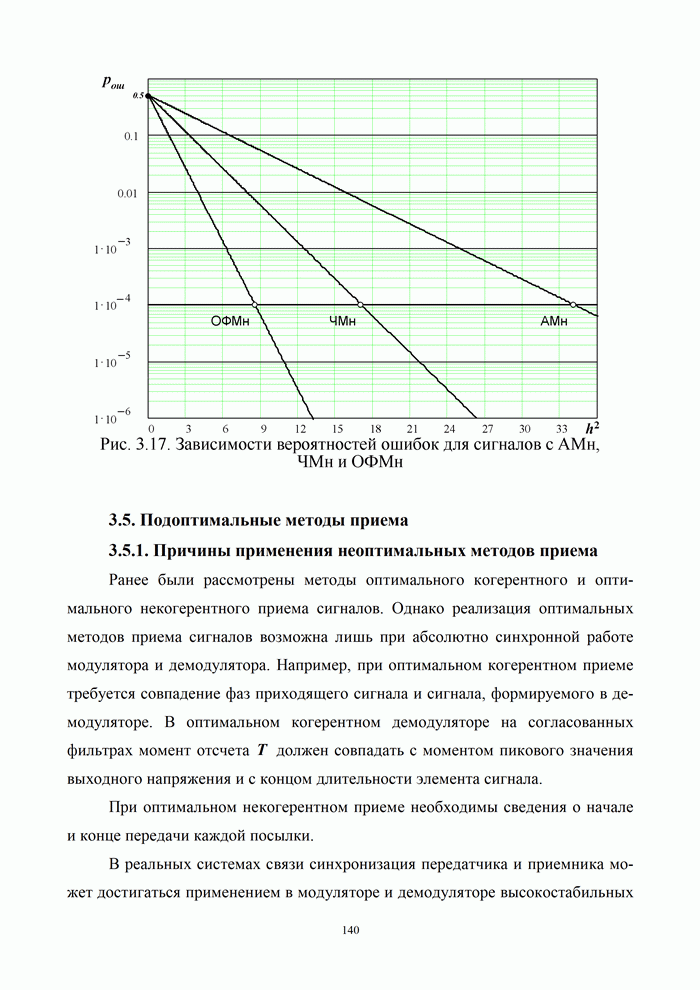
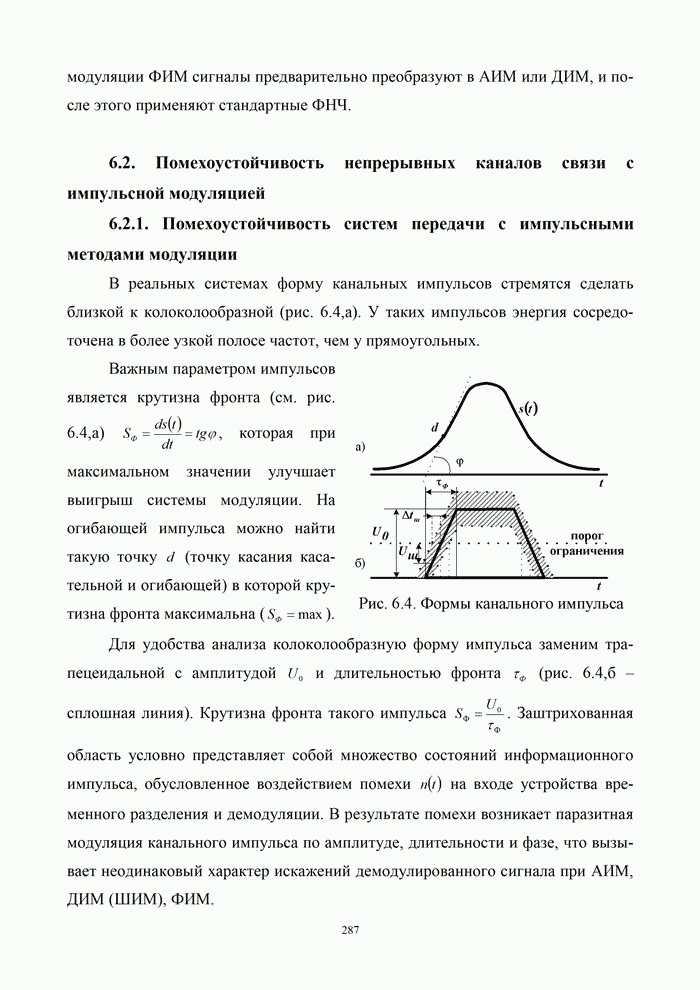
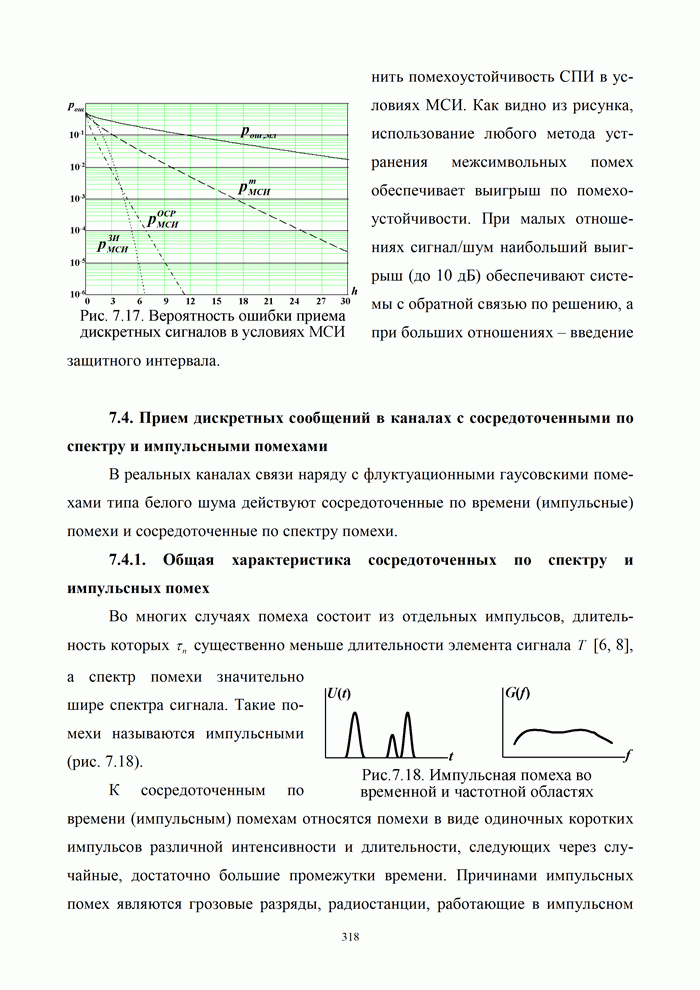
5.5.3. Методы реализации этапов декодирования кодов БЧХ
Изложенные в 5.5.2 основные идеи декодирования кодов БЧХ позволяют
представить процесс декодирования в виде
совокупности следующих трех основных
этапов.
Этап 1. Вычисление синдрома  по принятой комбинации символов
по принятой комбинации символов  .
.
Этап 2. Нахождение коэффициентов многочлена
локаторов ошибок  .
.
Этап 3. Вычисление корней многочлена ,
определение взаимных с ним величин – локаторов ошибок и исправление ошибочных
символов в принятой комбинации (для недвоичных кодов БЧХ
требуется найти, помимо локаторов, оценки компонентов  вектора ошибки).
вектора ошибки).
Каждый из перечисленных этапов процесса декодирования кодов БЧХ может быть реализован разными способами,
существенно отличающимися друг от друга по сложности реализации. Рассмотрим
основные из этих способов и
проиллюстрируем их примером.
Этап 1. Отыскание синдрома кода БЧХ по принятой последовательности
символов  может
осуществляться путем деления многочлена
может
осуществляться путем деления многочлена  на минимальные
многочлены
на минимальные
многочлены  ,
задающие порождающий многочлен
,
задающие порождающий многочлен  двоичного кода БЧХ (5.25).
Действительно:
двоичного кода БЧХ (5.25).
Действительно:
где  – остаток от деления
многочлена на минимальный многочлен .
– остаток от деления
многочлена на минимальный многочлен .
Подставив в  -е уравнение корень
-е уравнение корень  минимального многочлена ,
имеем
минимального многочлена ,
имеем
|
 , ,
|
(5.30)
|
поскольку
 . Учитывая (5.27),
получим, что -й
компонент синдрома
. Учитывая (5.27),
получим, что -й
компонент синдрома  .
.
Таким образом, первый этап декодирования кодов БЧХ может быть сведен к вычислению остатков от деления многочлена на минимальные
многочлены элементов  и
подстановке этих элементов в многочлены остатка .
и
подстановке этих элементов в многочлены остатка .
Сопоставляя выражение (5.30) с (5.23), описывающим
прямое преобразование Фурье, можно сделать вывод о том, что компонент  синдрома есть -й коэффициент ДПФ принятой последовательности
символов .
Учтем также, что -й коэффициент ДПФ этой
последовательности есть сумма -х коэффициентов ДПФ кодового слова
синдрома есть -й коэффициент ДПФ принятой последовательности
символов .
Учтем также, что -й коэффициент ДПФ этой
последовательности есть сумма -х коэффициентов ДПФ кодового слова  и вектора ошибки
и вектора ошибки  , поэтому
, поэтому
|
 . .
|
|
Поскольку по определению кода БЧХ  для
для
 , то
компонент синдрома
, то
компонент синдрома  , .
, .
Таким образом, блок компонентов синдрома как
бы образует в частотной области окно, через которое можно наблюдать  из
из
 частотных
составляющих спектра вектора ошибки. Заметим, что для двоичных
кодов БЧХ из этих компонентов компоненты
с нечетными номерами
частотных
составляющих спектра вектора ошибки. Заметим, что для двоичных
кодов БЧХ из этих компонентов компоненты
с нечетными номерами  вычисляются в соответствии
с (5.30), а с четными – по формуле с
вычисляются в соответствии
с (5.30), а с четными – по формуле с  . Справедливость
этой формулы следует из правила возведения многочлена над
. Справедливость
этой формулы следует из правила возведения многочлена над  в степень
в степень  (см. 5.3.5).
(см. 5.3.5).
Этап 2. Вычисления коэффициентов полинома локаторов ошибок кодов
БЧХ, ориентированных на исправление  ошибок,
оказываются наиболее трудоемкими.
Разработаны различные алгоритмы решения этой задачи, отличающиеся скоростью реализации.
ошибок,
оказываются наиболее трудоемкими.
Разработаны различные алгоритмы решения этой задачи, отличающиеся скоростью реализации.
При больших значениях кратности ошибок,
особенно интересных на практике, более эффективным оказывается
метод, предложенный Берлекэмпом [3, 26]. Суть метода состоит в сведении задачи
отыскания коэффициентов о,- многочлена локаторов ошибок к задаче нахождения
коэффициентов авторегрессионного фильтра (регистра сдвига минимальной длины с
линейной обратной связью), генерирующего известную
последовательность компонентов синдрома. Следует указать также на
возможность решения ключевого уравнения при помощи алгоритма Евклида [3],
являющегося рекуррентным и по сложности реализации близким к
алгоритму Берлекэмпа.
Этап 3. На данном этапе необходимо отыскать корни  многочлена локаторов ошибок , коэффициенты
которого найдены на предыдущем этапе. Эти
корни являются обратными локаторам
многочлена локаторов ошибок , коэффициенты
которого найдены на предыдущем этапе. Эти
корни являются обратными локаторам  , т.е.
, т.е.  (см. 5.4). По вычисленным таким образом
локаторам для двоичных кодов БЧХ
остается
лишь исправить (проинвертировать) ошибочные символы, номер
(см. 5.4). По вычисленным таким образом
локаторам для двоичных кодов БЧХ
остается
лишь исправить (проинвертировать) ошибочные символы, номер  которых соответствует локатору . При декодировании недвоичных кодов БЧХ
необходимо найти оценку компонентов
которых соответствует локатору . При декодировании недвоичных кодов БЧХ
необходимо найти оценку компонентов  вектора ошибки и лишь затем произвести
исправление, формируя оценки символов переданного кодового слова
вектора ошибки и лишь затем произвести
исправление, формируя оценки символов переданного кодового слова  .
.
Поиск элементов  поля
поля  , удовлетворяющих условию
, удовлетворяющих условию  , состоит в переборе всех
элементов поля. Именно этот способ реализован в процедуре Ченя [30], широко используемой для решения задач третьего
этапа декодирования кодов БЧХ.
Сущность процедуры состоит в том, что при известных коэффициентах
, состоит в переборе всех
элементов поля. Именно этот способ реализован в процедуре Ченя [30], широко используемой для решения задач третьего
этапа декодирования кодов БЧХ.
Сущность процедуры состоит в том, что при известных коэффициентах  декодер вычисляет значения
декодер вычисляет значения  ,
,  и т.д. (здесь
и т.д. (здесь  – примитивный элемент поля ).
– примитивный элемент поля ).
Если для некоторого  значение
значение  , то это означает, что
, то это означает, что  является корнем многочлена локаторов ошибки, а элемент
является корнем многочлена локаторов ошибки, а элемент  является
локатором, указывающим на ошибочную
позицию в кодовой последовательности, которую следует исправить.
является
локатором, указывающим на ошибочную
позицию в кодовой последовательности, которую следует исправить.