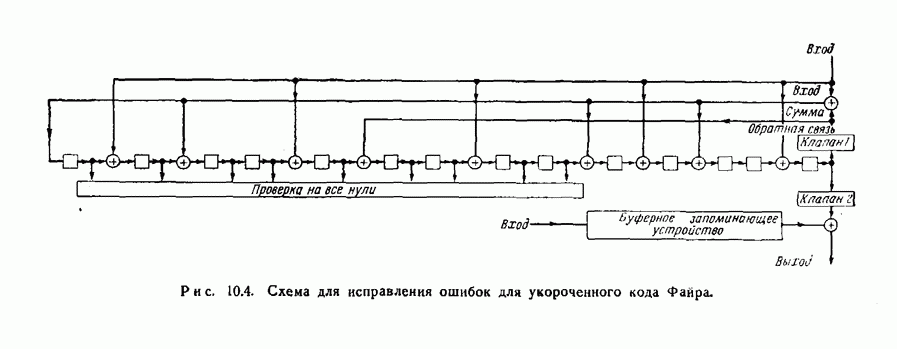
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
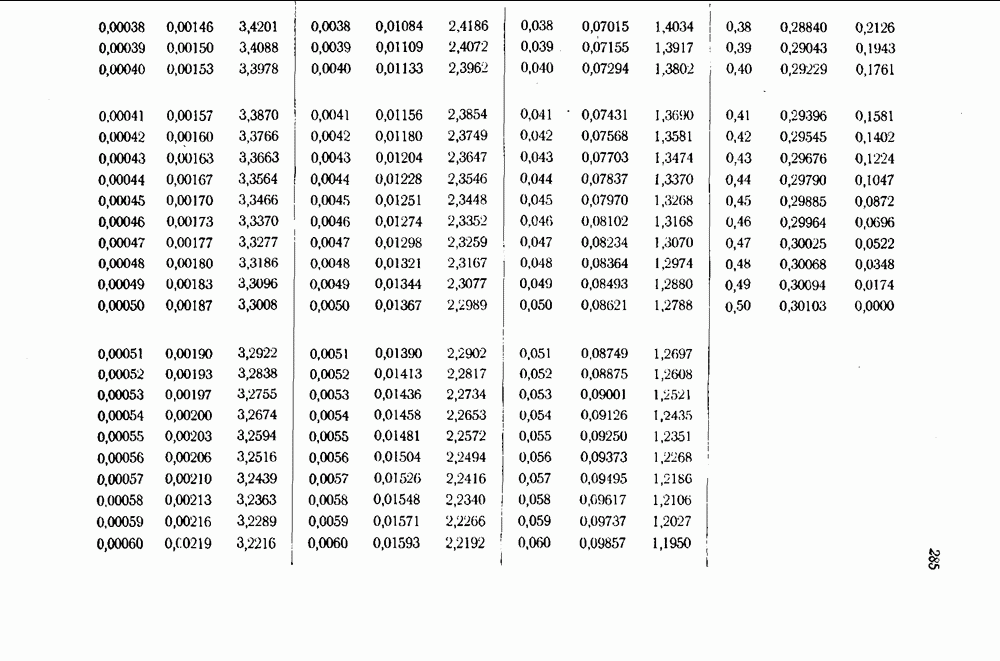
5.8. Итеративные кодыДля того чтобы получить более совершенные коды, можно использовать комбинации двух или более кодов. Например, при помощи единственной проверки на четность для компонент каждого вектора можно обнаружить все одиночные ошибки.
Рис. 5.2. Структура итеративных кодов. Рассмотрим теперь информационные символы, расположенные в прямоугольную таблицу, как это показано на рис. 5.2, с одной проверкой на четность по всем символам для каждой строки и каждого столбца. Этот код, полученный из простейшего кода с проверкой на четность, может исправлять все одиночные ошибки, ибо если произошла одна ошибка, строка и столбец, в которых она произошла, будут указаны неверными результатами проверок на четность. В самом деле, минимальный вес этого кода, являющегося линейным, равен 4 — весу минимального по весу кодового слова, имеющему ненулевые компоненты на пересечении двух строк и двух столбцов. Этот код используется на практике для обнаружения ошибок на магнитной ленте в вычислительных машинах фирмы ИБМ, Важным обобщением этого кода является код, получаемый в том случае, когда в качестве строк таблицы берутся векторы из одного кода, а в качестве столбцов векторы из другого кода. Итеративные коды можно также строить на основе трехмерных таблиц и таблиц более высоких размерностей. Получаются линейные коды. Итерация кодов была названа Слепяпом произведением кодов, так как порождающая матрица итерации двух кодов комбинаторно эквивалентна тензорному произведению порождающих матриц двух исходных кодов. Необходимо отметить, что некоторые символы, например, символ, расположенный на рис. 5.2 в нижнем правом углу, получаются как проверка проверочных символов. Они могут быть построены на основе проверок по строкам и тогда будут удовлетворять проверке по столбцам и наоборот. Если они построены при помощи проверок по строкам на основе соответствующих проверочных правил для кода, используемого в строках таблицы, то каждый проверочный столбец является в действительности линейной комбинацией столбцов, содержащих информационные символы. Проверочные символы добавлены к каждому из этих столбцов, что превращает каждый столбец в кодовый вектор, и, следовательно, проверочные столбцы, будучи линейными комбинациями кодовых векторов для кода, используемого в столбцах таблицы, также являются кодовыми векторами из этого кода. Можно сделать два замечания относительно возможности этих кодов исправлять ошибки. Теорема 5.3, Минимальный вес итерации, или произведения двух кодов, равен произведению минимальных весов этих кодов. Доказательство. Если минимальный вес одного кода равен Теорема 5.4. Если при передаче по двоичному симметричному каналу вероятность ошибки для первого кода равна Доказательство. Предположим, что первый код используется в качестве строк и что после получения всей информации декодирование производится только по строкам. Тогда вероятность ошибки в некоторой строке равна Элайес использовал интересным способом эти идеи для того, чтобы найти для двоичного симметричного канала последовательность кодов, вероятности ошибок для которых стремятся к нулю, когда длина кодов неограниченно возрастает, а скорости передачи при этом стремятся к пределу, который больше нуля. Это единственный известный пример кодовой системы, обладающей обоими этими свойствами. В рассматриваемой системе используется код Хэмминга, исправляющий одиночные ошибки и обнаруживающий двойные ошибки. Этот код содержит
и, следовательно, вероятность того, что после исправления ошибок в некотором символе останется ошибка, равна
Рассмотрим теперь итерации этих кодов, производимые последовательно
а последовательное применение неравенства 5.11 совместно с тождеством 4.25 дает
Это выражение стремится к нулю, когда Наконец, долю символов, которые будут информационными символами после
и на каждом шаге добавляются проверочные символы, сокращая долю всех информационных символов на это отношение. Следовательно, результирующая скорость передачи равна
Это выражение может быть ограничено снизу на основе неравенства
которое совместно с тождеством 4.25 дает
Из сказанного следует, что если вероятность ошибки в канале достаточно мала для того, чтобы среднее число ошибок в каждой строке первой итерации было меньше 1/2, то вероятность ошибки может быть сделана произвольно малой, если использовать достаточное число итераций, причем скорость передачи, или доля символов, несущих информацию, для любого числа итераций остается больше некоторой постоянной величины. Скорость передачи для этого кода оказывается меньше скорости передачи, которую можно достигнуть в соответствии с основной теоремой Шеннона для каналов с шумом. Действительно, эффективность рассматриваемого кода ограничена в некотором смысле эффективностью первой итерации. Вероятность ошибки (и эффективность) первой итерации ограничена для коротких кодов границей, полученной на основе принципа плотной упаковки сфер, так что для того, чтобы увеличить эффективность далее некоторого предела, надо увеличить длину первой итерации. (Используемое здесь понятие эффективности может быть сделано точным; см. работу Другое важное замечание состоит в том, что минимальный вес после
стремится к нулю при
|
 |
Оглавление
|



























































































































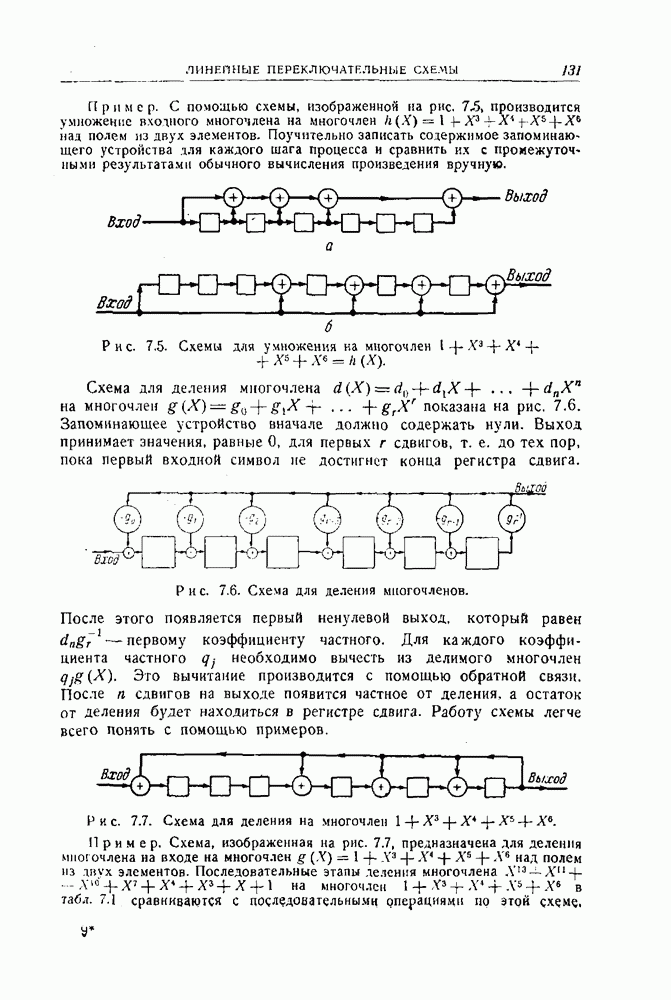

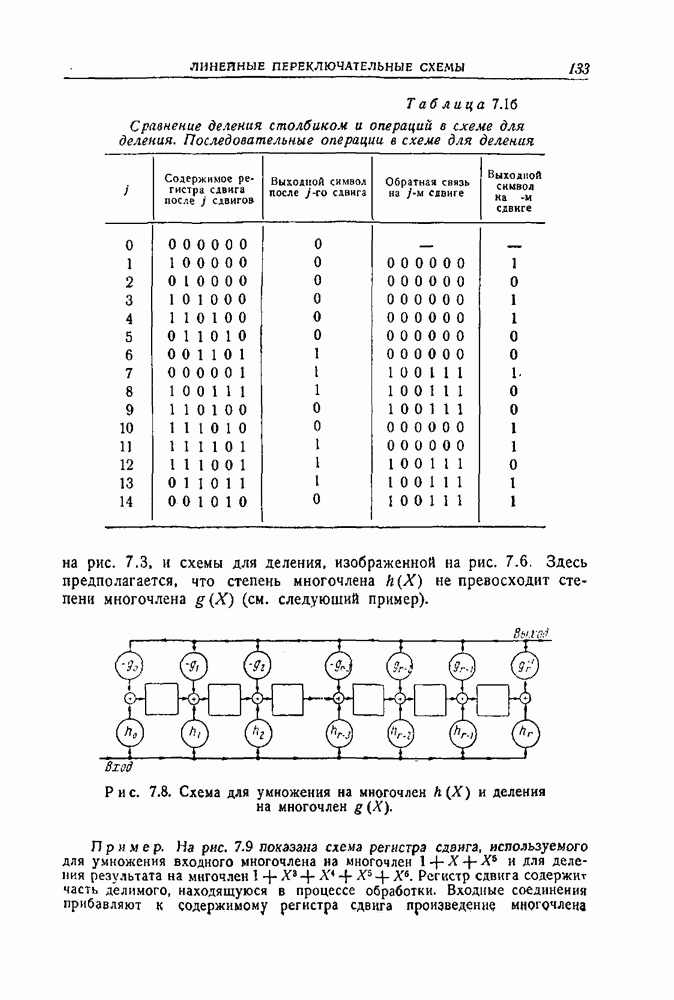




















































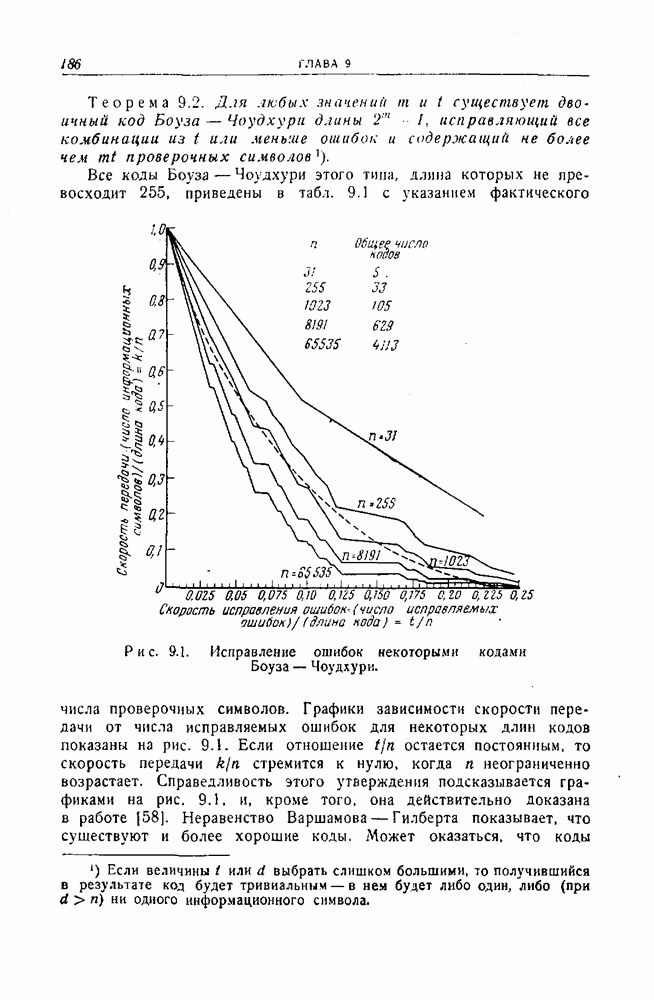




























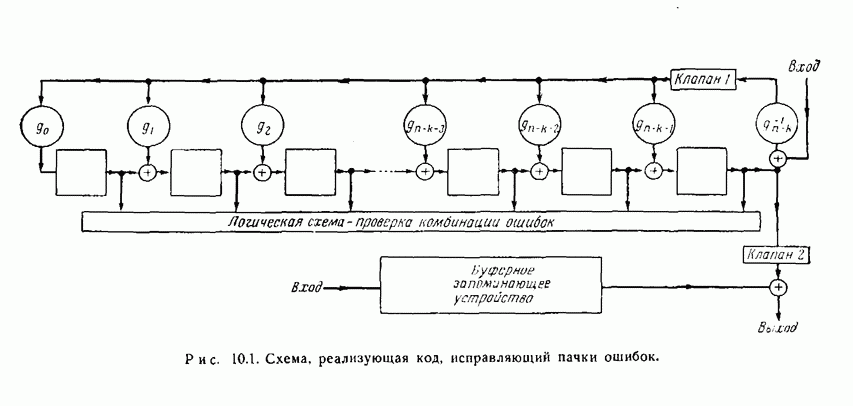






















































































 а другого
а другого  то вектор в произведении кодов должен иметь по крайней мере
то вектор в произведении кодов должен иметь по крайней мере  ненулевых элементов в каждой строке, которая содержит ненулевые элементы, и по крайней мере
ненулевых элементов в каждой строке, которая содержит ненулевые элементы, и по крайней мере  ненулевых элементов в каждом столбце, который содержит ненулевые элементы, и, следовательно, иметь
ненулевых элементов в каждом столбце, который содержит ненулевые элементы, и, следовательно, иметь  ненулевых элементов, если он вообще содержит ненулевые элементы. Кроме того, по крайней мере одна такая комбинация существует, если в первом коде найдется вектор веса
ненулевых элементов, если он вообще содержит ненулевые элементы. Кроме того, по крайней мере одна такая комбинация существует, если в первом коде найдется вектор веса  а во втором коде — вектор веса Ч. т. д.
а во втором коде — вектор веса Ч. т. д.
 а для второго кода
а для второго кода  то для произведения этих кодов возможно декодирование с вероятностью ошибка не большей, чем
то для произведения этих кодов возможно декодирование с вероятностью ошибка не большей, чем 
 следовательно, вероятность ошибки в любом заданном символе не превосходит этой величины. Кроме того, строки независимы между собой, и так как каждый столбец содержит только один символ из каждой строки, то элементы каждого столбца независимы между собой. Если теперь декодировать столбцы, используя код по столбцам, то получаемая вероятность ошибки не превзойдет
следовательно, вероятность ошибки в любом заданном символе не превосходит этой величины. Кроме того, строки независимы между собой, и так как каждый столбец содержит только один символ из каждой строки, то элементы каждого столбца независимы между собой. Если теперь декодировать столбцы, используя код по столбцам, то получаемая вероятность ошибки не превзойдет  Могут, конечно, существовать и лучшие способы декодирования. Ч. т. д.
Могут, конечно, существовать и лучшие способы декодирования. Ч. т. д.
 символов, из которых
символов, из которых  символов — проверочные и
символов — проверочные и  символов—информационные. (См. разд. 5.1.) Код исправляет одиночные ошибки. Все комбинации из четного числа ошибок обнаруживаются, но при этом в полученный вектор не вносятся никакие изменения. Однако если число ошибок нечетно и равно самое меньшее трем, то будет происходить исправление ошибок и один символ, вероятнее всего Правильный, будет изменен; таким образом, вводится еще одна ошибка. Вероятность заданной комбинации из
символов—информационные. (См. разд. 5.1.) Код исправляет одиночные ошибки. Все комбинации из четного числа ошибок обнаруживаются, но при этом в полученный вектор не вносятся никакие изменения. Однако если число ошибок нечетно и равно самое меньшее трем, то будет происходить исправление ошибок и один символ, вероятнее всего Правильный, будет изменен; таким образом, вводится еще одна ошибка. Вероятность заданной комбинации из  ошибок равна
ошибок равна  имеется всего
имеется всего  таких комбинаций, и, следовательно, вероятность того, что произойдет
таких комбинаций, и, следовательно, вероятность того, что произойдет  ошибок,
ошибок,  Среднее число ошибок в блоке тогда равно
Среднее число ошибок в блоке тогда равно



 раз, начиная с
раз, начиная с  так что длина кода каждый раз увеличивается вдвое и код, используемый на
так что длина кода каждый раз увеличивается вдвое и код, используемый на  шаге, имеет длину, равную
шаге, имеет длину, равную  Пусть
Пусть  вероятности ошибки в канале,
вероятности ошибки в канале,  вероятность ошибки после
вероятность ошибки после  итераций. Тогда в соответствии с неравенством 5.10
итераций. Тогда в соответствии с неравенством 5.10


 стремится к бесконечности, если только
стремится к бесконечности, если только  т. е. если среднее число ошибок в строке в первой итерации меньше чем
т. е. если среднее число ошибок в строке в первой итерации меньше чем 
 итераций, можно оценить следующим образом. Число проверочных символов кода, используемого в итерации, равно
итераций, можно оценить следующим образом. Число проверочных символов кода, используемого в итерации, равно  так что
так что  информационных символов равна
информационных символов равна




 Возможно, однако, что все это происходит не из-за плохого выбора самого кода, а лишь из-за плохого выбора метода декодирования.
Возможно, однако, что все это происходит не из-за плохого выбора самого кода, а лишь из-за плохого выбора метода декодирования.
 итераций равен
итераций равен  так как при каждой итерации используется код с минимальным весом 4. Отношение минимального веса к длине кода
так как при каждой итерации используется код с минимальным весом 4. Отношение минимального веса к длине кода

 стремящемся к бесконечности, и, следовательно, становится меньше, чем значение, которое гарантируется границей Варшамова — Гилберта. Кроме того, описанная система декодирования неоптимальна, так что исправляются даже не все ошибки, которые могли бы быть исправлены в соответствии с равенством (5.14). Рассматриваемый код оказался удачным из-за того, что он исправляет подавляющее большинство наиболее вероятных комбинаций ошибок, многие из которых содержат значительно больше, чем
стремящемся к бесконечности, и, следовательно, становится меньше, чем значение, которое гарантируется границей Варшамова — Гилберта. Кроме того, описанная система декодирования неоптимальна, так что исправляются даже не все ошибки, которые могли бы быть исправлены в соответствии с равенством (5.14). Рассматриваемый код оказался удачным из-за того, что он исправляет подавляющее большинство наиболее вероятных комбинаций ошибок, многие из которых содержат значительно больше, чем  ошибок.
ошибок.