Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
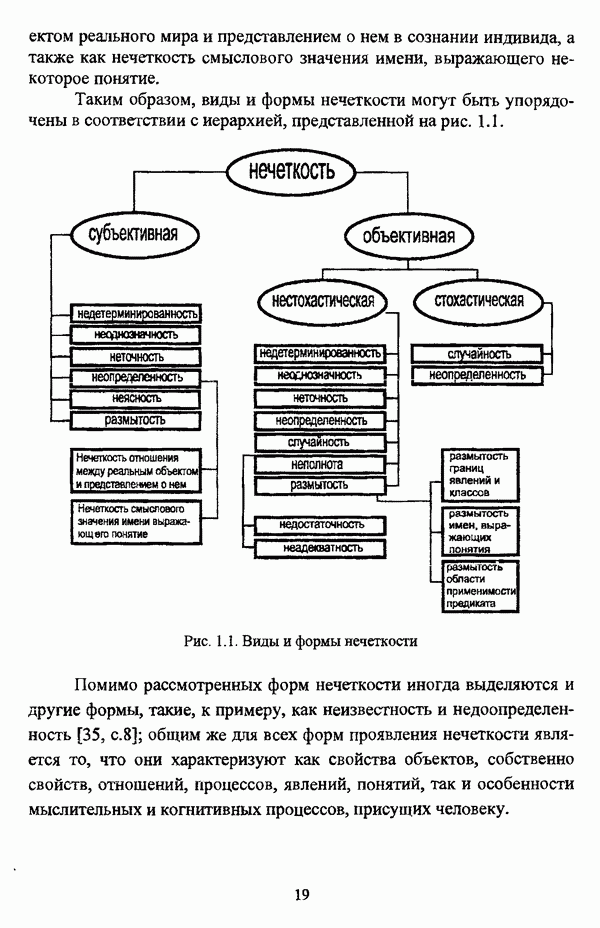
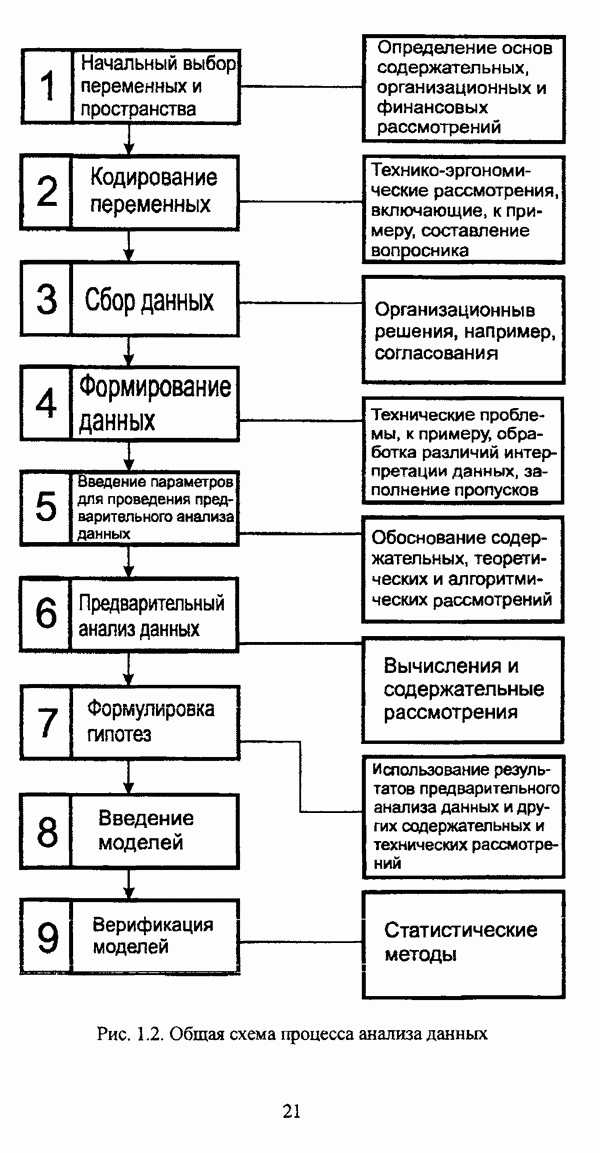
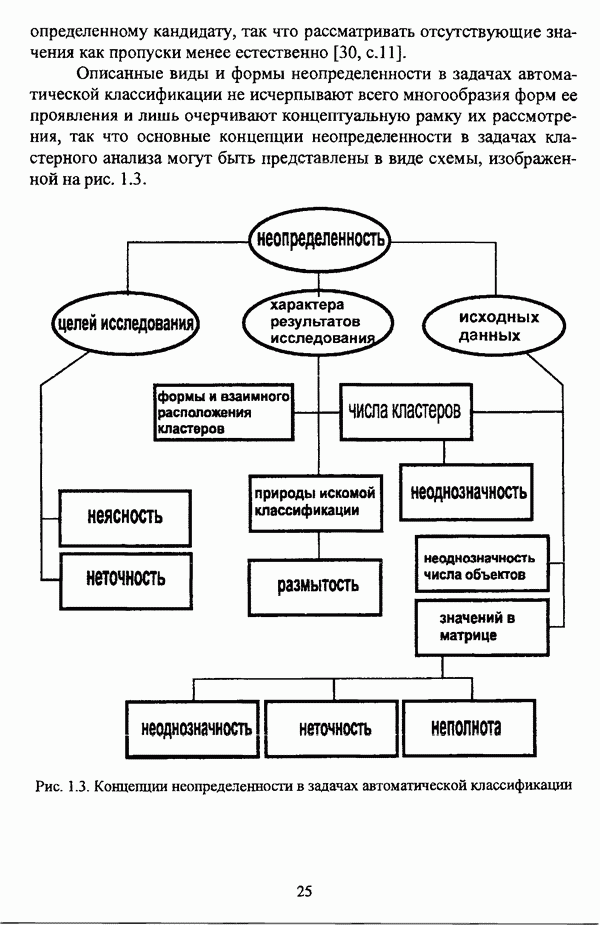
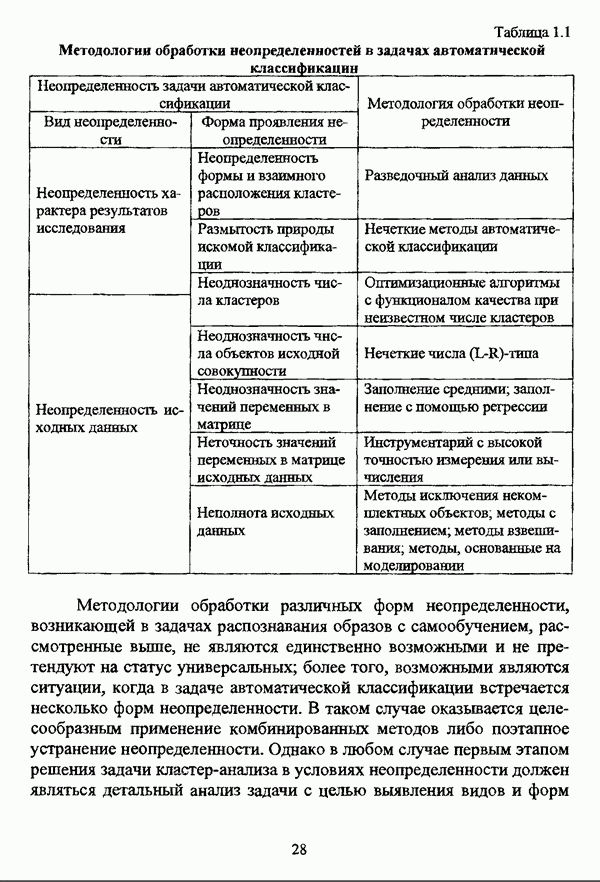
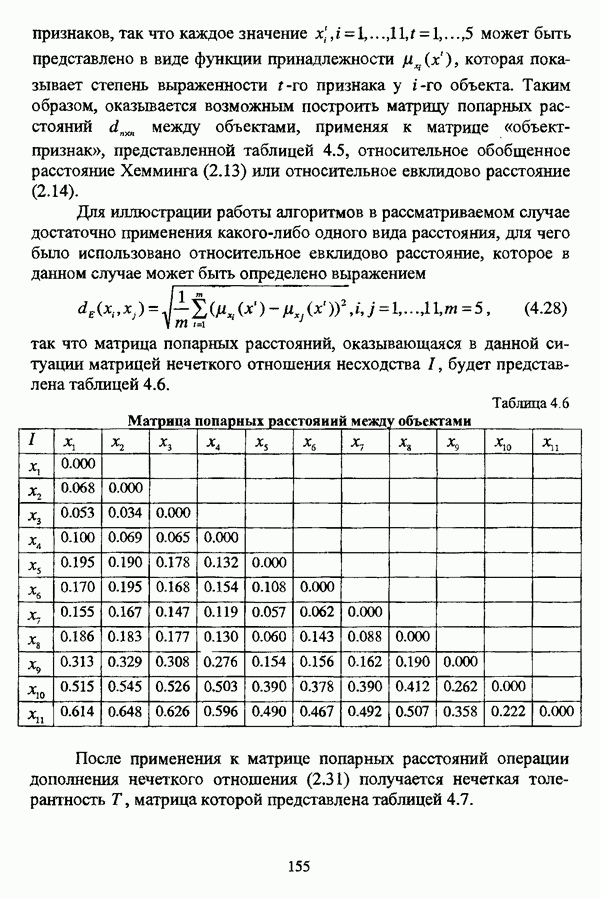
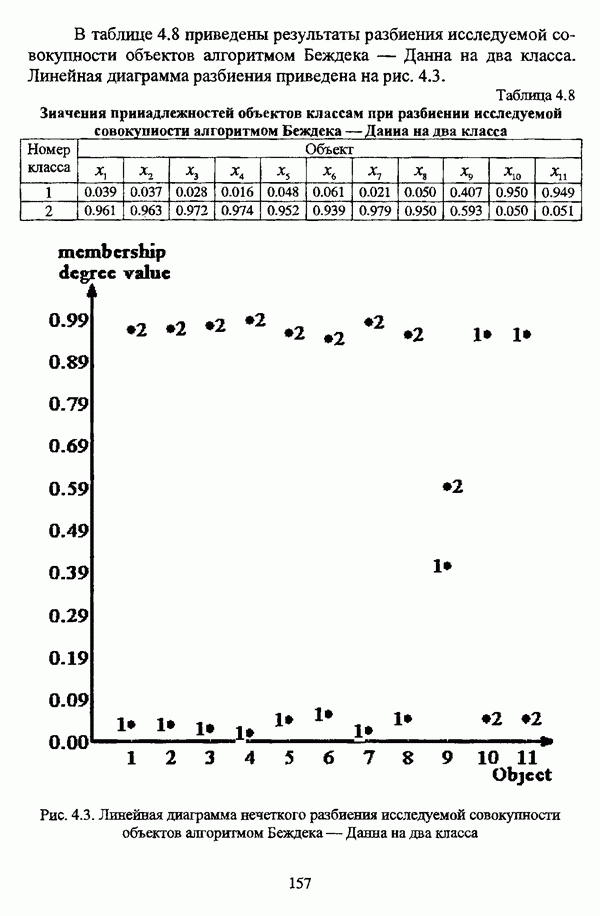
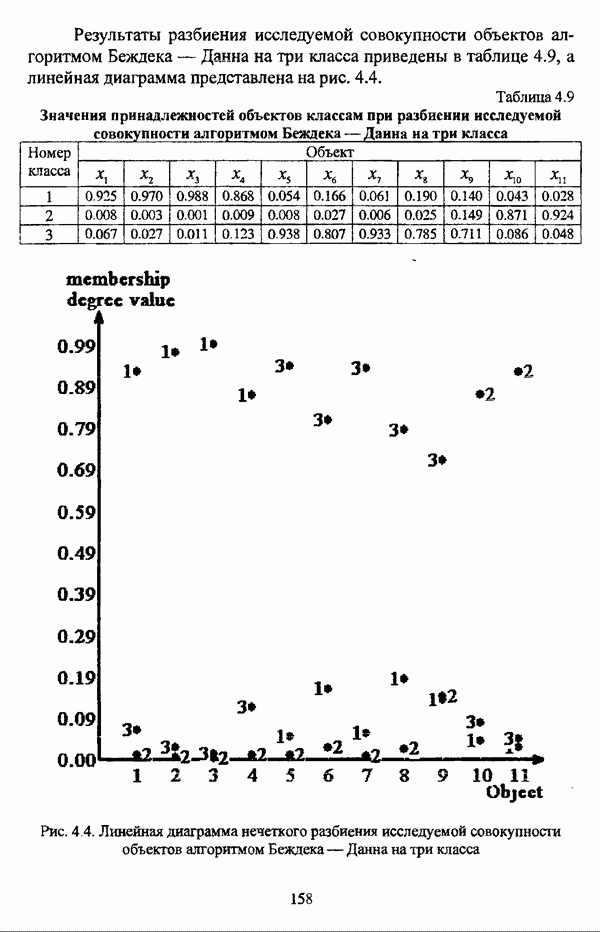
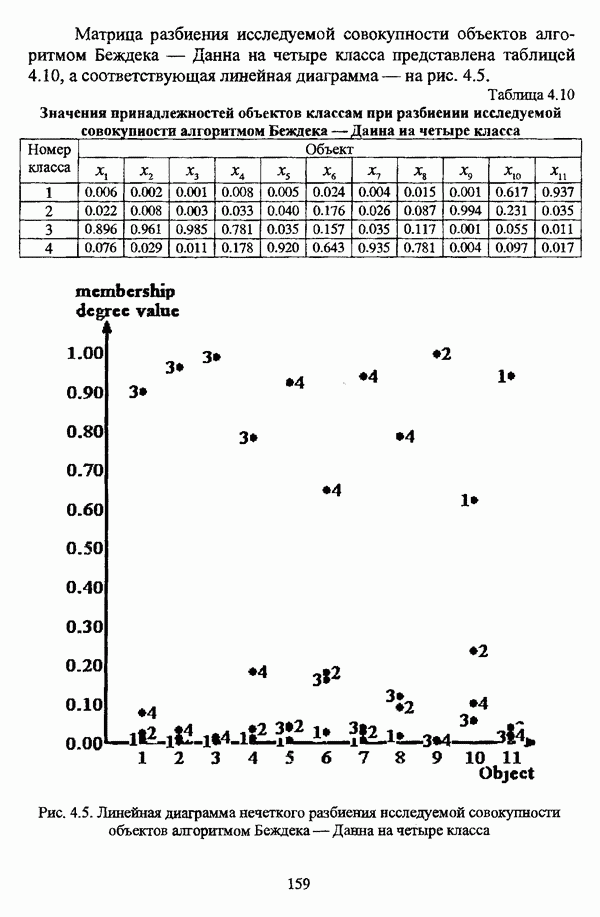
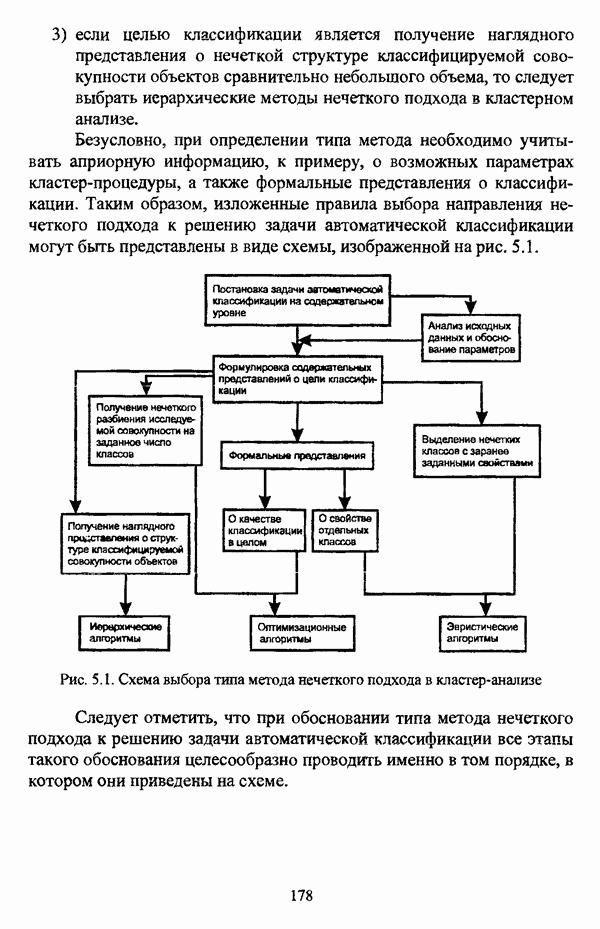
5.1.2. Выбор алгоритма нечеткого подхода к решению задачи автоматической классификации и обоснование параметровПосле того как определен тип метода нечеткого подхода к решению задачи автоматической классификации, исходя из вида матрицы исходных данных и имеющейся априорной информации, следует выбрать алгоритм, адекватный условиям конкретной задачи. Если для решения задачи классификации выбрано эвристическое направление нечеткого подхода, то главным критерием выбора алгоритма является соответствие особенностей того или иного алгоритма содержательной постановке задачи. Специфика нечетких методов автоматической классификации эвристического направления отражена в таблице 5.1. Таблица 5.1. Характеристики эвристических методов нечеткого подхода в кластерном анализе
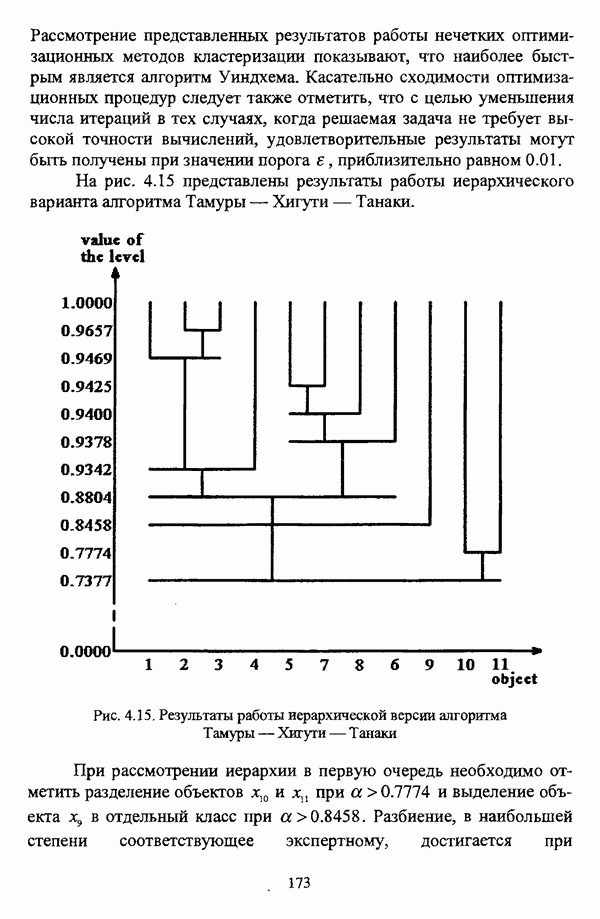
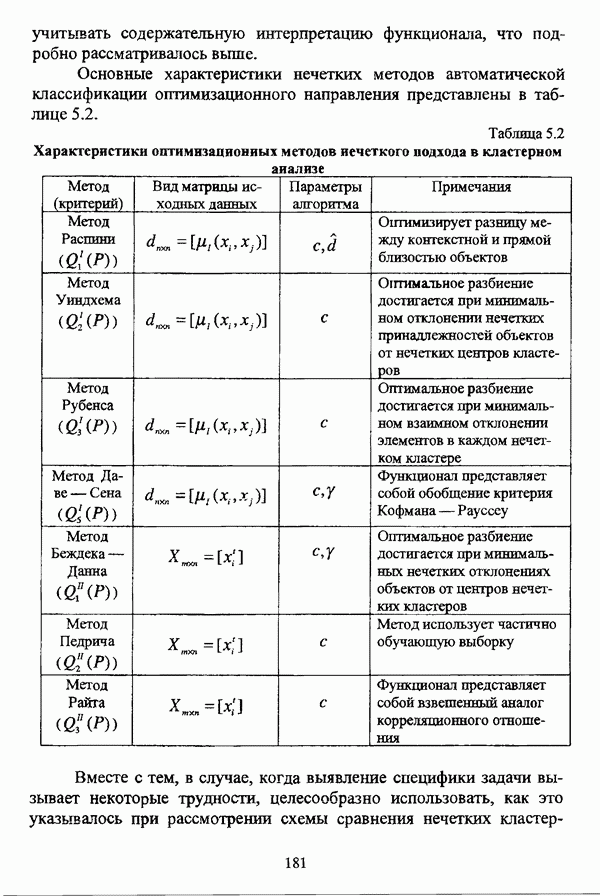
Как указывалось ранее, алгоритм Гитмана — Левина позволяет быстро обрабатывать достаточно большие массивы данных, а полученные в результате кластеры могут иметь как эллиптическую, так и сферическую форму. Таким образом, эта процедура может рассматриваться как процедура комбинированной прямой классификации в том смысле, в котором этот термин использовался И. Д. Манделем [31, с. 37]. Результаты применения процедуры Тамуры — Хигути — Танаки, как показали вычислительные эксперименты, могут оказаться некорректными, так что данную процедуру следует применять в качестве инструмента предварительного анализа исследуемой совокупности, причем в ее иерархическом варианте. Процедура Берштейна — Дзюбы позволяет выделять кластеры сложной формы, и, как указывалось выше, в принципе возможно выделение большего чем два числа классов, однако данная процедура, как и все процедуры классификации на графах, позволяет классифицировать объекты исследуемой совокупности сравнительно небольшого объема. Алгоритм Кутюрье — Фьо-лео предлагает исследователю весьма гибкий аппарат для анализа данных и не предполагает жестких ограничений на объем исследуемой совокупности. Таким образом, конкретный алгоритм эвристического направления нечеткого подхода к решению задачи автоматической классификации может быть выбран в соответствии со следующими рекомендациями: 1) если число объектов исследуемой совокупности достаточно велико и на множестве X оказывается возможным определить нечеткое множество 2) если целью классификации является предварительный анализ исследуемой совокупности объектов, в процессе которого требуется получить разбиение на с четких классов, то следует использовать алгоритм Тамуры — Хигути — Танаки; 3) если допускается пересечение нечетких кластеров, а также имеются предположения о минимальном числе и объектов в каждом нечетком кластере, то следует обосновать выбор порога а и использовать алгоритм Кутюрье — Фьолео; 4) если число элементов множества Если же для решения задачи выбрано оптимизационное направление, главной проблемой оказывается обоснование вида функционала. Поскольку выбор функционала определяется, помимо формы матрицы исходных данных, вида шкалы, в которой измерены признаки, и типа признакового пространства, также спецификой конкретной задачи, то при выборе функционала качества разбиения целесообразно учитывать содержательную интерпретацию функционала, что подробно рассматривалось выше. Основные характеристики нечетких методов автоматической классификации оптимизационного направления представлены в таблице 5.2. Таблица 5.2. Характеристики оптимизационных методов нечеткого подхода в кластерном анализе (см. скан) Вместе с тем, в случае, когда выявление специфики задачи вызывает некоторые трудности, целесообразно использовать, как это указывалось при рассмотрении схемы сравнения нечетких кластер-процедур, несколько функционалов, после чего выбрать наиболее эффективный критерий. Как отмечал в связи с этим И. Д. Мандель, «самый надежный способ обоснования вида критерия — это придание ему четкого содержательного смысла, совпадающего с конечным результатом, найденным в данной задаче или максимально близким к нему» [31, с. 153]. В случае, когда выбранный функционал является одним из функционалов семейства Касательно процедур иерархического направления следует отметить, что, поскольку данные процедуры не предусматривают задания входных параметров, то при выборе процедуры достаточно руководствоваться видом матрицы исходных данных и спецификой решаемой задачи. Особенности рассмотренных иерархических процедур представлены в таблице 5.3. Таблица 5.3. Характеристики иерархических методов нечеткого подхода в кластерном анализе
Правила выбора нечеткой кластер-процедуры иерархического направления также весьма просты: 1) если исходные данные заданы матрицей 2) если исходные данные заданы матрицей Следует, однако, отметить, что если исходные данные заданы в виде матрицы «объект — свойство», но в силу специфических особенной задачи или содержательных соображений необходимо прибегнуть к восходящей стратегии классификации, то следует перейти к матрице близости объектов «объект — объект» и воспользоваться восходящей версией алгоритма Ватады — Танаки — Асаи. Безусловно, предложенная схема выбора типа метода и алгоритма не претендует на универсальность и носит общий характер. Вместе с тем, следование рекомендациям предлагаемой методологии позволит исследователю, не знакомому со спецификой нечетких методов автоматической классификации, быстрее сориентироваться среди алгоритмов нечеткого подхода в кластерном анализе с целью выбора наиболее адекватного для решения конкретной задачи метода. Более того, рекомендации предложенной методологии могут послужить основой дня разработки консультационной экспертной системы выбора конкретного алгоритма. Касательно проблемы обоснования параметров следует отметить, что данный вопрос, в общем, рассматривался И. Д. Манделем [31, с. 156-159], так что в данном случае целесообразно указать лишь специфические особенности, присущие данной проблеме при использовании для решения задачи автоматической классификации нечетких методов. Число классов с требуется задавать в качестве входного параметра в алгоритме Тамуры — Хигути — Танаки, а также во всех оптимизационных кластер-процедурах и зачастую может быть определено на основании сущности решаемой задачи. Если же число классов априори неизвестно, то целесообразно задать ряд значений
Число объектов в классе и в алгоритме Кутюрье — Фьолео определяется спецификой решаемой задачи: к примеру, при формировании армейского подразделения требуется разбить множество Порог различия объектов а в алгоритме Кутюрье — Фьолео определяется исследователем исходя из содержательных соображений о компактности формируемых групп. Число объектов в области пересечения классов w в алгоритме Кутюрье — Фьолео так же, как и параметр и, задается в зависимости от особенностей задачи. При решении конкретной задачи рекомендуется провести серию экспериментов с различными значениями и и w и получением ряда результатов, на основании чего выбрать некоторое лучшее, в содержательном или формальном смысле, решение. Порог d выбирается в зависимости от используемой процедуры: в алгоритме Гитмана — Левина данный порог определяется исследователем в зависимости от вида функции принадлежности Показатель нечеткости классификации у, как уже отмечалось, чаще всего полагается равным 2, В работе [41] его предлагается варьировать в пределах от 2 до 5, а В. Педрич [144, с. 134] рекомендует задавать у в интервале от 1.5 до 30. Очевидно, значение у должно определяться исследователем исходя из количества объектов исследуемой совокупности и результатов предварительной обработки данных.
|
 |
Оглавление
|



























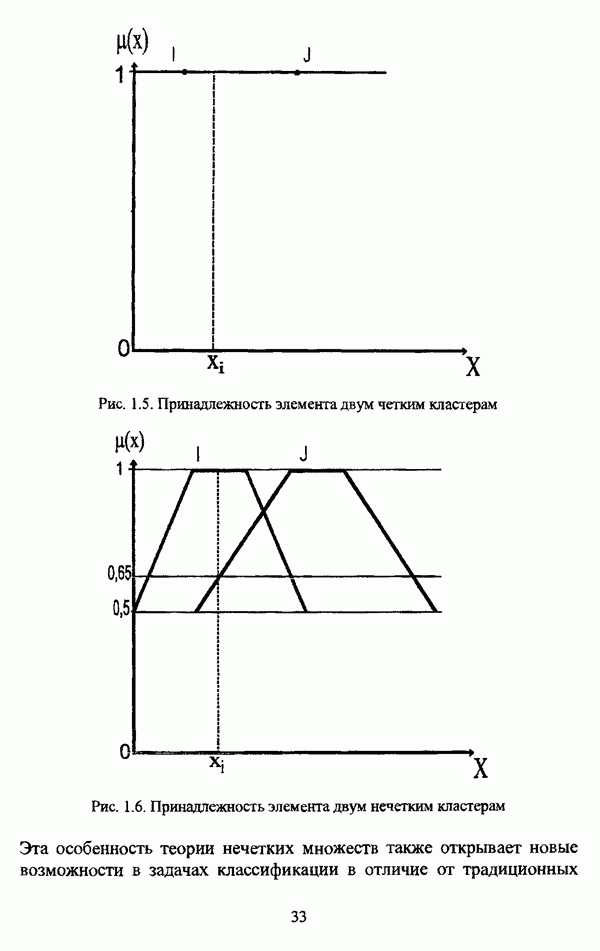






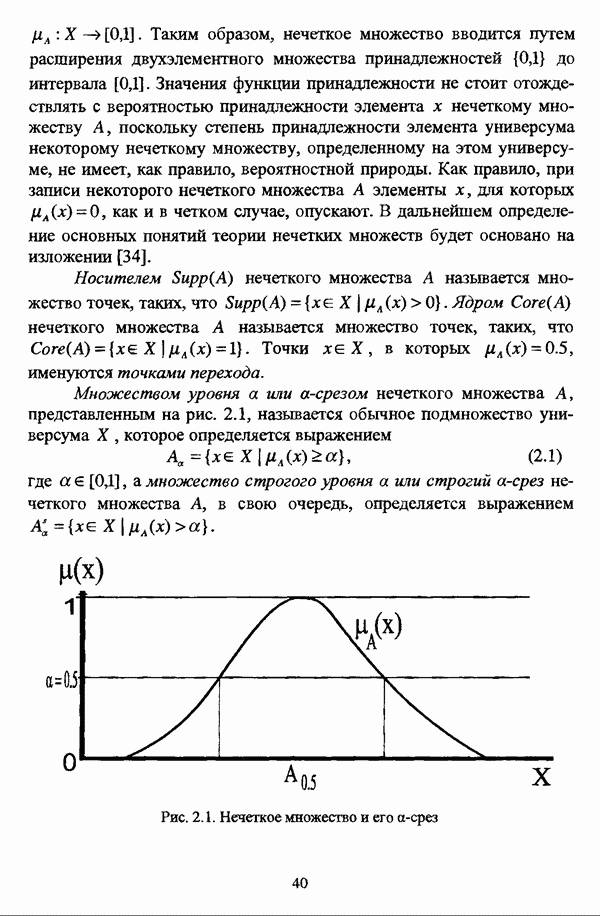


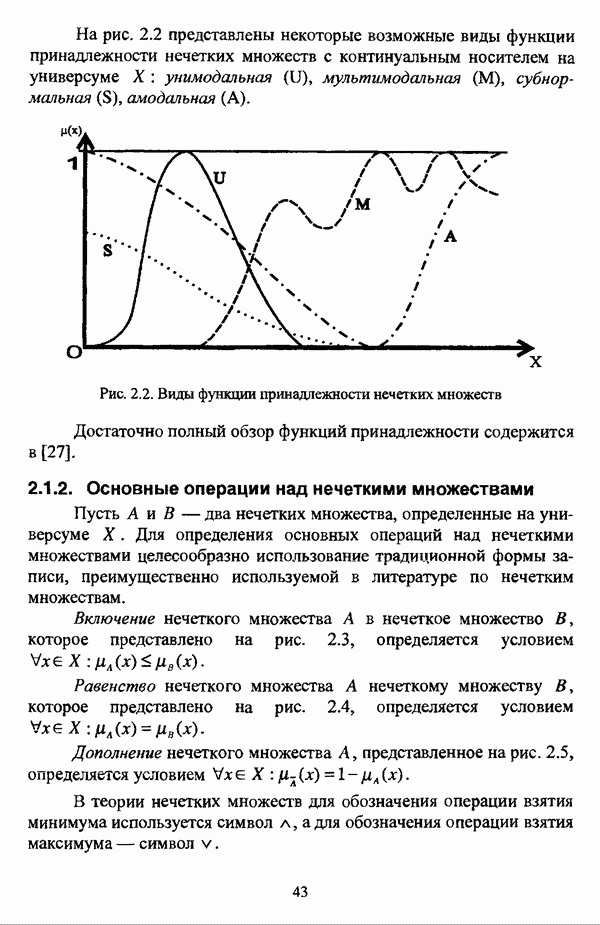
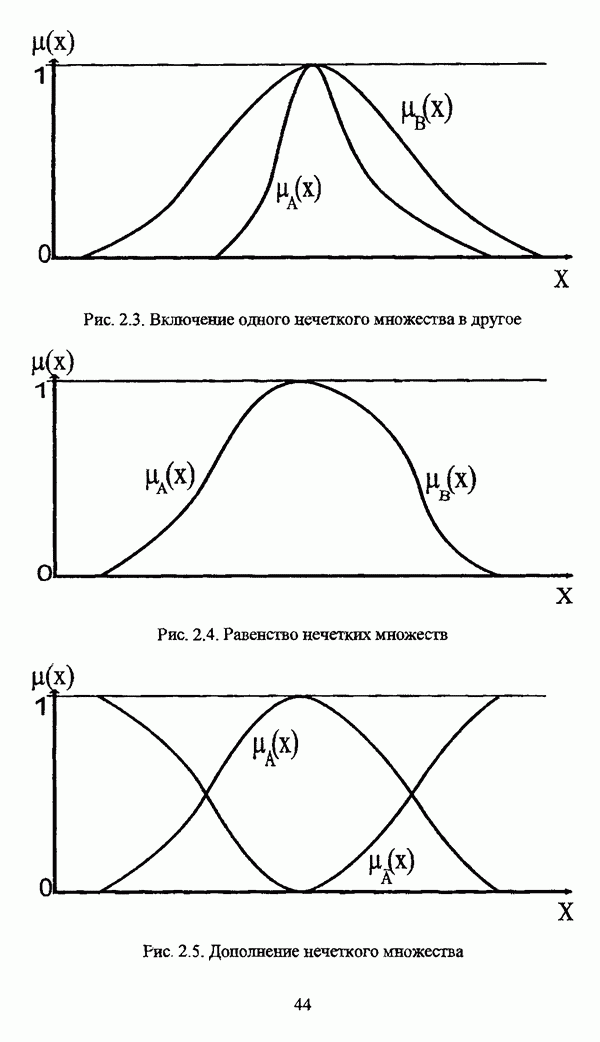







































































































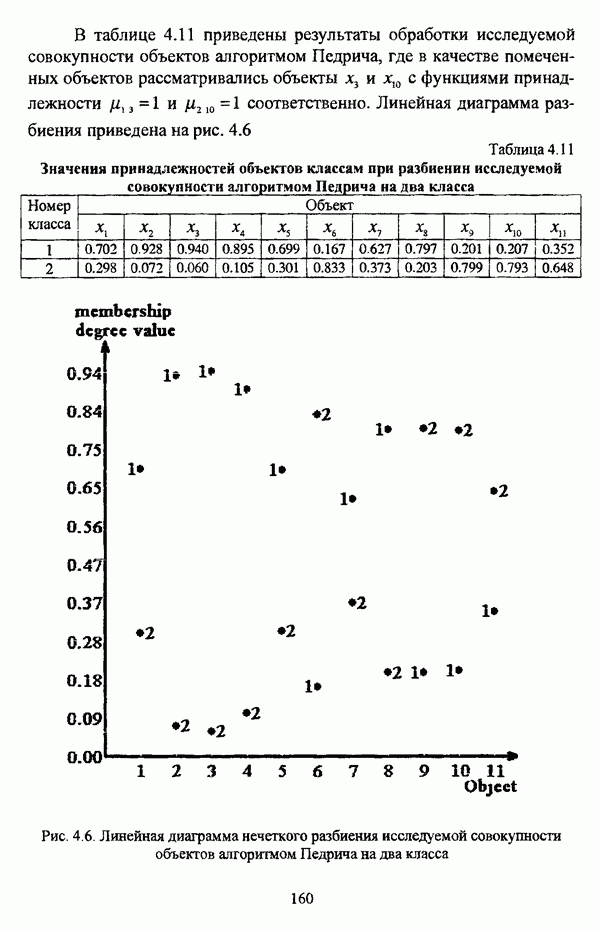
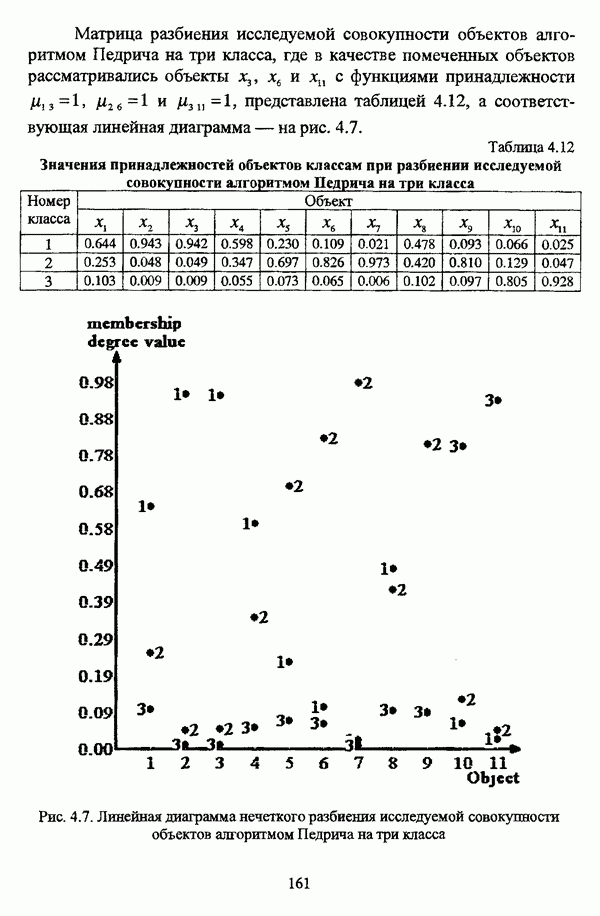
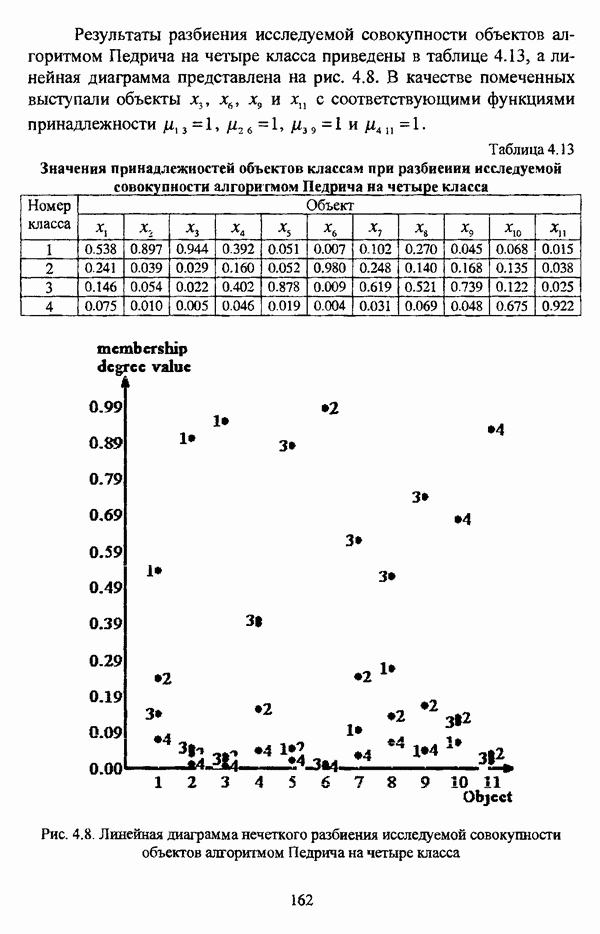
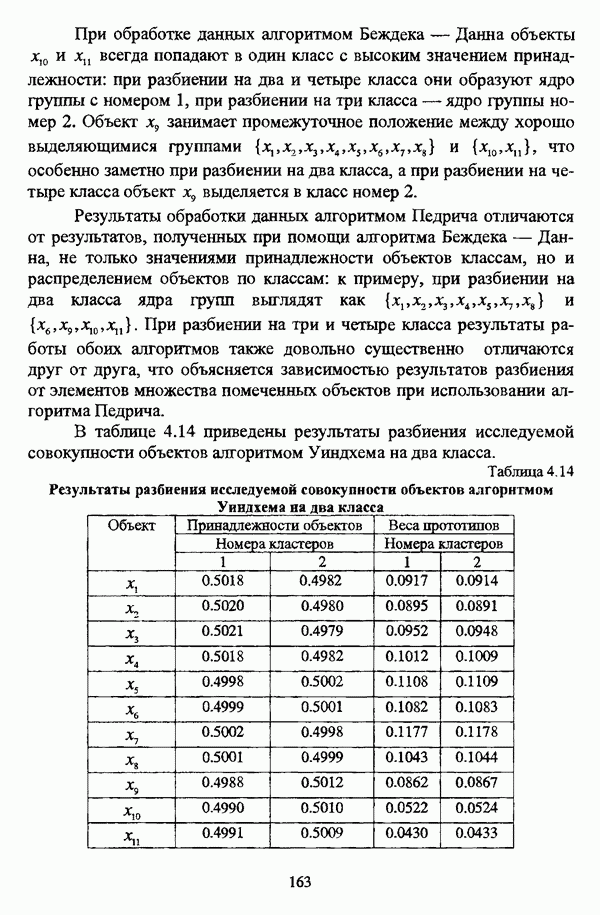
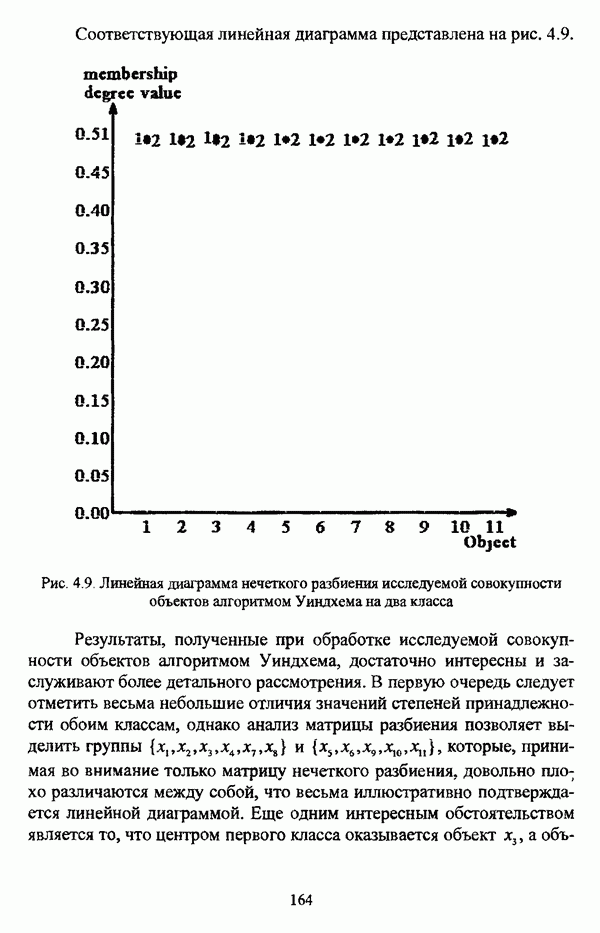
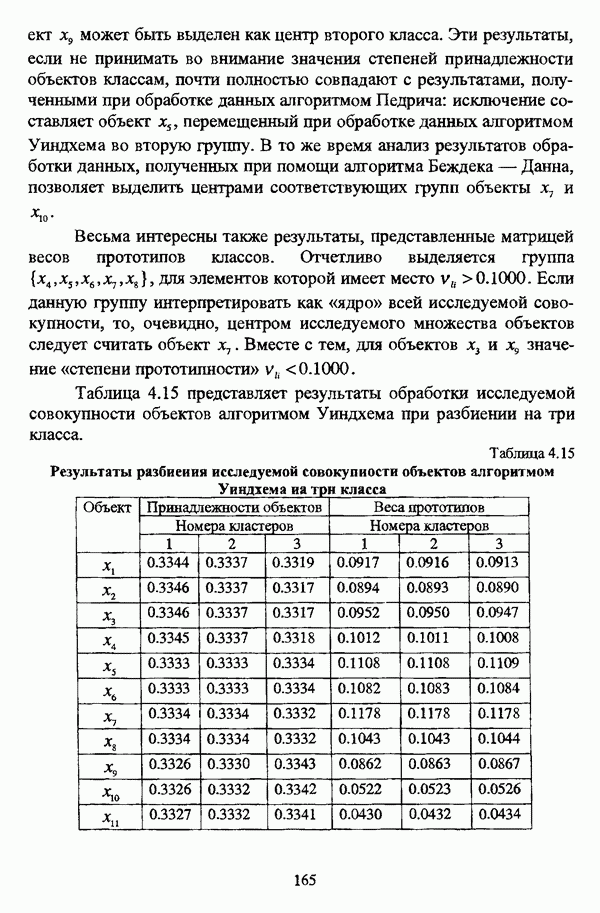
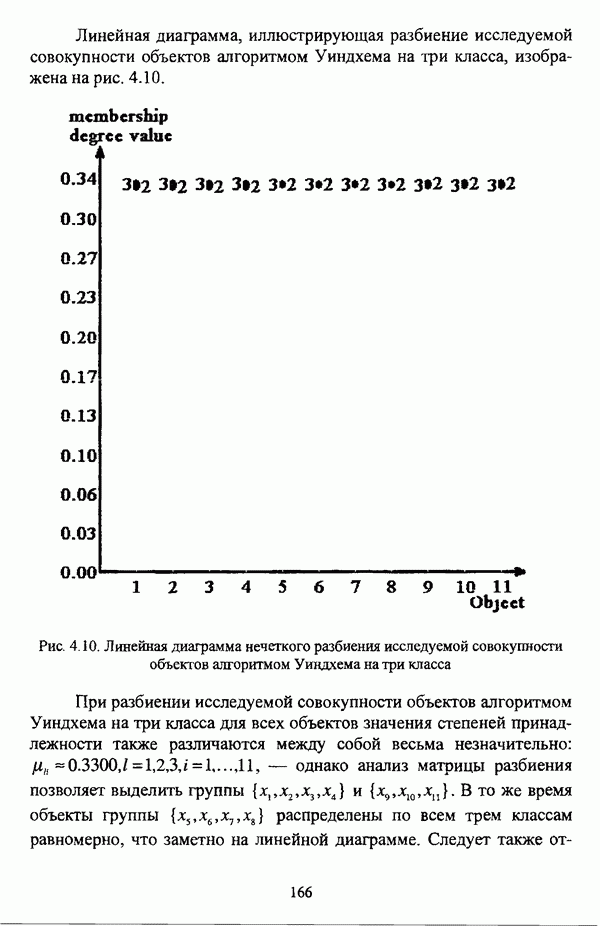
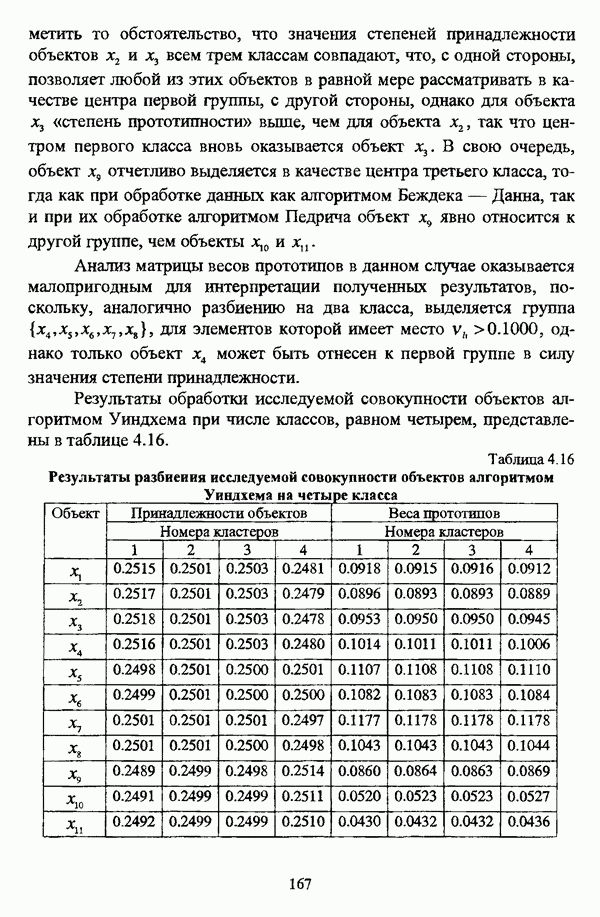
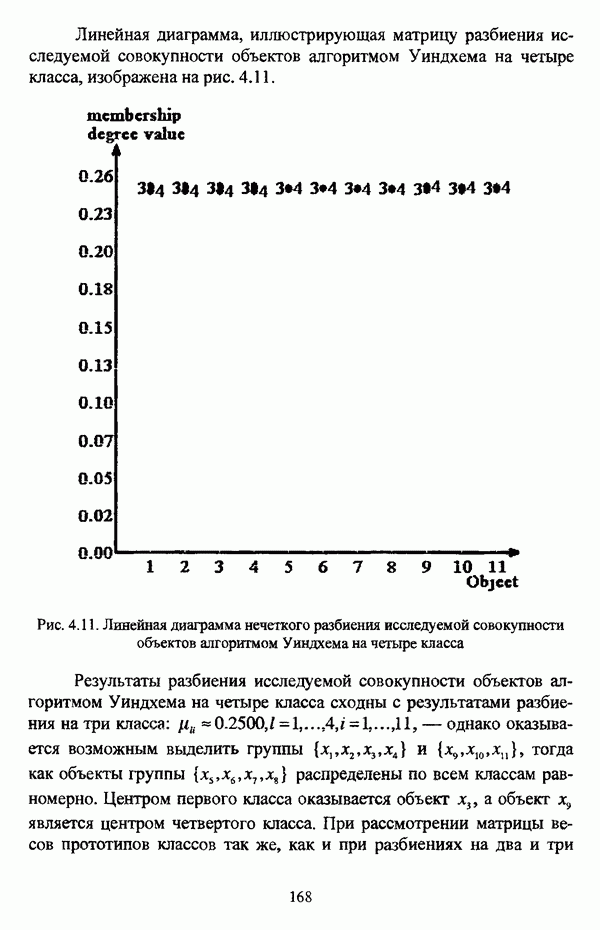

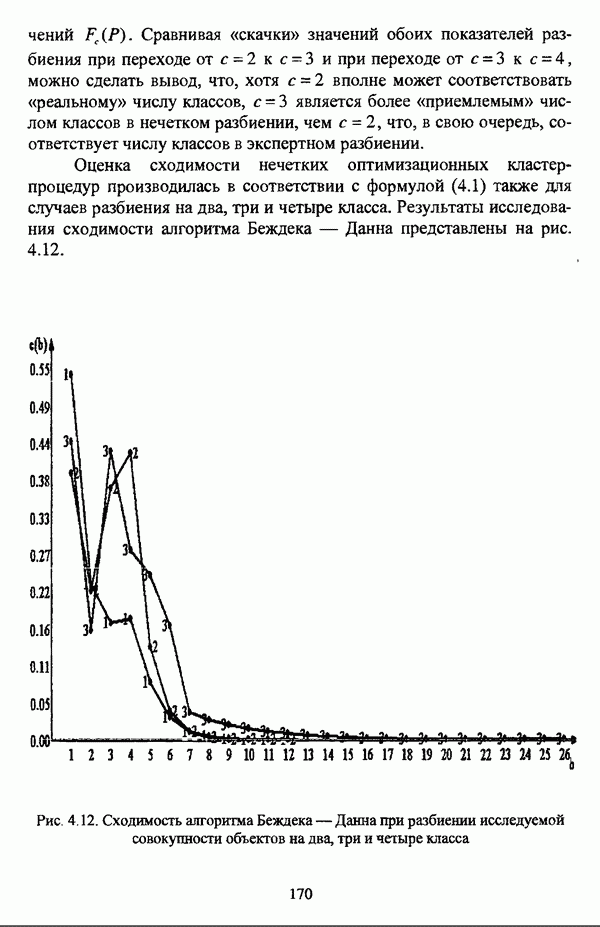
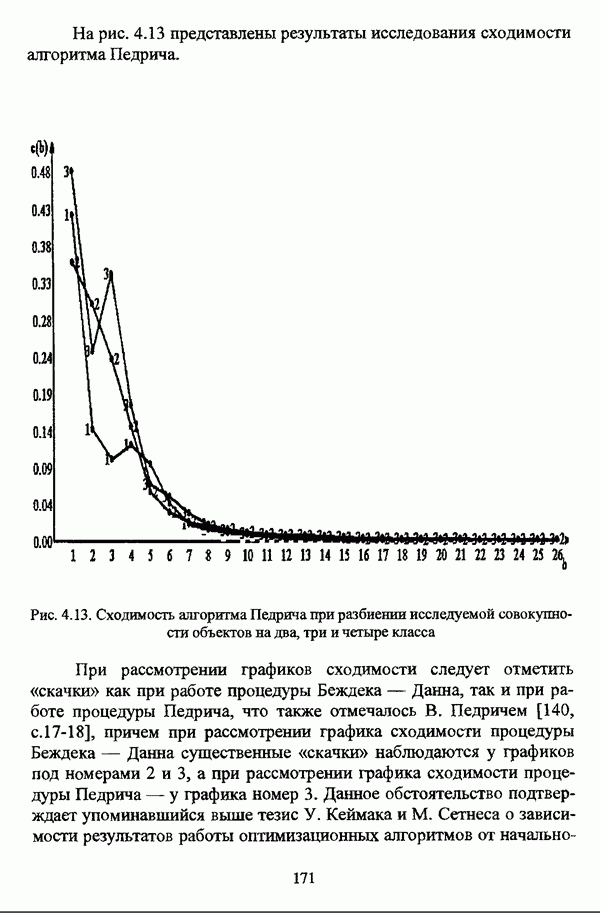
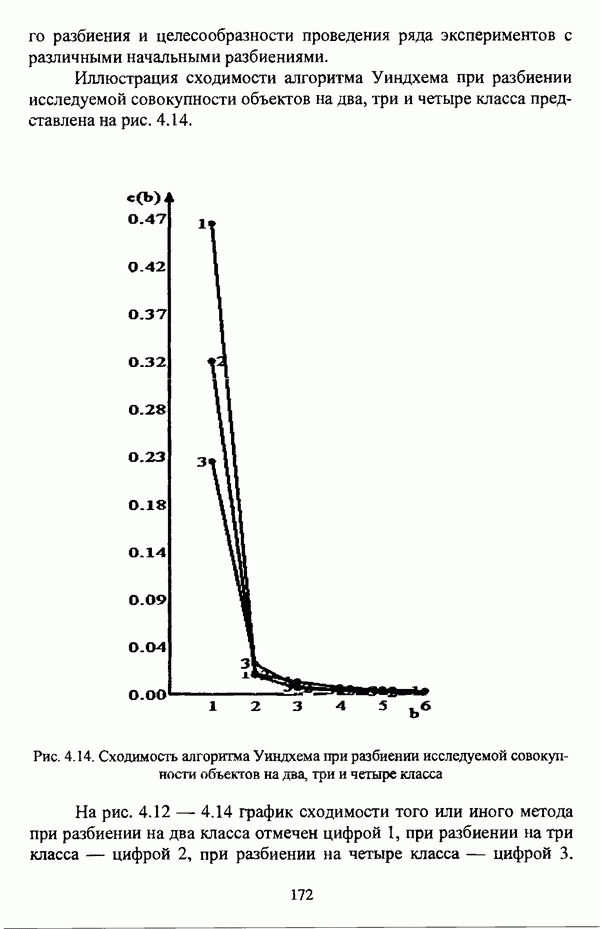
















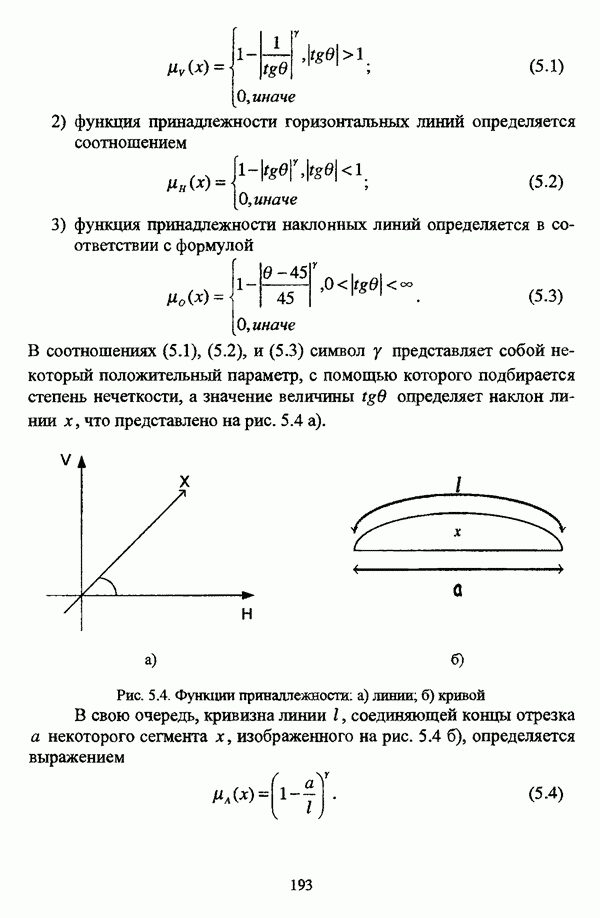
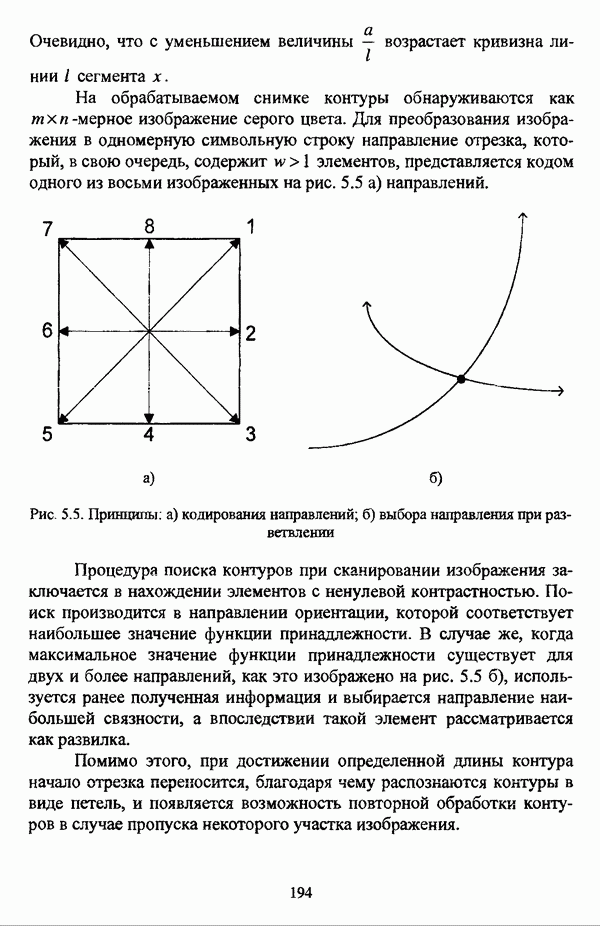




















 следует обосновать выбор метрики d и порога d и использовать алгоритм Гитмана — Левина;
следует обосновать выбор метрики d и порога d и использовать алгоритм Гитмана — Левина;
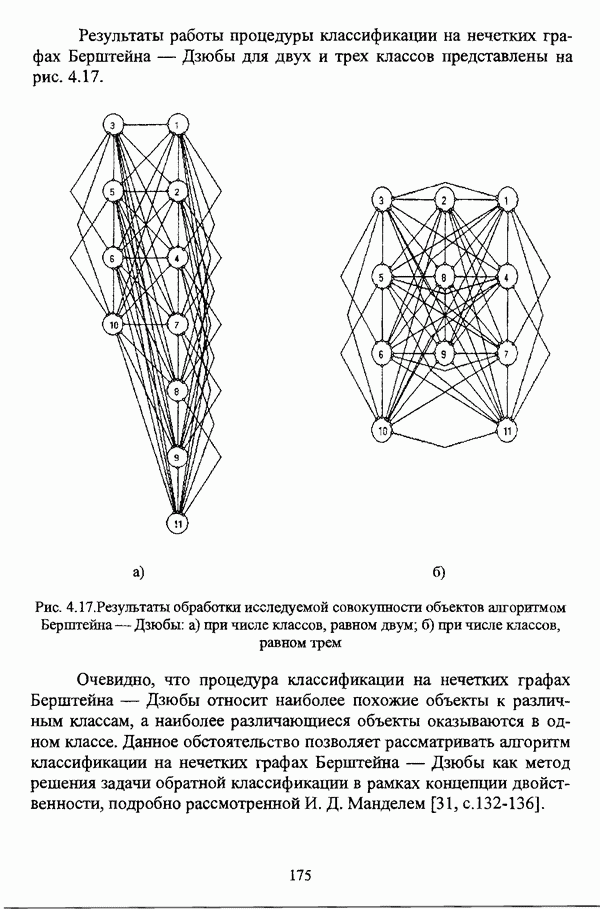
 сравнительно невелико, а также существуют предположения о сложной форме кластеров и требуется визуальное представление результатов классификации, то следует выбрать алгоритм классификации на нечетких графах Берштейна — Дзюбы.
сравнительно невелико, а также существуют предположения о сложной форме кластеров и требуется визуальное представление результатов классификации, то следует выбрать алгоритм классификации на нечетких графах Берштейна — Дзюбы.
 , при отсутствии предположений о форме и взаимном расположении кластеров, может возникнуть проблема выбора расстояния. В этом случае целесообразно проводить исследование с использованием различных метрик, как это рекомендуется С. А. Айвазяном [37, с. 328]. Вместе с тем, для выбора алгоритма оптимизационного направления также могут быть сформулированы правила, подобные рекомендациям для выбора эвристической нечеткой кластер-процедуры.
, при отсутствии предположений о форме и взаимном расположении кластеров, может возникнуть проблема выбора расстояния. В этом случае целесообразно проводить исследование с использованием различных метрик, как это рекомендуется С. А. Айвазяном [37, с. 328]. Вместе с тем, для выбора алгоритма оптимизационного направления также могут быть сформулированы правила, подобные рекомендациям для выбора эвристической нечеткой кластер-процедуры.

 то следует использовать бинарный дивизимиый алгоритм Думитреску;
то следует использовать бинарный дивизимиый алгоритм Думитреску;
 то следует использовать эвристический алгоритм Ватады — Танаки — Асаи.
то следует использовать эвристический алгоритм Ватады — Танаки — Асаи.
 где с, — наименее возможное число классов,
где с, — наименее возможное число классов,  - наиболее возможное число классов,
- наиболее возможное число классов,  после чего, при использовании алгоритма Тамуры — Хигути — Танаки, выбрать наиболее приемлемое разбиение, исходя из содержательных рассмотрений. В случае использования оптимизационных методов наилучшее разбиение можно выбрать на основании анализа значений показателей качества разбиения, к примеру, коэффициента разбиения
после чего, при использовании алгоритма Тамуры — Хигути — Танаки, выбрать наиболее приемлемое разбиение, исходя из содержательных рассмотрений. В случае использования оптимизационных методов наилучшее разбиение можно выбрать на основании анализа значений показателей качества разбиения, к примеру, коэффициента разбиения  или энтропии разбиения ЯДР). Другим способом определения числа классов перед обработкой данных оптимизационной кластер-процедурой является их первоначальная обработка нечеткой эвристической кластер-процедурой, как это предлагалось в работе И. И. Елисеевой и В. О. Рукавишникова
или энтропии разбиения ЯДР). Другим способом определения числа классов перед обработкой данных оптимизационной кластер-процедурой является их первоначальная обработка нечеткой эвристической кластер-процедурой, как это предлагалось в работе И. И. Елисеевой и В. О. Рукавишникова  либо нечеткой иерархической кластер-процедурой, что предлагается Д. Думитреску [81]. Подобный подход позволяет, по меньшей мере, значительно сократить интервал
либо нечеткой иерархической кластер-процедурой, что предлагается Д. Думитреску [81]. Подобный подход позволяет, по меньшей мере, значительно сократить интервал
 для которого рекомендуется проведение серии экспериментов. Вообще же, как отмечал И. Д. Мандель, определение числа классов представляет собой «узловую проблему кластер-анализа, и неудивительно, что она не находит однозначного решения» [31, с. 158].
для которого рекомендуется проведение серии экспериментов. Вообще же, как отмечал И. Д. Мандель, определение числа классов представляет собой «узловую проблему кластер-анализа, и неудивительно, что она не находит однозначного решения» [31, с. 158].
 на отделения; в таком случае, помимо учета уровня физической подготовки, профессиональных и специальных навыков, психологической совместимости кандидатов и других признаков, следует учитывать, что в составе каждого отделения должно быть не менее и человек. В случае, когда жесткие ограничения на минимальное количество объектов в классе отсутствуют, целесообразно полагать
на отделения; в таком случае, помимо учета уровня физической подготовки, профессиональных и специальных навыков, психологической совместимости кандидатов и других признаков, следует учитывать, что в составе каждого отделения должно быть не менее и человек. В случае, когда жесткие ограничения на минимальное количество объектов в классе отсутствуют, целесообразно полагать 
 в каждом конкретном случае, что отмечалось непосредственно при рассмотрении алгоритма, а в алгоритме Распини его можно задавать как среднюю связь в классе [31, с. 159].
в каждом конкретном случае, что отмечалось непосредственно при рассмотрении алгоритма, а в алгоритме Распини его можно задавать как среднюю связь в классе [31, с. 159].