Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
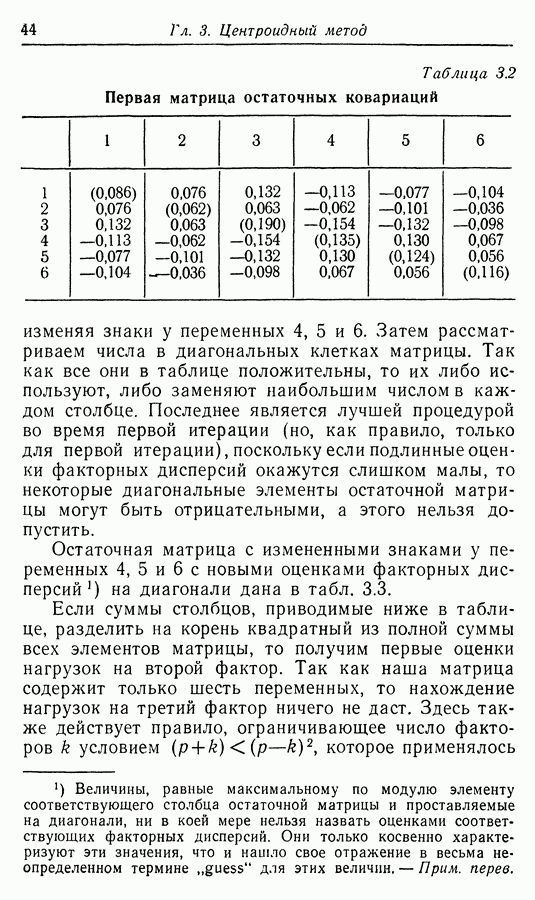
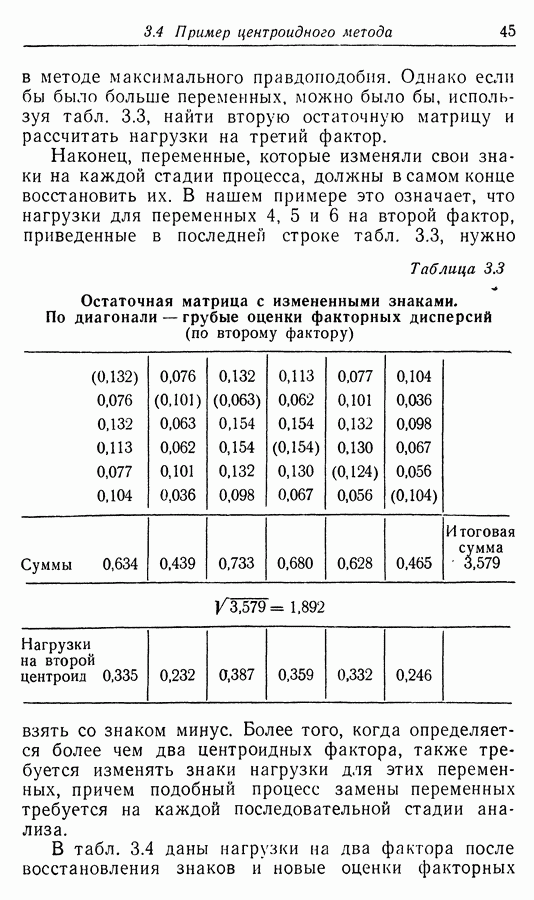
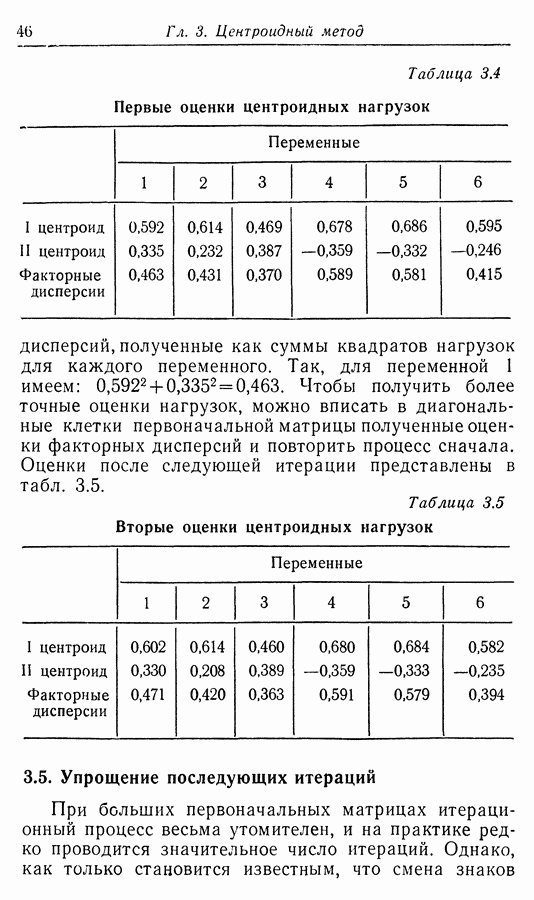
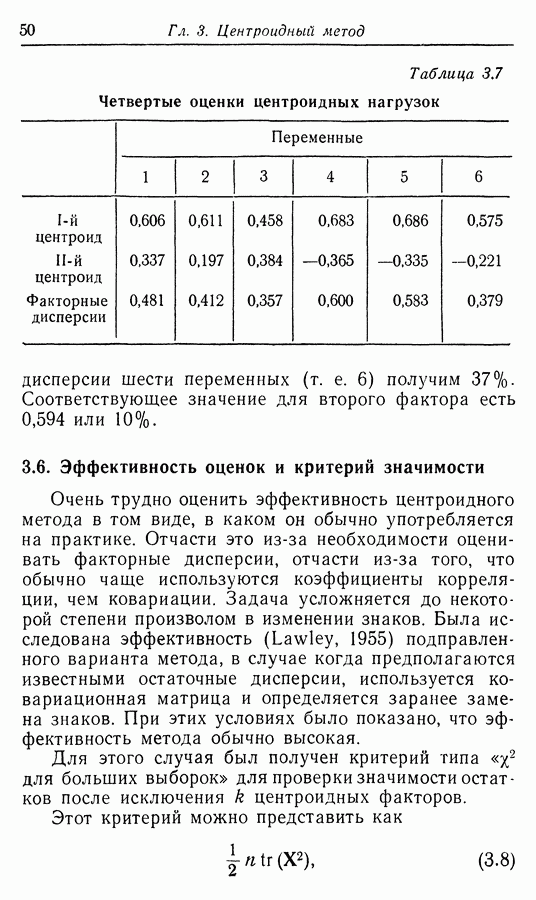
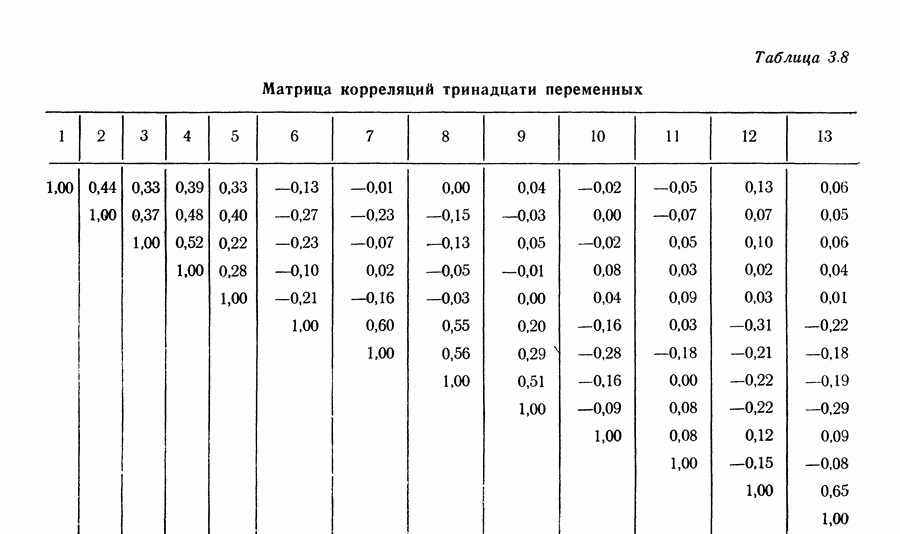
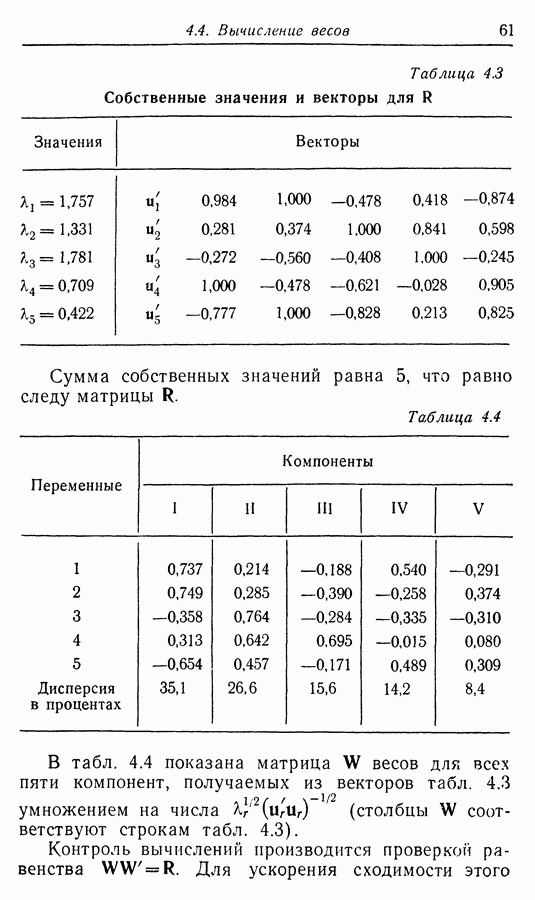
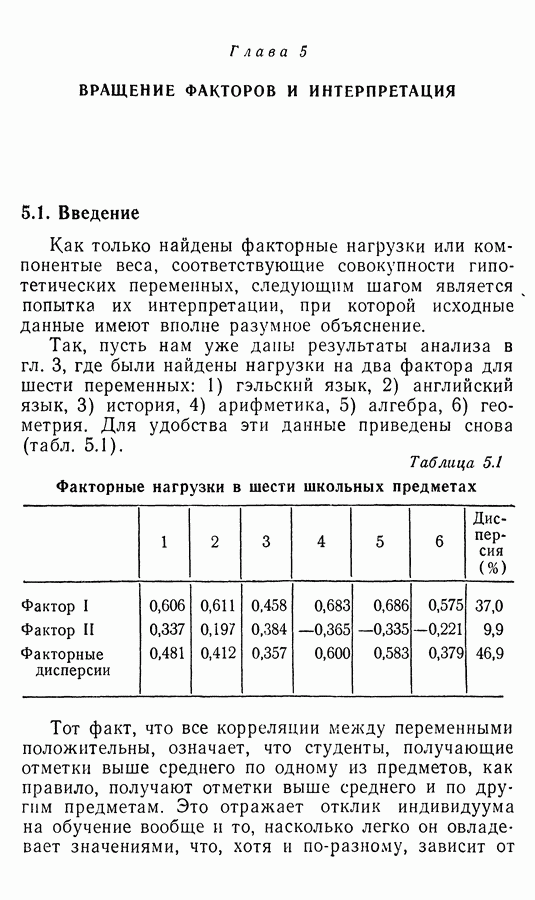
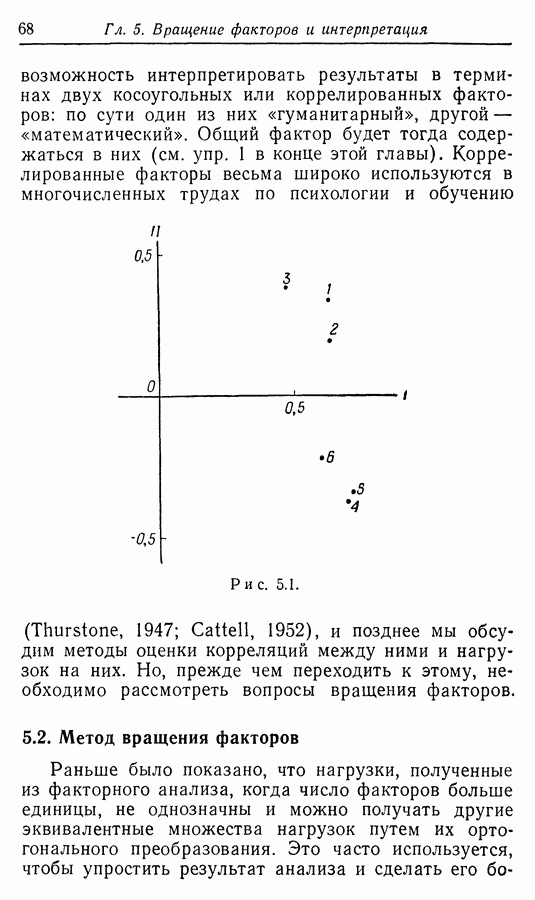
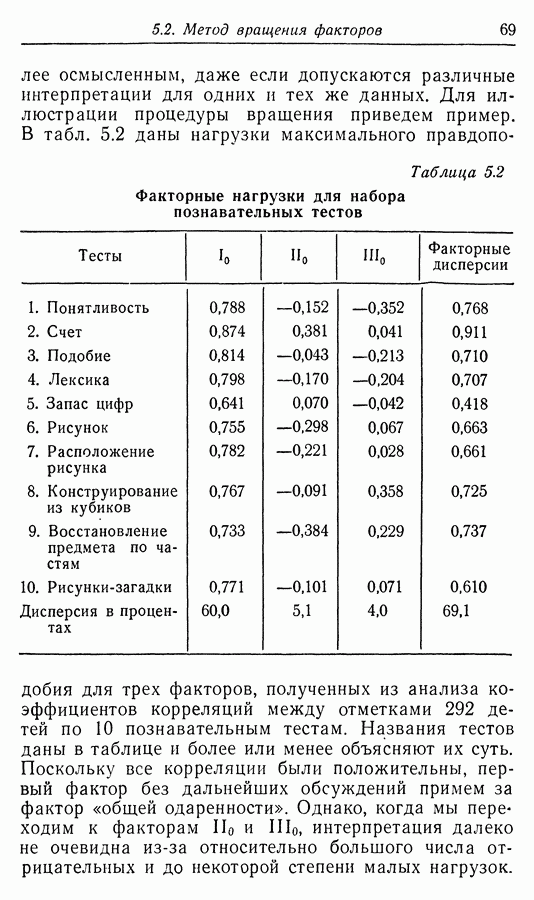
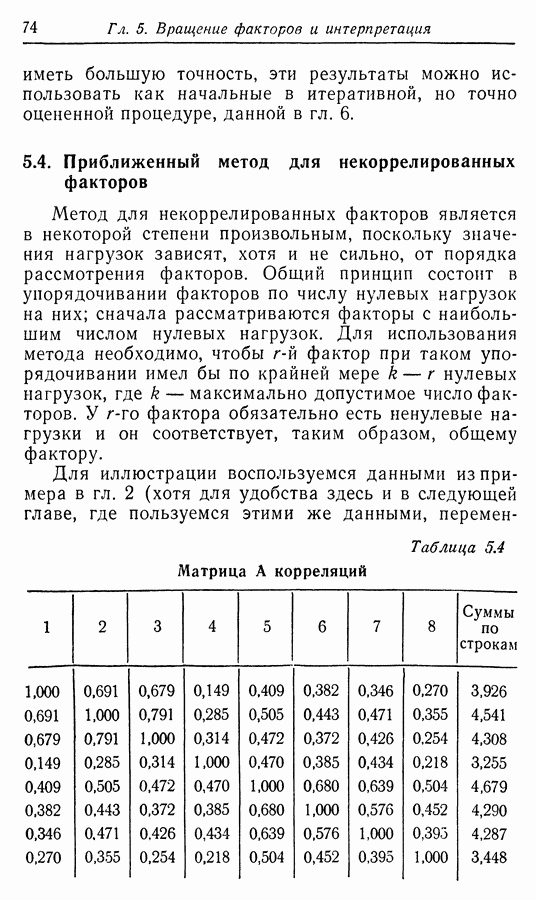
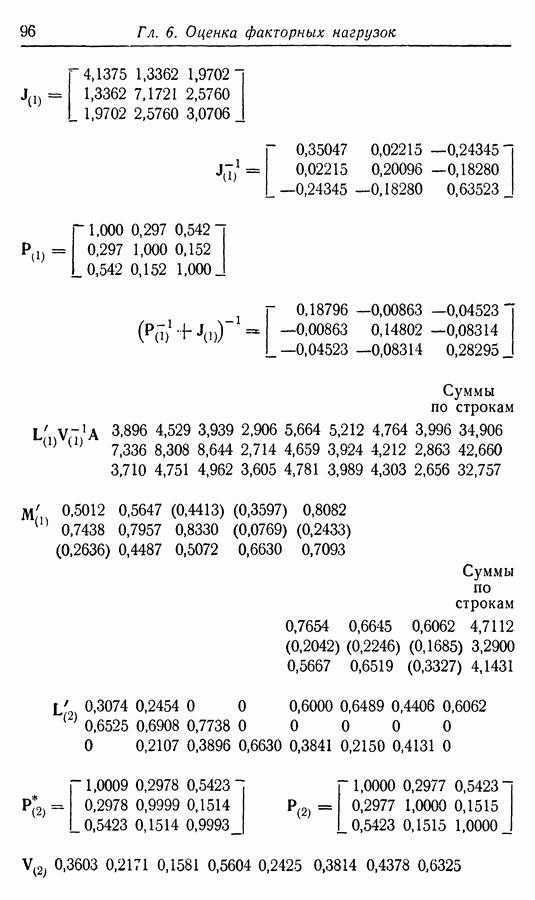
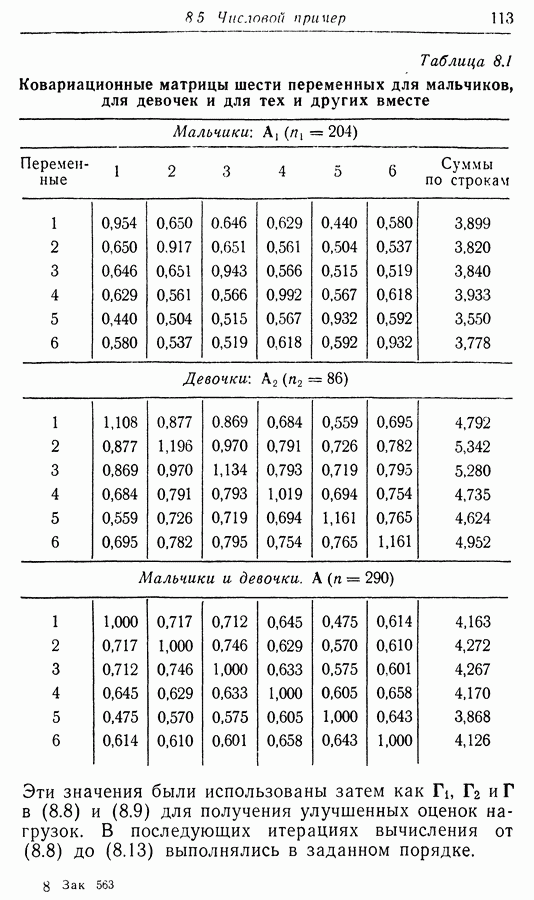
Приложение II. ОБЗОР МЕТОДОВ ОЦЕНКИ РАЗМЕРНОСТИ НАБОРОВ СЛУЧАЙНЫХ ВЕЛИЧИНЮ. Н. Благовещрнский 1. Введение.В настоящей книге факторный анализ сравнивается в какой-то мере лишь с анализом главных компонент. Да и в этом случае авторы в основном отмечают преимущества факторного анализа перед компонентным, не останавливаясь на некоторых сильных сторонах последнего. В многомерной статистике кроме этих двух есть еще несколько подходов к общей для них проблеме статистической оценки размерности набора наблюдаемых исследователем переменных. Основной из них (кроме указанных) - это регрессионный анализ. В этом приложении на простых модельных примерах даются основные принципы соответствующих методов, их основные достоинства и недостатки. Объяснение проводится по возможности без использования серьезного математического аппарата и предназначено для неспециалистов по многомерной статистике. 2. Некоторые обозначения и определенияБудем все случайные величины обозначать буквами
где
и линейно независимы в противоположном случае. Число равное максимальному числу линейно независимых случайных величин среди Вообще удобно называть минимум величины
минимальной дисперсией, а максимум — максимальной дисперсией набора
и через
Если 3. Факторный, компонентный и регрессионный анализы. Общая схемаИтак, у нас имеется набор случайных величин нулю. Каковы же могут быть гипотезы о структуре набора А. Есть такие случайные величины
B. Есть такие независимые между собой случайные величины Причем в обеих гипотезах можно различить два случая:
Удобно привести следующую схему: (см. скан) 4. Факторный анализ и компонентный анализ. МоделиВ этой формулировке легко обнаружить, что компонентный анализ является частным случаем факторного анализа. Однако это не значит, что, выбирая факторную модель, мы в результате ее исследования получим модель компонентного анализа как частный случай. Это совсем не так. Например, если все имеют ненулевые дисперсии, то размерность Пусть
Поскольку множество
где
Тогда
Таким образом, можно на при вращении сохраняются длины — это
С другой стороны, нам известна (или приближенно известна) матрица С ковариаций
Рассмотрим еще один крайний случай: пусть матрица С диагональна. Тогда факторная модель вообще состоит только из
есть ковариационная матрица для Проводя компонентный анализ, придем к равенствам
Отсюда видим, что Для проведения факторного анализа выдвинем гипотезу, что
Равенства (3) и (4) очень похожи, но и 5. Факторный анализ и компонентный анализ. Основные проблемыОдной из фундаментальных задач является описание спроектировать Проиллюстрируем сказанное на примере предыдущего параграфа. Из (3) получим
Из равенств (4) найти
Таким образом мы получим
Уравнения (5) и (6) уже существенно больше сходятся, чем различные гипотезы, выдвигавшиеся первоначально. Таким образом, в данном примере метод главных компонент совсем не так уж плох. Укажем, наконец, на ряд серьезных недоделок в факторном анализе даже для случая нормально распределенных совокупностей. Прежде всего фактически нет оценок того, какую погрешность привносят математические ожидания, вычисляемые по выборке. Хотя легко дать тривиально усовершенствованный алгоритм получения «оценок» Во-вторых, все алгоритмы, кроме центроидного метода (а именно он-то и не обоснован доконца), используют то, что можно сознательно добавить известный «шум» в каждое Укажем еще на одну сторону проблемы. При идентификации разных наборов случайных величин проблему надо ставить шире. Во-первых, очень существен разный размер наборов, во-вторых, весьма стеснительным является фиксация нулевых параметров (смотри равенство 6. Факторный анализ и регрессионный анализПусть у нас имеется набор
Нужно найти
Подставляя в (7) равенства (8), можно выбрать Этот путь кажется очень заманчивым по нескольким причинам. Каковы самые тяжелые предположения при использовании регрессивного анализа? Прежде всего — это измерение без ошибок. Второе — это интерпретация результатов. Первое при этом подходе снимается автоматически, а для интерпретации факторы являются существенно более широким понятием, чем линейная комбинация В этом отношении некоторую пользу регрессионному анализу может принести и метод главных компонент — регрессия по ортогональным направлениям проще и экономнее, и, по-видимому, коэффициенты регрессии по значимым компонентам более устойчивы даже при значительном числе переменных. В заключение еще раз подчеркнем, что все эти подходы линейные и изучают наборы нормально распределенных случайных величин.
|
 |
Оглавление
|




















































































































 с индексом или без индекса. Через
с индексом или без индекса. Через  будем обозначать математическое ожидание случайной величины
будем обозначать математическое ожидание случайной величины  Ниже, если не оговорено противное, будем предполагать, что
Ниже, если не оговорено противное, будем предполагать, что  для всякой рассматриваемой нами
для всякой рассматриваемой нами  Будем говорить, что
Будем говорить, что  случайных величин
случайных величин  линейно зависимы, если
линейно зависимы, если


 будем называть размерностью этого набора случайных величин. Если
будем называть размерностью этого набора случайных величин. Если  линейно зависимы, то размерность меньше
линейно зависимы, то размерность меньше  и дисперсия некоторого линейного соотношения равна нулю.
и дисперсия некоторого линейного соотношения равна нулю.

 случайных величин. Введем для них обозначения
случайных величин. Введем для них обозначения  и
и  или просто
или просто  , когда известно о каком именно наборе идет речь. Обозначим через
, когда известно о каком именно наборе идет речь. Обозначим через  ковариацию между
ковариацию между 

 или
или  матрицу ковариаций (ковариационную матрицу) для
матрицу ковариаций (ковариационную матрицу) для 

 подчиняются многомерному нормальному распределению, то по
подчиняются многомерному нормальному распределению, то по  и по матрице С ковариаций распределение однозначно восстанавливается. Далее практически все сделанное в многомерной статистике по оценке размерности относится к наборам нормально распределенных случайных величин. Поэтому мы ниже будем рассматривать моменты не старше вторых.
и по матрице С ковариаций распределение однозначно восстанавливается. Далее практически все сделанное в многомерной статистике по оценке размерности относится к наборам нормально распределенных случайных величин. Поэтому мы ниже будем рассматривать моменты не старше вторых.
 с матрицей ковариаций С (пусть пока известна) и математическими ожиданиями, равными
с матрицей ковариаций С (пусть пока известна) и математическими ожиданиями, равными

 что
что

 что набор —
что набор —  от них не зависит и имеет размерность
от них не зависит и имеет размерность  т. е. имеются такие случайные величины
т. е. имеются такие случайные величины 
 Случайные величины
Случайные величины  заданы.
заданы.
 Случайные величины
Случайные величины  неизвестны. Следовательно, в случае
неизвестны. Следовательно, в случае  можно считать, что дан набор
можно считать, что дан набор  случайных величин, а не всего
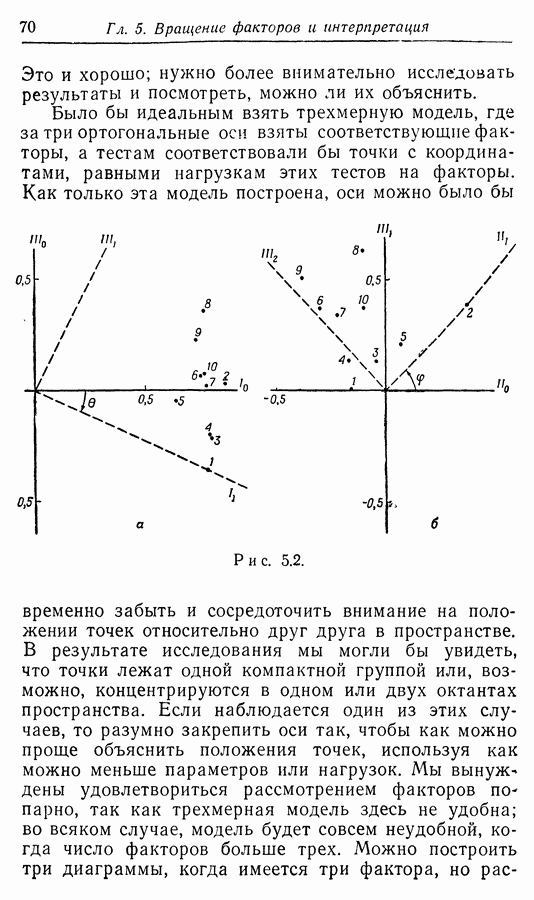
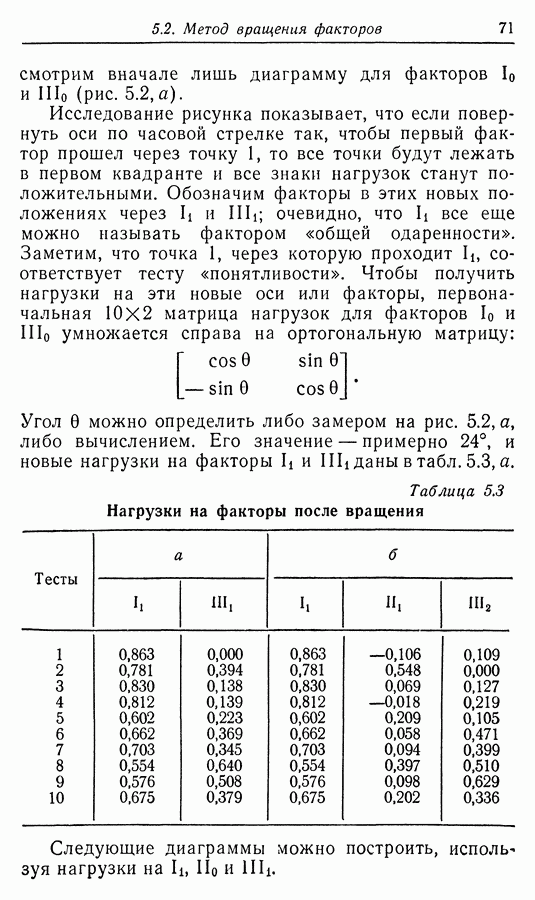
случайных величин, а не всего  штук
штук 

 всегда
всегда  и компонентная гипотеза тривиальна с к
и компонентная гипотеза тривиальна с к  Если
Если  имеет размерность
имеет размерность  среди
среди  имеют ненулевую дисперсию, то метод главных компонент приводит к размерности
имеют ненулевую дисперсию, то метод главных компонент приводит к размерности  в то время как факторный анализ приведет к размерности
в то время как факторный анализ приведет к размерности 

 определяет вместе с ей
определяет вместе с ей  модель, то нам лишь нужно определить
модель, то нам лишь нужно определить  однако мы не можем определить
однако мы не можем определить  точно. Пусть
точно. Пусть

 ортогональная матрица:
ортогональная матрица:

 снова независимы и между собой и с
снова независимы и между собой и с  также выражаются через них как в (1) через
также выражаются через них как в (1) через  только с
только с  вместо
вместо  где
где

 наложить столько условий, сколько параметров среди
наложить столько условий, сколько параметров среди  Если этих параметров
Если этих параметров  то тем самым останутся всегда неопределенными
то тем самым останутся всегда неопределенными  параметров среди
параметров среди  чисел
чисел  . Таким образом, мы определяем
. Таким образом, мы определяем  лишь с точностью до «вращения» (2) набора факторов
лишь с точностью до «вращения» (2) набора факторов  Остаются неизвестными
Остаются неизвестными  параметров. Подсчитаем
параметров. Подсчитаем  Очевидно, что
Очевидно, что
 соотношений; и попарная ортогональность — это
соотношений; и попарная ортогональность — это  соотношений. А всего в ортогональной матрице
соотношений. А всего в ортогональной матрице  членов. Так что
членов. Так что  Значит, число неизвестных параметров равно
Значит, число неизвестных параметров равно

 в которой
в которой  различных элементов. Таким образом, задача становится нетривиальной, когда
различных элементов. Таким образом, задача становится нетривиальной, когда

 и тривиально верна с
и тривиально верна с  в то время как компонентный анализ имеет смысл и дает размерность
в то время как компонентный анализ имеет смысл и дает размерность  Приведем один пример, чтобы нагляднее выделить эти два крайних момента. Пусть
Приведем один пример, чтобы нагляднее выделить эти два крайних момента. Пусть

 Тогда компонентный анализ проводится так, чтобы
Тогда компонентный анализ проводится так, чтобы  имели ту же огаах, что и
имели ту же огаах, что и  при этих условиях
при этих условиях  выбирается как случайная величина с максимально возможной дисперсией,
выбирается как случайная величина с максимально возможной дисперсией,  ищется такой же, но уже среди независимых от и т. д. После нормировки получим
ищется такой же, но уже среди независимых от и т. д. После нормировки получим 

 играет малую роль,
играет малую роль,  практически пропорциональны (при малых
практически пропорциональны (при малых  ).
).
 Из-за того, что
Из-за того, что  получаем, что
получаем, что  т. е. число неизвестных параметров и число равенств для них совпадают. Решение уравнений факторного анализа приводит к равенствам
т. е. число неизвестных параметров и число равенств для них совпадают. Решение уравнений факторного анализа приводит к равенствам

 независимы, а соответствующие члены равенства (3) линейно зависимы. Таким образом, уже в простейшей задаче мы приходим к двум принципиально разным объяснениям структуры матрицы С
независимы, а соответствующие члены равенства (3) линейно зависимы. Таким образом, уже в простейшей задаче мы приходим к двум принципиально разным объяснениям структуры матрицы С
 по
по  и если для компонентного анализа
и если для компонентного анализа  однозначно восстанавливаются по
однозначно восстанавливаются по  то для факторного анализа принципиально их восстановить нельзя. Однако можно найти такие линейные комбинации
то для факторного анализа принципиально их восстановить нельзя. Однако можно найти такие линейные комбинации  которые в том или ином смысле были бы как можно ближе к
которые в том или ином смысле были бы как можно ближе к  Один из способов —
Один из способов —
 Другой — выбирать замену для
Другой — выбирать замену для  так, чтобы, вернувшись к модели, мы получили бы возможно меньшую
так, чтобы, вернувшись к модели, мы получили бы возможно меньшую 

 нельзя. Получим «оценку»
нельзя. Получим «оценку»  для
для  Пусть
Пусть  Если мы хотим спроектировать, то
Если мы хотим спроектировать, то  нужно выбрать так, чтобы
нужно выбрать так, чтобы  была бы минимальна. Пользуясь уравнениями (4), найдем, что
была бы минимальна. Пользуясь уравнениями (4), найдем, что


 в тех случаях, когда математические ожидания оцениваются по выборке.
в тех случаях, когда математические ожидания оцениваются по выборке.
 Это, по-видимому, не очень существенно для проблемы в целом. Например,
Это, по-видимому, не очень существенно для проблемы в целом. Например,
 с помощью датчиков случайных чисел, а после получения результата — исключить. Однако авторы этот вопрос обходят. В-третьих, совершенно не изучена устойчивость оценок для параметров при, пусть небольших, отклонениях от нормального распределения. Некоторые косвенные доказательства этого можно указать: центроидный метод и метод максимального правдоподобия дают не слишком сильно расходящиеся нагрузки, но центроидный метод как непараметрический, по-видимому, весьма устойчив к колебаниям распределения.
с помощью датчиков случайных чисел, а после получения результата — исключить. Однако авторы этот вопрос обходят. В-третьих, совершенно не изучена устойчивость оценок для параметров при, пусть небольших, отклонениях от нормального распределения. Некоторые косвенные доказательства этого можно указать: центроидный метод и метод максимального правдоподобия дают не слишком сильно расходящиеся нагрузки, но центроидный метод как непараметрический, по-видимому, весьма устойчив к колебаниям распределения.
 Заметим, что эти подходы могут оказать большую помощь в задачах классификации при наличии «шумов» в исходных переменных. Для метода главных компонент, по-видимому, до сих пор наиболее трудной остается проблема выбора масштабов для
Заметим, что эти подходы могут оказать большую помощь в задачах классификации при наличии «шумов» в исходных переменных. Для метода главных компонент, по-видимому, до сих пор наиболее трудной остается проблема выбора масштабов для  Мерять все их в единицах дисперсий — это уравнивать по-разному информативные величины. Другая трудная задача — переносить метод на задачи идентификации наборов и их классификации.
Мерять все их в единицах дисперсий — это уравнивать по-разному информативные величины. Другая трудная задача — переносить метод на задачи идентификации наборов и их классификации.
 случайных величин с заданной ковариационной матрицей С. Тогда регрессионная задача выглядит так:
случайных величин с заданной ковариационной матрицей С. Тогда регрессионная задача выглядит так:

 Предположим теперь, что в результате исследования этого набора как факторной модели мы пришли к равенствам
Предположим теперь, что в результате исследования этого набора как факторной модели мы пришли к равенствам

 так, чтобы
так, чтобы  была бы минимальна.
была бы минимальна.
 Наконец, при этом подходе гораздо меньше чувствуется размерность
Наконец, при этом подходе гораздо меньше чувствуется размерность  когда ищутся линии регрессии по
когда ищутся линии регрессии по  вектора
вектора 