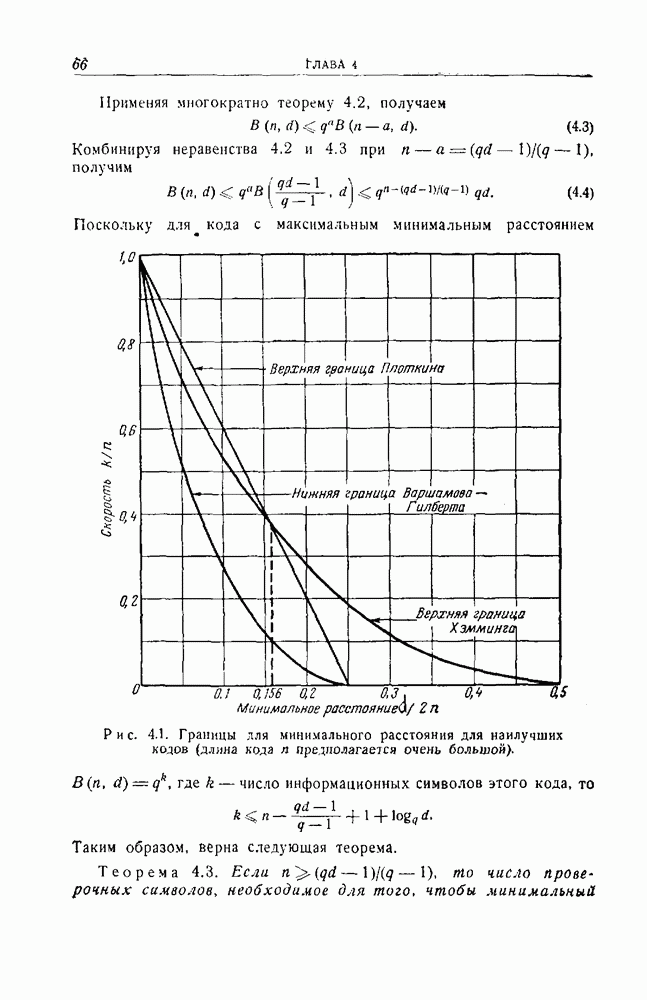
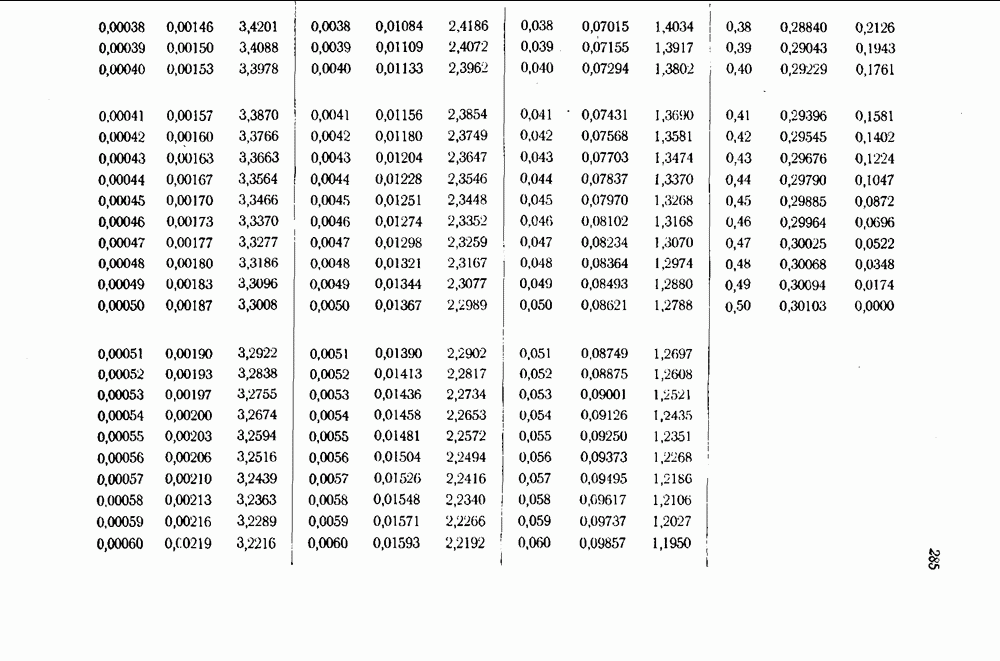
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
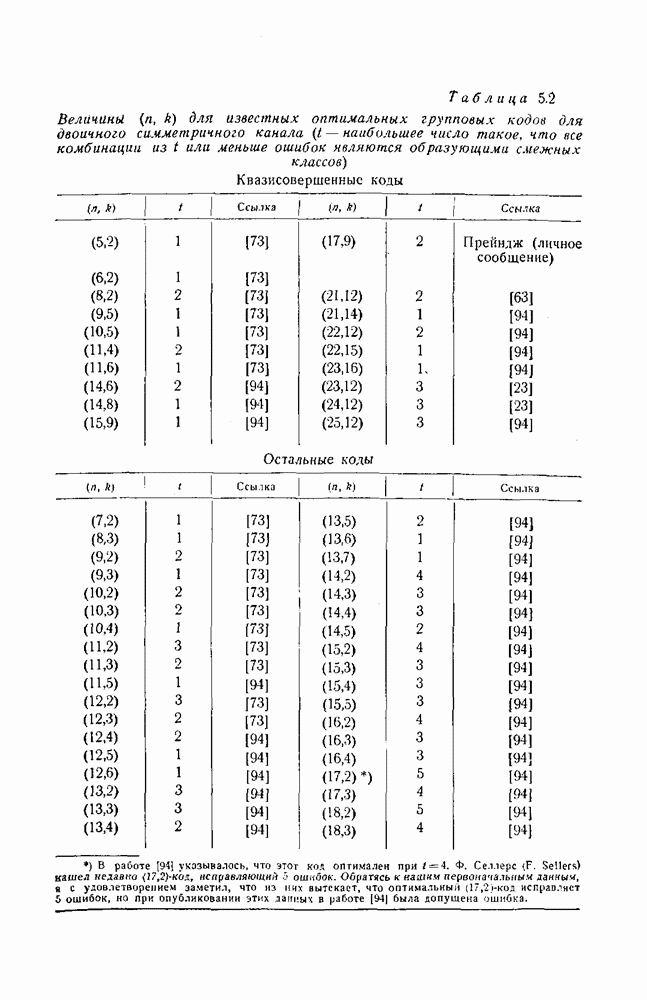
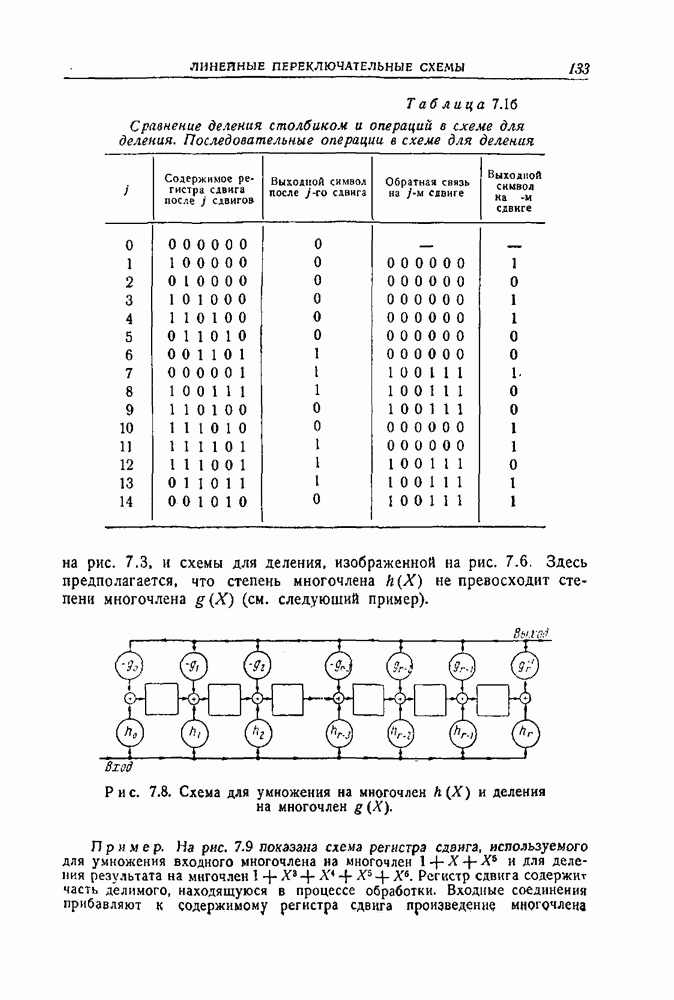
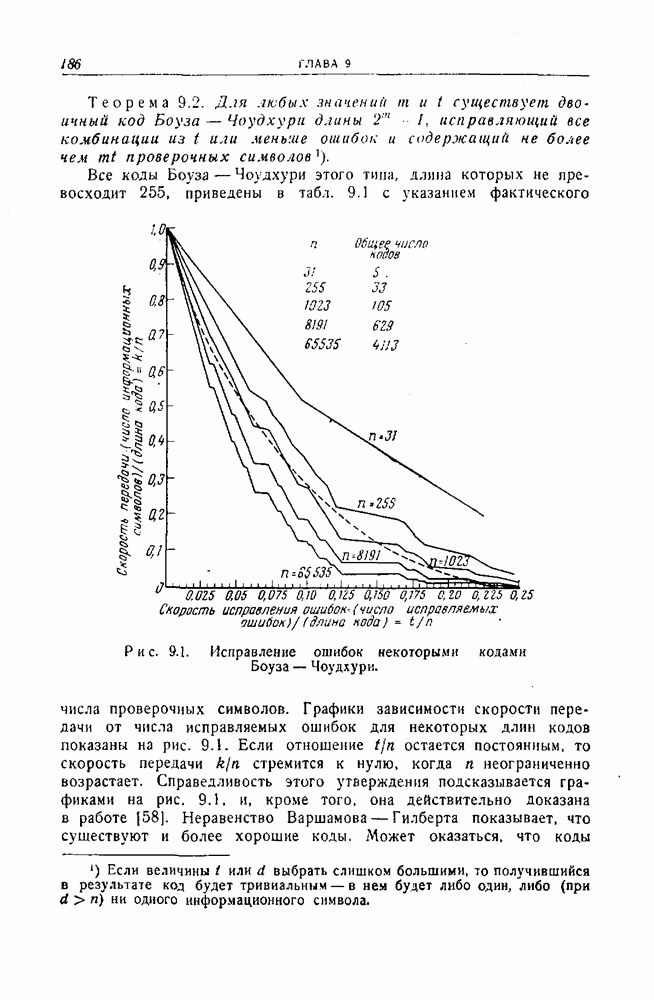
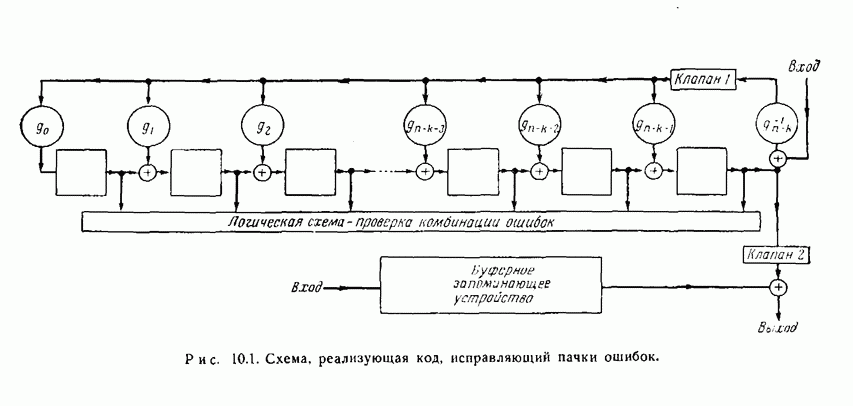
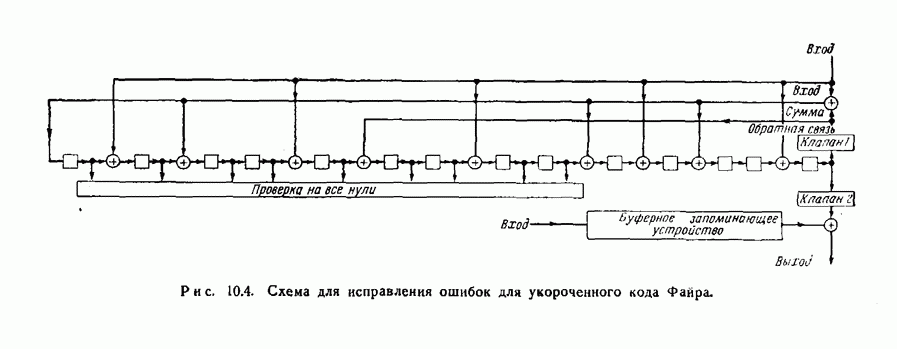
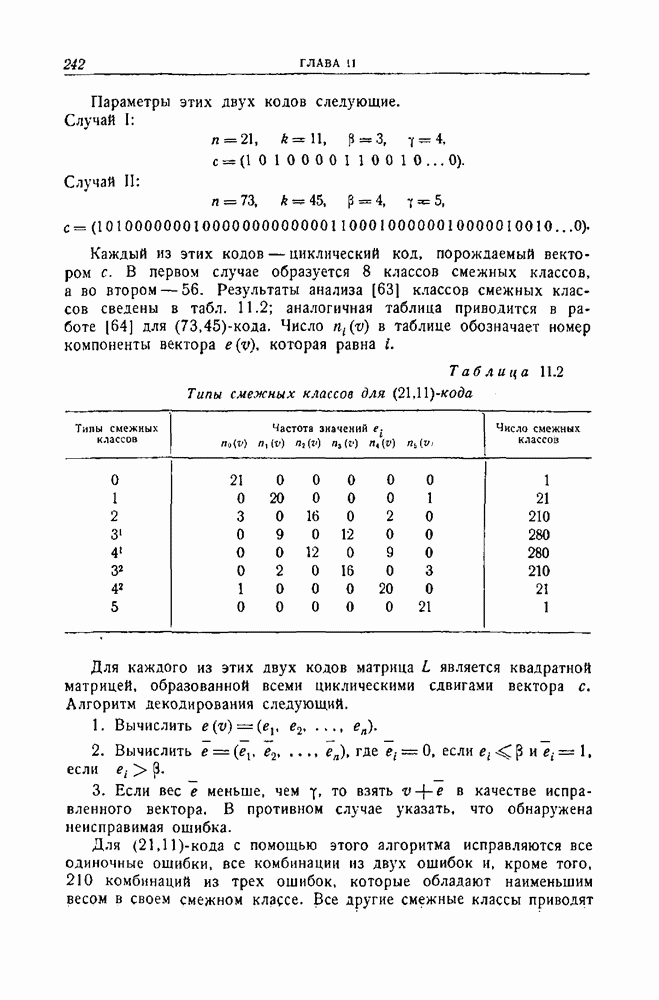
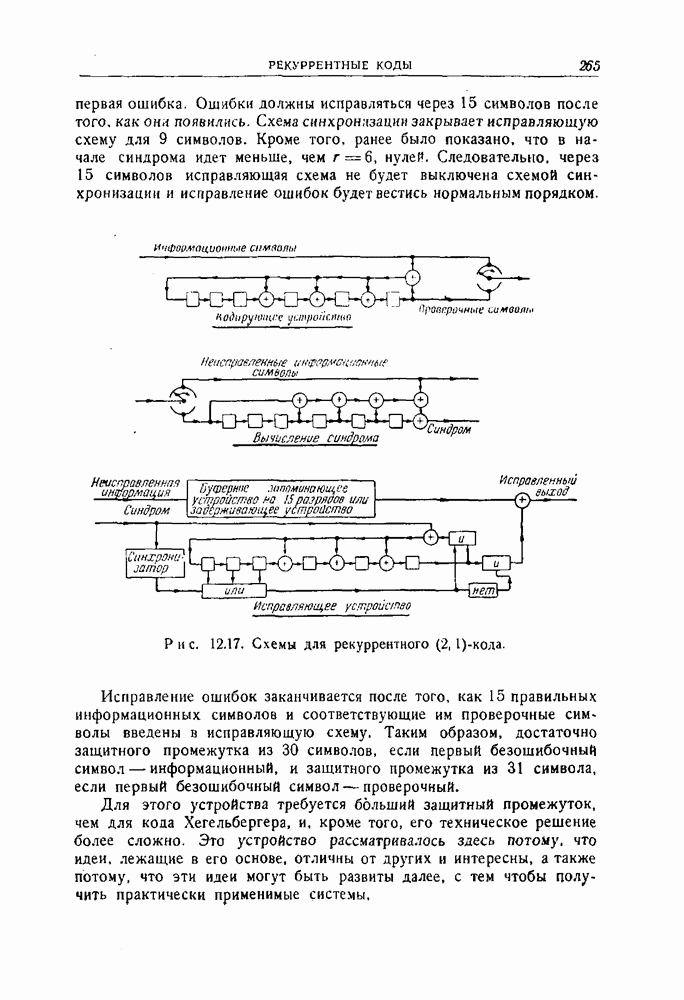
ГЛАВА 11. ДРУГИЕ СПОСОБЫ ДЕКОДИРОВАНИЯВ этой главе описываются три родственных способа декодирования, основанных на использовании свойств симметрии циклических кодов. Первый из них представляет собой интересное обобщение метода декодирования, разобранного в предыдущей главе, на случай кодов, не являющихся кодами, исправляющими пачки ошибок. Первый и второй способы декодирования — это по существу способы поэтапного декодирования, рассмотренного в разд. 3.4. Второй и третий методы декодирования пригодны и для других кодов, однако все же они особенно хорошо приспособлены к циклическим кодам. Все три метода декодирования, по-видимому, являются более простыми в применении к кодам небольшой длины, чем способ, описанный в гл. 9, для кодов Боуза — Чоудхури. Для кодов большой длины, однако, применение каждого из этих способов связано с утомительным, если не невозможным, анализом специфических особенностей кода, которые должны быть использованы, и, кроме того, насколько нам теперь это известно, с использованием чрезмерно сложного оборудования для их реализации. Тем не менее вполне возможно, что дальнейшее развитие теории облегчит преодоление этих трудностей. 11.1. Общее декодирующее устройство для циклических кодовМетод декодирования или исправления ошибок, описываемый в этом разделе, пригоден, в принципе, для любого циклического кода.
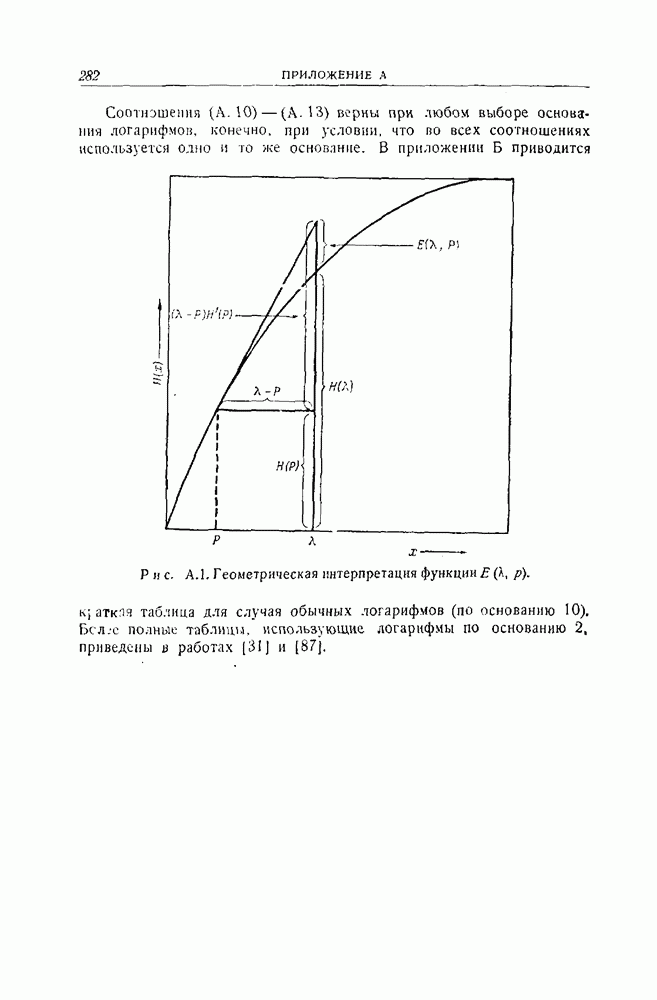
Рис. 11.1. Другое декодирующее устройство для кода Файра. На рис. 11.1 показана типичная схема декодирования, построенная для двоичного кода Файра, рассмотренного в разд. 10.5. В общих чертах работа этой схемы может быть описана следующим образом (для простоты это описание проводится для случая двоичного кода). 1. Полученный вектор вводится в буферное запоминающее устройство и одновременно в регистр сдвига, где производится вычисление синдрома. При этом используется регистр сдвига типа регистра, изображенного на рис. 8.2. 2. Между синдромом, вычисляемым в регистре сдвига, и образующим смежного класса, который совпадает с предполагаемой комбинацией ошибок, имеется взаимно однозначное соответствие. Комбинационная логическая схема устроена так, что единица появляется на ее выходе тогда и только тогда, когда синдром, полученный в регистре сдвига, соответствует комбинации ошибок, в которой ошибочный символ наивысшего разряда совпадает с символом, который должен появиться из буферного запоминающего устройства в следующий момент времени. Таким образом, если на выходе логической схемы появилась единица, то символ, появляющийся в следующий момент из буферного запоминающего устройства, является ошибочным и должен быть исправлен. Это осуществляется путем прибавления к этому символу выхода логической схемы. 3. Одновременно с появлением из буферного запоминающего устройства каждого символа производится сдвиг регистра. Если первый символ, появляющийся из буферного запоминающего устройства, подлежит исправлению, то синдром также должен быть изменен прибавлением выхода логической схемы с помощью обратной связи регистра сдвига. Это делается для того, чтобы синдром соответствовал измененному полученному вектору. Более детально этот вопрос рассматривается ниже. 4. Второй и третий шаги повторяются до тех пор, пока весь полученный вектор не будет считан из буферного запоминающего устройства. Считывание одного символа из буферного запоминающего устройства означает, по существу, сдвиг в этом устройстве на один разряд вправо. Каждому разряду, считываемому из буферного запоминающего устройства, должен соответствовать сдвиг на один разряд вправо одновременно запоминающего устройства и проверочного регистра сдвига. Так как код — циклический, то при этом все остается, по существу, таким же, как было первоначально, и выход логической схемы указывает каждый раз, подлежит или не подлежит исправлению очередной символ, появляющийся из буферного запоминающего устройства. 5. После того как считан весь полученный вектор, будут исправлены все ошибки, соответствующие комбинациям ошибок, предусмотренным логической схемой, и в разрядах регистра сдвига останутся одни нули. Если после окончания процесса в разрядах регистра сдвига содержатся не только нули, то это значит, что обнаружена ошибка, не исправимая с помощью данной логической схемы. Одна из сторон описанного метода нуждается в дальнейшем обосновании. Это касается нашего утверждения о том, что в течение всего процесса синдром правильно видоизменяется, так, чтобы на каждом этапе соответствовать полученному вектору, содержащемуся в буферном запоминающем устройстве. Пусть Синдром и содержимое буферного запоминающего устройства подвергаются воздействию двух операций: 1) из буферного запоминающего устройства считывается символ и одновременно производится сдвиг синдрома в регистре сдвига; 2) всякий раз, когда выход логической схемы равен 1, символ, который должен в следующий момент появиться из запоминающего устройства, исправляется, а к содержимому регистра сдвига, соответствующего синдрому, прибавляется 1 при помощи линий обратной связи. В следующих двух абзацах показывается, что каждая из этих операций сохраняет желаемое соотношение между синдромом и содержимым буферного запоминающего устройства. Как уже отмечалось, сдвиг содержимого буферного запоминающего устройства на один разряд можно рассматривать как умножение его на X, а сдвиг проверочного регистра сдвига эквивалентен умножению его содержимого на В результате исправления ошибочного символа к сдвинутому полученному вектору добавляется компенсировать добавление Описанный процесс непосредственно обобщается на случай циклических кодов, символы которых принадлежат произвольному полю. Выходом логической схемы должен быть элемент поля, соответствующий величине ошибки в символе, появляющемся из запоминающего устройства. Этот выход должен вычитаться из символа, появляющегося из буферного запоминающего устройства и из сигнала в линии обратной связи регистра сдвига. Декодирующее устройство довольно просто, за исключением, быть может, логической схемы. Будет ли этот метод практически осуществим, полностью зависит от сложности этой логической схемы. Для кодов, исправляющих пачки ошибок, логическая схема, вообще говоря, реализуется очень просто. Сравнение с методом декодирования, описанным в разд. 10.5, приводит к следующему Ситуация совершенно меняется, если рассматривать коды типа кодов Боуза — Чоудхури, которые исправляют случайные комбинации ошибок. Априори нет причин ожидать, что логическая схема будет достаточно простой. Один из возможных подходов состоит в том, чтобы составить таблицу всех входных комбинаций, для которых выход логической схемы должен быть равен 1, а затем с помощью вычислительной машины найти минимальную двузначную логическую схему, пользуясь стандартными методами минимизации. Это было проделано для 22 двойные ошибки и Для кодов, исправляющих две ошибки, этот метод декодирования практически осуществим во многих случаях. Его логическая структура не слишком сложна с самого начала. При условии, что последняя компонента вектора ошибки равна 1, существует единственная одиночная ошибка и Другой возможный подход состоял бы в том, чтобы попытаться использовать каким-либо образом структуру кода. Например, можно поставить вопрос так: при каких условиях изменение следующего символа, появляющегося из буферного запоминающего устройства, приведет к уменьшению веса смежного класса, содержащего полученный вектор. Если, например, вес смежного класса можно было бы вычислить практически осуществимым способом по синдрому или по полученному вектору, то можно было бы легко определить, уменьшит ли изменение следующего символа вес образующего смежного класса, и, таким образом, можно было бы определить, следует ли изменять следующий символ. Этот вопрос рассматривается в следующем разделе. Он связан с поэтапным декодированием, которое описано в разд. 3.4 и частным случаем которого, по существу, является декодирование, описанное в этом разделе.
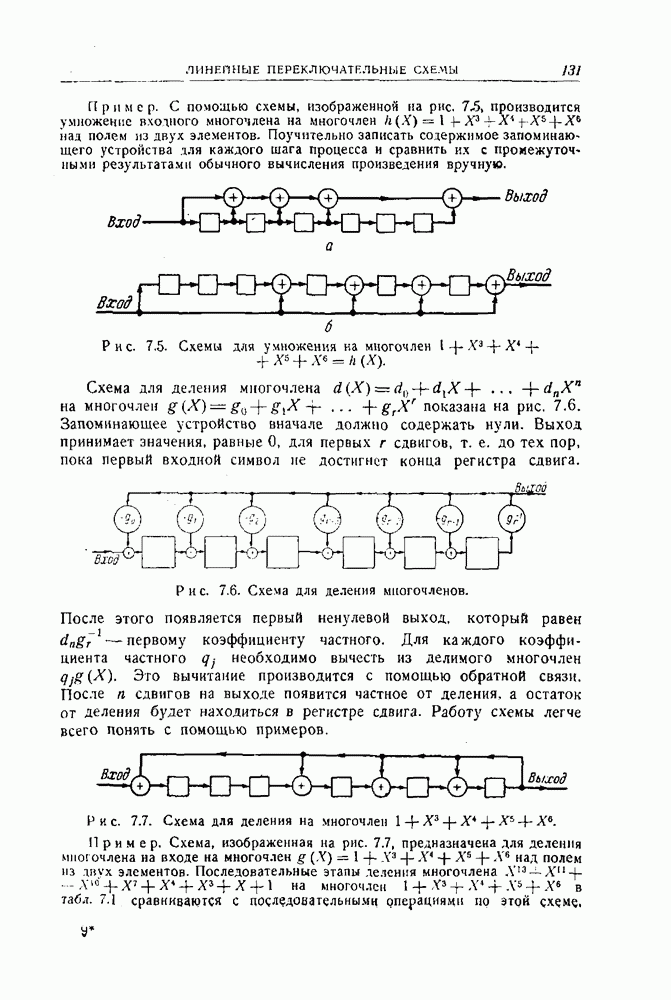
|
 |
Оглавление
|





















































































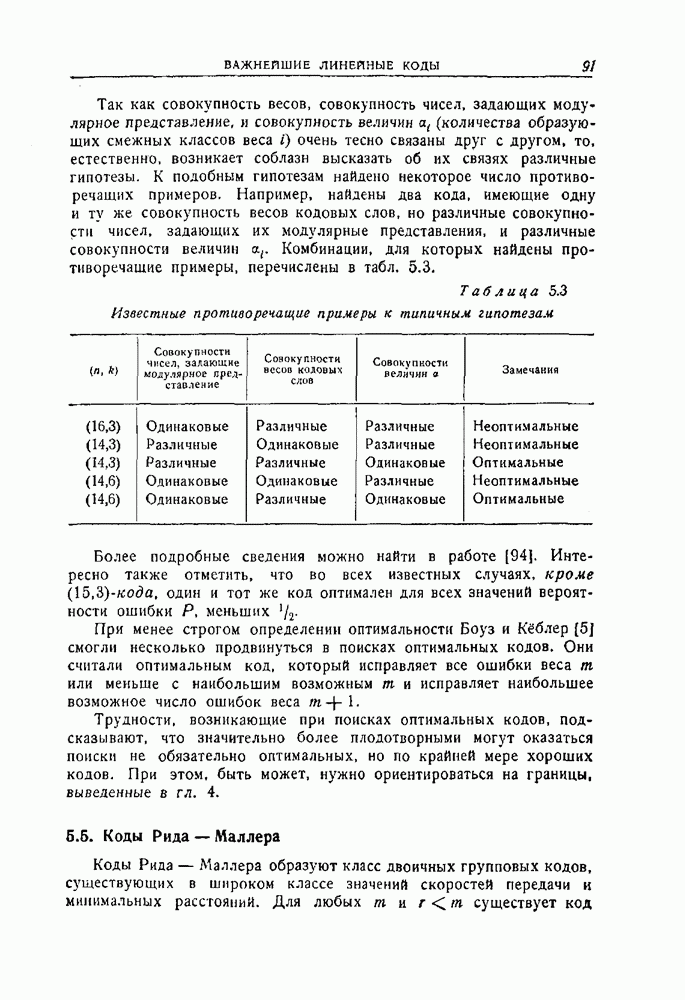













































































































































































































 обозначает содержимое запоминающего устройства, а
обозначает содержимое запоминающего устройства, а  полученный после передачи вектор. В начале процесса исправления ошибок в буферном запоминающем устройстве содержится полученный вектор,
полученный после передачи вектор. В начале процесса исправления ошибок в буферном запоминающем устройстве содержится полученный вектор,  а синдром равен вычету многочлена
а синдром равен вычету многочлена  по модулю
по модулю  образующего многочлена кода. Следовательно, первоначально в регистре сдвига, соответствующем синдрому, содержится вычет многочлена
образующего многочлена кода. Следовательно, первоначально в регистре сдвига, соответствующем синдрому, содержится вычет многочлена  по модулю
по модулю  . В следующих трех абзацах показывается, что такое соотношение между содержимым буферного запоминающего устройства и синдромом сохраняется в течение всего процесса исправления ошибок.
. В следующих трех абзацах показывается, что такое соотношение между содержимым буферного запоминающего устройства и синдромом сохраняется в течение всего процесса исправления ошибок.
 и приведению по модулю
и приведению по модулю  образующего код многочлена. Таким образом, после сдвига синдром и полученный вектор, очевидно, остаются в прежнем соотношении, если не производилось исправления ошибки.
образующего код многочлена. Таким образом, после сдвига синдром и полученный вектор, очевидно, остаются в прежнем соотношении, если не производилось исправления ошибки.
 поскольку символ наивысшего разряда в буферном запоминающем устройстве соответствует
поскольку символ наивысшего разряда в буферном запоминающем устройстве соответствует  а исправление ошибки состоит в прибавлении 1 к символу, который только что появился из буферного запоминающего устройства. Следовательно, прибавление многочлена
а исправление ошибки состоит в прибавлении 1 к символу, который только что появился из буферного запоминающего устройства. Следовательно, прибавление многочлена  приведенного по модулю
приведенного по модулю  к содержимому проверочного регистра сдвига будет компенсировать прибавление
к содержимому проверочного регистра сдвига будет компенсировать прибавление  к полученному вектору. Но многочлен
к полученному вектору. Но многочлен  делится на
делится на  поэтому при делении многочлена
поэтому при делении многочлена  на
на  получается тот же самый остаток, что при делении
получается тот же самый остаток, что при делении  на многочлен
на многочлен  Это означает, что добавление
Это означает, что добавление  к содержимому проверочного регистра сдвига будет
к содержимому проверочного регистра сдвига будет
 к полученному вектору. Но прибавление 1 в регистр сдвига при помощи обратной связи эквивалентно прибавлению
к полученному вектору. Но прибавление 1 в регистр сдвига при помощи обратной связи эквивалентно прибавлению  к содержимому регистра сдвига, и, следовательно, устройство для исправления ошибок, изображенное на рис. 11.1, обеспечивает соответствие синдрома и полученного вектора во все моменты времени.
к содержимому регистра сдвига, и, следовательно, устройство для исправления ошибок, изображенное на рис. 11.1, обеспечивает соответствие синдрома и полученного вектора во все моменты времени.
 гаму результату: выход логической схемы должен быть равен 1 (для двоичного кода), если в проверочном регистре сдвига появилась исправимая комбинация ошибок с 1 в качестве символа старшего разряда. В частности, код Файра соответствующий линиям обратной связи устройства, изображенного на рис. 11.1, исправляет все пачки ошибок длины 5 или меньше. Выход логической схемы должен быть равен 1 всякий раз, когда в девяти низших разрядах проверочного регистра сдвига появляются нули, а в наивысшем разряде одновременно появляется 1. Это. конечно, нетрудно осуществить, и фактически получается просто разновидность схемы, изображенной на рис. 10.3.
гаму результату: выход логической схемы должен быть равен 1 (для двоичного кода), если в проверочном регистре сдвига появилась исправимая комбинация ошибок с 1 в качестве символа старшего разряда. В частности, код Файра соответствующий линиям обратной связи устройства, изображенного на рис. 11.1, исправляет все пачки ошибок длины 5 или меньше. Выход логической схемы должен быть равен 1 всякий раз, когда в девяти низших разрядах проверочного регистра сдвига появляются нули, а в наивысшем разряде одновременно появляется 1. Это. конечно, нетрудно осуществить, и фактически получается просто разновидность схемы, изображенной на рис. 10.3.
 -кодов Боуза — Чоудхури, исправляющих две ошибки, и для
-кодов Боуза — Чоудхури, исправляющих две ошибки, и для  -кодов Боуза-Чоудхури и
-кодов Боуза-Чоудхури и  -кода Голея, исправляющих три ошибки. Рассматриваемые схемы упростились незначительно. Например, минимальная двузначная логическая схема для
-кода Голея, исправляющих три ошибки. Рассматриваемые схемы упростились незначительно. Например, минимальная двузначная логическая схема для  -кода содержит приблизительно всего на одну треть элементов меньше, чем исходная. Дальнейшая факторизация уменьшает это отношение до одной второй или немного меньше. В исходной схеме, исправляющей одну одиночную ошибку,
-кода содержит приблизительно всего на одну треть элементов меньше, чем исходная. Дальнейшая факторизация уменьшает это отношение до одной второй или немного меньше. В исходной схеме, исправляющей одну одиночную ошибку,
 тройные ошибки, у которых последний символ обязательно равен 1, содержится всего 485 элементов. Логическая схема, содержащая половину этого числа элементов, является все еще достаточно дорогой.
тройные ошибки, у которых последний символ обязательно равен 1, содержится всего 485 элементов. Логическая схема, содержащая половину этого числа элементов, является все еще достаточно дорогой.
 комбинаций из двух ошибок, и поэтому для
комбинаций из двух ошибок, и поэтому для  -кода, исправляющего две ошибки, в качестве его комбинационной переключательной схемы потребуется переключательная матрица размерности, самое большее
-кода, исправляющего две ошибки, в качестве его комбинационной переключательной схемы потребуется переключательная матрица размерности, самое большее  Для
Для  -кода Боуза — Чоудхури это означает, что понадобится матрица размерности
-кода Боуза — Чоудхури это означает, что понадобится матрица размерности  что еще непомерно много.
что еще непомерно много.