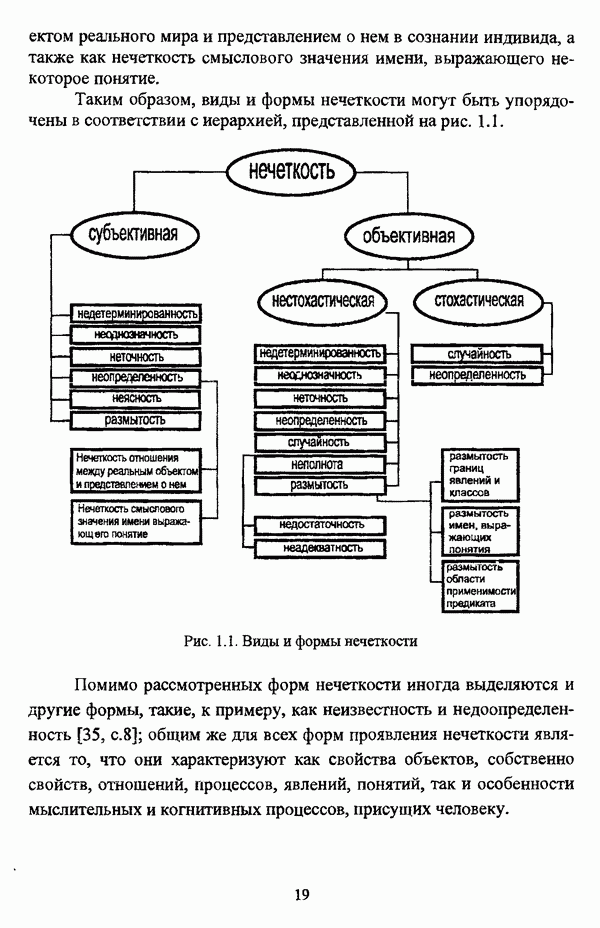
3.3.2.2. Алгоритм Думитреску (FDH algorithm)
[81] является дивизимной процедурой, последовательно строящей бинарное дерево нечеткой иерархии.
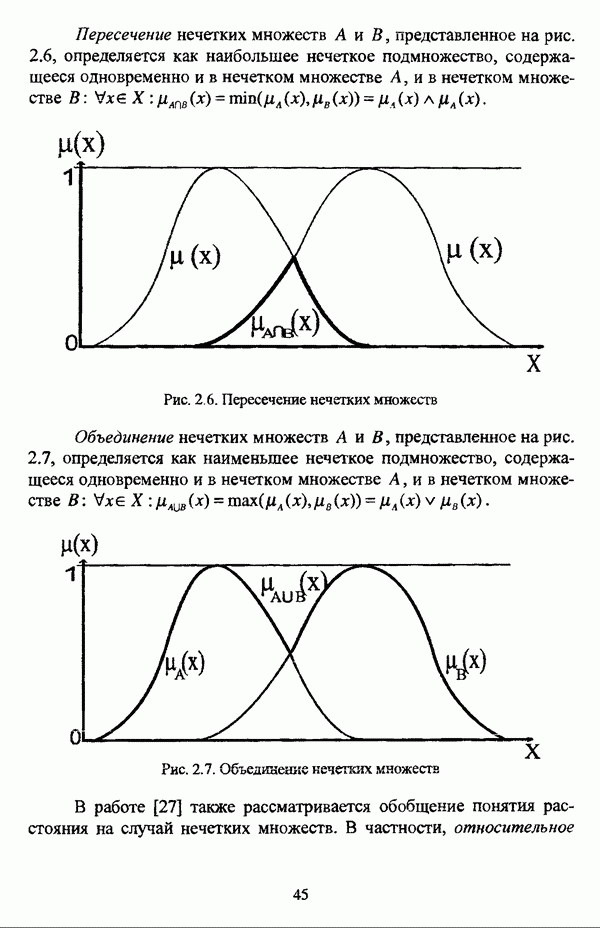
Основные понятия и определения
Пусть, как и ранее,  — исследуемая совокупность объектов, данные о которых представлены в виде матрицы «объект-свойство»
— исследуемая совокупность объектов, данные о которых представлены в виде матрицы «объект-свойство»  , то есть каждый объект представляет собой точку в пространстве признаков
, то есть каждый объект представляет собой точку в пространстве признаков  Кластерная структура исследуемого множества объектов X описывается семейством с разделенных нечетких множеств, образующих разбиение
Кластерная структура исследуемого множества объектов X описывается семейством с разделенных нечетких множеств, образующих разбиение  на нечеткие кластеры. Если некоторый нечеткий кластер
на нечеткие кластеры. Если некоторый нечеткий кластер  неоднороден, то можно рассматривать его субструктуру, которая, в свою очередь, также может быть описана некоторым разбиением нечеткого множества
неоднороден, то можно рассматривать его субструктуру, которая, в свою очередь, также может быть описана некоторым разбиением нечеткого множества  так что образуется многоуровневая нечеткая классификация, и каждое последующее разбиение является уточнением разбиения, соответствующего предыдущему уровню классификации. Перед рассмотрением основных определений, введенных Д. Думитреску, следует оговорить, что операции
так что образуется многоуровневая нечеткая классификация, и каждое последующее разбиение является уточнением разбиения, соответствующего предыдущему уровню классификации. Перед рассмотрением основных определений, введенных Д. Думитреску, следует оговорить, что операции  нечеткими множествами, в частности, рассмотренные в главе 2 операции пересечения и объединения нечетких множеств, в общем, определяются с помощью треугольных норм (
нечеткими множествами, в частности, рассмотренные в главе 2 операции пересечения и объединения нечетких множеств, в общем, определяются с помощью треугольных норм ( -норм), обозначаемых символом Т, и треугольных конорм (
-норм), обозначаемых символом Т, и треугольных конорм ( -конорм,
-конорм,  -норм), обозначаемых символом S [34, с. 29-36]; однако в данном случае полное рассмотрение треугольных норм нецелесообразно. При разработке процедуры Д. Думитреску [81, с. 146] определил операции пересечения и объединения нечетких множеств с помощью треугольных норм и треугольных конорм следующим образом:
-норм), обозначаемых символом S [34, с. 29-36]; однако в данном случае полное рассмотрение треугольных норм нецелесообразно. При разработке процедуры Д. Думитреску [81, с. 146] определил операции пересечения и объединения нечетких множеств с помощью треугольных норм и треугольных конорм следующим образом:
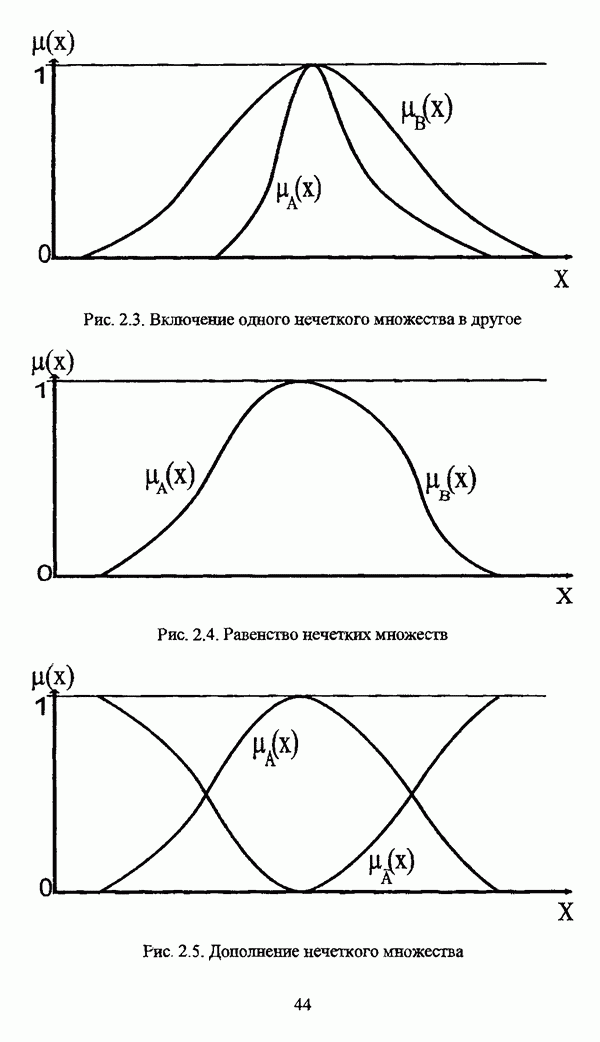
1) Пересечение нечетких множеств А и В определяется в соответствии с формулой
 (3.112)
(3.112)
где 
2) Объединение нечетких множеств А и В определяется в соответствии с формулой

где 
При дальнейшем рассмотрении метода, предложенного Д. Думитреску, будет приниматься, что операции пересечения и объединения нечетких множеств определены с помощью (3.112) и (3.113).
Нечеткие множества  называются разделенными, если для
называются разделенными, если для  выполняется условие
выполняется условие 
Семейство разделенных нечетких множеств  образует разбиение некоторого нечеткого множества
образует разбиение некоторого нечеткого множества  если вьшолняется условие
если вьшолняется условие  так что при
так что при  приведенное условие эквивалентно условию нечеткого разбиения, введенного Э. Распини,
приведенное условие эквивалентно условию нечеткого разбиения, введенного Э. Распини,  вьшолняющегося для каждого
вьшолняющегося для каждого  .
.
Поскольку символом П обозначается множество всех нечетких разбиений исследуемой совокупности объектов  то множество всех нечетких разбиений
то множество всех нечетких разбиений  некоторого нечеткого множества
некоторого нечеткого множества  будет обозначаться символом П и пусть имеет место
будет обозначаться символом П и пусть имеет место  Нечеткое разбиение
Нечеткое разбиение  предшествует нечеткому разбиению
предшествует нечеткому разбиению  или, как выражается автор процедуры [81, с. 146], «уточняет» нечеткое разбиение
или, как выражается автор процедуры [81, с. 146], «уточняет» нечеткое разбиение  что обозначается
что обозначается  в том случае, если каждый элемент, или, по выражению автора алгоритма, атом разбиения
в том случае, если каждый элемент, или, по выражению автора алгоритма, атом разбиения  может быть представлен объединением атомов разбиения
может быть представлен объединением атомов разбиения  что можно записать также следующим образом:
что можно записать также следующим образом:  если и только если z и и существует разбиение
если и только если z и и существует разбиение  множества
множества  такое, что вьшолняется условие
такое, что вьшолняется условие  и условие
и условие 
Если  является нечетким разбиением исследуемой совокупности объектов
является нечетким разбиением исследуемой совокупности объектов  то можно допустить, что каждый нечеткий
то можно допустить, что каждый нечеткий
к новому нечеткому разбиению  «уточняющему». Оптимальное нечеткое разбиение
«уточняющему». Оптимальное нечеткое разбиение  с функциями принадлежности
с функциями принадлежности  нечеткого класса
нечеткого класса  может быть найдено как решение оптимизационной задачи
может быть найдено как решение оптимизационной задачи  где
где  семейство всех нечетких разбиений нечеткого кластера
семейство всех нечетких разбиений нечеткого кластера  на с классов; нечеткое разбиение
на с классов; нечеткое разбиение  будет доставлять минимум целевой функции, которую теперь можно переписать в виде
будет доставлять минимум целевой функции, которую теперь можно переписать в виде
 (3.119)
(3.119)
если выполняются условия
 (3.120)
(3.120)
где  — центр нечеткого кластера
— центр нечеткого кластера  — степень принадлежности некоторой точки
— степень принадлежности некоторой точки  нечеткому кластеру А, a — степень принадлежности некоторой точки
нечеткому кластеру А, a — степень принадлежности некоторой точки  нечеткому кластеру
нечеткому кластеру 
Таким образом, используя в алгоритме Беждека — Данна соотношения (3.120) и (3.121) для вычисления центров нечетких кластеров и построения нечетких разбиений, можно получить процедуру, которую Д. Думитреску назвал обобщенной иечеткой процедурой ISODATA (Generalized Fuzzy ISODATA), или, сокращенно, GFI алгоритмом [81, с. 148]. В частности, при  данная процедура превращается в описанный выше алгоритм Беждека — Данна при
данная процедура превращается в описанный выше алгоритм Беждека — Данна при 
Далее, пусть при помощи  — алгоритма получено разбиение некоторого нечеткого кластера А на два кластера, так что
— алгоритма получено разбиение некоторого нечеткого кластера А на два кластера, так что  Если
Если  является компактным кластером, то для всех точек степени принадлежности обоим атомам разбиения
является компактным кластером, то для всех точек степени принадлежности обоим атомам разбиения  оказываются приблизительно одинаковы, и наоборот, если эти атомы представляют собой хорошо разделенные кластеры, то значения принадлежностей
оказываются приблизительно одинаковы, и наоборот, если эти атомы представляют собой хорошо разделенные кластеры, то значения принадлежностей  поляризуются у значений
поляризуются у значений  для всех
для всех  , так что структурированность данных подразумевает поляризацию,
, так что структурированность данных подразумевает поляризацию,
и степень поляризации нечеткого разбиения может рассматриваться как мера качества разбиения.
Пусть  — разбиения нечеткого кластера
— разбиения нечеткого кластера  на два кластера, так что
на два кластера, так что  где
где  — значение функции принадлежности i-й точки к
— значение функции принадлежности i-й точки к  нечеткому кластеру — атому
нечеткому кластеру — атому  нечеткого разбиения Р нечеткого кластера
нечеткого разбиения Р нечеткого кластера  Нечеткое разбиение
Нечеткое разбиение  поляризовано меньше, чем нечеткое разбиение
поляризовано меньше, чем нечеткое разбиение  что будет обозначаться
что будет обозначаться  в том и только в том случае, если для всех
в том и только в том случае, если для всех  вьшолняется условие
вьшолняется условие
 (3.122)
(3.122)
так что отношение  представляет собой определенный на
представляет собой определенный на  предпорядок.
предпорядок.
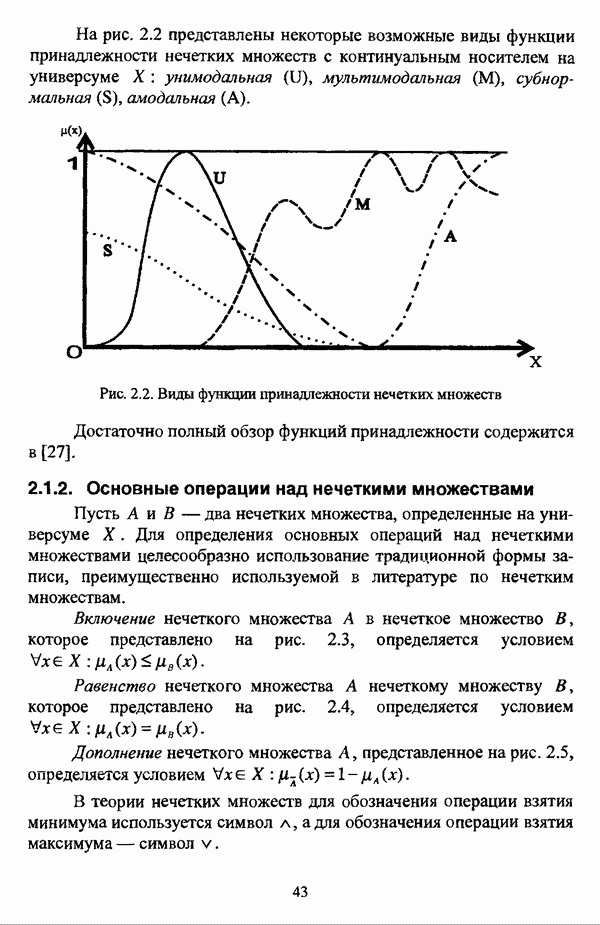
Пусть  — нечеткое множество и
— нечеткое множество и  — нечеткое разбиение
— нечеткое разбиение  Степень поляризации бинарного нечеткого разбиения нечеткого множества
Степень поляризации бинарного нечеткого разбиения нечеткого множества  представляет собой функцию
представляет собой функцию  удовлетворяющую следующим условиям:
удовлетворяющую следующим условиям:

Из условия 2) очевидно, что если Р является разбиением исследуемой совокупности объектов X, то  только в том случае, если Р является четким разбиением
только в том случае, если Р является четким разбиением  Данное обстоятельство вместе с условием 3) позволяют рассматривать
Данное обстоятельство вместе с условием 3) позволяют рассматривать  как своего рода «меру неразмытости»
как своего рода «меру неразмытости»  нечеткого разбиения Р.
нечеткого разбиения Р.
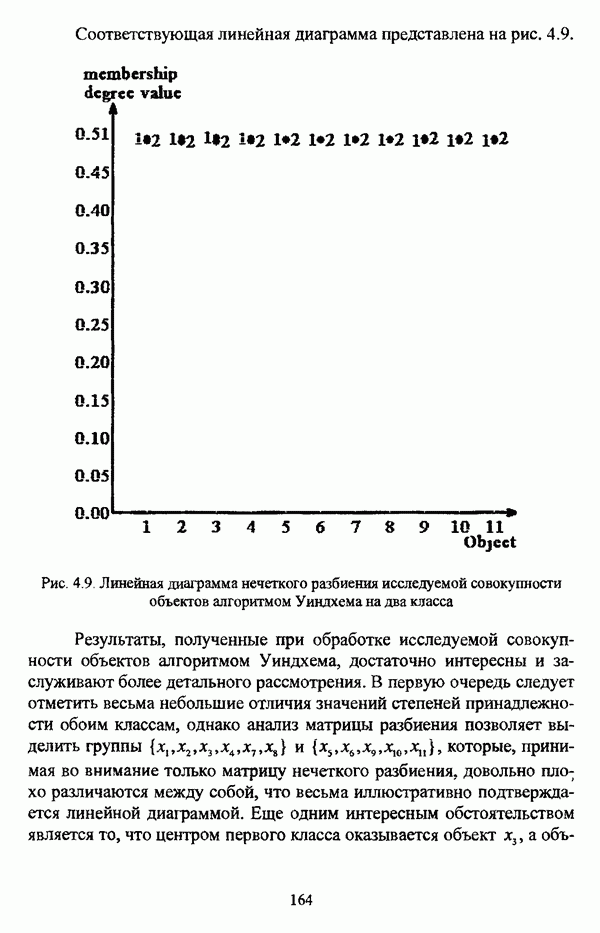
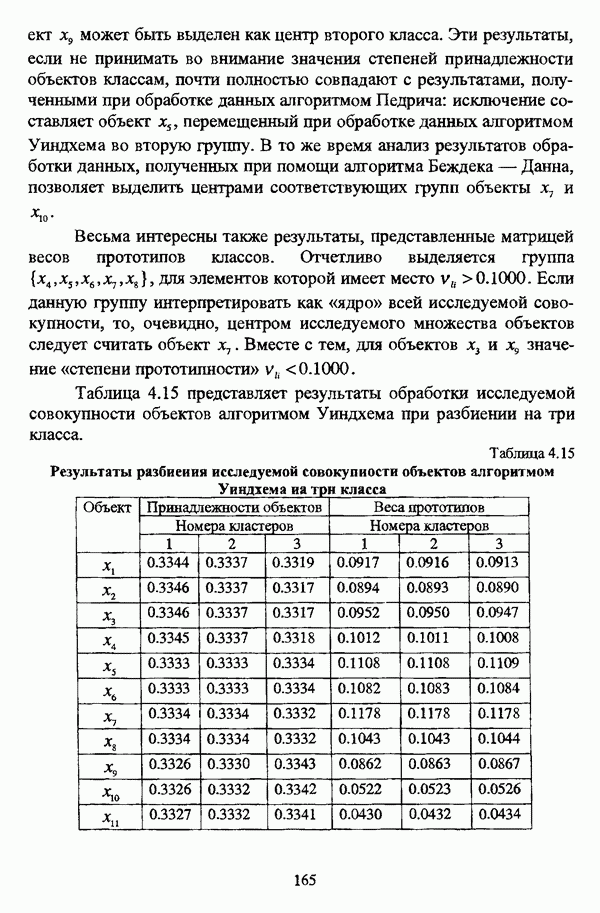
Степени принадлежности компактным и хорошо разделенным, или, используя авторскую терминологию, «реальным», кластерам, полученные последовательной бинарной декомпозицией данных, сохраняют поляризацию в областях 0 и 1. Значение степени принадлежности в области 0.5 говорит об отсутствии структурированности данных.
Подобные рассуждения непосредственно подводят к следующему способу определения степени поляризации:
 (3.123)
(3.123)
где, в свою очередь,  — значение принадлежности i-й точки нечеткому множеству
— значение принадлежности i-й точки нечеткому множеству  уровня 0.5, определяемому в соответствии с выражением (2.4), что в данной ситуации также можно записать в следующем виде:
уровня 0.5, определяемому в соответствии с выражением (2.4), что в данной ситуации также можно записать в следующем виде:
 (3.124)
(3.124)
и 0, иначе
Знаменатель в выражении (3.123) представляет собой просто количество точек в кластерах  разбиения
разбиения  Таким образом, для степени поляризации, определяемой в соответствии с выражением (3.123),
Таким образом, для степени поляризации, определяемой в соответствии с выражением (3.123),  в силу условий 1) — 4), и можно допустить, что нечеткое разбиение
в силу условий 1) — 4), и можно допустить, что нечеткое разбиение  описывает «реальные» кластеры в том и только в том случае, если для каждого класса
описывает «реальные» кластеры в том и только в том случае, если для каждого класса  существует х, такой, что
существует х, такой, что  . В таком случае
. В таком случае  представляет собой некоторый порог, выражающий уверенность в том, что кластеры являются «реальными». Для иллюстрации вышеизложенного целесообразно рассмотреть следующий пример [81, с. 151].
представляет собой некоторый порог, выражающий уверенность в том, что кластеры являются «реальными». Для иллюстрации вышеизложенного целесообразно рассмотреть следующий пример [81, с. 151].
Пусть  — исследуемая совокупность объектов и нечеткое разбиение
— исследуемая совокупность объектов и нечеткое разбиение  совокупности X описывается матрицей, представленной таблицей 3.2.
совокупности X описывается матрицей, представленной таблицей 3.2.
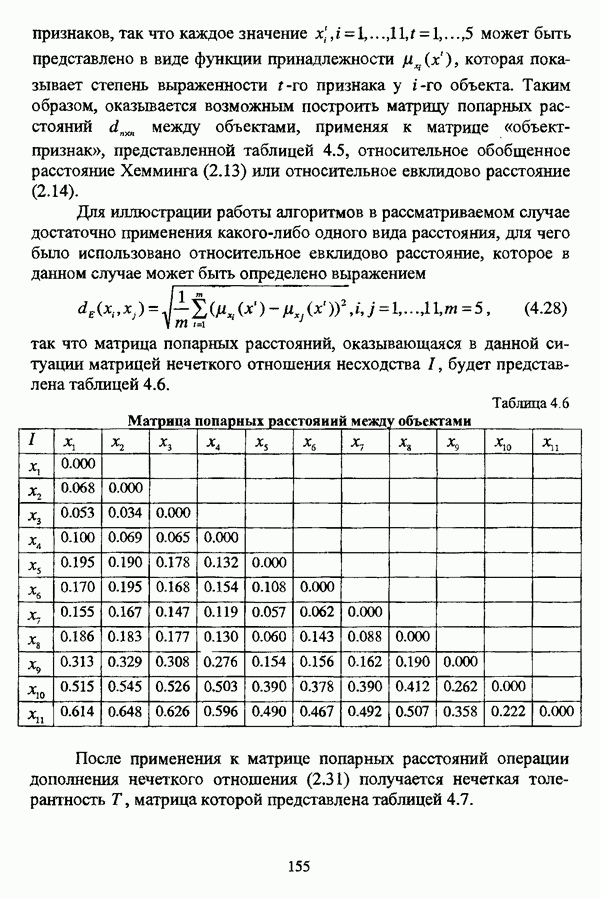
Таблица 3.2. Матрица нечеткого разбиения Р совокупности X на два класса

В соответствии с  так что при к:
так что при к:  нечеткие кластеры, описываемые разбиением Р, могут рассматриваться как «реальные».
нечеткие кластеры, описываемые разбиением Р, могут рассматриваться как «реальные».
Далее, пусть  — нечеткое разбиение кластера
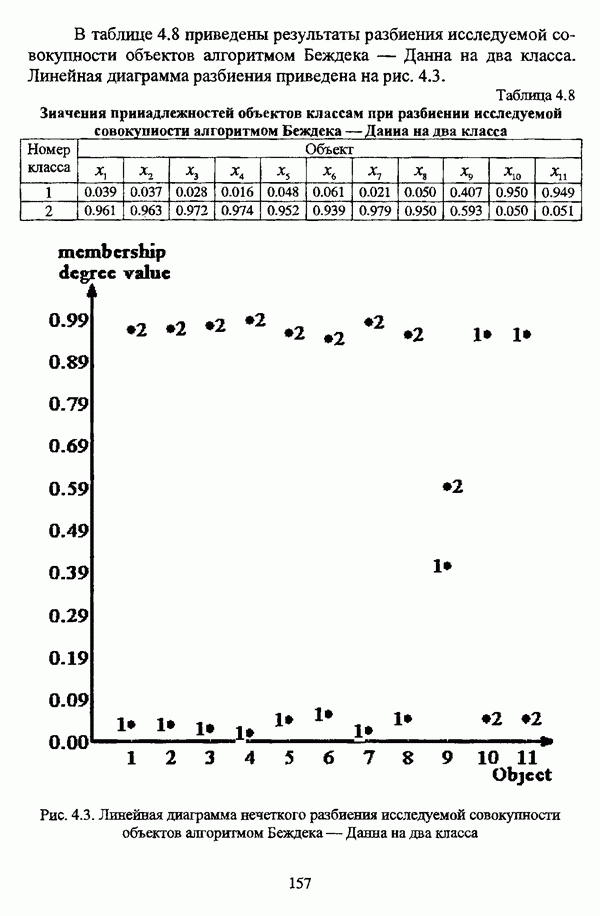
— нечеткое разбиение кластера  описываемое матрицей, представленной таблицей 3.3.
описываемое матрицей, представленной таблицей 3.3.
Таблица 3 3. Матрица нечеткого разбиения  кластера
кластера  на два класса
на два класса

Несмотря на достаточно высокое значение степени поляризации  значения принадлежностей всех объектов классу менее 0.5, так что разбиение
значения принадлежностей всех объектов классу менее 0.5, так что разбиение  не представляет «реальные» кластеры при любом значении порога к и нечеткий кластер
не представляет «реальные» кластеры при любом значении порога к и нечеткий кластер  является «реальным» неделимым кластером.
является «реальным» неделимым кластером.
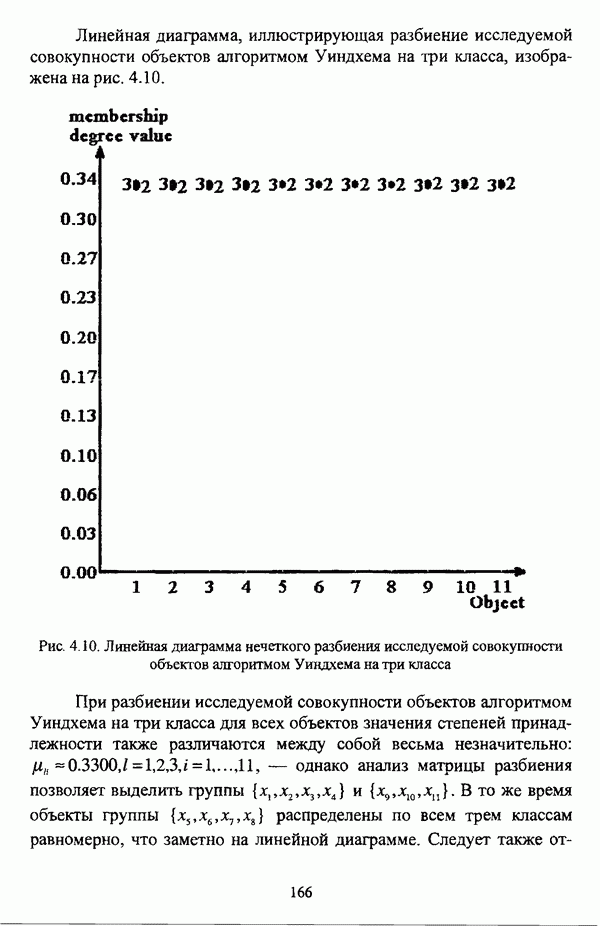
Теперь, пусть  — нечеткое разбиение кластера
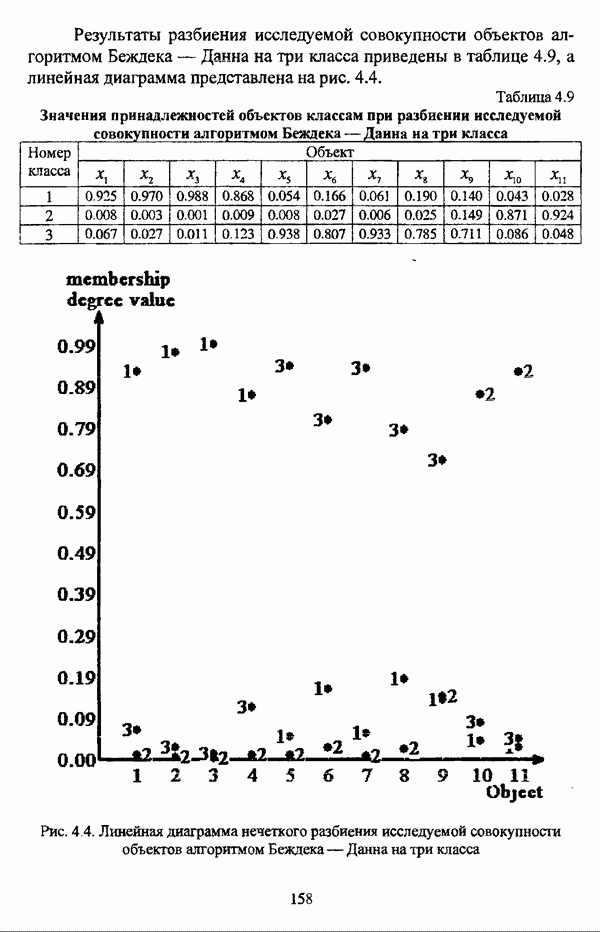
— нечеткое разбиение кластера  описываемое матрицей, представленной таблицей 3.4.
описываемое матрицей, представленной таблицей 3.4.
Таблица 3.4. Матрица нечеткого разбиения кластера А на два класса

При вычислении значения степени поляризации  становится очевидным, что
становится очевидным, что  являются «реальными» кластерами при
являются «реальными» кластерами при  причем нечеткий кластер А: содержит только объект
причем нечеткий кластер А: содержит только объект 
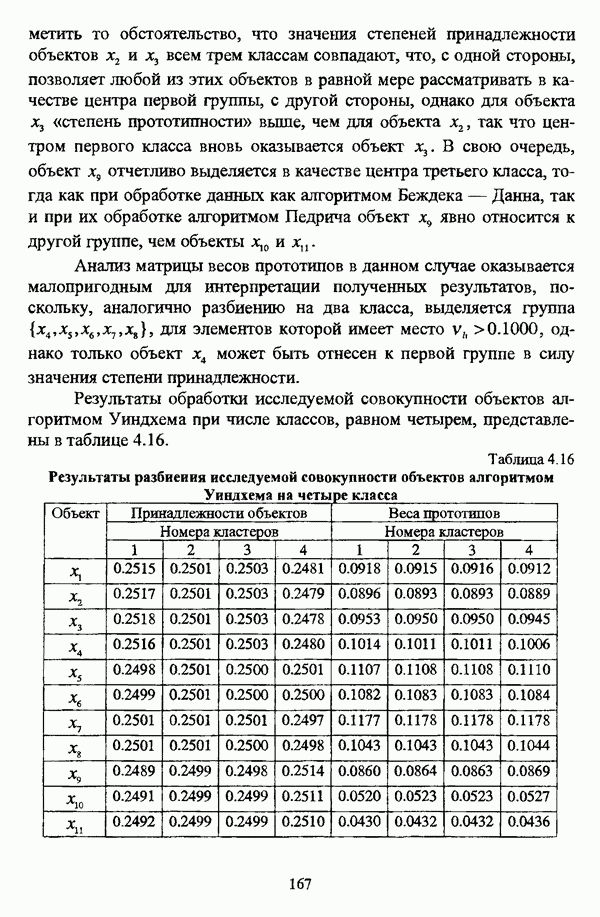
Семейство нечетких множеств, определенных на исследуемой совокупности объектов  образует нечеткую иерархию Н, если выполняются следующие условия:
образует нечеткую иерархию Н, если выполняются следующие условия:
1)  , либо
, либо  либо
либо  для всех
для всех 
2)  для каждого
для каждого  , так что
, так что  где
где

Иными словами,  — множество всех нечетких подмножеств, составляющих нечеткое множество
— множество всех нечетких подмножеств, составляющих нечеткое множество  Нечеткая иерархия Н
Нечеткая иерархия Н
называется всюду определенной, если  Нечеткая иерархия Я называется бинарной, если
Нечеткая иерархия Я называется бинарной, если  или
или  для каждого
для каждого  некоторый элемент А нечеткой иерархии Я, для которого вьшолняется
некоторый элемент А нечеткой иерархии Я, для которого вьшолняется  называется минимальным по включению в Н. Таким образом, всюду определенная бинарная нечеткая иерархия Н может быть представлена бинарным деревом, имеющим X в качестве корневого узла, терминальные узлы которого, в свою очередь, будут соответствовать минимальным по включению в Н множествам.
называется минимальным по включению в Н. Таким образом, всюду определенная бинарная нечеткая иерархия Н может быть представлена бинарным деревом, имеющим X в качестве корневого узла, терминальные узлы которого, в свою очередь, будут соответствовать минимальным по включению в Н множествам.
Стратификационный индекс  всюду определенной нечеткой иерархии Н представляет собой функцию
всюду определенной нечеткой иерархии Н представляет собой функцию  удовлетворяющую следующим условиям:
удовлетворяющую следующим условиям:
1) для любых  имеет место неравенство
имеет место неравенство

Стратификационный индекс, таким образом, представляет собой уровень декомпозиции исследуемой совокупности объектов  Сущность подхода заключается в том, что рассматриваются только те нечеткие разбиения в вышеуказанном смысле, атомы которых являются «реальными» кластерами. Процедура начинается с вычисления нечеткого разбиения
Сущность подхода заключается в том, что рассматриваются только те нечеткие разбиения в вышеуказанном смысле, атомы которых являются «реальными» кластерами. Процедура начинается с вычисления нечеткого разбиения  исследуемой совокупности объектов
исследуемой совокупности объектов  которую можно рассматривать как однородный кластер, центр которого вычисляется в соответствии с формулой
которую можно рассматривать как однородный кластер, центр которого вычисляется в соответствии с формулой
 (3.125)
(3.125)
где X; представляет собой элемент матрицы «объект-свойство» (1.1), то есть значение  признака на
признака на  объекте.
объекте.
Если атомы  не являются «реальными» кластерами, можно говорить об отсутствии кластерной структуры в исследуемой совокупности объектов
не являются «реальными» кластерами, можно говорить об отсутствии кластерной структуры в исследуемой совокупности объектов  Если же атомы
Если же атомы  являются «реальными» кластерами, то полагается
являются «реальными» кластерами, то полагается  Следует указать на небольшое изменение смысла обозначений: в обозначении разбиения
Следует указать на небольшое изменение смысла обозначений: в обозначении разбиения  индекс
индекс  обозначает уровень декомпозиции, символ I — номер разбиения соответствующего уровня, а символ
обозначает уровень декомпозиции, символ I — номер разбиения соответствующего уровня, а символ  обозначает
обозначает  кластер,
кластер,  разбиения
разбиения  уровня декомпозиции. Далее, используя
уровня декомпозиции. Далее, используя  -алгоритм, вычисляем бинарные нечеткие разбиения
-алгоритм, вычисляем бинарные нечеткие разбиения
атомов  разбиения
разбиения  если атомы новых разбиений являются «реальными» кластерами, то они будут атомами разбиений уровня
если атомы новых разбиений являются «реальными» кластерами, то они будут атомами разбиений уровня  в противном случае атом, не являющийся «реальным» кластером, оказывается неделимым нечетким кластером уровня 1-2. В свою очередь, атомы разбиения, не являющиеся неделимыми нечеткими кластерами, подвергаются дальнейшей обработке данной процедурой, напоминающей бэктрекинг в языке логического программирования PROLOG. Так, атомы предыдущего уровня декомпозиции будут именоваться формирующими нечеткие разбиения текущего уровня исследуемой совокупности объектов
в противном случае атом, не являющийся «реальным» кластером, оказывается неделимым нечетким кластером уровня 1-2. В свою очередь, атомы разбиения, не являющиеся неделимыми нечеткими кластерами, подвергаются дальнейшей обработке данной процедурой, напоминающей бэктрекинг в языке логического программирования PROLOG. Так, атомы предыдущего уровня декомпозиции будут именоваться формирующими нечеткие разбиения текущего уровня исследуемой совокупности объектов  Процесс декомпозиции останавливается тогда, когда не обнаруживается ни одного «реального» кластера, то есть два следующих друг за другом разбиения оказываются идентичны: при
Процесс декомпозиции останавливается тогда, когда не обнаруживается ни одного «реального» кластера, то есть два следующих друг за другом разбиения оказываются идентичны: при  для всех I уровень b оказывается последним уровнем декомпозиции
для всех I уровень b оказывается последним уровнем декомпозиции 
Последовательность разбиений различных уровней  полученных в результате декомпозиции, где разбиение уровня
полученных в результате декомпозиции, где разбиение уровня  представляет собой исследуемую совокупность объектов
представляет собой исследуемую совокупность объектов  что обозначается
что обозначается  удовлетворяет рассмотренному выше условию предшествования, так что
удовлетворяет рассмотренному выше условию предшествования, так что  а всюду определенная бинарная нечеткая иерархия может бьггь представлена в виде
а всюду определенная бинарная нечеткая иерархия может бьггь представлена в виде  . В свою очередь, стратификационный индекс определяется выражением
. В свою очередь, стратификационный индекс определяется выражением
 (3.126)
(3.126)
Естественно, что число классов в разбиении уровня  будет равно одному, а в разбиении уровня
будет равно одному, а в разбиении уровня  — двум, так что при
— двум, так что при  число собственно разбиений будет равно одному, следовательно, при обозначении разбиений
число собственно разбиений будет равно одному, следовательно, при обозначении разбиений  верхний индекс I можно опускать.
верхний индекс I можно опускать.
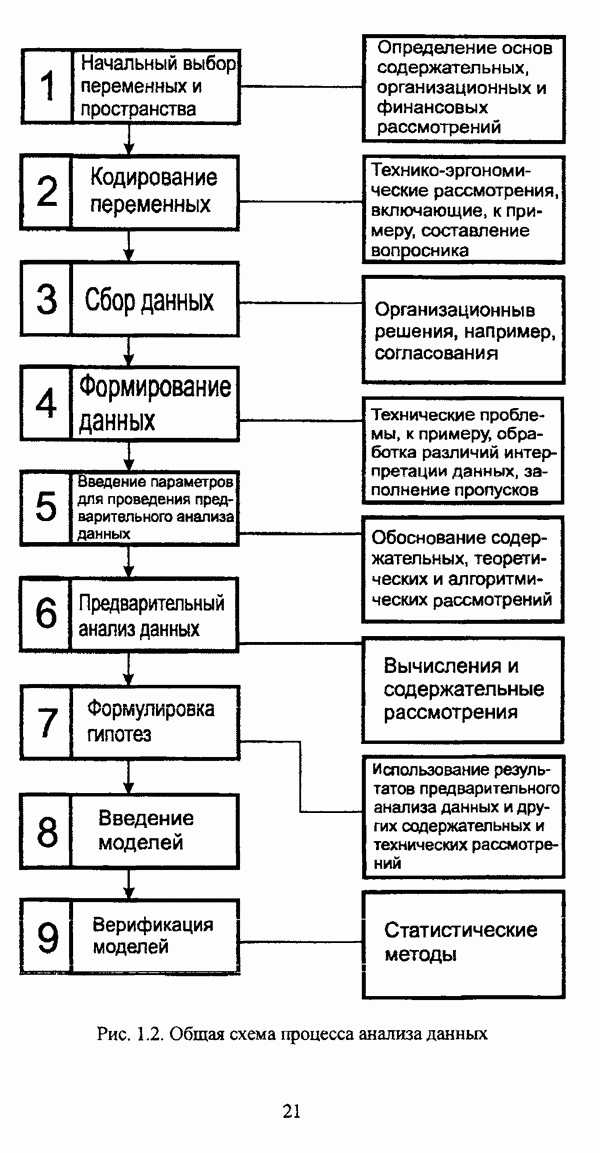
Параметры алгоритма:
Исходные данные задаются в виде матрицы «объект-свойство» (1.1). Входные параметры как таковые отсутствуют. В процессе работы алгоритма используется счетчик терминальных узлов с. Процесс присвоения номеров I разбиениям  ) детально не рассматривается.
) детально не рассматривается.
Схема алгоритма:
1 Полагается 
2 Для текущего уровня  нумеруются разбиения
нумеруются разбиения  для каждого разбиения
для каждого разбиения  просматриваются все атомы, и для каждого непустого
просматриваются все атомы, и для каждого непустого




























































































































































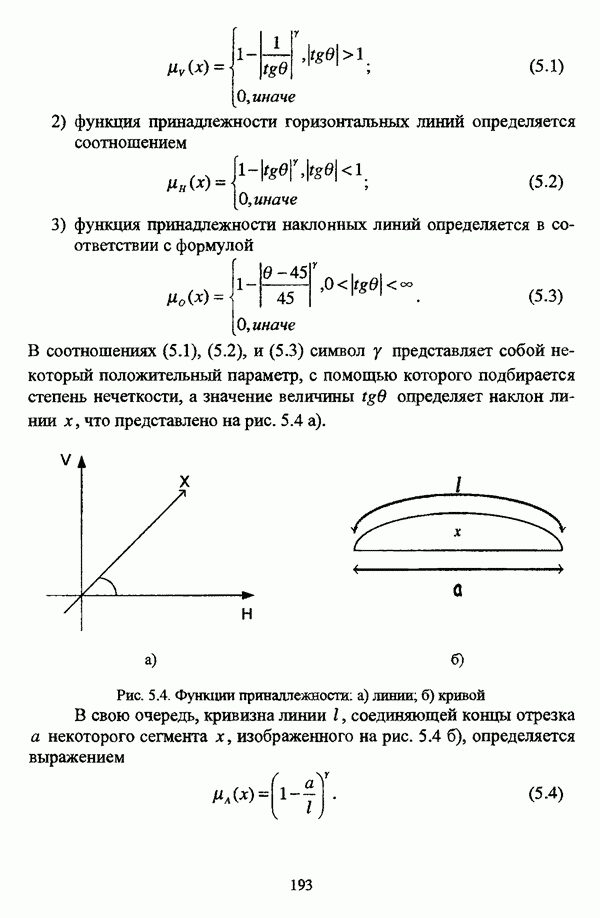



















 может быть представлен прототипом, или, иными словами, центром
может быть представлен прототипом, или, иными словами, центром 
 — функция расстояния, измеряющая степень отличия точки
— функция расстояния, измеряющая степень отличия точки  от
от  прототипа
прототипа  и представляющая собой квадрат евклидова расстояния:
и представляющая собой квадрат евклидова расстояния:  При обозначении собственно евклидова расстояния между объектами
При обозначении собственно евклидова расстояния между объектами  через
через  и определении понятия локального расстояния
и определении понятия локального расстояния  в пространстве признаков
в пространстве признаков  зависящего от функции принадлежности нечеткого множества
зависящего от функции принадлежности нечеткого множества  соотношением
соотношением
 (3.114)
(3.114)
 будет определяться, в свою очередь, соотношением
будет определяться, в свою очередь, соотношением
 (3.115)
(3.115)
 и центром
и центром  нечеткого кластера
нечеткого кластера  будет определяться выражением
будет определяться выражением
 (3.116)
(3.116)
 будет определяться выражением
будет определяться выражением
 (3.117)
(3.117)
 и набором его центров будет определяться формулой
и набором его центров будет определяться формулой
 (3.118)
(3.118)
 Дж. Беждека — Дж. Данна в виде (3.46) при
Дж. Беждека — Дж. Данна в виде (3.46) при  так что, естественно, интерес представляет задача минимизации функционала (3.118).
так что, естественно, интерес представляет задача минимизации функционала (3.118).
 может быть описана его нечетким разбиением. Разбиение неоднородных нечетких кластеров — элементов нечеткого разбиения Р приводит
может быть описана его нечетким разбиением. Разбиение неоднородных нечетких кластеров — элементов нечеткого разбиения Р приводит
 осуществляется выполнение условия, описанного на шаге 4; все кластеры
осуществляется выполнение условия, описанного на шаге 4; все кластеры  терминальные узлы распределяются в нечеткое разбиение
терминальные узлы распределяются в нечеткое разбиение  и в дальнейшем не подвергаются обработке GH алгоритмом;
и в дальнейшем не подвергаются обработке GH алгоритмом;
 то алгоритм прекращает работу, в противном случае полагается
то алгоритм прекращает работу, в противном случае полагается  ! и осуществляется переход на шаг 2;
! и осуществляется переход на шаг 2;
 атома разбиения
атома разбиения  при помощи GFI алгоритма вычисляется нечеткое разбиение
при помощи GFI алгоритма вычисляется нечеткое разбиение  если
если  являются «реальными» кластерами, то они образуют разбиение
являются «реальными» кластерами, то они образуют разбиение  -го уровня
-го уровня  в противном случае атом
в противном случае атом  не образует разбиения
не образует разбиения  уровня
уровня  и считается неделимым нечетким кластером — терминальным узлом, полагается с
и считается неделимым нечетким кластером — терминальным узлом, полагается с  и осуществляется переход к рассмотрению другого атома.
и осуществляется переход к рассмотрению другого атома.
 так что ГОН алгоритм может использоваться для отыскания естественного числа классов перед применением оптимизационной кластер-процедуры, использующей число классов с в качестве входного параметра.
так что ГОН алгоритм может использоваться для отыскания естественного числа классов перед применением оптимизационной кластер-процедуры, использующей число классов с в качестве входного параметра.