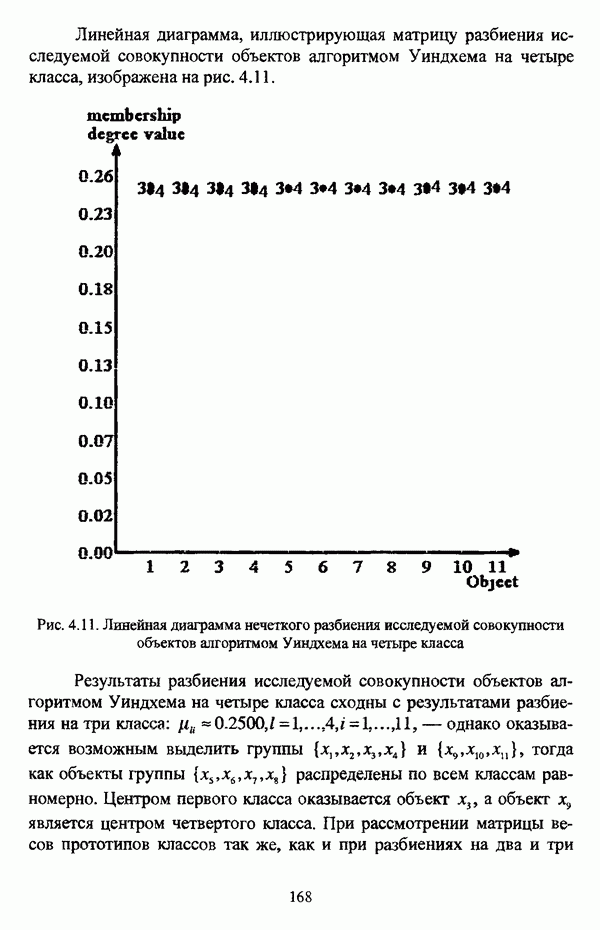
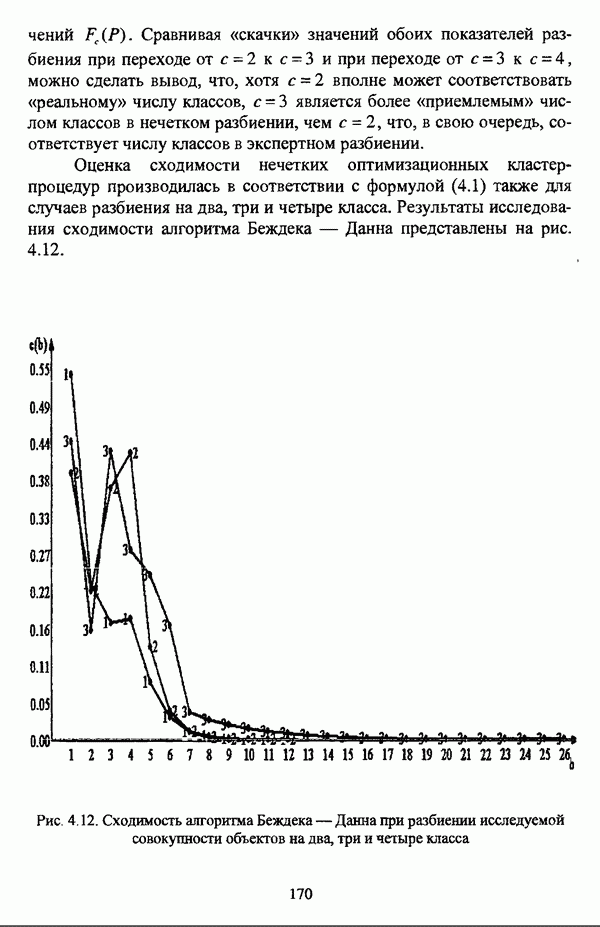
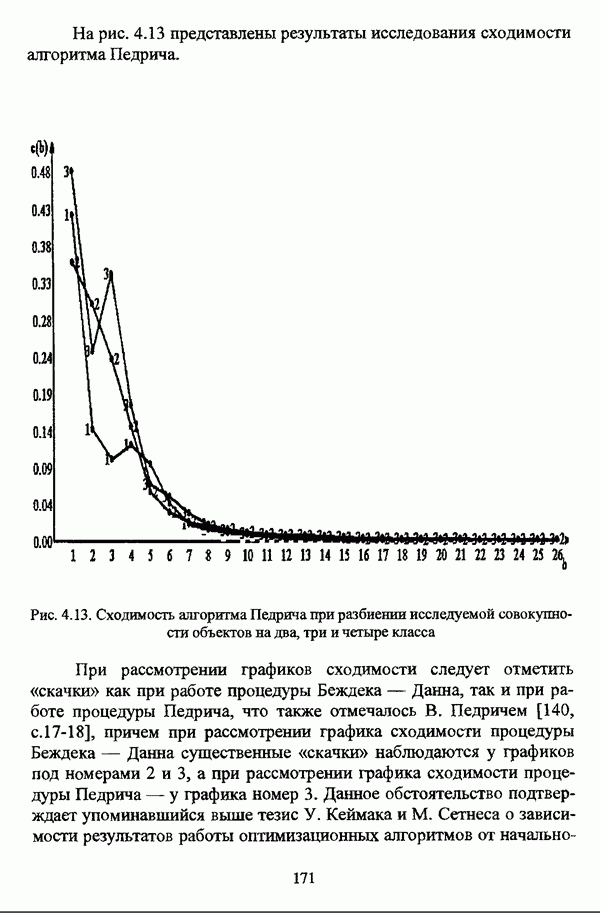
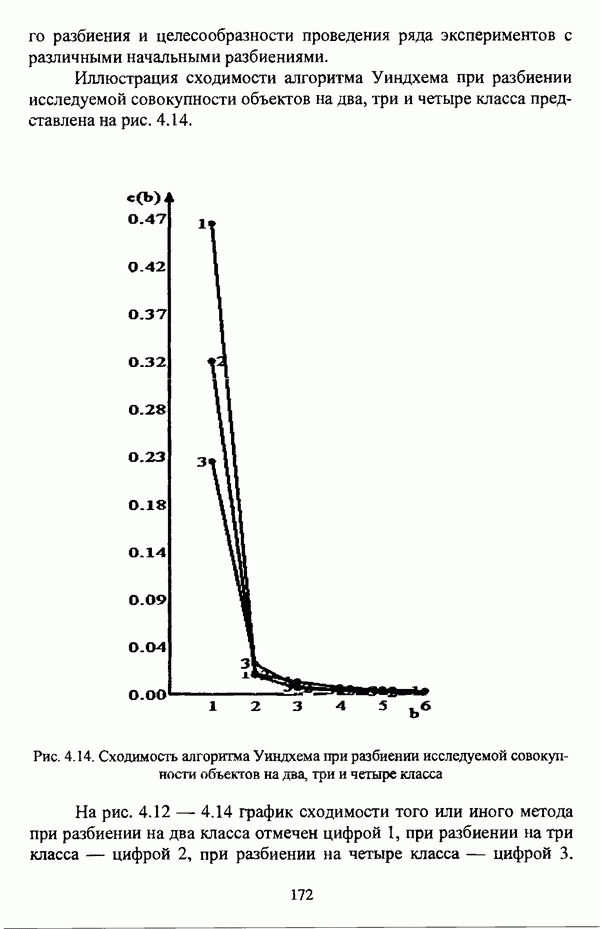
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
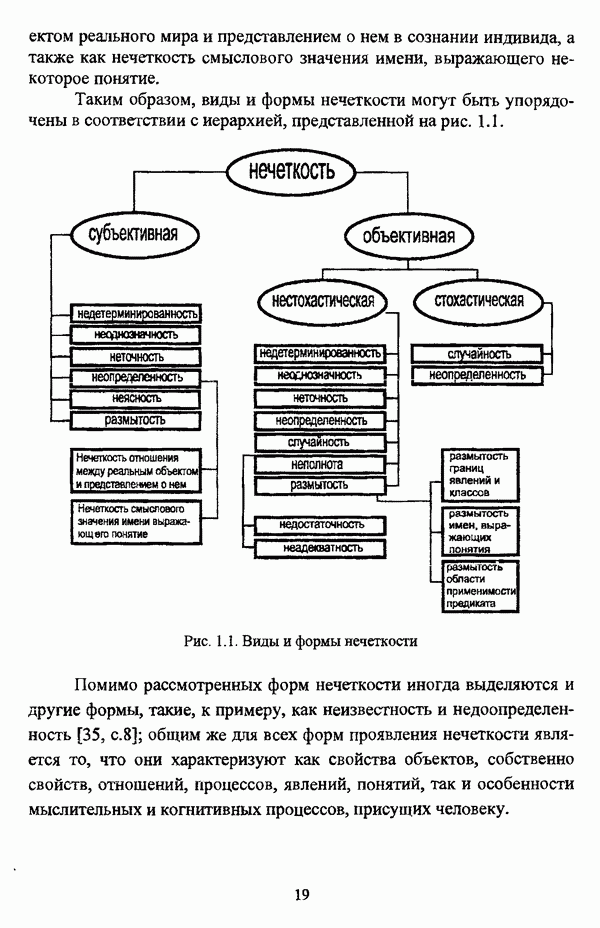
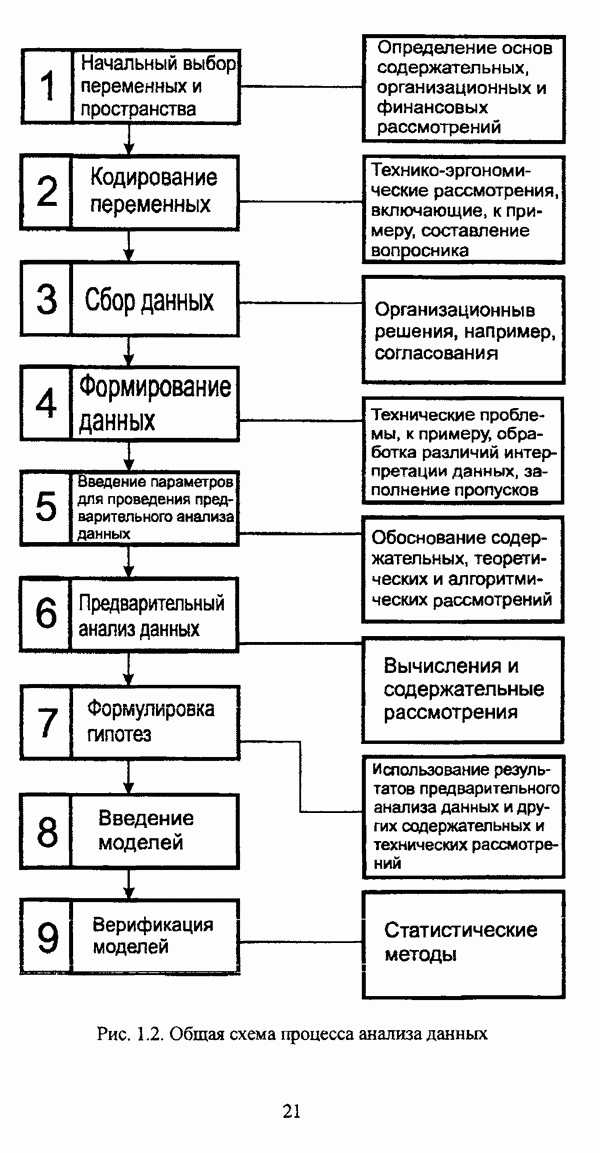
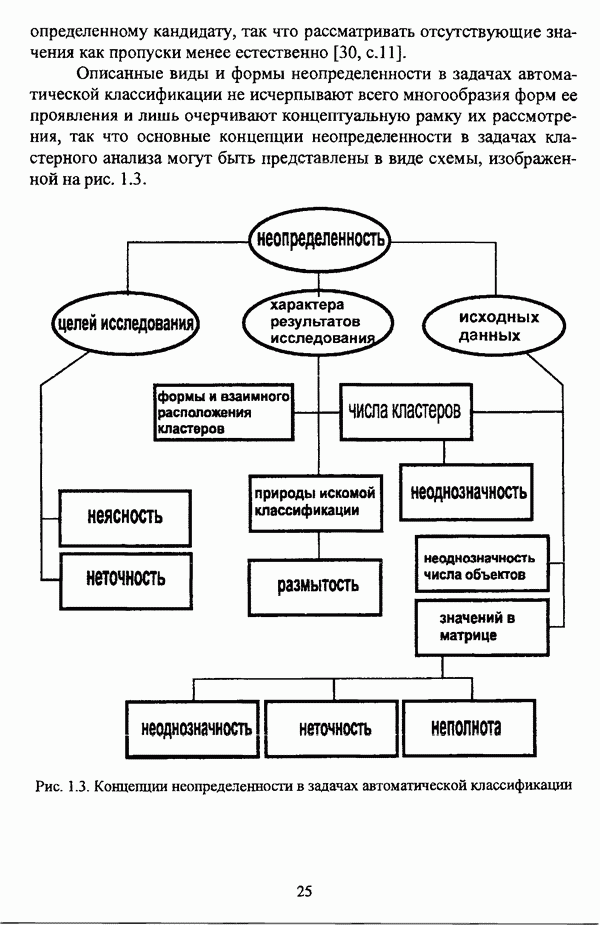
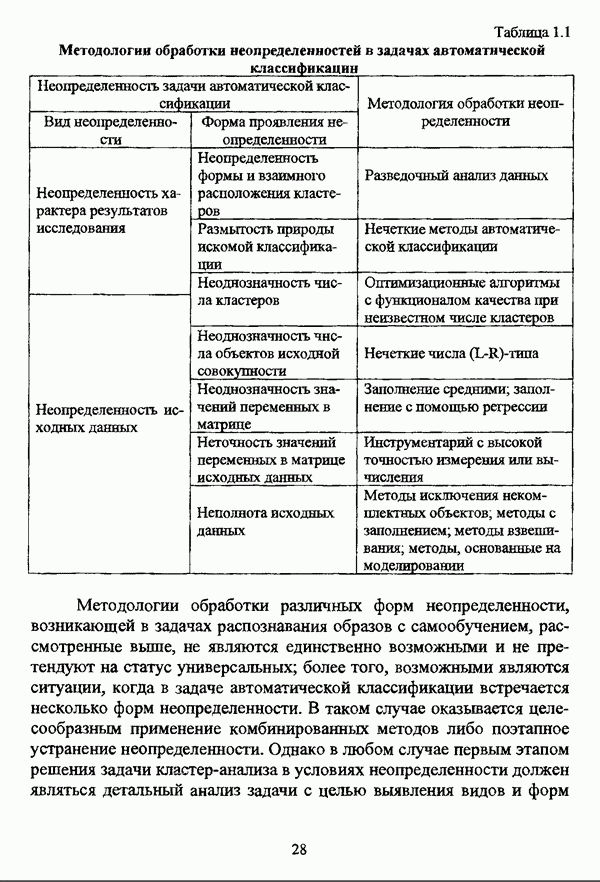
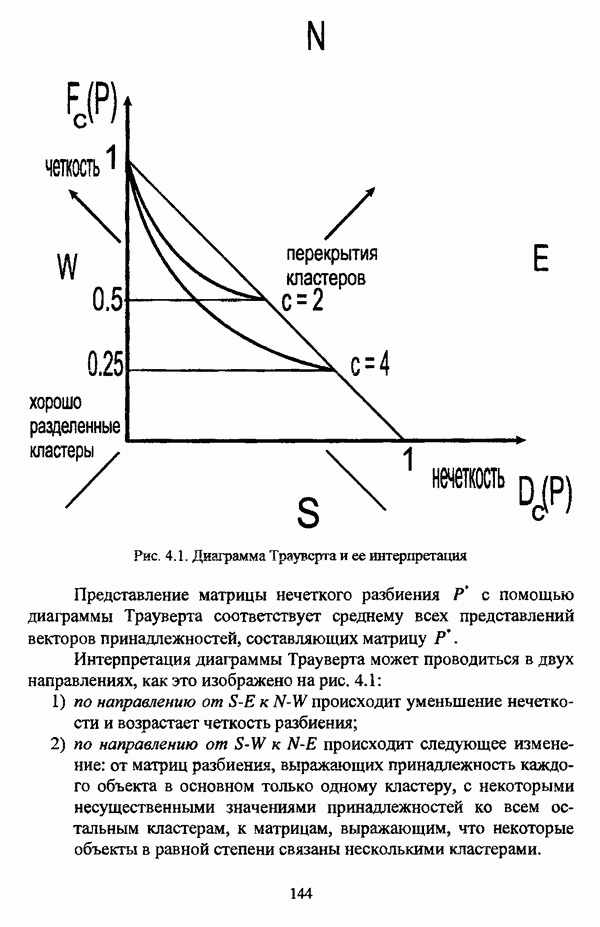
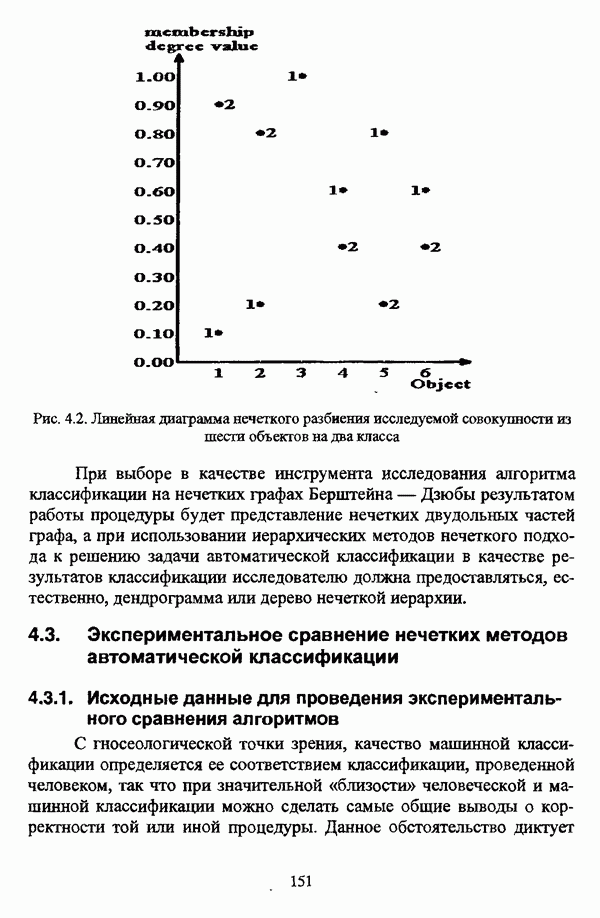
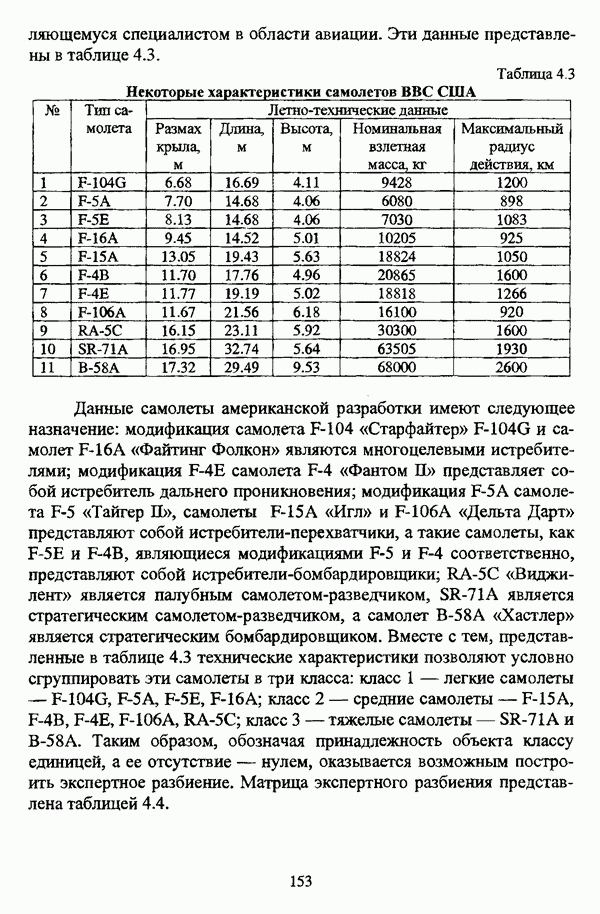
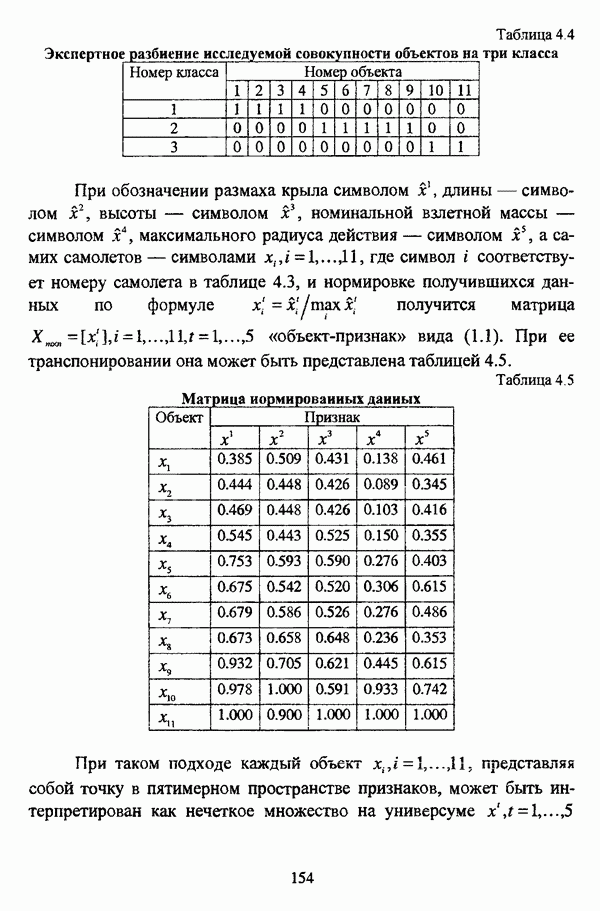
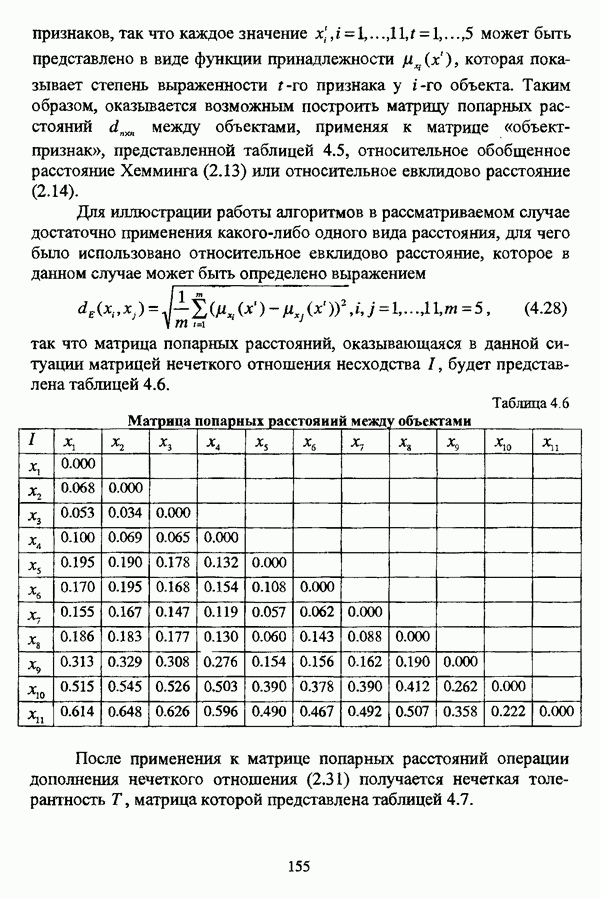
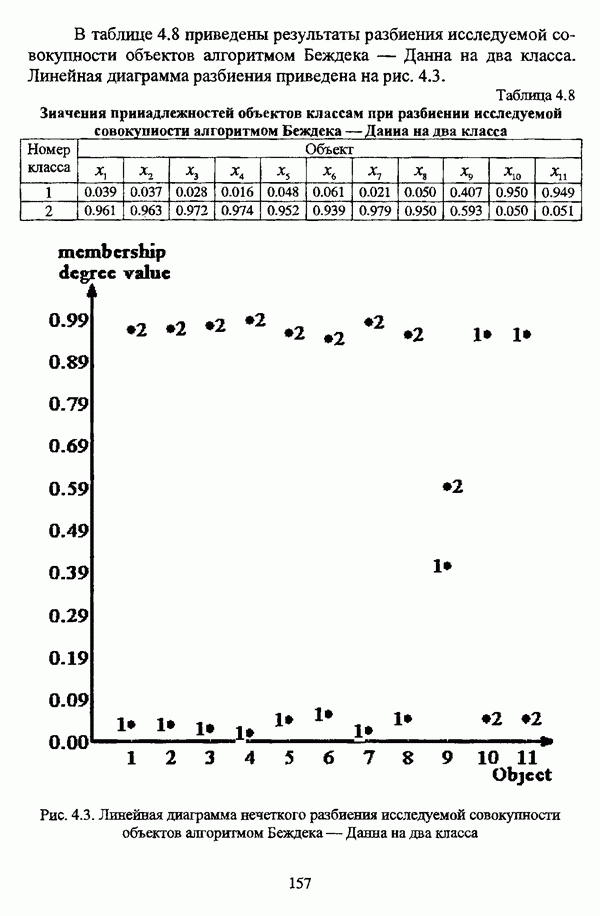
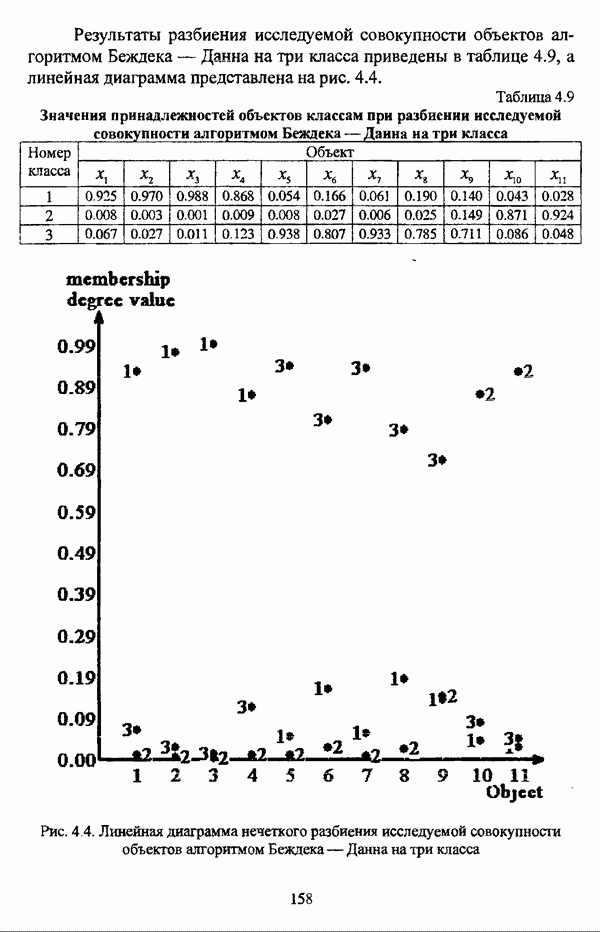
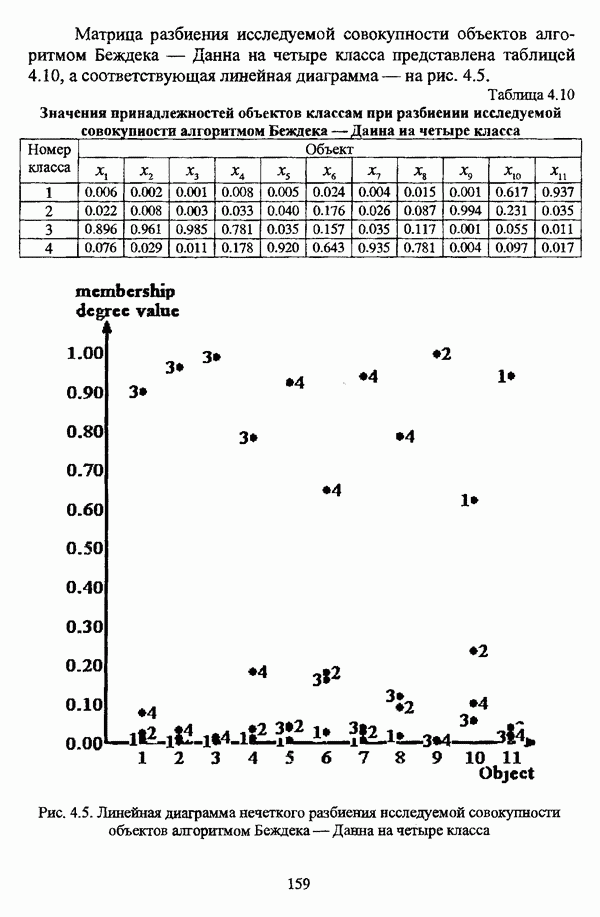
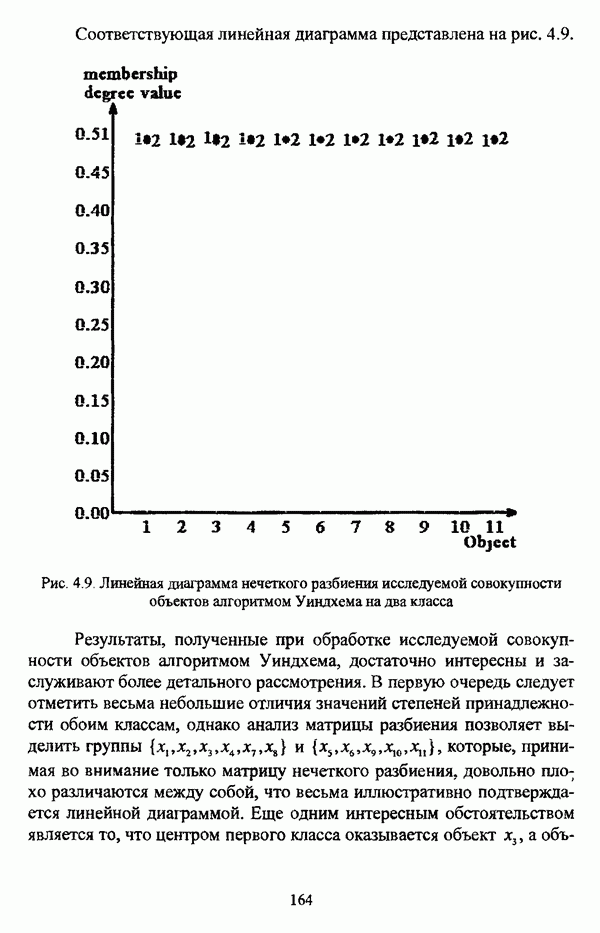
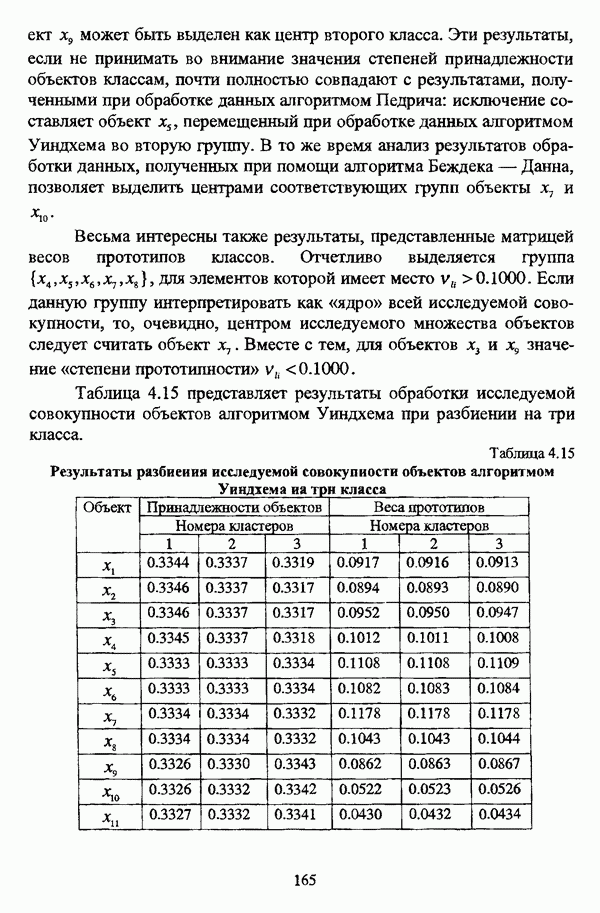
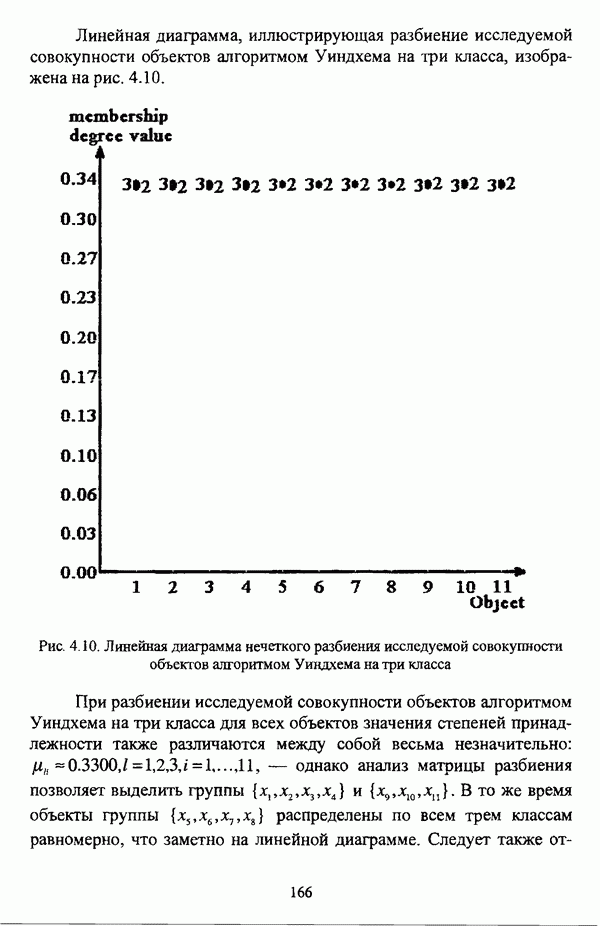
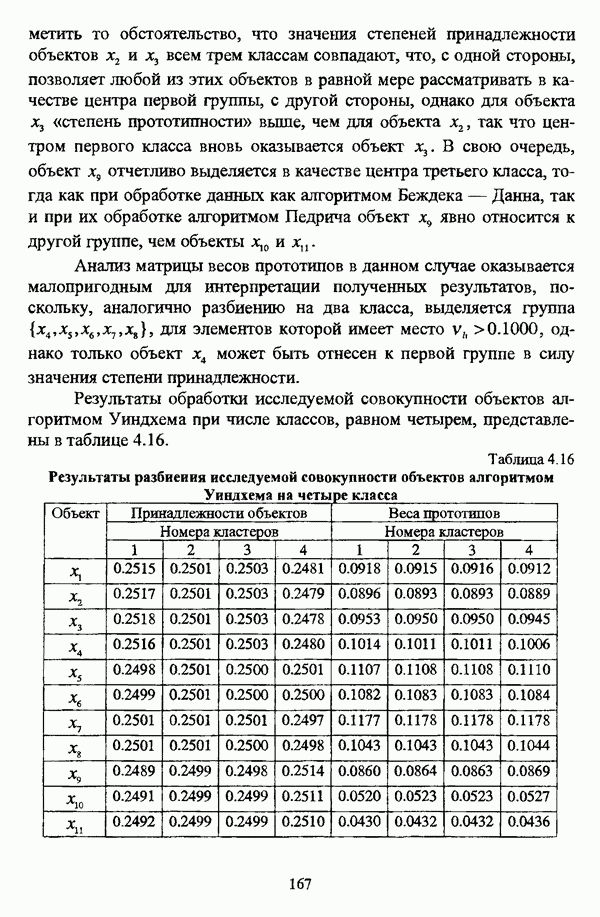
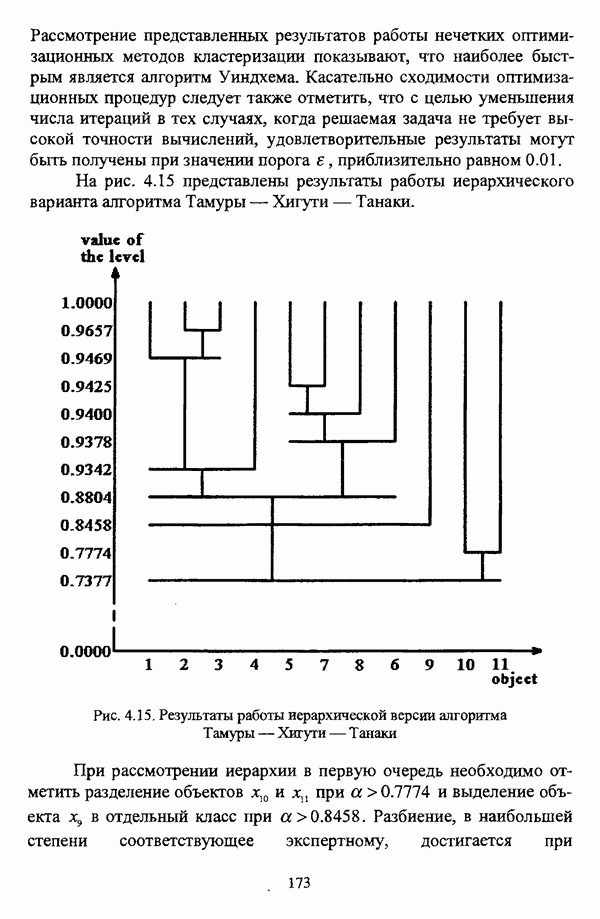
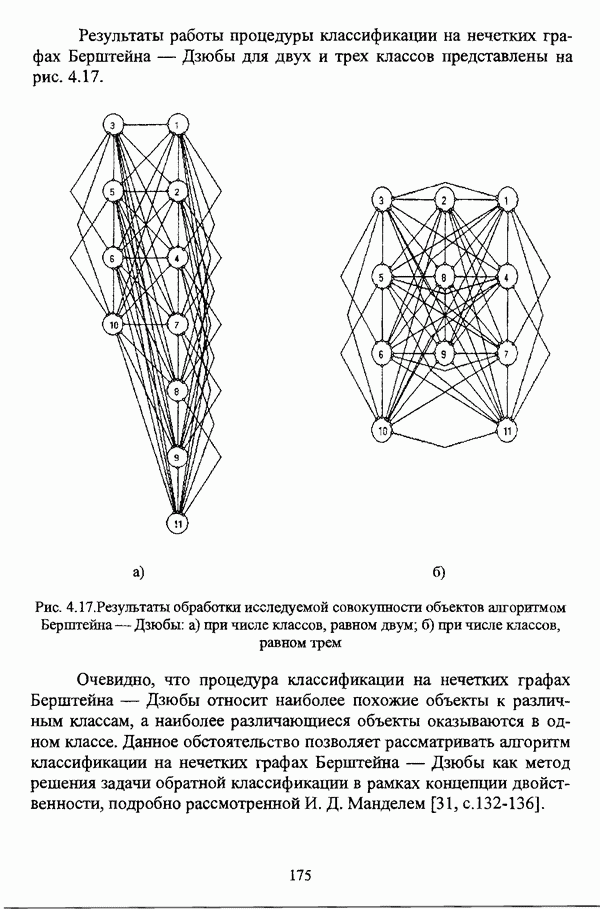
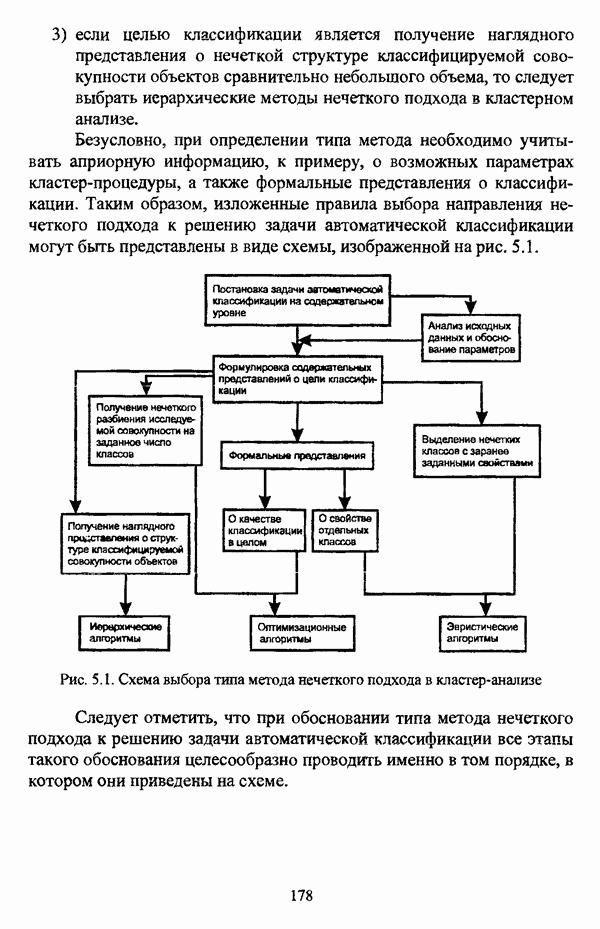
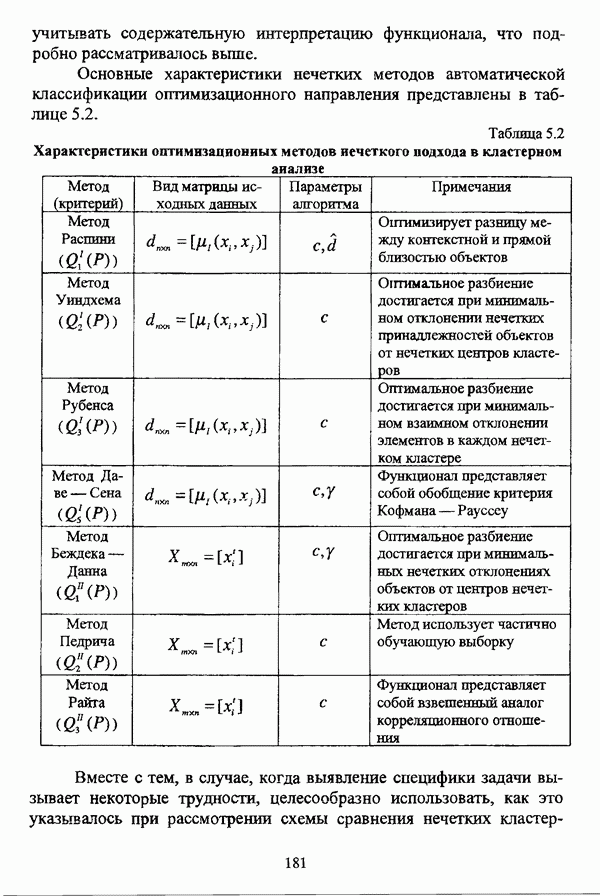
5.2.2. Нечеткие методы автоматической классификации и другие нечеткие методы распознавания образовКластерный анализ представляет собой методологию распознавания образов, специфика которой заключается в отсутствии обучающих выборок. Вместе с тем, при решении ряда задач могут быть использованы и другие нечеткие подходы к решению задачи распознавания образов. Рассмотрение вопросов, относящихся к нечетким методам кластерного анализа, целесообразно дополнить кратким рассмотрением других методов классификации, имеющих основой теорию нечетких множеств. Подобный обзор является полезным с методологической точки зрения и позволяет более полно рассмотреть современное состояние нечеткого подхода к распознаванию образов и сфер его применения. Как уже отмечалось, кластерный анализ применяется не только для классификации объектов, но и для решения задачи выделения признаков из множества данных. Различные аспекты применения нечетких методов автоматической классификации к решению этой задачи рассматриваются в работах [56], [81], [104]. Среди других нечетких подходов к решению задачи выделения признаков особо следует отметить методы, предложенные в работах [78], [94], [95], а также подход, предложенный Д. В. Гесу и М. Маккароне [89] и имеющий основой теорию возможностей. Данный подход также подробно рассматривается в работе [38, с. 183-186]. Кроме того, в работе [38, с. 192-195] рассматривается также применение средств нечеткой математики к распознаванию движущихся предметов. Нечеткие геометрические признаки формы, позволяющие построить нечеткие методы кластеризации при обработке плоских изображений, предлагаются в работе [26]. Сущность предлагаемого подхода заключается в построении геометрии плоскости, так что оказывается возможным ввести геометрические объекты, которые могут быть использованы для описания элементов изображений на дискретной плоскости, такие как точки, отрезки линий, а также множества точек, не являющихся отрезками линий. Помимо нечеткой кластеризации, для решения задачи распознавания образов используются также другие подходы, в частности, использующие обучающую выборку. Эти подходы, подробно рассматриваемые В. Педричем [144, с. 123-131], условно объединяются в три группы: основанные на вычислении нечетких отношений [127], [154], основанные на понятии сопоставления образов и основанные на процедурах принятия решений. Целесообразно также отметить лингвистический подход к распознаванию образов, обсуждающийся в работах [25], [87], [122], [130], [131], подход на основе так называемых самораспознающих нечетких классификаторов, предлагаемый С. И. Ватлиным [170], [171], [172], а также работы М. Сугэно [160], [161], посвященные применению теории нечетких интегралов к решению задач распознавания образов. Более того, получил развитие подход к решению задач распознавания образов, основанный на использовании нечетких нейронных сетей [62], [72, с. 177-212]. Кроме того, определенный интерес представляют также подходы к решению задач распознавания, изложенные в работах [80], [112], [113] и [117]. Нечеткие множества как вспомогательный инструментарий могут использоваться для усовершенствования неразмытых классификаторов. Из методов распознавания образов в условиях нестохастической неопределенности, непосредственно не использующих аппарат нечеткой математики, целесообразно отметить работы Р. С. Михальского [125], [126]. Весьма интересным и многообещающим подходом к решению задач распознавания образов является нечеткий дискриминантный анализ. К примеру, Л. И. Бородкиным [13] предложен метод, в основе которого лежит поиск линейной разделяющей функции, минимизирующей суммарную ошибку распознавания, которая, в свою очередь, оценивает степень сходства нечеткого с-разбиения Для классификации объектов также оказывается удобным использовать нечеткие отношения типа 2 [33], так что решение задачи классификации представляет собой трехэтапный процесс: 1. На классифицируемой совокупности объектов 2. Нечеткое отношение R типа 2 аппроксимируется отношением подобия S типа 1 или типа 2; 3. На множестве Интерес представляет также решение задачи классификации с использованием так называемых упорядоченных взвешенных усредняющих операторов (ordered weighted averaging operators). К примеру, в исследовании Л. Кунчевой [115] предложена схема классификации, в основе которой лежит объединение нескольких классификаторов и агрегирования их решений. Решения отдельных классификаторов обрабатываются как степени принадлежности, распределенные классификатором по классифицируемым объектам. В общем, весь конгломерат классификаторов выступает в едином качестве, как один наилучший классификатор. В исследовании производится сравнение метода классификации на основе упорядоченных взвешенных усредняющих операторов с экспертными оценками, а также с линейным и логарифмическим методами, на основании которого делается вывод о том, что метод, в основе которого лежит аппарат упорядоченных взвешенных усредняющих операторов, обладает лучшими характеристиками, чем сравниваемые с ним методы. Л. Кунчевой приводятся также иллюстративные примеры применения данного подхода для решения задачи классификации. Для решения задачи классификации применим также метод нечеткого дерева решений. В работе [20] рассматривается задача определения типовых характеристик клиентов некоторой компании на основе информации, содержащейся в базе данных. Типовые характеристики ориентированы на повышение эффективности обслуживания новых клиентов и выработки целенаправленной маркетинговой политики. Для решения задачи предлагается модифицированный алгоритм построения нечетких деревьев решений на основе частичных информационных оценок. Исходные данные представляют собой атрибуты, принимающие значения на некоторых множествах, причем для ряда атрибутов в исходных данных значения отсутствуют. Предлагаемый алгоритм построения нечетких деревьев решений позволяет обрабатывать атрибуты с частично заданными значениями. При построении дерева решений ключевыми задачами являются выбор атрибута, по которому происходит разбиение дерева, и определение условий ограничения роста дерева. Сущность предлагаемого подхода состоит в выборе атрибута с минимальным значением частичной условной энтропии, а для генерации листьев дерева используется понятие частичной совместной информации. Алгоритм построения нечеткого дерева решений заключается в вычислении для всех атрибутов значений частичной совместной информации и частичной условной энтропии, на основании чего происходит выбор текущего узла и определяется наличие листьев строящегося дерева решений, после чего процедура повторяется для остальных атрибутов. Некоторые другие алгоритмы построения нечетких деревьев решений представлены в работах [69],[118], [119], [191]. В работе [137] рассматривается применение средств нечеткой математики для обработки рентгеновских снимков. Метод, предложенный С. К. Палом, Р. А. Кингом и А. А. Хасимом, общая схема которого изображена на рис. 5.3, прост, нагляден и эффективен, так что представляется необходимым его более подробное рассмотрение.
Рис. 5.3. Схема метода Пала — Кинга — Хасима Сущность подхода, в основе которого лежит алгоритм обнаружения кривых и петель, предложенный Дж. Т. Тоу [165], с последующим сглаживанием и сегментацией, заключается в преобразовании неясных очертаний костных образований на снимке в четкие контуры. Неясные очертания состоят преимущественно из вертикальных, горизонтальных и наклонных линий, так что их можно определить как нечеткие множества: «вертикальные» «горизонтальные» «наклонные» В свою очередь, функции принадлежности соответствующих нечетких множеств также могут быть определены: 1) функция принадлежности вертикальных линий выражается соотношением
2) функция принадлежности горизонтальных линий определяется соотношением
3) функция принадлежности наклонных линий определяется в соответствии с формулой
В соотношениях (5.1), (5.2), и (5.3) символ у представляет собой некоторый положительный параметр, с помощью которого подбирается степень нечеткости, а значение величины
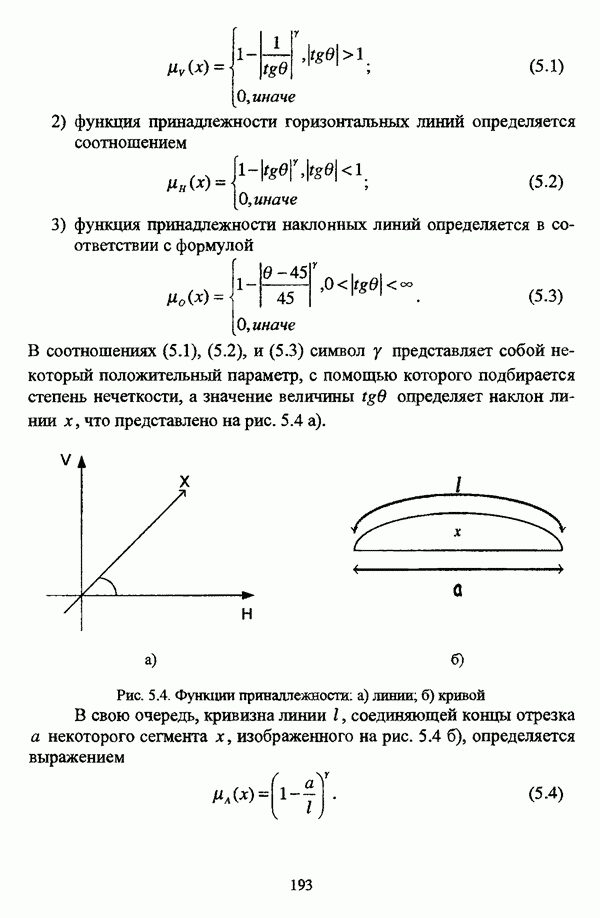
Рис. 5.4. Функции принадлежности: а) линии; б) кривой В свою очередь, кривизна линии I, соединяющей концы отрезка а некоторого сегмента х, изображенного на рис. 5.4 б), определяется выражением
Очевидно, что с уменьшением величины На обрабатываемом снимке контуры обнаруживаются как
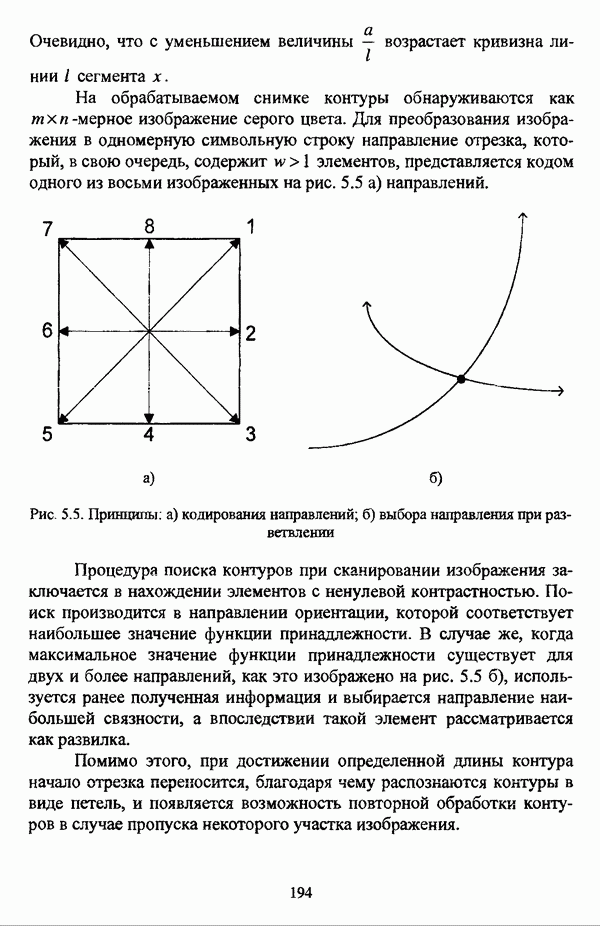
Рис. 5.5. Принципы: а) кодирования направлений; б) выбора направления при разветвлении Процедура поиска контуров при сканировании изображения заключается в нахождении элементов с ненулевой контрастностью. Поиск производится в направлении ориентации, которой соответствует наибольшее значение функции принадлежности. В случае же, когда максимальное значение функции принадлежности существует для двух и более направлений, как это изображено на рис. 5.5 б), используется ранее полученная информация и выбирается направление наибольшей связности, а впоследствии такой элемент рассматривается как развилка. Помимо этого, при достижении определенной длины контура начало отрезка переносится, благодаря чему распознаются контуры в виде петель, и появляется возможность повторной обработки контуров в случае пропуска некоторого участка изображения. На этапе сглаживания контуров используются следующие четыре процедуры: 1. Если подряд следуют четыре и более одинаковых кода, но между ними находится код другого направления, или два соседних кода, то этот код заменяется на последующий либо предыдущий, что изображено на рис. 5.6 а), либо исключается, что, в свою очередь, изображено на рис. 5.6 б);
Рис. 5.6. Принципы: а) замещения кода; б) исключения кода 2. Если сначала следуют подряд четыре и более одинаковых кода, а затем два других кода, либо эти коды принимают значения 6 и 3, то, как и в предыдущем случае, эти коды заменяются на последующий либо предыдущий код, либо исключаются; 3. Если два соседних элемента имеют противоположные направления, то они исключаются; 4. Если некоторое направление незначительно изменяется, то для пары кодов в промежуточном направлении формируются правила вычисления векторной суммы, благодаря которым оказывается возможным устранить незначительное изменение направления. Следующим этапом обработки изображения является сегментация контуров, которая представляет собой разграничение по изменениям свойств отрезков, в частности, граница выбирается в том месте, где изменение направления становится неодинаковым. Кривизна сегментированных участков определяется в соответствии с формулой (5-4). В качестве иллюстративного примера применения описанного подхода к обработке изображения приводится рентгеновский снимок запястья, представленный на рис 5.7, так что контуры костей представляют собой границы градаций серого цвета для 145x128 элементов при (см. скан) Рис. 5.7. Обрабатываемый рентгеновский снимок Множество особенностей костей выбирается на основании вычисления значений принадлежностей линейности и кривизны сегментов. Полученный результат оказывается полезным при формировании правил распознавания неизвестных участков контуров. На рис. 5.8 представлен фрагмент исходного изображения а) до и б) после сглаживания, так что полученный результат позволяет достаточно легко выделять специфические особенности костей запястья пациента. (см. скан) Рис. 5.8. Фрагмент обрабатываемого рентгеновского снимка: а) до сглаживания; б) после сглаживания Различные нечеткие подходы к распознаванию образов предлагаются в процессе решения конкретных задач. Таким образом, их специфика зачастую оказывается обусловленной областью применения того или иного подхода. Обзор сфер применения нечетких методов распознавания образов приводится в таблице 5.5. Таблица 5.5. Области применения нечетких методов распознавания образов
Таковы основные подходы к решению задачи распознавания образов в условиях нестохастической неопределенности. В завершение следует указать, что в силу ограниченности изложения и значительному прогрессу в области нечетких методов распознавания образов данный обзор не является полным.
|
 |
Оглавление
|



























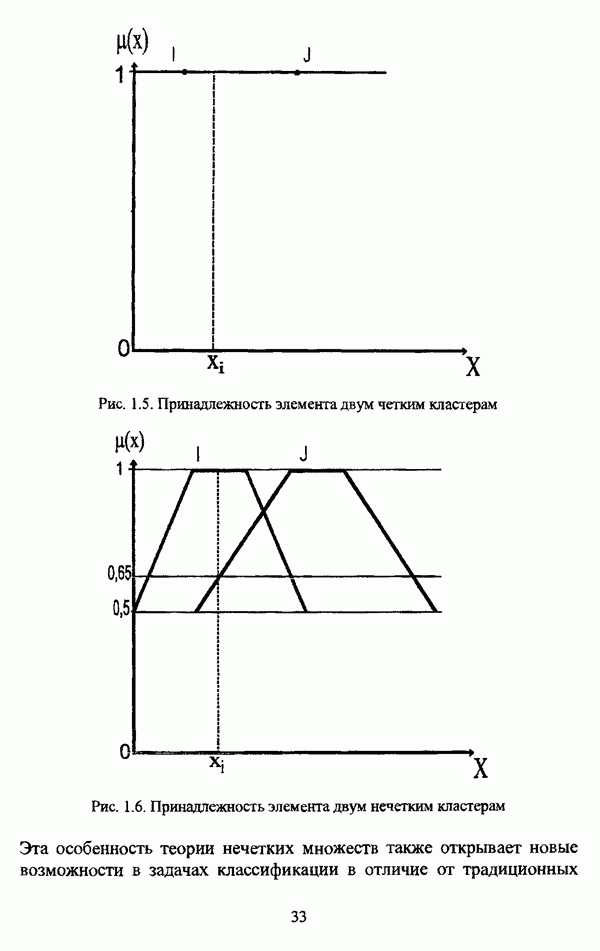






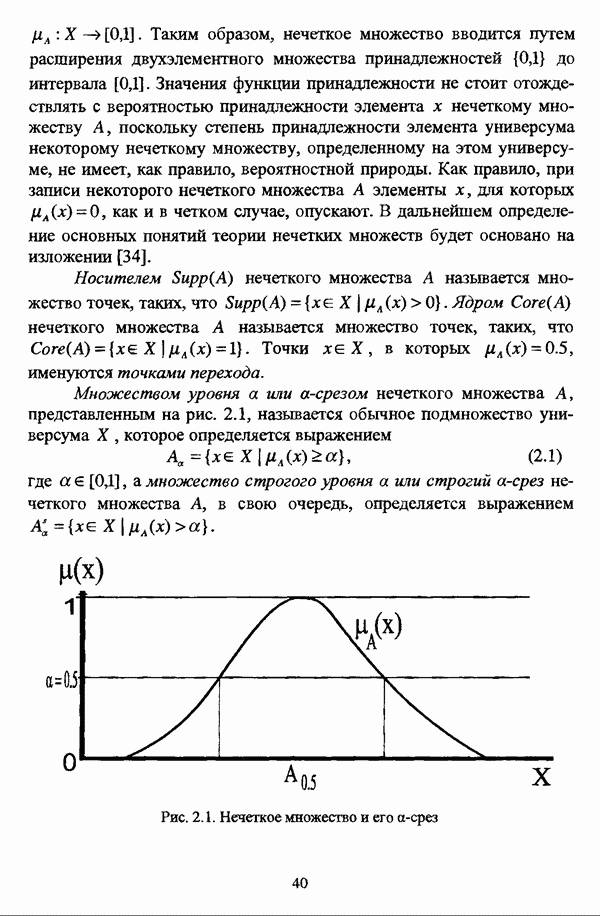


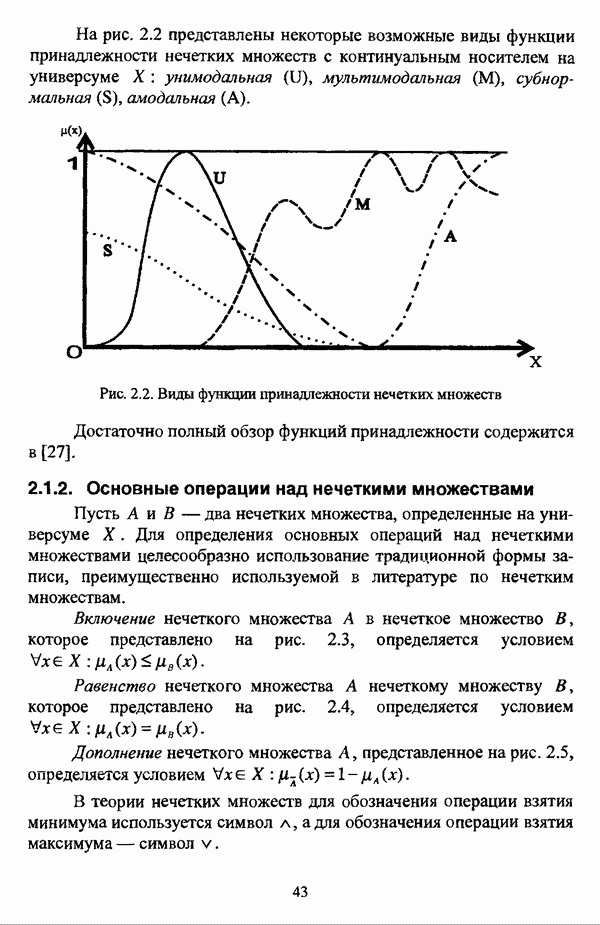
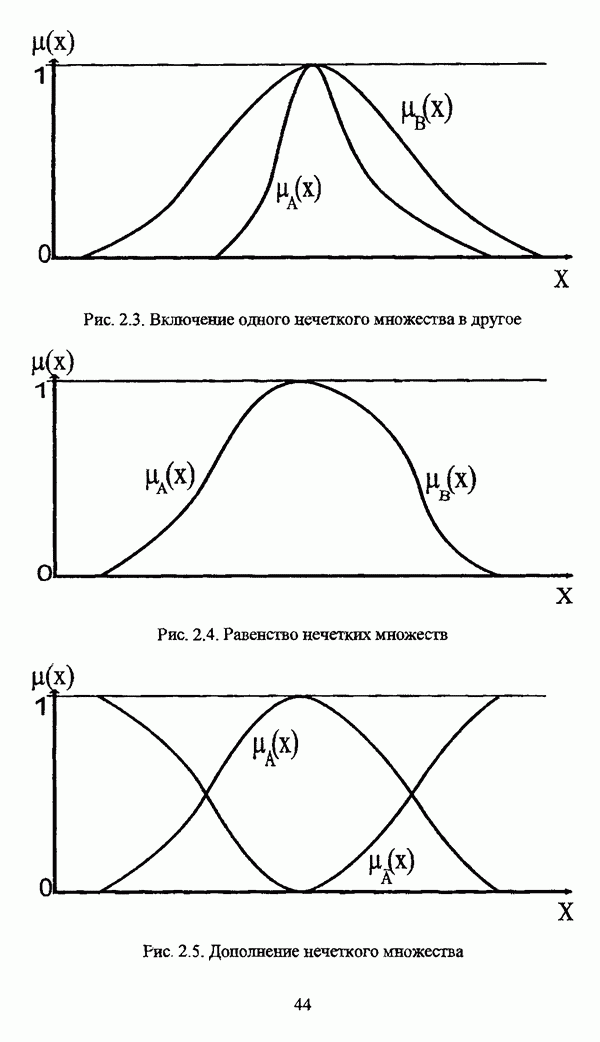
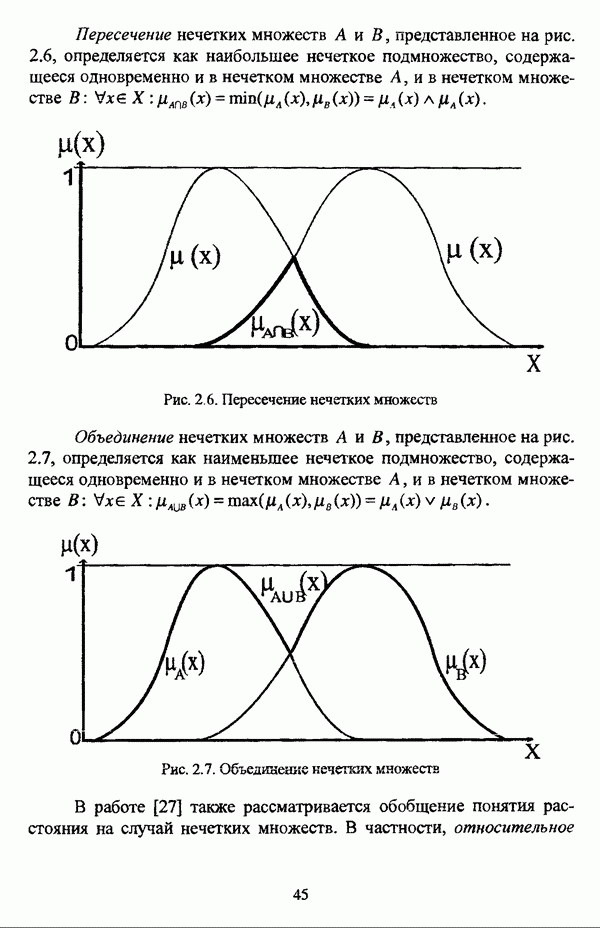


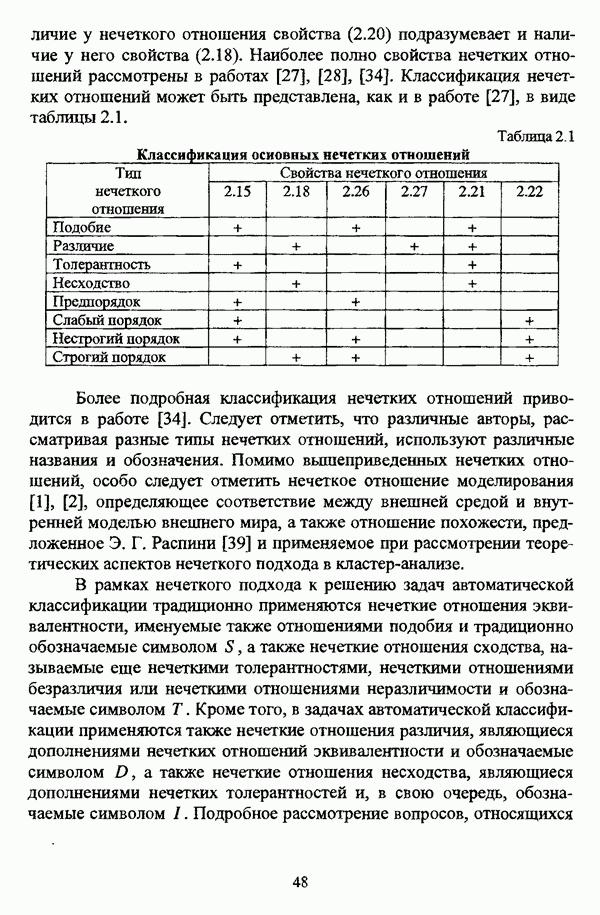

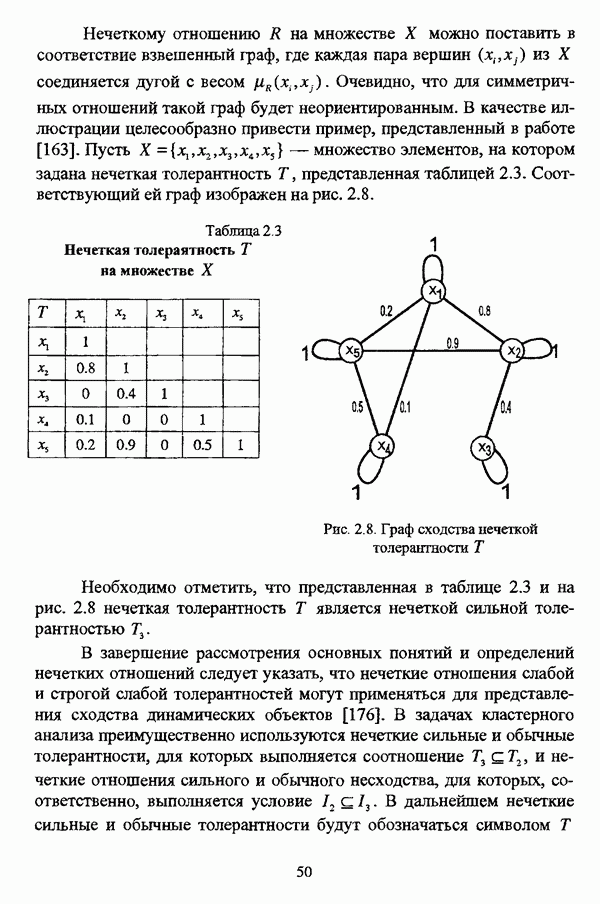
























































































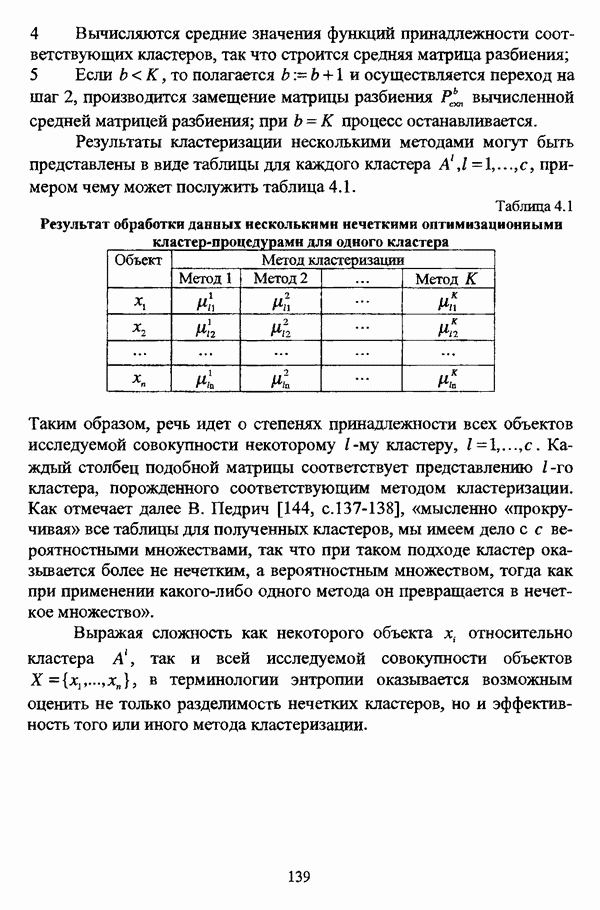
















































 с априорным четким разбиением исходного множества
с априорным четким разбиением исходного множества  с классов.
с классов.
 задается нечеткое отношение типа
задается нечеткое отношение типа  функция принадлежности
функция принадлежности  которого трактуется как степень уверенности в том, что объекты
которого трактуется как степень уверенности в том, что объекты  принадлежат одному и тому же классу;
принадлежат одному и тому же классу;
 строится иерархия классификации на основе сравнения элементов полученного отношения с разными нечеткими порогами по соответствующим отношениям.
строится иерархия классификации на основе сравнения элементов полученного отношения с разными нечеткими порогами по соответствующим отношениям.







 определяет наклон линии х, что представлено на рис. 5.4 а).
определяет наклон линии х, что представлено на рис. 5.4 а).


 возрастает кривизна линии
возрастает кривизна линии  сегмента
сегмента 
 -мерное изображение серого цвета. Для преобразования изображения в одномерную символьную строку направление отрезка, который, в свою очередь, содержит
-мерное изображение серого цвета. Для преобразования изображения в одномерную символьную строку направление отрезка, который, в свою очередь, содержит  элементов, представляется кодом одного из восьми изображенных на рис. 5.5 а) направлений.
элементов, представляется кодом одного из восьми изображенных на рис. 5.5 а) направлений.


 .
.
