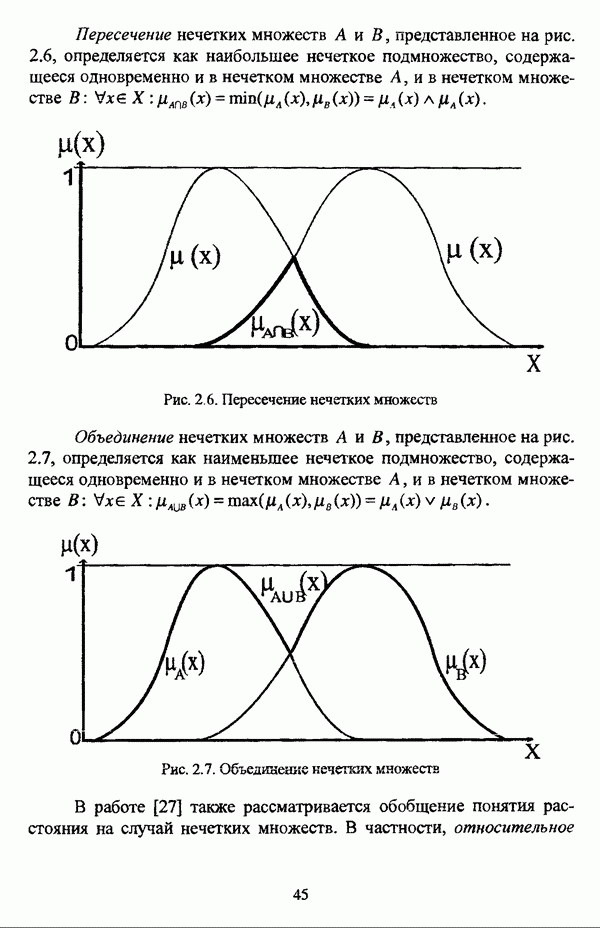
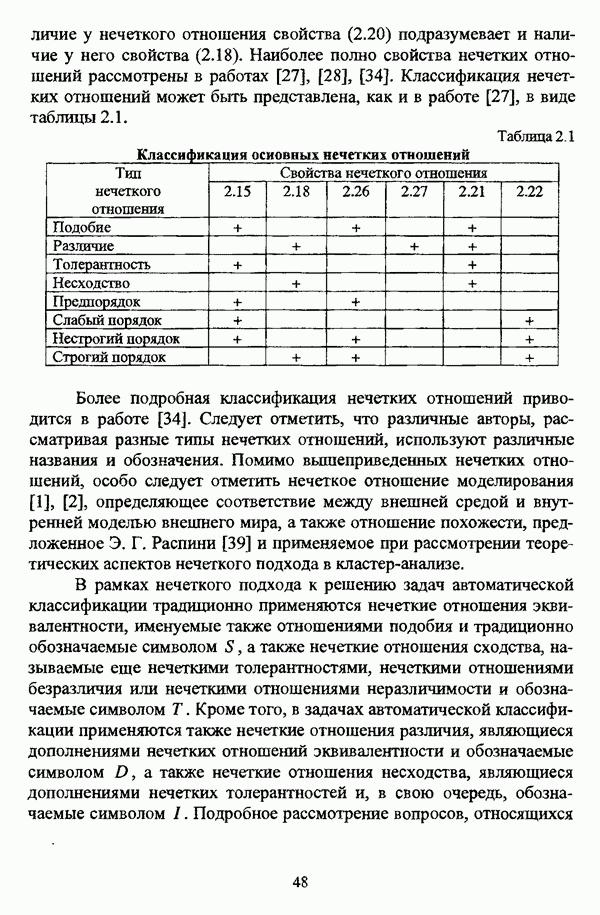
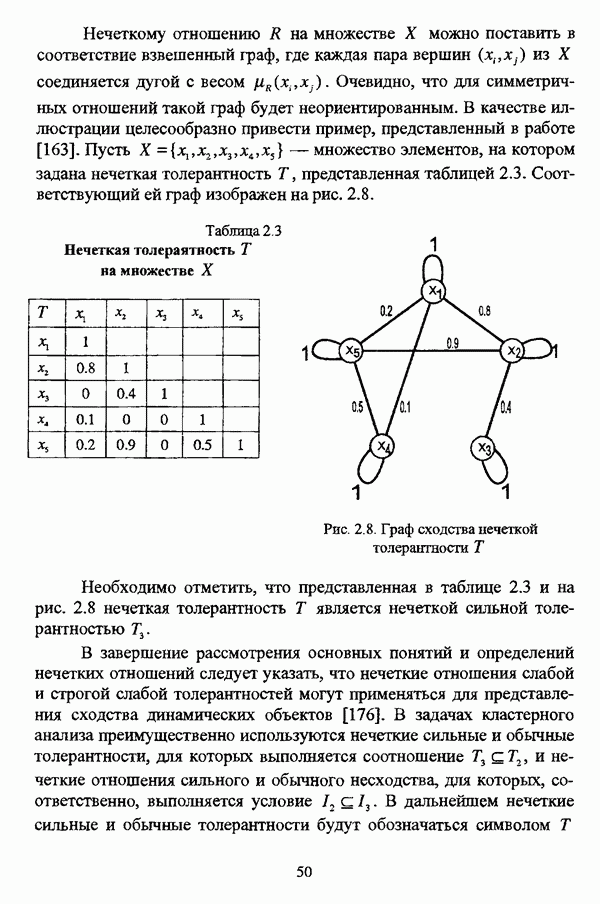
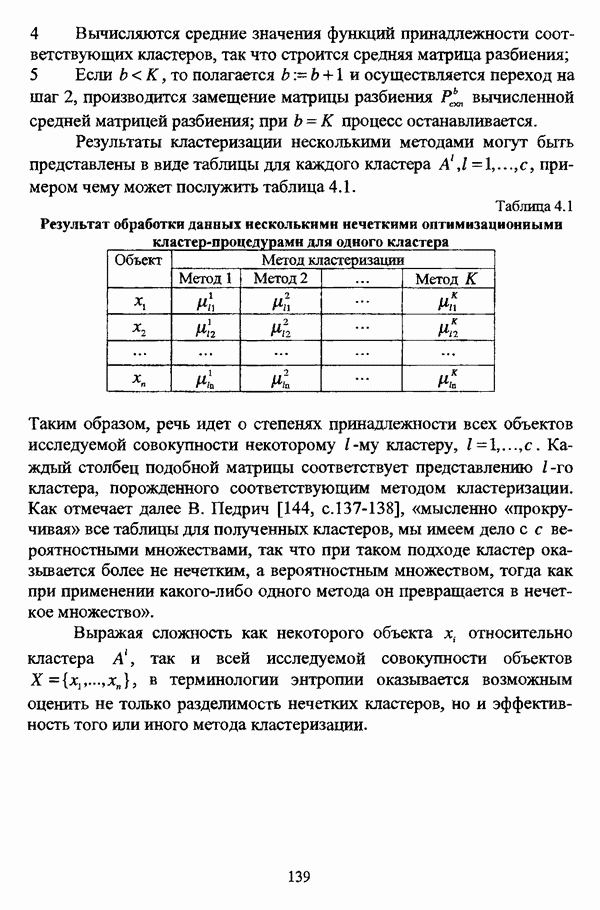
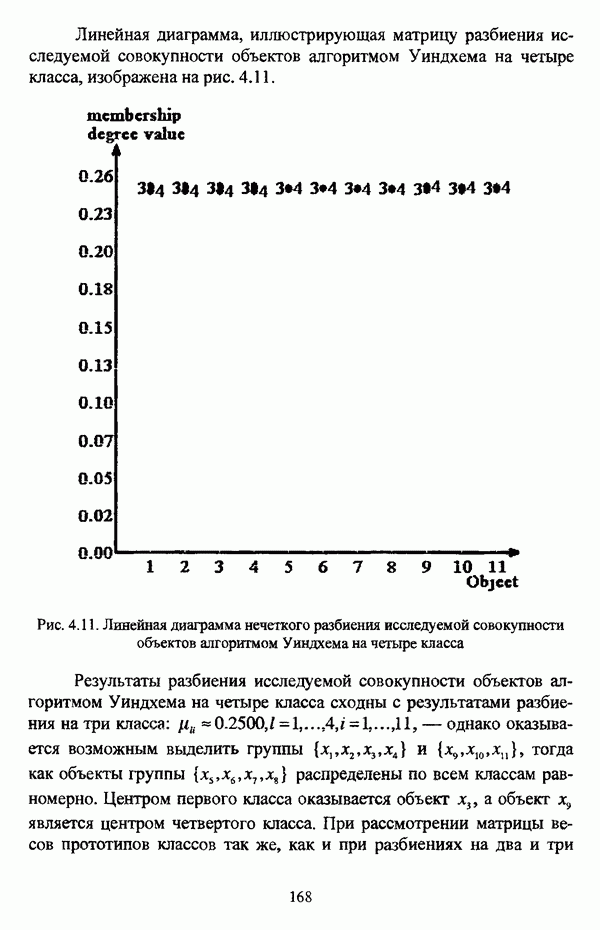
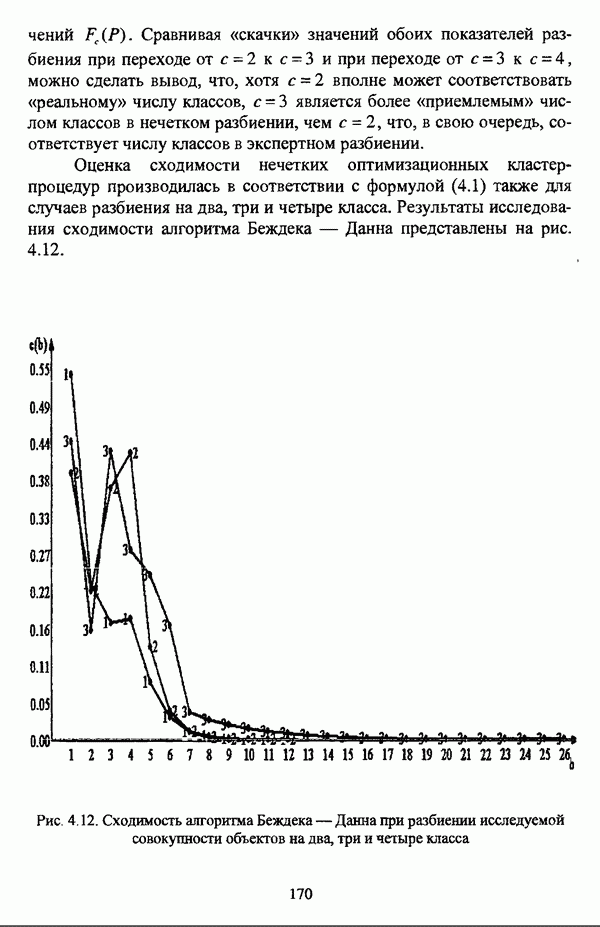
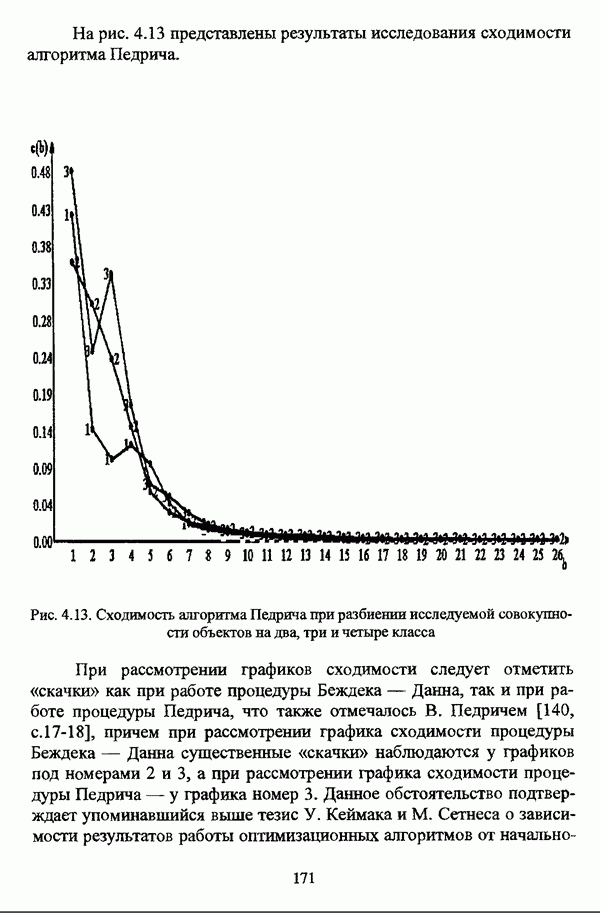
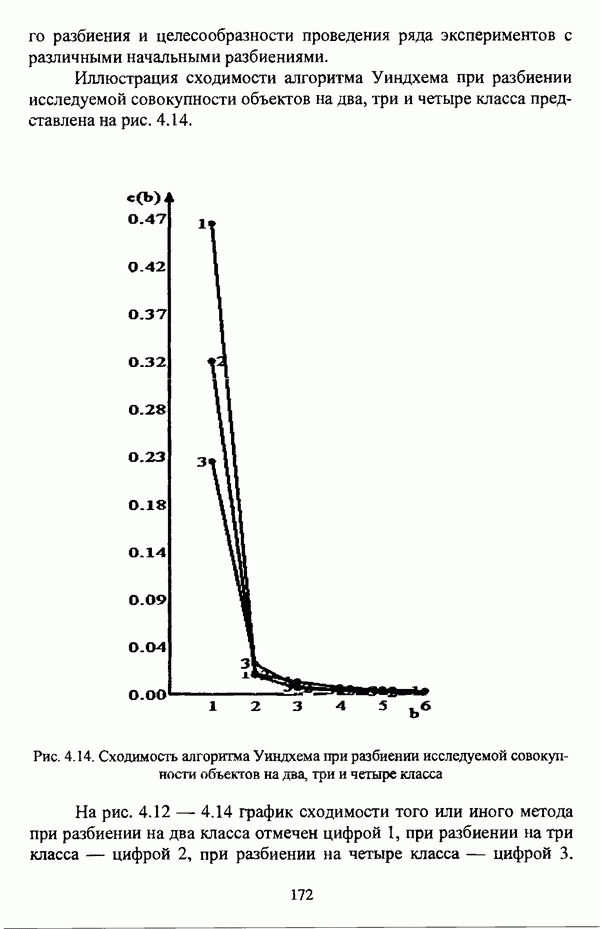
Резюме
Нечеткие методы автоматической классификации эвристического направления представлены алгоритмом И. Гитмана и М. Д. Левина, исходные данные для которого представляются в форме матрицы «объект-свойство» алгоритмом, предложенным С. Тамурой, С. Хигути и К. Танакой, алгоритмом А. Кутюрье и Б. Фьолео и алгоритмом классификации на нечетких графах Л. С. Берштейна и Т. А. Дзюбы, использующими в качестве исходных данных матрицу «объект-объект». Эти процедуры непосредственно опираются на постановку задачи выделения
в исследуемой совокупности объектов  структура которой характеризуется нечеткостью, групп объектов
структура которой характеризуется нечеткостью, групп объектов  являющихся нечеткими множествами с соответствующими функциями принадлежности
являющихся нечеткими множествами с соответствующими функциями принадлежности  Нечеткие оптимизационные методы автоматической классификации находят решение задачи
Нечеткие оптимизационные методы автоматической классификации находят решение задачи  где П — множество всех возможных нечетких разбиений Р исходного множества объектов
где П — множество всех возможных нечетких разбиений Р исходного множества объектов  В свою очередь, нечеткие множества
В свою очередь, нечеткие множества  определенные на универсуме
определенные на универсуме  с соответствующими функциями принадлежности
с соответствующими функциями принадлежности  , образуют нечеткое с-разбиение
, образуют нечеткое с-разбиение  в смысле Э. Г. Распини, если для каждого объекта
в смысле Э. Г. Распини, если для каждого объекта  вьполняется условие
вьполняется условие  В зависимости от вида матрицы исходных данных представленные оптимизационные методы условно объединяются в две группы: при задании исходных данных в виде матрицы «объект-объект» для решения задачи классификации применяются процедуры Э. Г. Распини, М. П. Уиндхема, М. Рубенса, Р. Н. Даве и С. Сена, находящие экстремум соответствующего функционала, а если исходные данные заданы в виде матрицы «объект-свойство», решение задачи классификации заключается в нахождении экстремума одного из функционалов, предложенных Дж. Беждеком и Дж. Данном, В. Педричем или В. Райтом. Общим для оптимизационных методов нечеткого подхода к решению задачи автоматической классификации ограничением является условие нечеткого разбиения Э. Г. Распини, а общим параметром является параметр с, определяющий число кластеров в искомом нечетком разбиении. Представлены также различные модификации некоторых из рассмотренных оптимизационных методов. Нечеткие иерархические кластер-процедуры представлены алгоритмом Д. Ватады, X. Танаки и К. Асаи, в качестве исходных данных использующим матрицу сходства объектов (1.3) и допускающим как восходящую, так и нисходящую версии, и бинарным дивизимным алгоритмом Д. Думитреску, который предполагает представление исходных данных в форме матрицы «объект-свойство». Модификация алгоритма Д. Думитреску применима для решения задачи снижения признакового пространства.
В зависимости от вида матрицы исходных данных представленные оптимизационные методы условно объединяются в две группы: при задании исходных данных в виде матрицы «объект-объект» для решения задачи классификации применяются процедуры Э. Г. Распини, М. П. Уиндхема, М. Рубенса, Р. Н. Даве и С. Сена, находящие экстремум соответствующего функционала, а если исходные данные заданы в виде матрицы «объект-свойство», решение задачи классификации заключается в нахождении экстремума одного из функционалов, предложенных Дж. Беждеком и Дж. Данном, В. Педричем или В. Райтом. Общим для оптимизационных методов нечеткого подхода к решению задачи автоматической классификации ограничением является условие нечеткого разбиения Э. Г. Распини, а общим параметром является параметр с, определяющий число кластеров в искомом нечетком разбиении. Представлены также различные модификации некоторых из рассмотренных оптимизационных методов. Нечеткие иерархические кластер-процедуры представлены алгоритмом Д. Ватады, X. Танаки и К. Асаи, в качестве исходных данных использующим матрицу сходства объектов (1.3) и допускающим как восходящую, так и нисходящую версии, и бинарным дивизимным алгоритмом Д. Думитреску, который предполагает представление исходных данных в форме матрицы «объект-свойство». Модификация алгоритма Д. Думитреску применима для решения задачи снижения признакового пространства.