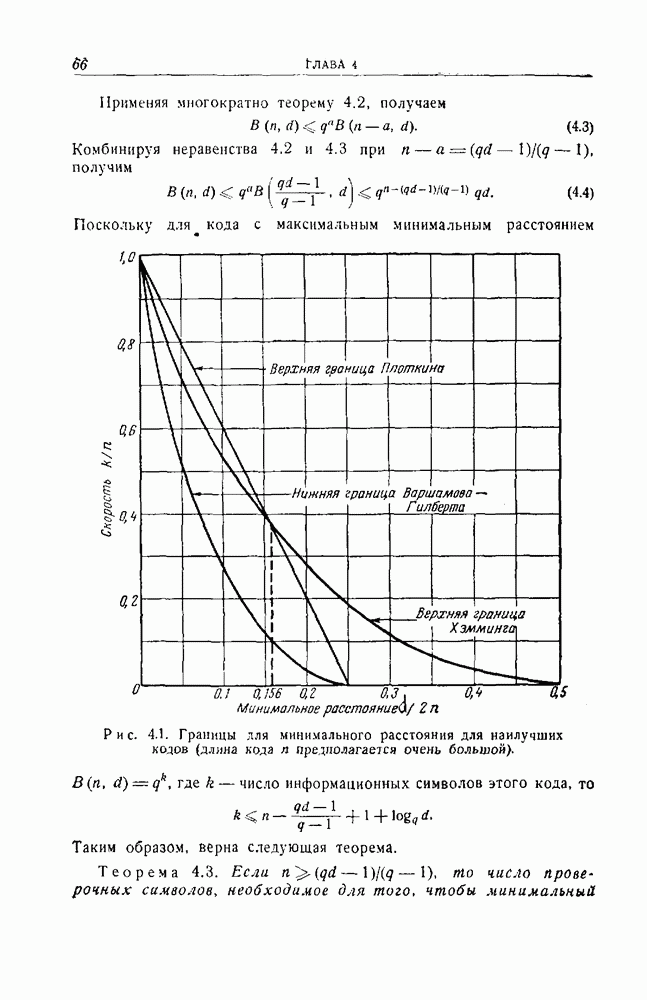
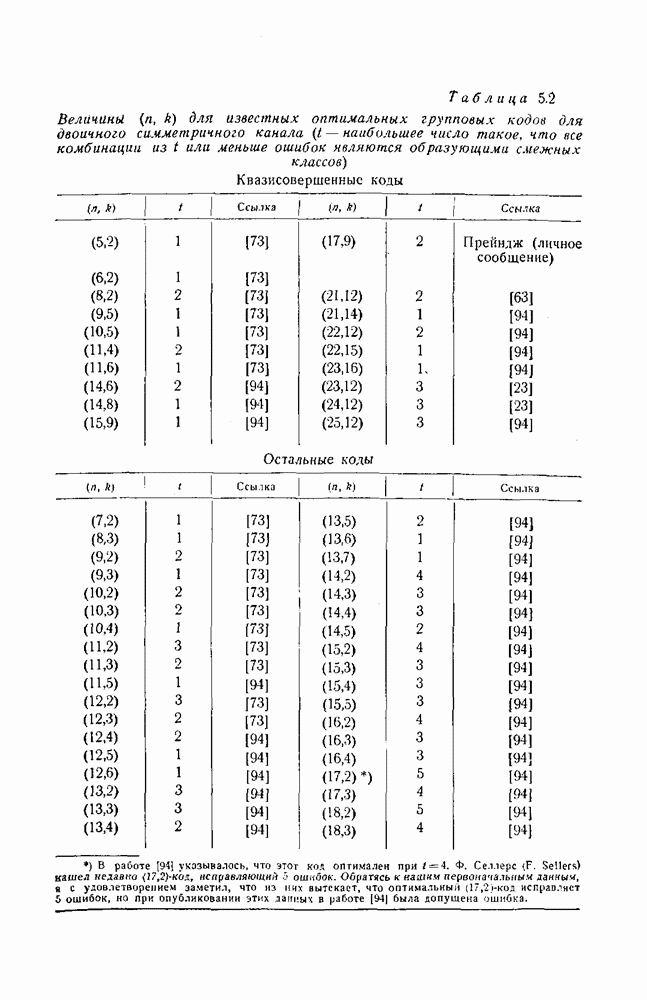
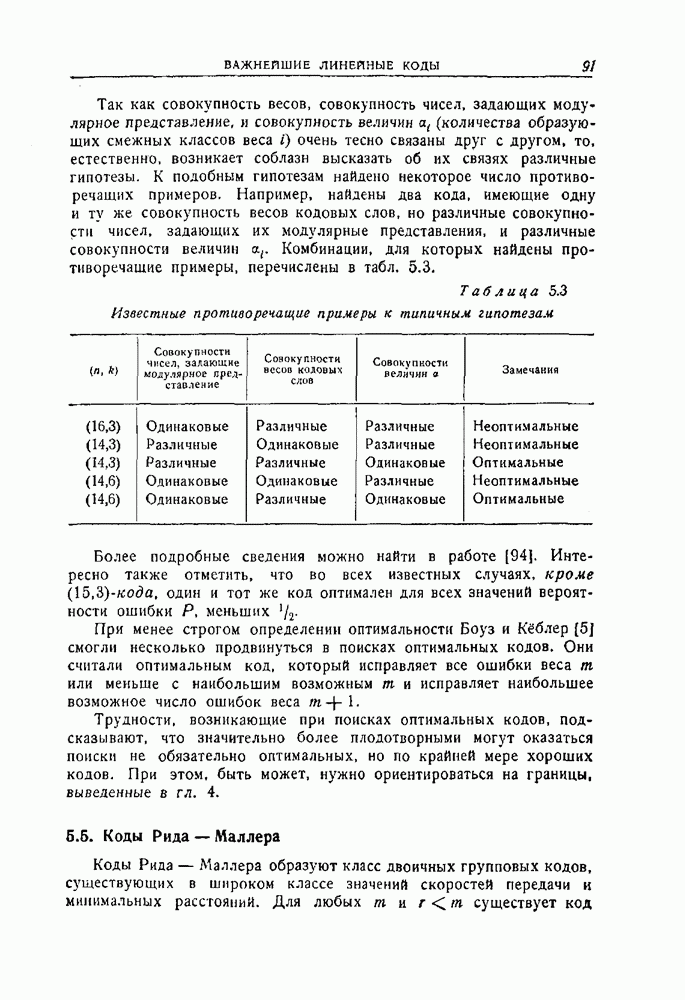
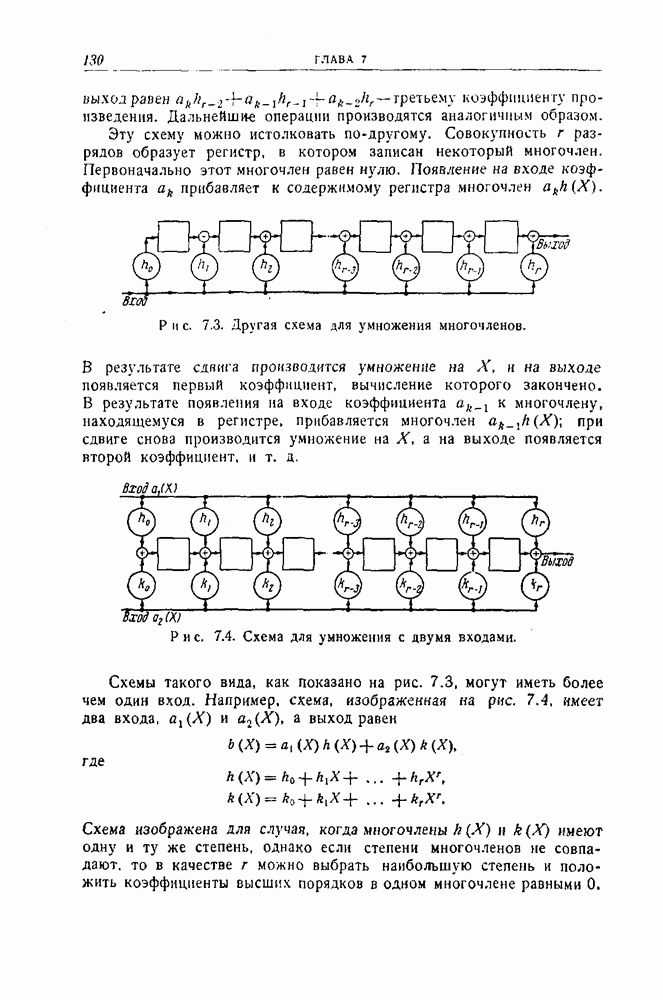
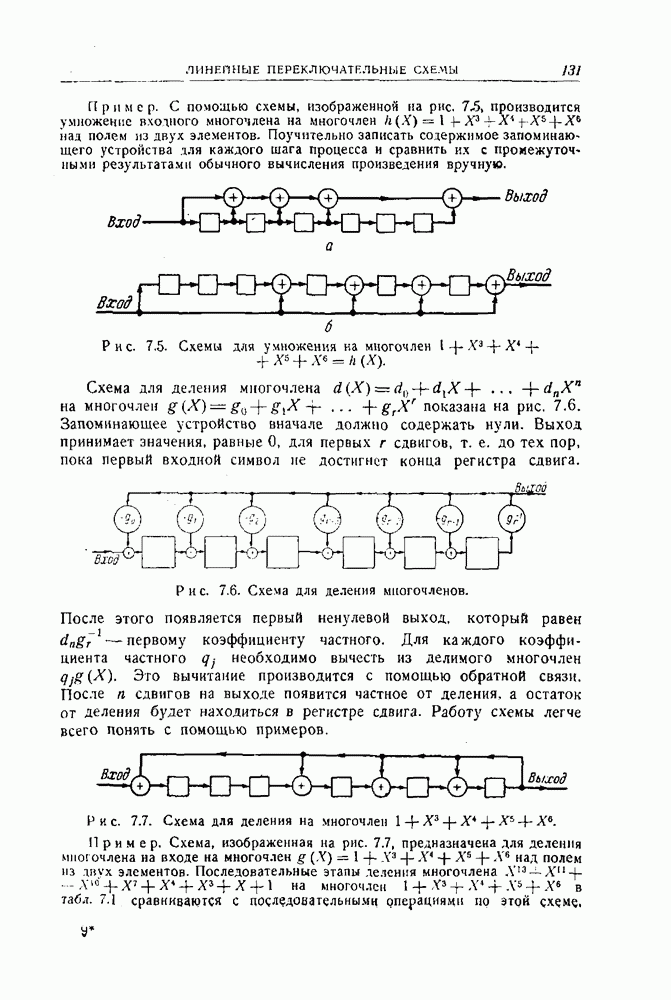
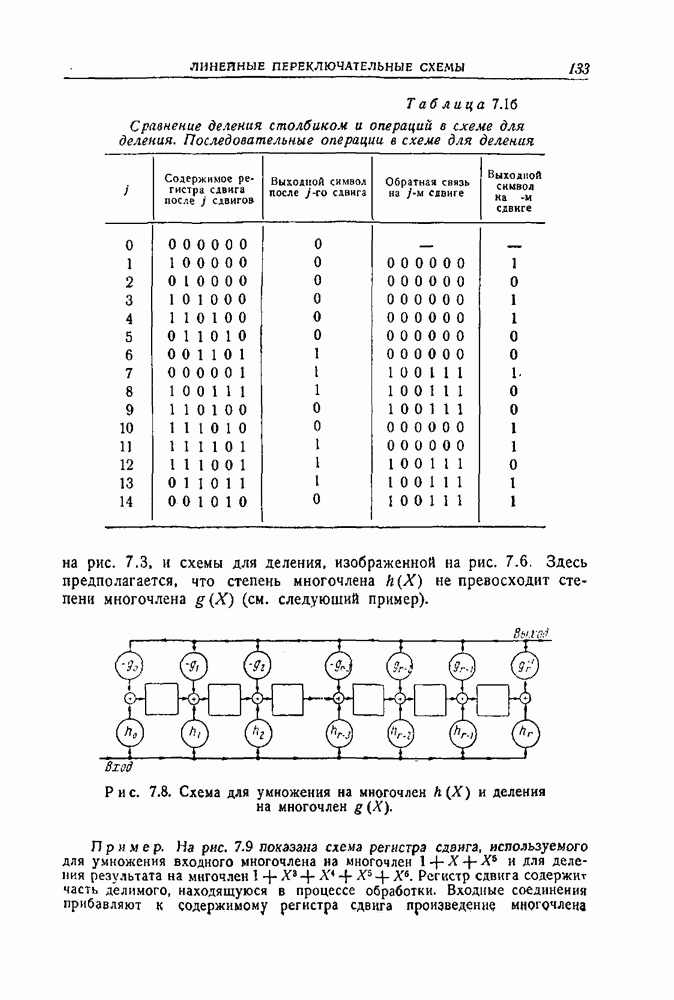
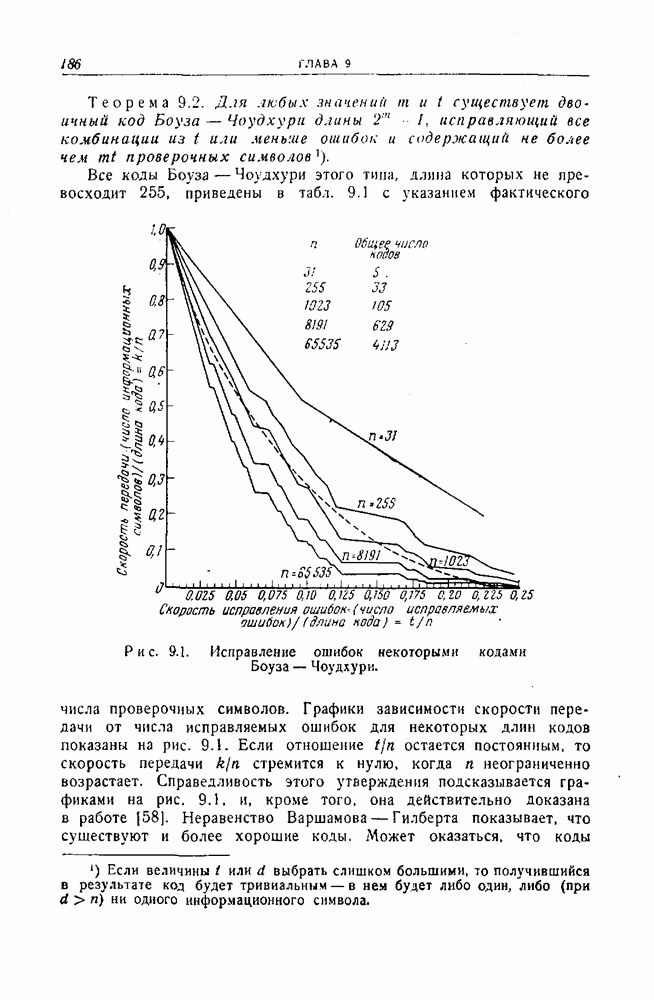
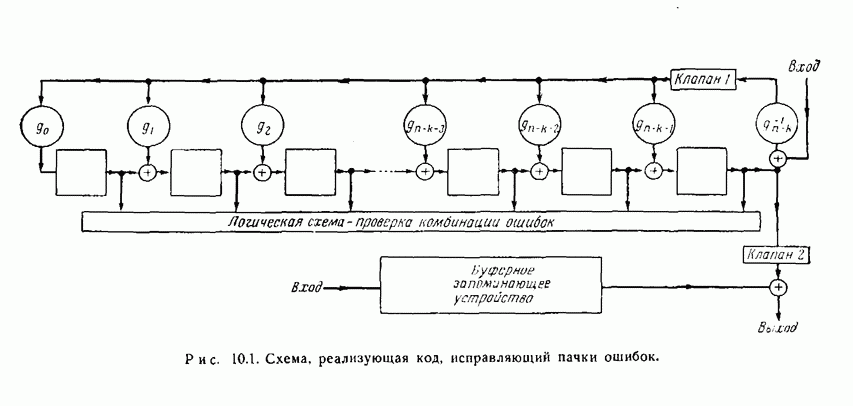
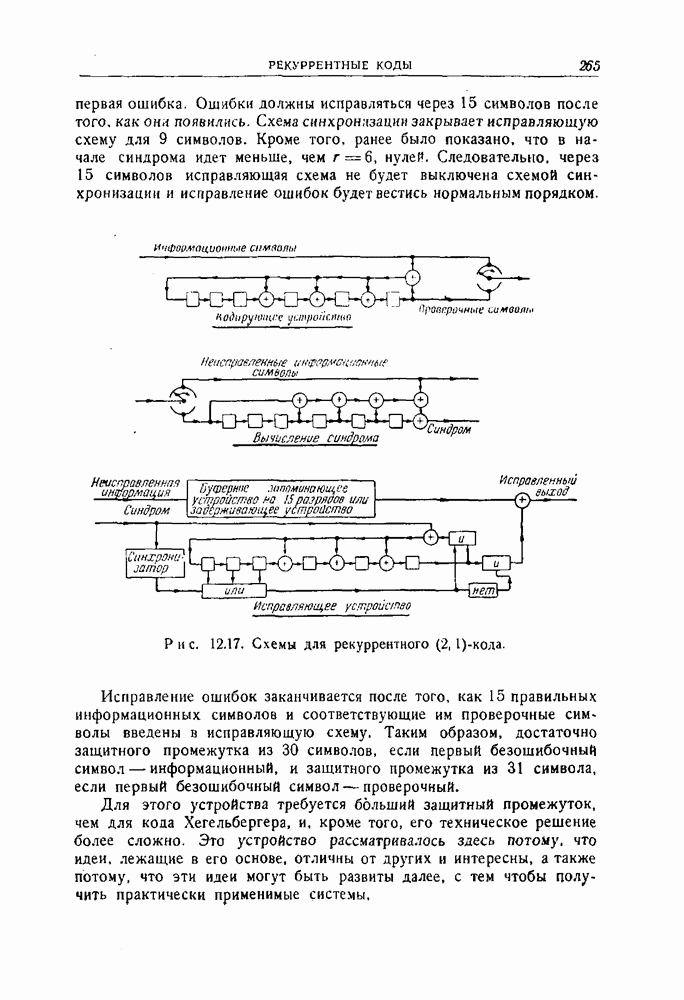
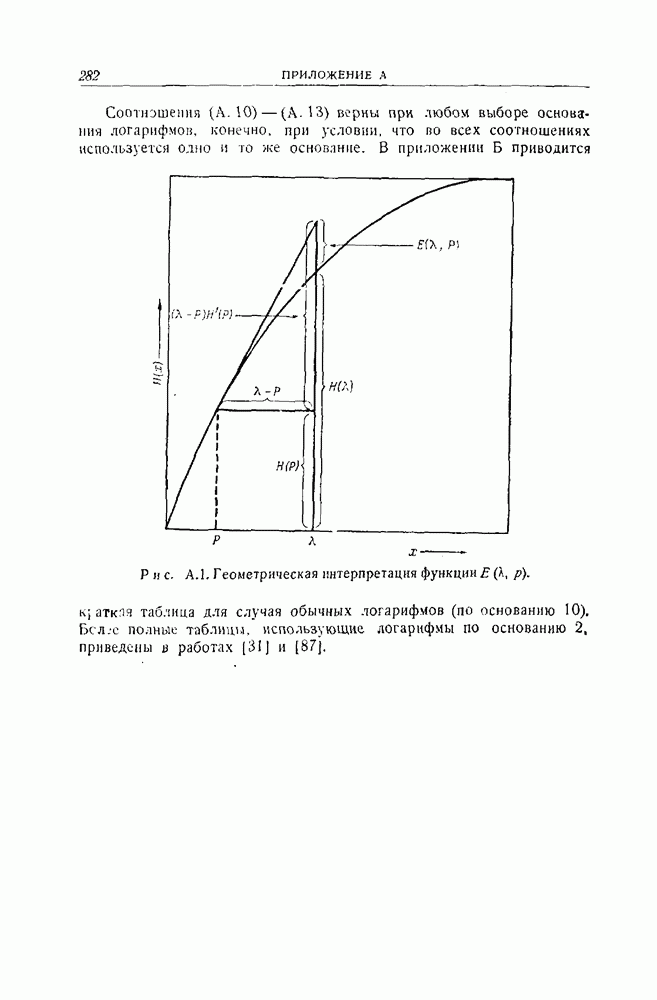
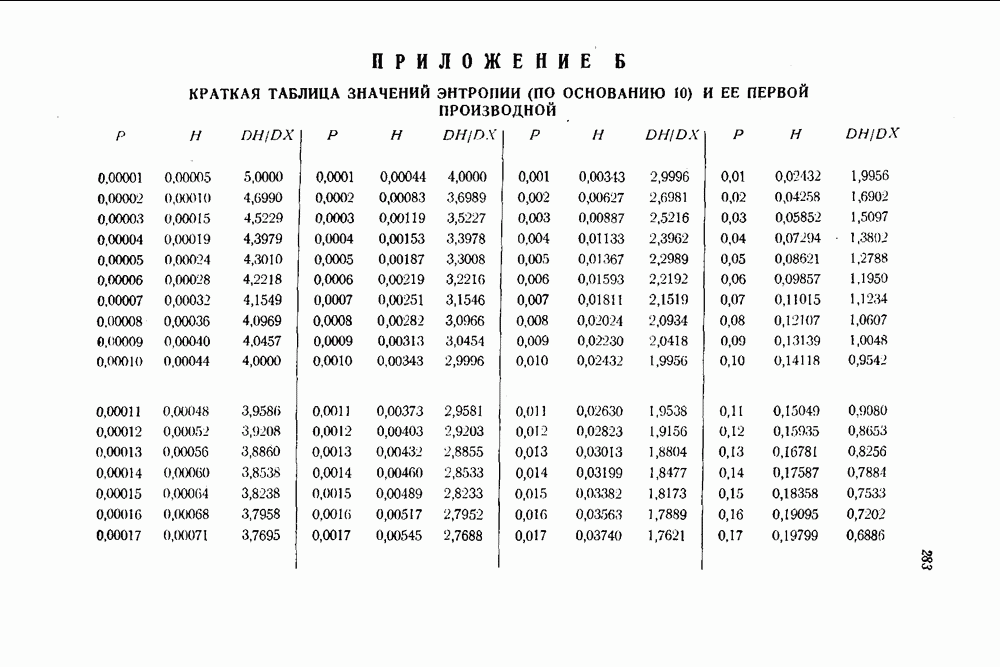
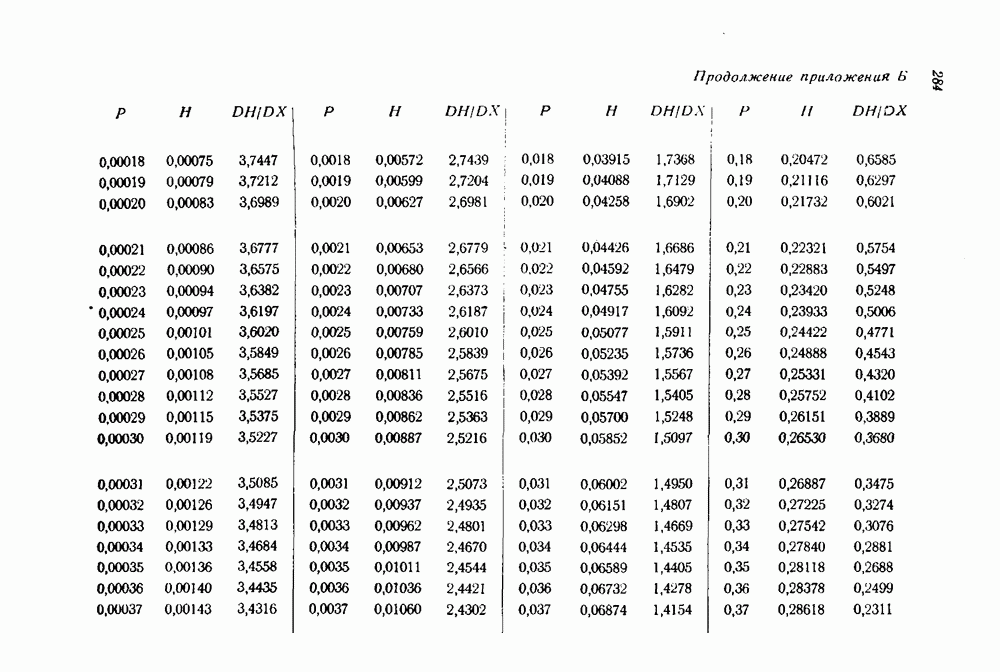
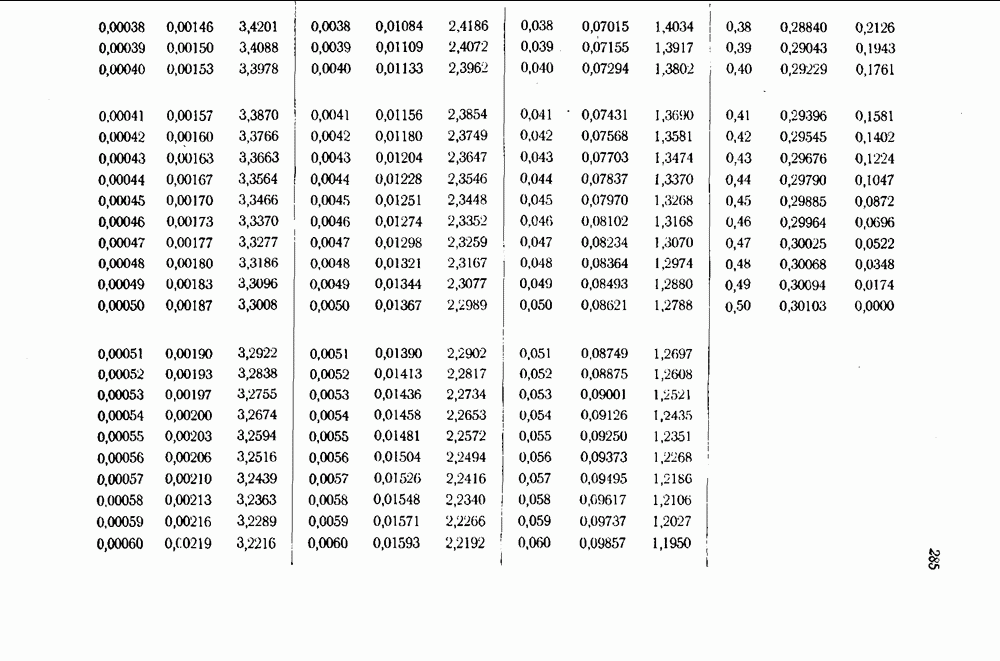
1.4. Расстояние Хэмминга
При изучении свойств кодов, исправляющих ошибки, полезно использовать понятие расстояния Хэмминга [107]. Расстояние Хэмминга между двумя словами определяется как число мест, в которых эти слова отличаются друг от друга. Таким образом, одна ошибка соответствует расстоянию Хэмминга между переданным и полученным словами, равному  Если код используется только для обнаружения ошибок, то для того, чтобы обнаружить все комбинации из d или меньше ошибок, необходимо и достаточно, чтобы минимальное расстояние Хэмминга между кодовыми словами было
Если код используется только для обнаружения ошибок, то для того, чтобы обнаружить все комбинации из d или меньше ошибок, необходимо и достаточно, чтобы минимальное расстояние Хэмминга между кодовыми словами было
равно  Действительно, если минимальное расстояние равно
Действительно, если минимальное расстояние равно  то никакая комбинация из d ошибок не может перевести одно кодовое слово в другое, в то время как если минимальное расстояние меньше или равно
то никакая комбинация из d ошибок не может перевести одно кодовое слово в другое, в то время как если минимальное расстояние меньше или равно  то существует некоторая пара слов, отстоящих друг от друга на расстоянии, скажем,
то существует некоторая пара слов, отстоящих друг от друга на расстоянии, скажем,  и существует комбинация из d ошибок, которая может перевести одно кодовое слово в другое.
и существует комбинация из d ошибок, которая может перевести одно кодовое слово в другое.
Аналогично декодирование, при котором исправляются все комбинации из  или меньше ошибок, возможно тогда и только тогда, когда минимальное расстояние между кодовыми словами равно по меньшей мере
или меньше ошибок, возможно тогда и только тогда, когда минимальное расстояние между кодовыми словами равно по меньшей мере  Тогда любое полученное слово с
Тогда любое полученное слово с  ошибками отличается от переданного кодового слова в
ошибками отличается от переданного кодового слова в  символах, а от каждого другого кодового слова в
символах, а от каждого другого кодового слова в  символах. С другой стороны, если минимальное расстояние меньше, чем
символах. С другой стороны, если минимальное расстояние меньше, чем  то возможен хотя бы один случай, когда
то возможен хотя бы один случай, когда  -кратная ошибка приведет к такому слову на выходе, которое по крайней мере столь же близко к одному из непередававшихся кодовых слов, как и к переданному кодовому слову. Наконец, аналогичными рассуждениями можно доказать, что декодирование, при котором исправляются все комбинации из
-кратная ошибка приведет к такому слову на выходе, которое по крайней мере столь же близко к одному из непередававшихся кодовых слов, как и к переданному кодовому слову. Наконец, аналогичными рассуждениями можно доказать, что декодирование, при котором исправляются все комбинации из  или меньше ошибок и одновременно обнаруживаются все комбинации из d или меньше ошибок
или меньше ошибок и одновременно обнаруживаются все комбинации из d или меньше ошибок  возможно тогда и только тогда, когда минимальное расстояние между кодовыми словами равно
возможно тогда и только тогда, когда минимальное расстояние между кодовыми словами равно 
(Утверждение "код исправляет все комбинации из t ошибок и обнаруживает все комбинации из d ошибок" означает, что если появилась комбинация из  ошибок,
ошибок,  то она будет обнаружена, но не будет интерпретирована как комбинация из
то она будет обнаружена, но не будет интерпретирована как комбинация из  или меньше ошибок. Другими словами, если появляется
или меньше ошибок. Другими словами, если появляется  ошибок, то декодирование не производится.)
ошибок, то декодирование не производится.)