Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
11.3. Алгоритмы декодирования Рида
Пусть  матрица размерности матрица размерности  составленная из нулей и единиц, все составленная из нулей и единиц, все  столбцов которой принадлежат нулевому пространству столбцов которой принадлежат нулевому пространству  двоичного двоичного  -кода -кода  Всякий вектор из нулевого пространства, по существу, определяет некоторое проверочное соотношение, которому должны удовлетворять кодовые векторы. Для любого полученного вектора Всякий вектор из нулевого пространства, по существу, определяет некоторое проверочное соотношение, которому должны удовлетворять кодовые векторы. Для любого полученного вектора  произведение произведение  это вектор, состоящий из это вектор, состоящий из  двоичных символов, причем единицы в этом векторе расположены на местах, соответствующих проверкам на четность, которым не удовлетворяет вектор двоичных символов, причем единицы в этом векторе расположены на местах, соответствующих проверкам на четность, которым не удовлетворяет вектор  Рассмотрим теперь результат умножения вектора Рассмотрим теперь результат умножения вектора  на матрицу на матрицу  полагая составляющие их символы действительными числами. В результате получается вектор, образованный полагая составляющие их символы действительными числами. В результате получается вектор, образованный  целыми числами: целыми числами:

при этом  компонента вектора компонента вектора  получается как сумма единиц по тем столбцам матрицы получается как сумма единиц по тем столбцам матрицы  которые, с одной стороны, задают проверки на четность, которым не удовлетворяет вектор которые, с одной стороны, задают проверки на четность, которым не удовлетворяет вектор  с другой стороны, с другой стороны,  компонента которых равна 1. Таким образом, компонента которых равна 1. Таким образом,  компонента вектора совпадает с числом проверок компонента вектора совпадает с числом проверок  четность, которые не удовлетворяются для полученного вектора и которые включают четность, которые не удовлетворяются для полученного вектора и которые включают  компоненту кодового вектора. компоненту кодового вектора.
Можно ожидать, по крайней мере при определенных условиях, что символ, входящий в большое число неудовлетворенных проверок на четность, вероятно, ошибочен. Это было бы еще более вероятно, если бы столбцы матрицы  ныбрались так, чтобы в них была мала плотность единиц, потому что в этом случае вероятность того, что заданный вектор-столбец матрицы L соответствует проверке на четность, включающей более чем одну ошибку, была бы наименьшей. Таким образом, для некоторых кодов при соответствующем выборе матрицы ныбрались так, чтобы в них была мала плотность единиц, потому что в этом случае вероятность того, что заданный вектор-столбец матрицы L соответствует проверке на четность, включающей более чем одну ошибку, была бы наименьшей. Таким образом, для некоторых кодов при соответствующем выборе матрицы  существует такой алгоритм исправления ошибок, в котором решение вопроса о том, подлежит или не подлежит исправлению заданный символ, определяется числом проверок на четность, включающих этот символ, которым не удовлетворяет полученный вектор. Поскольку эти способы связаны с декодированием для кодов Рида — Маллера, где решения также принимаются в зависимости от числа определенным образом выбираемых проверок на четность, которые удовлетворяются полученным вектором, они называются алгоритмами декодирования Рида. существует такой алгоритм исправления ошибок, в котором решение вопроса о том, подлежит или не подлежит исправлению заданный символ, определяется числом проверок на четность, включающих этот символ, которым не удовлетворяет полученный вектор. Поскольку эти способы связаны с декодированием для кодов Рида — Маллера, где решения также принимаются в зависимости от числа определенным образом выбираемых проверок на четность, которые удовлетворяются полученным вектором, они называются алгоритмами декодирования Рида.
Исходя из этих соображений, Галлагер провел интересное исследование. Используя случайные коды аналогично тому, как это делалось в разд. 4.4, он показал, что существуют коды, совпадающие с нулевым пространством матриц, в столбцах которых низка плотность единиц, причем вероятности ошибки для этих кодов ненамного больше, чем вероятности ошибки, получаемые для произвольных кодов при случайном кодировании. Он описал способ декодирования, являющийся усовершенствованием алгоритма декодирования Рида. Наконец, он наглядно показал осуществимость этих методов, промоделировав на вычислительной машине процесс исправления ошибок для кодов со случайно выбираемыми проверочными соотношениями, достигающими длины 500 символов. Оказалось, что для кодов такой длины при скорости передачи, равной  можно исправлять типичные комбинации, содержащие до 40 ошибок, а при скорости передачи, равной можно исправлять комбинации, содержащие около 80 ошибок. Тот факт, что такие большие комбинации ошибок могут быть исправлены в течение не очень большого промежутка времени, действительно весьма удивителен и указывает на то, что эти методы могут оказаться практически применимыми. можно исправлять типичные комбинации, содержащие до 40 ошибок, а при скорости передачи, равной можно исправлять комбинации, содержащие около 80 ошибок. Тот факт, что такие большие комбинации ошибок могут быть исправлены в течение не очень большого промежутка времени, действительно весьма удивителен и указывает на то, что эти методы могут оказаться практически применимыми.
Прейндж построил алгоритмы декодирования Рида для некоторых циклических кодов. Два из этих алгоритмов будут описаны здесь без доказательства. Доказательства можно найти в работах [63] и [64]. Эти доказательства в основном сводятся к тому, что сначала дается характеристика классов симметрии, составленных из смежных классов, и показывается, что алгоритмы одинаковым способом воздействуют на все векторы из одного и того же класса, а затем исчерпывающе показывается, что алгоритм надлежащим образом производит исправление ошибок в каждом классе.
только к обнаружению ошибки, причем в каждом случае, когда производится исправление ошибок, предполагаемая комбинация ошибок обладает минимальным весом в своем смежном классе. Для  -кода применение алгоритма приводит к исправлению всех комбинаций ошибок веса 4 или меньше а к обнаружению ошибок, соответствующих всем остальным смежным классам. -кода применение алгоритма приводит к исправлению всех комбинаций ошибок веса 4 или меньше а к обнаружению ошибок, соответствующих всем остальным смежным классам.
Прейндж нашел алгоритмы для  и и  -кодов и описал алгоритмы исправления ошибок по методу максимального правдоподобия для всех смежных классов всех этих кодов. В некоторых случаях матрица -кодов и описал алгоритмы исправления ошибок по методу максимального правдоподобия для всех смежных классов всех этих кодов. В некоторых случаях матрица  может состоять из всех циклических сдвигов более чем одного вектора. Алгоритм декодирования, данный Прейнджем для может состоять из всех циклических сдвигов более чем одного вектора. Алгоритм декодирования, данный Прейнджем для  -кода Голея, рассматриваемого как циклический код, основан на использовании циклических сдвигов 11 векторов, вероятно, большего числа, чем это необходимо. -кода Голея, рассматриваемого как циклический код, основан на использовании циклических сдвигов 11 векторов, вероятно, большего числа, чем это необходимо.
Имеется интересная связь между этими алгоритмами и идеями, изложенными в предыдущем разделе. В соответствии с обозначениями этого раздела, пусть — код,  его нулевое пространство, его нулевое пространство,  группа перестановок, относительно которой код инвариантен. Рассмотрим столбцы матрицы группа перестановок, относительно которой код инвариантен. Рассмотрим столбцы матрицы  соответствующие одному или нескольким полным классам симметрии пространства соответствующие одному или нескольким полным классам симметрии пространства  Тогда если Тогда если  —матрица перестановки из —матрица перестановки из  то в результате воздействия матрицы то в результате воздействия матрицы  на компоненты любого столбца матрицы на компоненты любого столбца матрицы  получается просто другой столбец матрицы получается просто другой столбец матрицы  таким образом, воздействие таким образом, воздействие  на строки матрицы на строки матрицы  эквивалентно воздействию некоторой другой перестановки эквивалентно воздействию некоторой другой перестановки  на столбцы на столбцы 

Вектор  для вектора для вектора  равен равен 

Этот вектор совпадает с результатом применения перестановки  к вектору к вектору  вычисленному по вектору вычисленному по вектору  Кроме того, поскольку столбцы матрицы Кроме того, поскольку столбцы матрицы  принадлежат нулевому пространству принадлежат нулевому пространству  то любые два вектора из одного и того же смежного класса приводят к одному и тому же вектору то любые два вектора из одного и того же смежного класса приводят к одному и тому же вектору  Таким образом, любые два вектора из эквивалентных смежных классов порождают векторы Таким образом, любые два вектора из эквивалентных смежных классов порождают векторы  совпадающие с точностью до перестановки. Наконец, если совпадающие с точностью до перестановки. Наконец, если  это число компонент вектора это число компонент вектора  равных равных  то для каждого то для каждого  величины величины  совпадают для любых двух векторов из эквивалентных смежных классов. Следовательно, по теореме 11.8 они представимы в виде линейных комбинаций функций определенных равенством (11.8). совпадают для любых двух векторов из эквивалентных смежных классов. Следовательно, по теореме 11.8 они представимы в виде линейных комбинаций функций определенных равенством (11.8).
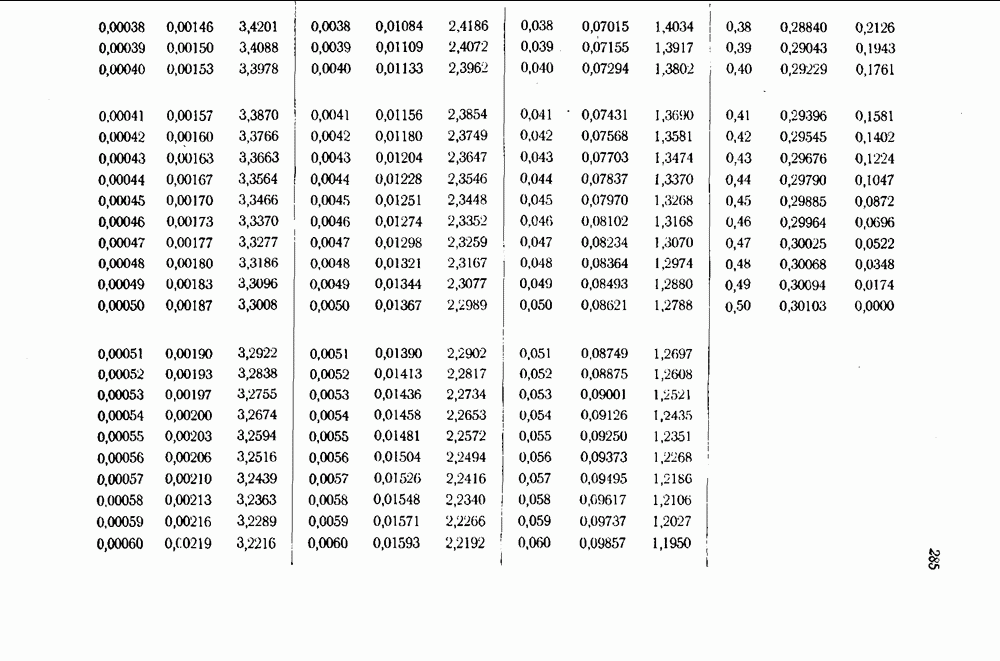
Вычисление  не требует значительно большего числа операций, чем вычисление одной функции не требует значительно большего числа операций, чем вычисление одной функции  и вместе с тем дает сразу несколько независимых функций и вместе с тем дает сразу несколько независимых функций  которые могут быть использованы для тою, чтобы различать классы смежных классов. В частности, для которые могут быть использованы для тою, чтобы различать классы смежных классов. В частности, для  -кода знания величин -кода знания величин  достаточно для различения всех классов смежных классов (см. табл. 11.1) и, таким образом, достаточно для поэтапного декодирования по способу максимального правдоподобия в случае двоичного симметричного канала. Для достаточно для различения всех классов смежных классов (см. табл. 11.1) и, таким образом, достаточно для поэтапного декодирования по способу максимального правдоподобия в случае двоичного симметричного канала. Для  -кода знания этих величин достаточно для определения тех смежных классов, вес образующих которых не превосходит 4, а когда эти классы уже выделены, то для определения веса их образующих. Этого в свою очередь достаточ! о для поэтапного декодирования во всех случаях, когда появляется не более четырех ошибок, и для обнаружения ошибок, когда полученный вектор принадлежит смежному классу, минимальный вес которого превосходит 4. -кода знания этих величин достаточно для определения тех смежных классов, вес образующих которых не превосходит 4, а когда эти классы уже выделены, то для определения веса их образующих. Этого в свою очередь достаточ! о для поэтапного декодирования во всех случаях, когда появляется не более четырех ошибок, и для обнаружения ошибок, когда полученный вектор принадлежит смежному классу, минимальный вес которого превосходит 4.
Хотя остается верным тот факт, что функции  образуют адекватную основу для выбора нужного решения при поэтапном декодировании по крайней мере для образуют адекватную основу для выбора нужного решения при поэтапном декодировании по крайней мере для  и и  -кодов и хотя вычисление этих функций, вообще говоря, проще, чем вычисление совокупности функций -кодов и хотя вычисление этих функций, вообще говоря, проще, чем вычисление совокупности функций  описанных в разд. 11.3, тем не менее представляется, что алгоритм декодирования Рида проще и экономичнее, чем поэтапное декодирование по крайней мере для упомянутых когов. Оба метода перспективны, хотя точно оценить их достоинства можно будет только после проведения дальнейших исследований. описанных в разд. 11.3, тем не менее представляется, что алгоритм декодирования Рида проще и экономичнее, чем поэтапное декодирование по крайней мере для упомянутых когов. Оба метода перспективны, хотя точно оценить их достоинства можно будет только после проведения дальнейших исследований.
|
1 |
Оглавление
- ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
- ГЛАВА 1. ПРОБЛЕМА КОДИРОВАНИЯ
- 1.2. Несколько замечаний о двоичных кодах, обнаруживающих и исправляющих ошибки
- 1.3. Блоковые коды
- 1.4. Расстояние Хэмминга
- 1.6. Проблема кодирования
- Замечания
- ГЛАВА 2. АЛГЕБРАИЧЕСКОЕ ВВЕДЕНИЕ
- 2.2. Кольца
- 2.3. Поля
- 2.4. Подгруппы и факторгруппы
- 2.5. Векторные пространства и линейные алгебры
- 2.6. Матрицы
- Замечания
- ГЛАВА 3. ЛИНЕЙНЫЕ КОДЫ
- 3.1. Определение линейного кода
- 3.2. Описание линейных кодов при помощи матриц
- 3.3. Стандартная расстановка
- 3.4. Поэтапное декодирование
- 3.5. Модулярное представление линейных кодов
- 3.6. Эквивалентность линейных кодов
- Замечания
- ГЛАВА 4. ВОЗМОЖНОСТИ ИСПРАВЛЕНИЯ ОШИБОК С ПОМОЩЬЮ ЛИНЕЙНЫХ КОДОВ
- 4.1. Граница Плоткина
- 4.2. Граница Варшамова-Гилберта
- 4.3. Граница, основанная на принципа плотной упаковки сфер
- 4.4. Граница, основанная на случайном выборе кода
- 4.5. Обсуждение границ
- 4.6. Границы для кодов, исправляющих или обнаруживающих пачки ошибок
- Замечания
- ГЛАВА 5. ВАЖНЕЙШИЕ ЛИНЕЙНЫЕ КОДЫ
- 5.1. Коды Хэмминга
- 5.2. Веса кодовых слов в коде Хэмминга
- 5.3. (23,12)-код Голея
- 5.4. Оптимальные коды для двоичного симметричного канала
- 5.5. Коды Рида — Маллера
- 5.6. Коды Макдональда
- 5.7. Коды, получаемые с помощью матриц Адамара
- 5.8. Итеративные коды
- Замечания
- ГЛАВА 6. КОЛЬЦА МНОГОЧЛЕНОВ И ПОЛЯ ГАЛУА
- 6.1. Идеалы, классы вычетов и кольцо классов вычетов
- 6.2. Идеалы и классы вычетов целых чисел
- 6.3. Идеалы многочленов и классы вычетов
- 6.4. Алгебра классов вычетов многочленов
- 6.5. Поля Галуа
- 6.6. Мультипликативная группа поля Галуа
- Замечания
- ГЛАВА 7. ЛИНЕЙНЫЕ ПЕРЕКЛЮЧАТЕЛЬНЫЕ СХЕМЫ
- 7.2. Умножение и деление многочленов
- 7.3. Вычисления в алгебрах многочленов и полях Галуа
- 7.4. Линейные рекуррентные соотношения и генераторы с регистром сдвига
- 7.5. Анализ линейных переключательных схем
- 7.6. Анализ общей линейной переключательной схемы с конечным числом состояний
- Замечания
- ГЛАВА 8. ЦИКЛИЧЕСКИЕ КОДЫ
- 8.1. Циклические коды и идеалы
- 8.2. Матричное описание циклических кодов
- 8.3. Последовательности максимальной длины
- 8.4. Кодирование с помощью регистра сдвига, содержащего k разрядов
- 8.5. Кодирование с помощью регистра сдвига, содержащего n — k разрядов
- 8.6. Обнаружение ошибок с помощью циклических кодов
- 8.7. Двоичные коды Хэмминга
- 8.8. Обобщенные коды Хэмминга
- 8.9. Укороченные циклические коды
- Замечания
- ГЛАВА 9. КОДЫ БОУЗА — ЧОУДХУРИ
- 9.2. Двоичные коды
- 9.3. Коды Рида — Соломона
- 9.4. Метод исправления ошибок
- 9.5. Другой способ исправления ошибок для двоичных кодов
- 9.6. Обнаружение ошибок с помощью кодов Боуза — Чоудхури
- 9.7. Использование кодов Боуза — Чоудхури при передаче по стирающему каналу
- Замечания
- ГЛАВА 10. ЦИКЛИЧЕСКИЕ КОДЫ, ИСПРАВЛЯЮЩИЕ ПАЧКИ ОШИБОК
- 10.1. Коды Файра
- 10.2. Возможности кодов Файра исправлять ошибки
- 10.3. Другие коды, исправляющие пачки ошибок
- 10.4. Двоичные коды, исправляющие пачки только с четным или только с нечетным числом ошибок
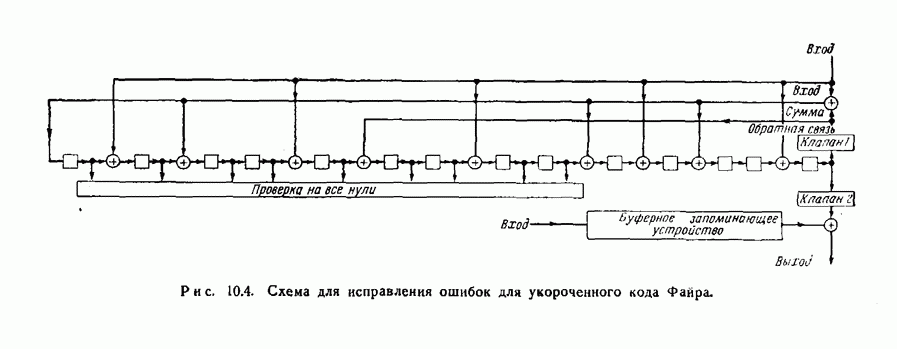
- 10.6. Практическая реализация кодов, исправляющих пачки ошибок
- 10.6. Другой метод исправления ошибок
- 10.7. Другой подход к задаче исправления пачек ошибок
- Замечания
- ГЛАВА 11. ДРУГИЕ СПОСОБЫ ДЕКОДИРОВАНИЯ
- 11.1. Общее декодирующее устройство для циклических кодов
- 11.2. Использование симметричности кода при поэтапном декодировании
- 11.3. Алгоритмы декодирования Рида
- Замечания
- ГЛАВА 12. РЕКУРРЕНТНЫЕ КОДЫ
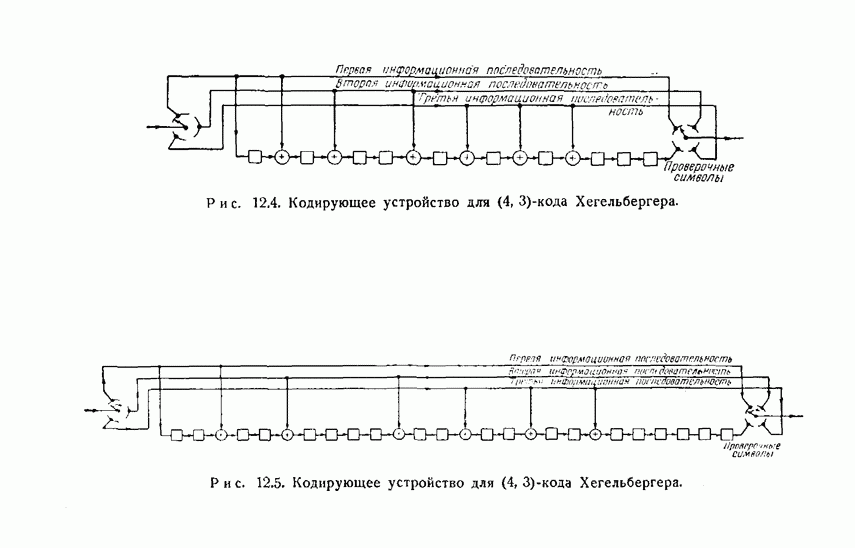
- 12.1. Определение рекуррентного кода
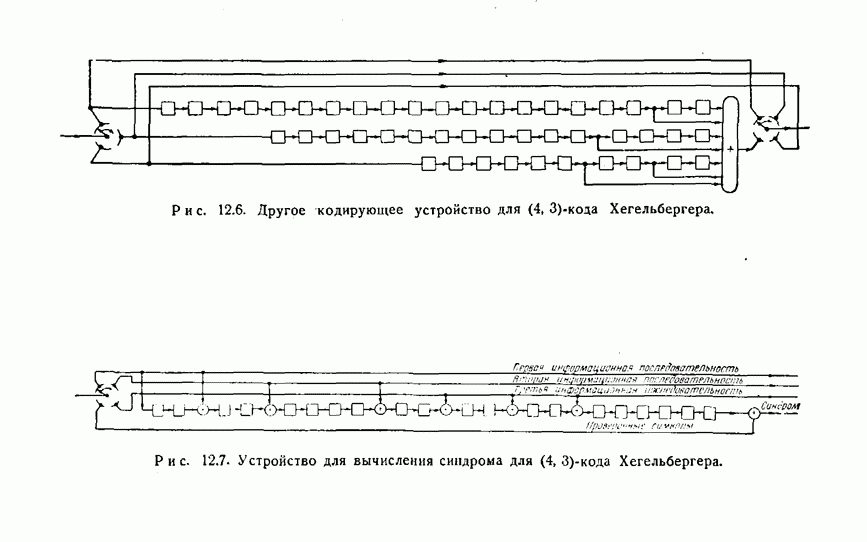
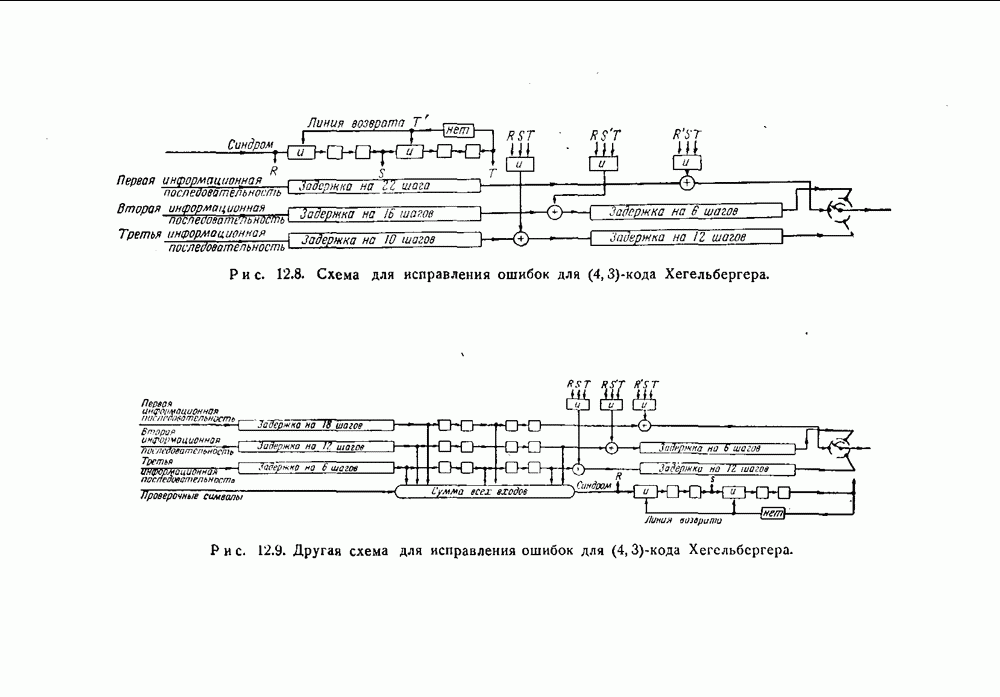
- 12.2. Коды Хегельбергера, исправляющие пачки ошибок
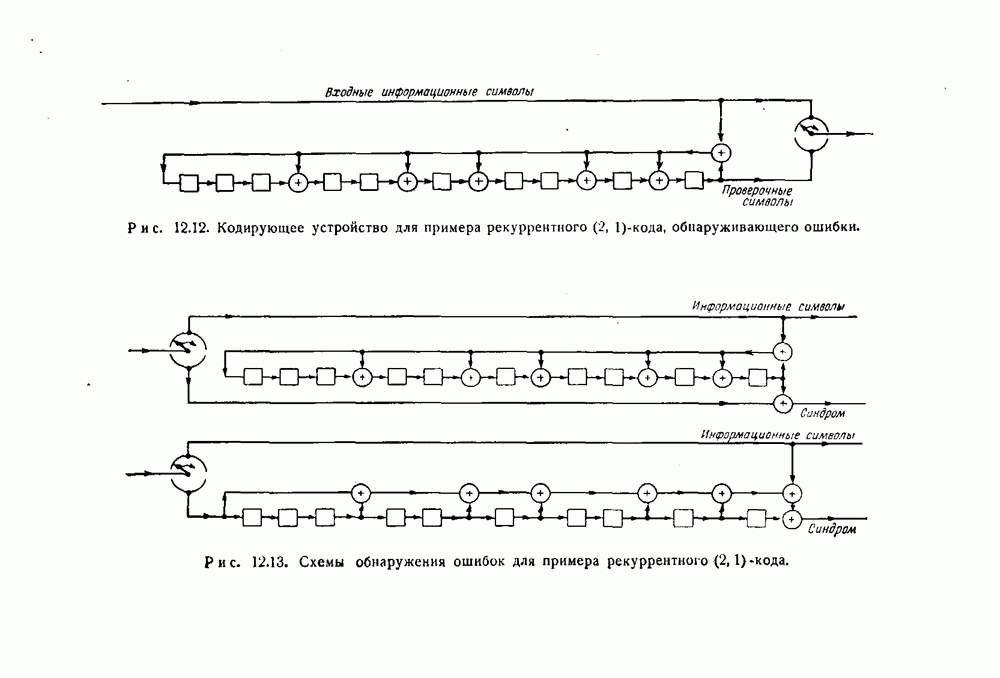
- 12.3. Обнаружение пачек ошибок с помощью рекуррентных кодов
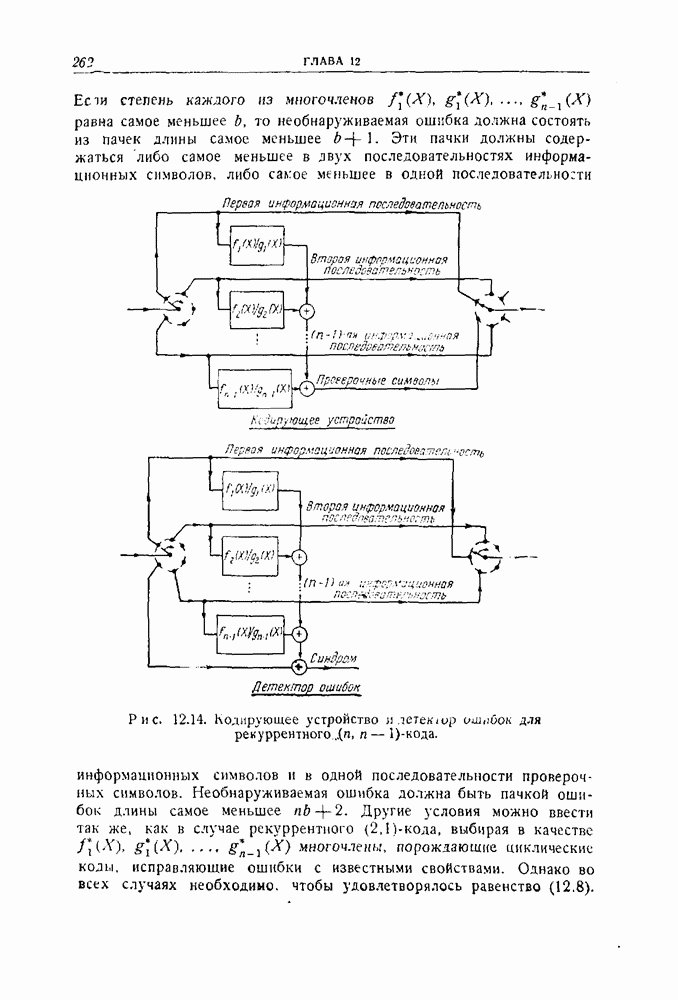
- 12.4. Рекуррентный код, исправляющий лачки ошибок и построенный на основе циклического кода
- 12.5. Последовательное декодирование
- ГЛАВА 13. КОДЫ ДЛЯ ПРОВЕРКИ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
- 13.2. AN-коды
- 13.3. Самодополняющиеся (AN+B)-коды
- 13.4. Реальное осуществление AN- и (AN+B)-кодов
- 13.6. Раздельные сумматор и проверяющее устройство
- ПРИЛОЖЕНИЕ А. НЕРАВЕНСТВА, ВКЛЮЧАЮЩИЕ БИНОМИАЛЬНЫЕ КОЭФФИЦИЕНТЫ
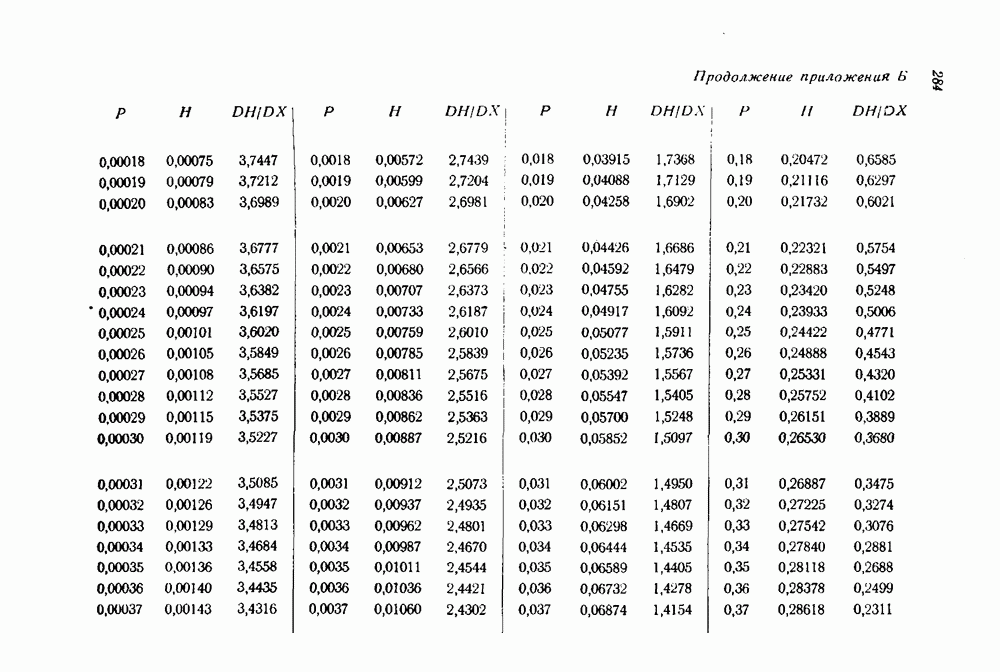
- ПРИЛОЖЕНИЕ Б. КРАТКАЯ ТАБЛИЦА ЗНАЧЕНИЙ ЭНТРОПИИ (ПО ОСНОВАНИЮ 10) И ЕЕ ПЕРВОЙ ПРОИЗВОДНОЙ
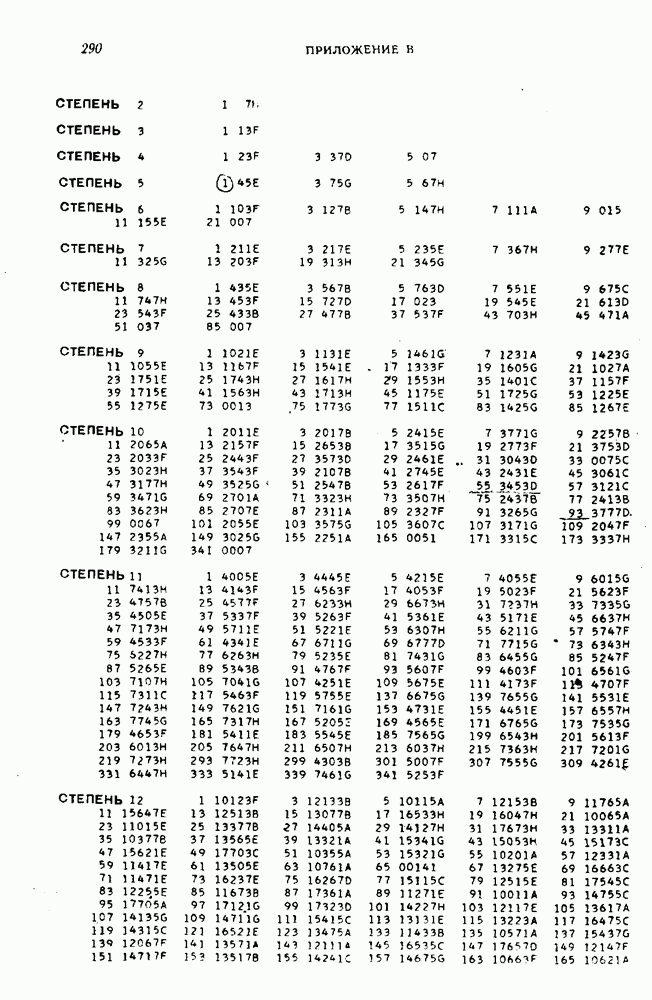
- ПРИЛОЖЕНИЕ В. ТАБЛИЦЫ НЕПРИВОДИМЫХ МНОГОЧЛЕНОВ НАД ПОЛЕМ GF(2)
|






































































































































































































































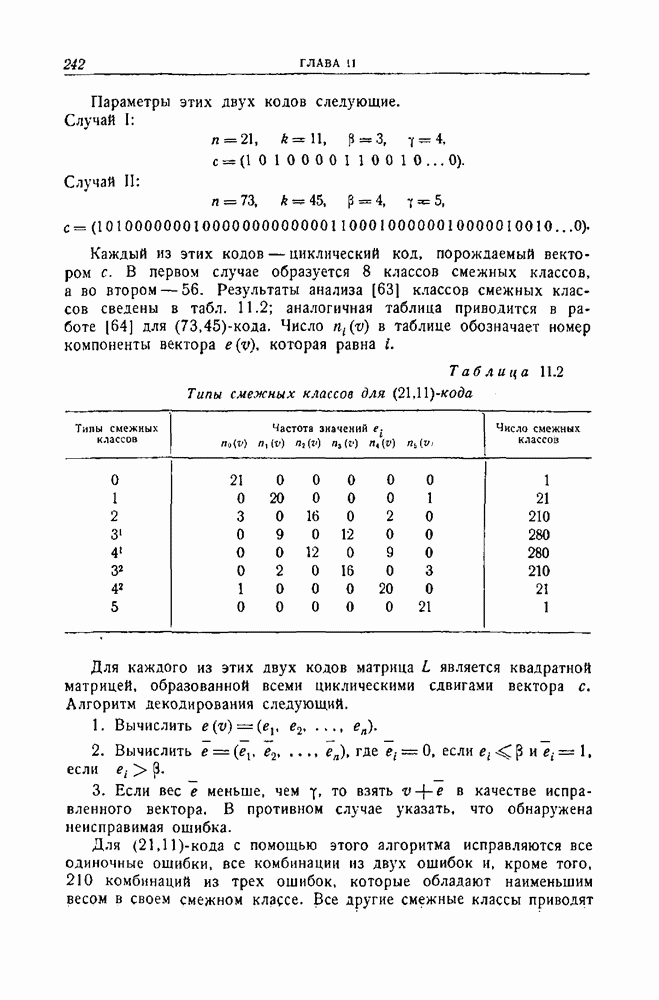
















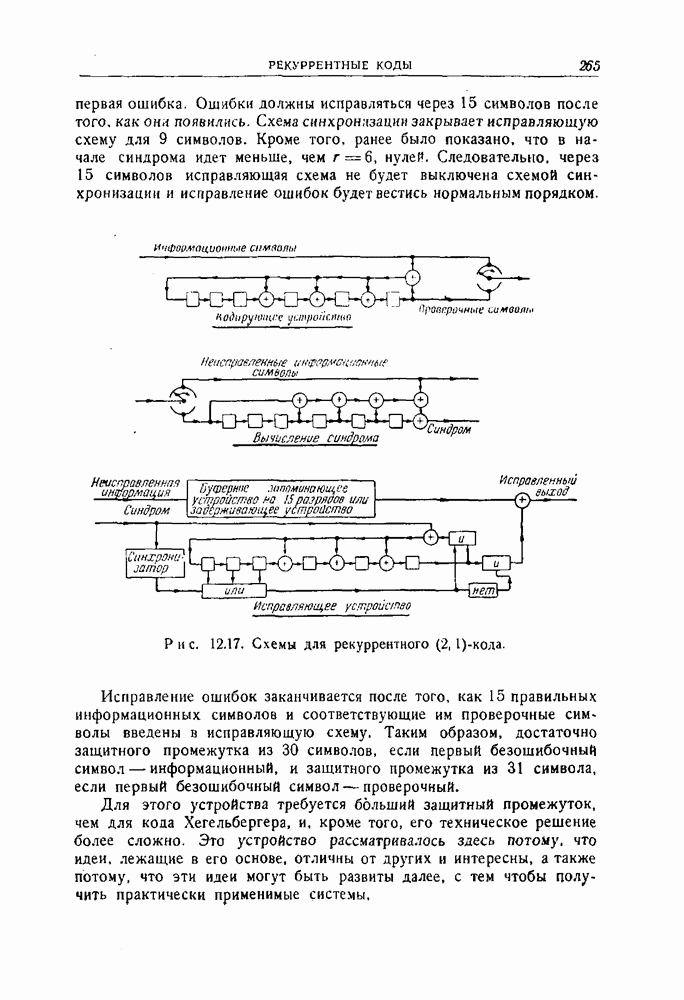














































 -кода. Число в таблице обозначает номер компоненты вектора
-кода. Число в таблице обозначает номер компоненты вектора  которая равна
которая равна 
 -кода
-кода
 является квадратной матрицей, образованной всеми циклическими сдвигами вектора с. Алгоритм декодирования следующий.
является квадратной матрицей, образованной всеми циклическими сдвигами вектора с. Алгоритм декодирования следующий.

 где
где  если
если  если
если 
 меньше, чем
меньше, чем  то взять
то взять  в качестве исправленного вектора. В противном случае указать, что обнаружена неисправимая ошибка.
в качестве исправленного вектора. В противном случае указать, что обнаружена неисправимая ошибка.
 -кода с помощью этого алгоритма исправляются все одиночные ошибки, все комбинации из двух ошибок и, кроме того, 210 комбинаций из трех ошибок, которые обладают наименьшим весом в своем смежном классе. Все другие смежные классы приводят
-кода с помощью этого алгоритма исправляются все одиночные ошибки, все комбинации из двух ошибок и, кроме того, 210 комбинаций из трех ошибок, которые обладают наименьшим весом в своем смежном классе. Все другие смежные классы приводят