Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
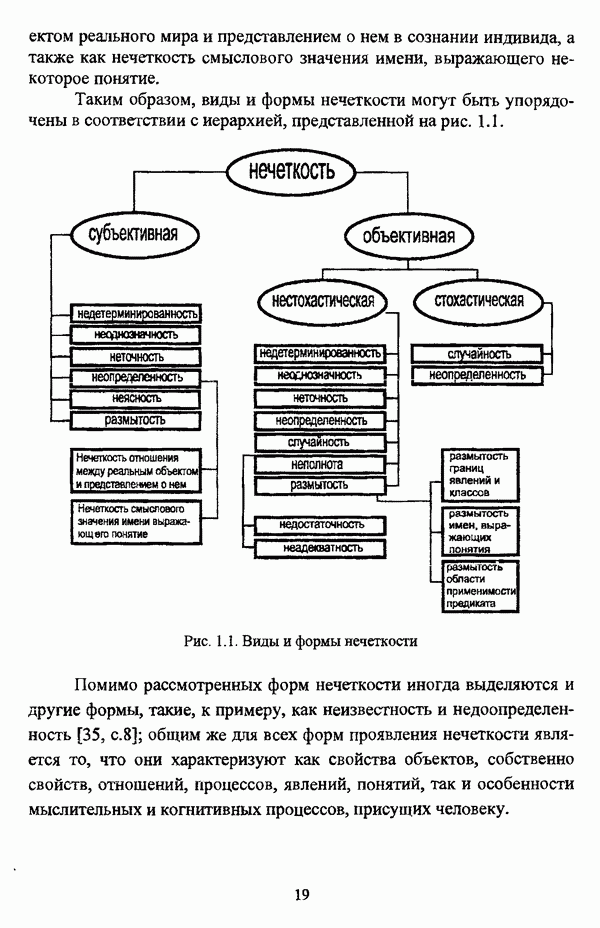
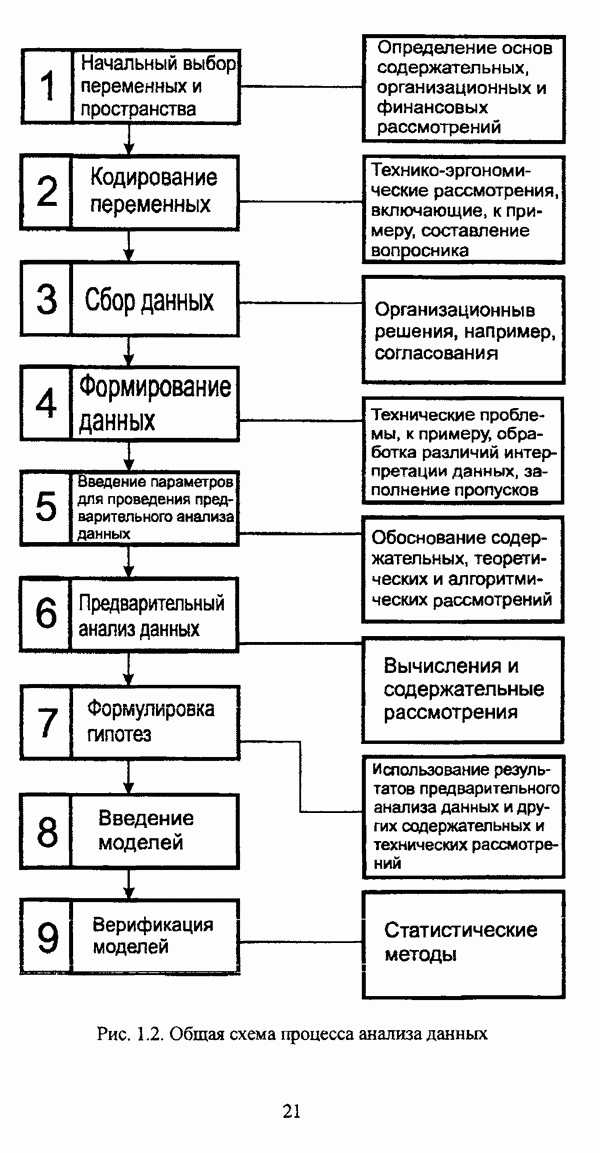
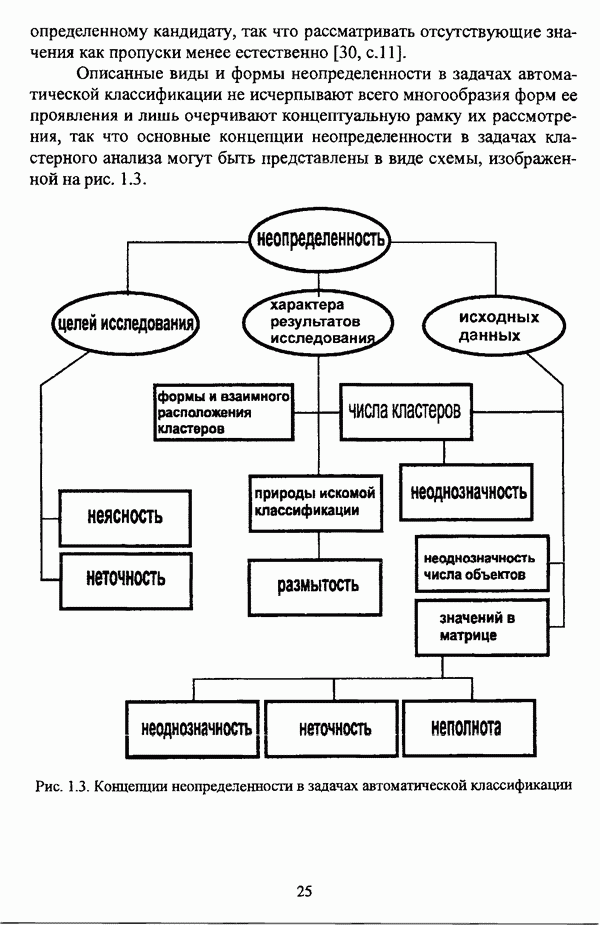
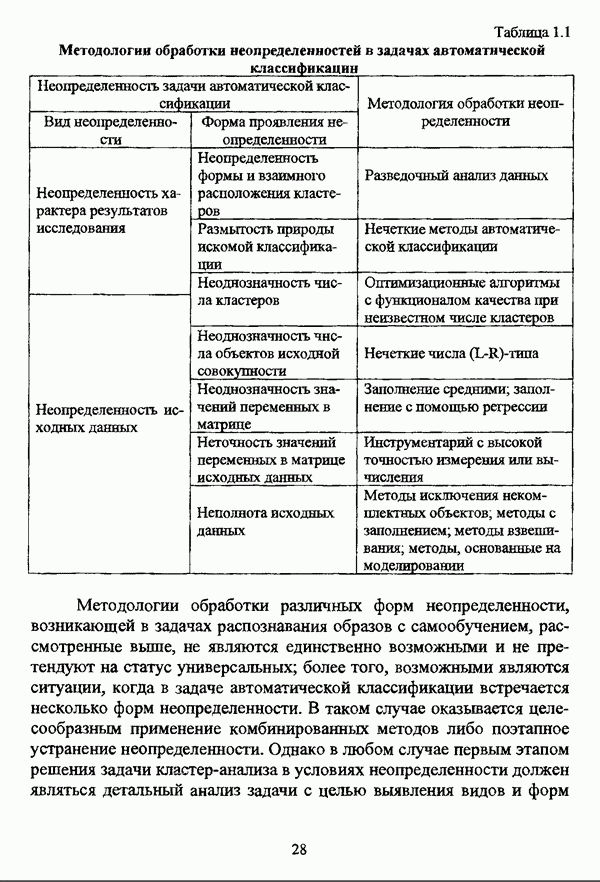
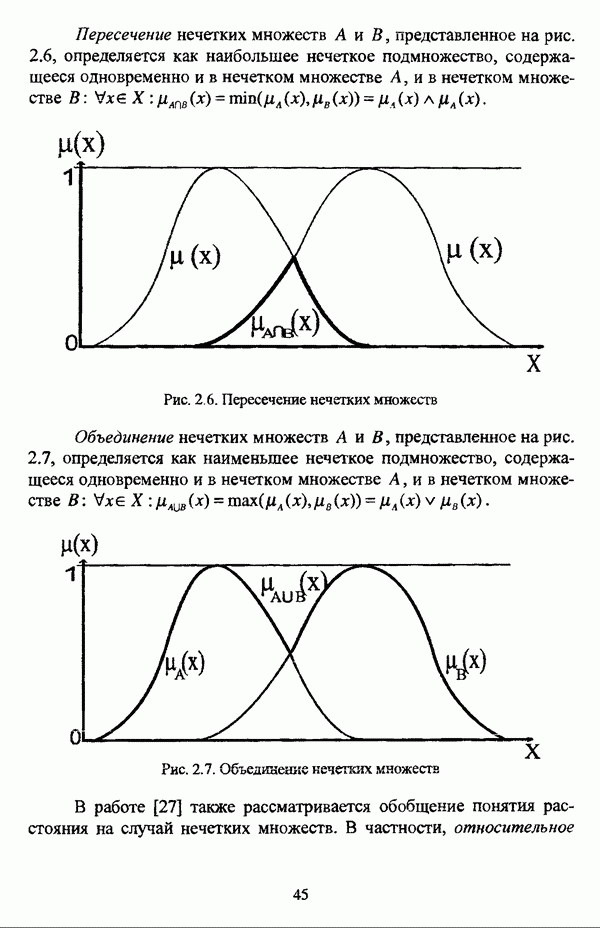
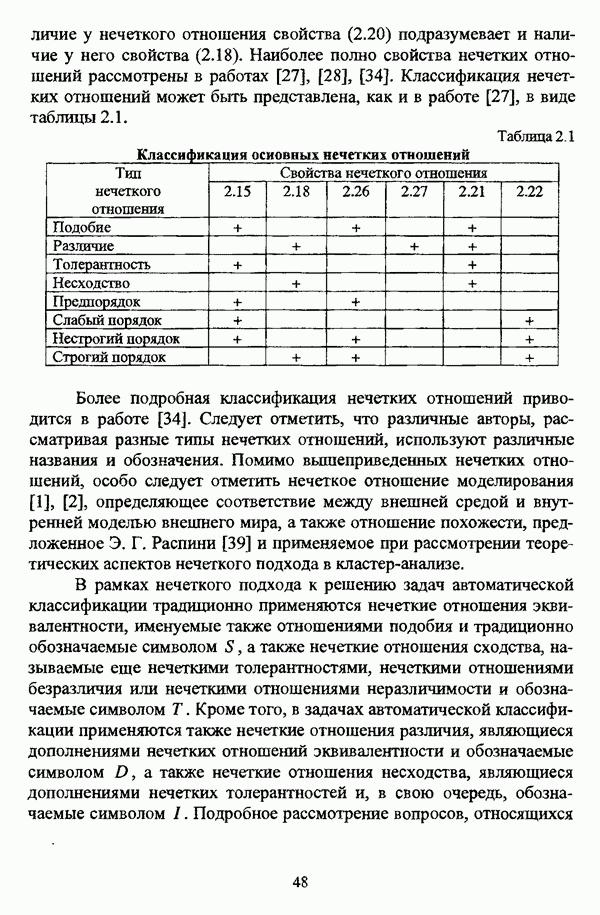
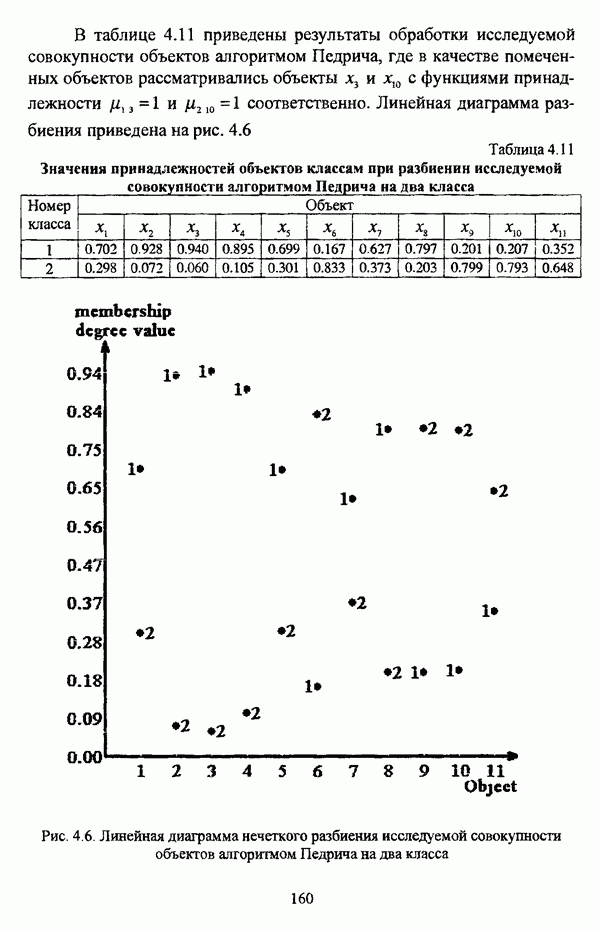
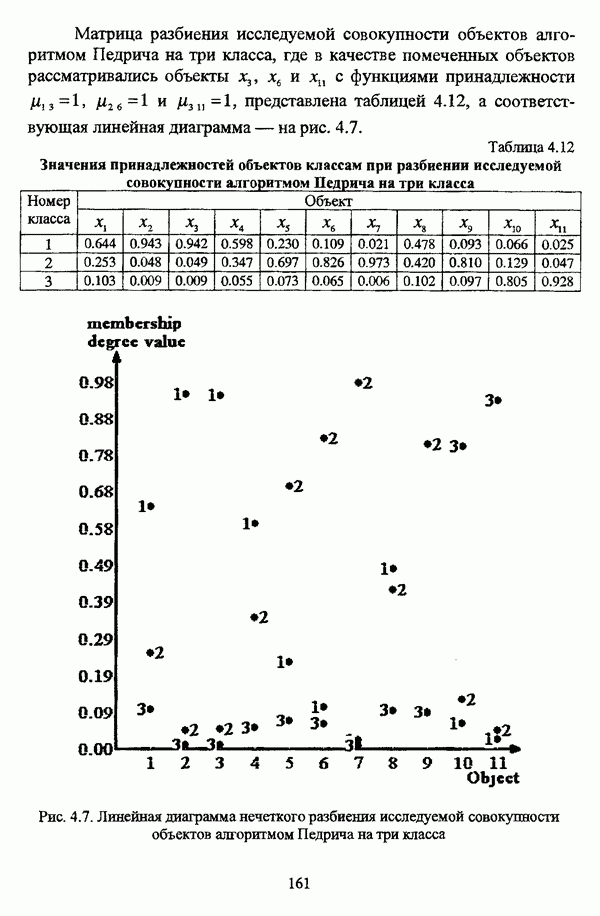
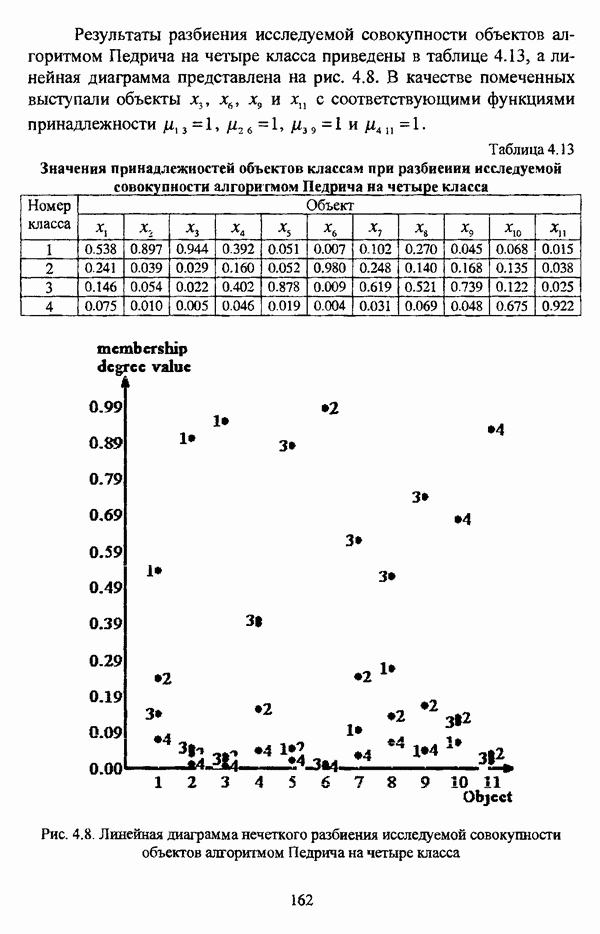
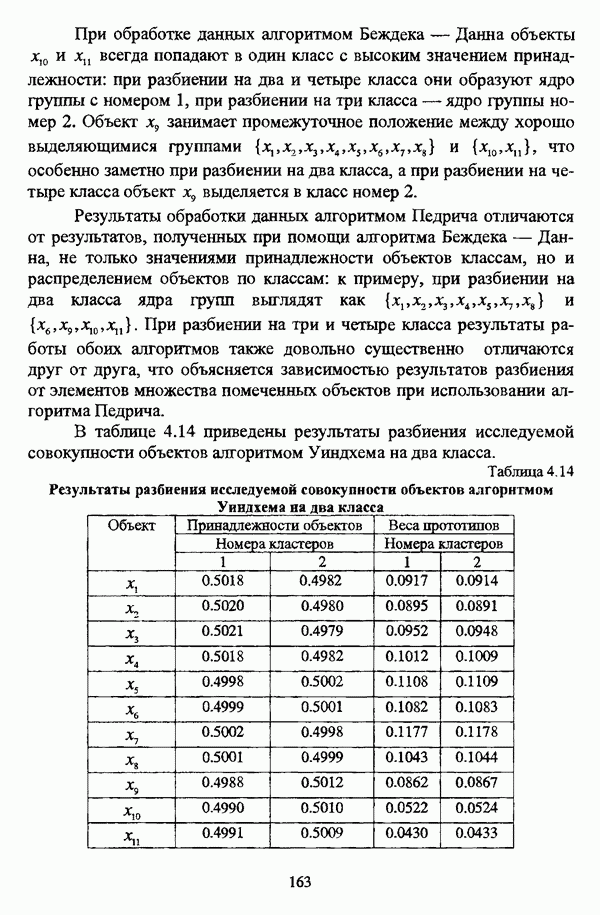
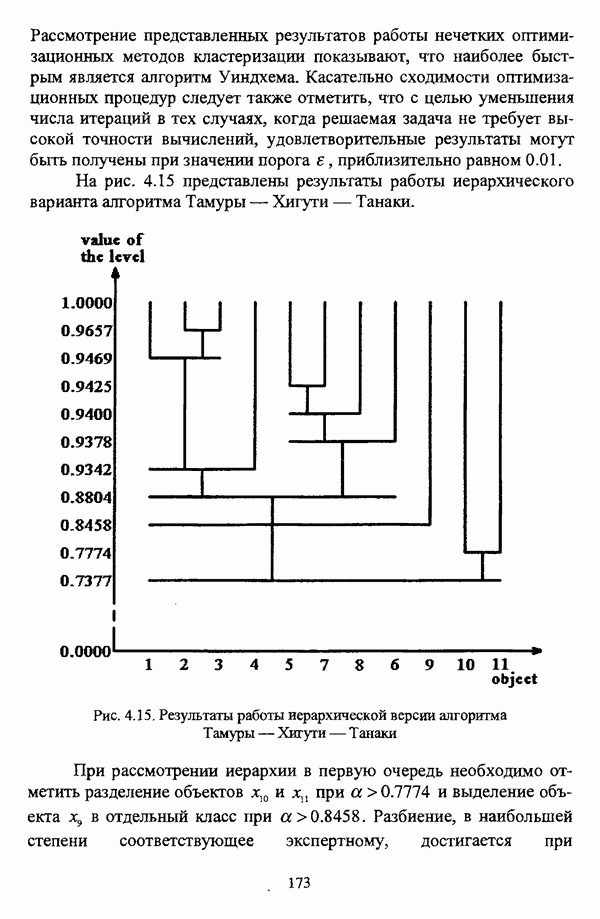
3.1.2. Описание алгоритмовРазличные нечеткие эвристические кластер-процедуры в качестве основы используют различные понятия и определения, так что их необходимо рассматривать перед изложением схемы алгоритма в каждом конкретном случае. 3.1.2.1. Алгоритм Гитмана — Левина[90] является одной из первых эвристических процедур, использующих понятие нечеткого множества, и строит разбиение нечеткого множества объектов, подлежащих классификации, на унимодальные нечеткие множества. Основные понятия и определения Пусть
и
где Нечеткое множество В является симметричным в том и только в том случае, если Нечеткое множество В является унимодальным в том и только в том случае, если четкое множество Дискретные нечеткие множества Некоторой точке что результат разбиения на группы Таким образом, если некоторая мода является внутренней точкой подмножества, то она является локальным максимумом функции Авторская версия алгоритма состоит из двух процедур, причем первая процедура, в свою очередь, состоит из двух частей: первая часть разбивает дискретное нечеткое множество В точек, подлежащих классификации, на симметричные нечеткие подмножества, а вторая часть отыскивает локальные максимумы мультимодальной функции принадлежности нечеткого множества В. Вторая процедура разбивает нечеткое множество В на унимодальные нечеткие множества, используя в качестве основы полученную в результате работы первой процедуры информацию о числе, взаимном расположении и значениях функции принадлежности точек Параметры алгоритма: Входными данными является матрица Хтул Схема алгоритма: 1 Строятся следующие последовательности: 1.1. последовательность 1.2. последовательность первым «кандидатом» в группу 2. Если 3. Производится формирование групп в соответствии со следующим правилом: пусть к некоторому моменту построено G групп, то есть сконструированы последовательности 3.1. если 3.2. если 3.3. если Процесс продолжается до исчерпания последовательности 4. Для каждой группы до точки 5. Ко всем точкам, за исключением локальных максимумов Приведенная версия процедуры основана на предположении, что при Может оказаться, что наибольшее значение функции принадлежности в некоторой группе сложно определить, какая из них является локальным максимумом. В качестве метода, позволяющего преодолеть подобное затруднение, может быть использовано на шаге 4 приведенной выше процедуры следующее правило: пусть Следует также указать, что в изложении схемы алгоритма, представленной в [22, с. 53-56], не описывается шаг, соответствующий второй процедуре авторской версии и, соответственно, шагу 5 версии, представленной выше, где группы 3.1.2.2. Алгоритм Тамуры — Хигути — Танаки[163] использует (max-min)-транзитивное замыкание нечеткой толерантности Г, описывающей исходные данные в виде матрицы близости Основные понятия и определения Пусть Параметры алгоритма: с — число кластеров в искомом разбиении Схема алгоритма: 1. Строится транзитивное замыкание f исходного отношения нечеткой толерантности Т в соответствии с формулой (2.40); 2. Вычисляются 3. Из полученной иерархии разбиений выбирается разбиение на Таким образом, объекты оказываются однозначно распределенными по четким классам, представляющим собой множества уровня а. Результат представляется в виде матрицы разбиения
3.1.2.3. Алгоритм Кутюрье — Фьолео[71] использует понятие так называемого максимально внутренне устойчивого множества (stable set internally maximal). Особенностью метода является возможность пересечения нечетких кластеров. Основные понятия и определения Пусть X — множество классифицируемых объектов, на котором задано нечеткое отношение обычного несходства I в виде соответствующей матрицы 1) нет элемента 2) для всех элементов 3) только для некоторых элементов Новое множество максимально внутренне устойчивых множеств упрощено: все максимально внутренне устойчивые множества, включенные в другие максимально внутренне устойчивые множества, выбывают из рассмотрения. Кластеры представляют собой максимально внутренне устойчивые множества, удовлетворяющие двум условиям: 1) условию представительства, в соответствии с которым любое максимально внутренне устойчивое множество с небольшим числом элементов не рассматривается; максимально внутренне устойчивое множество 2) условию разделимости, в соответствии с которым для любых двух максимально внутренне устойчивых множеств число элементов в области их пересечения не должно превышать пороговое значение w, задаваемое исследователем. Таким образом, множество кластеров
где символ 3 обозначает множество максимально внутренне устойчивых множеств. Параметры алгоритма: а — порог различия элементов, объединяемых в нечеткие кластеры,
Схема алгоритма: 1. Для некоторого задаваемого исследователем порога различия
2. Вычисляются максимально внутренне устойчивые множества для построенного четкого отношения несходства 3. В соответствии с критерием (3.3) для заданных исследователем параметров и и w из множества 3 максимально внутренне устойчивых множеств выделяются кластеры 4. Для каждого кластера
5. Строится матрица
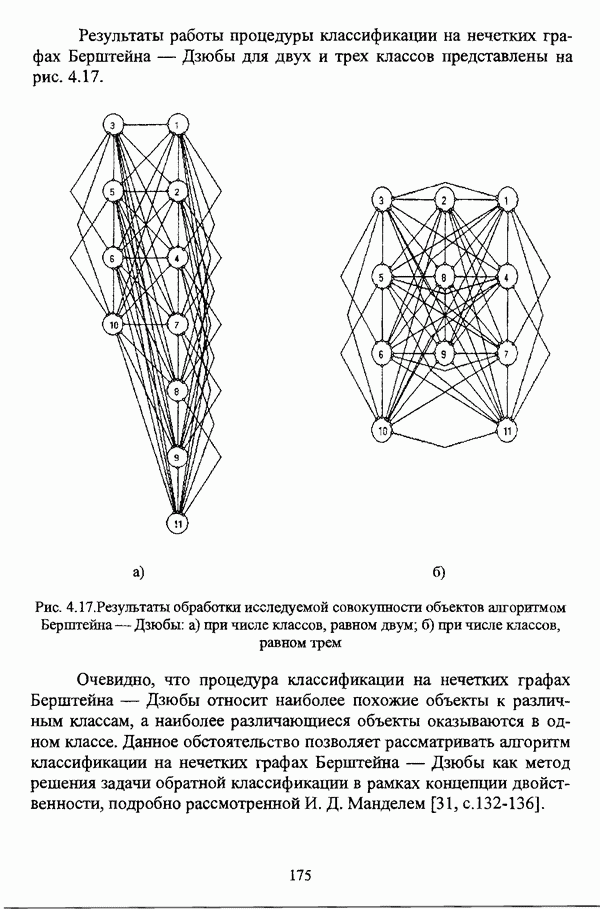
Алгоритм был применен 3.1.2.4. Алгоритм Берштейна — Дзюбы[11] в качестве критерия оптимизации разбиения вершин исходного нечеткого графа на два класса использует наибольшую степень двудольности. Основные понятия и определения Пусть Степень двудольности нечеткого графа
где Для определения степени двудольности S, может быть использован любой из двух следующих способов. Первый способ определения степени двудольности заключается в том, что любую часть
где значения
В дальнейшем, для упрощения обозначений, ребра, являющиеся элементами множества I, будут обозначаться символом Второй способ определения степени двудольности состоит в ее вычислении по следующей формуле:
где, в свою очередь, некоторого ребра Максимальная двудольная часть графа G представляет собой двудольную часть, не являющуюся частью никакой другой. Если число вершин в нечетком графе G является нечетным, то в общем случае число максимальных двудольных частей, которые можно выделить в данном максимальном нечетком графе, может быть вычислено по формуле
где символом
Если же число вершин в нечетком графе G является четным, то число максимальных двудольных частей, которые можно выделить в данном максимальном нечетком графе, вычисляется в соответствии с формулой
Критерием оптимизации разбиения вершин исходного нечеткого графа на два класса является наибольшая степень двудольности Параметры алгоритма: Нечеткий граф задается в виде матрицы гпхл Схема алгоритма: 1. В нечетком графе G ранжируются все ребра 2. Рассматривается первое ребро 3 Для остальных ребер из последовательности 3.1. если 3.2. если 3.3. если 3.4. если 3.5. если 3.6. если 3.6.1. вершина х, помещается в список 3.6.2. вершина х, помещается в список 4 Если были просмотрены все ребра, вычислить степени двудольности Частными случаями задачи являются ситуации, когда оказывается необходимым выделить для исходного графа с четным числом вершин такую максимальную нечеткую двудольную часть с наибольшей степенью двудольности, которая содержит одинаковое число вершин в каждой из долей, а для графа с нечетным числом вершин необходимо выделить такую максимальную нечеткую двудольную часть с наибольшей степенью двудольности, которая содержит в одной доле 1) если число вершин 2) если число вершин Таким образом, после упорядочивания ребер на шаге 1 сложность алгоритма зависит от числа несмежных ребер исходного графа, которые находятся в последовательности рядом друг с другом [11, с. 119-120]. Необходимо также еще раз подчеркнуть, что данный алгоритм разбивает множество объектов 3.1.2.5. Другие алгоритмы,представляющие эвристическое направление нечеткого подхода в кластерном анализе, также сравнительно немногочисленны. К примеру, в работе [123] описывается метод, использующий, как и в алгоритме Тамуры — Хигути [47] рассматривается процедура кластеризации, исходными данными для которой также является нечеткое отношение сходства. В работе [178] описывается человеко-машинный подход к решению нечеткой модификации задачи кластерного анализа. Сущность предлагаемого подхода состоит в том, что нечеткие кластеры, являющиеся нечеткими множествами уровня а, в свою очередь, порожденными некоторой нечеткой толерантностью Т, матрица которой является матрицей исходных данных, образуют так называемое представление
|
 |
Оглавление
|



























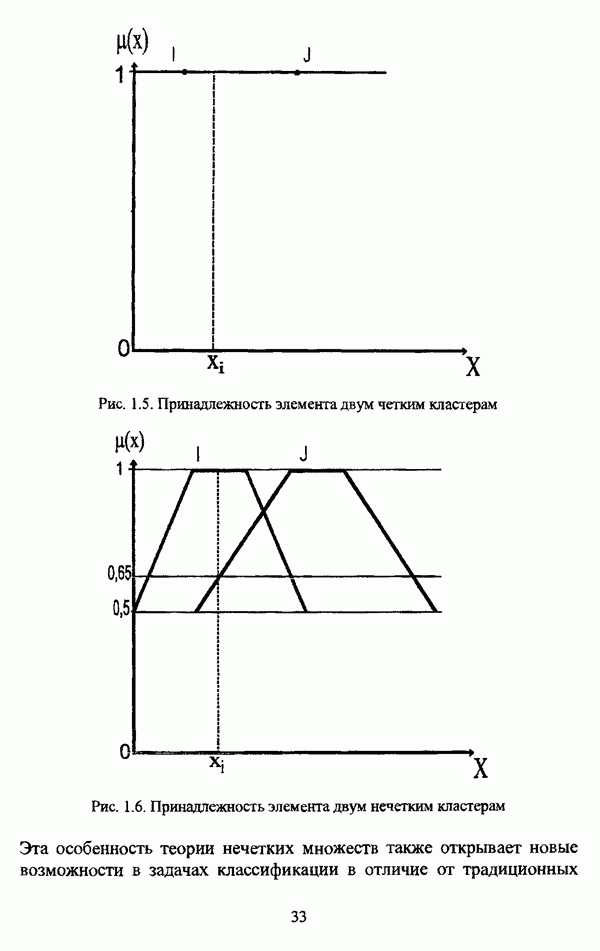






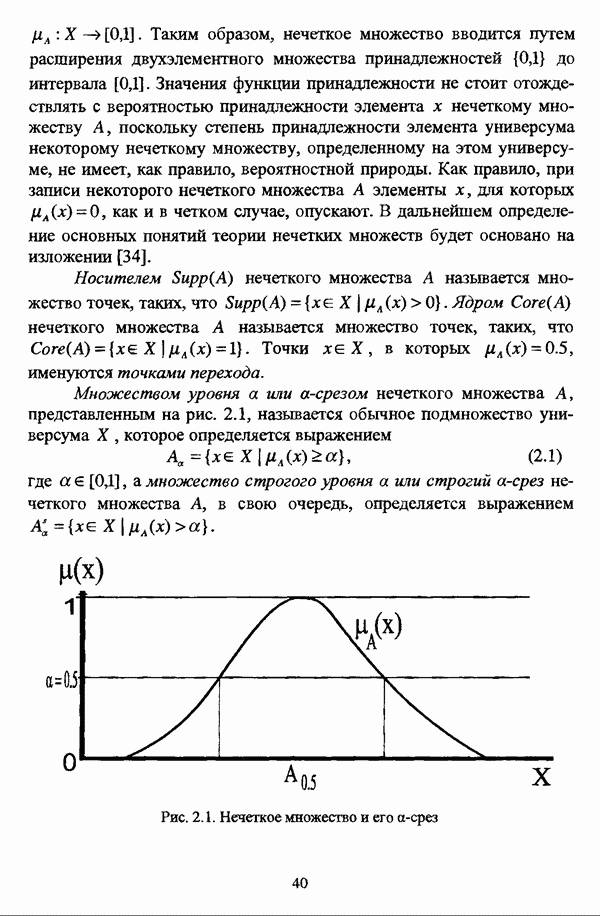


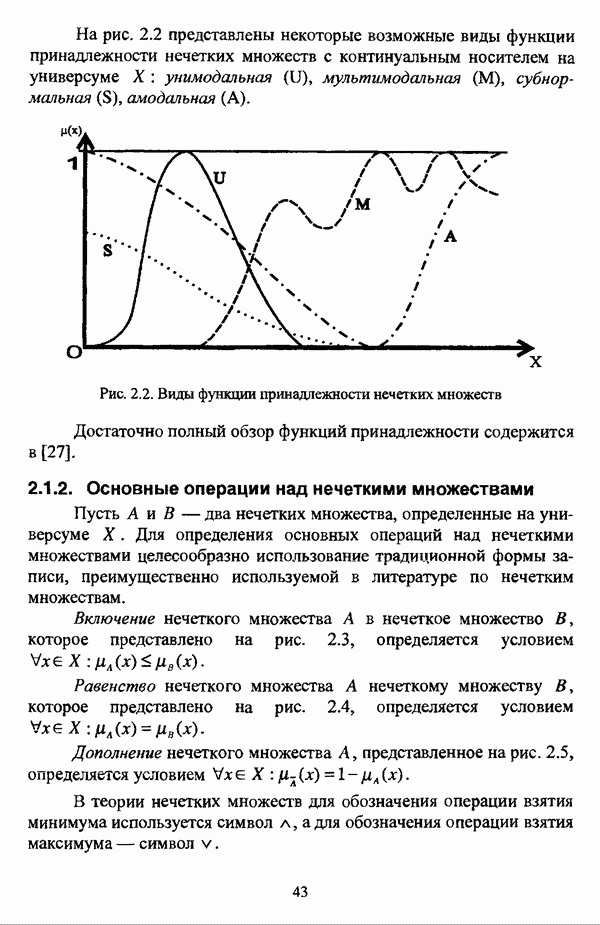
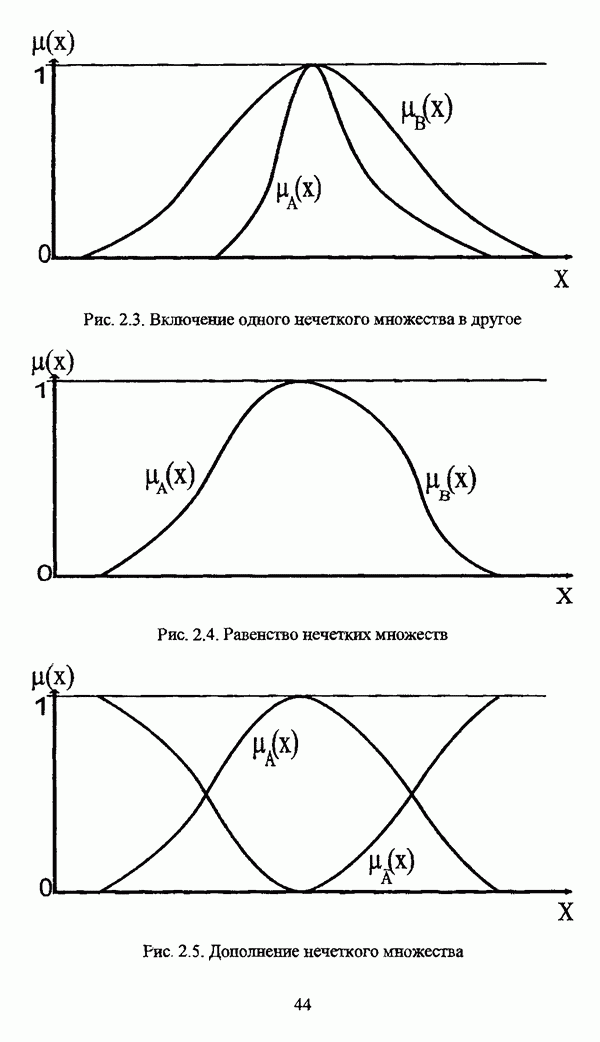































































































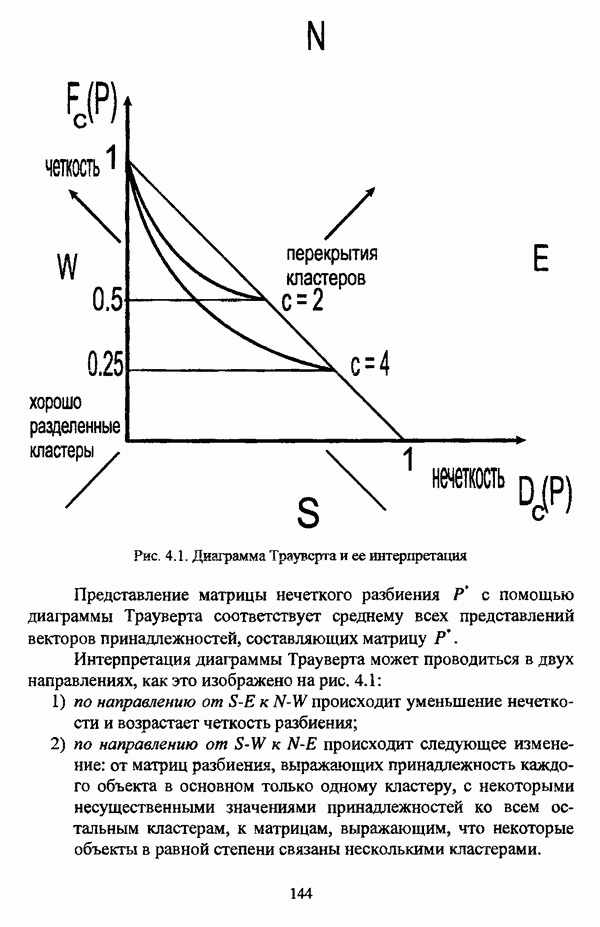






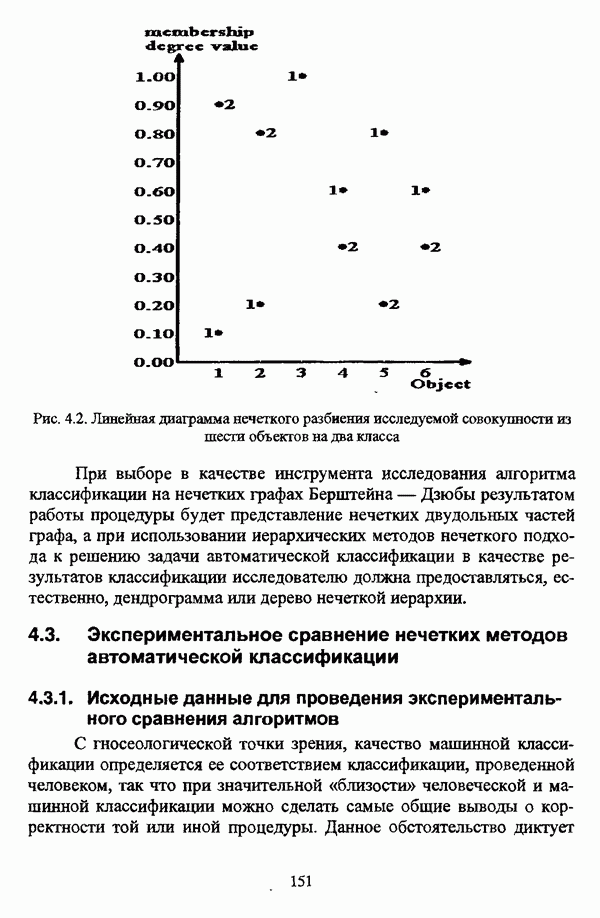

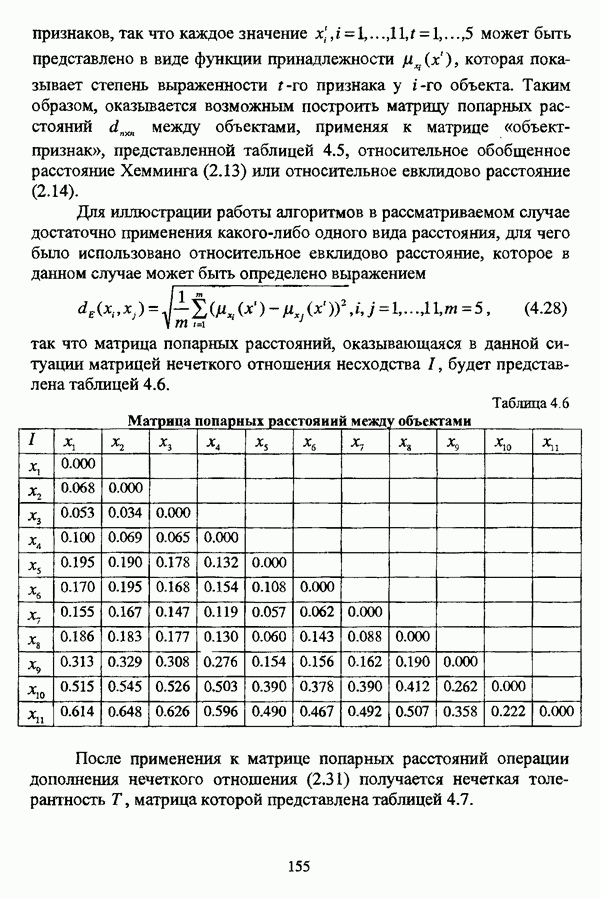

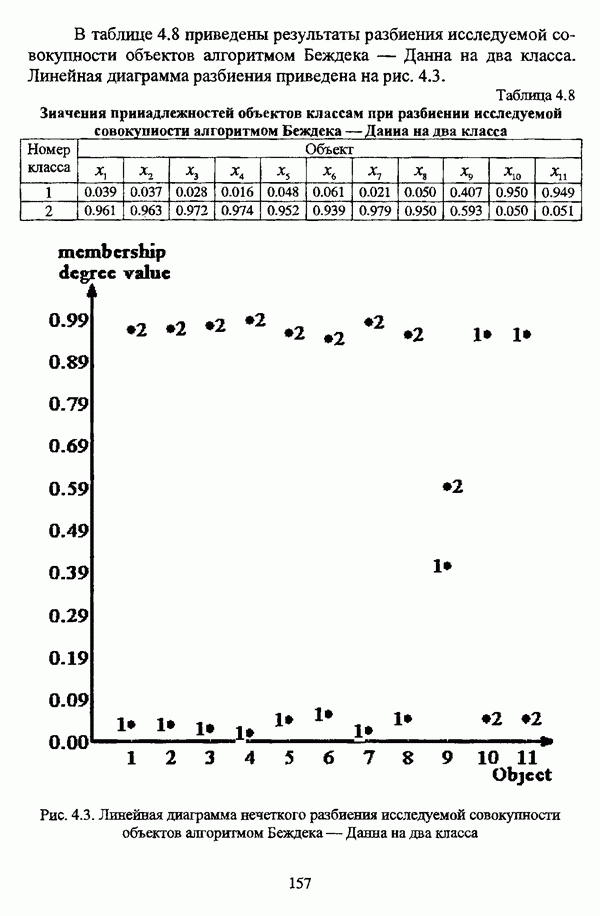
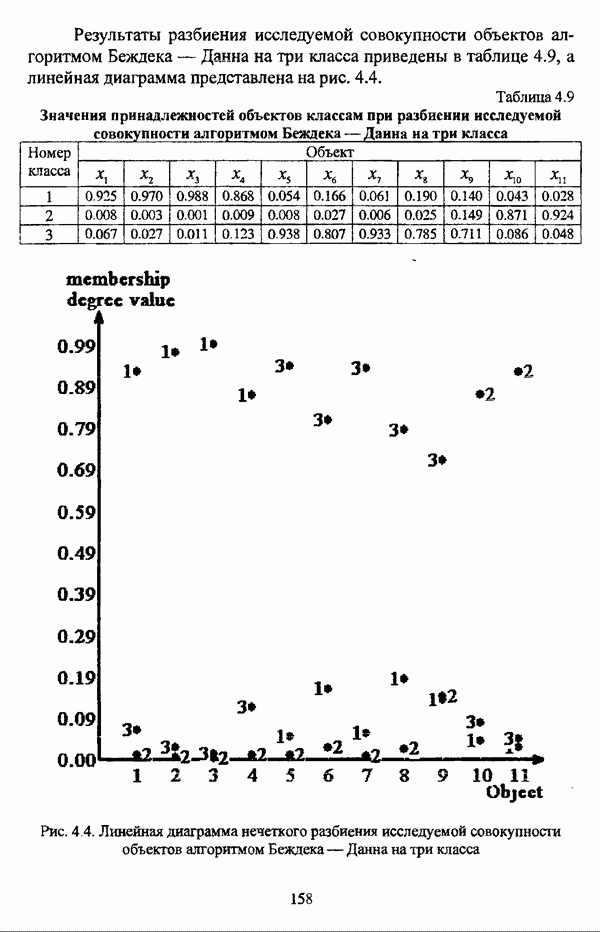
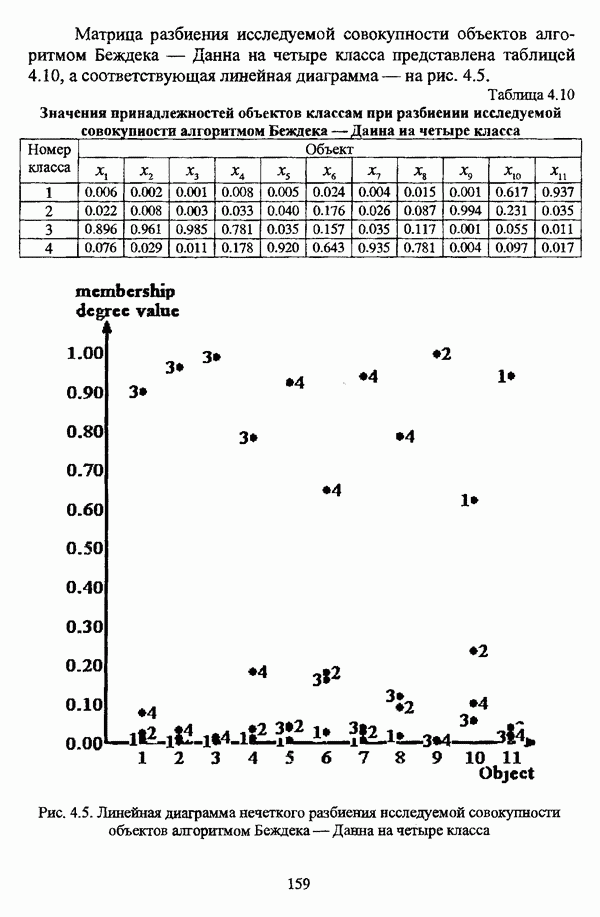
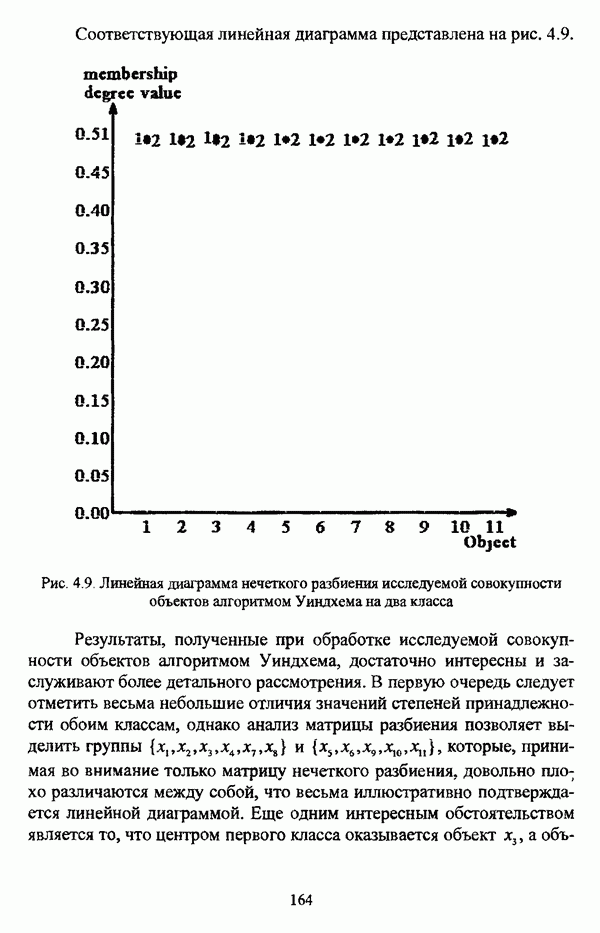
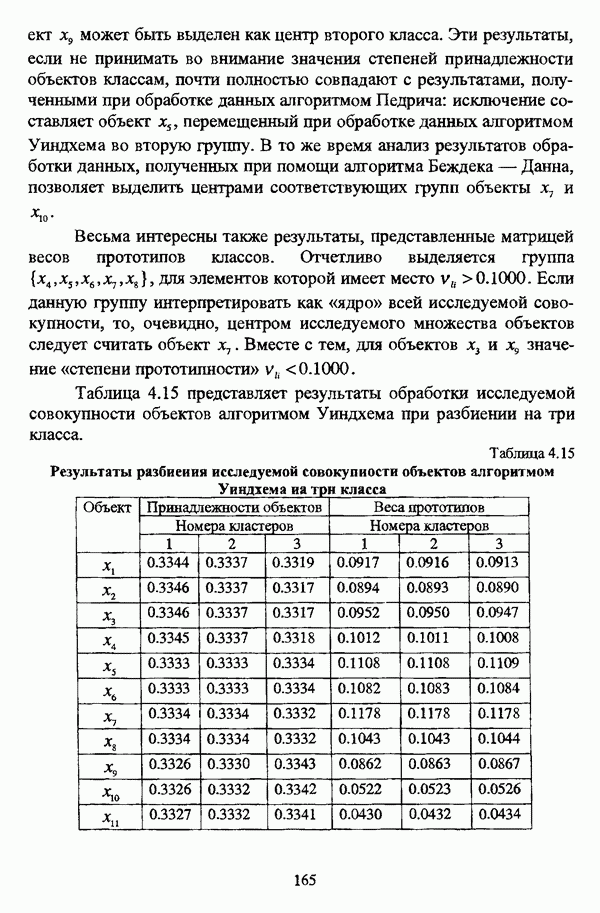
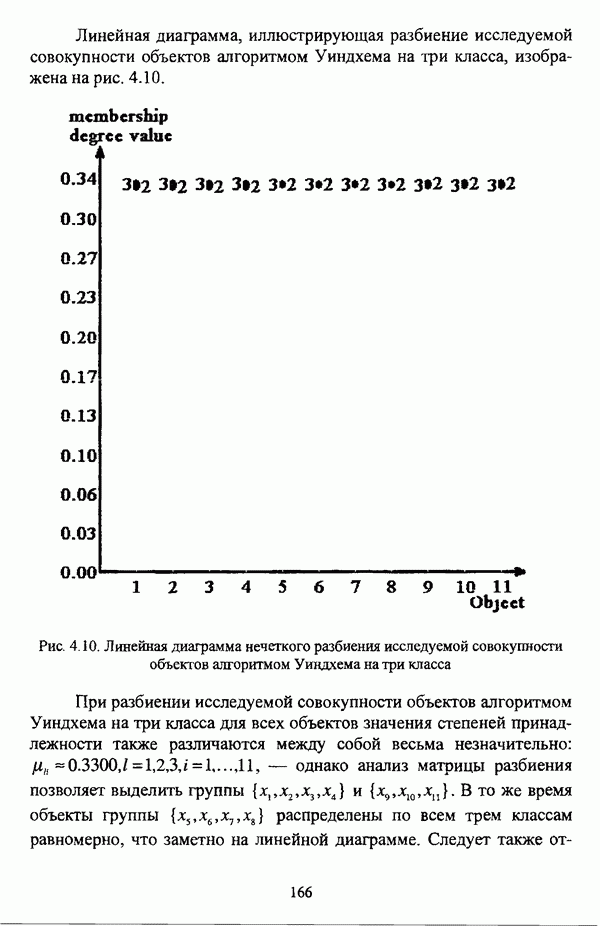
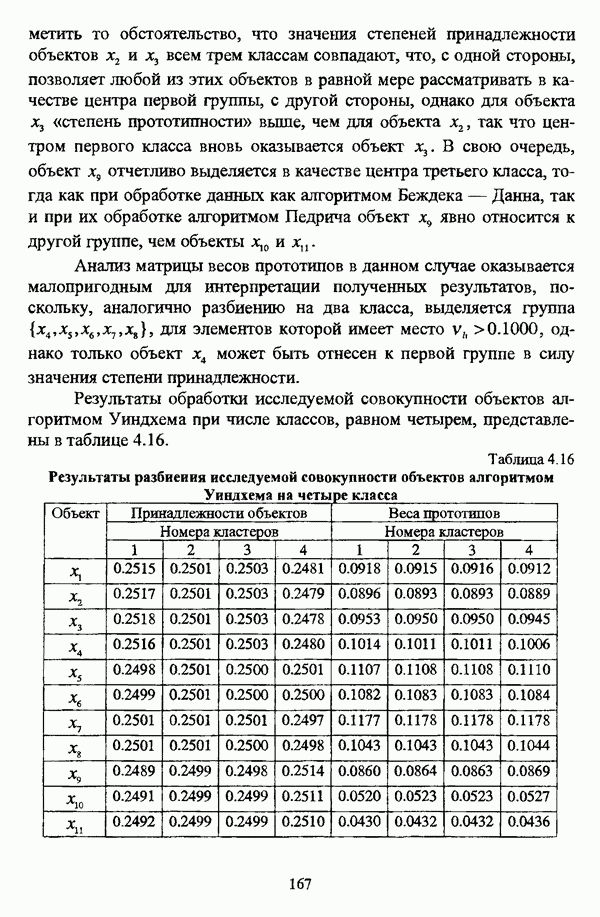
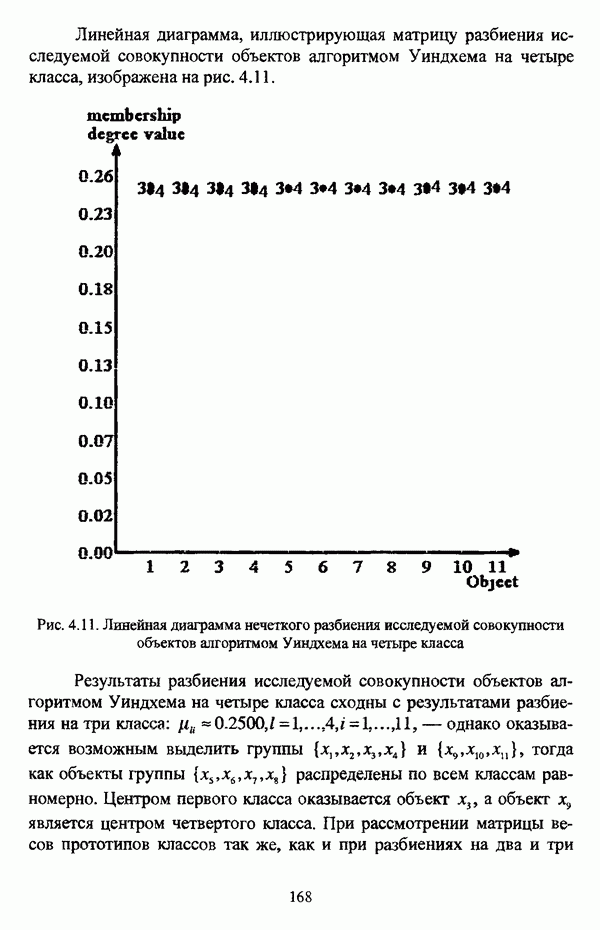

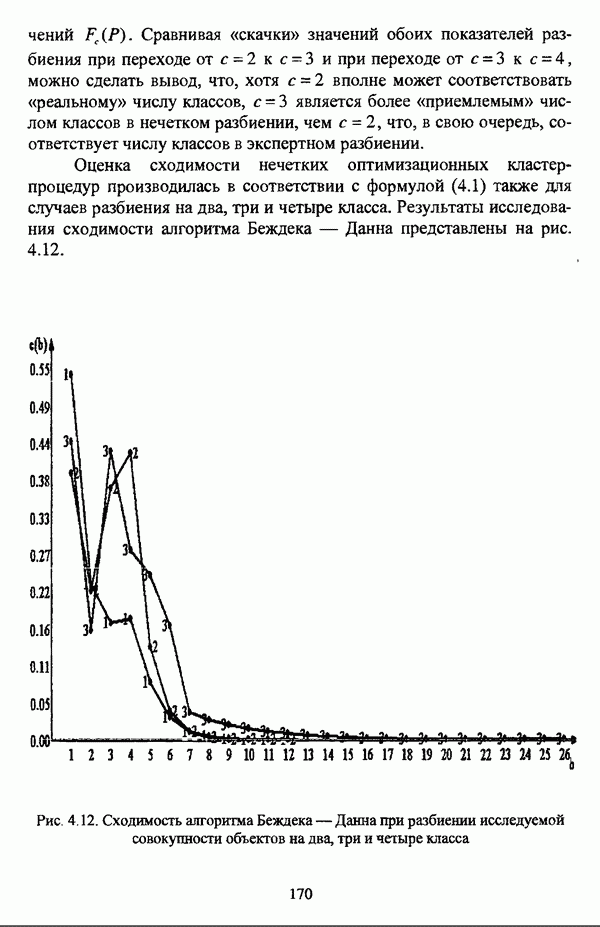
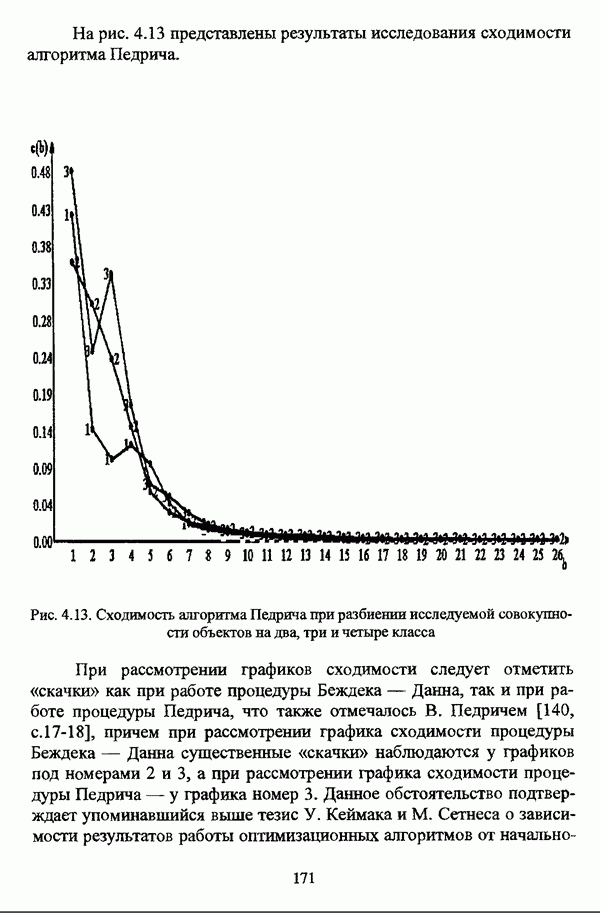
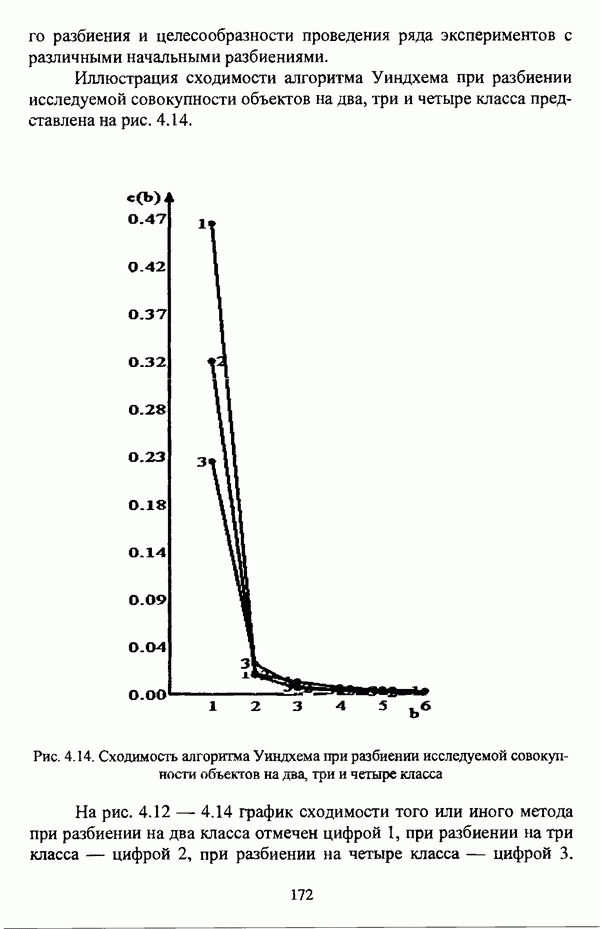



































 — множество классифицируемых объектов, на котором задано нечеткое множество
— множество классифицируемых объектов, на котором задано нечеткое множество  таким образом, В — дискретное нечеткое множество точек, подлежащих классификации. Пусть
таким образом, В — дискретное нечеткое множество точек, подлежащих классификации. Пусть  — точка, в которой значение функции принадлежности максимально, то есть
— точка, в которой значение функции принадлежности максимально, то есть  . В таком случае на множестве В могут быть определены следующие множества:
. В таком случае на множестве В могут быть определены следующие множества:


 — некоторая метрика. Необходимо отметить, что при
— некоторая метрика. Необходимо отметить, что при  четкое множество
четкое множество  представляет собой множество уровня а нечеткого множества В в смысле условия (2.1).
представляет собой множество уровня а нечеткого множества В в смысле условия (2.1).
 Очевидно, что если нечеткое множество В является симметричным, то справедливо соотношение
Очевидно, что если нечеткое множество В является симметричным, то справедливо соотношение 
 является связанным
является связанным 
 определяют разбиение нечеткого множества В на G нечетких подмножеств. Точка
определяют разбиение нечеткого множества В на G нечетких подмножеств. Точка  , для которой выполняется условие
, для которой выполняется условие  будет именоваться модальной точкой или просто модой группы
будет именоваться модальной точкой или просто модой группы  . Некоторая мода
. Некоторая мода  будет именоваться локальным максимумом функции
будет именоваться локальным максимумом функции  и обозначаться символом
и обозначаться символом  , если для нее выполняется соотношение
, если для нее выполняется соотношение 
 ставится в соответствие точка х,, такая, что
ставится в соответствие точка х,, такая, что  тогда точка
тогда точка  будет именоваться внутренней точкой подмножества А в том и только в том случае, если множество
будет именоваться внутренней точкой подмножества А в том и только в том случае, если множество  включает в себя по меньшей мере одну точку из множества А. Необходимо указать, что в оригинальной версии алгоритма
включает в себя по меньшей мере одну точку из множества А. Необходимо указать, что в оригинальной версии алгоритма  используется пороговое значение
используется пороговое значение  так что
так что  и с каждой точкой
и с каждой точкой  сопоставляется число
сопоставляется число  иными словами,
иными словами,  — число точек в d - окрестности точки
— число точек в d - окрестности точки  Очевидно, что если в качестве функции, сопоставляющей точке
Очевидно, что если в качестве функции, сопоставляющей точке  значение выступает функция принадлежности нечеткого множества В, то в качестве порога может быть выбрано некоторое значение а — порог различия элементов, объединяемых в кластеры,
значение выступает функция принадлежности нечеткого множества В, то в качестве порога может быть выбрано некоторое значение а — порог различия элементов, объединяемых в кластеры,  . Следует отметить,
. Следует отметить,
 полностью определяется порогом d, который должен быть не настолько низким, что
полностью определяется порогом d, который должен быть не настолько низким, что  , и не настолько высоким, чтобы
, и не настолько высоким, чтобы 

 локальных максимумов функции принадлежности
локальных максимумов функции принадлежности  В изложенном ниже варианте алгоритм представлен в виде единой кластер-процедуры.
В изложенном ниже варианте алгоритм представлен в виде единой кластер-процедуры.
 параметром алгоритма — порог различия объектов
параметром алгоритма — порог различия объектов 
 точек
точек  исследуемой совокупности, х,, упорядоченных в соответствии со значениями их функции принадлежности, так что
исследуемой совокупности, х,, упорядоченных в соответствии со значениями их функции принадлежности, так что  при
при  где
где  — функции принадлежности точек
— функции принадлежности точек  соответственно;
соответственно;
 представляющая собой упорядоченную в соответствии с их расстояниями до точки
представляющая собой упорядоченную в соответствии с их расстояниями до точки  то есть при
то есть при  последовательность точек — «кандидатов» в группу
последовательность точек — «кандидатов» в группу  то есть группу, для которой точка
то есть группу, для которой точка  будет являться модой, так что
будет являться модой, так что
 будет точка
будет точка  следующей точкой — «кандидатом» в группу
следующей точкой — «кандидатом» в группу  будет точка
будет точка  и так далее;
и так далее;
 то
то  распределяются в группу
распределяются в группу  а точка
а точка  рассматривается как мода второй группы, так что формируется последовательность
рассматривается как мода второй группы, так что формируется последовательность  в которой точки упорядочиваются по расстоянию до точки
в которой точки упорядочиваются по расстоянию до точки  так что
так что  при
при  подобный процесс выполняется для любой последовательности
подобный процесс выполняется для любой последовательности  так что если
так что если  — мода группы
— мода группы  то первым «кандидатом» в группу
то первым «кандидатом» в группу  будет точка
будет точка 
 точек — «кандидатов»
точек — «кандидатов»  и пусть некоторую точку
и пусть некоторую точку  требуется приписать некоторой группе
требуется приписать некоторой группе  тогда как все предшествующие ей точки
тогда как все предшествующие ей точки  расклассифицированы, тогда оказываются возможными следующие ситуации:
расклассифицированы, тогда оказываются возможными следующие ситуации:
 то точка
то точка  включается в формируемую группу А;
включается в формируемую группу А;
 некоторого
некоторого  где L — множество индексов, представляющих те группы, точки — «кандидаты» которых идентичны у q, то точка
где L — множество индексов, представляющих те группы, точки — «кандидаты» которых идентичны у q, то точка  включается в ту группу, к которой приписан ее ближайший сосед, имеющий наибольшее значение функции принадлежности;
включается в ту группу, к которой приписан ее ближайший сосед, имеющий наибольшее значение функции принадлежности;
 для
для  то формируется новая группа, для которой точка
то формируется новая группа, для которой точка  является модой;
является модой;

 и соответствующей ей моды
и соответствующей ей моды  находится минимальное расстояние
находится минимальное расстояние 
 , являющейся ближайшей к группе А и лежащей вне ее:
, являющейся ближайшей к группе А и лежащей вне ее:  точка
точка  будет локальным максимумом, если множество
будет локальным максимумом, если множество  включает в себя точки группы
включает в себя точки группы  в противном случае точка
в противном случае точка  является не локальным максимумом, а граничной точкой группы
является не локальным максимумом, а граничной точкой группы  данная процедура применяется ко всем модам
данная процедура применяется ко всем модам  так что формируется последовательность локальных максимумов
так что формируется последовательность локальных максимумов  упорядоченная в соответствии со следующим правилом: для локальных максимумов
упорядоченная в соответствии со следующим правилом: для локальных максимумов  локальные максимумы
локальные максимумы  к
к  расположены так, что
расположены так, что 
 порождающих кластеры
порождающих кластеры  применяется следующее правило: точка
применяется следующее правило: точка  , расположенная в последовательности
, расположенная в последовательности  в
в  -й позиции, то есть
-й позиции, то есть  распределяется в ту группу
распределяется в ту группу  в которой находится ее ближайший сосед с более высоким значением функции принадлежности, так что строится разбиение
в которой находится ее ближайший сосед с более высоким значением функции принадлежности, так что строится разбиение  и алгоритм прекращает работу.
и алгоритм прекращает работу.
 выполняется неравенство
выполняется неравенство  Вместе с тем, возможной оказывается также ситуация, когда значение функции принадлежности оказывается одинаковым для нескольких точек, то есть
Вместе с тем, возможной оказывается также ситуация, когда значение функции принадлежности оказывается одинаковым для нескольких точек, то есть  . В таком случае проблема решается внесением изменения на шаге 3 процедуры и перестановкой элементов в последовательности А следующим образом: при сформированных G группах некоторая точка
. В таком случае проблема решается внесением изменения на шаге 3 процедуры и перестановкой элементов в последовательности А следующим образом: при сформированных G группах некоторая точка  подлежит включению в некоторую группу
подлежит включению в некоторую группу  Если
Если  для
для  и если
и если  то необходимо проверить выполнение равенства
то необходимо проверить выполнение равенства  Новая группа с модой
Новая группа с модой  образуется только в том случае, если ни одна из точек
образуется только в том случае, если ни одна из точек  имеющих такое же значение функции принадлежности, как и точка
имеющих такое же значение функции принадлежности, как и точка  не идентична с точкой
не идентична с точкой 
 получают несколько точек, поэтому
получают несколько точек, поэтому
 подмножество точек из А, имеющих, как и точка
подмножество точек из А, имеющих, как и точка  максимальное значение функции принадлежности; каждая из точек подмножества
максимальное значение функции принадлежности; каждая из точек подмножества  проверяется как мода группы А, и если хотя бы одна из них является пограничной для группы А, то точка f не рассматривается как локальный максимум.
проверяется как мода группы А, и если хотя бы одна из них является пограничной для группы А, то точка f не рассматривается как локальный максимум.
 нечеткого множества В порождают унимодальные нечеткие множества
нечеткого множества В порождают унимодальные нечеткие множества  Вместо этого предлагается следующая процедура построения нечетких кластеров
Вместо этого предлагается следующая процедура построения нечетких кластеров  с: пусть
с: пусть  с — сформированная последовательность локальных максимумов; если на множестве
с — сформированная последовательность локальных максимумов; если на множестве  задана нечеткая толерантность Г, так что
задана нечеткая толерантность Г, так что  — степень сходства элементов
— степень сходства элементов  то степень принадлежности
то степень принадлежности  элемента кластеру
элемента кластеру  может быть вычислена по формуле
может быть вычислена по формуле  Многочисленные вычислительные эксперименты — для 1000 сгенерированных объектов — показали достаточно высокую скорость вычислений при небольших затратах памяти, а получаемые кластеры могут иметь как эллиптическую форму, так и форму окружности.
Многочисленные вычислительные эксперименты — для 1000 сгенерированных объектов — показали достаточно высокую скорость вычислений при небольших затратах памяти, а получаемые кластеры могут иметь как эллиптическую форму, так и форму окружности.
 и состоит из трех шагов.
и состоит из трех шагов.
 — множество классифицируемых объектов, на котором задана нечеткая толерантность Т в виде матрицы глхи
— множество классифицируемых объектов, на котором задана нечеткая толерантность Т в виде матрицы глхи  близости объектов (1.3).
близости объектов (1.3).

 -уровни,
-уровни,  полученного нечеткого отношения эквивалентности Т и для каждого
полученного нечеткого отношения эквивалентности Т и для каждого  выделяются кластеры
выделяются кластеры  в соответствии с правилом: если
в соответствии с правилом: если  для некоторых
для некоторых  то объекты
то объекты  принадлежат кластеру
принадлежат кластеру 
 классов
классов  соответствующее некоторому порогу
соответствующее некоторому порогу  , и алгоритм прекращает работу.
, и алгоритм прекращает работу.
 где
где

 Пусть для некоторого
Пусть для некоторого  четкое отношение
четкое отношение  является а-уровнем нечеткого отношения обычного несходства I и
является а-уровнем нечеткого отношения обычного несходства I и  некоторое подмножество исследуемой совокупности объектов,
некоторое подмножество исследуемой совокупности объектов,  Пусть
Пусть  обозначает множество объектов, наиболее отличающихся по крайней мере от некоторого одного элемента
обозначает множество объектов, наиболее отличающихся по крайней мере от некоторого одного элемента  . Тогда подмножество
. Тогда подмножество  будет именоваться максимально внутренне устойчивым множеством, если выполняются условие
будет именоваться максимально внутренне устойчивым множеством, если выполняются условие  и условие
и условие  При вычислении максимально внутренне устойчивых множеств рассматриваются три варианта:
При вычислении максимально внутренне устойчивых множеств рассматриваются три варианта:
 такого, что для некоторого
такого, что для некоторого  выполняется
выполняется  : максимально внутренне устойчивое множество
: максимально внутренне устойчивое множество  замещается множеством
замещается множеством 
 выполняется условие
выполняется условие  добавляется новое максимально внутренне устойчивое множество
добавляется новое максимально внутренне устойчивое множество 
 выполняется условие
выполняется условие  так что максимально внутренне устойчивое множество
так что максимально внутренне устойчивое множество  разбивается на два подмножества,
разбивается на два подмножества,  где
где  — подмножество элементов
— подмножество элементов  подобных элементу
подобных элементу  — подмножество элементов
— подмножество элементов  отличных от элемента
отличных от элемента  создается новое максимально внутренне устойчивое множество
создается новое максимально внутренне устойчивое множество 
 является кластером, если
является кластером, если  где
где  — порог, задаваемый исследователем;
— порог, задаваемый исследователем;
 должно удовлетворять следующему условию:
должно удовлетворять следующему условию:


 — минимальное число элементов в нечетком кластере
— минимальное число элементов в нечетком кластере 
 — максимальное число элементов в области пересечения любых двух нечетких кластеров;
— максимальное число элементов в области пересечения любых двух нечетких кластеров;
 строится
строится  — a-уровень нечеткого отношения несходства I в соответствии с условием
— a-уровень нечеткого отношения несходства I в соответствии с условием



 определяется точка
определяется точка  являющаяся его центром, и строится функция принадлежности
являющаяся его центром, и строится функция принадлежности  которая удовлетворяет следующему условию:
которая удовлетворяет следующему условию:

 нечеткого покрытия
нечеткого покрытия  элементами которой являются степени сходства
элементами которой являются степени сходства  элементов множества
элементов множества  с центрами
с центрами  кластеров
кластеров  в соответствии со следующей формулой:
в соответствии со следующей формулой:

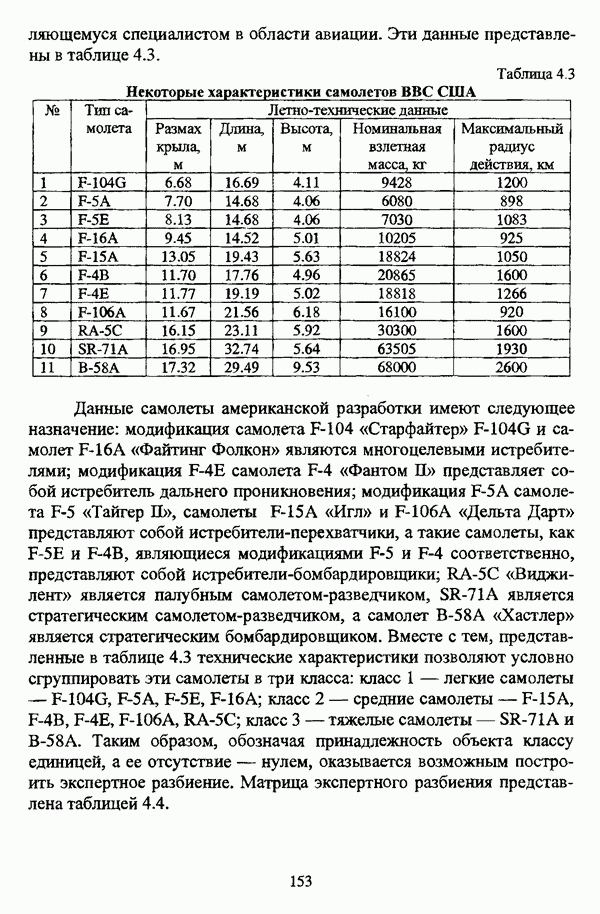
 для анализа состояния 165 французских фирм в 1995 финансовом году при различных значениях входных параметров и в сравнении с алгоритмом Беждека — Данна показал хорошие результаты.
для анализа состояния 165 французских фирм в 1995 финансовом году при различных значениях входных параметров и в сравнении с алгоритмом Беждека — Данна показал хорошие результаты.
 — нечеткий граф, где
— нечеткий граф, где  — множество вершин, а
— множество вершин, а  — нечеткое множество ребер нечеткого графа G, где
— нечеткое множество ребер нечеткого графа G, где  — функция принадлежности ребра
— функция принадлежности ребра  так что
так что 
 определяется в соответствии с выражением
определяется в соответствии с выражением

 символом
символом  обозначается степень двудольности 1-й двудольной части нечеткого графа G, а символом с — число различных максимальных двудольных частей данного нечеткого графа
обозначается степень двудольности 1-й двудольной части нечеткого графа G, а символом с — число различных максимальных двудольных частей данного нечеткого графа 
 где
где  можно рассматривать как нечеткую двудольную часть графа G со степенью двудольности, вычисляемой в соответствии с формулой
можно рассматривать как нечеткую двудольную часть графа G со степенью двудольности, вычисляемой в соответствии с формулой

 определяются по формулам
определяются по формулам

 а ребра, являющиеся элементами множества II, — символом
а ребра, являющиеся элементами множества II, — символом 

 — значение функции принадлежности некоторого ребра
— значение функции принадлежности некоторого ребра  — значение функции принадлежности
— значение функции принадлежности
 - максимально возможное число ребер между вершинами множества
- максимально возможное число ребер между вершинами множества  — максимально возможное число ребер между вершинами множества
— максимально возможное число ребер между вершинами множества  а символами
а символами  обозначено число вершин во множестве X и множестве
обозначено число вершин во множестве X и множестве  соответственно. В дальнейшем степень двудольности, вычисленная в соответствии с первым способом, то есть по формуле (3.5), будет обозначаться символом
соответственно. В дальнейшем степень двудольности, вычисленная в соответствии с первым способом, то есть по формуле (3.5), будет обозначаться символом  а если для этой цели применяется второй способ, то есть формула (3.8) — соответственно, символом
а если для этой цели применяется второй способ, то есть формула (3.8) — соответственно, символом  поскольку, в общем,
поскольку, в общем,  Таким образом, представляется очевидным, что если во множествах вершин
Таким образом, представляется очевидным, что если во множествах вершин  графа, полученного в результате выделения двудольной части, не существует ни одной дуги, то степень двудольности такого графа равна 1, причем независимо от способа вычисления величины
графа, полученного в результате выделения двудольной части, не существует ни одной дуги, то степень двудольности такого графа равна 1, причем независимо от способа вычисления величины 

 обозначается округление величины
обозначается округление величины  в меньшую сторону, а символ
в меньшую сторону, а символ  традиционно обозначает число сочетаний:
традиционно обозначает число сочетаний:


 или
или 
 отношения нечеткой толерантности. Ребра
отношения нечеткой толерантности. Ребра  процессе выполнения алгоритма не рассматриваются. Входные параметры как таковые отсутствуют.
процессе выполнения алгоритма не рассматриваются. Входные параметры как таковые отсутствуют.
 в порядке убывания их степеней принадлежности
в порядке убывания их степеней принадлежности 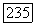 так что формируется последовательность
так что формируется последовательность 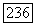
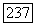 с максимальной степенью принадлежности
с максимальной степенью принадлежности 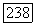 из последовательности
из последовательности 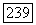 и вершина
и вершина 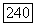 инцидентная этому ребру, помещается в первую долю, то есть список
инцидентная этому ребру, помещается в первую долю, то есть список 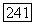 а вершина х, — в другую долю, то есть список
а вершина х, — в другую долю, то есть список 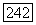
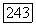
 , то вершина
, то вершина 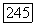 помещается в список
помещается в список 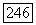
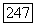 то вершина
то вершина 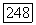 помещается в список X;
помещается в список X;
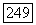 , то вершина
, то вершина 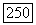 помещается в список
помещается в список 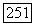
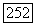 то вершина х, помещается в список X;
то вершина х, помещается в список X;
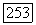 или
или 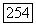 то ребро прибавляется к нечеткой двудольной части;
то ребро прибавляется к нечеткой двудольной части;
 или
или 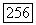 то оказываются возможны два варианта:
то оказываются возможны два варианта:
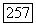 , вершина х, помещается в список
, вершина х, помещается в список 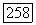
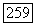 вершина
вершина 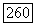 помещается в список
помещается в список 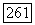
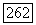 и/или
и/или 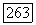 по соответствующим формулам, и алгоритм прекращает работу; в противном случае осуществляется переход на шаг 3.
по соответствующим формулам, и алгоритм прекращает работу; в противном случае осуществляется переход на шаг 3.
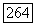 вершин и в другой доле
вершин и в другой доле 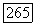 вершин. В таких случаях в шаг 3 вышеприведенной версии алгоритма следует включить проверку дополнительного условия в одной из следующих двух формулировок:
вершин. В таких случаях в шаг 3 вышеприведенной версии алгоритма следует включить проверку дополнительного условия в одной из следующих двух формулировок:
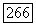 в исходном графе G — четное и
в исходном графе G — четное и 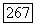 или число вершин
или число вершин 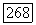 в исходном графе G — нечетное и
в исходном графе G — нечетное и 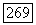 то все остальные, не просмотренные ранее вершины помещаются в список X
то все остальные, не просмотренные ранее вершины помещаются в список X
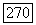 в исходном графе G — четное и
в исходном графе G — четное и 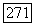 или число вершин
или число вершин 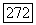 в исходном графе G — нечетное и
в исходном графе G — нечетное и 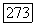 то все остальные, не просмотренные ранее вершины помещаются в список X.
то все остальные, не просмотренные ранее вершины помещаются в список X.
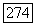 представленных в виде вершин графа, на два класса. Если же при решении задачи классификации множество объектов
представленных в виде вершин графа, на два класса. Если же при решении задачи классификации множество объектов 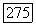 необходимо разбить на большее число групп, то сначала выделяется двудольная структура, после чего каждый из выделенных классов снова разбивается на два подкласса и так далее до тех пор, пока классифицируемое множество
необходимо разбить на большее число групп, то сначала выделяется двудольная структура, после чего каждый из выделенных классов снова разбивается на два подкласса и так далее до тех пор, пока классифицируемое множество 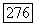 не будет разделено на заданное число классов [11, с. 121].
не будет разделено на заданное число классов [11, с. 121].
 Танаки, операцию транзитивного замыкания, а в исследовании И. 3. Батыршина
Танаки, операцию транзитивного замыкания, а в исследовании И. 3. Батыршина
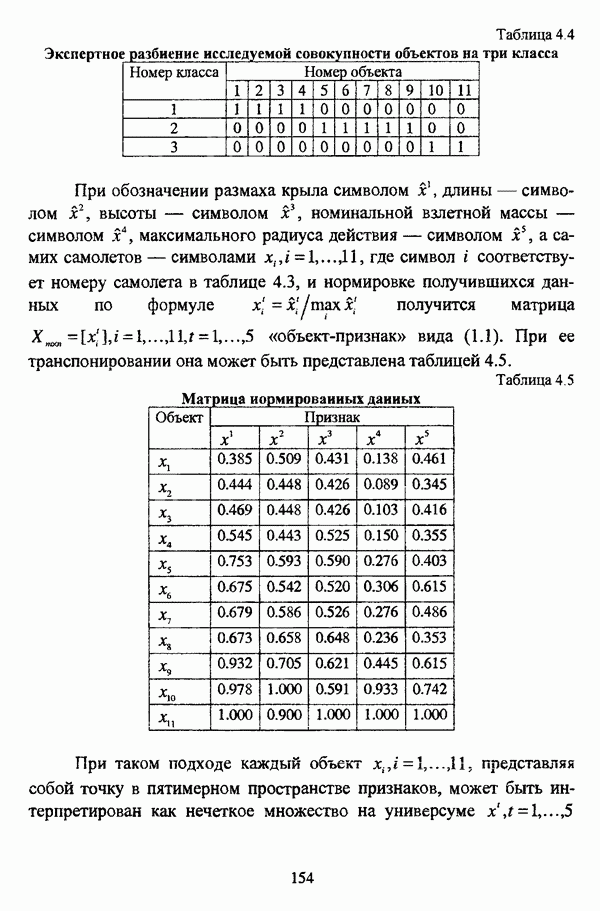
 исследуемой совокупности объектов
исследуемой совокупности объектов  для некоторого уровня
для некоторого уровня  если выполняется условие
если выполняется условие 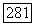 и число нечетких кластеров в представлении оказывается не меньшим, чем два, так что решение задачи классификации подразумевает выбор некоторого единственного представления
и число нечетких кластеров в представлении оказывается не меньшим, чем два, так что решение задачи классификации подразумевает выбор некоторого единственного представления 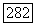 из множества различных представлений для различных значений
из множества различных представлений для различных значений 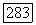 Значение а, таким образом, представляет собой порог сходства элементов, объединяемых в некоторый нечеткий кластер. Метод оправдан с гносеологической точки зрения, позволяет выделять кластеры сложной формы и классифицировать объекты, когда матрица близости классифицируемых объектов представляет собой матрицу любой нечеткой толерантности
Значение а, таким образом, представляет собой порог сходства элементов, объединяемых в некоторый нечеткий кластер. Метод оправдан с гносеологической точки зрения, позволяет выделять кластеры сложной формы и классифицировать объекты, когда матрица близости классифицируемых объектов представляет собой матрицу любой нечеткой толерантности  более того, поскольку нечеткие кластеры представляются как нечеткие множества уровня, то допускается их пересечение [17]. Вместе с тем, применение данного подхода вызывает затруднения обработки данных при большом объеме исследуемой совокупности; кроме того, выбор термина «представление» (representation), используемого для определения искомой структуры, является неудачным, поскольку традиционно в задачах кластер-анализа данный термин имеет отличный от используемого в [178] смысл.
более того, поскольку нечеткие кластеры представляются как нечеткие множества уровня, то допускается их пересечение [17]. Вместе с тем, применение данного подхода вызывает затруднения обработки данных при большом объеме исследуемой совокупности; кроме того, выбор термина «представление» (representation), используемого для определения искомой структуры, является неудачным, поскольку традиционно в задачах кластер-анализа данный термин имеет отличный от используемого в [178] смысл.