описанной в гл. 2. Строки являются смежными классами, а векторы в первом столбце — образующими смежных классов.
Если передавался вектор а, а получен вектор да, то да — а называется вектором-ошибкой.
Теорема 3.5. Если стандартное расположение используется как таблица декодирования, то по полученному вектору  будет правильно декодирован переданный вектор тогда и только тогда, когда вектор-ошибка
будет правильно декодирован переданный вектор тогда и только тогда, когда вектор-ошибка  и является образующим смежного класса.
и является образующим смежного класса.
Доказательство. Если  где
где  образующий
образующий  смежного класса, то вектор
смежного класса, то вектор  должен находиться в стандартном расположении в
должен находиться в стандартном расположении в  смежном классе под кодовым вектором и и поэтому будет правильно декодирован. Если же вектор
смежном классе под кодовым вектором и и поэтому будет правильно декодирован. Если же вектор  «не является образующим смежного класса, то вектор
«не является образующим смежного класса, то вектор  должен находиться в некотором смежном классе, например
должен находиться в некотором смежном классе, например  с образующим
с образующим  Тогда вектор расположен в
Тогда вектор расположен в  строке, но не под вектором и, потому что
строке, но не под вектором и, потому что 
Предположим, что линейный код является нулевым пространством матрицы И размерности  строки которой могут быть, хотя и не обязательно, линейно независимыми. Для любого полученного на выходе вектора да вектор
строки которой могут быть, хотя и не обязательно, линейно независимыми. Для любого полученного на выходе вектора да вектор

 компонентами, называемыми синдромом. Поскольку наш код — это нулевое пространство матрицы
компонентами, называемыми синдромом. Поскольку наш код — это нулевое пространство матрицы  то некоторый вектор является кодовым словом тогда и только тогда, когда его синдром равен нулю. Вообще каждой строке матрицы И соответствует проверочное соотношение, которому должно удовлетворять кодовое слово. Компоненты вектора
то некоторый вектор является кодовым словом тогда и только тогда, когда его синдром равен нулю. Вообще каждой строке матрицы И соответствует проверочное соотношение, которому должно удовлетворять кодовое слово. Компоненты вектора  равны нулю для тех соотношений, которые удовлетворяются, и не равны нулю для всех остальных.
равны нулю для тех соотношений, которые удовлетворяются, и не равны нулю для всех остальных.
Теорема 3.6. Два вектора  принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны.
принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны.
Доказательство. Во. второй главе было показано, что два элемента группы и  принадлежат одному и тому же смежному классу тогда и только тогда, когда
принадлежат одному и тому же смежному классу тогда и только тогда, когда  есть элемент подгруппы, которой в данном случае является кодовое векторное пространство. Если кодовое пространство — это нулевое пространство
есть элемент подгруппы, которой в данном случае является кодовое векторное пространство. Если кодовое пространство — это нулевое пространство
матрицы  то вектор
то вектор  принадлежит кодовому пространству тогда и только тогда, когда
принадлежит кодовому пространству тогда и только тогда, когда

Поскольку для умножения матриц справедлив дистрибутивный закон, то

так что вектор  является кодовым вектором тогда и только тогда, когда синдромы векторов
является кодовым вектором тогда и только тогда, когда синдромы векторов  равны. Ч. т. д.
равны. Ч. т. д.
Процесс декодирования может быть значительно упрощен за счет использования таблицы декодирования. Таблица строится так, что в ней приведены образующие смежных классов и синдромы для каждого из  смежных классов. После того как получен вектор, вычисляется его синдром. Затем по таблице отыскивается образующий смежного класса, являющийся предполагаемым вектором-ошибкой, и вычитание его из полученного вектора дает предположительно посланный кодовый вектор. Хотя в большинстве случаев такая процедура во много раз уменьшает требования к объему памяти при осуществлении декодирования, этот объем все-таки может быть очень большим; например, для двоичного
смежных классов. После того как получен вектор, вычисляется его синдром. Затем по таблице отыскивается образующий смежного класса, являющийся предполагаемым вектором-ошибкой, и вычитание его из полученного вектора дает предположительно посланный кодовый вектор. Хотя в большинстве случаев такая процедура во много раз уменьшает требования к объему памяти при осуществлении декодирования, этот объем все-таки может быть очень большим; например, для двоичного  -кода таблица декодирования требует
-кода таблица декодирования требует  входов, которые не могут быть перебраны в практически разумный отрезок времени. Число смежных классов равно
входов, которые не могут быть перебраны в практически разумный отрезок времени. Число смежных классов равно  — величине много меньшей, но тем не менее все еще практически необозримой.
— величине много меньшей, но тем не менее все еще практически необозримой.
Теорема 3.7. Пусть V — линейный двоичный  -код (т. е. групповой код), используемый для передачи по двоичному симметричному каналу. Предположим, что все кодовые векторы имеют одну и ту же вероятность быть переданными. Тогда средняя вероятность правильного декодирования совпадает с наибольшей возможной для этого кода, если в качестве таблицы, декодирования используется стандартное расположение, в котором каждый образующий смежного класса имеет минимальный вес в своем классе.
-код (т. е. групповой код), используемый для передачи по двоичному симметричному каналу. Предположим, что все кодовые векторы имеют одну и ту же вероятность быть переданными. Тогда средняя вероятность правильного декодирования совпадает с наибольшей возможной для этого кода, если в качестве таблицы, декодирования используется стандартное расположение, в котором каждый образующий смежного класса имеет минимальный вес в своем классе.
Доказательство. Обозначим через  вектор, стоящий в
вектор, стоящий в  строке и
строке и  столбце таблицы декодирования. Кодовое слово, стоящее в верхней строке столбца, обозначим
столбце таблицы декодирования. Кодовое слово, стоящее в верхней строке столбца, обозначим  Обозначим через
Обозначим через  расстояние Хэмминга между полученным вектором и кодовым словом
расстояние Хэмминга между полученным вектором и кодовым словом  в которое он преобразуется при декодировании. Тогда вероятность правильного декодирования, если было передано слово
в которое он преобразуется при декодировании. Тогда вероятность правильного декодирования, если было передано слово  равна
равна

где  вероятность ошибки в канале, a
вероятность ошибки в канале, a  (см. рис. 1.4). Поскольку имеется
(см. рис. 1.4). Поскольку имеется  кодовых слов, которые предполагаются равновероятными, то при осреднении вероятности правильного декодирования используется весовой множитель
кодовых слов, которые предполагаются равновероятными, то при осреднении вероятности правильного декодирования используется весовой множитель 

Каждому возможному двоичному вектору на выходе в этой сумме соответствует одно слагаемое, и каждое из этих слагаемых принимает максимальное значение, если соответствующий вектор декодируется в ближайший кодовый вектор в смысле Хэмминга, так как  есть монотонно убывающая функция от
есть монотонно убывающая функция от  Поэтому вероятность правильного декодирования будет максимальной, если каждый полученный вектор будет преобразовываться в ближайший кодовый вектор.
Поэтому вероятность правильного декодирования будет максимальной, если каждый полученный вектор будет преобразовываться в ближайший кодовый вектор.
Предположим теперь, что некоторый вектор  расположен в таблице декодирования под кодовым вектором и, так что расстояние Хэмминга между ними равно да. Предположим, что ближайший кодовый вектор
расположен в таблице декодирования под кодовым вектором и, так что расстояние Хэмминга между ними равно да. Предположим, что ближайший кодовый вектор  находится на расстоянии
находится на расстоянии  Пусть
Пусть  образующий смежного класса, содержащего вектора. Тогда вес вектора
образующий смежного класса, содержащего вектора. Тогда вес вектора  равен
равен  Элемент
Элемент  иимеет вес
иимеет вес  и лежит в том же самом смежном классе. Поскольку предполагалось, что
и лежит в том же самом смежном классе. Поскольку предполагалось, что  имеет минимальный вес в своем смежном классе, то и поэтому
имеет минимальный вес в своем смежном классе, то и поэтому  лежит по крайней мере так же близко к и, как и к
лежит по крайней мере так же близко к и, как и к 
Число образующих смежных классов веса  обозначим через
обозначим через  Вероятность правильного декодирования может быть записана тогда так:
Вероятность правильного декодирования может быть записана тогда так:

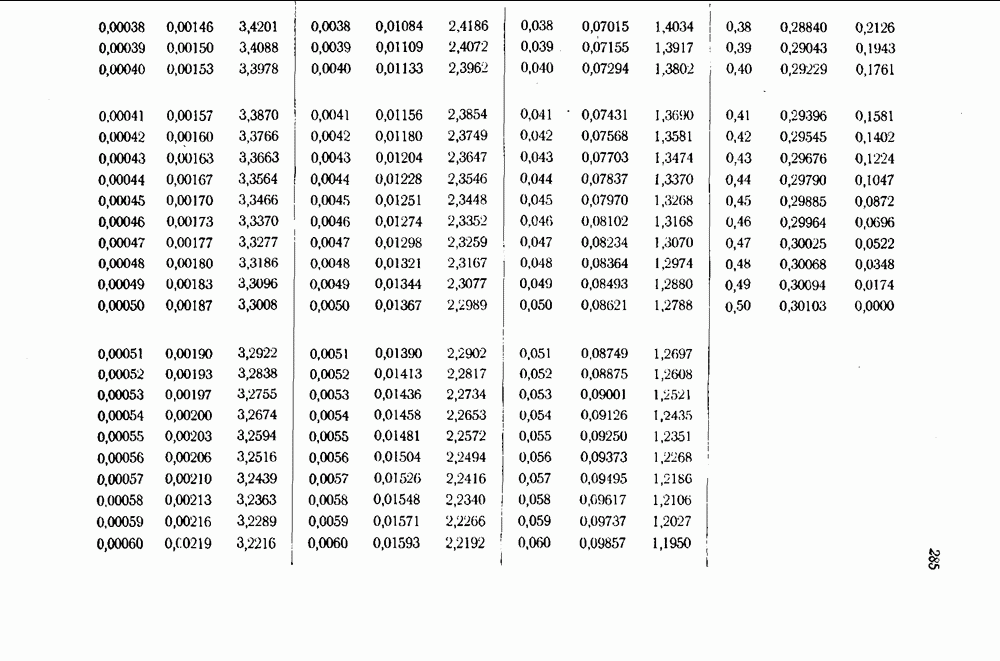
Пример. Стандартное расположение для кода, использованного в предыдущих примерах:

Во всех случаях в качестве образующего смежного класса выбран один из неиспользованных прежде векторов наименьшего веса, что приводит к оптимальному декодированию. (Заметим, что это не значит, что код оптимальный. Может случиться, хотя это неверно в данном случае, что другой выбор кодовых слов даст меньшую вероятность ошибки.) Этот код исправляет три из пяти возможных ошибок в одном символе. Заметим, что векторы  и
и  принадлежат одному и тому же смежному классу, поскольку
принадлежат одному и тому же смежному классу, поскольку  — их разность — есть кодовый вектор. Следовательно, оба эти типа ошибок не могут быть исправлены. Это
— их разность — есть кодовый вектор. Следовательно, оба эти типа ошибок не могут быть исправлены. Это
справедливо во всех случаях, когда имеется кодовое слово веса 2; минимальный вес 3 является необходимым и достаточным условием для исправления всех единичных ошибок.
Наш код удовлетворяет обеим проверкам на четность. Для первого за кодом смежного класса в стандартном расположении синдром равен  для следующего 10 и для последнего И. Заметим, что в каждом смежном классе имеется вектор с нулями в качестве информационных символов и синдромом в качестве проверочных символов.
для следующего 10 и для последнего И. Заметим, что в каждом смежном классе имеется вектор с нулями в качестве информационных символов и синдромом в качестве проверочных символов.




























































































































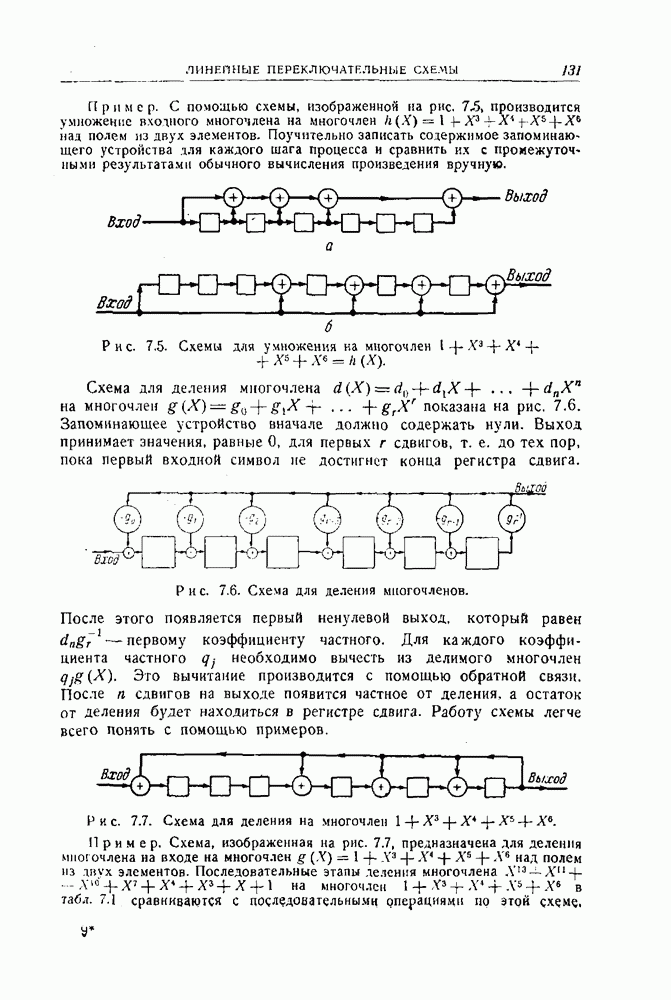

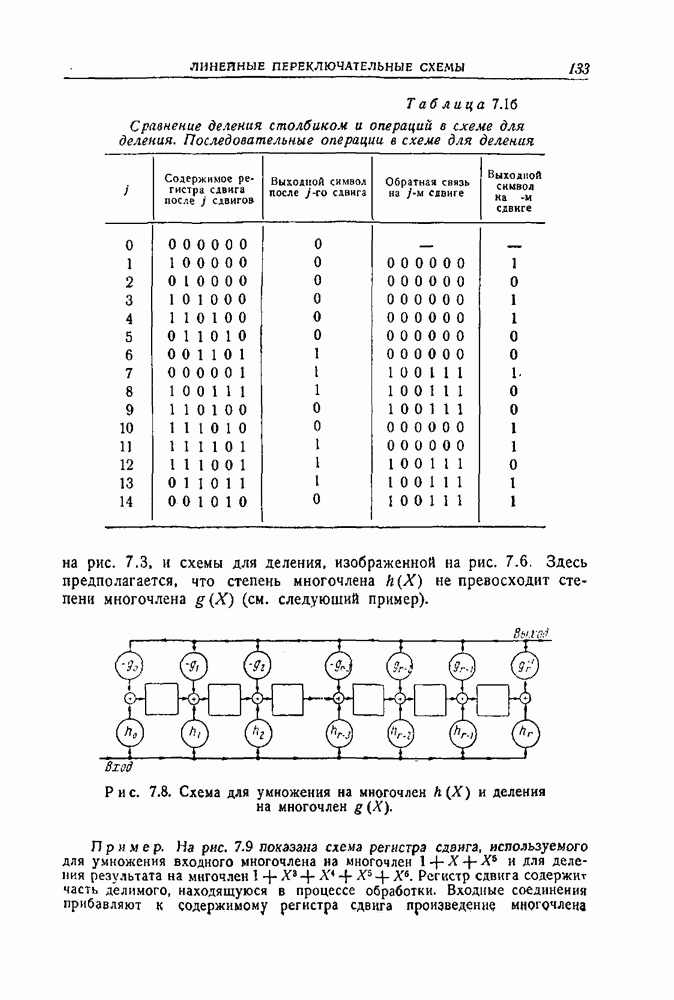

























































































































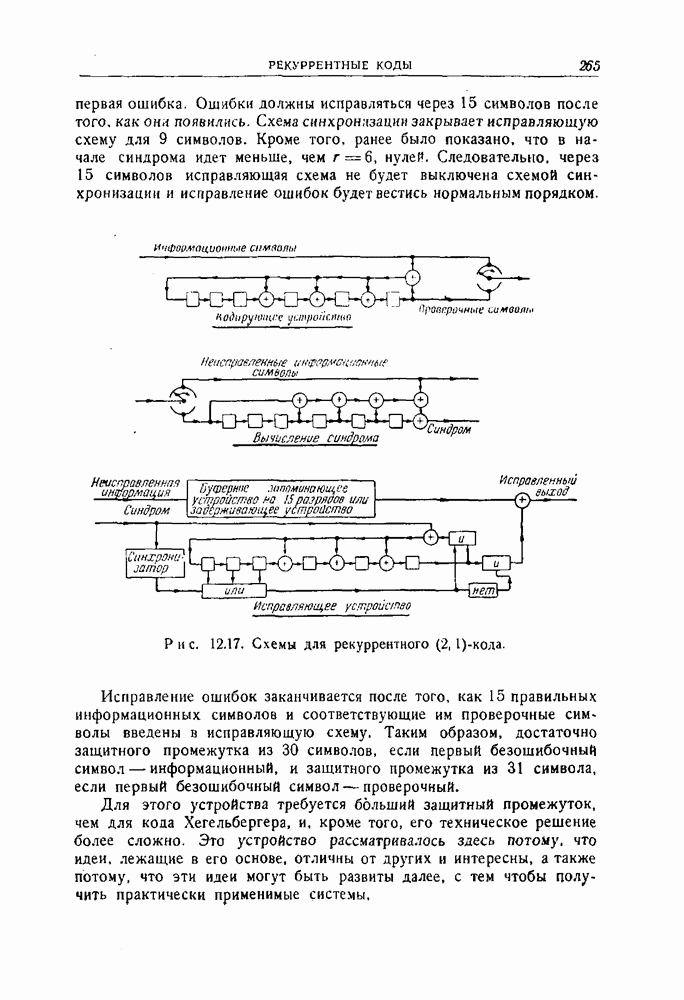
















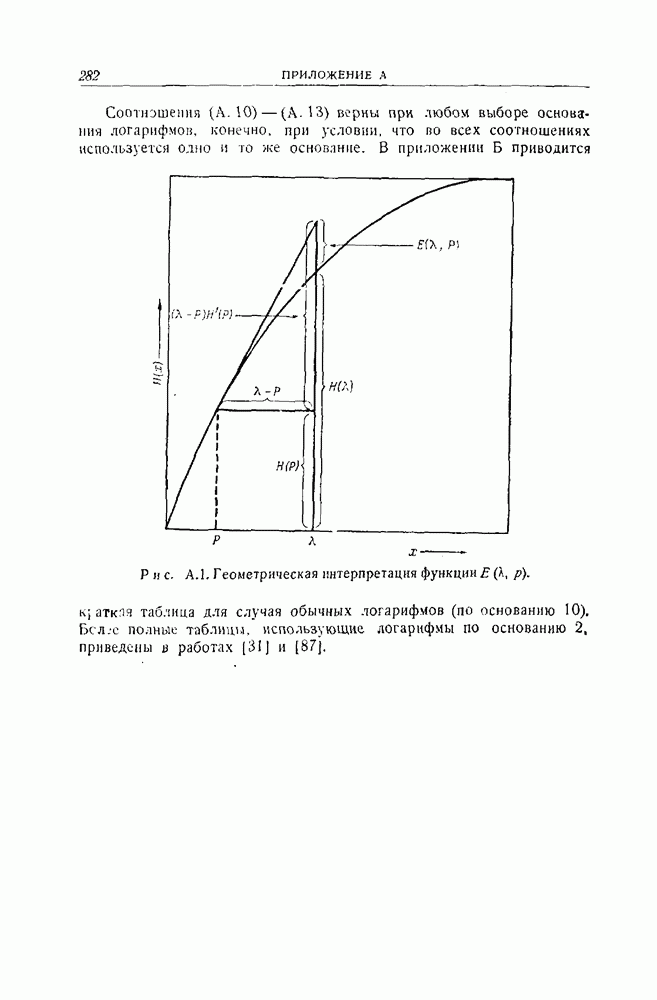
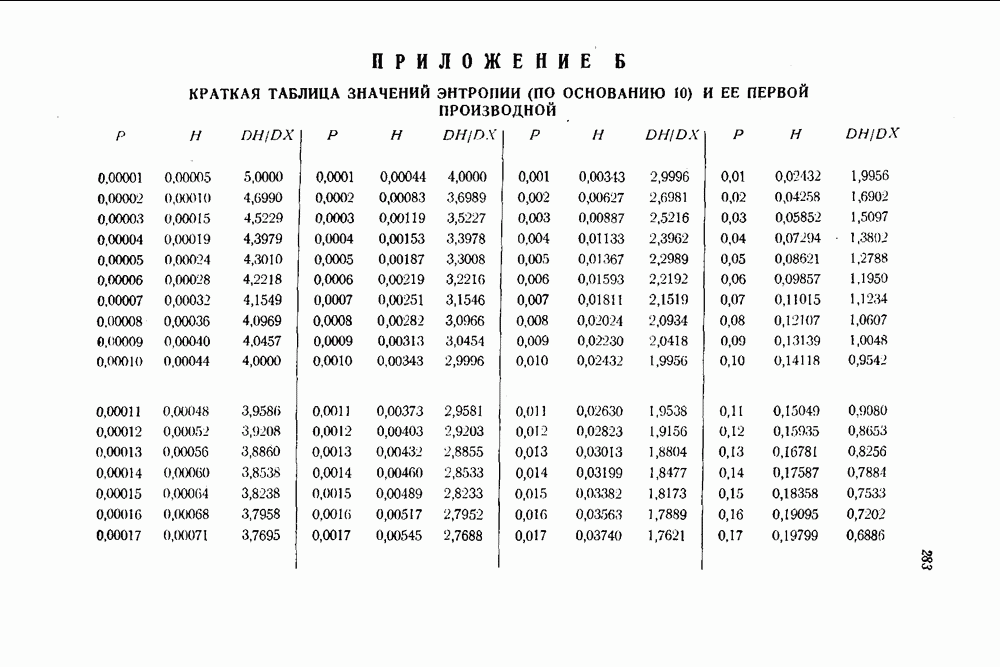
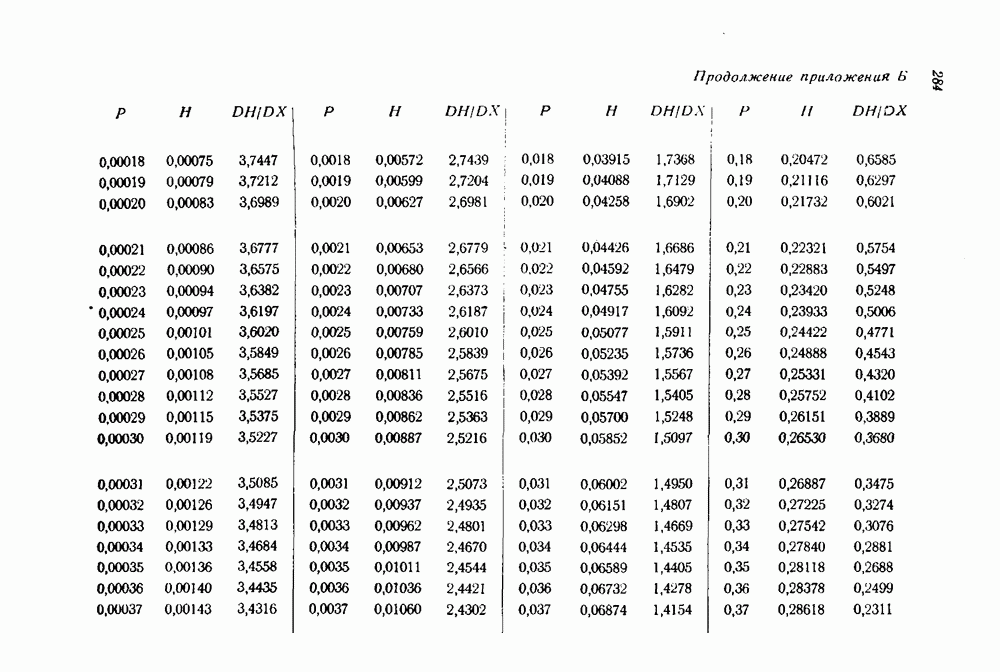




























 -код,
-код,  нулевой элемент и
нулевой элемент и  остальные кодовые векторы. Тогда можно следующим образом составить таблицу декодирования. Кодовые векторы расположим в виде строки с нулевым элементом слева. Затем одну из оставшихся последовательностей длины
остальные кодовые векторы. Тогда можно следующим образом составить таблицу декодирования. Кодовые векторы расположим в виде строки с нулевым элементом слева. Затем одну из оставшихся последовательностей длины  , например
, например  поместим под нулевым элементом. (Обычно это бывает одна из последовательностей, которые наиболее вероятно получить на выходе, если по каналу передавался нулевой вектор.) Далее заполним строку так, чтобы под каждым кодовым вектором
поместим под нулевым элементом. (Обычно это бывает одна из последовательностей, которые наиболее вероятно получить на выходе, если по каналу передавался нулевой вектор.) Далее заполним строку так, чтобы под каждым кодовым вектором  помещался вектор
помещался вектор  Аналогично в первый столбец второй строки помещается вектор
Аналогично в первый столбец второй строки помещается вектор  и строка заполняется таким же способом. Процесс продолжается до тех пор, пока каждая возможная последовательность длины
и строка заполняется таким же способом. Процесс продолжается до тех пор, пока каждая возможная последовательность длины  не появится где-нибудь в таблице. Это стандартное расположение, конечно, в точности совпадает с таблицей смежных классов,
не появится где-нибудь в таблице. Это стандартное расположение, конечно, в точности совпадает с таблицей смежных классов,