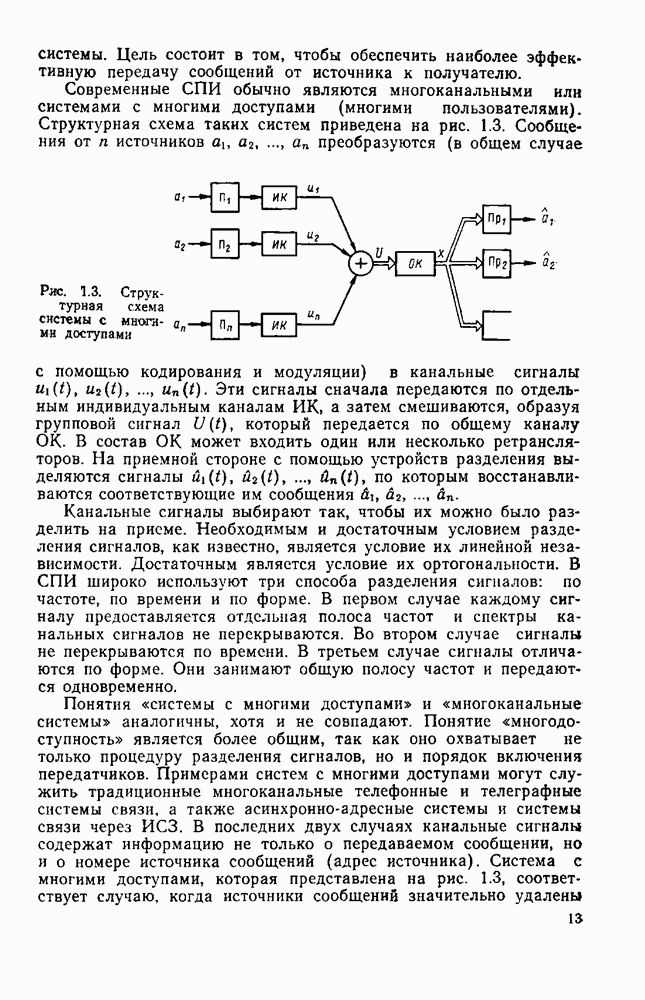
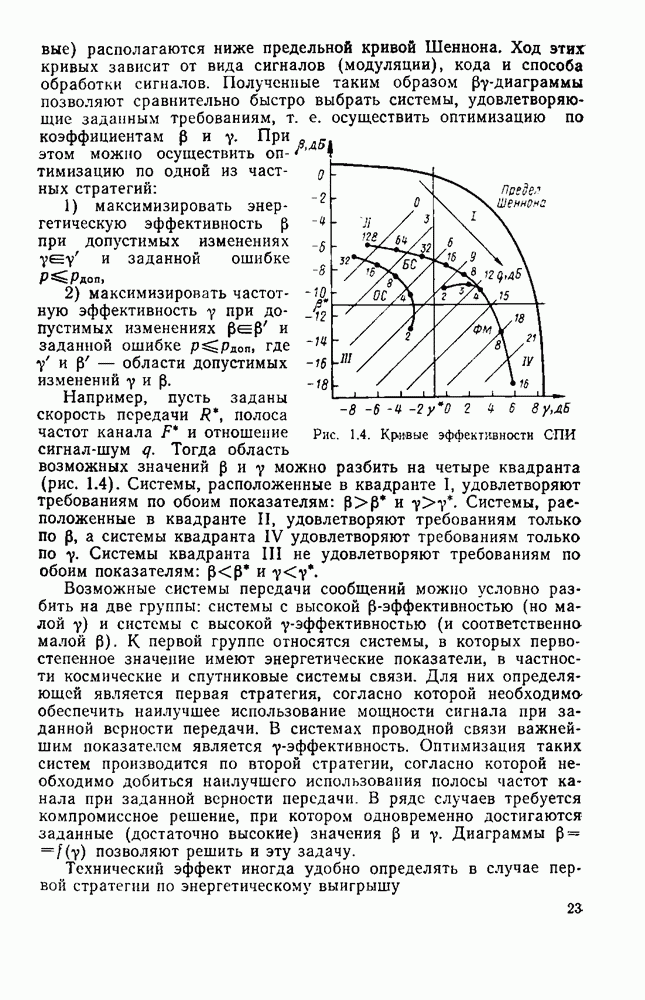
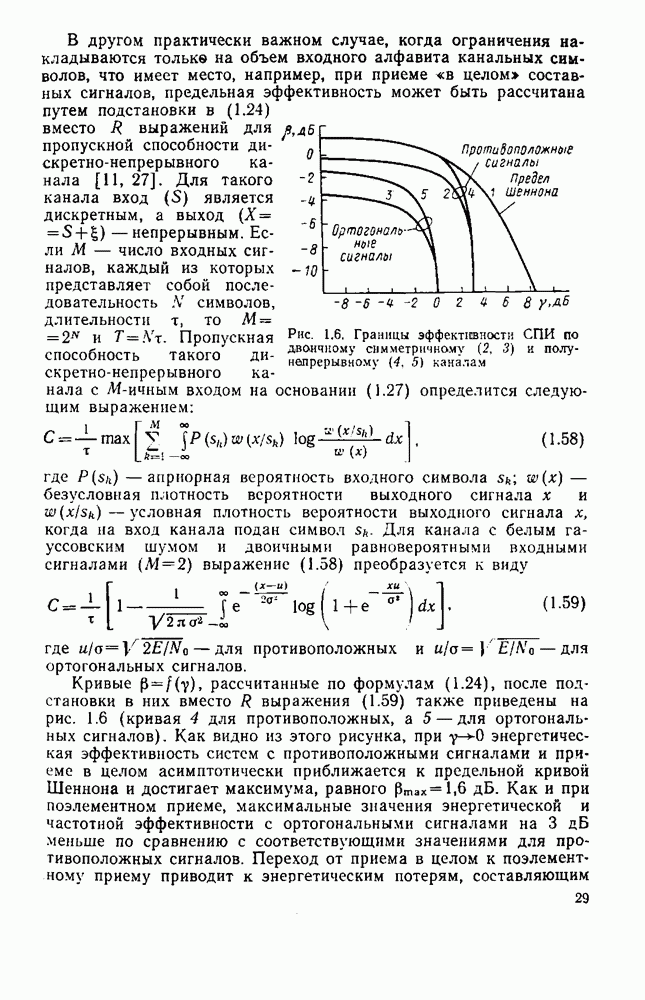
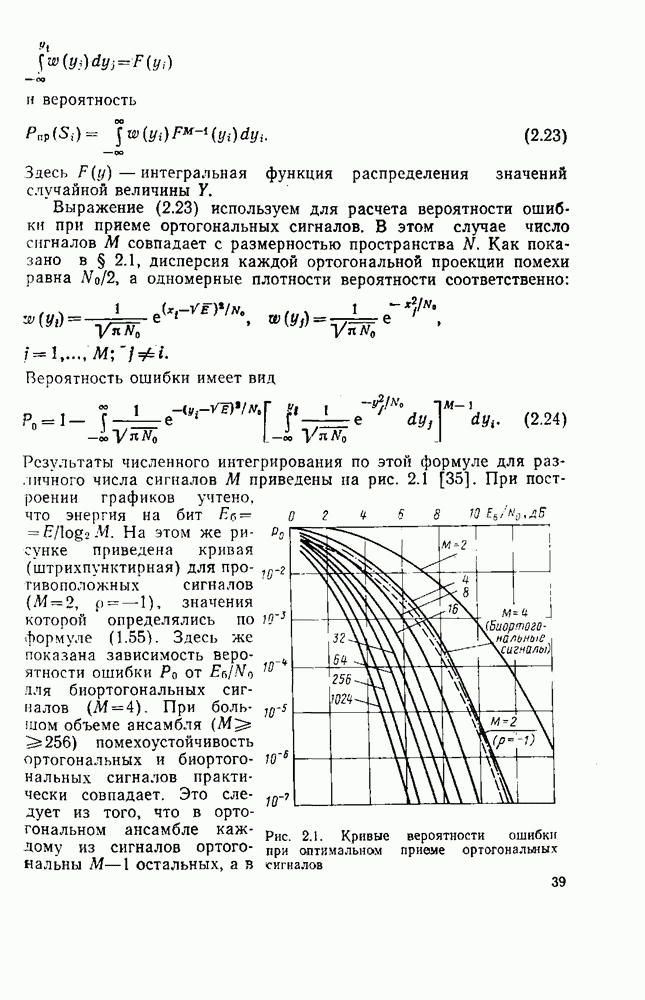
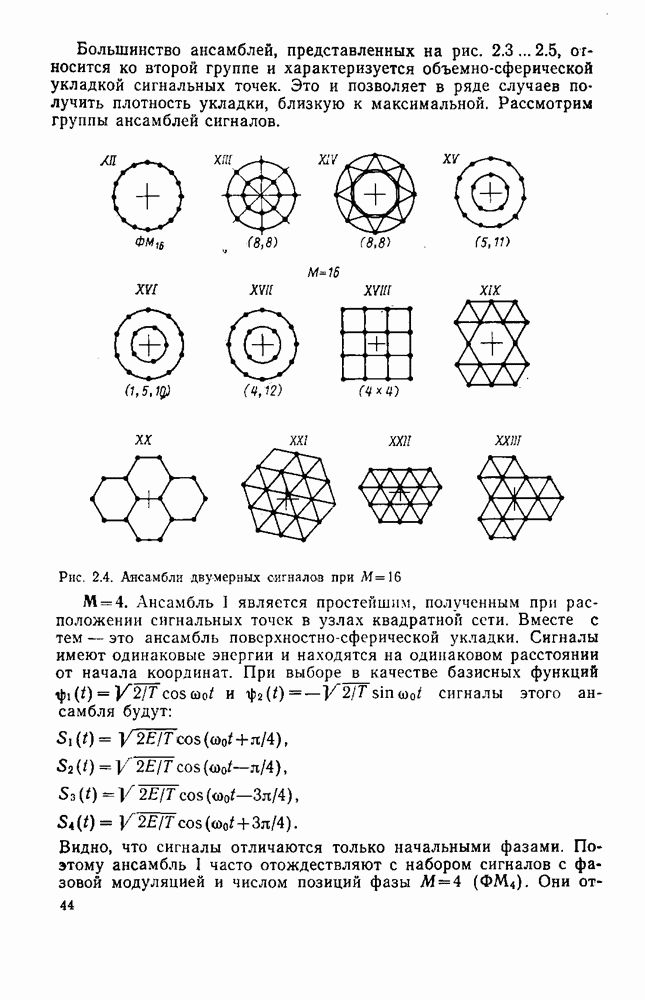
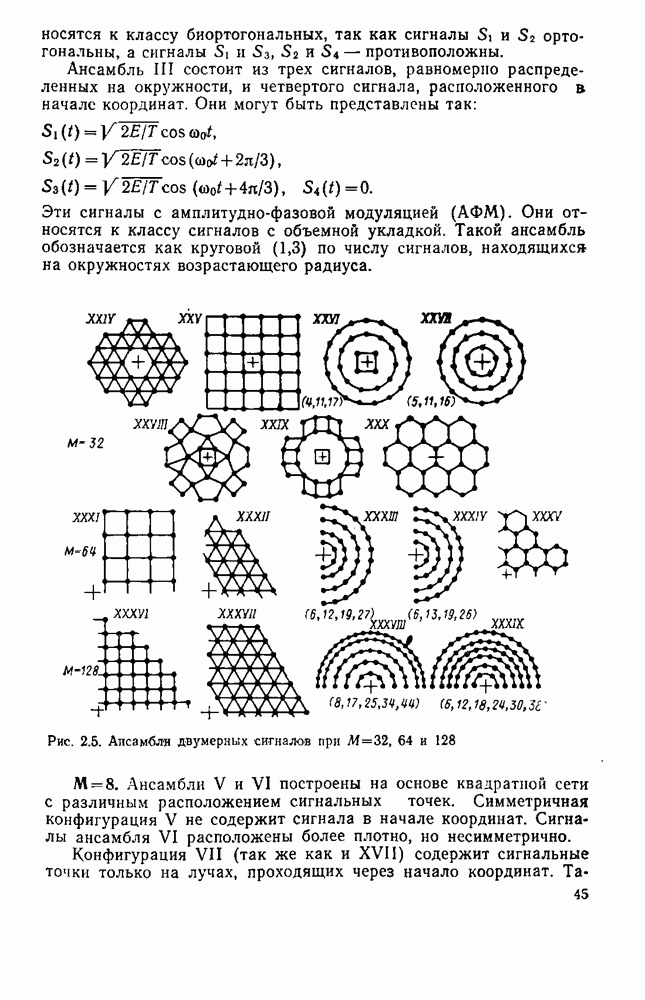
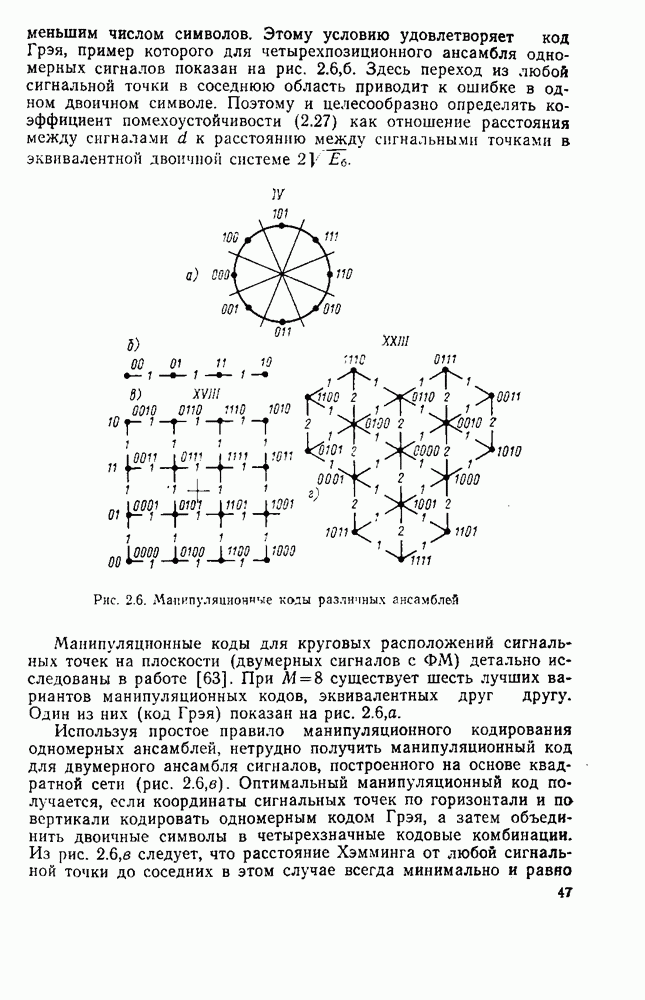
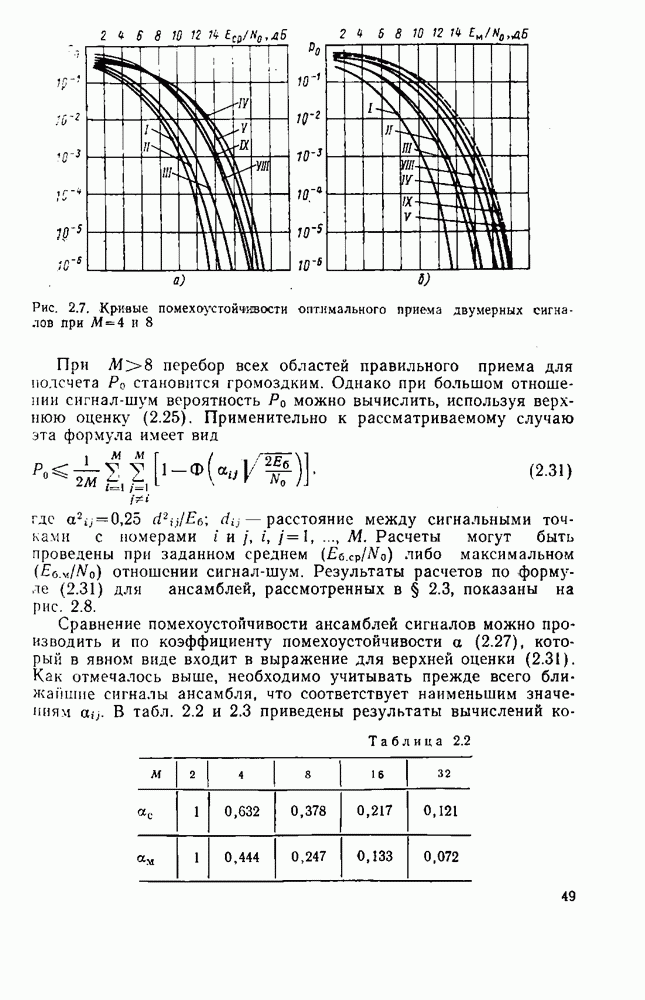
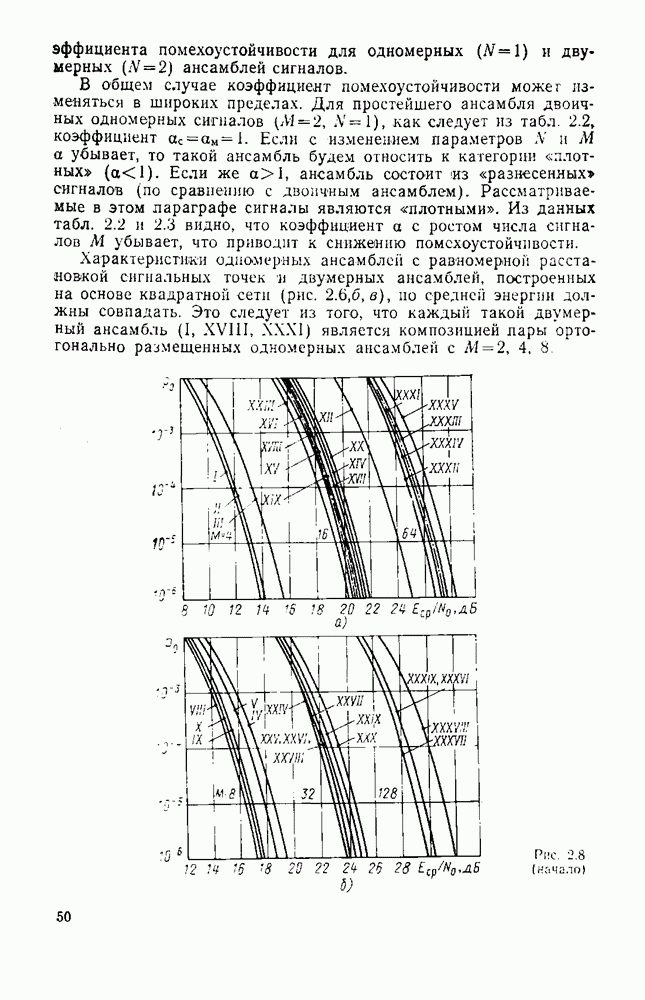
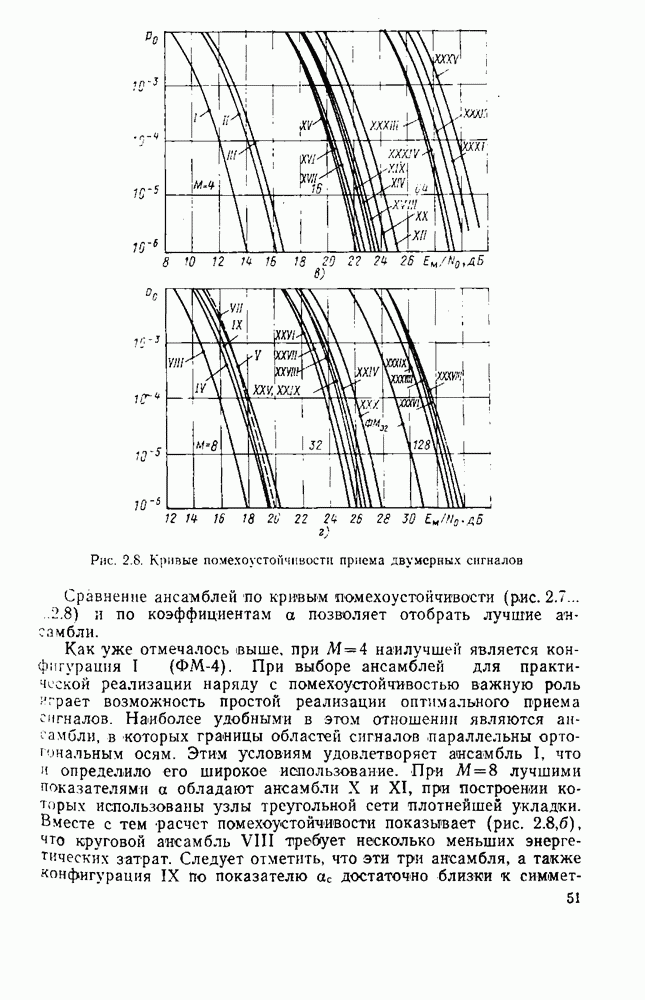
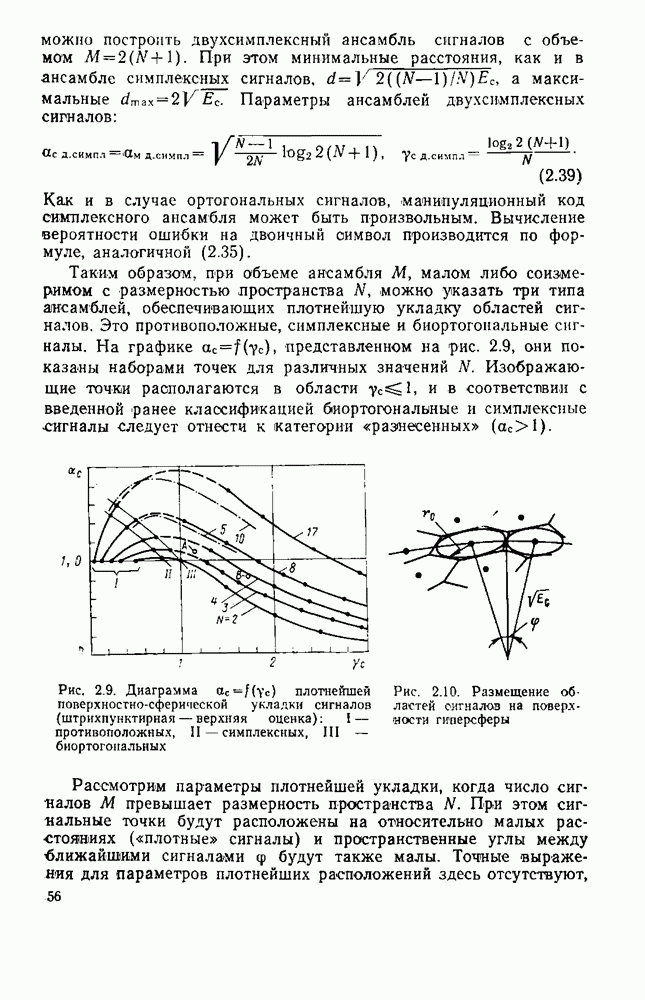
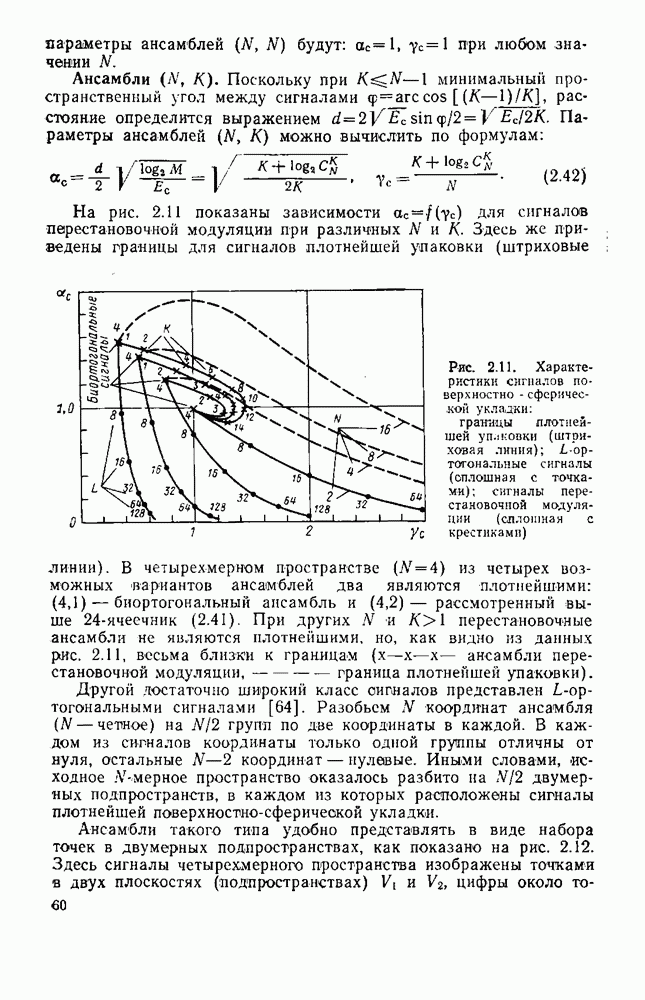
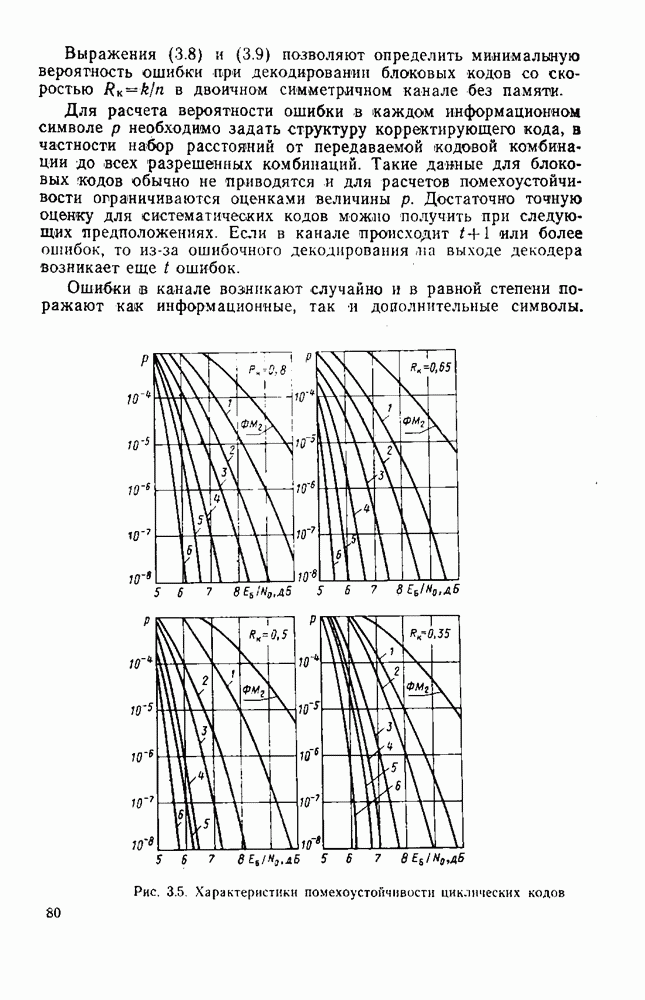
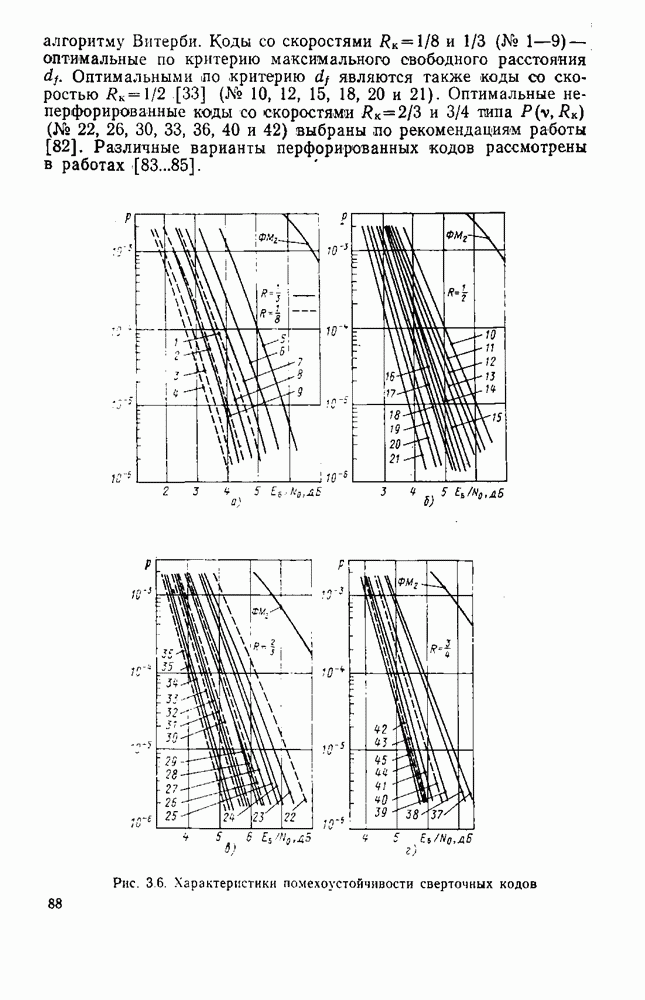
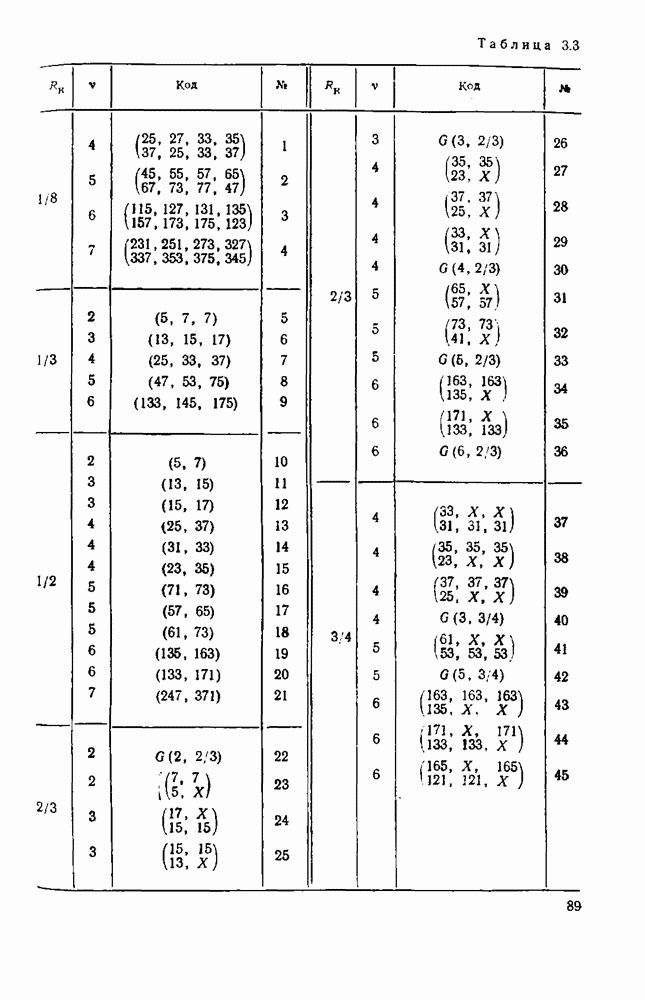
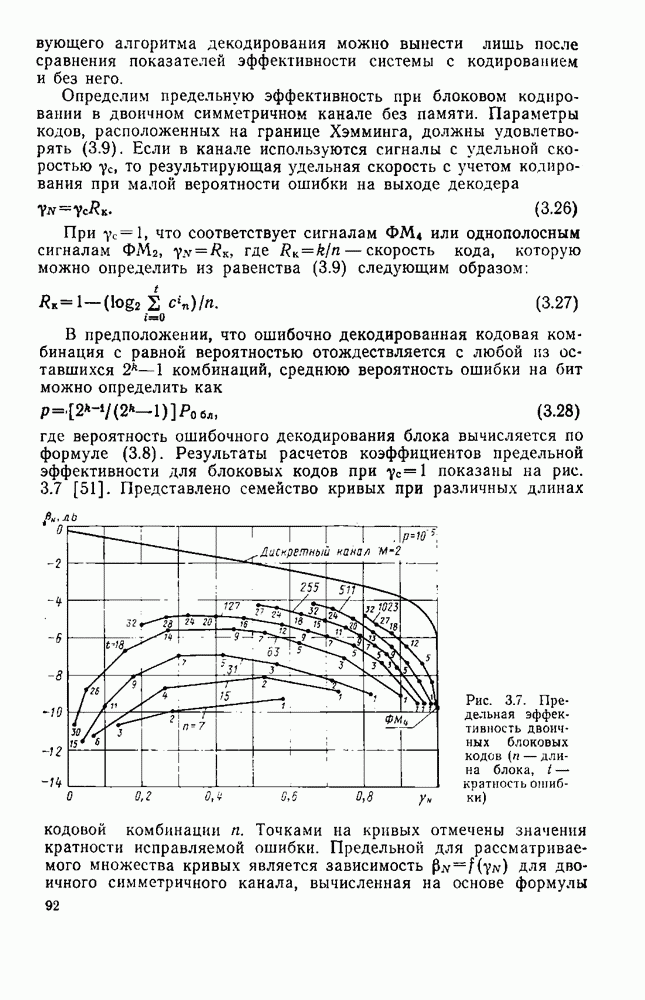
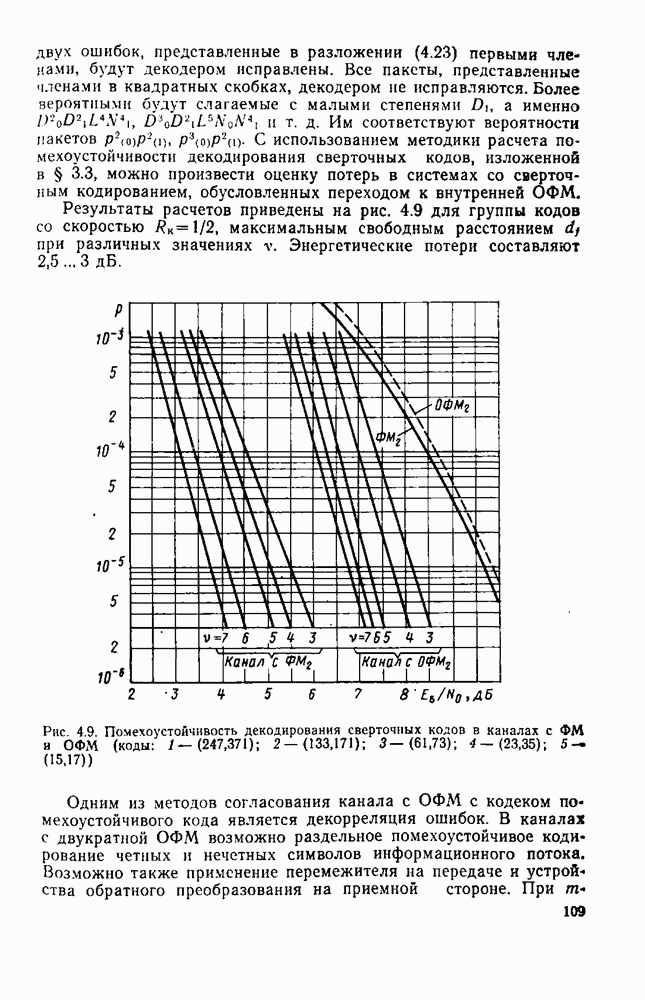
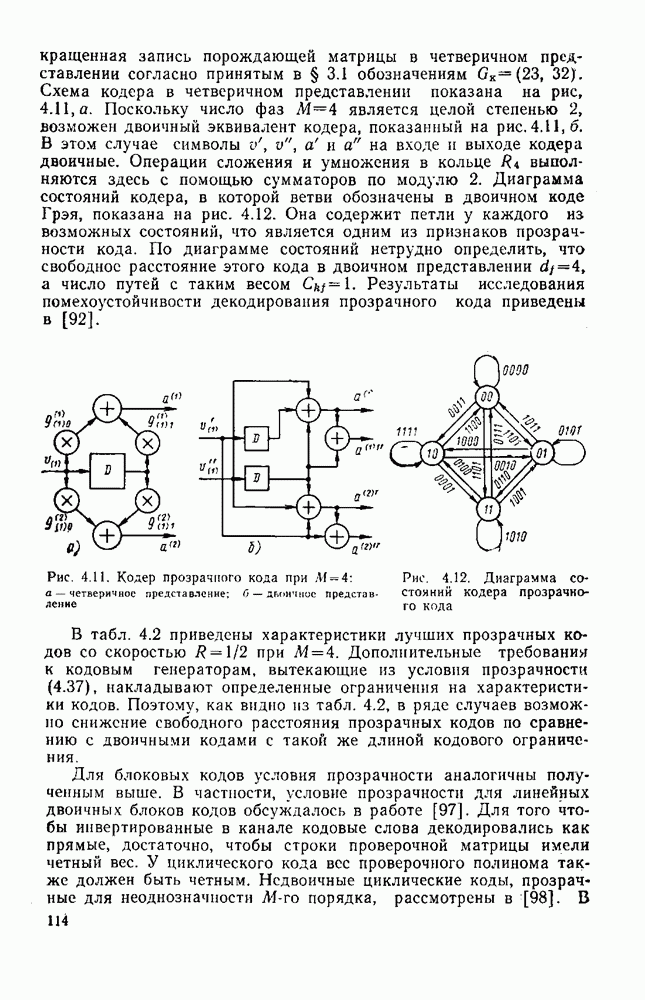
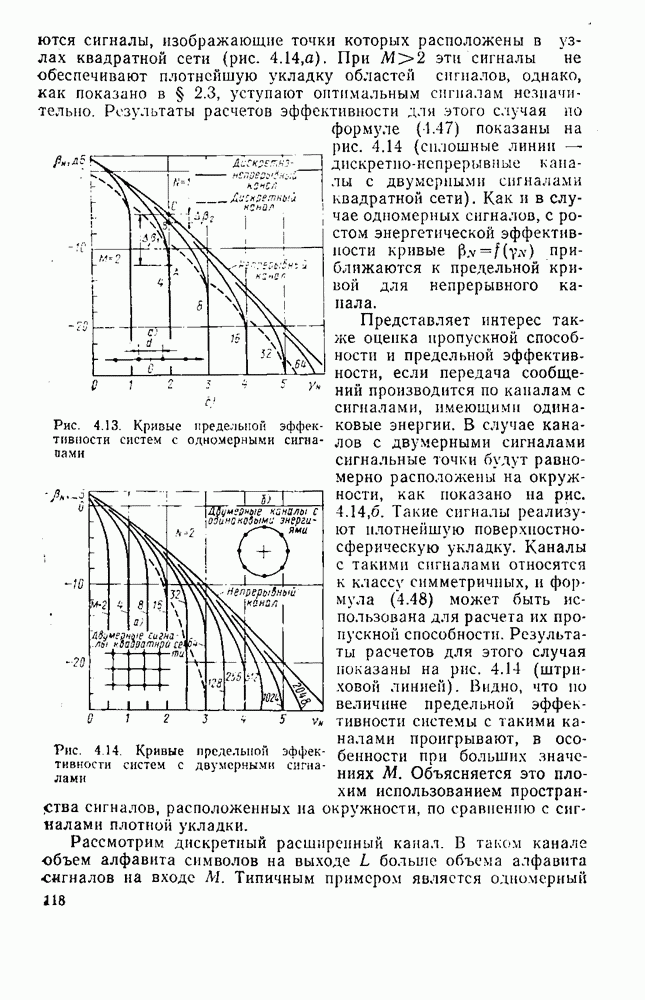
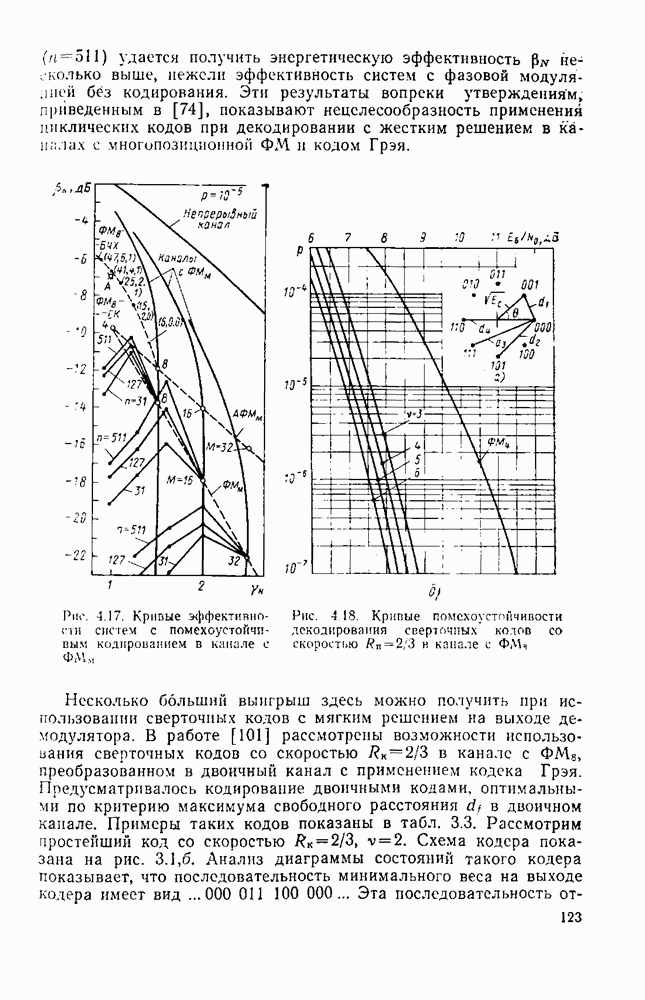
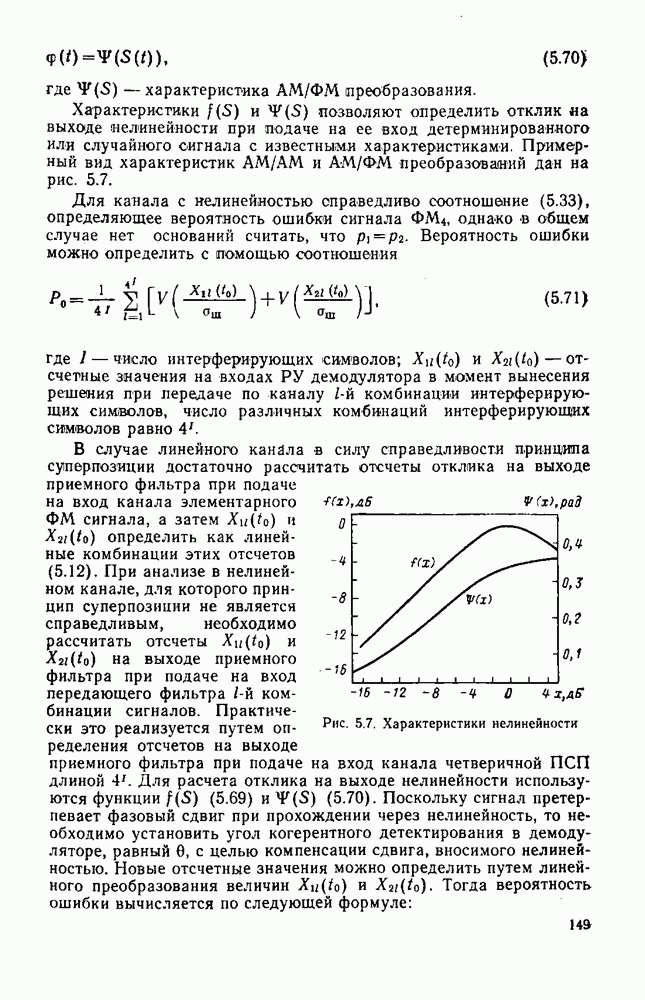
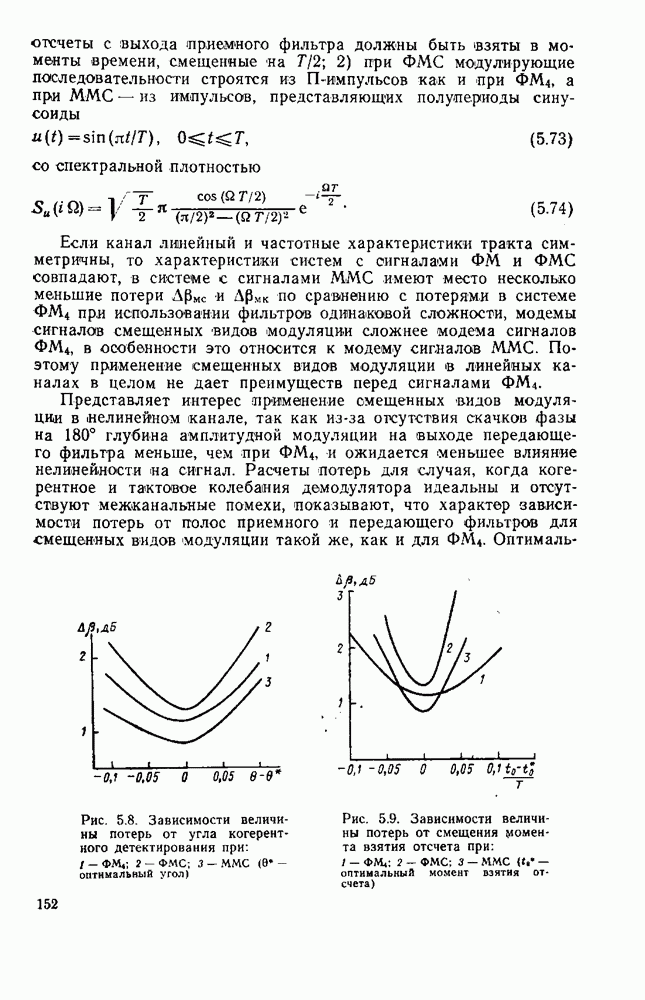
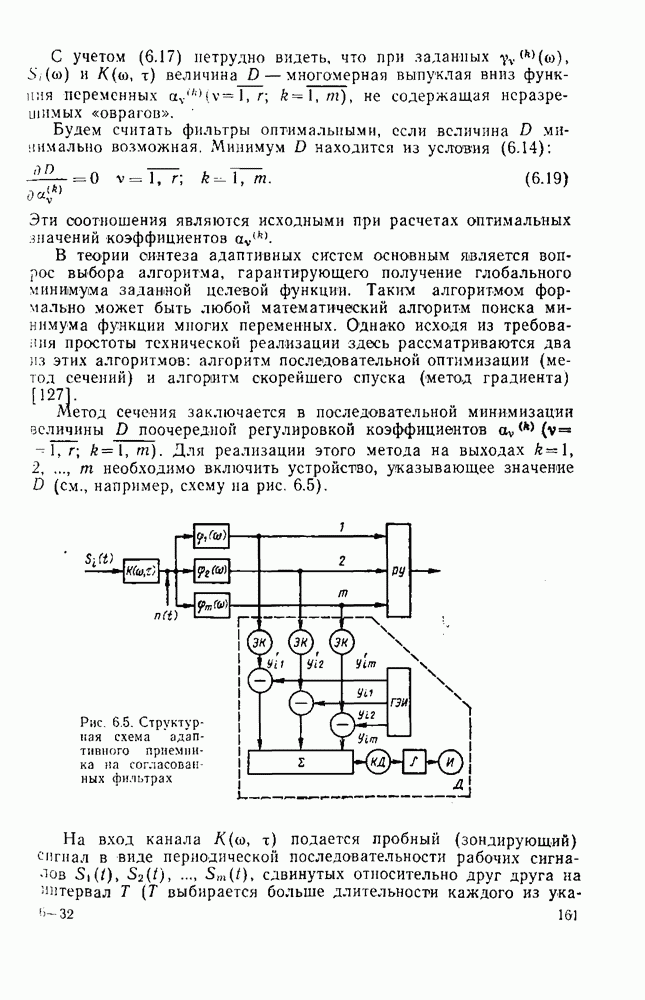
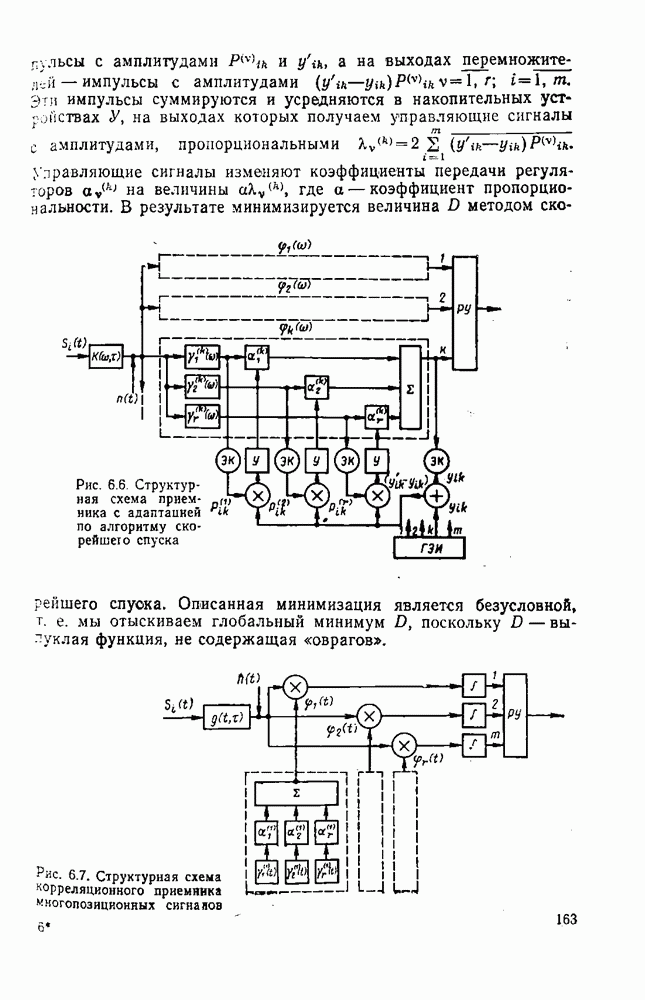
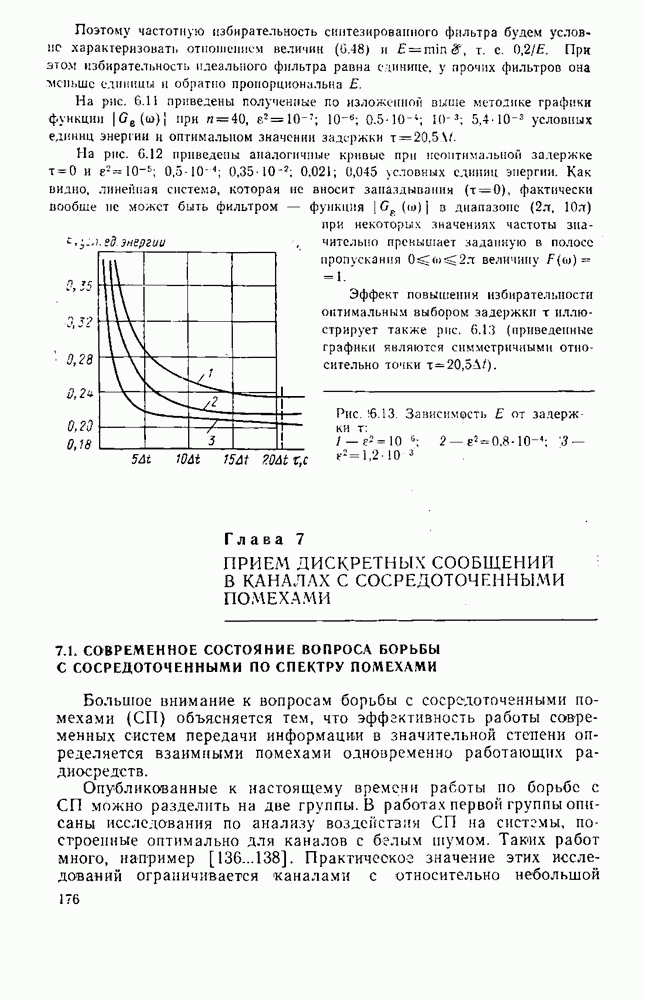
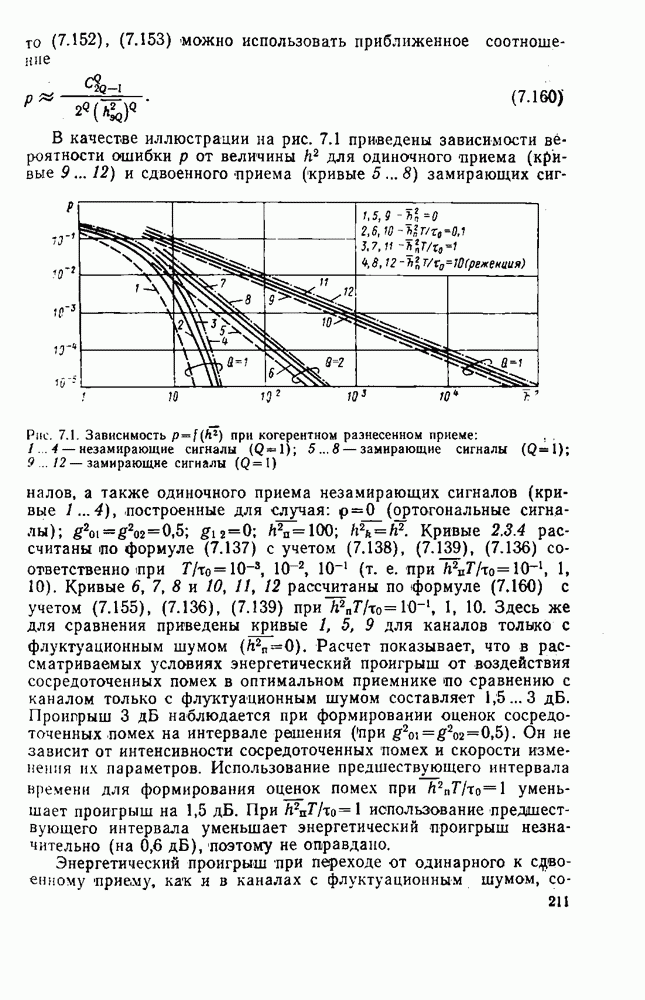
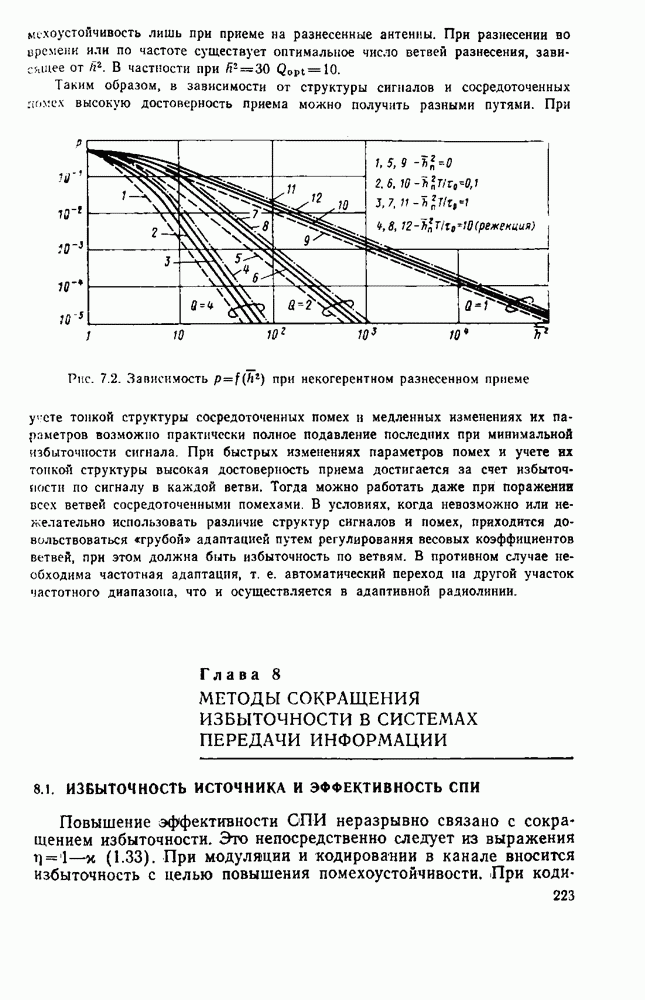
8.4. СОВМЕСТНОЕ КОДИРОВАНИЕ ДЛЯ ИСТОЧНИКА И КАНАЛА
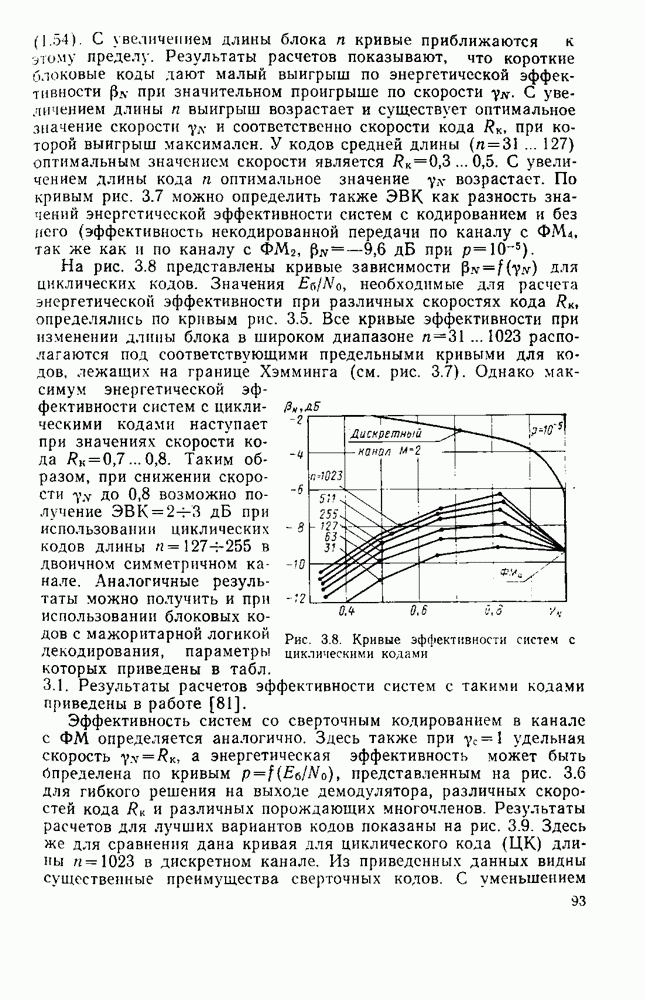
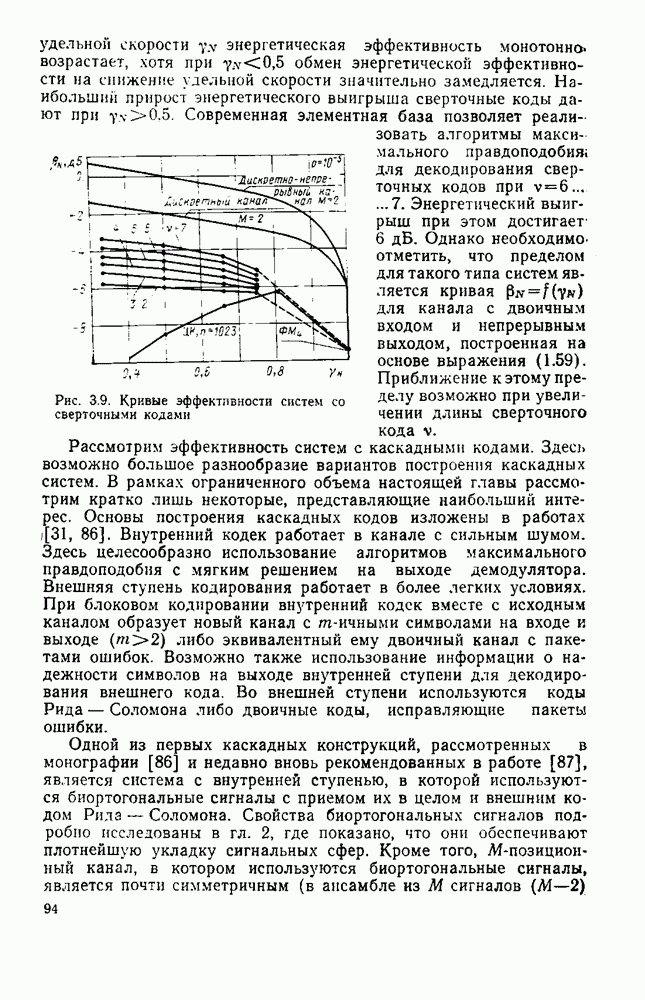
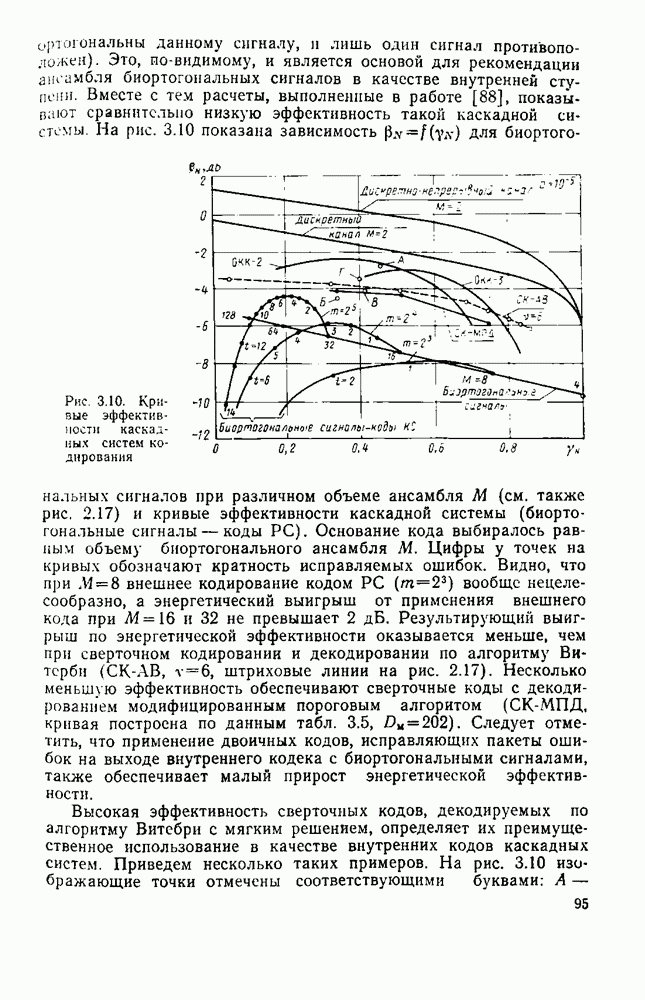
Оптимальную по Шеннону СПИ можно построить либо по схеме с раздельным кодированием для источника и для канала (см. рис. 1.2), либо по схеме с совместным кодированием (см. рис. 1.1), в которой функции кодирования для источника и для канала объединены в одном блоке-передатчике, а функции декодирования для канала и для источника — в другом блоке-приемнике, В принципиальном отношении эти схемы, очевидно, равноценны. Однако их практическая реализация и соответственно их сложность могут быть существенно различными Из теории информации [26] известно, что при данной эффективности  и заданной верности
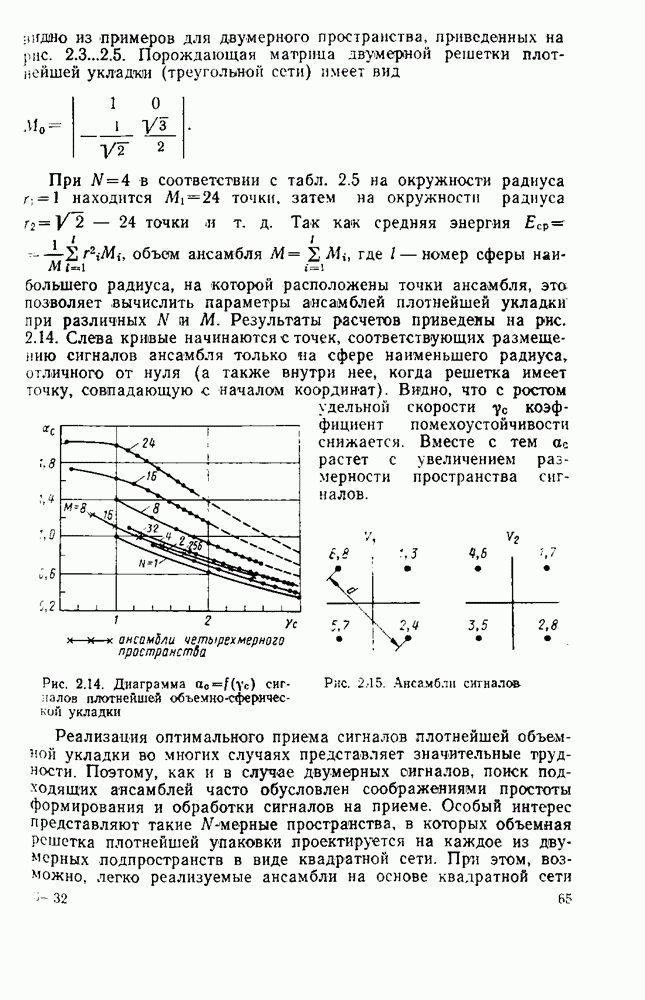
и заданной верности  достигаемых при раздельном кодировании источника и канала, существует система совместного кодирования для тех же источника и канала, которая при той же эффективности
достигаемых при раздельном кодировании источника и канала, существует система совместного кодирования для тех же источника и канала, которая при той же эффективности  обеспечивает ту же верность 8 и будет, по крайней мере, не сложнее системы раздельного кодирования. Это указывает на весьма привлекательную сторону совместного кодирования — возможность уменьшения сложности по сравнению с системами раздельного кодирования. Покажем эту возможность на примере СПИ, в которой используют линейное кодирование как для источника, так и для канала [181]. Источник будем считать двоичным без памяти с параметром
обеспечивает ту же верность 8 и будет, по крайней мере, не сложнее системы раздельного кодирования. Это указывает на весьма привлекательную сторону совместного кодирования — возможность уменьшения сложности по сравнению с системами раздельного кодирования. Покажем эту возможность на примере СПИ, в которой используют линейное кодирование как для источника, так и для канала [181]. Источник будем считать двоичным без памяти с параметром  Он выдает последовательность случайных символов
Он выдает последовательность случайных символов  Да, таких, что
Да, таких, что  для всех
для всех  Согласно (8.3) энтропия такого источника
Согласно (8.3) энтропия такого источника  на нифру (букву). Это минимальное в среднем число бит, которое необходимо для восстановления буквы источника с произвольно малой ошибкой (кодирование без искажений). Эпсилон-энтропия двоичного источника согласно (8.18)
на нифру (букву). Это минимальное в среднем число бит, которое необходимо для восстановления буквы источника с произвольно малой ошибкой (кодирование без искажений). Эпсилон-энтропия двоичного источника согласно (8.18)

где  побуквенная вероятность ошибки при восстановлении;
побуквенная вероятность ошибки при восстановлении;  определяет минимальное число бит на букву источника, необходимое для восстановления сообщения с ошибкой, не превышающей
определяет минимальное число бит на букву источника, необходимое для восстановления сообщения с ошибкой, не превышающей  (случай кодирования сообщений с искажениями). Эффективность кодека источника при этом
(случай кодирования сообщений с искажениями). Эффективность кодека источника при этом  которая в пределе при
которая в пределе при  равна Для передачи двоичных символов с выхода кодера источника используют двоичный симметричный канал без памяти с параметром
равна Для передачи двоичных символов с выхода кодера источника используют двоичный симметричный канал без памяти с параметром  Пропускную способность такого канала определяют по формуле (1-31), а эффективность кодека канала
Пропускную способность такого канала определяют по формуле (1-31), а эффективность кодека канала  Общая эффективность системы
Общая эффективность системы  При кодировании без искажений
При кодировании без искажений  эффективность достигает предельного значения
эффективность достигает предельного значения  Блочный линейный
Блочный линейный  двоичный кодер определяется с помощью порождающей матрицы
двоичный кодер определяется с помощью порождающей матрицы  размерности
размерности  и ранга К линейным оператором
и ранга К линейным оператором

где  информационный вектор-строка, определяющий кодовую последовательность на входе кодера канала,
информационный вектор-строка, определяющий кодовую последовательность на входе кодера канала,  их) — передаваемая по каналу последовательность двоичных символов. Операции в
их) — передаваемая по каналу последовательность двоичных символов. Операции в  и далее для всех матриц и векторов производятся в арифметике по модулю 2. Скорость кода
и далее для всех матриц и векторов производятся в арифметике по модулю 2. Скорость кода  Известно [27, 178], что для данного
Известно [27, 178], что для данного  существуют при достаточно большом
существуют при достаточно большом  линейные
линейные  кодеры и соответствующие декодеры, такие, что средняя ошибка
кодеры и соответствующие декодеры, такие, что средняя ошибка  при использовании двоичного симметричного канала с пропускной способностью
при использовании двоичного симметричного канала с пропускной способностью  независимо от статистики сообщений источника. Для данной матрицы
независимо от статистики сообщений источника. Для данной матрицы  всегда найдется матрица
всегда найдется матрица  называют проверочной) размерности
называют проверочной) размерности  и ранга
и ранга  что
что

где  означает транспонирование. Данный вектор
означает транспонирование. Данный вектор  является кодовым словом для какого-либо информационного вектора В тогда, и только тогда, когда
является кодовым словом для какого-либо информационного вектора В тогда, и только тогда, когда  Если записать принятый на выходе капала вектор
Если записать принятый на выходе капала вектор  в виде
в виде  где
где  шумовая последовательность, тогда из (8.23) следует, что
шумовая последовательность, тогда из (8.23) следует, что

Вектор-строка  называется синдромом и зависит только от шумовой последовательности
называется синдромом и зависит только от шумовой последовательности 
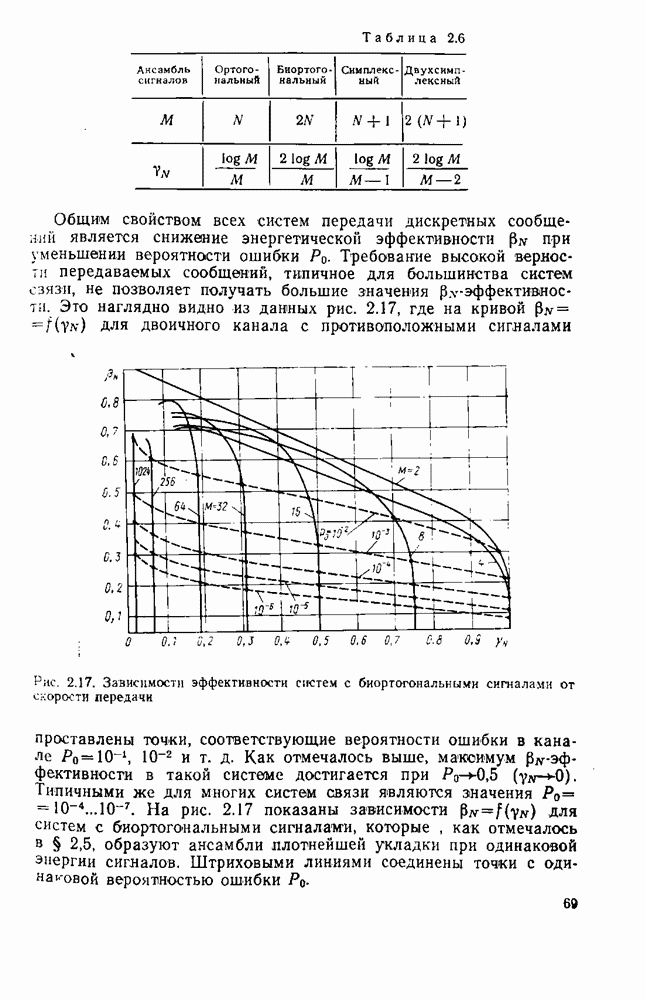
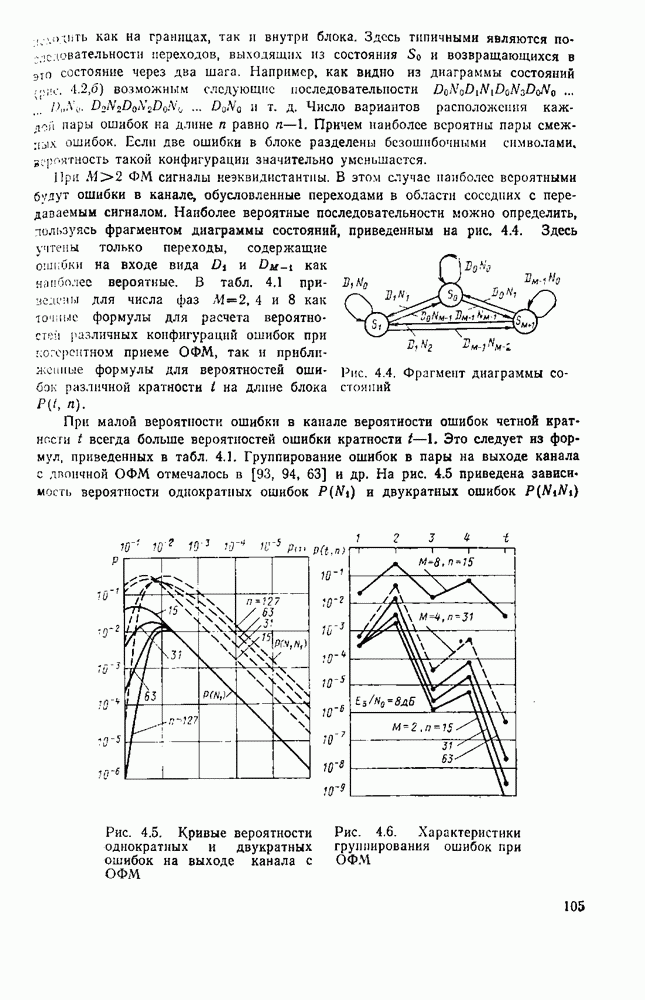
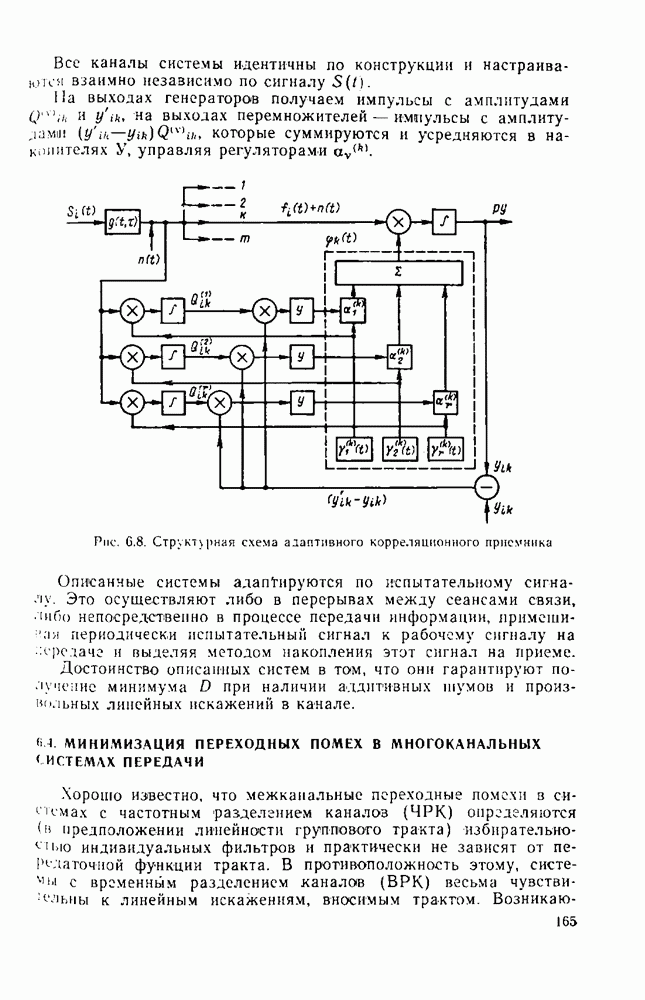
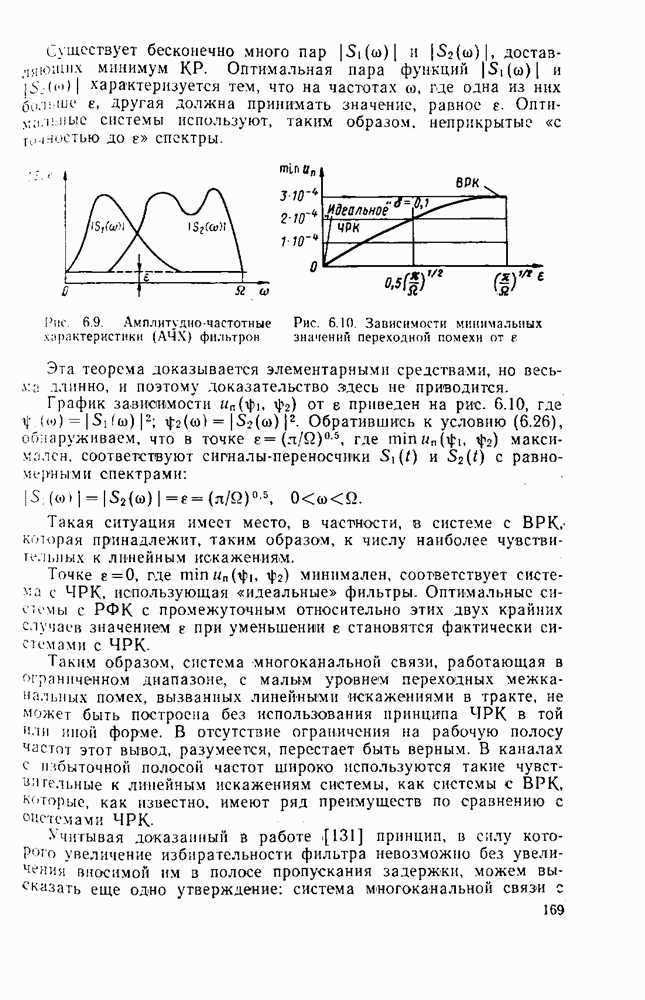
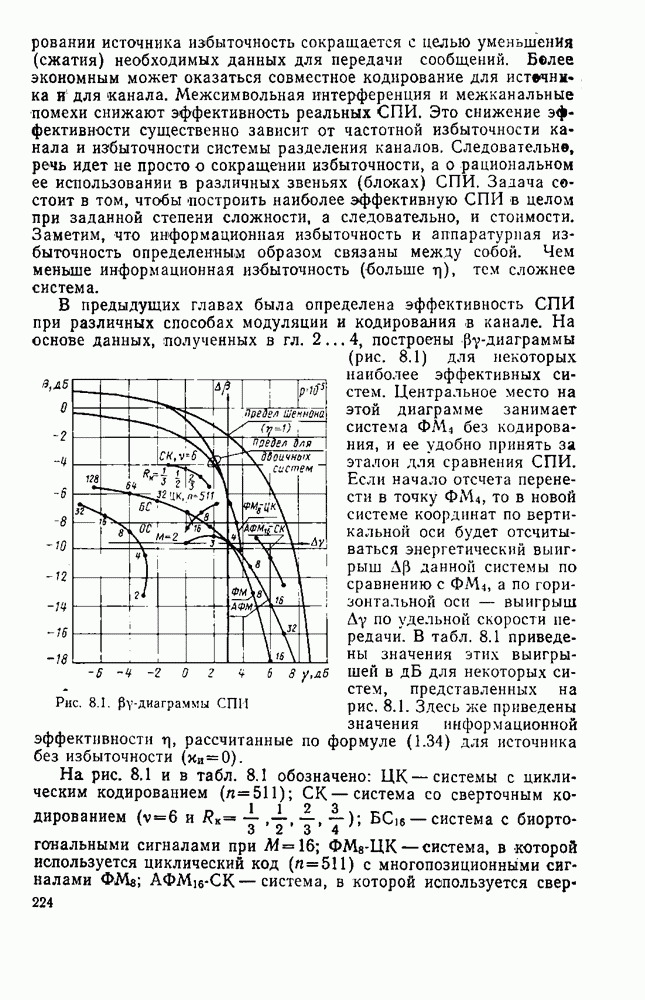
Из теории кодирования известно, что без потери оптимальности декодер для линейного кода может быть построен в виде, изображенном на рис. 8.2,

Рис. 8.2. Схема синдромного декодера линейного кода
Наиболее сложным для реализации в этой схеме является «оцениватель шумовой последовательности». Блочный линейный  кодер источника определяется с помощью двоичной матрицы
кодер источника определяется с помощью двоичной матрицы  размерности
размерности  и ранга
и ранга  оператором вида
оператором вида

где  исходное сообщение и
исходное сообщение и  закодированное сообщение на выходе кодера источника.
закодированное сообщение на выходе кодера источника.
При кодировании источника без искажений, когда требуется воспроизведение сообщений источника с пренебрежимо малой (но не нулевой) ошибкой  для симметричного двоичного канала с переходной вероятностью
для симметричного двоичного канала с переходной вероятностью  равной
равной  где будем считать
где будем считать  существует линейный кодер канала
существует линейный кодер канала  такой, что для любого данного
такой, что для любого данного  он имеет скорость
он имеет скорость

и достигает вероятности ошибки на букву в оцениваемом кодовом слове  не более
не более  Для этой схемы кодирования вероятность ошибки на букву и векторе
Для этой схемы кодирования вероятность ошибки на букву и векторе  на рис. 8.2 совпадает с вероятностью ошибки на букву в векторе
на рис. 8.2 совпадает с вероятностью ошибки на букву в векторе  Таким образом, если использовать те же самые матрицы в качестве
Таким образом, если использовать те же самые матрицы в качестве  в схеме кодирования источника и тот же самый «оцениватель шумовой последовательности», то из предыдущего следует, что вероятность ошибки на букву при восстановлении сообщения А будет той же самой, т. е. не более
в схеме кодирования источника и тот же самый «оцениватель шумовой последовательности», то из предыдущего следует, что вероятность ошибки на букву при восстановлении сообщения А будет той же самой, т. е. не более  Эффективность кодека источника при этом
Эффективность кодека источника при этом

и может быть сделана сколь угодно близкой к предельному значению  им образом, линейное кодирование источника не влечет за собой потери эффективности (оптимальности), когда требуется восстановление сообщений источника с пренебрежимо малой ошибкой. Для канала же линейное кодирование, как уже отмечалось, всегда может быть выполнено оптимальным. Кроме того, если
им образом, линейное кодирование источника не влечет за собой потери эффективности (оптимальности), когда требуется восстановление сообщений источника с пренебрежимо малой ошибкой. Для канала же линейное кодирование, как уже отмечалось, всегда может быть выполнено оптимальным. Кроме того, если  что всегда может быть достигнуто увеличением длины блоков в целое число раз, то для совокупной комбинации этих двух линейных систем можно записать
что всегда может быть достигнуто увеличением длины блоков в целое число раз, то для совокупной комбинации этих двух линейных систем можно записать

Оператор  можно рассматривать как матрицу, определяющую совместный линейный кодер источника и канала. Тогда оператор совместного декодера запишется в виде
можно рассматривать как матрицу, определяющую совместный линейный кодер источника и канала. Тогда оператор совместного декодера запишется в виде

Реализация матрицы  общем случае значительно проще, чем раздельная реализация матриц
общем случае значительно проще, чем раздельная реализация матриц  Следовательно, совместное линейное кодирование для источника и канала не вызывает потерн эффективности в случае, когда требуется восстановление сообщений с пренебрежимо малой ошибкой («без искажений»). При этом сложность системы совместного кодирования может быть проще, чем системы с раздельным кодированием.
Следовательно, совместное линейное кодирование для источника и канала не вызывает потерн эффективности в случае, когда требуется восстановление сообщений с пренебрежимо малой ошибкой («без искажений»). При этом сложность системы совместного кодирования может быть проще, чем системы с раздельным кодированием.
При кодировании с искажениями, как показано в [181], совместное кодирование может привести к заметной потере эффективности по сравнению с эффективностью системы раздельного кодирования.