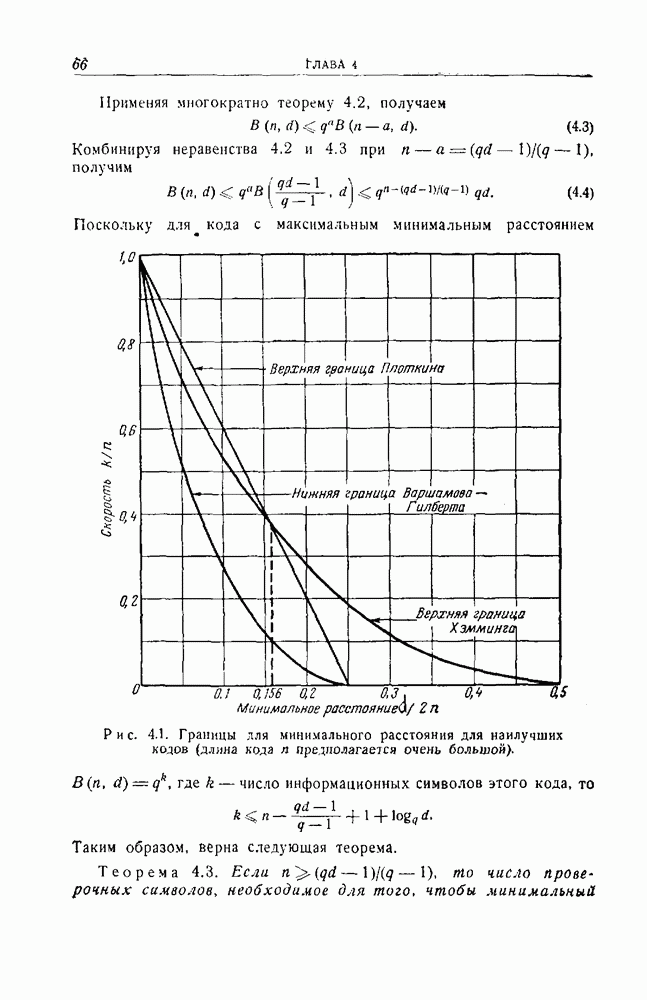
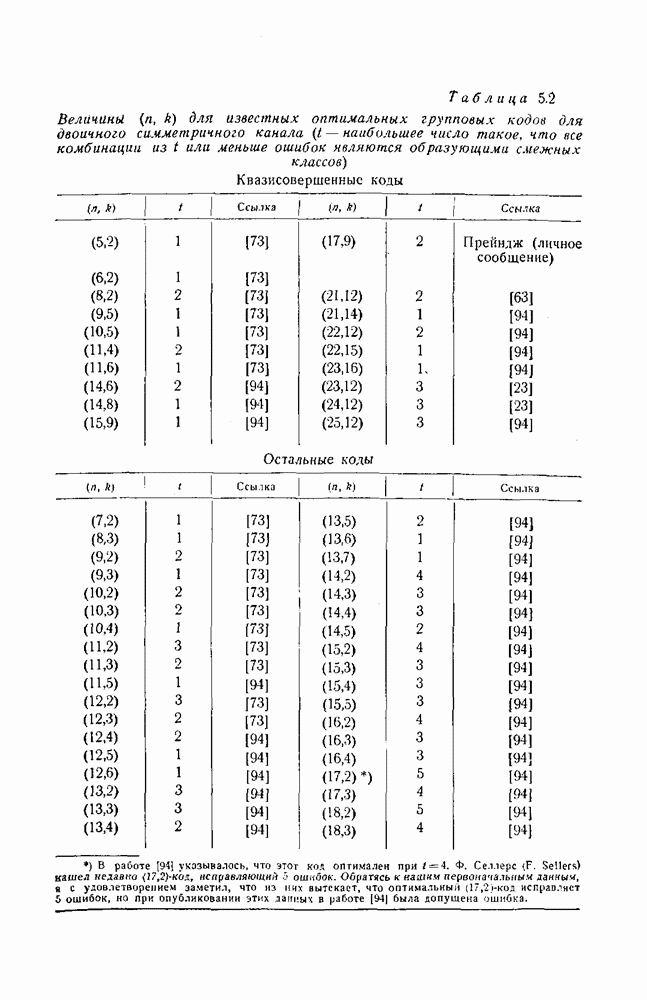
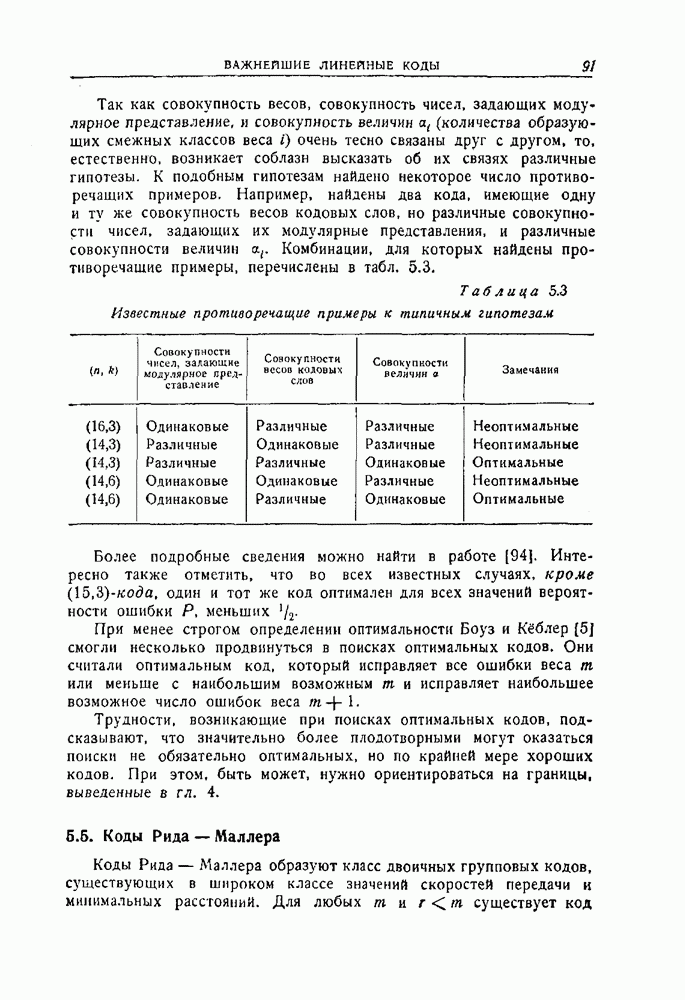
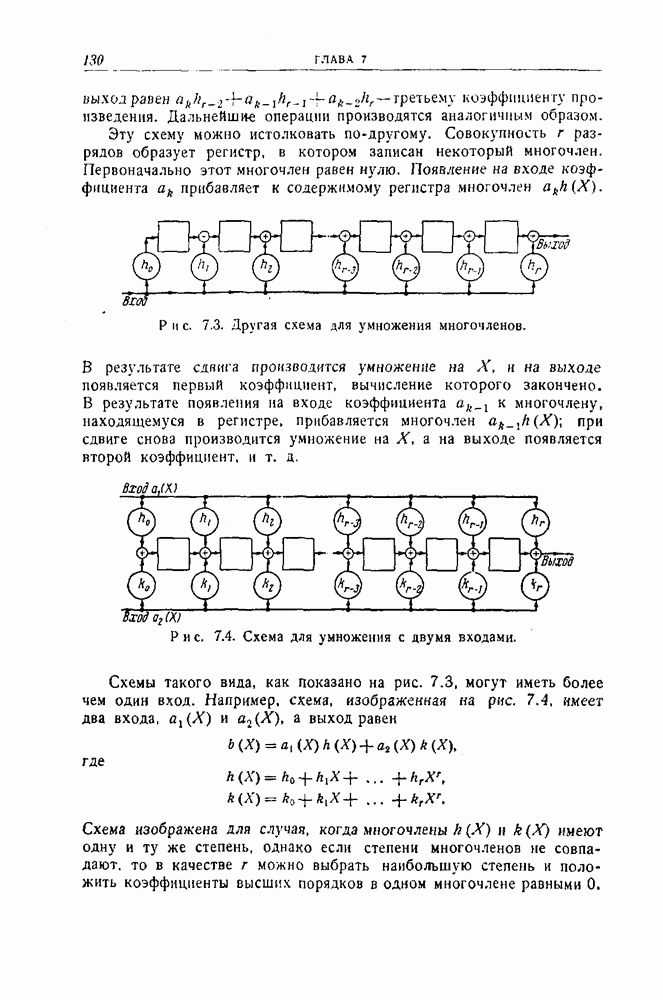
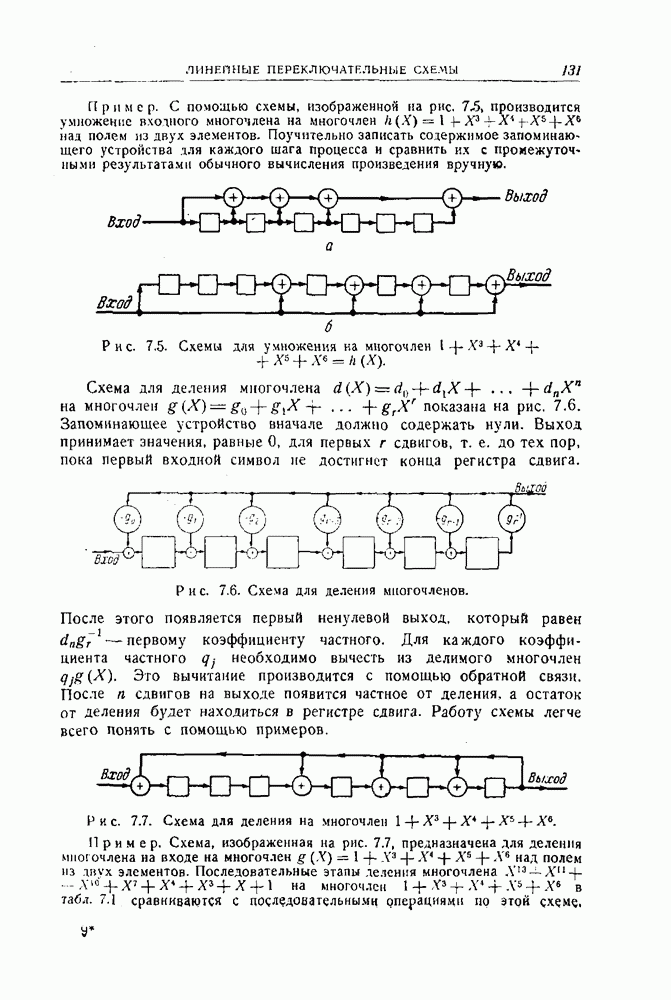
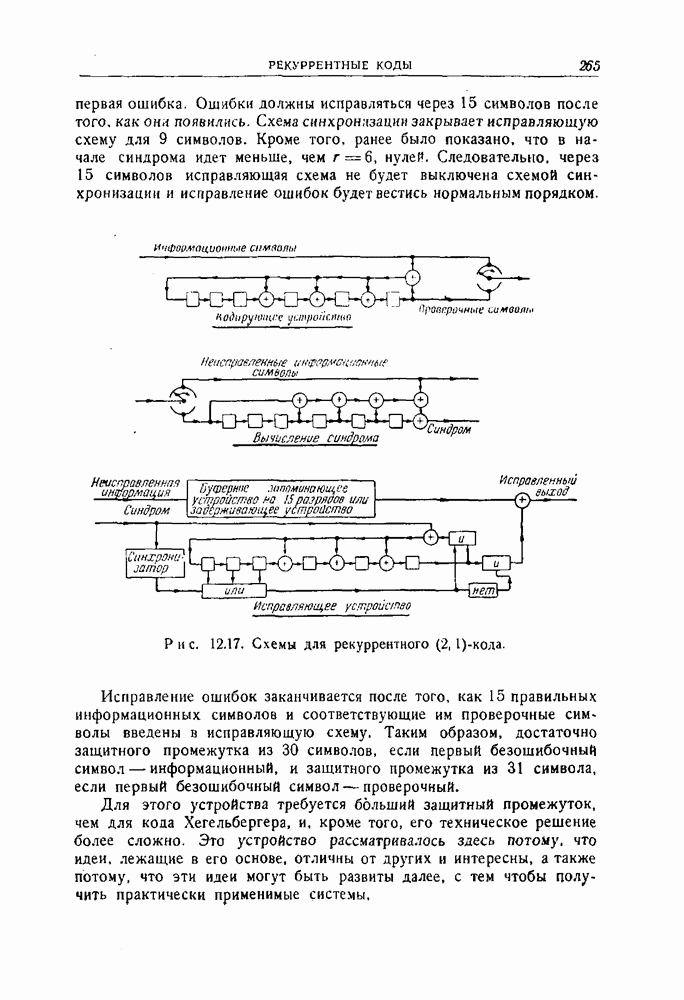
4.4. Граница, основанная на случайном выборе кода
Границы, полученные в этом разделе, справедливы только для групповых кодов, используемых при передаче по двоичному симметричному каналу, хотя Шенноном [117] были установлены более общие результаты. Эти границы выводятся на основе того факта, что иногда легче вычислить среднюю вероятность ошибки для класса кодов, чем
вероятность ошибки для отдельного кода, и что в классе кодов должен существовать некоторый код со свойствами, не хуже осредненных.
Рассматриваемый класс кодов будет включать пространства строк всех матриц вида  где
где  единичная матрица размерности
единичная матрица размерности  матрица с двоичными элементами размерности
матрица с двоичными элементами размерности  Каждая из возможных матриц
Каждая из возможных матриц  задает свой двоичный групповой код, хотя, вообще говоря, имеется много эквивалентных кодов с различными матрицами
задает свой двоичный групповой код, хотя, вообще говоря, имеется много эквивалентных кодов с различными матрицами  Верхняя граница описывается для вероятности ошибки для этих кодов, осредненных с равными весами.
Верхняя граница описывается для вероятности ошибки для этих кодов, осредненных с равными весами.
Начнем с вычисления числа кодов, содержащих в качестве кодо вого вектора фиксированную последовательность длины  Нулевой вектор имеется в каждом коде. Если все
Нулевой вектор имеется в каждом коде. Если все  первых символов вектора
первых символов вектора  (информационные символы) равны нулю, а остальные
(информационные символы) равны нулю, а остальные  к символов (проверочные символы) не все равны нулю, то такой вектор не может быть кодовым вектором ни для какого кода. Если, однако, не все информационные символы вектора
к символов (проверочные символы) не все равны нулю, то такой вектор не может быть кодовым вектором ни для какого кода. Если, однако, не все информационные символы вектора  равны нулю, то имеется
равны нулю, то имеется  кодов, содержащих вектор
кодов, содержащих вектор  Этот факт может быть доказан следующим образом. Пусть некоторый вектор
Этот факт может быть доказан следующим образом. Пусть некоторый вектор  содержит более чем одну единицу среди информационных символов. Будем прибавлять к нему строки порождающей матрицы так, чтобы в левой части среди информационных символов осталась только одна единица. Вектор
содержит более чем одну единицу среди информационных символов. Будем прибавлять к нему строки порождающей матрицы так, чтобы в левой части среди информационных символов осталась только одна единица. Вектор  полученный таким образом, является кодовым вектором тогда и только тогда, когда первоначальный вектор
полученный таким образом, является кодовым вектором тогда и только тогда, когда первоначальный вектор  был кодовым вектором. Поскольку среди его информационных символов имеется только одна единица, он должен совпадать со строкой порождающей матрицы, содержащей 1 в качестве той же самой компоненты. Остальные
был кодовым вектором. Поскольку среди его информационных символов имеется только одна единица, он должен совпадать со строкой порождающей матрицы, содержащей 1 в качестве той же самой компоненты. Остальные  строк порождающей матрицы произвольны, но после того как они выбраны, эта строка полностью определяется условием, что вектор
строк порождающей матрицы произвольны, но после того как они выбраны, эта строка полностью определяется условием, что вектор  должен быть кодовым вектором. Таким образом,
должен быть кодовым вектором. Таким образом,  элементов матрицы
элементов матрицы  могут быть выбраны произвольно, и можно построить кодов, содержащих вектор
могут быть выбраны произвольно, и можно построить кодов, содержащих вектор  в качестве кодового вектора.
в качестве кодового вектора.
Теперь рассмотрим вектор расположения ошибок  который содержит
который содержит  единиц и в том числе
единиц и в том числе  единиц среди информационных символов. Эта расстановка ошибок приведет к неправильному или неоднозначному декодированию, если найдется другой вектор
единиц среди информационных символов. Эта расстановка ошибок приведет к неправильному или неоднозначному декодированию, если найдется другой вектор  или меньшим числом единиц, лежащий в том же смежном классе, т. е. такой, что вектор
или меньшим числом единиц, лежащий в том же смежном классе, т. е. такой, что вектор  является кодовым вектором. Для любого вектора
является кодовым вектором. Для любого вектора  веса
веса  или меньше это произойдет в точности при
или меньше это произойдет в точности при  способах выбора кода, если вектор
способах выбора кода, если вектор  содержит хотя бы одну единицу среди информационных символов, и этого не будет ни при одном выборе кода, если сумма
содержит хотя бы одну единицу среди информационных символов, и этого не будет ни при одном выборе кода, если сумма  не содержит единиц среди информационных символов. Из векторов, содержащих
не содержит единиц среди информационных символов. Из векторов, содержащих
 единиц, векторов имеют информационные символы, совпадающие с соответствующими символами в векторе расположения ошибок; сумма каждого из этих векторов с вектором расположения ошибок не содержит единиц на местах информационных символов. Таким образом, остается
единиц, векторов имеют информационные символы, совпадающие с соответствующими символами в векторе расположения ошибок; сумма каждого из этих векторов с вектором расположения ошибок не содержит единиц на местах информационных символов. Таким образом, остается  векторов, каждый из которых содержит
векторов, каждый из которых содержит  единиц и в сумме каждого из которых с вектором расположения ошибок не все информационные символы равны нулю. Пусть через
единиц и в сумме каждого из которых с вектором расположения ошибок не все информационные символы равны нулю. Пусть через  обозначается число колов,
обозначается число колов,  которых фиксированное расположение
которых фиксированное расположение  ошибок, и в том числе
ошибок, и в том числе  ошибок в информационных символах, приводит к ошибке или к неоднозначному декодированию. Тогда
ошибок в информационных символах, приводит к ошибке или к неоднозначному декодированию. Тогда

(Заметим, что равенство достигается только в том случае, если для каждого кода, приводящего к неоднозначному декодированию для фиксированного расположения  ошибок, найдется ровно один отличный от него вектор расположения ошибок веса
ошибок, найдется ровно один отличный от него вектор расположения ошибок веса  или меньше, который принадлежит тому же самому смежному классу. В других случаях один и тот же код может быть сосчитан в правой части неравенства (4.14) несколько раз.) Далее, так как в рассматриваемом классе содержится кодов, то
или меньше, который принадлежит тому же самому смежному классу. В других случаях один и тот же код может быть сосчитан в правой части неравенства (4.14) несколько раз.) Далее, так как в рассматриваемом классе содержится кодов, то

и для получения более точной оценки нужно использовать ту из двух оценок, которая меньше.
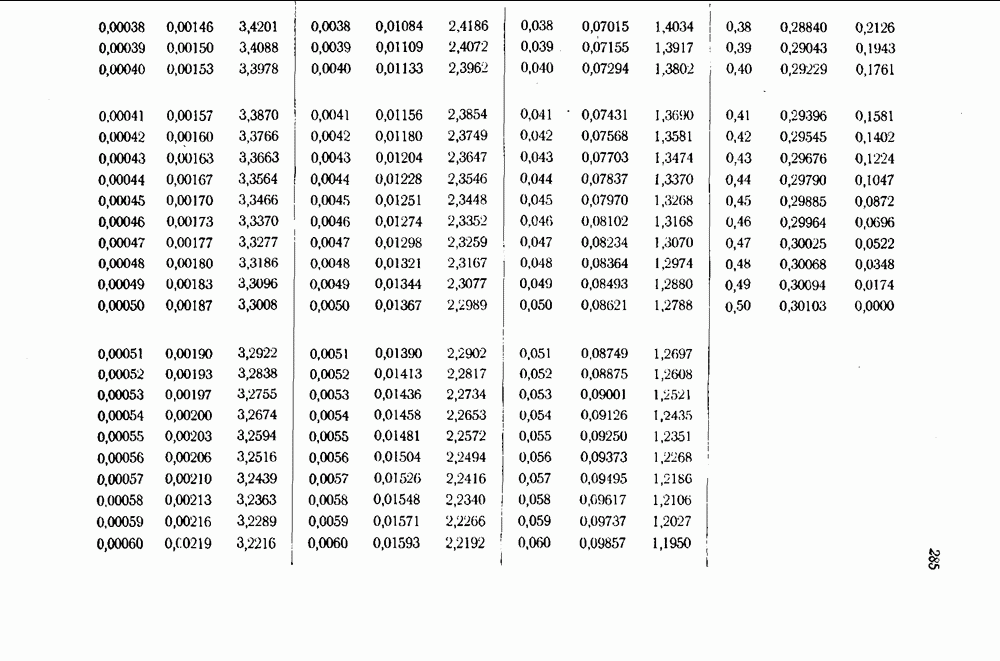
Каждая комбинация из  ошибок имеет вероятность
ошибок имеет вероятность  причем существует всего
причем существует всего  комбинаций из
комбинаций из  ошибок,
ошибок,  из которых произошли в информационных символах. Суммируя по у и по
из которых произошли в информационных символах. Суммируя по у и по  и деля на
и деля на  общее число кодов, получим вероятность неправильного или неоднозначного декодирования:
общее число кодов, получим вероятность неправильного или неоднозначного декодирования:

Теперь можно найти верхнюю границу, оценивая каждый раз величину  с помощью неравенств (4.14) или (4.15) в зависимости от того, какое, из них дает лучшую оценку. Заметим, что при
с помощью неравенств (4.14) или (4.15) в зависимости от того, какое, из них дает лучшую оценку. Заметим, что при  величина
величина  и поэтому в любом случае первое слагаемое в равенстве (4.16) равно нулю.
и поэтому в любом случае первое слагаемое в равенстве (4.16) равно нулю.
Вывод асимптотически верных результатов для этого случая более сложен. Можно получить не очень точную верхнюю границу, если в неравенстве (4.14) отбросить второе слагаемое:

Это неравенство следует предпочесть неравенству (4.15) для всех  где
где  наибольшее целое число, для которого
наибольшее целое число, для которого

Это условие определяет то же самое значение  как и то, которое задается соотношением (4.11). Тождество
как и то, которое задается соотношением (4.11). Тождество

означающее просто, что общее число возможных способов расположения  ошибок равно
ошибок равно  используемое совместно с неравенствами (4.15) и (4.17), приводит к оценке
используемое совместно с неравенствами (4.15) и (4.17), приводит к оценке

Отсюда можно вывести грубую, но простую оценку сверху, если заменить каждую сумму наибольшим из слагаемых, умноженным на число слагаемых. Итак,

если

если  поскольку слагаемое
поскольку слагаемое  является наибольшим слагаемым в сумме. Для оценки второй суммы
является наибольшим слагаемым в сумме. Для оценки второй суммы

нужно рассмотреть два случая в зависимости от того, будет или не будет наибольшим последнее слагаемое. Отношение  слагаемого к
слагаемого к  слагаемому равно
слагаемому равно

и наибольшее слагаемое появляется тогда, когда это отношение наиболее близко к единице. Если  настолько велики, что можно пренебречь числом 1 в знаменателе и числом 2 в числителе, то это отношение равно единице при
настолько велики, что можно пренебречь числом 1 в знаменателе и числом 2 в числителе, то это отношение равно единице при

Если  то наибольшим слагаемым в выражении (4.20) является последнее, и это выражение может быть оценено сверху произведением числа на последнее слагаемое
то наибольшим слагаемым в выражении (4.20) является последнее, и это выражение может быть оценено сверху произведением числа на последнее слагаемое

Рассмотрим теперь границу, получающуюся для надежности  наилучшего кода. Эта граница, конечно, не хуже средней границы по всем кодам
наилучшего кода. Эта граница, конечно, не хуже средней границы по всем кодам

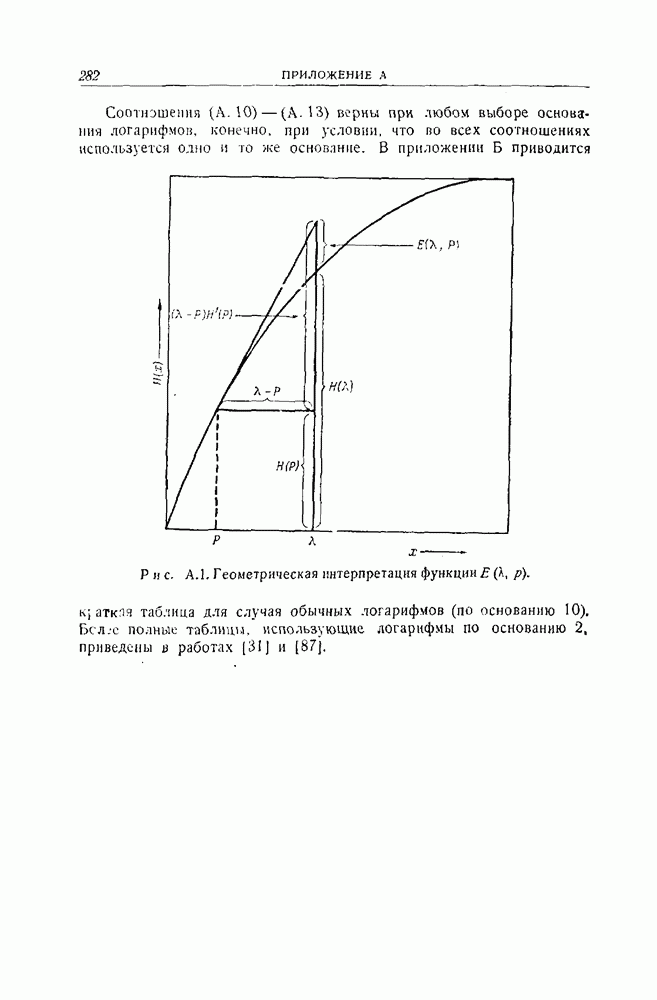
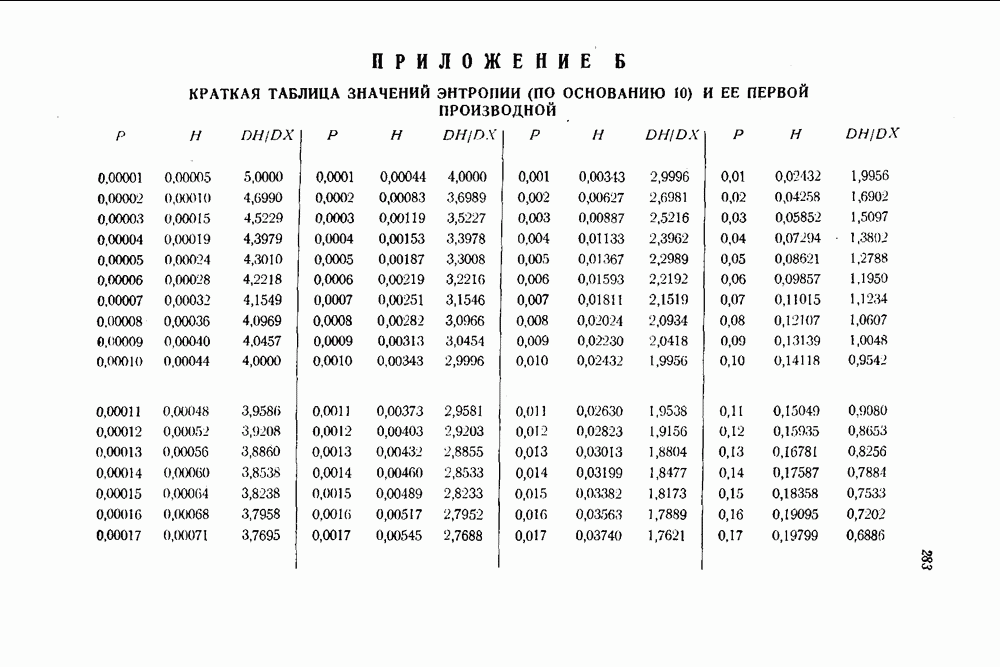
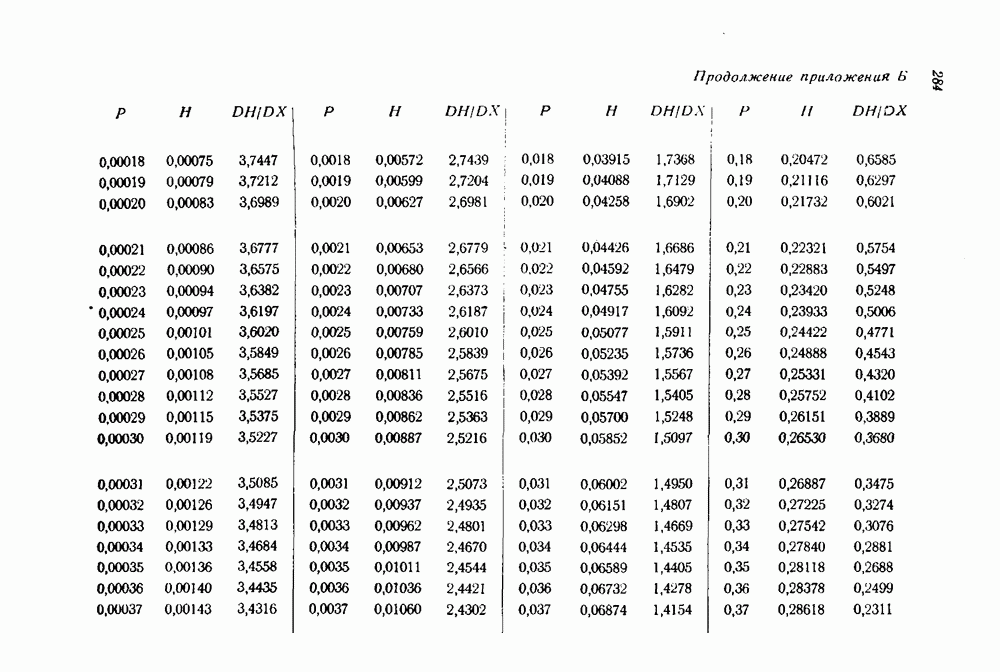
Первое слагаемое в пределе равно  функции, определяемой в приложении
функции, определяемой в приложении  той же самой функции, которая была получена в качестве нижней границы для
той же самой функции, которая была получена в качестве нижней границы для  с помощью границы, основанной на принципе плотной упаковки сфер. Относительно второго слагаемого можно показать, что оно равно нулю, если использовать тот факт, что поскольку
с помощью границы, основанной на принципе плотной упаковки сфер. Относительно второго слагаемого можно показать, что оно равно нулю, если использовать тот факт, что поскольку  определяется соотношением (4.11), то величина
определяется соотношением (4.11), то величина  не превосходит величины
не превосходит величины
Если  то наибольшим слагаемым в выражении (4.20) будет не последнее, а то, для которого отношение
то наибольшим слагаемым в выражении (4.20) будет не последнее, а то, для которого отношение  При этом выражение (4.20) может быть оценено сверху величиной
При этом выражение (4.20) может быть оценено сверху величиной

где  Так как
Так как  то можно показать, что отношение суммы, стоящей в правой части неравенства 4.19, к этому выражению близко к нулю при очень больших значениях
то можно показать, что отношение суммы, стоящей в правой части неравенства 4.19, к этому выражению близко к нулю при очень больших значениях  и поэтому второй суммой в соотношении 4,18 в пределе можно пренебречь, если в качестве границы для первой суммы использовать величину 4.22. Таким образом, применяя результаты приложения А и соотношение 4.13, получаем
и поэтому второй суммой в соотношении 4,18 в пределе можно пренебречь, если в качестве границы для первой суммы использовать величину 4.22. Таким образом, применяя результаты приложения А и соотношение 4.13, получаем

Эта оценка надежности определенно ниже, чем граница, получаемая на основе принципа плотной упаковки сфер. Несмотря на то что здесь были использованы лишь очень простые и приближенные оценки, неизвестны никакие лучшие оценки надежности при условии  Конечно, для вероятности ошибки могут быть получены гораздо более точные оценки, однако они более сложны. Дополнительные сведения можно найти в работах [93], [117], [125], |126].
Конечно, для вероятности ошибки могут быть получены гораздо более точные оценки, однако они более сложны. Дополнительные сведения можно найти в работах [93], [117], [125], |126].
Величина  равная доле информационных символов среди всех символов, называется скоростью передачи. Рассмотрим максимальную скорость, для которой при заданном значении вероятности
равная доле информационных символов среди всех символов, называется скоростью передачи. Рассмотрим максимальную скорость, для которой при заданном значении вероятности  надежность больше 0 в пределе для. кодов достаточно большой длины
надежность больше 0 в пределе для. кодов достаточно большой длины
В соответствии с равенством 4.13 увеличение отношения  означает уменьшение
означает уменьшение  Очевидно, величина
Очевидно, величина  может быть меньше, чем
может быть меньше, чем  так что
так что  . Из определения этой функции в приложении А можно вывести, что
. Из определения этой функции в приложении А можно вывести, что  тогда и только тогда, когда
тогда и только тогда, когда  или
или  или
или

Конечно, при условии, что удовлетворяется неравенство (4.24), вероятность ошибки для наилучшего кода длины  будет стремиться к нулю, когда
будет стремиться к нулю, когда  стремится к бесконечности. Это частный случай основной теоремы Шеннона для каналов с шумом. Величина
стремится к бесконечности. Это частный случай основной теоремы Шеннона для каналов с шумом. Величина  называется пропускной способностью канала. Вероятность ошибки можно сделать сколь угодно малой, выбирая коды достаточно большой длины, при условии, что скорость меньше пропускной способ ности канала.
называется пропускной способностью канала. Вероятность ошибки можно сделать сколь угодно малой, выбирая коды достаточно большой длины, при условии, что скорость меньше пропускной способ ности канала.
Эта граница была обобщена Элайессм  на некоторые более узкие классы кодов: для сверточных кодов и для скользящих кодов с проверкой на четность. Интересно также заметить, что довольно хорошие коды можно получить, выбирая случайным образом некоторое не слишком большое число кодов, а затем оставляя наилучший из них [93]. Кодирование для таких кодов производится довольно легко, и их вполне можно использовать, если не учитывать трудностей, связанных с декодированием.
на некоторые более узкие классы кодов: для сверточных кодов и для скользящих кодов с проверкой на четность. Интересно также заметить, что довольно хорошие коды можно получить, выбирая случайным образом некоторое не слишком большое число кодов, а затем оставляя наилучший из них [93]. Кодирование для таких кодов производится довольно легко, и их вполне можно использовать, если не учитывать трудностей, связанных с декодированием.