Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
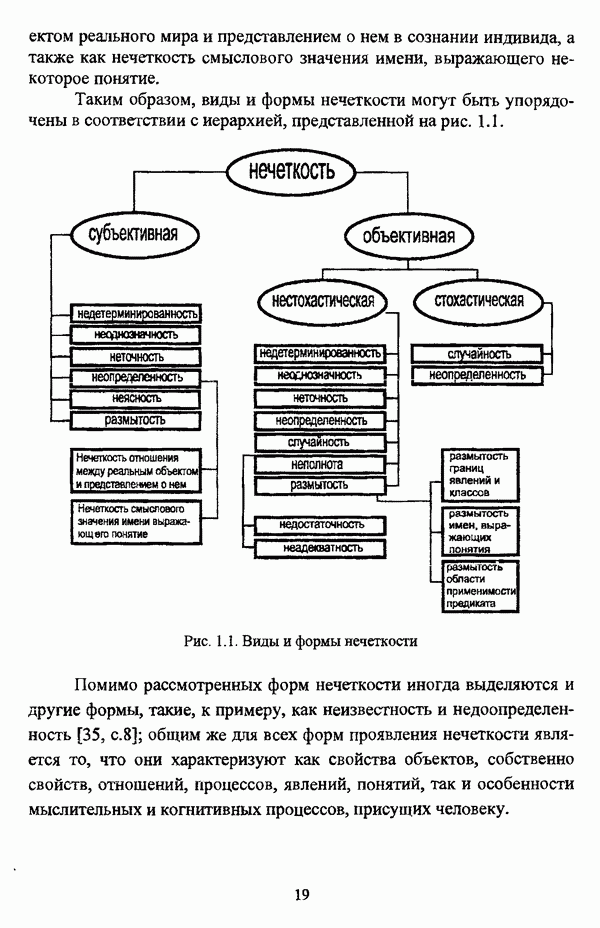
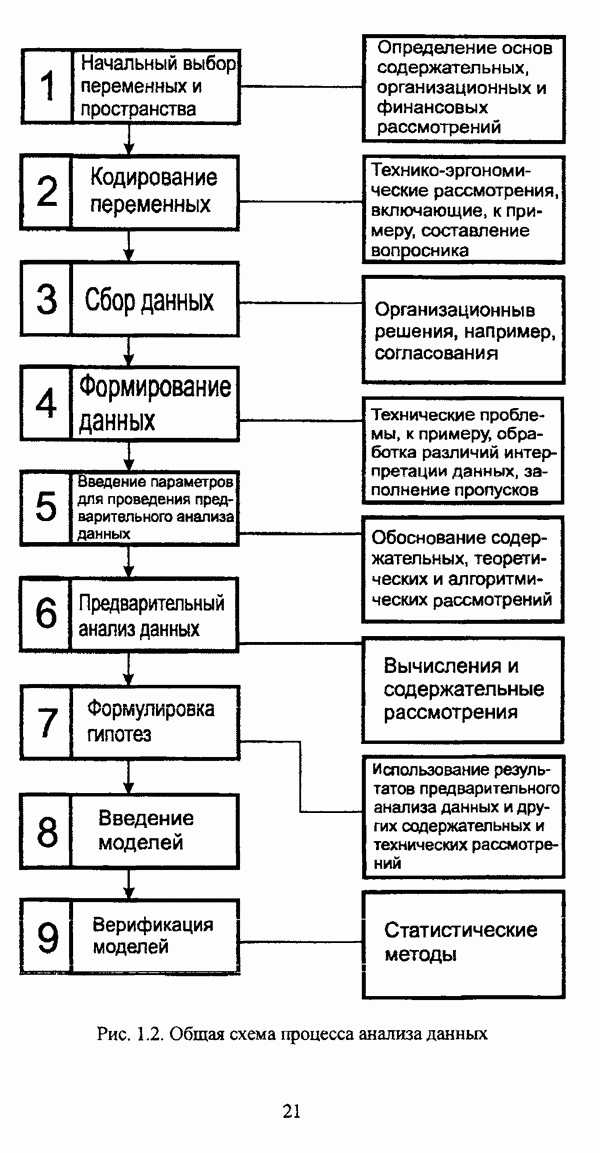
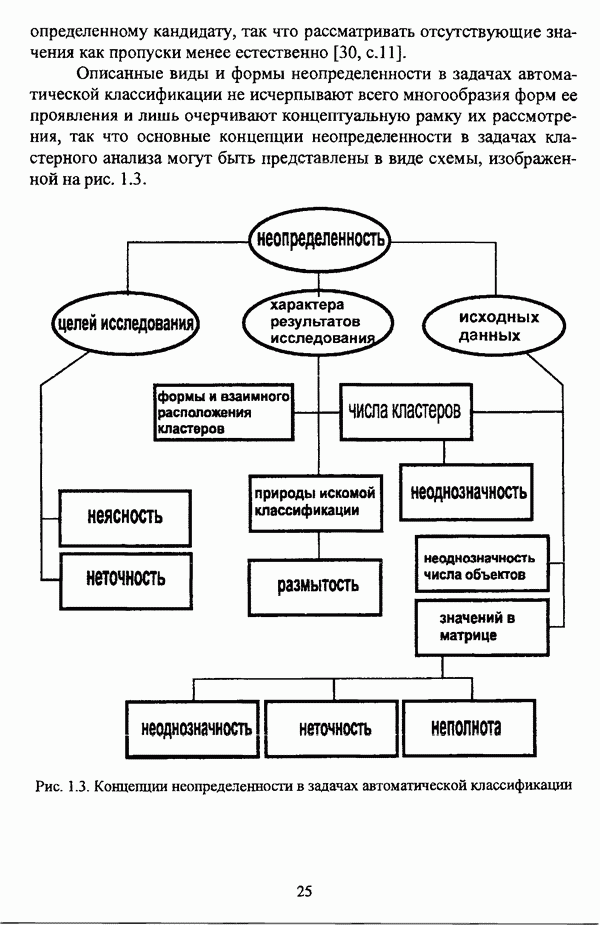
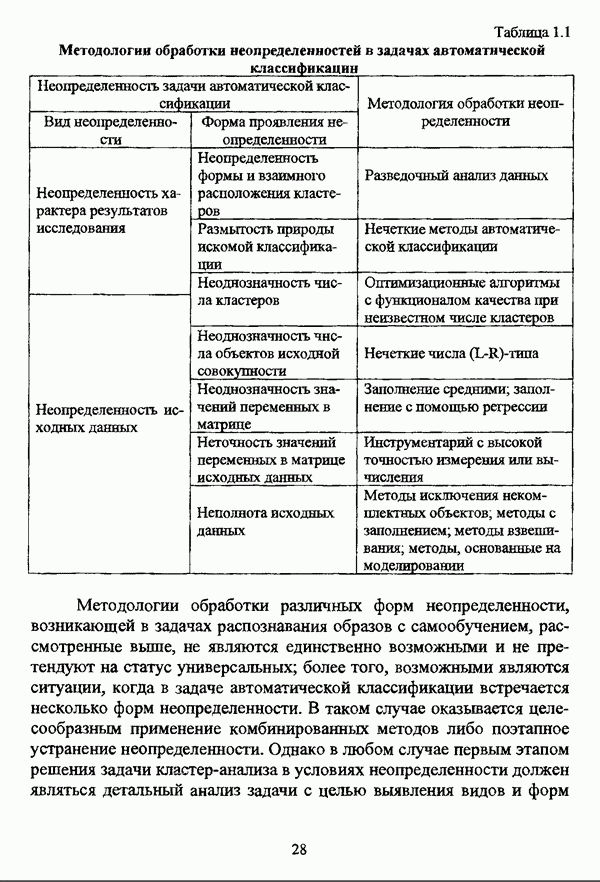
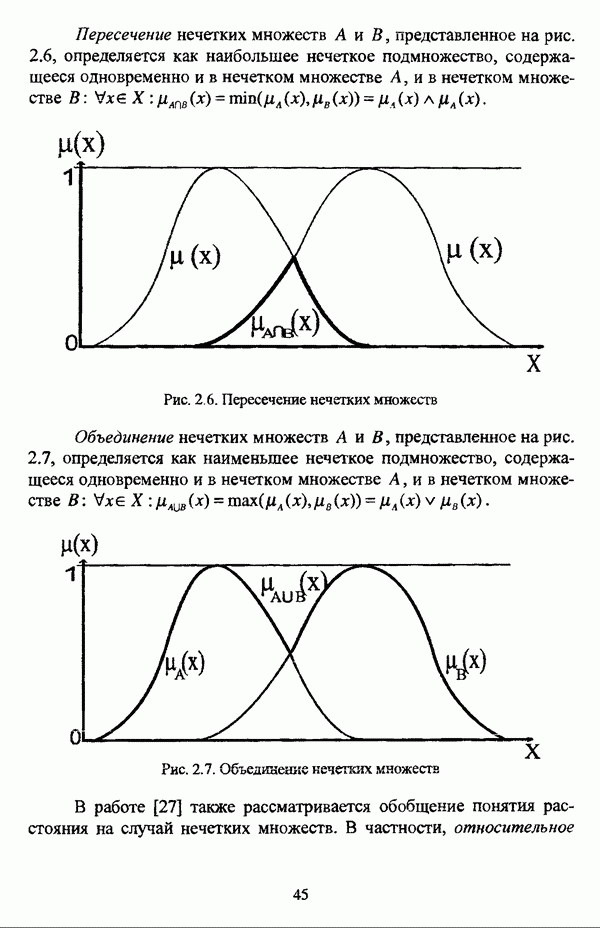
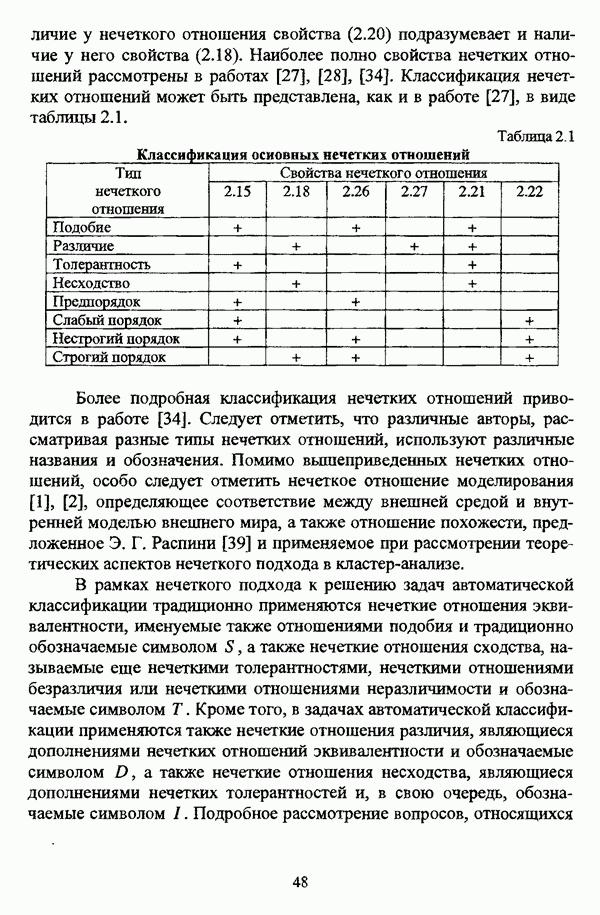
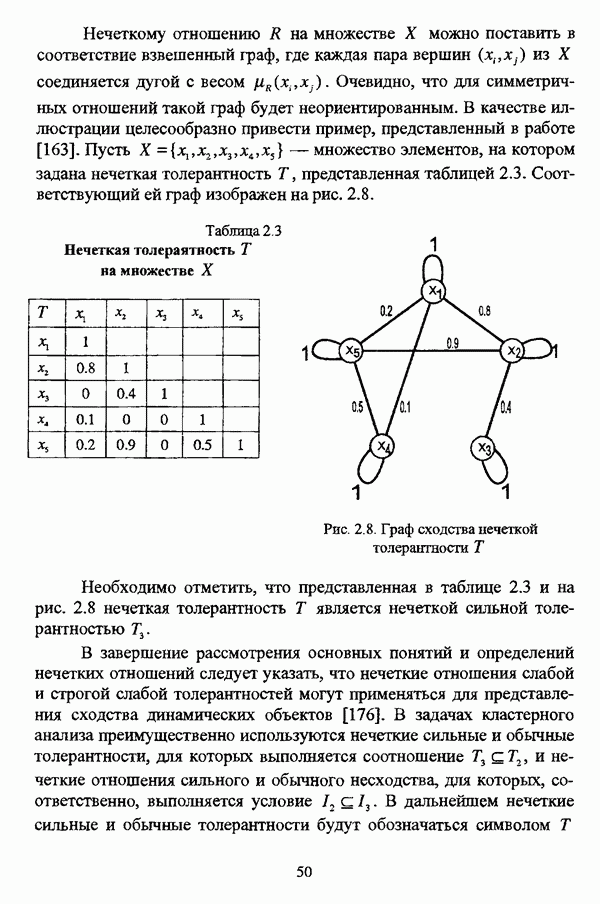
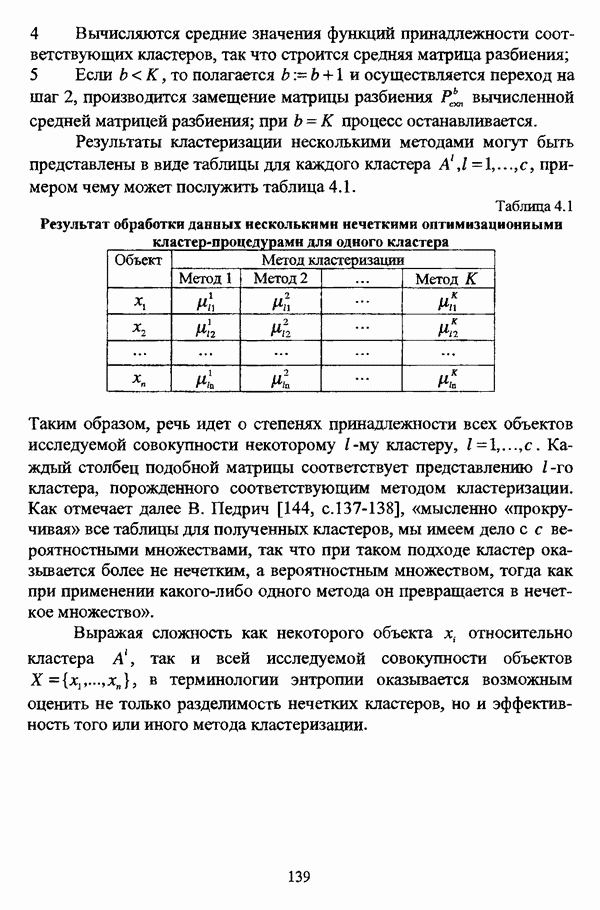
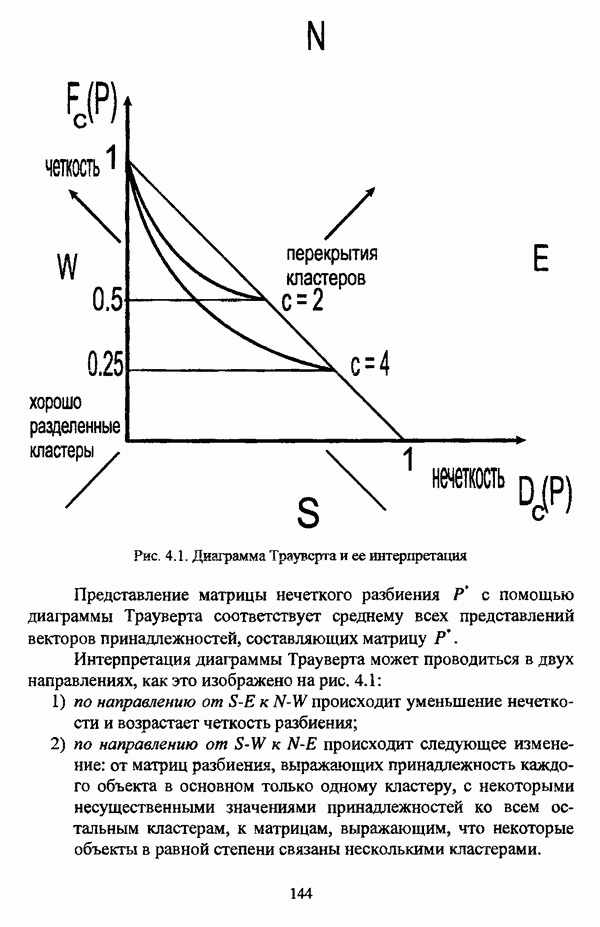
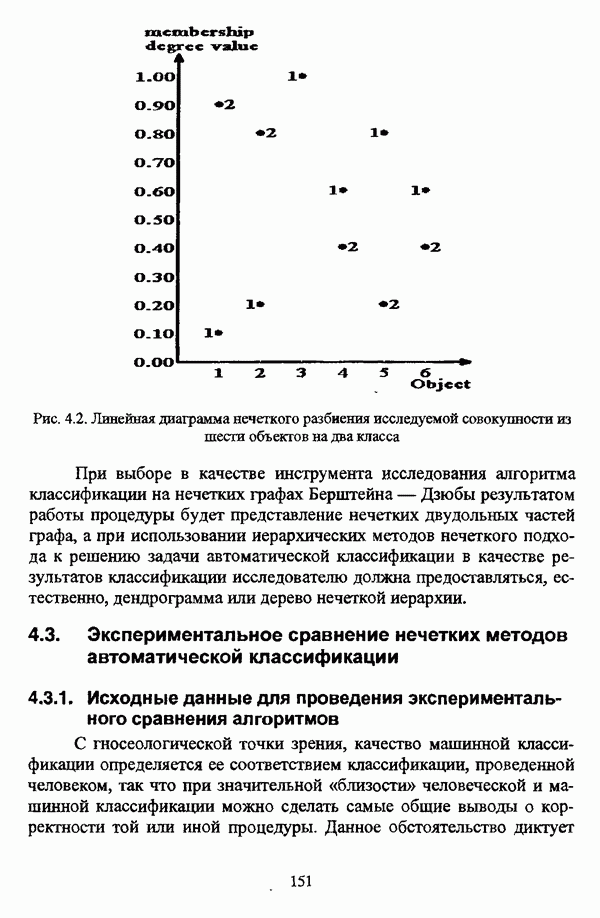
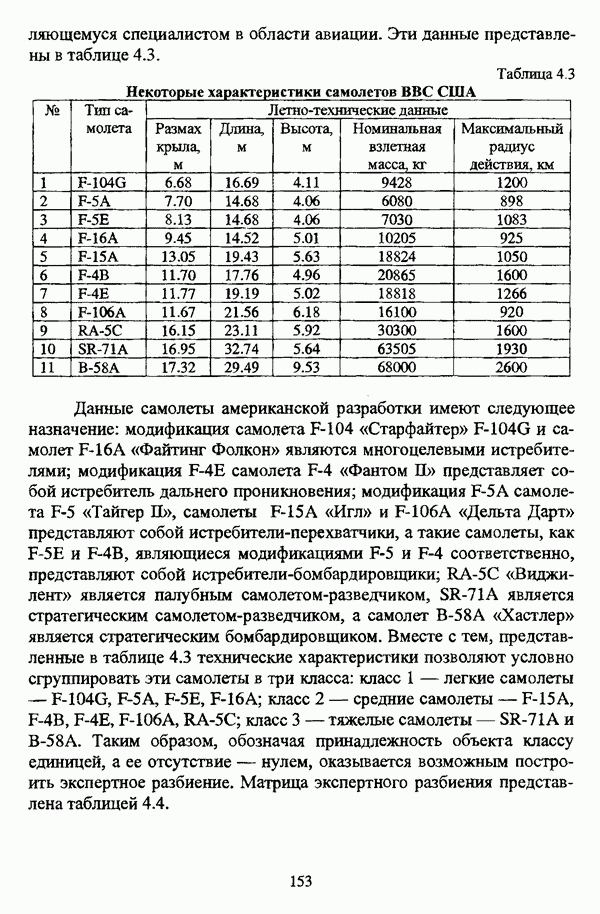
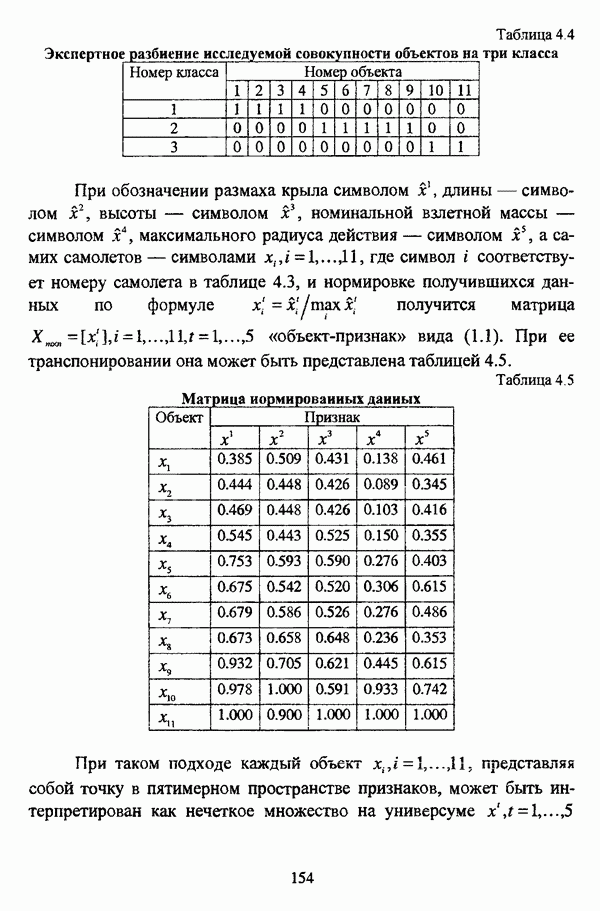
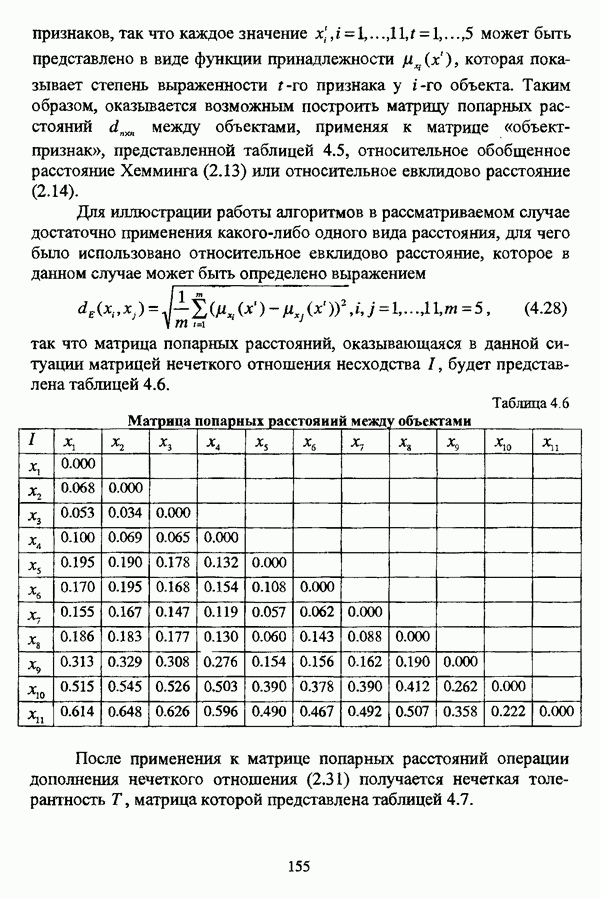
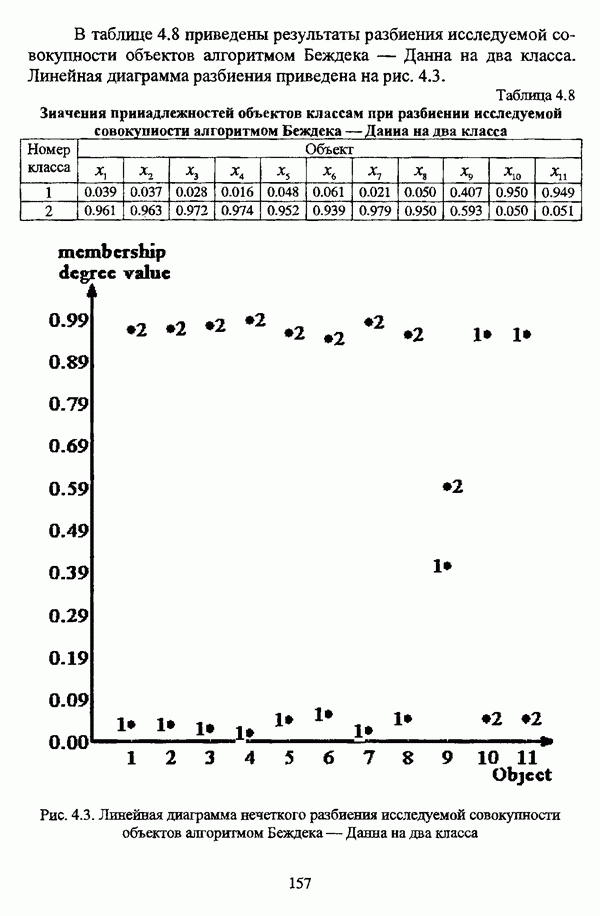
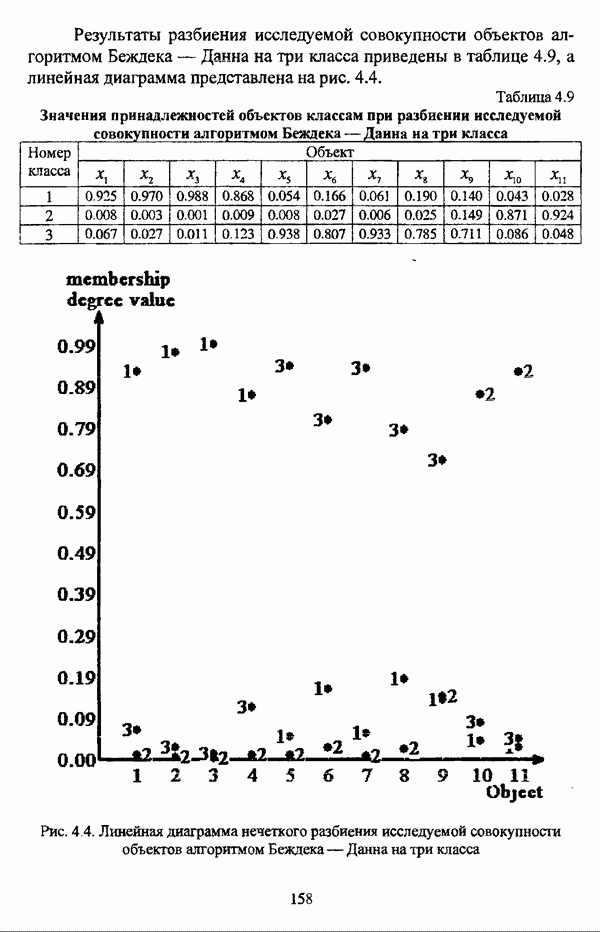
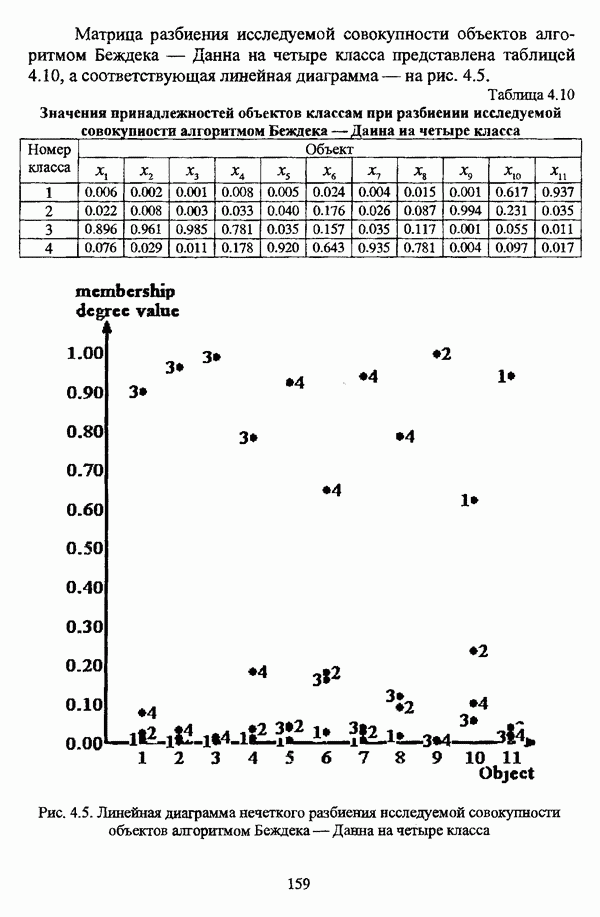
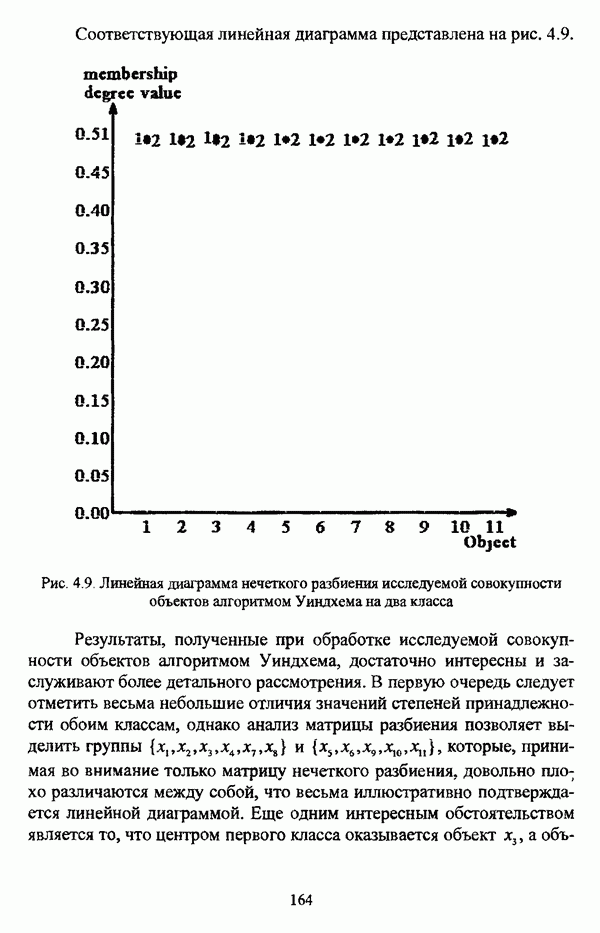
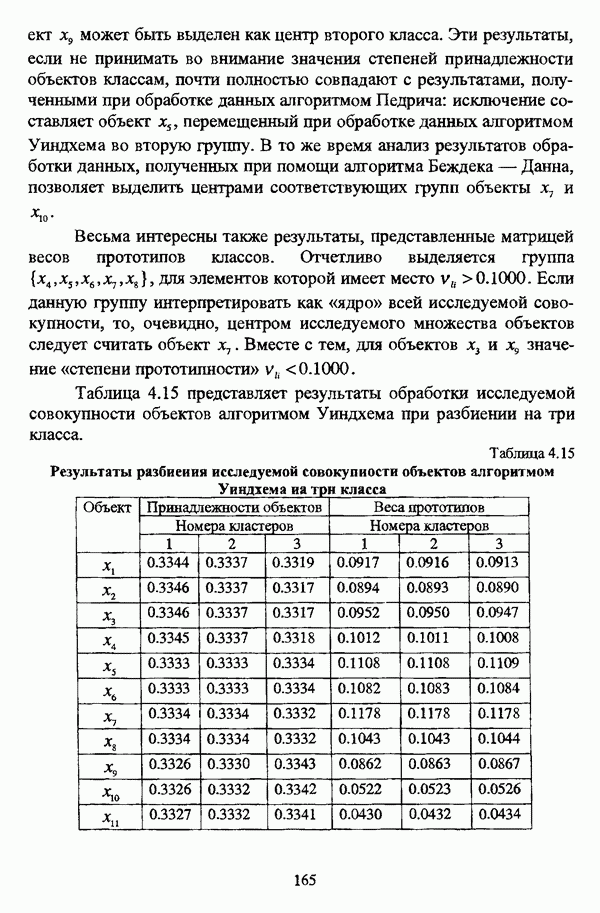
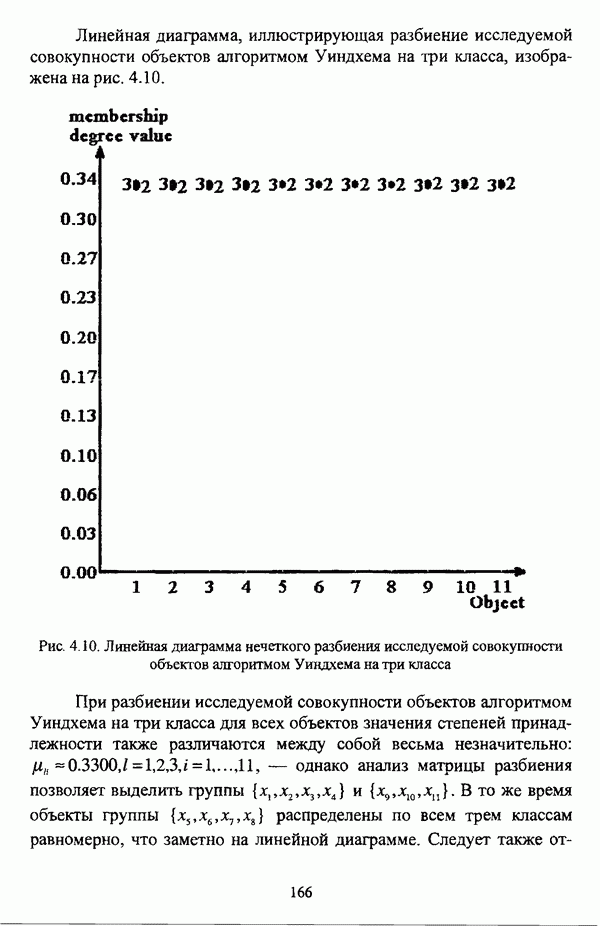
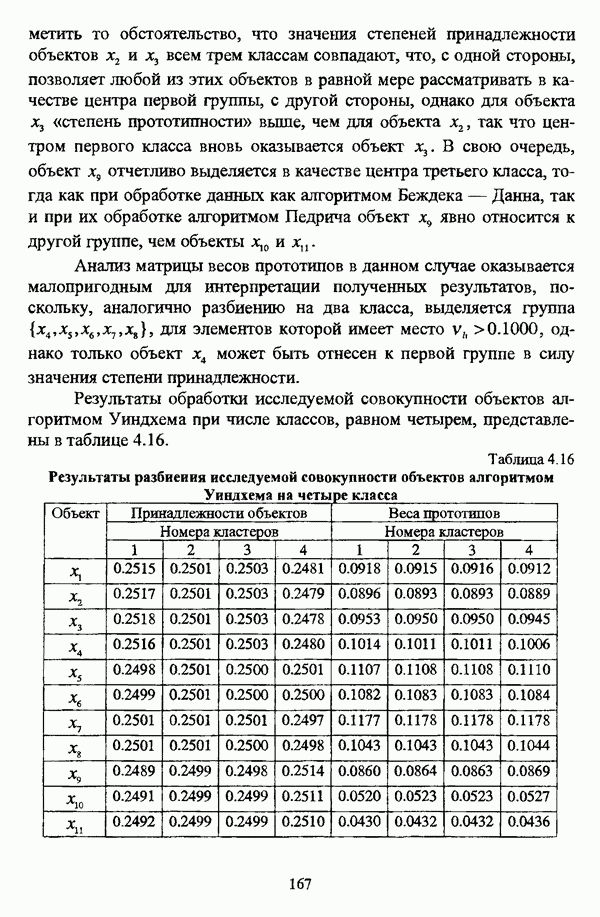
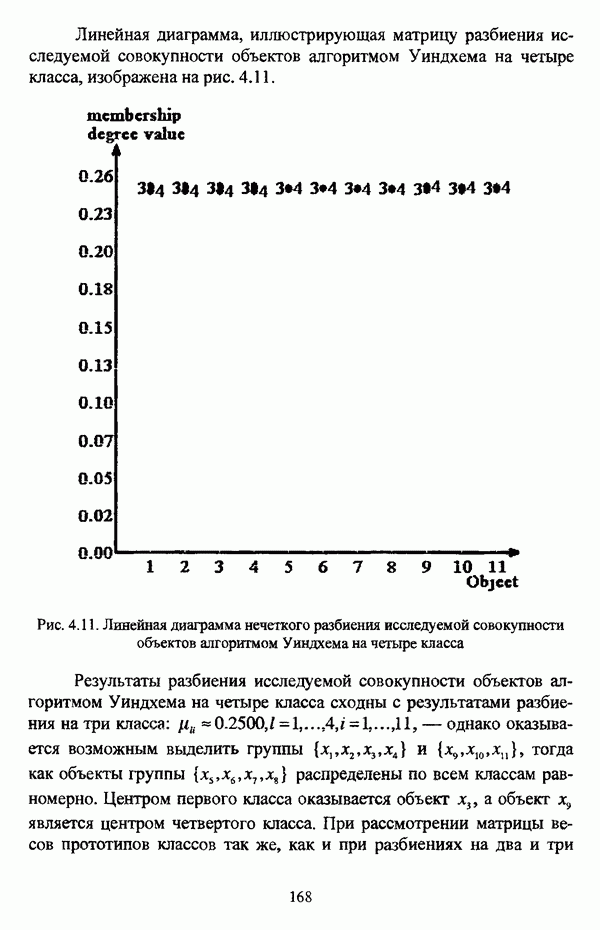
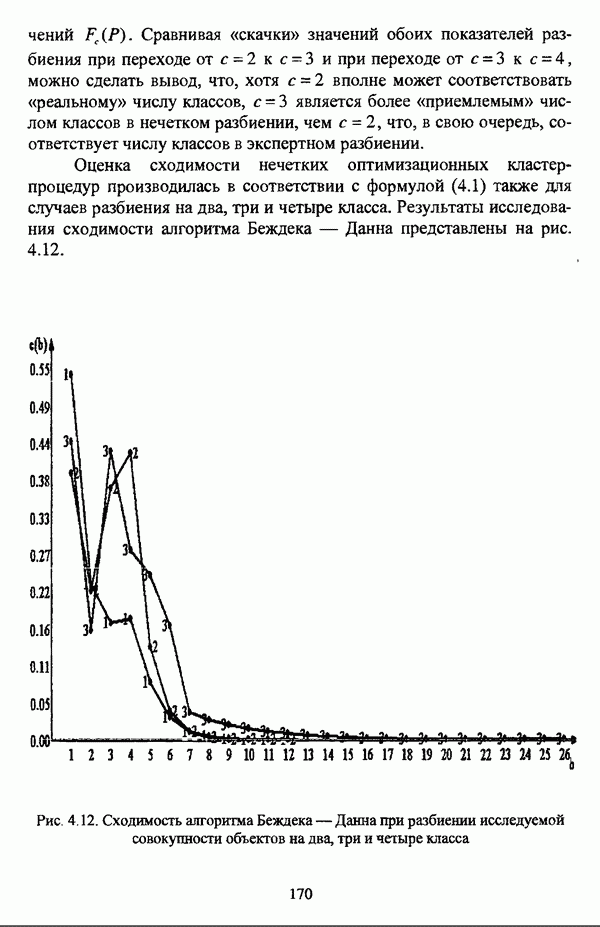
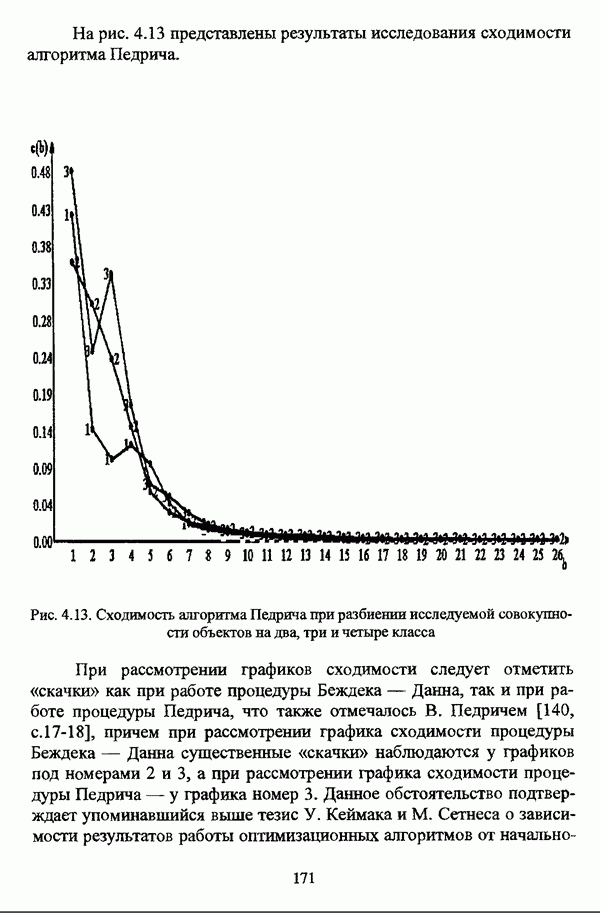
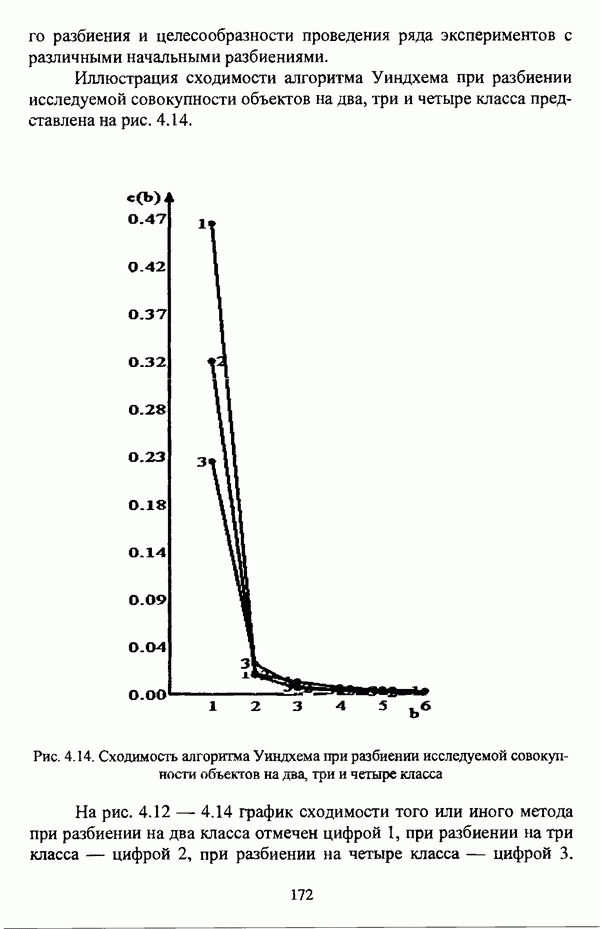
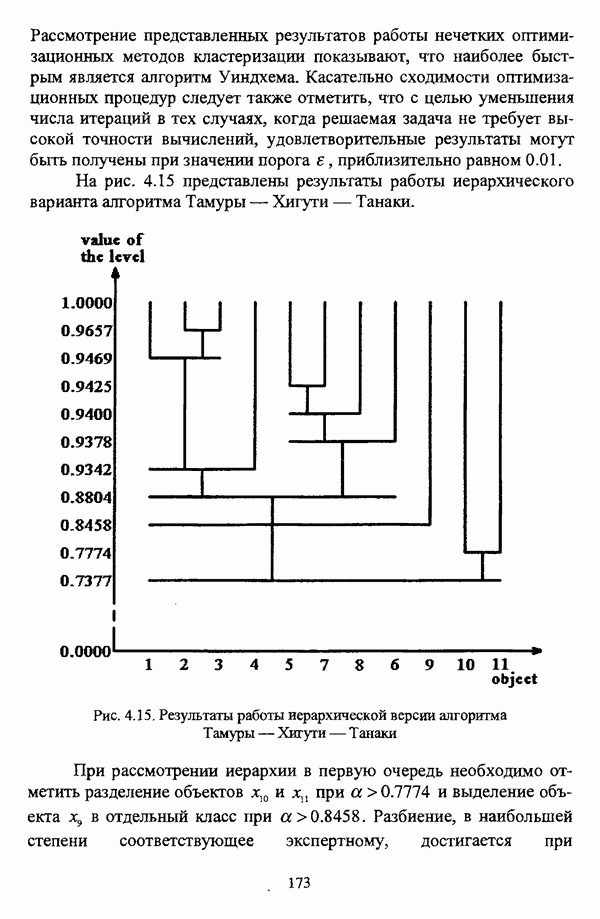
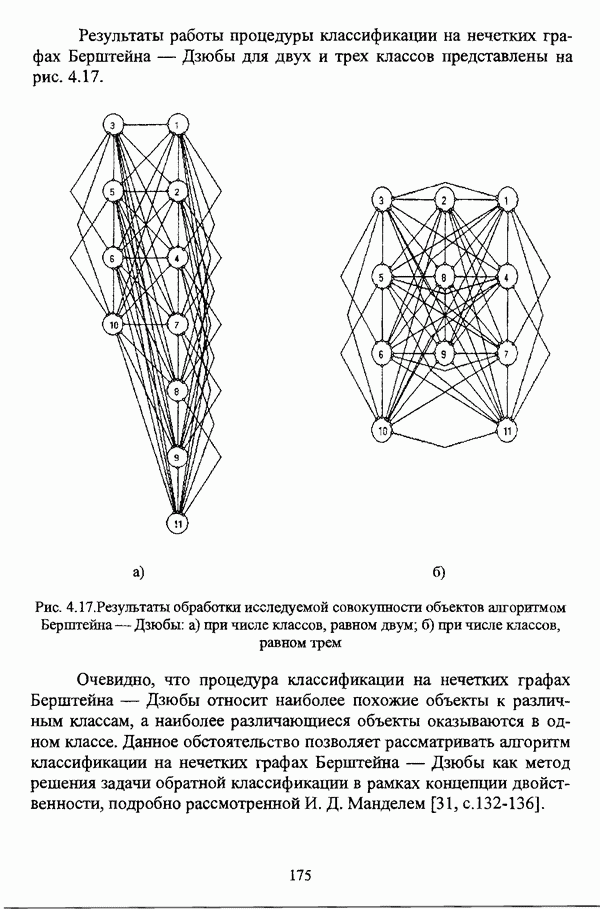
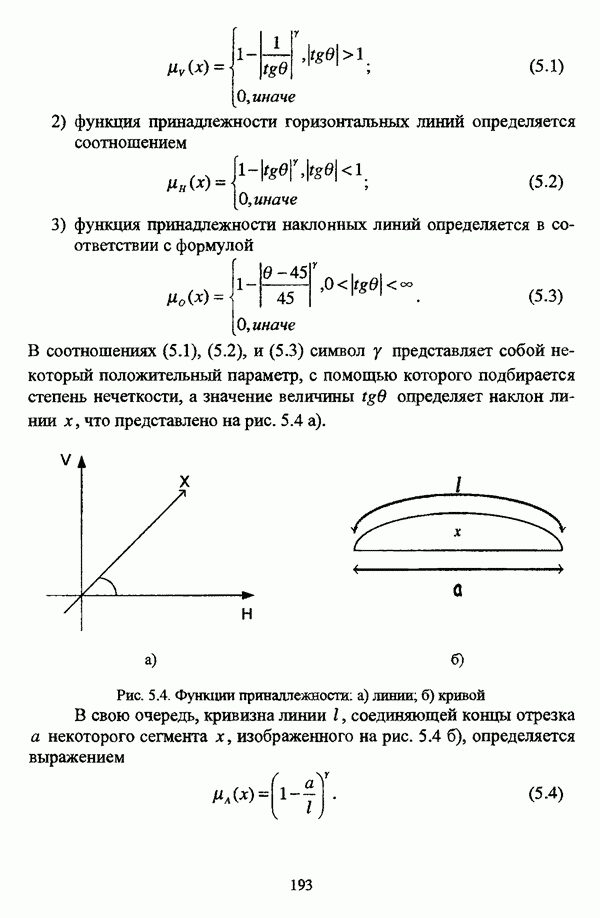
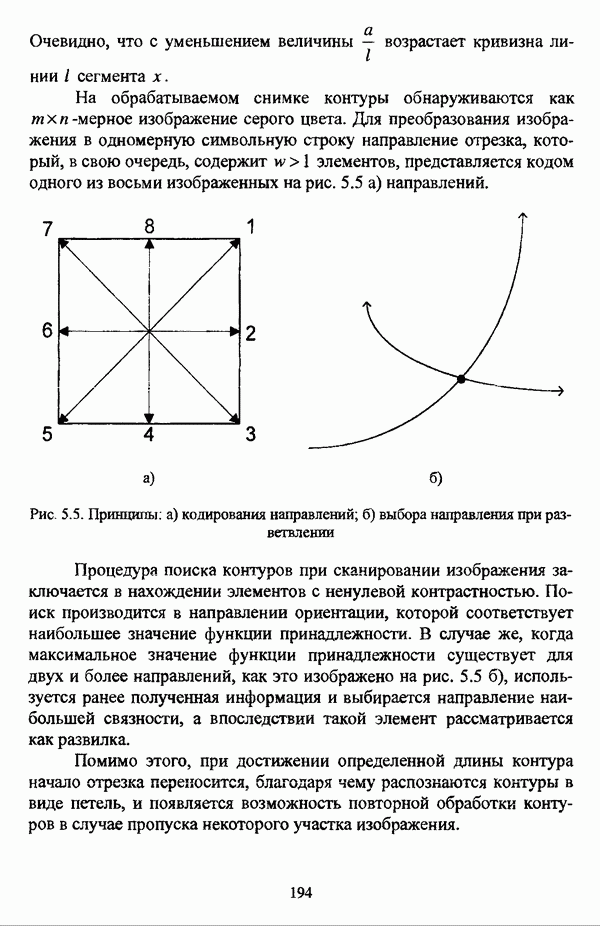
1.2. Подход к решению задачи автоматической классификации с позиции теории нечетких множеств1.2.1. Основные концепции неопределенности в задачах автоматической классификацииСобственно процесс решения задачи классификации, независимо от природы исходных данных, в общем, состоит из восьми этапов [37, с. 42-43]: установочного, на котором формулируется постановка задачи на содержательном уровне; постановочного, в ходе которого определяется тип прикладной задачи в терминах теории классификации; информационного, состоящего в выработке плана сбора исходной информации, ее предварительном анализе и редактировании; априорного математико-постановочного, заключающегося в выборе на основании выводов, полученных в результате реализации предыдущих этапов, базовых математических моделей для математической постановки конкретной задачи классификации; разведочного, предусматривающего применение специальных методов предварительного анализа исходных данных с целью выявления их вероятностной и геометрической природы; апостериорного математико-постановочного, в процессе которого уточняется выбор базовой математической модели с учетом результатов реализации разведочного этапа процесса решения задачи классификации; вычислительного, целью которого является программная реализация выбранного математического аппарата для решения конкретной задачи; итогового, на котором производится анализ и интерпретация результатов проведенного исследования. Таким образом, вид задачи классификации определяется в результате реализации первых трех этапов процесса исследования; к примеру, если предварительная выборочная информация отсутствует, а априорные сведения о классах объектов являют собой лишь некоторые предположения самого общего характера, то задача относится к классу задач распознавания образов с самообучением. Вместе с тем, на практике зачастую оказывается, что задаче свойственна нечеткость [14], значительно затрудняющая или вообще делающая невозможным получение решения, так что на первый план выходит проблема устранения нечеткости, присущей задаче классификации. Понятие нечеткости является общенаучным и может быть определено как внешнее выражение качества внутренней основы явлений, специфика которого заключается в непрерывности перехода от отсутствия проявления к полному выявлению качества предметов, свойств и отношений реального мира, что находит свое отражение в познавательной и мыслительной деятельности индивида. Содержание понятия нечеткости включает в себя последовательный ряд абстракций более низкого уровня. По отношению к человеческому сознанию выделяются такие категориальные виды нечеткости, как объективная и субъективная нечеткость; в свою очередь, объективная нечеткость может характеризоваться как стохастической, так и нестохастической детерминированностью. Объективная стохастическая нечеткость имеет такие формы проявления, как неопределенность и случайность. В данном случае неопределенность выступает в качестве нечеткой закономерности проявления свойств предмета, а случайность может быть определена как событие, имеющее нечеткое основание. Формами проявления объективной нестохастической нечеткости являются недетерминированность, рассматриваемая как нечеткость связи между предметами, свойствами или отношениями; размытость, характеризующая границы явлений, процессов, предметов, а также их классов и, кроме того, имена и область применимости предиката в логике; неоднозначность, определяемая как нечеткость значения признака объекта; неполнота, представляющая собой отсутствие всей возможной информации о рассматриваемом предмете или явлении, частными случаями которой выступают недостаточность как отсутствие необходимой информации и неадекватность как описание предмета по аналогии с рассмотренными ранее; неточность, являющаяся нечеткостью измерения или вычисления; неопределенность, трактуемая как нечеткость предела проявления характеристики предмета; случайность, определяемая как нечеткая реализация одной из нескольких существующих возможностей. Субъективная нечеткость имеет такие формы проявления, как неясность, под которой подразумевается нечеткость восприятия; размытость, которая в данном случае являет собой характеристику представления индивида о явлениях, процессах, предметах, свойствах, отношениях; недетерминированность, определяемая как свойство процесса логического вывода, производимого индивидом, в нечетких условиях; неоднозначность, понимаемая как нечеткость результата процесса интерпретации информации; неточность, которая в данном случае трактуется как мера соответствия знаний индивида о предмете объективным характеристикам рассматриваемого предмета; неопределенность, понимаемая как нечеткость отношения между объектом реального мира и представлением о нем в сознании индивида, а также как нечеткость смыслового значения имени, выражающего некоторое понятие. Таким образом, виды и формы нечеткости могут быть упорядочены в соответствии с иерархией, представленной на рис. 1.1. (см. скан) Рис. 1.1. Виды и формы нечеткости Помимо рассмотренных форм нечеткости иногда выделяются и другие формы, такие, к примеру, как неизвестность и недоопределенность [35, с. 8]; общим же для всех форм проявления нечеткости является то, что они характеризуют как свойства объектов, собственно свойств, отношений, процессов, явлений, понятий, так и особенности мыслительных и когнитивных процессов, присущих человеку. В процессе анализа данных, в частности, в контексте задачи автоматической классификации, понятие нечеткости принимает вполне определенный смысл и оказывается характеристикой классов объектов, чему более соответствует понятие размытости, так что при анализе форм нечеткости, свойственной процессу анализа данных, более уместным представляется использование понятия неопределенности, под которой следует понимать нечеткость соответствия математической постановки задачи анализа данных предметно-содержательной установке на цели исследования и исходным данным. Поскольку постановка задачи на предметно-содержательном уровне включает формулировку целей исследования, определяющих тип задачи, выявление характера исходных данных и определение характера результатов исследования [37, с. 42], то понятие неопределенности в той или иной степени характеризует каждую из этих составляющих. Рассматривая процесс анализа данных в виде схемы, изображенной на рис. 1.2 [133, с. 274], Я. В. Овсиньски и С. Задрожны отмечают, что «неопределенность может проникнуть в процесс анализа данных почти на каждом этапе... Эта неопределенность может не иметь вероятностного характера, что в большой степени свойственно природе переменных и процедуре их кодирования. Другой источник такой неопределенности относится к интерпретации содержания частных переменных, в случае, когда данные поступают от различных лиц» [133, с. 273]. Процесс анализа данных в условиях нестохастической неопределенности, как правило, основан на ряде довольно жестких, не допускающих неопределенности предположений. Таким образом, традиционные методы анализа данных целесообразно применять только в тех случаях, когда подобные предположения достаточно обоснованы как с содержательной, так и с формальной точек зрения. С другой стороны, такое обоснование оказывается возможным в очень немногочисленных случаях, так что целесообразным оказывается «представить различные типы неопределенности» [133, с. 275] для последующей обработки адекватными методами. (см. скан) Рис. 1.2. Общая схема процесса анализа данных Следовательно, одной из важнейших, с методологической точки зрения, задач в процессе анализа данных является установление форм проявления неопределенности и выбор соответствующих методологий для их обработки. Поскольку объектом предпринятого рассмотрения является такой подход к анализу данных, как автоматическая классификация, то дальнейшее рассмотрение видов и форм неопределенности следует проводить, соответственно, применительно к задачам кластерного анализа и основой подобного рассмотрения могут послужить результаты, представленные в работе [19]. Конечными целями решения задачи автоматической классификации являются либо выделение четко выраженных классов статистически обследованных объектов в анализируемом многомерном пространстве, либо получение наглядного представления о стратификационной структуре классифицируемой совокупности объектов, либо оценка параметров структуры искомой классификации, минимально отличающейся от структуры исходных данных, так что в качестве аппарата решения задачи распознавания образов с самообучением выбираются либо алгоритмы оптимизационного или эвристического направлений, либо иерархические алгоритмы, либо алгоритмы, соответствующие аппроксимационному подходу в численной таксономии. Таким образом, неопределенность установки на главные цели исследования может повлечь некорректность математической постановки задачи автоматической классификации. В процессе формулировки целей исследования неопределенность находит свое выражение в форме свойства интерпретации исследователем информации о предмете исследования и об исследуемой совокупности объектов ее реальным свойствам, то есть неясности, в форме характеристики соответствия знаний исследователя о свойствах совокупности объектов ее реальным свойствам, то есть неточности. Необходимо отметить, что обе формы неопределенности в данном случае носят субъективный характер. Касательно характера результатов прикладного исследования, который также определяется на первых двух этапах решения задачи классификации, следует указать, что главным свойством процесса формулировки требований к результатам является неопределенность, носящая объективный характер. Как качественная характеристика, неопределенность выступает в процессе выявления природы искомой классификации в том смысле, должна ли полученная классификация являться размытой, или, пользуясь устоявшейся в специальной литературе терминологией, нечеткой, или нет. Если же речь идет о форме и взаимном расположении кластеров, а также об их числе, то неопределенность выступает как количественная характеристика. Если в качестве цели исследования выдвигается требование обнаружения «естественного расслоения» совокупности объектов на классы, то их число априорно оказывается неизвестным. Противоположной является ситуация, когда задача состоит в разбиении совокупности объектов на заранее известное число однородных классов. Число классов в таком случае выступает также в качестве исходных данных при постановке задачи классификации. Данные ситуации обуславливают выбор алгоритма классификации, поскольку во многих алгоритмах число кластеров является задаваемым параметром [31, с. 156-158], [37, с. 157-159]; к примеру, если выбрано оптимизационное направление решения задачи, то известность или неизвестность числа кластеров, на которые требуется разбить совокупность объектов, диктует тот или иной вид функционала качества разбиения. Гораздо сложнее обстоит ситуация, когда число кластеров нельзя указать однозначно. В этом случае неопределенность как характеристика всей задачи кластер-анализа проявляется в форме неоднозначности, которая, в свою очередь, оказывается следствием неточности как характеристики знаний исследователя о свойствах совокупности объектов и является субъективным типом неопределенности. В свою очередь, неясность в вопросе о природе искомой классификации влечет некорректный выбор метода классификации; так, если классификация носит размытый характер, но при этом алгоритм кластер-анализа не является нечетким, то полученные результаты также окажутся некорректными. Неопределенность исходных данных в задачах численной таксономии также проявляется в различных формах. Первая из них, уже упоминавшаяся выше неоднозначность числа классов объектов исследуемой совокупности, может также рассматриваться как частный случай неполноты. Неоднозначность может также характеризовать число объектов совокупности, которую требуется разбить на классы. Если исходные данные представлены в виде матрицы «объект-свойство» и значения некоторых признаков могут изменяться в зависимости от состояния объекта, примером чего может послужить значение звездной величины переменных звезд [21, с. 206-207], представляя собой конечную совокупность либо интервал значений, неоднозначность выступает в качестве неопределенности значения признака объекта; при переходе от матрицы вида «объект-свойство» к матрице вида «объект-объект» неоднозначность выступает в качестве неопределенности расстояния либо меры близости между объектами. Поскольку значения признаков объектов могут быть измерены, вычислены либо определены путем экспертной оценки с некоторой погрешностью, то неопределенность исходных данных задачи численной таксономии в этом случае проявляется в форме неточности как свойства процесса измерения или вычисления. Неточность исходных данных также может быть характерна и для их представления в форме матрицы вида «объект-объект». Здесь также уместно отметить то обстоятельство, что неточность исходных данных, свойственная процессу измерения значений признаков объектов может возрасти при переходе от матрицы «объект-свойство» к матрице «объект-объект», поскольку вычисление расстояния между парой объектов, посредством которого осуществляется такой переход, сопровождается, как правило, погрешностью округления. Одним из наиболее часто встречающихся типов неопределенности, свойственной исходным данным, является недостаточность, проявляющаяся в отсутствии части значений в матрице исходных данных. Данная форма неопределенности может быть характерна как для матриц вида «объект-свойство», так и для матриц вида «объект-объект», хотя в специальной литературе по анализу данных преимущественно рассматриваются матрицы первого вида. Недостаточность данных в специальной литературе именуется неполнотой, а отсутствие значений в матрице исходных данных называется пропусками в данных [30]. Примерами причин, вызывающих пропуски в данных, могут послужить ситуации, когда в процессе социологического опроса часть респондентов отказывается сообщить размер дохода, когда в промышленном производстве вследствие поломок оборудования не удается получить данные для исследования, а также когда в период избирательной компании при опросе общественного мнения какая-то часть респондентов не окажет предпочтения одному кандидату перед другим. Пропускам в данных из первых двух примеров соответствуют истинные значения, которые были бы получены при более современном методе исследования или более высоком качестве промышленного оборудования, так что ненаблюдаемые значения естественно рассматривать как пропуски в данных. В третьем примере представляется менее правдоподобным, что за отсутствием ответа кроется предпочтение определенному кандидату, так что рассматривать отсутствующие значения как пропуски менее естественно [30, с. 11]. Описанные виды и формы неопределенности в задачах автоматической классификации не исчерпывают всего многообразия форм ее проявления и лишь очерчивают концептуальную рамку их рассмотрения, так что основные концепции неопределенности в задачах кластерного анализа могут быть представлены в виде схемы, изображенной на рис. 1.3. (см. скан) Рис. 1.3. Концепции неопределенности в задачах автоматической классификации Каждой из рассмотренных форм неопределенности в задачах автоматической классификации соответствует определенная методология ее формализации или устранения. Касательно неопределенности целей исследования следует указать, что поскольку формы ее проявления носят субъективный характер, необходимым условием для ее устранения является полное описание предмета исследования, сбор всей возможной информации об объектах исследуемой совокупности, а также о свойствах самой совокупности. Кроме того, необходимым также является привлечение специалистов из той предметной области, к которой относится решаемая задача, не только к выработке предметно-содержательной установки на цели исследования и формирования этих целей в терминах анализа данных, но и к выработке плана сбора исходной информации, а также ее аттестации. Для формализации или устранения неопределенности в процессе определения характера результатов исследования, являющейся, как правило, следствием отсутствия априорной информации о механизме порождения анализируемых данных, применяется аппарат разведочного анализа данных [37, с. 473-487], основной целью которого, в свою очередь, является построение некоторой модели данных. Подобная модель данных, в общем случае, требует верификации. Разведочный анализ данных может применяться как к данным, заданным в форме матрицы «объект-признак», так и к данным, заданным в форме матрицы «объект-объект», причем если исходные данные имеют форму матрицы «объект-признак», то переменные могут быть измерены в различных шкалах. Главным элементом разведочного анализа данных является визуализация данных, предполагающая получение графического отображения исследуемой совокупности точек в многомерном пространстве, так что путем непосредственного визуального анализа изображения структуры исследуемой совокупности оказывается возможным определить форму и взаимное расположение кластеров, их число, а также природу искомой классификации. В случае пересечения кластеров, их соприкосновения или соединения цепочкой, а также когда исходные данные представляют собой неоднородное облако, искомая классификация оказывается размытой, так что при выборе математического аппарата для решения задачи кластер-анализа предпочтение следует отдать нечетким кластер-процедурам. Более того, если скопление точек имеет четко выраженную форму, имеет смысл обратиться к эвристическим алгоритмам, реализующим одно или несколько определений кластера [31, с. 37]; последнее обстоятельство отражает ситуацию, когда различные скопления точек имеют различную форму. Помимо применения аппарата разведочного анализа данных, с целью определения характера классификации, которую необходимо получить, требуется также минимизировать неопределенность исходных данных, для чего следует выяснить ее причины. Если число кластеров, на которое требуется разбить исследуемую совокупность объектов, однозначно определить не удается, имеет смысл обратиться к оптимизационному направлению решения задачи автоматической классификации и выбрать функционал качества разбиения с неизвестным числом классов. В случае, когда неоднозначность является объективной характеристикой числа объектов исследуемой совокупности, следует прибегнуть к аппарату нечетких интервалов, в частности, к аппарату треугольных нечетких чисел (L-R)-типа [34, с. 105-106]. Нелишним будет отметить, что формализация или устранение неопределенности в данном случае оказывается необходимым условием для представления исходных данных в виде матрицы любой из указанных форм. В любом случае неоднозначность, являющаяся объективной характеристикой числа объектов исследуемой совокупности, влечет неполноту данных. Наиболее важным для рассмотрения случаем неопределенности исходных данных в задачах автоматической классификации является неопределенность значений в матрице исходных данных. В случае численной неточности значений, имеющей объективный характер, целесообразно прибегнуть к другому аппарату или инструментарию для повышения точности измерения. С целью устранения неоднозначности значений переменных в матрице исходных данных можно применять метод, именуемый заполнением средними, когда вместо множества либо интервала значений переменной подставляется некоторое среднее значение этого множества или интервал значений. Возможно также применение метода, основанного на оценке с помощью регрессии множества значений переменной. Неполные данные, как правило, обрабатываются с помощью четырех групп методов: методов исключения некомплектных объектов, методов с заполнением, методов взвешивания и методов, основанных на моделировании [30, с. 14-15]. Таким образом, методологии обработки основных видов объективной неопределенности в задачах автоматической классификации можно представить в виде таблицы 1.1. Таблица 1.1. Методологии обработки неопределенностей в задачах автоматической классификации (см. скан) Методологии обработки различных форм неопределенности, возникающей в задачах распознавания образов с самообучением, рассмотренные выше, не являются единственно возможными и не претендуют на статус универсальных; более того, возможными являются ситуации, когда в задаче автоматической классификации встречается несколько форм неопределенности. В таком случае оказывается целесообразным применение комбинированных методов либо поэтапное устранение неопределенности. Однако в любом случае первым этапом решения задачи кластер-анализа в условиях неопределенности должен являться детальный анализ задачи с целью выявления видов и форм неопределенности, механизма их возникновения и взаимной обусловленности. Только после успешной реализации этого этапа исследования следует определять методологию обработки неопределенности, после чего производить обработку в соответствии с выбранной методологией. После формализации или устранения неопределенности следует произвести оценку результатов обработки и только в случае получения удовлетворительных результатов переходить к решению задачи классификации.
|
 |
Оглавление
|