Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
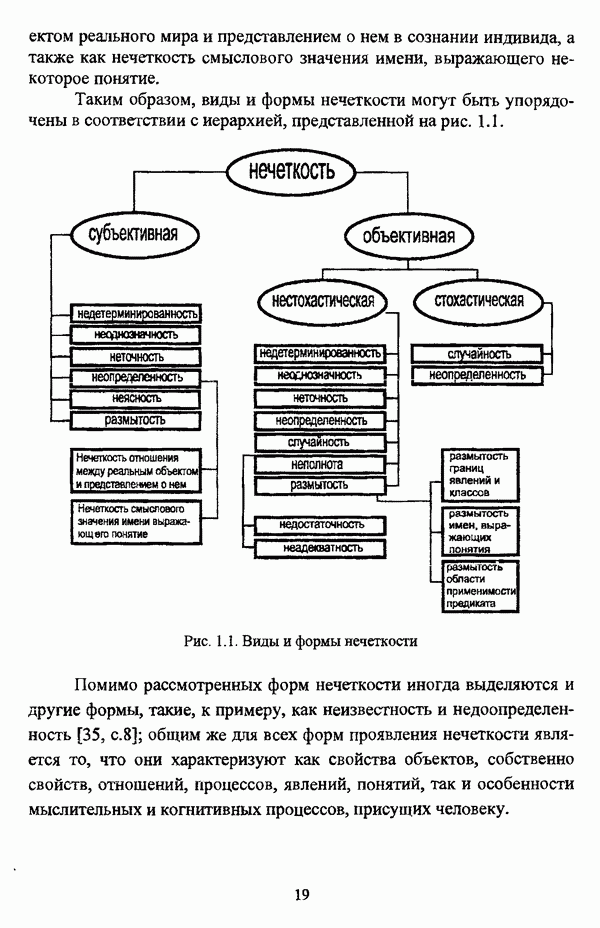
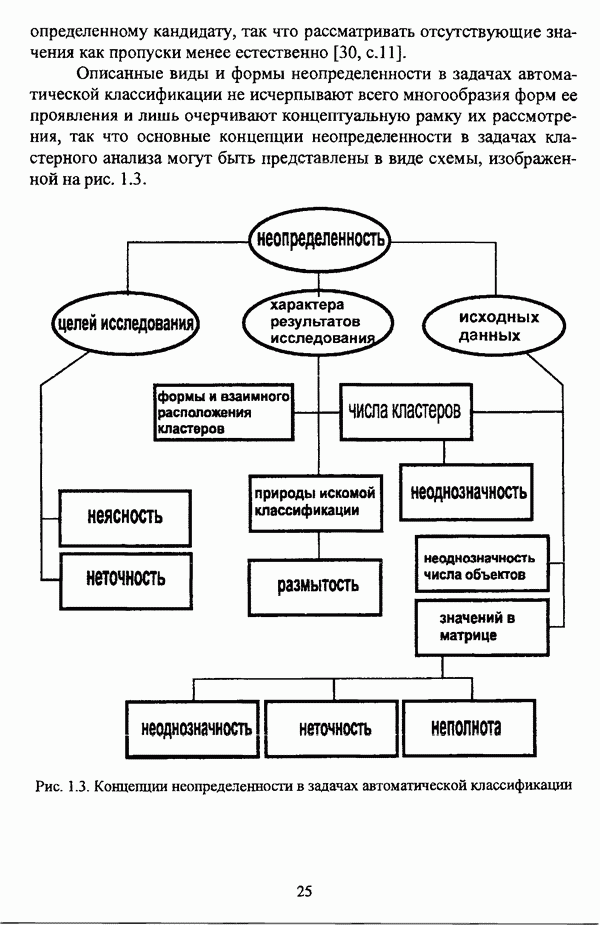
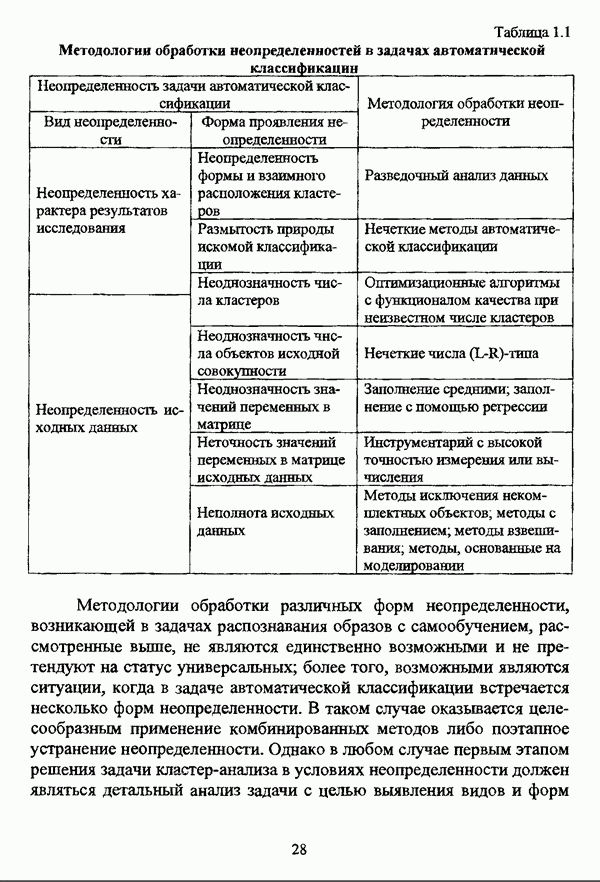
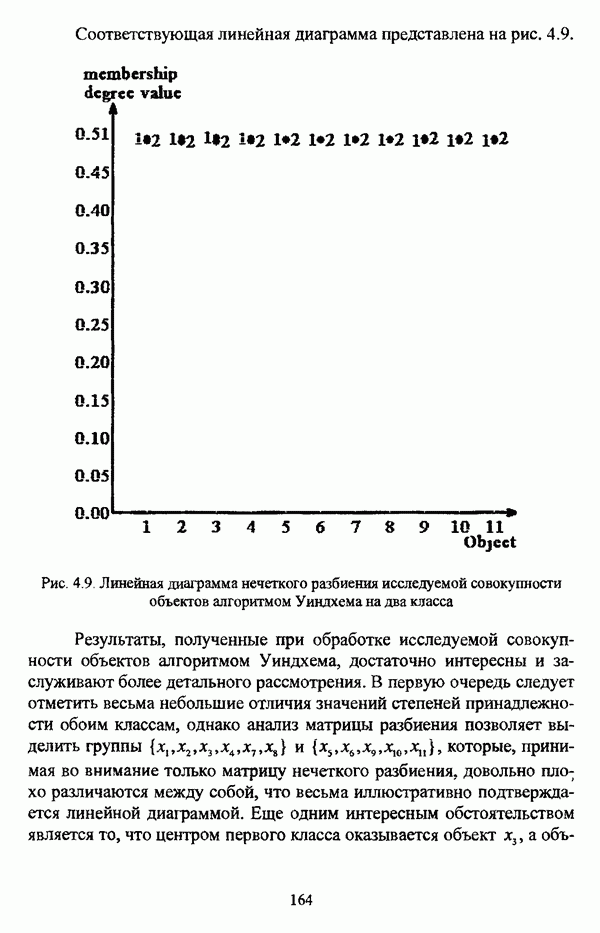
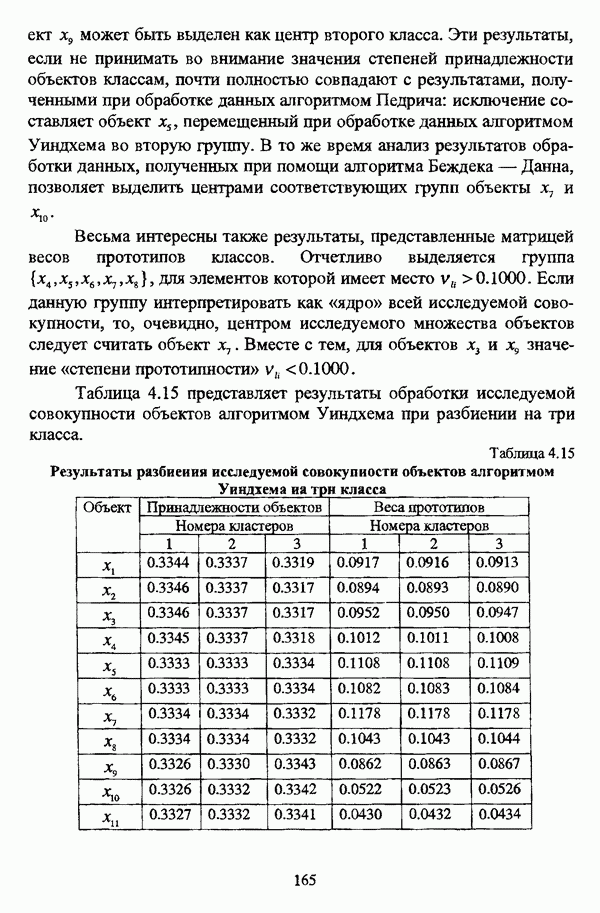
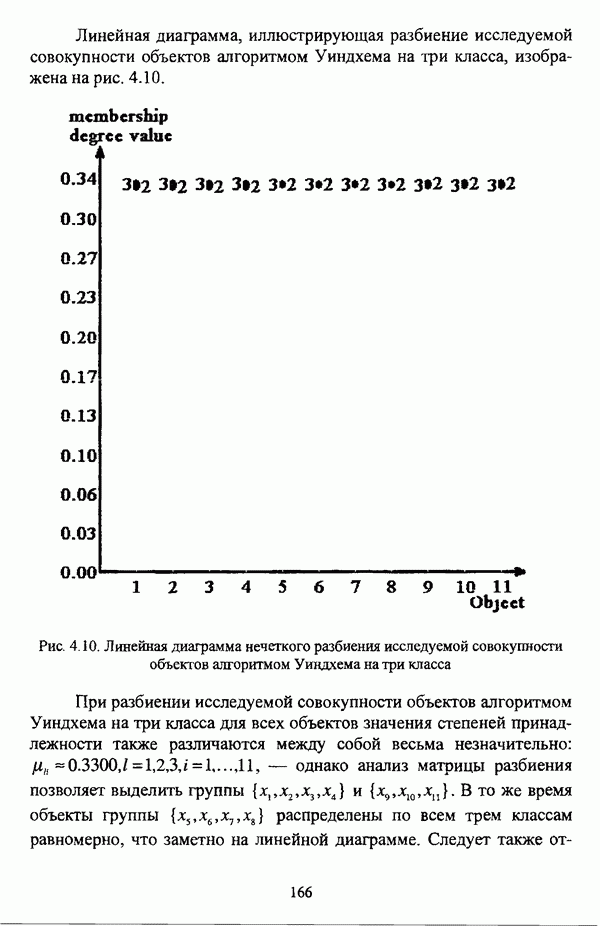
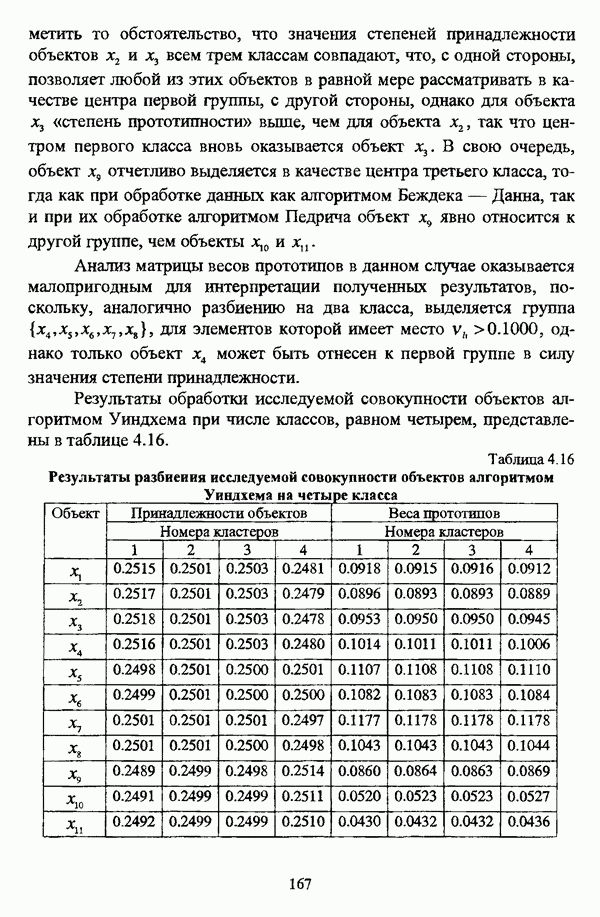
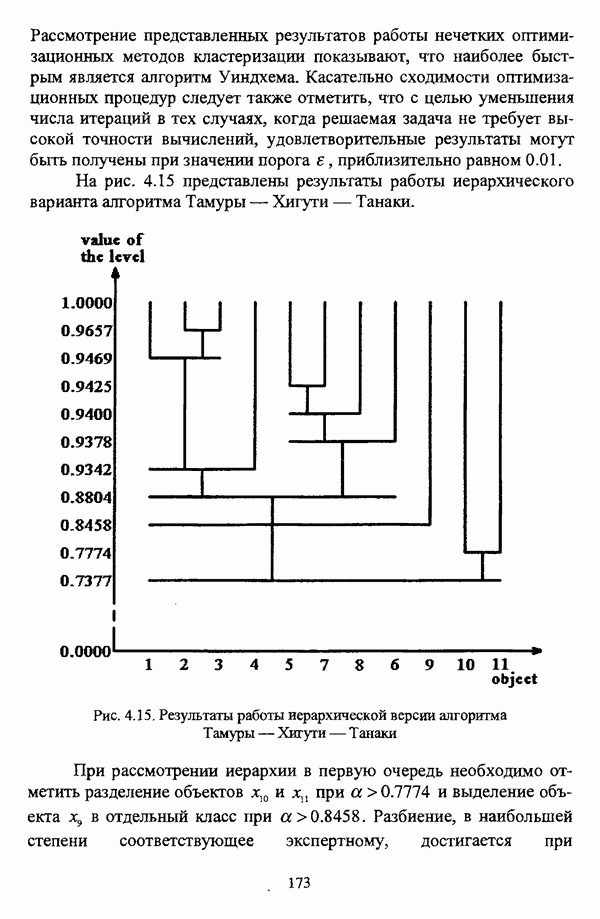
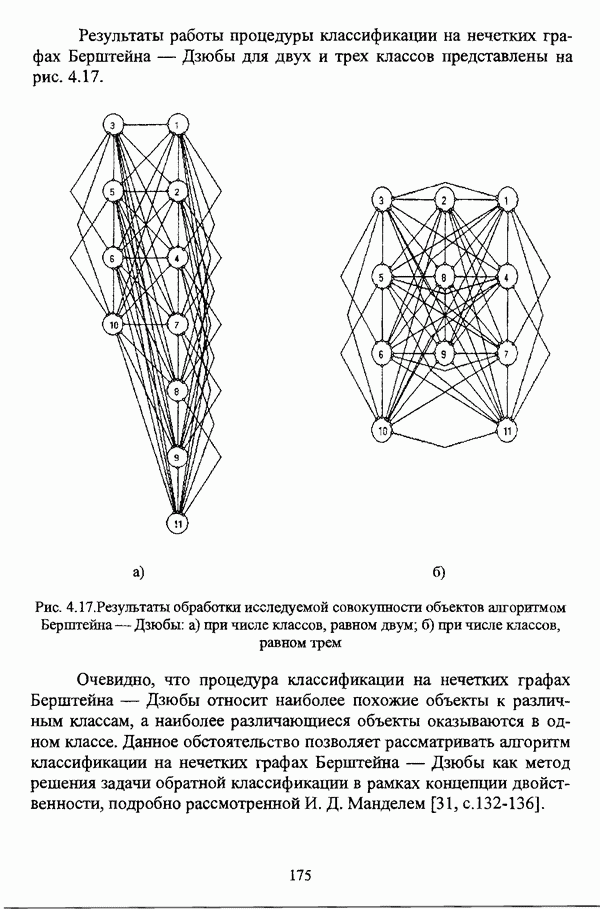
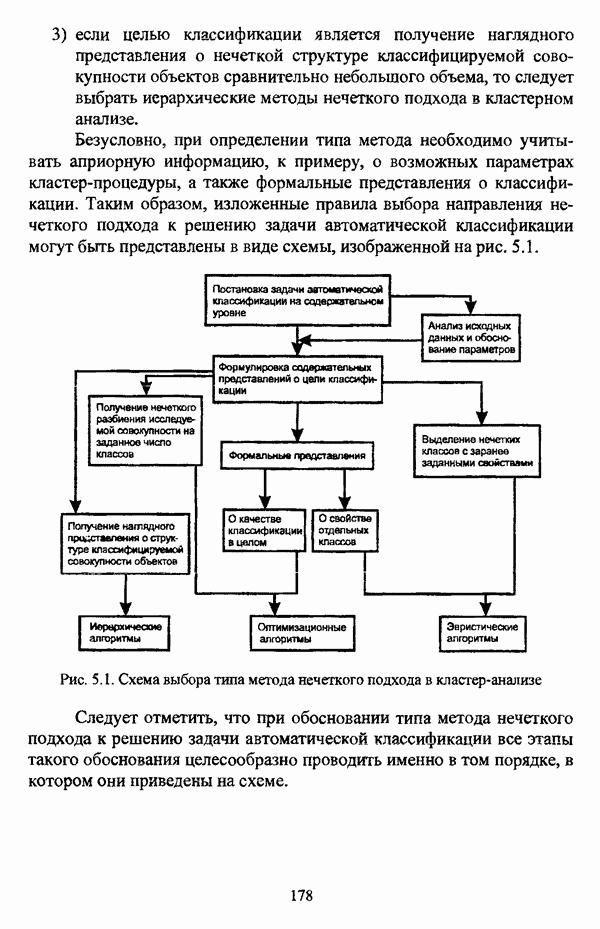
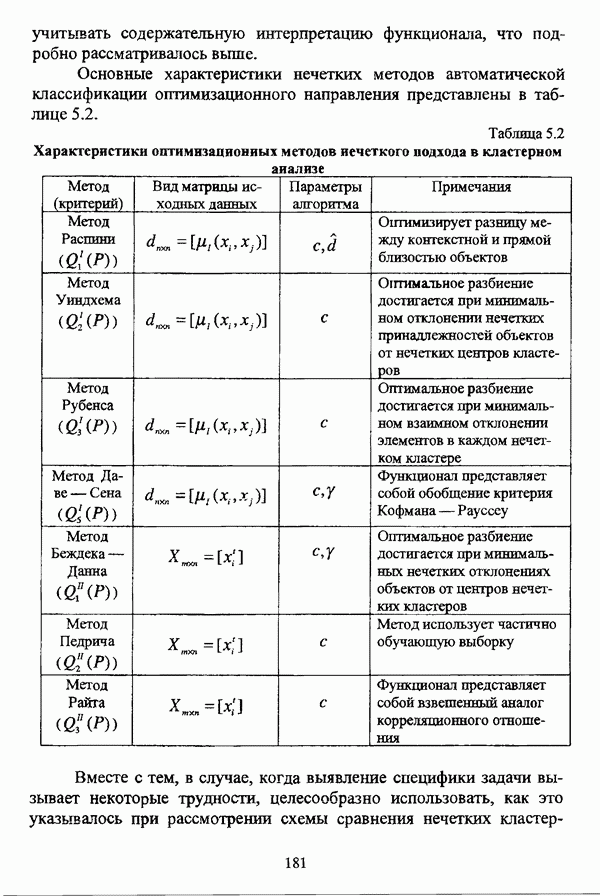
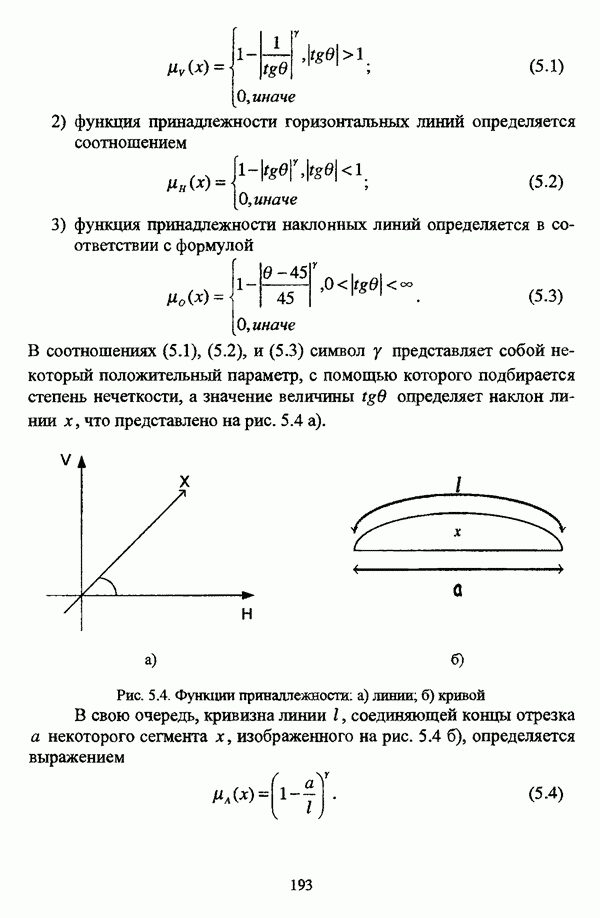
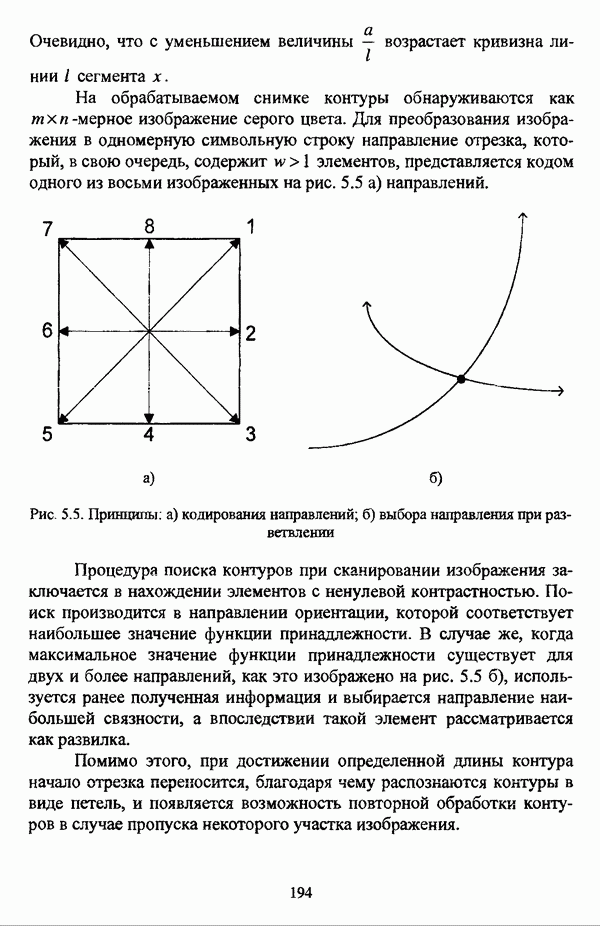
3.3.2.3. Другие алгоритмы иерархического подходак решению нечеткой модификации задачи автоматической классификации, различные аспекты которого более подробно рассматриваются С. Мийамото [128], также немногочисленны. Среди этих алгоритмов особо следует отметить агломеративную процедуру, описываемую С. Ф. Боклишем [64], методы, основанные на выделении классов толерантности, предлагаемые И. 3. Батыршиным [3], [4], [5], [6], [7], [8], и послужившие j основой программной системы КЛАСТИЕР [10], а также иерархическую версию эвристического алгоритма Тамуры — Хигути — Танаки, основанную на результатах, полученных Дж. Данном [82], [86], так что иерархия разбиений на четкие классы представляется в виде дерева иерархии или дендрограммы [182, с. 164].Алгоритм Думипреску (FHDR procedure) [81, с. 155-156] представляет собой модификацию ГОН алгоритма для решения задачи снижения признакового пространства. Основные понятия и определения Если данные об исследуемой совокупности объектов Среднее значение признака У для объектов класса
тогда вариация признака
так что, очевидно, имеет место
после чего значение признака
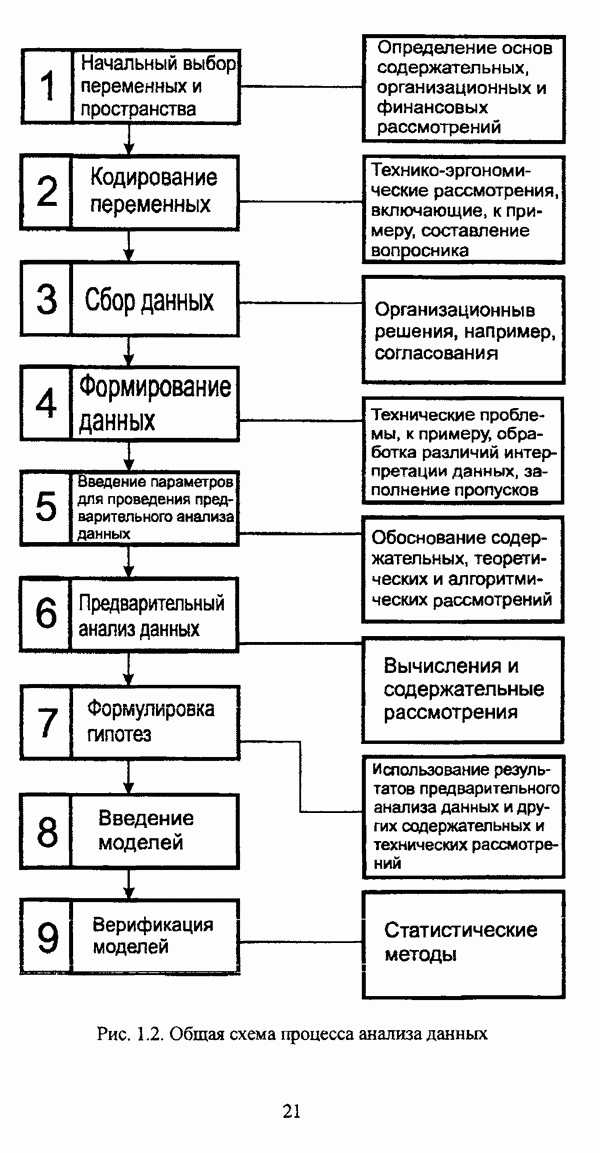
Процедура снижения размерности признакового пространства Параметры алгоритма: Как и в случае FDH алгоритма, исходные данные задаются в виде матрицы «объект-свойство» (1.1), а входные параметры отсутствуют. В процессе работы алгоритма используется счетчик т. Схема алгоритма: 1. Полагается 2. Для текущего уровня 3. Если для всех 4. Для каждого Таким образом, размерность исходного признакового пространства
|
 |
Оглавление
|



























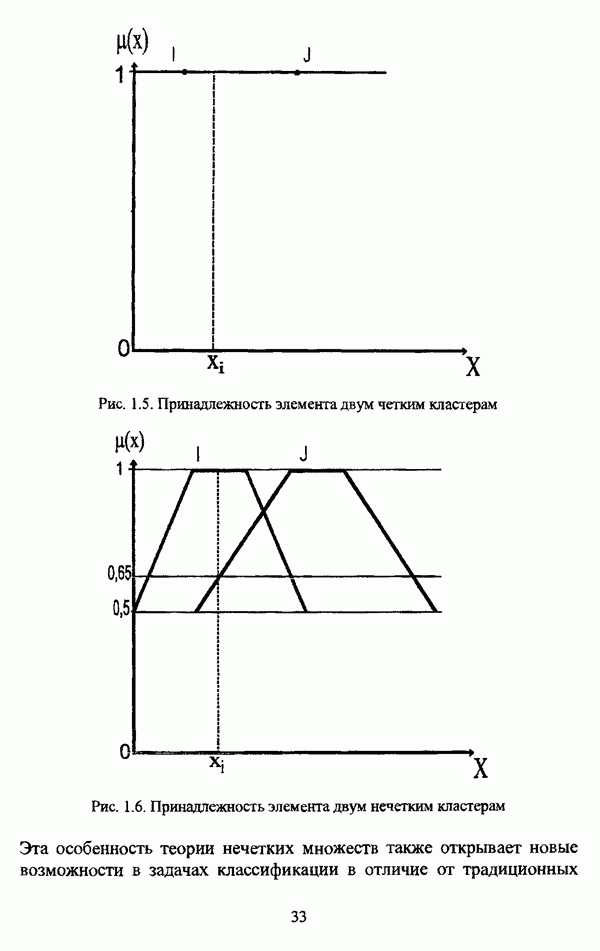






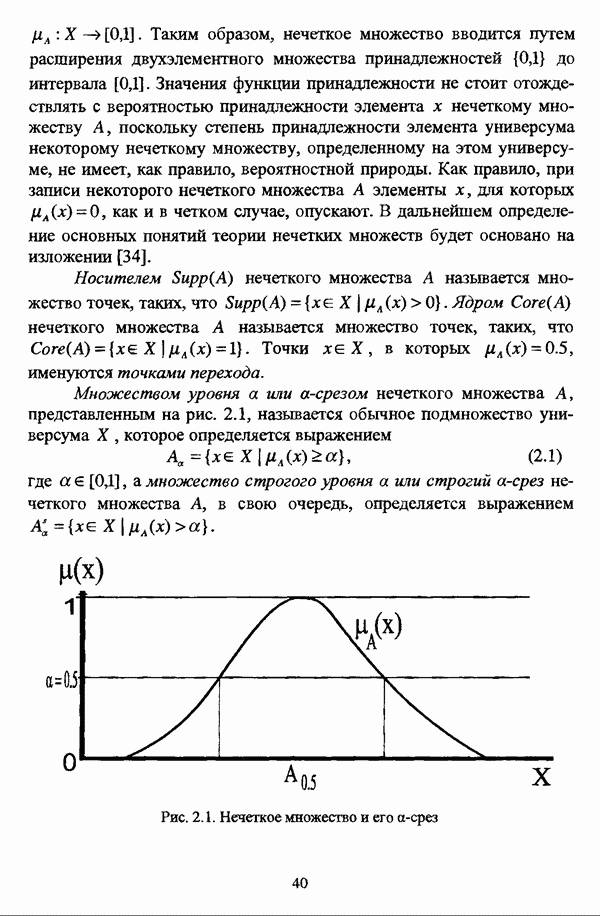


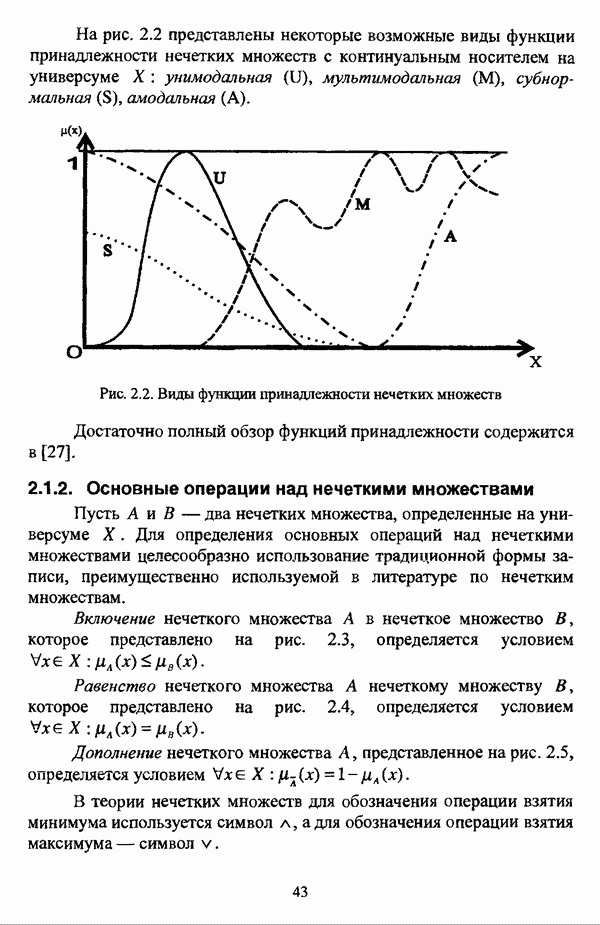
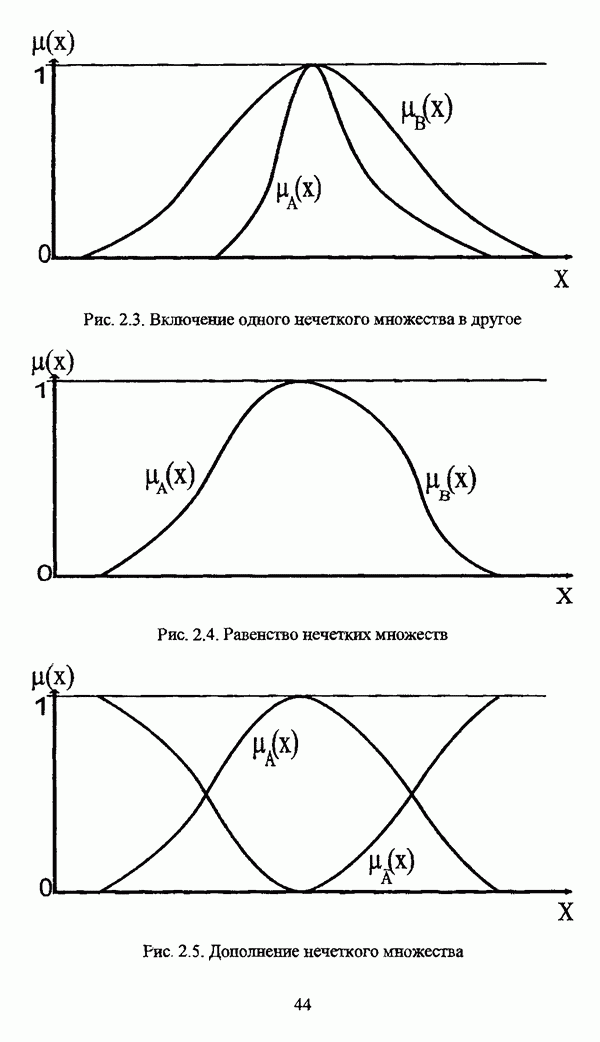































































































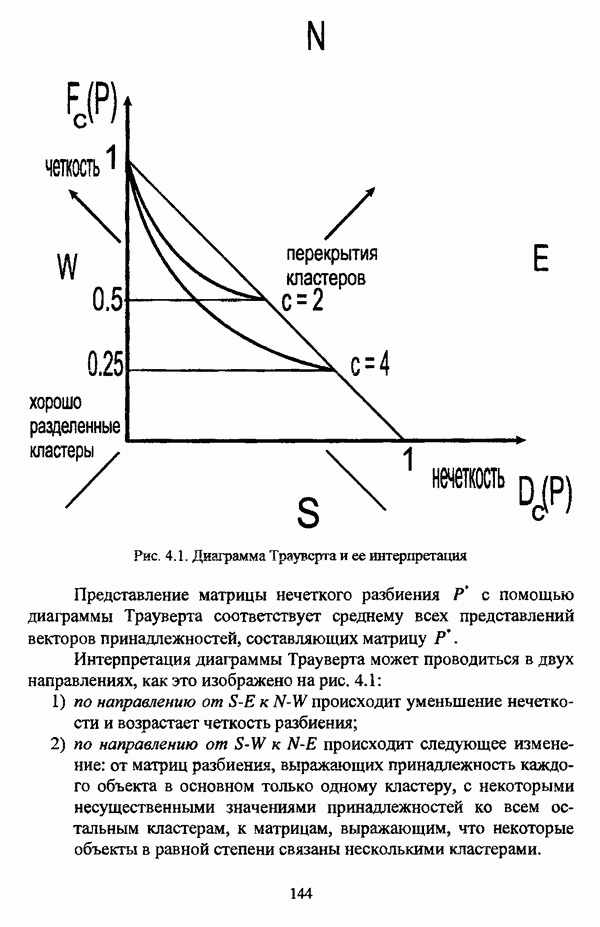






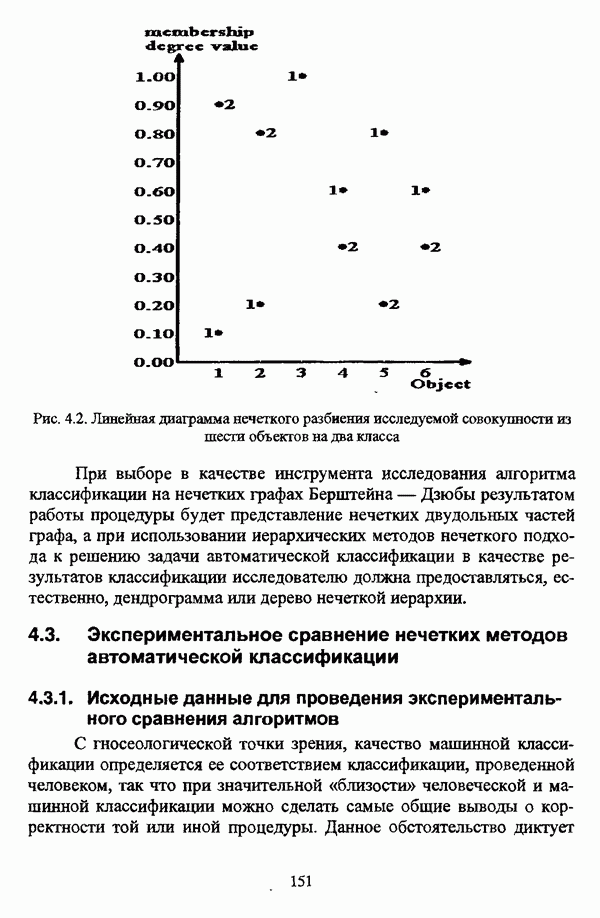

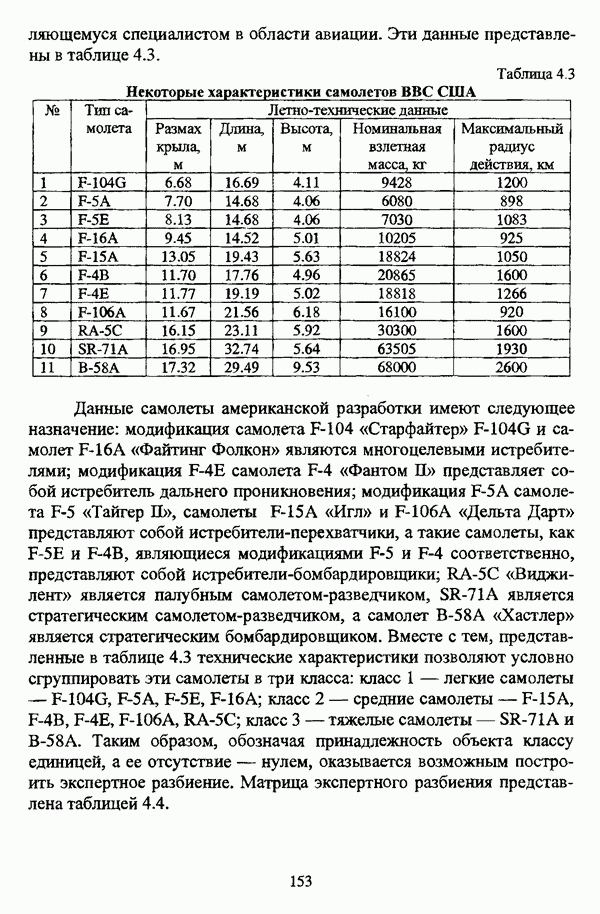
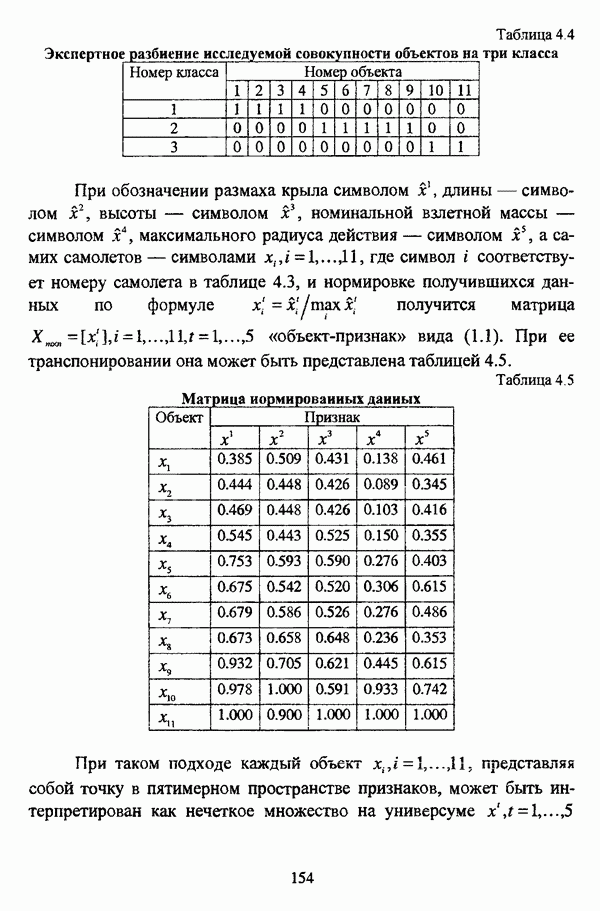
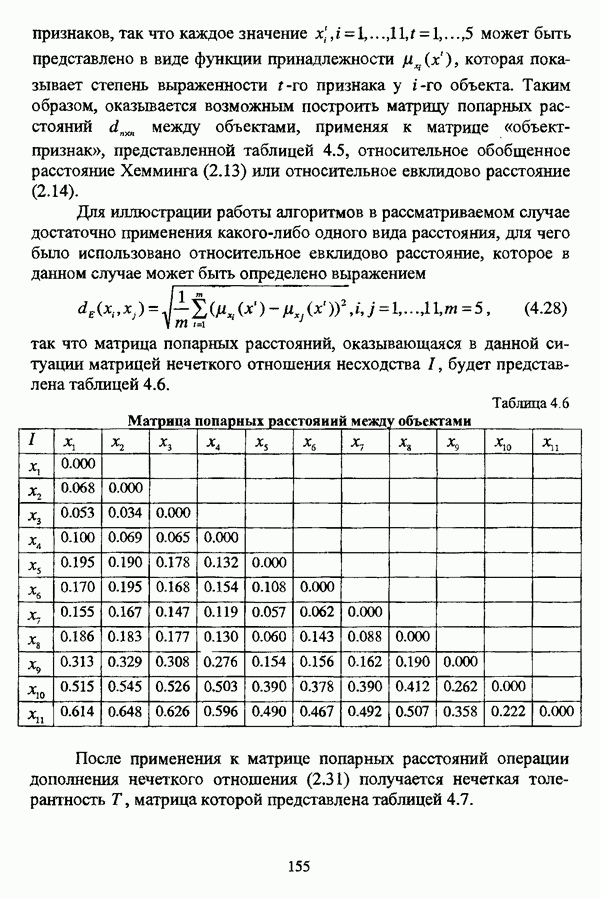

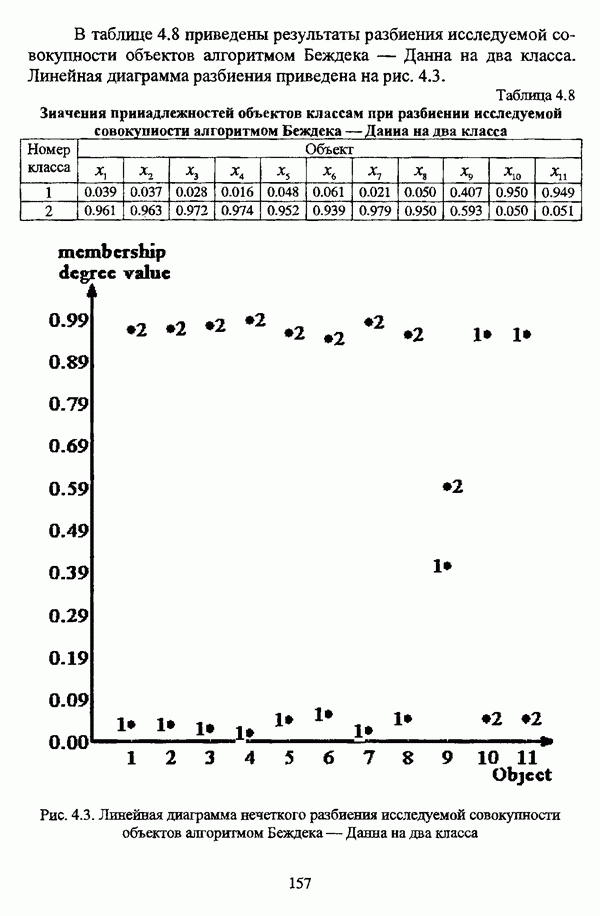
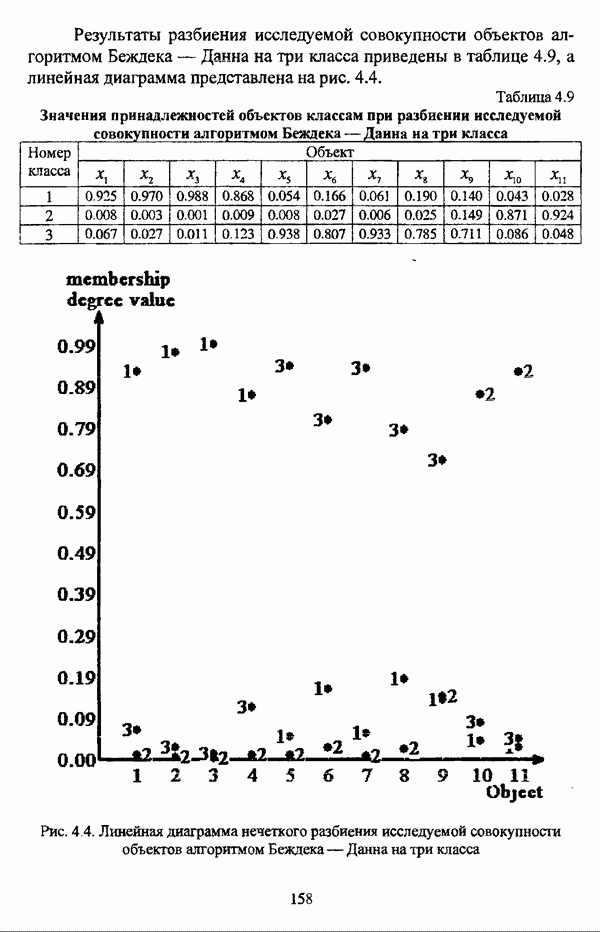
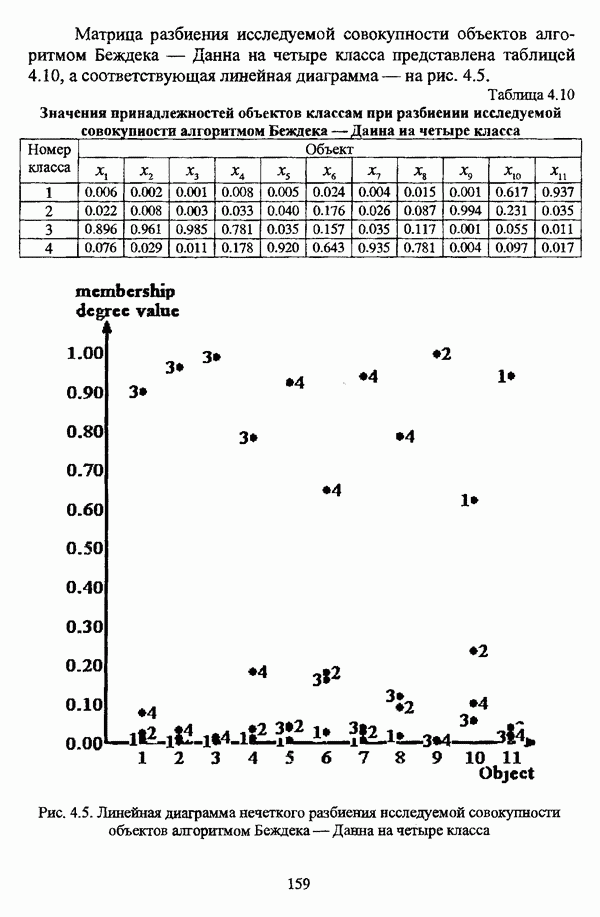
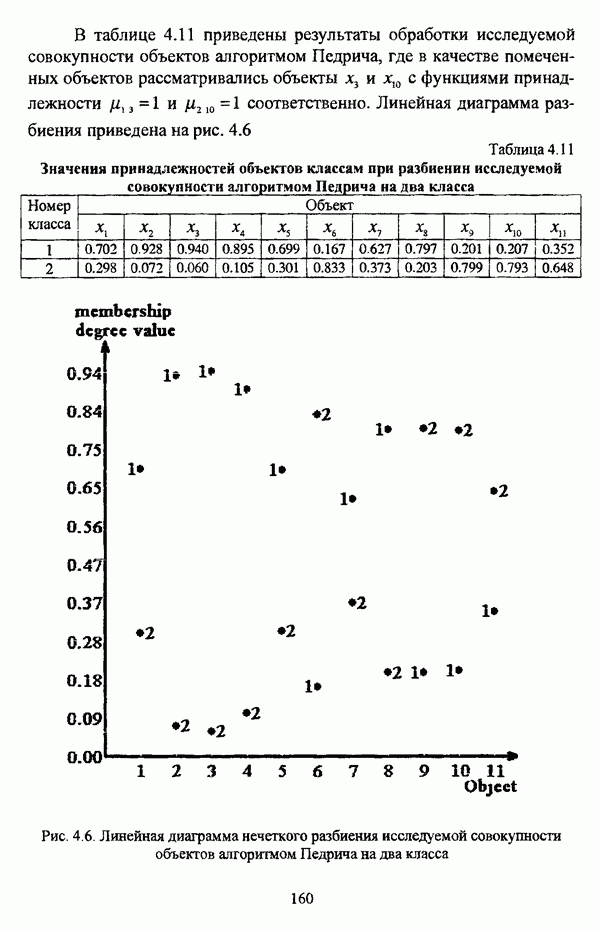
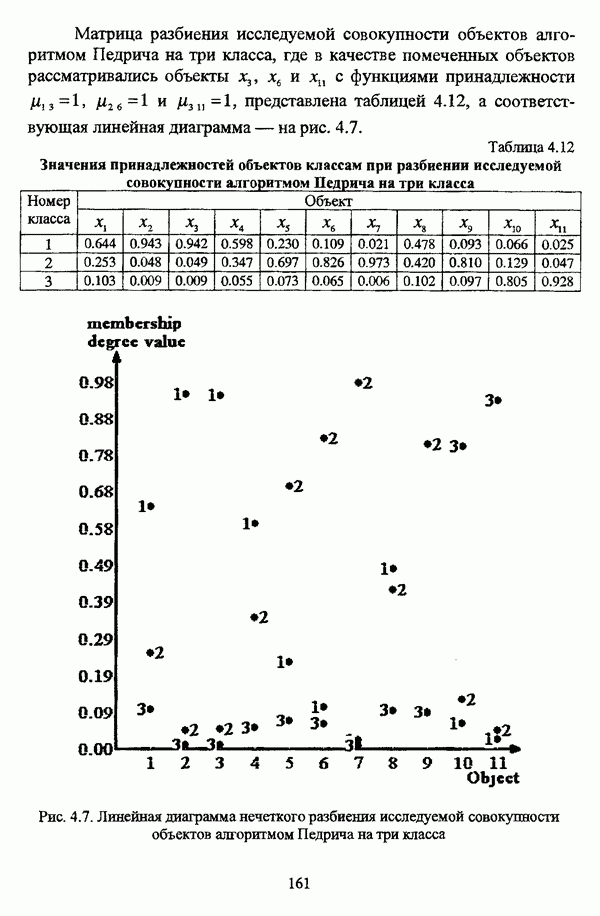
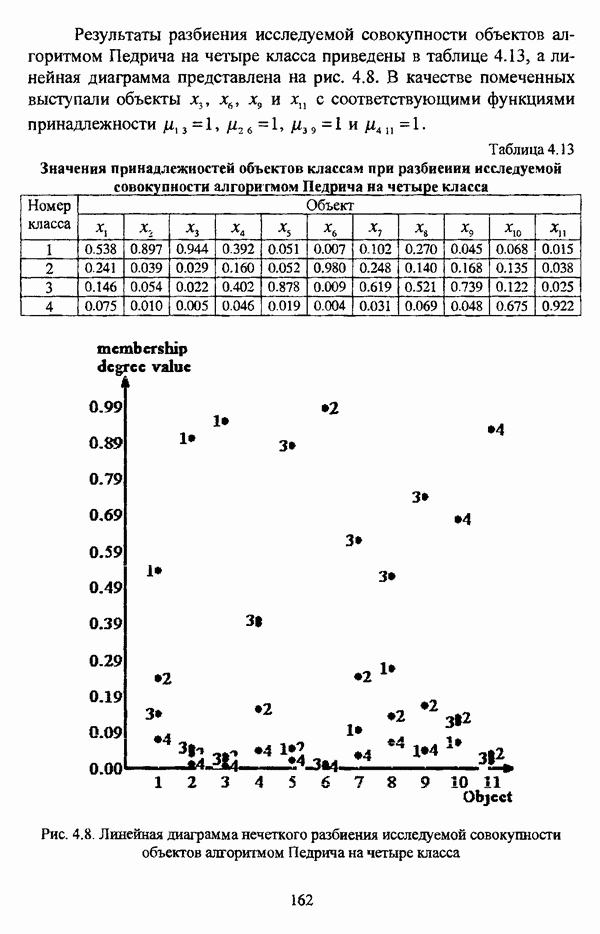
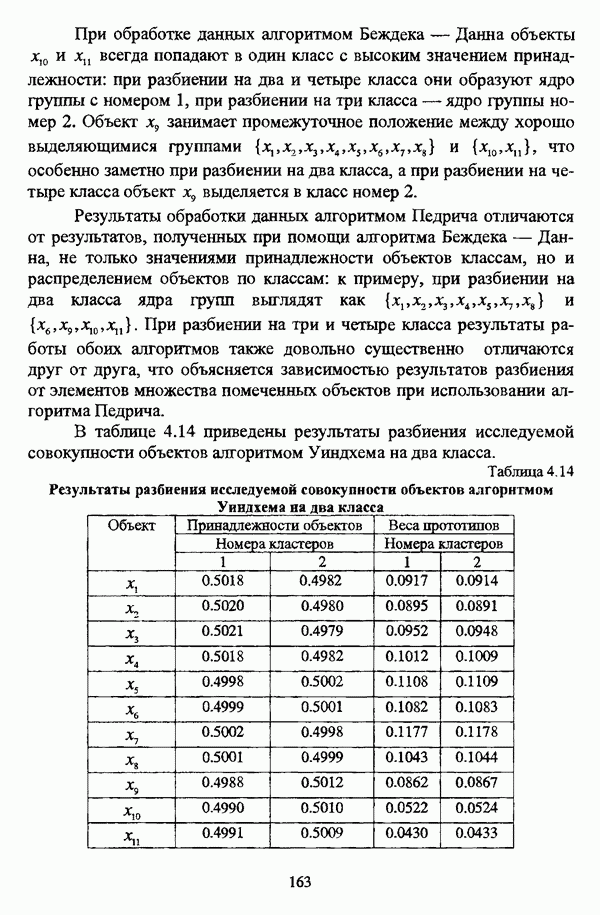
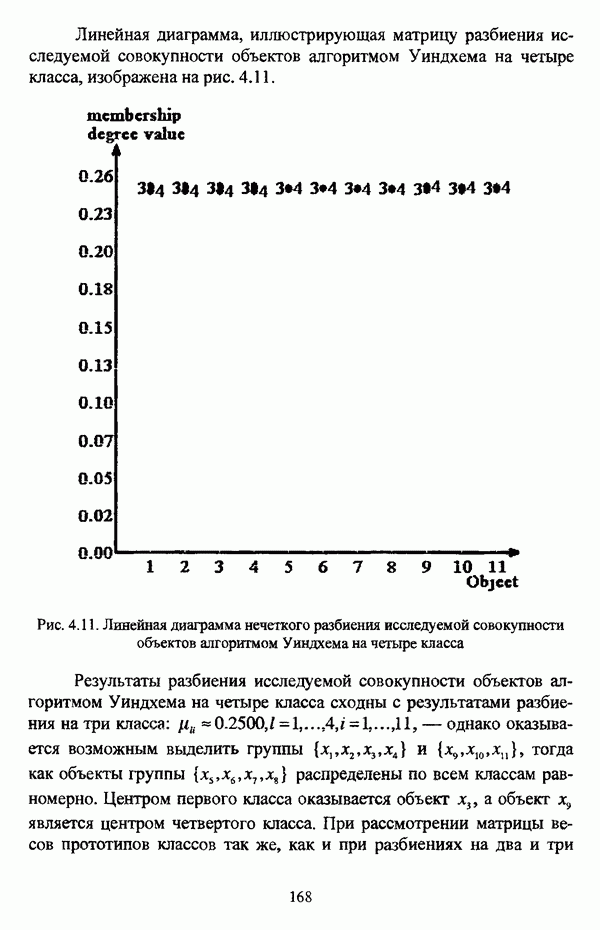

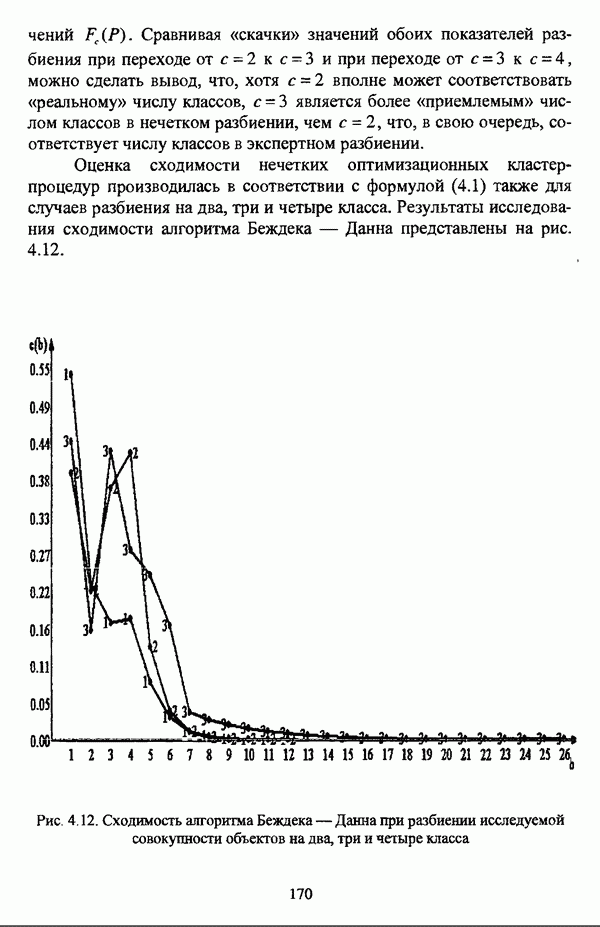
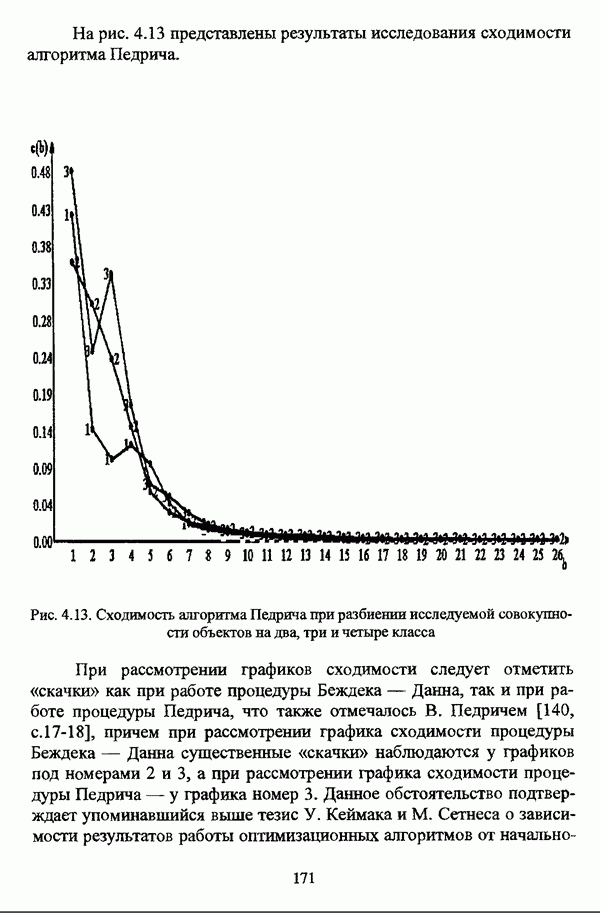
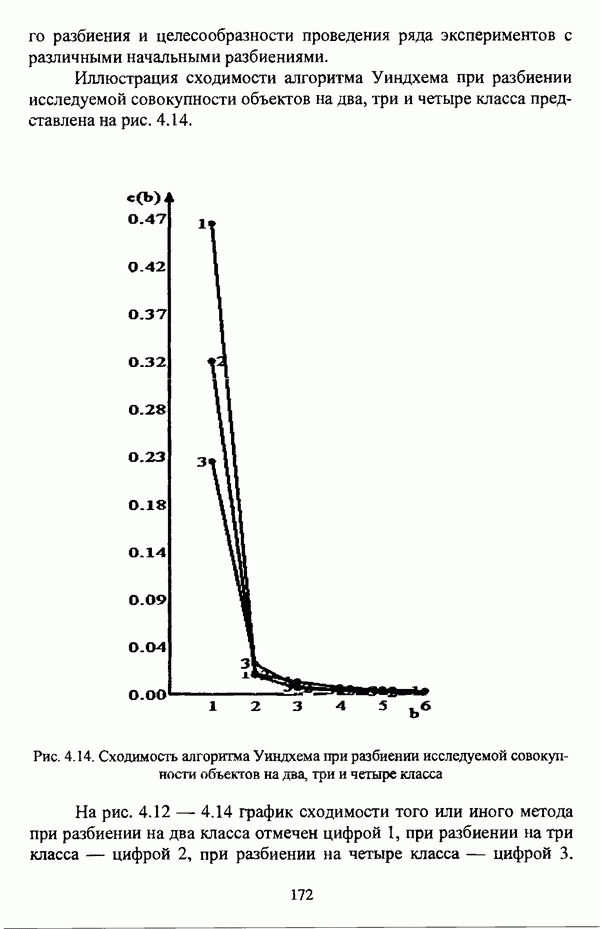



































 представлены в виде матрицы «объект-свойство»
представлены в виде матрицы «объект-свойство»  так что каждый объект рассматривается как точка в пространстве
так что каждый объект рассматривается как точка в пространстве  , то
, то  представляет собой значение
представляет собой значение  признака на
признака на  объекте. Таким образом,
объекте. Таким образом,  -я строка
-я строка  матрицы вида (1.1) полностью характеризует признак
матрицы вида (1.1) полностью характеризует признак 
 определяется выражением
определяется выражением

 в классе
в классе  может быть определена как
может быть определена как
 (3.128)
(3.128)
 (3.129)
(3.129)
 можно определить следующим образом:
можно определить следующим образом:
 (3.130)
(3.130)
 может рассматриваться как процесс классификации признаков
может рассматриваться как процесс классификации признаков  после их преобразования в соответствии с формулой (3.130) с целью отбора
после их преобразования в соответствии с формулой (3.130) с целью отбора  наиболее информативных признаков. Если классы признаков, характеризующие объекты множества
наиболее информативных признаков. Если классы признаков, характеризующие объекты множества  являются однородными и хорошо разделенными, то каждый класс может быть представлен некоторым наиболее информативным признаком. Во избежание путаницы с процессом классификации объектов ГОН алгоритмом при классификации признаков классы разбиения уровня
являются однородными и хорошо разделенными, то каждый класс может быть представлен некоторым наиболее информативным признаком. Во избежание путаницы с процессом классификации объектов ГОН алгоритмом при классификации признаков классы разбиения уровня  будут обозначаться символом
будут обозначаться символом  а сами разбиения
а сами разбиения  уровня — символом
уровня — символом 

 нумеруются разбиения
нумеруются разбиения  для каждого разбиения
для каждого разбиения  просматриваются все атомы, и для каждого непустого нечеткого кластера
просматриваются все атомы, и для каждого непустого нечеткого кластера  осуществляется выполнение условия, описанного на шаге 4; все неделимые кластеры
осуществляется выполнение условия, описанного на шаге 4; все неделимые кластеры  распределяются в нечеткое разбиение
распределяются в нечеткое разбиение  и в дальнейшем не подвергаются обработке
и в дальнейшем не подвергаются обработке  — алгоритмом;
— алгоритмом;
 текущего уровня вьшолняется
текущего уровня вьшолняется  то алгоритм прекращает работу, в противном случае полагается
то алгоритм прекращает работу, в противном случае полагается  и осуществляется переход на шаг 2;
и осуществляется переход на шаг 2;
 атома разбиения
атома разбиения  при помощи GFI алгоритма вычисляется нечеткое разбиение
при помощи GFI алгоритма вычисляется нечеткое разбиение  если
если  и являются «реальными» кластерами, то они образуют разбиение
и являются «реальными» кластерами, то они образуют разбиение  уровня
уровня  в противном случае атом
в противном случае атом  ) считается неделимым и полагается
) считается неделимым и полагается  полагается
полагается  где все значения
где все значения  вычисляются по формуле (3.130),
вычисляются по формуле (3.130),  — наиболее информативный признак класса
— наиболее информативный признак класса  так что
так что  и осуществляется переход к рассмотрению другого атома.
и осуществляется переход к рассмотрению другого атома.
 оказывается сниженной до
оказывается сниженной до  и отобранные признаки образуют множество
и отобранные признаки образуют множество 