Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
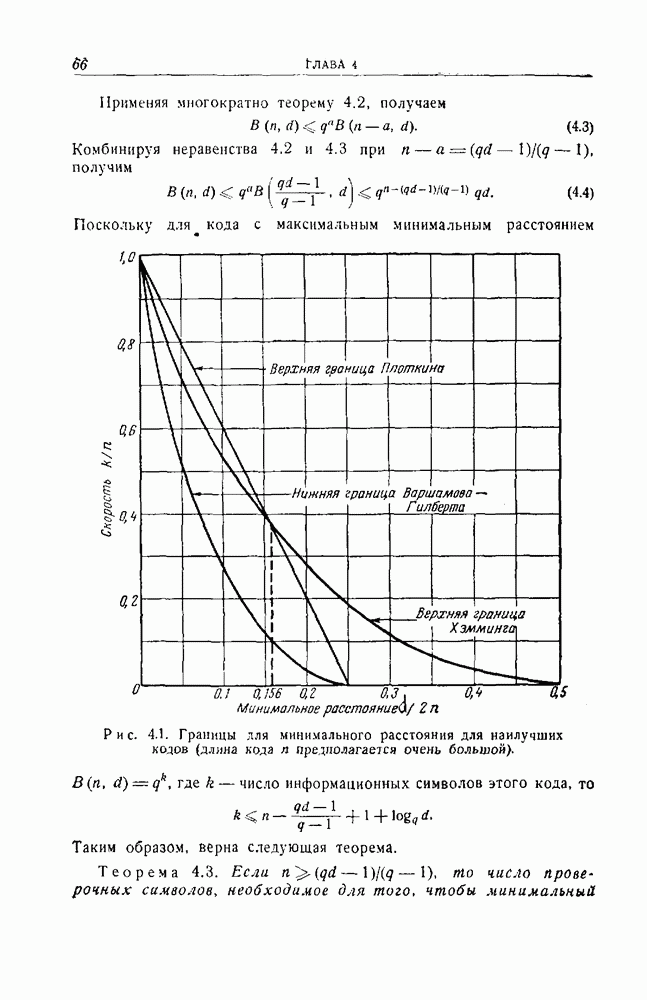
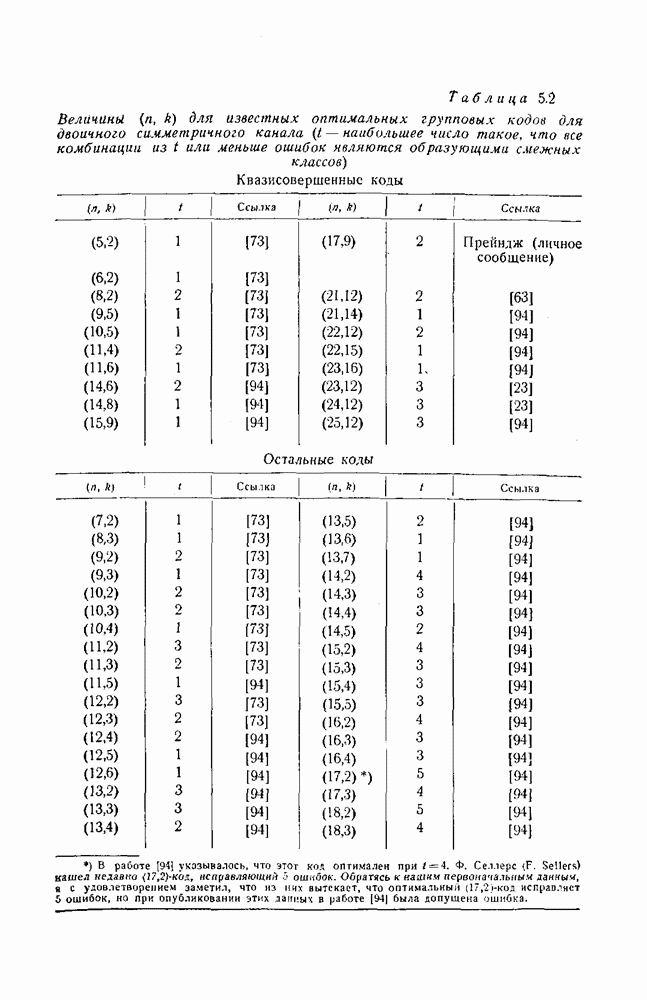
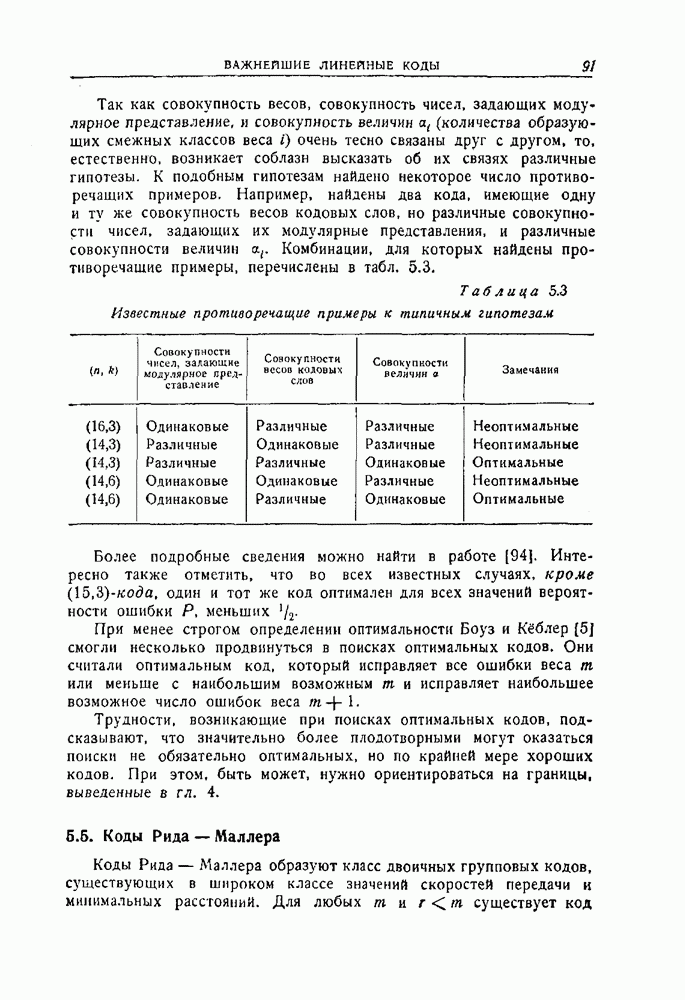
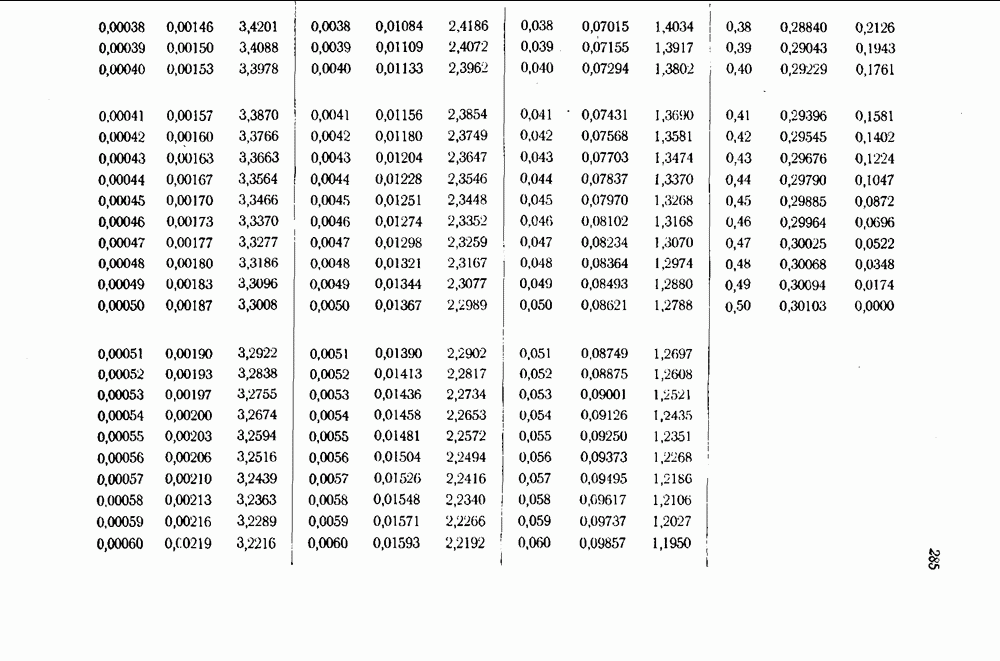
5.4. Оптимальные коды для двоичного симметричного каналаПоиски оптимальных кодов для двоичного симметричного канала до сих пор ведутся с весьма ограниченным успехом. Коды с одним информационным символом, повторенным Известные оптимальные коды распадаются на два класса: 1) коды про которые было доказано, что они являются квазисовершенными и, следовательно, оптимальными, и 2) коды, относительно которых было доказано, что они не хуже, чем любой другой код с тем же самым общим числом символов и с тем же самым числом информационных символов. Во втором случае типичная процедура состояла в том, чтобы получить по возможности хороший код, а затем сравнить его со всеми другими кодами. Так как эквивалентные коды имеют одинаковые вероятности ошибок, то из каждого класса эквивалентных кодов только один необходимо сравнивать с выбранным гипотетически наилучшим. Многие коды быстро исключаются на основе соображений, учитывающих веса кодовых слов. Во многих случаях приходится отыскивать образующие смежных классов для большого числа кодов и сравнивать их попарно. Даже с полным учетом современного уровня знаний по теории кодирования решение этой задачи остается очень трудоемким и утомительным даже для коротких кодов. Слепян провел такое исследование настолько полно, насколько это было возможно, — вручную и с помощью вычислительной машины. Поиски были продолжены Фонтейном и Питерсоном, использовавшими вычислительную машину ИБМ-704. Однако для исследования некоторых кодов, длина которых равна всего лишь 15 символам, потребовалось тем не менее много часов машинного времени для сравнения тысяч кодов с гипотетически наилучшим. (см. скан) Так как совокупность весов, совокупность чисел, задающих модулярное представление, и совокупность величин Таблица 5.3 (см. скан) Известные противоречащие примеры к типичным гипотезам Более подробные сведения можно найти в работе [94]. Интересно также отметить, что во всех известных случаях, кроме При менее строгом определении оптимальности Боуз и Кёблер [5] смогли несколько продвинуться в поисках оптимальных кодов. Они считали оптимальным код, который исправляет все ошибки веса Трудности, возникающие при поисках оптимальных кодов, подсказывают, что значительно более плодотворными могут оказаться поиски не обязательно оптимальных, но по крайней мере хороших кодов. При этом, быть может, нужно ориентироваться на границы, выведенные в гл. 4.
|
 |
Оглавление
|



























































































































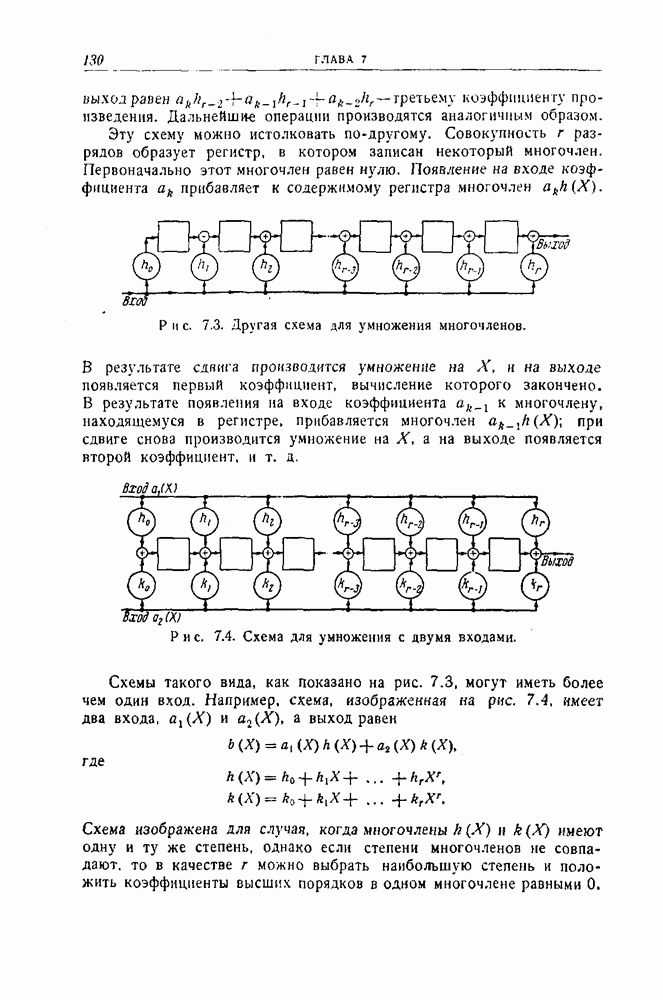


























































































































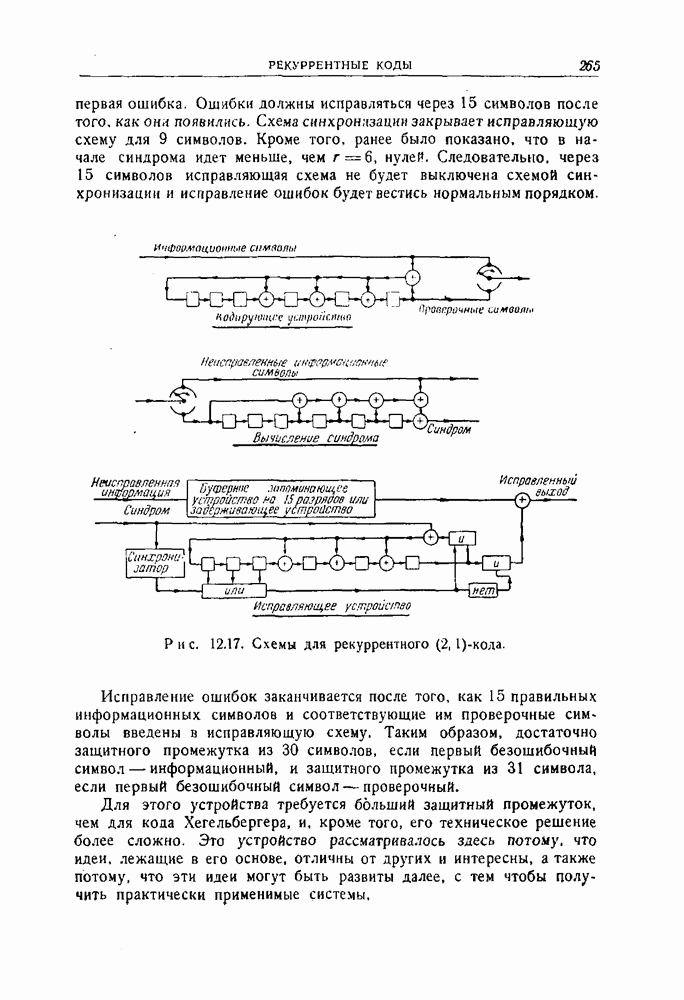
















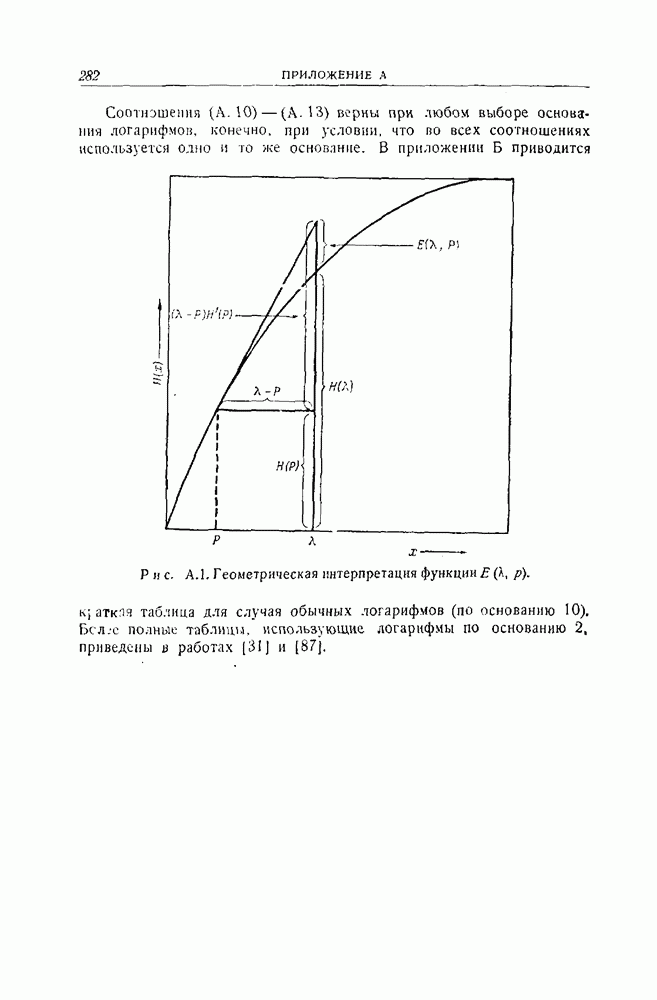
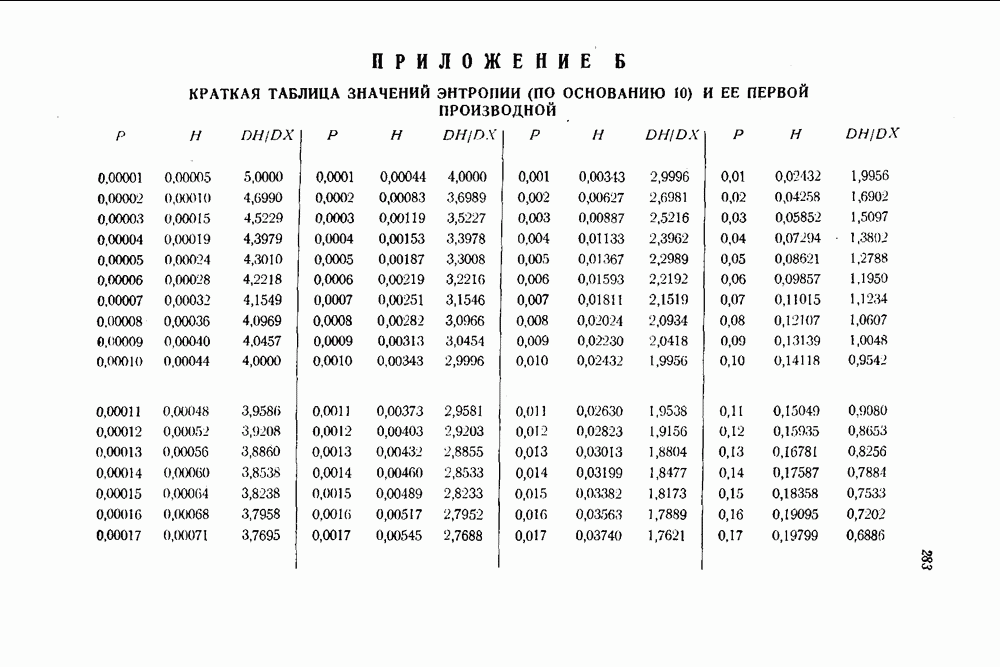
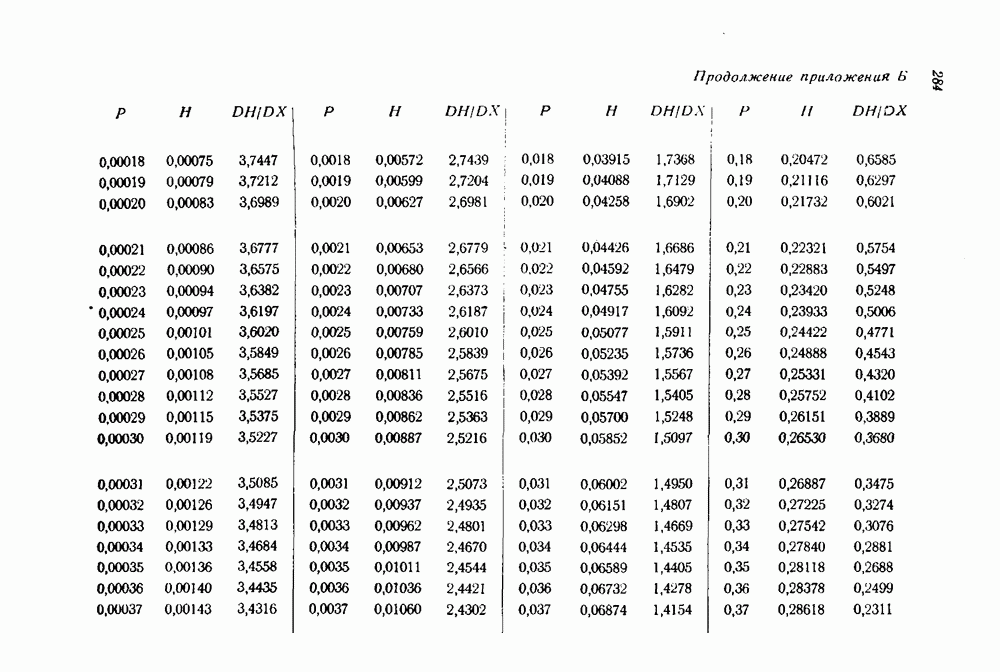




























 раз, где
раз, где  нечетное число, очевидно, оптимальны; коды Хэмминга образуют другой бесконечный класс оптимальных кодов. Некоторые коды, получаемые из кодов Хэмминга отбрасыванием столбцов, как можно показать, являются квазисовершенными и, следовательно, оптимальными. (См, задачу 5.3.) Коды Боуза — Чоудхури, исправляющие двойные ошибки, квазисовершенны и, следовательно, оптимальны [26]. Значения
нечетное число, очевидно, оптимальны; коды Хэмминга образуют другой бесконечный класс оптимальных кодов. Некоторые коды, получаемые из кодов Хэмминга отбрасыванием столбцов, как можно показать, являются квазисовершенными и, следовательно, оптимальными. (См, задачу 5.3.) Коды Боуза — Чоудхури, исправляющие двойные ошибки, квазисовершенны и, следовательно, оптимальны [26]. Значения  для остальных известных оптимальных кодов приведены в табл. 5.2.
для остальных известных оптимальных кодов приведены в табл. 5.2.
 (количества образующих смежных классов веса
(количества образующих смежных классов веса  очень тесно связаны друг с другом, то, естественно, возникает соблазн высказать об их связях различные гипотезы. К подобным гипотезам найдено некоторое число противоречащих примеров. Например, найдены два кода, имеющие одну и ту же совокупность весов кодовых слов, но различные совокупности чисел, задающих их модулярные представления, и различные совокупности величин Комбинации, для которых найдены противоречащие примеры, перечислены в табл. 5.3.
очень тесно связаны друг с другом, то, естественно, возникает соблазн высказать об их связях различные гипотезы. К подобным гипотезам найдено некоторое число противоречащих примеров. Например, найдены два кода, имеющие одну и ту же совокупность весов кодовых слов, но различные совокупности чисел, задающих их модулярные представления, и различные совокупности величин Комбинации, для которых найдены противоречащие примеры, перечислены в табл. 5.3.
 -кода, один и тот же код оптимален для всех значений вероятности ошибки
-кода, один и тот же код оптимален для всех значений вероятности ошибки  меньших
меньших 
 или меньше с наибольшим возможным
или меньше с наибольшим возможным  и исправляет наибольшее возможное число ошибок веса
и исправляет наибольшее возможное число ошибок веса 