Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
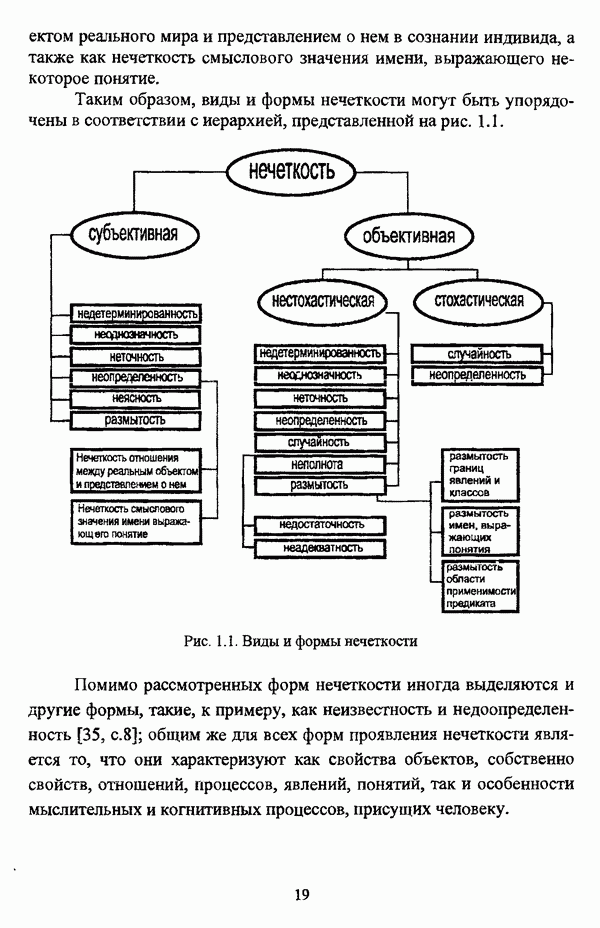
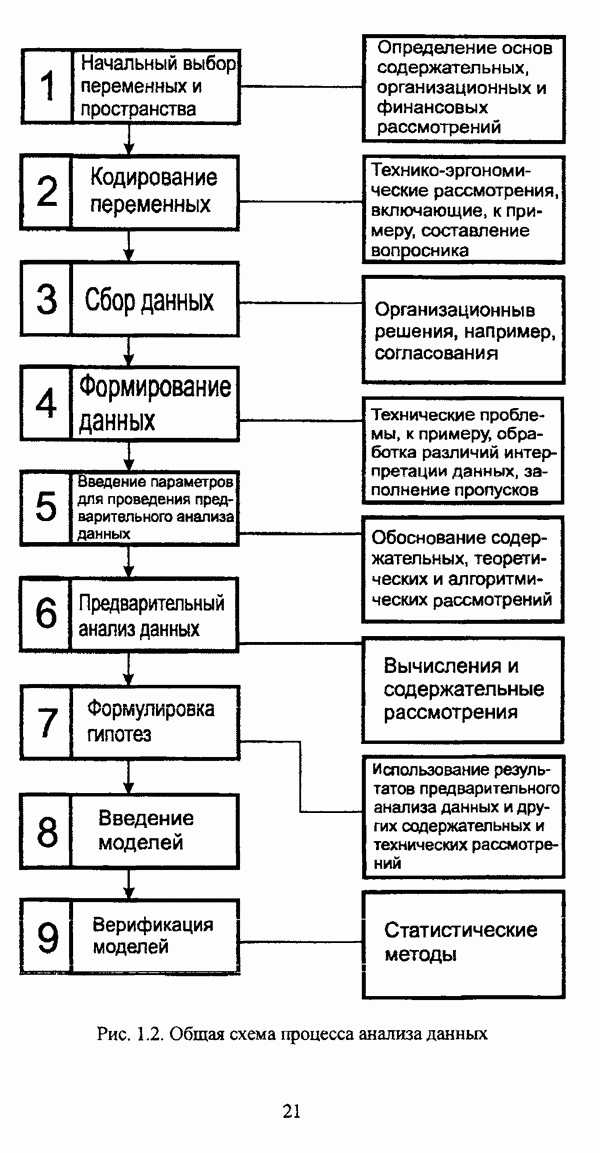
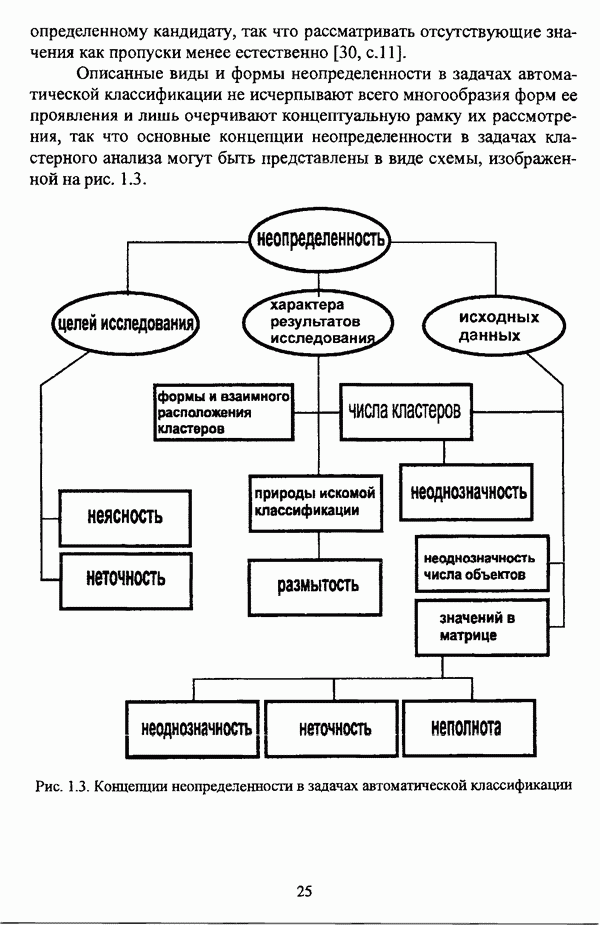
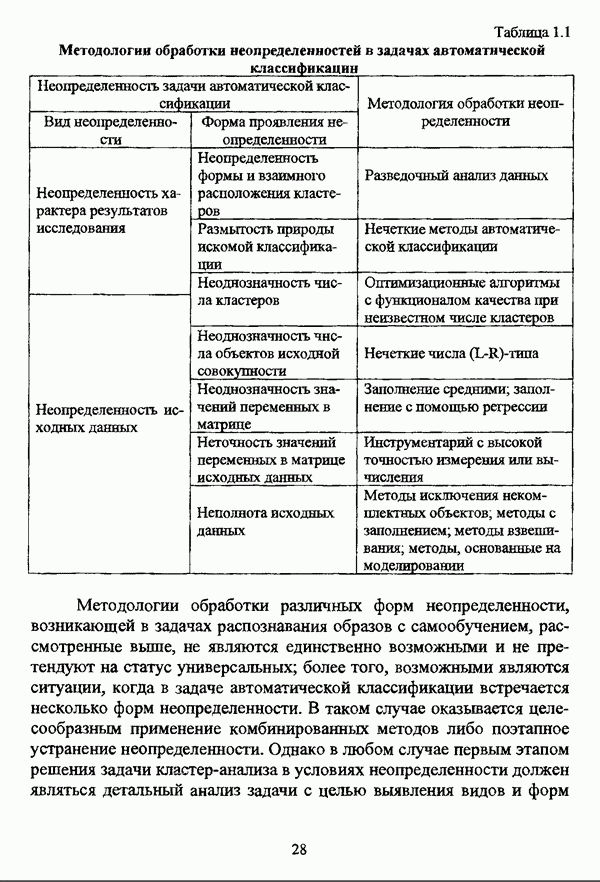
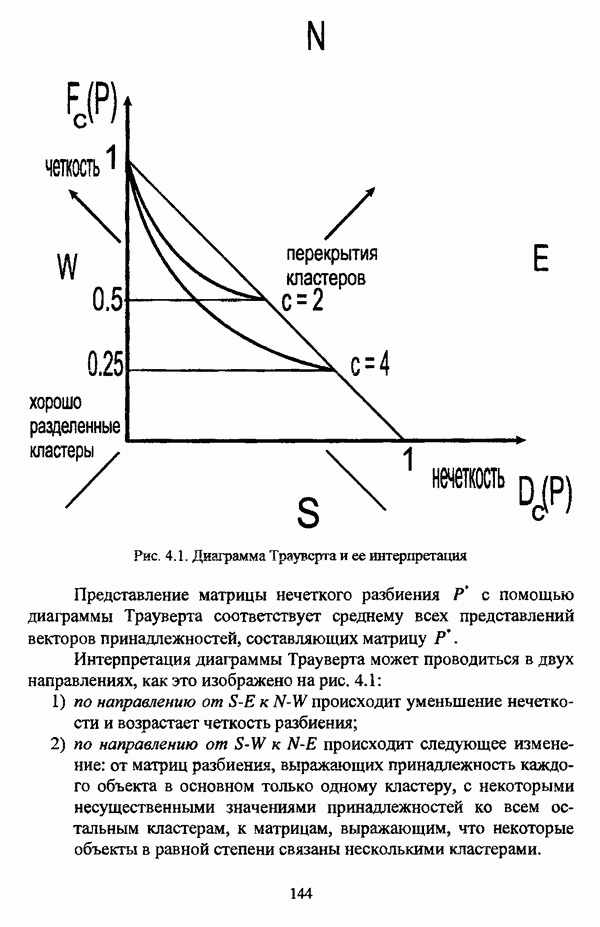
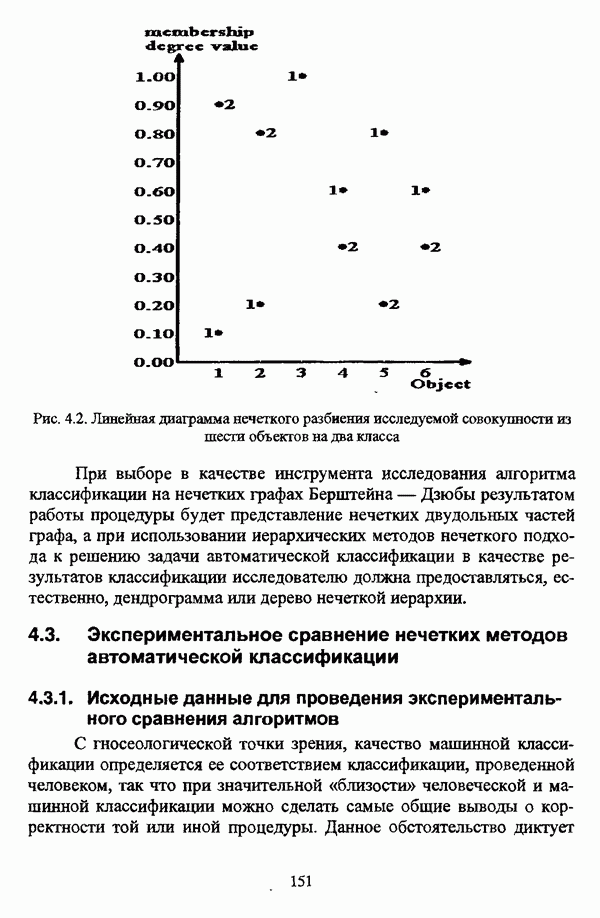
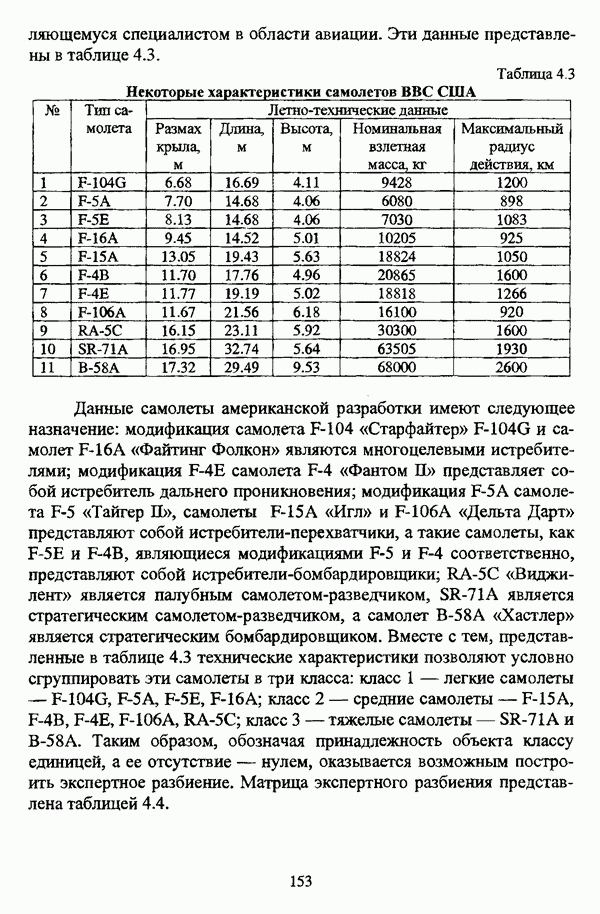
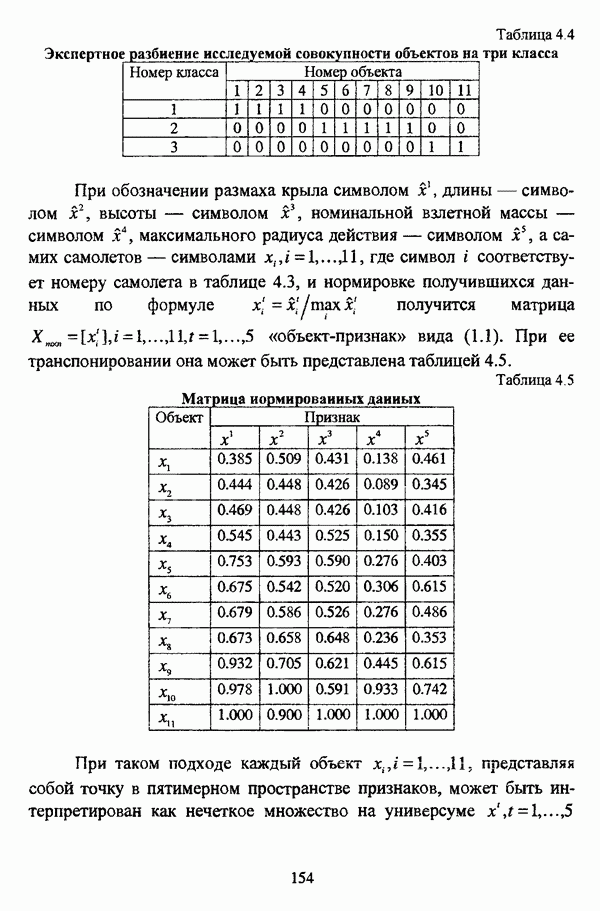
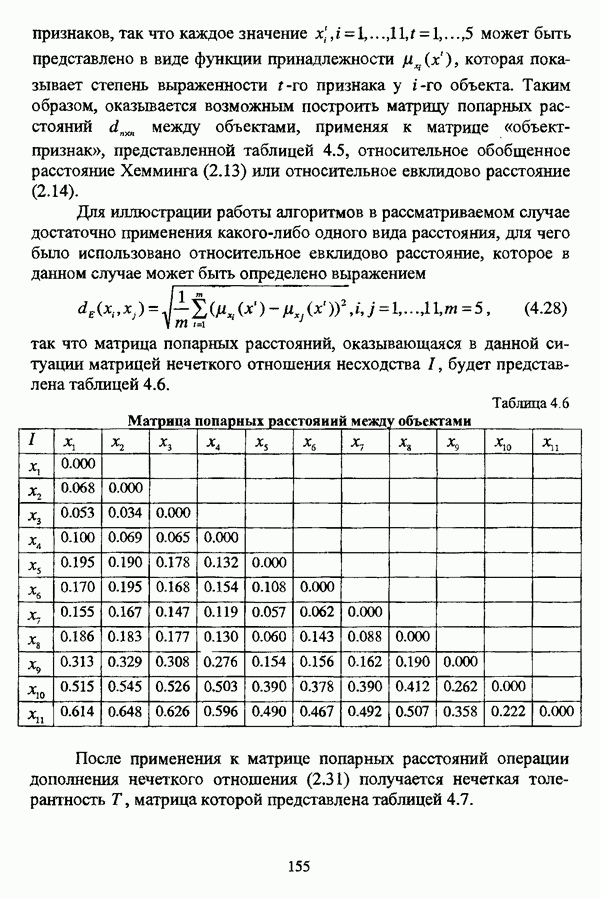
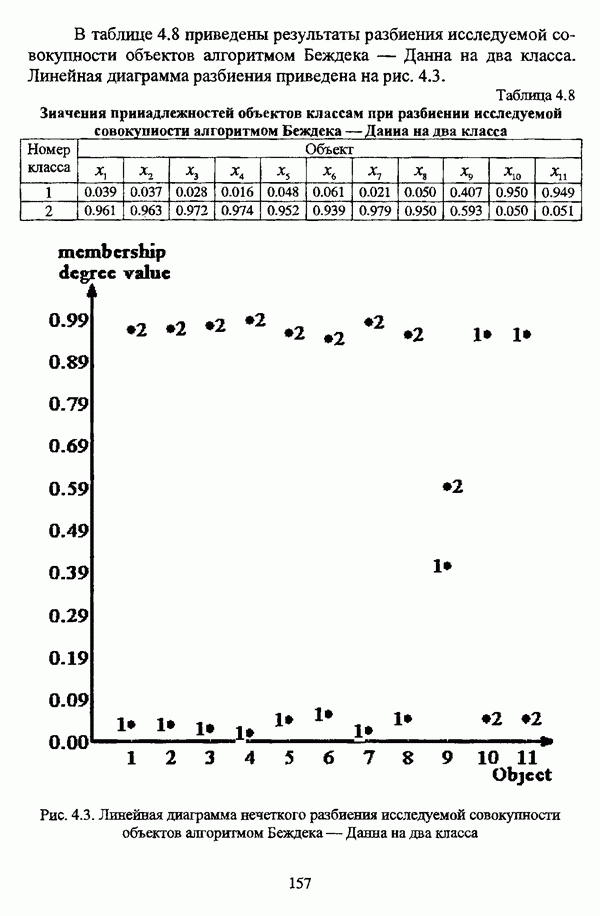
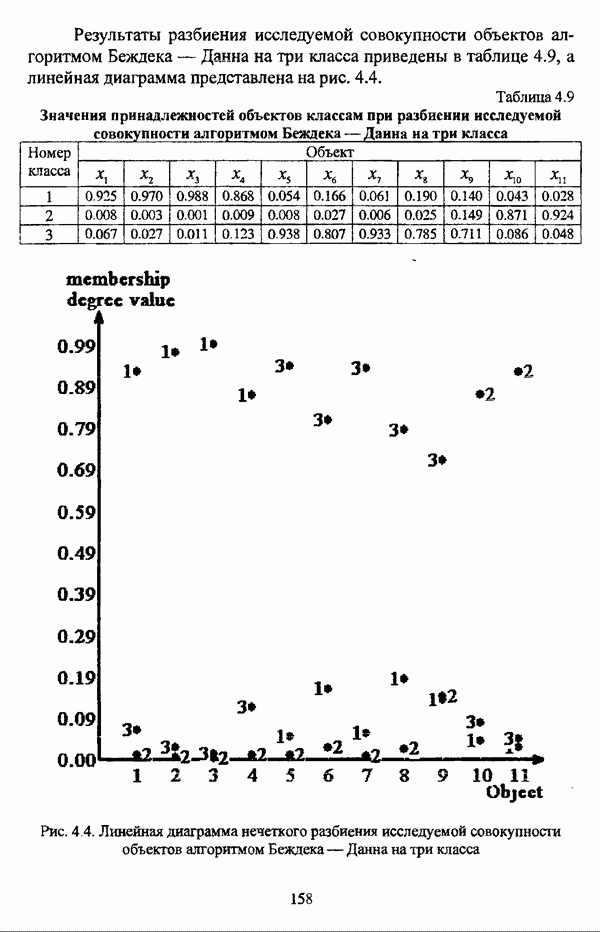
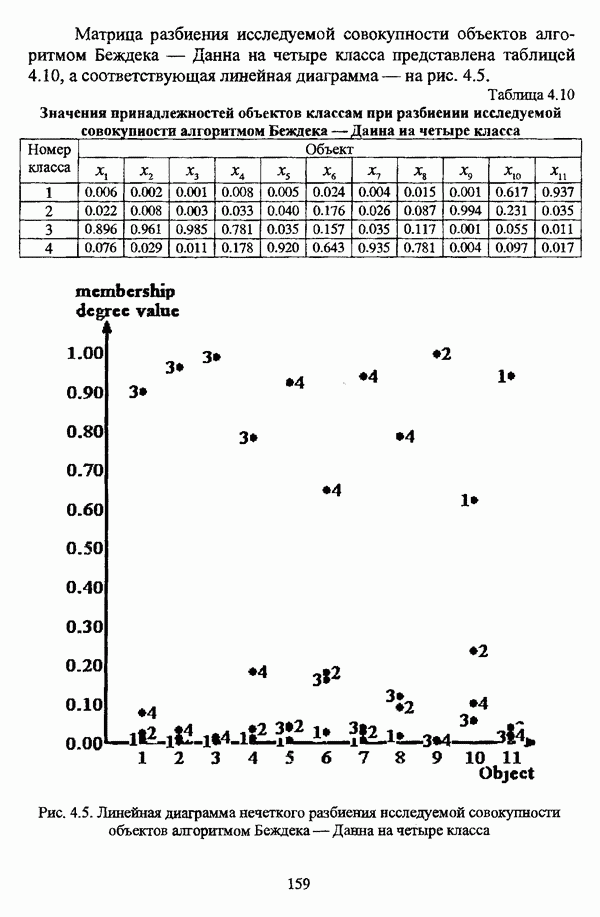
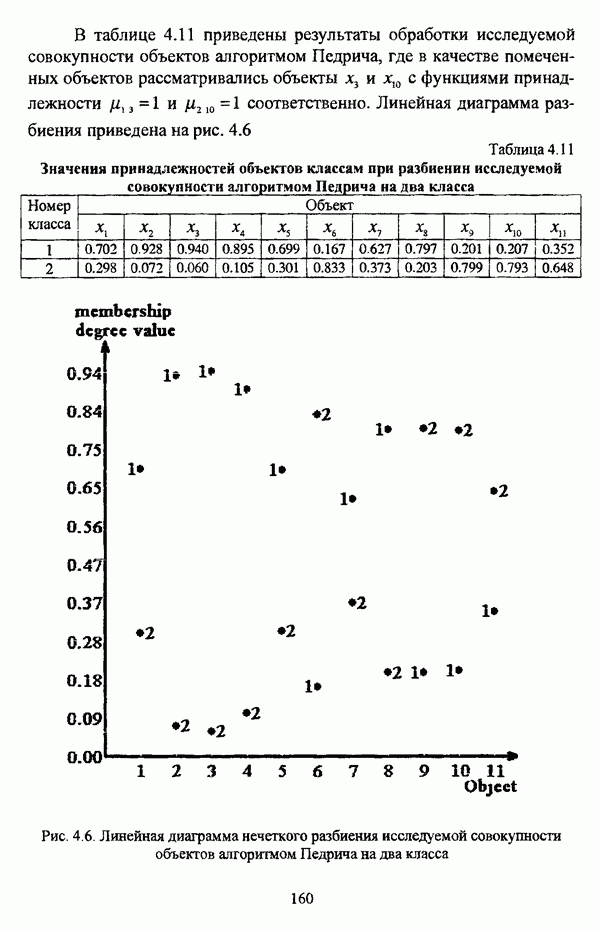
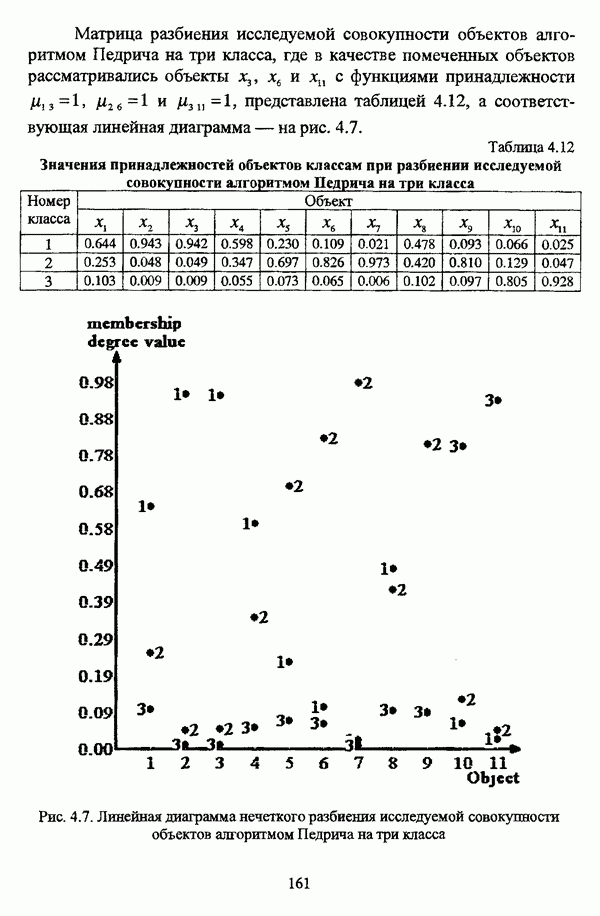
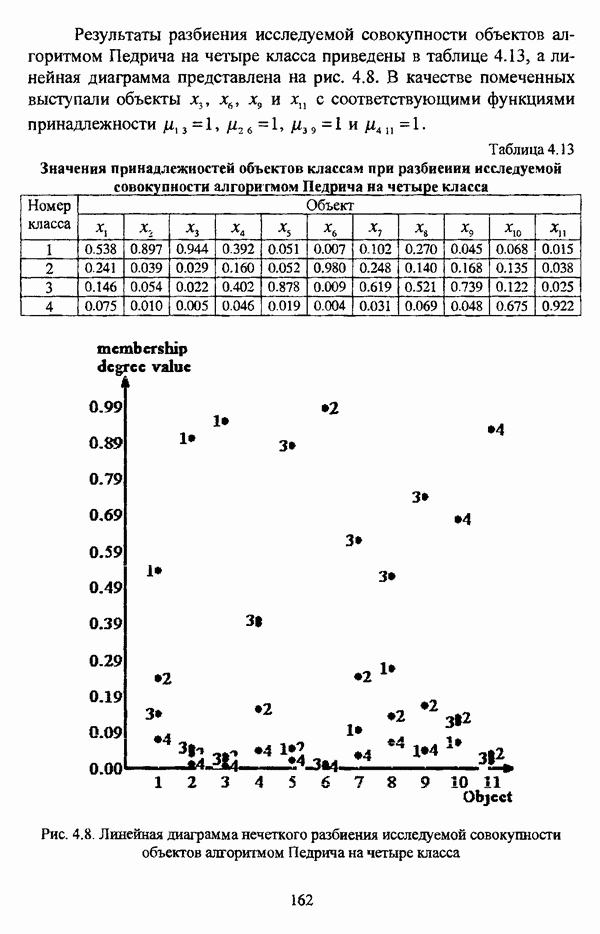
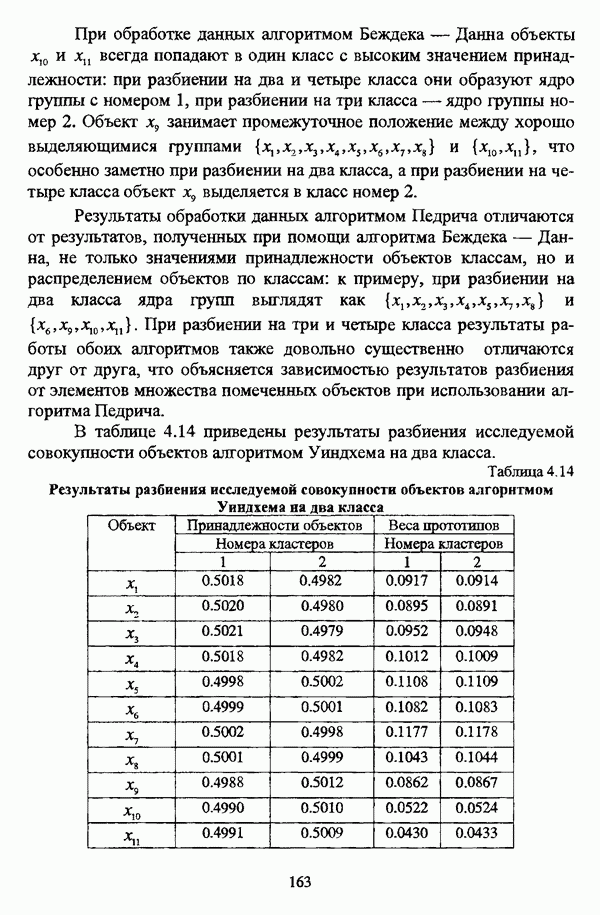
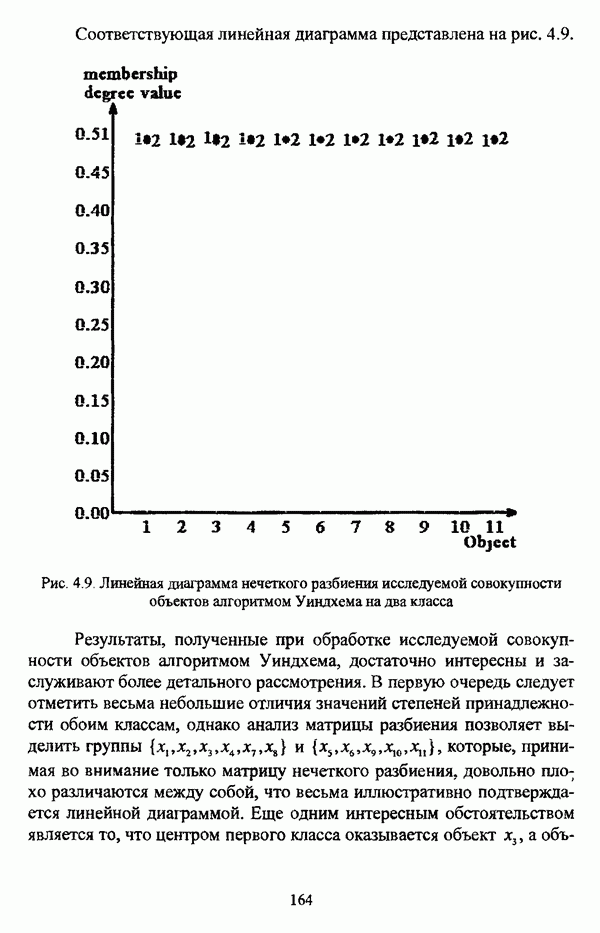
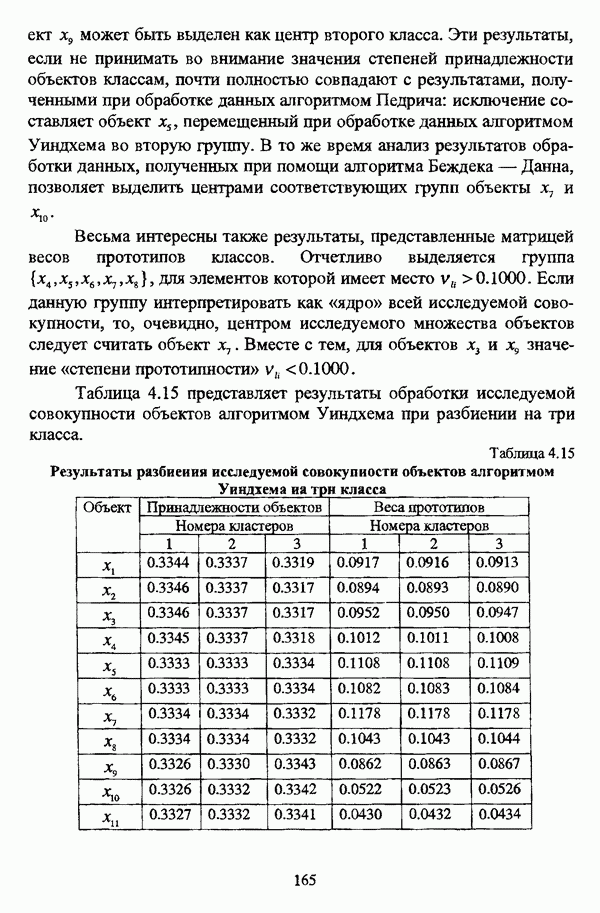
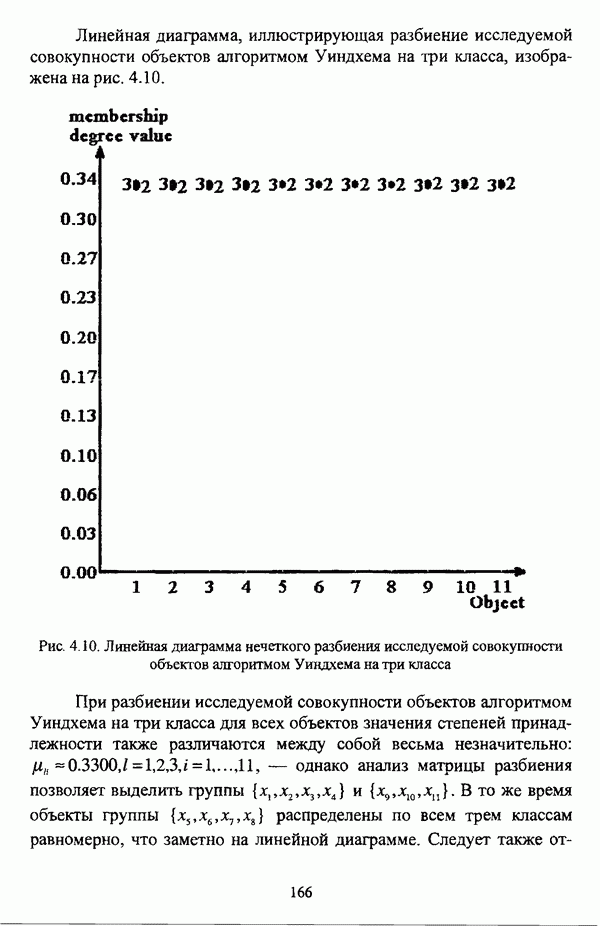
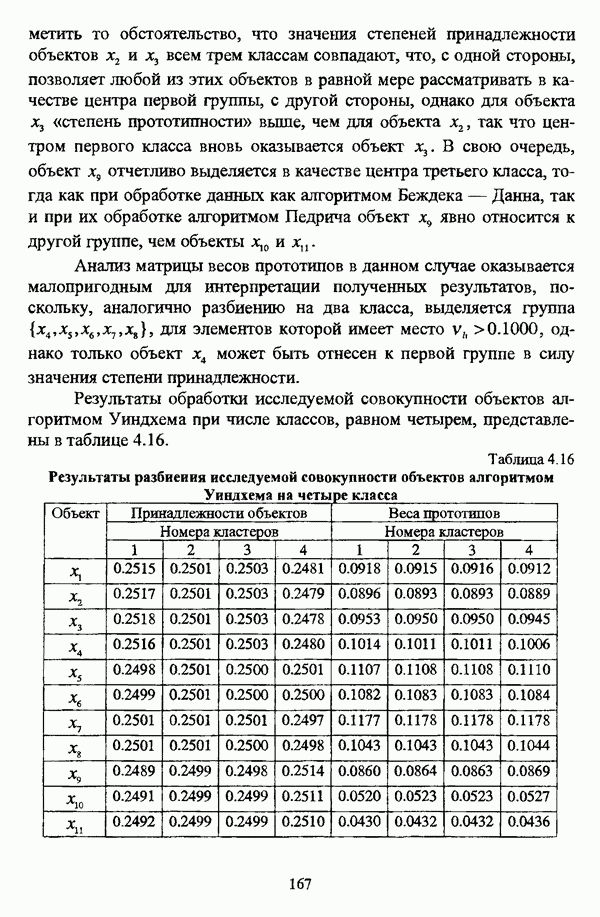
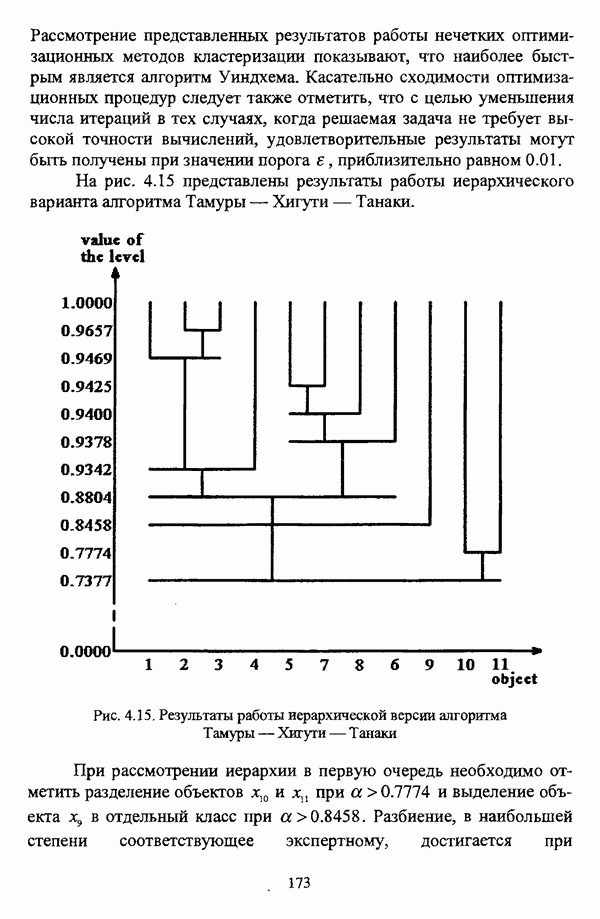
ГЛАВА 1. ПРОБЛЕМА НЕОПРЕДЕЛЕННОСТИ В ЗАДАЧАХ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ1.1. Понятие однородности и проблема классификации объектов1.1.1. Основные подходы к решению проблемы выделения однородных групп объектовВзаимосвязь понятий «однородность» и «классификация» представляется очевидной даже на интуитивном уровне. С, И. Ожегов в «Словаре русского языка» дает следующие трактовки этих понятий: «Однородный — относящийся к тому же роду, разряду; одинаковый» [36, с. 382]; «классифицировать — распределить по группам, разрядам, классам» [36, с. 238]. Если обе этих трактовки объединить в одну, то классификацию можно понимать как разбиение множества объектов на однородные группы или классы. В таком случае под однородностью подразумевается наличие у объектов одного класса общих свойств или признаков, определяющих некоторое сходство данных объектов и служащих основанием для отнесения этих объектов к одному классу. Вместе с тем, во многих областях математики, к примеру, в прикладной статистике, понятие однородности оказывается основополагающим. так как обработка статистических данных производится только в однородных группах [22, с. 11]. Требование однородности исследуемого множества объектов не ограничивается только лишь определением наблюдаемого объекта, так как любое реальное множество объектов являет собой систему дифференцированных, различающихся между собой элементов, что делает задачу разбиения исходного множества исследуемых объектов на однородные подмножества приоритетной при анализе систем любой природы: технических, биологических, социально-экономических. Одной из основных особенностей задачи классификации является наличие как качественных, так и количественных признаков в описании объектов исходного множества, в силу чего при выделении однородных групп различают такие виды группировки исходных данных, как структурная и типологическая. Структурной группировкой именуется разбиение качественно однородного исходного множества объектов на классы, которые характеризуют общее строение исходного множества объектов [40, с. 96]. Типологической группировкой называется разбиение исходного множества объектов на классы определенного качества. Таким образом, структурная группировка представляет собой способ выделения количественно однородных групп объектов, а типологическая — способ выделения качественно однородных групп. При сопоставлении этих определений происходит своеобразное противопоставление категорий качества и количества, сильно упрощающее понимание этих категорий и являющееся, вообще говоря, неправомерным [31, с. 7]. Если в основе типологической группировки находится некоторый качественный признак, причем единственный, то задача классификации, как правило, решается элементарно, однако в подавляющем большинстве случаев ее необходимо проводить по количественным признакам, что в значительной степени усложняет задачу. В таком случае на начальных этапах исследования рассуждения о качественной однородности исходных данных лишены всякого смысла, поскольку качественная однородность данных может быть установлена только в результате проведения анализа, основой которого, как справедливо указывали И. И. Елисеева и В. О. Рукавишников, должен быть синтез «теоретических концепций и опыта прошлых исследований» [22, с. 15]. Таким образом, представляется нецелесообразным различать методы выделения качественно и количественно однородных групп, однако имеет смысл, как отмечал И. Д. Мандель, «говорить только о непрерывном синтезе этих категорий в процессе классификации» [31, с. 10]. Методы выделения однородных групп объектов, в связи с вышеизложенным замечанием, условно объединяются в следующие основные подходы [31]: Вероятностный подход основан на предположении о том, что объекты, принадлежащие одному из выделяемых классов, описываются одинаково распределенными случайными векторами, а для различных классов характерны различные распределения вероятностей. В специальной литературе этот подход традиционно именуется расщеплением смесей распределений, где каждый класс понимается как некоторая параметрически заданная одномодальная совокупность, а наблюдения над объектами, подлежащими классификации, трактуются как выборка из смеси таких совокупностей, так что задача заключается в разделении этих совокупностей, исходя из значений параметра, определяющего совокупность, и некоторых предположений, к примеру, о числе классов. Вариативный подход состоит в разбиении множества объектов по выбранному исследователем признаку на интервалы группирования, в результате чего исходное множество объектов разбивается на группы таким образом, что объекты одной группы находятся на относительно небольшом расстоянии друг от друга. В многомерном же случае, при наличии нескольких признаков, данный подход представляет собой комбинационную группировку, для которой характерно поочередное использование признаков для выделения групп. Такой подход, когда единственный признак используется для разбиения всего множества объектов на группы, а также в случае поочередного использования различных признаков, когда каждый из них применяется для выделения одной группы, называется монотетическим [22, с. 7]. Структурный подход базируется на представлении об объектах как точках в многомерном пространстве. В этом случае задача состоит в выделении из исходного множества многомерных точек однородных подмножеств таким образом, чтобы элементы каждого подмножества были в определенном смысле сходны между собой, а сами подмножества — классы объектов — отличались бы друг от друга, так что отыскивается своего рода «естественное» расслоение исходного множества на классы. Данный подход иногда именуется геометрическим, поскольку, используя понятия расстояния между объектами и расстояния между классами, выделяет геометрически удаленные группы. Наиболее последовательно геометрический подход реализован в методах кластерного анализа, которые в специальной литературе называются также методами автоматической классификации, численной таксономией или распознаванием образов с самообучением. В отличие от монотетического подхода к проблеме классификации объектов, кластерный анализ использует одновременно все признаки и называется политетическим. Подробное исследование взаимосвязей между вышеизложенными подходами к решению проблемы выделения однородных групп объектов проведено И. Д. Манделем [31]. Вместе с тем, анализируя соотношение вероятностного и структурного подходов, в первую очередь необходимо отметить то обстоятельство, что многие зарубежные исследователи, такие как Дж. Хартиган [93], К. Фуку нага [42], М. Вонг [187], рассматривают кластер-анализ чрезмерно широко, включая в него и задачи расщепления смесей, то есть задачи классификации в условиях отсутствия обучающих выборок, когда исходные данные об исследуемых объектах имеют вероятностную природу и каждый класс интерпретируется как одномодальная генеральная совокупность при неизвестном значении определяющего ее параметра, а классифицируемые объекты рассматриваются как выборки из смеси таких генеральных совокупностей. Как способ представления исходных данных понятие смеси использует также известный польский исследователь Я. В. Овсиньски [134, с. 392] при рассмотрении общей постановки задачи кластер-анализа. В отечественной литературе подобное рассмотрение автоматической классификации прослеживается в работах М. И. Шлезингера [44] и А. В. Миленького [32]. Е. Е. Жук и Ю. С. Харин [23, с. 17-19] также указывают на существование в кластер-анализе вероятностного и геометрического подходов, отдавая предпочтение первому. Необходимо указать, что применимость методов расщепления смесей вероятностных распределений к решению задач классификации зависит от обоснованности предположений о вероятностной природе исходных данных и корректности выдвигаемой гипотезы о распределении вероятностей, описывающих классы объектов, тогда как успешное применение геометрических методов классификации зависит только от адекватности выбранной меры близости объектов. Отнесение же группы вероятностно-статистических методов классификации в условиях отсутствия обучающих выборок к кластерному анализу в силу причин методологического характера представляется спорным, так что следует говорить не о вероятностном подходе к решению задачи автоматической классификации, а о теоретико-вероятностной модификации задачи кластер-анализа, как это было предложено С. А. Айвазяном [37, с. 146]. Касательно соотношения вариативного и структурного подходов, здесь лишь укажем, что при использовании вариативного подхода, являющегося разновидностью типологической группировки, классы имеют субъективный характер, а сама группировка является полностью управляемой, так что «естественное» расслоение, отыскиваемое методами кластерного анализа, в случае применения вариативных методов не имеет места. Главным же отличием двух подходов является то, что понятия «близость» и «сходство» объектов в типологической группировке неформализованы, в отличие от структурного подхода, где они формализованы и выражаются рядом соотношений. Достаточно полный обзор метрик и мер близости, формализующих понятие сходства и используемых в задачах классификации, содержится в работах [29], [180].
|
 |
Оглавление
|