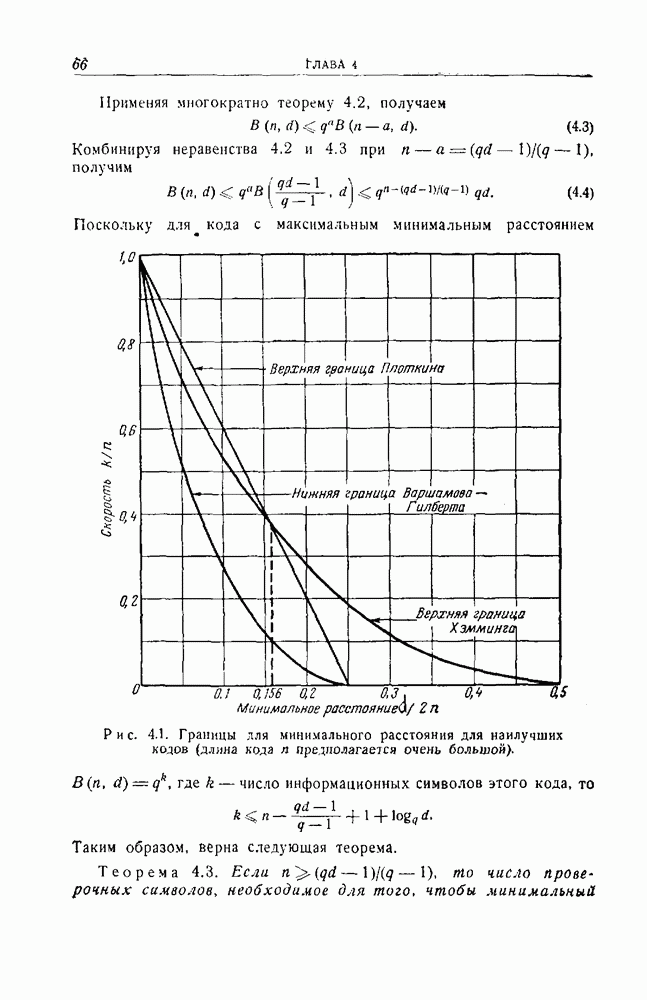
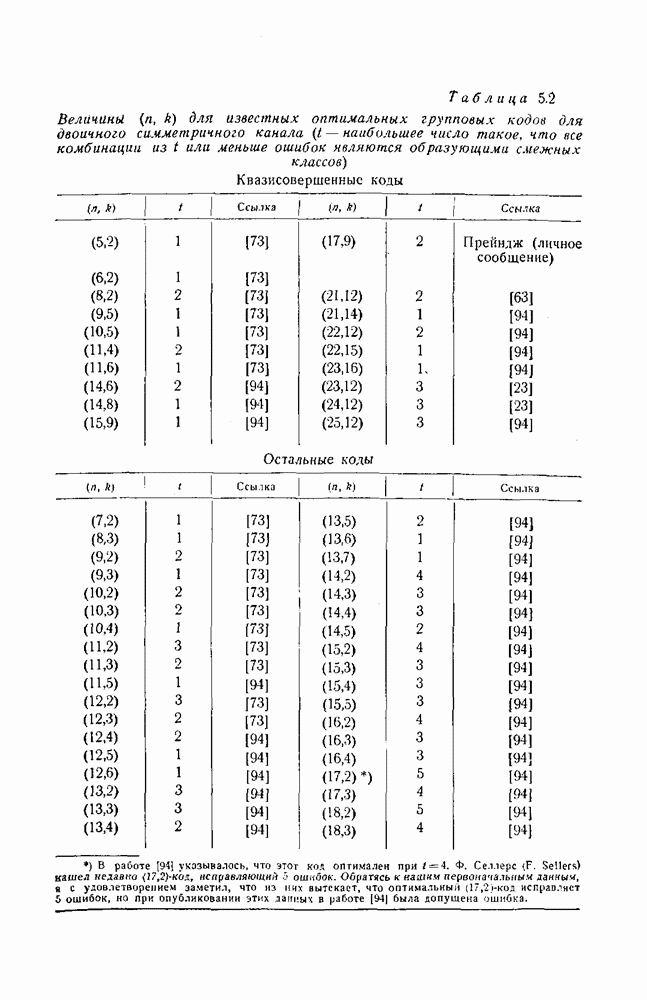
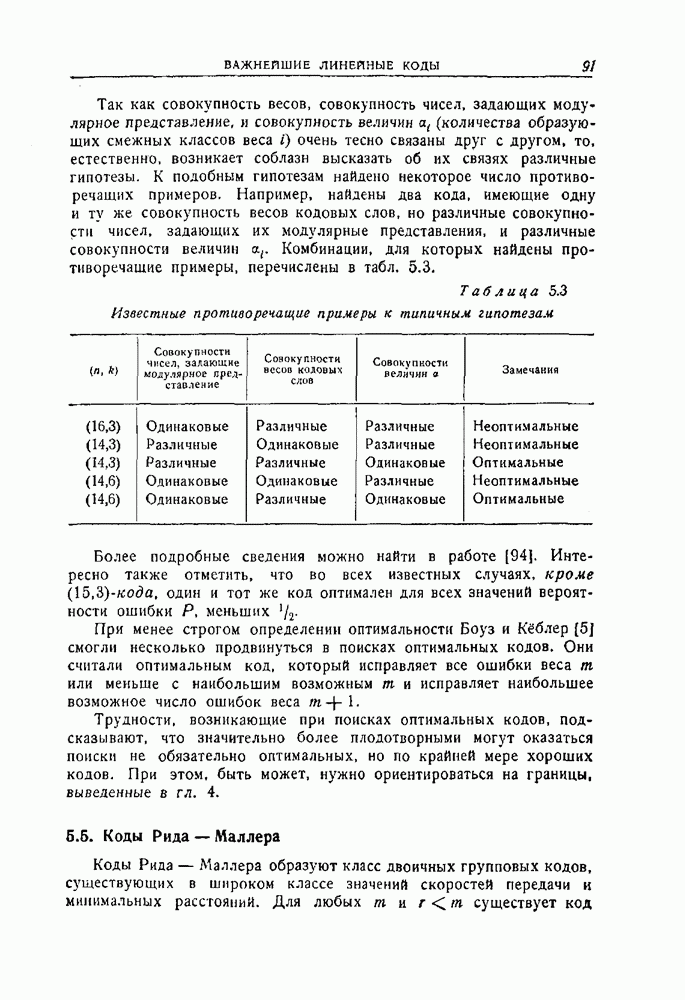
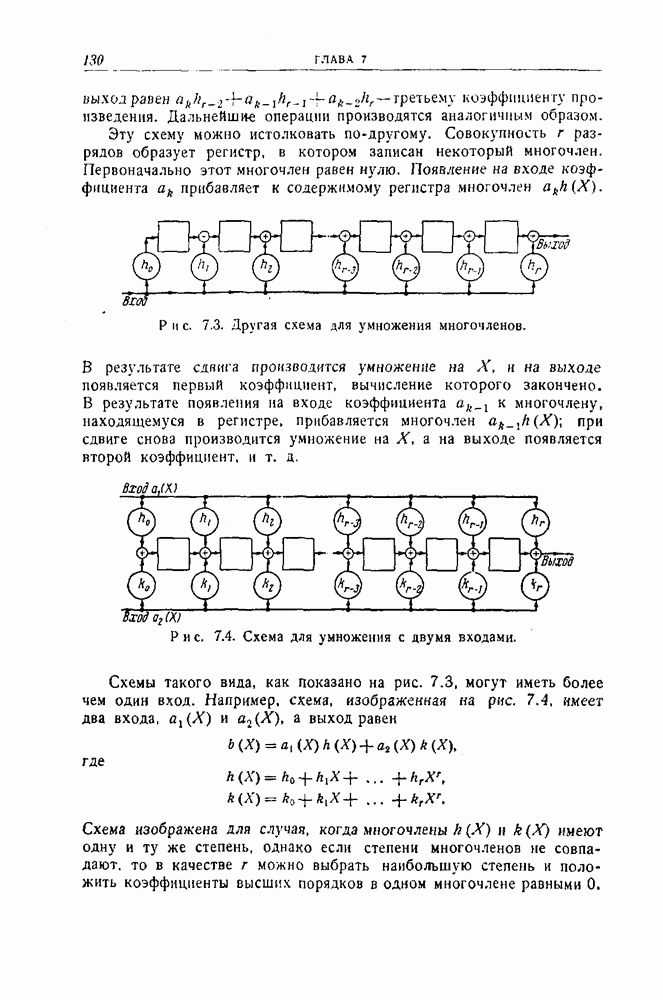
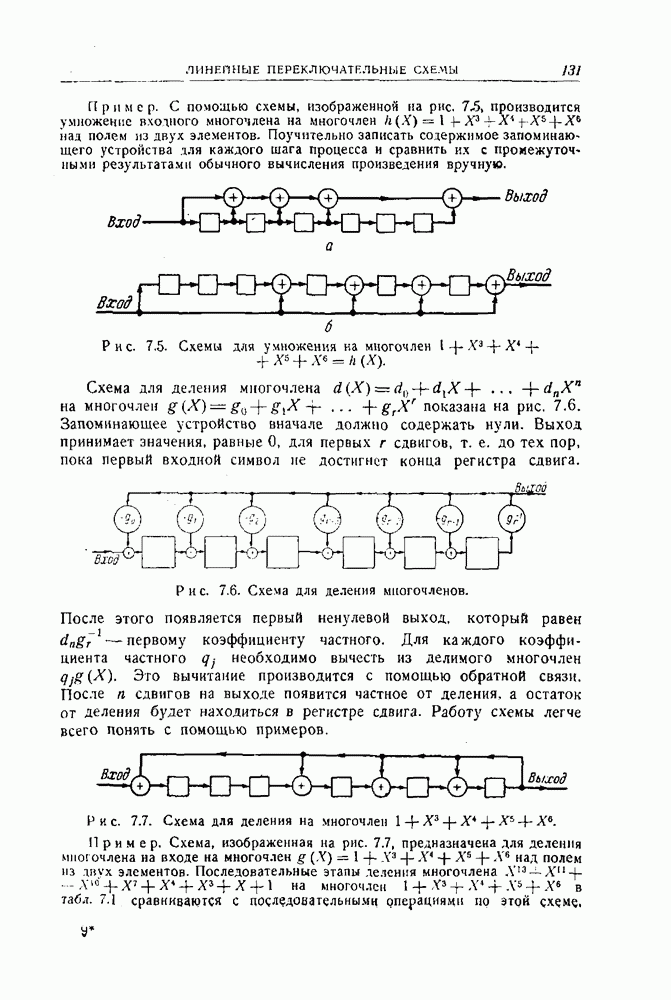
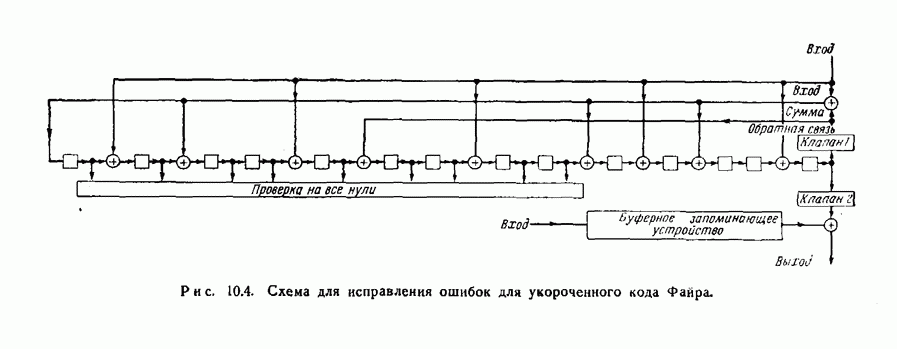
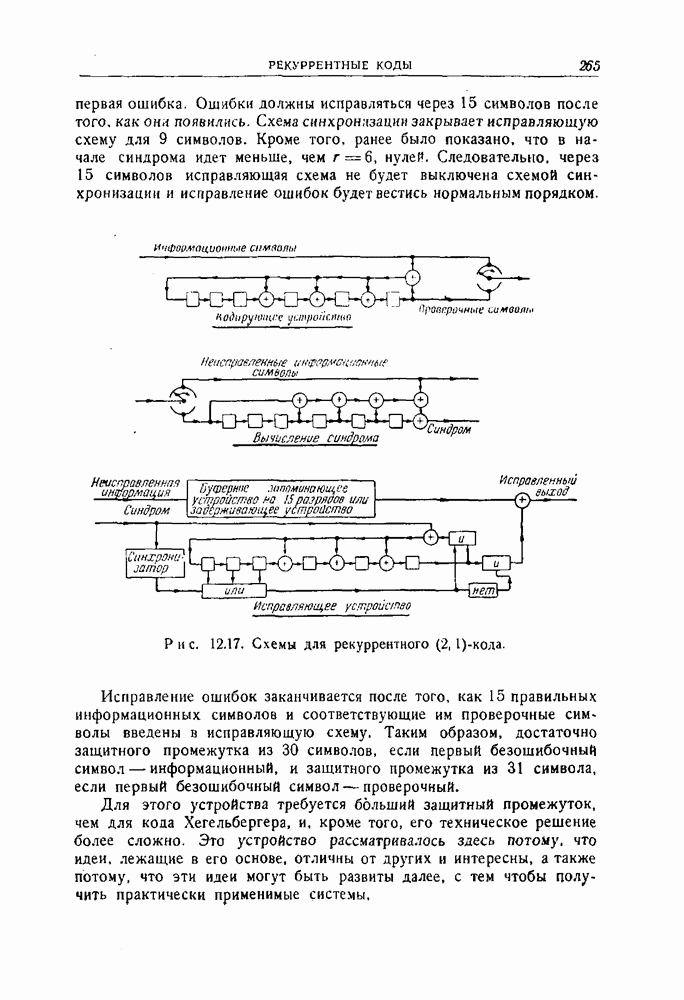
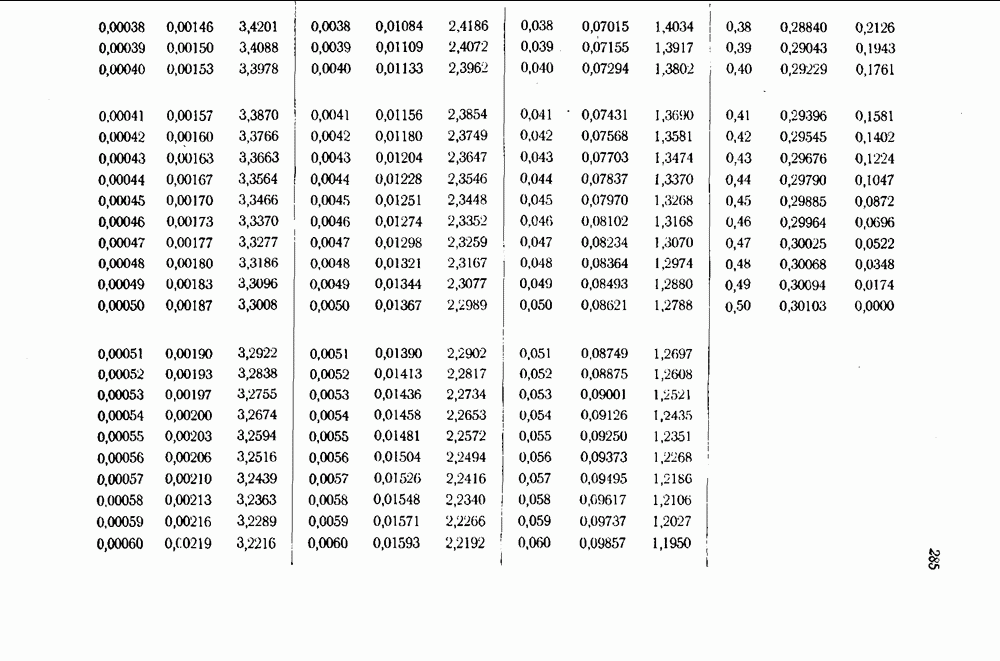
12.3. Обнаружение пачек ошибок с помощью рекуррентных кодов
Рассмотрим сперва для простоты  -рекуррентный код, которому соответствует схема, изображенная на рис. 12.10. Можно следующим образом установить условия, которым должна удовлетворять пачка ошибок, для того чтобы она не приводила ни к одному несовпадению при проверках на четность.
-рекуррентный код, которому соответствует схема, изображенная на рис. 12.10. Можно следующим образом установить условия, которым должна удовлетворять пачка ошибок, для того чтобы она не приводила ни к одному несовпадению при проверках на четность.

Рис. 12.10. Блок-схема системы, обнаруживающей ошибки.
Преобразователь, с помощью которого вычисляются проверочные символы, характеризуется передаточной функцией  Если при передаче не происходит ошибок, то выход преобразователя в точности соответствует полученным проверочным символам, и разность, совпадающая с синдромом, равна 0. Так как преобразователь линеен, то в том случае, когда к входной последовательности прибавляется некоторая
Если при передаче не происходит ошибок, то выход преобразователя в точности соответствует полученным проверочным символам, и разность, совпадающая с синдромом, равна 0. Так как преобразователь линеен, то в том случае, когда к входной последовательности прибавляется некоторая
комбинация ошибок, выходная последовательность для детектора ошибок равна сумме 1) выходной последовательности, возникающей, когда на вход поступает последовательность, содержащая информационные символы и не искаженная ошибками, и 2) выходной последовательности, содержащей комбинацию ошибок, для которой все информационные символы равны нулю. Так как при отсутствии ошибок синдром равен 0, то он зависит только от комбинации ошибок и не зависит от информационных символов. Его можно поэтому изучать в предположении, что все информационные символы равны нулю.
Так как пачка ошибок содержит конечное число ненулевых символов, то ее можно трактовать как некоторый многочлен. Предположим, что  комбинация ошибок среди информационных символов и что
комбинация ошибок среди информационных символов и что  комбинация ошибок среди проверочных символов, причем в качестве коэффициентов высших порядков выбраны символы, которые появляются по времени раньше, в соответствии с условием, введенным в разд. 7.1. Тогда, как показывает соотношение (7.19), воздействие фильтра состоит в умножении входной последовательности на
комбинация ошибок среди проверочных символов, причем в качестве коэффициентов высших порядков выбраны символы, которые появляются по времени раньше, в соответствии с условием, введенным в разд. 7.1. Тогда, как показывает соотношение (7.19), воздействие фильтра состоит в умножении входной последовательности на  и делении на Таким образом, для необнаруживаемой ошибки
и делении на Таким образом, для необнаруживаемой ошибки

и так как  то это равенство эквивалентно равенству
то это равенство эквивалентно равенству

(Заметим, что многочлен не может быть нулевой последовательностью для преобразователя.)
Если обозначить  наибольший общий делитель многочленов
наибольший общий делитель многочленов  и положить
и положить  то
то

Многочлены  взаимно просты, следовательно, многочлен
взаимно просты, следовательно, многочлен  должен делиться на
должен делиться на  а многочлен
а многочлен  должен делиться на
должен делиться на  Это ограничение на многочлены
Это ограничение на многочлены  не зависит от
не зависит от  общего делителя многочленов
общего делителя многочленов  поэтому для упрощения схемного решения многочлен
поэтому для упрощения схемного решения многочлен  обычно выбирается равным 1. Итак, в качестве
обычно выбирается равным 1. Итак, в качестве  должны выбираться взаимно простые многочлены. Впредь будет предполагаться, что это условие выполняется. Тогда многочлен
должны выбираться взаимно простые многочлены. Впредь будет предполагаться, что это условие выполняется. Тогда многочлен  должен делиться на
должен делиться на  а многочлен
а многочлен  должен делиться на
должен делиться на 
Итак, если степень многочлена  равна
равна  а степень многочлена
а степень многочлена  равна
равна  то многочлен
то многочлен  должен иметь степень самое меньшее
должен иметь степень самое меньшее  а многочлен
а многочлен  самое меньшее
самое меньшее  Это значит, что любая необнаруживаемая комбинация ошибок содержит одновре» менно пачку ошибочных информационных символов, длина которой
Это значит, что любая необнаруживаемая комбинация ошибок содержит одновре» менно пачку ошибочных информационных символов, длина которой
больше  и пачку ошибочных проверочных символов, длина которой больше
и пачку ошибочных проверочных символов, длина которой больше 
Обнаружение остальных наиболее вероятных комбинаций ошибок можно обеспечить путем надлежащего выбора многочленов  Так как многочлен
Так как многочлен  делится на то соответствующий ему вектор принадлежит циклическому коду, порожденному многочленом Используя результаты, полученные в гл. 8—11, можно выбрать многочлен
делится на то соответствующий ему вектор принадлежит циклическому коду, порожденному многочленом Используя результаты, полученные в гл. 8—11, можно выбрать многочлен  так, чтобы дальнейшие ограничения, накладываемые на многочлен
так, чтобы дальнейшие ограничения, накладываемые на многочлен  соответствовали бы необнаруживаемым ошибкам. В частности, коды Файра могут быть использованы для обнаружения пар пачек ошибок, а коды Боуза — Чоудхури — для обнаружения длинных пачек с малой плотностью ошибок.
соответствовали бы необнаруживаемым ошибкам. В частности, коды Файра могут быть использованы для обнаружения пар пачек ошибок, а коды Боуза — Чоудхури — для обнаружения длинных пачек с малой плотностью ошибок.
Например, предположим, что многочлен  степени
степени  порождает циклический код длины
порождает циклический код длины  с минимальным расстоянием
с минимальным расстоянием  Тогда не существует ни одного кодового вектора, вес которого был бы меньше, чем
Тогда не существует ни одного кодового вектора, вес которого был бы меньше, чем  или, что эквивалентно, не существует ни одного многочлена степени, меньшей
или, что эквивалентно, не существует ни одного многочлена степени, меньшей  делящегося на
делящегося на  и такого, что число ненулевых слагаемых в нем меньше
и такого, что число ненулевых слагаемых в нем меньше  Поэтому рекуррентный
Поэтому рекуррентный  -код с этим многочленом
-код с этим многочленом  в качестве знаменателя передаточной функции преобразователя гарантирует обнаружение любой комбинации ошибок
в качестве знаменателя передаточной функции преобразователя гарантирует обнаружение любой комбинации ошибок  среди информационных символов, являющейся пачкой длины
среди информационных символов, являющейся пачкой длины  или меньше, или пачкой длины
или меньше, или пачкой длины  или меньше, содержащей меньше, чем
или меньше, содержащей меньше, чем  ошибок. Заметим, что это условие, которому должны подчиняться ошибки только в информационных символах. Аналогичному условию, определяемому выбором многочлена
ошибок. Заметим, что это условие, которому должны подчиняться ошибки только в информационных символах. Аналогичному условию, определяемому выбором многочлена  должен удовлетворять многочлен
должен удовлетворять многочлен  Однако даже если доказано, что эти условия удовлетворяются, маловероятно, что многочлены
Однако даже если доказано, что эти условия удовлетворяются, маловероятно, что многочлены  и
и  будут удовлетворять соотношениям (12.4) и, следовательно, задавать необнаруживаемые комбинации ошибок.
будут удовлетворять соотношениям (12.4) и, следовательно, задавать необнаруживаемые комбинации ошибок.
Случай одиночной изолированной пачки ошибок уже был рассмотрен. Кажется совсем ясным, что если достаточно отделить друг от друга две пачки ошибок и если каждая из этих пачек порознь является обнаруживаемой, то они будут обнаруживаемыми и в совокупности. Посмотрим теперь, сколь велик должен быть защитный промежуток между пачками ошибок, для того чтобы обеспечить обнаружение обеих пачек.
Предположим, что

Предположим далее, что степени обоих многочленов  и
и  меньше, чем
меньше, чем  в то время как слагаемыми низших степеней в многочленах
в то время как слагаемыми низших степеней в многочленах  являются слагаемые степени Это условие соответствует наличию свободного от ошибок защитного промежутка
являются слагаемые степени Это условие соответствует наличию свободного от ошибок защитного промежутка  информационных символов и связанных с ними
информационных символов и связанных с ними 
проверочных символов, т. е. всего из символов. Ошибка является необнаруживаемой тогда и только тогда, когда удовлетворяется соотношение (12.3). Оно эквивалентно в данном случае соотношению

Отсюда следует, что если  не меньше степеней многочленов
не меньше степеней многочленов  то степень первых двух слагаемых в этом соотношении будет меньше, чем
то степень первых двух слагаемых в этом соотношении будет меньше, чем  а два последних слагаемых будут содержать
а два последних слагаемых будут содержать  в качестве сомножителя. Таким образом, уравнение (12.6) удовлетворяется тогда и только тогда, когда одновременно
в качестве сомножителя. Таким образом, уравнение (12.6) удовлетворяется тогда и только тогда, когда одновременно

и

Следовательно, если каждая из пачек ошибок в отдельности является обнаруживаемой, то для того, чтобы эти пачки обнаруживались при их одновременном появлении, достаточно, чтобы  разделял защитный промежуток, содержащий
разделял защитный промежуток, содержащий  информационных и
информационных и  определяемых ими проверочных символов, где
определяемых ими проверочных символов, где  наибольшая из степеней многочленов
наибольшая из степеней многочленов 

Рис. 12.11. Другая возможная схема для обнаружения ошибок.
Это можно проверить и другим способом. Синдром может быть вычислен с помощью схемы, изображенной на рис. 12.11. Этот способ вычисления синдрома хотя и отличается от вычисления синдрома с помощью схемы, изображенной на рис. 12.10, но эквивалентен ему. В соответствии с равенством (12.3) синдром равен нулю тогда и только тогда, когда либо не появилось ошибок, либо появились ошибки, не обнаруживаемые схемой, изображенной на рис. 12.11. Эта схема, обнаруживающая ошибки, может быть реализована, как регистр сдвига со связями в прямом направлении, но без обратной связи, состоящий из  разрядов, где
разрядов, где  — наибольшая степень многочленов
— наибольшая степень многочленов  (См. рис. 7.4.) Таком образом, если появляется свободный от ошибок защитный промежуток из
(См. рис. 7.4.) Таком образом, если появляется свободный от ошибок защитный промежуток из  информационных символов и
информационных символов и  определяемых ими проверочных символов, то регистр сдвига полностью заполняется правильными символами, и после такого защитного промежутка система действует так, как будто никаких ошибок вообще не появлялось.
определяемых ими проверочных символов, то регистр сдвига полностью заполняется правильными символами, и после такого защитного промежутка система действует так, как будто никаких ошибок вообще не появлялось.
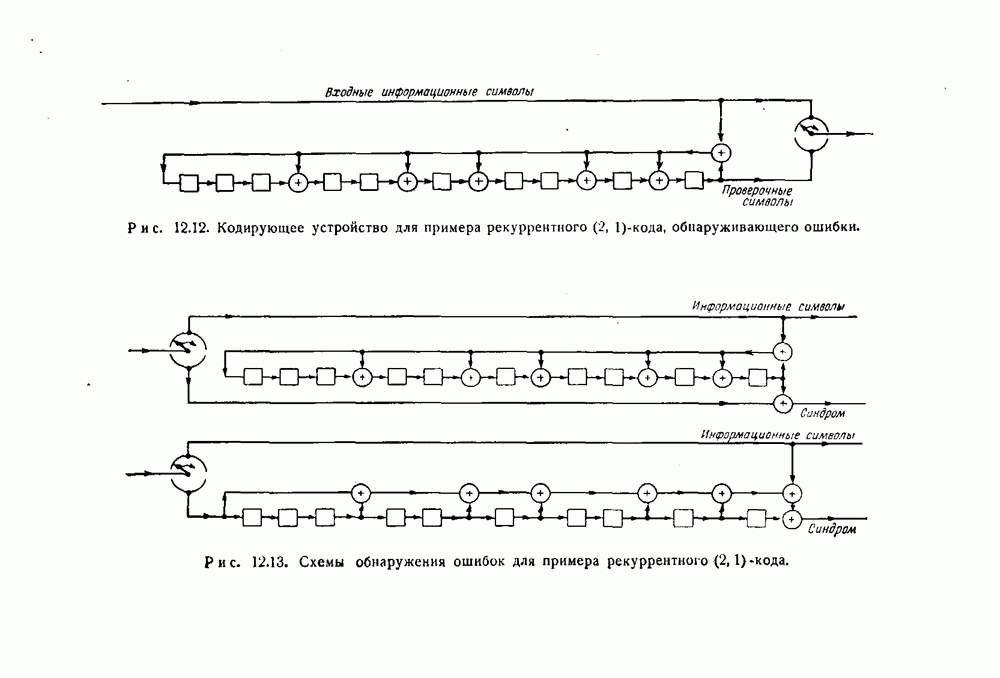
Пример. Многочлен

порождает двоичный  -код Боуза — Чоудхури с минимальным весом» равным 5. Следовательно, не существует многочлена степени меньшей, чем 31, делящегося на многочлен
-код Боуза — Чоудхури с минимальным весом» равным 5. Следовательно, не существует многочлена степени меньшей, чем 31, делящегося на многочлен  и имеющего меньше 5 отличных от нуля слагаемых. Поэтому рекуррентный
и имеющего меньше 5 отличных от нуля слагаемых. Поэтому рекуррентный  -код, который получается, когда используется кодирующее устройство, изображенное на рис. 12.10, с передаточной функцией
-код, который получается, когда используется кодирующее устройство, изображенное на рис. 12.10, с передаточной функцией  обнаруживает любую пачку ошибок, воздействующую на 10 или меньше последовательных информационных символов, или любую пачку ошибок, воздействующую меньше, чем на 5 из всех 31 последовательных информационных символов. В любом из этих случаев необнаруживаемая пачка должна удовлетворять равенству (12.4). Для разделения пачек достаточно свободного от ошибок защитного промежутка из 10 информационных символов и 10 определяемых ими проверочных символов.
обнаруживает любую пачку ошибок, воздействующую на 10 или меньше последовательных информационных символов, или любую пачку ошибок, воздействующую меньше, чем на 5 из всех 31 последовательных информационных символов. В любом из этих случаев необнаруживаемая пачка должна удовлетворять равенству (12.4). Для разделения пачек достаточно свободного от ошибок защитного промежутка из 10 информационных символов и 10 определяемых ими проверочных символов.
Кодирующее устройство для этого кода изображено на рис. 12.12. Две различные схемы для обнаружения ошибок показаны на рис. 12.13.
Анализ более общих рекуррентных кодов проводится так же, как в случае рекуррентного  -кода. При обнаружении ошибок обычно стремятся иметь по возможности меньшую избыточность, т. е. стремятся найти код, в котором на каждые
-кода. При обнаружении ошибок обычно стремятся иметь по возможности меньшую избыточность, т. е. стремятся найти код, в котором на каждые  информационных символов передается один проверочный символ. Такой код, в котором информационные символы передаются неизмененными, изображен на рис. 12.14. Снова выход, отмеченный словом "синдром", будет равен нулю в том случае, когда ошибки отсутствуют, и будет зависеть только от комбинации ошибок, если ошибки появились. Условие, выделяющее необнаруживаемые ошибки, состоит в том, что соответствующий синдром равен нулю, т. е. если
информационных символов передается один проверочный символ. Такой код, в котором информационные символы передаются неизмененными, изображен на рис. 12.14. Снова выход, отмеченный словом "синдром", будет равен нулю в том случае, когда ошибки отсутствуют, и будет зависеть только от комбинации ошибок, если ошибки появились. Условие, выделяющее необнаруживаемые ошибки, состоит в том, что соответствующий синдром равен нулю, т. е. если  комбинация ошибок в
комбинация ошибок в  последовательности информационных символов и
последовательности информационных символов и  комбинация ошибок в последовательности проверочных символов, то
комбинация ошибок в последовательности проверочных символов, то

Если, в частности,  и все многочлены
и все многочлены  взаимно просты, то это соотношение можно переписать в виде
взаимно просты, то это соотношение можно переписать в виде

где

Каждое слагаемое в левой части этого соотношения делится на  поэтому его правая часть также должна делиться на
поэтому его правая часть также должна делиться на  Но многочлены
Но многочлены  взаимно просты, и, следовательно, многочлен
взаимно просты, и, следовательно, многочлен  должен делиться на
должен делиться на  Точно так же можно показать, что каждый многочлен
Точно так же можно показать, что каждый многочлен  должен делиться на
должен делиться на  Это необходимое условие того, чтобы ошибка была необнаружнваемой
Это необходимое условие того, чтобы ошибка была необнаружнваемой

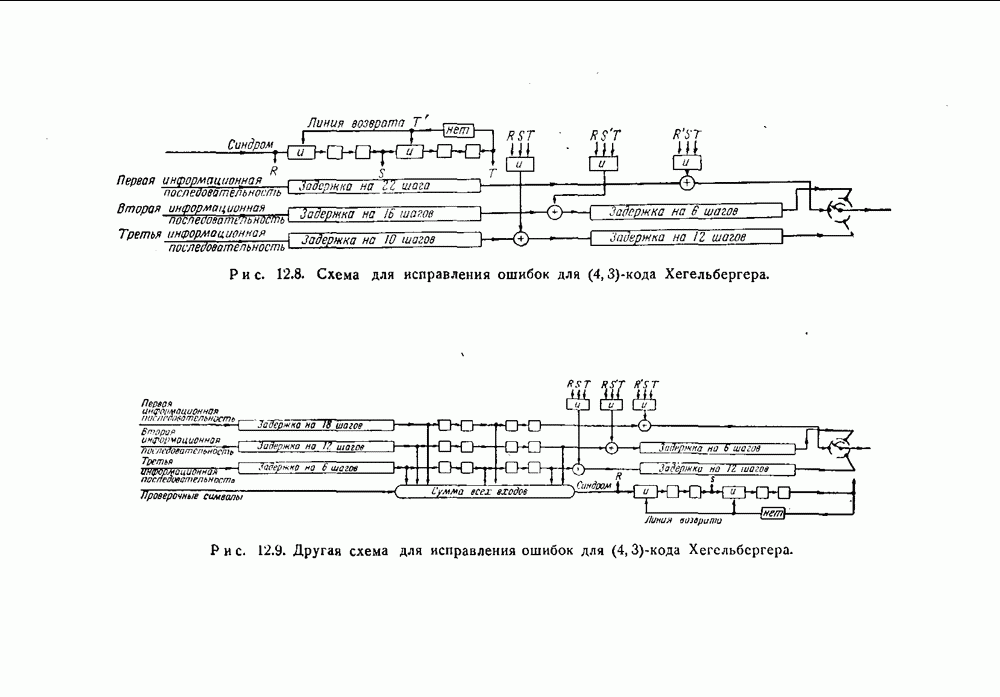
(кликните для просмотра скана)




















































































































































































































































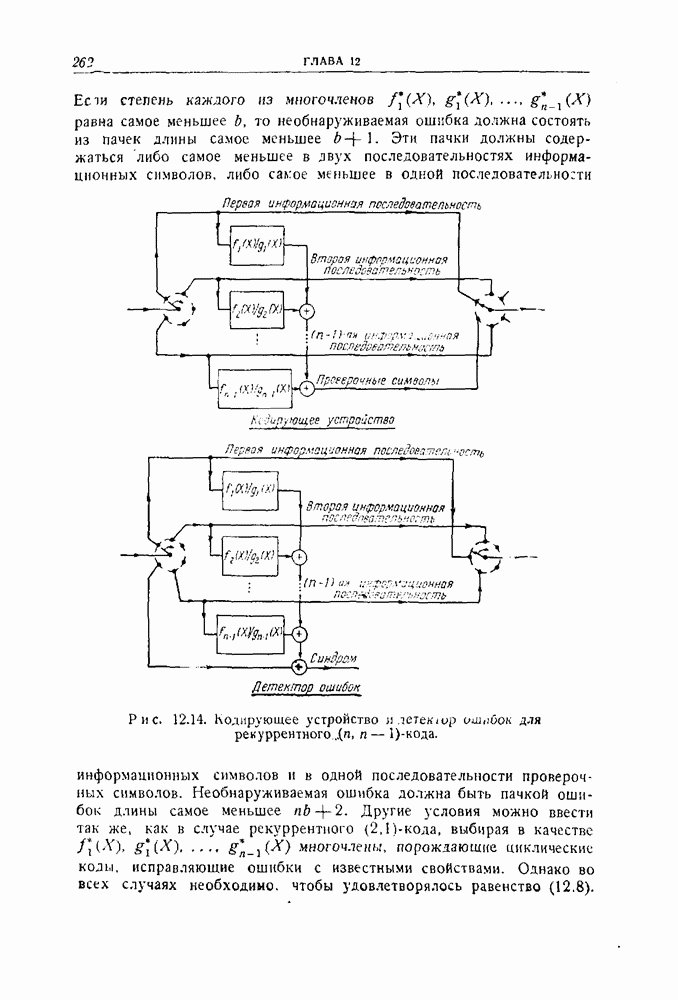














































 равна самое меньшее
равна самое меньшее  то необнаруживаемая ошибка должна состоять из пачек длины самое меньшее
то необнаруживаемая ошибка должна состоять из пачек длины самое меньшее  Эти пачки должны содержаться либо самое меньшее в лвух последовательностях информационных символов, либо самое меньшее в одной последовательности информационных символов и в одной последовательности проверочных символов.
Эти пачки должны содержаться либо самое меньшее в лвух последовательностях информационных символов, либо самое меньшее в одной последовательности информационных символов и в одной последовательности проверочных символов.

 -кода.
-кода.
 Другие условия можно ввести так же, как в случае рекуррентного
Другие условия можно ввести так же, как в случае рекуррентного  -кода, выбирая в качестве многочлены, порождающие циклические коды, исправляющие ошибки с известными свойствами. Однако во всех случаях необходимо, чтобы удовлетворялось равенство (12.8).
-кода, выбирая в качестве многочлены, порождающие циклические коды, исправляющие ошибки с известными свойствами. Однако во всех случаях необходимо, чтобы удовлетворялось равенство (12.8).