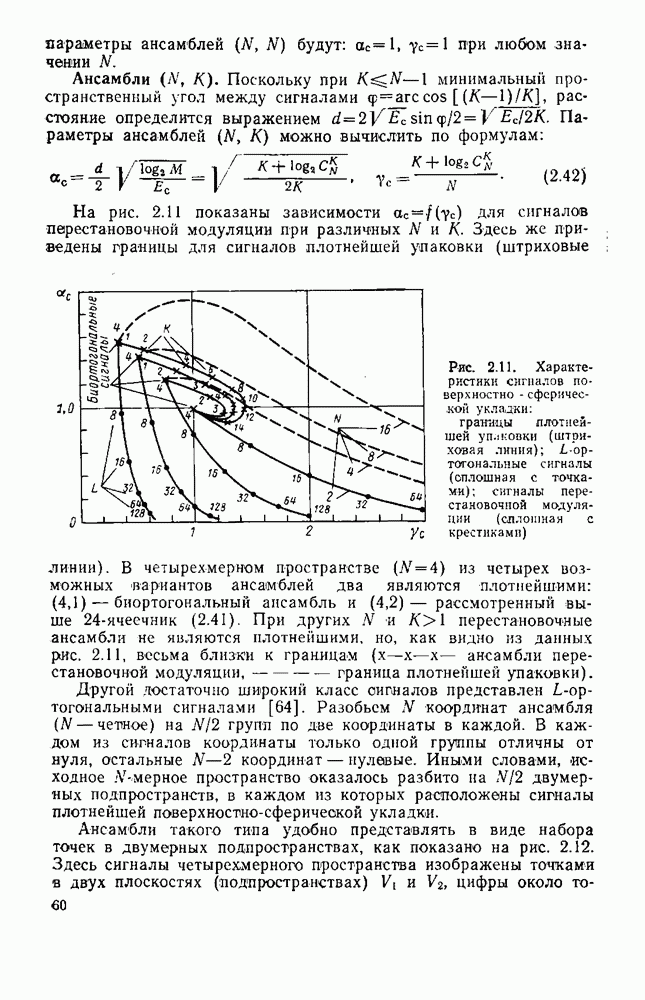














































































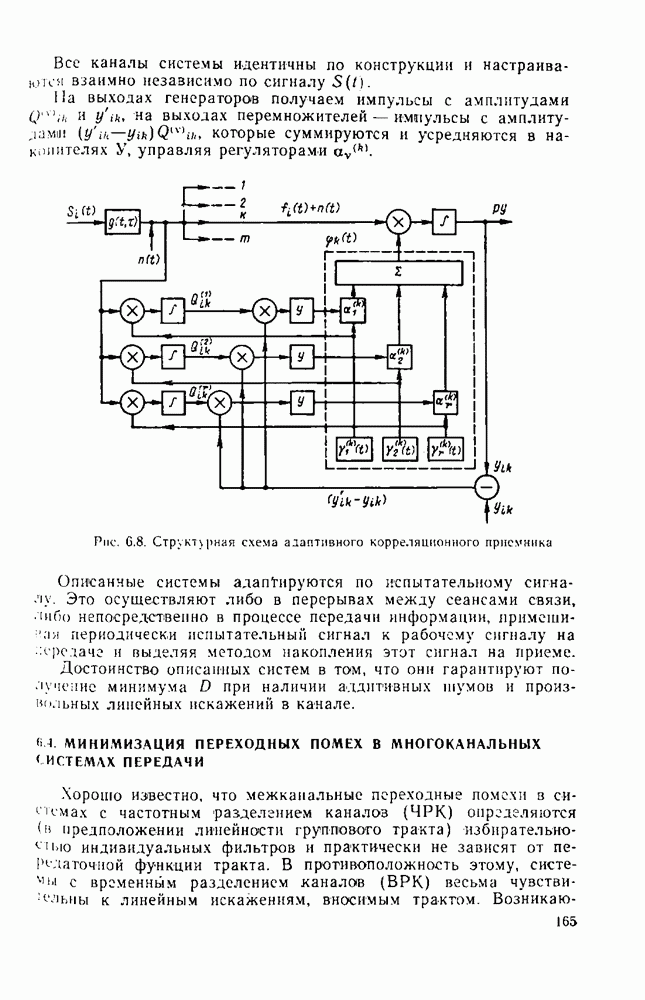



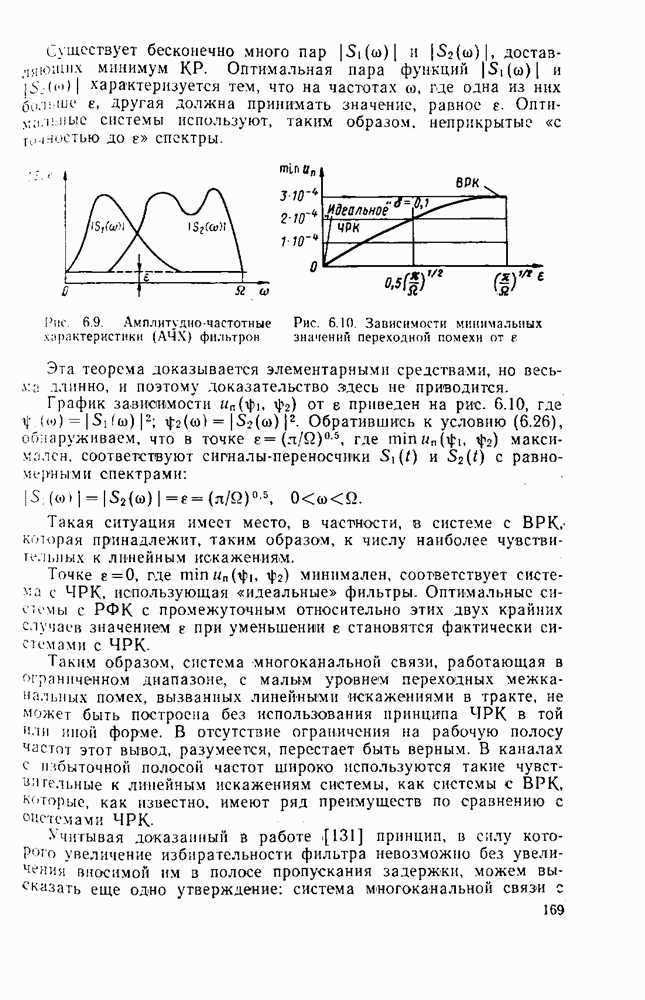




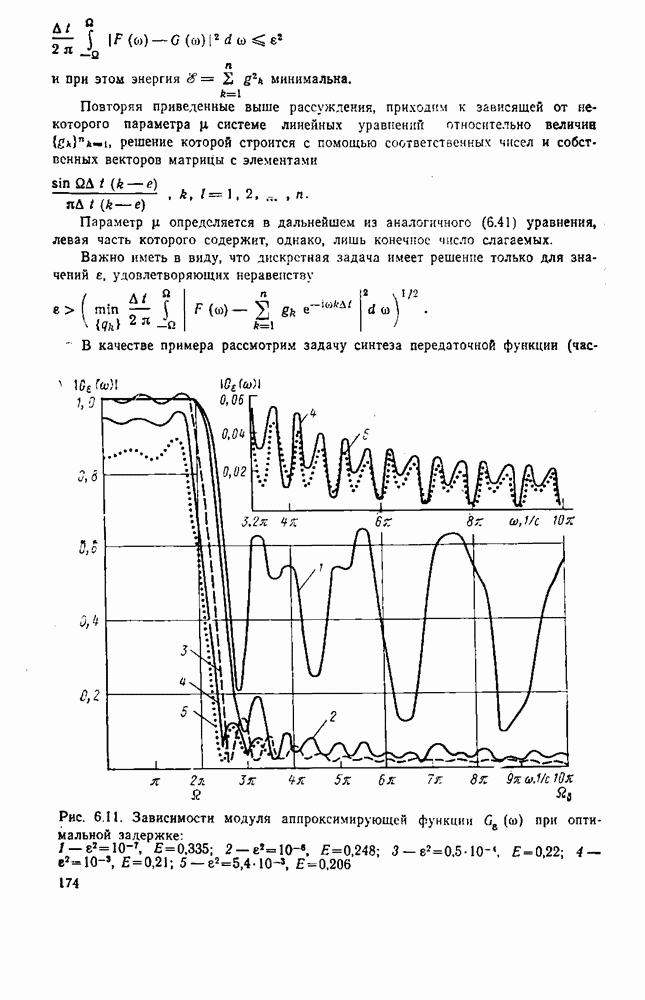
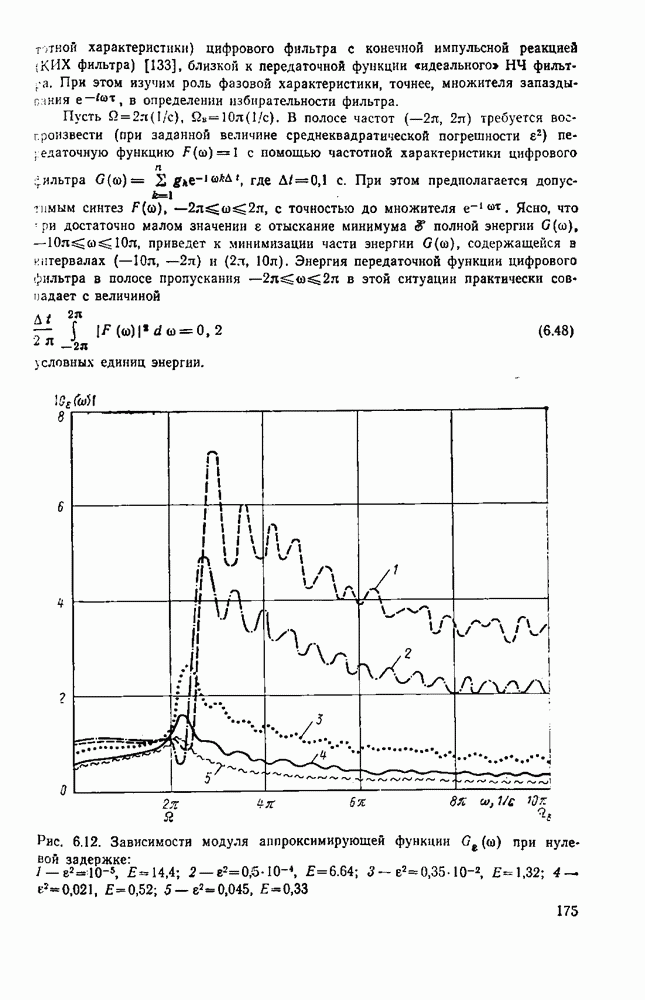
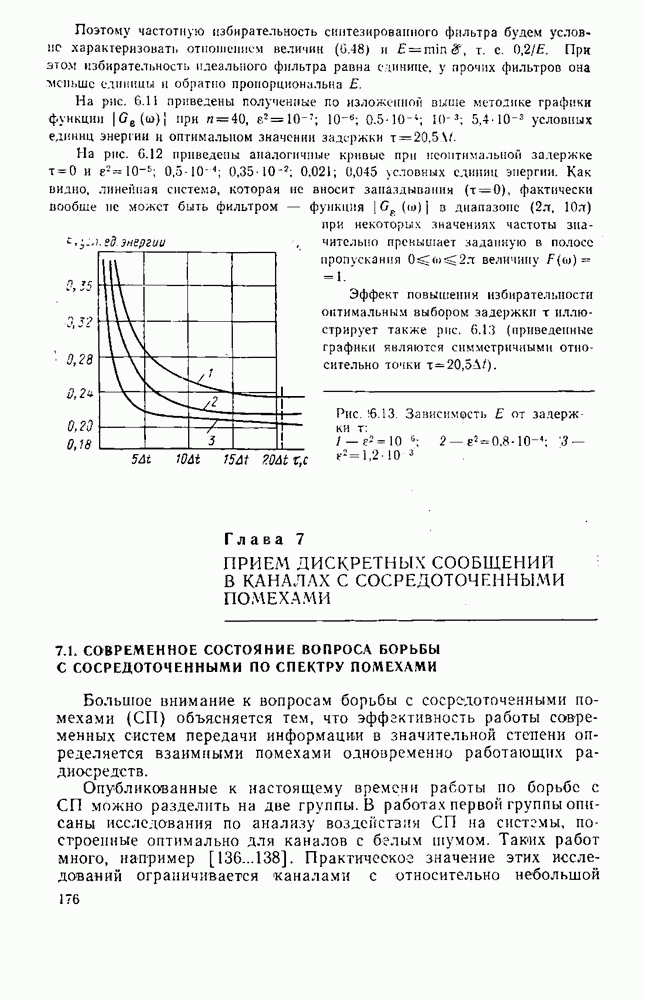










































































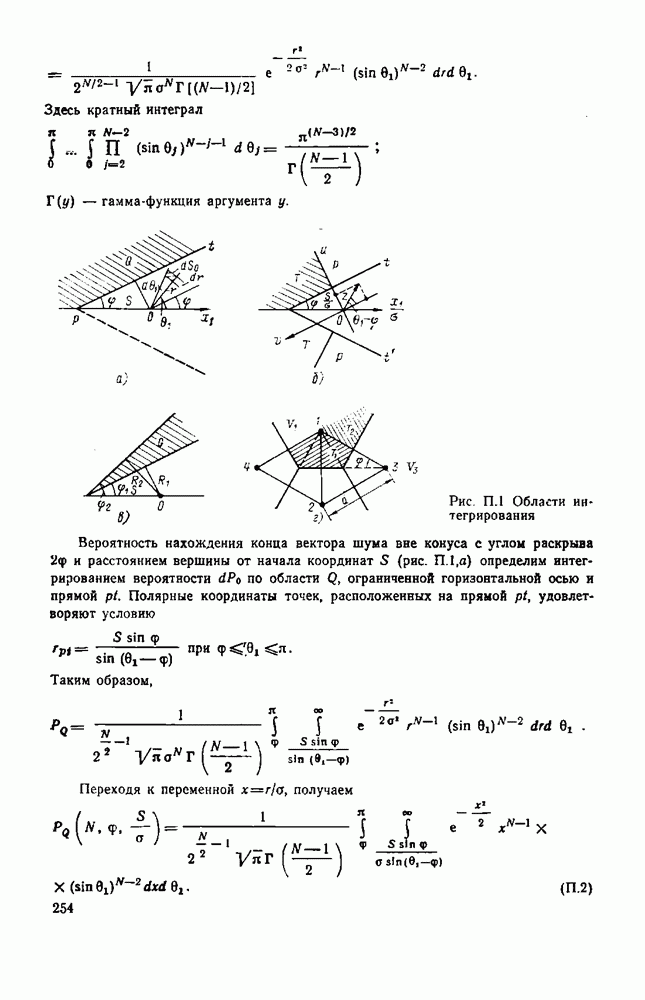














 вероятность того, что на выходе источника появляется буква
вероятность того, что на выходе источника появляется буква 
 . В этом случае
. В этом случае

 можно рассматривать как степень приближения распределения вероятностей сообщений данного источника к равномерному распределению.
можно рассматривать как степень приближения распределения вероятностей сообщений данного источника к равномерному распределению.
 Если
Если  то согласно (8.1)
то согласно (8.1)

 вероятность появления гласных О, Е, И больше, чем согласных; после гласных не может появиться мягкий знак, мала вероятность появления в тексте более трех согласных подряд и т. д.
вероятность появления гласных О, Е, И больше, чем согласных; после гласных не может появиться мягкий знак, мала вероятность появления в тексте более трех согласных подряд и т. д.
 букв. В частности, текст на русском языке достаточно хорошо аппроксимируется цепью Маркова.
букв. В частности, текст на русском языке достаточно хорошо аппроксимируется цепью Маркова.
 или условной энтропии
или условной энтропии  [27], т. е.
[27], т. е.



 энтропия источника, когда учитывается статистическая связь между двумя сообщениями
энтропия источника, когда учитывается статистическая связь между двумя сообщениями
 - энтропия источника с учетом трехбуквенных сочетании и т. д.
- энтропия источника с учетом трехбуквенных сочетании и т. д.


 обратная величине
обратная величине 

 данным различных авторов, для русского языка лежит в пределах
данным различных авторов, для русского языка лежит в пределах  бит на букву, для английского 0,6 1,3 бит. Расчеты показывают, что
бит на букву, для английского 0,6 1,3 бит. Расчеты показывают, что  (различие не превышает
(различие не превышает 

 и что между буквами имеется статистическая связь (обозначим эту избыточность через
и что между буквами имеется статистическая связь (обозначим эту избыточность через  Очевидно, полная избыточность источника [2]
Очевидно, полная избыточность источника [2]

 Следовательно, основная избыточность языка обусловлена статистической связью между буквами
Следовательно, основная избыточность языка обусловлена статистической связью между буквами 
 на букву источника. Этот минимум, как известно, определяется энтропией источника
на букву источника. Этот минимум, как известно, определяется энтропией источника  . В теории информации доказывается следующая теорема.
. В теории информации доказывается следующая теорема.
 ; 2) существует способ кодирования, при котором величина
; 2) существует способ кодирования, при котором величина  будет сколь угодно близкой к
будет сколь угодно близкой к 
 определяет предельное значение двоичных символов, необходимых для представления букв источника. Теорема 1 остается справедливой и в том случае, когда вместо двоичного используется
определяет предельное значение двоичных символов, необходимых для представления букв источника. Теорема 1 остается справедливой и в том случае, когда вместо двоичного используется  -ичное кодирование, по с той разницей, что логарифм при определении энтропии берется по основанию
-ичное кодирование, по с той разницей, что логарифм при определении энтропии берется по основанию  Для источника, все буквы которого независимы и равновероятны, оптимальным будет равномерный код. В этом случае
Для источника, все буквы которого независимы и равновероятны, оптимальным будет равномерный код. В этом случае  Выберем для передачи каждой буквы последовательность из
Выберем для передачи каждой буквы последовательность из  бинарных символов. Количество различных последовательностей равно
бинарных символов. Количество различных последовательностей равно  Далее можно потребовать, чтобы
Далее можно потребовать, чтобы  (предполагается, что К — целая степень двух). Отсюда
(предполагается, что К — целая степень двух). Отсюда 