Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
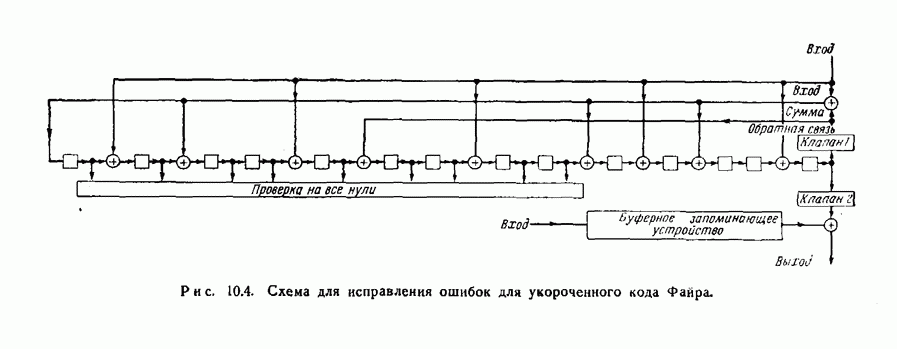
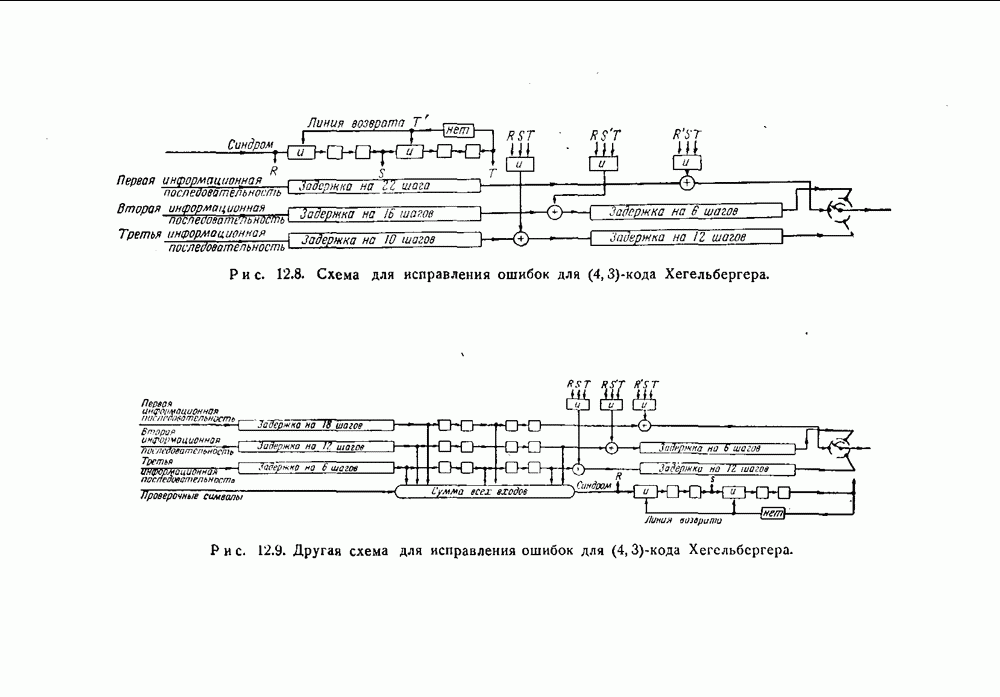
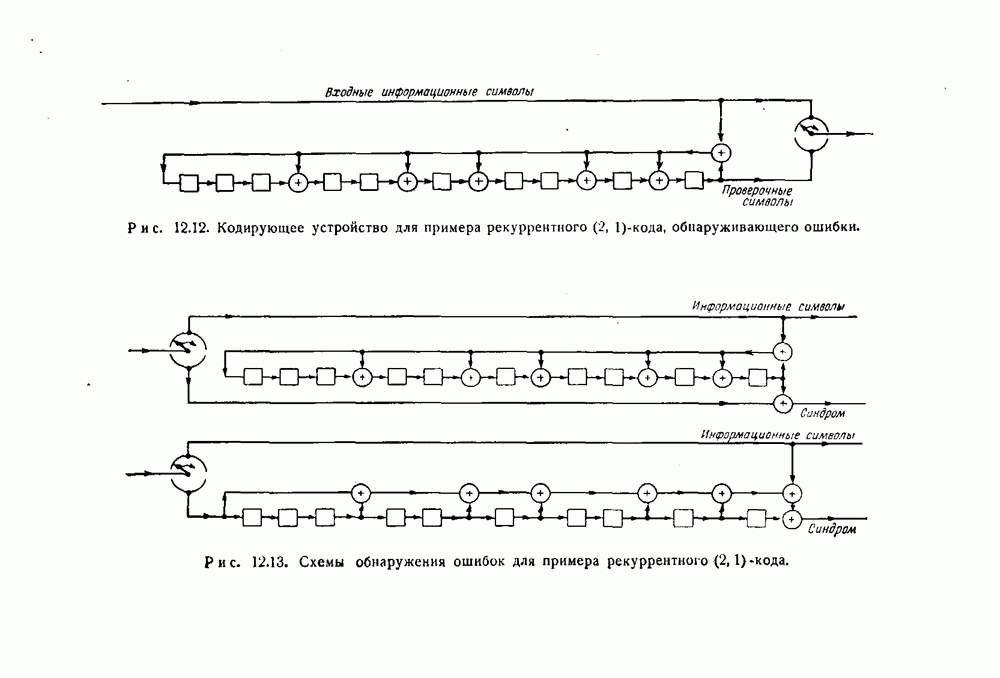
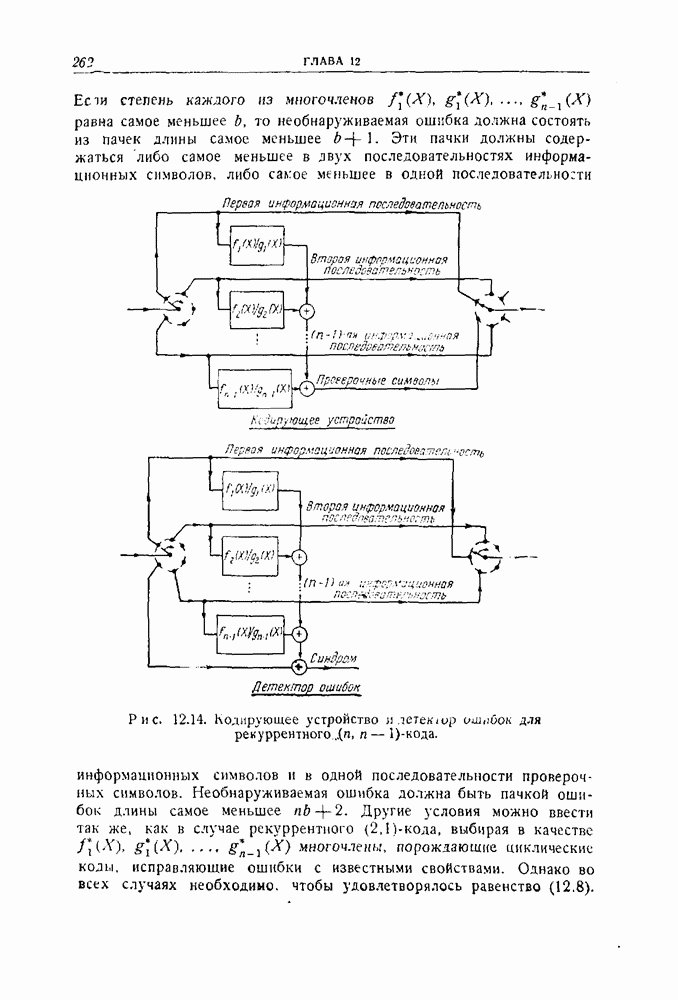
ГЛАВА 12. РЕКУРРЕНТНЫЕ КОДЫВ отличие от всех кодов, описанных в предыдущих главах, коды, рассматриваемые в этой главе, не являются блоковыми кодами. Их можно рассматривать как особый способ непрерывной переработки информации. В этих кодах проверочные символы перемежаются с информационными символами, и не существует никакой точки, которую естественно было бы считать начальной или конечной. Коды такого типа труднее для изучения, чем блоковые коды. Удовлетворительная и полная теория этого общего типа кодов пока еще не создана. Однако исследование нескольких частных примеров этих кодов показало, что использование их достаточно многообещающее, чтобы считать целесообразным их дальнейшее изучение. Оказалось, что коды Хегельбергера, исправляющие пачки ошибок и состоящие из чередующихся информационных и проверочных символов, более просты в конкретном осуществлении, чем любые другие известные коды. Технические способы реализации этих кодов во многом аналогичны способам реализации циклических кодов. Здесь находят непосредственное применение даже результаты некоторых исследований, приведенных в четырех предыдущих главах. 12.1. Определение рекуррентного кодаРекуррентный Если ни один из этих блоков не содержит памяти, то рекуррентный тот же эффект может быть достигнут с меньшим Вход кодирующего устройства состоит, таким образом, из
Рис. 12.1. Общее кодирующее устройство для рекуррентного Наконец, подобно тому как блоковые коды используются большей частью в форме, при которой первые
|
 |
Оглавление
|



























































































































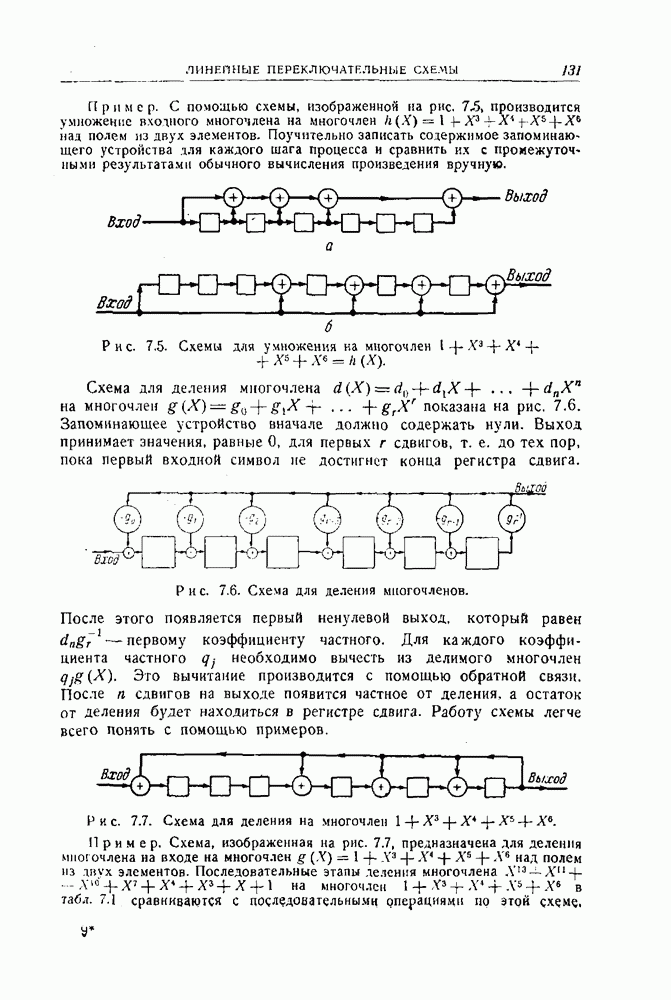

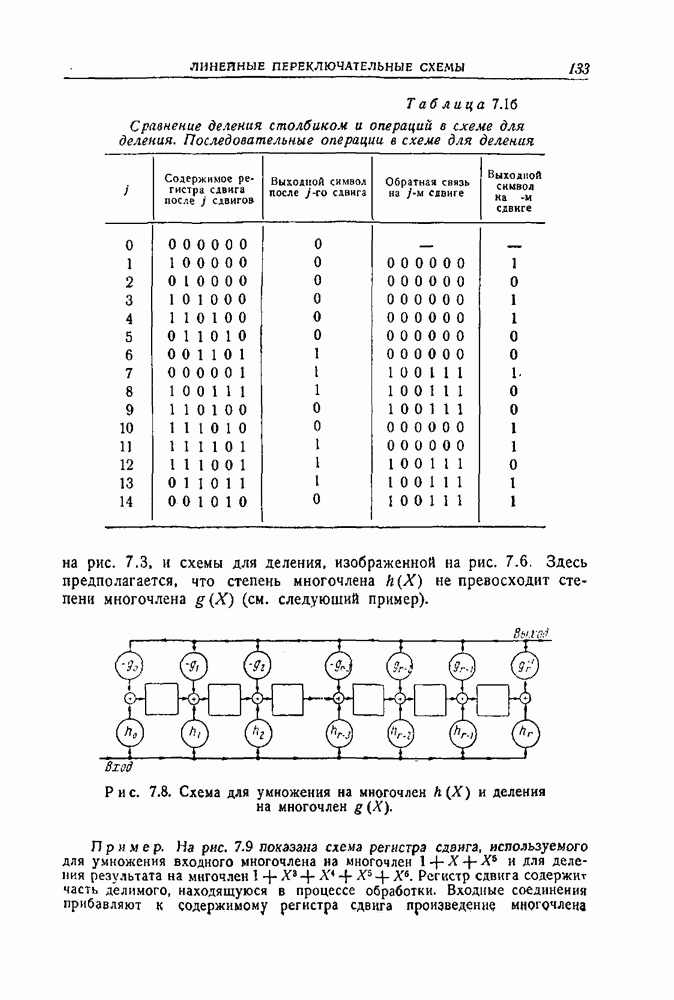




















































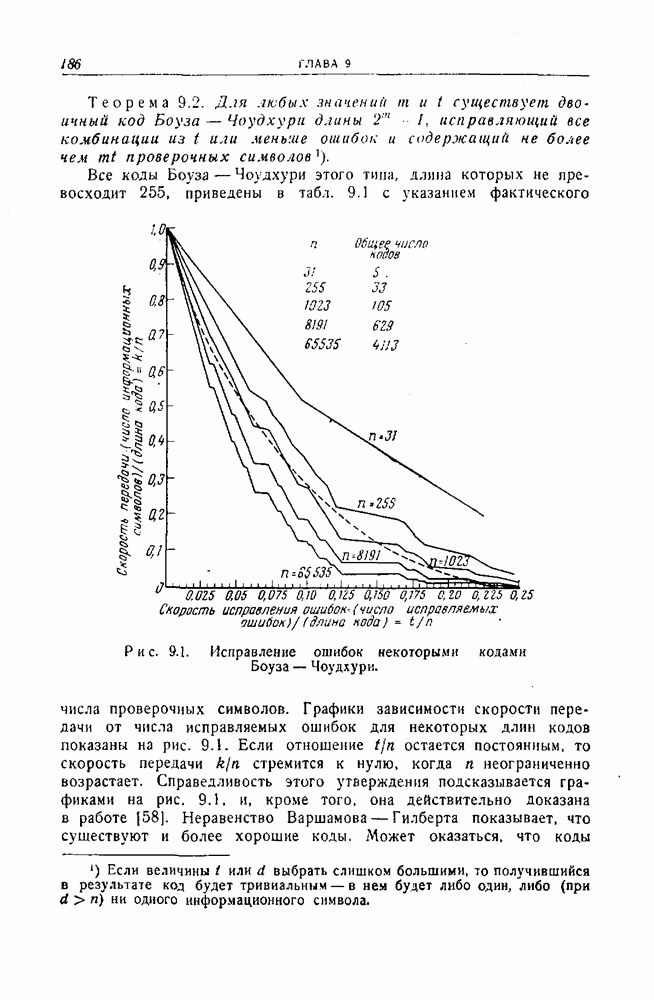




























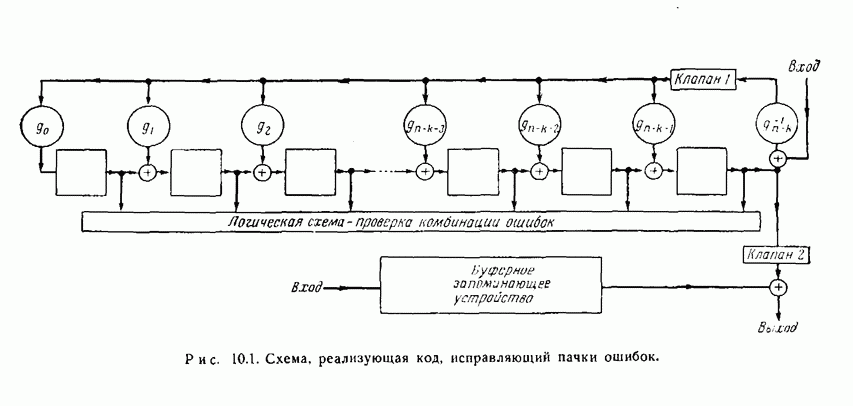

























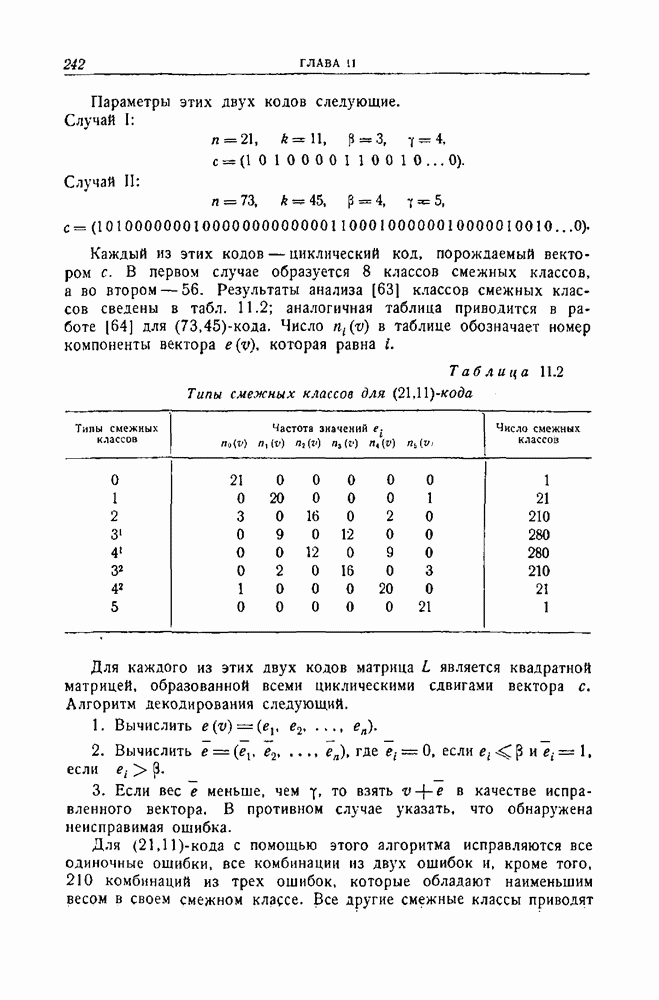







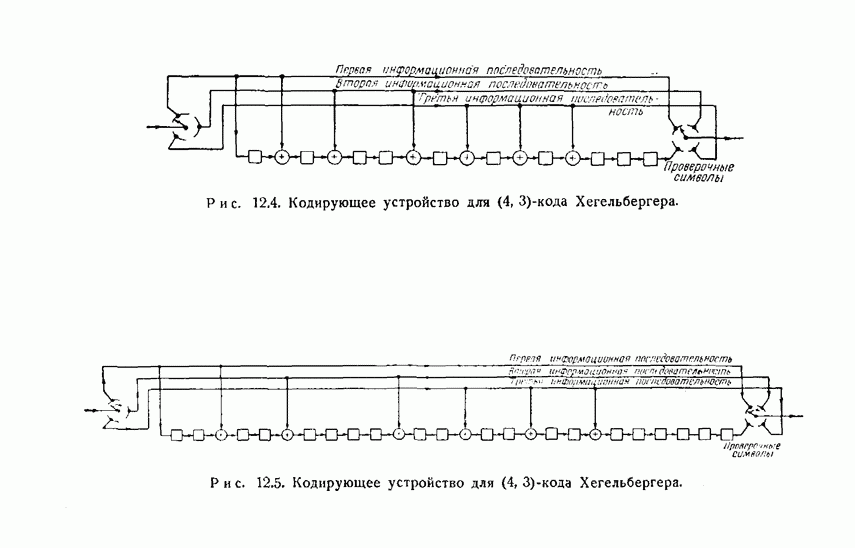
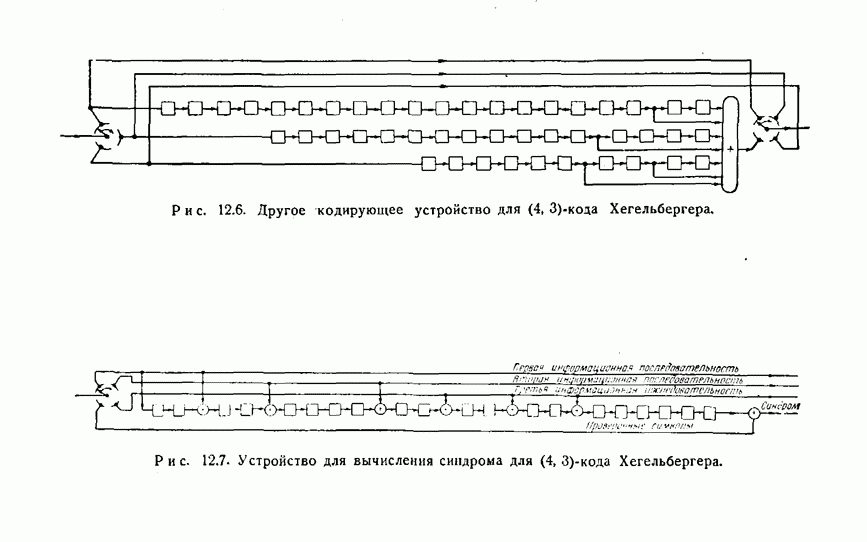









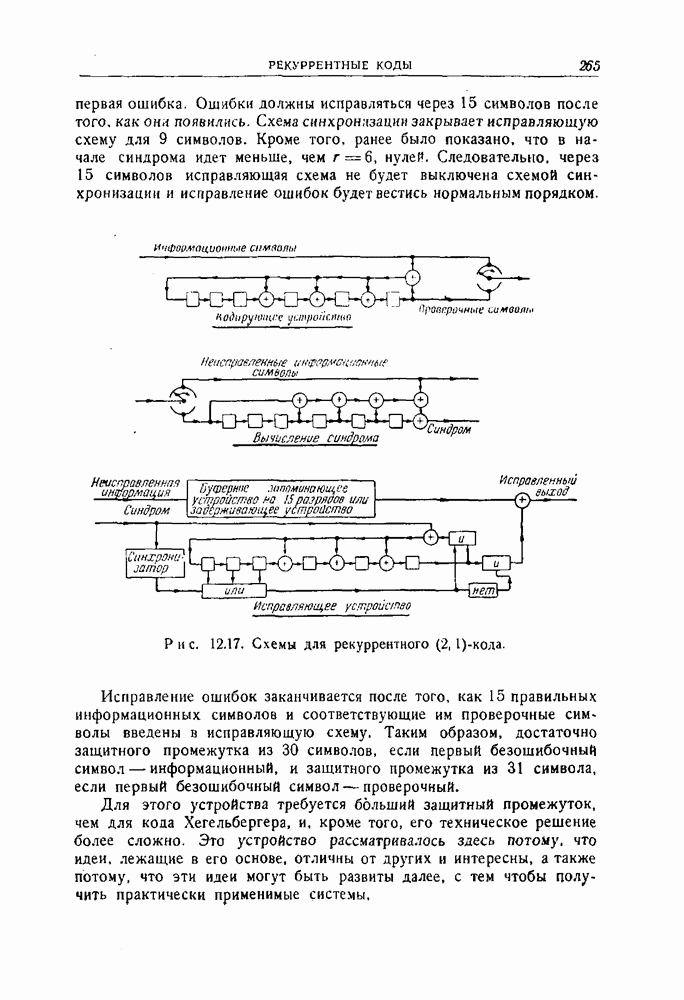












































 -код определяется описанием процесса кодирования: информационные символы поступают в кодирующее устройство блоками по
-код определяется описанием процесса кодирования: информационные символы поступают в кодирующее устройство блоками по  символов и выходят оттуда блоками по
символов и выходят оттуда блоками по  символов. Каждый из
символов. Каждый из  выходных символов является выходом линейного преобразователя с конечным числом состояний, или линейного кодирующего фильтра. Общая схема иллюстрируется рис. 12.1. Символы
выходных символов является выходом линейного преобразователя с конечным числом состояний, или линейного кодирующего фильтра. Общая схема иллюстрируется рис. 12.1. Символы  обозначают
обозначают  входных символов в момент I, а
входных символов в момент I, а  обозначают
обозначают  выходных символов в момент
выходных символов в момент  Предполагается, что символы являются элементами конечного поля. Каждый из блоков на схеме обозначает линейный преобразователь с конечным числом состояний, т. е. схему, состоящую из сумматоров, устройств умножения на постоянную величину и запоминающих устройств.
Предполагается, что символы являются элементами конечного поля. Каждый из блоков на схеме обозначает линейный преобразователь с конечным числом состояний, т. е. схему, состоящую из сумматоров, устройств умножения на постоянную величину и запоминающих устройств.
 -код сводится к обычному блоковому
-код сводится к обычному блоковому  -коду. В то время как для эффективных блоковых кодов
-коду. В то время как для эффективных блоковых кодов  должно быть достаточно велико для того, чтобы осреднение влияния шума производилось по большому промежутку времени, в рекуррентном коде
должно быть достаточно велико для того, чтобы осреднение влияния шума производилось по большому промежутку времени, в рекуррентном коде
 благодаря элементам памяти, содержащимся в преобразователях кода.
благодаря элементам памяти, содержащимся в преобразователях кода.
 последовательностей символов, а выход состоит из
последовательностей символов, а выход состоит из  последовательностей символов. На практике вход представляет собой обычно одну последовательность, преобразованную в
последовательностей символов. На практике вход представляет собой обычно одну последовательность, преобразованную в  последовательностей. Аналогично выходы разных блоков схемы обычно, хотя и не всегда, передаются поочередно.
последовательностей. Аналогично выходы разных блоков схемы обычно, хотя и не всегда, передаются поочередно.

 -кода.
-кода.
 символов в блоке представяют собой неизмененные информационные символы, а последние
символов в блоке представяют собой неизмененные информационные символы, а последние  символов являются проверочными символами, так и во всех детально изученных до сих пор рекуррентных кодах первые
символов являются проверочными символами, так и во всех детально изученных до сих пор рекуррентных кодах первые  символов в блоке на выходе представляют собой неизменные информационные символы (выдаваемые в некоторых случаях с задержкой). Такая расстановка символов упрощает как кодирование, так и декодирование.
символов в блоке на выходе представляют собой неизменные информационные символы (выдаваемые в некоторых случаях с задержкой). Такая расстановка символов упрощает как кодирование, так и декодирование.