Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
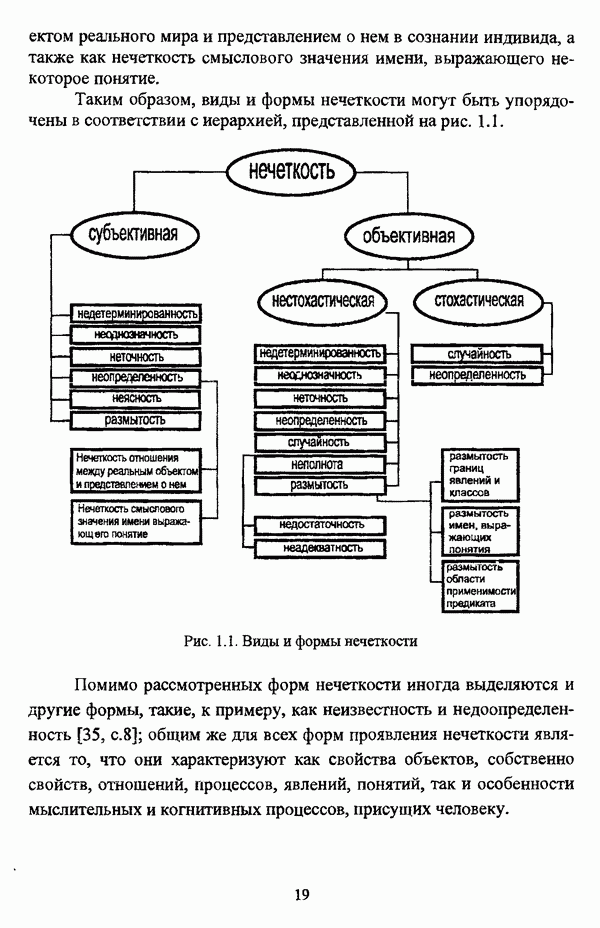
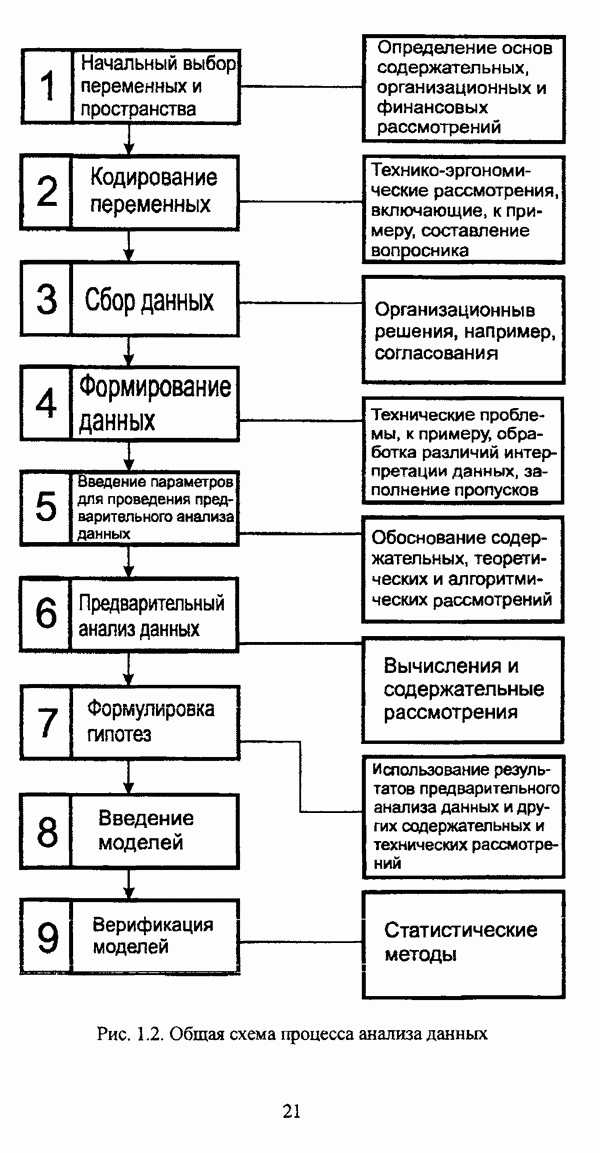
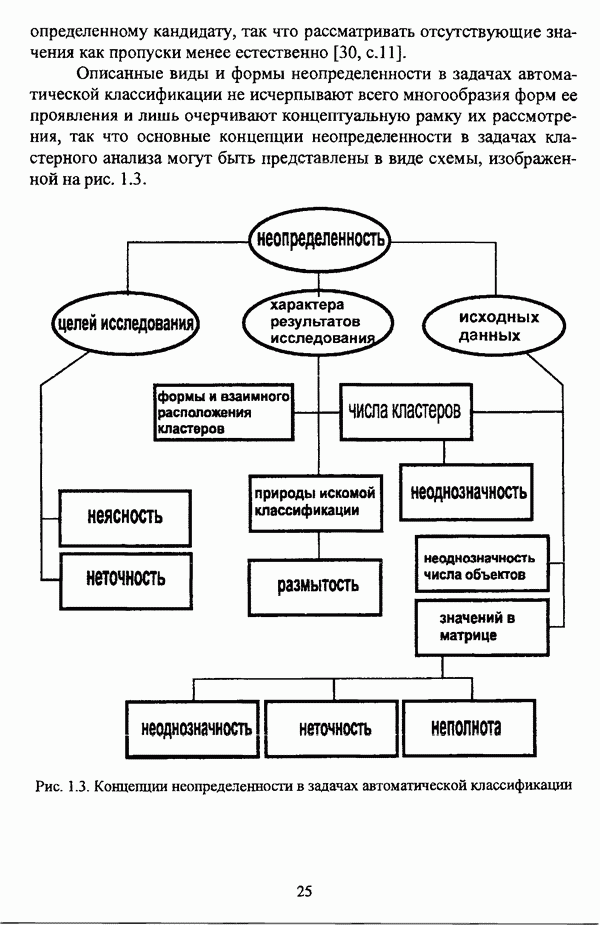
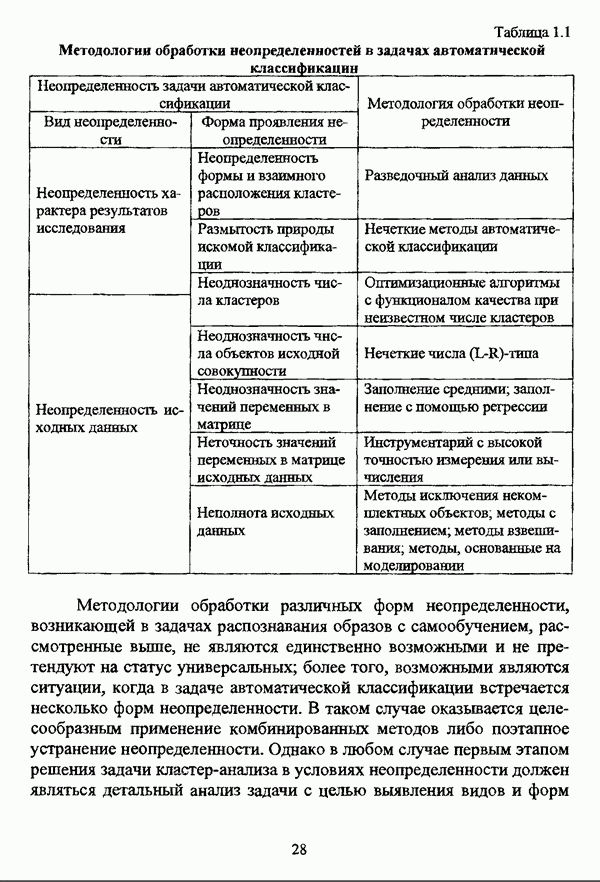
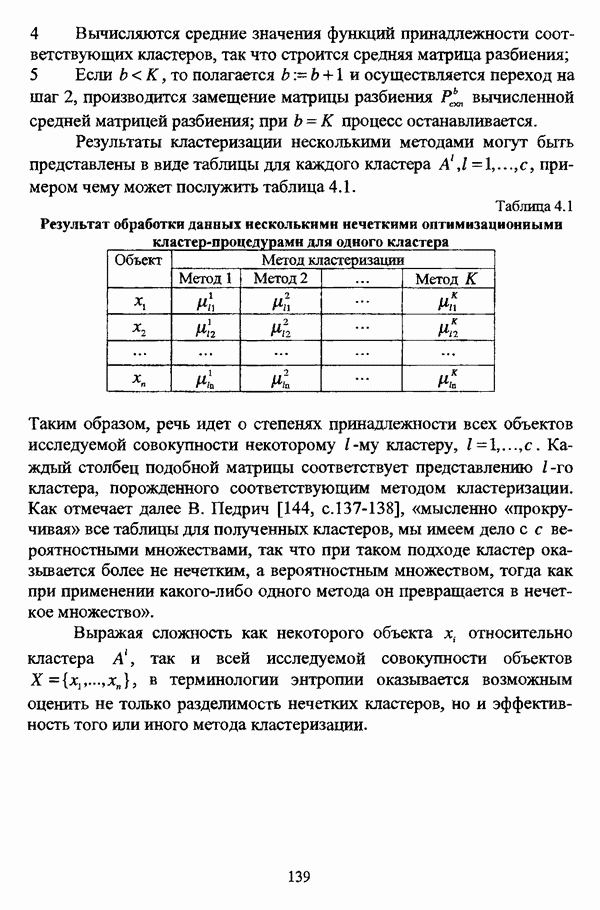
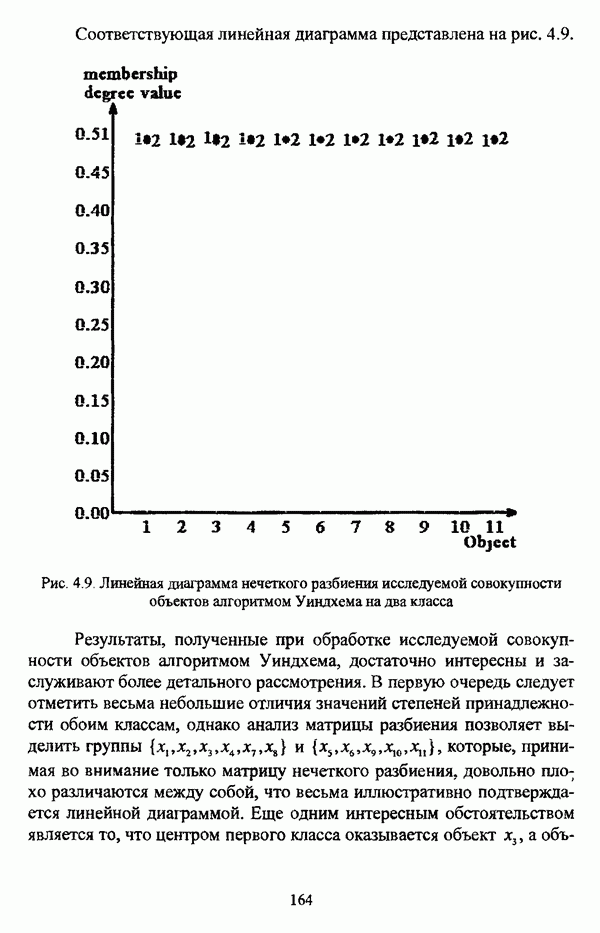
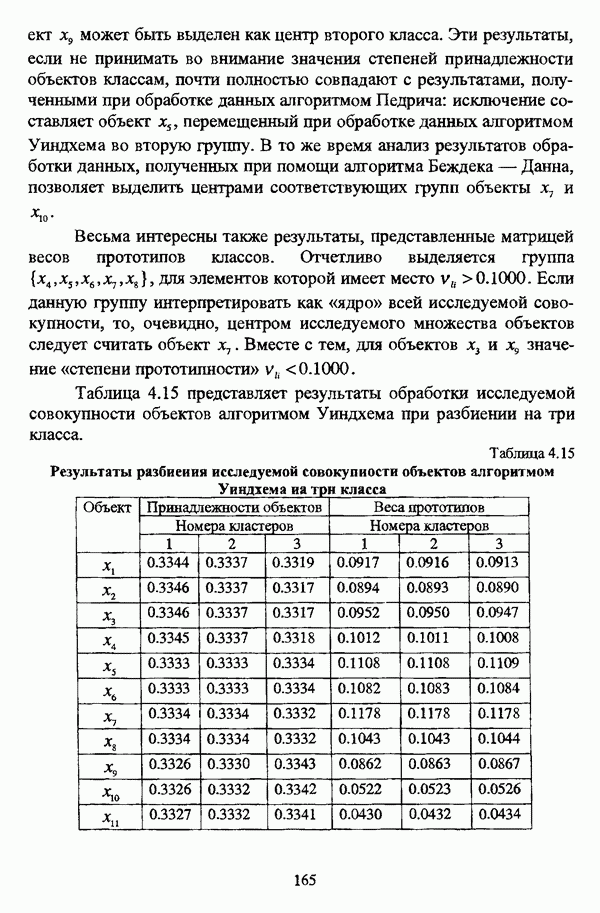
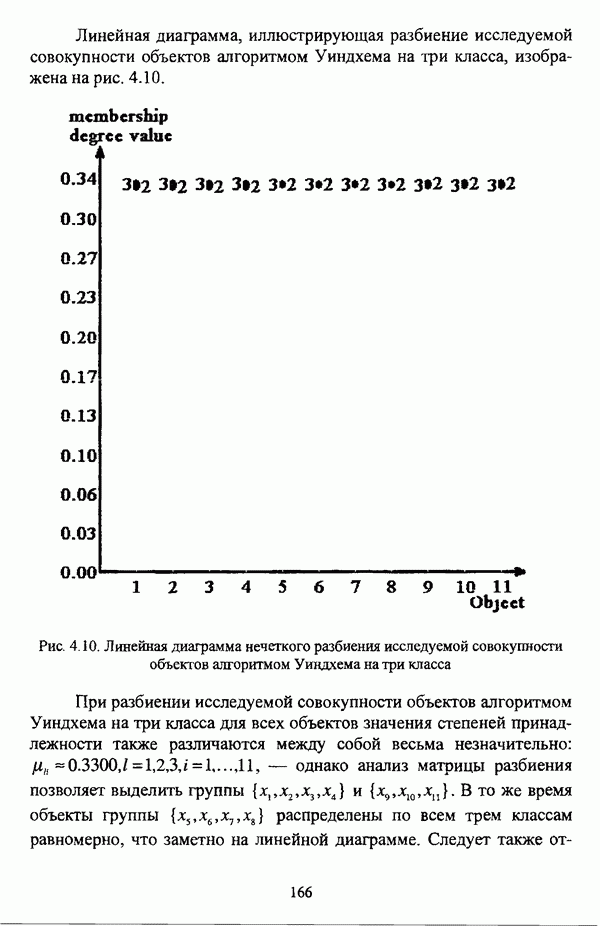
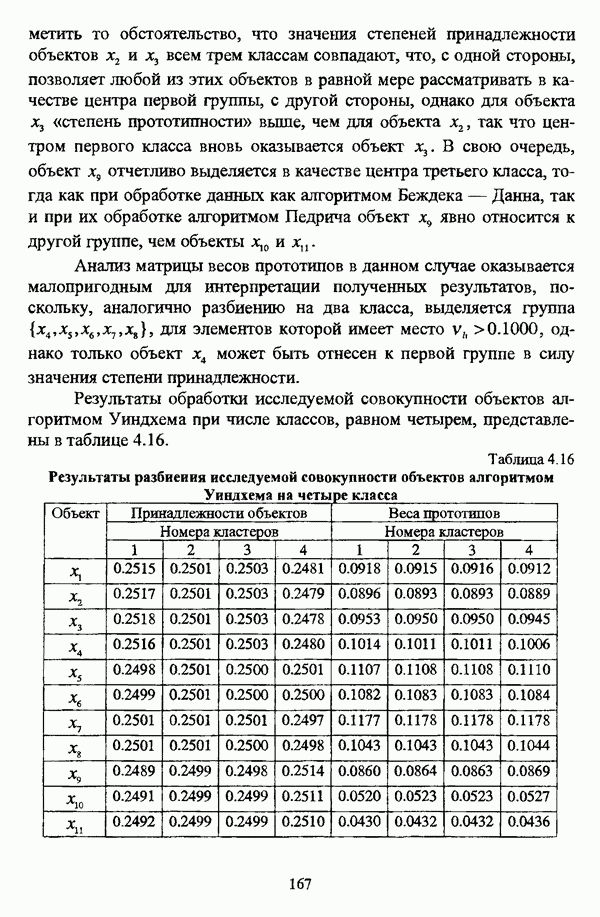
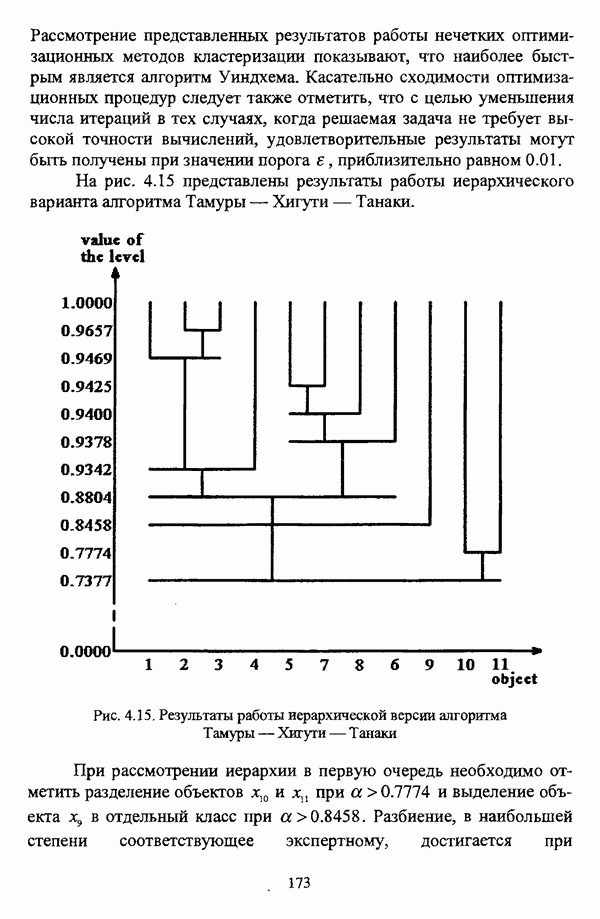
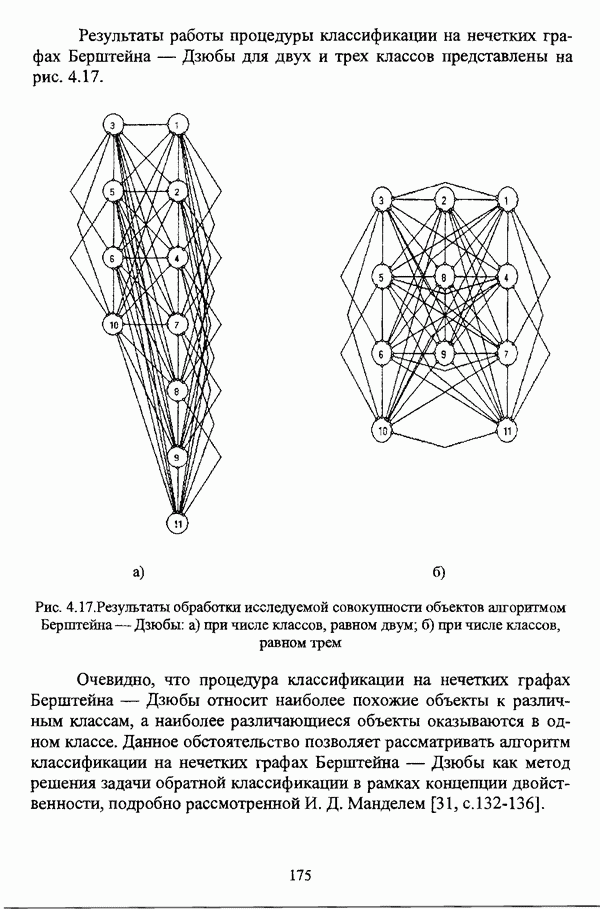
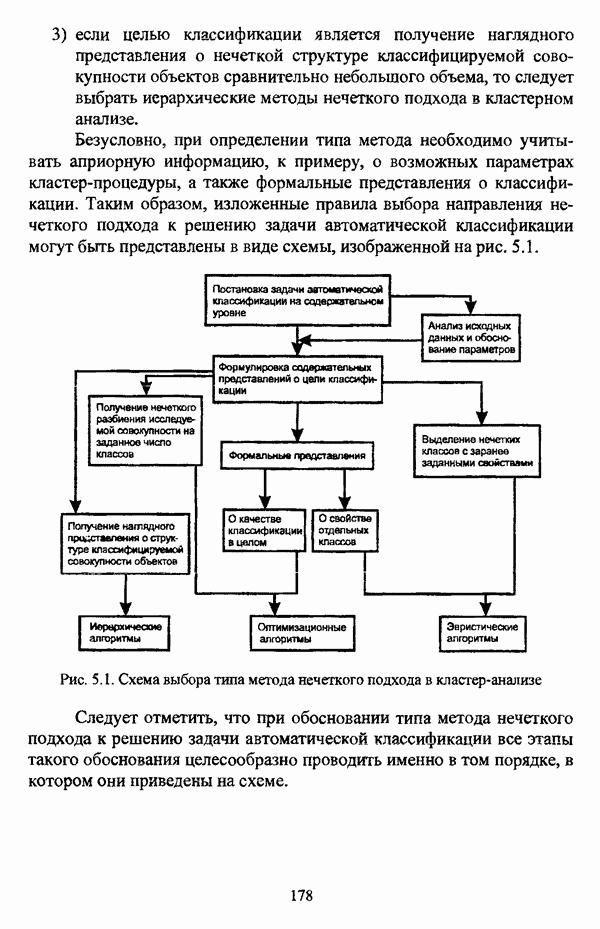
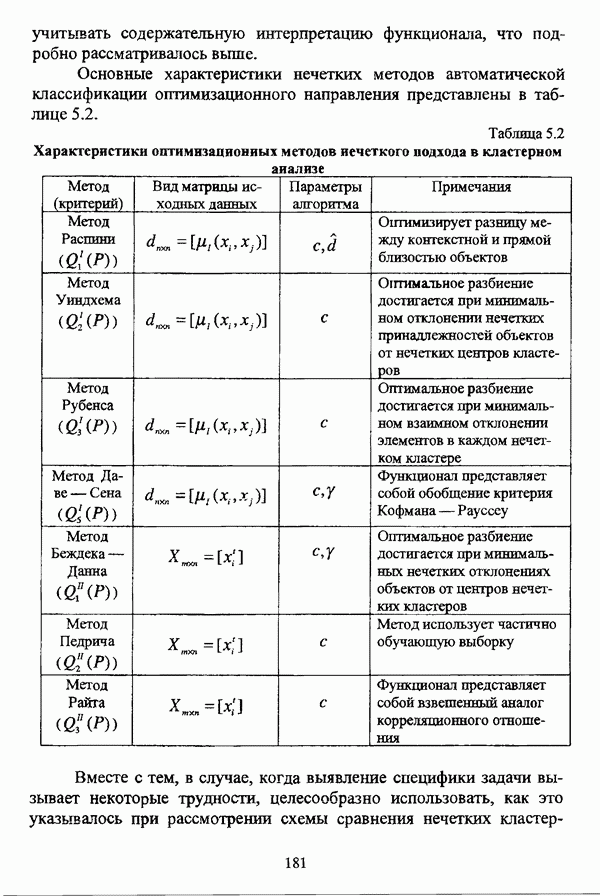
ГЛАВА 4. СРАВНИТЕЛЬНЫЙ АНАЛИЗ НЕЧЕТКИХ МЕТОДОВ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ4.1. Содержательные аспекты сравнения нечетких методов автоматической классификации4.1.1. Цели сравнения и оценка сходимости нечетких кластер-процедурВ существующих подходах к решению проблемы классификации объектов в условиях отсутствия обучающих выборок доля нечетких методов кластер-анализа составляет пока весьма незначительную часть от общего числа методов автоматической классификации. Как отмечал И. Д. Мандель, «мы не считаем язык теории размытых множеств особенно удобным для теории классификации. Он универсален так же, как и язык бинарных отношений и «обычных» мер близости объектов, а принципиально новые конструкции с его помощью не получаются. Но с точки зрения интерпретации полученных решений концепция размытых множеств весьма удобна...» [31, с. 62-63]. То обстоятельство, что динамика развития нечетких методов автоматической классификации остается сравнительно невысокой, обусловлено следующими взаимосвязанными факторами. Во-первых, теория нечетких множеств является новой областью математики, которая продолжает развиваться весьма бурными темпами. В силу этого обстоятельства использование как всего богатейшего арсенала, имеющегося в распоряжении теории нечетких множеств, так и ее последних достижений в задачах кластер-анализа продолжает оставаться незначительным. Во-вторых, в силу вышеизложенного основные понятия нечеткой классификации являются недостаточно хорошо осмыслены и, как следствие, отсутствует единая общепринятая формулировка нечеткой модификации задачи автоматической классификации. Этим фактором обусловлено также и то, что существующие нечеткие методы кластерного анализа в подавляющем большинстве представляют собой, как показывают теоретические рассмотрения, просто нечеткие аналоги, обобщения или, напротив, частные случаи традиционных алгоритмов автоматической классификации; в особенности это касается оптимизационных кластер-процедур [37, с. 241], [31, с. 77-96]. Таким образом, методология сравнительного анализа существующих алгоритмов нечеткой автоматической классификации не должна принципиально отличаться от методологии сравнения традиционных методов кластер-анализа. Однако перед рассмотрением схемы сравнения нечетких кластер-процедур целесообразно указать целн проводимого сравнения, поскольку любое сравнение кластер-процедур проводится в зависимости от цели этого сравнения. Собственно, цель сравнительного анализа обусловлена, как правило, либо теоретическими рассмотрениями, либо конкретным прикладным исследованием. В первом случае сравнительный анализ проводится с целью определения эффективности кластер-процедур для решения некоторого класса задач» Во втором случае, как правило, между собой сравниваются результаты работы нескольких алгоритмов для выявления реальной структуры исследуемой совокупности и последующего уточнения результатов. Эффективность любой кластер-процедуры может оцениваться по уровню устойчивости к возмущениям, оценке трудоемкости, а также оценке сходимости алгоритма; более подробно эти вопросы рассматриваются И. Д. Манделем [31]. Касательно оптимизационных кластер-процедур нечеткого подхода следует отметить, что для оценки их сходимости может быть использовано соотношение [140]
где
|
 |
Оглавление
|



































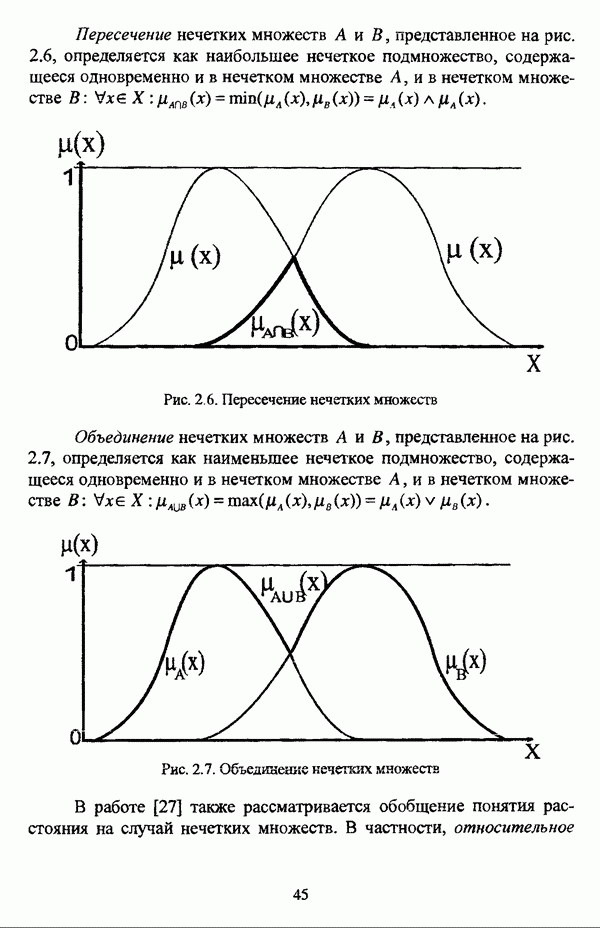


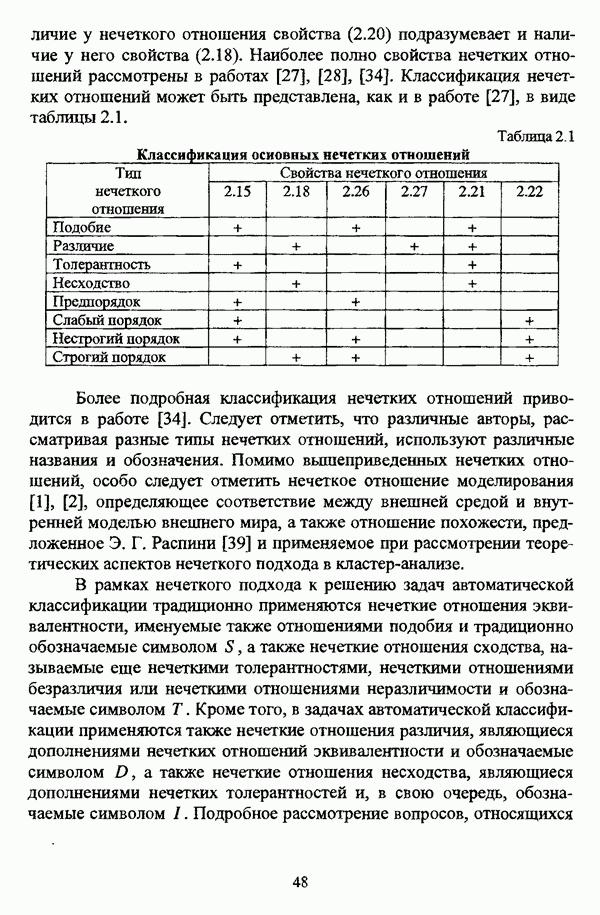

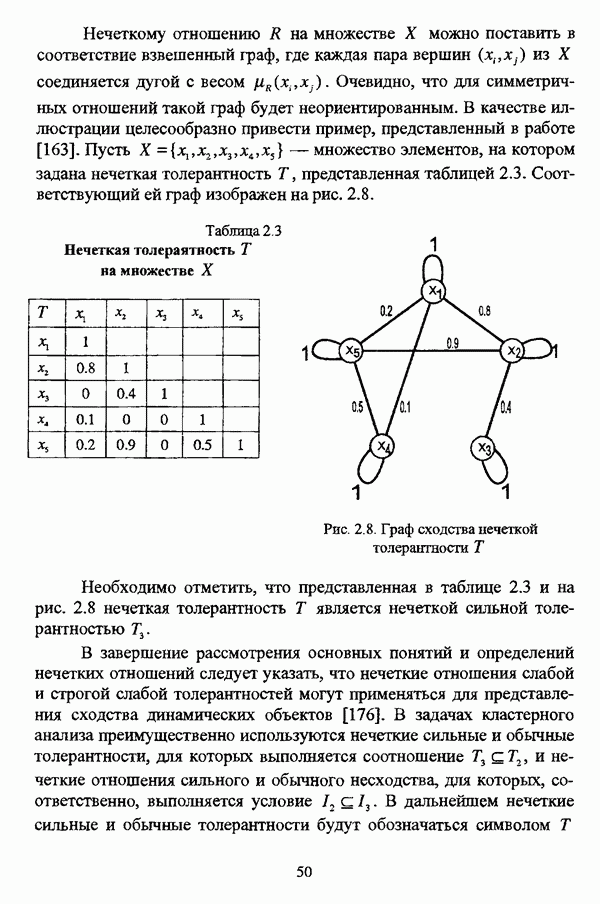




























































































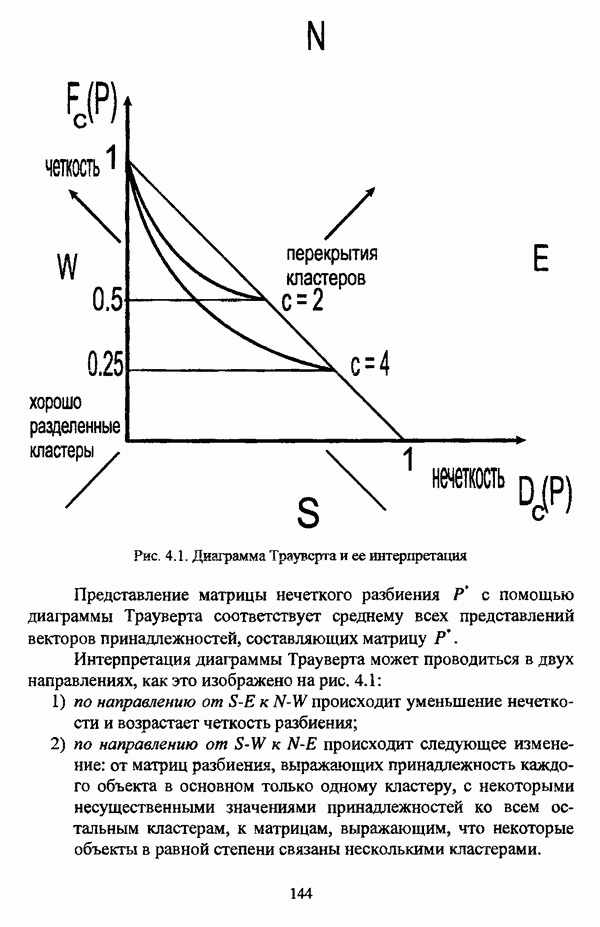






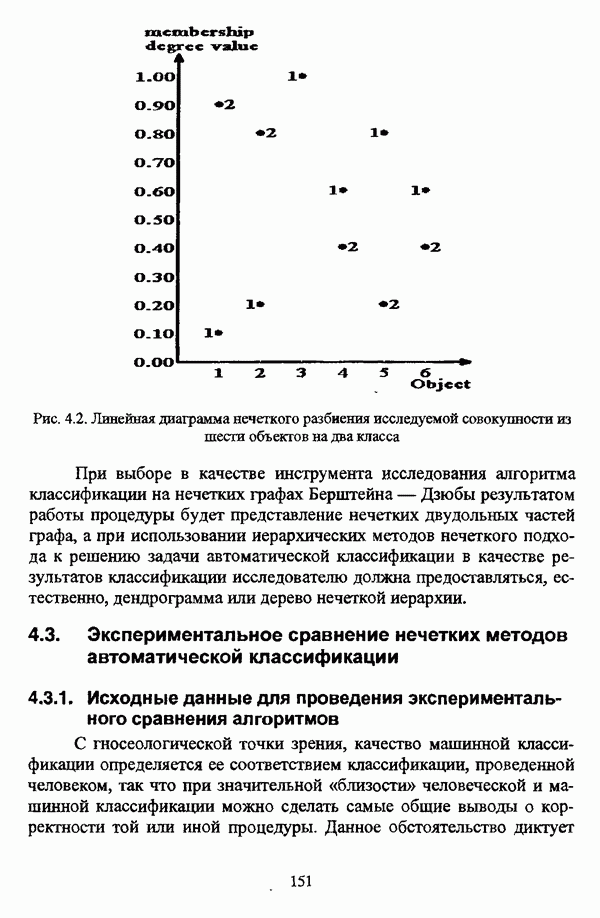

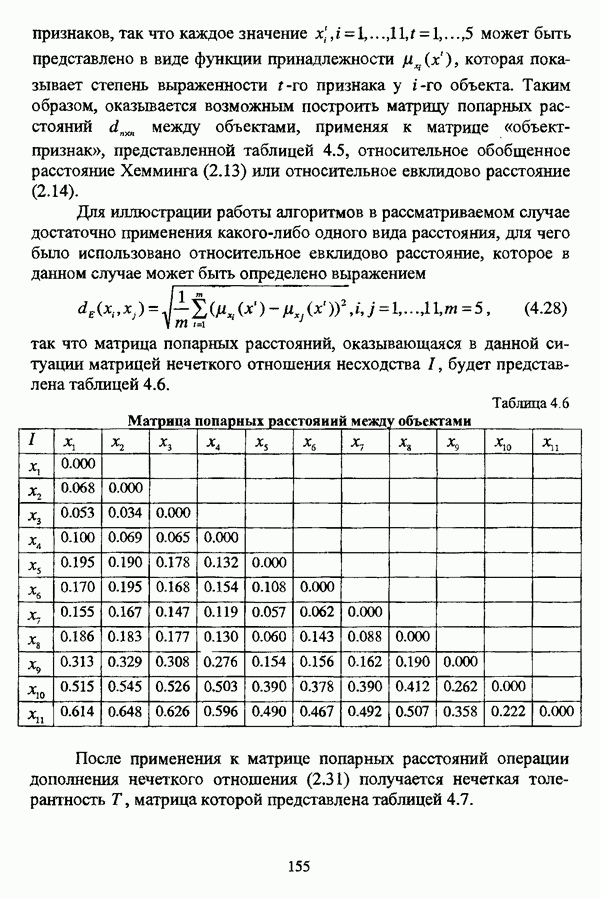

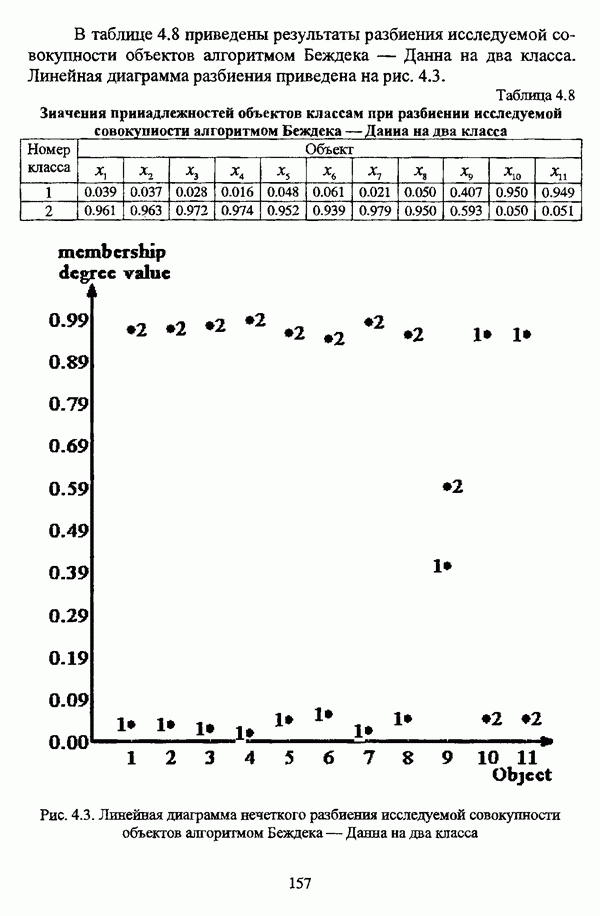
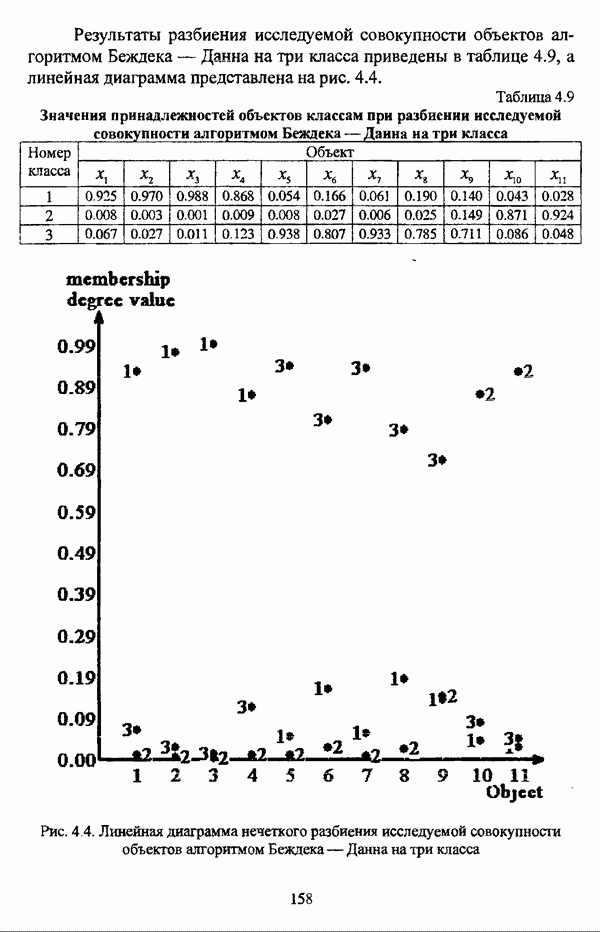
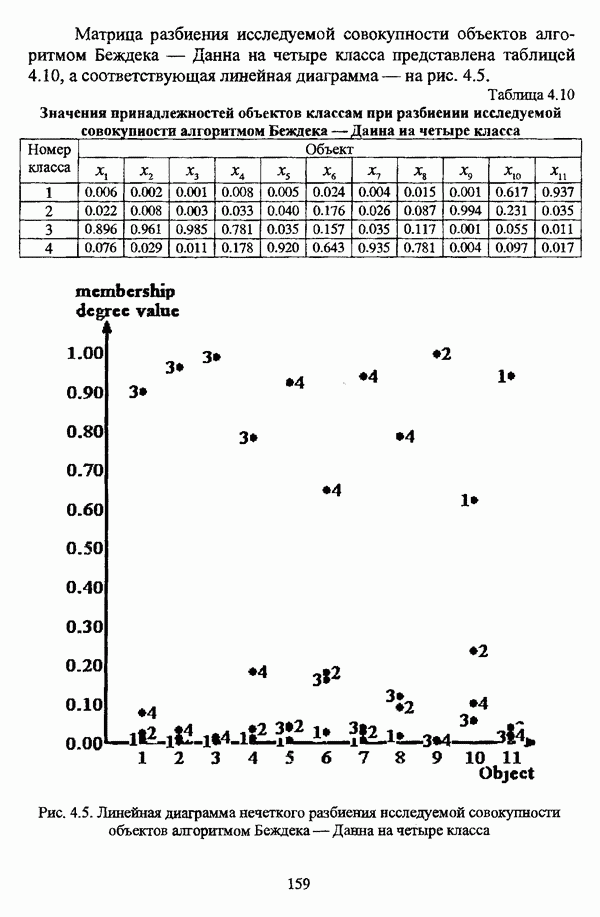
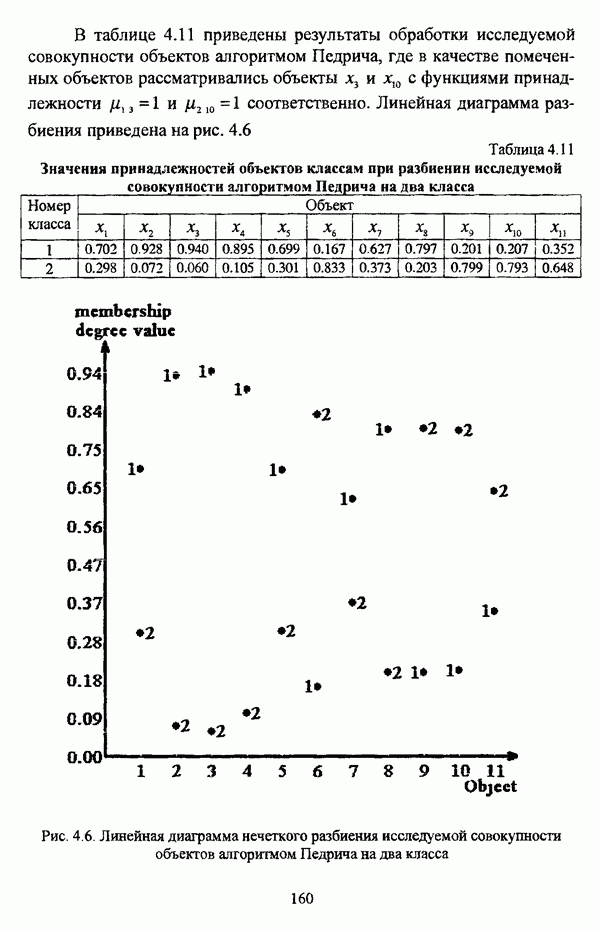
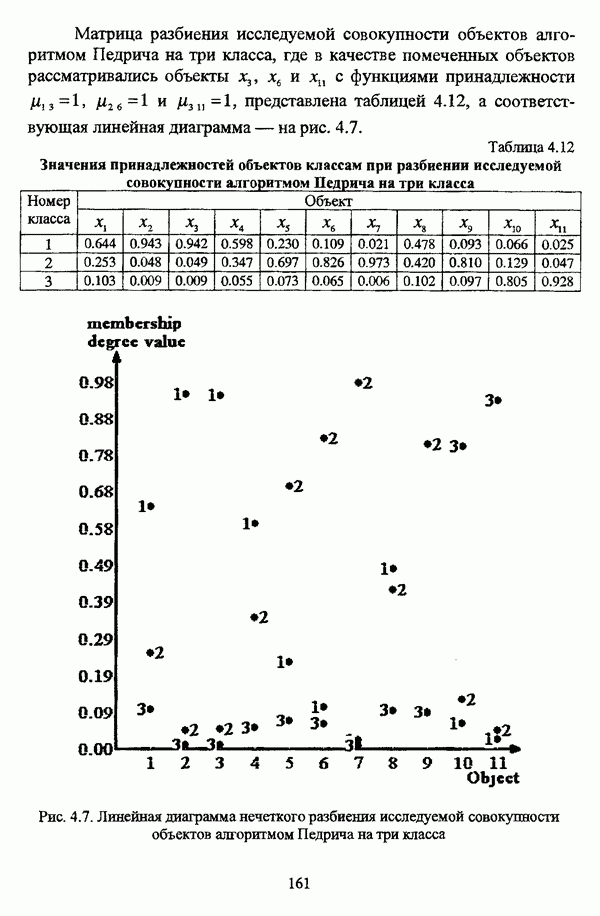
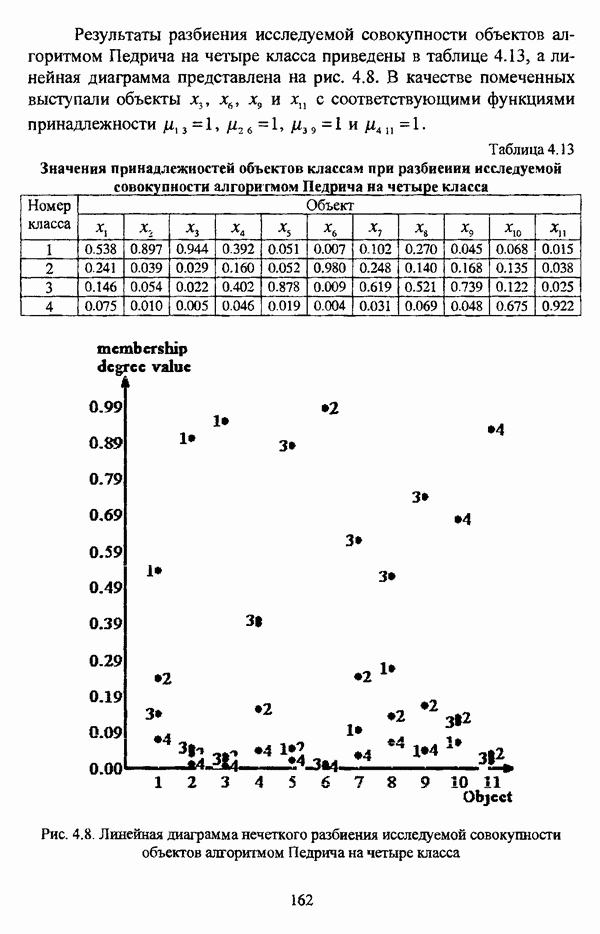
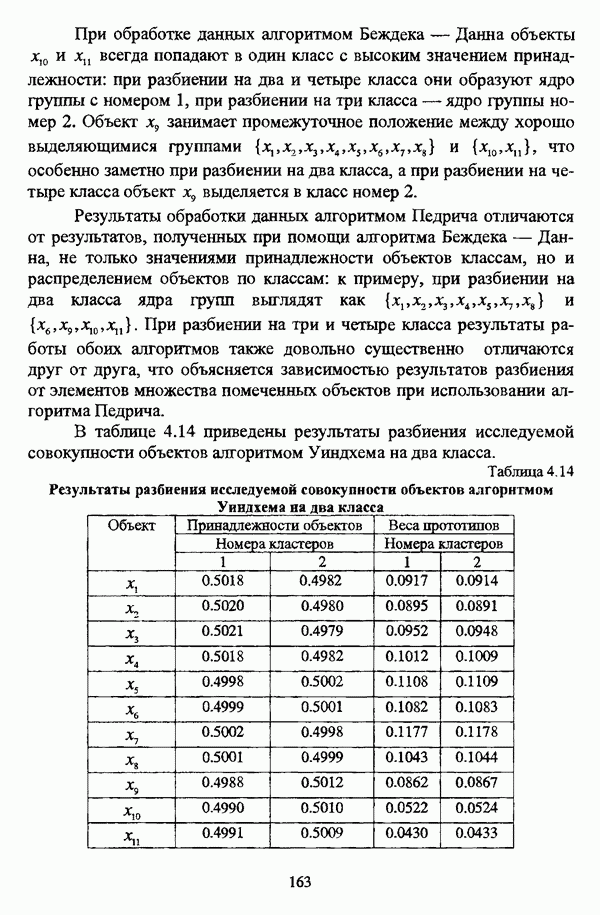
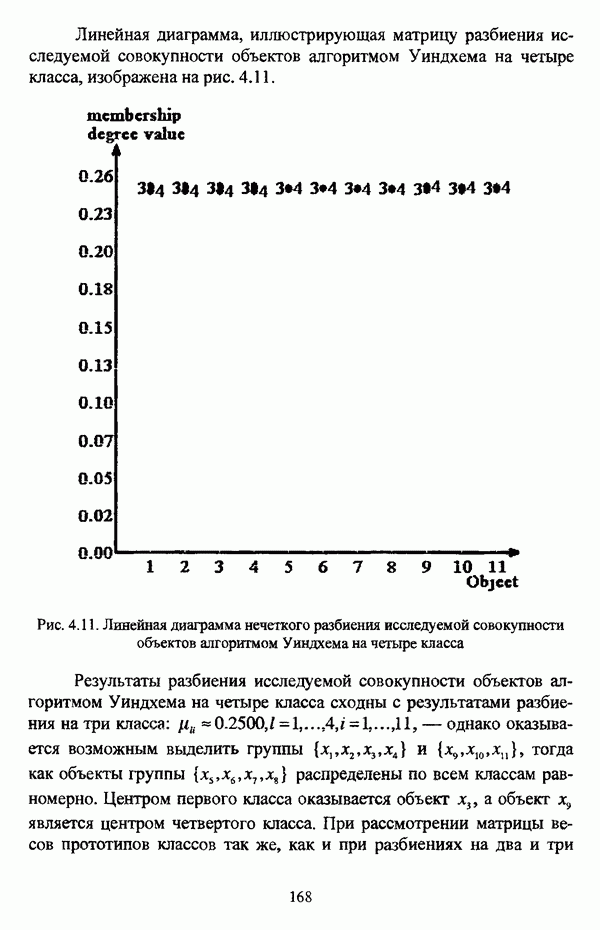

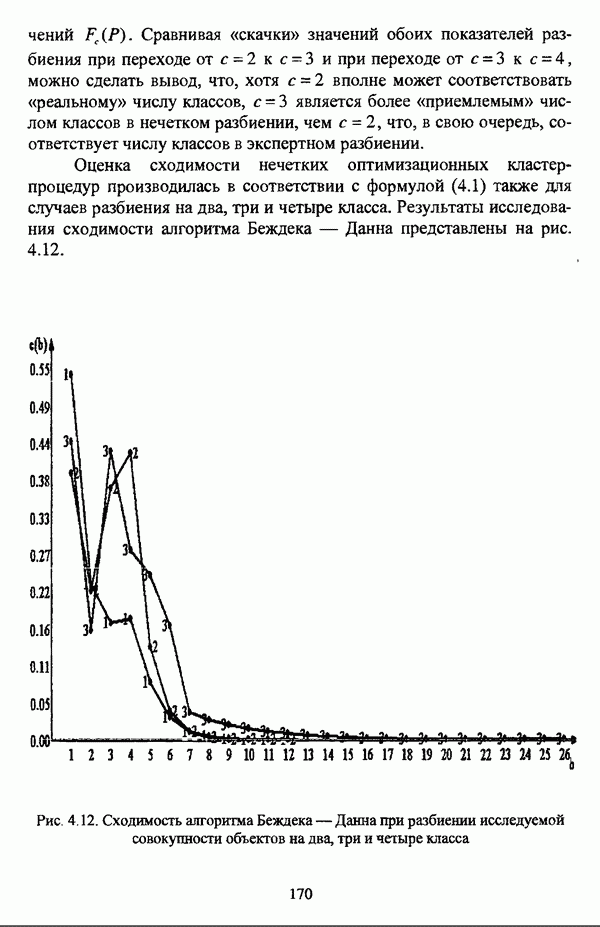
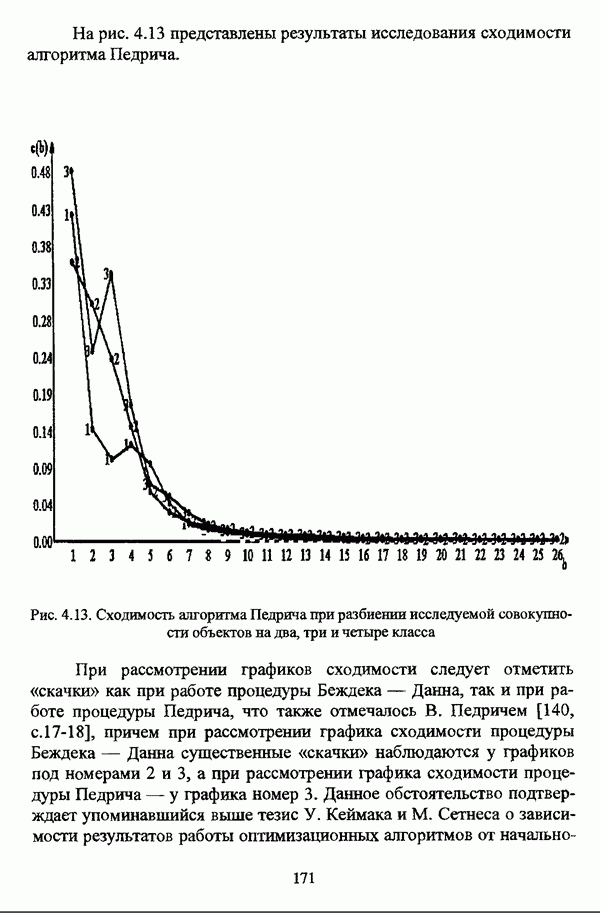
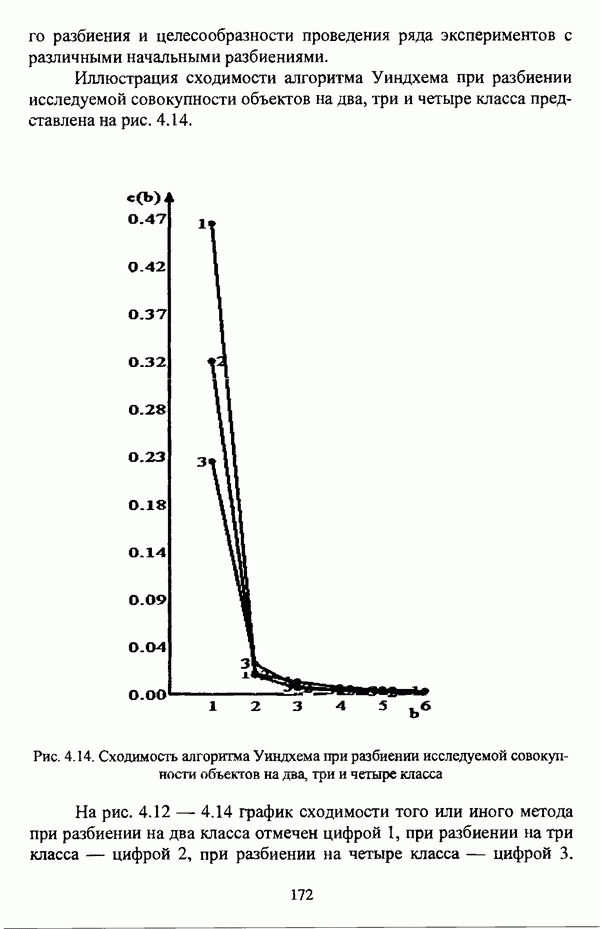
















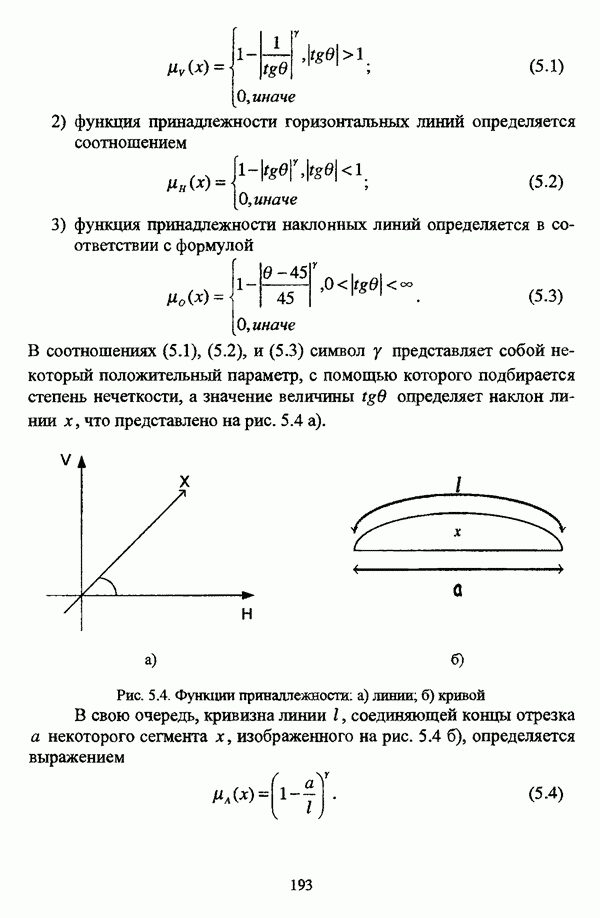




















 — значение принадлежности
— значение принадлежности  объекта
объекта  кластеру на
кластеру на  шаге вычислительного процесса,
шаге вычислительного процесса,  так что оказывается возможным построить график изменения величины
так что оказывается возможным построить график изменения величины  иллюстрирующий сходимость вычислительного процесса.
иллюстрирующий сходимость вычислительного процесса.