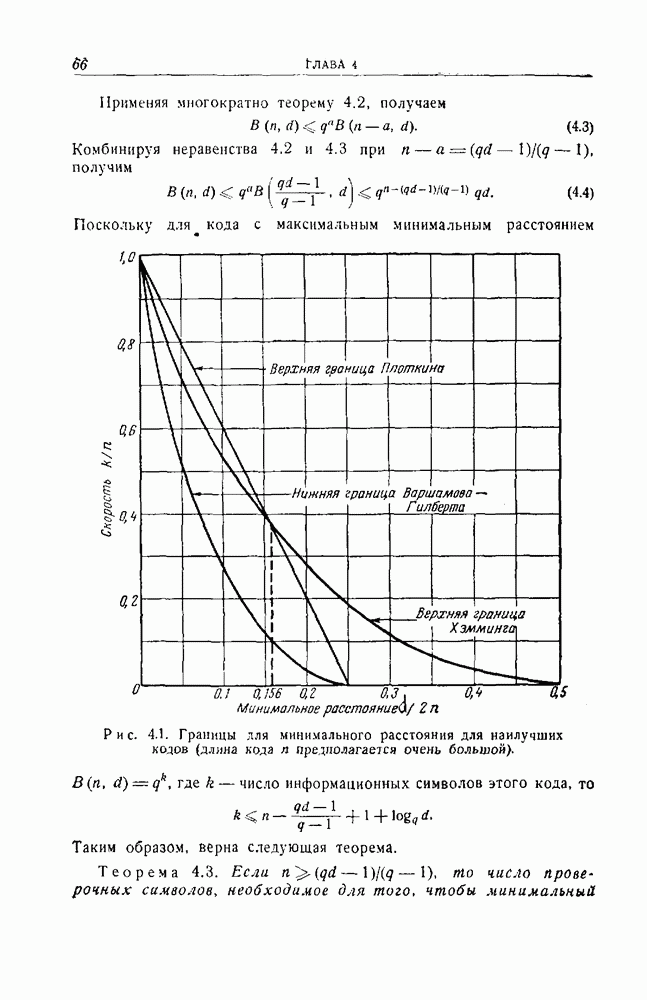
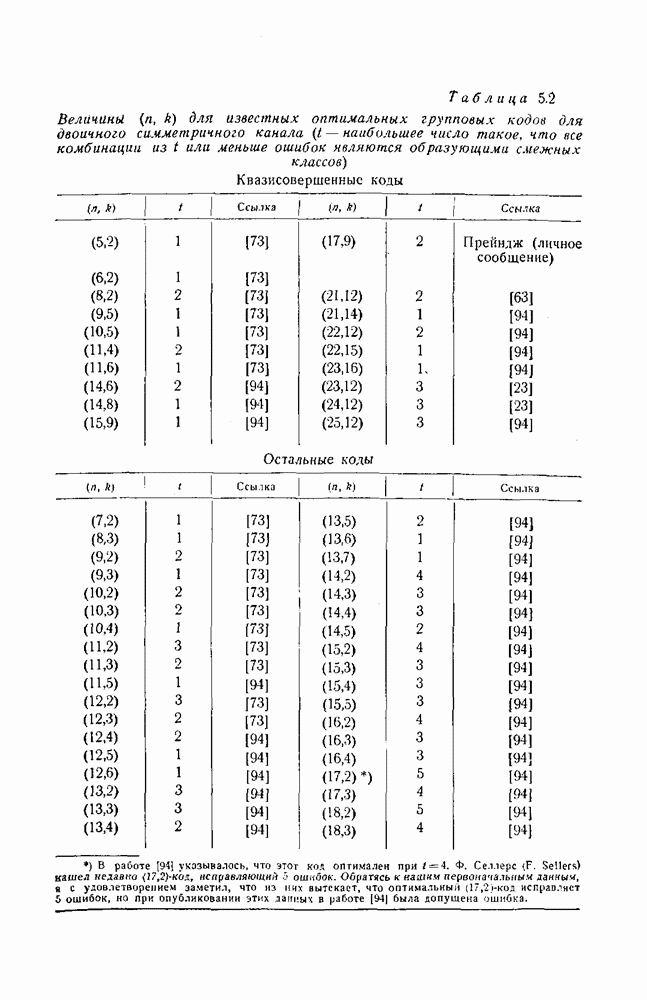
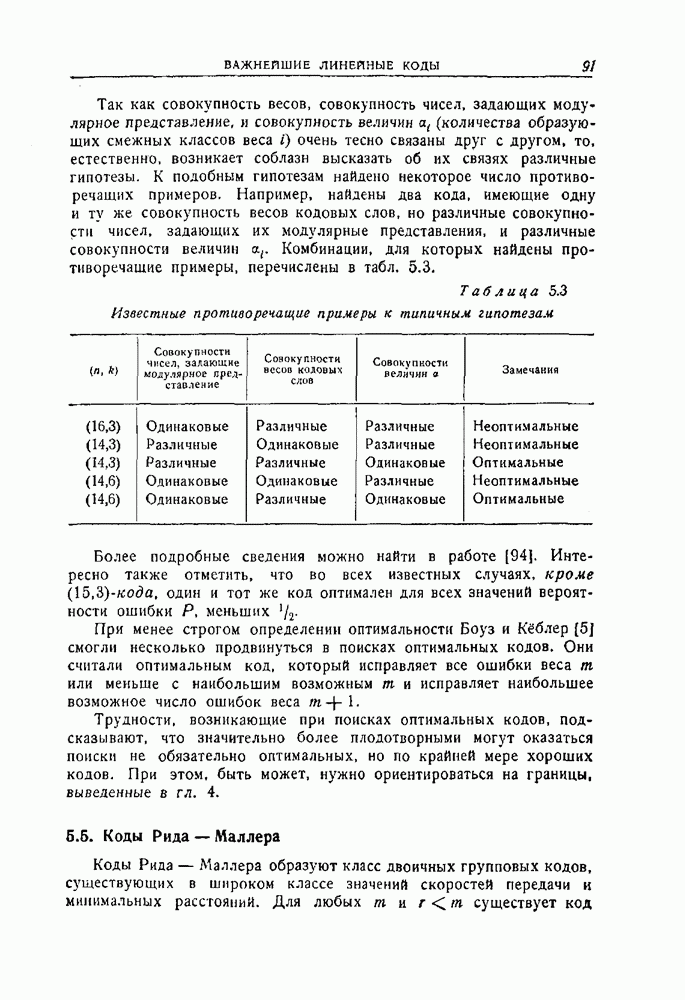
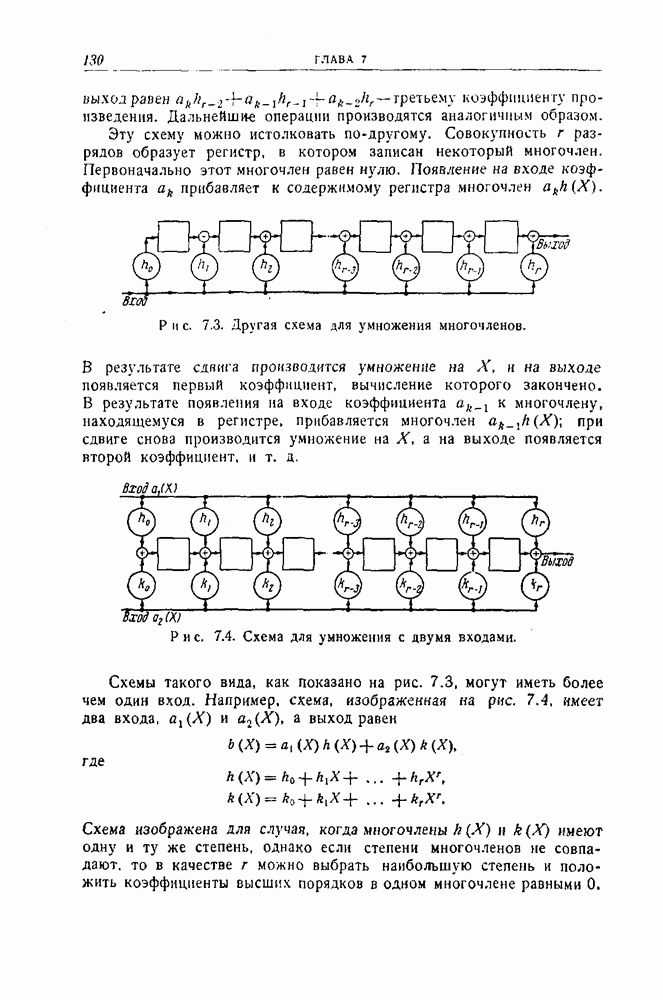
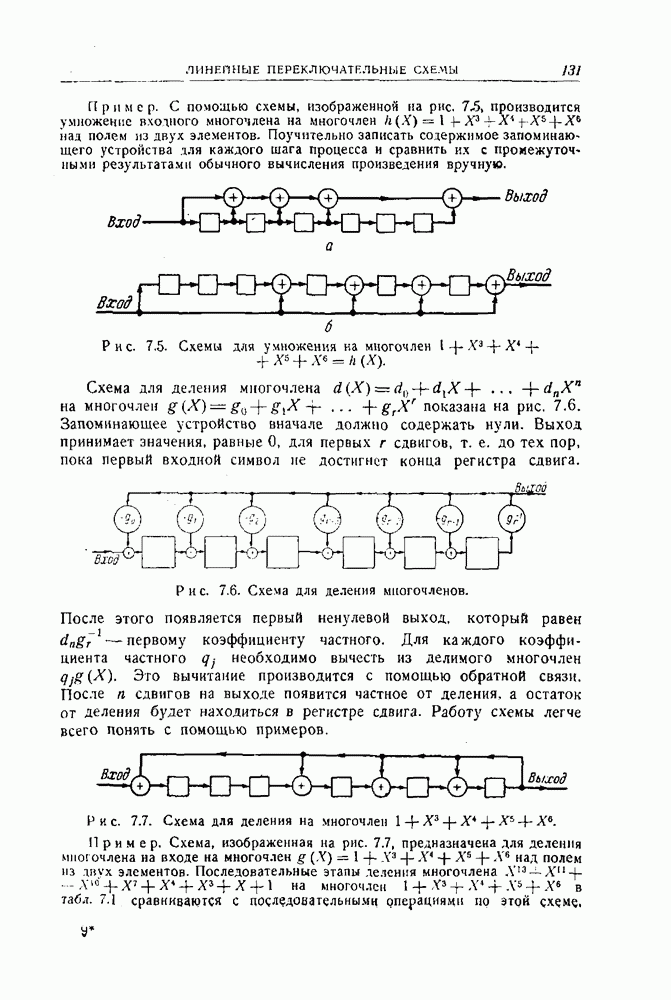
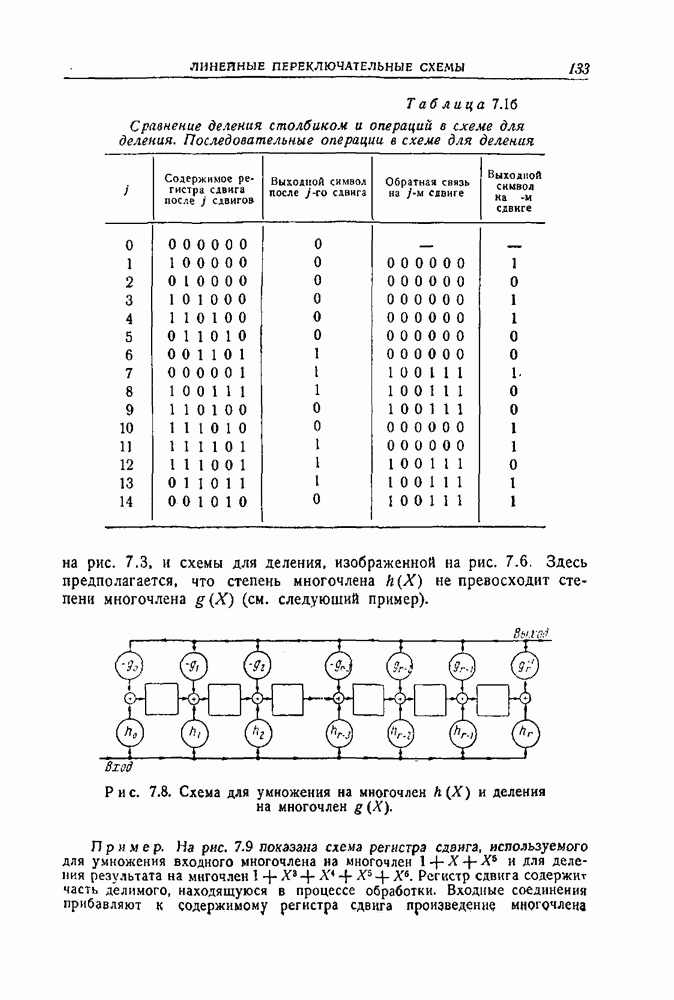
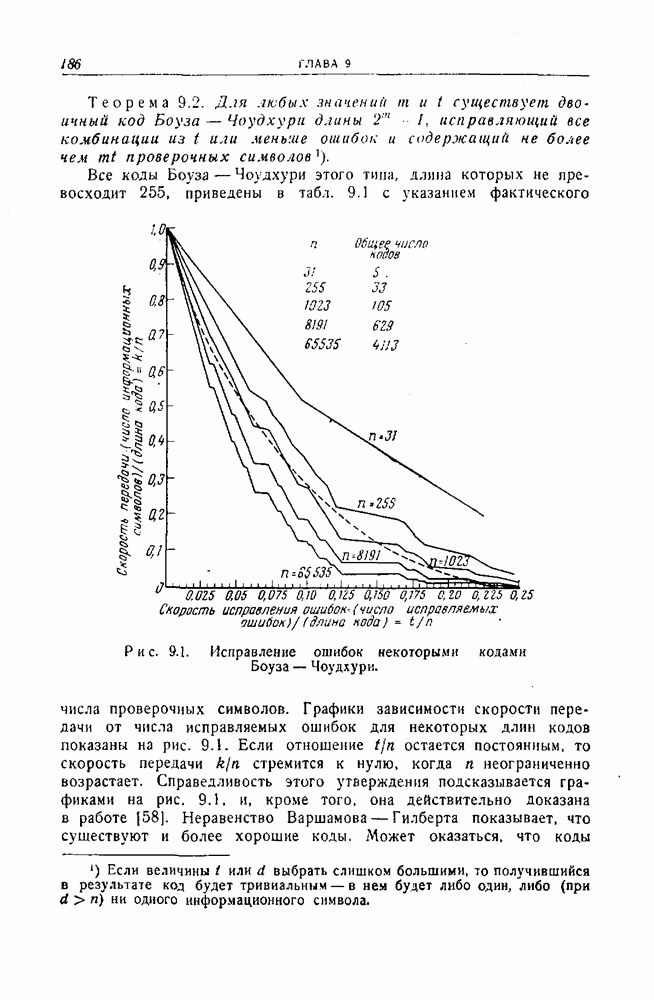
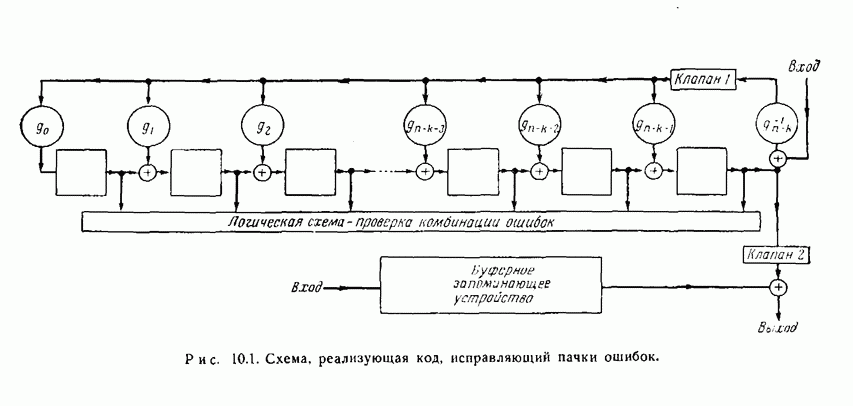
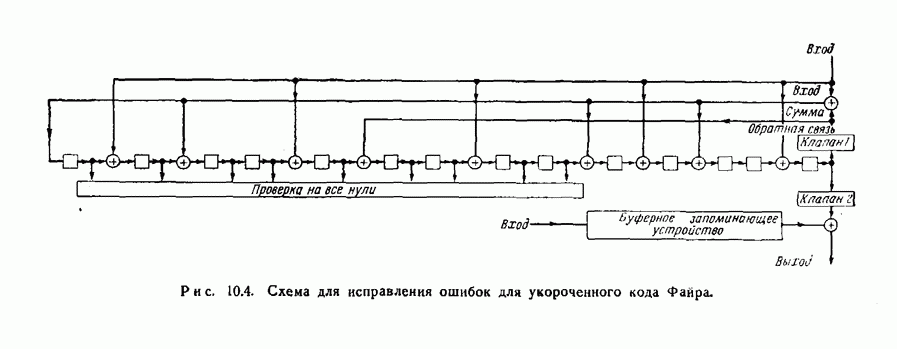
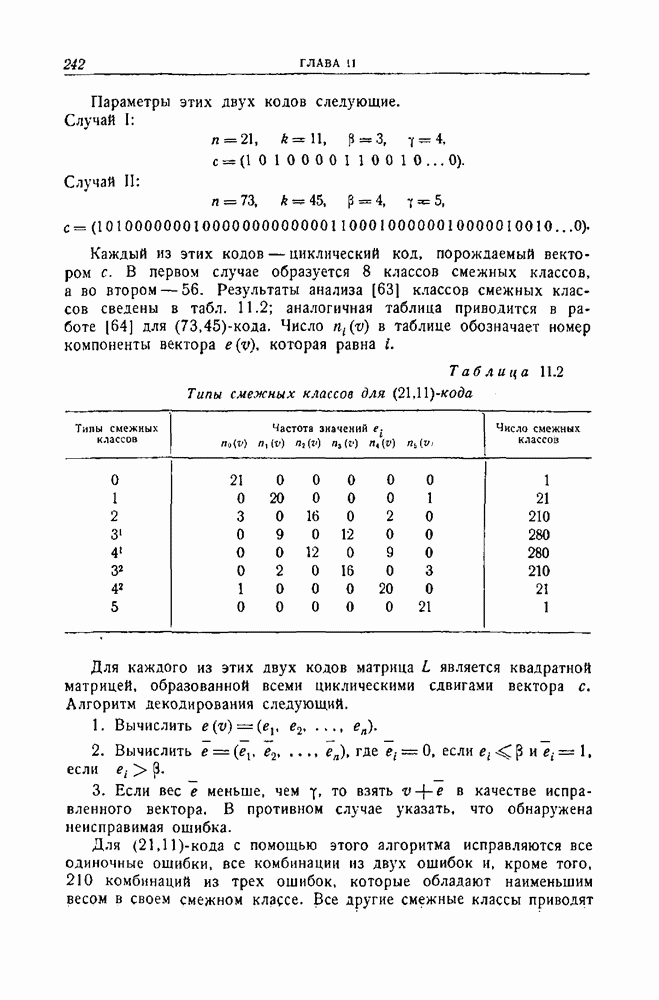
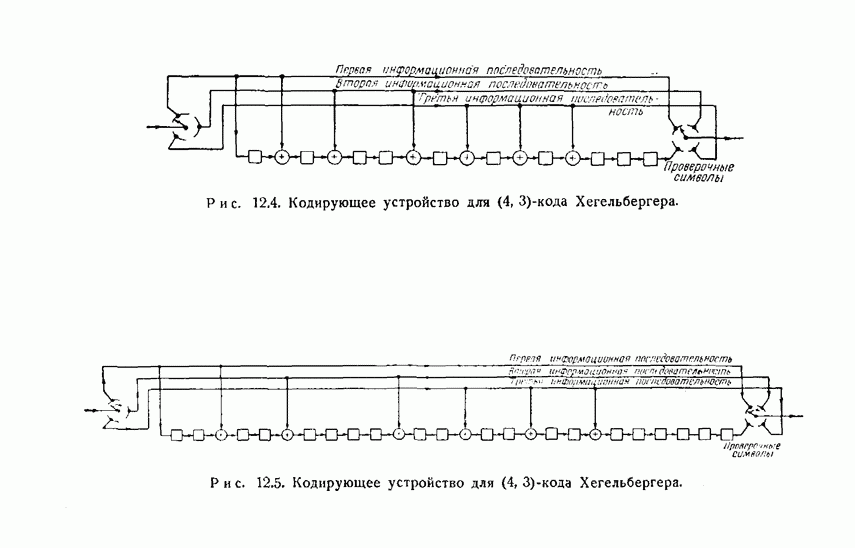
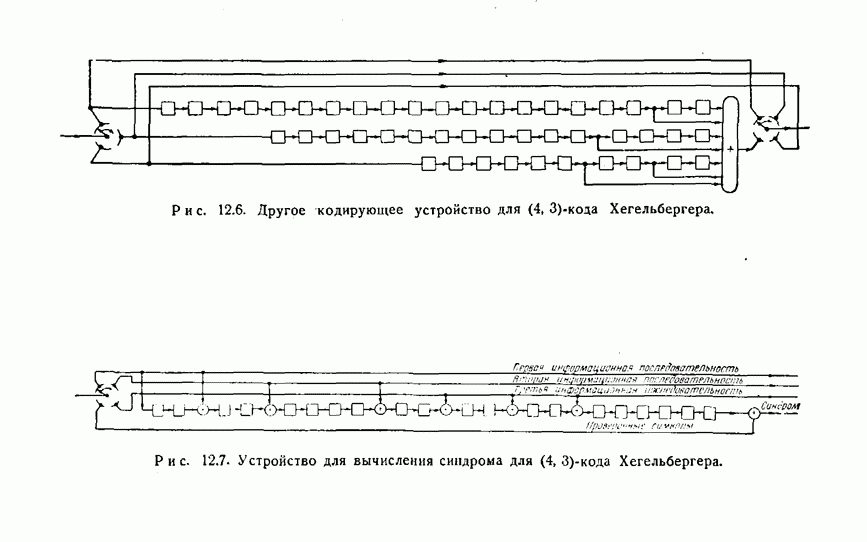
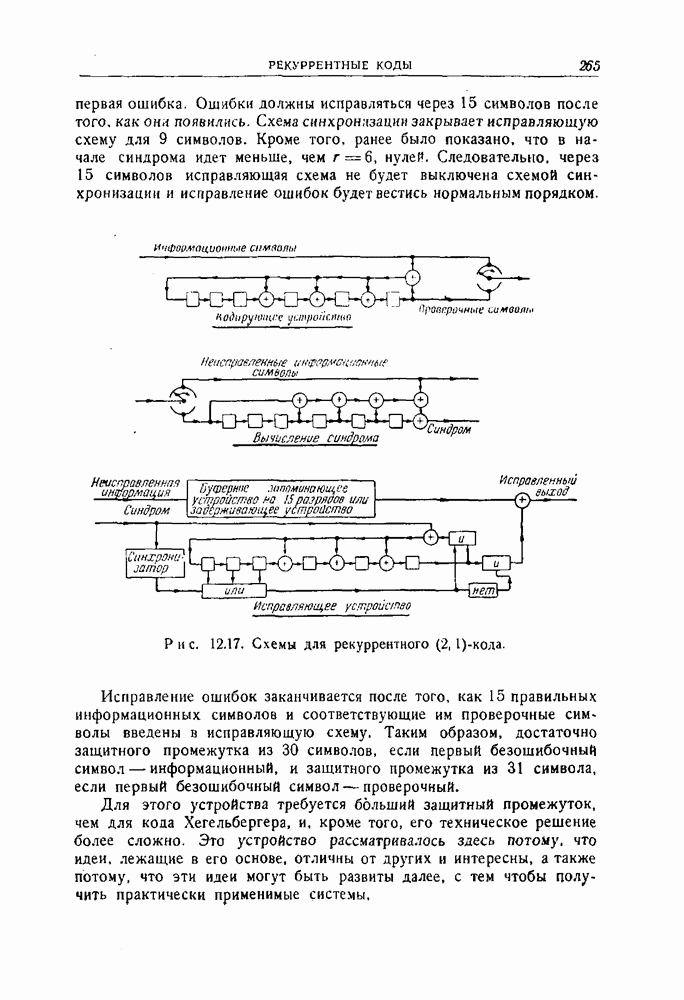
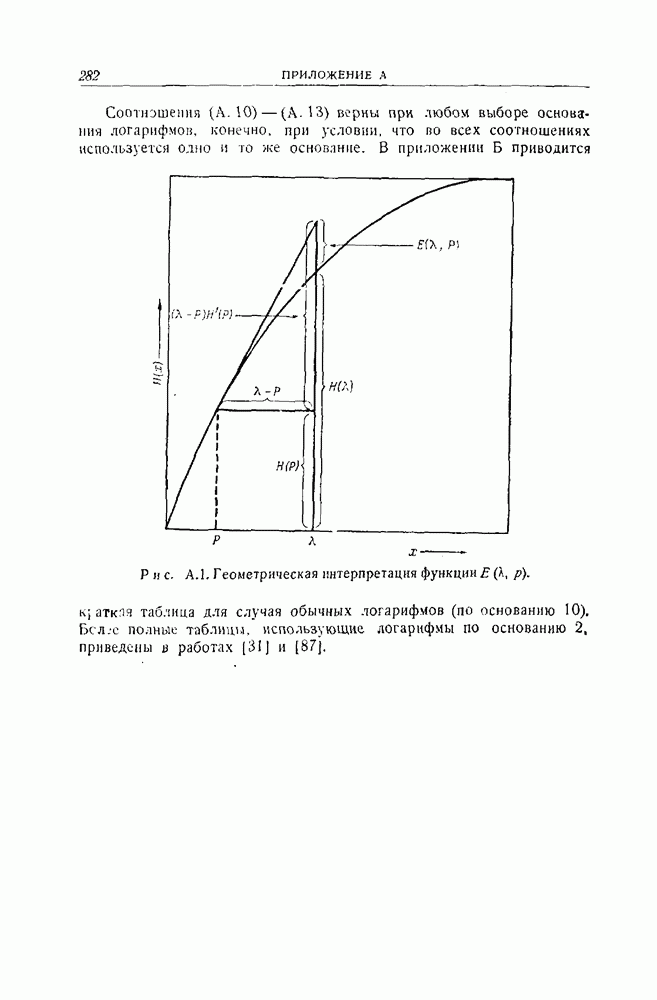
12.5. Последовательное декодирование
Возенкрафт детально исследовал возможность использования рекуррентных кодов в устройствах, предназначенных для исправления случайных ошибок. При этом он использовал схему, которую назвал последовательным декодированием.
Грубо говоря, по методу последовательного декодирования в каждый момент декодируется один информационный символ. Полученная на выходе последовательность сравнивается с каждой последовательностью из совокупности всех возможных передаваемых последовательностей, начинающихся с символа 1, и с каждой последовательностью из совокупности всех возможных передаваемых последовательностей, начинающихся с символа 0. Если только не произошло слишком много ошибок, то полученная на выходе последовательность будет отличаться от каждой последовательности в одном из этих подмножеств столь сильно, что из этого можно будет сделать вывод о том, что переданная последовательность принадлежала другому подмножеству. Таким способом определяется первый символ. Этот символ записывается, отбрасывается из последовательности и затем тот же критерий применяется для определения следующего символа и т. д. Сравнение гипотетически переданной последовательности с полученной последовательностью должно проводиться только до того места, где они уже отличаются достаточно сильно, чтобы можно было сделать вывод о том, что переданная и полученная последовательности несовместимы друг с другом.
Рассуждения, основанные на методе случайного кодирования, указывают, что можно добиться того, чтобы вероятность ошибки при последовательном декодировании стремилась к нулю экспоненциальным образом при увеличении длины кодирующего регистра сдвига и чтобы в то же время объем вычислений рос лишь линейно. Моделирование этого метода на вычислительной машине дало многообещающие результаты. Подробности можно найти в работе [18].
Замечания
Рекуррентные коды для исправления случайных ошибок были изучены впервые Возенкрафтом [15], [161; для исправления пачек ошибок и обнаружения ошибок Хегельбергером [101], [102] и сразу для обоих случаев — Килмером [37], (38]. Эта глава основана целиком на работе Хегельбергера, хотя в нее включен и некоторый дополнительный материал. Построения, описанные в этой главе, могут быть непосредственно обобщены на случай недвоичных кодов. Метод последовательного декодирования Возенкрафта был Обобщен на случай недвоичных кодов Рейффеном (16], [67].