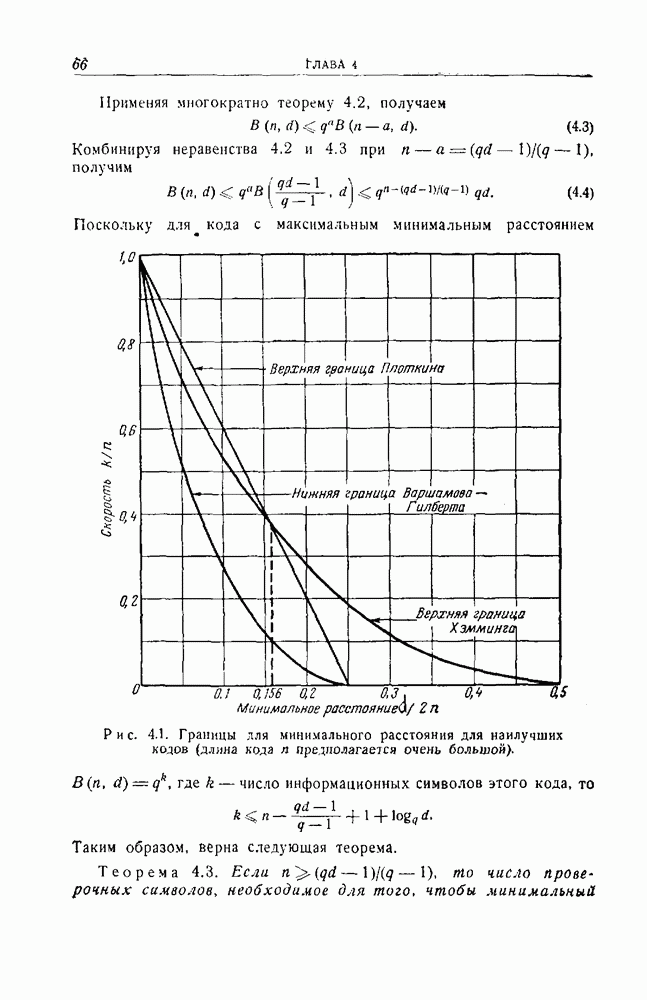
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
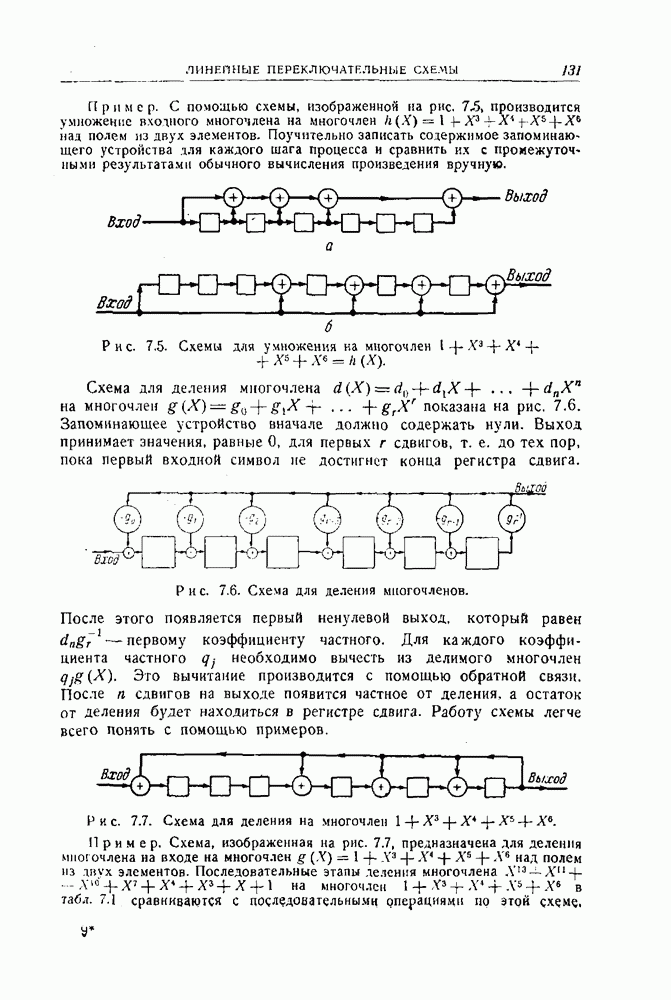
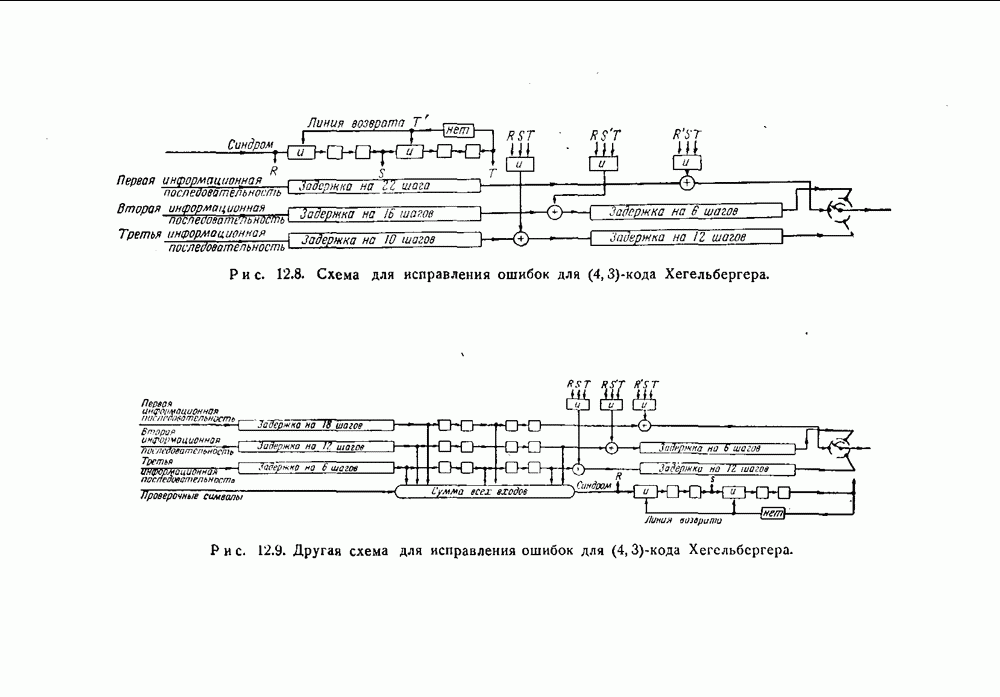
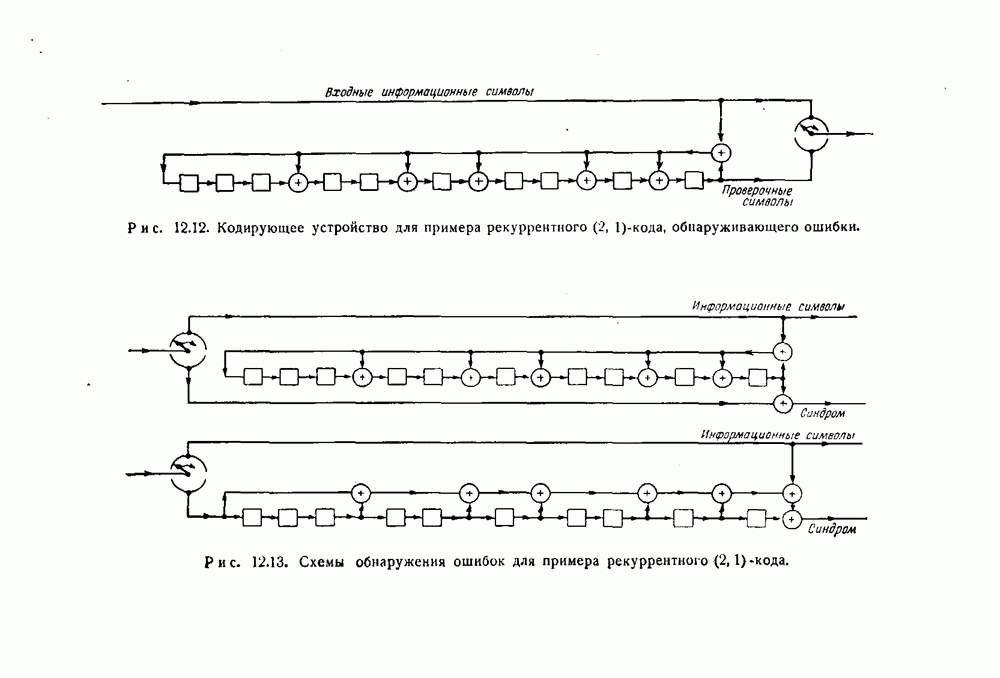
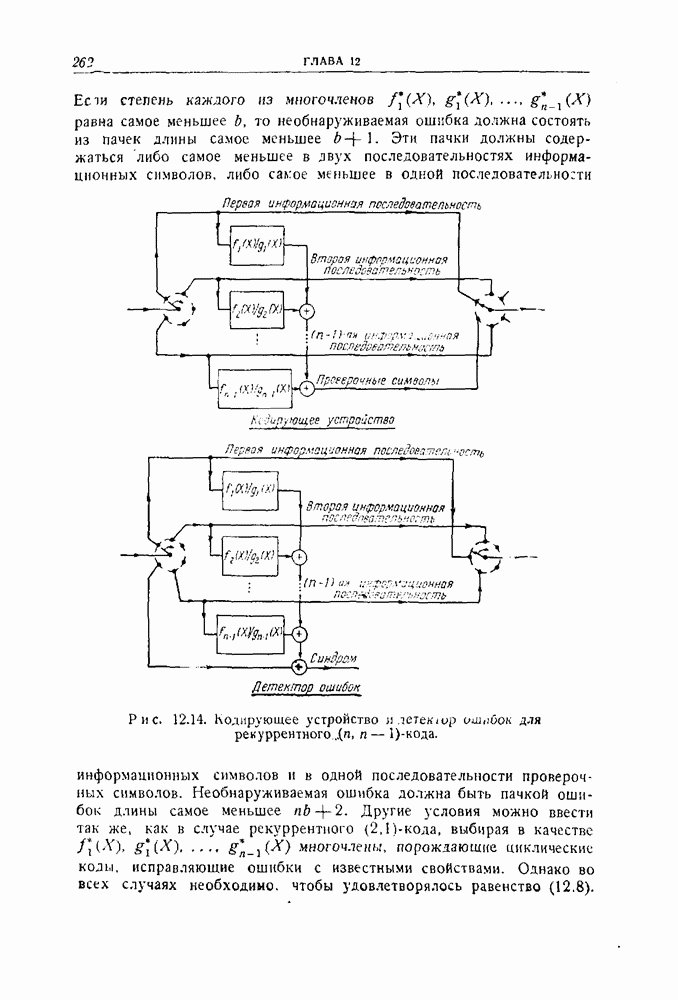
10.6. Практическая реализация кодов, исправляющих пачки ошибокПредположим, что передавался кодовый вектор
где степень многочлена Предположим, что рассматриваемый код удовлетворяет следующим условиям. Существует некоторый набор комбинаций ошибок Неукороченные циклические коды, рассматриваемые до сих пор в этой главе, удовлетворяют этим условиям, и описываемый ниже пропесс исправления ошибок пригоден для любого такого кода. (Изменения, которые необходимо ввести в случае укороченных циклических кодов, разбираются в конце этого раздела.) 1. Умножить 2. Проверить, будет ли полученный многочлен исправимой комбинацией ошибок. Если будет, то перейти к третьему шагу. Если не будет, то повторять первый и второй шаги до тех пор, пока это условие не будет удовлетворено, или до тех пор, пока первый и второй шаги не будут повторены 3. Если после 4. Если получающиеся остатки не совпадают ни с одной из исправимых комбинаций ошибок, то это значит, что обнаружена неисправимая комбинация ошибок. Обоснование описанного процесса проводится следующим образом. Предположим, что появилась некоторая комбинация ошибок
Далее, пусть остаток, полученный после умножения
Из равенств (10.10) и (10.11) получаем
откуда следует, что вектор Предположим теперь, что
и так как многочлен Наконец, предположим снова, что
что дает искомый результат. Ч. т. д. Проведенные выше рассуждения могут показаться более косвенными, чем это необходимо. Они были выбраны таким образом, чтобы придать дополнительную гибкость процессу исправления ошибок. Например, рассмотрим двоичный код длины
но, кроме того,
или
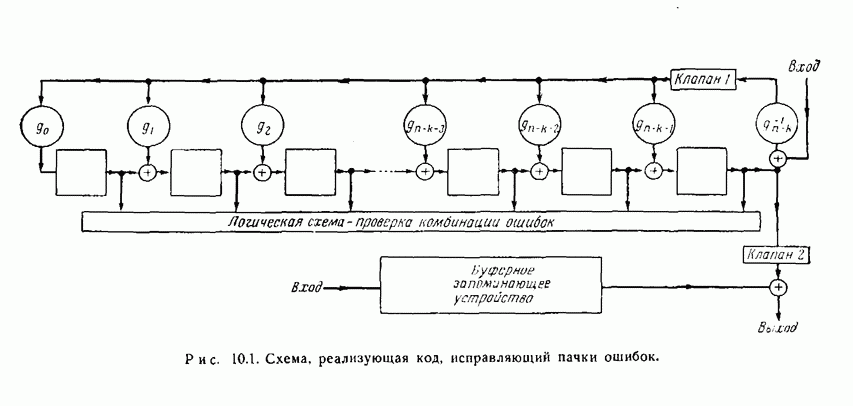
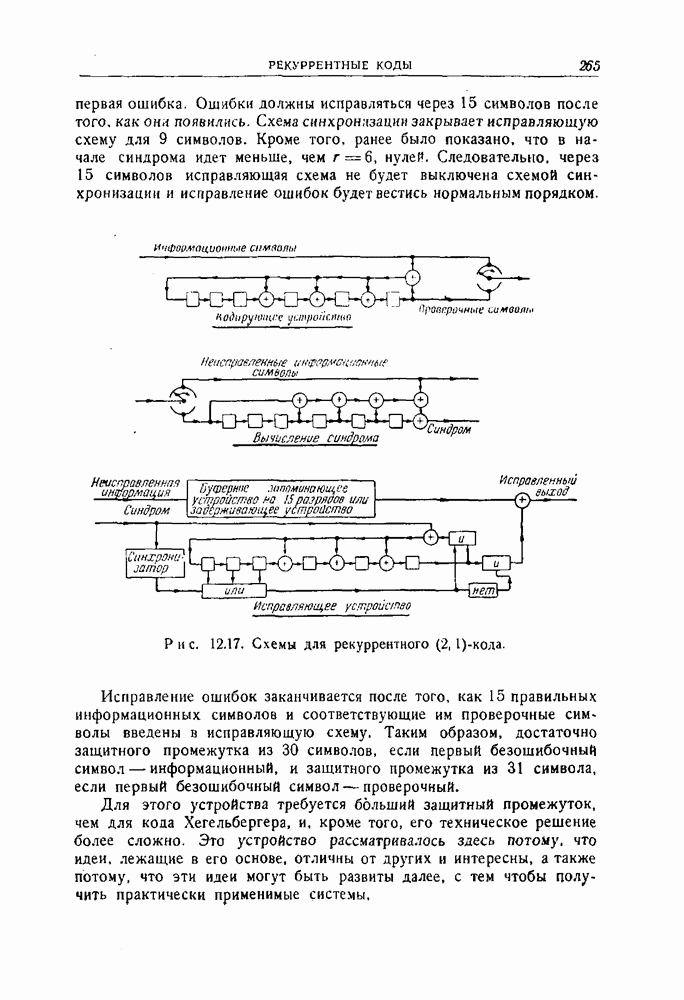
и все комбинации ошибок, соответствующие Кодирование для тих кодов лучше всего проводится методами, описанными в разд, 8.5. Регистр сдвига должен содержать Особенно простое устройство для исправления ошибок показано в виде упрощенной блок-схемы (на рис. 10.1). Оно работает следующим образом.
(кликните для просмотра скана) 1. Результаты проверочных вычислений находятся путем последовательных сдвигов полученного на выходе вектора в устройстве, идентичном устройству, используемому для кодирования. В то же самое время этот вектор вводится в буферное запоминающее устройство. 2. Проверяется, является ли содержимое регистра сдвига исправимой комбинацией ошибок. (Комбинация должна быть обнаружена, когда она занимает в регистре сдвига крайнее правое положение. Не важно, обнаруживалась ли она раньше.) Если исправимая комбинация ошибок не обнаружена, то регистр сдвигается с нулевым входом, одновременно считывается один символ из буферного запоминающего устройства, и затем этот шаг повторяется. 3. Если обнаружена исправимая комбинация ошибок, то это и есть комбинация ошибок, которая предположительно появилась в действительности. Ошибочные символы в полученном векторе совпадают со следующими символами, поступающими из буферного запоминающего устройства. Клапан 1 закрыт, клапан 2 открыт. Символы считываются по одному одновременно из буферного запоминающего устройства и из регистра сдвига, и символ, поступающий из регистра сдвига, вычитается из символа, поступающего из буферного запоминающего устройства. Это и есть исправление ошибок. Остальные символы полученного сообщения считываются из буферного запоминающего устройства. 4. Если при проведении проверок на четность выявятся несоответствия и если в регистре сдвига не появится исправимая комбинация ошибок к тому моменту, когда весь полученный вектор будет считан из буферного запоминающего устройства, то это значит, что обнаружена неисправимая комбинация ошибок. Реализовать такую операцию можно с помощью двух запоминающих устройств на триггерах. Первое из них
Если полученный вектор равен многочлена Можно проверить, что положение пачки ошибок в начале или в конце полученного вектора не вызывает дополнительных трудностей. Однако хотя код, будучи циклическим, будет способен исправлять комбинации ошибок, которые начинаются близко к концу блока и заканчиваются в начале блока, описанный здесь способ автоматизации на самом деле не позволяет исправлять такие комбинации ошибок. Например, (0000011) — пачка ошибок длины 2, ее циклический сдвиг на единицу вправо приводит к вектору (1000001), который с математической точки зрения также является пачкой ошибок длины 2, в принципе исправимой, но описанный здесь способ автоматизации не позволяет сделать это. Пример. Многочлен
порождает двоичный код Файра длины идентичен с регистром сдвига, используемым для кодирования. Работа по исправлению ошибок этим устройством производится по следующим этапам. 1. Весь полученный вектор вводится в буферное запоминающее устройство и одновременно в регистр сдвига, который каждый раз после поступления символа сдвигается. (Клапан 1 открыт, т. е. он дает возможность входной последовательности перемещаться к выходу. Клапан 2 закрыт.)
Рис. 10.2. Кодирование для кода Файра. 2. Затем полученный вектор считывается из буферного запоминающего устройства по одному символу в каждый момент времени, а регистр сдвига сдвигается на один разряд для каждого символа, причем на вход регистра сдвига ничего не подается. 3. Как только в первых девяти разрядах появятся только нули, в последних пяти разрядах должна появиться комбинация ошибок, а в буферном запоминающем устройстве ошибочные символы должны быть расположены в ближайших к выходу разрядах.
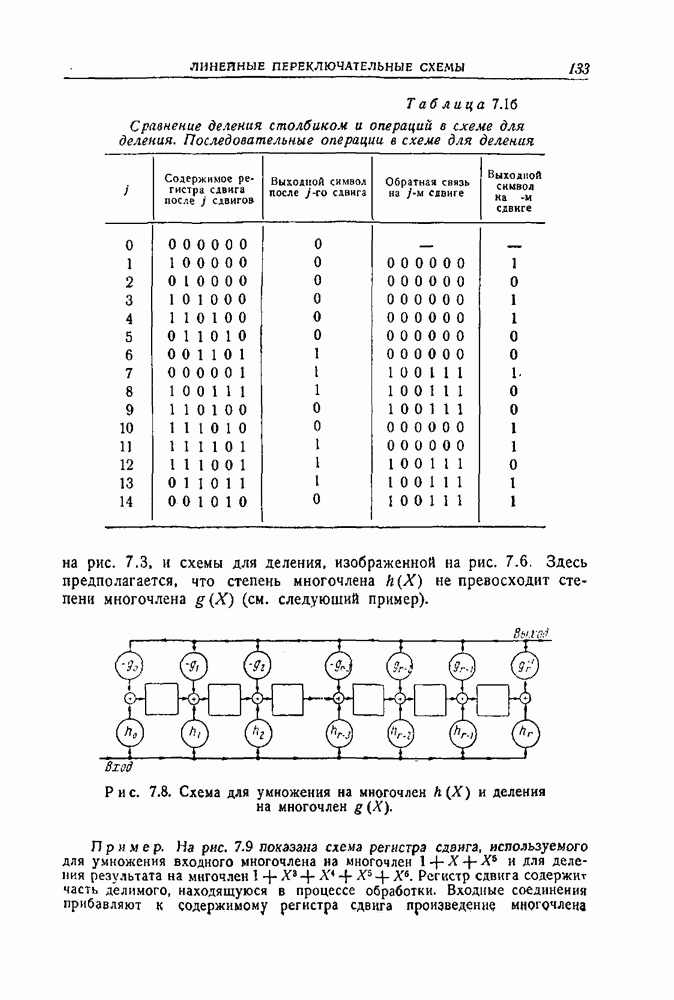
Рис. 10.3. Схема для исправления ошибок кода Файра. При этом клапан 1 закрыт, клапан 2 открыт, в результате чего произойдет исправление ошибочных символов. Если в первых девяти разрезах не появятся только нули, это будет означать, что обнаружена неисправимая комбинация ошибок. Может возникнуть необходимость укоротить код, исправляющий пачки ошибок либо потому, что пачки ошибок появляются слишком часто, либо потому, что общая длина или число информационных символов в коде ограничены другими требованиями, накладываемыми на систему. Если нельзя найти код подходящей естественной длины, то можно укоротить другой код, заменяя просто некоторые из его информационных символов высших порядков нулями и отбрасывая их. Это не повлияет на методы кодирования и проведения проверок на четность, поскольку на их осуществление не может повлиять наличие нулей среди информационных символов. Однако такая замена вызовет изменения в описанном выше процессе исправления ошибок. Предположим, например, что используется код, естественная длина которого равна 735, но 300 информационных символов его отброшены. Тогда для исправления ошибок прежним способом до того, как начнется считывание на самом деле полученного вектора из буферного запоминающего устройства, потребуется 300 сдвигов, соответствующих 300 отброшенным информационным символам, в предположении, что все эти символы равны 0. Один из способов несколько упростить этот процесс состоит в предварительном автоматическом умножении на Пример. Предположим, что нужен двоичный код, исправляющий любую пачку ошибок длины 5 и содержащий 200 информационных символов. Можно использовать код, описанный в предыдущем примере, если заменить в этом коде 65 информационных символов высших разрядов нулями и отбросить их. Для кодирования может быть использовано то же самое кодирующее устройство. Результаты проверок на четность, очевидно, равны вычету по модулю
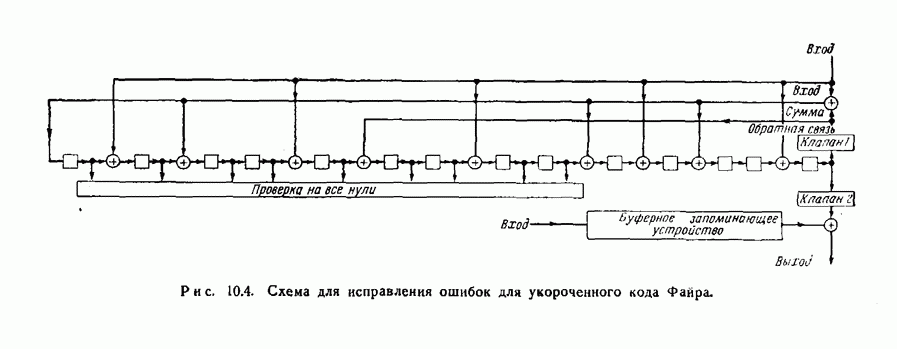
Схема, используемая для исправления ошибок этим кодом, показана на рис. 10.4. Она основана в точности на тех же самых принципах, что и схема, изображенная на рис. 10.3, и отличается только тем, что здесь кодовые слова содержат 200 информационных символов и 14 проверочных символов, в то время как в предыдущем случае они содержат 265 информационных и 14 проверочных символов.
|
 |
Оглавление
|

































































































































































































































































































 и появилась пачка ошибок
и появилась пачка ошибок  Тогда на выходе будет получен вектор
Тогда на выходе будет получен вектор  На основе полученного вектора можно произвести проверку на четность, деля многочлен
На основе полученного вектора можно произвести проверку на четность, деля многочлен  на многочлен
на многочлен  порождающий код, и сохраняя только остаток, который должен быть равен нулю, если на выходе получен кодовый вектор, и который в противном случае содержит информацию об ошибках. Поскольку
порождающий код, и сохраняя только остаток, который должен быть равен нулю, если на выходе получен кодовый вектор, и который в противном случае содержит информацию об ошибках. Поскольку  кодовый вектор, то многочлен
кодовый вектор, то многочлен  делится на
делится на  и, следовательно, остаток равен остатку от деления многочлена
и, следовательно, остаток равен остатку от деления многочлена  на
на  Пусть
Пусть

 меньше
меньше  степени
степени  Задача исправления ошибок состоит в том, чтобы, зная результат проверочных вычислений
Задача исправления ошибок состоит в том, чтобы, зная результат проверочных вычислений  найти многочлен
найти многочлен  т. е. точно определить расположение ошибок.
т. е. точно определить расположение ошибок.
 которые "исправимы" независимо от их расположения в полученном векторе. Если
которые "исправимы" независимо от их расположения в полученном векторе. Если  -исправимая комбинация ошибок, то вектор
-исправимая комбинация ошибок, то вектор  получаемый из
получаемый из  после
после  циклических сдвигов, является при любом
циклических сдвигов, является при любом  образующим некоторого смежного класса, и, разумеется, если
образующим некоторого смежного класса, и, разумеется, если  и
и  две различные исправимые комбинации ошибок, то векторы и
две различные исправимые комбинации ошибок, то векторы и  ни для каких
ни для каких  не могут лежать в одном и том же смежном классе. Некоторые смежные классы могут не содержать исправимых комбинаций ошибок; появление комбинации, принадлежащей одному из таких смежных классов, означает, что обнаружена неисправимая ошибка. Наконец, предполагается, что каждая исправимая комбинация ошибок является пачкой ошибок длины, не превосходящей
не могут лежать в одном и том же смежном классе. Некоторые смежные классы могут не содержать исправимых комбинаций ошибок; появление комбинации, принадлежащей одному из таких смежных классов, означает, что обнаружена неисправимая ошибка. Наконец, предполагается, что каждая исправимая комбинация ошибок является пачкой ошибок длины, не превосходящей 
 на
на  и привести полученный многочлен по модулю
и привести полученный многочлен по модулю  т. е. разделить многочлен
т. е. разделить многочлен  на
на  и рассмотреть остаток.
и рассмотреть остаток.
 раз.
раз.
 шагов остаток (X) окажется исправимой комбинацией ошибок, то образующий смежного класса равен
шагов остаток (X) окажется исправимой комбинацией ошибок, то образующий смежного класса равен  так что если при передаче появилась исправимая комбинация ошибок, она будет исправлена после тою, как из полученного на выходе вектора будет вычтен вектор
так что если при передаче появилась исправимая комбинация ошибок, она будет исправлена после тою, как из полученного на выходе вектора будет вычтен вектор 
 Пусть
Пусть  -результат проверочных вычислений, т. е.
-результат проверочных вычислений, т. е.

 на
на  и деления произведения на
и деления произведения на  равен
равен  Тогда
Тогда


 принадлежит коду и что оба вектора
принадлежит коду и что оба вектора  должны входить в один и тот же смежный класс. Заметим, что вопреки нашим обычным предположениям степень многочлена
должны входить в один и тот же смежный класс. Заметим, что вопреки нашим обычным предположениям степень многочлена  может превышать величину
может превышать величину  Если вектор
Если вектор  определяет комбинацию ошибок, которая может быть обнаружена, но не исправлена, то никакая другая комбинация ошибок
определяет комбинацию ошибок, которая может быть обнаружена, но не исправлена, то никакая другая комбинация ошибок  принадлежащая тому же самому смежному классу, также не может быть исправлена. В этом случае в качестве остатка на втором шаге не может появиться исправимая комбинация ошибок.
принадлежащая тому же самому смежному классу, также не может быть исправлена. В этом случае в качестве остатка на втором шаге не может появиться исправимая комбинация ошибок.
 где
где  исправимая комбинация ошибок, и пусть
исправимая комбинация ошибок, и пусть  . Тогда из уравнения (10.10) следует, что
. Тогда из уравнения (10.10) следует, что

 делится на
делится на  а степень многочлена
а степень многочлена  меньше, чем
меньше, чем  степень
степень  то
то  должен быть остатком от деления многочлена
должен быть остатком от деления многочлена  на
на  Таким образом, после
Таким образом, после  шагов в качестве остатка появится исправимая комбинация ошибок, именно
шагов в качестве остатка появится исправимая комбинация ошибок, именно 
 , где
, где  исправимая комбинация ошибок, и допустим, что после умножения на
исправимая комбинация ошибок, и допустим, что после умножения на  возникнет исправимая комбинация ошибок (X). Тогда в соответствии с равенством (10.12) векторы
возникнет исправимая комбинация ошибок (X). Тогда в соответствии с равенством (10.12) векторы  оба принадлежат одному и тому же смежному классу, итак как они оба
оба принадлежат одному и тому же смежному классу, итак как они оба  исправимые комбинации ошибок, то они должны совпадать. Если следовать описанному выше процессу исправления ошибок, то нужно взять в качестве комбинации ошибок вектор
исправимые комбинации ошибок, то они должны совпадать. Если следовать описанному выше процессу исправления ошибок, то нужно взять в качестве комбинации ошибок вектор  и считать, что эта комбинация расположена в полученном после передачи векторе, начиная с
и считать, что эта комбинация расположена в полученном после передачи векторе, начиная с  компоненты, Таким образом, вектор ошибок будет равен
компоненты, Таким образом, вектор ошибок будет равен

 порождаемый многочленом
порождаемый многочленом  степени
степени  и предположим, что появилась одна ошибка на месте, соответствующем
и предположим, что появилась одна ошибка на месте, соответствующем  Тогда
Тогда



 являются исправимыми. В каждом случае можно надлежащим образом провести исправление ошибки. Выбранные комбинации ошибок будут задаваться соответственно
являются исправимыми. В каждом случае можно надлежащим образом провести исправление ошибки. Выбранные комбинации ошибок будут задаваться соответственно  или
или  так что все они совпадают.
так что все они совпадают.
 разрядов. Регистр сдвига такого типа изображен на рис. 8.2.
разрядов. Регистр сдвига такого типа изображен на рис. 8.2.

 переходит в состояние 1, если когда-либо после первого шага в разряде высшего порядка регистра сдвига появится единица. Таким образом, в хранится 1, если имеются какие-либо несоответствия в проверках на четность. Второе устройство
переходит в состояние 1, если когда-либо после первого шага в разряде высшего порядка регистра сдвига появится единица. Таким образом, в хранится 1, если имеются какие-либо несоответствия в проверках на четность. Второе устройство  приводится в состояние 1 в зависимости от выхода сравнивающего устройства. Оно используется также для приведения в действие клапанов 1 и 2. Таким образом, возможны следующие комбинации:
приводится в состояние 1 в зависимости от выхода сравнивающего устройства. Оно используется также для приведения в действие клапанов 1 и 2. Таким образом, возможны следующие комбинации:

 то содержимое регистра сдвига после проведения проверок на четность равно остатку от деления многочлена
то содержимое регистра сдвига после проведения проверок на четность равно остатку от деления многочлена  на
на  После
После  дополнительных сдвигов содержимое регистра сдвига равно остатку от деления
дополнительных сдвигов содержимое регистра сдвига равно остатку от деления
 на многочлен
на многочлен  Автоматическое умножение на
Автоматическое умножение на  приводит к тому, что перед тем как из буферного запоминающего устройства начнут появляться ошибочные символы, в регистре сдвига будет содержаться обнаруженная комбинация ошибок. Таким образом, сопоставление с процессом исправления ошибок, описанным раньше, показывает, что если в регистре сдвига после автоматического умножения на
приводит к тому, что перед тем как из буферного запоминающего устройства начнут появляться ошибочные символы, в регистре сдвига будет содержаться обнаруженная комбинация ошибок. Таким образом, сопоставление с процессом исправления ошибок, описанным раньше, показывает, что если в регистре сдвига после автоматического умножения на  и после I дополнительных сдвигов обнаружена исправимая комбинация ошибок
и после I дополнительных сдвигов обнаружена исправимая комбинация ошибок  то появившаяся в действительности комбинация ошибок равна Если рассматривать содержимое регистра сдвига как многочлен степени
то появившаяся в действительности комбинация ошибок равна Если рассматривать содержимое регистра сдвига как многочлен степени  то элемент, лежащий в ячейке наивысшего порядка, равен коэффициенту при
то элемент, лежащий в ячейке наивысшего порядка, равен коэффициенту при  в многочлене
в многочлене  или коэффициенту при
или коэффициенту при  в комбинации ошибок
в комбинации ошибок  Так как коэффициент при
Так как коэффициент при  в многочлене
в многочлене  поступает из запоминающего устройства при первом сдвиге, то коэффициент при
поступает из запоминающего устройства при первом сдвиге, то коэффициент при  поступает при
поступает при  сдвиге. Таким образом, следующий симвот, появляющийся из буферного запоминающего устройства, соответствует символу наивысшего порядка в регистре сдвига. Символ, поступающий из регистра сдвига, должен быть вычтен из символа, поступающего из буферного запоминающего устройства, для того чтобы в этом последнем символе была исправлена ошибка, и аналогично для всех
сдвиге. Таким образом, следующий симвот, появляющийся из буферного запоминающего устройства, соответствует символу наивысшего порядка в регистре сдвига. Символ, поступающий из регистра сдвига, должен быть вычтен из символа, поступающего из буферного запоминающего устройства, для того чтобы в этом последнем символе была исправлена ошибка, и аналогично для всех  последующих символов.
последующих символов.

 исправляющий любую одиночную пачку ошибок длины 5 или меньше, Он содержит 14 проверочных символов и
исправляющий любую одиночную пачку ошибок длины 5 или меньше, Он содержит 14 проверочных символов и  информационных символов. Кодирование для этого кода может быть осуществлено с помощью регистра сдвига, изображенного на рис. 10.2. Регистры сдвига этого типа описывались в разд. 8.5. Там же описывалось действие таких регистров. Схема для исправления ошибок изображается на рис. 10.3. Заметим, что здесь регистр сдвига
информационных символов. Кодирование для этого кода может быть осуществлено с помощью регистра сдвига, изображенного на рис. 10.2. Регистры сдвига этого типа описывались в разд. 8.5. Там же описывалось действие таких регистров. Схема для исправления ошибок изображается на рис. 10.3. Заметим, что здесь регистр сдвига


 по модулю
по модулю  с использованием схемы умножения, изображенной на рис, 7.8. Техника этого приема иллюстрируется следующим примером.
с использованием схемы умножения, изображенной на рис, 7.8. Техника этого приема иллюстрируется следующим примером.
 многочлена
многочлена  Требуется провести дополнительное автоматическое умножение на
Требуется провести дополнительное автоматическое умножение на  т. е. нужен вычет многочлена
т. е. нужен вычет многочлена  Найденный в результате длинных вычислений остаток от деления
Найденный в результате длинных вычислений остаток от деления  на
на  равен
равен
