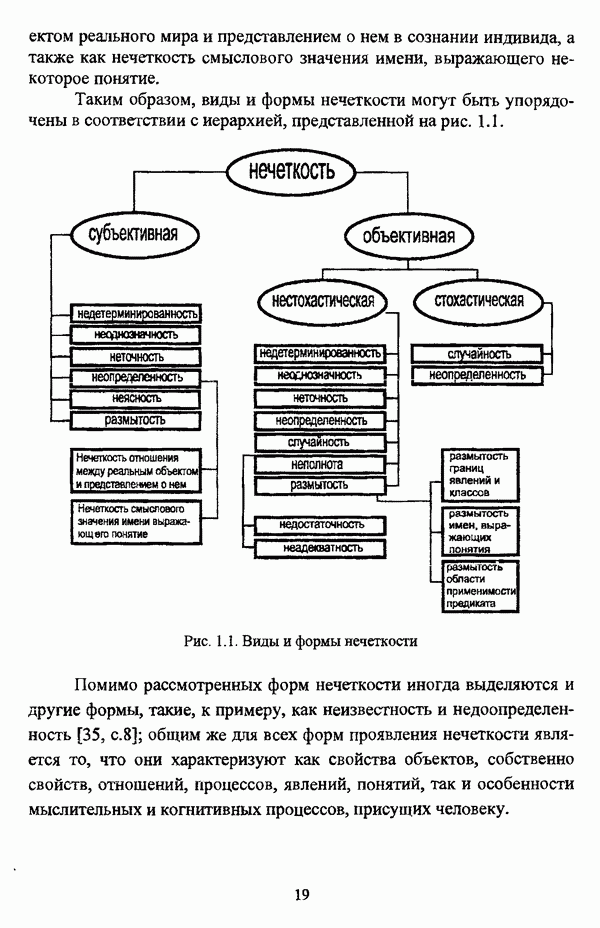
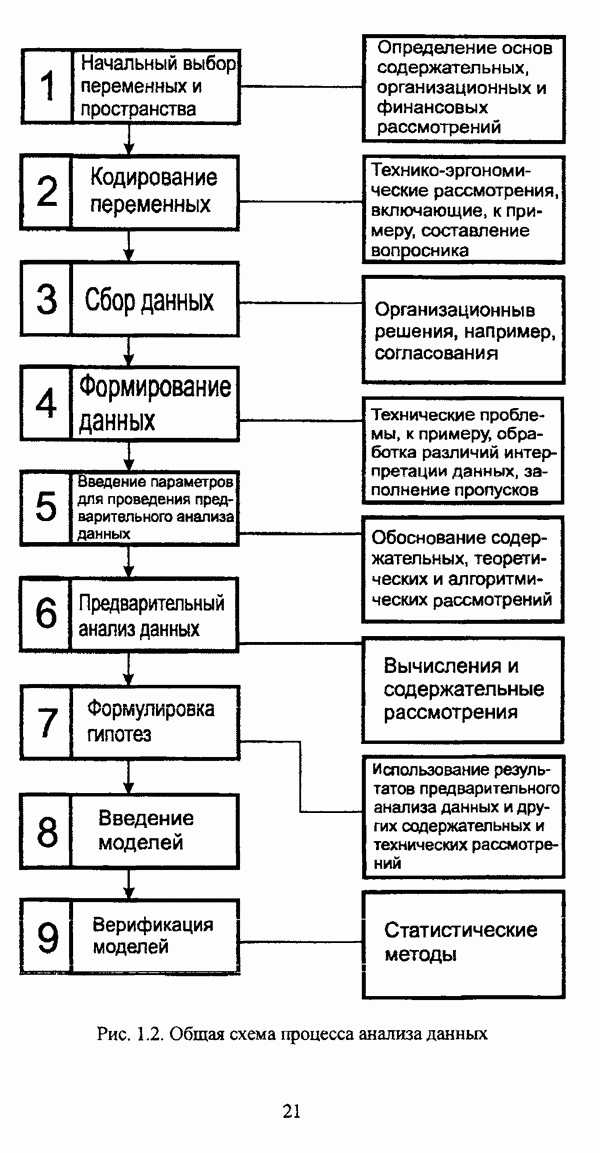
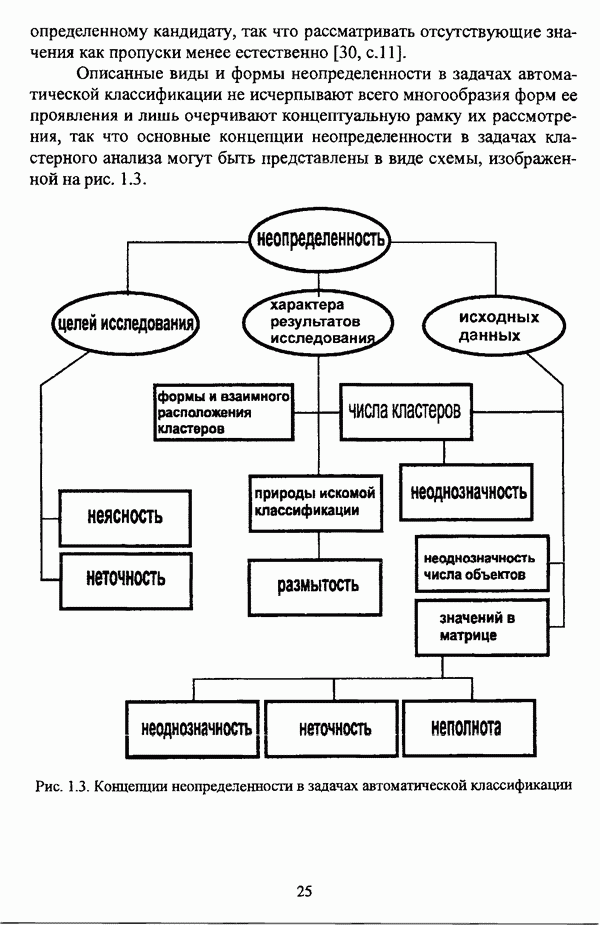
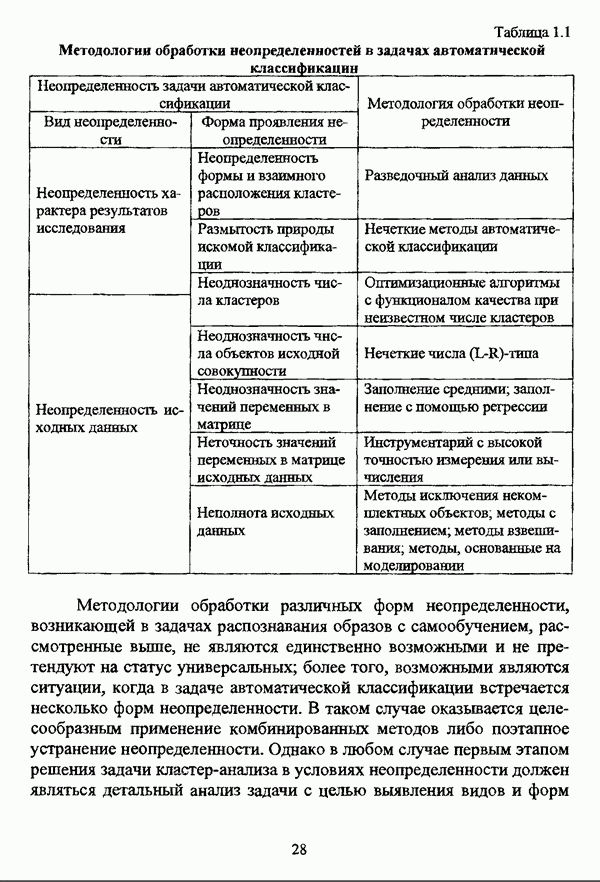
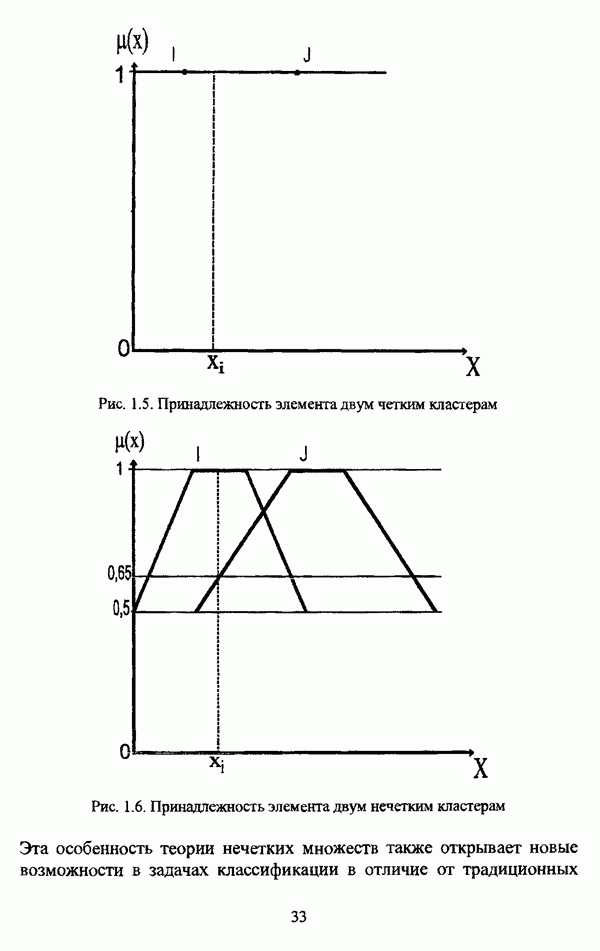
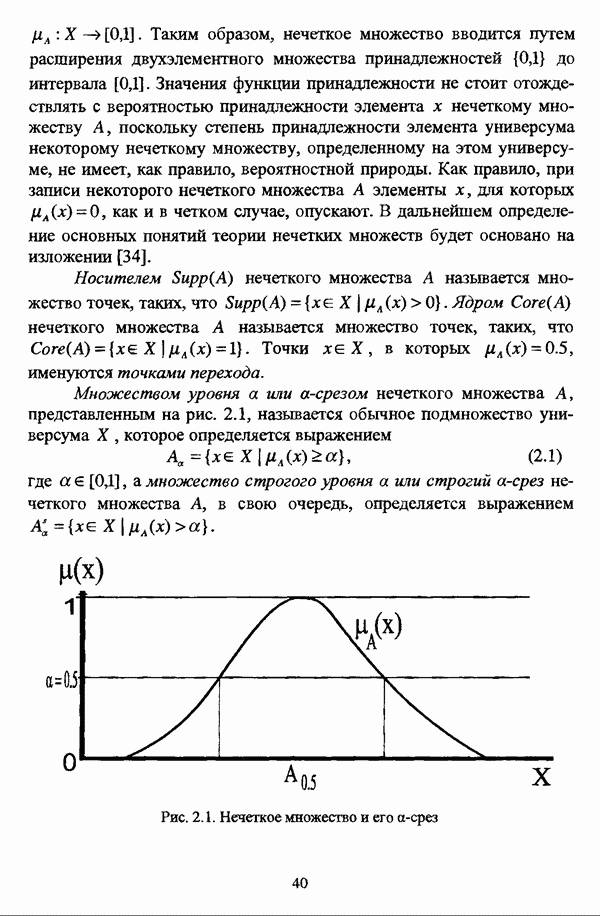
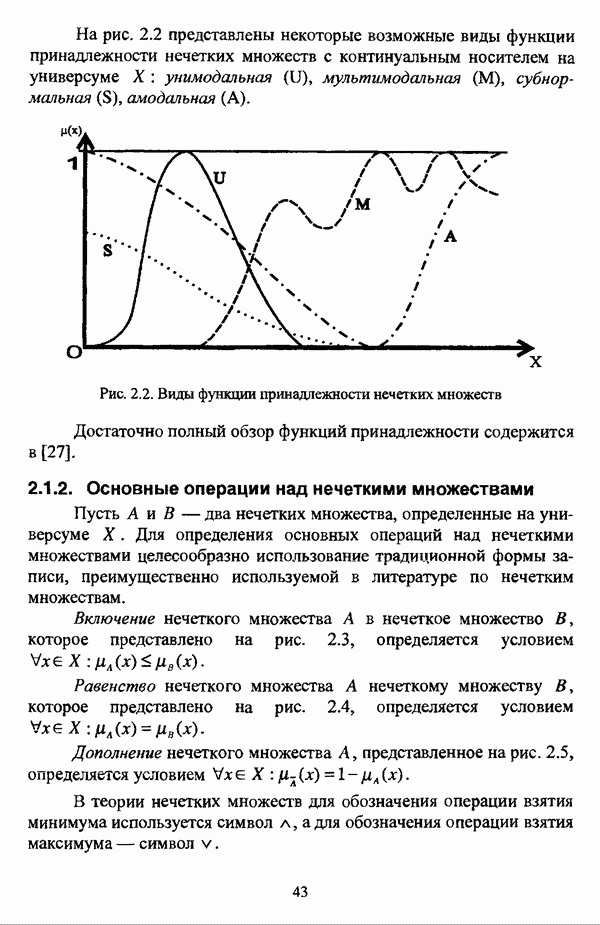
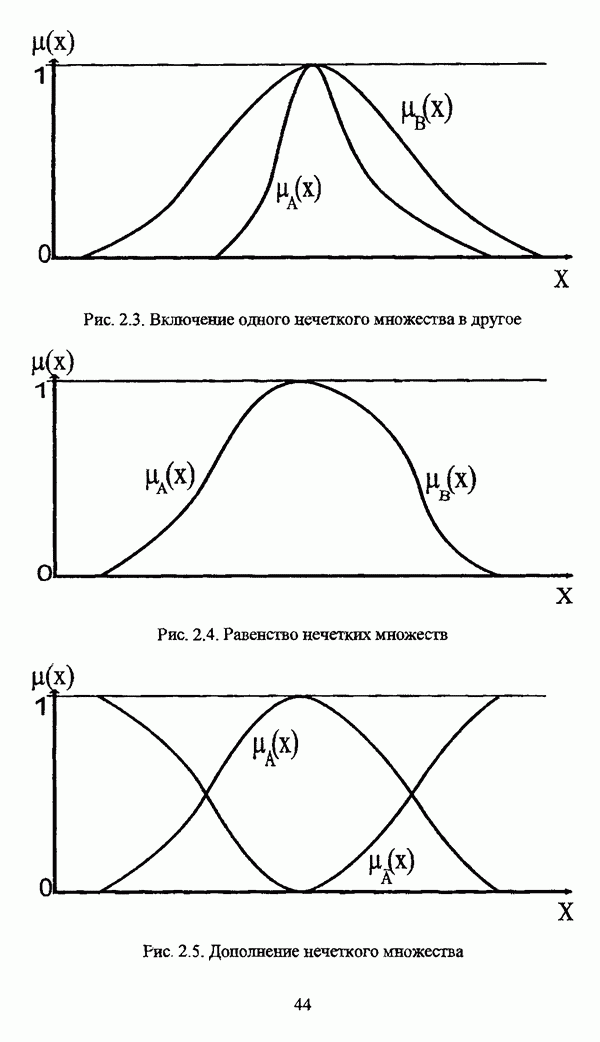
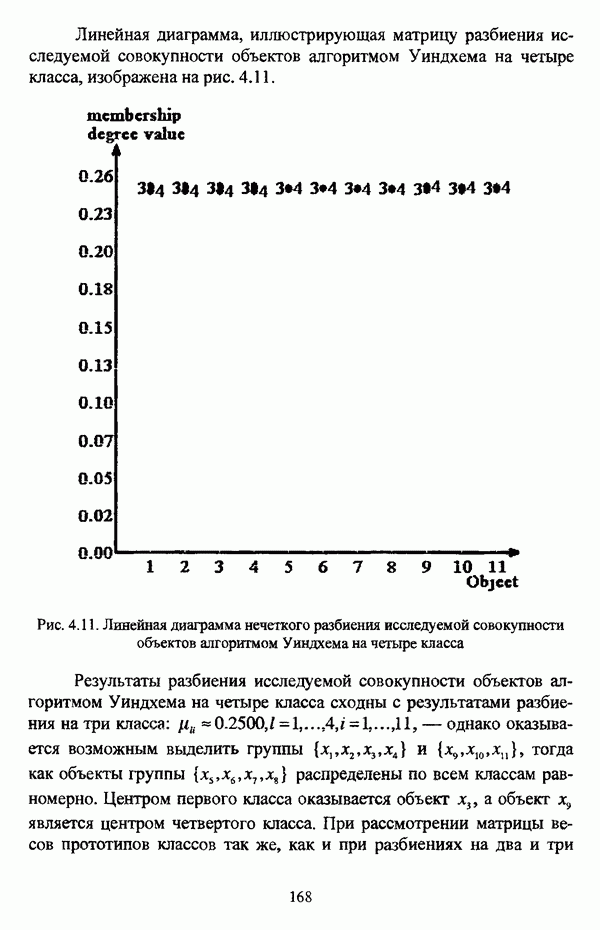
3.2. Оптимизационные методы
3.2.1. Нечеткая модификация экстремальной постановки задачи автоматической классификации и функционалы качества нечеткого разбиения
Как отмечал К. Яюга [106, с. 410], наиболее общим и распространенным подходом к решению задачи классификации в условиях нестохастической неопределенности является оптимизационный подход.
В подобных методах нечеткая кластеризация понимается как разбиение множества данных на совокупность его нечетких множеств, так что в качестве входного параметра в существующих нечетких методах оптимизационного направления автоматической классификации задается число нечетких кластеров, причем при данном подходе под нечетким кластером может пониматься любое нечеткое множество, определенное на универсуме. Нечеткие множества  определенные на универсуме X с соответствующими функциями принадлежности
определенные на универсуме X с соответствующими функциями принадлежности  образуют нечеткое с-разбиение
образуют нечеткое с-разбиение  в смысле Э. Г. Распини, если для каждого объекта
в смысле Э. Г. Распини, если для каждого объекта  выполняется условие
выполняется условие  и нечеткая модификация задачи автоматической классификации в экстремальной постановке заключается в нахождении экстремума, как правило, минимума, некоторого функционала
и нечеткая модификация задачи автоматической классификации в экстремальной постановке заключается в нахождении экстремума, как правило, минимума, некоторого функционала  на множестве всех нечетких разбиений, что также описывается формулой (1.5) с учетом того обстоятельства, что П — множество всех возможных нечетких разбиений Р исходного множества объектов
на множестве всех нечетких разбиений, что также описывается формулой (1.5) с учетом того обстоятельства, что П — множество всех возможных нечетких разбиений Р исходного множества объектов  Нечеткие разбиения подробно исследуются в работах [51], [54], [57]. Необходимо также указать, что условие, в соответствии с которым нечеткие множества, определенные на универсуме
Нечеткие разбиения подробно исследуются в работах [51], [54], [57]. Необходимо также указать, что условие, в соответствии с которым нечеткие множества, определенные на универсуме  образуют нечеткое разбиение, как отмечал Л. А. Заде
образуют нечеткое разбиение, как отмечал Л. А. Заде  является «достаточно сильным предположением».
является «достаточно сильным предположением».
Если исходные данные представлены матрицей расстояний  то функционал качества разбиения в общем виде выглядит следующим образом
то функционал качества разбиения в общем виде выглядит следующим образом 

где  — некоторые функционалы;
— некоторые функционалы;  — априорный вес для каждой точки
— априорный вес для каждой точки  — функция принадлежности элемента
— функция принадлежности элемента  некоторому нечеткому кластеру
некоторому нечеткому кластеру  — некоторая вспомогательная функция принадлежности,
— некоторая вспомогательная функция принадлежности,  — функция, определяющая расстояние между объектами
— функция, определяющая расстояние между объектами  как правило, представляющая собой элемент матрицы
как правило, представляющая собой элемент матрицы  , и где в качестве ограничений выступают условия
, и где в качестве ограничений выступают условия

так что нахождение классификации состоит в решении оптимизационной задачи

с соответствующими ограничениями.
При анализе функционала качества разбиения, предложенного Э. Г. Распини [149] в 1969 году и являющегося первым функционалом, сформулированным в терминах нечетких множеств, необходимо, следуя за автором критерия качества, кратко рассмотреть общую математическую модель задачи, поскольку, как отмечал М. П. Уиндхем, «к сожалению, критерий, на котором основан алгоритм Распини, труден для интерпретации, а численная процедура довольно сложна» [186, с. 159]. Подобная точка зрения высказывается также Дж. Беждеком [59, с. 58]. Более того, подобное рассмотрение оказывается нелишним для исследования эволюции нечетких методов кластер-анализа.
Пусть, как и ранее, X — множество  объектов и
объектов и  — функция распределения вероятностей, определенная в
— функция распределения вероятностей, определенная в  а символом Р обозначается множество кластеров
а символом Р обозначается множество кластеров  являющихся результатом группировки объектов исходной совокупности
являющихся результатом группировки объектов исходной совокупности  тогда функция
тогда функция  , в свою очередь, будет именоваться группообразующей, если она удовлетворяет следующим условиям: для каждого
, в свою очередь, будет именоваться группообразующей, если она удовлетворяет следующим условиям: для каждого  существуют функции
существуют функции

где  — декартовы произведения множеств X и F самих на себя соответственно и R — множество вещественных чисел, таких, что для всех пар
— декартовы произведения множеств X и F самих на себя соответственно и R — множество вещественных чисел, таких, что для всех пар  выполняется условие
выполняется условие

С содержательной точки зрения, группообразующая функция  устанавливает соответствие между элементами исследуемой совокупности
устанавливает соответствие между элементами исследуемой совокупности  и элементами множества кластеров
и элементами множества кластеров  — множество ограничений, выполнение которых необходимо для сохранения при преобразовании определенных свойств элементов исследуемой совокупности
— множество ограничений, выполнение которых необходимо для сохранения при преобразовании определенных свойств элементов исследуемой совокупности 
Если же группообразующая функция  не только удовлетворяет множеству ограничений
не только удовлетворяет множеству ограничений  но и доставляет экстремум некоторой целевой функции, то в этом случае полученное разбиение
но и доставляет экстремум некоторой целевой функции, то в этом случае полученное разбиение  оказывается в некотором смысле наилучшим на множестве всех возможных разбиений, порождаемых группообразующей функцией
оказывается в некотором смысле наилучшим на множестве всех возможных разбиений, порождаемых группообразующей функцией  . К примеру, группообразующая функция
. К примеру, группообразующая функция  может доставлять минимум некоторой целевой функции:
может доставлять минимум некоторой целевой функции:

Однако на практике ограничения являются столь жесткими, что группирующую функцию указать невозможно, для чего приходится вводить различные допущения. Если смягчить все ограничения, то в общем случае целевая функция примет следующий вид:

где  — весовые функции на общие ограничения.
— весовые функции на общие ограничения.
Функционал  является, в общем, частным случаем соотношения (3.19). При построении функционала Э. Г. Распини использовал два условия для выбора вида группообразующей функции. Если для каждой точки
является, в общем, частным случаем соотношения (3.19). При построении функционала Э. Г. Распини использовал два условия для выбора вида группообразующей функции. Если для каждой точки  допускается нечеткий кластер А, такой, что
допускается нечеткий кластер А, такой, что  то в соответствии с первым условием группообразующая функция должна минимизировать соотношение
то в соответствии с первым условием группообразующая функция должна минимизировать соотношение

выражающее среднюю плотность точек в том нечетком кластере, к которому они относятся с наибольшим значением функции принадлежности.
Если в формуле (3.12) положить  и будет иметь место
и будет иметь место

и
построении функционала, и поиск оптимума любого из них также может быть использован как метод кластеризации.
Таким образом, с учетом ограничений на группообразующую функцию

где  — неотрицательная неубывающая функция, такая, что
— неотрицательная неубывающая функция, такая, что  и
и

которые, исходя из формулы (3.19), можно объединить в одно условие оптимальности [150, с. 343]

функционал Э. Г. Распини примет вид

Величина, определяемая формулой (3.25), представляет собой измеритель общей близости объектов на множестве  и равна единице, если объекты со степенью принадлежности, равной единице, попадают в два разных класса, а если со степенью принадлежности, равной единице, объекты попадают в один класс, то эта величина равна, соответственно, нулю. Таким образом, величину
и равна единице, если объекты со степенью принадлежности, равной единице, попадают в два разных класса, а если со степенью принадлежности, равной единице, объекты попадают в один класс, то эта величина равна, соответственно, нулю. Таким образом, величину  можно трактовать и как своего рода «контекстную» меру близости объектов. В свою очередь, величина
можно трактовать и как своего рода «контекстную» меру близости объектов. В свою очередь, величина  характеризует прямую близость объектов, причем очевидно, что чем ближе объекты по величине
характеризует прямую близость объектов, причем очевидно, что чем ближе объекты по величине  тем ближе они и по величине
тем ближе они и по величине  . В качестве функции, характеризующей прямую близость объектов, может рассматриваться, например, соотношение
. В качестве функции, характеризующей прямую близость объектов, может рассматриваться, например, соотношение  где
где  при которой, как отмечал Э. Г. Распини [150], достигается хорошее разбиение на два класса, но результаты разбиения на большее число классов оказываются некорректными. Следовательно, с содержательной точки зрения, при минимизации функционала
при которой, как отмечал Э. Г. Распини [150], достигается хорошее разбиение на два класса, но результаты разбиения на большее число классов оказываются некорректными. Следовательно, с содержательной точки зрения, при минимизации функционала  производится минимизация разницы между контекстной и прямой близостью объектов. Подобная интерпретация функционала
производится минимизация разницы между контекстной и прямой близостью объектов. Подобная интерпретация функционала  , предложенного Э. Г. Распини, не является сложной для понимания; детальный же анализ математической
, предложенного Э. Г. Распини, не является сложной для понимания; детальный же анализ математической
постановки задачи и условий, предъявляемых к группообразующей функции, является важным с точки зрения установления взаимосвязи между общим видом функционала  и функционалом Э. Г. Распини
и функционалом Э. Г. Распини  Уместно также привести замечание И. Д. Манделя о том, что из построения функционала
Уместно также привести замечание И. Д. Манделя о том, что из построения функционала  видно, что его трактовка в терминологии теории нечетких множеств «не является принципиальной» [31, с. 89].
видно, что его трактовка в терминологии теории нечетких множеств «не является принципиальной» [31, с. 89].
Для анализа других функционалов качества разбиения достаточно только общего вида функционала (3.12) и ограничений (3.13). Если в формуле (3.12) положить

и

то получится функционал, предложенный в 1985 году М. П. Уиндхемом [186]:

где функции принадлежности  строятся в соответствии со следующими соотношениями:
строятся в соответствии со следующими соотношениями:

Как и в прочих критериях качества разбиения, в Q (Р) функция  является функцией принадлежности объекта
является функцией принадлежности объекта  нечеткому кластеру
нечеткому кластеру  . Вспомогательная же функция принадлежности
. Вспомогательная же функция принадлежности  выражает вес прототипа так, что
выражает вес прототипа так, что  если некоторый объект
если некоторый объект  в полной мере является прототипом, то есть фактически центром нечеткого кластера
в полной мере является прототипом, то есть фактически центром нечеткого кластера  в противном случае. Таким образом, нечеткой является не только степень принадлежности объекта классу,
в противном случае. Таким образом, нечеткой является не только степень принадлежности объекта классу,
но и сам представитель класса — каждый элемент классифицируемого множества  различной степени может быть, с одной стороны, прототипом того или иного класса, а с другой — просто элементом этого и всех остальных классов. Очевидно, функционал М, П. Уиндхема QUP) представляет собой наиболее сильное обобщение среди всех оптимизационных методов решения нечеткой модификации задачи кластерного анализа и с содержательной точки зрения, минимизация
различной степени может быть, с одной стороны, прототипом того или иного класса, а с другой — просто элементом этого и всех остальных классов. Очевидно, функционал М, П. Уиндхема QUP) представляет собой наиболее сильное обобщение среди всех оптимизационных методов решения нечеткой модификации задачи кластерного анализа и с содержательной точки зрения, минимизация  отыскивает оптимальное отклонение нечетких принадлежностей объектов от нечетких центров кластеров. Результатом работы алгоритма, доставляющего минимум функционалу
отыскивает оптимальное отклонение нечетких принадлежностей объектов от нечетких центров кластеров. Результатом работы алгоритма, доставляющего минимум функционалу  являются матрица разбиения
являются матрица разбиения  где
где  , и матрица весов прототипов
, и матрица весов прототипов  где также
где также  совместный анализ которых позволяет детально исследовать структуру множества объектов
совместный анализ которых позволяет детально исследовать структуру множества объектов 
Если же в формуле (3.12) положить

и

то получается функционал М. Рубенса [148]

минимизация которого отыскивает оптимальное взаимное отклонение элементов в каждом нечетком кластере.
В свою очередь, если положить в формуле (3.12)

и

где  — число элементов в кластере
— число элементов в кластере  получается функционал Е. Дидье:
получается функционал Е. Дидье:

М. Рубенс  отмечал, что классификация, получаемая при использовании функционала
отмечал, что классификация, получаемая при использовании функционала  предложенного Е. Дидье, является четкой, что очевидно из второго ограничения (3.37).
предложенного Е. Дидье, является четкой, что очевидно из второго ограничения (3.37).
где у представляет собой показатель нечеткости классификации, то получается функционал Дж. Беждека — Дж. Данна, алгоритм минимизации которого был предложен в работе [83] и обобщен в исследовании [59]:

Функционал Дж. Беждека — Дж. Данна представляет собой взвешенный вариант критерия качества разбиения, предложенного в 1965 году М. И. Шлезингером [44], минимизация которого, в свою очередь, отыскивала оптимальные суммарные отклонения координат объектов от центров классов. Поскольку для показателя нечеткости классификации у выполняется условие  алгоритм, оптимизирующий функционал Дж. Беждека — Дж. Данна и именуемый методом нечетких с-средних (с-means), представляет собой параметрическое семейство по у при фиксированном числе кластеров с [37, с.244].
алгоритм, оптимизирующий функционал Дж. Беждека — Дж. Данна и именуемый методом нечетких с-средних (с-means), представляет собой параметрическое семейство по у при фиксированном числе кластеров с [37, с.244].
При  полученное разбиение является четким, то есть каждый объект исследуемой совокупности оказывается однозначно принадлежащим какому-либо одному кластеру:
полученное разбиение является четким, то есть каждый объект исследуемой совокупности оказывается однозначно принадлежащим какому-либо одному кластеру:  Исследуя поведение функционала
Исследуя поведение функционала  при различных значениях параметра у, Дж. Данн [83], [84], [85] предложил
при различных значениях параметра у, Дж. Данн [83], [84], [85] предложил  при котором достигается наилучшее разбиение, поскольку при увеличении значения у возрастает неопределенность классификации, затрудняющая интерпретацию результатов, что можно выразить следующим образом:
при котором достигается наилучшее разбиение, поскольку при увеличении значения у возрастает неопределенность классификации, затрудняющая интерпретацию результатов, что можно выразить следующим образом:

В качестве функции расстояния в функционале  , как правило, используется квадрат евклидовой нормы в
, как правило, используется квадрат евклидовой нормы в  -мерном признаковом пространстве
-мерном признаковом пространстве  :
:

так что формула (3.44) может быть переписана, соответственно, в следующем виде:

Следует, однако, указать, что использование евклидова расстояния в функционале  оправдано в тех случаях, когда нечеткие кластеры имеют примерно одинаковый размер и форму гиперсферы.
оправдано в тех случаях, когда нечеткие кластеры имеют примерно одинаковый размер и форму гиперсферы.
При исследовании функционала Дж. Беждека — Дж. Данна в качестве функции  Д. Е. Густафсоном и В. С. Кесселем [92] рассматривался квадрат расстояния Махаланобиса:
Д. Е. Густафсоном и В. С. Кесселем [92] рассматривался квадрат расстояния Махаланобиса:

так что

где  — ковариационная матрица кластера
— ковариационная матрица кластера  то есть некоторая симметричная неотрицательно-определенная матрица, и Г — символ транспонирования. При таком подходе допускается пересечение нечетких кластеров, однако кластеры должны иметь гиперэллиптиче-скую форму. Уместно указать, что при выполнении условия
то есть некоторая симметричная неотрицательно-определенная матрица, и Г — символ транспонирования. При таком подходе допускается пересечение нечетких кластеров, однако кластеры должны иметь гиперэллиптиче-скую форму. Уместно указать, что при выполнении условия  расстояние
расстояние  определяемое выражением (3.47), будет представлять собой квадрат евклидовой нормы (3.45).
определяемое выражением (3.47), будет представлять собой квадрат евклидовой нормы (3.45).
Кроме того, П. Гроененом и К. Яюгой при исследовании функционала  (Р) в качестве функции
(Р) в качестве функции  было предложено использование расстояния Миньковского [106, с.415]. Более того, К. Яюгой в работе [105] рассматривается проблема применения
было предложено использование расстояния Миньковского [106, с.415]. Более того, К. Яюгой в работе [105] рассматривается проблема применения  метрики в методе нечетких с-средних, а С. Мийамото и
метрики в методе нечетких с-средних, а С. Мийамото и  Агуста в работе [129] предлагают быстрый алгоритм вычисления центров нечетких кластеров в методе нечетких с-средних в Ьгпространстве; вычислительные эксперименты проводились в сравнении с методом нечетких с-средних, использующим классическую евклидову метрику для 10 000 объектов, и показали высокую эффективность процедуры. Дж. Беждек, К. Корэй, Р. Гундерсон и Дж. Уотсон в работе [60] также предлагают несколько модификаций метода нечетких с-средних. Особо следует отметить результаты, описанные С. А. Айвазяном, В. М. Бухштабером, И. С. Енюковым и Л. Д. Мешалкиным в исследовании [37, с.291-300].
Агуста в работе [129] предлагают быстрый алгоритм вычисления центров нечетких кластеров в методе нечетких с-средних в Ьгпространстве; вычислительные эксперименты проводились в сравнении с методом нечетких с-средних, использующим классическую евклидову метрику для 10 000 объектов, и показали высокую эффективность процедуры. Дж. Беждек, К. Корэй, Р. Гундерсон и Дж. Уотсон в работе [60] также предлагают несколько модификаций метода нечетких с-средних. Особо следует отметить результаты, описанные С. А. Айвазяном, В. М. Бухштабером, И. С. Енюковым и Л. Д. Мешалкиным в исследовании [37, с.291-300].
С содержательной точки зрения интерпретация функционала Дж. Беждека — Дж. Данна оказывается весьма простой: минимизация
 отыскивает оптимальные нечеткие отклонения объектов
отыскивает оптимальные нечеткие отклонения объектов  от прототипов
от прототипов  с нечетких кластеров
с нечетких кластеров  или, как отмечал профессор Л. А. Заде, функционал
или, как отмечал профессор Л. А. Заде, функционал  «выполняет роль оценки взвешенной дисперсии точек из X относительно оптимального расположения центров [25,
«выполняет роль оценки взвешенной дисперсии точек из X относительно оптимального расположения центров [25,
с. 231]. Следует также отметить то обстоятельство, что функционал Дж. Беждека — Дж. Данна, как отмечает И. Д. Мандель [31, с. 92], «представляет собой, видимо, наиболее распространенный и изученный вариант экстремальной постановки задачи кластер-анализа в терминах размытых множеств».
Пусть XL — множество помеченных объектов,  элементы которого представлены булевыми векторами
элементы которого представлены булевыми векторами  где Т — символ транспонирования и
где Т — символ транспонирования и

 — матрица разбиения, составляемая исследователем в соответствии со следующим правилом: если
— матрица разбиения, составляемая исследователем в соответствии со следующим правилом: если  то
то  задается с соблюдением условия
задается с соблюдением условия  где
где  степень принадлежности помеченного объекта
степень принадлежности помеченного объекта  классу
классу  с; в противном случае, то есть если
с; в противном случае, то есть если  , соответствующий столбец в матрице оказывается неуместным и исследователь может его пропустить при рассмотрении [144, с. 142]. Тогда, полагая в формуле (3.39)
, соответствующий столбец в матрице оказывается неуместным и исследователь может его пропустить при рассмотрении [144, с. 142]. Тогда, полагая в формуле (3.39)

и

получаем функционал В. Педрича [140]

который может быть переписан в следующем виде:

Если в качестве функции расстояния в функционале  использовать квадрат евклидовой нормы (3.45), то формула (3.54) может быть записана в следующем виде:
использовать квадрат евклидовой нормы (3.45), то формула (3.54) может быть записана в следующем виде:

а формула (3.55), соответственно, в виде

В. Педрич исследовал различные модификации критерия (3.54) [140], первая из которых связана со взвешиванием обоих слагаемых в выражении (3.55), что приводит к следующей форме критерия 

где  причем в качестве функции
причем в качестве функции  в выражении (3.58) использовался квадрат евклидовой нормы (3.45).
в выражении (3.58) использовался квадрат евклидовой нормы (3.45).
Помеченные образы могут использоваться для изменения функции  различным образом. Очевидно, что помеченные образы частично определяют внутреннюю структуру исследуемой совокупности
различным образом. Очевидно, что помеченные образы частично определяют внутреннюю структуру исследуемой совокупности  и могут быть использованы для построения нормы в соответствующем
и могут быть использованы для построения нормы в соответствующем  -мерном признаковом пространстве
-мерном признаковом пространстве  для чего вводится матрица с помеченными объектами
для чего вводится матрица с помеченными объектами 

где Т — символ транспонирования, а нечеткие средние  вычисляются в соответствии с формулой
вычисляются в соответствии с формулой

что подразумевает введение в качестве функции  в вьфажение (3.54) квадрата расстояния Махаланобиса в виде
в вьфажение (3.54) квадрата расстояния Махаланобиса в виде

что, в свою очередь, дает вторую модификацию критерия  .
.
Третьей модификацией критерия  является функционал (3.58) с введением в качестве функции
является функционал (3.58) с введением в качестве функции  квадрата расстояния Махаланобиса (3.61).
квадрата расстояния Махаланобиса (3.61).
С содержательной точки зрения множество помеченных объектов XL представляет собой частично обучающую выборку, элементы которой являются своего рода «эталонами» для классификации. Смысл же собственно функционала  заключается в следующем: минимизация первого слагаемого в формуле (3.55), полностью совпадающего с
заключается в следующем: минимизация первого слагаемого в формуле (3.55), полностью совпадающего с  при
при  в формуле (3.44), минимизирует нечеткие суммы квадратов расстояний от объектов до центров нечетких кластеров, а второе слагаемое в (3.55) является взвешенной по квадратам расстояний суммой отклонений расчетных значений функции принадлежности объектов нечетким кластерам от заданных априорно.
в формуле (3.44), минимизирует нечеткие суммы квадратов расстояний от объектов до центров нечетких кластеров, а второе слагаемое в (3.55) является взвешенной по квадратам расстояний суммой отклонений расчетных значений функции принадлежности объектов нечетким кластерам от заданных априорно.
Особо следует отметить функционал качества разбиения, предложенный В. Райтом [189]:

где  — квадрат расстояния от точки
— квадрат расстояния от точки  до общего центра исследуемой совокупности, который может быть определен в соответствии с формулой
до общего центра исследуемой совокупности, который может быть определен в соответствии с формулой

 — квадрат расстояния от точки
— квадрат расстояния от точки  до центра
до центра  нечеткого кластера
нечеткого кластера  определяемый из соотношения
определяемый из соотношения

Нахождение оптимальной классификации в данном случае определяется как решение следующей оптимизационной задачи:

где в качестве ограничений выступают условия (3.40).
Вьфажение (3.62) представляет собой, по сути, взвешенный аналог корреляционного отношения и сравнивает внутриклассовые
расстояния с общими расстояниями. Вместе с тем, соотношения (3.63) и (3.64) для построения центрального элемента классифицируемого множества и центров классов применимы только в случае, когда все признаки  описания элементов исследуемой совокупности измерены на интервальных шкалах, а пространство признаков является евклидовым [22, с. 58].
описания элементов исследуемой совокупности измерены на интервальных шкалах, а пространство признаков является евклидовым [22, с. 58].
Следует указать, что функционал  прямо не связан с общим видом функционала
прямо не связан с общим видом функционала  , так же, как и различаются между собой задачи (3.41) и (3.65). Общим для функционалов
, так же, как и различаются между собой задачи (3.41) и (3.65). Общим для функционалов  является только вид матрицы исходных данных. Вместе с тем, функционал
является только вид матрицы исходных данных. Вместе с тем, функционал  показал хорошие свойства относительно 12 аксиом, выдвинутых В. Райтом [189], которым, по его мнению, должен удовлетворять функционал
показал хорошие свойства относительно 12 аксиом, выдвинутых В. Райтом [189], которым, по его мнению, должен удовлетворять функционал  ; при следовании этим положениям, по свидетельству В. Райта, в процессе выбора функционала качества форма
; при следовании этим положениям, по свидетельству В. Райта, в процессе выбора функционала качества форма  оказывается наиболее адекватной. Следует, однако, указать, что требования, выдвинутые В. Райтом, относятся к критериям качества разбиения вообще, а не только нечеткой классификации.
оказывается наиболее адекватной. Следует, однако, указать, что требования, выдвинутые В. Райтом, относятся к критериям качества разбиения вообще, а не только нечеткой классификации.
В. Райт рассматривает критерий качества разбиения как заданную на множестве упорядоченных пар  функцию, где, как и ранее,
функцию, где, как и ранее,  — число элементов классифицируемого множества
— число элементов классифицируемого множества  число признаков, или, иными словами, размерность пространства
число признаков, или, иными словами, размерность пространства  с — число нечетких кластеров — элементов множества
с — число нечетких кластеров — элементов множества  — элемент матрицы «объект-свойство»
— элемент матрицы «объект-свойство»  , выражающий значение
, выражающий значение  признака для
признака для  объекта; — элемент матрицы разбиения
объекта; — элемент матрицы разбиения  , представляющий степень принадлежности
, представляющий степень принадлежности  нечеткому кластеру
нечеткому кластеру  элемента исследуемого множества.
элемента исследуемого множества.
Целесообразно указать некоторые ограничения, накладываемые на матрицы Рсхп и Хтхп. В первую очередь необходимо отметить следующее обстоятельство: если в  столбце матрицы разбиения Рсхп один или несколько элементов
столбце матрицы разбиения Рсхп один или несколько элементов  принимают значение, равное нулю, то ни одна из
принимают значение, равное нулю, то ни одна из  строк не может содержать все нули, так как в этом случае подмножество
строк не может содержать все нули, так как в этом случае подмножество  оказывается пустым, что противоречит определению понятия кластера. Во вторую очередь следует указать, что
оказывается пустым, что противоречит определению понятия кластера. Во вторую очередь следует указать, что
в матрице разбиения  не может быть нулевых столбцов и число кластеров должно отвечать условию
не может быть нулевых столбцов и число кластеров должно отвечать условию  поскольку в случае
поскольку в случае  образуются пустые кластеры, а в случае
образуются пустые кластеры, а в случае  получается единственный кластер, так что невозможно оценить его сходство или отличие от других кластеров, что, в свою очередь, противоречит принципам построения любой классификации.
получается единственный кластер, так что невозможно оценить его сходство или отличие от других кластеров, что, в свою очередь, противоречит принципам построения любой классификации.
Таким образом, функционал качества  должен удовлетворять следующим основным, по мнению В. О, Рукавишникова [22, с.50-51], из двенадцати сформулированных В. Райтом, требованиям:
должен удовлетворять следующим основным, по мнению В. О, Рукавишникова [22, с.50-51], из двенадцати сформулированных В. Райтом, требованиям:
1)  должен быть инвариантен к изменению порядка строк в матрице
должен быть инвариантен к изменению порядка строк в матрице 
2)  должен быть инвариантен к изменению порядка строк и столбцов в матрице
должен быть инвариантен к изменению порядка строк и столбцов в матрице  ;
;
3)  должен быть инвариантен по отношению к объединению элементов в соответствии со следующим положением: любые два элемента классифицируемой совокупности
должен быть инвариантен по отношению к объединению элементов в соответствии со следующим положением: любые два элемента классифицируемой совокупности  которые имеют одни и те же координаты в признаковом пространстве
которые имеют одни и те же координаты в признаковом пространстве  и различные степени принадлежности к нечетким кластерам, эквивалентны одному элементу с теми же координатами и степенями принадлежности к соответствующим нечетким кластерам, равным половинам сумм степеней принадлежности к некоторому данному нечеткому кластеру объединяемых элементов.
и различные степени принадлежности к нечетким кластерам, эквивалентны одному элементу с теми же координатами и степенями принадлежности к соответствующим нечетким кластерам, равным половинам сумм степеней принадлежности к некоторому данному нечеткому кластеру объединяемых элементов.
4)  не должен зависеть от объединения идентичных по положению в пространстве
не должен зависеть от объединения идентичных по положению в пространстве  ) и по степеням принадлежности
) и по степеням принадлежности  к нечетким кластерам нечеткого разбиения
к нечетким кластерам нечеткого разбиения  элементов.
элементов.
Касательно второго требования следует указать, что по отношению к столбцам матрицы  В. Райтом выдвигается более жесткое требование, в соответствии с которым функционал
В. Райтом выдвигается более жесткое требование, в соответствии с которым функционал  не должен зависеть от преобразований координатных осей — признаков, к примеру, вращения или изменения шкал.
не должен зависеть от преобразований координатных осей — признаков, к примеру, вращения или изменения шкал.
Безусловно, рассмотренные выше критерии качества нечеткого разбиения не исчерпывают всего многообразия предложенных функционалов, Другие критерии рассматриваются в работах [46], [59], [64], [85], [101], [108], [167], [185] и, в основном, представляют собой различные
личные версии рассмотренных выше функционалов. В частности, в работе Р. Н. Даве и С. Сена [73] рассматривается функционал

отличающийся от функционала, предложенного Л. Кофманом и П. Дж. Рауссеу [108] тем, что в критерии Л. Кофмана — П. Дж. Рауссеу значение показателя нечеткости классификации у полагается равным двум, тогда как для критерия Р. Н. Даве и С. Сена  значение показателя у полагается более общим, так что выполняется условие
значение показателя у полагается более общим, так что выполняется условие 
Представляется целесообразным кратко рассмотреть такую весьма актуальную проблему, как робастность нечетких методов кластерного анализа. Термин «робастность», имеющий английское происхождение, означает устойчивость кластер-процедур к нарушениям модельных предположений о классифицируемых наблюдениях. Среди наиболее распространенных искажений следует отметить аномальные наблюдения, именуемые также «выбросами» или «шумом», пропуски значений признаков, зависимость наблюдений. Робастные методы получили весьма широкое распространение в вероятностных методах классификации. Среди зарубежных исследователей проблемы робастности в статистике следует указать таких авторов, как Дж. В. Тьюки, П. Хьюбер, П. Дж. Рауссеу, Ф. Р. Хампель, К. А. Дучинскас, Ш. Ю. Раудис, а также отметить труды известных отечественных специалистов: С. А. Айвазяна [37], Ю. С. Харина [110] и Е. Е. Жука [23].
Исследование проблемы робастности получило развитие также и в рамках нечеткого подхода к решению задачи распознавания образов с самообучением, несмотря на его новизну в сравнении с геометрическим и вероятностно-статистическим подходами к решению этой задачи. В силу ограниченности изложения рассмотрение проблемы робастности нечетких кластер-процедур будет проводиться на основе результатов, представленных Р. Н. Даве и С. Сеном в работе [73].
«Выбросы» могут рассматриваться как отдельный кластер А с центром  , расстояние до которого от всех объектов исследуемой совокупности неизменно, так что
, расстояние до которого от всех объектов исследуемой совокупности неизменно, так что  . Тогда функция принадлежности объектов
. Тогда функция принадлежности объектов  исследуемой совокупности X классу А может определяться в соответствии с формулой
исследуемой совокупности X классу А может определяться в соответствии с формулой
 (3.67)
(3.67)
так что с будет представлять собой число «хороших» нечетких кластеров, то есть кластеров, не содержащих аномальных наблюдений. Использование соотношения (3.67) приводит к следующему ослаблению условия нечеткого разбиения в смысле Э. Г. Распини:

Таким образом, точки класса А будут иметь малые значения принадлежностей «хорошим» кластерам, а кластер Л представляет собой, в сущности, класс «джокер» [37, с. 290-291]. В свою очередь, функционал Дж. Беждека - Дж. Данна (3,44) может быть переписан в виде

где символ R в обозначении функционала обозначает его робастность. При нахождении экстремума функционала  значения принадлежностей
значения принадлежностей  отыскиваются в соответствии с формулой
отыскиваются в соответствии с формулой

отличающейся от аналогичной в процедуре минимизации критерия  наличием второго слагаемого в делителе в правой части выражения (3.70). Как отмечают Р. Н. Даве и С. Сен, «выбор S является сложной проблемой» [73, с. 716], так как, в принципе, требуется знание о размере каждого кластера. Однако во многих практических задачах расстояние до «выбросов» является постоянным, так что значение 8 может быть определено исходя из выражения
наличием второго слагаемого в делителе в правой части выражения (3.70). Как отмечают Р. Н. Даве и С. Сен, «выбор S является сложной проблемой» [73, с. 716], так как, в принципе, требуется знание о размере каждого кластера. Однако во многих практических задачах расстояние до «выбросов» является постоянным, так что значение 8 может быть определено исходя из выражения

где множитель  выбирается в зависимости от типа данных [73, с. 716].
выбирается в зависимости от типа данных [73, с. 716].
Кластеризация данных с «выбросами» хорошо применима в ситуациях, когда исходные данные представлены в форме матрицы «объект-свойство», где расстояние S имеет вполне ясный смысл. Однако в случае, когда исходные данные представлены в форме матрицы «объект-объект», существуют некоторые очевидные трудности выделения класса «выбросов»  При рассмотрении робастности критериев вида
При рассмотрении робастности критериев вида  в работе [73] предлагается следующая модификация функционала М. Рубенса:
в работе [73] предлагается следующая модификация функционала М. Рубенса:

где число с отыскиваемых кластеров увеличивается на единицу. Этот дополнительный класс и будет классом «выбросов» А, однако из выражения (3.72) не ясно, каким образом класс А выделяется из остальных кластеров. Если выражение (3.72) переписать в виде

то первое слагаемое в правой части совпадает с функционалом М. Рубенса (3,35), а второе представляет собой своего рода «расширение» для классификации «выбросов». Индекс I в расстоянии  обозначает «существенность» различия объектов
обозначает «существенность» различия объектов  так, как это определяется кластером
так, как это определяется кластером  . В обычном случае различие между элементами исследуемой совокупности не зависит от кластера, так что
. В обычном случае различие между элементами исследуемой совокупности не зависит от кластера, так что  для всех
для всех  однако в случае, когда вводится класс «выбросов», его следует выделять как специфический кластер А и налагать на него приоритет определения существенности различия между объектами, так что
однако в случае, когда вводится класс «выбросов», его следует выделять как специфический кластер А и налагать на него приоритет определения существенности различия между объектами, так что  и, соответственно, класс «выбросов» А в случае представления исходных данных в виде матрицы «объект-объект» может быть определен как кластер, расстояние между объектами которого оценивается так же, как и до объектов других кластеров. Иными словами, кластер А определяется так, что
и, соответственно, класс «выбросов» А в случае представления исходных данных в виде матрицы «объект-объект» может быть определен как кластер, расстояние между объектами которого оценивается так же, как и до объектов других кластеров. Иными словами, кластер А определяется так, что  для всех
для всех  и расстояние 8 представляет собой константу. Следовательно, выражение (3.73) можно переписать так, что робастная модификация функционала М. Рубенса окончательно примет следующий вид:
и расстояние 8 представляет собой константу. Следовательно, выражение (3.73) можно переписать так, что робастная модификация функционала М. Рубенса окончательно примет следующий вид:

Таким образом, становится ясным смысл расстояния S с содержательной точки зрения: оптимальное разбиение исследуемой совокупности таково, что различие между объектами в «хороших» классах сравнительно невелико, а в классе «выбросов» все коэффициенты попарных различий между объектами принимают одно и то же значение S; таким образом, в каждом «хорошем» кластере ни одна пара объектов не имеет степени различия, большей чем  , поскольку, если какой-либо объект исследуемой совокупности отличается от каждого объекта в каждом «хорошем» кластере более чем на
, поскольку, если какой-либо объект исследуемой совокупности отличается от каждого объекта в каждом «хорошем» кластере более чем на  , он должен быть классифицирован как «выброс», и напротив, если этот объект отличается хотя бы от одного объекта, принадлежащего «хорошему» кластеру, менее чем на S, рассматриваемый объект должен быть приписан этому «хорошему» кластеру, а не классу «выбросов». В качестве иллюстративного примера Р. Н. Даве и С. Сен [73, с.717] рассматривают совокупность из семи объектов
, он должен быть классифицирован как «выброс», и напротив, если этот объект отличается хотя бы от одного объекта, принадлежащего «хорошему» кластеру, менее чем на S, рассматриваемый объект должен быть приписан этому «хорошему» кластеру, а не классу «выбросов». В качестве иллюстративного примера Р. Н. Даве и С. Сен [73, с.717] рассматривают совокупность из семи объектов  где первые три объекта представляют собой яблоки трех различных сортов, вторые три объекта представляют собой цитрусовые трех сортов, а седьмой объект — сливу. Матрица коэффициентов различия объектов исследуемой совокупности X представлена таблицей 3.1.
где первые три объекта представляют собой яблоки трех различных сортов, вторые три объекта представляют собой цитрусовые трех сортов, а седьмой объект — сливу. Матрица коэффициентов различия объектов исследуемой совокупности X представлена таблицей 3.1.
Таблица 3.1. Матрица попарных расстояний между объектами исследуемой совокупности

В данном простом примере, для иллюстрации понятия расстояния S отличия «выбросов», значение S можно положить равным 0.30, так что хорошо выделяются классы  расстояния внутри которых варьируются в
расстояния внутри которых варьируются в  до 0.20, тогда как степень отличия объекта
до 0.20, тогда как степень отличия объекта  от остальных части объектов превышает
от остальных части объектов превышает  что позволяет классифицировать как «выброс». В реальных
что позволяет классифицировать как «выброс». В реальных
задачах значение расстояния S можно вычислить по формуле, аналогичной соотношению (3.71).
Исходя из вышеизложенного, робастная модификация функционала  Р. Н. Даве — С. Сена может быть записана в следующем виде [73, с. 718]:
Р. Н. Даве — С. Сена может быть записана в следующем виде [73, с. 718]:

Р. Н. Даве и С. Сен отмечают [73, с. 718], что аналогичным путем, то есть введением класса «выбросов» и соответствующего расстояния  , получается робастная модификация функционала
, получается робастная модификация функционала  М. П. Уиндхема.
М. П. Уиндхема.
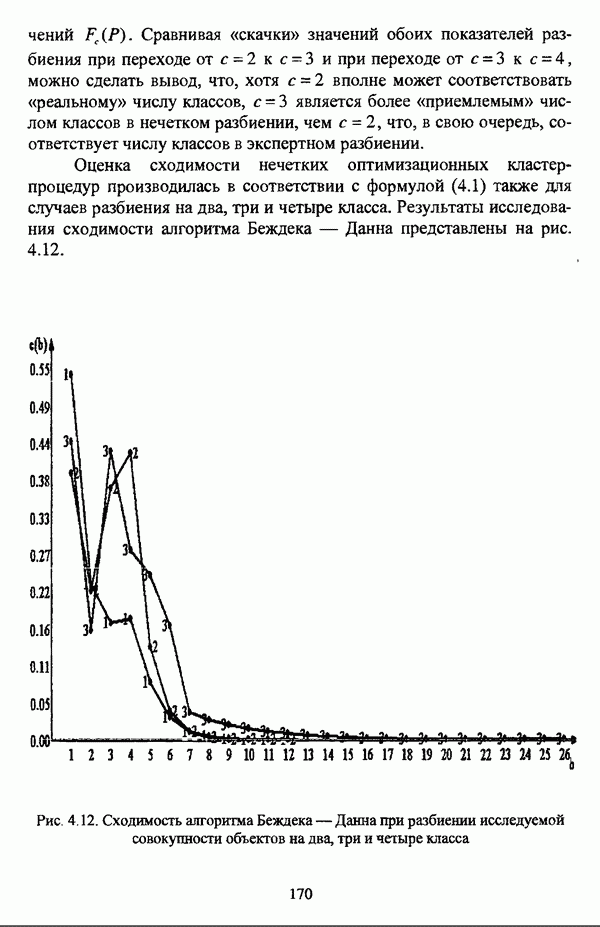
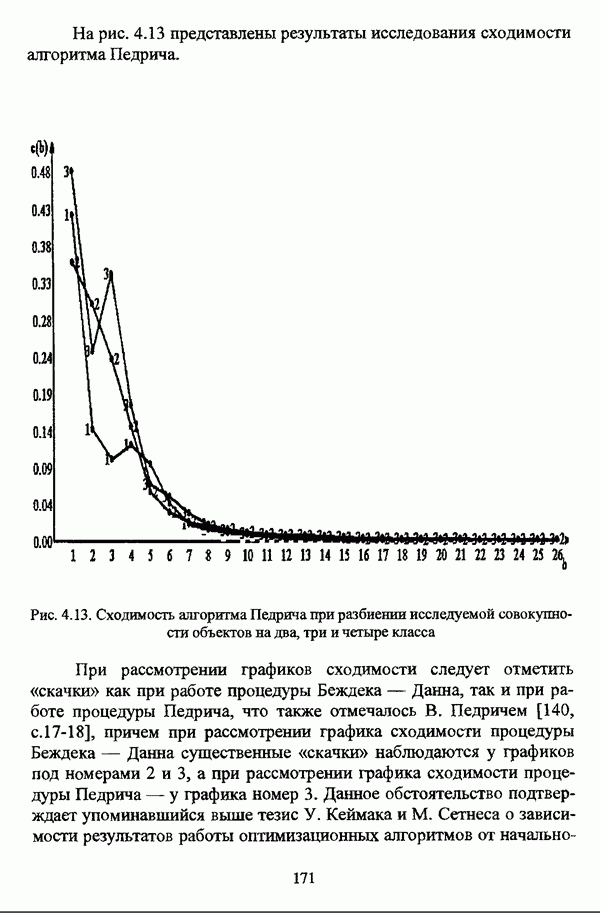
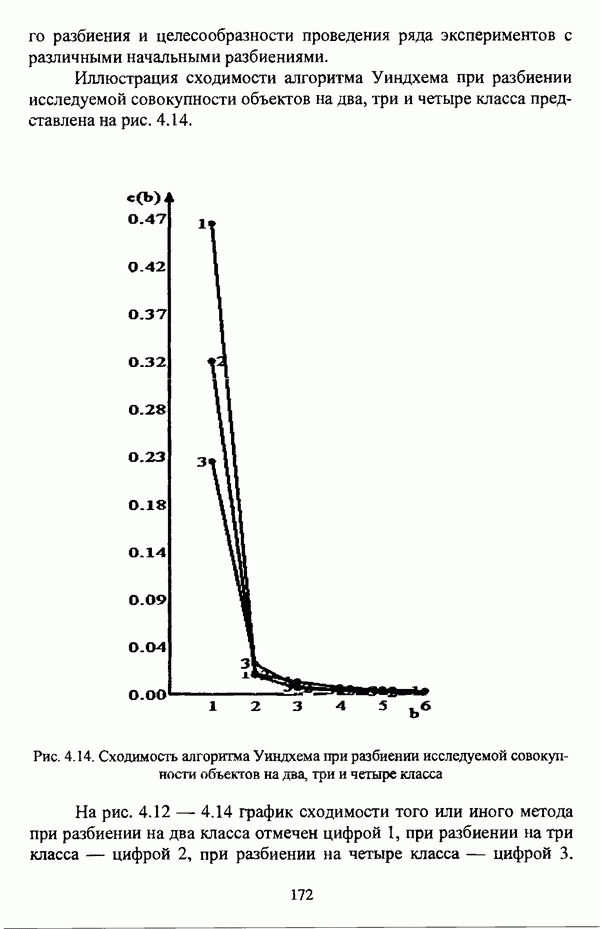
В завершение рассмотрения нечетких оптимизационных методов автоматической классификации необходимо отметить, что во всех рассмотренных выше критериях качества нечеткого разбиения учитывается число кластеров, так что число кластеров является параметром, который необходимо задавать при работе того или иного оптимизационного алгоритма. Данное число задается исследователем, исходя из сущности решаемой задачи. Вместе с тем, необходимо, чтобы число классов отвечало «естественному» расслоению объектов по классам, так что в ряде случаев отыскание «естественного» числа классов представляет собой довольно серьезную проблему, что более детально будет рассматриваться ниже. Предварительно следует лишь указать, что для решения проблемы отыскания «приемлемого» числа кластеров используются два подхода. Первый подход состоит в проведении ряда экспериментов для различного числа классов в искомом нечетком разбиении с последующим выбором нечеткого разбиения, число классов в котором отвечает формальным или содержательным представлениям исследователя о «естественности» числа классов. Второй подход состоит в задании заведомо большого числа классов ввиду того, что в процессе классификации наиболее близкие классы объединяются. Другим обстоятельством, на которое необходимо обратить внимание, является то, что в нечеткой кластеризации принадлежность точек кластерам уменьшается с возрастанием расстояния до точки — центра кластера. Вместе с тем, во многих практических задачах точки, вплотную прилегающие к прототипу нечеткого кластера, могут рассматриваться как полностью принадлежащие нечеткому множеству, представленному соответствующим кластером. Данное обстоятельство
диктует необходимость расширения прототипа кластера на определенное расстояние от центра кластера, так чтобы точки, попавшие в область расширения прототипа, считались бы принадлежащими соответствующему кластеру со степенью принадлежности 1.0. Все функционалы, рассмотренные выше, такой возможности исследователю не предоставляют.
Решение обозначенной проблемы «расширения» прототипа кластера и отыскания «естественного» числа классов в нечетком разбиении было предложено У. Кеймаком и М. Сетнесом в работе [109] путем введения понятия объемного прототипа и адаптивного объединения ближайших нечетких кластеров. Объемный прототип  некоторого нечеткого кластера
некоторого нечеткого кластера 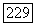 может быть определен как
может быть определен как 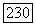 -мерное выпуклое и компактное подпространство и, таким образом, расширяет прототип кластера от единичной точки до области в пространстве
-мерное выпуклое и компактное подпространство и, таким образом, расширяет прототип кластера от единичной точки до области в пространстве 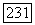 Следует указать на то, что подобное определение предполагает произвольную форму и размер объемного прототипа. Таким образом, объемный прототип образуется путем включения в область
Следует указать на то, что подобное определение предполагает произвольную форму и размер объемного прототипа. Таким образом, объемный прототип образуется путем включения в область 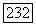 ) всех точек в радиусе
) всех точек в радиусе 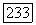 от центра
от центра 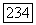 нечеткого кластера
нечеткого кластера 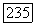 . Точки
. Точки 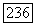 удовлетворяющие неравенству
удовлетворяющие неравенству 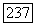 будут являться элементами объемного прототипа
будут являться элементами объемного прототипа 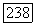 так что, по определению, их степень принадлежности кластеру
так что, по определению, их степень принадлежности кластеру 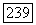 будет максимальна. Размер объемного прототипа
будет максимальна. Размер объемного прототипа 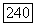 будет определяться радиусом
будет определяться радиусом 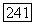 который, в свою очередь, может задаваться исследователем, так что все объемные прототипы
который, в свою очередь, может задаваться исследователем, так что все объемные прототипы 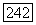 будут иметь фиксированный размер либо определяться для каждого кластера
будут иметь фиксированный размер либо определяться для каждого кластера 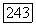 с в процессе классификации.
с в процессе классификации.
Естественным путем к определению радиуса  некоторого кластера
некоторого кластера 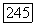 является его соотнесение с ковариационной матрицей
является его соотнесение с ковариационной матрицей 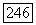 (3.50), детерминант
(3.50), детерминант 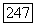 которой определяет объем кластера. Поскольку матрица
которой определяет объем кластера. Поскольку матрица 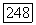 является неотрицательно-определенной и симметричной, она может быть представлена в виде
является неотрицательно-определенной и симметричной, она может быть представлена в виде 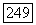 , где Т — символ транспонирования, а матрица А, является диагональной с ненулевыми элементами
, где Т — символ транспонирования, а матрица А, является диагональной с ненулевыми элементами 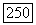 так что объемные прототипы расширяют расстояния
так что объемные прототипы расширяют расстояния 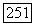 вдоль каясдого вектора
вдоль каясдого вектора 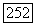
Кластеризация с объемными прототипами подразумевает минимизацию функционала

представляющего собой модификацию критерия (3.44), где символ Е в обозначении 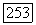 ) функционала обозначает «расширенный» (extended),
) функционала обозначает «расширенный» (extended), 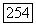 — функция расстояния, в качестве которой может быть использован, к примеру, квадрат расстояния Махаланобиса (3.47),
— функция расстояния, в качестве которой может быть использован, к примеру, квадрат расстояния Махаланобиса (3.47),  — постоянная, определяющая размер объемного прототипа нечеткого кластера
— постоянная, определяющая размер объемного прототипа нечеткого кластера 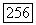 . В качестве ограничений на целевую функцию (3.76) выступает традиционное условие разбиения в смысле Э. Г. Распини. Таким образом, центры
. В качестве ограничений на целевую функцию (3.76) выступает традиционное условие разбиения в смысле Э. Г. Распини. Таким образом, центры 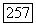 нечетких кластеров
нечетких кластеров  отыскиваются по формуле
отыскиваются по формуле

а значения принадлежностей, соответственно, по формуле

которая, в свою очередь, может быть переписана в виде

где взвешивающая компонента  определяется выражением
определяется выражением

При минимизации функционала  центры
центры  кластеров
кластеров 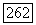 «расширяются» до объемных прототипов
«расширяются» до объемных прототипов 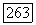 так что точки, попадающие в область объемного прототипа, будут иметь степень принадлежности соответствующему кластеру, равную единице, и, соответственно, нулю — другим кластерам. Поскольку метод, предложенный У. Кеймаком и М. Сетнесом [109], с
так что точки, попадающие в область объемного прототипа, будут иметь степень принадлежности соответствующему кластеру, равную единице, и, соответственно, нулю — другим кластерам. Поскольку метод, предложенный У. Кеймаком и М. Сетнесом [109], с
целью нахождения «естественного» числа кластеров 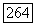 в отыскиваемом нечетком разбиении Р предполагает объединение ближайших кластеров, радиус кластера умножается на величину
в отыскиваемом нечетком разбиении Р предполагает объединение ближайших кластеров, радиус кластера умножается на величину 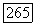 где
где 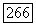 представляет собой число кластеров в разбиении
представляет собой число кластеров в разбиении 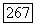 на
на 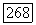 шаге вычислительного процесса, а алгоритм начинает работу при
шаге вычислительного процесса, а алгоритм начинает работу при 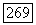 так что при объединении кластеров увеличение значения
так что при объединении кластеров увеличение значения 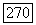 делает возможным увеличение размеров объемных прототипов.
делает возможным увеличение размеров объемных прототипов.
Объединение ближайших кластеров производится в соответствии с мерой сходства, определяемой выражением

Мера, определяемая выражением (3-81), принимает во внимание подобие точек, как принадлежащих объемным прототипам нечетких кластеров, так и лежащих вне их пределов.
Порог 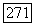 , при котором происходит объединение ближайших кластеров, зависит от различных характеристик исходных данных, таких, к примеру, как разделимость групп, плотность кластеров и их размер, а также параметров классификации, в первую очередь от показателя нечеткости у. В общем, в случае обращения к расширенным методам нечеткой классификации порог объединения а оказывается параметром, определяемым пользователем. Степень «близости» некоторых двух кластеров
, при котором происходит объединение ближайших кластеров, зависит от различных характеристик исходных данных, таких, к примеру, как разделимость групп, плотность кластеров и их размер, а также параметров классификации, в первую очередь от показателя нечеткости у. В общем, в случае обращения к расширенным методам нечеткой классификации порог объединения а оказывается параметром, определяемым пользователем. Степень «близости» некоторых двух кластеров 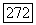 зависит также и от других кластеров в нечетком разбиении, что определяется таким ограничением, как условие разбиения в смысле Э. Г. Распини. Однако выбор порога исследователем при решении конкретной задачи может вызывать затруднения. Для решения подобного рода проблемы У. Кеймаком и М. Сетнесом [109] предлагается использовать адаптивный порог
зависит также и от других кластеров в нечетком разбиении, что определяется таким ограничением, как условие разбиения в смысле Э. Г. Распини. Однако выбор порога исследователем при решении конкретной задачи может вызывать затруднения. Для решения подобного рода проблемы У. Кеймаком и М. Сетнесом [109] предлагается использовать адаптивный порог 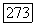 у зависящий от числа кластеров
у зависящий от числа кластеров 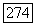 в нечетком разбиении на
в нечетком разбиении на 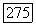 на
на 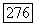 шаге вычислительного процесса, который определяется выражением
шаге вычислительного процесса, который определяется выражением

так что нечеткие кластеры 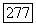 объединяются в случае, когда изменение значений меры сходства кластеров, определяемой выражением
объединяются в случае, когда изменение значений меры сходства кластеров, определяемой выражением











































































































































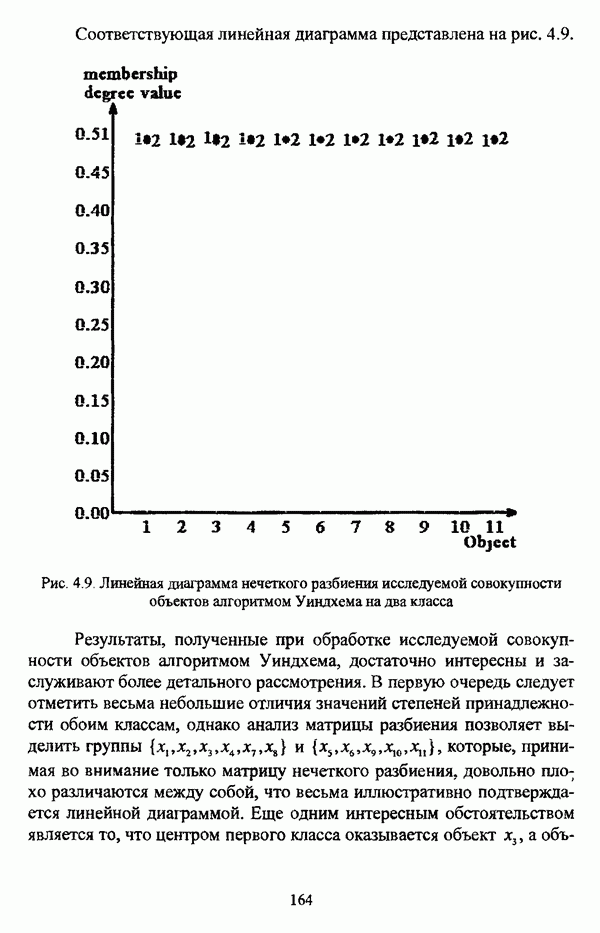





































 должна быть выбрана таким образом, чтобы соотношение
должна быть выбрана таким образом, чтобы соотношение

 что наибольшие средние плотности будут соответствовать наименьшим степеням принадлежности.
что наибольшие средние плотности будут соответствовать наименьшим степеням принадлежности.
 представляет собой ни что иное, как среднюю плотность точек вокруг точки
представляет собой ни что иное, как среднюю плотность точек вокруг точки  а выражение
а выражение  в соотношении (3.23) получается из произведения
в соотношении (3.23) получается из произведения  где, в свою очередь,
где, в свою очередь,  показывает относительный размер нечеткого кластера
показывает относительный размер нечеткого кластера  а выражение
а выражение  представляет собой среднюю плотность точек вокруг точки
представляет собой среднюю плотность точек вокруг точки  в нечетком кластере
в нечетком кластере  Аналогичные рассуждения можно провести относительно выражения в соотношении (3.20). Соотношения (3.20) и (3.23) рассматривались Э. Г. Распини в качестве предварительного этапа при
Аналогичные рассуждения можно провести относительно выражения в соотношении (3.20). Соотношения (3.20) и (3.23) рассматривались Э. Г. Распини в качестве предварительного этапа при
 то эти точки представляют собой ядро некоторого нечеткого кластера
то эти точки представляют собой ядро некоторого нечеткого кластера  так что второе ограничение в условии (3.37) можно
так что второе ограничение в условии (3.37) можно  переписать в виде
переписать в виде  Таким образом, в нечеткой модификации минимизация функционала
Таким образом, в нечеткой модификации минимизация функционала  отыскивает оптимальные отклонения от ядер нечетких кластеров нечетких принадлежностей элементов, не являющихся элементами ядер.
отыскивает оптимальные отклонения от ядер нечетких кластеров нечетких принадлежностей элементов, не являющихся элементами ядер.
 то функционал качества разбиения имеет следующий общий вид
то функционал качества разбиения имеет следующий общий вид 

 , g — некоторый функционал;
, g — некоторый функционал;  — априорный вес для каждой точки
— априорный вес для каждой точки  — функция принадлежности элемента
— функция принадлежности элемента  некоторому нечеткому кластеру
некоторому нечеткому кластеру  — функция, определяющая расстояние от элемента
— функция, определяющая расстояние от элемента  некоторого элемента
некоторого элемента  являющегося центром или, иначе говоря, прототипом нечеткого кластера
являющегося центром или, иначе говоря, прототипом нечеткого кластера  а в качестве ограничений выступают условия
а в качестве ограничений выступают условия




 и значение меры сходства на
и значение меры сходства на  шаге процесса превышает значение
шаге процесса превышает значение 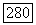 ). Для вычисления радиуса
). Для вычисления радиуса 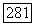 определяющего размер объемного прототипа, целесообразно представить ковариационную матрицу
определяющего размер объемного прототипа, целесообразно представить ковариационную матрицу 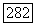 в виде
в виде 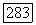 как это было предложено выше, так что с учетом условии (3.48) и (3.49)
как это было предложено выше, так что с учетом условии (3.48) и (3.49)

 может быть определен в соответствии с формулой
может быть определен в соответствии с формулой

 — элементы матрицы
— элементы матрицы